 Gary Libben
Gary Libben Jordan Gallant
Jordan Gallant Wolfgang U. Dressler2
Wolfgang U. Dressler2- 1Department of Applied Linguistics, Brock University, St. Catharines, ON, Canada
- 2Department of Linguistics, University of Vienna, Vienna, Austria
We sought to move beyond single word and sentence processing experiments in order to examine textual effects on the processing of compound words in English. We developed minimal texts (sentences pairs that together constitute a story) that had neutral, semantic or lexical relations between the last word of the first sentence and the second word of the second sentence (which was always a compound noun). This generated minimal text triplets that differed only in the last word of the first sentence (e.g., “She walked down to the path/river/water. The waterfall roared in the distance”). Four experiments were conducted with a total 143 native speakers of English. Experiment 1 employed a Modified Maze Task to identify cross-sentence effects on compound processing. Sentence pairs with lexical links differed from those with semantic links, which, in turn differed from neutral pairs, providing evidence of cross-sentence influence on compound processing. In Experiments 2a, 2b, and 2c, we examined compound production using typing tasks. Results indicated that morphological effects found in single word typing persisted in text typing. In addition, constituent priming effects on typing were seen in both single word typing and sentence typing. Finally, morphological effects were correlated with overall story ratings. We thus conclude that morphological effects are not restricted to single word processing, but rather reflect the dynamics of real-world language processing.
Introduction
A key challenge in the design of psycholinguistic research on lexical processing is to create experiments that have ecological validity and at the same time are sufficiently controlled so that specific variables and hypotheses regarding their effects can be examined. The achievement of ecological validity in lexical processing research can often be seen as the extent to which we are able to generalize experiment results to the processing of words in the world. We report on a series of experiments that have been designed to enhance ecological validity in the investigation of lexical processing by examining the processing of compound words within written texts. These texts have been constructed to more closely approximate naturally occurring language and at the same time be sufficiently controlled in their structure so that we can capture the interplay of factors in morphological processing. The specific structures that we have created can be described as minimal texts – two sentences that together constitute a story. An example of such a story is provided in 1) below:
1. “She walked down to the path. The waterfall roared in the distance”.
In this minimal text story, the second word of the second sentence is the compound “waterfall.” A great deal of psycholinguistic research on the processing of words in isolation has found that the internal morphological structure of such words plays a role in how they are processed (Libben et al., 2020). Our goal in this research was to trace the processing of compound words such as waterfall from its characteristics when presented in isolation to its characteristics when presented in such minimal texts. We thus ask the question: Is the morphological processing found in single word processing also found in text processing?
In text linguistics and corresponding psycholinguistic studies, text comprehension has been shown to depend on textual (more precisely, co-textual) top-down-processing (Kintsch and van Dijk, 1978; Beaugrande and Dressler, 1981; Dederding, 1983; Ehrlich, 1991; Graesser et al., 1997; Kintsch, 1998; Verhoeven and Perfetti, 2008). From the first sentence of a text onwards, expectations are created in the hearer/reader about what is to follow, and these co-textual expectations are then corrected and elaborated by the on-going text. Hearers and readers use background knowledge to make predictions about what is going to happen next. This background knowledge has various sources. These include world knowledge, the situational context, and the preceding co-text. Expectations about what will be heard or read next constitute inferences (cf. Graesser et al., 1994; Clinton et al., 2015) that may affect the relative contribution of morphological processing during online processing. To the best of our knowledge, there exists a single paper (Smith et al., 2014) on the influence of situational context, but no studies on the impact of co-text on morphological processing.
Textual coherence is either established by the semantic and pragmatic means of relating text elements one to another or most directly via cohesive elements which bind text elements together on the textual surface, such as anaphoric pronouns or the definite article of a noun phrase which refer to their antecedents, or lexical repetition which, by default, signals anaphorically semantic identity or vicinity (unless differentiated through words, such as another, a different, etc., cf. Beaugrande and Dressler, 1981). In order to study textual anaphora (i.e., relations of an element to a preceding antecedent) one needs as minimal textual unit two coherent (and perhaps also cohesive) sentences. Thus, to take a specific example, if the first sentence of such a text is “She walked down to the river.,” textual coherence can be enhanced if the next sentence begins with an anaphoric pronoun (e.g., “Her feet felt…”), or repetition (e.g., Walking always helped…), or a definite article (e.g., The waterfall roared …). This last type was the one employed in all our two-sentence texts.
A great deal of the literature on morphological effects in the processing of compound words such as waterfall has employed the priming technique (Forster and Davis, 1984) to address the question of whether the individual constituents water and fall are activated in the processing of the compound waterfall. The data, over a relatively large number of studies (seeSandra, 2019) provide evidence that this is the case – compound processing is facilitated by the prior presentation of one of its constituents (e.g., water→waterfall). In this research, we sought to track such priming effects from the domain of single word processing to the domain of minimal texts. Consider again, the two sentences in 1) above. Only by imagining pragmatically a bridging inference, might one suppose that the path might lead close to a waterfall. Would the story be made more coherent and would the processing of words within it be affected if the last word of the first sentence (i.e., path) were changed to a word such as river that bears a lexical semantic relation to the compound word waterfall? Such a case is shown in 2) below.
2. “She walked down to the river. The waterfall roared in the distance.”
And now, finally, would coherence and text processing be affected if the last word of the first sentence were changed so that it corresponded exactly to one of the constituents of the compound word waterfall as in 3) below? In this way, in addition to semantic coherence, the two-sentence text could also be said to possess cohesion.
3. “She walked down to the water. The waterfall roared in the distance.”
The research we report contrasts minimal texts such as 1), 2) and 3) in order to probe whether semantic and constituent priming effects that have been found in single word processing area also evident in the processing of minimal text. In this way, we are reporting a means to enhance the ecological validity of studies of processing and also to test the “ecological extendibility” of morphological effects in the processing of compound words.
Research on morphological processing in general and on compound processing in particular has suggested that lexical activation in reading involves automatic and obligatory access to the morphological constituents of words. The exact mechanism underlying this access is, to a large extent, still under debate (seeLibben et al., 2020). However, despite the lack of agreement on whether constituent activation precedes whole-word recognition (Taft and Forster, 1976), follows it (Giraudo and Grainer, 2001) or occurs in parallel with it, (Baayen and Schreuder, 1999), there is a general consensus that morphological processing is not under strategic control by participants. Libben (2006), Libben (2014) argued that the morphological system is intrinsically organized to maximize opportunity for meaning activation (seeKuperman et al., 2009) and that this drive to maximize meaning opportunity results in obligatory activation of both whole-words and constituents.
It is important to note that in all the research referred to above, participants are focused on individual words in a manner that is unlikely to be representative of their normal real-world lexical processing (seePollatsek et al., 2000). Visual lexical processing most often occurs in sentential and textual or discourse co-text and situational context. And, in such environments, any morphological processing of a single word would need to take its place among the many other processes and levels of processing that are active during text comprehension. Recently, studies have been reported that have attempted to bridge single word processing and sentence processing contexts. Mousikou and Schroeder (2019) found morphological effects using masked priming with affixed German words in isolation and also in sentence reading using the fast priming technique in eye tracking. In addition, Huang, et al. (2020), found a cross-modal constituent priming in a study in which Chinese compound words were heard in sentence context and visual lexical decision targets consisted of monomorphemic associates.
Studies such as these underline the advantages of linking the domains of single word processing and sentence processing. As we have indicated above, our goal in the present study is to go beyond the sentence level and to advance research that spans (and indeed bridges) the domains of single word processing and text processing by focusing on compound words in two-sentence texts such as those shown in 1), 2), and 3) above. This approach makes it possible to probe key features of morphological processing in a manner that both retains experimental control and enhances ecological validity. It also allows us to investigate whether morphological effects that have been observed in the study of single word processing could perhaps be artifacts of those types of studies. Indeed, it is critical that this possibility be investigated. In a single word processing experiment, there is, by definition, a single target word to process. It is therefore possible that the morphological effects that have been obtained do not generalize well to more natural language processing situations in which the processing of a single word is just one of many psycholinguistic activities being carried out. However, if these effects do generalize, we would have evidence that phenomena such as morphological constituent priming and morphological parsing play a role in the processing of text and, importantly also in the production of text (in which the words to be produced are part of the execution of a production plan (as opposed to an immediate early response to a surprise stimulus).
In the sections below, we describe the principles and procedures that we employed in order to bridge the investigation of lexical processing in single word experiments and lexical processing within texts. As we detail below, the present study focuses on English bimorphemic compound words. In our view, compound words represent an ideal stimulus type for an investigation such as this. The reason for this is that compounds are composed of identifiable constituents and those constituents can correspond to free-standing words.
Stimulus Design
Core Compound Stimuli
As pointed out by Dressler (2006) and Bauer (2016), compounds are core to word formation across languages. They thus provide a relatively simple and stable baseline from which to assess textual effects in lexical processing. A number of studies have shown that compound constituents are routinely activated in compound word processing (Libben 2014). There is also a relatively stable set of patterns that can be tracked across domains. One of these concerns the differences between morphological modifiers and heads. It is this difference that results in a compound such as houseboat being interpreted as a type of boat, but boathouse being interpreted as a type of house. In English, as a default, the morphological head is always the final element of the compound (with the exception of some unproductive patterns, e.g., daredevil, passport). In other languages however (e.g., Hebrew, Italian) it can be the initial element (Goral et al., 2008; Marelli et al., 2009).
Another matter that has been dominant in the compound processing literature concerns the extent to which a compound word is semantically transparent (e.g., Sandra, 1990; Zwitserlood, 1994; Ji, Gagné and Spalding, 2011; Davis et al., 2016). These factors have been reported to interact in English (Monahan et al., 2008; Fiorentino and Fund-Reznicek, 2009; Gagné and Spalding, 2009; Ji et al., 2011; Gagné and Spalding, 2014). This interaction was investigated in a compound typing task reported by Libben and Weber (2014). They classified compound words in terms of the extent to which the meaning of each constituent within the compound corresponds to its meaning as an independent word. Thus, a compound such as bedroom was classified as transparent-transparent (TT), a compound such as grapefruit was classified as opaque-transparent, a compound such as jailbird was classified as transparent-opaque, and finally a compound such as humbug, for which the meaning of neither constituent plays a role in the meaning of the compound as a whole, was classified as opaque-opaque (OO). They found that all four compound types showed elevated typing times at the compound constituent boundary. However, this boundary effect was attenuated for the OO compounds in comparison to the TT, OT, and TO compounds, which patterned together.
Libben (2014) has argued that in order to understand the dynamics of compound processing, it is important to distinguish between a word such as water in isolation and its homographic counterpart as a constituent water-in the compound waterfall. The reason for this is that a lexical priming experiment may, in fact, place these representations in competition. In an isolated word constituent priming experiment, however, it is not clear whether a constituent prime is perceived as a separate word, or a foreshadowing of a constituent. However, in the types of stimuli that we have employed in this study [e.g., sentences 1), 2) and 3) above], putative primes are presented as part of the text preceding a target compound word. Thus, there can be little debate over whether the prime is functioning as an independent word. In this way, the paradigm we employ, namely one in which compound processing is studied in sentential context creates a special opportunity to disentangle the potential facilitatory effects of repetition and the potentially inhibitory effects of competition.
The Creation of Two-Sentence Texts to Investigate Lexical Processing in Context
In the experimental paradigm reported in this paper, we developed balanced and structured two-sentence texts in order to explore compound processing in context. These two-sentence texts constituted the core stimuli in the study. Each of the two sentences was six words in length. Together, the sentences were designed to represent a coherent and cohesive (either minimally or very cohesive) text through which the interaction between lexical and textual effects could be investigated. A minimal text which consists only of two sentences has the advantage of excluding the influence of preceding but non-adjacent sentences.
To examine lexical influences in text, we ensured that, for each of our 56 six-word-sentence pairs, the first sentence of the pair served to establish the set of expectations that might affect the processing of the second sentence and, in particular, the target compound word within that second sentence. For all sentence pairs, the target compound word was always the second word of the second sentence. In all sentence pairs, this target word was immediately preceded by the word “The”, which, as a definite article, is itself a cohesive element. The definite article (which constituted the first word of every second sentence in the pair) was immediately preceded by one of the three types of antecedent conditions (neutral, semantically-related, lexical compound constituent).
These three conditions map onto the sentence pair triplet shown in Table 1. Together this triplet constitutes a within-item manipulation in which a single compound word (in this case, waterfall) is preceded by a sentence in which the final word completes the textual baseline control condition in which the first sentence of the text is textually (i.e., text-semantically) consistent with the second sentence of the text, but does not cue the target compound word explicitly. We therefore label this as the neutral condition. This is contrasted to the semantic condition in which the final word of the first sentence is a semantic associate of the target compound (in this case river - > waterfall) and thus creates an additional link of coherence. Finally, the lexical condition is one in which the last word of the first sentence corresponds to a constituent of the compound (in this case, water - > waterfall) and thus represents, in addition, lexical repetition as a means of strengthening cohesiveness.
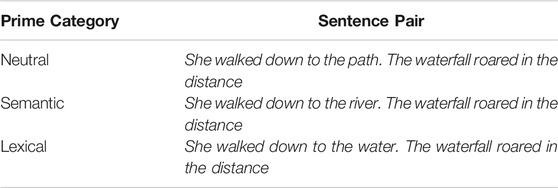
TABLE 1. A stimulus triplet. Each member of the triplet is composed of two sentences of six words each.
This stimulus structure shown in Table 1 constitutes the foundation of our investigation. By using this central structure, we sought to investigate morphological processing against the background of a common two-sentence minimal text structure. The common stimulus structure (two sentences of six words each) was designed to limit background variability in the experiment. The fixed positions of the compounds enabled us to ensure that they played a similar syntactic role in the sentence. Finally, the fixed position of the prime allowed us to standardize the distance of the prime to the target and to the sentence boundary, thus reducing textual and syntactic variability. Against this background, we could thus bring into the experiment, the key factors of transparency and morphological role (head vs. non-head) which, as we have noted above, have played an important role in the psycholinguistic literature on the online processing of compound words. To examine these effects, our stimuli were created so that half of the target stimuli were compounds containing two transparent (T-T) constituent morphemes (n = 28). The other half were partially transparent compounds, containing one semantically transparent and one opaque constituent. Of these, the modifier constituent was transparent (T-O) for 14 stimuli and the head was transparent (O-T) for the other 14 stimuli.
All prime words had the same lexical category within the first sentence of the text and were selected to be as comparable as possible in terms of lexical frequency. Lexical primes corresponded to the structures used in traditional constituent priming experiments in which a compound constituent serves as the prime and the entire compound serves as the target. However, because our design required that this priming relation be plausible in a two-sentence text, only semantic transparent constituents could be involved. The reason for this is that it would not be possible to create a coherent text in which the opaque constituent serves as the last word of the first sentence. Consider, for example, the first text with an OT compound shown in the Supplementary Material:
4. “He called everyday about the road/crack/hole. The pothole still hadn't been fixed.”
Although all three priming alternatives create a coherent text, the use of the opaque first constituent (pot) would not. Rather it would result in a situation in which either the text is noncoherent or the compound meaning would need to be changed: “He called everyday about the pot. The pothole still hadn't been fixed.”
For semantic primes, our design requirement that all priming conditions result in a coherent two-sentence text necessitated the use of semantic associates that were related to the compound as a whole, rather than any particular constituent. This can also be seen in the relation between the prime crack and the compound pothole in the example above.
Finally, the design resulted in the neutral primes being more related to the compound target than it would typically need to be in a single word priming experiment. The reason for this, again, is that it must result in a coherent two-sentence text (e.g., “He called everyday about the road. The pothole still hadn't been fixed”). The resulting priming design is summarized in Table 2.

TABLE 2. The three categories of compound stimuli and their associated prime words.
The stimulus design considerations discussed above and summarized in Tables 1, 2, enabled the development of the four experiments described below. These experiments call into two groups: Experiment 1 uses the Maze Task to examine priming effects in the reading of compounds in texts. Experiments 2a, 2b, and 2c all utilize the typing task as a window into within-word processing. Experiment 2a acquires baseline data for keystroke latencies in the typing of compound words. Experiment 2b adds a constituent priming paradigm to that typing paradigm, and Experiment 2c embeds primes and compound targets in two-sentence minimal texts. Together, these experiments are designed to address the following questions:
Question (a): Are priming effects found in the processing of individual compound words also evident when the compound is part of a text and the putative prime is an antecedent word within that text?
Question (b): Can the typing paradigm be used to examine constituent priming effects in the processing of compound words?
Question (c): Are the elevated keystroke latencies found at the morphological boundary in the typing of single compound words also evident when the compound is part of a text?
By addressing Question (a), we hope to assess the extent to which we can relate the highly constrained designs of lexical and morphological priming within single-word experiments to the links that can naturally occur among words within texts.
By addressing Question (b), we examine whether there is opportunity to use the typing task to both tap lexical activation (which is often revealed through priming effects) and lexical production (which we expect to be less driven by the characteristics of stimulus presentation). Moreover, if the typing task can be used in this way, it makes a rich set of dependent variables, linked to particular locations within a word, available for analysis.
Finally, by addressing Question (c), we seek to determine whether the morphological effects that have been linked to the typing of words in isolation are also found when words are typed in more natural texts. If this is the case, it would increase our confidence that these effects are relevant to the processing of “words in the world.”
Experiment 1: Compound Reading in a Modified Maze Task
In this experiment, we investigated whether compound processing is influenced by lexical semantic association (e.g., river → waterfall) and additional lexical constituent overlap (e.g., water→ waterfall) across sentences within minimal texts.
The experiment focused on reading times within a sentence. Building upon the report of Irsa et al. (2016) and the observations of Gallant and Libben (2020), we employed a Modified Maze Task. In this task, participants read text in a word-by-word manner as in a self-paced reading task. As noted by Forster et al. (2009), however, self-paced reading can lead participants to develop a reading rhythm. Because the focus of our study was a particular location (the compound word) in the text, we employed the maze task (Forster et al., 2009; Forster 2010). The task offers methodological advantages in the investigation of self-paced reading, particularly in cases in which researchers are targeting incremental effects.
As in self-paced reading, sentences in the maze task are presented word-by-word. However, each target word is presented alongside a distractor item. Participants must select the target to continue “weaving their way” through the sentence. Thus, each decision juncture has the effect of a “speedbump,” forcing participants to incrementally integrate each successive target into the sentence context and facilitating the observation of highly processing.
Gallant and Libben (2020) argue that lexical choice junctures need not be placed at every sentence position in order to observe localized lexical effects during reading. Rather, by selectively introducing lexical choices at key sentence positions, such effects can be observed without introducing additional processing load and the potential for spurious pre-activation caused by the introduction of numerous distractor items. In Experiment 1, it was this simplification of the maze task that was employed.
As is detailed below, the maze task enables a focused examination of the amount of time to choose a compound word (e.g. waterfall) over a distractor word (e.g., alfalfa) in sentence reading. We hypothesized that, if an inter-sentential “priming effect” were to be obtained, then we would see lower decision response times for the lexical and semantic conditions, as compared to the neutral condition. Such a finding would constitute an affirmative answer to the question of whether priming effects found in the processing of individual compound words are also evident when the compound is part of a text and the putative prime is an antecedent word within that text.
Method
Participants
Twenty-three native speakers of English (13 female, 10 male) residing in the United States participated in the experiment. Participants were recruited to the experiment using Amazon’s Mechanical Turk crowdsourcing platform. Access to the experiment was restricted such that only Mechanical Turk workers with experience (>100 tasks complete) and a high approval rating (>80%) were eligible to participate. All participants were required to have shown a response accuracy above chance (50%). The age of participants ranged from 23 to 69 with a mean of 37 (SD = 12). All participants had completed high school and 18 had received some post-secondary education. No visual or motor-articulatory impairments were reported by any participants.
Materials
The stimuli used in Experiment 1 were the 56 sentence pairs described above and 56 monomorphemic lexical items used as distractors in the modified maze task. In the design of our modified maze task, it was important that distractors be grammatically acceptable (i.e., nouns), but that they not be semantically and pragmatically plausible continuations of the text. This consideration ensured that response latencies would have a greater chance of reflecting prime-target properties. Accordingly, as a measure of experiment control, all three priming versions of a two-sentence text were linked to a single distractor item. In order to ensure the comparability of distractors across the set of two-sentence texts, the following materials development procedure was employed: The English Lexicon Project database (Balota et al., 2004) was used to create a list of potential distractor words that were comparable to the compound stimuli in terms of number of letters, mean bigram frequency, and wordform frequency. A subset of 56 distractors were randomly selected from this initial list, and those 56 distractors were randomly assigned to the 56 two-sentence texts. An example result of this procedure is shown in Table 3, which contains the stimulus triplet for the compound waterfall and its assigned distractor item (alfalfa).
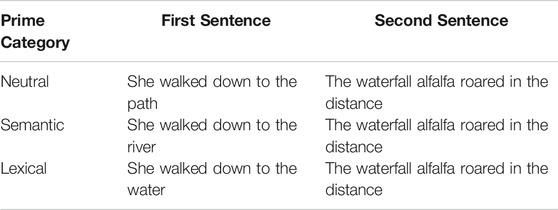
TABLE 3. Example priming conditions for one sentence-pair stimulus including the target and matched distractor (target = waterfall, distractor = alfalfa).
Procedure
The experiment was created in PsychoPy3 (Peirce et al., 2019) and hosted on the Pavlovia open behavioral-science platform. Participants accessed the experiment via a URL posted on Mechanical Turk. Each session began with a five-item demographic questionnaire asking for participants Mechanical Turk Worker ID, age, educational achievement, and native language. The final question asked participants whether they had any visual or motor-articulatory impairments.
Using the Modified Maze method, a single lexical choice juncture was placed at the target compound position (i.e., the second word of the second sentence). In each trial, participants read the sentence pairs word-by-word. The task began with a fixation point in the center of the screen, after which, the targets presented. Participants used the “up” arrow key to indicate that they were ready to proceed to the next target. This procedure continued until participants reached the lexical choice task, where the target compound and distractor appeared together in the middle of the screen separated by a ∼10 cm gap. The participants then used the “right” and “left” arrow keys to select the item they felt best fit the sentence context. Once they made their selection, the procedure continued as normal until the end of the second sentence. The response latency of each arrow key press was recorded. Trials in which the distractor was chosen instead of the target were marked as error trials. The order of trials was re-randomized for each participant.
Immediately after reading each sentence pair, participants were asked to rate its coherence on a 5-point scale. Participants were shown the whole sentence pair again and were provided with a description of both extremes on the scale: “1 = Together, the two sentences do not seem to make a story at all” and “5 = Together the two sentences make a connected, believable and interesting story.” Participants indicated their rating by clicking on a rating scale. They were able to change their response prior to submitting it by clicking on a different position. Once they were satisfied with their rating, they submitted it using the spacebar (at which time all selected ratings and response times were recorded).
Results
Trials with lexical choice RTs of greater than 2,000 ms (n = 263) were removed to ensure that the data reflected on-line lexical processing. All error trials were also removed (n = 79). The final subset of data used in the analysis contained 946 correct lexical choice responses from 23 participants.
A linear mixed effects model was created to determine whether the preceding co-text influenced lexical choice RT. The key variable included in this model is prime category, which represents the varying degree of textual coherence across sentence pairs in each stimulus triplet. Participant and compound noun were included as random effects and trial order and compound frequency were included as control variables. A summary of the model is provided in Table 4.
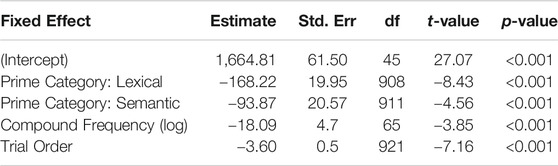
TABLE 4. Linear Mixed Effect model of lexical choice latency in the Experiment 1 maze task (neutral prime condition is on the intercept).
As is shown in Figure 1, model estimates indicated that lexical choices were significantly faster in both the semantic and lexical prime categories. Compared to the neutral condition, lexical choice RT was estimated to be 168 ms faster in the lexical prime condition (t = −8.43, p < 0.001) and 94 ms faster in the semantic prime condition (t = −4.56, p < 0.001). Using the “emmeans” package in R (Lenth, 2020), we obtained least square means for each prime condition and then used the “contrast ()” function to compare each level. There were significant differences among all levels (p < 0.0001).
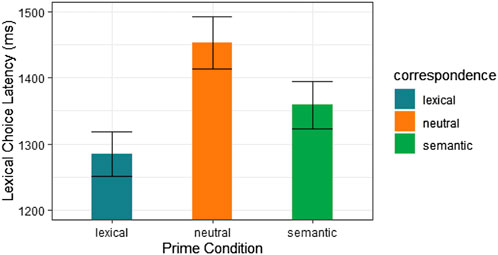
FIGURE 1. Model estimates of lexical choice latency (in milliseconds) to correctly choice a compound over a distractor in the modified maze task under three text priming conditions (lexical, neutral, semantic).
We thus observed that lexical choice was facilitated by lexical semantic association (e.g., river → waterfall) and additional lexical constituent overlap (e.g., water→ waterfall) between the last word of sentence 1 and the second word of sentence 2. We did not observe an effect of semantic transparency or an interaction of semantic transparency and prime condition. This variable was therefore not included in the model shown in Table 4 (which also improved model fit). Thus, for all compound types (TT, OT, and TO), recognition was affected by prior presentation of a transparent constituent. This finding is consistent with the view that the presence of semantic opacity in the compounds does not diminish the extent to which it is processed as a morphologically structured word (Libben, 2014). Finally, we interpret these results to show that lexical priming effects are revealed within the modified maze task paradigm and that these effects can span sentence boundaries within text.
Experiment 2A: Compound Word Typing
In Experiment 1 reported above, we found evidence that compound processing is affected by lexical semantic association and lexical constituent overlap across sentences within a minimal text.
In Experiments 2a, 2b, and 2c we use a typing production paradigm that enables us to build upon Experiment 1 in order to look inside the processing of compound words and thus address our second and third questions:
Question (b): Can the typing paradigm be used to examine constituent priming effects in the processing of compound words?
Question (c): Are the elevated keystroke latencies found at the morphological boundary in the typing of single compound words also evident when the compound is part of a text?
The Typing Task
Experiments 2a, 2b, and 2c all involve the examination of lexical production effects as revealed by the typing task. As has been shown in a number of recent investigations (e.g., Weingarten et al., 2004; Libben and Weber, 2014; Gagné and Spalding, 2016; Libben et al., 2016), typing presents an effective window into the processes of lexical production. As a natural and well-practiced production activity it has high ecological validity. Importantly, typing enables us to focus on particular locations within a word in a straightforward and effective manner.
It is important at the outset to underline the fact that typing is a language production activity. Thus, in contrast to activities such as lexical decision, which can be seen as providing a measure of lexical access, the typing task tracks the unfolding of language production over time. This is particularly relevant to an understanding of the processing of compound words, which are the focus of the present study. On average, it has been found that the typing of a letter in a compound word takes about 200–300 ms (Libben and Weber, 2014). Thus, the full production of an eight-letter compound word will likely take more than 1,600 ms. This is at least twice the amount of time that is normally seen in lexical decision latencies to compound words. During that period of processing time, the typing paradigm offers a window into ongoing cognitive activity and its potential relation to the characteristics of a word and those of its sub-elements. It has been shown that lexical constituent boundaries within compounds emerge as identifiable structures within compound typing because they are associated with larger keystroke intervals. In other words, participants would take more time to type the medial “f” in the compound waterfall, than they would take to type surrounding letters (Sahel et al., 2008; Libben and Weber, 2014; Gagné and Spalding, 2016). Thus, these studies have linked compound morphological structure to online language production. Under such a view, compound constituents can be considered to be units of planning and execution, so that the typing of a compound such as waterfall is carried out as the typing of water, pausing, and then the typing of fall. In Experiments, 2a, 2b, and 2c, we investigate whether this correspondence between keystroke latencies and compound morphological structure can be affected by lexical priming and by the text environment in which the compound is typed.
In all three experiments, our primary focus was the typing of the compound words that constituted the second word of the second sentence in each sentence pair (e.g., waterfall in the example shown in Table 1). In Experiment 2a, we examined the typing of the compound word in isolation. This allowed us to assess whether morphological constituent boundary effects are seen for these words when they are presented in isolation. In Experiment 2b, we built on this by examining priming effects in the single-word typing of these stimuli. To the best of our knowledge, this is the first reported study of constituent priming in compound word typing. Finally, in Experiment 2c, we were in a position to build on the single-word typing experiments to examine whether between-sentence priming effects are seen and to examine whether there are effects of morphological structure when compounds are typed in sentence context and how typing patterns may relate to participants’ ratings of the extent to which the sentence pairs form a story.
Method
Participants
Thirty-one participants (female = 19, male = 12) were recruited using Mechanical Turk. The same selection criteria as Experiment 1 were applied. All participants were native speakers of English residing in the United States. The age of participants ranged from 21 to 61 with a mean of 36 (SD = 10). The majority of participants were university graduates (n = 17). The remaining participants had either completed high school (n = 4), an MA (n = 5), or some college courses (n = 5). No participants reported any visual or motor-articulatory impairments.
Materials
The stimuli in this experiment were the 56 compound words that constituted the core of the study. All compounds were English nouns and were composed of two constituents. The compound words ranged in length from seven to twelve letters (mean = 8.4). The set of 56 compounds contained 28 fully transparent compounds and 28 that contained an opaque constituent (14 Opaque-Transparent and 14 Transparent-Opaque).
Procedure
This experiment was designed to collect baseline compound typing data against which we could compare the primed compound typing data from Experiment 2b and the compound typing within texts in Experiment 2c. Accordingly, the task was designed to contain as little experimental manipulation as possible. From the perspective of the participants, this experiment was a simple copying task. A compound word appeared in the middle of the computer screen and they were asked to type it immediately below. The stimulus remained on the screen during the typing process.
Each session began with the same 5-item demographic questionnaire from Experiment 1. There were 60 trials in total: four practice trials and 56 experiment trials. Thus, each compound was seen once and typed once. The order of compounds was in a different random order for each participant.
Each trial began with a 1,000 ms fixation point in the middle of the screen, after which the target word was presented. A marker (“>>>”) also appeared below the target, indicating the position on the screen where the participants typed input would appear. Participants copied out the word using a computer keyboard. When they had finished typing the word, they pressed the “return” key. This initiated the start of the next trial. Prior to pressing the “return key,” participants were able to correct typing errors using the “backspace” key. All keystrokes and their corresponding latencies were recorded.
Results
Data Preparation
To begin, trials containing typing errors were removed (n = 275). This included trials in which typing errors were made and subsequently corrected. One participant, with 0% typing accuracy, was removed as a result. To ensure that typed responses reflected on-line, automatic processing, trials containing inter-keystroke intervals (IKIs) greater than 2,000 ms (n = 91) were removed. Participants’ mean inter-keystroke intervals were analyzed to identify any potential outliers in terms of typing ability. A cut-off was set at three standard deviations from the group mean. However, no outlier participants were identified. After data trimming, the final data set used in the analysis contained 11,236 individual keystroke responses from 1,370 out of 1,736 trials (22% item removal). This rate accorded with previous patterns in the analysis of typing data—error rates tend to be high because any error in any part of the string requires its removal (because any error can affect typing times at other parts of the string).
Modeling of Within-Word Typing
Linear mixed effects modeling was used to analyze compound typing. Participant, compound word, and individual letter were included as random factors. Individual letter was included to capture variance originating from the arrangement of keys on the keyboard and the idiosyncrasies of participants’ typing styles and hand positions.
Our analysis focused on five letters within a compound word target—the two letters preceding the constituent boundary, the first letter of the second constituent (taken to be the constituent boundary position), and the two following letters. Thus, for the compound word waterfall, these five letters would be e, r, f, a, l, where the time taken to type the letter “f” was seen as the time taken at the constituent boundary. This was the key variable of analysis, allowing us to test whether there was elevation of typing times at the constituent boundary, as had been reported by Libben and Weber (2014) as well as Gagné and Spalding (2016).
The linear mixed effects model is shown in Table 5. As can be seen in this table, the model included the lexical frequencies of the free-standing words that corresponded to the compound modifier and compound head (e.g., water and fall for the compound waterfall). As is shown in the model, higher constituent lexical frequencies for the head constituent were associated with lower typing times. The effect of lexical frequency of the modifier did not reach significance (p = 0.07). We saw lower typing times associated with compounds that had higher modifier positional family sizes (i.e., the number of different compounds that begin with a particular constituent). In contrast, typing within compounds with longer heads was slower. Finally, as expected, the control variable, trigram frequency, was associated with lower typing times. A trigram consisted of the letter being typed and the letters immediately preceding and succeeding it. As a control variable, it captured the automaticity developed through repeated production of letter combinations.
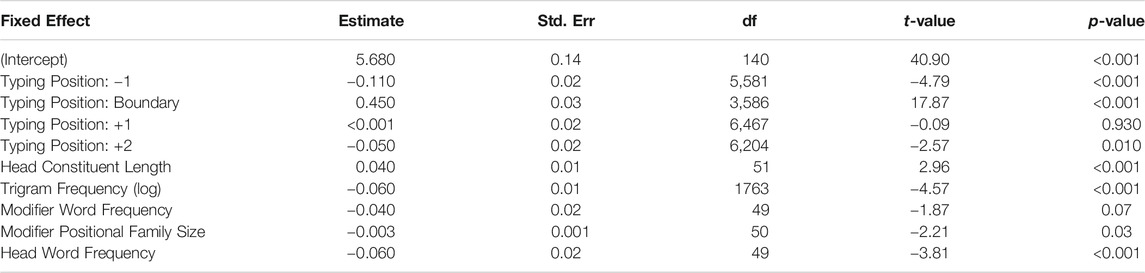
TABLE 5. Linear Mixed Effects modeling of inter-keystroke interval (IKI) latency at positions relative to the morpheme boundary (position -2 is the intercept) for typing in isolation in Experiment 2a.
Neither whole-word frequency nor semantic transparency showed significant effects and were, therefore, not included in the model, improving model fit.
Results provide evidence for morphological processes in the planning and execution of compound word typing. As shown in Figure 2, a significant elevation in IKI latency was observed at the boundary position between morphological constituents. This shows that the morphological structure of a compound word provides an organizational framework by which compounds can be decomposed, planned, and produced using constituent level production units. The presence of constituent boundary effect in typing latencies across TT, OT, and TO compounds is consistent with the results of Libben and Weber (2014).
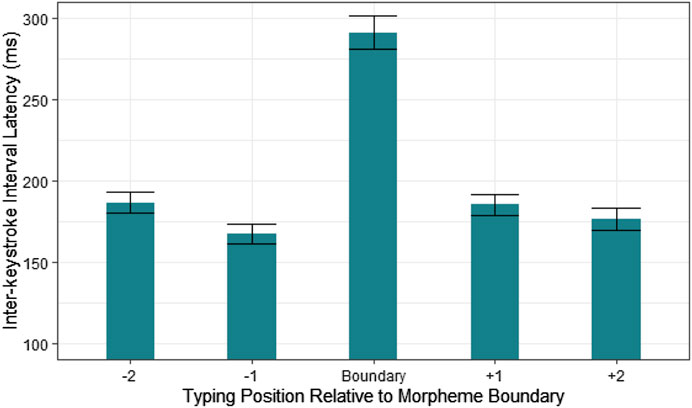
FIGURE 2. Model estimates of logged inter-keystroke interval (IKI) latencies for typing positions relative to the morpheme boundary in Experiment 2a. The boundary position is the first letter of the second constituent. Two positions both before and after the boundary are shown.
A significant facilitatory effect of modifier positional morphological family size was also observed (t = −2.21, p = 0.03), despite being highly colinear with modifier word frequency (−0.547). Following Wurm and Fisicaro (2014), we opted not to residualize these predictors, and instead, included both in the model. This result supports the notion that compound production is more fluent when the modifier constituent commonly occurs in that position.
Experiment 2b: Primed Compound Typing
In this experiment, we compared the typing of our core compound stimuli across three priming conditions: neutral, semantic, and lexical. The prime words used in this experiment were the same words that appear in the sentence conditions shown in Table 1. This was done to determine what types of priming effects are found when the compounds are produced as isolated words, thus setting the stage for our investigation of morphological effects in text typing in Experiment 2c. As we have stated above, to the best of our knowledge this is the first reported study of a constituent priming experiment which involves the typing of target stimuli. Thus, in addition to serving as a bridge to the typing of two-sentence texts in Experiment 2c, this experiment examined the extent to which constituent priming effects can be obtained when the dependent variable is keystroke latency within compounds.
Method
Participants
Twenty-nine participants (female = 4, male = 25) were recruited using Amazon Mechanical Turk. The same previous selection criteria were applied. All participants were native speakers of English residing in the United States. The age of participants ranged from 23 to 63 with a mean age of 39 (SD = 12). The majority of participants were university graduates (n = 20). The remaining participants had either completed high school (n = 2), an MA (n = 5), or some college courses (n = 2). No participants reported any visual or motor-articulatory impairments.
Materials
The core visual stimuli for Experiment 2b included the same 56 core compound stimuli from Experiment 2a as well as the 168 prime words which appear in position six of the sentence pair stimuli used in Experiment 1 (i.e., the final word of the first sentence). Each of the 56 core stimuli appeared in each of three prime conditions: lexical, semantic, and neutral, which were counterbalanced across sessions.
Procedures
The procedure mirrored that of Experiment 2, except for the inclusion of an unmasked prime which was presented visually prior to the compound stimulus. All participants saw all compound targets once, in one of three priming conditions. Each trial began with a 2,000 ms fixation cross in the center of the screen. This was followed by the presentation of the prime word for 100 ms. Following this, the screen went blank for 300 ms buffer, after which the compound stimuli were presented. After this point, the procedure was identical to Experiment 2a—participants typed the compound word. The compound stimulus remained on the screen during typing and the trial was terminated when the participant pressed the “return” key.
Results
Data Preparation
The same data preparation method was identical to that used in Experiment 2a. Trials containing typing errors (n = 261) and those containing IKI greater than 2,000 ms (n = 96) were removed. The resulting data set included 11,711 individual keystroke responses from 1,267 out of 1,624 trials. Thus, 357 trials (28%) were removed from the analysis.
Modeling
Linear Mixed Effect models were constructed for both typing onset latency and morpheme boundary IKI latency. As we have indicated above, the IKI at the constituent boundary during the typing of a compound word can be seen as reflecting the initiation of a motor plan for the typing of the second constituent of the compound. Interpreting the typing latency at the onset of typing, however, is somewhat more complex. The reason for this is that word-onset latency likely has a greater number of components. It has a forward-looking component because it involves the initiation of a motor plan for the typing of the first constituent (as well as the sequence of constituents for the word as a whole). In the paradigm that we have employed, however, it also has a retrospective component. Because typing can begin as soon as the compound appears on the screen, we expect that the time taken to initiate the typing of the compound will reflect the complexity of the processes involved in its recognition.
Typing Onset Latency
Our analysis of typing onset latency focused on three types of priming – neutral, semantic, and lexical. We also examined which of the two compound constituents was primed in the lexical condition. For TO compounds and the first set of TT compounds, this was always the first constituent. For OT compounds and the second set of TT compounds, this was always the second constituent. We also included a control variable, Trial Order, to capture practice effects over the course of the experiment. As can be seen in the linear mixed effects model in Table 6 and in Figure 3, lexical priming to the modifier (i.e., the first) constituent of the compound resulted in faster typing onset, as compared to all other priming conditions. Thus, compound typing onset is most affected when the first constituent to be typed was presented visually as a prime word. As is also shown in Table 6, participants took less time to initiate typing as they progressed through the experiment.

TABLE 6. Linear Mixed Effects modeling of typing onset latency of the modifier compound constituent for compounds typed in isolation in Experiment 2b.
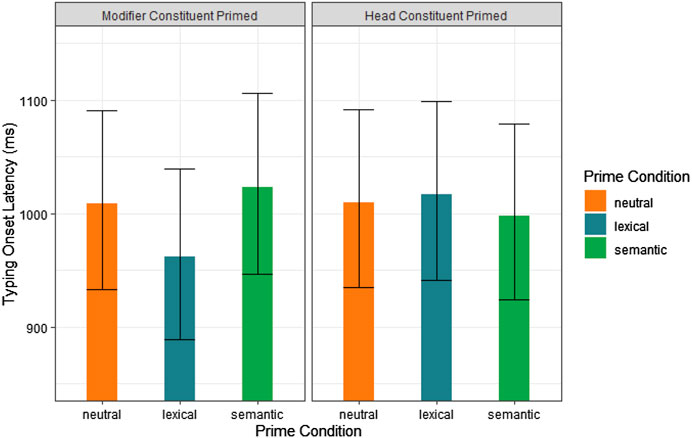
FIGURE 3. Model estimates of typing onset latencies for prime conditions and the constituent primed for compounds typed in isolation in Experiment 2b.
Within Word Typing
As in Experiment 2a, the analysis of typing times within the compound word was focused on the first letter of the second constituent (as the constituent boundary), the two letters leading up to it, and the two letters following it. As can be seen in the linear mixed effects model shown in Table 7, typing times were elevated at the boundary position, thus replicating the pattern seen in Experiment 2a. The pattern of effects for the additional variables also accorded with the pattern seen in Experiment 2a. Head frequency, modifier positional family size, and trigram frequency increased typing speed; head length slowed it down. The results with respect to the effect of modifier frequency were aligned with those of Experiment 2a—they showed a trend toward facilitation, but failed to reach significance (p = 0.14). Finally, as in Experiment 2a, within word typing times were not affected by whole-word frequency or compound transparency.

TABLE 7. Linear Mixed Effects modeling of inter-keystroke interval latency at positions relative to the morpheme boundary (position -2 is the intercept) for compound typing in Experiment 2b.
Experiment 2c: Sentence Typing
This experiment builds upon Experiment 1, 2a, and 2b by examining the production of the two sentence minimal texts used in Experiment 1 in a typing task. Our analysis focused on the typing of the compound word that occurred as the second word of the second sentence in the text. We examined whether the morphological effects that we observed in single-word typing are also seen when lexical production is part of the production of meaningful coherent text. This question is critical to our understanding of whether morphological processing could be an artifact of the attention that can be allocated to the internal structure of a word under conditions in which that word is presented in isolation.
We also examined lexical priming during the production of text. In a classical lexical priming paradigm, each trial contains only two stimuli—the prime and the target. Our goal in this experiment was to understand the extent to which the priming patterns observed in Experiment 2b would also be seen under more natural text processing conditions in which the prime target relations coexist with other within-text relations.
Method
Participants
Participants were recruited using Mechanical Turk with the same previous eligibility restrictions as were used for Experiments 1, 2a, and 2b. Data were collected from 61 (female = 33, male = 28) participants living in the United States. Participants ranged in age from 23 to 62, with an average of 40. One participant reported being near sighted. No other participants reported any visual impairments. Most participants were university graduates (n = 39). Other had completed high school (n = 8) or graduate school (n = 3). Some participants also indicated that they had completed some college courses (n = 9). Two participants did not respond to this question.
Procedure
Each session of Experiment 2c began with the same five-item demographic questionnaire used in previous experiments. Each trial began with a 2,000 ms buffer followed by the presentation of the target sentence pair as a single line of text centered in the middle of the screen. Thus, unlike Experiment 1, where sentence pairs were presented incrementally, here the entire pair was presented all at once. As participants typed out the sentence pair, their typed input appeared on the screen directly below the target next to a marker (“>>>”). The two-sentence text remained on the screen during the typing process. Each individual keystroke and its response latency relative to the beginning of the trial was recorded. Once participants had finished typing, they submitted their response by pressing the “return/enter” key. Participants then completed the same sentence pair rating task (as in Experiment 1) and went on to the next trial.
Materials
The same 56 core sentence pairs used in Experiment 1 were used in this experiment (see description in Table 1 and full stimulus list in the Supplementary Material).
Results
Data Preparation
Compound typing data were extracted from the overall data set and trimmed following the same criteria as were used for Experiment 1 and 2a. Trials containing typing errors prior to or during the typing of the compound word were removed (n = 622). Trials in which errors were made after the typing of the compound were retained. Correct trials containing IKI greater than 2,000 ms were also removed (n = 146). The final data set included 24,823 individual keystroke responses from 2,648 out of 3,416 trials (22.5% item loss).
Modelling of Typing Onset Latency
As in Experiment 2b, priming effects were examined in a linear mixed effects model using typing onset time as the dependent variable. This enabled us to assess whether the results accorded with those of Experiment 2b--namely that lexical primes associated with the compound modifier showed faster onset times. It is also important to note that, in addition to differing in terms of text vs. single word processing, this experiment differed from Experiment 2b in two other ways: First, in this experiment, both the prime and that target were typed, whereas, in Experiment 2b, only the target was typed. Second, in this experiment, the prime and target were visible from the outset of the trial, whereas, in Experiment 2b, the prime was removed from the screen before the target was shown.
To model the effect of priming of typing onset in text, a model was created using the same predictors from Experiment 2b. We also included two additional control variables. These were the average initial keystroke latency for the compound word in Experiment 2a, labelled “Baseline” in the model, and that word’s average naming latency from the English Lexicon Project (Balota et al., 2004). This variable was labelled “Mean Naming RT” in the model.
A summary of the model is shown in Table 8. As can be seen in this table, the pattern of priming effects corresponded to those seen for the typing of words in isolation. Lexical primes for the modifier constituent of the compound resulted in faster typing onset times (see Figure 4). We took the results of this experiment to indicate that lexical priming can be observed in two-sentence text typing. We note, however, that text typing is, by its nature, more complex than single word typing and therefore also likely subject to more performance variability. In addition, we note that the typing onset measure in this text typing experiment is less likely to reflect ease of word recognition because, in contrast to the single word typing task reported in Experiment 2b, compounds in this experiment are presented long before they are typed.
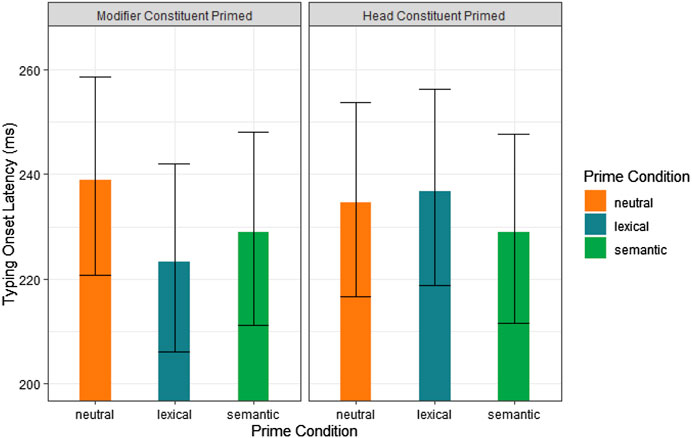
FIGURE 4. Model estimates of typing onset latencies for prime conditions and the constituent primed for compounds typed in sentence context in Experiment 2c.
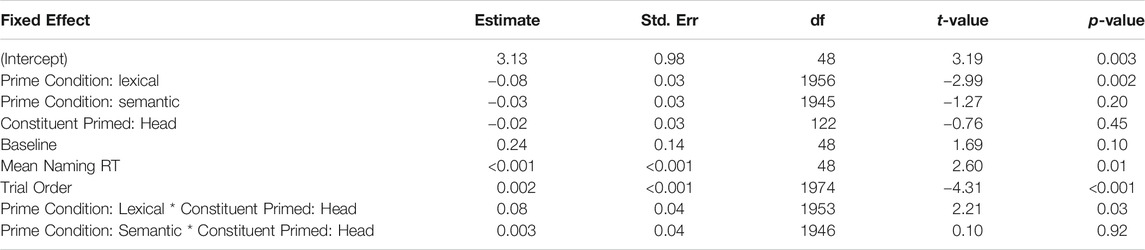
TABLE 8. Linear Mixed Effects modeling of typing onset latency of the modifier compound constituent for compound typed in two-sentence texts in Experiment 2c.
Modeling of Within-Word Typing
To investigate whether the constituent boundary effects during within-word typing found in Experiments 2a and 2b, were also evident when compounds were typed as part of a text, a model containing the same predictors as in Experiment 2a and 2b was constructed.
As in Experiments 2a and 2b, there was a significant elevation in IKI latency at the constituent boundary. In addition, the effects of modifier frequency, head frequency, modifier positional family size, and trigram frequency accorded with the effects seen in Experiment 2a and 2b. N this experiment, however, we did not see an effect of head length. We thus conclude that the morphological structure of a compound affects typing latencies during compound processing in text, as they do when words are typed in isolation. As in the previous experiments, neither whole-word compound frequency nor transparency were significant predictors (i.e., there was no difference among the categories of TT, OT, and TO compounds). A summary of this model is shown in Table 9.
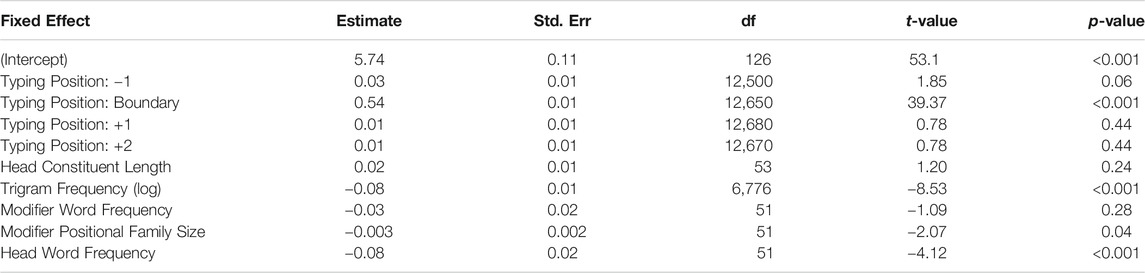
TABLE 9. Linear Mixed Effects modeling of inter-keystroke interval latency at positions relative to the morpheme boundary (position −2 is the intercept) for compound typing in sentence context in Experiment 2c.
Ratings of texts collected at the end of each trial were analyzed to determine whether the lexical priming conditions contributed in any way to participants’ perception of connectedness across sentences. Rating collected in Experiments 1 and 2c were combined. Several key control variables, such as response latency and prime effect were included. In order to adequately compare response latency across the two experiments, z-scores for the total response time of each trial were calculated on a participant-by-participant basis. These z-scores were used in the model to reflect individual variation in response latencies across trials. Since prime conditions were counterbalanced, individual priming effects for each participant could not be determined. Thus, mean response latencies for each compound in each condition was calculated in Experiments 1 and 2c. Priming effect coefficients were then obtained by dividing mean responses to each compound in the semantic and lexical conditions by those in the neutral condition. This produced a coefficient indicating the proportional difference in response latency across priming conditions that could be compared across all compounds and between both experiments.
Coherence ratings were converted to individual z-scores to capture the degree of individual rating variation from trial-to-trial. A linear mixed effect model was created for this dependent variable. Participants and items were included as random effects, and prime effect and response latency were included as control variables. The summary of the fixed effects for this model are presented in Table 10.

TABLE 10. Summary of the linear mixed effect model of participants ratings of sentence pairs (prime condition: neutral is on the intercept).
The estimates produced by this model indicate that participants perceived sentence pairs to be more connected when they exhibited lexical constituent overlap or lexical semantic association between lexical items spanning the sentence boundary. Compared to neutral, the highest relative ratings were observed in the lexical priming condition (t = 5.9, p = <0.001). A significant effect was also observed in the semantic condition (t = 2.9, p = 0.005). This pattern of results is shown in Figure 5 and accords with our expectations. As we discuss again below, this accord raises the question of the directionality of causality. The data do not, in themselves, reveal whether it is the lexical co-activation that makes the text feel more coherent or whether more coherent texts enable greater lexical coactivation. At present, it seems to us that both may play a role. In this way, the accord between our text rating results and text processing results may reflect the interactive nature of language processing within texts.
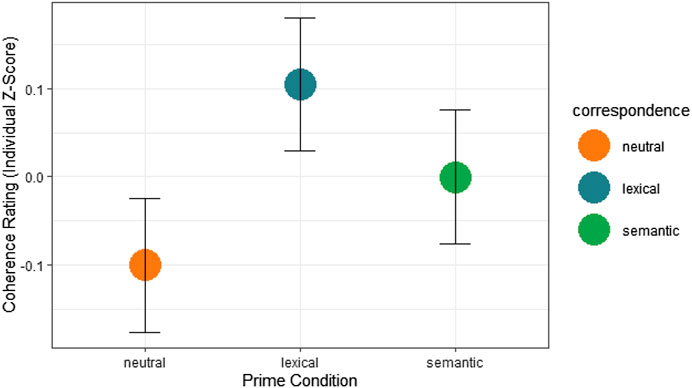
FIGURE 5. Model estimates of sentence pair coherence rating by prime condition. Ratings are based on z-scores for each participant, indicating how much each rating deviated from that participant’s mean rating.
General Discussion
In this study, we set out to understand morphological effects in compound processing by examining production and priming in a more natural linguistic context-one that goes beyond the processing of words in isolation.
The core stimuli in the study were two-sentence texts. Each sentence in the text was composed of six words. In each text, the second word of the second sentence was a compound noun. These compound words were the focus of our study.
We constructed the two-sentence texts so that we could control the relationship between the last word of the first sentence and the second word of the second sentence (which was always a compound noun). There were three types of relationships: neutral (e.g., path → waterfall), semantic (e.g., river → waterfall), and lexical (e.g., water → waterfall). In Experiment 1, a maze task was employed to determine whether the speed with which the word such as waterfall could be chosen as a correct sentence continuation would differ depending on whether it was preceded in the text by a neutral, semantically related, or lexically related antecedent. Results indicated significant differences among all three levels, with the fastest response times associated with lexical relations. In Experiments 2a, 2b, and 2c, this finding was further investigated within a typing paradigm. In Experiment 2a, we verified that the compound words in our minimal texts showed a typing profile in which the time required to type individual medial letters within a word is greatest at the boundary between morphological constituents. In other words, in the typing of the compound word waterfall, it takes longer to type the letter “f” than it does to type adjacent letters. We interpreted this to constitute a signature of morphological processing – a signature that was present irrespective of the semantic transparency of the compound. In Experiment 2b, we verified that this signature remains under all conditions of priming (neutral, semantic, lexical). In addition, we found that production onset (i.e., the speed with which the first letter of the compound word was typed) was faster in the lexical condition than in either the semantic or neutral conditions (which did not differ from each other).
Having established, through Experiments 2a and 2b, the typing profiles for the core compound stimuli in isolation, we were in a position to examine whether those profiles persisted in the processing of text. This was the goal of Experiment 2c. In this experiment, participants were presented with the entire two-sentence texts and were asked to type them. We found that the morphological boundary effects seen in the typing of isolated words were replicated in the typing of words in context. We also found lexical priming effects in typing onset that were parallel to those found in single compound word typing (Experiment 2b). We thus conclude that the typing task can be used to investigate priming relations for compound words presented both in isolation and in text and that the morphological boundary signature that we observed in the typing of single compound words is also found in the typing of text. In our view, this constitutes evidence that the role of compound constituents as planning units in production is not restricted to single word processing. Indeed, our expectation is that the underlying dynamic would be in the opposite direction. It seems to us that morphological structure enables the language production system to reduce the size of the unit to be produced. Thus, morphology may play a greater role in situations in which processing demands are increased (e.g., in the free composition of text).
Turning our attention to priming, although we found constituent facilitation effects in text typing that bear similarity to the constituent priming effects found in visual priming experiments, it seems to us that the priming paradigm – so prevalent in the single-word processing literature – may have different underlying dynamics when transposed to a text processing environment. This is even more so when it is text production that is being considered. One reason for this is that the typed production task is not primarily a recognition task in the way that, for example, lexical decision is. The traditional interpretation of priming effects in a lexical decision task is that priming facilitates the “activation” of a target word. In this way, it can be considered to be a bottom-up facilitator. In our two-sentence texts, we expect that such bottom-up effects would be quite weak. On average, more than 2 s elapsed between the onset of the prime (as the last word of sentence 1) and the target (as the second word of sentence 2). However, because it is text that was being processed, it seems to us to be reasonable to posit that a function of a prime word in our minimal texts (and in a more generalized text environment) would be to set up expectations that can be described as “top-down” processing.
This leads us to a consideration of how the properties of text processing may be related to the processing of smaller linguistic units such as words and word constituents. Our first relevant finding in this domain of inquiry is that the priming patterns that we had embedded into the sentence stimuli, affected not only the lexical processing of the compounds under investigation, but also the ratings of the text as a whole. Specifically, lexical primes were associated with the highest text ratings. This was followed by semantic primes and then by neutral primes. These findings underline, in our view, the fact that although language activity can be analyzed at distinct levels (e.g., at the level of word structure, sentence structure, and text structure), real-world language processing is characterized by the integration of information and the creation of meaning.
Methodological Considerations
It seems to us that the modified maze task that we employed in Experiment 1 has great potential to unlock the interplay of lexical processing and text processing effects. This paradigm, introduced by Gallant and Libben (2020) builds upon the maze task created by Forster et al. (2009). As noted by Forster (2010), the maze task provides more reliable data than self-paced reading in cases in which there is a need to isolate processing times at specific text locations. In our study that need was critical, as we wished to use the task to investigate whether prime condition differences in Sentence 1 influenced target word processing in Sentence 2.
The use of the typing task in Experiments 2a, 2b, and 2c demonstrates the ease with which the task enables researchers to “scale up” experiments, while retaining task similarity and dependent variable comparability. Moreover, the typing task is naturally suited to studies that focus on incremental processing. Because it allows for within-word measurements, it is naturally suited to the investigation of morphological processing which is, by definition, a within-word phenomenon. The typing task also opens up new opportunities for conceptualizing the dynamics of lexical processing. For example, throughout this study, we have conceptualized morphological processing in compound production as advantageous. Yet, it seems that the signature of that advantage is a decrease in speed –perhaps best characterized as a dysfluency at particular locations. In this way, typing offers us the opportunity to relate the location of demands on computational resources to properties of the language produced and thus, potentially, to ongoing psycholinguistic processes.
Our maze task finding corresponded to the expected pattern of processing ease. The target compound word was selected with greatest speed when it was preceded by a constituent prime. This was followed by the condition in which the compound was preceded by a semantic prime. The neutral prime condition resulted in the longest maze task latencies.
Conclusion
This study examined three questions: 1) Are priming effects found in the processing of individual compound words also evident when the compound is part of a text and the putative prime is an antecedent word within that text? 2) Can the typing paradigm be used to examine constituent priming effects in the processing of compound words? 3) Are the elevated keystroke latencies found at the morphological boundary in the typing of single compound words also evident when the compound is part of a text?
Our interpretation of the data obtained from four experiments is that the answer to all the questions is “yes.” We found corresponding constituent priming effects and morphological processing effects across experiments and, indeed, almost identical patterns in the analysis of maze task speed and the analysis of text ratings. We see this as suggesting the confluence of text effects and lexical effects (which, themselves typically bundle together form and meaning overlap). Thus, it may be advantageous to consider priming in sentence and text environments as more a matter of “interactive fit”, which, by definition cannot be unidirectional.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Ethics Statement
The studies involving human participants were reviewed and approved by Brock University Research Ethics Board. The patients/participants provided their written informed consent to participate in this study.
Author Contributions
All authors have contributed to the research design, to the development of stimuli, and to the writing of this paper.
Funding
This research was supported by the Social Sciences and Humanities Research Council of Canada Partnership Grant 895-2016-1008 (“Words in the World”).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We wish to thank Tamara Irsa-Timofeev for her stimulus development, testing and analysis that led to the study of text processing in German reported in Irsa, Dressler and Libben (2016) as well as her subsequent work on English. We also wish to thank Katharina Korecky-Kröll from the Comparative Psycholinguistics Working Group of the Department of Linguistics of University of Vienna for her support. We thank Andrea Versteeg at Brock University for her work in the development and piloting of earlier versions of English stimuli that led up to this study.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2021.646454/full#supplementary-material.
References
Baayen, H., and Schreuder, R. (1999). War and peace: morphemes and full forms in a noninteractive activation parallel dual-route model. Brain Lang. 68, 27–32. doi:10.1006/brln.1999.2069
Balota, D. A., Cortese, M. J., Sergent-Marshall, S. D., Spieler, D. H., and Yap, M. J. (2004). Visual word recognition of single-syllable words. J. Exp. Psychol. Gen. 133, 283–316. doi:10.1037/0096-3445.133.2.283
Beaugrande, R. D., and Dressler, W. U. (1981). Introduction to text linguistics. London, United Kingdom: Longman.
Clinton, V., Carlson, S. E., and Seipel, B. (2015). Linguistic markers of inference generation while reading. J. Psycholinguist. Res. 45 (3), 553–574. doi:10.1007/s10936-015-9360-8
Davis, C. P., Libben, G., and Segalowitz, S. J. (2019). Compounding matters: Event-related potential evidence for early semantic access to compound words. Cognition 184, 44–52.
Dederding, H-M. (1983). Wortbildung und Text. Zur Textfunktion (TF) von Nominalkomposita (NK). Zeitschrift für Germanistische Linguistik 11, 49–65. doi:10.1515/zfgl.1983.11.1.49
Dressler, W. U. (2006). “Compound types,” in The representation and processing of compound words. Editors G. Libben , and G. Jarema (Oxford:Oxford University Press), 23–44.
Ehrlich, M.-F. (1991). The processing of cohesion devices in text comprehension. Psychol. Res. 53, 169–174. doi:10.1007/bf01371825
Fiorentino, R., and Fund-Reznicek, E. (2009). Masked morphological priming of compound constituents. Ment. Lexicon 4 (2), 159–193. doi:10.1075/ml.4.2.01fio
Forster, K. I. (2010). Using a maze task to track lexical and sentence processing. Ment. Lexicon 5, 347–357. doi:10.1075/ml.5.3.05for
Forster, K. I., and Davis, C. (1984). Repetition priming and frequency attenuation in lexical access. J. Exp. Psychol. Learn. Mem. Cogn. 10, 680–698. doi:10.1037/0278-7393.10.4.680
Forster, K. I., Guerrera, C., and Elliot, L. (2009). The maze task: measuring forced incremental sentence processing time. Behav. Res. Methods 41, 163–171. doi:10.3758/brm.41.1.163
Gagné, C. L., and Spalding, T. L. (2014). Typing time as an index of morphological and semantic effects during English compound processing. Lingue e linguaggio 13 (2), 241–262. doi:10.1418/78409
Gagné, C. L., and Spalding, T. L. (2009). Constituent integration during the processing of compound words: does it involve the use of relational structures? J. Mem. Lang. 60 (1), 20–35. doi:10.1016/j.jml.2008.07.003
Gagné, C. L., and Spalding, T. L. (2016). Effects of morphology and semantic transparency on typing latencies in English compound and pseudocompound words. J. Exp. Psychol. Learn. Mem. Cogn. 42, 1489–1495. doi:10.1037/xlm0000258
Gallant, J., and Libben, G. (2020). Can the maze task be even more amazing? Adapting the maze task to advance psycholinguistic experimentation. The Mental Lexicon 15 (2), 366–383.
Giraudo, H., and Grainger, J. (2001). Priming complex words: evidence for supralexical representation of morphology. Psychon. Bull. Rev. 8, 127–131. doi:10.3758/bf03196148
Goral, M., Libben, G., Obler, L. K., Jarema, G., and Ohayon, K. (2008). Lexical attrition in younger and older bilingual adults. Clin. Linguist. Phon. 22 (7), 509–522. doi:10.1080/02699200801912237
Graesser, A. C., MillisMillis, K. K., and Zwaan, R. A. (1997). Discourse comprehension. Annu. Rev. Psychol. 48, 163–189. doi:10.1146/annurev.psych.48.1.163
Graesser, A. C., Singer, M., and Trabasso, T. (1994). Constructing inferences during narrative text comprehension. Psychol. Rev. 101 (3), 371. doi:10.1037/0033-295x.101.3.371
Huang, J., Tsang, Y-K., Xiao, W., and Wang, S. (2020). Morphosemantic activation of opaque Chinese words in sentence comprehension. PLoS One 15 (8), e0236697. doi:10.1371/journal.pone.0236697
Irsa, T., Dressler, W. U., and Libben, G. (2016). “Competition and cooperation between top-down and bottom-up processing of compounds,” in Paper presented at the 17th International Morphology Meeting, Vienna, Austria, February 18–February 21, 2016.
Ji, H., Gagné, C. L., and Spalding, T. L. (2011). Benefits and costs of lexical decomposition and semantic integration during the processing of transparent and opaque English compounds. J. Mem. Lang. 65 (4), 406–430. doi:10.1016/j.jml.2011.07.003
Kintsch, W. (1998). Comprehension: a paradigm for cognition. Cambridge, UK: Cambridge University Press.
Kintsch, W., and van Dijk, T. A. (1978). Toward a model of text comprehension and production. Psychol. Rev. 85, 363–394. doi:10.1037/0033-295x.85.5.363
Kuperman, V., Schreuder, R., Bertram, R., and Baayen, R. H. (2009). Reading polymorphemic Dutch compounds: toward a multiple route model of lexical processing. J. Exp. Psychol. Hum. Perception Perform. 35, 876–895. doi:10.1037/a0013484
Lenth, R. (2020). emmeans: estimated marginal means, aka least-squares means. package version 1.5.0NAvailable at: https://CRAN.R-project.org/package=emmeans.
Libben, G., Curtiss, K., and Weber, S. (2014). Psychocentricity and participant profiles: implications for lexical processing among multilinguals. Front. Psychol. 5, 557. doi:10.3389/fpsyg.2014.00557
Libben, G., Gagné, C., and Dressler, W. U. (2020). “The representation and processing of compounds words,” in Word knowledge and word usage: a cross-disciplinary guide to the mental Lexicon. Editors V. Pirreli, I. Plag, and W. U. Dressler (Berlin, Germany: De Gruyter Mouton).
Libben, G., Jarema, G., Derwing, B., Riccardi, A., and Perlak, D. (2016). Seeking the -ationalinderivationalmorphology. Aphasiology 30, 1304–1324. doi:10.1080/02687038.2016.1165179
Libben, G. (2006). “Why study compounds? An overview of the issues,” in The representation and processing of compound words. Editors G. Libben , and G. Jarema (Oxford:Oxford University Press), 1–21.
Libben, G. (2014). The nature of compounds: a psychocentric perspective. Cogn. Neuropsychol. 31, 8–25. doi:10.1080/02643294.2013.874994
Libben, G., and Weber, S. (2014). “Semantic transparency, compounding, and the nature of independent variables,” in Morphology and meaning. Editors F. Rainer, U. Wolfgang, F. Gardani, W. U. Dressler, and H. C. Luschützky (Amsterdam, Netherlands: John Benjamins).
Pollatsek, A., Hyönä, J., and Bertram, R. (2000). The role of morphological constituents in reading Finnish compound words. J. Exp. Psychol. Hum. Perception Perform. 26 (2), 820. doi:10.1037/0096-1523.26.2.820
Marelli, M., Crepaldi, D., and Luzzatti, C. (2009). Head position and the mental representation of nominal compounds. Ment. Lexicon 4 (3), 430–454. doi:10.1075/ml.4.3.05mar
Monahan, P. J., Fiorentino, R., and Poeppel, D. (2008). Masked repetition priming using magnetoencephalography. Brain Lang. 106 (1), 65–71. doi:10.1016/j.bandl.2008.02.002
Mousikou, P., and Schroeder, S. (2019). Morphological processing in single-word and sentence reading. J. Exp. Psychol. Learn. Mem. Cogn. 45, 881–903. doi:10.1037/xlm0000619
Peirce, J., Gray, J. R., Simpson, S., MacAskill, M., Höchenberger, R., Sogo, H., et al. (2019). PsychoPy2: experiments in behavior made easy. Behav. Res. Methods 51 (1), 195–203. doi:10.3758/s13428-018-01193-y
Sahel, S., Nottbusch, G., Grimm, A., and Weingarten, R. (2008). Written production of German compounds: effects of lexical frequency and semantic transparency. Written Lang. Literacy 11 (2), 211–227. doi:10.1075/wll.11.2.06sah
Sandra, D. (2019). Morphological units: a theoretical and psycholinguistic perspective. Oxford encyclopedia of linguistics. Oxford, UK: Oxford University Press.
Sandra, D. (1990). On the representation and processing of compound words: automatic access to constituent morphemes does not occur. Q. J. Exp. Psychol. 42 (3), 529–567. doi:10.1080/14640749008401236
Smith, V., Barratt, D., and Zlatev, J. (2014). Unpacking noun-noun compounds: interpreting novel and conventional foodnames in isolation and on food labels. Cogn. Linguist. 25 (1), 99–147. doi:10.1515/cog-2013-0032
Taft, M., and Forster, K. I. (1976). Lexical storage and retrieval of polymorphemic and polysyllabic words. J. Verbal Learning Verbal Behav. 15 (16), 607–620.
Verhoeven, L., and Perfetti, Ch.. (2008). Advances in text comprehension: model, process and development. Appl. Cogn. Psychol. 22,.293–301. doi:10.1002/acp.1417
Weingarten, R., Nottbusch, G., and Will, U. (2004). Morphemes, syllables, and graphemes in written word production. Trends Linguist. Studies Monographs 157, 529–572. doi:10.1515/9783110894028.529
Wurm, L. H., and Fisicaro, S. A. (2014). What residualizing predictors in regression analyses does (and what it does not do). J. Mem. Lang. 72, 37–48. doi:10.1016/j.jml.2013.12.003
Keywords: text, cohesion, coherence, compounds, morphology, priming, typing, maze task
Citation: Libben G, Gallant J and Dressler WU (2021) Textual Effects in Compound Processing: A Window on Words in the World. Front. Commun. 6:646454. doi: 10.3389/fcomm.2021.646454
Received: 26 December 2020; Accepted: 15 February 2021;
Published: 05 May 2021.
Edited by:
Carlo Semenza, University of Padua, ItalyReviewed by:
Christina Manouilidou, University of Ljubljana, SloveniaValantis Fyndanis, Cyprus University of Technology, Cyprus
Copyright © 2021 Libben, Gallant and Dressler. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gary Libben, Z2xpYmJlbkBicm9ja3UuY2E=