Abstract
Conversation partners tend to copy elements of each other’s utterances during a spoken interaction. This article investigates possible asymmetries in this adaptive process. We study game-based dialogues between Flemish and Dutch speakers, who officially speak the same language, but who can differ in their default use of words and in their pronunciation. Our general hypothesis, mainly based on previous studies that focused on long-term forms of adaptation and on previous studies on exchanges between categorical and variable language users, is that Flemish speakers adapt more in interactions towards Dutch speakers, than vice versa. The article describes two experiments using variants of the same experimental paradigm. Experiment 1 investigates lexical adaptation and tests whether Flemish speakers indeed adapt more to Dutch ones than the other way around. Experiment 2 looks at how adaptation of lexical forms relates to adaptation in terms of pronunciation. Both experiments bring to light that Flemish speakers indeed converge more to Dutch ones, than vice versa, especially in terms of choice of lexical forms.
Introduction
Linguistic Adaptation
During a spoken interaction, it sometimes happens that one person, when uttering a specific sentence, takes over linguistic forms that his or her dialogue partner had produced in a prior turn. For instance, a speaker of English may initially feel inclined to use the word “mountain” to refer to a peak in the landscape, but then switches to “hill” after having noticed that the other conversant is using the latter word to indicate that piece of land that is higher than its surroundings. Such forms of adaptation generally appear to proceed smoothly: speakers tend not to explicitly negotiate about the choice of words, but spontaneously and implicitly come to a lexical agreement. In addition to adaptation at the level of the word, speaking partners may converge regarding a whole range of other linguistic features as well. There is work that shows that people can also copy each other’s syntactic structures (Levelt and Kelter, 1982), pronunciation (Babel 2012; Harrington et al., 2019), prosodic features (Babel and Bulatov, 2011; Nilsenova et al., 2009) and nonverbal characteristics, such as posture (Chartrand and Bargh, 1999), gestures (Mol et al., 2012) and facial expressions (Mui et al., 2018). The current paper focuses on the convergence between speaking partners in terms of lexical forms and pronunciation, and on the possible asymmetries in levels of adaptation during interactions between native speakers of Dutch from the Flemish part of Belgium and from the Netherlands.
One question that has intrigued different researchers working in this domain regards the degree of automaticity in adaptation, i.e., whether it should be viewed as an automatic, basically unconscious process or as one that is more reflective in nature and implies an explicit decision component. Many studies that promote the first view have been framed in terms of the model by Pickering and Garrod (2004), where adaptation is largely explained as a result of a perception-behavior link in human interaction. More specifically, a central idea in the model is that a conversation partner, when contributing to the ongoing discourse, is “primed” to re-use linguistic structures that he or she has perceived during the prior interaction with the interlocutor. It has been argued that such immediate and in essence mechanistic copying behavior is important in order to make the sequences of interactions in a conversation proceed in an efficient and time-saving manner. That is, conversants are viewed as “lazy speakers,” who seek to minimize efforts to compute linguistic structures themselves, or to search for words in their mental lexicon, and instead simply take over lexical, syntactic or other features from the dialogue partner’s turns. In this view, alignment at its core is thus an automatic process whereby production and comprehension are coupled, which does not involve any advanced listener modeling. Additional support for the latter comes from work that shows that priming behavior has also been documented for speakers with impoverished social skills (Branigan et al., 2016), which strengthens the viewpoint that it represents a basic characteristic of people’s communicative behavior that does not require deep cognitive or social processing.
A strong interpretation of the model by Pickering and Garrod may lead to the prediction that conversation partners have an almost equal and symmetric role in the adaptive process. The schematic representation of the various stages of production and comprehension of their alignment model (their Figure 2) indeed visualizes a completely bidirectional architecture with two interlocutors who contribute in identical manners to the ongoing interaction. However, it is intuitively clear that there are specific situations in which complete and symmetric linguistic convergence is unlikely to happen. Indeed, different scholars have argued that the extent to which speakers adapt to their conversation partners is often mediated by certain beliefs they have about those partners. In particular, there may be social factors that come into play, especially due to differences in the status of the conversation partners: for instance, speakers of some languages may use markedly different linguistic structures depending on whether they address a person who has a higher or lower status, so that copying behavior is unlikely to happen in interactions between dialogue partners who represent different hierarchical positions. Along the same lines, Bourhis and Giles (1977) found a tendency for speakers to diverge when a talker’s ethnic identity was devalued. Gregory and Webster (1999) analyzed 25 dyadic interviews between a talk-show host and his guests, and found that the guest’s status relative to that of the host determined the degree of to which the guest’s pitch would converge to that of the host: higher-status guests changed less than their lower-status counterparts. In parent-child interactions or in interactions between partners who are not equally fluent, one can also observe or expect that adaptation is prohibited or asymmetric. For instance, if a person thinks that the addressee is a non-native speaker, he or she may avoid using rare words and use more common ones instead to name a specific object. Also, speakers have been shown to align more when they are made to believe their communication partner is a computer (rather than a human being), and align even more with “basic” computers compared to “advanced” ones, suggesting that the degree of a speaker’s adaptation depends on his/her beliefs about the interlocutor’s communicative capabilities (Branigan et al., 2010; Branigan et al., 2011). One specific factor that is related to this status differential that we address in the current study is concerned with another speaker-related variable that may have an impact on the amount of convergence, i.e., whether a speaker tends to use only one variety of a specific language, or is likely to use multiple variants.
Language Varieties
Languages across the globe do not come in one form, but generally comprise a range of varieties, where sometimes one variety is considered to represent the norm. For instance, one can distinguish different kinds of Englishes, both in a global sense as Englishes spoken on the different continents can be quite distinct, but also more locally within a specific community, as there can be variation between dialects and more standard forms, for instance. While some speakers are accustomed to using only one variety, irrespective of the specific context, others may switch between varieties, depending on the addressee or the specific situation. For instance, speakers may use a dialect in their encounters with friends and family members, but use a standard variety during more formal interactions at work. Likewise, a speaker of Belgian French may use words like “septante” and “nonante” to refer to “seventy” and “ninenty” with fellow Belgians, but use “soixante-dix” and “quatre-vingt-dix” when talking to French citizens during a trip to Paris; a French citizen may stick to the French variety, irrespective of the context or whether the addressee uses the same or a different variety of French. The research question we want to tackle in this article is concerned with linguistic adaptation in interactions between conversation partners who use different variants of the same language, while still being mutually intelligible. A review of the literature reveals quite a mixed pattern as to what one could expect.
First, there is work that has investigated interactions between variable users, meaning speakers who make use of multiple phonological, lexical or syntactic variants, and more categorical speakers, referring to speakers who are more constrained in their use of various linguistic forms. Fehér et al. (2019) found that the former type of speakers are more likely to accommodate to the latter, than vice versa. That is, variable users have a tendency to become more categorical, whereas categorical speakers are not likely to become more variable. That study was based on experimentally obtained results with artificial language data, where speakers were first trained to acquire some linguistic structures, with one group primarily being trained with multiple variants (variable) and another with single variants (categorical). Afterwards, variable and categorical speakers participated in a game-based experiment in which it was tested which of the two speaker types would accommodate more. While this study presented some interesting findings, it needs to be noted that the experimental data may differ from natural languages in that there was no intrinsic normative difference (e.g., good versus bad variants) between the different structures to which participants were exposed. Interestingly, however, there are studies to show that the level of adaptation between language users who represent different varieties may be mediated by certain beliefs or qualifications speakers may have about the language they are using, as one variety may be perceived as being more formal or prestigious.
An interesting case at hand is provided by a series of studies of Lüthi and Vorwerg (2015) who looked at priming effects in speakers of Swiss German. The Swiss participants in their study could typically be labeled as variable speakers, as they were both proficient in the Swiss version of German and in Standard German (Hochdeutsch). The study revealed that Bernine German speakers were very likely to be lexically primed when being exposed to stimuli in Bernine German, in line with effects in other monolingual studies. In comparison, the effects were drastically smaller when these speakers were primed with stimuli in Standard German. This was probably due to the sociolinguistic status of Standard German, which is often perceived by native speakers of German in Switzerland as being a distant, formal and even foreign language, which would prohibit alignment. In any case, the lack of priming effects was not a result of some inherent syntactic factor that would inhibit the effect. Indeed, when the experiment was conducted with German speakers of Paderborn, who use Hochdeutch as their default variety, they showed effects which were comparable to what could be observed with Bernine German speakers being primed with stimuli of Bernine German. In other words, while speakers of Swiss German may be variable in that they can switch between different varieties, that finding does not automatically imply that they would adapt to a more categorical speaker of a different language variety, such as a speaker of Hochdeutch, presumably because the status of that other language has an inhibitory effect that blocks adaptation. In view of such results, the current paper wants to explore adaptive patterns in interactions between speakers of Dutch from the Flemish part of Belgium and from the Netherlands.
Netherlandic Dutch vs. Belgian Dutch
In the current article, we explore alignment in interactions between speakers of Dutch from the Flemish part of Belgium and the Netherlands. Citizens of the Netherlands and the Flemish part of Belgium officially speak the same language, namely Dutch. However, the varieties of Dutch spoken in these two communities, i.e., Belgian Dutch (BD) and Netherlandic Dutch (ND), can diverge in terms of lexical, phonological and syntactic properties (e.g. Martin and Smedts, 2009; Haeseryn, 2013; van Bezooijen and Gerritsen, 1994; van Heuven and van de Velde, 2010; van de Velde, 1996; van de Velde 2010; van de Velde and van Hout, 2002; van Keymeulen, 2013; Geeraerts et al., 1999). Examples of lexical differences are the Dutch and Belgian way to describe a microwave oven (BD: microgolf oven; ND: magnetron) or a couch (BD: zetel; ND: bank). In addition, some referring expressions may be lexically identical, but pronounced differently. For instance, words like “croissant” are only pronounced in the French way by BD speakers; on the other hand, words like “tram” more often get an English-like pronunciation by ND speakers.
The general question of the article is whether BD and ND speakers take over each other’s lexical choices or forms of pronunciation during a spoken interaction. Our overall hypothesis is that conversations between BD and ND speakers exhibit more adaptation from the former speakers towards the latter ones, than the other way around. We have a number of reasons for taking this specific assumption. First, Dutch is generally considered to be a pluricentric language (Geeraerts and Van de Velde, 2013; Geeraerts, 2017; De Caluwe, 2013, 2017), because it has more than one center that determines the linguistic norm for that specific community. While citizens of the Netherlands would generally assume that the variant spoken in Haarlem represents the “best” version of Dutch, there is less consensus among Flemings about a variant of a specific city which could be taken as their linguistic norm (Smakman 2012). In addition, the variety of Dutch spoken in Belgium is traditionally viewed as the less-dominant version, and it is known that “convergence is generally in the direction of the dominant varieties when speakers of different national varieties communicate.” (Muhr, 2012, p 41). Second, diachronic research has shown linguistic convergence between Flanders and the Netherlands, especially regarding the lexicon (e.g., Geeraerts et al., 1999). However, this convergence has been asymmetrical, with Belgian Dutch adapting more to Netherlandic Dutch, and it has been argued that the evolution of convergence has come to a halt in recent time (Daems et al., 2015). Third, Flemish speakers have comparatively fewer problems to understand speakers from the Netherlands, than the other way around (Impe, 2010). Likewise, van Bezooijen and van den Berg (1994) found that citizens of Netherlands have comparatively more problems to understand dialects spoken in the western part of Flanders than those spoken in the Netherlands. Finally, both the Netherlands and Flanders have witnessed a process of structural and functional dialect loss, but this loss has started much later in Flanders than in Netherlands (Vandekerckhove, 2009), which may imply that Flemish speakers are more often exposed to different language varieties, and may therefore also be more sensitive to variation in language.
Previous studies on convergence between BD and ND speakers have been concerned with adaptive patterns between the two language varieties that are long-term, as they dealt with processes of convergence that happen in the course of years that can explain gradual changes in language use. The current study is different because it focuses on immediate adaptation within a spoken interaction. In addition, it remains to be investigated how possible levels of linguistic adaptation relate to each other. The current paper will primarily look at convergence regarding the choice of words, and see how that relates to adaptation in terms of pronunciation. In general, we would expect more lexical than phonological convergence, given that a lexical difference may be perceived as being more drastic than a phonological difference, and consequently the former is more likely to lead to problems of understanding. In addition, we want to explore whether the lexical and phonological forms of adaptation are completely independent of each other (e.g. by having speakers who do adapt lexically, but do not change their pronunciation), or whether we may observe some “boosting effects,” whereby lexical adaptation triggers adaptation in terms of pronunciation as well, and vice versa.
For this research, we conducted two experiments that use the same paradigm. Experiment 1 tests to what extent speakers from the two communities converge in terms of lexical forms. Experiment 2 again looks at lexical adaptation, but additionally tests whether speakers also adapt in terms of the way they pronounce words, and whether this phonetic or phonological adaptation has a boosting effect on lexical convergence. Before we discuss the actual experiments, we first present the experimental paradigm that we used in both experiments to elicit different forms of adaptation between BD and ND speakers.
Paradigm
The experiments to be described below made use of the same paradigm, presented as a variant of the well-known battle ship game, which was played between pairs of participants. The paradigm was developed in order to elicit spontaneous interactions that would not involve much metalinguistic reasoning as participants would primarily be engaged in the game itself. The game was always played via a skype connection, with a Dutch and Flemish participant at two different locations in either Flanders or Netherlands, who could hear but could not see each other, nor could they see the other participant’s game materials. Before the game started, the Flemish and Dutch participant were only informed that they would have to play against another person on a different site, but they were not told about the location of that site or about the other person’s nationality or language background. However, post-hoc questionnaires revealed that they could immediately detect the linguistic origin of the other speaker already in the first minute after they had been introduced to each other, and had heard the other person speak.
The procedure for both experiments below was identical, and was always administered by two different experimenters, i.e., one on the Flemish and one on the Dutch side, who would use the respective variety of the participants (BD or ND) to interact with them before the game to introduce themselves and to explain the details of the game that they were about to play. First, before they were introduced to each other and after having read and signed the informed consent documents, the participants were separately shown a number of icons that were going to be used in the actual game later on, and they were asked to name all the objects that they would see. This step was explained to them as a check to make sure that participants would recognize the objects and be able to name them, in order to avoid confusion afterwards. Figure 1 shows some exemplary icons that are representative of the materials used for the chessboard game. If there was a certain item they would not immediately recognize or name falsely (which happened only rarely), the experimenter could give a hint as to what it was meant to depict, without actually naming it. In reality, this preliminary round of descriptions was included to obtain our baseline data, i.e., to learn about the default way in which participants name or pronounce the words they use to describe objects before the interaction, in order to be able to measure whether their default descriptions would have altered during the game.
FIGURE 1

Examples of icons used in the experiment that are likely to be named differently by BD and ND speakers (top row) or to receive different pronunciations by BD and ND speakers (bottom row).
The participants were then informed about the game itself. They were each given a chessboard (of which the rows and columns would be marked with letters and numbers, respectively), a set of seven green cards and eight red ones, and a set of 40 cards on which iconic representations of specific objects were depicted (like a microwave oven, a couch, etc.). All these cards had the exact same size as the white and black squares of the board. Figure 2 shows a typical set-up for the game that one participant would be presented with. At the start of the game, both participants at either side would have to put seven green cards and one red one on eight black or white squares of their respective chessboards. They were free to choose which squares they wanted to pick for that purpose. Then they were told that the basic idea of the game is that participants need to instruct each other on where to put specific cards with depicted objects on the chessboard. Participant B would earn a point if participant A instructs him or her to put an object on a green card, but loses a point if that object lands on a red card, while no points are won or lost when the card lands on any of the other squares. As an additional game element, the participants have to replace one of the green cards with a red one with every new set of icons, until all the green cards are replaced with red ones. As a result it becomes increasingly more difficult to earn points, and the likelihood of losing points becomes higher. They are not expected to inform each other on where a specific card had landed on a chessboard, but the experimenter on their side kept track of the number of points earned or lost. A typical instruction could sound as the Dutch equivalent of an utterance like “Take the microwave oven, and put it on B5.”
FIGURE 2

Typical set-up for one of the two game players with a laptop with skype connection, and set of icons to be named during the game, and the chessboard (with green and red squares) on which the icons have to be placed.
After the explanation of the game, the experimenters start the skype connection and both participants are introduced to each other and play the game. When they had finished the total experiment, the experimenters would inform them about their scores and who had won the most points. The skype connection would then be closed, and participants would separately be briefly interviewed about how they had experienced the game, and about their impressions of the other participant. It turned out that basically none of the participants had been aware that the real purpose of the experiment was to explore to what extent they would adapt to the other participant (they usually reported that they thought that the game was about guessing behavior, or strategic game choices), even when they indicated that they had immediately recognized that the other game player was either Dutch or Flemish.
Figure 3 visualizes the structure of the total experiment. The whole experiment consisted of two rounds of four games each, and each game was played in two turns. For each game, 10 icons had to be described by the two participants in two turns, and that set was replaced with 10 new ones in a next game, etc. The 40 icons of games 1, 2, 3 and 4 are re-used in the second round and therefore identical to those of games 5, 6, 7 and 8, respectively. Within a game, one of the participants (A) starts as the instructor, and describes where all the icons are to be put on the chessboard of the other participant (B), who is thus a follower in that turn. Participants are free to choose the order in which items are named. After all icons are described by A, the icons are removed from the chessboard, and then B acts as the instructor with the same set of icons, and A becomes the follower. The order of the roles of instructor and follower switch between every next game, so that the person who was instructor in the first turn of game 1 becomes follower in turn 1 of game 2, but now with a new set of icons. In round 2 (starting with game 5), the same icons of game 1 are re-used, except that the person who was instructor in game 1 now becomes follower in game 5, etc. The whole experiment typically would take between 30 and 40 min. In the following, we describe 2 experiments that made use of the paradigm described above.
FIGURE 3
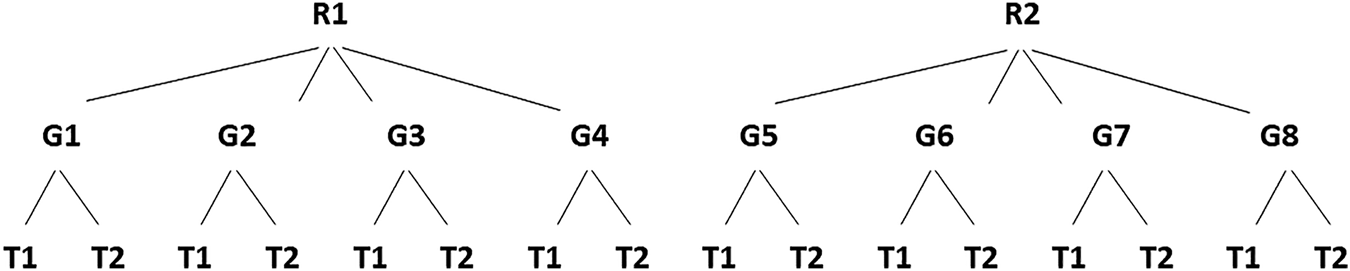
Schematic representation of the experimental paradigm which consists of 2 rounds (R1, R2) with each 4 games (G1 to G8) that each have two turns (T1, T2). Icons used in round 1 are re-used in round 2.
Experiment 1
Materials and Methods
Stimuli
The stimuli for this experiment consisted of 20 icons that could easily be recognized as to what these were supposed to visualize, and were expected to be named differently by speakers of BD and ND. Typical examples are words (that were pretested regarding such differences) these speakers typically use to name a microwave oven (Flemish: microgolf oven; Dutch: magnetron), a cooking pot (Flemish: pot; Dutch: pan), or a couch (Flemish: zetel; Dutch: bank). For a full list of stimuli of experiment 1, see Supplementary Appendix A. The 20 test items were mixed with 20 others that were not expected to lead to differences between BD and ND speakers, such as the names for the moon (maan) or a tree (boom). The icons were distributed over the different games of the experiment so that each game would include 10 icons (of which 5 were test items) (see Figure 3). It appeared that BD and ND speakers, before they started the actual game, used different names for the icons in 72% of the cases.
Participants
The participants were recruited in Tilburg (Netherlands) and Antwerp (Belgium), and consisted of 20 students of the Communication and Information Science program at Tilburg University and 20 students of Interior Design of the University of Antwerp, respectively, who all participated on a voluntary basis. The Dutch students would receive course credits, while the Flemish ones participated by invitation through social networks, and could choose a candy snack after the experiment. Despite the differences in type of education and rewards, all participants on either side of the border appeared to share a similar degree of enthusiasm for participating, as revealed by their feedback in post-experiment interviews. All speakers were predominantly raised in the Tilburg and Antwerp region, which both belong to what is known by dialectologists as the Brabantian dialect area of Dutch (Taeldeman and Hinskens, 2013).
Labeling
Given that game players could lexically adapt in different ways, we considered the following four categories: 1) complete adaptation are cases where one conversation partner no longer uses the word he or she produced before the experiment (e.g., bankkaart) and replaces it with the word that the partner used (e.g., pinpas); 2) alternative adaptation are cases where speakers describe an object by mentioning both the BD and ND variant (bankkaart, pinpas); 3) partial adaptation comprises cases where a speaker no longer uses the original description, but uses a variant which resembles that of the partner, but is not identical (e.g., bankpas instead of bankkaart) and 4) corrective adaptation refers to cases where a speaker first uses the description he used initially, but then uses an alternative after noticing that a partner has a problem of understanding (e.g., a speakers first uses the word bankkaart, and then switches to pinpas because the addressee didn’t comprehend the first word).
Dependent Variable
The dependent variable for the analyses below consisted of the proportion of cases where a participant has adapted to the other participant, whereby all four forms of adaptation specified above are combined into one dependent variable. This was done in the following manner. First, we determined per pair of game players to what extent they diverged initially (before the start of the experiment) in the names they had used to refer to specific sets of icons, whereby we only focused on the test items listed in Supplementary Appendix A. To this end, we combined the references to icons into 4 sets of 10 items, i.e., icons of games where a player had either started or followed a game (so those of game 1 plus 3, and of games 2 plus 4 for Round 1, and those of games 5 plus 7, and games 6 plus 8 for Round 2), and for each set, we determined the number of cases where a pair of game players had diverged in their naming of the icons before the start of the game. Theoretically, they could diverge on all 10 items or none at all, where in practice it turned out that game players did not differ initially for all 10 items. Next, we counted the number of cases, for each separate set, where a game player adapted lexically during the actual experiment (in terms of the 4 forms of adaptation specified above) to that of his/her speaking partner, and expressed that as a proportion of the total number of cases per set on which they diverged initially. The proportions of adaptation were lognormalized so that they could be analyzed with analyses of variances, and converted back to proportions for presentation purposes.
Results
The data were analyzed with a 2 × 2 × 2 × 2 repeated measures anova with Nationality (two levels: Belgian, Dutch), Round (two levels: Round 1, Round 2) and Turn (two levels: first turn, second turn) as within-subject factors and Whostarts (two levels: BD player starts, ND player starts) as between-subject variable, and the lognormalized proportion of lexical adaptations per participant as dependent variable. The average percentages of lexical adaptation for BD and ND speakers for different experimental settings are given in Figure 4. The analysis revealed a main effect of Nationality (F(1,18) = 25.850, p <0.001, = 0.590): overall, it turns out that BD speakers adapt more to ND ones, than the other way around (BD: 34% vs ND: 10%). In addition, there was a main effect of Turn (F(1,18) = 25.112, p <0.001, = 0.582), whereby players during the first turn (when they initiate the game) appear to adapt less than in the second turn (after they had been follower in the first turn) (turn 1: 17% vs. turn 2: 27%). There was also a significant 2-way interaction between Round and Turn: (F(1,18) = 15.948, p < 05, =0.271): in round 1, there was a relatively large increase in adaptation in the second turn compared to the first one, whereas in round 2, the amount of adaptation in first and second turn was more similar (Round 1: turn 1: 12% and turn 2: 29% vs. Round 2: turn 1: 22% and turn 2: 25%). All other 2-way and higher-level interactions turned out not to be significant. If we look at the distribution of the different kinds of adaptation (see Figure 5), we also observe a marked difference between BD and ND speakers: in a large majority of the cases, the BD speakers opt for complete adaptation, i.e., by no longer using the word they had chosen before the experiment started, but replacing it with the word of the game partner; the ND speakers, however, do not have such a strong preference for this most drastic form of adaptation.
FIGURE 4
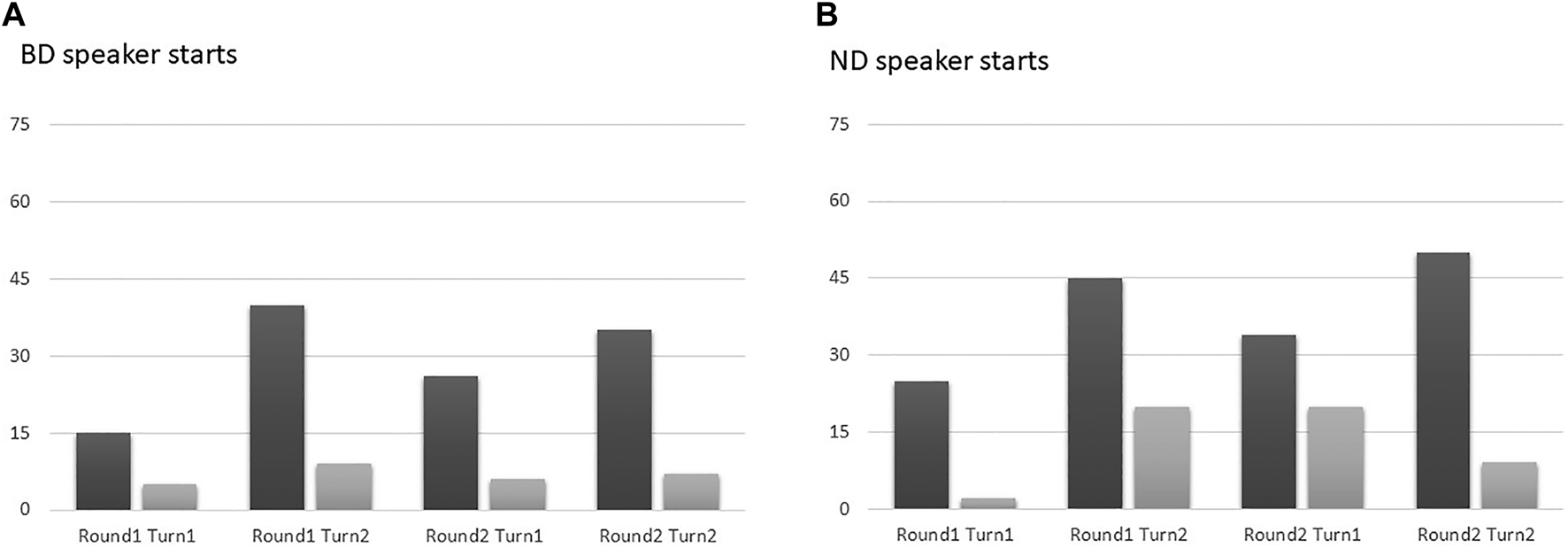
Percentage of lexical adaptation by BD speakers (black bars) and ND speakers (gray bars) for different stages of the experiment, when either the BD speaker (A) or ND speaker (B) started the game (Experiment 1).
FIGURE 5
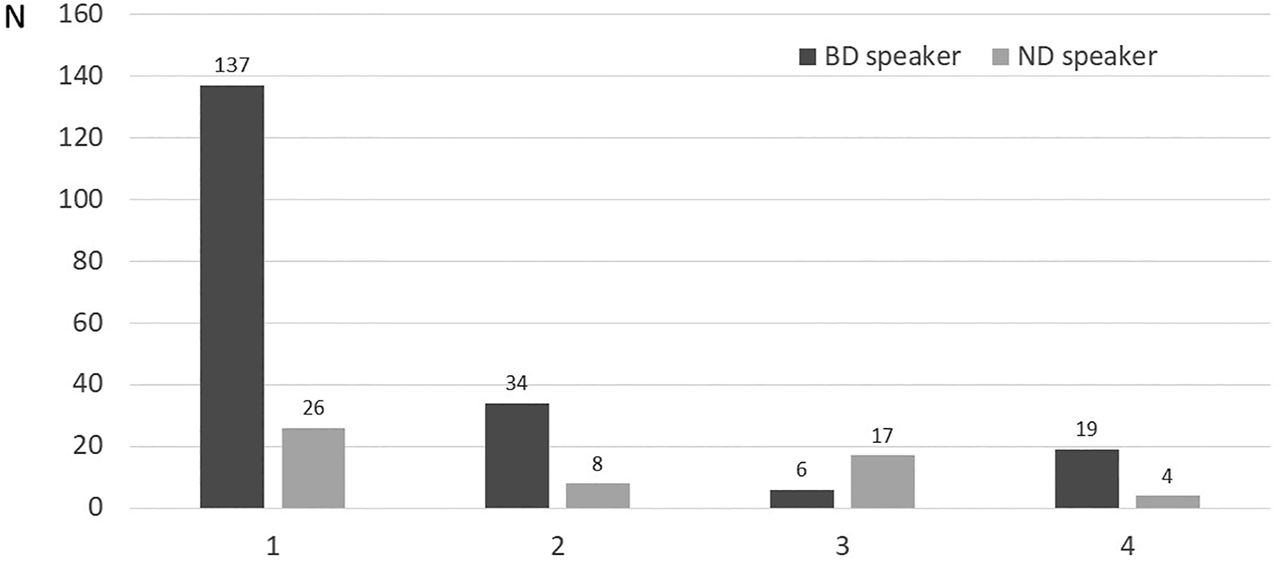
Distribution of different forms of adaptation for BD and ND speakers: (1) complete adaptation, (2) alternative adaptation, (3) partial adaptation and (4) corrective adaptation. Further explanations in the text.
Discussion
Experiment 1 focused on the degree to which BD and ND speakers would adapt to each other in terms of the words they use to name specific objects. Adaptation was operationalized as a case where a speaker would switch to a lexical item that was different from the one that he or she had used before the experiment started to the one that the game partner had used. Our experiment shows clear cases of lexical adaptation, but also reveals clear asymmetries in that respect, as, in line with our expectations, BD speakers more often adapt to their ND partner, than vice versa. In addition, there was an effect of Turn as well: while it was to be expected that speakers adapt in their second turn when they become instructor and have to name a set of objects they had heard in the first turn from their game partner, there also appears to be a bit of adaptation already in the first turn. In Round 2, this may be less surprising as the icons had already appeared in the previous Round. But in Round 1, this also happens, suggesting that speakers sometimes exhibit a prescient form of adaptation, as they switch to a vocabulary they expect to match their speaking partner better, whose linguistic background they have guessed based on the first exchanges. It is also interesting to note that BD and ND speakers are distinct in the distribution of type of adaptations. Only BD speakers appear to exhibit a strong preference for the most drastic, complete form adaptation (e.g. replacing their initial word with the one used by the game partner), while the ND speakers tend to more evenly use “milder” forms of adaptation as well (partial, alternative and corrective ways, see Figure 4).
Experiment 1 only looked at lexical adaptation, but, as stated in the general introduction, conversation partners may also align regarding other aspects of linguistic structure, such as syntax or pronunciation. One issue that naturally comes up is how lexical forms of adaptation relate to those other forms of linguistic adaptation, e.g., whether one is stronger than the other. Along the same lines, one may ask whether one form of adaptation may boost that of another level as well, i.e., that alignment at one level may trigger alignment at another level as well. To explore these questions, the next experiment focuses on adaptation in terms of pronunciation in addition to that at the lexical level.
Experiment 2
Materials and Methods
Stimuli
Half of the items used for the second experiment were identical to the test items of experiment 1, i.e., icons that were likely to receive different lexical names by BD and ND speakers (see Supplementary Appendix A). While experiment 1 mixed those items with more neutral ones that would normally not be named differently, the current experiment replaced the latter set with icons that were likely to receive lexically identical names, but would be pronounced differently by BD and ND speakers (see appendix B). More specifically, inspired by the overview of van der Sijs (1996), we included 1) a set of French loan words that tend to be pronounced in a French way only by BD speakers (e.g. parfum (perfume)), 2) a set of English loan words that tend to be pronounced in an English way only by ND speakers (e.g. tram), 3) a set of words that would be pronounced with a diphthong by ND speakers and without a diphthong by BD speakers [e.g. prei (leeks)] (Geeraerts, 2001), and 4) a set of words that would differ in the position of the word stress, depending on whether they would be pronounced by BD or ND speakers (e.g. bikini) (Taeldeman and van de Velde, 1997). BD and ND speakers, before they started the actual game, used different names for the icons in 77% of the cases, and pronounced words differently in 79% of the cases. These percentages for lexical and pronunciation adaptation are comparable with each other, and though slightly higher, to those for lexical adaptation in experiment 1.
Participants
The participants, who were all different from those of Experiment 1, were recruited in Tilburg (Netherlands) and Antwerp or Louvain (Belgium), and consisted of 20 students of Communication and Information Science from Tilburg University, 15 students of Applied linguistics of the University of Antwerp, and five from the department of Business Communication of the Humanities Faculty of Louvain University. The Dutch students again participated for course credits, while the Flemish ones participated on a voluntary basis, and could choose a candy snack after the experiment. All speakers came from regions where the Dutch or Flemish variant of the Brabant dialect is spoken.
Labeling and Dependent Variable
The labeling procedure and computation of the dependent variable for lexical adaptation were identical to those of experiment 1. For adaptation in terms of pronunciation, we used similar procedures, except that we did not distinguish between four categories as with lexical adaptation, as it turned out that speakers, when adapting, opted only for a pronunciation that was entirely different from the one they had used before the game started (cfr category one of lexical adaptation). The labeling of the pronunciation was determined by the fourth co-author, and checked by the first author, and turned out to be trivially easy, as it consisted of deciding on pronunciations that were categorically very distinct (e.g. labeling whether or not a word as “parfum” was produced with a French pronunciation, or whether a word like “bikini” had received an accent on the first of third syllable).
Results
Similar to experiment 1, the data were again analyzed with a 2 × 2 × 2 × 2 repeated measures anova with Nationality (two levels: Belgian, Dutch), Round (two levels: Round 1, Round 2) and Turn (two levels: first turn, second turn) as within-subject factors and Whostarts (two levels: BD player starts, ND player starts) as between-subject variable, and the lognormalized proportion of adaptation as dependent variable. The average percentages of lexical adaptation and adaptation of pronunciation for BD and ND speakers for different experimental settings are given in Figures 6, 7. For lexical adaptation, the analysis revealed a main effect of Nationality [F(1,18) = 35.529, p <0.001, = 0.664]: again, it turns out that overall BD speakers adapt more to ND ones, than the other way around (BD: 40% vs. ND: 15%). In addition, there was a significant main effect (which was not significant in experiment 1) of Round [F(1,18) = 8.565, p <0.01, = 0.322], as speakers appear to adapt more to the game partner in Round 2 than in Round 1 (Round 1: 21% vs. Round 2: 34%); and, similarly to experiment 1, there was a main effect of turn [F(1,18) = 22.353, p <0.001, = 0.554], with more adaptation in the second turn (turn 1: 26% vs. turn 2: 29%). Again, as in experiment 1, there was a significant 2-way interaction of Round and Turn [F(1,18) = 15.969, p < 001, =0.470], which was due to the fact the effect of turn was large in round 1, whereas in round 2, the level of adaptation was more similar in the turns, and even slightly lower in turn 2 (Round 1: turn 1: 10% and turn 2: 42% vs. Round 2: turn 1: 33% and turn 2: 26%). Unlike in experiment 1, there were 2-way interactions between Round and Whostarts [F(1,18) = 5.461, p < 05, = 0.322] and between Turn and Whostarts [F(1,18) = 4.459, p < 05, = 0.199], whereby it appeared that the relative increase in adaptation from round 1 to round 2, and from turn 1 to turn 2, was larger when the BD speakers started the first game, than when the ND speakers started the first game. All other higher-level interactions turned out not to be significant.
FIGURE 6
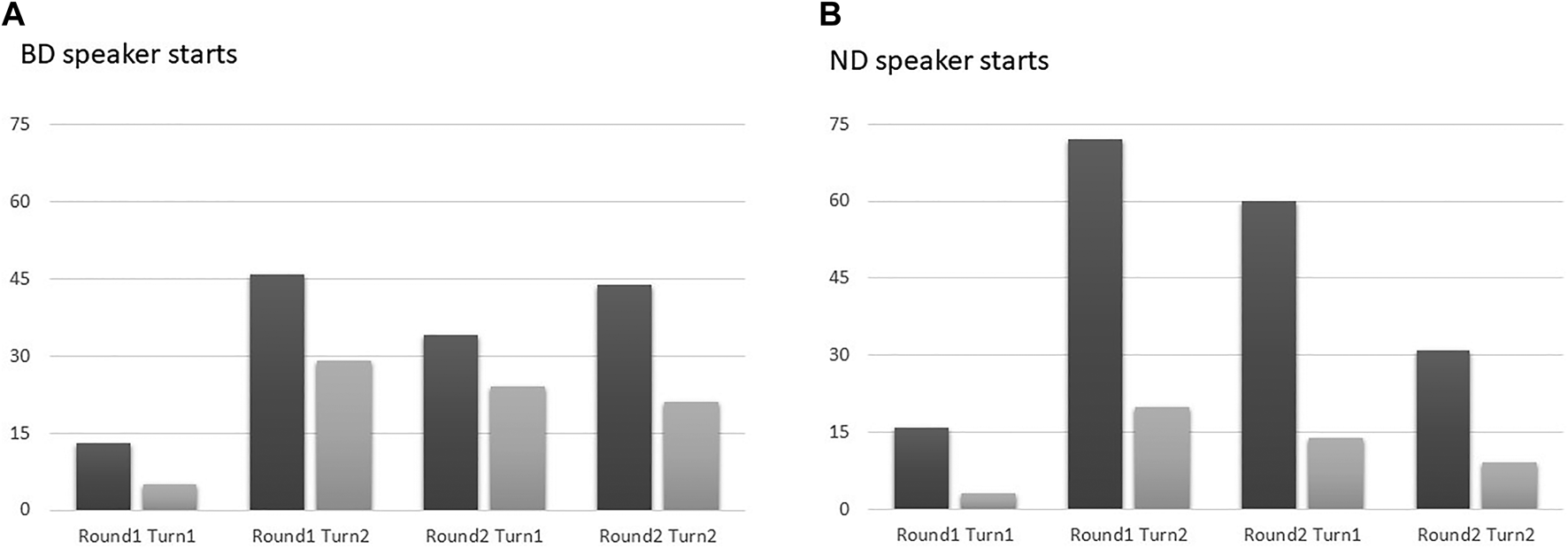
Percentage of lexical adaptation by BD speakers (black bars) and ND speakers (gray bars) for different stages of the experiment, when either the BD speaker (A) or ND speaker (B) started the game (Experiment 2).
FIGURE 7
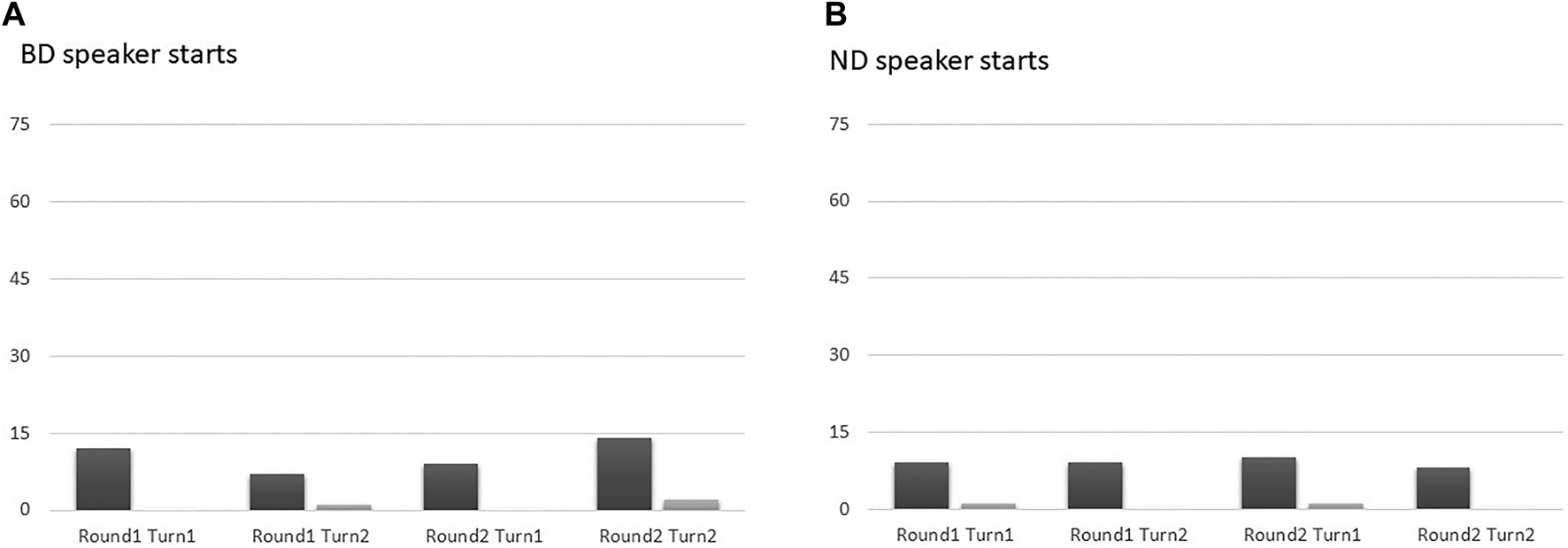
Percentage of pronunciation adaptation by BD speakers (black bars) and ND speakers (gray bars) for different stages of the experiment, when either the BD speaker (A) or ND speaker (B) started the game (Experiment 2).
For adaptation in terms of pronunciation, the anova revealed only a main effect of Nationality [F(1,18) = 14.622, p <0.001, = 0.646]: BD speakers adapted their pronunciation more to that of ND speakers, than vice versa (BD: 10% vs. ND: 1%). For this dependent variable, all other main effects and interactions turned out not to be significant. When comparing the degree of adaptation for lexical forms with that in terms of pronunciation via a paired t-test, we find that speakers significantly more often align their lexical forms to that of the game partner (27%) than their pronunciation (5%) [t(19) = 10.711, p < 0.001]. However, the proportions of adaptation for the two dependent variable did not correlate significantly (r = 0.013, p = 0.956). If we compare the data of experiments 1 and 2 with an independent-samples t-test, we observe that the amount of lexical adaptation in the two experiments (experiment 1: 25%; experiment 2: 29%) did not differ significantly (t(38) = 1.483, p = 0.146).
Discussion
Our second experiment in which a different set of participants played the game produced results that were consistent with those of experiment 1 in terms of lexical adaptation, in that BD speakers again adapted more to ND speakers, than vice versa. For this variable, Round also again turned out to be important, either as a main effect (with relatively more adaption in the second than in the first round), or as part of an interaction with other factors, such as Turn and Nationality, where effects for the other factor become larger in the second round compared to the first one. Interesting to note is also that BD speakers appear to be more inclined to lexically adapt when the other, ND game partner started the experiment. In comparison with lexical adaptation, the effect for pronunciation was in the same direction, but much weaker. This relative difference could not be due to the fact that BD and ND speakers already diverged less in terms of pronunciation than in lexical forms before they entered the game, which might have caused fewer options to change pronunciation in the first place, as the pronunciation differences before the game were in a comparable range as the lexical ones. In addition, the two forms of adaptation studied in this experiment appear to be independent: we could not find evidence that the two variables correlated. Moreover, the levels of adaptation in lexical forms of experiments 1 and 2 were not significantly different, which suggests the absence of a boosting effect of adaptation in terms of pronunciation on lexical forms of adaptation.
General Discussion and Conclusion
The two studies presented above have provided a nuanced picture regarding the claims that have often been put forward in previous literature that speakers adapt linguistically to the partners with whom they are interacting. In particular, we have focused on Dutch, more specifically looking at speakers of the varieties of Dutch as spoken in Belgium and the Netherlands, that are mutually intelligible, but that can vary somewhat in lexical forms and in terms of pronunciation (as well as syntax, which was not addressed here). At the same time, however, we found that this copying behavior does not need to be symmetric, an expectation which could be derived from an unqualified interpretation of the model which simply assumes that dialogue partners play an equivalent role in the dialogue exchange process. Instead, what we find is that BD speakers are in general more likely to take over linguistic forms of ND speakers, than vice versa. This appears to be true for both lexical variables and pronunciation, albeit that adaption of the former is overall much stronger than the latter. This may partly be related to the fact that, historically speaking, there has been a relatively strong policy to strive for uniform use of words in the varieties of Dutch spoken in Belgium and the Netherlands, whereas there was more tolerance for variation in pronunciation (Kloots, 2002). In any case, the two forms of adaptation appear to operate independently, meaning that we do not get much support for the idea of a boosting effect, whereby adaptation on one level of linguistic structure (e.g. phonology) would function as an incentive to converge at another level as well (e.g. lexicon).
The results on these asymmetric forms of adaptation between BD and ND speakers are in line with our predictions, and compatible with the outcome of recent work by Fehér et al. (2019) on differences between what they labeled categorical and variable speakers, where it was found that the former are less likely to adapt than the latter. From a variationist perspective, it can be stated that ND speakers are more of the categorical type and BD speakers more variable in nature. Indeed, there is a whole tradition of research to show that BD speakers often make use of more than one language variety in their interactions with others, for instance, typically a more standard form at work and in public contexts and a variety closer to their regional dialect in more informal settings with family and friends (Geeraerts, 2001; Grondelaers and van Hout 2011; Grondelaers et al., 2016). Instead, ND speakers in general are more consistent in their use of a specific variety, irrespective of the kind of addressee or situation. While it has been shown before that, historically speaking, the BD variant has been converging to the ND one over a longer period of time (but see Daems et al., 2015), the current paper shows that, also at the level of individual interactions, BD speakers have a stronger tendency to immediately adapt to ND speakers in the course of their spoken exchange. In follow-up studies, it would be interesting to supplement the results of the current type of experiment with data from questionnaires in which participants are asked about their attitude towards their own and the conversant’s language variety, to see whether potential differences in perceived status or dominance may explain the degree of asymmetry in linguistic adaptation.
In addition, not all linguistic structures may be equally susceptible to adaptation. While the Pickering and Garrod model presents an overall architecture that includes adaptation at various levels (lexical, syntactic, phonological, …), the effects at various levels need not be equivalent. In that respect, it is interesting that we show that the degree of adaptation differs between lexical and phonological levels of linguistic structure. A logical explanation for this difference could simply be due to the nature of the variation, given that a switch between words may be a more drastic choice. While differences in pronunciation are noticeable (e.g. a word stress on a first or second syllable, or a French vs English vs Dutch way of articulating a certain loan word), these forms of variation do not change the choice of word as such, so that there may be less urgency to adapt. Lexical differences, however, are of a more categorical type, and could possibly lead to miscommunication in the course of the interaction, as people are unsure as to what the dialogue partner’s choice of words may be referring to. Note that during the experiment participants could not see each other and could not see the other person’s icons, so that they could not rely on possible visual or nonverbal cues to refer to specific objects, which could have been an extra incentive to converge on lexical choice. From that perspective, a difference in pronunciation is less crucial, as it this has more to do with the packaging of the word. Still, it remains remarkable that BD speakers feel a stronger need to switch lexical expressions than ND speakers, maybe because they are intrinsically more often exposed to variation than their counterparts.
More generally, it is interesting to reflect on what our results mean for various models that make predictions on how interlocutors align to each other in spoken interactions. The one by Pickering and Garrod (2004) has been very influential and states that participants’ copying behavior is a highly automatic process which does not need an advanced form of addressee modeling or other higher-order cognitive processes. That would be at variance with a model that includes an audience design component, which assumes that a speaker takes into account characteristics of the addressee and adapts his/her linguistic behavior accordingly. Our results appear to be more in line with the latter perspective, as the outcome of our study shows that the degree of accommodation in Dutch depends on the status of the language variety a conversant is using: BD speakers adapt more to ND speakers, than vice versa, and sometimes even switch to linguistic forms of the other variety in turn 1 of round 1 before they have even heard those forms from their dialogue partner (results of lexical adaptation in experiment 1). In that sense, our results are in line with those from previous studies that brought to light that the level of adaptation between conversants is socially and situationally conditioned, and may depend on characteristics of the participants (e.g. the sex of the pair of speakers), and the role he/she has in an interaction (e.g. being a director vs. follower in a map task) (Pardo, 2006; Pardo et al., 2010; Pardo et al., 2012).
While our results could be interpreted as evidence for some form of audience design, it seems unlikely to be the result of a rational, conscious process, for instance, as participants in post-experiment interviews (in which they were informed about the purpose of the study) stated that they had not been aware that they were linguistically adapting to their partner and had not guessed that the goal of the study was related to that specific research question. It would be informative to find out in future studies to what extent BD speakers would be persistent in their use of ND variants, when they are being paired in a subsequent game with another BD speaker, as this would shed light on the extent to which a shift in lexical choice is only due to adaptation to speaking partner or to a linguistic norm that is independent of that partner.
The current paper contributes to two areas of linguistic research that have received quite some scholarly attention. On the one hand, while this has been a central topic in sociolinguistics, there is a growing interest in aspects of language variation in other domains of linguistic research as well. Whereas in the past, languages were often treated as coherent and uniform systems that apply similarly to all members of a specific community, researchers are now much more aware that there is both between- and within-speaker variability in how languages are used, though we still do not have full knowledge about underlying mechanisms that explain this variability. On the other hand, researchers working in fields like psycholinguistics, dialectology and sociolinguistics are nowadays exploring adaptive processes between conversation partners, as it has been shown repeatedly that the way we speak is determined by characteristics of our speaking partner, including the speech the other person is using. However, it is clear that the adaptive processes between speaking partners are more complex than being simple copying mechanisms.
Of course, one important limitation of the current study is that it was based on a game-like paradigm in which the interaction between the partners was very much constrained. Basically, speakers were in charge for approximately eight consecutive turns to instruct their partner on a number of actions, after which the other would take over for his/her series of actions. This staged kind of interaction, though still allowing for spontaneous descriptions of the different icons of interest, is obviously different from more natural conversations in which turn exchanges between dialogue partners occur more frequently and randomly. Possibly, in our experiment, the priming effects may therefore be less clear as speakers take their turn with some delay. Consequently, it would be interesting to explore to what extent the results of our study would generalize to more spontaneous, natural interactions. We do feel, though, that our article has introduced an innovative paradigm that is suitable for eliciting adaptive behavior, which in principle could also be used for speakers of other languages that exhibit different varieties, to explore forms and frequencies for different aspects of linguistic adaptation.
Statements
Data availability statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Ethics statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The patients/participants provided their written informed consent to participate in this study.
Author contributions
AH collected the lexical data of experiment 1 as part of her MA thesis. CN collected the lexical data and EO the pronunication data of experiment 2, resp, as part of their MA thesis. HK was supervising the Flemish part of the project. MS was responsible for the whole project, and the final writing process.
Acknowledgments
The work presented in this paper is based on MA theses of the second, third and fourth co-author who had been supervised by the first author, and helped by the fifth author. All authors have jointly created the paradigm, and have all been actively involved in the collection and recording of the speech data. We thank Hannelien Del’Haye, Sofie Gordts and Koen Jaspaert of the Department of Business Communication of the Humanities Faculty at Louvain University for help with recruiting participants and help with the logistics of the experiment. We thank Stefan Grondelaers (Radboud University Nijmegen, Netherlands) and Ad Backus (Tilburg University, Netherlands) for comments on an earlier version of this manuscript. Parts of the study have previously been presented at a conference in Lisbon (Exling, September 2019), and colloquia in Saarbrücken and Tilburg. We thank the audiences at these events for useful feedback and suggestions.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2021.716444/full#supplementary-material
References
1
BabelM.BulatovD. (2011). The Role of Fundamental Frequency in Phonetic Accommodation. Lang. Speech55 (2), 231–248. 10.1177/0023830911417695
2
BabelM. (2012). Evidence for Phonetic and Social Selectivity in Spontaneous Phonetic Imitation. J. Phonetics40 (1), 177–189. 10.1016/j.wocn.2011.09.001
3
BourhisR. Y.GilesH. (1977). “The Language of Intergroup Distinctiveness,” in Language, Ethnicity, and Intergroup Relations. Editor GilesH. (London: Academic), 119–135.
4
BraniganH. P.PickeringM. J.PearsonJ.McLeanJ. F.BrownA. (2011). The Role of Beliefs in Lexical Alignment: Evidence from Dialogs with Humans and Computers. Cognition121 (1), 41–57. 10.1016/j.cognition.2011.05.011
5
BraniganH. P.PickeringM. J.PearsonJ.McLeanJ. F. (2010). Linguistic Alignment Between People and Computers. J. Pragmatics42, 2355–2368. 10.1016/j.pragma.2009.12.012
6
BraniganH. P.TosiA.Gillespie-SmithK. (2016). Spontaneous Lexical Alignment in Children with an Autistic Spectrum Disorder and Their Typically Developing Peers. J. Exp. Psychol. Learn. Mem. Cogn.42 (11), 1821–1831. 10.1037/xlm0000272
7
ChartrandT. L.BarghJ. A. (1999). The Chameleon Effect: The Perception-Behavior Link and Social Interaction. J. Personal. Soc. Psychol.76, 893–910. 10.1037/0022-3514.76.6.893
8
DaemsJ.HeylenK.GeeraertsD. (2015). Wat Dragen We Vandaag: Een Hemd Met Blazer of Een Shirt Met Jasje?. Taal en Tongval67 (2), 307–342. 10.5117/tet2015.2.daem
9
De CaluweJ. (2013). Nederland en Vlaandeen:(a)symmetrisch pluricentrisme in taal en cultuur. Internationale neerlandistiek51 (1), 45–59. 10.5117/IVN2013.1.CALU
10
De CaluweJ. (2017). “Van an Naar BN, NN, SN Het Nederlands Als Pluricentrische Taal,” in De vele gezichten van het Nederlands in Vlaanderen. Een inleiding tot de variatietaalkunde. Editor de SutterG. (Leuven: Uitgeverij Acco), 121–141.
11
FehérO.RittN.SmithK. (2019). Asymmetric Accommodation during Interaction Leads to the Regularisation of Linguistic Variants. J. Mem. Lang.109, 10403610.1016/j.jml.2019.104036
12
GeeraertsD. (2001). Een Zondagspak? Het Nederlands in Vlaanderen: Gedrag, Beleid, Attitudes. Ons Erfdeel44 (3), 337–343.
13
GeeraertsD.GrondelaersS.SpeelmanD. (1999). Convergentie en divergentie in de Nederlandse woordenschat. Een onderzoek naar kleding- en voetbaltermen. Amsterdam: Meertens.
14
GeeraertsD. (2017). “Het kegelspel der taal. De naorloogse evolutie van de standaardnederlandsen,” in De vele gezichten van het Nederlands in Vlaanderen. Een inleiding tot de variatietaalkunde. Editor de SutterG. (Leuven: Uitgeverij Acco), 100–119.
15
GeeraertsD.Van de VeldeH. (2013). “Supra-regional Characteristics of Colloquial Dutch,”. Language and Space. An International Handbook of Linguistic Variation. Editors HinskensF.TaeldemanJ. (DutchBerlin/Boston: Walter de Gruyter), Vol. 3, 532–556.
16
GregoryS. W.WebsterS. (1999). A Nonverbal Signal in Voices of Interview Partners Effectively Predicts Communication Accommodation and Social Status Perceptions. J. Pers Soc. Psychol.70 (6), 1231–1240. 10.1037//0022-3514.70.6.1231
17
GrondelaersS.van HoutR. (2011). The Standard Language Situation in the Low Countries: Top-Down and Bottom-Up Variations on a Diaglossic Theme. J. Ger. Ling23 (3), 199–243. 10.1017/s1470542711000110
18
GrondelaersS.van HoutR.van GentP. (2016). Destandardization Is Not Destandardization. Taal en Tongval68 (2), 119–149. 10.5117/tet2016.2.gron
19
HaeserynW. (2013). “Belgian Dutch,”. Language and Space. An International Handbook of Linguistic Variation. Editors HinskensF.TaeldemanJ. (DutchBerlin/Boston: Walter de Gruyter), Vol. 3, 700–720.
20
HarringtonJ.GubianM.StevensM.SchielF. (2019). Phonetic Change in an Antarctic winter. The J. Acoust. Soc. America146, 3327–3332. 10.1121/1.5130709
21
ImpeL. (2010). Mutual Intelligibility of National and Regional Varieties of Dutch in the Low Countries. KU Leuven: Unpublished PhD Thesis.
22
KlootsH. (2002). “Southern Standard Dutch in Flemish Pronunciation Guides,” in Phonetic Work in Progress. Antwerp Papers in Linguistics. Editor VerhoevenJ. (Antwerp: Antwerp University Press), 47–61.
23
LeveltW. J. M.KelterS. (1982). Surface Form and Memory in Question Answering. Cogn. Psychol.14 (1), 78–106. 10.1016/0010-0285(82)90005-6
24
LüthiJ.VorwergC. (2015). “Status Matters! Syntactic Priming in Standard German Depends on its Sociolinguistic Status,” In Architectures & Mechanisms for Language Processing (AMLaP), Valletta, Malta, Sept. 2015.
25
MartinW.SmedtsV. (2009). Prisma Handwoordenboek Nederlands: Met Onderscheid Tussen Nederlands-Nederlands en Belgisch-Nederlands. (Houten: Prisma).
26
MolL.KrahmerE.MaesA.SwertsM. (2012). Adaptation in Gesture: Converging Hands or Converging Minds?. J. Mem. Lang.66 (1), 249–264. 10.1016/j.jml.2011.07.004
27
MuhrR. (2012). “Linguistic Dominance and Non-dominance in Pluricentric Languages. A Typology,” in Non-Dominant Varieties of Pluricentric Languages. Getting the Picture. Editor MuhrR. (Frankfurt: Peter Lang), 23–48.
28
MuiH. C.GoudbeekM. B.RoexC.SpiertsW.SwertsM. (2018). Smile Mimicry and Emotional Contagion in Audio-Visual Computer-Mediated Communication. Front. Psychol.9, 2077. 10.3389/fpsyg.2018.02077
29
NilsenovaM.SwertsM. G. J.HoutepenV.DittrichH. (2009). “Pitch Adaptation in Different Age Groups: Boundary Tones versus Global Pitch,” in Proceedings of Interspeech 2009, Brighton, United Kingdom, September 6-10, 2009, 1015–1018.
30
PardoJ. S.GibbonsR.SuppesA.KraussR. M. (2012). Phonetic Convergence in College Roommates. J. Phonetics40 (1), 190–197. 10.1016/j.wocn.2011.10.001
31
PardoJ. S.JayI. C.KraussR. M. (2010). Conversational Role Influences Speech Imitation. Attention, Perception, & Psychophysics72 (8), 2254–2264. 10.3758/bf03196699
32
PardoJ. S. (2006). On Phonetic Convergence During Conversational Interaction. J. Acoust. Soc. America119 (4), 2382–2393. 10.1121/1.2178720
33
PickeringM. J.GarrodS. (2004). Toward a Mechanistic Psychology of Dialogue. Behav. Brain Sci.27 (2), 169–190. 10.1017/s0140525x04000056
34
SmakmanD. (2012). The Definition of the Standard Language: A Survey in Seven Countries. Int. J. Sociol. Lang.218, 25–58. 10.1515/ijsl-2012-0058
35
TaeldemanJ.HinskensF. (2013). “The Classification of the Dialects of Dutch,”in Language and Space. An International Handbook of Linguistic Variation. Editors HinskensF.TaeldemanJ. (DutchBerlin/Boston: Walter de Gruyter), Vol. 3, 129–142.
36
TaeldemanJ.Van de VeldeJ. K. (1997). Onderzoek naar de uitspraak van recentere leenwoorden in het Belgisch Nederlands. Universiteit Gent: Vakgroep Nederlandse Taalkunde.
37
van BezooijenR.GerritsenM. (1994). De Uitspraak Van Uitheemse Woorden in Het Standaard-Nederlands: Een Verkennende Studie. De Nieuwe Taalgids87 (2), 145–160.
38
Van de VeldeH.KissineM.TopsE.van der HarstS.van HoutR. (2010). Will Dutch Become Flemish? Autonomous Developments in Belgian Dutch. Multilingua29, 385–416. 10.1515/mult.2010.019
39
Van de VeldeH.van HoutR. (2002). “Uitspraakvariatie in Leenwoorden,” in NVT-onderwijs en -onderzoek in Franstalig gebied, deel. Editors HiligsmannP.LeijnseE. (Nijmegen: Vantilt), 1, 77–95.
40
Van de VeldeH. (1996). Variatie en verandering in het gesproken Standaard-Nederlands. PhD thesis. Nijmegen: Katholieke Universiteit Nijmegen.
41
van der SijsN. (1996). Leenwoordenboek. Den Haag/Antwerpen: Sdu/Standaard. 10.1142/9789814447140_0004
42
van HeuvenV.Van de VeldeH. (2010). “De uitspraak van het hedendaags Nederlands in de Lage Landen,” in Internationale Neerlandistiek: Een Vak in Beweging. Editors FenoulhetJ.RenkemaJ. (Gent: Academia Press), 183–209.
43
Van KeymeulenJ. (2013). “Geographical Patterns of Lexical Variaion in the Dutch-speaking Area,” in Language and Space. An International Handbook of Linguistic Variation. Editors HinskensF.TaeldemanJ. (DutchBerlin/Boston: Walter de Gruyter), Vol. 3, 512–531.
44
VandekerckhoveR. (2009). Dialect Loss and Dialect Vitality in Flanders. Int. J. Sociol. Lang.196-197, 73–97. 10.1515/IJSL.2009.017
Summary
Keywords
Belgian Dutch, Netherlandic Dutch, adaptation, lexical, pronunciation, boosting effects
Citation
Swerts M, Van Heteren A, Nieuwdorp C, Von Oerthel E and Kloots H (2021) Asymmetric Forms of Linguistic Adaptation in Interactions Between Flemish and Dutch Speakers. Front. Commun. 6:716444. doi: 10.3389/fcomm.2021.716444
Received
28 May 2021
Accepted
29 July 2021
Published
06 August 2021
Volume
6 - 2021
Edited by
Niels O. Schiller, Leiden University, Netherlands
Reviewed by
Holger Mitterer, University of Malta, Malta
Rose Stamp, Bar Ilan University, Israel
Updates
Copyright
© 2021 Swerts, Van Heteren, Nieuwdorp, Von Oerthel and Kloots.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Marc Swerts, m.g.j.swerts@tilburguniversity.edu
This article was submitted to Language Sciences, a section of the journal Frontiers in Communication
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.