 Rene Altrov
Rene Altrov Hille Pajupuu
Hille Pajupuu Jaan Pajupuu1
Jaan Pajupuu1 Aet Kiisla
Aet Kiisla- 1Department of Speech Research and Technology, Institute of the Estonian Language, Tallinn, Estonia
- 2Narva College, University of Tartu, Narva, Estonia
Objective: The goal of the study was to find out if, in a society where there is a large community of people for whom the official state language is a second language, they prefer to listen to state-language radio advertisements in the same performance style as listeners for whom the official state language is their first language.
Method: An experiment was conducted in Estonia, with two groups: those who spoke Estonian as their first language and those who spoke Russian as their first language and Estonian as their second. Both groups listened to Estonian-language radio advertisements presented by various spokespeople, half of which were performed in a calm style (low arousal) and half in an energetic style (high arousal). They then rated the likability of each performance.
Results: The results showed that both groups preferred the calm style but there were significant differences in the scores: the first group gave the calm style significantly higher scores than the second group, while the latter scored the energetic style more highly.
Conclusion: Knowing the advertising style preferences in a society where people have different first languages may allow for better targeting of advertising.
1. Introduction
Nearly 3 billion people worldwide listen to the radio weekly, making it one of the most powerful communication mediums (Stewart, 2019). People hear advertisements via radio at home, in cars, and in public spaces, which motivates businesses to invest ever more in them (Götting, 2022; Guttmann, 2022). In Europe, some of the highest spenders on radio advertisements are found in the Baltics (9% of total advertising expenditure in Lithuania, 10% in Estonia, and 13% in Latvia (Krutaine et al., 2018). This has led to advertisers increasing interest in discovering ways to prevent their advertisements from becoming background noise or the subject of avoidance actions such as listeners leaving the room or muting or turning their radios off (Speck and Elliott, 1997; Michelon et al., 2020).
In addition to semantic content, the performance style and sound of the spokesperson's voice plays a crucial role in the effectiveness of a radio advertisement. Desmarais and Vignolles (2019) showed in their intercultural study that due to cultural differences there is no universal consumer preference for vocal approaches. Culture-specific performance styles, which develop over years, are institutionalized and reinforced by the industry and the mass media until they become part of the everyday cultural environment. As consumers like the kind of vocal approaches familiar to them from their cultural environment, voices used in advertising should be chosen carefully to fit the culture in which the advertisement is circulated (Desmarais, 2000; Desmarais and Vignolles, 2019). More effective advertisements can be developed by taking cultural differences into account and observing how advertisements can vary by culture (Bradley et al., 1994).
Rodero and Larrea (2021) stressed that an effective advertising voice draws the listener's attention, encourages recall, and creates an emotional impact. However, despite the importance, there are few studies on the selection of voice in advertising, and in the advertising industry voices are chosen mostly by intuition (Chattopadhyay et al., 2003; Westermann, 2008; Nagano et al., 2023). Rodero and colleagues have studied Spanish radio advertisements and pointed out the overuse of male voices (Rodero et al., 2013), over-emphatic high-pitch performances that disturb listeners (Rodero et al., 2017; Rodero and Potter, 2021), and an excessively rapid speech rate, rather than the moderate speech rate listeners preferred (Rodero, 2020). Dubey et al. (2018) concluded that native Australian English-speaking consumers found a low-pitched voice (142–148 Hz) more persuasive. However, different types of delivery are preferred in other cultures. For example, in Japan, the willingness to buy was raised by higher-pitched and faster advertising speech (Nagano et al., 2023). Unfortunately, many studies do not state the country and language of the advertisements involved in the study.
In advertising, the selection of a voice may also be impacted by the sales strategy. Hard-sell advertising focuses on the description of the product's characteristics and advantages; it is information-based, explicit, direct, and rational, with the goal of making the consumer open their wallet immediately. By contrast, soft-sell advertising is indirect and image-based, selling moods and dreams to the consumer rather than products, encouraging them to make purchase decisions based on emotions (Bradley et al., 1994; Beard, 2004; Almurshidee, 2017). Intercultural studies have revealed that different cultures may prefer one strategy to the other (Okazaki et al., 2010, 2013; Desmarais and Vignolles, 2019). The voices chosen for the advertisements can vary according to the strategy, but they are largely chosen subconsciously or mechanically under the influence of cultural stereotypes (Desmarais, 2000).
According to Desmarais' (2000) comparison of voices used in advertisements in France and New Zealand, in the latter, where hard-sell advertising is preferred, there is a tendency to use male voices. The tone is dramatic, aggressive, and extremely enthusiastic, with drawn-out rising and falling intonation, emphatic accentuation, and rapid speech. The speech rate and volume are almost equivalent to shouting. This vocal hammering helps create a sense of urgency. The voice is usually deep, sonorous, and resonant. Female spokespeople are used for products that target women, where the tone of voice is happy or casual and does not emphasize femininity. In France where soft-sell advertising is preferred, male and female voices are used equally, with the latter considered suitable for all products, including technical ones. A flatter intonation pattern, fewer emphatic accents, slower speech rate, and voices that are often sensual, soft, and sometimes whispered or breathy are the norm, with a wider emotional breadth. The male voices in French soft-sell advertisements might be considered feminine. Desmarais and Vignolles (2019) have pointed out that the expectations for the soundscape of advertisements are culturally determined. Whether the connection between voice and the culturally dominant sales strategy is universal is unknown as of yet, as there are few relevant intercultural studies on the topic.
Many researchers have drawn attention to the influence of culture in advertising (e.g., Okazaki and Mueller, 2007; de Mooij and Hofstede, 2010; Lee, 2019). Lee's (2019) overview across and within countries revealed that the influence of culture on advertisements has been studied primarily in the United States of America and China, somewhat less in South Korea, Central, and Western Europe, and relatively little in the Near East, Africa, Nordic countries, and Eastern Europe. According to Gazley et al. (2012), advertising studies of diverse cultures tend to use contrasting focus groups to compare Western and Eastern countries, without taking into account the differences in within-country regions, while few studies have been conducted on geographically proximate and culturally similar areas. Their study showed that the impact of the likability and dislikability of television advertisements in various Asian countries on consumers' purchase intentions is not universal and varies by culture. It may be concluded that there is no global audience for standardized advertising and marketing approaches need to adapt to local cultures. According to Almurshidee (2017) content analysis has been the primary focus of intercultural studies on advertisements. Performance styles and the voices of spokespeople are not noted beyond the global tendency to use male voices.
Although there are few studies of spokesperson and performance style preference, especially from an intercultural perspective, there have been studies on the likability of voices and speech style. According to Altrov et al. (2018), the likability of a voice is tied to speech style. The likability of three speech styles were assessed: radio commentaries, talk shows, and lectures. The results showed that listeners least liked flat, high-pitched, tense, and creaky lecturing voices. Pajupuu et al. (2019) demonstrated that similar voices were considered likable in the linguistically and culturally close neighboring states of Estonia and Finland, whether the voices spoke in the listeners native language or not. Likability was dependent on speech style: both Estonians and Finns preferred the voices in Estonian interviews and Finnish poetry readings. Some studies have revealed a preference for culturally familiar performance styles, a phenomenon known as the similarity-attraction effect (Dahlbäck et al., 2007) and others, the reverse (Trouvain and Zimmerer, 2017).
There is, however, a relatively wide gap in knowledge regarding the exact kind of advertising voices people from different cultures prefer. Multicultural societies often contain people whose first language is not the official state language, but who are at an independent user level in the latter, that is, they can use it for everyday tasks. While different ethnic groups have been investigated in intercultural advertising, the present study aimed to determine whether a community, for whom the official state language is their second language, prefer radio advertisements performed in the same style as those for whom the official state language is their first. The conclusions might enable better targeting of advertisements. Our study was carried out in the East European country of Estonia. The study participants were Estonians from Tallinn who spoke the official state language Estonian as their first language (L1) and members of the Russian-speaking community from Ida-Virumaa who spoke Russian as their first language, and for whom Estonian was their second language (L2).
According to the 2021 census, the population of Estonia that year was 1.3 million. Sixty-seven percent of the population speak Estonian as their first language and 28.5%, Russian. Tallinn, the capital, has a population of around 460 000. While Estonia is geographically small, one region Ida-Virumaa, which borders Russia, differs from the rest of the country due to its social, economic, geographic, and demographic background (Trimbach and O'Lear, 2015). It is the region with the lowest number of Estonians and most ethnic Russians: in the census, 73.2% of the population assigned their ethnicity as Russian and 18.5% as Estonian, and 83.1% of the population considered their first language to be Russian and 14.5% Estonian (Census, 2021/2022).
According to Estonian Integration Monitoring (2020), a fifth of the ethnically non-Estonian population has an active knowledge of the official state language. An ability to communicate in the official state language Estonian is expected in both schooling and work environments. Even if those who speak Estonian as a second language in Ida-Virumaa tend to consume Russian language media, they hear Estonian language advertisements on state-run radio and shopping center sound systems (Kõuts-Klemm et al., 2019).
There are few comparative studies of the speech styles of Estonians and Russians living in Estonia. Altrov (2013) ascertained that Russians who live in Estonia, and for whom Estonian is a second language, recognized emotions in Estonian speech like Estonians, unlike Russians living in Russia, for whom most emotions expressed in Estonian remained elusive. As previous studies have shown a similarity in the perception of emotions between Estonians and Russians living in Estonia, we wished to find out whether they also prefer the same advertisement styles. This enables us to see the effects of living in a shared cultural environment on different ethnicities. We formulated the following research question:
Do listeners who speak Estonian as their first language and listeners who speak Estonian as a second language prefer similar Estonian language radio advertisement performance styles?
2. Method
2.1. Material
The research material was taken from the voice database of the audio-visual post-production studio Orbital Vox Studios. The database includes one Estonian commercial advertisement text performed by 94 female and 122 male spokespeople (mostly actors) in two performance styles: calm and energetic (wav, 44.1 kHz, 16 bit, mono, average length of advertisement 20 sec). The spokespeople were only broadly instructed to present the advertisements in a calm or in an energetic manner, leaving further interpretation to their discretion. The advertisement did not hint at any concrete product, service, or brand. The text of the advertisement was as follows:
Kõigepealt sule silmad, lõdvestu ja tunne end täiesti rahulikult. Mõtle selle peale, mis on sulle kõige-kõige kallim ja mine osta see lihtsalt ära. Kallid asjad nüüd odavalt. [At first, close your eyes, relax, and feel perfectly at ease. Think about the thing which is most precious to you and then just go and buy it! Precious things are now cheap.]
To obtain an overview of the acoustic features that differentiated calm and energetic advertisement styles in the database, an acoustic analysis was run using the open-source toolkit openSMILE (Eyben et al., 2010, 2013). The parameters of the extended Geneva Minimalistic Acoustic Parameter Set (eGeMAPS) were calculated for each performance: 24 frequency-related, 15 energy/amplitude-related, 43 spectral, and 6 temporal parameters (Eyben et al., 2016). The Kruskal-Wallis test (R Core Team, 2022) indicated that the calm and energetic advertising performance styles were acoustically very different: out of the 88 eGeMAPS parameters, 66 significantly differentiated the styles for female spokespeople, and 77 for male spokespeople. The eGeMAPS parameters can be found in the Supplementary Tables S1–S3 and Supplementary Figures S1, S2. The acoustic data and examples of the audio files in the database are included in the dataset (https://figshare.com/projects/Radio_advertisement_styles/160124).
Generally, the Estonian calm advertising style was differentiated from the energetic by a lower pitch (lower f0); faster speech (shorter voiced segment length and more voiced segments per sec); longer pauses between phrases (longer unvoiced segment length); a quieter voice without rapid changes in loudness (lower loudness, smaller rising and falling slopes of loudness). Spectral features revealed differences in timbre; speech in the calm style was laxer and the voice breathier and softer (Kuang and Liberman, 2016; Nordström, 2019: 27 and 40; higher/larger MFCC1-4, a steeper spectral slope, higher Hammarberg index, more shimmer, and among male spokespeople a lower HNR, see e.g., Teixeira et al., 2013). The calm performance style was less emotional (see Weninger et al., 2013; Pralus et al., 2019; a lower spectral flux, lower f0, lower loudness). See Figure 1. Based on the acoustic features we could assume that calm vs. energetic advertising styles are linked to arousal-related emotions: the calm style to rather low arousal emotions (pleasure, interest, etc.) and the energetic to rather high arousal emotions (about the arousal dimension see e.g., Frick, 1985; Scherer, 1986; Goudbeek and Scherer, 2010; Weninger et al., 2013; elation, excitement, joy, etc.).
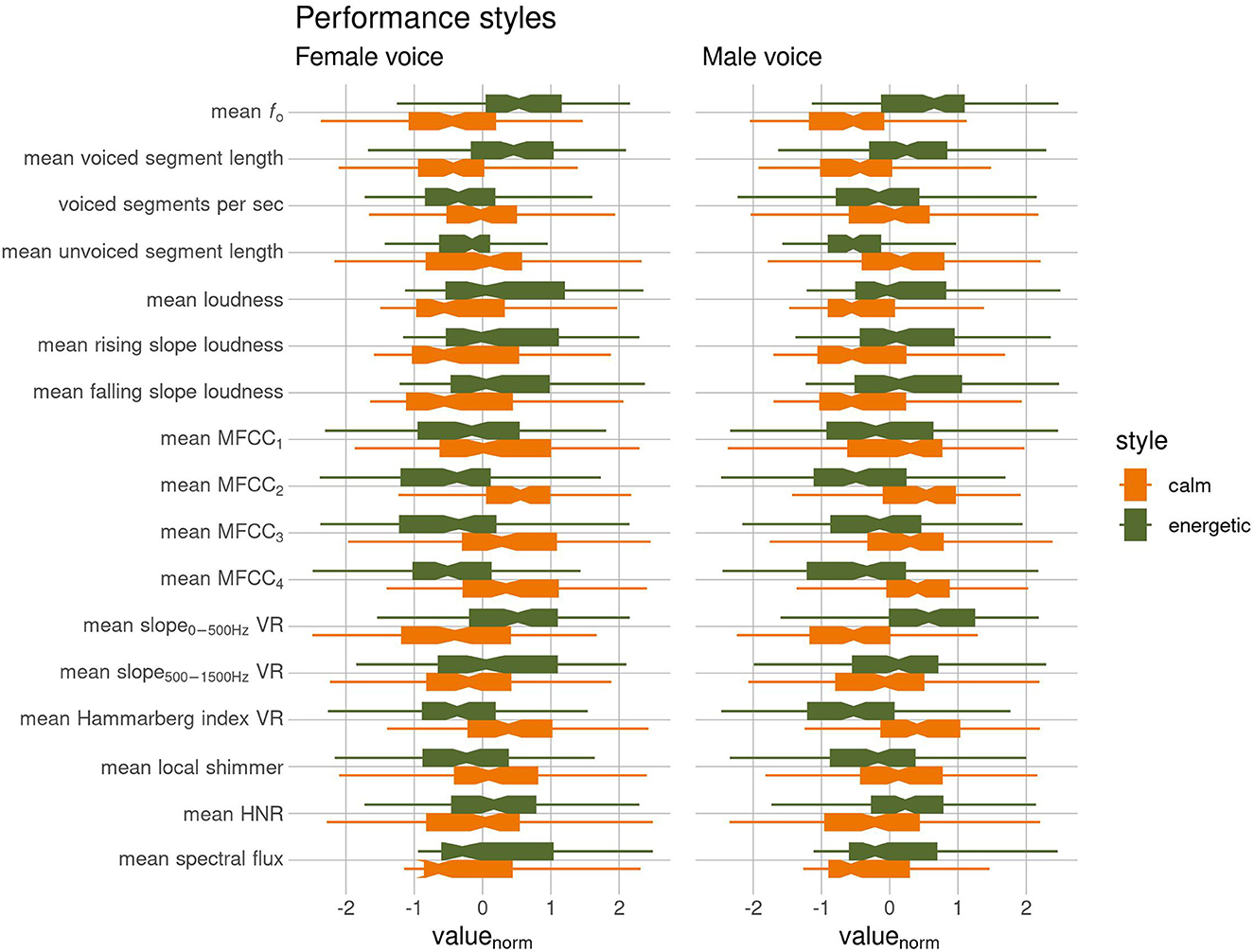
Figure 1. A selection of the acoustic features that differentiated the calm and energetic performance styles.
2.2. Listening test
For the web-based listening test, 10 female spokespeople (aged 17–55, M = 33.5 years, SD = 10.9) and 10 male spokespeople (aged 32–44, M = 37.6 years, SD = 5.8) were chosen at random from the database (see 2.1). For each spokesperson, two advertisement performances were used, one in the energetic style and one in the calm style. All 40 performances were presented to the listeners in one order, generated by chance. For the eGeMAPS acoustic features of these advertisement performances see Supplementary material.
The listeners were asked to evaluate the likability of the performance on a 7-point Likert scale, where 1 = not likable at all and 7 = very likable. Two groups of listeners with a similar age structure participated as raters: (1) eight women (aged 35–63, M = 45.9 years, SD = 9.4) and nine men (aged 34–65, M = 46.4 years, SD = 9.5) who spoke Estonian as their first language (L1); and (2) eight Russian-speaking women (aged 33–61, M = 44.9, SD = 9.3) and nine men (aged 29–65, M = 46.7, SD = 11.5) who spoke Estonian as a second language (L2), most at an upper intermediate level. L1 listeners claimed that they hear Estonian language advertisements every day; L2 listeners were split equally between half who claimed to hear Estonian language advertisements every day and half who claimed not to notice the language of the advertisements. The listeners participated voluntarily. Their identity was kept confidential, and no conflict of interest can be identified. For the metadata of both performers and listeners see Supplementary material.
The planned duration of the test was ~10 min. The following instructions were given to the listeners:
Advertisements are often heard on the radio and in stores. They cannot be abolished but can be made more pleasant to listen to. Please help us in this endeavor! Find some headphones, listen to the following advertisements, and rate the likability of the performance. You do not have to listen to all of the advertisements at once; you can save some and return to them later. You can also change previous ratings.
2.3. Statistical analysis
To find out the degree of agreement among the listeners (i.e., inter-rater reliability), the intra-class correlation coefficient (ICC2k) for the two groups (the Estonian-speaking group and the Russian-speaking group) was calculated using the “psych” package in R (Revelle, 2022). To analyze the results the scores for each listener were normalized:
where x is the score, X is the mean, and s is the standard deviation of the listener's scores.
The spokespeople's performances were sorted based on the normalized scores. Performances with scores above zero were classified as likable and those below zero as unlikeable. A Welch Two Sample t-test was used to determine whether the advertisement style affected likability ratings (R Core Team, 2022).
To estimate the likability score of the performances a multiple linear regression was used. A model was built for predicting average scores using a subset of eGeMAPS parameters described in Figure 1. All eGeMAPS parameters were normalized separately. The model was calculated by performing a selective regression (Venables and Ripley, 2002), in which only the variables that are statistically relevant are taken into account.
3. Results
An excellent reliability was found within L1 listener measurements. The average measure ICC2k was 0.94, with a 95% confidence interval from 0.92 to 0.97 F(39, 624) = 18, p < 0.0001. A good to excellent reliability was found within L2 listener measurements. The average measure ICC2k was 0.87 with a 95% confidence interval from 0.80 to 0.92 F(39, 624) = 7.6, p < 0.0001.
The L1 listeners scored the calm style significantly higher than the energetic style. The scores for female (F) and male (M) spokespeople were not significantly different: ML1_F_calm = 0.58 vs. ML1_M_calm = 0.65, t(338) = −0.90, p = 0.369; ML1_F_energetic = −0.61 vs. ML1_M_energetic = −0.62, t(328) = 0.20, p = 0.841, see Figure 2.
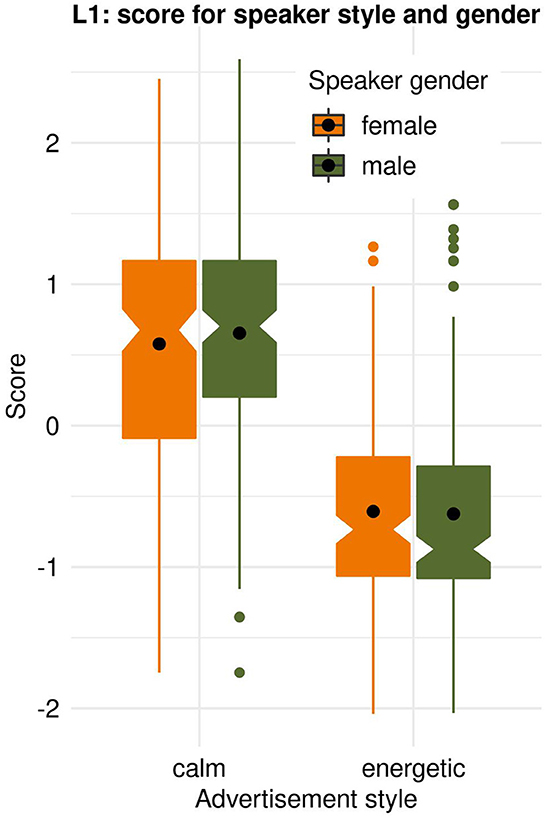
Figure 2. Likability scores for female and male spokespeople's calm and energetic performance styles given by listeners with Estonian as their first language (L1).
Russian speaking listeners with Estonian as their second language (L2) also preferred the calm style. As with L1, there was no significant difference in the calm style scores given to the female and male spokespeople. However, there was a difference in the scores given to advertisements presented in the energetic style: while both male and female voices received low scores, the former were significantly lower: ML2_F_calm = 0.38 vs. ML2_M_calm = 0.24, t(321) = 1.25, p = 0.211; ML2_F_energetic = −0.20 vs. ML2_M_energetic = −0.41, t(329) = 2.13, p = 0.034, see Figure 3.
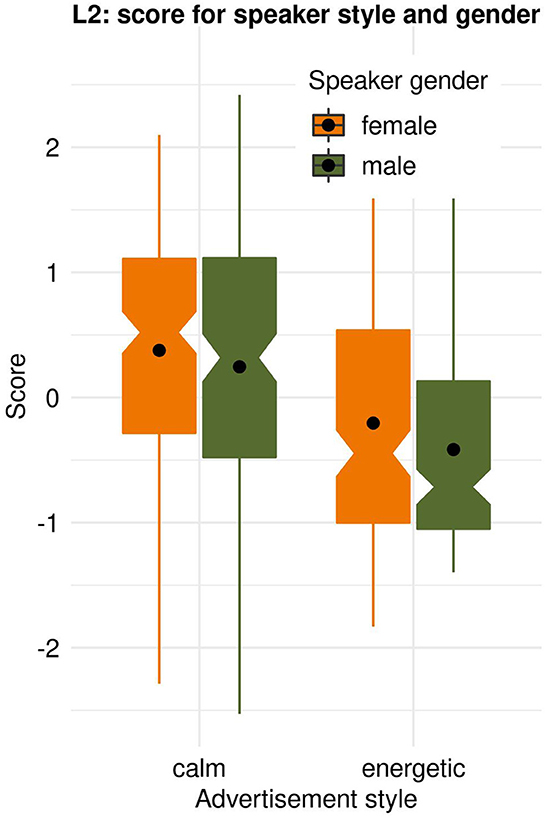
Figure 3. Likability scores for female and male spokespeople's calm and energetic performance styles among listeners with Estonian as their second language (L2).
Although both groups preferred the calm style, L1 scored it significantly higher than L2: ML1_calm = 0.62 vs. ML2_calm = 0.31, t(647) = −4.54, p < 0.0001. The energetic style appealed to neither group, but L1 scored it significantly lower than L2: ML1_energetic = −0.62 vs. ML2_energetic = −0.31, t(656) = 4.70, p < 0.0001, see Figure 4. All L1 and L2 listeners' scores are presented in Supplementary material.
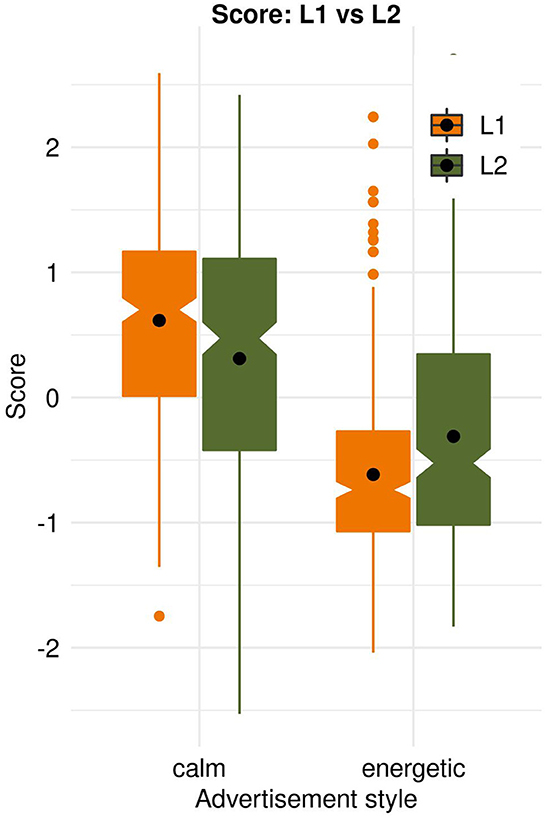
Figure 4. Likability scores given by listeners with Estonian as their first language (L1) and Russian speaking listeners with Estonian as their second language (L2).
The linear regression model built by selective regression resulted in a reduced linear model with only three variables: mean f0, mean falling slope loudness, and mean unvoiced segment length. The fitted regression model was:
The overall regression was statistically significant, R2 = 0.79, F(3, 26) = 37.64, p < 0.0001. All three variables added statistically significantly to the prediction, p < 0.01.
4. Discussion
Both groups preferred the calm style, which was acoustically characterized by a lower pitch, a faster speech rate with longer pauses, and a softer and breathier voice than the energetic style. This was expected for the L1 group; a voice likability study by Altrov et al. (2018) demonstrated a dislike for high-pitched, tense, and creaky voices. There was no prior knowledge concerning the preferences of Russian speakers.
Although the calm style was preferred by both groups, the L1 group rated it significantly higher, while the L2 group were more tolerant of the generally disliked energetic style (Figure 4). The former group expressed no preference for any gender in either case (Figure 2), while the latter group expressed no gender preference for the calm style but did prefer female spokespeople in the energetic style (Figure 3). This was an interesting finding given the prevalence of male spokespeople in radio advertisements (cf. Rodero et al., 2013; Almurshidee, 2017). Overall, the preferences of both groups were similar. One reason for this might be that the L2 group have adapted to local culture-specific vocal styles, so when they hear the calm style, the similarity attraction effect is engaged (Dahlbäck et al., 2007; Desmarais and Vignolles, 2019). On the other hand, calm-style advertisements may form an exotic contrast with advertisements on Russian-language radio (cf. Trouvain and Zimmerer, 2017). Further research could show which styles are present in Russian radio advertisements, and which are preferred by listeners in Russia. Either way, energetic Estonian-language advertisements did not appeal to either group, although in Estonian everyday life it is possible to hear radio advertisements in both styles.
The model built by selective regression showed that the likability score can be estimated by just three acoustic features: pitch (- mean f0), changes in loudness (- mean falling slope loudness), and length of speech pauses (+ mean unvoiced segment length). This also confirms that the calm style gets higher scores.
It may be assumed that the calm style tends to correspond to the soft-sell strategy and the energetic style to the hard-sell described by Desmarais (2000), with the former preferred in Estonia. Whether this assumption is correct would require an analysis that entails studying advertisements from many other aspects beyond their performance style, for example the content of the advertisement texts, the gendering of adverts, and the likability of hard-sell and soft-sell coded advertisements in Estonia. Although Desmarais' (2000) characterizations of the voices in soft-sell (French) and hard-sell (New Zealand) advertising resemble the calm and energetic styles, there are also differences. The main difference is in the speech rate, which in the case of French soft-sell is slower than the New Zealand hard-sell, whereas the Estonian calm style, on the contrary, is faster than the Estonian energetic style (cf. Desmarais, 2000), see Figure 1. Comparing the calm style preferred in Estonia to the advertising style preferred in Spain – the latter which featured both the soft- and hard-sell strategy (see Okazaki et al., 2010) –, there were once again similarities: a lower pitch, a not overtly emphatic performance, with both women and men considered equally suitable as spokespeople (Rodero et al., 2013, 2017; Rodero and Potter, 2021). Again, there may have been a difference in speech rate: in Estonia, a more rapid one was preferred, while what was described as a moderate rate of speech was preferred in Spain (cf. Rodero, 2020). Yet this comparison of speech rate is indirect because the methodology of the studies is different. In our study, we based our assessment of speech rate on the acoustic features of the advertisements: the voiced segment length and the number of voiced segments per second, and we also took into account the unvoiced segments of speech, i.e., pauses in speech – the latter which were significantly longer in the Estonian calm style compared to the energetic style. In the Spanish study, the speech rate was determined by the word count in advertisements, while pause lengths for all speech tempos were kept the same (cf. Rodero, 2020). Therefore, there are cultural particularities that become clear by studying the preferences of target groups in depth and which could be considered in the production of advertisements. Avoiding dislikable attributes is of extreme importance to marketers and media producers if they wish to produce effective advertisements (see Gazley et al., 2012).
The present study is limited largely by the fact that there are few cross-country and within-country studies on the preference and likability of radio advertisement performance styles and voices with which its findings might be compared and contrasted. In addition, if our understanding is to be improved, non-cross-cultural studies should state in what country and language they have been conducted. Be that as it may, the results of the present study affirm the need for advertisers to take into account the preferences of potential consumers and to recognize that those preferences may vary within a particular country. Future research should involve a larger number of participants and should focus on which emotions are elicited by the advertisement styles preferred in a culture, whether advertisement styles affect advertisement recall and influence purchase intentions, and what cultural expectations people of different ages and genders have for radio advertisements.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: Figshare https://figshare.com/projects/Radio_advertisement_styles/160124.
Ethics statement
Ethical approval was not required for the study involving human participants in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants in accordance with the national legislation and institutional requirements.
Author contributions
RA and HP contributed to the conception of the study and wrote sections of the manuscript. HP and JP carried out the data analysis and compiled the listening test and RA and AK conducted it. All authors interpreted results, contributed to the manuscript revision, approved the submitted version, and had full access to the data used in the study.
Funding
The present study was financed by the European Union through the European Regional Development Fund (Centre of Excellence in Estonian Studies) and by basic governmental financing of the Institute of the Estonian Language from the Estonian Ministry of Education and Research.
Acknowledgments
The authors would like to thank Orbital Vox Studios, an audio-visual post-production studio, for the opportunity to use their voice database and the study participants.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2023.1176423/full#supplementary-material
References
Almurshidee, K. A. (2017). Cross-cultural advertising execution style: past trends and future directions. Indian J. Sci. Technol. 10, 1–9. doi: 10.17485/ijst/2017/v10i20/111108
Altrov, R. (2013). Aspects of cultural communication in recognizing emotions. Trames J. Humanit. Soc. 2, 159–174. doi: 10.3176/tr.2013.2.04
Altrov, R., Pajupuu, H., and Pajupuu, J. (2018). “Phonogenre affecting voice likability,” in P. 9th International Conference of Speech Prosody 2018, Poznań, 177–181. doi: 10.21437/SpeechProsody.2018-36
Beard, F. K. (2004). Hard sell ‘killers,' and soft sell ‘poets': modern advertising's enduring message strategy debate. J. History 30, 141–149. doi: 10.1080/00947679.2004.12062656
Bradley, S., Hitchon, J., and Thorson, E. (1994). “Hard sell versus soft sell: a comparison of American and British advertising,” in Global and Multinational Advertising, ed. B. D. Englis (New York: Psychology Press), 141–157.
Census (2021/2022). Population by Mother Tongue, Sex, Age Group and Place of Residence. Statistics Estonia. Available online at: https://andmed.stat.ee/et/stat/rahvaloendus__rel2021__rahvastiku-demograafilised-ja-etno-kultuurilised-naitajad__rahvus-emakeel/RL21434 (accessed April 3, 2023).
Chattopadhyay, A., Dahl, D. W., Ritchie, R. J. B., and Shahin, K. N. (2003). Hearing voices: the impact of announcer speech characteristics on consumer response to broadcast advertising. J. Consum. Psychol. 13, 198–204. doi: 10.1207/S15327663JCP1303_02
Dahlbäck, N., Wang, Q., Nass, C., and Alwin, J. (2007). “Similarity is more important than expertise,” in P. SIGCHI Conference on Human Factors in Computing Systems – CHI '07, San José, CA, 1553–1556. doi: 10.1145/1240624.1240859
de Mooij, M., and Hofstede, G. (2010). The Hofstede model. Applications to global branding and advertising strategy and research. Int. J. Advert. 29, 85–110. doi: 10.2501/S026504870920104X
Desmarais, F. (2000). Authority versus seduction: the use of voice-overs in New Zealand and French television advertising. Media Int. Austr. Incorp. Cult. 96, 135–152. doi: 10.1177/1329878X0009600116
Desmarais, F., and Vignolles, A. (2019). “Customer engagement through the vocal touchpoint: an exploratory cross-cultural study,” in Advances in Advertising Research X, eds. E. Bigne, and S. Rosengren (Wiesbaden: Springer Gabler), 67–78.
Dubey, M., Farrell, J., and Ang, L. (2018). “How accent and pitch affect persuasiveness in radio advertising,” in Advances in Advertising Research IX. Power to Consumers, eds. V. Cauberghe, L. Hudders, and M. Eisend (Wiesbaden: Springer Gabler), 117–130. doi: 10.1007/978-3-658-22681-7_9
Estonian Integration Monitoring (2020). Available online at: https://www.kul.ee/en/estonian-integration-monitoring-2020 (accessed April 3, 2023).
Eyben, F., Scherer, K., Schuller, B., Sundberg, J., Andre, E., Busso, C., et al. (2016). The Geneva minimalistic acoustic parameter set (GeMAPS) for voice research and affective computing. IEEE T. Affect. Comput. 7, 190–202. doi: 10.1109/TAFFC.2015.2457417
Eyben, F., Weninger, F., Groß, F., and Schuller, B. (2013). “Recent developments in openSMILE, the Munich open-source multimedia feature extractor,” in P. 21st ACM International Conference on Multimedia, MM 2013, Barcelona, 835–838. doi: 10.1145/2502081.2502224
Eyben, F., Wöllmer, M., and Schuller, B. (2010). “openSMILE: The Munich versatile and fast open-source audio feature extractor,” in P. 18th ACM International Conference on Multimedia, MM 2010, Florence, 1459–1462. doi: 10.1145/1873951.1874246
Frick, R. (1985). Communicating emotion: the role of prosodic features. Psychol. Bull. 97, 412–429. doi: 10.1037/0033-2909.97.3.412
Gazley, A., Krisjanous, J., and Fam, K-. S. (2012). Like it or not: differences in advertising likeability and dislikeability within Asia. Asia. Pac. J. Market. Logist. 24, 23–40. doi: 10.1108/13555851211192687
Götting, M. C. (2022). U.S. Radio Industry – Statistics & Facts. Statista. Available online at: https://www.statista.com/topics/1330/radio/#topicHeader__wrapper (accessed April 3, 2023).
Goudbeek, M., and Scherer, K. R. (2010). Beyond arousal: valence and potency/control in the vocal expression of emotion. J. Acoust. Soc. Am. 128, 1322–1336. doi: 10.1121/1.3466853
Guttmann, A. (2022). Radio Advertising Spending in Western Europe 2000–2022. Statista. https://www.statista.com/statistics/799781/radio-ad-spend-in-western-europe (accessed December 5, 2022).
Kõuts-Klemm, R., Harro-Loit, H., Ibrus, I., Ivask, S., Juurik, M., Jõesaar, A., et al (2019). Meediapoliitika olukorra ja arengusuundade uuring [Survey of the situation and trends of Estonian media policy]. Available online at: https://www.digar.ee/viewer/et/nlib-digar:399372 (accessed July 3, 2023).
Krutaine, A., Springe, I., Donauskaite, D., Himma-Kadakas, M., and Sile, E. (2018). Baltic media health check 2017–2018. Riga/Tallinn/Vilnius: The Baltic Center for Investigative Journalism Re: Baltica. Available online at: https://www.sseriga.edu/sites/default/files/inline-files/BalticMediaHealthCheck_2017-2018_21.11..pdf (accessed April 3, 2023).
Kuang, J., and Liberman, M. (2016). “Pitch-range perception: the dynamic interaction between voice quality and fundamental frequency,” in P. Interspeech 2016, San Francisco, CA, 1350–1354. doi: 10.21437/Interspeech.2016-1483
Lee, W-. N. (2019). Exploring the role of culture in advertising: resolving persistent issues and responding to changes. J. Advert. 48, 115–125. doi: 10.1080/00913367.2019.1579686
Michelon, A., Bellman, S., Faulkner, M., Cohen, J., and Bruwer, J. (2020). A new benchmark for mechanical avoidance of radio advertising. J. Advert. Res. 60, 407–416. doi: 10.2501/JAR-2020-007
Nagano, M., Ijima, Y., and Hiroya, S. (2023). Perceived emotional states mediate willingness to buy from advertising speech. Front. Psychol. 13, 1014921. doi: 10.3389/fpsyg.2022.1014921
Nordström, H. (2019). Emotional Communication in the Human Voice. [PhD thesis]. Stockholm: Stockholm University.
Okazaki, S., and Mueller, B. (2007). Cross-cultural advertising research: where we have been and where we need to go. Int. Market. Rev. 24, 499–518. doi: 10.1108/02651330710827960
Okazaki, S., Mueller, B., and Diehl, S. (2010). Measuring soft-sell versus hard-sell advertising appeals. J. Advert. 39, 5–20. doi: 10.2753/JOA0091-3367390201
Okazaki, S., Mueller, B., and Diehl, S. (2013). A multi-country examination of hard-sell and soft-sell advertising comparing global consumer positioning in holistic- and analytic-thinking cultures. J. Advert. Res. 53, 258–272. doi: 10.2501/JAR-53-3-258-272
Pajupuu, H., Altrov, R., and Pajupuu, J. (2019). The effects of culture on voice likability. Trames J. Humanit. Soc. 23, 239–257. doi: 10.3176/tr.2019.2.08
Pralus, A., Fornoni, L., Bouet, R., Gomot, M., Bhatara, A., Tillmann, B., et al. (2019). Emotional prosody in congenital amusia: impaired and spared processes. Neuropsychologia 134, 107234. doi: 10.1016/j.neuropsychologia.2019.107234
R Core Team (2022). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing, Vienna, Austria. Available online at: https://www.R-project.org/ (accessed April 3, 2023).
Revelle, W. (2022). Psych: Procedures for Psychological, Psychometric, and Personality Research. Northwestern University, Evanston, Illinois. R Package Version 2.2.9. Available online at: https://CRAN.R-project.org/package=psych (accessed April 3, 2023).
Rodero, E. (2020). Do your ads talk too fast to your audio audience? J. Advert. Res. 60, 337–349. doi: 10.2501/JAR-2019-038
Rodero, E., and Larrea, O. (2021). “Audio design in branding and advertising,” in Innovation in Advertising and Branding Communication, ed. L. Mas-Manchón (New York, NY: Routledge), 69–85. doi: 10.4324/9781003009276-5
Rodero, E., Larrea, O., and Vázquez, M. (2013). Male and female voices in commercials: analysis of effectiveness, adequacy for the product, attention and recall. Sex Roles 68, 349–362. doi: 10.1007/s11199-012-0247-y
Rodero, E., and Potter, R. F. (2021). Do not sound like an announcer. The emphasis strategy in commercials. Psychol. Market. 38, 1417–1425. doi: 10.1002/mar.21525
Rodero, E., Potter, R. F., and Prieto, P. (2017). Pitch range variations improve cognitive processing of audio messages. Hum. Commun. Res. 43, 397–413. doi: 10.1111/hcre.12109
Scherer, K. R. (1986). Vocal affect expression: a review and a model for future research. Psychol. Bull. 99, 143–165. doi: 10.1037/0033-2909.99.2.143
Speck, P. S., and Elliott, M. T. (1997). Predictors of advertising avoidance in print and broadcast media. J. Advert. 26, 61–76. doi: 10.1080/00913367.1997.10673529
Stewart, D. (2019). Radio. Revenue, Reach, and Resilience. Deloitte Insights. Technology, Media, and Telecommunications Predictions 2019, 60–69. Available online at: https://www2.deloitte.com/content/dam/Deloitte/ua/Documents/technology-media-telecommunications/DI_TMT-predictions_2019.pdf (accessed April 3, 2023).
Teixeira, J. P., Oliveira, C., and Lopes, C. (2013). Vocal acoustic analysis – jitter, shimmer and HNR parameters. Procedia Technol. 9, 1112–1122. doi: 10.1016/j.protcy.2013.12.124
Trimbach, D. J., and O'Lear, S. (2015). Russians in Estonia: is Narva the next Crimea? Eurasian Geogr. Econ. 56, 493–504. doi: 10.1080/15387216.2015.1110040
Trouvain, J., and Zimmerer, F. (2017). “Attractiveness of French voices for German listeners: results from native and non-native read speech,” in P. Interspeech 2017, Stockholm, 2238–2242. doi: 10.21437/Interspeech.2017-367
Venables, W. N., and Ripley, B. D. (2002). Modern Applied Statistics with S, Fourth edition. New York, NY: Springer.
Weninger, F., Eyben, F., Schuller, B., Mortillaro, M., and Scherer, K. (2013). On the acoustics of emotion in audio: what speech, music, and sound have in common. Front. Psychol. 4, 292. doi: 10.3389/fpsyg.2013.00292
Keywords: radio advertisement, speech style, speech perception, GeMAPS, official state language, second language
Citation: Altrov R, Pajupuu H, Pajupuu J and Kiisla A (2023) Radio advertisement speech style preferences among listeners with different first languages within one country. Front. Commun. 8:1176423. doi: 10.3389/fcomm.2023.1176423
Received: 28 February 2023; Accepted: 31 August 2023;
Published: 18 September 2023.
Edited by:
Steven Bellman, University of South Australia, AustraliaReviewed by:
Plinio Almeida Barbosa, State University of Campinas, BrazilSandra Madureira, PUCSP, Brazil
Copyright © 2023 Altrov, Pajupuu, Pajupuu and Kiisla. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Rene Altrov, cmVuZS5hbHRyb3ZAZWtpLmVl