 Didong Li
Didong Li Phuc Nguyen
Phuc Nguyen Zhengwu Zhang
Zhengwu Zhang David Dunson
David Dunson- 1Department of Biostatistics, University of North Carolina at Chapel Hill, Chapel Hill, NC, United States
- 2Department of Statistical Science, Duke University, Durham, NC, United States
- 3Department of Statistics and Operations Research, University of North Carolina at Chapel Hill, Chapel Hill, NC, United States
The brain structural connectome is generated by a collection of white matter fiber bundles constructed from diffusion weighted MRI (dMRI), acting as highways for neural activity. There has been abundant interest in studying how the structural connectome varies across individuals in relation to their traits, ranging from age and gender to neuropsychiatric outcomes. After applying tractography to dMRI to get white matter fiber bundles, a key question is how to represent the brain connectome to facilitate statistical analyses relating connectomes to traits. The current standard divides the brain into regions of interest (ROIs), and then relies on an adjacency matrix (AM) representation. Each cell in the AM is a measure of connectivity, e.g., number of fiber curves, between a pair of ROIs. Although the AM representation is intuitive, a disadvantage is the high-dimensionality due to the large number of cells in the matrix. This article proposes a simpler tree representation of the brain connectome, which is motivated by ideas in computational topology and takes topological and biological information on the cortical surface into consideration. We demonstrate that our tree representation preserves useful information and interpretability, while reducing dimensionality to improve statistical and computational efficiency. Applications to data from the Human Connectome Project (HCP) are considered and code is provided for reproducing our analyses.
1. Introduction
The human brain structural connectome, defined as the white matter fiber tracts connecting different brain regions, plays a central role in understanding how brain structure impacts human function and behavior (Park and Friston, 2013). Recent advances in neuroimaging methods have led to increasing collection of high quality functional and structural connectome data in humans. There are multiple large datasets available containing 1,000s of connectomes, including the Human Connectome Project (HCP) and the UK Biobank (Essen et al., 2012; Bycroft et al., 2018). We can now better relate variations in the connectomes between individuals to phenotypic traits (Wang et al., 2012; Hong et al., 2019; Roy et al., 2019). However, the large amount of data also creates the need for informative and efficient representations of the brain and its structural connectome (Galletta et al., 2017; Zhang et al., 2018; Jeurissen et al., 2019; Pizarro et al., 2019; Sotiropoulos and Zalesky, 2019). The main focus of this article is a novel and efficient representation of the processed connectome data as an alternative to the adjacency matrix (AM) as input to statistical analyses.
Diffusion magnetic resonance imaging (dMRI) uses diffusion-driven displacement of water molecules in the brain to map the organization and orientation of white fiber tracts on a microscopic scale (Bihan, 2003). Applying tractography to the dMRI data, we can construct a “tractogram” of 3D trajectories of white fiber tracts (Jeurissen et al., 2019). It is challenging to analyze the tractogram directly because (1) the number of fiber trajectories is extremely large; (2) the tractogram contains geometric structure; and (3) alignment of individual tracts between subjects remains difficult (Zhang et al., 2019). Because of these challenges, it is common to parcellate the brain into anatomical regions of interest (ROIs; Desikan et al., 2006; Destrieux et al., 2010; Wang et al., 2010), and then extract fiber bundles connecting ROIs. We can then represent the brain structural connectome as a weighted network in the form of an AM, a p by p symmetric matrix, with i, j-th entry equal to the number of fiber curves connecting region i and region j, where p is the total number of regions in the parcellation.
Statistical analyses of structural connectomes are typically based on this AM representation, which characterizes the connectome on a fixed scale depending on the resolution of ROIs. However, research has shown that brain networks fundamentally organize as multi-scale and hierarchical entities (Bassett and Siebenhühner, 2013). Some research has attempted to analyze community structures in functional and structural brain networks across resolutions (Betzel and Bassett, 2017); however, these works are limited to community detection. Brain atlases have anatomically meaningful hierarchies but only one level can be captured by the AM representation. If the lowest level in the atlas hierarchy with the greatest number of ROIs is used, this creates a very high-dimensional representation of the brain. The number of pairs of ROIs often exceeds the number of connectomes in the dataset. This presents statistical and computational challenges, with analyses often having low power and a lack of interpretability (Cremers et al., 2017; Poldrack et al., 2017).
For instance, to infer relationships between the connectome and a trait of interest, it is common to conduct hypothesis tests for association between each edge (connection strength between a pair of ROIs) and the trait (Fornito et al., 2016; Gou et al., 2018; Wang et al., 2019; Lee and Son, 2021). As the number of edges is very large, such tests will tend to produce a large number of type I errors without multiple testing adjustment. If a Bonferroni adjustment is used, then the power for detecting associations between particular edges and traits will be very low. A common alternative is to control for false discovery rate, for example via the Benjamini-Hochberg approach (Genovese et al., 2002). However, such corrections cannot solve the inevitable increase in testing errors that occur with more ROIs. An alternative is to take into account the network structure of the data in the statistical analysis (see, for example Leek and Storey, 2008; Fornito et al., 2016; Alberton et al., 2020). Such approaches can potentially improve power to detect differences while controlling type I errors through appropriate borrowing of information across the edges or relaxation of the independence assumption, but statistical and computational problems arise as the number of ROIs increases. Finally, it is common to vectorize the lower-triangular portion of the brain AM and then apply regression or classification methods designed for high-dimensional features (e.g., by penalizing using the ridge or lasso penalties).
To make the problems more concrete, note that a symmetric p × p connectome AM has pairs of brain ROIs. For the popular Desikan-Killiany parcellation (Desikan et al., 2006) with p = 68, . A number of other common atlases have many more than p = 68 brain regions, leading to a much larger number of edges. Even if one is relying on data from a large cohort, such as the UK Biobank, the sample size (number of subjects) is still much smaller than the connectivity features, leading to statistical efficiency problems without reducing the dimensionality greatly from . Dimensionality reduction methods, such as Principal Components Analysis (PCA), tensor decomposition, or non-negative matrix factorization, can be a remedy for studying relationships between the connectome and traits (Yourganov et al., 2014; Smith et al., 2015; Zhang et al., 2019; Patel et al., 2020). But, they may lack interpretability and fail to detect important relationships when the first few principal components are not biologically meaningful or predictive of traits.
In this paper, we propose a new representation of the brain connectome that is inspired by ideas in computational topology, a field focused on developing computational tools for investigating topological and geometric structure in complex data (Carlsson, 2009; Edelsbrunner and Harer, 2010). A common technique in computational topology is persistent homology, which investigates geometry/topology of the data by assessing how features of the data come and go at different scales of representation. Related ideas have been used successfully in studying brain vascular networks (Bendich et al., 2016), hippocampal spatial maps (Dabaghian et al., 2012), dynamical neuroimaging spatiotemporal representations (Lee et al., 2011; Geniesse et al., 2019), neural data decoding (Rybakken et al., 2019), and so on (Sizemore et al., 2019). We propose a fundamentally different framework, which incorporates an anatomically meaningful hierarchy of brain regions within a persistent homology approach to produce a new tree representation of the brain structural connectome. This representation reduces dimensionality substantially relative to the AM approach, leading to statistical and computational advantages, while enhancing interpretability. After showing our construction and providing mathematical and biological justification, we contrast the new representation with AM representations in analyses of data from the Human Connectome Project (HCP).
2. Method
2.1. Tree construction
There is a rich literature defining a wide variety of parcellations of the brain into regions of interest (ROIs) that are motivated by a combination of biological and statistical justifications (Desikan et al., 2006; Destrieux et al., 2010; Klein and Tourville, 2012). The ROIs should ideally be chosen based on biological function and to avoid inappropriately merging biologically and structurally distinct regions of the brain. Also, it is important to not sub-divide the brain into regions that are so small that (a) it may be difficult to align the data for different subjects and (b) the number of ROIs is so large that the statistical and computational problems mentioned in the introduction are exacerbated. Based on such considerations, the Desikan-Killiany (DK) atlas is particularly popular, breaking the brain into p = 68 ROIs (Desikan et al., 2006).
A parcellation such as DK is typically used to construct an AM representation of the structural connectome at a single level of resolution. However, we instead propose to introduce a multi-resolution tree in which we start with the entire cortical surface of the brain as the root node, and then divide into the right and left hemisphere to produce two children of the root node. We further sub-divide the two hemispheres into large sub-regions, then divide these sub-regions into smaller regions. We continue this sub-division until obtaining the regions of DK (or another target atlas) as the leaf nodes in the tree. In doing this, we note that there is substantial flexibility in defining the tree structure; we need not choose a binary tree and can choose the regions at each level of the tree based on biological function considerations to the extent possible. Finally, we summarize the connectivity information at different resolutions in the weights of the tree nodes.
In this article, we focus primarily on the following tree construction based on the DK atlas for illustration, while hoping that this work motivates additional work using careful statistical and biological thinking to choose the regions at each layer of the tree. The DK parcellation is informed by standard neuroanatomical conventions, previous works on brain parcellations, conversations with expert scientists in neuroscience, and anatomic information on local folds and grooves of the brain (Desikan et al., 2006). We use the Freesurfer software to obtain the DK parcellation for each individual brain, and DK parcellation divides each hemisphere into 34 regions that can be organized hierarchically (Desikan et al., 2006). Specifically, each hemisphere has six regions: frontal lobe, parietal lobe, occipital lobe, cingulate cortex, temporal lobe, and insula. All of these regions, except the insula, have multiple sub-regions, many of which are further sub-divided in the DK atlas. The full hierarchy can be found in Appendix 1.1 (Supplementary material). We calculate the weight of each node as the sum of all connections between its immediate children. For instance, the weight at the root node will equal the sum of all the inter-hemisphere connections. The weight of the left hemisphere node will equal the sum of all connections among the left temporal lobe, frontal lobe, parietal lobe, occipital lobe, cingulate cortex, and insula. The weight of the left temporal lobe is the sum of all connections between regions within the temporal medial aspect and lateral aspect. We continue this calculation for all nodes that have children. The weights of a leaf node will be all connections within that region, or equivalently, the diagonal element at that region's index on the AM representation.
To rephrase the tree construction in math notations, let be the whole brain, be the left hemisphere, be the right hemisphere, and be the i-th region at level l, where l = 1, ⋯ , L and i = 1, ⋯ , Nl. For example, in DK, L = 5, N1 = 1, N2 = 2, N3 = 12, N4 = 44, N5 = 32 (Appendix 1.1 in Supplementary material). Define the weight of region , denoted by , as for all l = 1, 2, ⋯ , L and i = 1, ⋯ , Nl. For example, for DK-based tree, is the number of fibers connecting children of left hemisphere, that is, fibers between temporal lobe, cingulate cortex, occipital lobe, parietal lobe, and frontal lobe. Similarly, is the number of fibers connecting children of temporal lobe, that is, fibers between medial aspect and lateral aspect.
Figure 1 provides an illustration of the DK-based tree structure and the connections summarized at each node. Often the connections within the leaf nodes are not estimated in the AM representation (i.e., the diagonal elements of an AM are set to zero), thus, they have weights zero and are omitted from the figure. We also introduce a more compact visualization of the tree based on circle chord plots. Figure 2 shows the steps in our pipeline to construct a brain tree. The final output circle plot displays bundles of white matter tracts as overlapping chords scaled inversely proportional to the level of the tree they belong to and color-coded by the node they belong to.
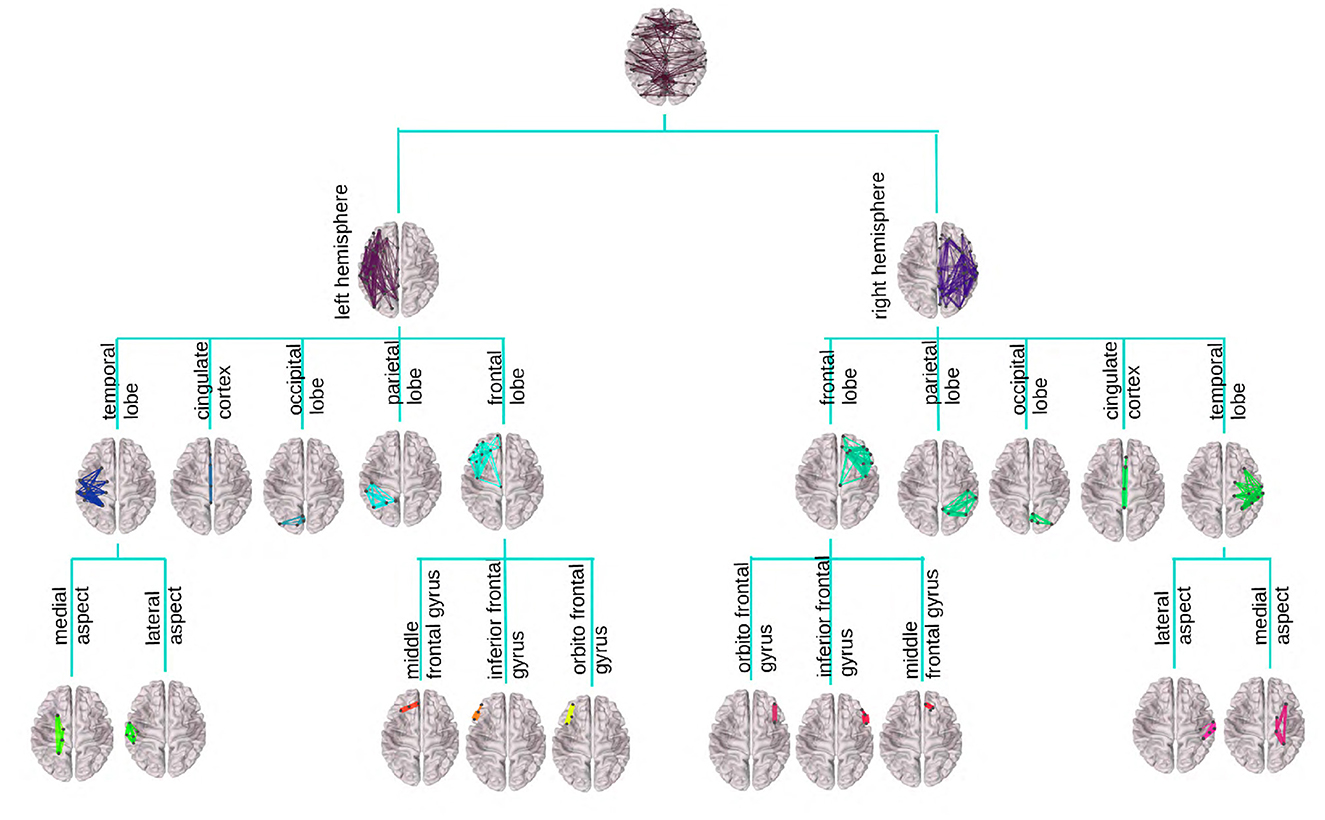
Figure 1. Visualization of the DK tree structure and connections summarized at each node on the brain image. Leaves, including the insula, have no internal connections and are omitted for readability. Individual brains were created using the brainconn R package (Orchard et al., 2021).
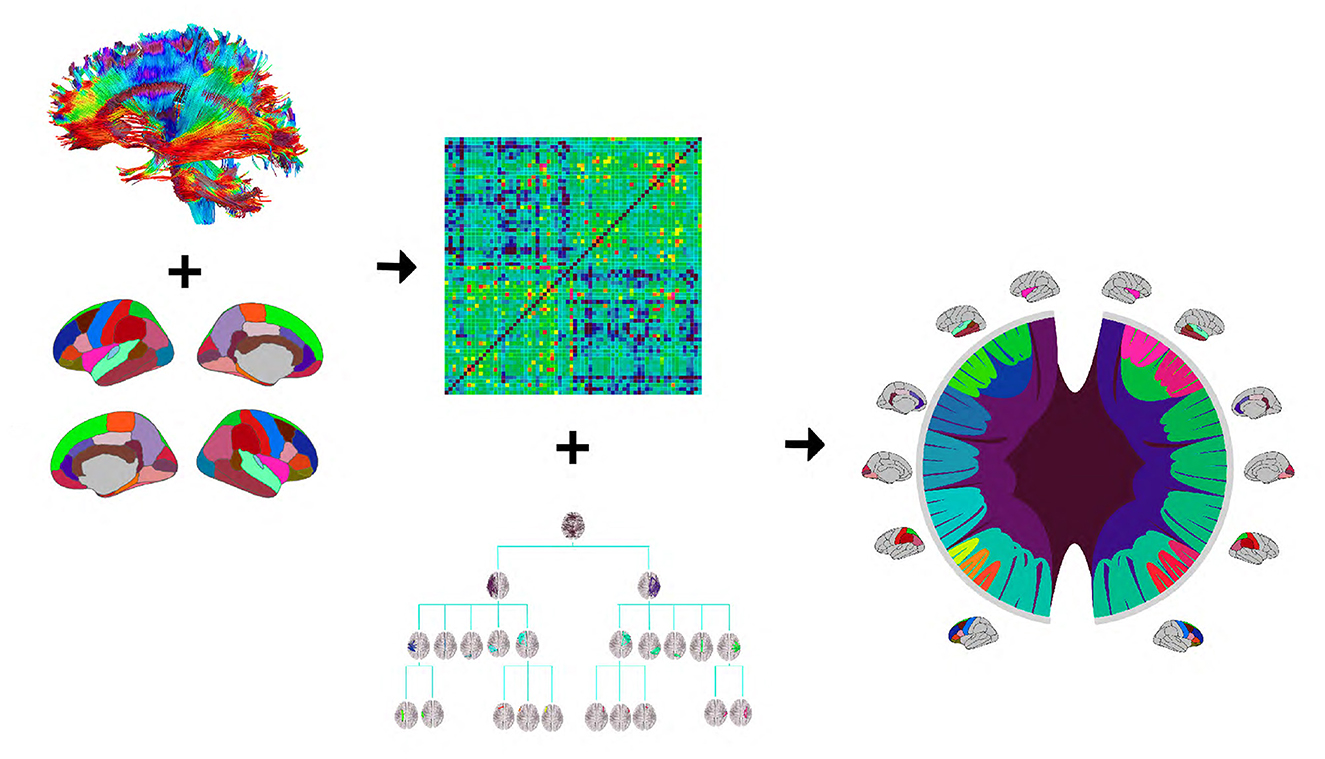
Figure 2. The tree construction pipeline: first, tractography and Desikan-Killiany (DK) protocol are used to estimate an adjacency matrix; then, the adjacency matrix and a hierarchy based on the DK protocol are combined to produce the tree representation. We introduce a compact circle chord plot that shows the tree representation of white matter fiber tracts connecting brain regions from the DK protocol. Connections are color-coded by the node they belong to, the same color codes as in Figure 1, and scaled inversely proportional to the level they belong to in the tree.
2.2. A persistent homology interpretation
Persistent homology is a method for computing topological features of a space at different resolutions. As quantitative features of noisy data, persistent homology is less sensitive to the choice of coordinate and metric and robust to noise (Carlsson, 2009). The key construction in persistent homology is the filtration, a multi-scale structure similar to the brain network. As a result, we can interpret the above defined as corank of the persistent homology. As a rigorous definition of persistent homology is highly technical, we present a simple version and leave the rigorous version and the proof to the Appendix in Supplementary material. For relevant background in topology (see Hatcher, 2002; Munkres, 2016).
Theorem 1. is the corank of the persistent homology.
Theorem 1 provides a topological interpretation of , and partially explains why the tree T = (A, H) is a powerful representation of the brain network. It states that , our proposed summary statistic, is the corank of the persistent homology. In simpler terms, this means that our statistic measures the “holes” or loops in the structure of the brain network that persist across different levels of partition. These holes can be thought of as stable features of the network, in that they remain even when we change our perspective or level of detail. As we increase the resolution (i.e., when we move from looking at large-scale structures to focusing on smaller-scale details), some holes may “close up” (disappear), while others continue to exist. These persistent holes can inform us about the topological structure of the brain network. Thus, , by capturing these persistent features, provides a summary statistic that is less sensitive to changes in perspective and robust against noise.
We consider the tree T = (A, H) to be a powerful representation because it captures not just the connections between different regions of the brain (as the adjacency matrix A does), but also the persistent homological features (captured by ). This allows us to include topological information, like the persistence of holes at different scales, which can potentially capture complex structural information about the brain network that a simple adjacency matrix might miss. In effect, T = (A, H) provides us with a richer, more nuanced view of the brain network, thus making it a powerful representation for brain connectivity analysis.
3. Results
3.1. Data description
We investigate our tree representation's ability to preserve information from the AM representation while improving interpretability in analyses relating brain structures to behavioral traits. We use neuroimaging data and scores on various behavioral assessments from the HCP (Glasser et al., 2013, 2016). The HCP collects high-quality diffusion MRI (dMRI) and structural MRI (sMRI) data, characterizing brain connectivity of 1,200 healthy adults, and enables comparison between brain circuits, behavior and genetics at the individual subject level (Essen et al., 2012). We use data from the 2017 release accessed through ConnectomeDB. Details on data acquisition and preprocessing pipeline of dMRI and sMRI data in the HCP can be found in Essen et al. (2012) and Glasser et al. (2013, 2016). To produce connectome data from raw dMRI/sMRI data, we use the reproducible probabilistic tractography algorithm in Girard et al. (2014) to construct tractography data for each subject, the DK atlas (Desikan et al., 2006) to define the brain parcellation, and the preprocessing pipeline in Zhang et al. (2018) to extract weighted matrices of connections. More details of these steps can be found in Zhang et al. (2019). In the extracted data matrices, each connection is described by a scalar number. The HCP data include scores for many behavioral traits related to cognition, motor skills, substance use, sensories, emotions, personalities, and many others. Details can be found at https://wiki.humanconnectome.org/display/PublicData/HCP-YA+Data+Dictionary-+Updated+for+the+1200+Subject+Release. The final data set consists of n = 1, 065 brain connectomes and 175 traits. We construct the tree representations of the connectomes based on the construction described in Section 2.1.
We conduct purely visual exploratory comparisons of the tree and AM representation in Figure 3. Figure 3A shows how four example brain connectomes are visualized differently under two representations. We see that different nodes in the tree representation correspond to different pixel patterns in the AM representation. Figure 3B shows the percent difference in brain connections between the top and bottom ten percent of scores in four cognitive tasks. The percent difference in the AM representation of a trait is calculated as , where is the average AM of people who score in the top 10% of that trait, and is the average AM of people who score in the bottom 10%. Similarly, the percent difference in the tree representation of a trait is calculated as , where is the average tree of people who score in the top 10% of that trait, and is the average tree of people who score in the bottom 10%. Figure 3B shows the visualization of the tree representation as a more effective exploratory analysis tool to find regions of the brain with large percentage change between the top and bottom scores. On the other hand, the AM, being a much higher dimensional representation, can capture connection-specific associations, especially negative ones that get washed out at the brain-region level.
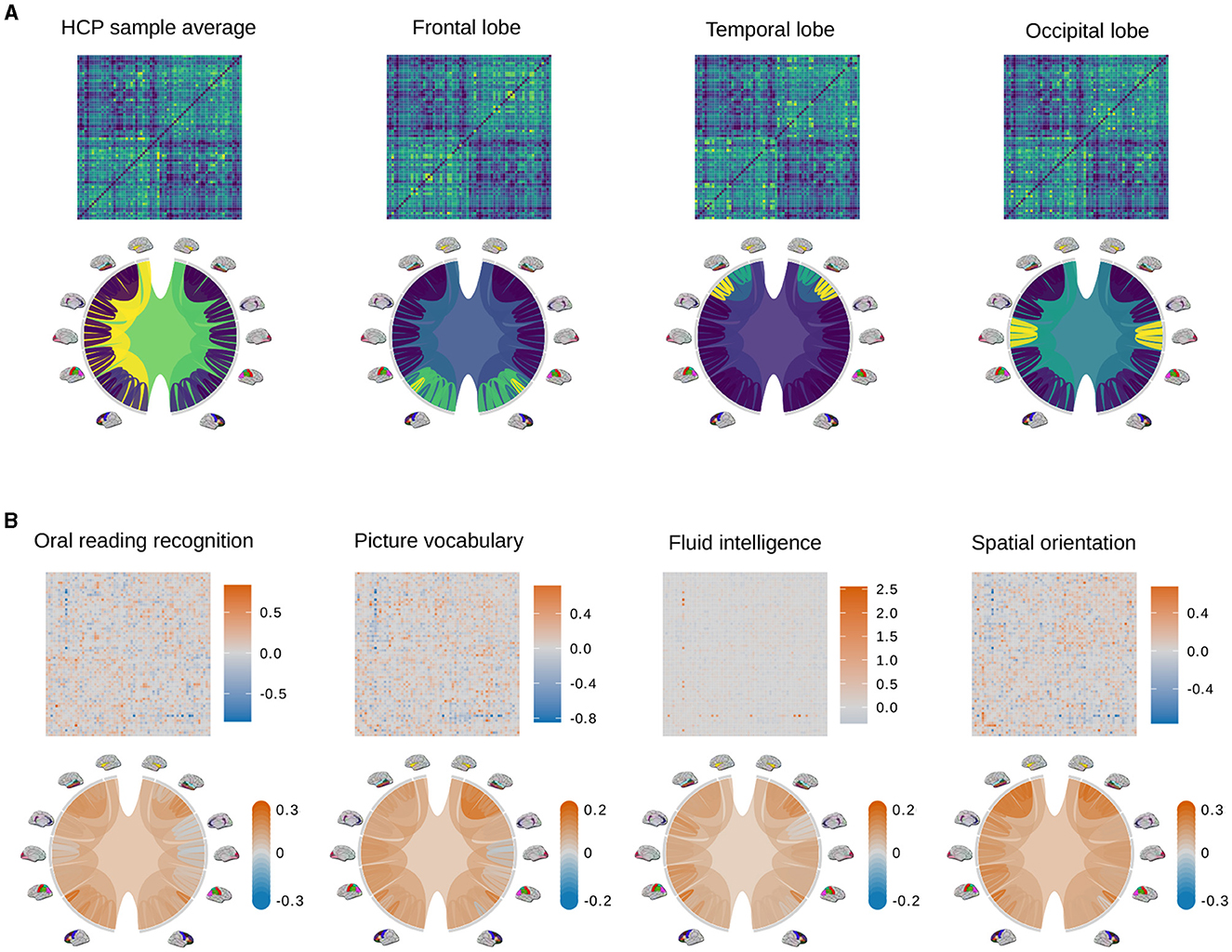
Figure 3. Examples of adjacency matrices and corresponding tree representations of brain connectomes. (A) The sample average from the HCP data (left most) and its modifications so that different regions of the brain (i.e., the frontal lobe, temporal lobe, and occipital lobe) have denser connections. Because these modifications are unrealistic and only meant to better distinguish how connections are visualized differently in the AM and tree representations, color scales are omitted. Values in the adjacency matrices are normalized for visual clarity. (B) Percent difference in brain connections between the top and bottom ten percent of scores in four cognitive tasks.
To quantitatively compare the strengths and weaknesses of the AM and tree-based representations of the brain connectome in the next subsections, we use a simple two-step approach: first vectorizing the connectome data, and then applying a regression method. Since a connectome matrix is symmetric, we only vectorize the upper triangular part, resulting in a 2,278-dimensional vector for each matrix. We also remove pairs of ROIs that show no variability in connectivity across subjects, reducing the vectorized matrices to 2,202 dimensions. Self-edges are not recorded in the connectome matrices, so the leaves in the tree representation have zero weights. As a result, we remove the leaf nodes, leaving the vectorized trees to be 23-dimensional instead of 91-dimensional.
To apply regression algorithms, we first reduce the dimension of the adjacency matrix to K ≪ 2, 202 by selecting the top principal components (PCs). We observed that the regression MSEs of commonly used algorithms including linear regression, decision trees, support vector machines (SVM), boosting, Gaussian process (GP) regression, etc., did not decrease when we increased the number of PCs, and Zhang et al. (2019) also observed that the regression performance is robust for K = 20–60. As a result, we keep the first K = 23 PCs to match the dimension of the tree for a fair comparison. We refer to the data from the vectorized trees as Dtree and that from principal components of the vectorized matrices as DPCA.
3.2. Canonical correlation analysis
Human brain connectivity has been shown to be capable of explaining significant variation in a variety of human traits. Specifically, data on functional and structural connectivity have been used to form latent variables that are positively correlated with desirable, positive traits (i.e., high scores on fluid intelligence or oral reading comprehension) while also being negatively correlated with undesirable traits (i.e., low sleep quality, frequent use of tobacco, or cannabis; Smith et al., 2015; Tian et al., 2020). In this first analysis, we compare how strongly latent variables inferred from the two representations are associated with the perceived desirability of traits. We choose to work with a subset of 45 traits that have been shown to strongly associate with brain connectome variations, including cognitive traits, tobacco/drug use, income, years of education, and negative and positive emotions (Smith et al., 2015; Zhang et al., 2019). We include only traits with continuous values to simplify the analyses. The full list of variables used can be found in the Appendix (Supplementary material). We will use a statistical method called canonical correlation analysis (CCA), which finds linear combinations of the predictors that are most correlated with some other linear combinations of the outcomes. In our case, the predictors are principal components of the vectorized AM or features of the vectorized trees, and the outcomes are scores measured on 45 traits. Mathematically, let X ∈ ℝn × p be the feature matrix (n = 1, 065, p = 23), and Y ∈ ℝn × q be the outcome matrix (q = 39 with some traits being removed due to extensive missing values, see the next paragraph for more details). Additionally, let and , k = 1, ..., min(p, q) be pairs of linear transformation of the data. We refer to (rk, sk) = (Xak, Ybk) as the feature and outcome canonical variates or the kth pair of canonical variates. CCA aims to learn ak, bk such that (ak, bk) = argmaxak, bkcorr(rk, sk), so the linear transformations maximize the correlation between components of the canonical variates pair. Pairs of canonical variates are also constrained to be orthogonal, that is, and for k ≠ h.
Since this analysis considers all traits simultaneously, we remove traits with extensive missing values (i.e., more than 10% of all observations) and are left with 39 traits. We then normalize Dtree, DPCA, and these 39 trait scores, and fill in missing values with the feature's mean. We fit two CCAs using Dtree and DPCA separately, and use the Wilks's lambda test to check that the first canonical variate pair, which has the largest co-variation, is significant at the 5% level in each model. We hand-label the traits as desirable or not desirable based on previous research (Smith et al., 2015; Tian et al., 2020). Figure 4 plots the correlation of the trait scores with the first feature canonical variate and color-codes traits by desirability. Traits with smaller fonts have smaller contributions to the linear combination that makes up the first outcome canonical variate. It shows that desirable traits tend to be more highly negatively correlated with the first feature canonical variate compared to the undesirable traits, which tend to be weakly correlated. This is most clear with traits with strong signal such as fluid intelligence and spatial orientation. With the same number of features, the tree representation produces a canonical variate that can separate traits into groups of the same desirability slightly better than the principal components of the AM can.
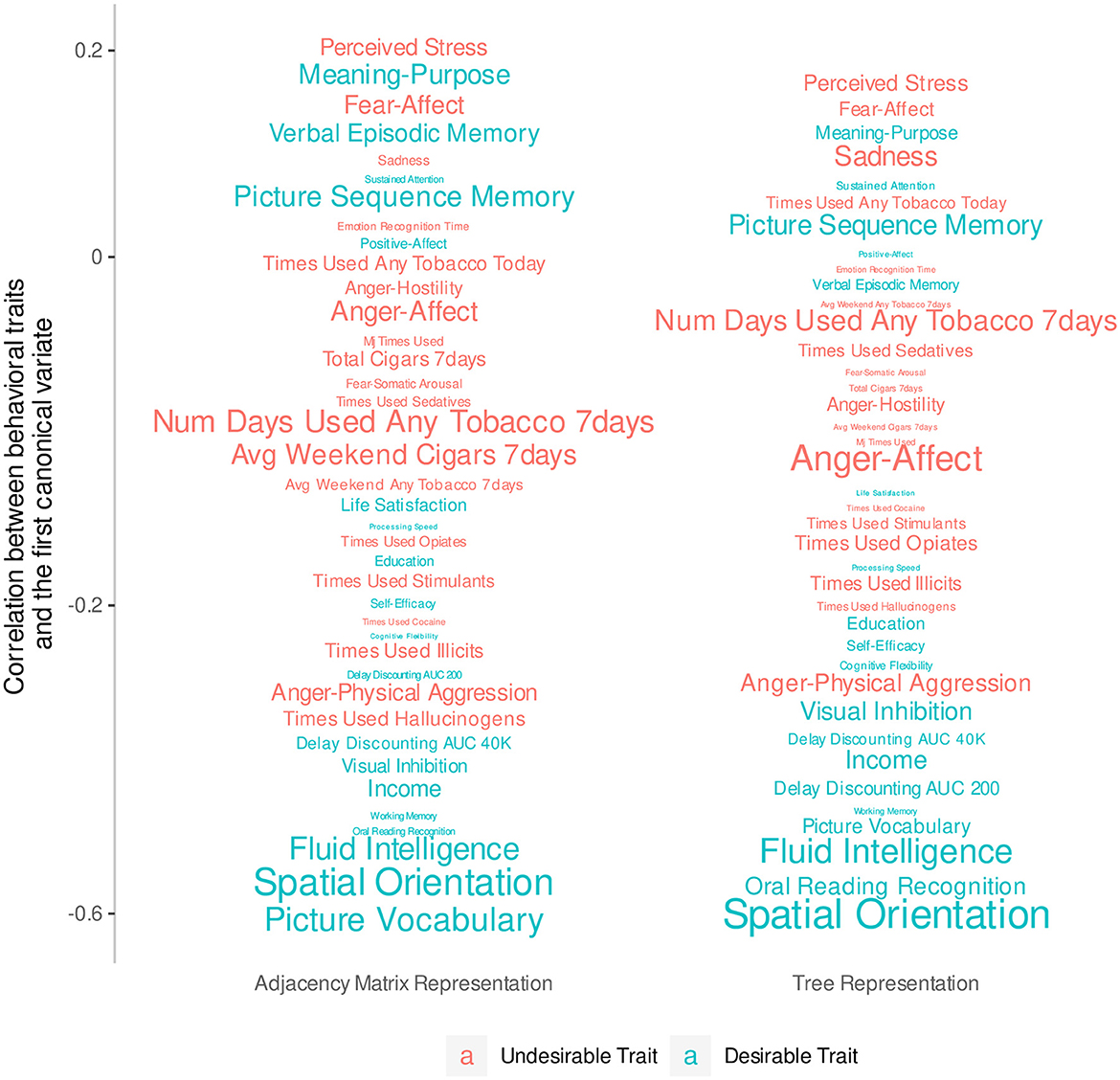
Figure 4. Correlations between behavioral traits and the first canonical variate extracted from 23 principal components of the AM compared to the 23 non-leaf nodes of the tree representation. The y-axis has been transformed so that traits do not overlap. The font size of each trait indicates the magnitude of the coefficients of a linear combination that defines the first canonical variate.
3.3. Prediction
Additionally, we consider the performance of these representations in predictive tasks. We hypothesize that if the tree representation preserves important information from the AM representation, they will provide comparable performance in predicting trait scores. Since in Section 3.2, cognitive traits generally have the largest correlations with the first feature canonical variate, we will examine cognitive traits in more details in this section. Specifically, we include all 45 cognitive traits in the HCP data, including different metrics of the same trait. We fit a baseline model that returns the sample mean and 19 popular machine learning models (including linear regression, decision tree, SVM, ensemble trees, GP regression, and their variants) to the Dtree and DPCA data. To evaluate predictive performance, we consider two scale-free metrics: (1) correlations between predictions and true outcomes and (2) the percentage of improvement in test MSE compared to the baseline predictor. We calculate these metrics using five-fold cross validation repeated 10 times. Figures 5, 6 shows the cross-validated predictive performance for two representative regression algorithms: linear regression and GP regression. Linear regression represents a simple, interpretable, and widely used algorithm, while GP regression is a flexible algorithm that has the best overall performance among the 19 algorithms we studied. For each algorithm and each trait, the x-axis is the performance of the AM representation while the y-axis is that of the tree representation. Points above the diagonal line y = x indicate better performance by the tree representation, while points below the line indicate better performance by the AM representation.

Figure 5. Percentage of change in MSE compared to baseline of linear regression and GP regression using tree and AM representation in predicting 45 cognitive traits.
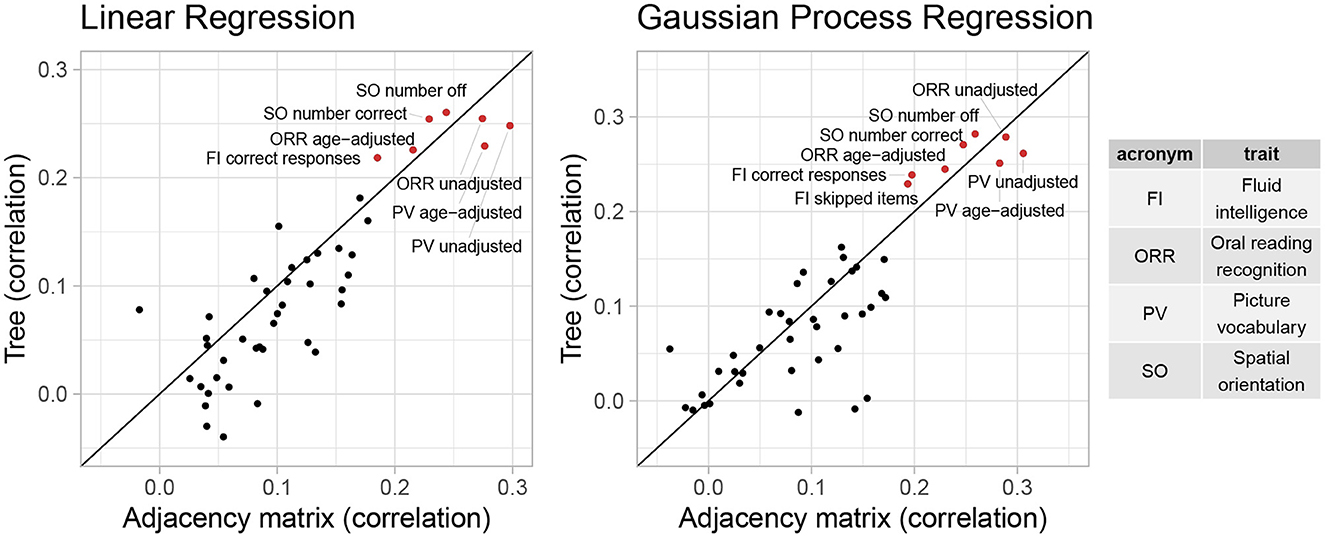
Figure 6. Correlation between predictions and observed outcomes of linear regression and GP regression using tree and AM representation in predicting 45 cognitive traits.
Overall, the performance of both representations seems similar. However, for most traits, even when considering the GP regression with best overall performance, the correlation is smaller than 0.2, and the improvement in test MSE is <3%. This suggests that the vectorized brain connectivity might not be relevant to predicting most of these traits. If we focus on traits with large correlations or improvement in MSE, the tree representation has better performance in terms of both correlation and improvement in MSE for five out of eight traits with correlations >0.2. These traits include fluid intelligence, picture vocabulary, spatial orientation, and oral reading recognition, which also have the largest correlations with the canonical variate in Section 3.2.
3.4. Interpretability of regression
Finally, we compare interpretability of the two representations. Scientists are often interested in identifying structures in the connectomes that are associated with traits to answer questions such as which kind of connections might be damaged by routine use of drugs or which might be responsible for enhanced working memory. Therefore, we compare interpretability, in terms of biologically meaningful inference, of regression results using the two representations. We focus on spatial orientation (number correct), picture vocabulary (age-adjusted), fluid intelligence (correct responses), oral reading recognition (age-adjusted), and working memory (age-adjusted) because these traits show strong associations with the connectomes in the CCA and prediction tasks.
We fit a separate linear regression with Bayesian model selection on Dtree and DPCA to infer associations between brain connectomes and the traits mentioned above. Bayesian model selection accounts for uncertainty in the model selection process by posterior probabilities for the different possible models. The regression coefficients are averaged across all models, weighted by estimated model posterior probabilities. For feature selection, we define important features as those with posterior inclusion probabilities of more than 0.75. For models using Dtree, we simply interpret posterior means and credible intervals of the estimated effects of important features directly. Figures 7, 8 (left column) show tree features whose colors are based on their estimated coefficients, and opacity are based on their posterior inclusion probabilities.
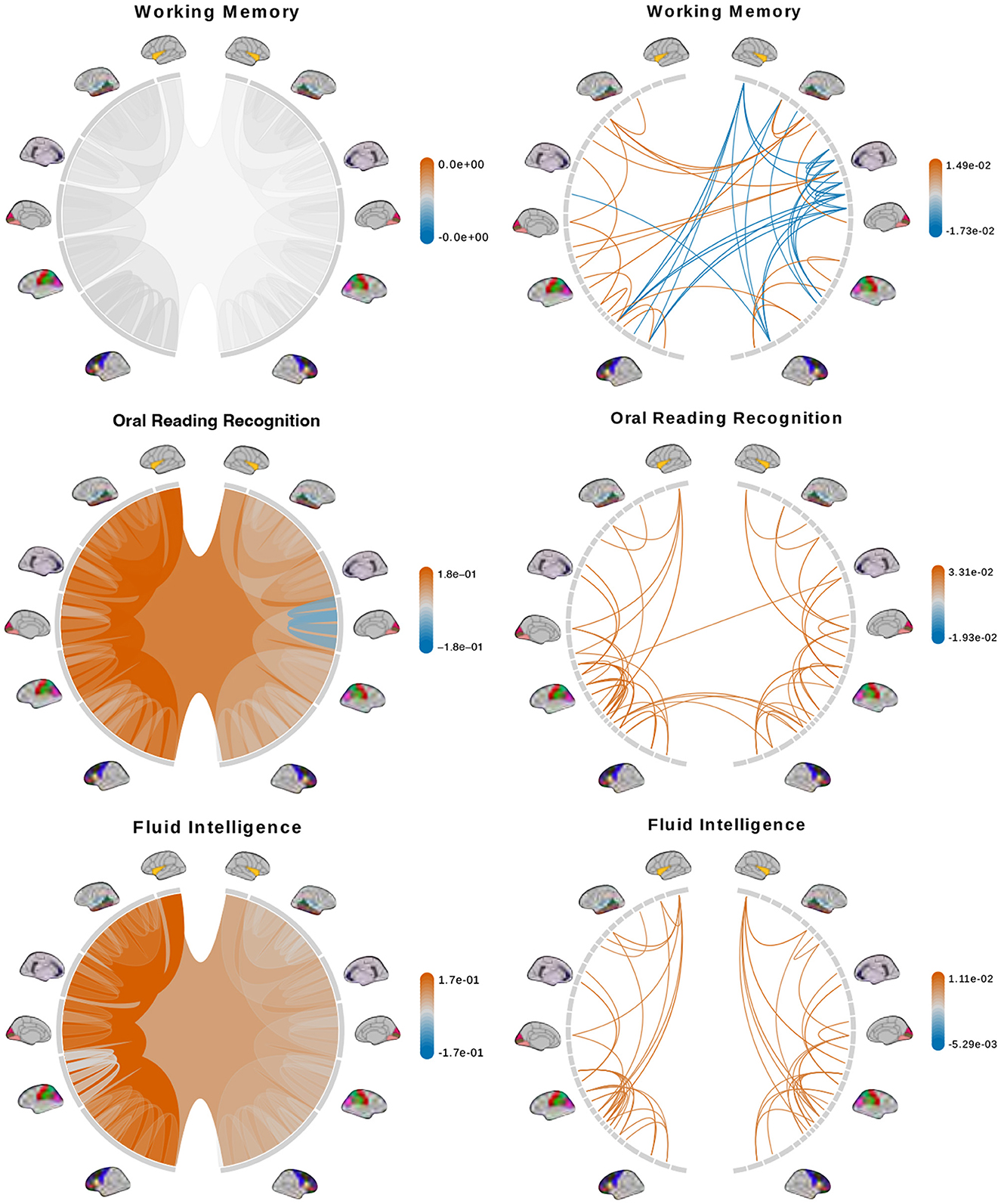
Figure 7. Brain connectome structures significantly associated with each trait inferred using the tree representation (left) and principal components of the AM representation (right). Colors represent the sign and magnitude of significant (i.e., posterior inclusion probability >0.75) regression coefficients. For tree-based results, the opacity also represents the posterior inclusion probability to improve the visibility of bundles of connections with larger effects.
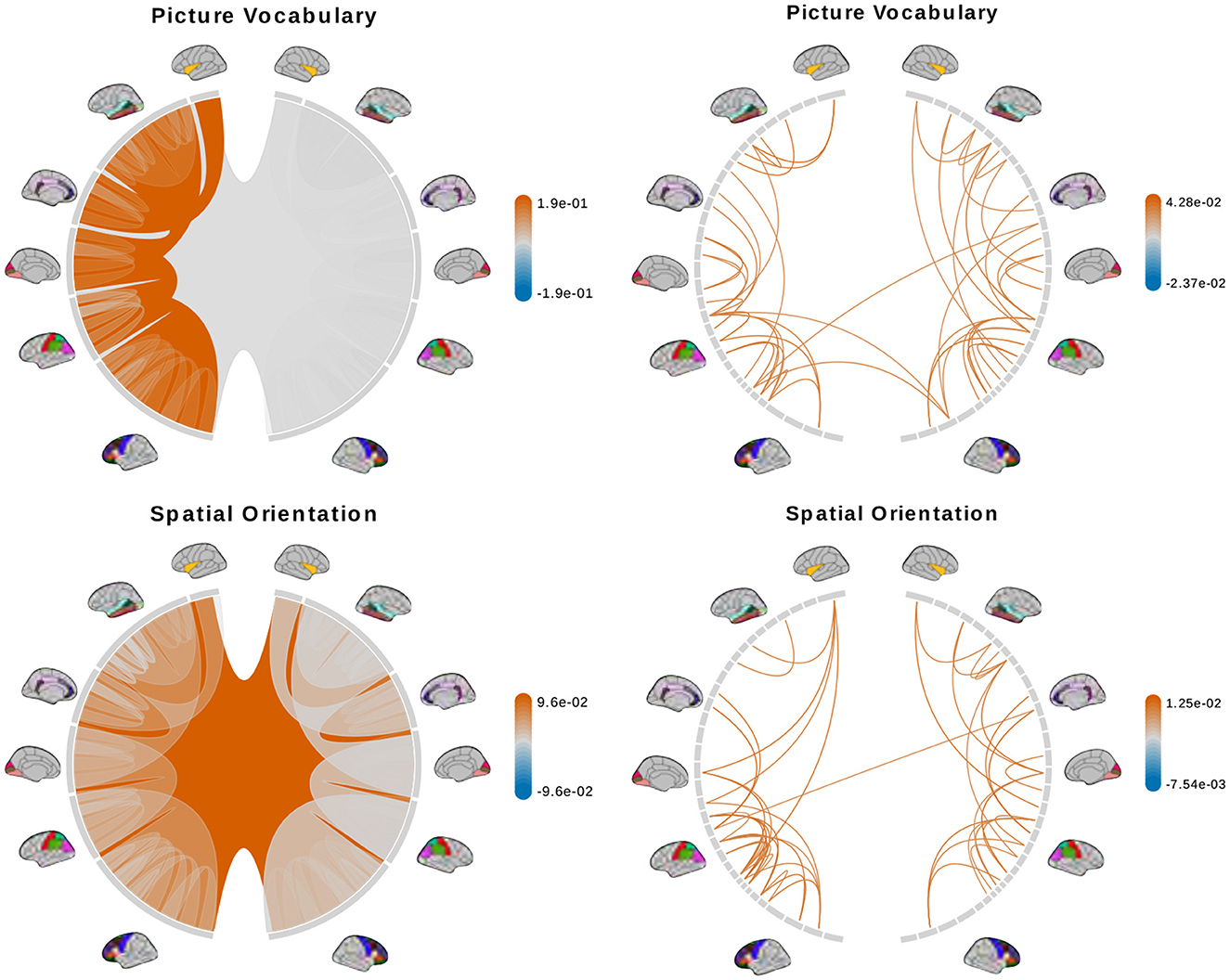
Figure 8. (Continue) Brain connectome structures significantly associated with each trait inferred using the tree representation (left) and principal components of the AM representation (right). Colors represent the sign and magnitude of significant (i.e., posterior inclusion probability >0.75) regression coefficients. For tree-based results, the opacity also represents the posterior inclusion probability to improve the visibility of bundles of connections with larger effects.
For the models using DPCA, after selecting important principal components, we can calculate a regression coefficient for each brain connection from the regression coefficients of these important principal components. Let X be an n × p matrix of vectorized brain connections whose columns have been standardized. Recall that PCA is based on the singular-value decomposition of the data matrix X = UDVT, where VVT = I, UTU = I and D is a diagonal matrix of p non-negative singular values, sorted in decreasing order. The jth principal axis is the jth eigenvector or the jth column of V, and the jth principal component is the jth column of UD. With K PCs, we get a rank-K approximation of where MK contains the first K columns of matrix M. Applying the approximation to the linear model Y = Xβ + ϵ ≈ UKDKθ + ϵ, we get , where θ is a K-vector of regression coefficients of the principal components. There are multiple generalized inverses for b such that . We will use b = 0 to get the standard least-norm inverse as estimates of the regression coefficient for the original brain connections (Bernardo et al., 2003). We interpret the results based on 50 connections with the largest coefficient magnitude. Figures 7, 8 (right column) show these connections colored by their estimated coefficients.
The tree-based model finds no structure statistically significant (with posterior inclusion probability >0.75) in predicting enhanced working memory. This is consistent with previous sections showing weak signals for associations between working memory and brain connectomes. The matrix-based model finds some cross-hemispheric connections between temporal lobes positively correlated with enhanced memory, which is supported by prior research (Eriksson et al., 2015). However, it also finds many right hemispheric connections negatively correlated with these scores, which contradicts some prior findings (Poldrack and Gabrieli, 1998). For oral reading recognition, the models find cross-hemispheric and left-hemispheric connections important in both the tree and adjacency matrix representations. This is consistent with prior research that showed better reading ability associated with more cross-hemispheric connections between frontal lobes (Zhang et al., 2019) and with increased fractional anisotropy in some left hemispheric fiber tracts (Yeatman et al., 2012). The matrix-based model additionally finds many connections across all regions in the right hemisphere to be important, among which the insula, frontal opercular, and lateral temporal lobe have previously been found to correlate with this score (Kristanto et al., 2020). On the other hand, the tree-based model found increased connectivity in the right occipital lobe to negatively correlate with higher scores. While healthy adults typically have larger left occipital lobar volume, research has found associations between developmental stuttering and phonological dyslexia with rightward occipital asymmetry or no occipital asymmetry (Foundas et al., 2003; Zadina et al., 2006), which is consistent with our tree-based model's result. For fluid intelligence, the tree-based model finds connections within the left hemisphere and between hemispheres to be important. The matrix-based model finds within-hemisphere connections, especially those involving the frontal lobes, to be important. The fluid intelligence score serves as proxy for “general intelligence” (Raven, 2000; Gershon et al., 2014), which relies on many sub-networks distributed across the brain (Dubois et al., 2018). For the vocabulary task, the tree-based model finds connections within the left hemisphere, while the matrix-based model finds connections within both hemispheres, to be important. Both results support existing findings that interpreting meanings of words activates many regions across the brain (Huth et al., 2016). Finally, in the spatial orientation task, the tree-based model finds cross-hemispheric connections to be important and positively correlated with better scores, while the matrix-based model does for connections between regions within each hemisphere (Figure 8, bottom). Both are somewhat similar to prior research that found decreased cross-hemispheric and right hemispheric connectivity to be associated with impaired spatial recognition of stroke patients (Ptak et al., 2020). Overall, we observe that the results from the tree representation are easier to interpret because of the inherent low-dimensional and biologically meaningful structure. The results from the AM representation tend to be noisier, and more likely to involve negative correlations between connectivity and better performance in cognitive tasks. Potentially, the representations may better encode different kinds of information that are both important.
4. Discussion
We propose a novel and efficient tree representation based on persistent homology for the brain network. Through analyses of the HCP data, we show that the tree representation preserves information from the AM representation that relates brain structures to traits while being much simpler to interpret. Simultaneously, it reduces the computational cost and complexity of the analysis because of its inherent lower dimension. We believe the advantages of the tree representation will be more evident on small brain imaging data sets.
Our new representation opens doors to new mathematical and statistical methods to analyze brain connectomes; in particular, taking into account the tree structure of the data. Topological data analysis (TDA) uses notions of shapes and connectivity to find structure in data, and persistent homology is one of the most well-known TDA methods (Wasserman, 2017). TDA has been used successfully in studying brain networks (Saggar et al., 2018; Gracia-Tabuenca et al., 2020), but we provide a fundamentally different approach. Our analyses of the connectome trees in this paper are simplistic. We treat tree nodes as independent and non-interacting. Future work should consider the tree structure to enforce dependence between the nodes, and hence, between their effects on behavioral traits. The tree structure may also be exploited to model interactions between connectome structures across different scales. For instance, Bayesian treed models are flexible, nonparametric methods that have found widespread and successful applications in many domains (Linero, 2017). Existing treed models might prove unwieldy to fit and interpret on AM-based brain networks but their modifications may fit the nature of our tree representation well.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found at: https://github.com/phuchonguyen/brain-topology; https://wiki.humanconnectome.org/display/PublicData/How+to+Access+Data+on+ConnectomeDB.
Author contributions
DL, PN, ZZ, and DD designed the method, analyzed the results, and edited the manuscript. DL and PN implemented the method, conducted data analysis, and wrote the manuscript. All authors contributed to the article and approved the submitted version.
Funding
DL was supported by NIH/NCATS award UL1 TR002489, NIH/NHLBI award R01 HL149683, and NIH/NIEHS award P30 ES010126. PN and DD were supported by NIH award R01ES035625. ZZ was supported by NIH award R01 MH118927.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnins.2023.1200373/full#supplementary-material
References
Alberton, B. A., Nichols, T. E., Gamba, H. R., and Winkler, A. M. (2020). Multiple testing correction over contrasts for brain imaging. NeuroImage 216, 116760. doi: 10.1016/j.neuroimage.2020.116760
Bassett, D. S., and Siebenhühner, F. (2013). Multiscale network organization in the human brain. Multisc. Analysis Nonlin. Dyn. 179–204. doi: 10.1002/9783527671632.CH07
Bendich, P., Marron, J. S., Miller, E., Pieloch, A., and Skwerer, S. (2016). Persistent homology analysis of brain artery trees. Ann. Appl. Stat. 10, 198. doi: 10.1214/15-AOAS886
Bernardo, J., Bayarri, M., Berger, J., Dawid, A., Heckerman, D., Smith, A., et al. (2003). Bayesian factor regression models in the “large p, small n” paradigm. Bayesian Statist. 7, 733–742.
Betzel, R. F., and Bassett, D. S. (2017). Multi-scale brain networks. NeuroImage 160, 73–83. doi: 10.1016/j.neuroimage.2016.11.006
Bihan, D. L. (2003). Looking into the functional architecture of the brain with diffusion MRI. Nat. Rev. Neurosci. 4, 469–480. doi: 10.1038/nrn1119
Bycroft, C., Freeman, C., Petkova, D., Band, G., Elliott, L. T., Sharp, K., et al. (2018). The UK Biobank resource with deep phenotyping and genomic data. Nature 562, 203–209. doi: 10.1038/s41586-018-0579-z
Carlsson, G. (2009). Topology and data. Bull. Am. Math. Soc. 46, 255–308. doi: 10.1090/S0273-0979-09-01249-X
Cremers, H. R., Wager, T. D., and Yarkoni, T. (2017). The relation between statistical power and inference in fMRI. PLoS ONE 12, e0184923. doi: 10.1371/journal.pone.0184923
Dabaghian, Y., Mémoli, F., Frank, L., and Carlsson, G. (2012). A Topological Paradigm for Hippocampal Spatial Map Formation Using Persistent Homology. San Francisco, CA: Public Library of Science. doi: 10.1371/journal.pcbi.1002581
Desikan, R. S., Ségonne, F., Fischl, B., Quinn, B. T., Dickerson, B. C., Blacker, D., et al. (2006). An automated labeling system for subdividing the human cerebral cortex on MRI scans into gyral based regions of interest. NeuroImage 31, 968–980. doi: 10.1016/j.neuroimage.2006.01.021
Destrieux, C., Fischl, B., Dale, A., and Halgren, E. (2010). Automatic parcellation of human cortical gyri and sulci using standard anatomical nomenclature. NeuroImage 53, 1–15. doi: 10.1016/j.neuroimage.2010.06.010
Dubois, J., Galdi, P., Paul, L. K., and Adolphs, R. (2018). A distributed brain network predicts general intelligence from resting-state human neuroimaging data. Philos. Trans. R. Soc. B Biol. Sci. 373, 20170284. doi: 10.1098/rstb.2017.0284
Edelsbrunner, H., and Harer, J. (2010). Computational Topology: An Introduction. Providence, Rhode Island: American Mathematical Society.
Eriksson, J., Vogel, E., Lansner, A., Bergstrm, F., and Nyberg, L. (2015). Neurocognitive architecture of working memory. Neuron 88, 33–46. doi: 10.1016/j.neuron.2015.09.020
Essen, D. C. V., Ugurbil, K., Auerbach, E., Barch, D., Behrens, T. E. J., Bucholz, R., et al. (2012). The human connectome project: a data acquisition perspective. NeuroImage 62, 2222–2231. doi: 10.1016/j.neuroimage.2012.02.018
Fornito, A., Zalesky, A., and Bullmore, E. (2016). Fundamentals of Brain Network Analysis. San Diego, CA: Academic press.
Foundas, A., Corey, D., Angeles, V., Bollich, A., Crabtree-Hartman, E., and Heilman, K. (2003). Atypical cerebral laterality in adults with persistent developmental stuttering. Neurology 61, 1378–1385. doi: 10.1212/01.WNL.0000094320.44334.86
Galletta, A., Celesti, A., Tusa, F., Fazio, M., Bramanti, P., and Villari, M. (2017). “Big mri data dissemination and retrieval in a multi-cloud hospital storage system” in Proceedings of the 2017 International Conference on Digital Health (London), 162–166.
Geniesse, C., Sporns, O., Petri, G., and Saggar, M. (2019). Generating dynamical neuroimaging spatiotemporal representations (DyNeuSR) using topological data analysis. Netw. Neurosci. 3, 763–778. doi: 10.1162/netn_a_00093
Genovese, C. R., Lazar, N. A., and Nichols, T. (2002). Thresholding of statistical maps in functional neuroimaging using the false discovery rate. NeuroImage 15, 870–878. doi: 10.1006/nimg.2001.1037
Gershon, R. C., Cook, K. F., Mungas, D., Manly, J. J., Slotkin, J., Beaumont, J. L., et al. (2014). Language measures of the NIH toolbox cognition battery. J. Int. Neuropsychol. Soc. 20, 642–651. doi: 10.1017/S1355617714000411
Girard, G., Whittingstall, K., Deriche, R., and Descoteaux, M. (2014). Towards quantitative connectivity analysis: reducing tractography biases. NeuroImage 98, 266–278. doi: 10.1016/j.neuroimage.2014.04.074
Glasser, M. F., Smith, S. M., Marcus, D. S., Andersson, J. L. R., Auerbach, E. J., Behrens, T. E. J., et al. (2016). The Human Connectome Project's neuroimaging approach. Nat. Neurosci. 19, 1175–1187. doi: 10.1038/nn.4361
Glasser, M. F., Sotiropoulos, S. N., Wilson, J. A., Coalson, T. S., Fischl, B., Andersson, J. L., et al. (2013). The minimal preprocessing pipelines for the human connectome project. NeuroImage 80, 105–124. doi: 10.1016/j.neuroimage.2013.04.127
Gou, L., Zhang, W., Li, C., Shi, X., Zhou, Z., Zhong, W., et al. (2018). Structural brain network alteration and its correlation with structural impairments in patients with depression in de novo and drug-naıve Parkinson's disease. Front. Neurol. 9, 608. doi: 10.3389/fneur.2018.00608
Gracia-Tabuenca, Z., Díaz-Patiño, J. C., Arelio, I., and Alcauter, S. (2020). Topological data analysis reveals robust alterations in the whole-brain and frontal lobe functional connectomes in attentiondeficit/hyperactivity disorder. eNeuro 7. doi: 10.1523/ENEURO.0543-19.2020
Hong, S.-J., Vos de Wael, R., Bethlehem, R. A., Lariviere, S., Paquola, C., Valk, S. L., et al. (2019). Atypical functional connectome hierarchy in autism. Nat. Commun. 10, 1–13. doi: 10.1038/s41467-019-08944-1
Huth, A. G., De Heer, W. A., Griffiths, T. L., Theunissen, F. E., and Gallant, J. L. (2016). Natural speech reveals the semantic maps that tile human cerebral cortex. Nature 532, 453–458. doi: 10.1038/nature17637
Jeurissen, B., Descoteaux, M., Mori, S., and Leemans, A. (2019). Diffusion MRI fiber tractography of the brain. NMR Biomed. 32, e3785. doi: 10.1002/nbm.3785
Klein, A., and Tourville, J. (2012). 101 labeled brain images and a consistent human cortical labeling protocol. Front. Neurosci. 6, 171. doi: 10.3389/fnins.2012.00171
Kristanto, D., Liu, M., Liu, X., Sommer, W., and Zhou, C. (2020). Predicting reading ability from brain anatomy and function: from areas to connections. NeuroImage 218, 116966. doi: 10.1016/j.neuroimage.2020.116966
Lee, D., and Son, T. (2021). Structural connectivity differs between males and females in the brain object manipulation network. PLoS ONE 16, e0253273. doi: 10.1371/journal.pone.0253273
Lee, H., Chung, M. K., Kang, H., Kim, B.-N., and Lee, D. S. (2011). “Discriminative persistent homology of brain networks” in 2011 IEEE International Symposium on Biomedical Imaging: From Nano to Macro (IEEE), 841–844.
Leek, J. T., and Storey, J. D. (2008). A general framework for multiple testing dependence. Proc. Natl. Acad. Sci. U.S.A. 105, 18718–18723. doi: 10.1073/pnas.0808709105
Linero, A. (2017). A review of tree-based Bayesian methods. CSAM 24, 543–559. doi: 10.29220/CSAM.2017.24.6.543
Orchard, E. R., Ward, P. G., Chopra, S., Storey, E., Egan, G. F., and Jamadar, S. D. (2021). Neuroprotective effects of motherhood on brain function in late life: a resting-state fMRI study. Cereb. Cortex 31, 1270–1283. doi: 10.1093/cercor/bhaa293
Park, H.-J., and Friston, K. (2013). Structural and functional brain networks: from connections to cognition. Science 342, 1238411. doi: 10.1126/science.1238411
Patel, R., Steele, C. J., Chen, A. G., Patel, S., Devenyi, G. A., Germann, J., et al. (2020). Investigating microstructural variation in the human hippocampus using non-negative matrix factorization. NeuroImage 207, 116348. doi: 10.1016/j.neuroimage.2019.116348
Pizarro, R., Assemlal, H.-E., Nigris, D. D., Elliott, C., Antel, S., Arnold, D., et al. (2019). Algorithms to automatically identify the brain MRI contrast: implications for managing large databases. Neuroinformatics 17, 115–130. doi: 10.1007/s12021-018-9387-8
Poldrack, R. A., Baker, C. I., Durnez, J., Gorgolewski, K. J., Matthews, P. M., Munafò, M. R., et al. (2017). Scanning the horizon: towards transparent and reproducible neuroimaging research. Nat. Rev. Neurosci. 18, 115–126. doi: 10.1038/nrn.2016.167
Poldrack, R. A., and Gabrieli, J. D. (1998). Memory and the brain: what's right and what's left? Cell 93, 1091–1093. doi: 10.1016/S0092-8674(00)81451-8
Ptak, R., Bourgeois, A., Cavelti, S., Doganci, N., Schnider, A., and Iannotti, G. R. (2020). Discrete patterns of cross-hemispheric functional connectivity underlie impairments of spatial cognition after stroke. J. Neurosci. 40, 6638–6648. doi: 10.1523/JNEUROSCI.0625-20.2020
Raven, J. (2000). The Raven's progressive matrices: change and stability over culture and time. Cogn. Psychol. 41, 1–48. doi: 10.1006/cogp.1999.0735
Roy, H. A., Griffiths, D. J., Aziz, T. Z., Green, A. L., and Menke, R. A. L. (2019). Investigation of urinary storage symptoms in Parkinson's disease utilizing structural MRI techniques. Neurourol. Urodyn. 38, 1168–1175. doi: 10.1002/nau.23976
Rybakken, E., Baas, N., and Dunn, B. (2019). Decoding of neural data using cohomological feature extraction. Neural Comput. 31, 68–93. doi: 10.1162/neco_a_01150
Saggar, M., Sporns, O., Gonzalez-Castillo, J., Bandettini, P. A., Carlsson, G., Glover, G., et al. (2018). Towards a new approach to reveal dynamical organization of the brain using topological data analysis. Nat. Commun. 9, 1399. doi: 10.1038/s41467-018-03664-4
Sizemore, A. E., Phillips-Cremins, J. E., Ghrist, R., and Bassett, D. S. (2019). The importance of the whole: topological data analysis for the network neuroscientist. Netw. Neurosci. 3, 656–673. doi: 10.1162/netn_a_00073
Smith, S., Nichols, T., Vidaurre, D., Winkler, A., Behrens, T., Glasser, M., et al. (2015). A positive-negative mode of population covariation links brain connectivity, demographics and behavior. Nat. Neurosci. 18, 1565–1567. doi: 10.1038/nn.4125
Sotiropoulos, S. N., and Zalesky, A. (2019). Building connectomes using diffusion MRI: why, how and but. NMR Biomed. 32, e3752. doi: 10.1002/nbm.3752
Tian, Y., Margulies, D. S., Breakspear, M., and Zalesky, A. (2020). Topographic organization of the human subcortex unveiled with functional connectivity gradients. Nat. Neurosci. 23, 1421–1432. doi: 10.1038/s41593-020-00711-6
Wang, J., Zuo, X., Dai, Z., Xia, M., Zhao, Z., Zhao, X., et al. (2012). Disrupted functional brain connectome in individuals at risk for Alzheimer's disease. Biol. Psychiatry 73, 471–481. doi: 10.1016/j.biopsych.2012.03.026
Wang, J., Zuo, X., and He, Y. (2010). Graph-based network analysis of resting-state functional MRI. Front. Syst. Neurosci. 4, 16. doi: 10.3389/fnsys.2010.00016
Wang, L., Zhang, Z., and Dunson, D. (2019). Symmetric bilinear regression for signal subgraph estimation. IEEE Trans. Signal Process. 67, 1929–1940. doi: 10.1109/TSP.2019.2899818
Wasserman, L. (2017). Topological data analysis. Annu. Rev. Stat. Appl. 5, 501–532. doi: 10.1146/annurev-statistics-031017-100045
Yeatman, J. D., Dougherty, R. F., Ben-Shachar, M., and Wandell, B. A. (2012). Development of white matter and reading skills. Proc. Natl. Acad. Sci. U.S.A. 109, E3045–E3053. doi: 10.1073/pnas.1206792109
Yourganov, G., Schmah, T., Churchill, N. W., Berman, M. G., Grady, C. L., and Strother, S. C. (2014). Pattern classification of fMRI data: applications for analysis of spatially distributed cortical networks. NeuroImage 96, 117–132. doi: 10.1016/j.neuroimage.2014.03.074
Zadina, J. N., Corey, D. M., Casbergue, R. M., Lemen, L. C., Rouse, J. C., Knaus, T. A., et al. (2006). Lobar asymmetries in subtypes of dyslexic and control subjects. J. Child Neurol. 21, 922–931. doi: 10.1177/08830738060210110201
Zhang, Z., Allen, G. I., Zhu, H., and Dunson, D. (2019). Tensor network factorizations: relationships between brain structural connectomes and traits. NeuroImage 197, 330–343. doi: 10.1016/j.neuroimage.2019.04.027
Keywords: adjacency matrix, brain connectome, persistent homology, structural connectivity, tree
Citation: Li D, Nguyen P, Zhang Z and Dunson D (2023) Tree representations of brain structural connectivity via persistent homology. Front. Neurosci. 17:1200373. doi: 10.3389/fnins.2023.1200373
Received: 04 April 2023; Accepted: 05 September 2023;
Published: 13 October 2023.
Edited by:
Xi-Nian Zuo, Beijing Normal University, ChinaReviewed by:
Liang Ma, University of Chinese Academy of Sciences, ChinaKun Meng, Brown University, United States
Shuo Chen, University of Maryland, United States
Copyright © 2023 Li, Nguyen, Zhang and Dunson. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Didong Li, ZGlkb25nbGlAdW5jLmVkdQ==
†These authors have contributed equally to this work and share first authorship