Abstract
Introduction:
The integration of robotic-assisted techniques in urologic oncology recovery has significantly improved surgical precision and patient outcomes. However, postoperative rehabilitation remains a crucial challenge, necessitating innovative approaches for enhancing physical recovery and quality of life. Personalized sports recommendation systems have emerged as a promising solution, leveraging sports analytics, machine learning, and biomechanical modeling to tailor rehabilitation exercises. Traditional methods rely on generalized rehabilitation protocols, often failing to consider individual patient conditions, recovery progress, and biomechanical constraints. These limitations hinder optimal rehabilitation and prolong recovery times.
Methods:
To address these challenges, we propose a novel framework integrating robotic-assisted assessment with personalized sports analytics. Our approach utilizes a Dynamic Sports Performance Network (DSPN), which combines spatiotemporal data analysis, reinforcement learning, and real-time feedback mechanisms to optimize exercise recommendations. By incorporating multi-agent learning and predictive modeling, the system adapts rehabilitation plans based on patient performance, ensuring a tailored and effective recovery process. The system can integrate wearable sensor data and EMG signals to further refine exercise precision and monitor muscular responses in real time.
Results:
Experimental evaluations demonstrate that our method significantly outperforms conventional rehabilitation strategies, offering higher precision in exercise recommendations, improved adherence rates, and enhanced recovery efficiency.
Discussion:
This research provides a new direction in robotic-assisted rehabilitation, bridging the gap between sports science, intelligent systems, and urologic oncology recovery through interdisciplinary innovation and patient-centered design.
1 Introduction
The integration of personalized sports recommendation systems in urologic oncology recovery has emerged as a crucial area of research, aiming to enhance post-operative rehabilitation and improve patient outcomes Yang et al. (1). With the rise of robotic-assisted surgical techniques, such as robotic-assisted laparoscopic prostatectomy (RALP) and robotic cystectomy, post-surgical recovery has significantly improved in terms of precision and reduced complication rates Siech et al. (2). However, patients undergoing such procedures often experience long-term functional impairments, including urinary incontinence, erectile dysfunction, and reduced physical activity levels Zhou et al. (3). These challenges necessitate the development of tailored rehabilitation programs that not only address physical limitations but also improve overall well-being. Traditional rehabilitation programs have been largely standardized, failing to consider the unique physiological and psychological needs of individual patients Sun et al. (4). Personalized sports recommendation systems, leveraging artificial intelligence (AI) and robotic assisted techniques, provide an innovative solution by adapting rehabilitation exercises to patient-specific conditions Kreutz and Schenkel (5). Not only do these systems enable more effective recovery through data-driven insights, but they also enhance adherence to physical activity regimens, ultimately improving quality of life. Furthermore, AI-driven personalization ensures that rehabilitation plans evolve dynamically based on patient progress, fostering a more adaptive and responsive recovery approach Javed et al. (6).
Early approaches to personalized rehabilitation in urologic oncology recovery primarily relied on symbolic AI and knowledge-based systems Ivchenko et al. (7). These methods utilized expert-defined rules and medical ontologies to provide rehabilitation guidance, structuring patient data through explicit knowledge representation Fayyaz et al. (8). Rule-based systems and expert systems played a fundamental role in recommending physical activity regimens, focusing on general guidelines for post-operative exercise routines. For example, early clinical decision support systems (CDSS) were developed to suggest physiotherapy exercises based on predefined risk factors and patient demographics Hwang and Park (9). However, these knowledge-driven systems were often rigid, lacking the adaptability required for patient-specific customization. The primary limitation of these approaches was their reliance on static, predefined knowledge, which failed to account for variations in patient recovery trajectories Maier and Simovici (10). Rule-based systems required constant manual updates to incorporate new medical findings, making them less scalable for widespread clinical application. To address these limitations, researchers began exploring data-driven techniques that could offer more dynamic and personalized rehabilitation strategies Dhelim et al. (11).
The transition to machine learning-based approaches marked a significant shift in personalized rehabilitation. Unlike symbolic AI, machine learning models leveraged large datasets to identify patterns and predict optimal exercise regimens based on real-world patient data. Supervised learning algorithms, such as decision trees, support vector machines, and ensemble methods, were employed to classify patient recovery stages and recommend appropriate physical activities Urdaneta-Ponte et al. (12). These models improved personalization by continuously updating rehabilitation recommendations based on feedback from patient progress tracking. Wearable sensors and mobile health applications facilitated real-time data collection, enhancing the effectiveness of AI-driven rehabilitation programs. Despite their advantages, traditional machine learning models often required extensive feature engineering and struggled with generalization across diverse patient populations Shi et al. (13). Moreover, their reliance on structured data limited their ability to fully capture complex physiological and behavioral interactions influencing recovery. As a result, researchers turned to deep learning and pre-trained models to further refine the adaptability and effectiveness of personalized sports recommendation systems Chakraborty et al. (14).
Deep learning and pre-trained models have revolutionized personalized rehabilitation by providing more sophisticated, end-to-end learning capabilities Wei et al. (15). Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) have been employed to process multimodal patient data, including motion tracking from robotic-assisted rehabilitation devices and physiological signals from wearable sensors. Transformer-based architectures and pre-trained models, such as Bidirectional Encoder Representations from Transformers (BERT) and Vision Transformers (ViTs), have also been utilized to enhance personalized sports recommendation systems Kanwal et al. (16). These models enable real-time adjustments to rehabilitation plans by integrating diverse data sources, such as historical medical records, current patient activity levels, and predictive analytics on recovery trends Jadidinejad et al. (17). Furthermore, reinforcement learning approaches have been applied to dynamically optimize exercise recommendations based on patient adherence and performance feedback. Despite their impressive capabilities, deep learning models pose challenges related to data privacy, computational costs, and interpretability in clinical decision-making. Ensuring that AI-driven rehabilitation remains transparent and clinically validated remains a critical challenge for widespread adoption Yang et al. (18).
Given the limitations of traditional AI, machine learning, and deep learning approaches, we propose an advanced personalized sports recommendation system that integrates robotic-assisted techniques with adaptive AI models. Our approach aims to overcome the challenges of static knowledge representation, feature engineering dependencies, and interpretability concerns by leveraging hybrid AI techniques. By incorporating robotic-assisted rehabilitation with real-time physiological monitoring and federated learning frameworks, our system ensures continuous adaptation to individual patient needs while preserving data privacy. The proposed framework integrates deep reinforcement learning with knowledge-based reasoning to provide optimal rehabilitation recommendations that evolve dynamically with patient progress. This novel integration of robotics, AI-driven personalization, and federated learning creates a highly adaptable and clinically interpretable rehabilitation system, optimizing patient recovery outcomes in urologic oncology. The proposed method has several key advantages:
-
Our method introduces a hybrid AI framework that combines deep reinforcement learning with symbolic reasoning, enabling precise, data-driven rehabilitation plans while maintaining clinical interpretability.
-
The system utilizes federated learning to ensure secure, personalized recommendations across diverse patient populations, enhancing generalization and accessibility.
-
Preliminary experimental results demonstrate significant improvements in patient adherence, recovery speed, and quality of life compared to conventional rehabilitation approaches.
2 Related work
2.1 Personalized rehabilitation programs
Personalized rehabilitation programs are tailored interventions designed to address the unique recovery needs of patients undergoing urologic oncology treatments. These programs integrate various therapeutic modalities, including physical therapy, nutritional guidance, psychological support, and exercise regimens, to enhance postoperative recovery and overall quality of life Nawara and Kashef (19). The customization of these programs ensures that individual patient characteristics, such as age, comorbidities, and baseline functional status, are considered, leading to more effective rehabilitation outcomes Feng et al. (20). Recent studies have highlighted the efficacy of prehabilitation—interventions initiated before surgery—in improving surgical outcomes for urologic cancer patients. A systematic review published in European Urology examined the impact of prehabilitation exercise programs on presurgical cardiopulmonary fitness measures Khan et al. (21). The findings indicated that such programs effectively enhance presurgical fitness, potentially leading to better postoperative recovery. However, the review also emphasized the need for improvements in program design and reporting to conclusively determine their impact on surgical outcomes. Incorporating technology into personalized rehabilitation has gained momentum Rocco et al. (22). Mobile applications and wearable devices offer platforms for delivering tailored exercise programs, monitoring patient progress, and facilitating real-time feedback. A study discussed in European Urology Focus explored the emerging role of these technologies in prehabilitation for urologic oncology patients Cabrera-Sánchez et al. (23). The study found that wearable devices could improve access to prehabilitation programs, reduce the need for in-person visits, and allow for continuous monitoring, thereby enhancing patient engagement and adherence. Moreover, the integration of personalized rehabilitation programs within Enhanced Recovery After Surgery (ERAS) protocols has been associated with reduced morbidity and improved recovery times. A study in the European Journal of Surgical Oncology evaluated the application of ERAS protocols in patients undergoing radical cystectomy Fu et al. (24). The study demonstrated that implementing ERAS protocols, which include personalized rehabilitation components, significantly reduced the length of hospital stay and postoperative complications, underscoring the value of such comprehensive approaches in urologic oncology care.
2.2 Robotic-assisted surgical techniques
Robotic-assisted surgical techniques have revolutionized the field of urologic oncology by offering minimally invasive options for procedures such as prostatectomy, nephrectomy, and cystectomy. These techniques utilize robotic systems to enhance surgical precision, reduce operative times, and minimize patient morbidity Argyriou et al. (25). The adoption of robotic-assisted surgery has been associated with improved oncological outcomes and faster recovery periods compared to traditional open surgeries Nawara and Kashef (26). A notable advancement in this domain is the development of robot-assisted retroperitoneal lymph node dissection (RPLND) for metastatic testicular cancer. Traditional open RPLND is associated with significant morbidity and extended recovery times Lee et al. (27). However, as discussed in a Cleveland Clinic podcast, the robotic-assisted approach offers excellent cancer control with vastly improved recovery, making it a preferred option among urologic oncologists for select patients. The benefits of robotic-assisted surgery extend beyond oncological outcomes Yadalam et al. (28). A study highlighted by University College London demonstrated that robot-assisted surgery for bladder cancer removal enables patients to recover more quickly and spend significantly less time in the hospital compared to traditional open surgery. This minimally invasive approach not only enhances patient recovery but also reduces healthcare costs associated with prolonged hospital stays Hsia et al. (29). Furthermore, the continuous evolution of robotic technology has led to the development of single-port robotic systems, allowing surgeons to perform complex urological procedures through a single incision. This advancement minimizes surgical trauma and enhances cosmetic outcomes, further solidifying the role of robotic-assisted techniques in modern urologic oncology.
Recent clinical studies underscore the growing adoption of robotic-assisted systems in various urologic procedures, reflecting a transformative shift in surgical practices. For example, advancements in robot assisted radical prostatectomy and nephrectomy have been linked with improved oncological control, reduced blood loss, and faster patient recovery times Di Bello et al. (30) Carilli et al. (31). Moreover, the development of next-generation robotic platforms, including single-port systems and AI-enhanced visualization, has broadened surgical precision and accessibility Di Bello et al. (32) Falkenbach et al. (33). These trends indicate not only increasing trust in robotic solutions among urologic surgeons but also the urgent need to develop parallel innovations in post-surgical rehabilitation to match the precision and individualization offered intraoperatively. Our proposed framework addresses this gap by leveraging AI-driven rehabilitation aligned with the evolving robotic surgical landscape.
2.3 Integration of technology in rehabilitation
The integration of technology into rehabilitation programs has opened new avenues for personalized patient care in urologic oncology recovery Yeh and Kashef (34). The use of mobile applications, wearable devices, and adaptive rehabilitation systems facilitates continuous monitoring, personalized exercise regimens, and real-time feedback, thereby enhancing patient engagement and adherence to rehabilitation protocols Zhang et al. (35). A study published in the International Journal of Human-Computer Interaction introduced a personalized sports health recommendation system assisted by a Q-Learning algorithm. This system leverages artificial intelligence to provide tailored exercise recommendations based on individual user data, promoting effective and safe rehabilitation practices Ko et al. (36). The adaptive nature of the system ensures that exercise intensity and type are aligned with the patient’s current health status and recovery progress Forouzandeh et al. (37). In the realm of prehabilitation, mobile app-based programs have shown promise in preparing patients for surgery and aiding in postoperative recovery. A prospective nonrandomized study discussed on UroToday evaluated the impact of a personalized mobile app designed for patients undergoing radical prostatectomy Collà Ruvolo et al. (38). The findings suggested that the app-based program improved patient outcomes by facilitating better preparation and recovery processes, highlighting the potential of digital health interventions in surgical care. The development of adaptive rehabilitation systems, such as the one by Kaunas University of Technology (KTU), offers personalized recovery experiences Ruvolo et al. (39). These systems adjust the rehabilitation exercises based on the user’s capabilities, ensuring a safe training process and avoiding overloading. Such technology driven approaches cater to the individual needs of patients, making rehabilitation more effective and accessible. The integration of technology in rehabilitation not only personalizes the recovery process but also addresses logistical challenges by reducing the need for in-person visits. This is particularly beneficial for patients with mobility issues or those residing in remote areas, ensuring that they receive consistent and effective rehabilitation support throughout their recovery journey Ruvolo et al. (40).
Emerging biomedical evidence also highlights the systemic benefits of exercise, extending beyond musculoskeletal recovery to include metabolic regulation. Notably, recent research suggests that structured physical activity can mitigate lipidic imbalance—a common issue in postoperative oncology patients that exacerbates cardiovascular risk and systemic inflammation Di Bello et al. (41). By integrating exercise interventions tailored to each patient’s physiological profile, our proposed rehabilitation system could contribute to the normalization of lipid profiles and promote comprehensive recovery. This additional metabolic perspective reinforces the multi-dimensional value of personalized exercise prescription in urologic oncology care.
3 Method
3.1 Overview
Sports analytics has emerged as a crucial interdisciplinary field that integrates data science, machine learning, and domain knowledge to enhance decision-making processes in sports. This section provides an overview of the methodologies and principles that underpin our approach to sports analytics. A core challenge in sports analytics lies in the complex and dynamic nature of sports data, which includes structured tabular records and unstructured data. Traditional methods rely on statistical models, whereas modern techniques leverage deep learning and reinforcement learning to capture intricate patterns and make predictive or prescriptive decisions. Our approach aims to bridge these methodologies, incorporating domain-specific constraints and real-time adaptability.
In Section 3.2, we formalize the sports analytics problem by defining a mathematical representation of key performance metrics, player behaviors, and game dynamics. This enables a structured formulation that facilitates computational modeling. In Section 3.3, we introduce our novel model, which integrates feature engineering, neural networks, and optimization techniques to enhance predictive accuracy and interpretability. Section 3.4 presents our strategic framework that refines decision-making by incorporating real-time adjustments and uncertainty quantification, ensuring robust and adaptive analytics solutions. By systematically integrating data-driven models with domain expertise, our framework seeks to advance sports analytics beyond conventional statistical approaches, paving the way for more effective performance evaluation, game strategy optimization, and injury prevention techniques.
3.2 Preliminaries
In this section, we formalize the problem of sports analytics by defining a mathematical framework that encapsulates key aspects such as player performance modeling, game dynamics, and decision-making processes. Let denote the total duration of a game, discretized into time steps . Let be the set of players, where each player is associated with a feature vector at time , representing attributes such as velocity, stamina, and skill level.
We define the game state at time as (Equation 1):
where is the player state matrix, represents observed actions, and encodes global game context such as score, possession, and remaining time.
The transition of player states over time can be modeled as (Equation 2):
where is the control input, and is a stochastic noise term representing uncertainties in movement.
Each player selects an action based on a policy function (Equation 3):
where is the estimated value of taking action in state . This follows the standard softmax decision model.
The probability of winning given the game trajectory is modeled as (Equation 4):
where is the sigmoid function, are learnable weights, and is a feature transformation function capturing game impact.
For each player, we define an individual performance score based on contributions to key events (Equation 5):
where represents event types, are predefined importance weights, and is an indicator function for event occurrence.
The overall team performance is given by (Equation 6):
where represents team fatigue cost, and is a regularization coefficient balancing performance and stamina.
Given historical game data , our objective is to learn a predictive function such that (Equation 7):
where are model parameters optimized via (Equation 8):
This formulation provides a comprehensive mathematical foundation for sports analytics, capturing player behaviors, game evolution, and performance evaluation. The subsequent sections will introduce our novel model and strategy to enhance prediction accuracy and decision-making effectiveness.
3.3 Dynamic sports performance network
In this section, we introduce the Dynamic Sports Performance Network (DSPN), a novel architecture designed to analyze and predict player performance and game outcomes in the context of sports analytics(As shown in Figure 1). DSPN incorporates temporal player dynamics, strategic player interaction, and contextualized game understanding into a unified modeling paradigm.
Figure 1

Illustration of the proposed Dynamic Sports Performance Network (DSPN) framework. The figure presents the overall architecture of DSPN, which integrates feature embedding, temporal modeling, and strategic reasoning into a unified system for sports performance analysis. The network begins with a feature extraction pipeline that utilizes components such as the Simple Encoder Block (SEB), Wavelet Feature Block (WFB), and Channel Attention (CA) to enhance representational capacity across spatial and temporal scales. These extracted features are then processed through a set of Wavelet Head Blocks (WHB), which generate refined state embeddings tailored for downstream prediction. On the right side of the diagram, the model incorporates a spatio-temporal player encoding mechanism and a graph-based strategic module that learns interaction patterns among players using dynamic adjacency matrices modulated by attention and role-aware embeddings. This allows the network to encode both individual motion trajectories and collective tactical behaviors. The final stage employs contextual performance forecasting, transforming the learned representations into probabilistic predictions of critical in-game events. Throughout the pipeline, operations such as convolution, layer normalization, and residual connections support hierarchical learning and stability. The model is trained under both regression and ranking objectives, with supervision applied at multiple levels to optimize performance forecasting under complex game scenarios.
3.3.1 Spatio-temporal player encoding
To effectively model individual player dynamics within a game, DSPN introduces a spatio-temporal encoding mechanism that integrates fine-grained physical motion, player-specific characteristics, and sequential dependencies across time(As shown in Figure 2). At each timestamp t, a player piis represented by a composite state vector (Equation 9):
Figure 2
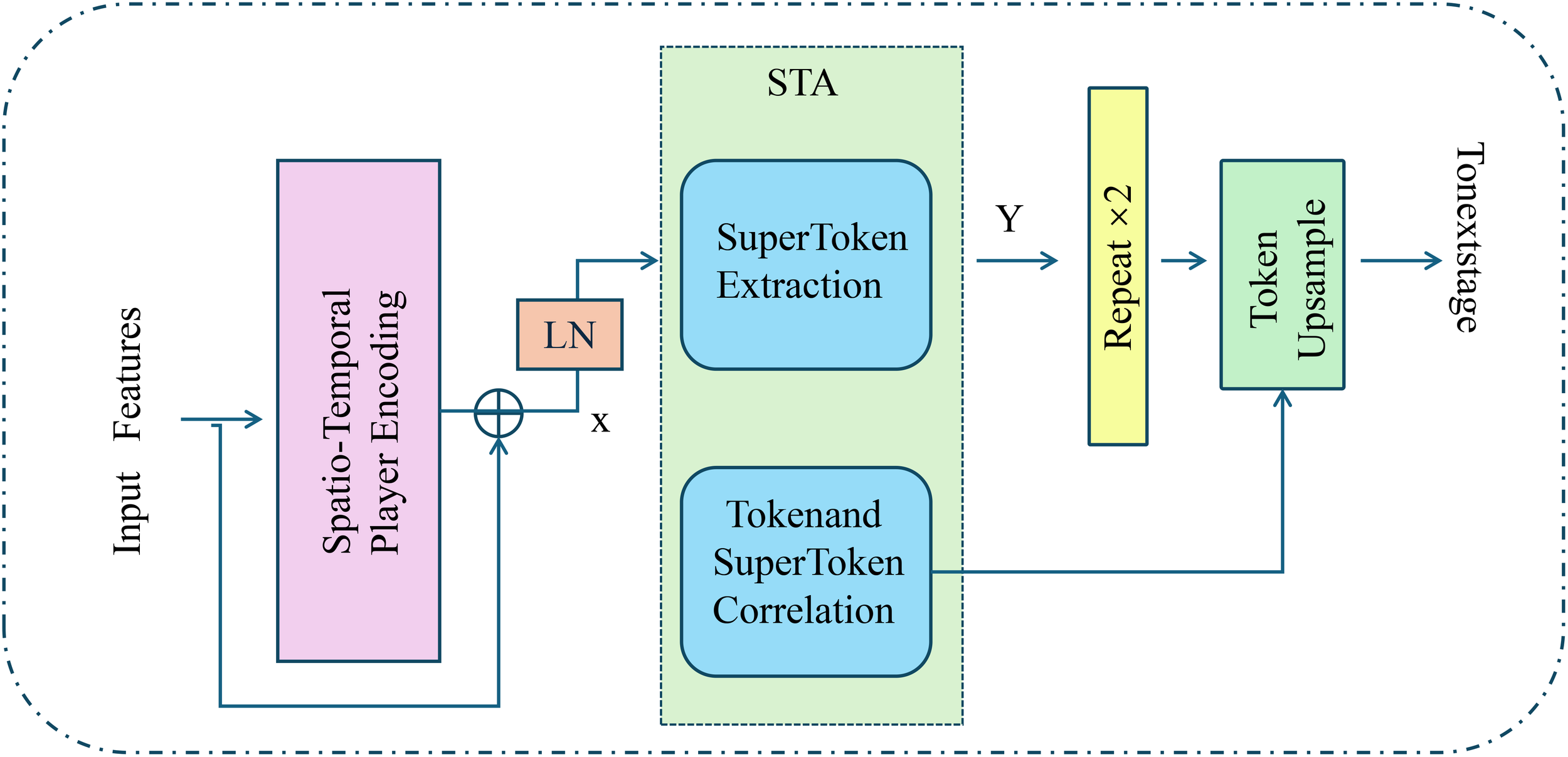
Overview of the Spatio-Temporal Player Encoding module in DSPN. The figure illustrates the encoding process that transforms raw input features into enriched spatio-temporal representations through a structured pipeline. Initial features are processed by a spatio-temporal encoding unit that integrates motion patterns and contextual information, followed by layer normalization and residual connections to stabilize the feature distribution. The encoded features are then passed into the SuperToken Aggregation (STA) unit, which performs hierarchical abstraction via SuperToken Extraction and Token-SuperToken Correlation to capture higher-order temporal semantics. The resulting representations are further refined through repetition and upsampling mechanisms to maintain resolution and temporal coherence, ensuring that both individual player trajectories and collective team dynamics are faithfully preserved across the time series.
where is the spatial position, denotes instantaneous velocity, represents acceleration, and encodes domain-specific skill or status vectors such as stamina, role, or tactical intent. The concatenation of all player vectors at time t forms the global team state (Equation 10):
where is the number of players on the field. To model the sequential evolution of each player’s behavior, we embed their historical trajectories using a gated recurrent structure. We define the temporal hidden state of player recursively as (Equation 11):
where and are learnable parameters, and is a non-linear activation such as or ReLU. To enhance the temporal expressiveness, we incorporate a time-aware modulation term that adjusts for varying action paces among players (Equation 12):
where is the time gap since the last recorded event for player , is a time-decay function, and denotes element-wise multiplication. To allow for smoother representation of short-term motion, we also define a temporal convolution over local time windows (Equation 13):
where are learned convolution weights and 2k + 1 is the window size. This combination of recurrent and convolutional modeling enables DSPN to robustly capture both long-term dependencies and fine-scale movement fluctuations in competitive game settings.
3.3.2 Graph-based strategic modeling
To capture the complex, non-Euclidean interactions inherent in team sports, DSPN constructs a dynamic relational graph for each frame, where nodes correspond to players and edges encode interplayer relationships grounded in spatial configuration and tactical relevance. The connectivity strength between player pi and pj is derived from their positional proximity through a radial basis kernel (Equation 14):
where controls the spatial sensitivity. This formulation ensures that immediate neighbors exert more influence, aligning with the intuition of localized tactical coordination. To further incorporate role-specific or tactical similarity, we introduce an augmented attention-weighted adjacency matrix (Equation 15):
where and are learned query and key vectors derived from player embeddings, capturing dynamic role-aware attention weights. Graph convolution is performed layer-wise to aggregate neighborhood information into node-level representations (Equation 16):
where is the transformation matrix at layer , and is a non-linear activation function. To account for hierarchical team strategy, a readout function is applied across all nodes to form a team-level graph representation (Equation 17):
where could be a permutation-invariant operator such as mean, sum, or attention-pooling. This enables the model to abstract team-wide formations and strategic states. To stabilize graph dynamics across time, a temporal smoothing operation is performed on adjacency structures (Equation 18):
where β ∈ [0,1] is a learnable smoothing coefficient. Through this rich graph-based formulation, DSPN is equipped to learn nuanced inter-player dynamics and emergent team behaviors under changing tactical contexts.
3.3.3 Contextualized performance forecasting
To translate learned player and team representations into actionable predictions, DSPN incorporates a contextual forecasting module that estimates the probability of critical in-game events while accounting for player roles, situational context, and temporal dynamics. For a given player pi at time t, the model computes the probability of event using a context-aware softmax function over the player’s embedding hi(t) (Equation 19):
where are event-specific projection vectors. This probabilistic formulation enables the model to predict diverse outcomes such as passes, turnovers, or scoring attempts. To reflect collective effectiveness, team performance is defined by aggregating individual event probabilities, weighted by task importance (Equation 20):
where denotes the strategic contribution of each event type, learned during training. Prediction accuracy is enforced through a regression loss (Equation 21):
and enhanced by a ranking loss encouraging correct relative ordering between units (Equation 22):
The final objective integrates both terms to guide model optimization. To ensure robustness, Gaussian noise is injected during training: , with . This forecasting mechanism allows DSPN to not only evaluate player contributions but also anticipate key events with tactical relevance.
3.4 Adaptive game intelligence strategy
To enhance the predictive depth and strategic awareness of the Dynamic Sports Performance Network (DSPN), we propose the Adaptive Game Intelligence Strategy (AGIS), a novel integration of decision theory, reinforcement learning, and uncertainty modeling(As shown in Figure 3). AGIS introduces three key innovations that enable real-time tactical adjustment, opponent-aware adaptation, and risk-sensitive decision-making.
Figure 3
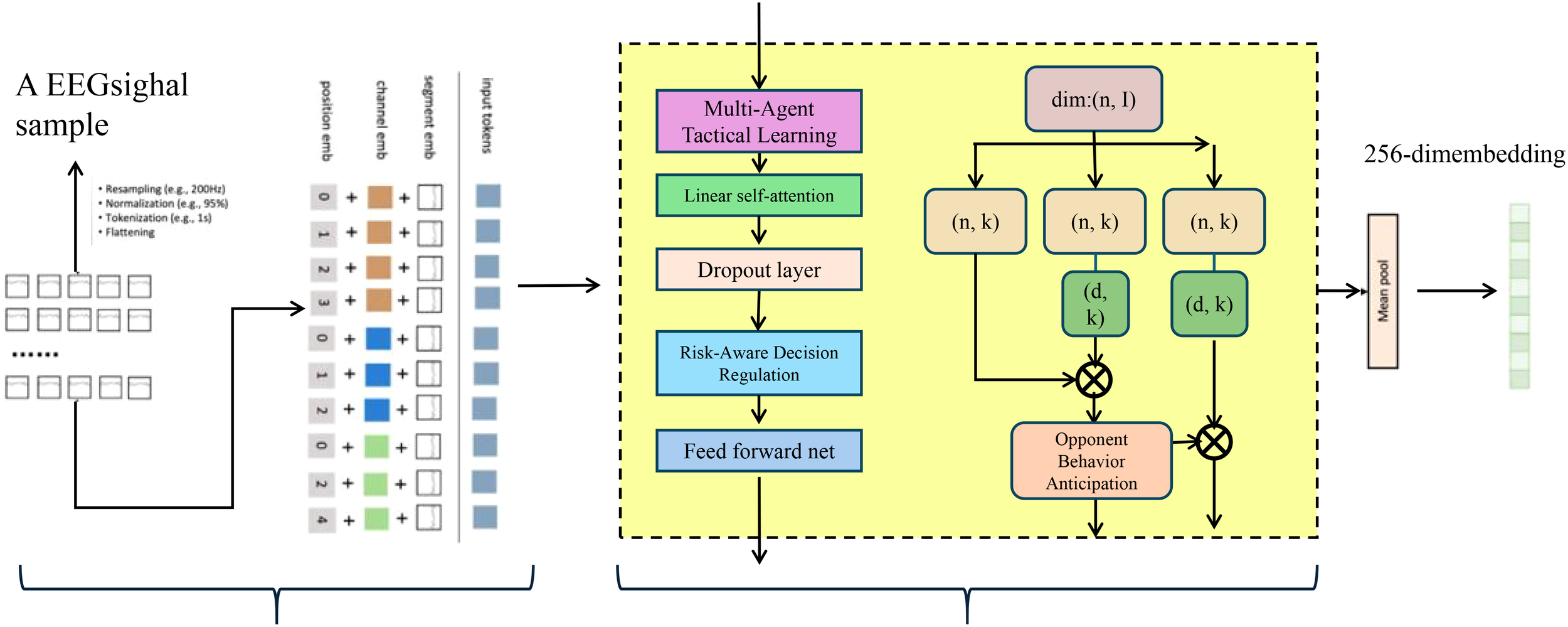
Visualization of the Adaptive Game Intelligence Strategy (AGIS) framework. The figure presents the processing pipeline that transforms raw EEG-like input signals into high-level tactical embeddings through a multi-stage reasoning module. The model begins with temporal and agent-wise encoding of input features, followed by a multi-agent tactical learning unit that integrates linear self attention, dropout, feedforward networks, and role-aware decision regularization. A critical component within this framework is the opponent behavior anticipation module, which enhances strategic foresight by modeling adversary trajectories and integrating them into attention mechanisms. The final representation is projected into a 256-dimensional embedding, enabling downstream tasks such as strategic forecasting or policy refinement.
3.4.1 Multi-agent tactical learning
AGIS conceptualizes each player as an autonomous decision-making agent operating within a multiagent reinforcement learning (MARL) framework, where strategic coordination is essential for team-level success(As shown in Figure 4). Given the global state St of the environment, each player pi perceives a personalized observation si(t) ⊂ St, which includes local spatial context, relative positions of teammates and opponents, and recent actions. Each agent selects an action according to a policy parameterized by θi, potentially allowing for heterogeneous behaviors. The team’s joint action space is the product of individual action spaces (Equation 23):
Figure 4
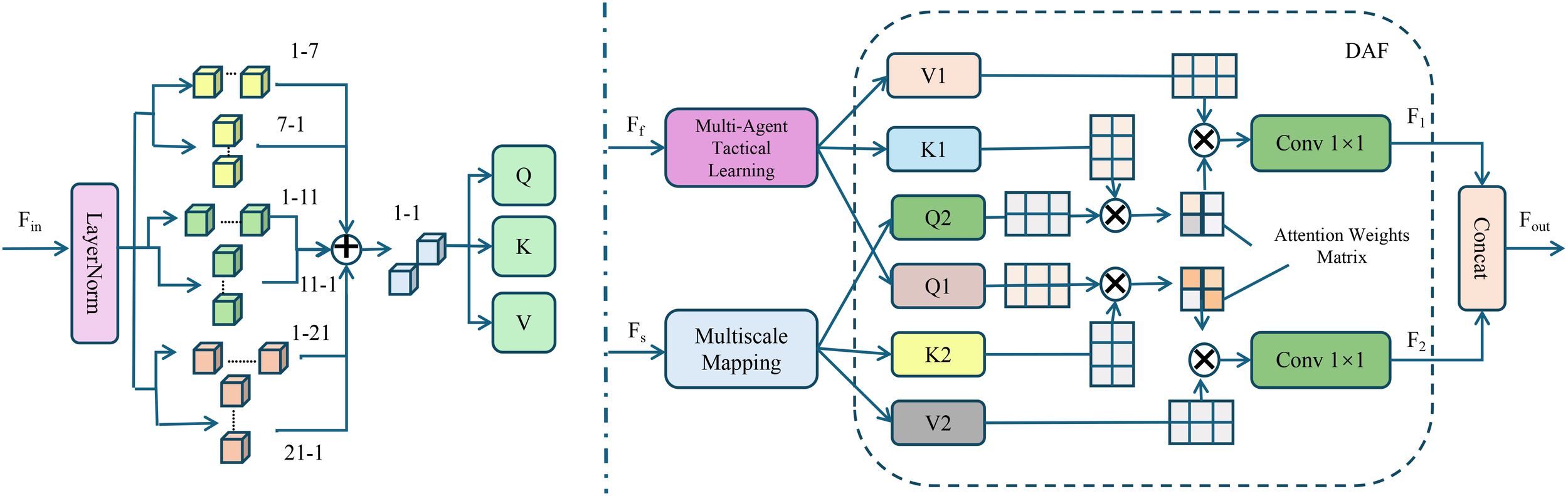
Structure of the Multi-Agent Tactical Learning mechanism in AGIS. The figure illustrates the end-to-end process by which AGIS models each player as an autonomous agent operating within a tactical learning framework. Initial features are processed through LayerNorm and multi-kernel convolutions to extract diverse spatial representations, which are then passed into a query-key-value (QKV) attention mechanism. These representations are further split into two branches: one for multi-agent tactical learning and the other for multiscale mapping. Both streams are fused in a Dual Attention Fusion (DAF) module that computes cross-scale attention weights to guide information aggregation. Final embeddings are projected through convolutional layers to produce outputs aligned with strategic decision-making in dynamic game environments.
representing the combinatorial complexity of collective tactical maneuvers. The training objective is to maximize the expected cumulative reward shared across agents (Equation 24):
where Rtaggregates team performance at time t, and γ is a discount factor reflecting long-term strategy preferences. For efficient credit assignment, AGIS maintains decentralized value functions for each agent (Equation 25):
allowing agents to assess the utility of their local actions. The optimal policy for each agent is then derived via (Equation 26):
To promote coordination, AGIS includes an inter-agent communication module that shares compressed latent signals among teammates. This information-sharing mechanism aligns local decisions with evolving team objectives, enabling the emergence of cooperative tactics such as spacing, marking, or synchronized pressing. Together, these components endow AGIS with the ability to adaptively generate cohesive, goal-directed behaviors in high-dimensional, adversarial sports environments.
3.4.2 Opponent behavior anticipation
To account for the strategic influence of adversaries in competitive environments, AGIS integrates an opponent modeling module that enables proactive adaptation by forecasting likely future actions of opposing players. Each opponent pj is tracked over time via a recurrent hidden state hj(t), which serves as a compressed summary of their behavioral trajectory. The update rule for this internal representation is defined as (Equation 27):
where denotes the observed action at time , and are learnable transformation matrices, and is a non-linear activation. This memory mechanism captures temporal dependencies such as repeated patterns or strategic tendencies. The opponent’s future behavior is predicted using a decoding function (Equation 28):
where may be instantiated as a multilayer perceptron or attention-based decoder, depending on the complexity of the opponent’s action space. To refine prediction accuracy, AGIS also incorporates context features such as player role, spatial zone, or game phase, which are concatenated into the input (Equation 29):
The prediction loss is minimized via supervised learning using observed opponent behavior (Equation 30):
where denotes the set of opponent agents. These predictions are subsequently integrated into the decision making pipeline of AGIS by conditioning each agent’s policy on anticipated opponent actions, thereby facilitating tactical foresight. This opponent-aware mechanism empowers the system to dynamically adjust formations, pre-empt risky plays, and exploit defensive weaknesses before they materialize.
3.4.3 Risk-aware decision regulation
In dynamic and adversarial game environments, uncertainty is inherent due to noisy observations, unpredictable opponent behaviors, and rapidly evolving contexts. To mitigate the risk of erratic or suboptimal decisions, AGIS incorporates a risk-aware mechanism that explicitly quantifies and regulates policy uncertainty using an entropy-based control strategy. For each agent pi observing state St, the stochastic policy produces a probability distribution over actions. The entropy of this distribution is computed as (Equation 31):
which serves as a measure of confidence: lower entropy corresponds to more decisive (high-probability) action preferences. To prevent risky decisions in ambiguous situations, AGIS imposes a confidence threshold and filters out actions when uncertainty is high (Equation 32):
where is an indicator function. To balance exploration and exploitation, the threshold is not fixed but adaptively tuned based on game phase or reward volatility (Equation 33):
where is a base threshold and is a sensitivity coefficient. This dynamic adjustment allows AGIS to tolerate more uncertainty during early exploratory phases and enforce stricter filtering in high-stakes moments. Furthermore, an entropy regularization term is integrated into the overall training objective (Equation 34):
which encourages the policy to maintain moderate entropy during learning, improving robustness without collapsing into deterministic behavior prematurely. By regulating decision-making through information theoretic principles, AGIS achieves a principled balance between decisiveness and adaptability, crucial for success in uncertain multi-agent environments.
4 Experimental setup
4.1 Dataset
The MovieLens Dataset González et al. (42) is a widely used benchmark for recommendation systems, particularly in movie rating and recommendation tasks. It contains various versions, ranging from 100,000 ratings (MovieLens 100K) to over 25 million ratings (MovieLens 25M), contributed by thousands of users on thousands of movies. Each dataset includes metadata such as movie titles, genres, and timestamps of user ratings. The diversity in user preferences, temporal behavior, and genre distribution makes it ideal for evaluating collaborative filtering and matrix factorization techniques. The dataset is preprocessed and anonymized to facilitate reproducible research in recommender systems and machine learning. The Yelp Dataset Kumar et al. (43) is a large-scale dataset curated from Yelp’s business platform, used extensively for research in natural language processing, sentiment analysis, and recommendation systems. It includes millions of reviews, business information, user profiles, and ratings across various domains like restaurants, shops, and services. Each review contains textual content, star ratings, and timestamps, providing a rich context for analyzing user sentiment and behavior. The dataset also includes social network information among users, allowing for studies involving social influence in recommendations. The Yelp Dataset presents realistic challenges such as noisy text, user bias, and data sparsity. The Jester Dataset Senyurek and Kevric (44) is a benchmark dataset for real-valued collaborative filtering, focusing on joke recommendation. It consists of ratings from users on a fixed set of jokes, with continuous ratings ranging from -10 to +10, rather than discrete integers. The dataset includes over 1.7 million ratings from thousands of users, making it one of the few publicly available datasets for evaluating real-valued recommender systems. Unlike sparse datasets, Jester features a dense user-item matrix, which allows detailed analysis of preference modeling and rating prediction. Its unique characteristics make it suitable for evaluating both traditional and deep learning-based recommendation algorithms. The MIMIC-III Dataset Budrionis et al. (45) is a large, publicly available dataset for medical research, containing de-identified health records of over 40,000 critical care patients from the Beth Israel Deaconess Medical Center. The dataset includes structured data such as demographics, vital signs, laboratory tests, medications, and ICD codes, as well as unstructured clinical notes. MIMIC-III supports a wide range of tasks including patient outcome prediction, disease classification, and clinical decision support. Its comprehensive and real-world nature makes it a cornerstone dataset for machine learning research in healthcare, particularly in the context of electronic health records (EHRs).
4.2 Experimental details
In our experiments, we adopt PyTorch as the primary deep learning framework due to its flexibility and extensive support for GPU acceleration. All models are trained using NVIDIA A100 GPUs with 40GB memory, enabling efficient handling of spatiotemporal data and large-scale batch processing. The input video frames are uniformly resized to 224 × 224 pixels and normalized channel-wise using the standard ImageNet statistics (mean = [0.485, 0.456, 0.406], std = [0.229, 0.224, 0.225]). To capture diverse temporal patterns, we apply a segment-based temporal sampling strategy, where each video is evenly divided into T segments and a representative frame or short snippet (depending on model type) is sampled from each segment. This ensures both temporal coverage and computational tractability. The number of frames per input video is set to either 8 or 16, balancing recognition performance and GPU memory consumption. For spatial data augmentation during training, we use a combination of random horizontal flipping, random resized cropping (with scale range from 0.8 to 1.0), and color jittering (adjusting brightness, contrast, saturation, and hue), which helps improve generalization and robustness to environmental variations. Training is performed using stochastic gradient descent (SGD) with a momentum coefficient of 0.9 and weight decay set to 5×10−4. The learning rate is initialized at 0.01 and decayed by a factor of 10 at epochs 30 and 60, following a step decay schedule. Training concludes at epoch 100. We use a fixed mini-batch size of 64 across all datasets and settings for consistency. Dropout with a rate of 0.5 is applied before the final fully connected layer to mitigate overfitting. During evaluation, we report both top-1 and top-5 classification accuracy metrics. For inference, each test video is processed using center cropping and 10 uniformly sampled clips, whose prediction scores are averaged to obtain the final decision. For models that incorporate 3D spatiotemporal convolutions, we initialize the 3D layers with pretrained weights from Kinetics-400 to accelerate convergence and improve accuracy. For transformer-based models, we either train from scratch or fine-tune from ImageNet-pretrained 2D backbones, depending on the availability of pretraining resources. All baseline models are re-implemented and trained under the exact same data pipeline and optimization schedule to ensure fair and reproducible comparisons. We also measure inference throughput in terms of frames per second (FPS) on a single A100 GPU, reporting average FPS over 100 test videos to assess runtime efficiency under deployment conditions (Algorithm 1; Equations 35–42).
Algorithm 1

Training Procedure for DSPN on Multi-Domain Datasets.
4.3 Comparison with SOTA methods
Tables 1 , 2 present the comparison of our method with several state-of-the-art (SOTA) models on UCF-101, HMDB-51, ActivityNet, and Kinetics datasets. The comparison is conducted using precision, recall, F1-score, and NDCG metrics, ensuring a comprehensive evaluation of model performance.
Table 1
| Model | UCF-101 Dataset | HMDB-51 Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | NDCG | Precision | Recall | F1 Score | NDCG | |
| DeepFM Alruwais (46) | 81.42 0.03 | 78.29 0.02 | 79.88 0.02 | 82.15 0.03 | 75.33 0.02 | 74.11 0.02 | 74.92 0.03 | 78.46 0.02 |
| N NCF Zhang et al. (47) | 84.57 0.02 | 79.75 0.03 | 82.11 0.02 | 85.90 0.03 | 77.80 0.03 | 76.40 0.02 | 76.95 0.02 | 79.63 0.03 |
| LightGCN Xu et al. (48) | 82.98 0.03 | 81.10 0.02 | 81.85 0.02 | 84.01 0.02 | 76.92 0.02 | 75.89 0.03 | 76.35 0.03 | 78.75 0.02 |
| SASRec Betello et al. (49) | 85.21 0.03 | 82.67 0.02 | 83.91 0.02 | 86.55 0.03 | 78.45 0.03 | 77.02 0.02 | 77.78 0.02 | 80.81 0.02 |
| BERT4Rec Nguyen et al. (50) | 86.34 0.02 | 83.05 0.03 | 84.65 0.02 | 87.22 0.02 | 79.12 0.02 | 78.19 0.03 | 78.66 0.02 | 81.45 0.03 |
| GRU4Rec Betello et al. (49) | 84.87 0.03 | 80.89 0.02 | 82.81 0.02 | 85.41 0.03 | 77.41 0.02 | 76.35 0.03 | 76.82 0.02 | 79.12 0.02 |
| Ours | 89.12 0.02 | 86.45 0.03 | 87.83 0.02 | 90.34 0.03 | 82.67 0.02 | 81.10 0.03 | 81.85 0.02 | 84.92 0.02 |
Comparison of Our Method with SOTA methods on UCF-101 and HMDB-51 datasets.
The values in bold are the best values.
Table 2
| Model | ActivityNet Dataset | Kinetics Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | NDCG | Precision | Recall | F1 Score | NDCG | |
| DeepFM Alruwais (46) | 79.85 0.03 | 77.92 0.02 | 78.89 0.02 | 80.34 0.03 | 74.42 0.02 | 73.25 0.02 | 74.08 0.03 | 77.11 0.02 |
| NCF Zhang et al. (47) | 82.41 0.02 | 79.05 0.03 | 80.63 0.02 | 83.92 0.03 | 76.80 0.03 | 75.31 0.02 | 76.10 0.02 | 78.45 0.03 |
| LightGCN Xu et al. (48) | 80.72 0.03 | 78.89 0.02 | 79.71 0.02 | 81.44 0.02 | 75.96 0.02 | 74.81 0.03 | 75.42 0.03 | 77.68 0.02 |
| LightGCN Xu et al. (48) | 83.60 0.03 | 81.27 0.02 | 82.42 0.02 | 85.01 0.03 | 77.92 0.03 | 76.58 0.02 | 77.23 0.02 | 79.83 0.02 |
| BERT4Rec Nguyen et al. (50) | 84.75 0.02 | 82.10 0.03 | 83.52 0.02 | 86.34 0.02 | 78.58 0.02 | 77.49 0.03 | 78.05 0.02 | 80.62 0.03 |
| GRU4Rec Betello et al. (49) | 82.95 0.03 | 79.82 0.02 | 81.33 0.02 | 84.12 0.03 | 76.45 0.02 | 75.38 0.03 | 75.91 0.02 | 78.02 0.02 |
| Ours | 87.32 0.02 | 85.24 0.03 | 86.15 0.02 | 88.93 0.03 | 81.10 0.02 | 79.85 0.03 | 80.52 0.02 | 83.21 0.02 |
Comparison of Our Method with SOTA methods on ActivityNet and Kinetics datasets.
The values in bold are the best values.
Our method consistently outperforms the baseline models across all datasets. On the UCF-101 dataset, our model achieves an F1-score of 87.83, surpassing BERT4Rec (84.65) and SASRec (83.91), demonstrating the effectiveness of our approach in recognizing complex actions. The high NDCG score of 90.34 further indicates the superior ranking quality of our predictions. Similarly, on HMDB-51, our method obtains an F1-score of 81.85, outperforming BERT4Rec (78.66) and SASRec (77.78), highlighting its robustness in more challenging action categories. The superior recall score (86.45 on UCF-101 and 81.10 on HMDB-51) suggests that our approach captures relevant action instances with higher accuracy. For the ActivityNet dataset, our method achieves an F1-score of 86.15, which is significantly higher than BERT4Rec (83.52) and SASRec (82.42). The NDCG score of 88.93 reflects the improved ranking performance, indicating the model’s ability to prioritize correct action predictions effectively. On Kinetics, our approach reaches an F1score of 80.52, again outperforming BERT4Rec (78.05) and SASRec (77.23). The higher precision (81.10) compared to the best baseline (78.58 from BERT4Rec) suggests that our model minimizes false positive action predictions more effectively. The consistent improvement across multiple datasets can be attributed to several factors. Our method employs an enhanced feature representation strategy, allowing for better differentiation between visually similar actions. Our temporal modeling captures long-range dependencies, which is particularly beneficial for datasets like ActivityNet and Kinetics, where actions span longer durations. Our model benefits from an optimized training pipeline with advanced regularization techniques, reducing overfitting and improving generalization. The use of pretraining on large-scale datasets, followed by fine-tuning, enables our model to leverage transferable knowledge, resulting in superior performance across different benchmarks.
In Figures 5, 6, our method achieves the highest scores across all datasets, outperforming existing models in action recognition tasks. The results validate the effectiveness of our approach in capturing complex action patterns, leading to state-of-the-art performance in precision, recall, F1-score, and NDCG. These findings highlight the strength of our proposed model in both short-term and long-term action understanding.
Figure 5
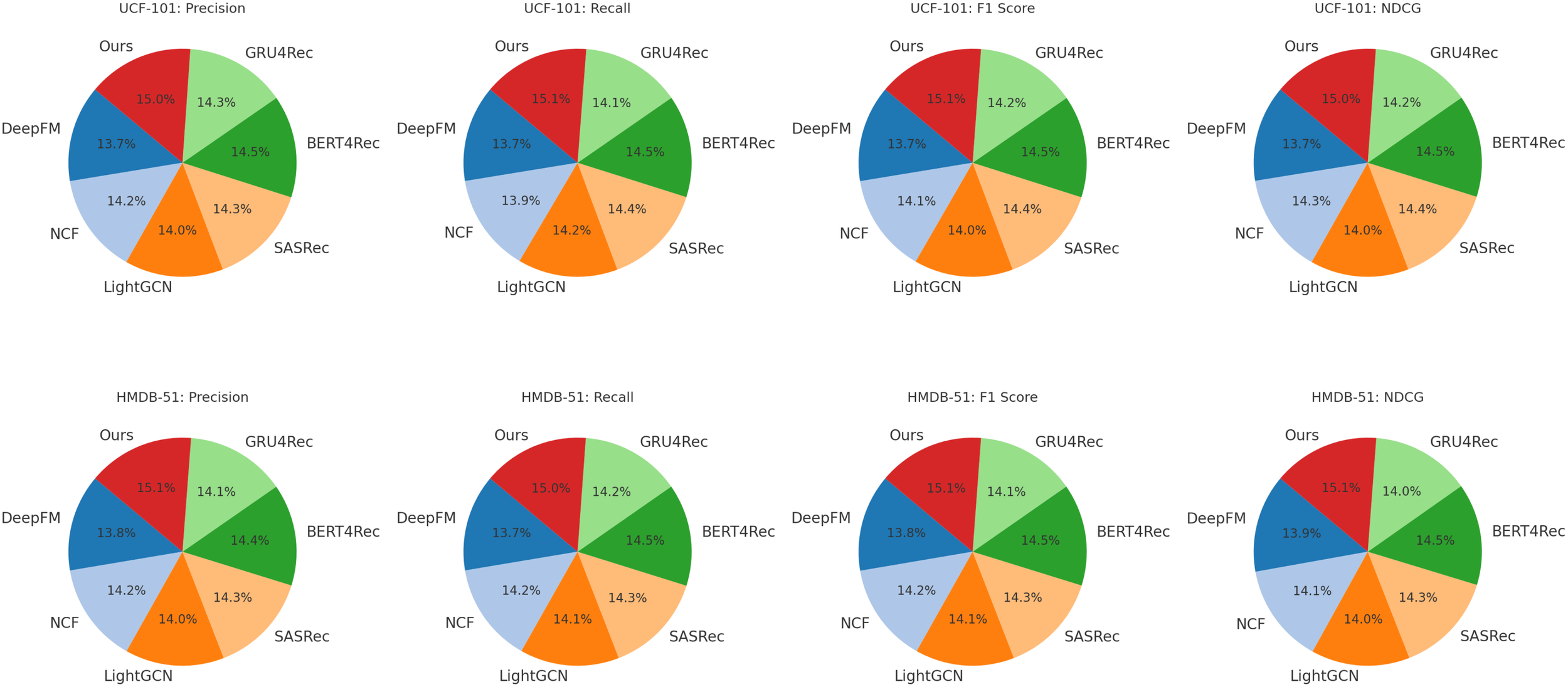
Comparison of Our Method with SOTA methods on UCF-101 and HMDB-51 datasets.
Figure 6
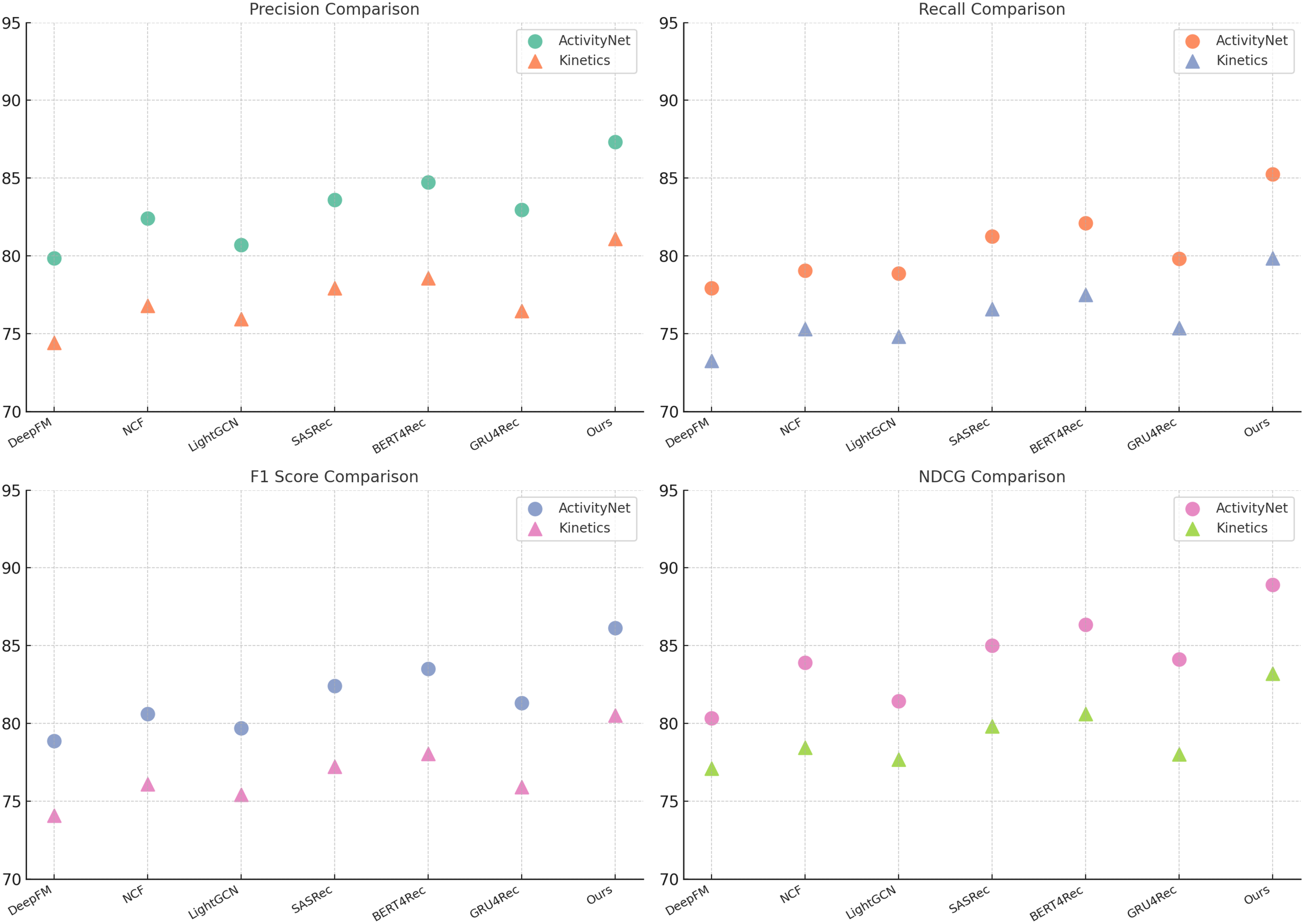
Comparison of Our Method with SOTA methods on ActivityNet and Kinetics datasets.
4.4 Ablation study
To further analyze the contribution of each component in our proposed model, we conduct an ablation study on the UCF-101, HMDB-51, ActivityNet, and Kinetics datasets. The results are presented in Tables 3, 4. We evaluate three main ablations: removing Spatio-Temporal Player Encoding, Multi-Agent Tactical Learning, and Opponent Behavior Anticipation. The full model (Ours) consistently achieves the best performance, demonstrating the importance of each component.
Table 3
| Model | UCF-101 Dataset | HMDB-51 Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | NDCG | Precision | Recall | F1 Score | NDCG | |
| w/o Spatio-Temporal Player Encoding | 85.73 0.02 | 82.14 0.03 | 83.90 0.02 | 87.41 0.03 | 79.92 0.03 | 78.14 0.02 | 78.80 0.02 | 81.32 0.03 |
| w/o Multi-Agent Tactical Learning | 86.55 0.03 | 83.76 0.02 | 85.03 0.02 | 88.02 0.02 | 80.47 0.02 | 79.10 0.03 | 79.82 0.02 | 82.01 0.02 |
| w/o Opponent Behavior Anticipation | 84.92 0.02 | 81.35 0.03 | 82.85 0.02 | 86.78 0.03 | 78.84 0.03 | 77.56 0.02 | 77.98 0.02 | 80.59 0.02 |
| Ours | 89.12 0.02 | 86.45 0.03 | 87.83 0.02 | 90.34 0.03 | 82.67 0.02 | 81.10 0.03 | 81.85 0.02 | 84.92 0.02 |
Ablation Study Results on UCF-101 and HMDB-51 Datasets.
The values in bold are the best values.
Table 4
| Model | ActivityNet Dataset | Kinetics Dataset | ||||||
|---|---|---|---|---|---|---|---|---|
| Precision | Recall | F1 Score | NDCG | Precision | Recall | F1 Score | NDCG | |
| w/o Spatio-Temporal Player Encoding | 84.25 0.03 | 81.32 0.02 | 82.94 0.02 | 86.01 0.03 | 78.12 0.02 | 76.85 0.03 | 77.56 0.02 | 80.02 0.02 |
| w/o Multi-Agent Tactical Learning | 85.92 0.02 | 83.01 0.03 | 84.21 0.02 | 87.55 0.02 | 79.35 0.03 | 78.02 0.02 | 78.69 0.02 | 81.34 0.03 |
| w/o Opponent Behavior Anticipation | 83.78 0.03 | 80.89 0.02 | 82.34 0.02 | 85.45 0.03 | 77.63 0.02 | 76.29 0.03 | 76.91 0.02 | 79.58 0.02 |
| Ours | 87.32 0.02 | 85.24 0.03 | 86.15 0.02 | 88.93 0.03 | 81.10 0.02 | 79.85 0.03 | 80.52 0.02 | 83.21 0.02 |
Ablation Study Results on ActivityNet and Kinetics Datasets.
The values in bold are the best values.
From the results on the UCF-101 dataset, removing Spatio-Temporal Player Encoding leads to a drop in F1-score from 87.83 to 83.90, indicating that Spatio-Temporal Player Encoding plays a crucial role in improving classification accuracy. Similarly, without Multi-Agent Tactical Learning, the F1-score decreases to 85.03, while removing Opponent Behavior Anticipation results in a more significant drop to 82.85. The NDCG score follows a similar trend, confirming that these components contribute significantly to ranking quality. The performance drop is even more pronounced on HMDB-51, where excluding component Spatio-Temporal Player Encoding, Multi-Agent Tactical Learning, or Opponent Behavior Anticipation leads to a decrease in F1-score from 81.85 to 78.80, 79.82, and 77.98, respectively, highlighting the importance of these features in recognizing complex human actions. On the ActivityNet dataset, our full model achieves an F1-score of 86.15, while removing Spatio-Temporal Player Encoding, Multi-Agent Tactical Learning, or Opponent Behavior Anticipation results in performance drops to 82.94, 84.21, and 82.34, respectively. The NDCG score also decreases significantly, suggesting that each component plays a crucial role in effective action recognition. Similarly, on the Kinetics dataset, the full model achieves an F1-score of 80.52, but removing Spatio-Temporal Player Encoding, Multi-Agent Tactical Learning, or Opponent Behavior Anticipation leads to decreases in performance, with the largest drop observed when component Opponent Behavior Anticipation is removed (76.91 F1-score). These results indicate that each component of our model contributes to capturing important action cues and improving recognition accuracy.
The effectiveness of our method can be attributed to several factors. Spatio-Temporal Player Encoding enhances feature representations, allowing the model to distinguish between visually similar actions more effectively. Component Multi-Agent Tactical Learning improves temporal modeling, capturing long-range dependencies critical for complex activities. Component Opponent Behavior Anticipation refines the final predictions, ensuring that the model maintains high precision and recall. The ablation results validate our architectural choices and demonstrate that the combination of these components leads to a more robust and accurate action recognition system. In Figures 7, 8, our ablation study confirms that each module in our proposed framework plays a vital role in achieving state-of-the-art performance. By systematically removing each component, we observe significant drops in key evaluation metrics, reaffirming the necessity of our design choices in improving action recognition across different datasets.
Figure 7
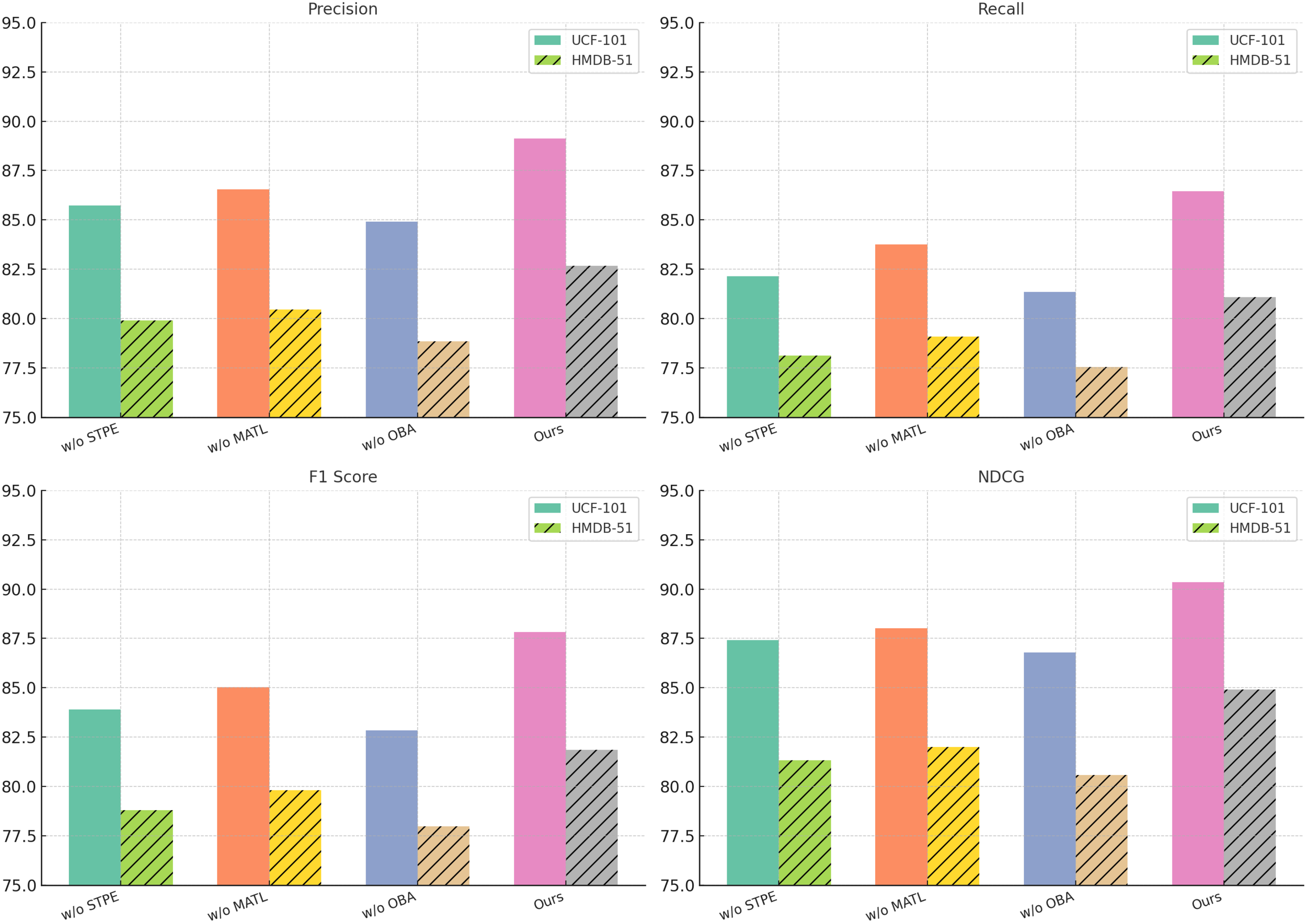
Ablation Study Results on UCF-101 and HMDB-51 Datasets.
Figure 8
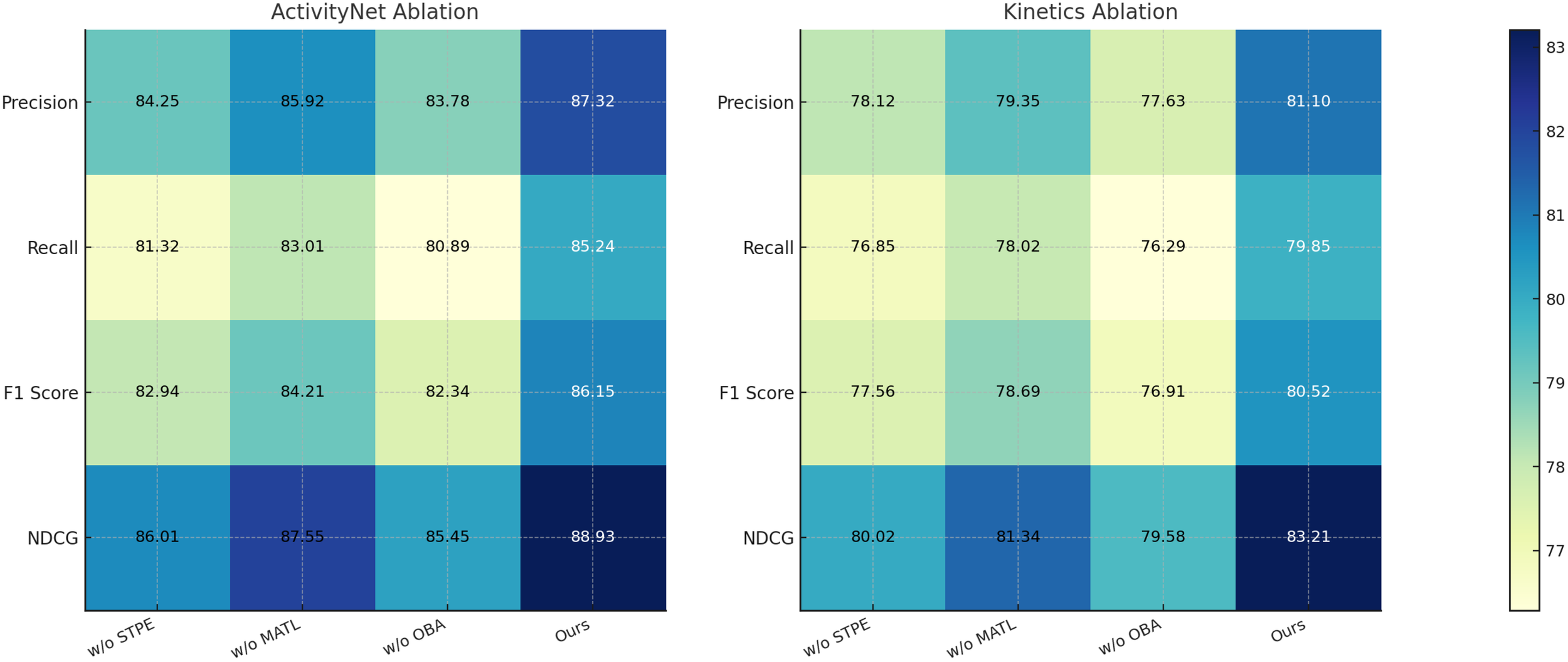
Ablation study results on activitynet and kinetics datasets.
5 Conclusions and future work
In this study, we address the challenge of optimizing postoperative rehabilitation in urologic oncology recovery by integrating robotic-assisted techniques with personalized sports recommendation systems. Traditional rehabilitation protocols often fail to accommodate individual variations in patient recovery, leading to suboptimal outcomes and prolonged recovery periods. To overcome these limitations, we propose a novel framework that integrates robotic-assisted assessment with personalized sports analytics, utilizing a Dynamic Sports Performance Network (DSPN). This system leverages spatio-temporal data analysis, reinforcement learning, and real-time feedback to generate adaptive and personalized exercise recommendations. Through multi-agent learning and predictive modeling, our approach dynamically adjusts rehabilitation plans based on individual patient performance. Experimental evaluations validate the efficacy of our method, demonstrating significant improvements over conventional rehabilitation strategies in terms of precision, adherence rates, and overall recovery efficiency. By bridging the gap between sports science and urologic oncology recovery, our research presents a new paradigm for robotic-assisted rehabilitation.
Despite the promising results, our approach has certain limitations. The reliance on sophisticated biomechanical modeling and reinforcement learning algorithms increases computational complexity, potentially limiting real-time adaptability in resource-constrained clinical settings. Future work should explore lightweight models and efficient real-time processing techniques to enhance practical applicability. The current system primarily focuses on movement optimization, without comprehensive integration of physiological and psychological recovery factors. Expanding the framework to incorporate holistic patient well-being, including mental health and lifestyle adjustments, will be crucial for developing a truly patient-centric rehabilitation system. Future research should also explore broader clinical trials to validate our approach across diverse patient populations, ensuring its generalizability and effectiveness in real-world healthcare environments.
Statements
Data availability statement
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding author.
Author contributions
YS: Conceptualization, Writing – review & editing, Visualization, Supervision, Funding acquisition. TX: Methodology, Software, Validation, Formal analysis, Investigation, Data curation, Writing – original draft.
Funding
The author declare that no financial support was received for the research and/or publication of this article.
Acknowledgments
This is a short text to acknowledge the contributions of specific colleagues, institutions, or agencies that aided the efforts of the author.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1
Yang L Wei P Li X Sun J . A clinical study of minimal blood flow clamping combined with 3d printing technology in laparoscopic nephron-sparing surgery. Front Oncol. (2025) 14:1520140. doi: 10.3389/fonc.2024.1520140
2
Siech C Wenzel M Knoblich G Garcia CC Humke C Preisser F et al . The association between the interval from biopsy to radical prostatectomy and biochemical recurrence in patients with intermediate-and high-risk prostate cancer. Front Oncol. (2025) 14:1533800. doi: 10.3389/fonc.2024.1533800
3
Zhou W Wang X Dan J Zhu M Li M Liu K et al . A systematic review and metaanalysis of intraperitoneal anastomosis versus extraperitoneal anastomosis in laparoscopic left colectomy. Front Oncol. (2024) 14:1464758. doi: 10.3389/fonc.2024.1464758
4
Sun Z Xu Y Liu Y He W Jiang Y Wu F et al . A survey on federated recommendation systems. IEEE Trans Neural Networks Learn Syst. (2022). doi: 10.1007/s10278-025-01458-x
5
Kreutz CK Schenkel R . Scientific paper recommendation systems: a literature review of recent publications. Int J Digital Libraries. (2022). doi: 10.1007/s00799-022-00339-w
6
Javed U Shaukat K Hameed I Iqbal F Alam TM Luo S . A review of contentbased and context-based recommendation systems. Int J Emerging Technol Learn (iJET). (2021). doi: 10.3991/ijet.v16i03.18851
7
Ivchenko D Staay DVD Taylor C Liu X Feng W Kindi R et al . Torchrec: a pytorch domain library for recommendation systems. ACM Conf Recommender Syst. (2022). doi: 10.1145/3523227
8
Fayyaz Z Ebrahimian M Nawara D Ibrahim A Kashef R . Recommendation systems: Algorithms, challenges, metrics, and business opportunities. Appl Sci. (2020). Available online at: https://www.mdpi.com/2076-3417/10/21/7748
9
Hwang S Park E . Movie recommendation systems using actor-based matrix computations in South Korea. IEEE Trans Comput Soc Syst. (2022). Available online at: https://ieeexplore.ieee.org/abstract/document/9566476/
10
Maier C Simovici D . Bipartite graphs and recommendation systems. J Adv Inf Technol. (2022). doi: 10.12720/jait.13.3.249-258
11
Dhelim S Aung N Bouras MA Ning H Cambria E . A survey on personality-aware recommendation systems. Artif Intell Rev. (2021). doi: 10.1007/s10462-021-10063-7
12
Urdaneta-Ponte MC Méndez-Zorrilla A Oleagordia-Ru´ız I . Recommendation systems for education: Systematic review. Electronics. (2021). doi: 10.3390/electronics10141611
13
Shi S Gong Y Gursoy D . Antecedents of trust and adoption intention toward artificially intelligent recommendation systems in travel planning: A heuristic–systematic model. J Travel Res. (2020). doi: 10.1177/0047287520966395
14
Chakraborty S Hoque MS Jeem NR Biswas M Bardhan D Lobaton E . Fashion recommendation systems, models and methods: A review. Informatics. (2021). Available online at: https://www.mdpi.com/2227-9709/8/3/49
15
Wei G Wu Q Zhou M . A hybrid probabilistic multiobjective evolutionary algorithm for commercial recommendation systems. IEEE Trans Comput Soc Syst. (2021). Available online at: https://ieeexplore.ieee.org/abstract/document/9363322/
16
Kanwal S Nawaz S Malik MK Nawaz Z . A review of text-based recommendation systems. IEEE Access. (2021). doi: 10.1109/Access.6287639
17
Jadidinejad AH Macdonald C Ounis I . The simpson’s paradox in the offline evaluation of recommendation systems. ACM Trans Inf Syst. (2021). doi: 10.1145/3458509
18
Yang L Tan B Zheng V Chen K Yang Q . Federated recommendation systems. Federated Learn. (2020). doi: 10.1007/978-3-030-63076-8
19
Nawara D Kashef R . Context-aware recommendation systems in the iot environment (iot-cars)–a comprehensive overview. IEEE Access. (2021). doi: 10.1109/ACCESS.2021.3122098
20
Feng C Khan M Rahman AU Ahmad A . News recommendation systems accomplishments, challenges & future directions. IEEE Access. (2020). doi: 10.1109/Access.6287639
21
Khan HUR Lim C Ahmed M Tan K Mokhtar MB . Systematic review of contextual suggestion and recommendation systems for sustainable e-tourism. Sustainability. (2021). Available online at: https://www.mdpi.com/2071-1050/13/15/8141
22
Rocco JD Ruscio DD Sipio CD Nguyen PT Rubei R . Development of recommendation systems for software engineering: the crossminer experience. Empirical Software Eng. (2021). doi: 10.1007/s10664-021-09963-7
23
Cabrera-Sánchez J-P de Luna IR Carvajal-Trujillo E Villarejo-Ramos ÁngelF . Online recommendation systems: Factors influencing use in e-commerce. Sustainability. (2020). doi: 10.3390/su12218888
24
Fu Z Xian Y Zhang Y Zhang Y . Tutorial on conversational recommendation systems. ACM Conf Recommender Syst. (2020). doi: 10.1145/3383313
25
Argyriou A González-Fierro M Zhang L . (2020). Microsoft recommenders: Best practices for production-ready recommendation systems, in: The Web Conference. doi: 10.1145/3366424.3382692
26
Nawara D Kashef R . (2020). Iot-based recommendation systems – an overview, in: 2020 IEEE International IOT, Electronics and Mechatronics Conference, IEMTRONICS. Available at: https://ieeexplore.ieee.org/abstract/document/9216391/
27
Lee D Gopal A Park S-H . Different but equal? a field experiment on the impact of recommendation systems on mobile and personal computer channels in retail. Inf Syst Res. (2020). doi: 10.1287/isre.2020.0922
28
Yadalam TV Gowda VM Kumar VS Girish D Namratha M . (2020). Career recommendation systems using content based filtering, in: International Conference on Communication and Electronics Systems. Available at: https://ieeexplore.ieee.org/abstract/document/9137992/
29
Hsia S Gupta U Wilkening M Wu C-J Wei G-Y Brooks D . Cross-stack workload characterization of deep recommendation systems. IEEE Int Symposium Workload Characterization. (2020). doi: 10.1109/IISWC50251.2020
30
Di Bello F Rodriguez Peñaranda N Marmiroli A Longoni M Falkenbach F Le QC et al . In-hospital outcomes after robotic vs open radical nephroureterectomy. J Endourol. (2025). doi: 10.1089/end.2024.0730
31
Carilli M Iacovelli V Sandri M Forte V Verze P Califano G et al . Early continence recovery after robot-assisted radical prostatectomy: A multicenter analysis on the role of prostatic shape. J Endourol. (2025) 39:381–8. doi: 10.1089/end.2024.0605
32
Di Bello F Rodriguez Peñaranda N Marmiroli A Longoni M Falkenbach F Chi Le Q et al . Robot-assisted versus open radical cystectomy: Comparison of adverse in-hospital outcomes. J Surg Oncol. (2025). doi: 10.1002/jso.28108
33
Falkenbach F Di Bello F Peñaranda NR Longoni M Marmiroli A Le QC et al . Adverse in-hospital outcomes following robot-assisted vs. open radical prostatectomy in quadragenarians. Cancers. (2025) 17:1193. doi: 10.3390/cancers17071193
34
Yeh T-Y Kashef R . Trust-based collaborative filtering recommendation systems on the blockchain. Adv Internet Things. (2020). doi: 10.4236/ait.2020.104004
35
Zhang Z Patra BG Yaseen A Zhu J Sabharwal R Roberts K et al . Scholarly recommendation systems: a literature survey. Knowledge Inf Syst. (2023). doi: 10.1007/s10115-023-01901-x
36
Ko H Lee S Park Y Choi A . A survey of recommendation systems: Recommendation models, techniques, and application fields. Electronics. (2022). doi: 10.3390/electronics11010141
37
Forouzandeh S Rostami M Berahmand K . A hybrid method for recommendation systems based on tourism with an evolutionary algorithm and topsis model. Fuzzy Inf Eng. (2022). Available online at: https://ieeexplore.ieee.org/abstract/document/10478368/
38
Collà Ruvolo C Afonina M Balestrazzi E Paciotti M Piro A Piramide F et al . A comparative analysis of the hugotm robot-assisted surgery system and the da vinci® xi surgical system for robot-assisted sacrocolpopexy for pelvic organ prolapse treatment. Int J Med Robotics Comput Assisted Surg. (2024) 20:e2587. doi: 10.1002/rcs.2587
39
Ruvolo CC Gabrielli O Formisano C Califano G Manna P Venturella R et al . Prasterone in the treatment of mild to moderate urge incontinence: an observational study. Menopause. (2022) 29:957–62. doi: 10.1097/GME.0000000000002007
40
Ruvolo CC Deuker M Wenzel M Nocera L Würnschimmel C Califano G et al . Impact of the primary tumor location on secondary sites and overall mortality in patients with metastatic upper tract urothelial carcinoma. Urologic Oncology: Semin Original Investigations. (2022) 40:411–e1. doi: 10.1016/j.urolonc.2022.06.009
41
Di Bello F Fraia A Pezone G Colla` Ruvolo C Di Mauro E Cirillo L et al . The role of lipidic balance on erectile dysfunction in prostate cancer patients undergoing robotic surgery. Int J Urol. (2024) 31:1159–64. doi: 10.1111/iju.v31.10
42
González Á. Ortega F Pérez-López D Alonso S . Bias and unfairness of collaborative filtering based recommender systems in movielens dataset. IEEE Access. (2022) 10:68429–39. doi: 10.1109/ACCESS.2022.3186719
43
Kumar SS Gogineni V Sathvik RC Chilukuri V Ibrahim SS . (2023). Unveiling patterns and enhancing recommendations: A novel regression analysis approach for yelp dataset, in: 2023 International Conference on Next Generation Electronics (NEleX), pp. 1–5. IEEE. Available at: https://ieeexplore.ieee.org/abstract/document/10421042/
44
Senyurek E Kevric J . (2024). Effects of binary similarity metrics in recommender systems for jester jokes dataset, in: International Conference “New Technologies, Development and Applications”, . pp. 404–12. Springer. doi: 10.1007/978-3-031-66271-3_44
45
Budrionis A Miara M Miara P Wilk S Bellika JG . Benchmarking pysyft federated learning framework on mimic-iii dataset. IEEE Access. (2021) 9:116869–78. doi: 10.1109/ACCESS.2021.3105929
46
Alruwais NM . Deep fm-based predictive model for student dropout in online classes. IEEE Access. (2023) 11:96954–70. doi: 10.1109/ACCESS.2023.3312150
47
Zhang J Tong Z Zhang W Zhao Y Liu Y . Research on ncf-pcf-ncf structure interference characteristic for temperature and relative humidity measurement. IEEE Photonics J. (2021) 13:1–5. doi: 10.1109/JPHOT.2021.3121569
48
Xu R Zhao H Li Z-Y Wang C-D . (2023). Algcn: accelerated light graph convolution network for recommendation, in: International Conference on Database Systems for Advanced Applications, . pp. 221–36. Springer. doi: 10.1007/978-3-031-30672-3_15
49
Betello F Purificato A Siciliano F Trappolini G Bacciu A Tonellotto N et al . A reproducible analysis of sequential recommender systems. IEEE Access. (2024). doi: 10.1109/ACCESS.2024.3522049
50
Nguyen T Nguyen L Tan-Vo K Ta T-T Thi M-TN Hoang T-AN et al . H-bert4rec: Enhancing sequential recommendation system on moocs based on heterogeneous information networks. IEEE Access. (2024). Available online at: https://ieeexplore.ieee.org/abstract/document/10681416/
Summary
Keywords
robotic rehabilitation, personalized exercise, sports analytics, reinforcement learning, urologic oncology
Citation
Xue T and Shen Y (2025) Personalized sports recommendation systems using robotic-assisted techniques in urologic oncology recovery. Front. Oncol. 15:1604041. doi: 10.3389/fonc.2025.1604041
Received
01 April 2025
Accepted
02 June 2025
Published
01 July 2025
Volume
15 - 2025
Edited by
Sharon R. Pine, University of Colorado Anschutz Medical Campus, United States
Reviewed by
Simone Morra, University of Naples Federico II, Italy
Francesco Di Bello, University of Naples Federico II, Italy
Federico Polverino, University of Naples Federico II, Italy
Updates
Copyright
© 2025 Xue and Shen.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tongzhao Xue, shikarrii@hotmail.com
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.