 David Windridge
David Windridge- Department of Computer Science, Middlesex University, London, United Kingdom
A cognitively autonomous artificial agent may be defined as one able to modify both its external world-model and the framework by which it represents the world, requiring two simultaneous optimization objectives. This presents deep epistemological issues centered on the question of how a framework for representation (as opposed to the entities it represents) may be objectively validated. In this article, formalizing previous work in this field, it is argued that subsumptive perception-action learning has the capacity to resolve these issues by (a) building the perceptual hierarchy from the bottom up so as to ground all proposed representations and (b) maintaining a bijective coupling between proposed percepts and projected action possibilities to ensure empirical falsifiability of these grounded representations. In doing so, we will show that such subsumptive perception-action learners intrinsically incorporate a model for how intentionality emerges from randomized exploratory activity in the form of “motor babbling.” Moreover, such a model of intentionality also naturally translates into a model for human–computer interfacing that makes minimal assumptions as to cognitive states.
1. Introduction
Significant deficits have been apparent in traditional approaches to embodied computer vision for some time (Dreyfus, 1972). In the conventional approach to autonomous robotics, a computer vision system is employed to build a model of the agent’s environment prior to the act of planning the agent’s actions within the modeled domain. Visuo-haptic data arising from these actions will then typically be used to further constrain the environment model, either actively or passively (in active learning the agent actions are driven by the imperative of reducing ambiguity in the environment model (Koltchinskii, 2010; Settles, 2010)).
However, it is apparent, in this approach, that there exists a very wide disparity between the visual parameterization of the agent’s domain and its action capabilities within it (Nehaniv et al., 2002). For instance, the agent’s visual parametric freedom will typically encompass the full intensity ranges of the RGB channels of each individual pixel of a camera CCD, such that the range of possible images generated per time-frame is of an extremely large order of magnitude, despite the fact that only a minuscule fraction of this representational space would ever be experienced by the agent. (Note that this observation is not limited purely to vision-based approaches—alternative modalities such as LIDAR and SONAR would also exhibit the same issues.) On the other hand, the agent’s motor capability is likely to be very much more parametrically constrained (perhaps consisting of the possible Euler angle settings of the various actuator motors). This disparity is manifested in classical problems such as framing (McCarthy and Hayes, 1969) and symbol grounding. (The latter occurs when abstractly manipulated symbolic objects lack an intrinsic connection to the real-world objects that they represent; thus a chess-playing robot typically requires a prior supervised computer vision problem to be solved in order to apply deduced moves to visually presented chess pieces.)
Perception-Action (P-A) learning was proposed in order to overcome these issues, adopting as its informal motto, “action precedes perception” (Granlund, 2003; Felsberg et al., 2009). By this it is meant that, in a fully formalizable sense, actions are conceptually prior to perceptions; i.e., perceptual capabilities should depend on action-capabilities and not vice versa. (We thus distinguish PA-learning from more generalized forms of learning within a perception/action context (cf., e.g., (Mai et al., 2013; Masuta et al., 2015; Millan, 2016)), in which the nature of the perceptual domain remains fixed a priori [albeit with potential variations in, e.g., visual saliency].)
It will be the argument of this article that perception-action learning, as well as having this capacity to resolve fundamental epistemic questions about emergent representational capacity, also naturally gives a model for emergent intentionality that applies to both human and artificial agents, and may thus be deployed as an effective design-strategy in human–computer interfacing.
2. Perception-Action Learning
Perception-Action learning agents thus proceed by randomly sampling their action space (“motor babbling”). For each motor action that produces a discernible perceptual output in the bootstrap representation space S (consisting of, e.g., camera pixels), a percept pi ∈ S is greedily allocated. The agent thus progressively arrives at a set of novel percepts that relate directly to the agent’s action capabilities in relation to the constraints of the environment (i.e., the environment’s affordances); the agent learns to perceive only that which it can change. More accurately, the agent learns to perceive only that which it hypothesizes that it can change—thus, the set of experimental data points ∪ipi ⊂ S can, in theory, be generalized over so as to create an affordance-manifold that can be mapped onto the action space via the injective relation {actions} → {perceptinitial} × {perceptfinal} (Windridge and Kittler, 2008, 2010; Windridge et al., 2013a).
2.1. Subsumptive Perception-Action Learning
Importantly, this approach permits Cognitive Bootstrapping (Windridge and Kittler, 2010), the bootstrapping of an autonomous agent’s representational framework simultaneously with the world-model represented in terms of that framework. This centers on the fact that the learned manifold embodying the injective relation {actions} → {perceptinitial} × {perceptfinal} represents a constrained subset of the initial action domain, and as such, is susceptible to parametric compression. Furthermore, this parametric compression in the action domain (corresponding to the bootstrapping of a higher level action) necessarily corresponds to a parametric compression in the perceptual domain (P-A learning enforces a bijective relation such that each hypothesizable action (i.e., intention primitive) has a unique, discriminable outcome (Windridge and Kittler, 2008, 2010; Windridge et al., 2013a)).
Each induced higher level action/intention (e.g., Translate) is thus created coextantly with a higher level percept domain (e.g., Object). The falsifiability of such induced representational concepts arises from actively addressing the question of whether this higher level perception in fact constitutes a useful description of the world, i.e., whether it yields a net compression in the agent’s internal representation of its own possible interactions with the world (its affordances). In particular, it is argued in Windridge and Kittler (2008), that the perception-action bijectivity constraint applied in such a hierarchical manner is uniquely sufficient to enable simultaneous empirical falsifiability of the cognitive agent’s world model and the means by which this world is perceived (by virtue of the implicit grounding of the unique set of higher level percepts so generated).
Very often parametric compressibility will be predicated on the discovery of invariances in the existing perceptual space with respect to randomized exploratory actions. Thus, for example, an agent might progress from a pixel-based representation of the world to an object-based representation of the world via the discovery that certain patches of pixels retain their (relative) identity under translation, i.e., such that it becomes far more efficient to represent the world in terms of indexed objects rather than pixel intensities (though the latter would, of course, still constitute the base of the representational hierarchy). This particular representational enhancement can represent an enormous compression (Wolff, 1987); a pixel-based representation has a parametric magnitude of Pn (with P and n being the intensity resolution and number of pixels, respectively), while an object-based representation typically has a parametric magnitude of ~ no, o ≪ n, where o is the number of objects.
When such a high level perceptual manifold is created it permits proactive sampling—the agent can propose actions with perceptual outcomes that have not yet been experienced by the agent, but which are consistent with its current representational model (this guarantees falsifiability of both the perceptual model as well as the generalized affordance model). Perception-Action learning thus constitutes a form of active learning: randomized selection of perceptual goals within the hypothesized perception-action manifold leads more rapidly to the capture of data that might falsify the current hypothesis than would otherwise be the case (i.e., if the agent were performing randomly selected actions within the original motor domain). Thus, while the system is always “motor babbling” in a manner analogous to the learning process of infant humans, the fact of carrying out this motor babbling in a higher level P-A manifold means that the learning system as a whole more rapidly converges on the “correct" model of the world. (Correct in the sense of being a true model of the world’s affordances; i.e., every possible instantiation of the induced high-level actions terminates in the anticipated percept, with no possible environmental actions being overlooked.)
This P-A motor-babbling activity can take place in any P-A manifold, of whatever level of abstraction; we may thus, by combining the idea of P-A learning with Brooke’s notion of task subsumption, conceive of a hierarchical perception-action learner (Shevchenko et al., 2009), in which a vertical representation hierarchy is progressively constructed for which randomized exploratory motor activity at the highest level of the corresponding motor hierarchy would rapidly converge on an ideal representation of the agent’s world in terms of its affordance potentialities. Such a system would thus converge upon both a model of the world, and an ideal strategy for representation of that world in terms of the learning agent’s action capabilities within it. In the example given, which juxtaposes a simulated camera-equipped robot arm in relation to a child’s shape-shorter puzzle, the robotic agent commences by motor babbling in the initial motor-actuator domain, and eventually progresses to motor-babbling in the bootstrapped “move-shape-to-hole” action domain (i.e., placing a randomly chosen object into its corresponding hole). This apparently intentional activity amounts to solving the shape-sorter puzzle, even though the system is still only motor babbling albeit at a higher level of the induced hierarchy, and has no prior programming as to the “goal” of the environment.1
Procedurally, this takes place as a recursive loop alternating between exploration, generalization, and representation as in Algorithm 1. Note in particular, in Algorithm 1, that the act of parametrically instantiating a proposed bijective perception-action term with respect to an initial perceptual state and a sought perceptual end-state is equivalent to formulating an intention (which may or may not be achievable in the environment).
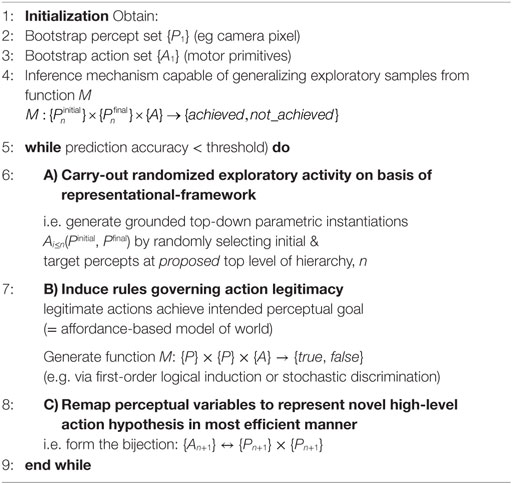
Algorithm 1. Ab Initio Induction of Perception-Action Hierarchy in Artificial Agents.
Perceptual goals thus exist at all levels of the hierarchy, and the subsumptive nature of the hierarchy means that goals and sub-goals are scheduled with increasingly specific content as the high-level abstract goal is progressively grounded through the hierarchy.2 (Thus, as humans, we may conceive the high-level intention “drive to work,” which in order to be enacted, involves the execution of a large range of sub-goals with correspondingly lower level perceptual goals, e.g., the intention “stay in the center of the lane,” etc.) (The hierarchical perception-action paradigm at no stage specifies how the scheduled sub-task is to achieve the perceptual goal—this is free within the framework, and may be achieved by a variety of mechanisms, e.g., optimal control, minimum jerk, etc.)
Moreover, these perceptual goals have no internal content; in a fully achieved perception-action learning agent, the environment effectively “becomes it own representation” (Newell and Simon, 1972), representing a significant compression of the information that an agent needs to retain. This relates directly to the issue of symbol grounding, a seminal problem in the conceptual underpinning of the classical approach to machine learning (Harnad, 1990). The problem arises when one attempts to relate an abstract symbol manipulation system (it was a common historical assumption that computational reasoning would center on a system such as first-order logic deduction (McCarthy and Hayes, 1969)) with the stochastic, shifting reality of sensor data. In hierarchical P-A learning the problem is eliminated by virtue of the fact that symbolic representations are abstracted from the bottom-up (Marr, 1982; Gärdenfors, 1994; Granlund, 2003; Modayil and Kuipers, 2004). They are thus always intrinsically grounded (for an example of utilization of first-order logic induction within a subsumption hierarchy see Windridge and Kittler (2010)).
The subsumption hierarchy is thus typically characterized by continuous stochastic relationships on the lower levels with more discrete, symbolic manipulations occurring at the higher levels—for this reason, consistent with findings of Shevchenko et al. (2009), motor-babbling at the top of the representation hierarchy involves the spontaneous scheduling of perceptual goals and subgoals at the lower level of the hierarchy in a way that (as the hierarchy becomes progressively deeper) looks increasingly intentional. (This phenomenon is readily apparent in the development of motor movement of human infants as schema abstraction takes place—for instance, the intuition of a generalized percept category container correlates with the attempt to validate this notion via the repeated placing of a variety of objects into a variety of containers; cf., Hintzman (1986) for an analysis of scheme abstraction in infants.)
Such high-level schema-employment in humans can, in principle, be detected via an appropriate classification system, enabling novel forms of intentional interfacing between humans and machines.
3. Human–Computer Interfacing
The percept-action relationship may thus be modeled in reverse to characterize human intentional behavior; consider how, as humans we typically represent our environment when driving a vehicle. At one level, we internally represent the immediate environment in metric-related terms (i.e., we are concerned with our proximity to other road users, to the curb and so on). At a higher level, however, we are concerned primarily with navigation-related entities (i.e., how individual roads are connected). That the latter constitutes a higher hierarchical level, both mathematically and experientially, is guaranteed by the fact that the topological representation subsumes, or supervenes upon, the metric representation; i.e., the metric-level provides additional “fine-grained” information to the road topology: the metric representation can be reduced to the topological representation, but not vice versa.
We can thus adopt the perception-action bijectivity principle as a design paradigm in building HCI systems by demanding that intentional acts on the part of the user are correlated maximally efficiently (i.e., bijectively) with perceptual transitions apparent to the user. This thus permits a user interface that makes minimal assumptions as to underlying cognitive processes, assuming nothing more than the ability to discriminate percept termina. This subsumption architecture paradigm was used in Windridge et al. (2013b) to demonstrate, in the context of a driver assistance system, induction of the intentional hierarchy for drivers of a vehicle in which action and eye-gaze take place with respect an external road camera view. The corresponding system constructed for the project demonstrator was thus able to determine the driver’s intentional hierarchy in relation to the current road situation and provide assistance accordingly. In principle, such an interface can also be extended to direct mechanical assistance by substituting the computationally modeled perception-action system for the human perception-action system along the lines of the horse–rider interaction paradigm.
Such P-A HCI interfaces will generally require the ability to adaptively link high-level reasoning processes (modeled by, e.g., first-order logic) with low-level reactive processes (modeled, for example, stochastically). This amounts to a requirement to propagate learning across the symbolic/sub-symbolic divide. However, because the P-A hierarchy does not make intrinsic distinction between these (there is only progressively grounded P-A abstraction), it is possible to conceive of P-A learning platforms that embody a variety of different learning approaches at different hierarchical levels, but which are all able to learn together by passing derivatives between hierarchical layers in a manner analogous to deep learning approaches.
An example utilizing a two-layer P-A hierarchy is given in Windridge et al. (2013a) which incorporates a fuzzy first-order logic reasoning process on the top level and an Euler-Lagrange-based trajectory optmization process on the lower level. The fuzzy-reasoning process employs predicates embodying the P-A bijectivity condition to compute the fixed point of the logical operator TP; i.e., TP(I) = I for each time interval t.
I is thus the Herbrand model, the minimal logically consistent “world model” for time t, of the logical programme P (where P = fixed clauses + temporalized detections + ground atom queries for t + 1; P hence embodies a series of first-order logical rules concerning traffic behavior). This functionalization of the logical reasoning enables the predicate-prediction disparity with respect to the lower level to modulate the lower level’s Euler-Lagrange optimization via the interlevel Jacobean derivatives. The net result is logically weighted updating of the Euler-Lagrange optimization that allows for on-line (top-down and bottom-up) adaptivity to human inputs. For example, in top-down terms, this allows a logically influenced Bayesian prior for gaze-location at junctions to be derived. It also allows for adaptive symbol tethering; for example actively associating eye-gaze clusters with specific semantically described road entities (such as stop and give-way signs) via their logical context.
In principle, any high-level abstract reasoning or induction process can be incorporated with low-level stochastic learning in this manner; highly flexible human–computer interfaces are thus made possible through adopting perception-action bijectivity as a design principle.
4. Conclusion
We have proposed perception-action hierarchies as a natural solution to the problem of representational induction in artificial agents in a manner that maintains empirical validatability. In such ab initio P-A hierarchies (i.e., where cognitive representations are bootstrapped in a bottom-up fashion), exploration is conducted via motor-babbling at progressively higher levels of the hierarchy. This necessarily involves the spontaneous scheduling of perceptual goals and subgoals in the induced lower levels of the hierarchy in such a way that, as the hierarchy becomes deeper, that the randomized exploration becomes increasingly “intentional” (a phenomenon that is readily apparent in the development of motor movement in human infants).
This has implications for social robotics; in particular, it becomes possible to envisage communicable actions within collections of agents employing P-A hierarchies. Here, the same bijectivity considerations apply to perceptions and actions as before, however, the induction and grounding of symbols would be conducted through linguistic exchange (we note in passing that the perception-action bijectivity constraint implicitly embodies the notion of mirroring without requiring specific perceptual apparata—“mirror neurons,” etc.).
P-A subsumption hierarchies naturally also encompass symbolic/subsymbolic integration and permit adaptive learning with respect to existing knowledge bases; in this case a bijective P-A consistency criterion is imposed on the engineered subsumption hierarchy. Moreover, P-A-subsumption hierarchies naturally lend themselves to a “deep” formulation in neural-symbolic terms (d’Avila Garcez et al., 2009); this is the subject of ongoing research.
We therefore conclude that perception-action learning, as well as enabling autonomous cognitive bootstrapping architectures, also constitutes a particularly straightforward approach to modeling human intentionality, in that it makes fewest cognitive assumptions—the existence of perceptual representation is only assumed in so far as it directly relates to an observable high-level action concept (such a “navigating a junction,” “stopping at a red light,” etc.); conversely, the ability to correctly interpret a human agent’s action implicitly invokes a necessary and sufficient set of perceptual representations on the part of the agent. This bijectivity of perception and action also gives a natural explanation for wider intention-related phenomenon such as action mirroring.
Author Contributions
The author is responsible for all aspects of the work.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Funding
The author would like to acknowledge financial support from the Horizon 2020 European Research project DREAMS4CARS (no. 731593).
Footnotes
- ^In this case, the “move-shape-to-hole” action is induced following the failure of the “move-shape-onto-surface” action to produce the anticipated result (i.e., when, following exploratory “move-shape-onto-surface” actions, the object happens by chance to fall into a hole to which matches its shape and orientation). This immediately falsifies the existing rule-base such that that the action domain is necessarily modified, by first-order logical rule-induction, to account for this possibility. In the context of the PA bijectivity condition this requires the existence of an action “move-shape-to-hole” perceptually parameterized by a set of labels corresponding to the perceptual representation of holes. Exploratory instantiation of this higher-level rule then corresponds to placing random objects into their corresponding holes, i.e., “solving the shapesorter,” even though no such external goal specification has taken place.
- ^The subsumption hierarchy thus acts bidirectionally; the hierarchy is learned bottom-up, while exploratory actions are instantiated top-down.
References
d’Avila Garcez, A. S., Lamb, L. C., and Gabbay, D. M. (2009). Neural-Symbolic Cognitive Reasoning. Berlin, Heidelberg: Springer.
Felsberg, M., Wiklund, J., and Granlund, G. (2009). Exploratory learning structures in artificial cognitive systems. Image Vis. Comput. 27, 1671–1687. doi: 10.1016/j.imavis.2009.02.012
Gärdenfors, P. (1994). “How logic emerges from the dynamics of information,” in Logic and Information Flow, eds J. van Eijck and A. Visser (Cambridge, MA: MIT Press), 49–77.
Granlund, G. (2003). “Organization of architectures for cognitive vision systems,” in Proceedings of Workshop on Cognitive Vision (Germany: Schloss Dagstuhl).
Harnad, S. (1990). The symbol grounding problem. Physica D 42, 335–346. doi:10.1016/0167-2789(90)90087-6
Hintzman, D. L. (1986). Schema abstraction in a multiple-trace memory model. Psychol. Rev. 93, 411–428. doi:10.1037/0033-295X.93.4.411
Koltchinskii, V. (2010). Rademacher complexities and bounding the excess risk in active learning. J. Mach. Learn. Res. 11, 2457–2485.
Mai, X., Zhang, X., Jin, Y., Yang, Y., and Zhang, J. (2013). “Simple perception-action strategy based on hierarchical temporal memory,” in IEEE International Conference on Robotics and Biomimetics (ROBIO), Shenzhen, 1759–1764.
Masuta, H., Lim, H. O., Motoyoshi, T., Koyanagi, K., and Oshima, T. (2015). “Direct perception and action system for unknown object grasping,” in 24th IEEE International Symposium on Robot and Human Interactive Communication (RO-MAN), Kobe, 313–318.
McCarthy, J., and Hayes, P. (1969). Some philosophical problems from the standpoint of artificial intelligence. Mach. Intell. 4, 463–502.
Millan, J. D. R. (2016). “Brain-controlled devices: the perception-action closed loop,” in 4th International Winter Conference on Brain-Computer Interface (BCI), Taebaek, 1–2.
Modayil, J., and Kuipers, B (2004). “Bootstrap learning for object discovery,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS-04) (Sendai: IEEE).
Nehaniv, C. L., Polani, D., Dautenhahn, K., te Boekhorst, R., and Canamero, L. (2002). “Meaningful information, sensor evolution, and the temporal horizon of embodied organisms,” in Artificial Life VIII, eds R. Standish, M. A. Bedau, and H. A. Abbass (Cambridge, MA: MIT Press), 345–349.
Newell, A., and Simon, H.A. (1972). Human Problem Solving, Vol. 104. Englewood Cliffs, NJ: Prentice-Hall.
Shevchenko, M., Windridge, D., and Kittler, J. (2009). A linear-complexity reparameterisation strategy for the hierarchical bootstrapping of capabilities within perception-action architectures. Image Vis. Comput. 27, 1702–1714. doi:10.1016/j.imavis.2008.12.002
Windridge, D., Felsberg, M., and Shaukat, A. (2013a). A framework for hierarchical perception-action learning utilizing fuzzy reasoning. IEEE Trans. Cybern. 43, 155–169. doi:10.1109/TSMCB.2012.2202109
Windridge, D., Shaukat, A., and Hollnagel, E. (2013b). Characterizing driver intention via hierarchical perception-action modeling. IEEE Trans. Hum. Mach. Syst. 43, 17–31. doi:10.1109/TSMCA.2012.2216868
Windridge, D., and Kittler, J. (2008). “Epistemic constraints on autonomous symbolic representation in natural and artificial agents,” in Applications of Computational Intelligence in Biology. Studies in Computational Intelligence, Vol. 122, eds T. G. Smolinski, M. G. Milanova, and A. E. Hassanien (Berlin, Heidelberg: Springer), 395–422.
Windridge, D., and Kittler, J. (2010). “Perception-action learning as an epistemologically-consistent model for self-updating cognitive representation,” in Brain Inspired Cognitive Systems 2008, Vol. 657. eds A. Hussain, I. Aleksander, L. Smith, A. Barros, R. Chrisley, and V. Cutsuridis (New York, NY: Springer), 95–134.
Keywords: perception-action learning, intention recognition, embodied cognition, subsumption hierarchies, symbol grounding
Citation: Windridge D (2017) Emergent Intentionality in Perception-Action Subsumption Hierarchies. Front. Robot. AI 4:38. doi: 10.3389/frobt.2017.00038
Received: 21 April 2017; Accepted: 25 July 2017;
Published: 15 August 2017
Edited by:
Serge Thill, Plymouth University, United KingdomReviewed by:
Terrence C. Stewart, University of Waterloo, CanadaTarek Richard Besold, University of Bremen, Germany
Copyright: © 2017 Windridge. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: David Windridge, ZC53aW5kcmlkZ2VAbWR4LmFjLnVr