 Seyed Mehran Kazemi
Seyed Mehran Kazemi David Poole
David Poole- Laboratory of Computational Intelligence, Computer Science Department, University of British Columbia, Vancouver, BC, Canada
The aim of statistical relational learning is to learn statistical models from relational or graph-structured data. Three main statistical relational learning paradigms include weighted rule learning, random walks on graphs, and tensor factorization. These paradigms have been mostly developed and studied in isolation for many years, with few works attempting at understanding the relationship among them or combining them. In this article, we study the relationship between the path ranking algorithm (PRA), one of the most well-known relational learning methods in the graph random walk paradigm, and relational logistic regression (RLR), one of the recent developments in weighted rule learning. We provide a simple way to normalize relations and prove that relational logistic regression using normalized relations generalizes the path ranking algorithm. This result provides a better understanding of relational learning, especially for the weighted rule learning and graph random walk paradigms. It opens up the possibility of using the more flexible RLR rules within PRA models and even generalizing both by including normalized and unnormalized relations in the same model.
1. Introduction
Traditional machine learning algorithms learn mappings from a feature vector indicating categorical and numerical features to an output prediction of some form. Statistical relational learning (Getoor and Taskar, 2007), or statistical relational AI (StarAI) (De Raedt et al., 2016), aims at probabilistic reasoning and learning when there are (possibly various types of) relationships among the objects. The relational models developed in StarAI community have been successfully applied to several applications such as knowledge graph completion (Lao et al., 2011; Nickel et al., 2012; Bordes et al., 2013; Pujara et al., 2013; Trouillon et al., 2016), entity resolution (Singla and Domingos, 2006; Bhattacharya and Getoor, 2007; Pujara and Getoor, 2016; Fatemi, 2017), tasks in scientific literature (Lao and Cohen, 2010b), stance classification (Sridhar et al., 2015; Ebrahimi et al., 2016), question answering (Khot et al., 2015; Dries et al., 2017), etc.
During the past two decades, three paradigms of statistical relational models have appeared. The first paradigm is the weighted rule learning where first-order rules are learned from data and a weight is assigned to each rule indicating a score for the rule. The main difference among these models is in the types of rules they allow and their interpretation of the weights. The models in this paradigm include Problog (De Raedt et al., 2007), Markov logic (Domingos et al., 2008), probabilistic interaction logic (Hommersom and Lucas, 2011), probabilistic soft logic (Kimmig et al., 2012), and relational logistic regression (Hommersom and Lucas, 2011).
The second paradigm is the random walk on graphs, where several random walks are performed on a graph each starting at a random node and probabilistically transitioning to neighboring nodes. The probability of each node being the answer to a query is proportional to the probability of the random walks ending up at that node. The main difference among these models is in the way they walk on the graph and how they interpret obtained results from the walks. Examples of relational learning algorithms based on random walk on graphs include PageRank (Page et al., 1999), FactRank (Jain and Pantel, 2010), path ranking algorithm (Lao and Cohen, 2010b; Lao et al., 2011), and HeteRec (Yu et al., 2014).
The third paradigm is the tensor factorization paradigm, where for each object and relation an embedding is learned. The probability of two objects participating in a relation is a simple function of the objects’ and relation’s embeddings (e.g., the sum of the element-wise product of the three embeddings). The main difference among these models is in the type of embeddings and the function they use. Examples of models in this paradigm include YAGO (Nickel et al., 2012), TransE (Bordes et al., 2013), and ComplEx (Trouillon et al., 2016).
The models in each paradigm have their own advantages and disadvantages. Kimmig et al. (2015) survey the models based on weighted rule learning. Nickel et al. (2016) survey models in all paradigms for knowledge graph completion. Kazemi et al. (2017) compare several models in these paradigms for relational aggregation. None of these surveys, however, aims at understanding the relationship among these paradigms. In fact, these paradigms have been mostly developed and studied in isolation with few works aiming at understanding the relationship among them or combining them (Riedel et al., 2013; Nickel et al., 2014; Lin et al., 2015).
With several relational paradigms/models developed during the past decade and more, understanding the relationship among them and pruning the ones that either do not work well or are subsets of the other models is crucial. In this article, we study the relationship between two relational learning paradigms: graph random walk and weighted rule learning. In particular, we study the relationship among path ranking algorithm (PRA) (Lao and Cohen, 2010b) and relational logistic regression (RLR) (Kazemi et al., 2014). The former is one of the most well-known relational learning tools in graph random walk paradigm, and the latter is one of the recent developments in weighted rule learning paradigm. By imposing restrictions on the rules that can be included in models, we identify a subset of RLR models that we call RC-RLR. Then we provide a simple way to normalize relations and prove that PRA models correspond to RC-RLR models using normalized relations. Other strategies for walking randomly on the graph (e.g., data-driven path finding (Lao et al., 2011)) can then be viewed as structure learning methods for RC-RLR. Our result can be extended to several other weighted rule learning and graph random walk models.
The relationship between weighted rules and graph random walks has not been discovered before. For instance, Nickel et al. (2016) describe them as two separate classes of models for learning from relational data in their survey. Lao et al. (2011) compare their instance of PRA to a model based on weighted rules empirically, reporting their PRA model outperforms the weighted rule model, but not realizing that their PRA model could be a subset of the weighted rule model if they had normalized the relations.
Our result is beneficial for both graph random walk and weighted rule learning paradigms, as well as for researchers working on theory and applications of statistical relational learning. Below is a list of potential benefits that our results provide:
• It provides a clearer intuition and understanding on two relational learning paradigms, thus facilitating further improvements of both.
• It opens up the possibility of using the more flexible RLR rules within PRA models.
• It opens up the possibility of generalizing both PRA and RLR models by using normalized and unnormalized relations in the same model.
• It sheds light on the shortcomings of graph random walk algorithms and points out potential ways to improve them.
• One of the claimed advantages of models based on weighted rule learning compared to other relational models is that they can be easily explained to a broad range of people (Nickel et al., 2016). Our result improves the explainability of models learned through graph random walk, by providing a weighted rule interpretation for them.
• It identifies a subclass of weighted rules that can be evaluated efficiently and have a high modeling power as they have been successfully applied to several applications. The evaluation of these weighted rules can be even further improved using sampling techniques developed within graph random walk community (e.g., see Fogaras et al. (2005); Lao and Cohen (2010a); Lao et al. (2011)). Several structure learning algorithms (corresponding to random walk strategies) have been already developed for this subclass.
• It facilitates leveraging new insights and techniques developed within each paradigm (e.g., weighted rule models that leverage deep learning techniques (Šourek et al., 2015; Kazemi and Poole, 2018), or reinforcement learning-based approaches to graph walk (Das et al., 2017)) to the other paradigm.
• For those interested in the applications of relation learning, our result facilitates decision-making on selecting the paradigm or the relational model to be used in their application.
2. Background and Notations
In this section, first we define some basic terminology. Then we introduce a running example, which will be used throughout the article. Then we describe relational logistic regression and path ranking algorithm for relational learning. While semantically identical, our descriptions of these two models may be slightly different from the descriptions in the original articles as we aim at describing the two algorithms in a way that simplifies our proofs.
2.1. Terminologies
Throughout the article, we assume True is represented by 1 and False is represented by 0.
A population is a finite set of objects (or individuals). A logical variable (logvar) is typed with a population. We represent logvars with lower case letters. The population associated with a logvar x is Δx. The cardinality of Δx is |Δx|. For every object, we assume that there exists a unique constant denoting that object. A lower case letter in bold represents a tuple of logvars, and an upper case letter in bold represents a tuple of constants. An atom is of the form V(t1, …, tk), where V is a functor, and each ti is a logvar or a constant. When range(V) ∈ {0,1}, V is a predicate. A unary atom contains exactly one logvar, and a binary atom contains exactly two logvars. We write a substitution as θ = {⟨x1, …, xk⟩/⟨t1, …, tk⟩}, where each xi is a different logvar and each ti is a logvar or a constant in Δxi. A grounding of an atom V(x1, …, xk) is a substitution θ = {⟨x1, …, xk⟩/⟨X1, …, Xk⟩} mapping each of its logvars xi to an object in Δxi. Given a set 𝒜 of atoms, we denote by 𝒢(𝒜) the set of all possible groundings for the atoms in 𝒜. A value assignment for a set of groundings 𝒢(𝒜) maps each grounding V(X) ∈𝒢(𝒜) to a value in range(V).
A literal is an atom or its negation. A formula φ is a literal, a disjunction φ1 ∨ φ2 of formulae or a conjunction φ1 ∧ φ2 of formulae. Our formulae correspond to open formulae in negation normal form in logic. An instance of a formula φ is obtained by replacing each logvar x in φ by one of the objects in Δx. Applying a substitution θ = {⟨x1, …, xk⟩/⟨t1, …, tk⟩} on a formula φ (written as φθ) replaces each xi in φ with ti. A weighted formula (WF) is a pair ⟨w, φ⟩ where w is a weight and φ is a formula.
A binary predicate S(x, y) can be viewed as a function whose domain is Δx and whose range is 2Δy : each X ∈Δx is mapped to {Y : S(X, Y)}. Following Lao and Cohen (2010b), we consider S−1 as the inverse of S whose domain is Δy and whose range is 2Δx, such that S−1 (x, y) holds iff S(y, x) holds. A path relation 𝒫 ℛ is of the form x0 x1 … xl, where R1, R2, … Rl are predicates, x0, …, xl are different logvars, domain(Ri) = Δxi−1 and range(Ri) = Δxi. We define domain(𝒫 ℛ) = Δx0 and range(𝒫 ℛ) = Δxi. Applying a substitution θ = {⟨x1, …, xk⟩/⟨t1, …, tk⟩} on a path relation 𝒫 ℛ (written as 𝒫 ℛθ) replaces each xi in 𝒫 ℛ with ti. A weighted path relation (WPR) is a pair ⟨w, 𝒫 ℛ⟩, where w is a weight and 𝒫 ℛ is a path relation.
2.2. Running Example
As a running example, we use the reference recommendation problem: finding relevant citations for a new paper. We consider three populations: the population of new papers for which relevant citations are to be found, the population of existing papers whose citations are known, and the population of publication years. The atoms used for this problem throughout the article are the following. WillCite(q, p) is the atom to be predicted and indicates whether a query/new paper q will cite an existing paper p. Cited (p1, p2) shows whether an existing paper p1 has cited another existing paper p2. PubIn(p, y) shows that p has been published in year y. ImBef(y1, y2) indicates that y2 is the year immediately before y1. The reference recommendation problem can be viewed as follows: given a query paper Q, find a subset of existing papers that Q will cite (i.e., find any paper P such that WillCite(Q, P) holds).
2.3. Relational Logistic Regression
Relational logistic regression (Kazemi et al., 2014) defines conditional probabilities based on weighted rules. It can be viewed as the directed analog of logistic regression and as the directed analog of Markov logic (Domingos et al., 2008).
Let V(x) be an atom whose probability depends on a set 𝒜 of atoms, ψ be a set of WFs containing only atoms from 𝒜, Î be a value assignment for the groundings in 𝒢(𝒜), X be an assignment of objects to x, and {x/X} be a substitution mapping logvars x to objects X.
Relational logistic regression (RLR) defines the probability of V(X) given Î as follows:
where η(φ{x∕X}, Î) is the number of instances of φ{x/X} that are True with respect to Î and σ is the sigmoid function. RLR makes the closed-world assumption: any ground atom that has not been observed to be True is False. Note that η(True, Î) = 1.
Following Kazemi et al. (2014) and Fatemi et al. (2016), we assume that formulae in WFs have no disjunction and replace conjunction with multiplication. Then atoms whose functors have a continuous range can be also allowed in formulae. For instance, if a value assignment maps R(X) to 1, S(X) to 0.9 and T(X) to 0.3, then the formula R(X) ∗ S(X) ∗ T(X) evaluates to 1 ∗ 0.9 ∗ 0.3 = 0.27.
Example 1: An RLR model may use the following WFs to define the conditional probability of WillCite(q, p) in our running example:
WF0 is a bias. WF1 considers existing papers that have been published a year before the query paper. A positive weight for this WF indicates that papers published a year before the query paper are more likely to be cited. WF2 considers existing papers cited by the other papers published in the same year as the query paper. A positive weight for this WF indicates that as the number of times a paper has been cited by the other papers published in the same year as the query paper grows, the chances of the query paper citing that paper increases. WF3 considers existing papers that have been cited by other papers that have been themselves cited by other papers. Note that the score of the last WF depends only on the paper being cited not on the paper citing.
Consider the citations among existing papers in Figure 1A, and let the publication year for all the six papers be 2017. Suppose we have a query paper Q that is to be published in 2017 and we want to find the probability of WillCite(Q, Paper2) according to the WFs above. Applying the substitution {⟨q, p⟩/⟨Q, Paper2⟩} to the above four WFs gives the following four WFs, respectively:
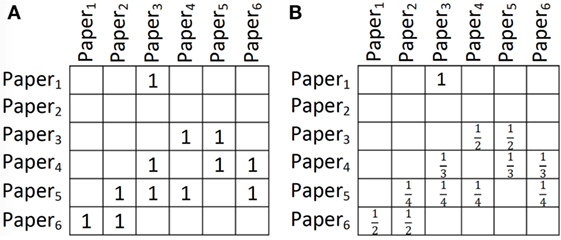
Figure 1. (A) A relation showing citations among papers (papers on the Y axis cite papers on the X axis). (B) The relation in part (A) after row-wise count normalization.
Then we evaluate each WF. The first one evaluates to w0. The second evaluates to 0 as Q is being published in 2017 and Paper2 has also been published in 2017. The third WF evaluates to w2 ∗ 2 as there are 2 papers that have been published in the same year as Q and cite Paper2. The last WF evaluates to w3 ∗ 4 as Paper5 and Paper6 (that cite Paper2) are each cited by two other papers. Therefore, the conditional probability of WillCite(Q, Paper2) is as follows:
2.4. Path Ranking Algorithm
Let V(s, e) be a target binary predicate, i.e., for a query object S ∈ Δs, we would like to find the probability of any E ∈ e having the relation V with S. Path ranking algorithm (PRA) (Lao and Cohen, 2010b) defines this probability using a set of WPRs ψ. The first logvar of each path relation in ψ is either s or a logvar other than s and e, the last logvar is always e, and the middle logvars are neither s nor e.
In PRA, each path relation 𝒫 ℛ= x0 x1 … e defines a distribution over the objects in Δe. This distribution corresponds to the probability of following 𝒫 ℛ and landing at each of the objects in Δe and is computed as follows. First, a uniform distribution D0 is considered on the objects in Δx0, corresponding to the probability of landing at each of these objects if the object is selected randomly. For instance, if there are α objects in Δx0, D0 for all objects is . Then, the distribution D1 over the objects in Δx1 is calculated by marginalizing over the variables in D0 and following a random step on R1. For instance, for an object X1 ∈Δx1, assume R1 (x0, X1) holds only for two objects (0 and X′0 in Δx0. Also assume X0 and X′0 have the R1 relation with β and γ objects in x1, respectively. Then the probability of landing at X1 is . The following distributions D2, …, Dl can be computed similarly. Dl gives the probability of landing at any object in Δe.
Let θ = {⟨s, e⟩/⟨S, E⟩}. To find Prob(V(S, E)), for each path relation 𝒫 ℛ ∈ ψ, PRA calculates the probability of landing at E according to 𝒫 ℛθ (denoted by h(𝒫 ℛθ)) and calculates Prob(V(S, E)) by taking the sigmoid of the weighted sum of these probabilities as follows:
Algorithm 1 shows a recursive algorithm for calculating h(𝒫 ℛ) for a path relation 𝒫 ℛ. The first if statement specifies that the walk starts randomly at any object in Δx0. uniform (Δx0) indicates a uniform probability over the objects in Δx0. This is the termination criterion of the recursion. When 𝒫 ℛ= x0 x1 … xl is not empty (l ≠ 0), first the probability of landing at any object E′ in the range of 𝒫 ℛl = x0 x1 … is calculated using a recursive call to h(𝒫 ℛ′) and stored in pLandl −1. The probability of landing at any object E in range of 𝒫 ℛ by randomly walking on 𝒫 ℛ can then be calculated as the sum of the probabilities of landing at each object E′ by randomly walking on 𝒫 ℛ′ multiplied by the probability of reaching E from E′ by a random walk according to the predicate Rl. The two nested for loops calculate the probability of landing at any object E ∈ range(𝒫 ℛ) according to Rl. Rl (E′, E) indicates whether there is a link from E′ to E (otherwise the probability of transitioning from E′ to E according to Rl is 0), and CRl is a normalization constant indicating the number of possible transitions from E′ according to Rl. pWalk(E′, E) indicates the probability of walking from E′ to E if one of the objects connected to E′ through Rl is selected uniformly at random, which equals . pLandl stores the probability of landing at any object E in the range of (𝒫 ℛ) following 𝒫 ℛ and is returned as the output of the function.

ALGORITHM 1. h(𝒫 ℛ).
Example 2: A PRA model may use the following WPRs to define the conditional probability of WillCite(q, p) in our running example:
WPR0 is a bias, WPR1 considers the papers published a year before the query paper, WPR2 considers papers cited by other papers published in the same year as the query paper, and WPR3 mimics PageRank algorithm for finding important papers in terms of citations (cf. (Lao and Cohen, 2010b) for more detail). Consider the citations among existing papers in Figure 1A, and let the publication year for all the six papers be 2017. Suppose we have a query paper Q, which is to be published in 2017 and we want to find the probability of WillCite(Q, Paper2) according to the PRA model above. Applying the substitution {⟨q, p⟩/⟨Q, Paper2⟩} to the above WPRs gives the following WPRs, respectively:
WPR0 evaluates to w0. WPR1 evaluates to 0. WPR2 evaluates to w2 as for the path y p′, there is probability for randomly walking to either Paper5 or Paper6 and then there is probability to walk randomly from Paper5 to Paper2 and probability to walk randomly from Paper6 to Paper2 according to Cited relation. WPR3 evaluates to w3 ≈ w3 ∗ 0. 083. The outside parenthesis is the probability of randomly starting at any paper, ∗ is the probability of transitioning from Paper3 to Paper5 and then to Paper2, and so forth. Therefore, the conditional probability of WillCite (Q, Paper2) is as follows:
3. RLR with Normalized Relations Generalizes PRA
To prove that RLR with normalized relations generalizes PRA, we first define relation chains and describe some of their properties.
3.1. Relations Chain
Definition 1: We define a relations chain as a list of binary atoms V1(x0,x1),…, Vm(xm −1, xm) such that for each Vi and Vi+1, the second logvar of Vi is the same as the first logvar of Vi+1, x0,…,xm are different logvars, and Vi and Vj can be the same or different predicates.
Example 3: V1(x, y), V2(y, z) is a relations chain, and V1(x, y), V2(z, y) and V1(x, y), V2(y, z), V3(z, x) are not relations chains.
Definition 2: A first-order formula corresponds to a relations chain if all its literals are binary predicates and non-negated, and there exists an ordering of the literals, i.e, a relations chain.
Example 4: The first-order formula V1(x1, x2) ∗ V2(x3, x1) corresponds to a relations chain as the order V2(x3, x1), V1(x1, x2) is a relations chain.
It follows from RLR definition that re-ordering the literals in each of its WFs does not change the distribution. For any WF whose formula corresponds to a relations chain, we assume hereafter that its literals have been re-ordered to match the order of the corresponding relations chain.
Definition 3: Let V(x, y) be a target atom. Relations chain RLR (RC-RLR) is a subset of RLR for defining a conditional probability distribution for V(x, y), where:
• formulae of WFs correspond to relations chains,
• for each WF, the second logvar of the last atom is y,
• x may only appear as the first logvar of the first atom,
• y may only appear as the second logvar of the last atom.
For RLR models, to evaluate a formula, one may have nested loops over logvars of the formula that do not appear in the target atom or conjoin all literals one by one and then count. WFs of RC-RLR, however, can be evaluated in a special way. To evaluate a formula in RC-RLR, starting from the end (or beginning), the effect of each literal can be calculated and then the literal can be removed from the formula. Algorithm 2 indicates how a formula corresponding to a relations chain can be evaluated. This evaluation grows with the product of the number of literals in the formula and the number of observed data, which makes it highly scalable.

ALGORITHM 2. Eval(φ).
When l = 0, the formula corresponds to True and evaluates to 1 for any X0 ∈ x0. Therefore, in this case, the algorithm returns a vector of ones of size |Δx0 |. Otherwise, the algorithm first evaluates φ′ = R1(x0,x1) ∗ R2(x1,x2) ∗ … ∗ Rl −1(x1 −2,xl −1) using a recursive call to the Eval function. The resulting vector is stored in evall −1, such that for a E′∈Δxl−1, evall −1[E′] indicates the result of evaluating φ′ = R1(x0,x1) ∗ R2(x1,x2) ∗ … ∗ Rl −1(xl −2,E′). Then to evaluate φ for some E ∈Δxl, we sum evall −1[E′] s for any E′∈Δxl−1 such that Rl(E′,E) holds. canWalk in the algorithm is 1 if Rl(E′,E) holds and 0 otherwise, and evall(E) + = evall −1(E′) ∗ canwalk(E′, E) + = adds evall −1[E′] to eval1[E] if canWalk is 1.
Proposition 1: Algorithm 2 is correct.
Proof: Let φ = R1(x0,x1) ∗ R2(x1,x2) ∗ … ∗ Rl (xl− 1,xl) ∗ evall(xl) (evall(xl) can be initialized to a vector of ones at the beginning of the algorithm. Since by definition of relations chain xl only appears in Rl and evall (xl), for any Xl−1 ∈Δxl−1 we can evaluate evall−1(Xl−1) = ∑ Xl∈Δxl Rl(Xl−1, Xl) * evall(Xl) separately and replace R1(xl−1,x1) ∗ evall(xl) with evall−1 (xl−1), thus getting φ′ = R1(x0,x1) ∗ R2(x1,x2) ∗ … ∗ Rl− 1(xl− 2,xl− 1) ∗ evall− 1 (xl− 1). The same procedure can compute φ′.
3.2. From PRA to Relation Chains
Proposition 2: A path relation corresponds to a relations chain.
Proof: Let 𝒫 ℛ= x0 x1 … xl be a path relation. We create a relation atom R i(xi−1, xi) for any subpath xi−1 xi resulting in relations R 1(x0, x1), R 2(x1, x2), …, Rl(xl− 1, xl). By definition of path relations, the second logvar of any relation Ri is the same as the first logvar of the next relation. Since by definition the logvars in a path relation are different, the second logvar of any relation R i is only equivalent to the first logvar of the next relation.
Example 5: Consider the path relation q y p′ p from Example 2. This path relation corresponds to a relations chain with atoms PubIn(q, y), PubIn−1(y, p′), and Cited(p′, p).
3.3. Row-Wise Count Normalization
Having a binary predicate V(x, y) and a set of pairs of objects for which V holds, one may consider the importance of these pairs to be different. For instance, if a paper has cited only 20 papers, the importance of these citations may be more than the importance of citations for a paper citing 100 papers. One way to take the importance of the pairs into account is to normalize the relations. A simple way to normalize a relation is to normalize it by row-wise counts. For some X ∈ Δx, let α represent the number of Y ′ ∈ Δy, such that V(X, Y′) holds. When α ≠ 0, instead of considering V(X, Y) = 1 for a pair ⟨X, Y⟩, we normalize it to V(X, Y) = . After this normalization, the citations of a paper with 20 citations are 5 times more important than the citations of a paper with 100 citations overall. Note that when α = 0, we do not change any values. We refer to this normalization method as row-wise count (RWC) normalization. Figure 1B shows the result of applying RWC normalization to the relation in Figure 1A. Note that there may be several other ways to normalize a relation; here, we introduced RWC because, as we will see in the upcoming sections, it is the normalization method used in PRA.
3.4. Main Theorem
Theorem 1: Any PRA model is equivalent to an RC-RLR model with RWC normalization.
Proof: Let Ψ = {⟨w0, 𝒫 ℛ0⟩, …, ⟨wk, 𝒫 ℛk⟩} represent a set of WPRs used by a PRA model. We proved in Proposition 2 that any path relation 𝒫 ℛi in Ψ corresponds to a relations chain. By multiplying the relations in the relation chain, one gets a formula φi for each 𝒫 ℛi, and this formula is by construction guaranteed to correspond to a relations chain. We construct an RC-RLR model whose WFs are ψ = {⟨v0, φ0⟩, …, ⟨vk, φk⟩}. Given that the relations (and their order) used in 𝒫 ℛi and φi are the same for any i, the only differences between the evaluation of 𝒫 ℛi and φi according to Algorithm 1 and Algorithm 2 are: (1) Algorithm 1 divides Rl(E′, E) by CRl (E′), while Algorithm 2 does not, and (2) in the termination condition, Algorithm 1 returns a uniform distribution over objects in Δx0, while Algorithm 2 returns a vector of ones of size |Δx0 |. Dividing Rl(E′, E) by CRl (E′) is equivalent to RWC normalization, and the difference in the constant value of the function in the termination condition gets absorbed in the weights that are multiplied to each path relation or formula. Therefore, the RC-RLR model with WFs ψ is identical to the PRA model with WPRs Ψ after normalizing the relations using RWC.
Example 6: Consider the PRA model in Example 2. For the four WPRs in that model, we create the following corresponding WFs for an RC-RLR model by multiplying the relations in the path relations:
Consider computing WillCite (Q, Paper2) according to an RC-RLR model with the above WFs, where all existing papers and Q have been published in 2017 and the relations have been normalized using RWC normalization (e.g., as in Figure 1B for relation Cited). Then the first formula evaluates to v0. The second WF evaluates to 0. The third WF evaluates to v2 ∗ ∗ ( + ) as the values in relation PubIn−1 have been normalized to for year 2017 and the values in relation Cited have been normalized to and for Paper5 and Paper6 as in Figure 1B. The last WF evaluates to v3 ∗ ( ∗ + ∗ ( + ) + ∗ ). The ∗ comes from Cited(Paper3, Paper5) ∗ Cited(Paper5, Paper2), ∗ ( +) comes from Cited(Paper4, Paper5) ∗ Cited(Paper5, Paper2) and Cited(Paper4, Paper6) ∗ Cited(Paper6, Paper2), and ∗ comes from Cited(Paper5, Paper6) ∗ Cited(Paper6, Paper2). As it can be viewed from Example 2, after creating the equivalent RC-RLR model and normalizing the relations using RWC normalization, all WPRs evaluate to the same value as their corresponding WF, except the last WF. The before the parenthesis in Example 2 is missing when evaluating the last WF. This , however, is a constant independent of the query (it is the constant value of the uniform distribution in the if statement corresponding to the termination criteria in Algorithm 1). Assuming v3 = w3 ∗ and all other vis are the same as wis, the conditional probability of Cited(Q, Paper2) according to the RC-RLR model above will be the same as the PRA model in Example 2.
3.5. From Random Walk Strategies to Structure Learning
The restrictions imposed on the formulae by path relations in PRA reduce the number of possible formulae to be considered in a model compared to RLR models. However, there may still be many possible path relations, and considering all possible path relations for a PRA model may not be practical.
Lao and Cohen (2010b) allow the random walk to follow any path, but restrict the maximum number of steps. In particular, they only allow for path relations whose length is less than some l. The value of l can be selected based on the number of objects, relations, available hardware, and the amount of time one can afford for learning/inference. This strategy automatically gives a (very simple) structure learning algorithm for RC-RLR by considering only formulae whose number of relations are less than l.
Lao et al. (2011) follow a more sophisticated approach for limiting the number of path relations. Besides limiting the maximum length of the path relations to l, Lao et al. (2011) impose two more restrictions: for any path relation to be included, (1) the probability of reaching the target objects must be non-zero for at least a fraction α of the training query objects, and (2) it should at least retrieve one target object in the training set. During parameter learning, they impose a Laplacian prior on their weights to further reduce the number of path relations. In an experiment on knowledge completion for NELL (Carlson et al., 2010), they show that these two restrictions plus the Laplacian prior reduce the number of possible path relations by almost 99.6 and 99.99% when l = 3 and l = 4, respectively. Therefore, their random walk strategy is capable of taking more steps (i.e., selecting a larger value for l) and capture features that require longer chains of relations. This random walk strategy is called data-driven path finding.
Both restrictions in data-driven path finding can be easily verified for RC-RLR formulae and the set of possible formulae can be restricted accordingly. Furthermore, during parameter learning, a Laplacian prior can be imposed on the weights of the weighted formulae. RC-RLR models learned in this way correspond to PRA models learned using data-driven path finding. Therefore, data-driven path finding can be also considered as a structure learning algorithm for RC-RLR. With the same reasoning, several other random walk strategies can be considered as structure learning algorithms for RC-RLR, and vice versa. This allows for faster development of the two paradigms by leveraging ideas developed in each community in the other.
4. PRA vs. RLR
An advantage of PRA models over RLR models is their efficiency: there is a smaller search space for WFs, and all WFs can be evaluated efficiently. Such efficiency makes PRA scale to larger domains where models based on the weighted rule learning such as RLR often have scalability issues. It also allows PRA models to scale to and capture features that require longer chains of relations. However, the efficiency comes at the cost of losing modeling power. In the following subsections, we discuss such costs.
4.1. Shortcomings of Relations Chains
Since PRA models restrict themselves to relations chains of a certain type, they lose the chance to leverage many other WFs. As an example, to predict Cites(p1,p2) for the reference recommendation task, suppose we would like to recommend papers published a year before the target paper that have been cited by the papers published in the same year as the target paper. Such a feature requires the following formula: PubIn (p1, y) ∗ Before(y, y′) ∗ PubIn (p2, y′) ∗ Cites(p′, p2) ∗ PubIn(p′, y). It is straightforward to verify that this formula cannot be included in RC-RLR (and consequently in PRA) as p2 (the second logvar of the target atom) is appearing twice in the formula, thus violating the last condition in Definition 3. While restricting the formulae to the ones that correspond to relations chain may speed up learning and reasoning, it reduces the space of features that can be included in a relational learning model, thus potentially decreasing accuracy.
4.2. Non-Binary Atoms
One issue with PRA models is the difficulty in including unary atoms in such models. As an example, suppose in Example 2, we would like to treat conference papers and journal papers differently. For an RLR model, this can be easily done by including Conference(p) or Journal(p) as an extra atom in the formulae. For PRA, however, this cannot be done. The way unary atoms are currently handled in PRA models is through isA and isA−1 relations (Lao et al., 2011). For instance, a path relation may contain paper type, but the only next predicate that can be applied to this path is isA−1 giving the other papers with the same type as the paper in the left of the arrow. However, this is limiting and does not allow for, e.g., treating conference and journal papers differently.
Atoms with more than two logvars are another issue for PRA models because they restrict their models to binary atoms. While any relation with more than two arguments can be converted into several binary atoms, the random walk strategies used for PRA models (and the probabilities for making these random steps) make it unclear how atoms with more than two logvars can be leveraged in PRA models.
4.3. Continuous Atoms
For any subpath x y in a path relation of a PRA model, R typically has a range {0, 1}: for any object X ∈ Δx, this subpath gives the objects in Δy participating in relation R with X. PRA models can be extended to handle some forms of continuous atoms. For instance for the reference recommendation problem, suppose we have an atom Sim (p, p′) indicating a measure of similarity between the titles of two papers. The higher the Sim (p, p′), the more similar the titles of the two papers. A sensible WF for an RLR model predicting Cites (p1, p2) may be Sim (p1, p′) ∗ Cites(p′, p2). To extend PRA models to be able to leverage such continuous atoms, one has to change line 8 in Algorithm 1 to sum the values of Rl(E′, E) instead of counting how many times the relation holds.
For many types of continuous atoms, however, it is not straightforward to extend PRA models to leverage them. As an example, suppose we have an atom Temperature(r, d) showing the temperature of a region in a specific date. It is not clear how a random walk step can be made based on this atom as the temperature can, e.g., be positive or negative.
4.4. Relational Normalization
Normalizing the relations is often ignored in models based on weighted rule learning. For the most part, this ignorance may be because several of these models cannot handle continuous atoms. Given that PRA is a special form of weighted rule learning models such as RLR with RWC normalization, not normalizing the relations may be the reason why in Lao et al.’s (Lao et al., 2011) experiments, PRA outperforms the weighted rule learning method FOIL (Quinlan, 1990) for link prediction in NELL (Carlson et al., 2010).
The type of normalization used in PRA (RWC) may not be the best option in many applications. As an example, suppose for the reference recommendation task we want to find papers similar to the query paper in terms of the words they use. Let Contains−1 (w, p) show the relation for words in each paper. It is well known in information retrieval that words do not have equal importance and a normalization of Contains−1 (w, p) is necessary to take such importance into account. PRA models consider the importance of each word W as Score1(W) =, where f(W) is the number of papers containing the word W (see, e.g., Lao and Cohen (2010b)). However, it has been well known in information retrieval community for several decades, and information theoretically justified more than a decade ago (Robertson, 2004), which Score2(W) = log() provides a better importance score. Most TF-IDF based information retrieval algorithms (Salton and Buckley, 1988) currently rely on Score2. It is straightforward to include the latter score in an RLR model: one only has to multiply the formulae using word information by Score2(W), without normalizing the Contains−1 (w, p) relation [see, e.g., Fatemi (2017)]. However, it is not straightforward how such a score can be incorporated into PRA models as they do not include unary or continuous atoms.
4.5. Evaluating Formulae
Evaluating the formulae in models based on weighted rule learning is known to be expensive, especially for relations with lower sparsities and for longer formulae. In practice, approximations are typically used for scaling the evaluations. Since formulae in RC-RLR correspond to path relations, these formulae can be approximated efficiently using sampling techniques developed within graph random walk community such as fingerprinting (Fogaras et al., 2005; Lao and Cohen, 2010a), weighted particle filtering (Lao and Cohen, 2010a), and low-variance sampling (Lao et al., 2011), without noticeably affecting the accuracy. Extending sampling ideas to other formulae is an interesting future direction.
5. Conclusion
With abundance of relational and graph data, statistical relational learning has gained great amounts of attention. Three main relational learning paradigms have been developed during the past decade and more: weighted rule learning, graph random walk, and tensor factorization. These paradigms have been mostly developed and studied in isolation with few works aiming at understanding the relationship among them or combining them. In this article, we studied the relationship between two relational learning paradigms: weighted rule learning and graph random walk. In particular, we studied the relationship between relational logistic regression (RLR), one of the recent developments in weighted rule learning paradigm, and path ranking algorithm (PRA), one of the most well-known algorithms in graph random walk paradigm. Our main contribution was to prove that PRA models correspond to a subset of RLR models after row-wise count normalization. We discussed the advantages that this proof provides for both paradigms and for statistical relational AI community in general. Our result sheds light on several issues with both paradigms and possible ways to improve them.
Author Contributions
SK did this work under supervision of DP.
Funding
This work is funded by an NSERC discovery grant to DP.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
Bhattacharya, I., and Getoor, L. (2007). Collective entity resolution in relational data. ACM Trans. Knowl. Discov. Data 1, 5. doi: 10.1145/1217299.1217304
Bordes, A., Usunier, N., Garcia-Duran, A., Weston, J., and Yakhnenko, O. (2013). “Translating embeddings for modeling multi-relational data,” in NIPS, Lake Tahoe, 2787–2795.
Carlson, A., Betteridge, J., Kisiel, B., Settles, B. Jr., Hruschka, E. R., and Mitchell, T. M. (2010). “Toward an architecture for never-ending language learning,” in AAAI, Atlanta, Vol. 5, 3.
Das, R., Dhuliawala, S., Zaheer, M., Vilnis, L., Durugkar, I., Krishnamurthy, A., et al. (2017). “Go for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases with Reinforcement Learning,” in NIPS-17 Workshop on Automatic Knowledge-Base Construction, Long Beach.
De Raedt, L., Kersting, K., Natarajan, S., and Poole, D. (2016). Statistical relational artificial intelligence: logic, probability, and computation. Synth. Lect. Artif. Intell. Mach. Learn. 10, 1–189. doi:10.2200/S00692ED1V01Y201601AIM032
De Raedt, L., Kimmig, A., and Toivonen, H. (2007). “Problog: a probabilistic prolog and its application in link discovery,” in IJCAI, Hyderabad, 7.
Domingos, P., Kok, S., Lowd, D., Poon, H., Richardson, M., and Singla, P. (2008). “Markov logic,” in Probabilistic Inductive Logic Programming, eds L. D. Raedt, P. Frasconi, K. Kersting, and S. Muggleton (New York: Springer), 92–117.
Dries, A., Kimmig, A., Davis, J., Belle, V., and De Raedt, L. (2017). “Solving probability problems in natural language,” in IJCAI, Melbourne.
Ebrahimi, J., Dou, D., and Lowd, D. (2016). “Weakly supervised tweet stance classification by relational bootstrapping,” in EMNLP, Austin, 1012–1017.
Fatemi, B. (2017). Finding a Record in a Database. Vancouver: Master’s thesis, University of British Columbia.
Fatemi, B., Kazemi, S. M., and Poole, D. (2016). “A Learning Algorithm for Relational Logistic Regression: Preliminary Results,” in IJCAI-16 Workshop on Statistical Relational AI, New York.
Fogaras, D., Rácz, B., Csalogány, K., and Sarlós, T. (2005). Towards scaling fully personalized pagerank: algorithms, lower bounds, and experiments. Internet Math. 2, 333–358. doi:10.1080/15427951.2005.10129104
Getoor, L., and Taskar, B. (2007). Introduction to Statistical Relational Learning. Cambridge: MIT Press.
Hommersom, A., and Lucas, P. J. (2011). “Generalising the interaction rules in probabilistic logic,” in IJCAI, Barcelona.
Jain, A., and Pantel, P. (2010). “Factrank: random walks on a web of facts,” in Proceedings of the 23rd International Conference on Computational Linguistics, Beijing, 501–509.
Kazemi, S. M., Buchman, D., Kersting, K., Natarajan, S., and Poole, D. (2014). “Relational logistic regression,” in KR, Vienna.
Kazemi, S. M., Fatemi, B., Kim, A., Peng, Z., Tora, M. R., Zeng, X., et al. (2017). “Comparing Aggregators for Relational Probabilistic Models,” in UAI Workshop on Statistical Relational AI, Sydney.
Kazemi, S. M., and Poole, D. (2018). “Relnn: a deep neural model for relational learning,” in AAAI, New Orleans.
Khot, T., Balasubramanian, N., Gribkoff, E., Sabharwal, A., Clark, P., and Etzioni, O. (2015). “Markov Logic Networks for Natural Language Question Answering,” in Empirical Methods in Natural Language Processing, Lisbon.
Kimmig, A., Bach, S., Broecheler, M., Huang, B., and Getoor, L. (2012). “A short introduction to probabilistic soft logic,” in Proceedings of the NIPS Workshop on Probabilistic Programming: Foundations and Applications, Lake Tahoe, 1–4.
Kimmig, A., Mihalkova, L., and Getoor, L. (2015). Lifted graphical models: a survey. Mach. Learn. 99, 1–45. doi:10.1007/s10994-014-5443-2
Lao, N., and Cohen, W. W. (2010a). “Fast query execution for retrieval models based on path-constrained random walks,” in Proceedings of the 16th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (Washington, DC: ACM), 881–888.
Lao, N., and Cohen, W. W. (2010b). Relational retrieval using a combination of path-constrained random walks. Mach. Learn. 81, 53–67. doi:10.1007/s10994-010-5205-8
Lao, N., Mitchell, T., and Cohen, W. W. (2011). “Random walk inference and learning in a large scale knowledge base,” in EMNLP, Edinburgh, UK, 529–539.
Lin, Y., Liu, Z., Luan, H., Sun, M., Rao, S., and Liu, S. (2015). “Modeling Relation Paths for Representation Learning of Knowledge Bases,” Empirical methods in natural language processing, Lisbon.
Nickel, M., Jiang, X., and Tresp, V. (2014). “Reducing the rank in relational factorization models by including observable patterns,” in NIPS, Montreal, 1179–1187.
Nickel, M., Murphy, K., Tresp, V., and Gabrilovich, E. (2016). A review of relational machine learning for knowledge graphs. Proc. IEEE 104, 11–33. doi:10.1109/JPROC.2015.2483592
Nickel, M., Tresp, V., and Kriegel, H.-P. (2012). “Factorizing yago: scalable machine learning for linked data,” in Proceedings of the 21st International Conference on World Wide Web (Inria: ACM), 271–280.
Page, L., Brin, S., Motwani, R., and Winograd, T. (1999). The Pagerank Citation Ranking: Bringing Order to the Web. Technical Report. Stanford: Stanford InfoLab.
Pujara, J., Miao, H., Getoor, L., and Cohen, W. W. (2013). “Knowledge graph identification,” in International Semantic Web Conference (ISWC) (Sydney: Springer).
Pujara, J., and Getoor, L. (2016). “Generic Statistical Relational Entity Resolution in Knowledge Graphs,” in IJCAI-16 Workshop on Statistical Relational AI, New York.
Quinlan, J. R. (1990). Learning logical definitions from relations. Mach. Learn. 5, 239–266. doi:10.1023/A:1022699322624
Riedel, S., Yao, L., McCallum, A., and Marlin, B. M. (2013). “Relation extraction with matrix factorization and universal schemas,” in HLT-NAACL, Atlanta, 74–84.
Robertson, S. (2004). Understanding inverse document frequency: on theoretical arguments for IDF. J. Doc. 60, 503–520. doi:10.1108/00220410410560582
Salton, G., and Buckley, C. (1988). Term-weighting approaches in automatic text retrieval. Info. Process. Manag. 24, 513–523. doi:10.1016/0306-4573(88)90021-0
Singla, P., and Domingos, P. (2006). “Entity resolution with Markov logic,” in Data Mining, 2006. ICDM’06. Sixth International Conference on (Hong Kong: IEEE), 572–582.
Šourek, G., Aschenbrenner, V., Železny, F., and Kuželka, O. (2015). “Lifted relational neural networks,” in Proceedings of the 2015th International Conference on Cognitive Computation: Integrating Neural and Symbolic Approaches-Volume 1583 (Montreal: CEUR-WS.org), 52–60.
Sridhar, D., Foulds, J. R., Huang, B., Getoor, L., and Walker, M. A. (2015). “Joint models of disagreement and stance in online debate,” in ACL, Beijing, Vol. 1, 116–125.
Trouillon, T., Welbl, J., Riedel, S., Gaussier, É, and Bouchard, G. (2016). “Complex embeddings for simple link prediction,” in ICML, New York, 2071–2080.
Keywords: statistical relational artificial intelligence, relational learning, weighted rule learning, graph random walk, relational logistic regression, path ranking algorithm
Citation: Kazemi SM and Poole D (2018) Bridging Weighted Rules and Graph Random Walks for Statistical Relational Models. Front. Robot. AI 5:8. doi: 10.3389/frobt.2018.00008
Received: 17 October 2017; Accepted: 18 January 2018;
Published: 19 February 2018
Edited by:
Sriraam Natarajan, Indiana University System, United StatesReviewed by:
Elena Bellodi, University of Ferrara, ItalyNicola Di Mauro, Università degli studi di Bari Aldo Moro, Italy
Copyright: © 2018 Kazemi and Poole. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Seyed Mehran Kazemi, c21rYXplbWlAY3MudWJjLmNh