 Iman Sharifi
Iman Sharifi Heidar Ali Talebi1
Heidar Ali Talebi1 Rajni R. Patel
Rajni R. Patel Mahdi Tavakoli
Mahdi Tavakoli- 1Electrical Engineering Department, Amirkabir University of Technology, Tehran, Iran
- 2Electrical & Computer Engineering Department, Western University, London, ON, Canada
- 3Electrical & Computer Engineering Department, University of Alberta, Edmonton, AB, Canada
In this paper, a new scheme for multi-lateral remote rehabilitation is proposed. There exist one therapist, one patient, and several trainees, who are participating in the process of telerehabilitation (TR) in this scheme. This kind of strategy helps the therapist to facilitate the neurorehabilitation remotely. Thus, the patients can stay in their homes, resulting in safer and less expensive costs. Meanwhile, several trainees in medical education centers can be trained by participating partially in the rehabilitation process. The trainees participate in a “hands-on” manner; so, they feel like they are rehabilitating the patient directly. For implementing such a scheme, a novel theoretical method is proposed using the power of multi-agent systems (MAS) theory into the multi-lateral teleoperation, based on the self-intelligence in the MAS. In the previous related works, changing the number of participants in the multi-lateral teleoperation tasks required redesigning the controllers; while, in this paper using both of the decentralized control and the self-intelligence of the MAS, avoids the need for redesigning the controller in the proposed structure. Moreover, in this research, uncertainties in the operators' dynamics, as well as time-varying delays in the communication channels, are taken into account. It is shown that the proposed structure has two tuning matrices (L and D) that can be used for different scenarios of multi-lateral teleoperation. By choosing proper tuning matrices, many related works about the multi-lateral teleoperation/telerehabilitation process can be implemented. In the final section of the paper, several scenarios were introduced to achieve “Simultaneous Training and Therapy” in TR and are implemented with the proposed structure. The results confirmed the stability and performance of the proposed framework.
1. Introduction
Telerehabilitation (TR) can be regarded as a telemedicine branch. While this field is considerably new, it is used in developed countries and has expanded rapidly. Patients living in remote areas where conventional rehabilitation services may not be readily available, will benefit from this technology. TR technologies are open to the patient with existing devices, such as laptops or mobile phones. In such methods, video calls, web-based and mobile apps can be used as well (Bostrom et al., 2020). TR typically lowers the costs of both healthcare services and patients compared to conventional inpatient or individual-to-person rehabilitation. Few studies have been conducted on the economic aspects of TR in which the cost of hospitalization in clinics is significantly reduced (Peretti et al., 2017; Schröder et al., 2019). TR is mainly applied to the physiotherapy process, and neural rehabilitation is used to monitor the rehabilitation process of stroke patients (Gal et al., 2015; Mani et al., 2017). The TR process is also performed with neuro-rehabilitative techniques, such as telemonitoring of cardiovascular parameters including oxygen saturation, ECG, and blood pressure for patients with heart disease (Tousignant et al., 2019). These techniques belong to another branch of telemedicine called telemonitoring, which has significantly expanded in recent years (Batalik et al., 2020). TR for regular training sessions can be accomplished several times in the week as oppose to clinical rehabilitation, which is usually done once or twice a week. TR can also be done individually or in groups (Rogante et al., 2015). These groups include a large number of patient, trainees, and therapists (Sharifi et al., 2017). Interactive tools, such as gamification can increase motivation while the training/therapy process is in progress. Also, TR, if done at home, can support more frequent exercises both in terms of numbers in the week and duration length (Peretti et al., 2017). Furthermore, TR can be delivered with haptic-enabled robotic manipulators in which the patient can interact directly with them. Therefore, the TR process can be performed in virtual reality, while the rehabilitation for neurological conditions is done using robots and gamification (Larson et al., 2014). Also, due to the presence of position and force sensors in the haptic-enabled devices, the progress of a patient's treatment can be shown numerically and on a graph (Schröder et al., 2019).
The specific idea of the proposed TR methods in this paper, came to the minds of the authors after frequent presence in physiotherapy clinics, observing the rehabilitation process, observing the training of trainees, and consulting with physiotherapists. For the implementation of the idea, the project was divided into three phases. In the first phase, the controller should be designed to involve several robots in the rehabilitation process, and to study its feasibility on non-homogeneous and conventional manipulators for the teleoperation process. In the second phase, dedicated manipulators will be built for rehabilitation operations, and the results of the first phase will be studied on it. In the third phase, the products of the previous phases will be tested in the clinic and on real patients. This article will cover the first phase of our TR project, and the rest of the phases will be reported in separate articles. So, in this paper, the concept of collaborative teleoperation and its usage in TR will be extended. All the participants in the experiments of this article are students and non-patients. In the continuation of this introduction, the available researches in the teleoperation and, the advances in robotic rehabilitation that have been made in this field, will be discussed.
Recently, teleoperation frameworks have incredibly extended human control capacities in critical or dangerous situations (Ferre et al., 2007). Up until this point, many propelled control schemes have been accounted for teleoperation frameworks (e.g., Nuño et al., 2009, 2011; Chan et al., 2016; Jafari and Spong, 2017) to give some examples, where a large portion of the previously mentioned examinations concern the control of single-master, single-slave setups. Given that numerous viable assignments cannot be finished by only a single robot. For example, conveying a heavy or delicate thing needs more than one manipulators to do more precise tasks. Another vital concern is the method by which to teleoperate various slave robots in a cooperative configuration. Presently, an ever-increasing number of researches have been committed to this field (Mohajerpoor et al., 2013; Zhai and Xia, 2016), which for the most part, incorporates single-master multi-slave and multi-master multi-slave arrangements (Khademian and Hashtrudi-Zaad, 2013; Zhai and Xia, 2016). Moreover, the multilateral cooperative teleoperation framework has quickly risen in numerous conceivable applications that range from industrial assembly tasks to material handling in perilous situations and afterward to TR tasks for neurological lesions.
A stroke and spinal cord injuries are two principal purposes behind neurological lesions. Since 2008, just in the US, adding up to the cost of stroke is 34.3 billion dollars, and in 2016 it was estimated to be 69.1 billion dollars (Writing et al., 2016). In the light of the results of experiments, frequent movement repetition challenges regular physiotherapeutic methods for the motor rehabilitation of the central paretic forearm in the way that early starting of dynamic developments has a superior result than decreasing spasticity in the recovery of patients (French et al., 2016). This means task-oriented repetitive movements have a direct positive effect on muscle strength enhancement and development in neurologically injured patients. Robotics and automation technology are capable of assisting and enhancing rehabilitation by acquiring a high number of moves in repetition (Atashzar et al., 2017).
The traditional physiotherapy has several limitations with respect to the manually-assisted therapy criteria. In traditional physiotherapy, it is complicated to teach a trainee. Also, evaluating the trainee's performance is laborious and time-consuming. Training consistency is tied to therapist experience and performance. Unlike conventional methods, the rehabilitation procedure can be automated by implementing robotic devices, which increases device training sessions and process duration. As mentioned earlier, robotics therapy can be a practical and highly motivational context for virtual reality applications, and therefore treatment can achieve better results (Nef et al., 2016).
There are typically two types of rehabilitation robots, the first is the robots mounted on the end-effector, and the second is the exoskeletons. Exoskeletons have a resemblance to human anatomy and could be actuated by specific methods, whereas robots with end-effectors could be in any configuration. There is some kind of upper-extremity rehabilitation of exoskeleton robots like MAHI Exo-II, ETS-MARS, and CADEN-7 and some form of end-effector like MIT-MANUS and MIME (Krebs et al., 1998; Pehlivan et al., 2012; Niyetkaliyev et al., 2017; Brahmi et al., 2019; McDonald et al., 2020).
A major problem in multi-lateral teleoperation systems occurs when the number of robots involved in the interactions is increased. In this situation, the control design and stability analysis problems may become more challenging. The self-intelligence that exist between multiple agents interacting with each other in a MAS can be a key to solve the mentioned problem.
A multi-agent system consists of agents who can interact with their neighbors while making decisions. The shared information between the agents will help them together achieve the desired objective. The goal could be synchronization, coverage, or consensus (Sharifi et al., 2016; Wang et al., 2017; Wen et al., 2017; Xiang et al., 2017). One of the fundamental goals in multi-agent systems is synchronization, which means an agreement between agents over a target given the network's limitations (Peng et al., 2014; Sun, 2016). Consequently, the concept of remote multi-lateral TR based on MAS synchronization was previously introduced in Sharifi et al. (2016). It has been shown that the issue of bilateral teleoperation can be viewed as a problem of synchronization, in which the MAS synchronizes the operators' forces and positions. Although, the similar concept was defined in Spong and Chopra (2007) and Abdessameud and Tayebi (2011), it was considered that the dynamics of manipulators are Lagrangian without the effects of exerted external force. However, in TR systems, the concept of external force (operator forces) is not ignorable.
Based on these facts, in this paper, a new control scheme based on MAS is developed for several rehabilitation scenarios, that can deal with non-linear uncertain manipulators. Moreover, the scheme has the ability to design a desired hand force for each operator, which helps deal with training and therapy, concurrently. This new methodology is called “simultaneous training and therapy.” Additionally, the concept of decentralized controllers is introduced for multi-lateral teleoperation systems. Through decentralized control, the reliability of the systems increases while the number of communication links decreases (Hou et al., 2009; Hernández-Méndez et al., 2016). Because of the self-intelligence feature in the MAS, the delay does not distribute between agents synergistically (Cao et al., 2013). Furthermore, time- varying delays in communication links are considered in the current work, which allows the implementation of a multi-lateral teleoperation system through the internet or other communication networks (Chopra et al., 2003; Wu et al., 2017). The structure of a dual-user teleoperation system with a shared environment is one of the most popular structure in multi-lateral teleoperation systems in recent years (Khademian and Hashtrudi-Zaad, 2012; Li et al., 2015; Shamaei et al., 2015; Hashemzadeh et al., 2016). The authority sharing structures in those papers can be regarded as a special case of the current research by applying matrices D, L, and P ≥ 0 that are investigated in section 6.
The remainder of the paper is organized as follows. Section 2, presents mathematical preliminaries concerning, the MAS, properties of serial link manipulators and multi-lateral teleoperation systems. Moreover, it introduces correspondence between the MAS, and multi-lateral teleoperation systems. Section 3 presents a new centralized controller for a multi-lateral teleoperation system. Throughout section 5, the controller is strengthened with a passivity-based adaptive control scheme in the presence of uncertainty in both of the environment and the operator. Afterward, in section 5, the decentralized controller based on the intelligence of a multi-agent framework is introduced to solve the problem of time-varying in communication networks while minimizing the number of communication links. Section 6 shows the relevance of the proposed method and the similar existing methods for multi-lateral teleoperation/telerehabilitation, such as “teach and repeat” and “assist as needed” (Staubli et al., 2009; Babaiasl et al., 2016; Luo et al., 2019). Moreover, it proposes novel schemes for multi-lateral remote rehabilitation systems and experimentally investigates them. Finally, section 7 discusses the conclusions and future works.
2. Mathematical Preliminaries
A brief introduction about the terms and expressions used in the proposed structure is presented in this section. The first subsection relates to MAS, and the second subsection explores the serial link manipulators. Afterward, the third subsection presents the terms and equations for multi-lateral teleoperation systems. Lastly, in the fourth subsection, the multi-lateral teleoperation approach based on the MAS is implemented.
2.1. MAS Framework
The theory of graphs is a powerful tool to study MAS and its behaviors. An undirected graph on the vertex set contains and a set of unordered pairs which are called the edges of . Two vertices are called adjacent, if there is a line between them.
Consider a system consisting of N agents. The position of the ith agent is denoted by xi for i = 1, …, N. Considering the N agents as the vertices in , the relationships between the N agents can be explained by a simple and undirected graph .
The weighted adjacency matrix for the graph is denoted such that αij = 0 if there exists no input from the jth agent to ith agent; otherwise, αij ≠ 0.
The degree matrix is a diagonal matrix, where diagonal elements are for i = 1, …, N. Then, the weighted graph's Laplacian matrix is defined as . If there is a path between any two vertices, a directed graph is connected.
Remark 1. The Laplacian L has real eigenvalues for graph , which can be ordered in succession as 0 = λ1(L) ≤ λ2(L) ≤ … ≤ λn(L) ≤ 2dmax. The smallest eigenvalue is always zero, and the second smallest eigenvalue λ2(L) is called the graph's algebraic connectivity (Olfati-Saber et al., 2007).
Remark 2. If there exists a MAS with a connected graph and positive weights, then a vector γ (with positive elements) exists such that it satisfies γTL = 0, where the vector γ is defined as for the N agents scenario (Cao et al., 2013; Zhou et al., 2014).
The latter remark points to a fundamental matter, which is the existence of a connected graph. This principle is instrumental in our proofs of stability as well as experimentations in section 6, for the Laplacian matrix (L).
2.2. Serial Link Manipulator Properties
Some properties of serial link manipulators, which can be found in Sciavicco and Siciliano (2012) are written in this subsection. The robot that interacts with the slave(s) and master(s) in teleoperation systems is regarded as n-DOF serial links with totally revolute joints. The related non-linear dynamics of these robots can be defined as follows.
in which and are inertia matrix, Coriolis/centrifugal matrix, and gravitational vector, respectively. In addition, , and for i = 1, 2, …, N are the joint angle, angular velocities, and angular accelerations of the ith robot (Sharifi et al., 2011).
If the ith robot is interacting directly with the human, then τexti = −τhi (torque applied by the operator of ith robot). If the one is interacting with the environment, then τexti = τei (torque applied by the ith environment). Finally, are control torques for the master and slave robots.
Property 1. For manipulators with totally revolute joints, the Coriolis/centrifugal terms are bounded, and the form of the bounds are as follows
The fact can easily be generalized to the augmented equation that diagonally puts the Ci(qi, x)y matrices for i = 1, …, N together, like the one in (4), that is
in which, , , and is a diagonal matrix and is defined as .
Property 2. The relationship between the Coriolis/centrifugal and the inertia matrix for a serial manipulator is is a skew symmetric matrix; in other words,
Property 3. The inertia matrix M(q) is symmetric positive-definite for a manipulator with revolute joints, and has the following upper and lower bounds:
or equivalently,
where λi denotes the ith eigenvalue of a matrix, and I ∈ Rn×n is the identity matrix.
Furthermore, the derivative of the inverse of a matrix can be calculated as:
Property 4. The dynamics of the manipulator, written in (1) equation, can be parameterized linearly as
in which, the matrix is the regressor matrix including known robot signals, and is the vector of unknown robot parameters (Cheah et al., 2006). τhi is the torque applied by the operator of the ith robot, and is the control torque of the ith robot.
Assumption 1. (Deng, 2014) Based on the passivity assumption of human operators and the environment, there are positive constants κi such that for the ith operator, the passivity relation is
Summing the above equations for i = 1, …, N and rewriting in matrix form we have
where , , and .
2.3. Some Definitions in Multi-Lateral Teleoperation Systems
In the following, some definitions that are useful for the rest of the paper are addressed.
Definition 1. Shared Environment is a virtual collaborative environment that brings together users who are geographically distributed but connected via a network.
Definition 2. Assistive/Resistive Rehabilitation: Assistive Rehabilitation provides an assistant force for the users to complete the target movement. Conversely, Resistive Rehabilitation provides a resistant force against the movement. The proposed system in this paper, can provide the both phases, meaning that it can either help the user's movement in the target direction in assistive phase or constrain the direction of the user's movements, preventing deviations from the target trajectory in the resistive phase (Brewer et al., 2007).
Definition 3. The term Transparency refers to the fact that if the operators feel they are directly interacting with the remote task, the teleoperation system would be completely transparent. Meaning that the operator's position (Xm) can be exerted on the remote task while he/she simultaneously feels the force of the environment (Fs).
Definition 4. The term Hierarchical Teleoperation can be defined as an attempt to handle the problem of cooperative multi-lateral teleoperation systems by decomposing the problem of teleoperation into smaller subproblems and reassembling their solutions into a hierarchical structure. In this structure, the operators located in an upper layer command the weighted average of their forces/positions to the lower layer, and get the desired forces/positions from the operators in the lower layers.
In this structure, the operators (agents) at the master or slave sides may not connect directly together and can get/share the information indirectly from/to other operators via an intermediate operator.
Definition 5. Multi-lateral Teleoperation system is the system in which multiple robots interact with each other to perform a remote task in shared environments. So, these robots can manipulate an object in the shared virtual environment through an intervening tool or directly. In the multi-lateral teleoperation system, the information can flow between all sites. Depending on the number of channels used in the control architecture, this information can include position and/or force information. A multi-lateral teleoperation system comprises multiple robots as haptic interfaces for multiple operators.
Definition 6. The force sensed by the hand of the operator, in the teleoperation process is called Sensed Force in this literature. It is equal to τexti in (1).
2.4. Using MAS Framework for Multi-Lateral Teleoperation
In this subsection, a correspondence (mapping) between the multi-lateral teleoperation systems and MAS will be constituted. Due to this correspondence, the following consideration should be taken.
All the master robots in the teleoperation system are considered as leaders in the MAS, and all the slave robots are assumed as followers. Hence, the structure of cooperative teleoperation can be considered as the leader-follower scheme in the MAS. In addition, the masters' and slaves' positions must track each other. This objective is similar to the convergence of the positions of the agents in the MAS. Moreover, any latency in the communication channels is regarded as delays of the agent to agent connections in the MAS. One property of MAS is the synchronization, meaning that despite the limited connectivity between the neighbors the tracking objective is done if the spanning tree exists (Zuo et al., 2016). Based on this fact, in the proposed method, the tracking of positions in a multi-lateral teleoperation system is shown to be possible as long as the spanning tree still exists, even if some connections in the network are broken.
A graph of multi-agent system with network topology is considered. In this topology, if the agent i cannot receive any information from agent j, then αij in the adjacency matrix will be chosen as zeros; otherwise, it will be a positive scalar related to the connection weight. The index of αij shows the value of connection weight from the jth agent to the ith agent. Theses values can be regarded as the “performance” or “interference” index in the related studies like Rohrer et al. (2002).
In this study, the position error for the ith agents is defined as , and the torque effort for ith manipulator should contain the following terms as a function of position error:
where is a weight scalar. In section 3 it will be shown that the use of (3) as part of the control effort, helps to make the multilateral teleoperation system transparent.
Remark 3. The term Centralized Controller refers to the original multi-variable controller, which is located in the main computer (consisting of the interacting local controllers), while the term Decentralized Controller refers to a set of controllers inside each individual operator, which can communicate with each other with a reduced number of interconnection links. Consequently, using decentralized controllers may help the stability and connectivity of the system even if some certain commutation links in the system are lost. Moreover, in the decentralized controller scheme, each part (agent) has its own local controller that helps the system's reliability.
3. Multi-Lateral Teleoperation Based on Centralized Controller
For a multi-lateral teleoperation system, a new centralized controller based on centralized MAS is introduced in this section. So, this section is a reference for the next section about the MAS-based decentralized controllers.
Consider the non-linear dynamic equation given as (1) for the n-DOF manipulator robots. The N robots (agents) equation can be augmented together, based on the following definitions,
in which
Property 5. It is easy to show that Property 2 can be generalized to the augmented dynamics of the operators in (4). The augmented version of Property 2 is
Remark 4. Consider the matrix and the following equation:
So, the following equation can directly be shown, based on the Kronecker product properties:
It is also straightforward to show that if a positive definite P is chosen, then will be positive definite, too.
The controller's augmented position error is described as:
where ei(t) is
which is the position errors for the ith agent and its neighbors.
The controller is designed as
in which is defined as (3). The augmented form of and τci(t) is as follows:
where Γ is the positive-definite damping factor of the system and is a positive definite matrix which can be chosen as
The idea of the centralized controller is depicted in Figure 1. Accordingly, the closed-loop equation of the system would results as follows
In the following part, the first result of the suggested controller is presented as a theorem.
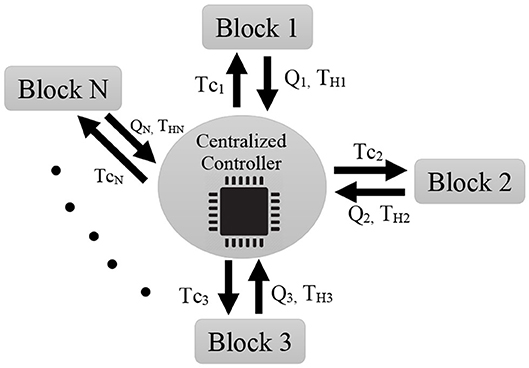
Figure 1. Centralized controller. Each block sends its position and sensed force to the central controller. The central controller calculates the control torque using (8) and sends its associated part to each individual block (i.e., {TC1, …, TCN}). As a drawback of the centralized controller, it is clear that if the centralized controller is damaged, the whole system will fail.
Theorem 1. If the augmented controller (8) is exerted on the multi-lateral teleoperation system (4), and considering the assumption 1, then the vectors of augmented joint velocity and acceleration , and the augmented joint position error will remain bounded for αij ≥ 0.
Proof. Consider the Lyapunov candidate as the following scalar functionals:
So, by summing up Vis we have
Subsequently,
Using (8) and (9) results in
Thus, the positive scalar V(t) in (11) is non-increasing for any αij ≥ 0; it satisfies the boundedness of and .
Using Equation (14), and property 1 and 3, it is easy to show that is bounded, too, which completes the proof. □
Remark 5. It is easy to see from (10) that, at the steady-state , the sensed force is as follows:
The above-mentioned fact is utilized in section 6.
Corollary 1. In the multi-lateral teleoperation system with the same conditions as in Theorem 1 and working in free motion, i.e., τhi(t) = 0 for i = 1, …, N (or equivalently ), and the other assumptions as in Theorem 1, the absolute values of the position errors (|ei(t)|) and the joint velocities () asymptotically converge to zero.
Proof. Integrating (12), and noting that in relation (11), results in
Therefore, . So, , which yields in . Furthermore, with a lower-bounded decreasing function , it is concluded that
And on the other side,
So, from (16), it is obvious that , which yields in . Up to now, it was shown that , and for all i ∈ {1, …, N}. Accordingly, using the Barbalat's lemma, . Hence, from (6), ei(t) converge to zero, asymptotically.
On the other hand, from (16) Equation (17) is concluded as follows:
Based on the properties I and III, is bounded. Therefore, it can be concluded that (17) is bounded or equivalently . So, . Therefore, is continuous in time. Hence, using Barbalet's lemma, .
Accordingly, from (10), . Consequently, the operators' sensed forces asymptotically converge to zero. □
Remark 6. In Theorem 1 and Corollary 1, it was shown that by certain control efforts, the position errors could be reduced. On the other hand, by Remark 5 the hands' sensed force of the operators can be adjusted in the steady-state. So, the transparency of the system defined in Definition 3 can be achieved.
4. Uncertain Dynamics in the Environment and the Manipulators
Uncertainty in the dynamics of the manipulators is discussed in this section. Consider the augmented dynamics of the manipulators as before mentioned:
The controller is now defined as
while is defined as
The adaptation law is regarded as
in which Ω is positive definite matrix. We can re-write the controller (19) as
The symbol ± means that is added and subtracted to and from the equation. Subsequently, using the controller (19), we can re-arrange the closed-loop dynamics of the system (18) as
yielding
Therefore, the parameter is chosen based on (22) as
is inherently a low-pass filter. So, this filter can be considered as follows
meaning that
Assumption 2. The human operators' hand force follows the below equation
in which is as defined in (24) and
Moreover, it is assumed that every element of κ0 and κ1 are bounded. Furthermore, note that κ0(t) can be argued as a pure muscular force of the operators' hand, which is obviously bounded.
Theorem 2. By Assumption 2 on the operators hand force, in the multi-lateral teleoperation system with the uncertain augmented dynamics (18), and the controllers (19), (21), (23), and (25) with damping coefficient Γ as a positive-definite matrix and αij ≥ 0, the augmented joint position error will ultimately remain bounded.
Proof. Consider the following Lyapunov functionals
The summation of Vis are as
Then, we have
Using (24) inside V4(t), we have,
So, the result of would be as follows,
by using Assumption 2, the result can be written as
Using the fact that Ξ = K + κ1 is positive definite and symmetric,
So,
is positive semi-definite, therefore
On the other hand, if we choose Ω as follows
then, outside the closed set Ω, is negative or zero. Therefore, , , and are UUB.
Considering the closed-loop dynamic (22), the fact , , and , and it is concluded that . Moreover, from (24) it is concluded that
So, using the fact that , it is easy to show that , which completes the proof. □
Remark 7. Non-Passive Operators: If Assumption 2 holds and if the parameters κ0 or κ1 are negative; in other words, the operators are not passive, then the system is stable if K + κ1 still remain positive. According to non-passivity of the operators, the value of κ0(t) and κ1 may be negative (Chopra et al., 2008).
Assumption 3. Pre-filtered passivity: A condition can be defined on the passivity filter as follows
This condition is similar to assumption 1, however, the velocity signal is replaced with the pre-filtered passivity of the velocity signal as depicted in Figure 2 (Sharifi et al., 2017).
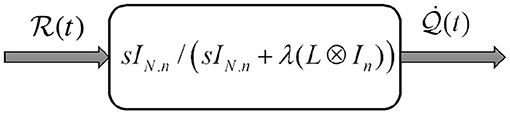
Figure 2. Pre-filtered passivity. This figure shows a multi-variable filter made of the passive filter. The division sign (forward slash) means that the left matrix is multiplied by the inverse of the right matrix.
Theorem 3. Assuming that the operators and the environment are pre-filtered passive as defined in assumption 3, in the multi-lateral teleoperation system with the uncertain augmented dynamics (18), and the controllers (19), (23), and (25), beside adaptation law (21), the augmented joint position error goes to zero asymptotically.
Proof. Consider the following Lyapunov functionals as in (26) in addition to V4(t) defined in the following
The Lyapunov function can be achieved by adding Vi(t) where i ∈ 1, .., 4 as (30)
Moreover,
thus,
Consequently, , , and . So, from (23), . Considering and integrating (32), we have
Therefore,
Given 0 ≤ λmin(K) I ≤ K and 0 ≤ λmin(Υ) I ≤ Υ, it can be concluded that
Thus, and ∈ L2. Therefore, based on Barbalat's Lemma, the parameter converge to zero asymptotically. □
5. Decentralized Controller for Uncertain Systems in Presence of Varying Time Delay
In this section, the intelligence of each agent in the MAS is utilized in the concept of multi-lateral teleoperation systems, which were introduced in previous sections. Each operator works as an agent in MAS, and the local controller on each operator helps to synchronize positions and forces in the overall network based on Definition 3. These local controllers help to minimize the connection links, while minimizing the defective effects of varying time delays. There is no need to have a full connection between operators to set the multi-lateral teleoperation system (Figure 3). The only thing to have full control over the system is to have a spanning tree in the graph of the system (Su and Lin, 2016).
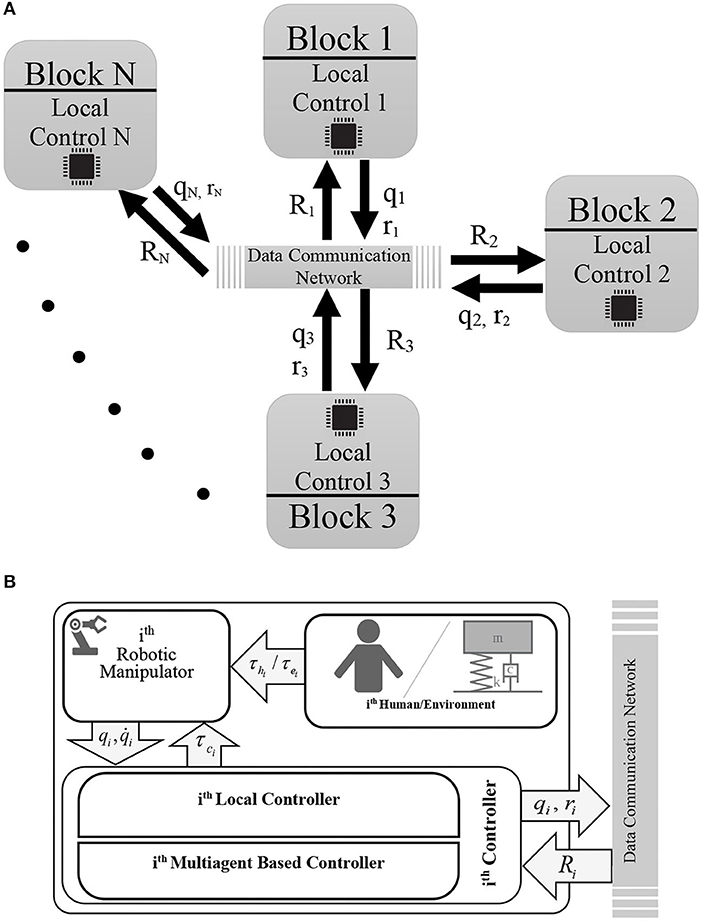
Figure 3. Diagram of the proposed method for decentralized controller. Part (A) shows the general overview of the decentralized controller. Part (B) depicts the inside of each block of the part (A). In this diagram, the schematic of the local controller (35) is depicted. This controller consists of a local controller plus the multiagent based controller (37). To implement the latter one, the vector Ri is received from the adjacent agents of the ith manipulator, containing their intermediate variables rj (). On the other hand, the information about the ith position (qi) and the ith intermediate variable (ri) related to the ith robot itself, are shared with the neighbors via the data communication network.
Moreover, it is shown in the rest part of this section that the proposed local controller can overcome uncertainty in the environment and the operator, while having time communication delays.
Assumption 4. The delays which exist between the communication links of the operators, can be arbitrary and unknown, while its derivative should be bounded with a known upper-bound ψ of , i.e.,
Because of the causality of the delay, the derivative of the delay is considered to be less than unity, i.e., ψ ≤ 1.
The non-linear uncertain dynamics of the ith operator are as follows,
Note that, the parameters are functions of time; however, for the sake of simplicity, the time parameter (t) is not written. In this part, because of time delays, the simple form of the augmented system (4) is not usable. So, the equation of each agent is written separately and integrated together. Moreover, the control law is chosen as
in which
Note that . Furthermore, is chosen as
in which rj(t − τji(t)) is received from the jth operator and γi is the ith element of the vector γ, which is the left eigen-vector of the Laplacian matrix according to zero eigenvalue of Laplacian matrix (see Remark 2).
So, the controller is consisted of two parts, the local controller [] and the multiagent part (). In addition ri(t) and υi(t) are intermediate variables and are defined as and υi(t) = −λei(t). Hence,
consequently, (38) is a passive filter, containing the encoded data about the force/position errors. So, the closed loop system becomes
or, equivalently:
Furthermore, the adaptation law is considered as follows,
in which, Ωi is a positive definite matrix.
Theorem 4. Consider a group of multi-lateral teleoperation systems, consisting of N manipulators with n degrees of freedom, with dynamical Equation (34), and control inputs (35), (37), and (41) with assumptions (33) and (36), then the synchronization error converges to zero asymptotically.
Proof. Choosing the following Lyapunov candidate
the derivative is
Equivalently, using (40) we have
It should be noted that,
knowing that based on assumption 4, the upper-bound of is ψ.
Now, by adding and subtracting the term,
in inequality (43), the following inequality is obtained
Three notes are to be considered. First, the self delays of operators are negligible, i.e., τii ≃ 0. The second factor is that using Remark 2, and is equal to zero.
Substituting (44) in (42) and using the constraint (36), the Lyapunov derivative becomes:
Therefore, based on Lyapunov theory, ri(t) asymptotically converge to zero, which completes the proof. □
6. Novel Design for Simultaneous Training and Therapy in Telerehabilitation Tasks
The main idea that led to the concept of “Simultaneous Training and Therapy,” came to the minds of the authors of this article after several attending the clinics and closely observing the trainees and the rehabilitating patients in the field. The main problem was the presence of a large number of trainees and their short training time. Therefore, the use of manipulators in the TR process for trainees, patients, and therapists can significantly reduce the cost of patients attending the clinic and the cost of one-to-one teaching for trainees as well as its duration time.
Consequently, this is the most important section, and in fact the practical conclusion of this article, because it implements the main idea of the authors. To show the effectiveness of the proposed method in this article, various examples in the field of rehabilitation will be given along with practical experiments.
Therefore, to show the effectiveness of the proposed method in the sections 4 and 5, utilizing the power of theoretical parts achieved, some novel designs in the simultaneous training and therapy for TR systems are proposed. Two tuning matrices L and D as Laplacian and Sensed Force, are used to implement such schemes. For Laplacian matrix L, it is enough to be connected, as mentioned in Remark 2. The tuning matrix D has a decisive role in the TR scenarios.
Based on the controllers in Theorems 1–3, we have the freedom to design multiple scenarios for the TR tasks. The primary item in this structure that gives the freedom, is the matrix D, which can be used in designing the remote rehabilitation structure. It has been shown that the controller guarantees the position synchronization. As described in Remark 5, by selecting a suitable matrix D, we can design the desired Sensed Forces at a steady-state as the following:
the desired force is achieved, which is a function of operator position errors. Thus, the equation D = LTPL should be solved by choosing a proper positive (semi-)definite matrix P. However, it is already known from Remark 1, the Laplacian matrix is singular by its nature. Therefore, the following remark is to be noted.
Remark 8. Applying the Theorems 1–3, to ensure the stability of the system, the matrix P should be positive semi-definite. As stated in Remark 1, all of eigen-values associated to L are positive or zero. So, L is a positive semi-definite (Golub and Van Loan, 1996). Adding a small positive value to zero eigenvalue(s) of L retains the Laplacian matrix being positive definite. In addition, the desired force matrix (D) is chosen as a positive definite matrix. Therefore, would be positive semi-definite. The algorithm is depicted in Figure 4.

Figure 4. The steps to calculate the Positive semi-definite matrix P.
Up to now, the centralized and decentralized controllers were proposed that can accommodate various multi-lateral TR for several users, including patient, trainees, and therapist interaction using a multi-DOF tele-robotic system. The authority sharing structure in related papers like in Khademian and Hashtrudi-Zaad (2012), Li et al. (2015), and Hashemzadeh et al. (2016) can be regarded as a particular case of the current research by applying matrices D, L, and P ≥ 0. For example, the one proposed in Hashemzadeh et al. (2016) can be implemented in the structure of this paper by considering
The above equation directly points to Equation (5) of Hashemzadeh et al. (2016); so, the remark 2 is satisfied. To achieve Equations (6)–(8) of the mentioned paper, it is easy to consider D as follows
Therefore, considering the algorithm in Figure 4, the matrix P will be calculated as follows:
It is obvious that the matrix P is positive semi-definite. So, it can be used in the Lyapunov function (26). Furthermore, by considering exactly the same L as in (46), for Equations (10)–(12) of Khademian and Hashtrudi-Zaad (2012) and considering the following D for Equations (13)–(15) of the mentioned paper, the system can be implemented easily.
Thus, considering the algorithm in Figure 4, the matrix P will be calculated as follows:
It is easy to verify that the leading principal minors of P are all positive, guaranteeing that the matrix P is positive definite in this example. More comparisons with similar existing frameworks are illustrated in Figure 5 at the end of the paper.
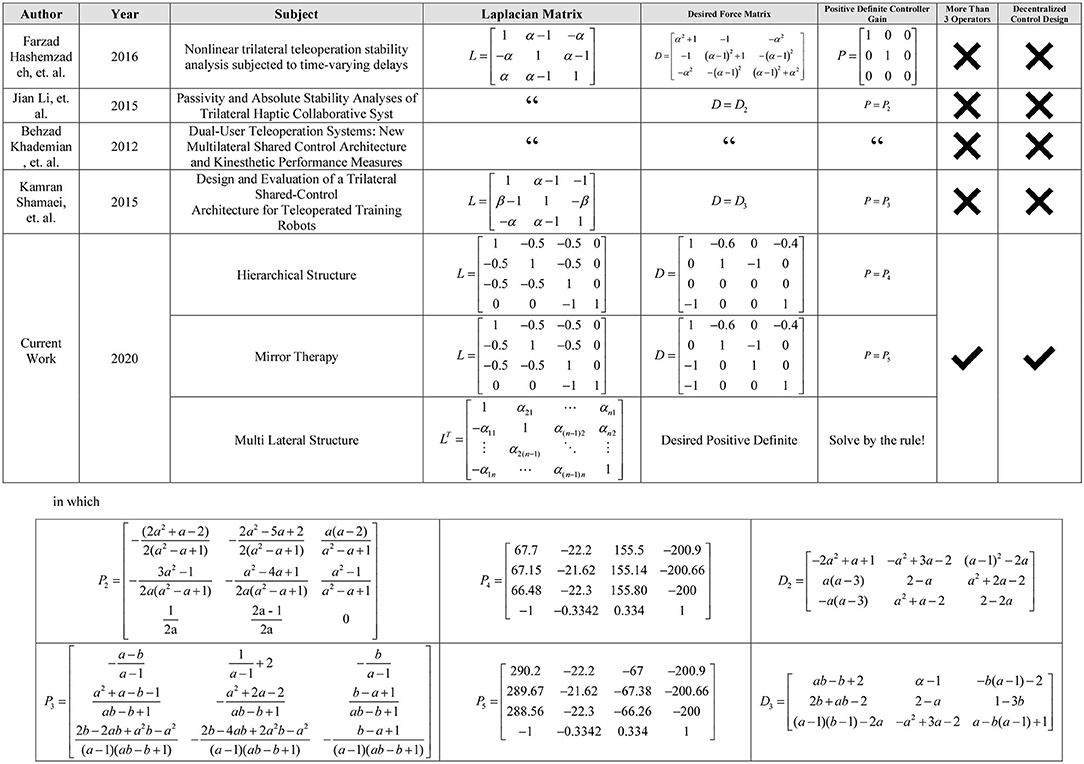
Figure 5. Table of comparison of similar works.
In addition, to implement the structure of the proposed method, the shared environment is used for all the experiments in this section. To implement the shared environment, the model of virtual manipulator, and impedance of the environment, a software called Unity3D© is used. Furthermore, the controller is implemented in Simulink Desktop Real-TimeTM (Sahin et al., 2017), and it is connected to Unity3D© via the UDP protocol. The delays considered in the system for all of the experimentation are as in (45), which obviously satisfies Assumption 4. The participants in all of the experimentation are healthy people emulating the behavior of the therapist, patient, and trainees inside the virtual environment1. The proposed structure will be examined in the succeeding subsections for some novel rehabilitation scenarios.
6.1. Design and Control of Hierarchical Telerehabilitation Systems
The idea of the Hierarchical Telerehabilitation System (HTS) is similar to the idea of driving instruction in driving school. In the training cars, a dual pedal is placed under the instructor's feet, and the instructor can override the trainee's pedals, meaning that a hierarchy exists between the instructor and the trainee (Figure 6). The trainee cannot affect the pedal of the instructor, while the instructor can depress his/her pedal and override the trainee's pedal. This idea has been used for the HTS. However, in the HTS, three users participate in the process instead of two users, i.e., therapist, trainee, and patient. In this hierarchy, the therapist has the highest rank, and the patient has the lowest rank. So, the therapist can override the movements of the trainee and the patient. And, the trainee can override the movements of the patient.
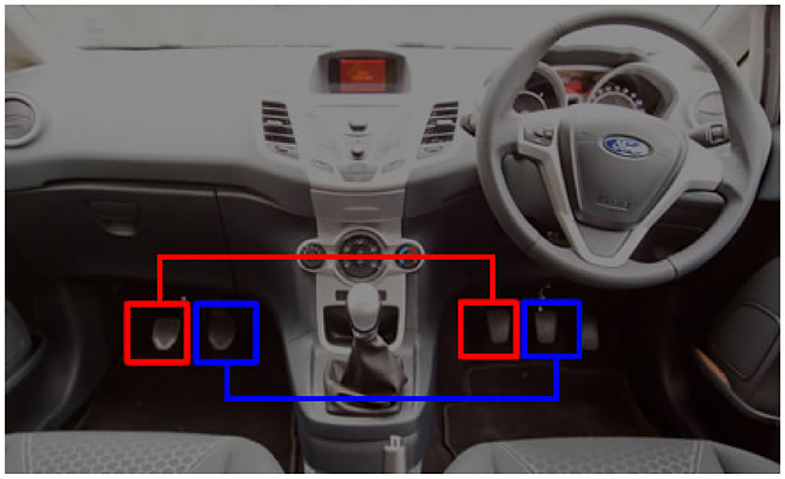
Figure 6. There are pedals under the feet of the trainee and the instructor in driving school. However, if the instructor wishes, he/she can depress each pedal even though the instructor has not depressed it. So, there exist a hierarchy between the instructor and the trainee.
On the other hand, the virtual environment interacts with the patient and put him/her in a predetermined path. So, the virtual environment can play a decisive role in this process. Many conventional rehabilitation therapies can be implemented using the HTS. Two of them are “teach and repeat therapy” and “assist as need therapy.” For teach and repeat therapy, the virtual environment can be trained by an expert therapist's hand movements (record the movement task) in periodic tasks, e.g., moving on a circle or square. After the therapist leaves the process, the virtual environment repeats the therapist's hand movements. The virtual environment can also play the role of “assist as need therapy” (Staubli et al., 2009). It means that if the patient's movement is in the desired path, no extra force is exerted to the patient's hand. However, if the patient's movement error exceeds a specified limit, the virtual environment assists the patient's hand return to the desired path. This can be implemented easily by choosing the appropriate functions for matrix D.
To show the performance of the HTS, a practical scenario is proposed. Three operators consisting of a therapist (operator 3), a student/trainee (operator 2), and a patient (operator 1) are considered. These operators are working in a shared virtual environment (operator 4). In this experiment, operator 1 has the highest rank while the operator 4 has the lowest rank. Additionally, the robots considered for these experiments are non-homogeneous, including one Phantom Omni® and two Novint Falcons®, interacting with the Therapist, Trainee, and the Patient, respectively (Figure 7). The experimental parts are described in the Appendix. The desired matrix of the sensed force and the Laplacian matrix are selected for position synchronization as follows
By looking at Laplacian matrix L it is easy to verify that the Remark 2 is satisfied. The third row of matrix D is totally zero, showing that the therapist's desired sensed force is not affected by other operators. The results of the experiments are shown in Figure 8. As depicted in the figures in the first phase, the positions of both the trainee and the patient follow the position of the therapist, and the system assists both of them for moving. In the second phase, the therapist stops moving and the trainee goes to the resistive phase, while the patient is still in the assistive mode. So, the trainee should enforce a larger amount of effort to move in the direction. In the third phase, both the therapist and the trainee stop moving, and the patient is asked to move. Therefore, the patient goes to the resistive mode and the amount of the patient's force becomes larger. So, both assistive and resistive scenarios can be implemented in this method.

Figure 7. Implementation of the HTS. In part (A), the overview of three non-homogeneous robots, two of which are Novint Falcon© and one Phantom©, is shown. The X and Y coordinate frames, which represent two-dimensional motion, are assigned to them in part (B).
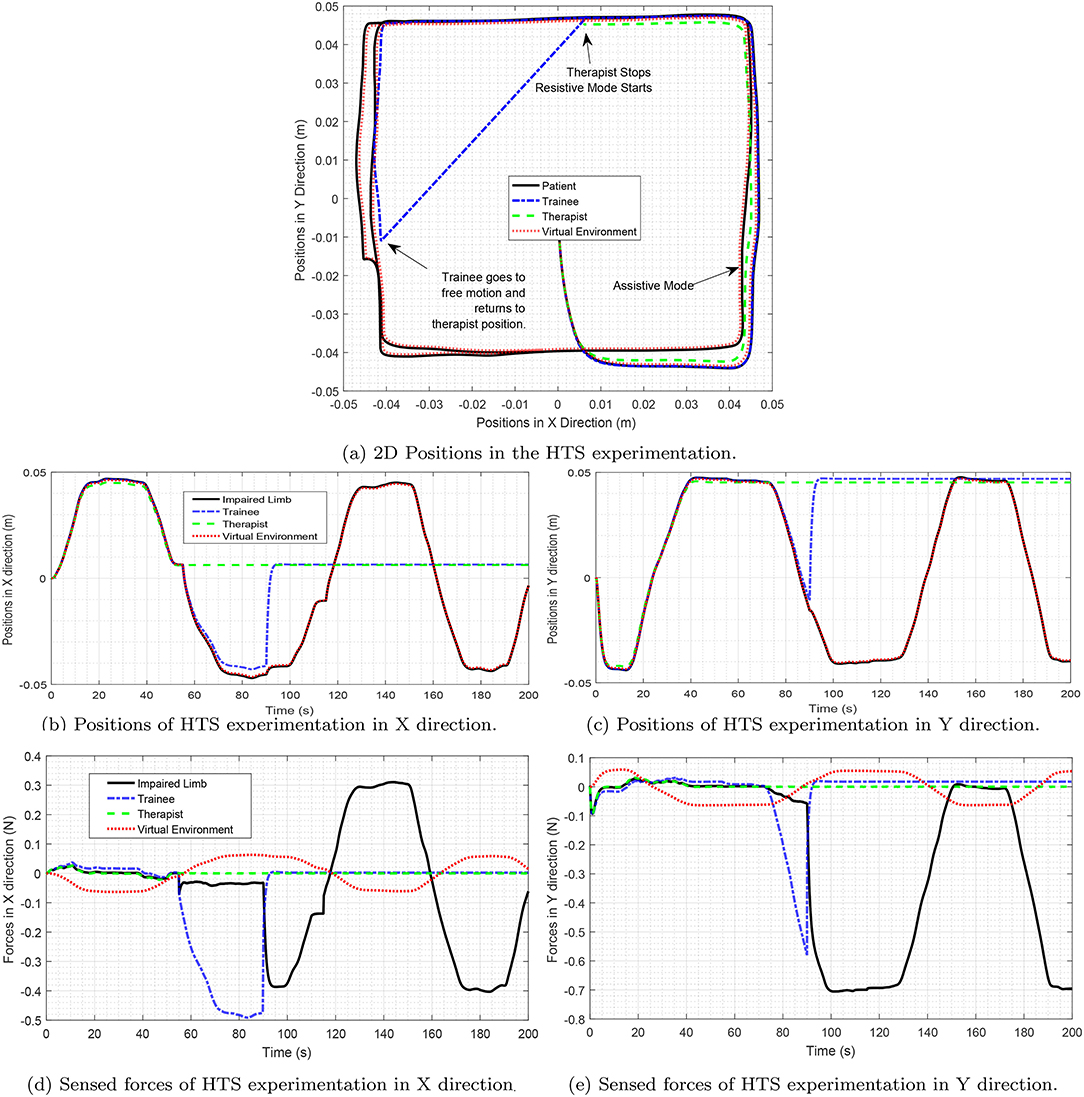
Figure 8. Forces in hierarchical therapy. This figure illustrates three phases of therapy. In the first phase, all the operators participate in the TR process. So, the therapist assists all of them to move in the correct path. In the second phase, when the therapist stops moving, the trainee's force is of larger magnitude. Moreover, in the third phase, the patient's force increases. The phase stage, is resistive for the trainee, that helps them to learn the process of rehabilitation. The third phase, is resistive for the patient trainee.
6.2. Teach and Repeat Therapies
The virtual environment proposed in this project has the ability to store the therapist's hand movements and then replay it for the rehabilitation process (Babaiasl et al., 2016). Therefore, the virtual environment can play the role of “teach and repeat.” In the experiment performed as the teach and repeat role, a square path of the therapist's hand movements in section 6.1 is stored and then replayed in the rehabilitation process. Moreover, as can be seen from Figure 9, the teach and repeat therapy, was performed in the first 60 s of this experiment. Due to the capability of this method, there would be freedom for the therapist to put the process in teach and repeat mode and observe the process without his/her intervention.
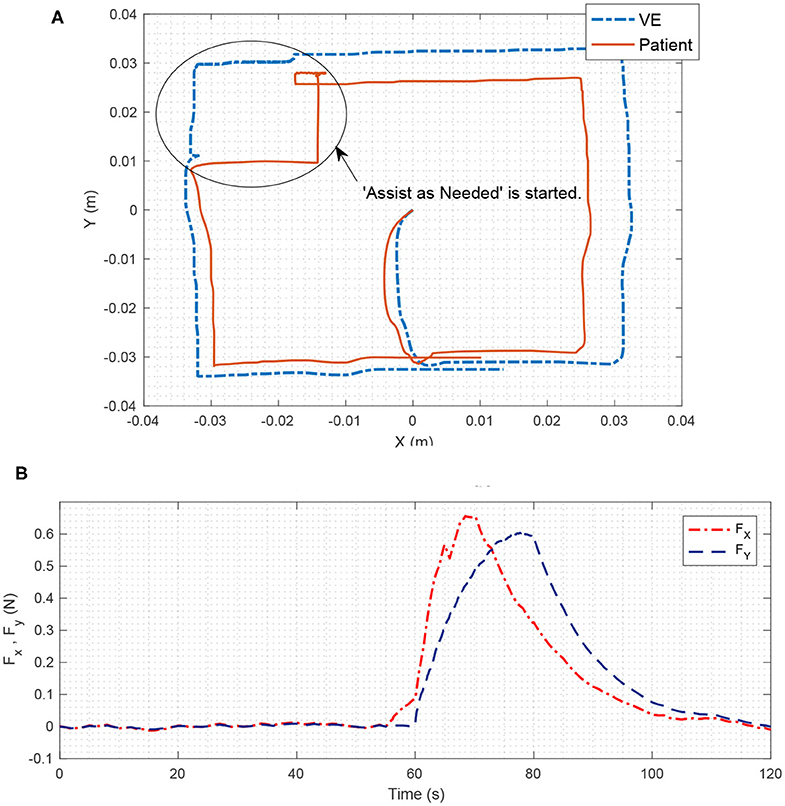
Figure 9. (A) The 2D position of “Assist as Needed” is shown. (B) Assistive force in X and Y direction is illustrated. In the first 60 s of the therapy, teach and repeat method is applied. The path is recorded in the VE and is replied to the patient. The patient moves freely in the specified path, which is a square here. The VE also moves on the square. If the patient's movement error is greater than the specified limit, Assist as Needed force is activated and attempts to return the patient's robot position to the original square path with assistive force. As can be seen in part (B) the assistive force is almost zero before the 60th second; however, from about 60th second, it is activated in the X and Y directions and tries to return the patient to the desired path. Note that, in this figure, the absolute values of the assistive forces are shown to the reader for better understanding.
6.3. Assist as Needed
During the replay discussed in the experiment of section 6.2, the patient follows a square path, and if he/she deviates from the specified path, the assistive force returns the patient's hand to the square path, which is “Assist as Needed” therapy (Luo et al., 2019). To implement such therapy with our proposed method, consider a case study with similar participants as section 6.1. Then, the following switching criteria for matrix D is chosen.
If the tracking error (e) is less than the allowable limit (ρ), the matrix D is set to 04×4. Conversely, if the tracking error is greater than the specified limit, the first line of matrix D, which is related to the patient's hand, would changes as [], meaning that the virtual environment tries to return it to the main path. The other zero rows, mean that other operators move freely without getting any force feedback.
As can be seen in Figure 9, in the 60th second, the patient is out of the marked square path (e > ρ), and the assistive force returns the patient's hand to the main path. When the patient returns to the square path, the assistive force will gradually vanish from the rehabilitation process.
6.4. Supervised Mirror Therapy
In this part, the scenario of Supervised Mirror Therapy (SMT) is implemented. In SMT, the patient attempts bi-manual symmetric movements as moving in the mirror trajectory. Meanwhile, the (remote) therapist helps the patient to move his hand in a desired trajectory. The manipulators keep the limbs in symmetry that helps the affected limb to rehabilitate. For the sake of synchronization in this SMT, the desired sensed force matrix D and the Laplacian matrix L are selected as follows:
By looking at Laplacian matrix L it is easy to verify that the Remark 2 is satisfied. The only difference between (47) and (49) is the third row of the matrix D, meaning that the therapist's sensed force is a function of the patient's position (see Figure 10). So, the concept of unilateral teleoperation is changed to multi-lateral teleoperation, because the desired force forms a closed-loop structure. The varying delays in the channels are considered as (45), and remaining delays in the channels are selected as (50).

Figure 10. Desired graphs, considered for the proposed system in sections 6.1 and 6.4. This diagram is equivalent to the D matrices in (47) and (49) in which, the circles represent the role of each user. Next to the diagram, meaning of the numbers inside each circle is written. Moreover, on the arrows in the diagram, numbers are written that are equal to the numbers expressed in the rows of the D matrices of (47) and (49). Part (A) shows the force graph of HTS. It is the graph of matrix D in (47). Part (B) depicts the force graph of the proposed SMT. It is the graph of matrix D in (49).
The results of the experiments and the 2D plots of positions of the operators are depicted in Figure 11. It is demonstrated that the hands of the patient are aligned with the positions of the hand of the therapist. At the steady-state, the operator forces are such that the summation of the forces will be zero.
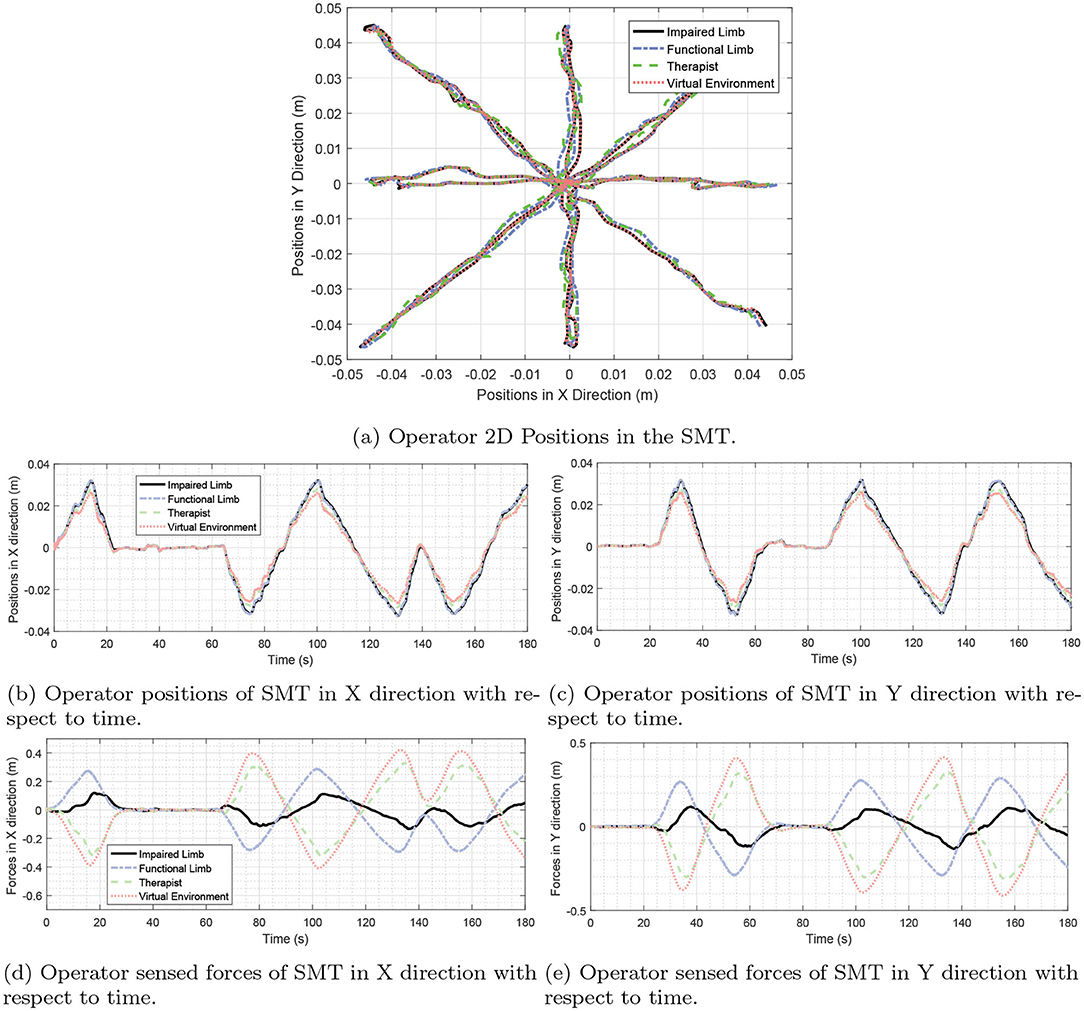
Figure 11. SMT experimentation. Participants in this TR process include a therapist, a functional hand, and impaired hand. Also, the virtual environment as the last operator in this process cooperates with other operators. As shown in the figure, there is a star path for users to move. Part (a) Shows the movement of the operators in two dimensions and part (b,c) show the movement of the operators in the X and Y dimensions separately. Sections (d,e) also show the force of the operators in the x and y directions. As can be seen, according to Equation (51), the sum of the forces in each case will be close to zero.
The above equation is easily verifiable through (15) and (49). This is reflected in Figures 11D,E.
6.5. Several Trainees in Telerehabilitation Process
In this part, the scenario called Several Trainees in Telerehabilitation Process (STTRP) is introduced. The idea of STTRP is based on the fact that, while the patient is undergoing the process of stroke recovery, several numbers of the trainees can learn the required skills via robots without interrupting the interaction of the patient and the expert therapist. The proposed system forces the trainee's position to track the desired position and sense the desired force of the system. The numbers of trainees may vary from 0 to any number. By choosing the correct matrix D, the trainees sense exactly what the expert therapist wants to teach them without interfering in the rehabilitation process. By advancing the process of therapy, one or more trainees can participate more efficiently in the process. The scenario for this experiment is tracking a circular path in 2-D space. All the operators move in the same direction, and the positions are almost a circle. The experimental results are depicted in Figure 12 which shows the impaired limb (black route) will finally move neatly on the circular path after some iterations. So, the experiment confirms the stability and synchronization of operators.
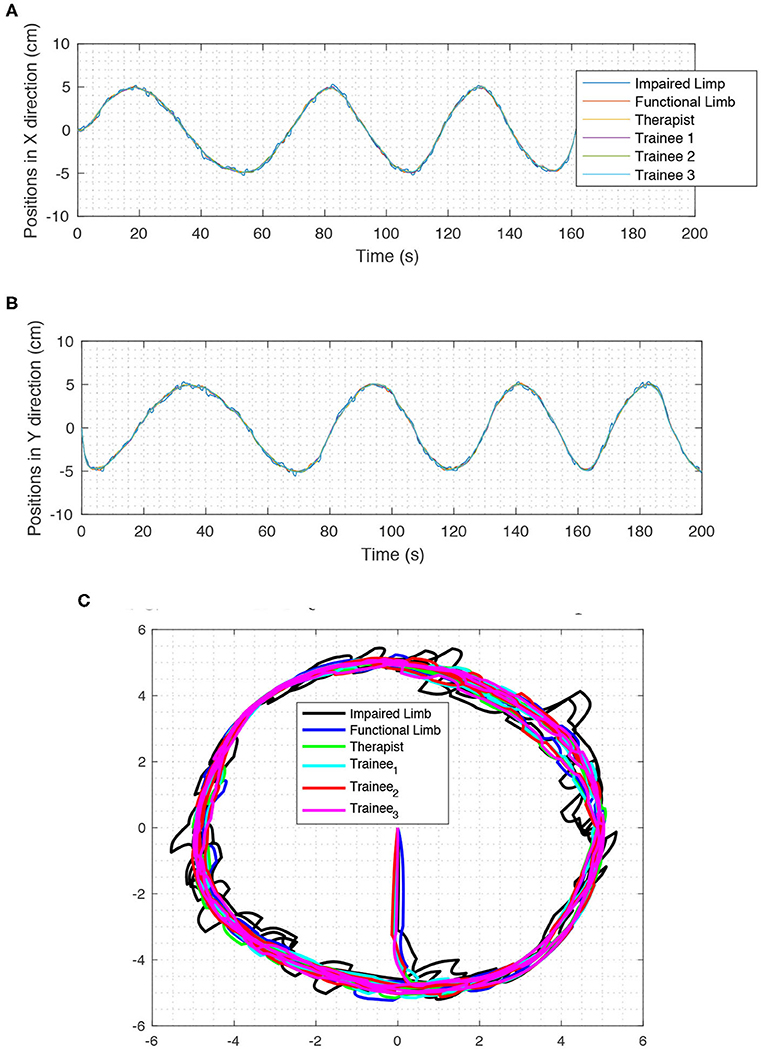
Figure 12. The positions in STTRP. In this process, six operators participate in TR, simultaneously. impaired hand, functional hand, Therapist, and trainee #1, participate in the force interaction of TR process, and neither of these four operators is superior to the other. Operator #2 and #3 do not participate in the force interaction. (A) Positions in X direction in STTRP experiment. (B) Positions in Y direction in STTRP experiment. (C) Positions in 2D space in STTRP experiment (XY Direction).
7. Conclusion
In this paper, the problem of multi-lateral TR with non-linear and uncertain dynamics was addressed. To deal with the theoretical parts of such systems, a novel structure based on the MAS was presented. This structure could solve the complexity of multi-lateral rehabilitation system due to several numbers of operators in the process. The key factor in the MAS is the self-intelligence between the agents that shows the consciousness of each agent about the other ones. Moreover, uncertainties in the operators' dynamics, as well as time-varying delays in the communication channels, were addressed by using the power of the MAS and passivity based adaptive controls. Furthermore, this paper introduced a framework for simultaneous training and therapy in multi-lateral TR systems. The method can be used in medical education centers. It could help the trainee to be involved in a “hands-on” manner during the rehabilitation process by an expert therapist. So, they were introduced and tested particularly with the tuning parameters L (Laplacian Matrix) and D (Sensed Force Matrix) that verified the reliability and performance of the proposed framework. All the experimentation were accomplished with the volunteer students in the “Telerobotic and Biorobotic Systems Lab.” Because of acceptable results, in the near future, the experimentation will be implemented in clinical centers and on real patients.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation, to any qualified researcher.
Ethics Statement
The studies involving human participants were reviewed and approved by All subjects provided informed consent to the experimental procedures, which were reviewed and approved by the University of Alberta Research Ethics Board (Study ID: Pro00033955). The patients/participants provided their written informed consent to participate in this study.
Author Contributions
IS conceived of the presented idea and developed the theory and performed the computations. HT and MT verified the analytical methods. RP encouraged HT and MT to investigate experimental scenarios and supervised the findings of this work. IS, HT, and MT carried out the experiment. IS wrote the manuscript with support from MT, HT, and RP. All authors discussed the results and contributed to the final manuscript.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1. ^ All subjects provided informed consent to the experimental procedures, which were reviewed and approved by the University of Alberta Research Ethics Board (Study ID: Pro00033955).
References
Abdessameud, A., and Tayebi, A. (2011). Synchronization of networked lagrangian systems with input constraints. IFAC Proc. Vol. 44, 2382–2387. doi: 10.3182/20110828-6-IT-1002.01272
Atashzar, S. F., Shahbazi, M., Tavakoli, M., and Patel, R. (2017). A grasp-based passivity signature for haptics-enabled human-robot interaction: application to design of a new safety mechanism for robotic rehabilitation. Int. J. Robot. Res. 36, 778–799. doi: 10.1177/0278364916689139
Babaiasl, M., Mahdioun, S. H., Jaryani, P., and Yazdani, M. (2016). A review of technological and clinical aspects of robot-aided rehabilitation of upper-extremity after stroke. Disabil. Rehabil. Assist. Technol. 11, 263–280. doi: 10.3109/17483107.2014.1002539
Batalik, L., Filakova, K., Batalikova, K., and Dosbaba, F. (2020). Remotely monitored telerehabilitation for cardiac patients: a review of the current situation. World J. Clin. Cases 8:1818. doi: 10.12998/wjcc.v8.i10.1818
Bostrom, J., Sweeney, G., Whiteson, J., and Dodson, J. A. (2020). Mobile health and cardiac rehabilitation in older adults. Clin. Cardiol. 43, 118–126. doi: 10.1002/clc.23306
Brahmi, B., Laraki, M. H., Saad, M., Rahman, M. H., Ochoa-Luna, C., and Brahmi, A. (2019). Compliant adaptive control of human upper-limb exoskeleton robot with unknown dynamics based on a modified function approximation technique (MFAT). Robot. Auton. Syst. 117, 92–102. doi: 10.1016/j.robot.2019.02.017
Brewer, B. R., McDowell, S. K., and Worthen-Chaudhari, L. C. (2007). Poststroke upper extremity rehabilitation: a review of robotic systems and clinical results. Top. Stroke Rehabil. 14, 22–44. doi: 10.1310/tsr1406-22
Cao, Y., Yu, W., Ren, W., and Chen, G. (2013). An overview of recent progress in the study of distributed multi-agent coordination. IEEE Trans. Ind. Inform. 9, 427–438. doi: 10.1109/TII.2012.2219061
Chan, L., Naghdy, F., and Stirling, D. (2016). Position and force tracking for non-linear haptic telemanipulator under varying delays with an improved extended active observer. Robot. Auton. Syst. 75, 145–160. doi: 10.1016/j.robot.2015.10.007
Cheah, C.-C., Liu, C., and Slotine, J.-J. E. (2006). Adaptive tracking control for robots with unknown kinematic and dynamic properties. Int. J. Robot. Res. 25, 283–296. doi: 10.1177/0278364906063830
Chopra, N., Spong, M. W., Hirche, S., and Buss, M. (2003). Bilateral teleoperation over the internet: the time varying delay problem. Urbana 101:61801. doi: 10.1109/ACC.2003.1238930
Chopra, N., Spong, M. W., and Lozano, R. (2008). Synchronization of bilateral teleoperators with time delay. Automatica 44, 2142–2148. doi: 10.1016/j.automatica.2007.12.002
Deng, M. (2014). Operator-Based Nonlinear Control Systems Design and Applications. Piscataway, NJ: John Wiley & Sons.
Ferre, M., Aracil, R., Balaguer, C., Buss, M., and Melchiorri, C. (2007). Advances in Telerobotics, Vol. 31. Berlin: Springer.
French, B., Thomas, L. H., Coupe, J., McMahon, N. E., Connell, L., Harrison, J., et al. (2016). Repetitive task training for improving functional ability after stroke. Cochrane Database Syst. Rev. 11:CD006073. doi: 10.1002/14651858.CD006073.pub3
Gal, N., Andrei, D., Nemeş, D. I., Nădăşan, E., and Stoicu-Tivadar, V. (2015). A kinect based intelligent e-rehabilitation system in physical therapy. Stud. Health Technol. Inform. 210, 489–493. doi: 10.3233/978-1-61499-512-8-489
Hashemzadeh, F., Sharifi, M., and Tavakoli, M. (2016). Nonlinear trilateral teleoperation stability analysis subjected to time-varying delays. Control Eng. Pract. 56, 123–135. doi: 10.1016/j.conengprac.2016.08.004
Hernández-Méndez, A., Linares-Flores, J., and Sira-Ramírez, H. (2016). “Decentralized adaptive control for interconnected boost converters based on backstepping approach,” in 2016 IEEE Energy Conversion Congress and Exposition (ECCE) (Milwaukee, WI: IEEE), 1–6.
Hou, Z.-G., Cheng, L., and Tan, M. (2009). Decentralized robust adaptive control for the multiagent system consensus problem using neural networks. IEEE Trans. Syst. Man Cybernet. B Cybernet. 39, 636–647. doi: 10.1109/TSMCB.2008.2007810
Jafari, B. H., and Spong, M. W. (2017). “Passivity-based switching control in teleoperation systems with time-varying communication delay,” in American Control Conference (ACC) (Seattle, WA: IEEE), 5469–5475. doi: 10.23919/ACC.2017.7963805
Karbasizadeh, N., Zarei, M., Aflakian, A., Tale Masouleh, M., and Kalhor, A. (2018). Experimental dynamic identification and model feed-forward control of novint falcon haptic device. Mechatronics 51, 19–30. doi: 10.1016/j.mechatronics.2018.02.013
Khademian, B., and Hashtrudi-Zaad, K. (2012). Dual-user teleoperation systems: new multilateral shared control architecture and kinesthetic performance measures. IEEE/ASME Trans. Mechatron. 17, 895–906. doi: 10.1109/TMECH.2011.2141673
Khademian, B., and Hashtrudi-Zaad, K. (2013). A framework for unconditional stability analysis of multimaster/multislave teleoperation systems. IEEE Trans. Robot. 29, 684–694. doi: 10.1109/TRO.2013.2242377
Krebs, H. I., Hogan, N., Aisen, M. L., and Volpe, B. T. (1998). Robot-aided neurorehabilitation. IEEE Trans. Rehabil. Eng. 6, 75–87. doi: 10.1109/86.662623
Larson, E. B., Feigon, M., Gagliardo, P., and Dvorkin, A. Y. (2014). Virtual reality and cognitive rehabilitation: a review of current outcome research. Neurorehabilitation 34, 759–772. doi: 10.3233/NRE-141078
Li, J., Tavakoli, M., Mendez, V., and Huang, Q. (2015). Passivity and absolute stability analysesof trilateral haptic collaborative systems. J. Intell. Robot. Syst. 78, 3–20. doi: 10.1007/s10846-014-0049-2
Luo, L., Peng, L., Wang, C., and Hou, Z.-G. (2019). A greedy assist-as-needed controller for upper limb rehabilitation. IEEE Trans. Neural Netw. Learn. Syst. 30, 3433–3443. doi: 10.1109/TNNLS.2019.2892157
Mani, S., Sharma, S., Omar, B., Paungmali, A., and Joseph, L. (2017). Validity and reliability of internet-based physiotherapy assessment for musculoskeletal disorders: a systematic review. J. Telemed. Telec. 23, 379–391. doi: 10.1177/1357633X16642369
McDonald, C. G., Sullivan, J. L., Dennis, T. A., and O'Malley, M. K. (2020). A myoelectric control interface for upper-limb robotic rehabilitation following spinal cord injury. IEEE Trans. Neural Syst. Rehabil. Eng. 28, 978–987. doi: 10.1109/TNSRE.2020.2979743
Mohajerpoor, R., Sharifi, I., Talebi, H. A., and Rezaei, S. M. (2013). “Adaptive bilateral teleoperation of an unknown object handled by multiple robots under unknown communication delay,” in 2013 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM) (Wollongong: IEEE), 1158–1163. doi: 10.1109/AIM.2013.6584250
Nef, T., Klamroth-Marganska, V., Keller, U., and Riener, R. (2016). “Three-dimensional multi-degree-of-freedom arm therapy robot (armin),” in Neurorehabilitation Technology (London: Springer), 351–374. doi: 10.1007/978-3-319-28603-7_17
Niyetkaliyev, A. S., Hussain, S., Ghayesh, M. H., and Alici, G. (2017). Review on design and control aspects of robotic shoulder rehabilitation orthoses. IEEE Trans. Hum. Mach. Syst. 47, 1134–1145. doi: 10.1109/THMS.2017.2700634
Nuño, E., Basañez, L., and Ortega, R. (2011). Passivity-based control for bilateral teleoperation: a tutorial. Automatica 47, 485–495. doi: 10.1016/j.automatica.2011.01.004
Nuño, E., Basañez, L., Ortega, R., and Spong, M. W. (2009). Position tracking for non-linear teleoperators with variable time delay. Int. J. Robot. Res. 28, 895–910. doi: 10.1177/0278364908099461
Olfati-Saber, R., Fax, J. A., and Murray, R. M. (2007). Consensus and cooperation in networked multi-agent systems. Proc. IEEE 95, 215–233. doi: 10.1109/JPROC.2006.887293
Pehlivan, A. U., Lee, S., and O'Malley, M. K. (2012). “Mechanical design of ricewrist-s: a forearm-wrist exoskeleton for stroke and spinal cord injury rehabilitation,” in 2012 4th IEEE RAS & EMBS International Conference on Biomedical Robotics and Biomechatronics (BioRob) (Rome: IEEE), 1573–1578. doi: 10.1109/BioRob.2012.6290912
Peng, Z., Wang, D., Zhang, H., and Sun, G. (2014). Distributed neural network control for adaptive synchronization of uncertain dynamical multiagent systems. IEEE Trans. Neural Netw. Learn. Syst. 25, 1508–1519. doi: 10.1109/TNNLS.2013.2293499
Peretti, A., Amenta, F., Tayebati, S. K., Nittari, G., and Mahdi, S. S. (2017). Telerehabilitation: review of the state-of-the-art and areas of application. JMIR Rehabil. Assist. Technol. 4:e7. doi: 10.2196/rehab.7511
Rogante, M., Kairy, D., Giacomozzi, C., and Grigioni, M. (2015). A quality assessment of systematic reviews on telerehabilitation: what does the evidence tell us? Ann. Ist. Super Sanita 51, 11–18. doi: 10.4415/ANN_15_01_04
Rohrer, B., Fasoli, S., Krebs, H. I., Hughes, R., Volpe, B., Frontera, W. R., et al. (2002). Movement smoothness changes during stroke recovery. J. Neurosci. 22, 8297–8304. doi: 10.1523/JNEUROSCI.22-18-08297.2002
Sahin, O. N., Uzunoglu, E., Tatlicioglu, E., and Dede, M. (2017). Design and development of an educational desktop robot R3D. Comput. Appl. Eng. Educ. 25, 222–229. doi: 10.1002/cae.21792
Schröder, J., van Criekinge, T., Embrechts, E., Celis, X., Van Schuppen, J., Truijen, S., et al. (2019). Combining the benefits of tele-rehabilitation and virtual reality-based balance training: a systematic review on feasibility and effectiveness. Disabil. Rehabil. Assist. Technol. 14, 2–11. doi: 10.1080/17483107.2018.1503738
Sciavicco, L., and Siciliano, B. (2012). Modelling and Control of Robot Manipulators. London: Springer Science & Business Media.
Shamaei, K., Kim, L. H., and Okamura, A. M. (2015). “Design and evaluation of a trilateral shared-control architecture for teleoperated training robots,” in 2015 37th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC) (Milan: IEEE), 4887–4893. doi: 10.1109/EMBC.2015.7319488
Sharifi, I., Talebi, H., and Tavakoli, M. (2017). “Multi-lateral nonlinear time-delayed teleoperation in a multi-agent systems framework,” in 2017 5th RSI International Conference on Robotics and Mechatronics (ICRoM) (Tehran: IEEE), 180–185. doi: 10.1109/ICRoM.2017.8466167
Sharifi, I., Talebi, H. A., and Motaharifar, M. (2016). A framework for simultaneous training and therapy in multilateral tele-rehabilitation. Comput. Electric. Eng. 56, 700–714. doi: 10.1016/j.compeleceng.2016.08.002
Sharifi, I., Talebi, H. A., Suratgar, A. A., and Ghafarirad, H. (2011). “A position driftless, modified wave variable scheme for time varying delayed teleoperation system,” in 2011 2nd International Conference on Control, Instrumentation and Automation (ICCIA) (Shiraz: IEEE), 904–910. doi: 10.1109/ICCIAutom.2011.6356782
Spong, M. W., and Chopra, N. (2007). “Synchronization of networked lagrangian systems,” in Lagrangian and Hamiltonian Methods for Nonlinear Control 2006 (Berlin: Springer), 47–59. doi: 10.1007/978-3-540-73890-9_3
Staubli, P., Nef, T., Klamroth-Marganska, V., and Riener, R. (2009). Effects of intensive arm training with the rehabilitation robot armin II in chronic stroke patients: four single-cases. J. Neuroeng. Rehabil. 6:46. doi: 10.1186/1743-0003-6-46
Su, S., and Lin, Z. (2016). Distributed consensus control of multi-agent systems with higher order agent dynamics and dynamically changing directed interaction topologies. IEEE Trans. Autom. Control 61, 515–519. doi: 10.1109/TAC.2015.2444211
Sun, D. (2016). Synchronization and Control of Multiagent Systems, Vol. 41. Boca Raton, FL: CRC Press.
Taati, B., Tahmasebi, A. M., and Hashtrudi-Zaad, K. (2008). Experimental identification and analysis of the dynamics of a phantom premium 1.5 a haptic device. Presence Teleoper. Virtual Environ. 17, 327–343. doi: 10.1162/pres.17.4.327
Tousignant, M., Mampuya, W. M., Bissonnette, J., Guillemette, E., Lauriault, F., Lavoie, J., et al. (2019). Telerehabilitation with live-feed biomedical sensor signals for patients with heart failure: a pilot study. Cardiovasc. Diagn. Ther. 9:319. doi: 10.21037/cdt.2019.03.05
Wang, C., Zuo, Z., Sun, J., Yang, J., and Ding, Z. (2017). Consensus disturbance rejection for lipschitz nonlinear multi-agent systems with input delay: a DOBC approach. J. Frankl. Inst. 354, 298–315. doi: 10.1016/j.jfranklin.2016.09.019
Wen, G., Zhang, H.-T., Yu, W., Zuo, Z., and Zhao, Y. (2017). Coordination tracking of multi-agent dynamical systems with general linear node dynamics. Int. J. Robust Nonlin. Control 27, 1526–1546. doi: 10.1002/rnc.3753
Writing, G. M., Mozaffarian, D., Benjamin, E., Go, A., Arnett, D., Blaha, M., et al. (2016). Heart disease and stroke statistics-2016 update: a report from the American Heart Association. Circulation 133, 38–53. doi: 10.1161/CIR.0000000000000350
Wu, Y., Lu, R., Su, H., Shi, P., and Wu, Z.-G. (2017). “Sampled-data control with time-varying coupling delay,” in Synchronization Control for Large-Scale Network Systems (Springer), 67–91. doi: 10.1007/978-3-319-45150-3_4
Xiang, J., Li, Y., and Hill, D. J. (2017). Cooperative output regulation of linear multi-agent network systems with dynamic edges. Automatica 77, 1–13. doi: 10.1016/j.automatica.2016.11.016
Zhai, D.-H., and Xia, Y. (2016). Adaptive fuzzy control of multilateral asymmetric teleoperation for coordinated multiple mobile manipulators. IEEE Trans. Fuzzy Syst. 24, 57–70. doi: 10.1109/TFUZZ.2015.2426215
Zhou, B., Wang, W., and Ye, H. (2014). Cooperative control for consensus of multi-agent systems with actuator faults. Comput. Electr. Eng. 40, 2154–2166. doi: 10.1016/j.compeleceng.2014.04.015
Zuo, L., Cui, R., and Yan, W. (2016). Terminal sliding mode-based cooperative tracking control for non-linear dynamic systems. Trans. Inst. Meas. Control 39, 144–151. doi: 10.1177/0142331216629201
8. Appendix: Experimentation Setup
All the experiments performed in this article have been implemented by the hardware and software described in this subsection. The experiments were implemented with capability of handling six non-homogeneous manipulators consisting of a dual set of Novint Falcon® (Karbasizadeh et al., 2018), one Phantom Omni®, Two Phantom Premium® robots (Taati et al., 2008), and one Quanser® robot (Atashzar et al., 2017), respectively (Figure A1). A software was developed in Windows platform that can connect and control the hardwares used in the experiments. The overview of the software is given in Figure A2. It is composed of five interactive modules. The main application (Block #1) is written in C# language and is based on multi-threaded programming. It is connected to C# console application (Block #2) via shared memory and C++ Library 1 (Block #3) via C# wrapper, and finally, to the dual Novint Falcon robots via USB protocol.

Figure A1. In this figure, six non-homogeneous robots participate in a rehabilitation process as discussed in Figure A2. A dual set of Novint Falcon®, one Phantom Omni®, Two Phantom Premium® robots, and one Quanser® robot participate in the process, forming R1–R6, respectively.
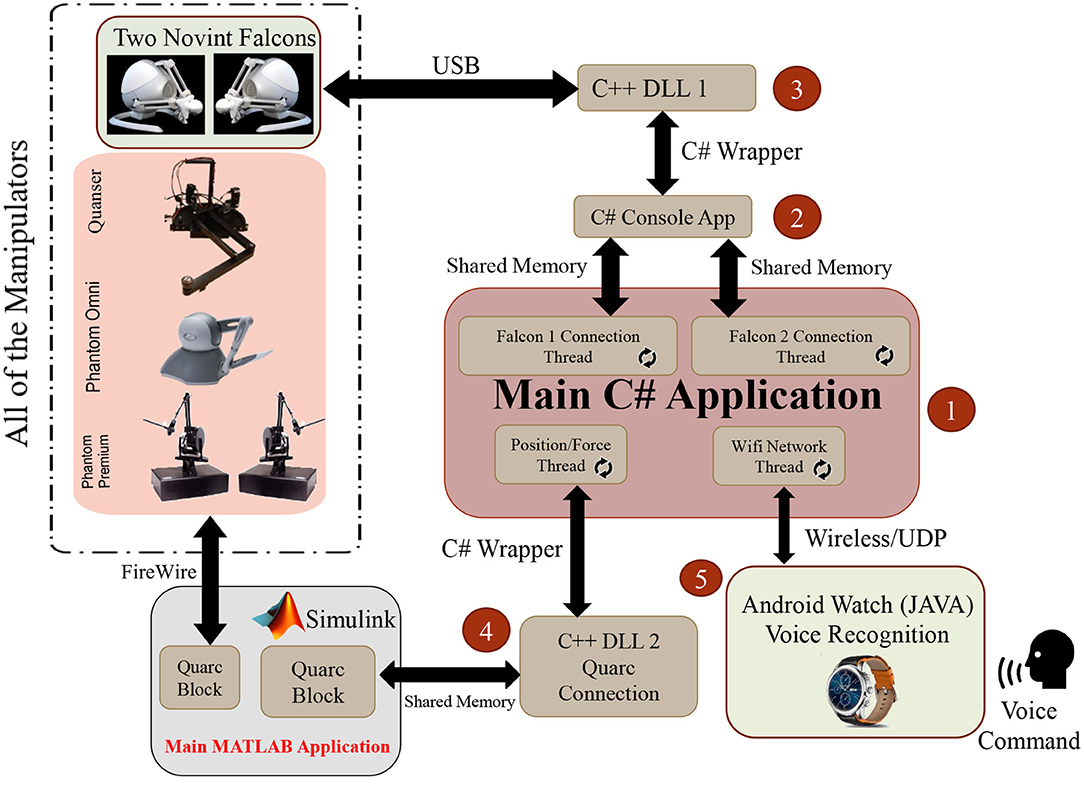
Figure A2. Overview of the implemented software for the proposed method. As it is seen, the manipulators are selected in a non-homogeneous manner. That is, a dual set of Novint Falcon®, one Phantom Omni®, Two Phantom Premium® robots, and one Quanser® robot are provided for this purpose (R1–R6 in Figure A1). The software written for this system consists of five parts, all of which have been prepared and implemented by the authors of this article. Bilateral arrows represent the two-way communication between the marked blocks. For example, Novint Falcon robots send/receive data to/from the main system through the USB protocol and via the intermediate programs “C++ DLL 1” (Block #3) and “C# Console App” (Block #2). Block #3 and Block #2 are connected to each other via C# wrapper, and Block #2 is connected to the Block #1 via the shared memory. All the other blocks are connected to the robots in similar situation as shown in this figure.
Moreover, the main application is connected to the C++ Library 2 (Block #4) via C# wrapper, and afterward, Block #4 is connected to the Quarc Simulink© via shared memory. Consequently, Quarc Simulink© is connected to the three robots including two Phantoms and one Quanser® via the FireWire® protocol. All five blocks shown in Figure A2 are written by the authors of this article. It is worth mentioning that the quarc block in MATLAB Simulink© has been used for the real-time implementation of this system. For lack of space, the functionality of the software modules will not be discussed in this paper.
Keywords: tele-rehabilitation system, robotics, non-linear control, multi-agent systems (MAS), force control, cooperative teleoperation
Citation: Sharifi I, Talebi HA, Patel RR and Tavakoli M (2020) Multi-Lateral Teleoperation Based on Multi-Agent Framework: Application to Simultaneous Training and Therapy in Telerehabilitation. Front. Robot. AI 7:538347. doi: 10.3389/frobt.2020.538347
Received: 27 February 2020; Accepted: 30 September 2020;
Published: 11 November 2020.
Edited by:
William Harwin, Culham Centre for Fusion Energy, United KingdomReviewed by:
Chad Gregory Rose, Auburn University, United StatesFabian Just, ETH Zürich, Switzerland
Copyright © 2020 Sharifi, Talebi, Patel and Tavakoli. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Iman Sharifi, aW1hbnNoYXJpZmlAYXV0LmFjLmly