 Nguyen Tran Minh Nguyet
Nguyen Tran Minh Nguyet Dang Xuan Ba
Dang Xuan Ba- 1Faculty of Electrical and Electronics Engineering, HCMC University of Technology and Education (HCMUTE), Ho Chi Minh City, Vietnam
- 2Department of Automatic Control and Smart Robotic Center, HCMC University of Technology and Education (HCMUTE), Ho Chi Minh City, Vietnam
This paper proposes an adaptive robust Jacobian-based controller for task-space position-tracking control of robotic manipulators. Structure of the controller is built up on a traditional Proportional-Integral-Derivative (PID) framework. An additional neural control signal is next synthesized under a non-linear learning law to compensate for internal and external disturbances in the robot dynamics. To provide the strong robustness of such the controller, a new gain learning feature is then integrated to automatically adjust the PID gains for various working conditions. Stability of the closed-loop system is guaranteed by Lyapunov constraints. Effectiveness of the proposed controller is carefully verified by intensive simulation results.
1 Introduction
Today, the great development of science and technology has created a premise for scientific research to develop to a new level in which the field of robotics has being chosen to be the leading industry by many countries. To promote science and technology backgrounds, intelligent robots in the industrial application are starting to prosper strongly, attracting many research experts. To control robot moving safely to desired positions with obstacles, collision avoidance and path planning were matters of concern. In recent years, various strategies have been studied for collision avoidance control purpose. The basic idea behind the collision avoidance algorithms is to design a proper controller which can result in a conflict-free trajectory. Path selection methods are the one of several techniques to avoid obstacles. It uses off-line/on-line algorithms to produce a curve that connects the starting and target points with a predefined initial position, velocity and acceleration. For example, an online trajectory generation algorithm called Ruckig considered third-order constraints (for velocity, acceleration, and jerk), so the complete kinematic state could be specified for waypoint-based trajectories (Berscheid and Kroeger, 2021). The smooth trajectory based on method combining of fourth and fifth order polynomial functions was presented in (Boscario et al., 2012) in which, the outcome of the method was the optimal time distribution of the via points, with respect to predefined objective function. After that, the joint based controller might use the inverse kinematic to solve the desired joint angular. Early collision avoidance approaches concentrated on the static obstacles handling by the sensor-based motion planning methods (Borenstein and Koren, 1991), using nearness diagram navigation to successfully navigate in troublesome scenarios (Minguez and Montano, 2004) and using trajectory planning algorithms to avoid obstacles (Shiller, 2015). In reality, many techniques have been proposed to cope with moving obstacles. For instance, a reactive avoidance method incorporating with a non-linear differential geometric guidance was presented in (Mujumdar and Padhi, 2011) and a collision avoidance algorithm based on the potential fields was proposed in (Huang et al., 2019). It can be seen that in normal applications of robotic manipulators, the controllers were designed in the joint space in which it requires exact inverse kinematic computation as well. Non-etheless, complex internal dynamics and external disturbances coming from divergent working conditions are main obstacles hindering development of excellent controllers.
To realize control objectives of the robots in real-life missions, simple proportional-integral-derivative (PID) controllers are priority options (Bledt et al., 2018), (Wensing et al., 2017) due to simple design. If the proper control gains were found, the high control outcomes could be obtained (Park et al., 2015), (Ba and Bae, 2020). A lot of research have been then studied to improve the performance of the PID controllers using intelligent approaches such as evolutionary optimization and fuzzy logic (Astrom and Hagglund, 1995). The methods exhibited promising control results thanks to using both online and offline sections (Tan et al., 2004). The off-line control one could flexibly select the proper PID parameters based on the system overshoot, settling time and steady-state error, while the on-line one would adopt the operating control errors to adjust fuzzy logic parameters to re-optimize the system, improving the system quality significantly. However, the tuning methodology of fuzzy logic controllers is mostly based on experiences of operators (Juang and Chang, 2011). Another series of the intelligent control category was based on the biological properties of animals in which a genetic algorithm was combined with a bacterial foraging method to simulate natural optimization processes such as hybridization, reproduction, mutation, natural selection, etc., (Cucientes et al., 2007). This evolution could deliver the most optimal solution. That the solving process requires a large number of samples and takes a long-running time limits its application. Recently, tuning PID control parameters using neural networks has become an effective approach with many contributions (Kim and Cho, 2006), (Neath et al., 2014). The conventional PID one itself is a robust controller (Thanh and Ahn, 2006). The learning ability integrated to the controllers makes it flexible to the working environment (Ye, 2008). Lack of an intensive consideration of learning rules in steady-state time could make the system unstable in a long time used (Ba et al., 2019), (Ye, 2008), (Rocco, 1996).
To further improve the control performance, internal and external dynamics of robots need to be compensated during working processes. To this end, classical methods could be employed based on accurate mathematical models of the robots (Craig, 2018), (Zhu, 2010). Good control results were exhibited using such the conventional approaches, but it is not easy to extend the control outcome to complicated robot structures. Intelligent modeling methods could be adopted to increase applicability of the controllers to various robots in different working environments (Karayiannidis et al., 2016), (Gao et al., 2022). Excellent control performances were accomplished with the intelligent control approaches. However, convergence of the learning process is still not explicitly proven (He et al., 2020), (Wang et al., 2020). To support this kind of theoretical drawback, linear leakage functions were integrated the estimation phases of the network operation. However, this term could be slowdown the overall learning performance. Hence, advanced learning behaviors for the network need to be extensionally studied.
In this paper, an intelligent direct PID controller is proposed for position-tracking control in task space of robotic manipulators. Without using inverse kinematics, the operator just needs to input the desired position value, the controller will calculate and give the desired control position to the robot by itself (Craig, 2005; Ba and Bae, 2021; Ba et al., 2021). This process will be of great help since, in practice, there are quite few robots with quite complex hardware structures that make the inverse kinematics calculation difficult. The more degrees of freedom a robot has, the more difficult the calculation process, requiring more time and effort. The proposed controller is built based on a conventional PID framework. A non-linear neural network is then employed to eliminate internal/external disturbances during the working process. To increase the adaptive robustness of the controller, a new gain learning rule is integrated to flexible tune the PID gain for different working conditions.
Outline of the paper is structured as follows. Section 2 discusses system modeling and problem statements. Section 3 presents design of the proposed controller. Section 4 analyzes verification results. The paper is then concluded in Section 5.
2 System modelling and problem statements
Behaviors of a general robotic manipulator can be presented in the following form (Craig, 2018), (He et al., 2020):
where
Remark 1: the control objective of this paper is to find out a proper control signal (
where
where
Remark 2: It is very difficult to determine accurate parameters of model (1), (2) or (3). Furthermore, the parameters sometimes vary during the working processes. To treat this drawback, the proposed controller is required to be model-free, robust and flexible.
3 Neural flexible PID controller
In this section, the proposed controller is designed with new features to realize the control mission stated. Theoretical effectiveness of the closed-loop system is then analyzed using Lyapunov constraints.
3.1 A flexible PID control framework
The controller is developed based on a conventional PID (Tan et al., 2004) structure as in Eq. 4.
where
We assume that the desired trajectory xd is inside of the workspace of the robot and the end-effector x of the robot can reach to the desired position selected. Advanced path-planning and obstacle-avoidance algorithms (Mujumdar and Padhi, 2011; Shiller, 2015; Huang et al., 2019) could be employed to generate appropriate desired profiles for the robot.
In real-time control, one can tune the control gains
where
Remark 3: As seen in Eq. 5, the PID gains are structured from static and dynamic gains which respectively yield robustness and adaptation of the closed-loop system. The control gains are varied in non-linear manners to drive the control error to go into the desired region regardless of unknown environments. For faster control results, the disturbance term
3.2 Additional neural network control signal
First of all, the disturbance
where
Based on the neural network model (6), the control signal (4) is modified by adding an additional intelligent control term, as follows:
where
where
Remark 4: The system (8) uses rich information including time-derivative, linear, and integral function of the control error to activate the learning process. The weight matrix of the neural network is automatically updated to ensure the minimum control error.
3.3 Stability analysis
In this section, we discuss the stability of the closed-loop system to ensure reliability of the proposed controller for the robotic system (3). From the above design, we have the following statements.
Theorem 1: Give a task-space model (3) of robotic manipulators, if employing a conventional neural PID control signal (7) supported by adaptive rules (5) and (8), the following properties hold:
1) The control error
2) In the stationary phase, the control error
Proof:
We first synthesize a virtual control error
The time derivative of the new error
By substituting the control signal Eq. 7 and the gain structure Eq. 5 into the dynamics Eq. 10, we have a simpler form:
where
Differentiating the function Eq. 12 with respect to time and noting the dynamics Eq. 11 lead to
Applying Cauchy-Schwarz inequality, we obtain the following result:
where
Since
Remark 5: As carefully observing on the definition (15), one could select
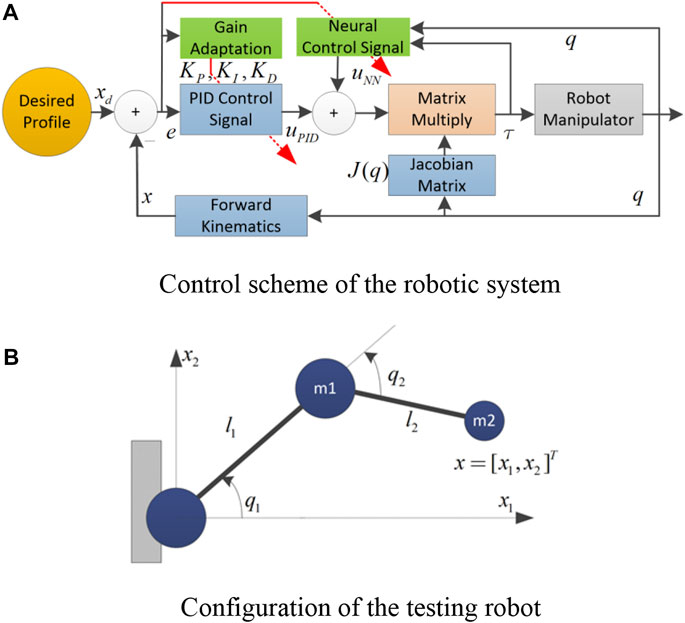
FIGURE 1. The testing robot. (A) Control scheme of the robotic system. (B) Configuration of the testing robot.
4 Validation results
This section presents validation results of the proposed controller in simulations. The control algorithm was applied to a 2-degree-of-freedom (DOF) robot, as sketched in Figure 1B. The manipulator was modeled as two rigid links with lengths of l1 and l2. The mass was distributed at the end of each link (m1, m2). The robot would work in a vertical plane with downward gravitational acceleration. Viscous friction was modeled at the joints (a1, a2). Although this robot is quite simple, it contains all the necessary components of a general multi-degree of freedom manipulator including moment of inertia, centrifugal terms, Coriolis terms, gravity terms and friction effects.
The detailed dynamic equations of the robot are as follows:
To estimate the disturbances
The actual values of the length of links, mass and viscous friction coefficients were chosen as follows:
To evaluate the adaptability and robustness of the controller under divergent working conditions, we compared the proposed controller (called anPID) with a conventional PID controller (referred to as cPID) and an adaptive PID controller with using only automatic tuning law for PID gains (referred to as aPID). The parameters of the controller were chosen as:
To carefully express the performance of the proposed controller, the robotic manipulators were simulated in three cases. In the first simulation, the robot was controlled to track the desired trajectories of smooth multi-step signals. Furthermore, process disturbances in the form of white noises, as shown in Figure 2C, were added to the output torques of the actuators. Simulation results of the conventional and intelligent PID controllers for the tracking control mission are also shown in Figure 2.
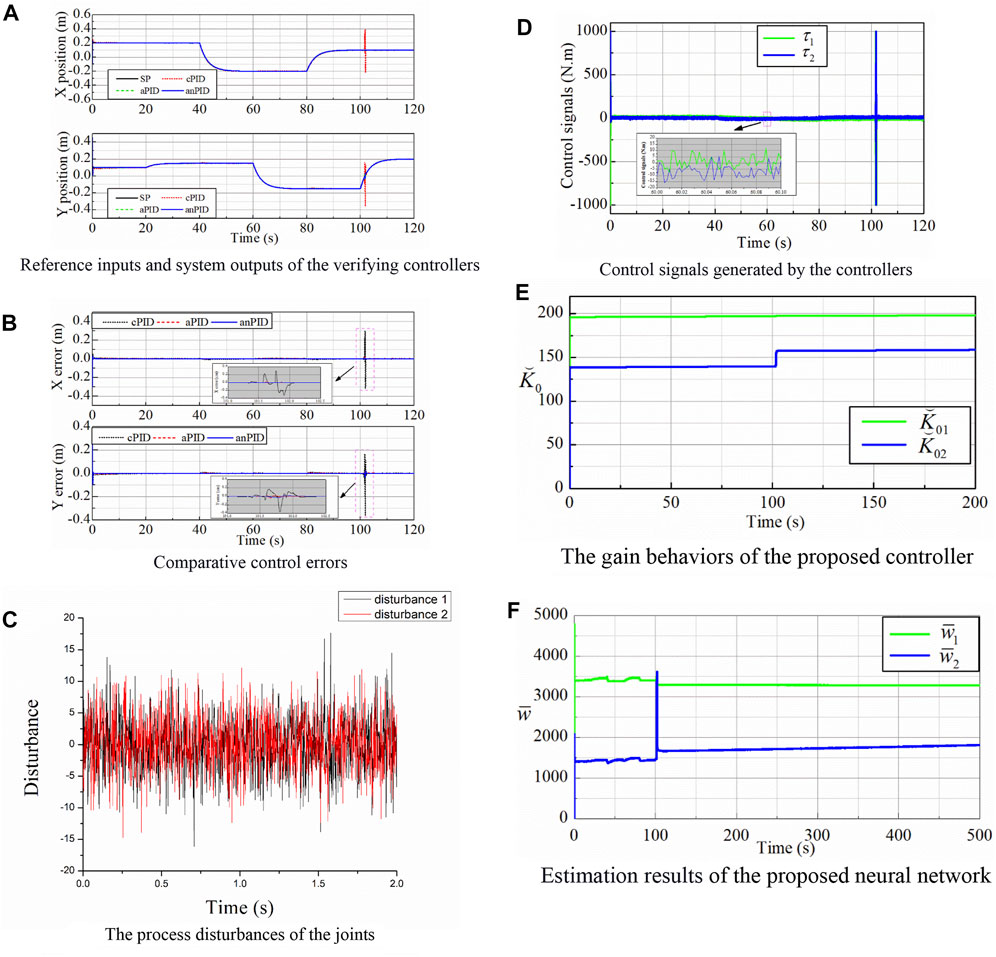
FIGURE 2. Simulation data of the controllers in the first simulation. (A) Reference inputs and system outputs of the verifying controllers. (B) Comparative control errors. (C) The process disturbances of the joints. (D) Control signals generated by the controllers. (E) The gain behaviors of the proposed controller. (F) Estimation results of the proposed neural network.
Figures 2A,B shows that the proposed controller maintained good control errors even though the end-effector of the manipulator worked throughout a singularity point of (0.1; 0) (m). Figure 2D exhibits the control signals of the smart PID controller which had large values at the initial and singularity points in order to decrease the control errors as fast and much as possible. This superior property was the achievement of the learning laws (5) and (8) that are demonstrated by the gain and weight variations as depicted in Figures 2E, F, respectively. These terms were first started from the zero value, then their values had a large overshoot to bring the system to the steady state rapidly. It can be seen that the system adapted to the reasonable approximation of the disturbances to bring the control error to the smallest possible value. Therefore, the learning ability of the system has been confirmed with uncertain non-linearities and perturbations through this simulation validation.
The manipulator was employed to draw a circle whose radius was 0.15 m and origin was at a point of (0.3; 0) (m) with a frequency of 1 Hz in the second simulation. The reference input used is shown in Figure 3A.
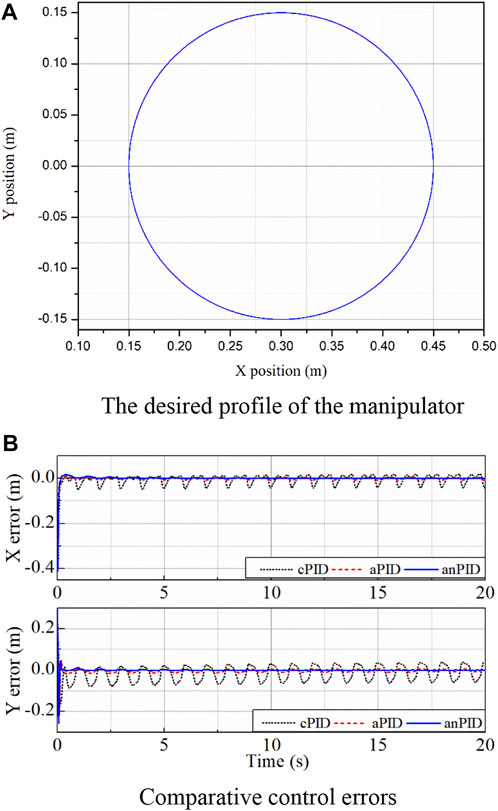
FIGURE 3. Simulation data of the controllers in the second simulation. (A) The desired profile of the manipulator. (B) Comparative control errors.
With the application of the neural flexible PID controller for unknown environments but using the adaptive rule (7), the control results obtained are presented in Figure 3B. From the data in this figure, although disturbances were not known in advance, the control qualities of the joints were good at both the transient and steady-state phases. The results were achieved thanks to the learning characteristics of the PID gains and the designed RBF neural network. There was a little overshoot in the y-direction error due to the large learning rate selected, but this overshoot might cause the system to quickly reach steady state. From the comparison of the control data in Figure 3B, it can be seen that the quality of proposed controller (anPID) was better than that of the aPID controller which was employed only one learning law (5). This is possible because the more adaptive terms the controller had, the more approximation with disturbances it gained.
In the third simulation, the end effector of robot manipulator was controlled to move from a point of (0.35; 0.25) (m) to another point of (0.15; 0.05) (m). After applying the three controllers for this mission in a free condition in which the desired trajectory was planned as a straight line, their control outcomes including the actual outputs and the control errors were illustrated in Figures 4A, B, respectively. In these figures, although the proposed controller (anPID) had more oscillation in the transient state to find adaptive term quickly, it had smallest overshoot and steady state error when compared with cPID and aPID controllers.
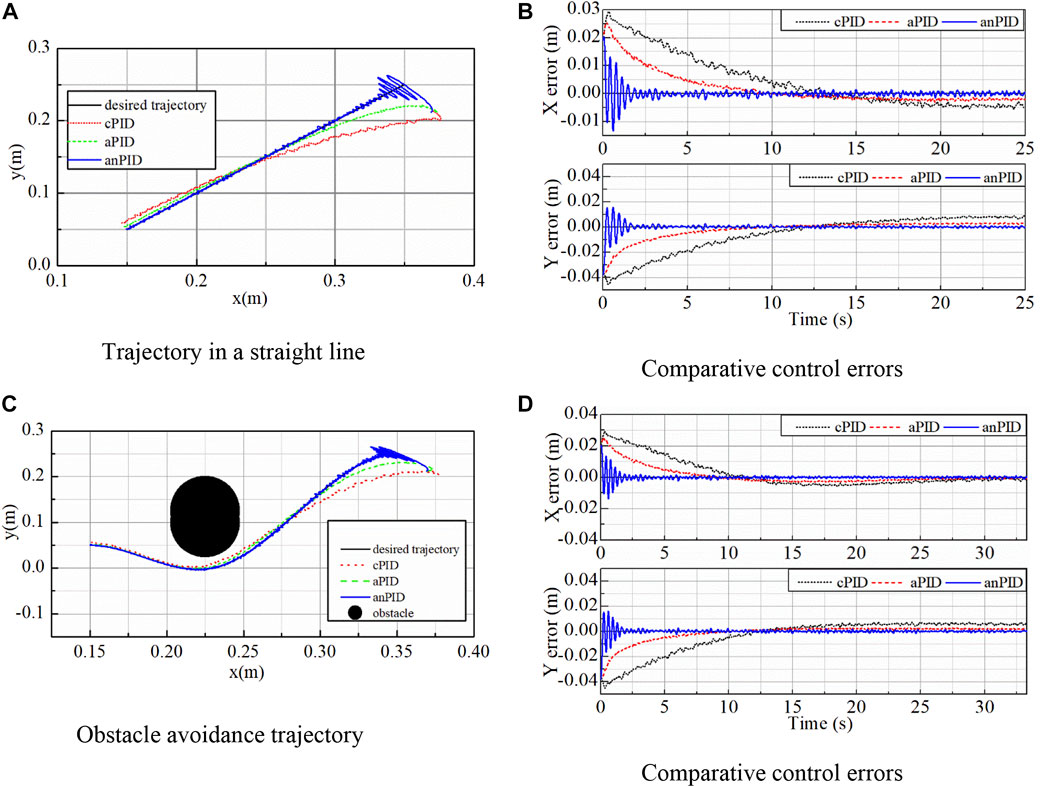
FIGURE 4. Simulation data of the controllers in the third simulation. (A) Trajectory in a straight line. (B) Comparative control errors. (C) Obstacle avoidance trajectory. (D) Comparative control errors.
To further challenge the controllers with a more difficult working condition, an obstacle was set on the moving trajectory of the robot in the task space. By applying the trajectory planning method and the referred avoidance collision method (Borenstein and Koren, 1991), (Craig, 2005), the desired trajectory was generated as a curve by using two third-order-segment polynomials for the position, velocity and acceleration of the end-effector. The control data in this case are shown in Figures 4C, D. From the comparison of the data in these figures, it can be seen that the control quality of proposed controller (anPID) was better than that of the others (aPID and cPID) even though with the non-linear trajectory generated.
Table 1 described the maximum absolute (MA) and root-mean-square (RMS) values of the control performances for a specified manipulated time (20 s–25 s). The proposed controller always provided the best MA and RMS error in all cases. These results show that the proposed control technology compensated efficiently for the non-linear uncertainties and unknown disturbances. Here, the advantages of the proposed controller have been confirmed. Therefore, the simulation results have proved that the studied control method outperform over the previous ones.
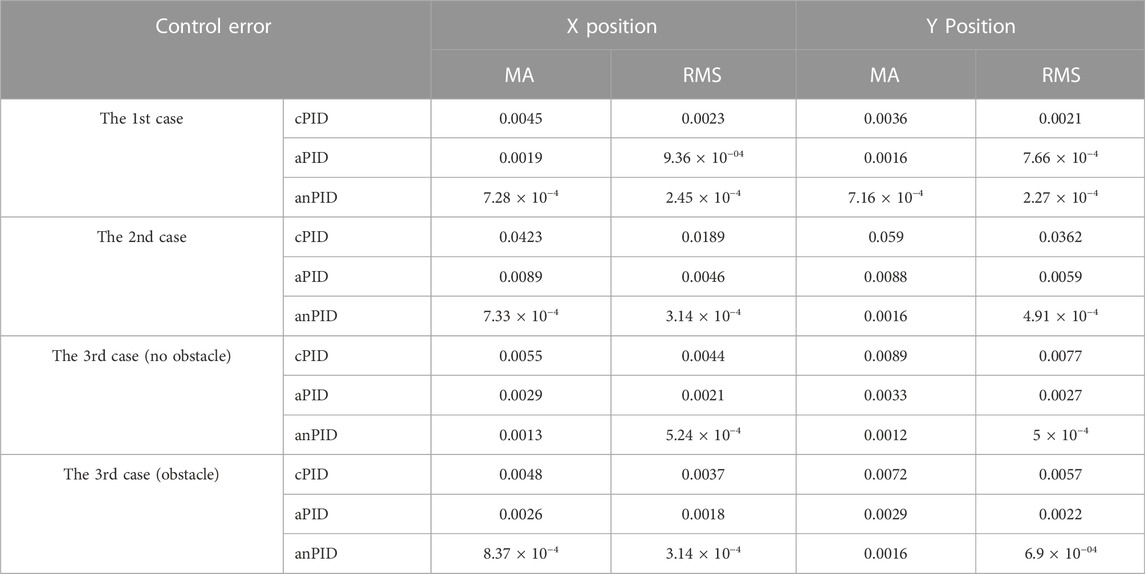
TABLE 1. Statistical computation of the controllers from the validation results.
5 Conclusion
In this paper, an intelligent controller is proposed to optimize the position control performance of a 2DOF robotic manipulator. The controller is developed based on a conventional PID structure. New advanced features designed for disturbance learning and gain adaptation are then integrated into the ordinary control signal to improve its robustness and result in high control accuracies. The control efficiency of the proposed approach was then successfully verified by theoretic proof and comparative simulations. It can confirm that the controller is model-free, simple, robust and flexible. In the near future, the proposed control algorithm will be integrated with an additional control term that could result in asymptotic control performances for dynamical trajectories. Furthermore, advanced path-planning and obstacle-avoidance algorithms will be considered to combine with the controller to increase the flexibility when the system works in complex environments.
Data availability statement
The raw data supporting the conclusion of this article will be made available by the authors, without undue reservation.
Author contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Astrom, K., and Hagglund, K. (1995). PID controllers: Theory, design and tuning. Washington, DC, USA: ISA Press.
Ba, D. X., and Bae, J. B. (2020). A nonlinear sliding mode controller of serial robot manipulators with two-level gain-learning ability. IEEE Access 8, 189224–189235. doi:10.1109/access.2020.3032449
Ba, D. X., and Bae, J. B. (2021). A precise neural-disturbance learning controller of constrained robotic manipulators. IEEE Access 9, 50381–50390. doi:10.1109/access.2021.3069229
Ba, D. X., Tran, M. S., vu, V. P., Tran, V. D., Tran, M. D., Tai, N. T., et al. (2021). “A neural-network-based nonlinear controller for robot manipulators with gain-learning ability and output constraints,” in 2021 International Symp. Electrical and Electronics Engineering (ISEE), Ho chi minh, Vietnam, 149–153.
Ba, D. X., Yeom, H., and Bae, J. B. (2019). A direct robust nonsingular terminal sliding mode controller based on an adaptive time-delay estimator for servomotor rigid robots. Mechatronics 59. May. doi:10.1016/j.mechatronics.2019.03.007
Berscheid, L., and Kroeger, T. (2021). “Jerk-limited real-time trajectory generation with arbitrary target states,” in Proceedings of Robotics: Science and Systems, July 2021.
Bledt, G., Powell, M. J., Katz, B., Carlo, F. D., Wensing, P. W., and Kim, S. (2018). MIT cheetah 3: Design and control of a robust, dynamic quadruped robot in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain.
Borenstein, J., and Koren, Y. (1991). The vector field histogram-fast obstacle avoidance for mobile robots. IEEE Trans. Robot. Autom. 7 (3), 278–288. doi:10.1109/70.88137
Boscario, P., Gasparetto, A., and Vidoni, R. (2012). “Planning continuous-jerk trajectories for industrial manipulators,” in Proceedings of the ASME 2012 11th Biennial Conference on Engineering Systems Design and Analysis, Nantes, France, July 2012.
Craig, J. J. (2018). Introduction to robotics: Mechanics and control. 4. Hoboken, NJ, USA: Pearson Prentice Hall. th ed.
Craig, J. J. (2005). Manipulator dynamic Introduction to robotics: Mechanics and control,. 3. Hoboken, NJ, USA: Pearson Prentice Hall, 165–200. inrd ed.s
Cucientes, M., Moreno, D. L., Bugarin, A., and Barro, S. (2007). Design of a fuzzy controller in mobile robotics using genetic algorithms. Appl. Soft Comput. 7 (2), 540–546. doi:10.1016/j.asoc.2005.05.007
Gao, X., Li, X., Sun, Y., Hao, L., Yang, H., and Xiang, C. (2022). Model-free tracking control of continuum manipulators with global stability and assigned accuracy. IEEE Trans. Syst. Man. Cybern. Syst. 52 (2), 1345–1355. doi:10.1109/tsmc.2020.3018756
He, W., Sun, Y., Yan, Z., Yang, C., Li, Z., and Kaynak, O. (2020). Disturbance observer-based neural network control of cooperative multiple manipulators with input saturation. IEEE Trans. Neural Netw. Learn. Syst. 31 (5), 1735–1746. doi:10.1109/tnnls.2019.2923241
Huang, S., Teo, R. S. H., and Tan, K. K. (2019). Collision avoidance of multi unmanned aerial vehicles: A review. Annu. Rev. Control 48, 147–164. doi:10.1016/j.arcontrol.2019.10.001
Juang, C. F., and Chang, Y. C. (2011). Evolutionary-group-based particle-swarm-optimized fuzzy controller with application to mobile-robot navigation in unknown environments. IEEE Trans. Fuzzy Syst. 19 (2), 379–392. doi:10.1109/tfuzz.2011.2104364
Karayiannidis, Y., Papageorgiou, D., and Doulgeri, Z. (2016). A model-free controller for guaranteed prescribed performance tracking of both robot joint positions and velocities. IEEE Robot. Autom. Lett. 1 (1), 267–273. doi:10.1109/lra.2016.2516245
Kim, D. H., and Cho, J. H. (2006). A biological inspired intelligent PID controller tuning for AVR systems. Int. J. Control, Automation, Syst. 4 (5), 624–636.
Minguez, J., and Montano, L. (2004). Nearness diagram (ND) navigation: Collision avoidance in troublesome scenarios. IEEE Trans. Robot. Autom. 20 (1), 45–59. doi:10.1109/tra.2003.820849
Mujumdar, A., and Padhi, R. (2011). Reactive collision avoidance of using nonlinear geometric and differential geometric guidance. J. Guid. Control Dyn. 34 (1), 303–311. doi:10.2514/1.50923
Neath, M. J., Swain, A. K., Madawala, U. K., and Thrimawithana, D. J. (2014). An optimal PID controller for a bidirectional inductive power transfer system using multiobjective genetic algorithm. IEEE Trans. Power Electron. 19 (3), 1523–1531. doi:10.1109/tpel.2013.2262953
Park, H. W., Park, S., and Kim, S. (2015). “Variable-speed quadrupedal bounding using impulse planning: Untethered high-speed 3D Running of MIT Cheetah 2,” in 2015 IEEE International Conference on Robotics and Automation (ICRA), Seattle, USA. in.,
Rocco, P. (1996). Stability of PID control for industrial robot arms. IEEE Trans. Robot. Autom. 12 (4), 606–614. doi:10.1109/70.508444
Shiller, Z. (2015). Off-line and on-line trajectory planning Motion and operation planning of robotic systems, mechanisms and machine science. Switzeland: Springer International Publishing, 29–62.
Tan, G. Z., Zeng, Q. D., and Li, W. B. (2004). Intelligent PID controller based on ant system algorithm and fuzzy inference and its application to bionic artificial leg. J. Cent. South Univ. Technol. 11, 316–322. doi:10.1007/s11771-004-0065-7
Thanh, T. D. C., and Ahn, K. K. (2006)., 16. Mechatronics. doi:10.1016/j.mechatronics.2006.03.011Nonlinear PID control to improve the control performance of 2 axes pneumatic artificial muscle manipulator using neural network
Wang, M., Wang, Z., Chen, Y., and Sheng, W. (2020). Adaptive neural event-triggered control for discrete-time strict-feedback nonlinear systems. IEEE Trans. Cybern. 50 (7), 2946–2958. doi:10.1109/tcyb.2019.2921733
Wensing, P. M., Wang, A., Seok, S., Otten, A., Lang, J., and Kim, S. (2017).Proprioceptive actuator design in the MIT cheetah: Impact mitigation and high-bandwidth physical interaction for dynamic legged robots, IEEE Trans. Robot, 33. IEEE Transactions on Robotics, 509–522. doi:10.1109/tro.2016.2640183
Ye, J. (2008). Adaptive control of nonlinear PID-based analog neural networks for a nonholonomic mobile robot. Neurocomputing 71. doi:10.1016/j.neucom.2007.04.014
Keywords: intelligent controller, robotic, manipulators, PID controller, neural network
Citation: Minh Nguyet NT and Ba DX (2023) A neural flexible PID controller for task-space control of robotic manipulators. Front. Robot. AI 9:975850. doi: 10.3389/frobt.2022.975850
Received: 22 June 2022; Accepted: 06 December 2022;
Published: 04 January 2023.
Edited by:
Holger Voos, University of Luxembourg, LuxembourgReviewed by:
Sunan Huang, National University of Singapore, SingaporeDechao Chen, Sun Yat-sen University, China
Copyright © 2023 Minh Nguyet and Ba. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dang Xuan Ba, YmFkeEBoY211dGUuZWR1LnZu