 Emil Beurer
Emil Beurer Moritz Feuerle
Moritz Feuerle Niklas Reich
Niklas Reich Karsten Urban
Karsten Urban- Institute for Numerical Mathematics, Ulm University, Ulm, Germany
We investigate an ultraweak variational formulation for (parameterized) linear differential-algebraic equations with respect to the time variable which yields an optimally stable system. This is used within a Petrov-Galerkin method to derive a certified detailed discretization which provides an approximate solution in an ultraweak setting as well as for model reduction with respect to time in the spirit of the Reduced Basis Method. A computable sharp error bound is derived. Numerical experiments are presented that show that this method yields a significant reduction and can be combined with well-known system theoretic methods such as Balanced Truncation to reduce the size of the DAE.
1. Introduction
Differential-Algebraic Equations (DAEs) are widely used to model several processes in science, engineering, medicine, and other fields. Theory and numerical approximation methods have intensively been studied in the literature, refer to e.g., [1–4], or [5, 6], which are part of a forum series on DAEs. Quite often, the dimension of DAEs modeling realistic problems is so large that an efficient numerical solution (in particular in realtime environments or within optimal control) is impossible. To address this issue, Model Order Reduction (MOR) techniques have been developed and successfully applied. There is a huge amount of literature, we just mention [7–12].
All methods described in those references address a reduction of the dimension of the system, whereas the temporal discretization is untouched. This article starts at this point. We have been working on space-time variational formulations for (parameterized) partial differential equations (pPDEs) over the last decade. One particular issue has been the stability of the arising discretization which admits tight error-residual relations and thus builds the backbone for model reduction. It turns out that an ultraweak formulation is a right tool to achieve this goal. In [13], we have used this framework for deriving an optimally stable variational formulation of linear time-invariant systems (LTIs). In this article, we extend the ultraweak framework to (parameterized) DAEs and show that this can be combined with system theoretic methods such as Balanced Truncation (BT, [11]) to derive a reduction in the system dimension and time discretization size.
1.1. Differential-Algebraic Equations
Let E, A ∈ ℝn × n, n ∈ ℕ, be two matrices (E is typically singular), I = (0, T), T > 0, a time interval, some initial value and f : I → ℝn a given right-hand side. Then, we are interested in the solution x : I → ℝn (the state) of the following initial value problem of a linear DAE with constant coefficients
In order to ensure well-posedness (in an appropriate manner), we shall always assume that the initial value x0 is consistent with the right-hand side f, which means that there exist some such that holds. Finally, we assume that the matrix pencil {E, −A} is regular (i.e., det(λE − A) ≠ 0 for some λ ∈ ℝ) with index ind{E, −A} = : k ∈ ℕ, [14].1
1.2. Parameterized DAEs (pDAEs)
We are particularly interested in the situation, where one does not only have to solve the above DAE once but several times and highly efficient (e.g., in realtime, optimal control, or cold computing devices) for different data. In order to describe that situation, we are considering a parameterized DAE (pDAE) as follows. For some parameter vector , being a compact set, we are seeking such that
where Aμ, fμ, and x0,μ are a parameter-dependent matrix, a right-hand side and an initial condition, respectively, whereas E is assumed to be independent of μ, refer to footnote 5. In order to be able to solve such a pDAE highly efficient for many parameters, it is quite standard to assume that parameters and variables can be separated, refer to e.g., [16]. This is done by assuming a so-called affine decomposition of the data, i.e., E is (for simplicity of exposition) assumed to be parameter-independent and
If such a decomposition is not given, we may produce an affinely decomposed approximation by means of the (Discrete) Empirical Interpolation Method [(D)EIM, [17, 18]; refer also to [9] for a system theoretic MOR for such pDAEs]. For well-posedness, we assume that the matrix pencil {E, −Aμ} is regular with index ind{E, −Aμ} = kμ for all .
1.3. Reduction to Homogeneous Initial Conditions
Using some standard arguments, eq. (1.1) can be reduced to homogeneous initial conditions xμ(0) = 0. To this end, construct some smooth extension of the initial data , . Then, let solve eq. (1.1) with fμ replaced by and homogeneous initial condition . Then, solves the original problem eq. (1.1). If the pDAE and the extension of the initial conditions possess an affine decomposition (for a decomposable refer to Section 3.2.2), it is readily seen that the modified right-hand side also admits an affine decomposition. Hence, we can always restrict ourselves to the case of homogeneous initial conditions xμ(0) = 0, keeping in mind that variable initial conditions can be realized by different right-hand sides.
1.4. Organization of the Material
The remainder of this paper is organized as follows. In Section 2, we derive an ultraweak variational formulation of (1.1) and prove its well-posedness. Section 3 is devoted to a corresponding Petrov-Galerkin discretization and the numerical solution, which is then used in Section 4 to derive a certified reduced model. In Section 5, we report the results of our numerical experiments and end with conclusion and an outlook in Section 6.
2. An Ultraweak Variational Formulation
It is well-known that, for any fixed parameter , the problem (1.1) admits a unique classical solution for consistent initial conditions provided that , e.g., [3, Lemma 2.8.]. This is a severe regularity assumption, which is one of the reasons why we are interested in a variational formulation. As we shall see, an ultraweak setting is appropriate in order to prove well-posedness, in particular stability. It turns out that this setting is also particularly useful for model reduction of (1.1) with respect to the time variable in the spirit of the reduced basis method, refer to Section 4 below.
2.1. An Ultraweak Formulation of pPDEs
In order to describe an ultraweak variational formulation for the above pDAE, we will review such formulations for parametric partial differential equations (pPDEs). In particular, we are going to follow [19] in which well-posed (ultraweak) variational forms for transport problems have been introduced, refer also to [20–22]. We will then transfer this framework to pDAEs in Section 2.2.
Let Ω ⊂ ℝd be some open and bounded domain. We consider a classical2 linear operator Bμ; ∘ on Ω with classical domain
and aim at solving
Note that the definition of Bμ; ∘ also incorporates essential homogeneous boundary conditions (in the case of a pDAE described below this is the initial condition, which is independent of the parameter). Let denote the operator, which is adjoint to {Bμ; ∘, D(Bμ; ∘)}, i.e., is defined as the formal adjoint of Bμ; ∘ by for all and its domain which includes the corresponding adjoint essential boundary conditions (so that the above equation still holds true for all x ∈ D(Bμ; ∘), ). Denoting the range of an operator B by R(B), we have Bμ; ∘ : D(Bμ; ∘) → R(Bμ; ∘) and . The following assumptions3 turned out to be crucial for ensuring the well-posedness:
(B1) with all embeddings being dense;
(B2) is injective on .
Due to (B2), the injectivity of the adjoint operator, the following quantity
is a norm on , where is to be understood as the continuous extension of onto Yμ, i.e., , where
is a Hilbert space. Defining the bilinear form
yields an ultraweak form of (2.1): For 4, determine xμ ∈ L2(Ω) such that
Well-posedness including optimal stability is now ensured:
Lemma 2.1. Problem eq. (2.2) has a unique solution xμ ∈ L2(Ω) and is optimally stable, i.e., , where the continuity constant is defined as
and primal respectively dual inf-sup constants read
Proof: Refer to [19, Proposition 2.1].
2.2. An Ultraweak Formulation of pPDAEs
We are now going to apply the framework of Section 2.1 to the classical form (1.1) of the pDAE. Again, without loss of generality we restrict ourselves to homogeneous initial conditions xμ(0) = 0, as stated in Section 1.3.
It is immediate that we can generalize ultraweak formulations for scalar-valued functions in L2(Ω) as above to systems, i.e., . For pDAEs, we choose with the inner product , whereas (·, ·) denotes the Euclidean inner product of vectors. The linear operator {Bμ; ∘, D(Bμ; ∘)} corresponding to (1.1) reads
The formal adjoint operator is easily derived by integration by parts, i.e.,
which shows that
In fact, for all x ∈ D(Bμ; ∘) and since the boundary terms above still vanish due to x(0) = 0 and y(T) ∈ ker(ET). Moreover, and .
Lemma 2.2. We have with dense embeddings.
Proof: By the definition of and [23, Cor. 7.24] (for H1(I)n instead of H1(I) there, which is a trivial extension), we have
With that, is easy to see. Since is dense in , its supersets are also dense in .
The above lemma ensures assumption (B1). Next, we consider (B2).
Lemma 2.3. The adjoint operator is injective, i.e., for with we have yμ = zμ.
Proof: Setting dμ: = yμ − zμ, we get and
Due to regularity of {E, −Aμ} (and, thus, also of ), there are regular matrices Pμ, , which allow us to transform the problem into Weierstrass-Kronecker normal form, [2, 3], i.e.,
where is the identity and Nμ is a nilpotent matrix with nilpotency index kμ. This yields the equivalent representation
The ODE (2.4a) has the general solution . By (2.4c), we get
Thus, uμ(T) = 0 and hence for all t ∈ I.
The initial value problem , t ∈ I, vμ(T) = vμ, T with some has the unique solution , if the initial value vμ, T is consistent, refer to e.g., [1]. We apply this for . Then, by the solution formula, we get vμ ≡ 0, since the initial value in eq. (2.4c) is by definition trivially consistent. This yields dμ ≡ 0, i.e., yμ = zμ.
Hence, we set and choose trial and test spaces as
refer to (2.3) and obtain the following result.
Lemma 2.4. Under the above assumptions, we have for all that Yμ ≡ Y, where
Proof: Clearly , so that Yμ ⊆ Y for all . Now, let , then, by density, there is a sequence such that as ℓ → 0. Since is compact, we have that
as ℓ → ∞. Hence, , i.e., Y ⊆ Yμ.
The latter result must be properly interpreted. It says that Yμ and Y coincide as sets. However, the norm |||·|||μ (and thus the topology) still depends on the parameter. The same holds true for the dual space Y′ of Y induced by the L2-inner product and normed by
In particular, we have a generalized Cauchy-Schwarz inequality .
Lemma 2.5. Let . Then, there exists a unique weak solution xμ ∈ X of
If (1.1) admits a classical solution, then it coincides with xμ. Moreover, for the constants defined in Lemma 2.1.
Proof: The existence of a unique solution xμ ∈ X (as well as ) is an immediate consequence of Lemma 2.1. It only remains to show that xμ satisfying (2.6) is a weak solution to (1.1). To this end, let be given such that there exists a classical solution with and . Then, define by . We need to show that the classical solution of (1.1) is also the unique solution of (2.6). First, for , integration by parts yields . Second, let , then there is converging to y in Y, i.e., . Then, by the generalized Cauchy-Schwarz inequality
so that (2.6) holds for .
For the ultraweak pDAE (2.6), we need a right-hand side . However, typically, the right-hand side is given within the context of (1.1) as a function of time, i.e., . Then, we simply define by
3. Petrov-Galerkin Discretization
The next step toward a numerical method for solving an ultraweak operator equation is to introduce finite-dimensional trial and test spaces yielding a Petrov-Galerkin discretization. In this section, we shall first review Petrov-Galerkin methods in general terms and then detail the specification for pDAEs.
3.1. Petrov-Galerkin Method
In order to determine a numerical approximation, we are going to construct an appropriate finite-dimensional trial space and a parameter-independent test space of finite (but possibly large) dimension . Then, we are seeking such that
which leads to solving a linear system of equations in .
Remark 3.1. (a) If one would choose a discretization with , one would need to solve a least squares problem .
(b) If one defines the trial space according to , then it is easily seen that the discrete problem eq. (3.1) is well-posed and optimally conditioned, [20], i.e.,
(c) The Xu-Zikatanov lemma [24] ensures that the Petrov-Galerkin error is comparable with the error of the best approximation, namely
so that the Petrov-Galerkin approximation is the best approximation (i.e., an identity) for .
The Petrov-Galerkin framework induces a residual-based error estimation in a straightforward manner. To describe it, let us recall that the residual is defined for some as
Then, it is a standard estimate that
and is a residual-based error estimator. Note that for βμ = 1 we have an error-residual identity .
3.2. pPDAE Petrov-Galerkin Discretization
We are now going to specify the above general framework to pDAEs. This means that we need to introduce a suitable discretization in time. We fix a constant time step size Δt: = T/K (i.e., K ∈ ℕ is the number of time intervals) and choose for simplicity equidistant nodes tk: = kΔt, k = 0, …, K in I. Denote by σk, k = 0, …, K piecewise linear splines corresponding to the nodes tk−1, tk and tk+1, refer to Figure 1. For k ∈ {0, K}, the hat functions are restricted to the interval Ī. For realizing a discretization of higher order, one could simply use splines of higher degree.
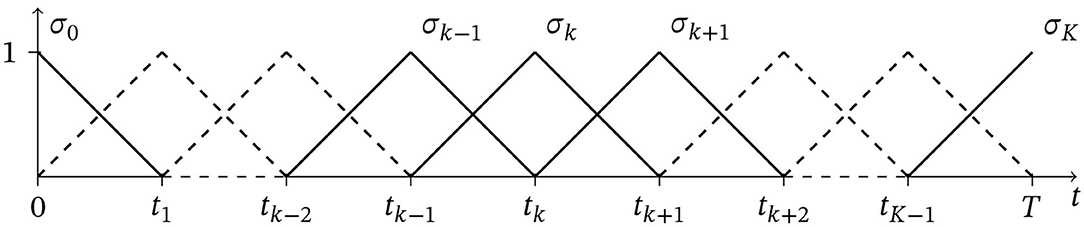
Figure 1. Piecewise linear temporal discretization (hat functions).
As in [20], we start by defining the test space and then construct inf-sup optimal trial spaces. To this end, let d: = dim(ker ET) and assume that we have a basis {v1, …, vd} of ker ET at hand5 and form a matrix by arranging the vectors as columns of V. Then, we construct independent of the parameter and choose the trial space as , which will then guarantee that . We suggest a piecewise linear discretization by
where denotes i-th canonical vector. Then, we set
with dimensions . Then, Lemma 2.5 and Remark 3.1 ensure and thus
3.2.1. The Linear System
To construct the discrete linear system we need bases of and of . The stiffness matrix can be computed by . We recall that , which implies that , so that and is in fact symmetric positive definite.
The right-hand side reads . The discrete solution then reads .
Recalling the finite element functions σk in Figure 1, we define the inner product matrices for k, ℓ = 0, …, K by
and subdivide the matrices for ΠΔt ∈ {KΔt, LΔt, OΔt} according to
Then, the stiffness matrix also has a block structure
in form of Kronecker products of matrices, i.e., (with as above),
For the right-hand side, given some function , we obtain a discretization in the sense of (2.7) by , . This means that we discretize fμ in time by means of piecewise linears. Collecting the sample values of fμ in one vector, i.e., we get that
and again denoting the n-dimensional identity matrix.
As already noted above, of course, one could use different discretizations (e.g., higher order or different discretizations for fμ and the test functions) and we choose the described one just for simplicity.
Due to the Kronecker product structure, the dimension of the system grows rapidly even for moderate n and K. The efficient numerical solution thus requires a solver that takes the specific Kronecker product structure into account in order to accommodate the large system dimension. For similar Kronecker product systems arising from space-time (ultraweak) variational formulations of heat, transport, and wave equations, such specific efficient solvers have been introduced in [21, 25]. However, the solvers in these article are adapted to pPDEs and cannot be used for such kinds of pDAEs we are considering here. Hence, we will devote the development of efficient solvers for ultraweak formulations of pDAEs to future research and refer to Section 6.
3.2.2. Special Case: Fully Linear DAEs
We are going to specify the above general setting to the special case of DAEs with parameter-independent A ≡ Aμ and linear right-hand side which we will call in in the following fully linear DAEs, i.e.,
in which the right-hand side depends on the composite parameter μ: = (u, μ2) and is given in terms of a matrix D ∈ ℝn×m, a control u : Ī → ℝm, m denoting some input dimension and a function , which arises from the reduction to homogeneous initial conditions, refer to Section 1.3. The initial condition is assumed to be parameterized through gμ2 by , p2 ∈ ℕ. In view of (1.2) and Section 1.3, we get
where are smooth extensions of , i.e., , q = 1, …, Qx.
We view the control and the initial condition (via gμ2) as parameters, i.e., fμ(t) = Dμ1(t) + gμ2(t), μ = (μ1, μ2), which means that the parameter set would be infinite-dimensional and needs to be discretized. Using the same kind of discretization as above, we can use the samples of the control as a parameter, i.e.,
and similar to the initial condition , q = 1, …, Qx. Then, we get
so that the parameter dimension is p = p1 + p2 = m(K + 1) + p2, which might be large. The right-hand side thus also admits an affine decomposition with Qf = p1 + Qx = m(K + 1) + Qx terms. However, this number might be an issue concerning efficiency if K is large, we nevertheless have if m ≪ n.
Moreover, in the fully linear case, the matrix Aμ ≡ A is independent of the parameter, which means (among other facts) that trial and test spaces are parameter-independent, as sets and also with respect to their topology. Note that this is the most common case for system theoretic MOR methods (like BT), which are often even restricted to this case, [10, 11], with the exception [9]. Our setting seems more flexible in this regard and fully linear DAEs are just a special case.
4. Model Order Reduction: The Reduced Basis Method
The Reduced Basis Method (RBM) is a model order reduction technique that has originally been constructed for parameterized partial differential equations (pPDEs), refer to e.g., [7, 16, 26]. In an offline training phase, a reduced basis of size is constructed (typically in a greedy manner, refer to Algorithm 1 below) from sufficiently detailed approximations for certain parameter samples (also called truth approximations or snapshots), which are computed e.g., by a Petrov-Galerkin method as described above. In particular, is assumed to be sufficiently large in order to ensure that is (at least numerically) indistinguishable from the exact state xμ, which explains the name truth. As long as an efficient solver for the detailed problem is available, we may assume that the snapshots can be computed in complexity.
Given some parameter value μ, the reduced approximation xN(μ)6 is then computed by solving a reduced system of dimension N. As a result of the affine decomposition (1.2), several quantities for the reduced system can be precomputed and stored so that a reduced approximation is determined in operations, independent of (which is called online efficient). Moreover, an a posteriori error estimator ΔN(μ) guarantees a certification in terms of an online efficiently computable upper bound for the error, i.e., .
We are going to use this framework for pDAEs of the form (1.1). Model reduction of (1.1) may be concerned (at least) with the following quantities
• Size n of the system,
• Dimension K of the temporal discretization,
where we have in mind to solve (1.1) extremely fast for several values of the parameter μ. As mentioned earlier, the first issue has extensively been studied in the literature e.g., by system theoretic methods, in particular for fully linear DAEs (3.5). This can be done independently from the subsequent reduction with respect to K (both for parameterized and non-parameterized versions), so we even might assume that such Model Order Reduction (MOR) techniques have already been applied in a preprocessing step. We mention [9] a system theoretic MOR for parameter-dependent DAEs. Here, we are going to consider the reduction with respect to time using the RBM based upon a variational formulation with respect to the time variable.
We restrict ourselves to the reduction of the fully linear case of (3.5) as it easily shows how the RBM-inspired model reduction can be combined with existing system theoretic approaches to reduce the size of the system (e.g., in a preprocessing step). In the fully linear case, the matrix Aμ ≡ A and, hence, all operators and bilinear forms on the left-hand side are parameter-independent. This implies in addition that the ansatz space and the norm |||·|||μ ≡ |||·||| inducing the topology on the test space are parameter-independent as well, which of course simplifies the framework. However, parameter-dependent matrices Aμ can be treated similar to the RBM for ultraweak formulations of pPDEs as described e.g., in [20–22]. We further note that the RB approach also allows the treatment of more general pDAEs and is not restricted to fully linear systems (3.5), in particular with respect to the right-hand side.
The idea of the RBM can be described as follows: One determines sample values
of the parameters in an offline training phase by a greedy procedure described in Algorithm 1 below. Then, for each μ ∈ SN, we determine a sufficiently detailed snapshot by the ultraweak Petrov-Galerkin discretization as in Section 3.2 and obtain a reduced space of dimension N by setting
We also need a reduced test space for the Petrov-Galerkin method. Recalling that the operator is parameter-independent here (Bμ ≡ B) and also the trial space is independent of μ, we can easily identify the optimal test space. In fact, for each snapshot, there exists a unique such that . Then, we define
Then, given a new parameter value , one determines the reduced approximation xN(μ) ∈ XN by solving (recall that here bμ ≡ b).
If , we can compute a reduced approximation with significantly less effort as compared to the Petrov-Galerkin (or a time-stepping) method. To determine the reduced approximation xN(μ), we have to solve a linear system of the form BNxN(μ) = fN(μ), where the stiffness matrix is given by [BN]j,i = b(ζi, ηj), i, j = 1, …, N, recalling that the bilinear form is parameter-independent. Hence, can be computed and stored in the offline phase. For the right-hand side, we use the affine decomposition (1.2) and get . The quantities can be precomputed and stored in the offline phase so that fN(μ) is computed online efficiently in operations. Obtaining the coefficient vector xN(μ), the reduced approximation results in . Note that the matrix BN is typically densely populated so the numerical solution requires in general operations.
The announced greedy selection of the samples is based upon the residual error estimate (here identity) in (3.3) respectively (3.4) for the reduced system described as follows: In a similar manner as deriving in (3.3), we get a residual based error estimator for the reduced approximation
since the bilinear form and the norm in Y are parameter-independent here. Hence, the inf-sup constant is parameter-independent as well, i.e., and it is unity by Remark 3.1, so that
Its computation can be done in an online efficient manner in operations by determining Riesz representations in the offline phase, refer to [7, 16, 26]. We use this error identity in the greedy method in Algorithm 1 below.

Algorithm 1. (Weak) Greedy method
5. Numerical Experiments
In this section, we report on the results of some of our numerical experiments. Our main focus is on the numerical solution of the ultraweak form of the pDAE, the error estimation, and the quantitative reduction. We solve the arising linear systems for the Petrov-Galerkin and the reduced system by MATLAB's backslash operator, refer also to our remarks in Section 6 below. The code for producing the subsequent results is available via https://github.com/mfeuerle/Ultraweak_PDAE.
5.1. Serial RLC Circuit
We start with a standard problem which (in some cases) admits a closed formula for the analytical solution. This allows us to monitor the exact error and comparison with standard time-stepping methods. Our particular interest is the approximation property of the ultraweak approach, which is an L2-approximation.
The serial RLC circuit consists of a resistor with resistance R, an inductor with inductance L, a capacitor with capacity C and a voltage source fed by a voltage curve fVS : Ī → ℝ. Kirchhoff's circuit and further laws from electrical engineering yield a DAE with the data.
whose index is k = 1. The solution x consists of the electric current xI and the voltages at the capacitor xVC, at the inductor xVL, and the resistor xVR.
5.1.1. Convergence of the Petrov-Galerkin Scheme
In Figure 2, we compare the exact solution with approximations generated by a standard time-stepping scheme (using MATLAB's fully implicit variable order solver with adaptive step size control ode15i, [27]) and by our ultraweak formulation from Section 3.2. We choose two specific examples for fVS, namely a smooth and a discontinuous one,
For the smooth right-hand side (left graph in Figure 2), both ode15i and the ultraweak method give good results. Concerning the deviations for the ultraweak approach at the start and end time, we recall that the ultraweak form yields an approximation in L2 so pointwise comparisons are not necessarily meaningful.
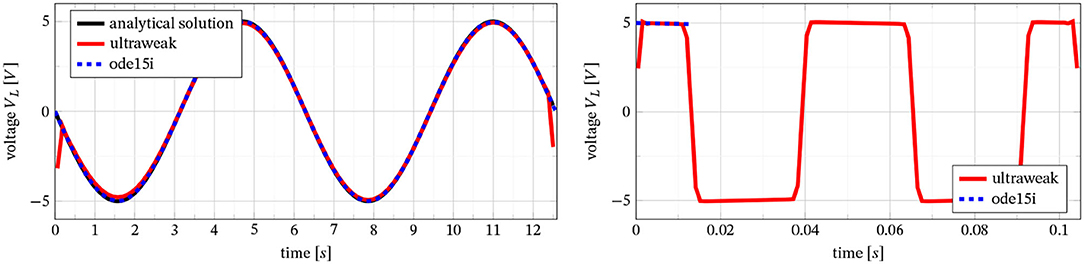
Figure 2. Serial RLC circuit, the exact voltage at the inductor; comparison of time-stepping (ode15i – blue) and ultraweak (red) approximation for smooth (left, including analytical solution) and discontinuous (right) right-hand side.
In the discontinuous case, the existence of a classical solution cannot be guaranteed by the above arguments. In particular, there is no closed solution formula. As we see in the right graph in Figure 2, ode15i stops at the first jump. This is to be expected, since , so that the solution lacks sufficient regularity to guarantee convergence of a time-stepping scheme like ode15i (even though it is an adaptive variable order method). We could resolve the jumps even better by choosing more time steps K, while ode15i still fails. We conclude that the ultraweak method also converges for problems lacking regularity.
5.1.2. Convergence Rate
Next, we investigate the rate of convergence for the ultraweak form. To that end, we use , since the analytical solution x* is known and we can thus compute the relative error . Using the lowest order discretization as mentioned above (namely piecewise linear test functions ψj, which yield discontinuous trial functions ), we can only hope for the first order (with respect to the number of time steps K), which we see in Figure 3 and was observed in all cases we considered. We obtain higher order convergence by choosing test functions of higher order, provided the solution has sufficient smoothness.
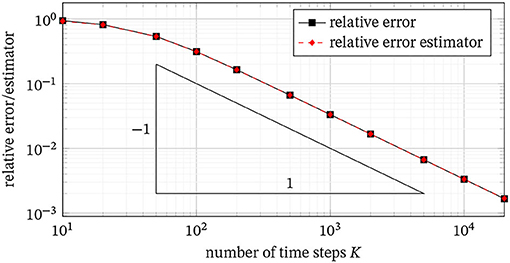
Figure 3. Relative error and relative error estimator with respect to the analytical solution x* for increasing numbers of time steps K.
Moreover, we compare the exact relative error with our error estimator (refer to Section 3.1). Figure 3 shows a perfect matching confirming the error-residual identity (3.4) also for the numerically computed error estimator.
5.2. Time-Dependent Stokes Problem
In order to investigate the quantitative performance of the model reduction, we consider a problem, which has often been used as a benchmark, [28–31], namely the time-dependent Stokes problem on the unit square (0, 1)2, discretized by a finite volume method on a uniform, staggered grid for the spatial variables with n unknowns, [31], where we choose n = 644. The arising homogeneous fully linear DAE with output function y : I → ℝ takes the form (3.5),
where C ∈ ℝ1 × n is an output matrix, D ∈ ℝn×1 is the control matrix, and u : I → ℝ is a control, which serves as a parameter μ ≡ u as described in Section 3.2.2 above. We use a parameter-independent initial condition, so that gμ ≡ g and Qx = 1.
In order to combine system theoretic model reduction with the RBM from Section 4, we use the system theoretic model order reduction package [28]. In particular, we use Balanced Truncation (BT) from [30] during a preprocessing step to reduce the above system of dimension n to a system
with , , as well as and . We note that the resulting reduced system typically provides regular matrices . Then, the reduced system is an LTI system, which is an easier problem than a DAE and in fact a special case. Hence, our presented approach is still valid, even though designed for pDAEs. For an ultraweak formulation of LTI systems, we refer to [13].
Remark 5.1. We use the RBM here for deriving a certified reduced approximation of the state x. If we would want to control the output y along with a corresponding error estimator , it is fairly standard in the theory of RBM to use a primal-dual approach with a second (dual) reduced basis, e.g., [16, 26]. For simplicity of exposition, we leave this to future study and compute the output from the state by , respectively Cx(t).
5.2.1. Discretization of the Control Within the RBM
Since we use a variational approach, we are in principle free to choose any discretization for the control (we only need to compute inner products with the test basis functions). We tested piecewise linear discretizations as described in Section 3.2 for different step sizes T/Ku, where Ku might be different from K, which we choose for discretizing the state. Doing so, the parameter reads , i.e., the parameter dimension is p = Ku + 1, which might be large. Large parameter dimensions are potentially an issue for the RBM since the curse of dimension occurs. Hence, we investigate if we can reduce Ku within the RBM.
In order to answer this question, we apply Algorithm 1 to the time-dependent Stokes problem (5.1a) (without BT) setting ε = 0, Nmax = Qf from (1.2) (i.e., Qf = p + 1 for the fully linear system with parameter-independent initial value) and consisting of 500 random vectors for Ku ≡ K ∈ {75, 150, 300}, i.e., , where d = 224. For these three cases, we investigate the max greedy training error, i.e., . The results in Figure 4 show an exponential decay with respect to the dimension N of the reduced system with slower decay as K grows. This is to be expected as the discretized control space is much richer for growing Ku and the reduced model has to be able to represent this variety. However, in relative terms (i.e., reduced size N compared with full size K), we see that the compression rates are almost the same. This shows that the RBM can effectively reduce the system no matter how strong the influence of the control on the state is. It is expected that this potential is even more pronounced if a primal-dual RBM is used for the output.
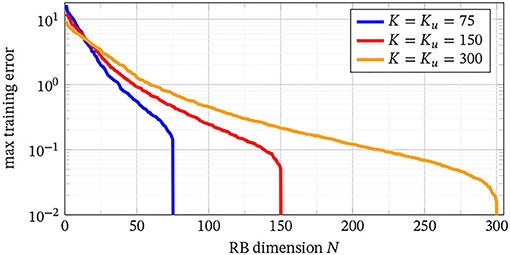
Figure 4. Maximal greedy training error for different time resolutions Ku = K ∈ {75, 150, 300} over the reduced dimension N.
Next, we note that for A ≡ Aμ as (5.1a), the reduced model is always exact for N ≥ Qf, which explains the drop off of the curves in Figure 4. For fully linear DAEs, a reduced model with N ≥ Qf = Ku + 2 is always exact. Hence, if m ≪ n (here m = 1 ≪ 644 = n), we obtain an exact reduced model of dimension . Even though this seems to be attractive for low-dimensional outputs, we stress the fact that the reduced dimension still depends on the temporal dimension Ku, which might be large. Hence, a combination of a possibly small discretization of the control and an RBM seems necessary.
Let us comment on the error decay of the RBM produced by the greedy method using the error estimator derived from the ultraweak formulation of the pDAE. We obtain exponential decay of the error, which in fact shows the potential of the RBM. The question whether a given pDAE permits a fast decay of the greedy RBM error is well-known to be linked to the decay of the Kolmogorov N-width, [7, 16, 22], which is a property only of the problem at hand. In other words, if a pDAE can be reduced with respect to time, the greedy method will detect this.
The results in Figure 4 use Ku = K. The next question is how the error behaves for Ku < K. To this end, we determine the error in the state with respect to the full resolution, i.e., we compare the state derived from the control with Ku degrees of freedom with the state of the fully resolved control. In Figure 5, we display errors for different values for K. We obtain fast convergence, which again shows the significant potential for a reduced temporal discretization of the control.
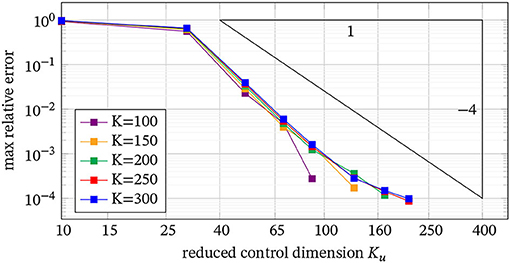
Figure 5. Max error for control dimensions of size Ku < K.
5.2.2. Combination With BT/RBM Error Decay
Next, we wish to investigate if a combination of a system theoretic MOR (here BT) and an RBM-like reduction with respect to time can be combined. To this end, we fix the temporal resolution (i.e., the number of time steps, here K = Ku = 300) and determine the RBM error using Algorithm 1 for the full and the BT-reduced system. We use [28] to compute the BT from [30] and obtain an LTI system of dimension .
The results are shown in Figure 6, where we again show the maximal training error. As can be seen, the error for the BT-reduced system is smaller than the original one7, which in fact indicates that we can combine both methods. We get similar results for other choices of K. This shows that there is as much reduction potential in the reduced system eq. (5.2a) as in the original system eq. (5.1a). In other words, a combination of BT and RBM shows significant compression potential.
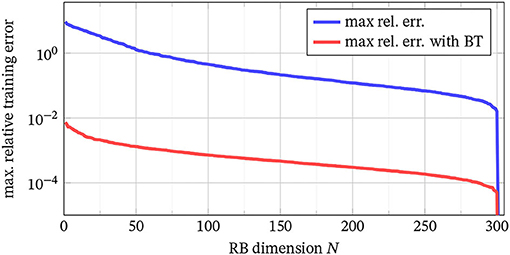
Figure 6. Maximal RBM relative error decay over the reduced dimension N for the full system eq. (5.1a) (blue) and the reduced system eq. (5.2a) with K = 300 (red).
However, applying BT first implies that the error estimator measures the difference with respect to the BT-reduced model and not with respect to the original problem, which means that we somehow lose part of the rigor implied by the fact that our error estimator coincides with the error. If one wants to preserve the rigor, it seems that a full pPDE model is required, which is possible in cases where the pDAE originates from a (known) discretization of a pPDE.
6. Conclusion and Outlook
In this article, we introduced a well-posed ultraweak formulation for DAEs and an optimally stable Petrov-Galerkin discretization, which admits a sharp error bound. The scheme shows the expected order of convergence depending on the regularity of the solution and the smoothness of the trial functions. The scheme also converges in low-regularity cases, where classical standard time-stepping schemes fail. Moreover, the stability of the Petrov-Galerkin scheme allows us to choose any temporal discretization without satisfying other stability criteria like a CFL condition.
Based upon the ultraweak framework, we introduced a model order reduction in terms of the Reduced Basis Method with an error/residual identity. We have obtained fast convergence and the possibility to combine the RBM for a reduction with respect to time with system theoretic methods such as Balanced Truncation to reduce the size of the system.
There are several open issues for future research. We already mentioned a primal-dual RBM for an efficient reduction of the output, the generalization to parameter-dependent matrices Aμ, and more general DAEs (not only fully linear). We also mentioned that the system matrix is a sum of Kronecker products of high dimension, which calls for specific solvers as in [21] for the (parameterized) wave equation. Another issue in that direction is the need for a basis of ker(ET), which might be an issue for high-dimensional problems.
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Author Contributions
All authors listed have made a substantial, direct, and intellectual contribution to the work and approved it for publication.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We acknowledge support by the state of Baden-Württemberg through bwHPC.
Footnotes
1. ^Each regular matrix pencil can be transformed into Weierstrass-Kronecker canonical form P(λE − A)Q = diag(λId − W, λN − Id) with regular matrices P, Q ∈ ℂn × n, [15]. The index of a regular matrix pencil {E, − A} is then defined by ind{E, − A}: = ind{N}: = min{k ∈ ℕ : Nk = 0}.
2. ^By classical we mean defined in a pointwise manner.
3. ^The framework in [19] is slightly more general.
4. ^ denotes the dual space of Yμ with respect to the pivot space L2(Ω).
5. ^This is in fact the reason why we restricted ourselves to parameter-independent matrices E instead of Eμ. We would then need to have a parameter-dependent basis for , which is, of course, possible, but causes a quite heavy notation.
6. ^For all quantities of the reduced system, we write the parameter μ as an argument in order to clearly distinguish the detailed approximation from the reduced approximation xN(μ) for the same parameter.
7. ^This remains true even after additionally normalizing the training error by the dimensions of the DAE (n and , respectively) or the dimension of the resulting linear system (Kn + d and , respectively).
References
1. Brenan KE, Campbell SL, Petzold LR. Numerical Solution of Initial-Value Problems in Differential-Algebraic Equations. Philadelphia, PA: SIAM (1995). doi: 10.1137/1.9781611971224
2. Hairer E, Wanner G. Solving Ordinary Differential Equations II. Vol. 14. Berlin: Springer (2010).
3. Kunkel P, Mehrmann V. Differential-Algebraic Equations. Zürich: European Mathematical Society (EMS) (2006).
4. Trenn S. In: Ilchmann A, Reis T. Solution Concepts for Linear DAEs: A Survey. Berlin: Springer (2013). doi: 10.1007/978-3-642-34928-7_4
5. Grundel S, Reis T, Schöps S. Progress in Differential-Algebraic Equations II. Cham: Springer (2020).
6. Schöps S, Bartel A, Günther M, ter Maten EJ, Müller PC. Progress in Differential-Algebraic Equations. Berlin: Springer (2014).
7. Benner P, Cohen A, Ohlberger M, Willcox K. Model Reduction and Approximation: Theory and Algorithms. Philadelphia, PA: SIAM (2017). doi: 10.1137/1.9781611974829
8. Benner P, Stykel T. Model order reduction for differential-algebraic equations: A survey. In: Ilchmann A, Reis T, editors. Surveys in Differential-Algebraic Equations IV. Cham: Springer (2017). p. 107–60. doi: 10.1007/978-3-319-46618-7_3
9. Chellappa S, Feng L, Benner P. Adaptive basis construction and improved error estimation for parametric nonlinear dynamical systems. Int J Num Methods Eng. (2020) 121:5320–49. doi: 10.1002/nme.6462
10. Mehrmann V, Stykel T. Balanced truncation model reduction for large-scale systems in descriptor form. In: Benner P, Sorensen DC, Mehrmann V, editors. Dimension Reduction of Large-Scale Systems. Berlin: Springer (2005). p. 83–115. doi: 10.1007/3-540-27909-1_3
11. Stykel T. Balanced truncation model reduction for descriptor systems. PAMM. (2003) 3:5–8. doi: 10.1002/pamm.200310302
12. Stykel T. Gramian-based model reduction for descriptor systems. Math Control Signals Syst. (2004) 16:297–319. doi: 10.1007/s00498-004-0141-4
13. Feuerle M, Urban K. A variational formulation for LTI-systems and model reduction. In: Vermolen FJ, Vuik C, editors. Numerical Mathematics and Advanced Applications ENUMATH 2019. Cham: Springer (2021). p. 1059–67. doi: 10.1007/978-3-030-55874-1_105
14. Gear CW, Petzold LR. Differential/algebraic systems and matrix pencils. In: Kragström B, Ruhe A, editors. Matrix Pencils. Berlin: Springer (1983). p. 75–89. doi: 10.1007/BFb0062095
16. Hesthaven JS, Rozza G, Stamm B. Certified Reduced Basis Methods for Parametrized Partial Differential Equations. Cham: Springer (2016). doi: 10.1007/978-3-319-22470-1
17. Barrault M, Maday Y, Nguyen NC, Patera AT. An empirical interpolation method: application to efficient reduced-basis discretization of partial differential equations. C R Acad Sci. (2004) 339:667–72. doi: 10.1016/j.crma.2004.08.006
18. Chaturantabut S, Sorensen D. Nonlinear model reduction via discrete empirical interpolation. SIAM J Sci Comput. (2010) 32:2737–64. doi: 10.1137/090766498
19. Dahmen W, Huang C, Schwab C, Welper G. Adaptive Petrov-Galerkin methods for first order transport equations. SIAM J Num Anal. (2012) 50:2420–45. doi: 10.1137/110823158
20. Brunken J, Smetana K, Urban K. (Parametrized) First order transport equations: realization of optimally stable Petrov-Galerkin methods. SIAM J Sci Comput. (2019) 41:A592–621. doi: 10.1137/18M1176269
21. Henning J, Palitta D, Simoncini V, Urban K. An ultraweak space-time variational formulation for the wave equation: Analysis and efficient numerical solution. ESAIM: Math Modell Numer Anal. (2022) 56:1173–98. Available online at: https://www.esaim-m2an.org/articles/m2an/pdf/2022/04/m2an210138.pdf
22. Urban K. The Reduced Basis Method in Space and Time: Challenges, Limits and Perspectives. Ulm: Ulm University (2022).
23. Arendt W, Urban K. Partial Differential Equations: An analytic and Numerical Approach. Transl. by J. B. Kennedy. New York, NY: Springer (2022).
24. Xu J, Zikatanov L. Some observations on Babuška and Brezzi theories. Num Math. (2003) 94:195–202. doi: 10.1007/s002110100308
25. Henning J, Palitta D, Simoncini V, Urban K. Matrix oriented reduction of space-time Petrov-Galerkin variational problems. In: Vermolen FJ, Vuik C, editors. Numerical Mathematics and Advanced Applications ENUMATH 2019. Cham: Springer (2019). p. 1049–57. doi: 10.1007/978-3-030-55874-1_104
26. Quarteroni A, Manzoni A, Negri F. Reduced Basis Methods for Partial Differential Equations: An Introduction. vol. 92. Springer (2015). doi: 10.1007/978-3-319-15431-2
28. Saak J, Köhler M, Benner P. MM.ESS-2.2-The Matrix Equations Sparse Solvers Library. (2022). Available online at: https://www.mpi-magdeburg.mpg.de/projects/mess
29. Schmidt M. Systematic Discretization of Input/Output Maps and Other Contributions to the Control of Distributed Parameter Systems. Berlin: TU Berlin (2007).
30. Stykel T. Balanced truncation model reduction for semidiscretized Stokes equation. Linear Algebra Appl. (2006) 415:262–289. doi: 10.1016/j.laa.2004.01.015
Keywords: differential-algebraic equations, parametric equations, ultraweak formulations, Petrov-Galerkin methods, model reduction
Citation: Beurer E, Feuerle M, Reich N and Urban K (2022) An Ultraweak Variational Method for Parameterized Linear Differential-Algebraic Equations. Front. Appl. Math. Stat. 8:910786. doi: 10.3389/fams.2022.910786
Received: 01 April 2022; Accepted: 31 May 2022;
Published: 14 July 2022.
Edited by:
Benjamin Unger, University of Stuttgart, GermanyReviewed by:
Robert Altmann, University of Augsburg, GermanyMartin Hess, International School for Advanced Studies (SISSA), Italy
Copyright © 2022 Beurer, Feuerle, Reich and Urban. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Karsten Urban, a2Fyc3Rlbi51cmJhbkB1bmktdWxtLmRl