 Keisuke Otaki
Keisuke Otaki Akihisa Okada
Akihisa Okada Hiroaki Yoshida
Hiroaki Yoshida- Toyota Central R&D Labs., Inc., Bunkyo-ku, Tokyo, Japan
The aim of this study was to explore the information disclosure (ID) problem, which involves selecting pairs of two sides before matching toward user-oriented optimization. This problem is known to be useful for mobility-on-demand (MoD) platforms because drivers' choice behaviors are appropriately modeled, but solving the problem is still under development, although heuristic solvers have been proposed. We develop new branch-and-bound-based (BnB) solvers and a new heuristic solver based on a quadratic unconstrained binary optimization (QUBO) formulation. Our numerical experiments show that the QUBO-based solver indeed works within the limit of available bits, and the BnB solver performs slightly better than existing heuristic ones.
1. Introduction
Matching between two sides (e.g., items and users, items and markets) is an essential task in many real-world applications. Bipartite graph matching has been investigated as a fundamental problem to model such a matching between two sides [1]. A weighted variant of bipartite matching is often applied to find the best matching in terms of associated weights and some global objective functions defined on bipartite graphs. Individual weights could represent various indicators, such as prices, distances, times, and probabilities of taking certain pairs. Real-world applications of matching include matching between children and schools [2, 3], resource allocation [4, 5], and transportation [6, 7]. In another category of settings, the weights of edges can be defined following some probabilistic semantics to represent intuitionistic phenomena [8]. From the optimization viewpoint related to matching, particularly on transportation, other related studies using Fuzzy logic for the intuitionistic phenomena are found in Kumar [9, 10]. Previously, several global properties desired by participants (e.g., platformer/service provider, and individual users) have been studied for bipartite graph matching; an example is to consider stable matching with stated preferences (e.g., given preferences concerning items on another side) [11]. Other examples representing preferences include the use of ranked lists of elements to represent preferences and the use of utility values to quantify preferences (e.g., [12–14]).
Figure 1 illustrates a global optimization task on bipartite matching between drivers and customer orders in the transportation domain. Therefore, each driver has four possible assignments. Typically, driver–order pairs have given weights, representing benefits earned by the service, for example. Then, weighted bipartite matching is used to decide a bipartite matching to select the most profitable pairs as a traditional global optimization task. The optimized result on matching is meaningful for some platformers. However, it is not always valuable and acceptable for individuals; for example, some drivers in the traditional matching should pick up some less profitable orders due to the global optimal matching criteria.
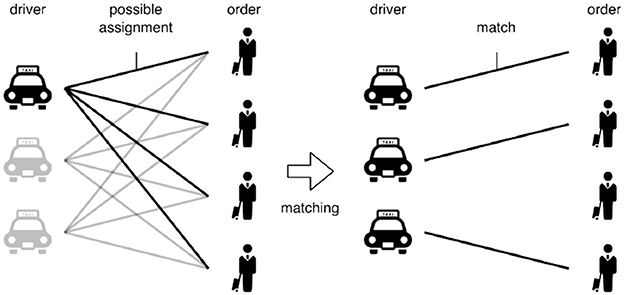
Figure 1. Global optimization task on bipartite graphs for the transportation domain. Out of possible driver–order assignments, pairs among drivers and orders are decided in terms of some global metric (e.g., total profit).
Focusing on individual participants on each side of bipartite matching is now an emerging topic for human-oriented decision-making. In contrast to the traditional scenario illustrated in Figure 1, possible assignments are not equivalently acceptable, and weights are not fixed by users from the user-oriented perspective. Yang et al. [15] studied the information disclosure (ID) problem, where weights are not directly and explicitly given, but weights themselves are determined following relative values of items displayed to drivers. In particular, such weights can be optimized by selecting displayed items for each driver. Figure 2 illustrates the idea discussed in the ID problem. The authors adopted discrete choice models to represent the probability of each driver wanting to choose orders and try to optimize the probabilities of drivers' choices. In the ID problem, the authors proposed to prune redundant choices. Pruning redundant choices can be beneficial to drivers as they match with items with higher probabilities than those without pruning, where we can design candidates of choice for users by focusing on the aspect from the users' side. The idea of the ID problem is to cover as many orders as possible with higher probabilities using selection probability (see Section 2 for details), and finally, to solve ordinal weighted matching to realize the driver–order pairs. The authors showed that the aforementioned indirect optimization task is valuable for real-world mobility-on-demand (MoD) services. Note that such a user-oriented aspect of optimization problems has attracted much attention (e.g., user-oriented routing [16, 17] and on-demand transportation [18]). In particular, the adopted discrete choice model is connected to stated preferences, which are studied in the stable matching literature. However, the essential difference is whether or not such preferences are given. That is, in the ID problem, we optimize our decisions to fix such choice probabilities, which indirectly represent preferences among orders.
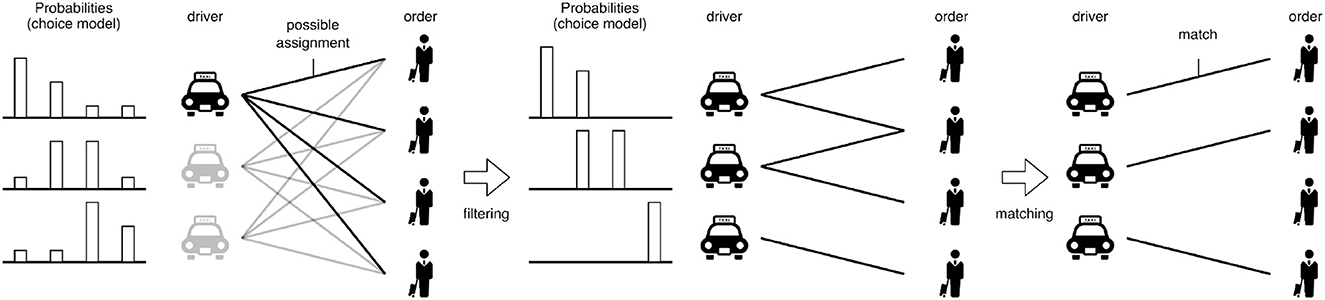
Figure 2. Concepts of the information disclosure, where probabilities, drivers, and orders are illustrated. In the first step, choice probabilities are optimized by selecting disclosures in the ID problem to clarify the structure among drivers and orders. In the second step, we try to solve the matching problem.
Along with the formulation of the ID problem, Yang et al. developed two heuristic solvers, which are reviewed in Section 2.2 and [15]. However, comparisons with other solvers have yet to be made and the ability of these solvers in terms of algorithms is unknown. Since Yang et al. [15] discussed and evaluated the ID problem in real-world MoD applications, we expect that studying solvers for the ID problem improves such service qualities directly. Furthermore, experimentally comparing the solvers give us insights into the ID problem itself, as it is a relatively new optimization problem. In article paper, we propose new approaches and make comparisons with their previous results. The systematic comparisons clarify the performance of existing methods and the newly developed three approaches: a method based on a quadratic unconstrained binary optimization (QUBO) formulation compatible with the quantum annealing, an enumeration-based exact method, and a branch-and-bound-based solver. We experimentally evaluate these approaches together with re-implemented existing solvers using two sets of randomly generated ID problems with (a) uniform distribution and (b) truncated Gaussian distribution in accordance with Yang et al. [15]. Throughout the experiments, the existing algorithms perform well empirically, particularly in instances of (b). The QUBO-based formulation is shown to give good solutions, but the problem size is rather limited mainly because of the many dummy variables required to transform the original problem. The enumeration-based and the branch-and-bound-based solvers are found to provide slightly better solutions than the existing solvers in certain ranges of the number of orders and drivers.
2. Materials and methods
2.1. Preliminary
2.1.1. Discrete choice model
Following an MoD scenario, let D = {d1, …, dm} and O = {o1, …, on} be sets of drivers and customer orders, respectively. We assume that each driver d∈D selects an order o∈O with probability pd, o1, which is formally defined following a discrete choice model [14, 19]. From the perspective of MoD platforms, a utility2 Ûd, o is the sum of a deterministic term Ud, o and a random term ϵd, o, that is, Ûd, o: = Ud, o+ϵd, o. Therefore Ud, o is evaluated for each transportation service with the fee fo of an order o∈O, and the distance τd, o of a pair (d, o)∈D×O, Ud, o is defined as Ud, o: = β0+β1fo+β2τd, o with three preference parameters β: = {β0, β1, β2}. In particular, these parameters β can be estimated from collected data by using maximum-likelihood estimation3 [20]. The use of this model is a standard approach in MoD research (e.g., Hikima et al. [18]).
Let Od⊂O be a set of orders displayed to the driver d∈D. Let be the initial utility4 of driver d. Furthermore, we denote by {s} that d does not select any order from Od. Yang et al. adopted the following nested multinomial logit (NMNL) model in Equation (1) to define pd, o with the parameter α [15]5:
Where , , , and .
2.1.2. Evaluation with decision variables
We prepare the binary decision variables , where xd, o = 1 means the system displays o to d. Table 1 shows an example of evaluating pd, o when Ud, o and are given. Figure 3 illustrates four possible displays for the orders Od = {o1, o2}; that is, we have (xd,o1, xd,o2)∈{(0, 0), (0, 1), (1, 0), (1, 1)}. The probabilities computed with different are summarized in Table 1. In the following, means the probabilities evaluated with the decision variables .
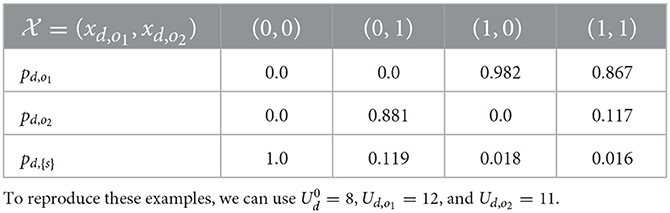
Table 1. Examples of evaluating probabilities pd, o with Od = {o1, o2}, α = 1 under different four (xd,o1, xd,o2) values [i.e., (0, 0), (0, 1), (1, 0), and (1, 1)].
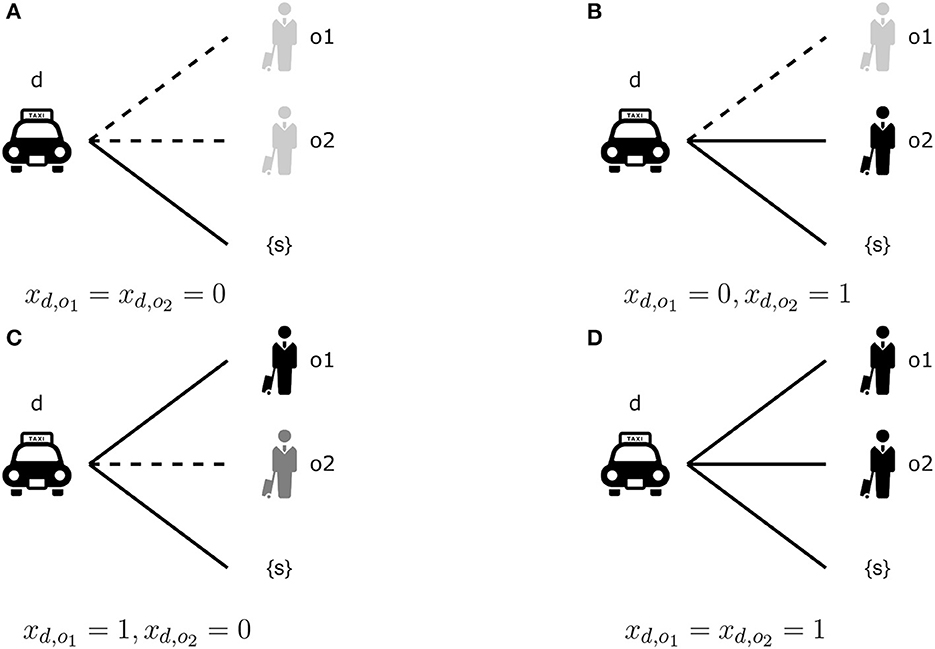
Figure 3. Four possible disclosure instances. (A) means no choice is shown. (B, C) Mean only one order is displayed. (D) The case all orders are given to the driver d. Note that pd, o = 0 if xd, o = 0, i.e., a driver cannot select an order that is not displayed.
The ID problem studied in Yang et al. [15] is an unconstrained maximization problem of the objective function:
Where the term is the probability of at least one driver selecting o for each order o∈O.
2.2. Existing solvers
The solvers studied in Yang et al. [15] are classified into two categories: (1) closed-form solvers and (2) optimization-based solvers. Therefore, we focus on (2), which is actually the main contribution of Yang et al. [15] showing their solvers to be promising. Optimization-based solvers in (2) are designed to maximize Equation (2). The authors proposed a greedy local search method called intuitive edge cutting (IEC) and a method called minimal-loss edge cutting (MLEC), which accelerates IEC by pruning redundant candidates.
The basic idea of the two methods is to design a greedy method by evaluating the increments of objective values. Let be a current disclosure solution, and be a modified solution, where one edge (d, o)∈D×O is removed from , that is, . The difference for of the probability for (d, o′) affects the probability as . Furthermore, the difference arises for o. With these differences combined, the gain of removing (d, o) is defined as follows:
With Equation (3), IEC and MLEC are executed as follows:
• IEC: Begin with . Find (d′, o′) that maximizes Δ, and updates while such (d′, o′) exists.
• MLEC: When computing Δ in IEC, filter (d, o) with the probabilities and reduces the number of candidates of size O(nm) to O(m).
Recall that Yang et al. stated that (1) MLEC can be faster than IEC, (2) MLEC can find better solutions within limited computational resources, and (3) the use of ID problem enhances matching results (e.g., more beneficial for MoD platforms) [15]. However, we have no insights on how well IEC and MLEC perform, as they are greedy solvers.
2.3. Proposed methods
To deeply understand and conduct experimental comparisons to analyze the ID problem, we develop new solvers. For complex combinatorial optimization problems such as the ID problem in this article, the standard approach to design a solver is to follow the branch-and-bound idea [21]. Therefore, this article develops a branch-and-bound-based solver for the experimental study of the ID problem. Furthermore, recent advantages of quantum-based methods have attracted much attention to the use of quantum-inspired methods to solve combinatorial problems. From this perspective, we also design how to apply such a quantum-inspired method to the ID problem.
2.3.1. QUBO formulation
Quantum annealing (QA) is a heuristic optimization method that is to solve combinatorial optimization problems [22] and has been attracting attention from the theory and industry communities [23]. Its theoretical and physics-based backgrounds are stated in Lucas [22]. The QA is supposed to efficiently and approximately solve QUBO problems, which minimizes as follows:
Although the current objective function in Equation (2) is not a quadratic function, any higher order terms are essentially transformed into linear combinations of quadratic terms once the problem is expressed in terms of binary variables. We, therefore, try to develop a QUBO-based solver, considering that the upcoming performance of QUBO solvers, including the QA should be promising for optimization [23, 24].
2.3.1.1. Formulation revisited for QUBO formulation
From and , we solve . From Equation (1),
and leads to a fraction of the following form:
We then need to minimize . To solve this fractional optimization problem (i.e., ) with higher order multiplications (i.e., ∏d), we apply a technique [25, 26] to minimize
Where , , and the positive number K∈ℝ+. This technique is based on the fact that minimizing is equal to simultaneously minimizing A and maximizing B. A direct method of minimizing Equation (4) is labeled QUBO-Exact in this article.
2.3.1.2. Implementation
As mentioned earlier, any higher order unconstrained binary optimization problem (HUBO) is essentially transformable to a QUBO problem; see Zaman et al. [27] for the transformation algorithm. Note that, however, the transformation often requires many binary variables on top of the original ones.
Then, we implement a method labeled QUBO-Approx, which removes the redundant higher-order terms of and/or of Equation (4). Note that , which means that values in F1 and F2 can be exponentially shifted by a constant, such as exp(L). With this technique, parts of terms in and/or can reach zero in the HUBO optimization problem. Hence, we expect that QUBO-approx could approximately solve ID problem instances with a smaller number of bits than QUBO-Exact.
2.3.2. Branch-and-bound-based solver
We develop a solver labeled BnB, based on the branch-and-bound idea [21].
2.3.2.1. Branching phase
We have the set and . The number of possible assignments of is 2mn if we branch the problem into two sub-problems, namely, with xd, o = 0 or xd, o = 1. There are different possibilities for splitting the problem, e.g., driver-wise branching for d∈D enables us to generate 2n with n orders in O. An appropriate branching implementation is selected considering the scalability and/or possibilities of evaluating objective values in the bounding phase.
2.3.2.2. Bounding phase
We need to assess the upper/lower bounds of a sub-problem to prune any redundant sub-problems generated. Since the upper bound of pd, o, denoted by , is obtained from xd, o = 1 and for , collecting for d∈D leads to the upper bound of ℙo, denoted by for o∈O. Therefore, we can prune redundant sub-problems if for the current-best feasible solution .
Together with the branching phase, we can discuss the computational aspect of branch-and-bound solvers for the ID problem. That is, the computational complexity of BnB solvers is straightforward in the worst case. Numerical evaluations of the average running times of the branch-and-bound-based solvers still need to be investigated in the current status.
2.3.2.3. Incremental deepening with implicit constraints
Since the set of 2nm decision variables is quite large, the aforementioned branch-and-bound-based solver is still inefficient for some ID problem instances. We then incorporate a new perspective into our branch-and-bound-based solver for the ID problem using implicit constraints. Typical solutions obtained with IEC/MLEC often satisfy for d∈D. This is because increasing the number of displayed orders reduces pd, o, and so the value of ℙo.
Based on the aforementioned implicit constraints, we propose a heuristic, range-constrained branch-and-bound-based solver. Here, a range [Ld, Hd] should be given for each d∈D, which means that items whose numbers are in [Ld, Hd] are assumed to be displayed. If [Ld, Hd] = [1, 1], then d accepts only one order. These range constraints drastically reduce the number of sub-problems. The solutions obtained with the aforementioned range constraints are approximations when Hd<m = |O|. In this article, we always assume that Ld = 1 for d∈D and that Hd = H for d∈D. This range-constrained branch-and-bound-based solver is labeled BnBH with value H. Then, we implement an iterative deepening procedure [28] for the hyperparameter H, i.e., we run BnBH iteratively as H = 1, 2, … and if the obtained solutions with H and H+1 are the same, then we halt the increment of H.
3. Results and discussions
We experimentally evaluate methods for the ID problem.
3.1. Datasets
We prepare two sets of randomly generated instances and name them UnifID and NormID. UnifID is generated using uniform distributions, denoted by Unif in Table 2, for U and U0, while NormID is based on truncated normal distributions, denoted by TrunNorm in Table 2, in accordance with Yang et al. [15]. For simplicity, we focus on the case, where N = m = n (i.e., N = |O| = |D|) following the experiments using the synthetic datasets in Yang et al. [15]. Table 2 summarizes two datasets.
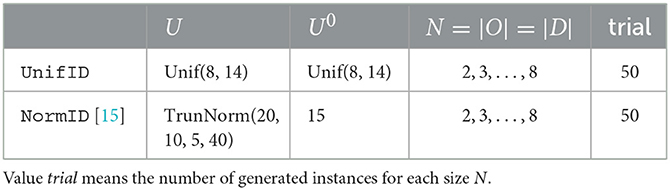
Table 2. Summary of two datasets, UnifID and NormID.
3.2. Methods
Here, we compare the following methods:
• Random: a random assignment of ,
• ExactEnum: generate-and-test method for 2nm variables,
• BnB: branch-and-bound-based method,
• BnBH: heuristic solver with BnB and range constraints H,
• QUBO-Exact: a naive QUBO-based method,
• QUBO-Approx: a method approximating higher-order terms up to dim 3, and
• IEC/MLEC: our re-implementation of the IEC/MLEC [15].
3.3. Experimental results
Figures 4, 5 show experimental results of UnifID and NormID, respectively. Both figures illustrate the mean objective values (Figures 4A, 5A), computational times (Figures 4B, 5B), and objective values (Figures 4C, 5C) of selected methods with standard variations with filled ribbons. Note that computational times of QUBO-based methods are not illustrated because we use a GPU-based annealing solver, and we repeatedly use them (e.g., 30 times) fixed times. According to the results on the two datasets, the two existing heuristic solvers (IEC and MLEC) efficiently find approximate solutions. As seen in Figures 4C, 5C, compared with results of BnB (up to N = 5, meaning that 225 binary variables in ), IEC and MLEC are efficient heuristic solvers. Our results seem to indicate that IEC is better than MLEC for small instances, although Yang et al. [15] reported that MLEC could find better solutions with shorter computational times. That is, we can conjecture the two methods are almost comparable for small instances used in this article. We can interpret our experimental results as follows. First, obtained solutions by IEC and MLEC were almost competitive for NormID, as shown in Figure 5A. Second, Yang et al. did not investigate uniform distributions to evaluate their heuristic solvers in their experiments using synthetic data [15]. One possible reason is that MLEC is not good at solving instances generated in UnifID since MLEC halts at some local optima. Another possible explanation is that the two solvers, IEC and MLEC, have different properties according to the sizes of instances. We only adopt small instances in this experimental study due to computational issues of the current status of developed solvers.
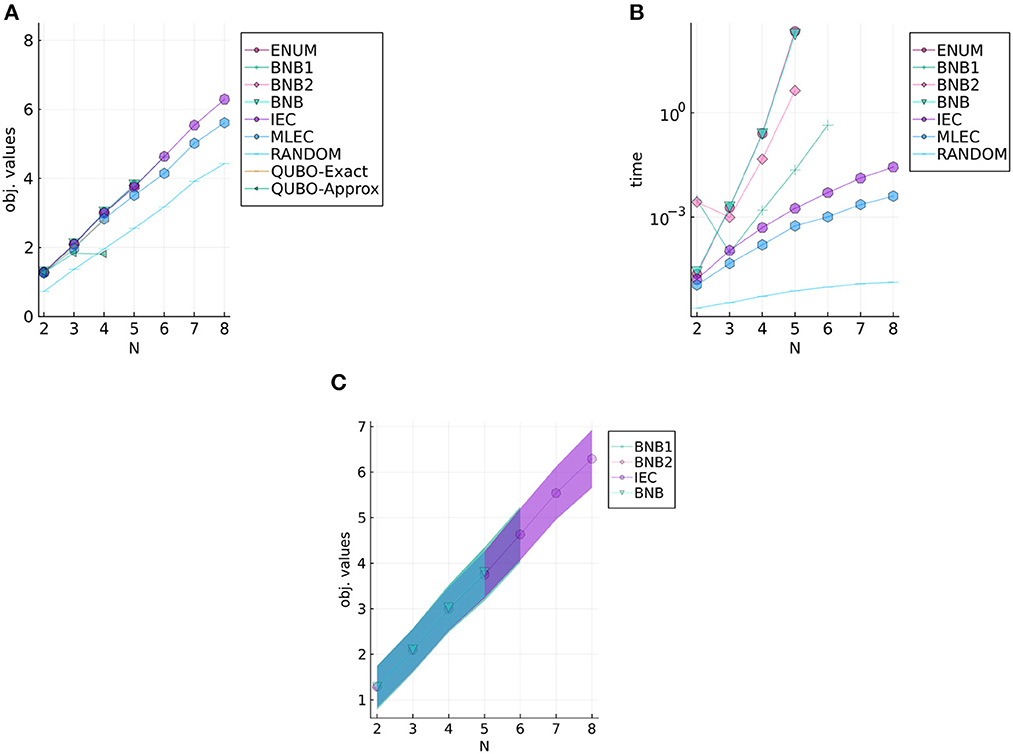
Figure 4. Results for UnifID, objective values, computational times, and objective values of selected methods. (A) Objective values of UnifID. (B) Computational times of UnifID. (C) Selected results of UnifID with standard variations in filled regions.
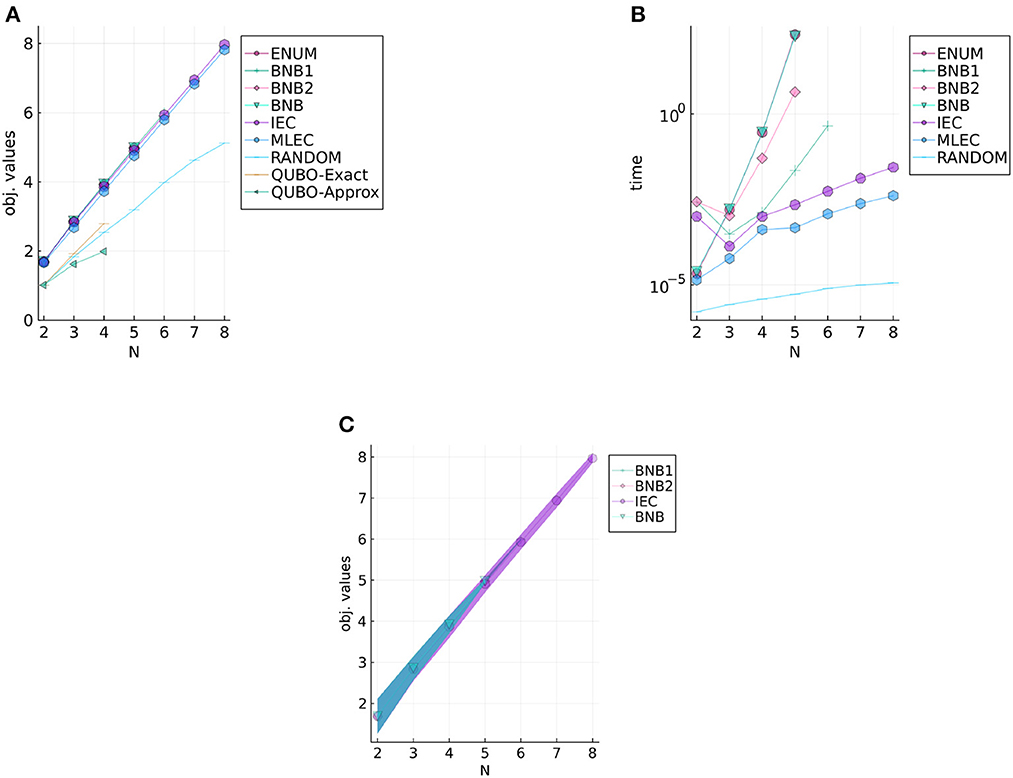
Figure 5. Results for NormID, objective values, computational times, and objective values of selected methods. (A) Objective values of NormID. (B) Computational times of NormID. (C) Selected results of NormID with standard variations in filled regions.
Furthermore, the QUBO-based methods did find optimal solutions for N ≤ 3. The applicability is still limited for practical use; however, since the binary variables consumed for transformation to the QUBO problem are significant for the current QUBO solver. We expect that the significance of these methods will be pronounced as the development of hardware for the QUBO solvers.
Compared with BnB and ExactEnum, the current BnB is not much efficient; yet, since the computational times of the two methods are similar. We conjecture that this is because (1) current branching evaluations are not tight enough and (2) the targeting ID objective function fID does not suit the branch-and-bound-based solver. Since ℙo depends on the whole , there is no clear structure (e.g., independence) for dividing fID, and BnB could be less effective in estimating the upper and lower bounds of fID. Linear relaxations of xd, o (i.e., relaxation of xd, o∈{0, 1} to 0 ≤ xd, o ≤ 1) do not accelerate the bounding phase as fID is the sum of high-dimensional products. Therefore, developing an efficient bounding method would be an important next step in elucidating the branch-and-bound-based method for the ID problem. Such a development could be valuable also for evaluating the performance of ICE and MLEC since the current experimental study in this article focuses on small instances.
To estimate the performance of IEC in greater detail, we compare BnB, BnB1, and IEC on 50 random instances sized N∈{2, 3, 4, 5} with both NormID and UnifID settings. The results of BnB1 and IEC are summarized in Table 3 and those between BnB and IEC are given in Table 4. The columns show the number of instances after a comparison of objective values with the two methods. For example, with N = 2 on NormID, BnB1, and IEC obtain the same objective values for 47 out of 50 instances. According to Table 3, BnB1 obtains better solutions than IEC on average, particularly on NormID. Similar results are observed in Table 4. Note that BnB requires much longer computational times, as shown in Figures 4B, 5B, indicating that BnB1 is to find better solutions than those of IEC. These results may be due to the distributions of Ud, o in the computation pd, o, i.e., the possible ranges in UnifID are less than those in NormID, and so pd, o values are similar (i.e., modifications in xd, o change objective values drastically).
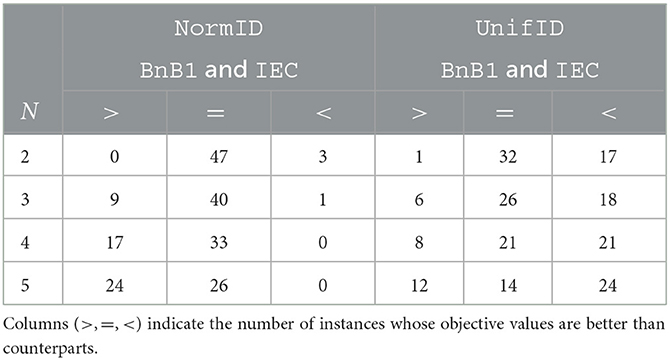
Table 3. Objective values comparison with BnB1 and IEC for UnifID and NormID.
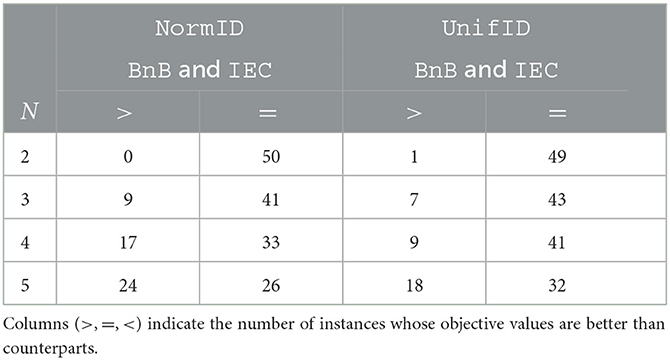
Table 4. Objective values comparison with BnB and IEC for UnifID and NormID.
4. Conclusion and future study
In the present article, we have studied the ID problem by revisiting the methods proposed by Yang et al. [15]. Our experimental evaluations comparing their solvers revealed that the heuristic solver IEC and MLEC are comparable for small instances. These results can also support the findings in Yang et al. [15]. In addition, experimental results on uniformly random data (i.e., UnifID) indicate that MLEC cannot find better solutions than those by IEC on specific instances. We also expect that we could improve the current heuristic MLEC according to the property of input data in future study to find better solutions to the ID problem. We confirm that the QUBO-based methods give optimal solutions for N ≤ 3, but significant hardware development is demanded for practical applications with larger N. This is because the transformation to the QUBO problem requires many dummy binary variables. Better approximation incorporating the effect of higher order terms than the one we employed in this study as a first step would accelerate the application of QUBO solvers. For branch-and-bound-based solvers, BnB1 slightly improves IEC solutions with shorter computational times than BnB. We expect that developing better branching estimation for BnB1 and BnB could improve the quality of solutions with shorter times.
These results for a class of optimization problems based on decision models (i.e., probabilities of selecting items) are valuable for discussions of human-centric optimization tasks. In our future study, we will investigate the theoretical background of problems and other objective functions for real applications involving MoD services.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
KO conceived of the presented idea and developed the method and performed the computations. AO and HY verified the analytical methods and results, encouraged KO to investigate quantum annealing solvers and quadratic unconstrained binary optimization (QUBO) problems to discuss the targeting optimization problem, and supervised the findings of this work. All authors discussed the results and contributed to the final manuscript. All authors contributed to the article and approved the submitted version.
Conflict of interest
KO, AO, and HY are employed by Toyota Central R&D Labs., Inc.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fams.2023.1150921/full#supplementary-material
Footnotes
1. ^The original notation in Yang et al. [15] is po, d, but we write it as pd, o for the convenience.
2. ^The term utility is from economics that refers to the total (objective) satisfaction received from consuming a good or service.
3. ^Yang et al. [15]. reported that β0 = 0, β1 = 1[USD], β2 = −0.7[USD/km], α = 1.0, [USD] in New York city.
4. ^Intuitively, the value means the objective satisfaction without any choice. If of an order o, the driver possibly chooses o.
5. ^The choice becomes at random (α → 0) and seems to be deterministic (α → ∞).
References
1. Korte B, Vygen J. Combinatorial Optimization: Theory Algorithms. Springer (2018). Available online at: https://link.springer.com/book/10.1007/978-3-662-56039-6
2. Kamada Y, Kojima F. Efficient matching under distributional constraints: theory and applications. Am Econ Rev. (2015) 105:67–99. doi: 10.1257/aer.20101552
3. Kurata R, Hamada N, Iwasaki A, Yokoo M. Controlled school choice with soft bounds and overlapping types. J Artif Intell Res. (2017) 58:153–84. doi: 10.1613/jair.5297
4. De Francisci Morales G, Gionis A, Sozio M. Social content matching in MapReduce. Proc VLDB2011. (2011) 4:460–9. doi: 10.14778/1988776.1988782
5. Mehta A. Online matching and ad allocation. Foundat Trends®Theor Comput Sci. (2013) 8:265–368. doi: 10.1561/0400000057
6. Alonso-Mora J, Samaranayake S, Wallar A, Frazzoli E, Rus D. On-demand high-capacity ride-sharing via dynamic trip-vehicle assignment. Proc Natl Acad Sci USA. (2017) 114:462–7. doi: 10.1073/pnas.1611675114
7. Zhang H, Zhao J. Mobility sharing as a preference matching problem. IEEE Trans Intell Transport Syst. (2018) 20:2584–92. doi: 10.1109/TITS.2018.2868366
8. Hussain RJ, Kumar PS. Algorithmic approach for solving intuitionistic fuzzy transportation problem. Appl Math Sci. (2012) 6:3981–9. Available online at: http://www.m-hikari.com/ams/ams-2012/ams-77-80-2012/senthilkumarAMS77-80-2012.pdf
9. Kumar PS. Intuitionistic fuzzy solid assignment problems: a software-based approach. Int J Syst Assurance Eng Manag. (2019) 10:661–75. doi: 10.1007/s13198-019-00794-w
10. Kumar PS. Algorithms for solving the optimization problems using fuzzy and intuitionistic fuzzy set. Int J Syst Assurance Eng Manag. (2020) 11:189–222. doi: 10.1007/s13198-019-00941-3
11. Gale D, Shapley LS. College admissions and the stability of marriage. Am Math Monthly. (1962) 69:9–15. doi: 10.1080/00029890.1962.11989827
12. Domshlak C, Hüllermeier E, Kaci S, Prade H. Preferences in AI: an overview. Artif Intell. (2011) 175:1037–52. doi: 10.1016/j.artint.2011.03.004
13. Debreu G. Representation of a preference ordering by a numerical function. Decis Proc. (1954) 3:159–65.
15. Yang Y, Shi Y, Wang D, Chen Q, Xu L, Li H, et al. Improving the information disclosure in mobility-on-demand systems. In: Proceedings of the KDD2021. (2021). p. 3854–64.
16. Mandi J, Canoy R, Lopez VB, Guns T. Data driven VRP: a neural network model to learn hidden preferences for VRP. In: Proceedings of the CP2021. (2021). p. 42.
17. Canoy R, Bucarey V, Mandi J, Guns T. Learn-n-Route: learning implicit preferences for vehicle routing. arXiv:210103936. (2021). doi: 10.48550/arXiv.2101.03936
18. Hikima Y, Kohjima M, Akagi Y, Kurashima T, Toda H. Price and time optimization for utility-aware taxi dispatching. In: Proceedings of the PRICAI2021. (2021). p. 370–81.
19. Train KE. Discrete Choice Methods With Simulation. Cambridge: Cambridge University Press (2009).
20. Henningsen A, Toomet O. maxLik: a package for maximum likelihood estimation in R. Comput Stat. (2011) 26:443–58. doi: 10.1007/s00180-010-0217-1
21. Lawler EL, Wood DE. Branch-and-bound methods: a survey. Operat Res. (1966) 14:699–719. doi: 10.1287/opre.14.4.699
22. Lucas A. Ising formulations of many NP problems. Front Phys. (2014) 2:5. doi: 10.3389/fphy.2014.00005
23. Yarkoni S, Raponi E, Schmitt S, Bäck T. Quantum annealing for industry applications: introduction and review. arXiv:211207491. (2021) doi: 10.1088/1361-6633/ac8c54
24. Vert D, Sirdey R, Louise S. Benchmarking quantum annealing against “hard” instances of the bipartite matching problem. SN Comput Sci. (2021) 2:1–12. doi: 10.1007/s42979-021-00483-1
25. Ajagekar A, Humble T, You F. Quantum computing based hybrid solution strategies for large-scale discrete-continuous optimization problems. Comput Chem Eng. (2020) 132:106630. doi: 10.1016/j.compchemeng.2019.106630
26. Wils K. Quantum computing for structural optimization (2020). Available online at: https://repository.tudelft.nl/islandora/object/uuid%3A5167107a-7c26-4779-825a-e99702949870
27. Zaman M, Tanahashi K, Tanaka S. PyQUBO: Python library for mapping combinatorial optimization problems to QUBO form. arXiv preprint arXiv:210301708. (2021) doi: 10.1109/TC.2021.3063618
Keywords: information disclosure, heuristics, branch-and-bound, quantum annealing, quadratic unconstrained binary optimization
Citation: Otaki K, Okada A and Yoshida H (2023) Experimental study on the information disclosure problem: Branch-and-bound and QUBO solver. Front. Appl. Math. Stat. 9:1150921. doi: 10.3389/fams.2023.1150921
Received: 25 January 2023; Accepted: 22 February 2023;
Published: 29 March 2023.
Edited by:
Jianke Zhang, Xi'an University of Posts and Telecommunications, ChinaCopyright © 2023 Otaki, Okada and Yoshida. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Keisuke Otaki, b3Rha2lAbW9zay50eXRsYWJzLmNvLmpw