 Florin Zai
Florin Zai Tobias Rohrbach
Tobias Rohrbach Regula Hänggli Fricker1
Regula Hänggli Fricker1- 1Department of Communication and Media Research (DCM), University of Fribourg, Fribourg, Switzerland
- 2Institute of Communication and Media Studies (ICMB), University of Bern, Bern, Switzerland
The rise of artificial intelligence (AI) has been accompanied by extensive reporting by news media, serving as a forum for public debate about its risks and potential for society. This study sheds light on this AI debate in news media by using the theoretical concepts of standing and framing and by combining manual and automated content analysis [reversed Joint Sentiment Topic model (rJST) and Named Entity Recognition (NER)]. Based on news articles published in Swiss, German, UK, and US quality and tabloid outlets between November 2020 and November 2022, we examine which actors have standing in the AI debate, which frames they use, and which positions they hold. We also compare manual and automated methods as a methodological contribution. We see that economic and scientific actors have a high standing in reporting and journalists themselves provide a considerable part of contextualization as speakers. As in previous studies, the progress and economic consequences frames dominate, with mostly pro positions. The ethics and morality frame, however, is underrepresented. More diverse voices could enrich the AI debate. Comparing the two methods, we see that the automated analysis (via rJST) detects topics relatively reliably. By contrast, there are differences between the results of the two methods regarding the framing of these topics which are mainly due to the lack of sensitivity of the automated analysis regarding nuanced contextual information such as individual positions. Further, the automated analysis overestimates political actors in the debate and underestimates journalistic actors, as named entities do not necessarily act as speakers.
1 Introduction
Artificial intelligence (AI) is developing rapidly and has increasingly become part of everyday life. As the public lacks expert knowledge, it relies on media content to form its views on AI (Nader et al., 2022; Zhai et al., 2020)—much like it has with previous emerging technologies (Nisbet and Lewenstein, 2002; Scheufele and Lewenstein, 2005). Therefore, understanding news media reporting on AI is crucial to understand public perceptions. Various studies (e.g., Brennen et al., 2018; Chuan et al., 2019; Cools et al., 2024; Ouchchy et al., 2020; Sun et al., 2020) have analyzed AI reporting in news media. However, they often focus on general themes without considering how different perspectives from distinct actors shape the public debate about AI. In complex issues (like AI), there is a greater risk that the public debate will be one-sided and that the leaders of the debate will be less able to bring social, long-term interests into the debate than economic interests (Hänggli, 2020). Therefore, understanding the diversity and prevalence of actors’ views is key to assess their impact on opinion formation and, ultimately, policy-making.
Before AI technologies became the focus of attention, nuclear power, information technology, biotechnology, and nanotechnology were the primary areas of scientific and public interest (Metag, 2019). What these technologies have in common is that they develop rapidly, affect multiple areas of life and society, and are accompanied by new regulations. Therefore, various actors try to have standing in the debate and make their voices heard. In technology coverage, such actors include politicians, economic actors, scientists, experts, interest groups, and ordinary citizens (Gurr and Metag, 2023). In the media, risks and benefits are weighed against each other. This means that dystopian and utopian media portrayals can be in direct competition (Kitzinger and Williams, 2005). For many technologies that are generally less controversial, such as nanotechnology or digital platforms (Metag, 2019), positive portrayals in the media predominate (Arceneaux and Schmitz Weiss, 2010; Metag and Marcinkowski, 2014) However, this optimism depends on the technology and can be observed especially when there are no known major accidents or damages (Metag, 2019).
AI’s growing societal and scientific relevance is reflected in media attention. Until the early 2010s, AI was a latent issue on the media agenda (Fast and Horvitz, 2017; Sun et al., 2020). Afterward, there was a drastic and continuous rise in AI news coverage, indicating that the debate became increasingly important. The exact reasons for the increase are unclear but could be linked to “a renaissance in the use of neural nets (“deep learning”) in natural language and perceptual applications” (Fast and Horvitz, 2017, p. 966). The number of articles addressing artificial intelligence (Figure 1) illustrates this increase in importance.
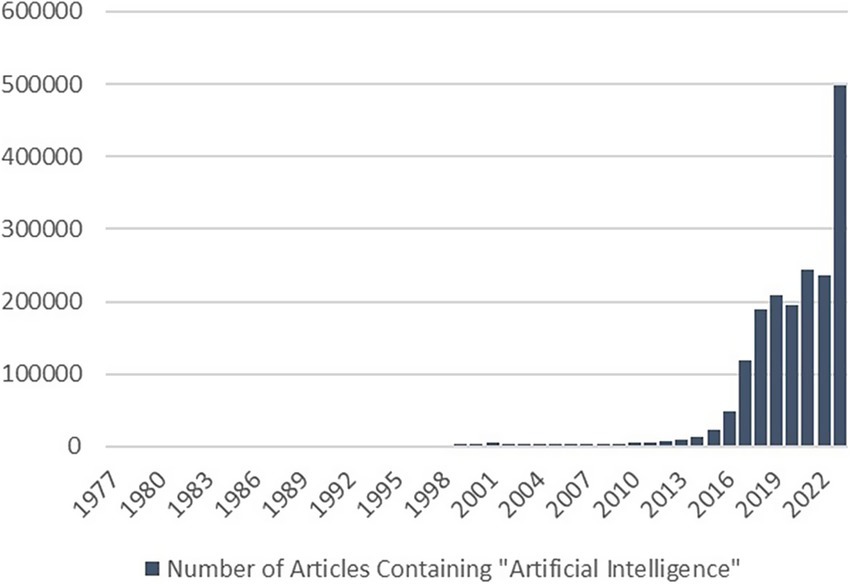
Figure 1. Number of articles mentioning “Artificial Intelligence.” The graph depicts the increase of reporting on AI. Data was retrieved from the Factiva Database using the keyword “artificial intelligence” (English) for all publications, authors, companies, subjects, industries, regions, and languages.
Several studies that specifically examine AI frames use a computational approach. They either do so by using automated analysis, such as topic modeling, alone (e.g., Nguyen and Hekman, 2024; Sun et al., 2020), or by combining automated and manual content analysis (e.g., Bunz and Braghieri, 2022; Cools et al., 2024). While computational methods allow to analyze a high number of articles, they often miss nuances and context (Fogel-Dror et al., 2019), and often lack testing and reporting of reliability and validity (Hase, 2023; Nelson, 2019). While existing work has discussed the advantages and disadvantages of manual and automated content analytic approaches in more general terms (e.g., de Graaf and van der Vossen, 2013; Hase et al., 2020), there are only a few studies that explicitly combine and compare the two approaches in empirical applications (Hase et al., 2020). Referring to framing research, Hase (2023) states that the main issue with automated content analysis lies in the absence of a clear link to theoretical concepts. She further argues that it is questionable whether automated approaches simply detect diffuse issues covered in media reporting or, if clustered and aggregated, can capture conceptually bounded frames. Though both variants of content analysis are established in analyses of AI media debates, there is currently little understanding of how the methodological choice between manual or automated approaches affects key conclusions.
Building on the existing research on AI in news coverage, this study aims to (a) trace which actors have standing in the mediated AI debate, (b) investigate which frames become how prominent using theory-driven manual and automated content analysis, (c) link the detected frames to different actors to assess which actors bring up which arguments in the AI debate, and (d) compare the manual content analysis to automated content analysis.
2 Voices and frames
For our theoretical framework, we first introduce the concepts of standing and framing based on the approach by Ferree et al. (2002). We will then present the state of research on AI in reporting before finally presenting our own typology with generic AI frames as a basis for analysis.
2.1 Standing and framing in communication research
For shaping a debate, it is important to have a voice in the media. This is called standing (Ferree et al., 2002). It makes a person or group treated as an agent, not merely as an object. By this, an agent argues for themselves, instead that they are discussed by others. However, not every actor has a voice. The chance of having a voice in the news media is unequal. Powerful actors have higher chances of this (e.g., Ferree et al., 2002; Hänggli, 2011). In addition to power, their activity, prominence, resources, and goals, as well as context matter (e.g., Hänggli, 2020). In Germany, parties dominate (Ferree et al., 2002; Kriesi et al., 2019). In the US, UK, and Switzerland, the standing of state actors can be expected to be lower than in Germany, whereas standing of associations, companies, movements, and individuals can be expected to be higher than in Germany.
The public debates we are investigating here are largely “event-driven” (Lawrence, 2023; Livingston and Bennett, 2003; Hänggli Fricker and Beck, 2024). The institutions do not set the agendas of news organizations in these debates. Accordingly, they are less anticipated, planned and administratively managed. Events play a key role in triggering public debate and increasing coverage. In other words, these debates take place in the public without an institutional driver (such as an election, a direct democratic campaign, or a parliamentarian debate). Journalists have more say in those debates (Hänggli and Trucco, 2022).
There are different understandings of frames in communication (for an overview see Hänggli Fricker, 2025). We adopt a content-related perspective (not a formal one, such as how a frame is presented for instance) and look at what the story is about. In this way, “frames are interpretive storylines that set a specific train of thought in motion, communicating why an issue might be a problem, who or what might be responsible for it, and what should be done about it” (Nisbet, 2009, p. 15). Any frame can include pro, anti, and neutral positions, though one position might be more commonly used than others (Dahinden, 2002; Ferree et al., 2002; Hänggli, 2020).
Frames can be categorized as issue-specific or generic (de Vreese, 2005; Semetko and Valkenburg, 2000). We are dealing with generic frames here. Frames that can be identified concerning different topics are labeled generic (e.g., economic consequences, morality, or responsibility). By contrast, issue-specific frames are pertinent only to a specific topic. Some generic frames are fully universal and usable across all topics, whereas others are tied to topic areas but still transcend a single issue. For our deductive typology (see Table 1), we relied on frames identified across technology- and science-related policy debates (Dahinden, 2002; Gamson and Modigliani, 1989; Nisbet, 2009; Nisbet and Scheufele, 2009), as well as Semetko and Valkenburg's (2000) fully universal frames. For the examples on each frame, we also relied on the frames found in the analyses on AI (see the following paragraph).
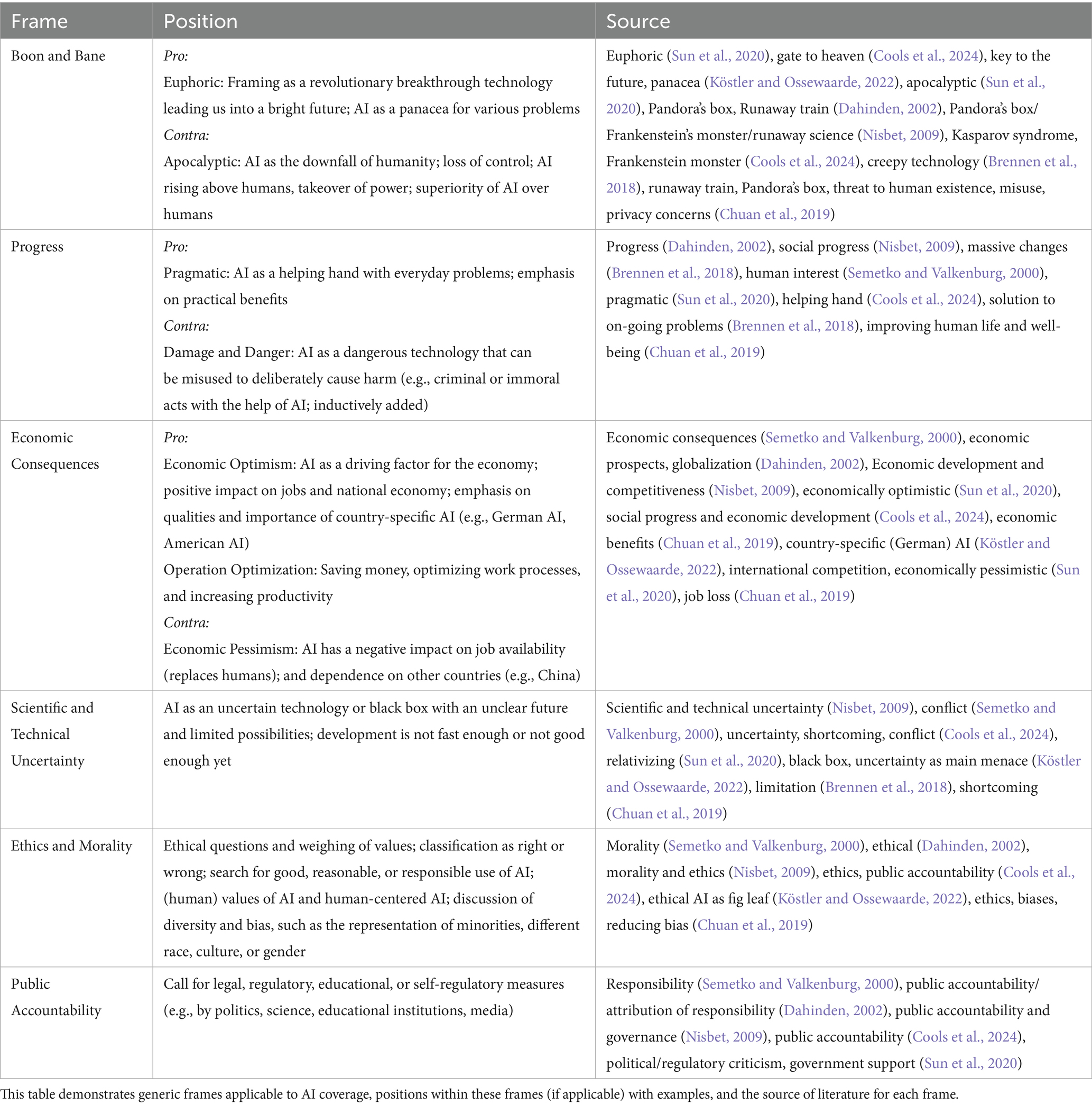
Table 1. Generic AI frames and positions.
2.2 Standing and framing in the AI debate
To our knowledge, there are only a few studies specifically addressing the standing of different actors in the AI debate. In the case of the UK, Brennen et al. (2018) found that economic voices dominate the debate. The authors conclude that a “wider range of voices in discussions of AI” (p. 10) is needed. This is contrary to other debates on emerging technologies, such as nanotechnology, where scientists also have high standing in the debate (Metag and Marcinkowski, 2014).
When it comes to framing in the AI debate, there are more findings, as many studies use a framing approach (e.g., Brennen et al., 2018, 2022; Bunz and Braghieri, 2022; Chuan et al., 2019; Cools et al., 2024; Köstler and Ossewaarde, 2022; Sun et al., 2020). Frames and positions used in these studies will be addressed in detail in the following section. At this point, we first want to say more about frames and positions in the AI debate from previous research. Media coverage on AI proves to predominantly contain economy and social progress frames (Brennen et al., 2018, 2022; Chuan et al., 2019; Cools et al., 2024; Fast and Horvitz, 2017; Köstler and Ossewaarde, 2022). In addition to the economy and progress orientation, these studies found the debate to be mainly positive (i.e., containing more pro positions). Common examples of such pro positions are the interpretation of AI as a promising solution to a variety of problems (e.g., Brennen et al., 2018; Bunz and Braghieri, 2022; Cools et al., 2024; Sun et al., 2020) and interpreting AI as boosting the economy (e.g., Köstler and Ossewaarde, 2022; Sun et al., 2020). Chuan et al. (2019) note that with the general increase in AI coverage, the proportion of negative coverage (i.e., contra positions) is also increasing. Examples of negative positions are economic pessimism (e.g., job loss) or portraying AI as a threat to human existence.
There are also frames with no clear (i.e., ambivalent or neutral) position, such as the scientific and technical uncertainty frame. Sun et al. (2020) found a relativizing position on AI, pointing out its limits, to be one of the most present in media coverage. Another frame with ambivalent positions is the ethics and morality frame. Chuan et al. (2019) note that while ethic frames played a subordinate role in early AI coverage, ethical aspects might get more attention with the increasing importance of AI. However, there are mixed findings. Brennen et al. (2018) found ethics to be one of the most discussed issues in UK news coverage, although this was more common in left-leaning outlets. The extent to which ethics are discussed could also be topic-specific, as it has been shown that ethics frames are used more frequently in the context of military and AI (Cools et al., 2024).
2.3 AI frames and positions
Drawing on the literature on emerging technologies (Dahinden, 2002), science communication (Nisbet, 2009; Nisbet and Scheufele, 2009), and framing (Semetko and Valkenburg, 2000), we identify six generic frames that can be linked to previous findings in AI coverage. (1) A boon and bane frame; (2) a progress frame; (3) a scientific and technical uncertainty frame; (4) an economic consequences frame; (5) an ethics and morality frame; and (6) a public accountability frame. Table 1 provides an overview of all the frames and their positions. If there is no clear pro or contra position (i.e., ambivalent/neutral position), only one position is listed. The last column contains the corresponding origin in literature.
The boon and bane frame involves in the pro position a very positive, euphoric interpretation of AI (Sun et al., 2020) that sees it as a gate to heaven (Cools et al., 2024), key to the future or panacea (Köstler and Ossewaarde, 2022), or predicts massive changes leading to a new age (Brennen et al., 2018). In the contra position, it manifests as an apocalyptic (Sun et al., 2020) or dystopian (Cools et al., 2024) view. It is a portrayal of AI as a creepy technology (Brennen et al., 2018) that might overrule humans and possibly lead to extinction. Descriptions of corresponding frames in literature often stem from mythology or religion (Dahinden, 2002). For various technologies and scientific issues, authors use a Pandora’s Box (Chuan et al., 2019; Dahinden, 2002; Durant et al., 1998; Nisbet, 2009), runaway train (Chuan et al., 2019; Durant et al., 1998; Gamson and Modigliani, 1989; Nisbet, 2009; Nisbet and Scheufele, 2009), or Frankenstein’s Monster frame (Cools et al., 2024; Nisbet, 2009). As those frames all include framing new technologies as a substantial threat or glorifying them, we chose to combine them in one frame. To demystify AI, we use the term boon and bane instead of the existing terms used in other studies to describe corresponding frames.
Several aspects of progress are discussed in the AI debate. Pragmatic perspectives (Sun et al., 2020) highlight the technology’s usefulness in everyday life. This includes interpretations of AI as a helping hand (Cools et al., 2024) or a solution to ongoing problems (Brennen et al., 2018). This also includes portraying AI as improving human life and well-being (Chuan et al., 2019). However, the contra position points out concrete threats of damage and danger, such as the misuse of AI or privacy concerns (Chuan et al., 2019).
The economic consequences frame emphasizes the economic aspects of AI. Economic consequences is a common generic frame that can be applied to several debates (Semetko and Valkenburg, 2000), and similar frames were used in several technology and science communication studies (Dahinden, 2002; Nisbet, 2009). For the AI debate, we see two aspects of a pro position. First, economic optimism (Sun et al., 2020), which is the portrayal of AI as a positive economic development (Cools et al., 2024), bringing wealth and possibly leading to a new industrial revolution. Second, we also see a business application of pragmatic aspects. We summarize it as operation optimization, which includes increasing productivity, saving money, and optimizing business processes. The contra position consists of economic pessimism (Sun et al., 2020), pointing out possible job loss (Chuan et al., 2019), and dependence on other countries, if a country does not keep up with the global AI competition. This goes in line with addressing country-specific AI [e.g., German AI (Köstler and Ossewaarde, 2022)] or international competition (Sun et al., 2020). This can occur as a pro position if a country’s technological and industrial strength is emphasized, and as a contra position if the country is portrayed as lagging behind.
The scientific and technical uncertainty frame (Nisbet, 2009) covers two aspects of AI literature. Due to their similarity, we combined them into one. The first aspect is explicit (scientific) uncertainty (Cools et al., 2024). It addresses the fact that AI technologies are still evolving and that a lot is still unknown (e.g., how self-learning models exactly work). Köstler and Ossewaarde (2022) refer to this as a black box and uncertainty as the main menace. The second aspect points out the limits and flaws of AI which can be seen as implicit uncertainty. Cools et al. (2024) use a conflict frame addressing the conflict of using AI technologies despite certain flaws (e.g., to still cut costs), and a shortcoming frame highlighting the flaws and limits of the technology. Chuan et al. (2019) also use a shortcoming frame. This is also referred to as limitation (Brennen et al., 2018) or relativizing (Sun et al., 2020). Here, we do not see clear positions as pointing out potential and certain flaws at the same time is ambivalent.
Ethics and morality is a generic frame applicable to many contexts (Semetko and Valkenburg, 2000) and often used in studies analyzing coverage of emerging technologies (Dahinden, 2002; Nisbet, 2009) As with other technologies, this frame is also primarily about weighing up right and wrong in the context of AI (Chuan et al., 2019; Cools et al., 2024). This can include pointing out ethical risks like creating bias, but can also be positive, such as reducing bias using AI (Chuan et al., 2019). With ethical AI as fig leaf, Köstler and Ossewaarde (2022) provide a slightly more nuanced frame. This is a media interpretation of the government’s AI strategy, which includes the accusation that ethics is only used as a pretext to avert possible skepticism by the public, but that ethical AI cannot be implemented with the strategy. As this is a frame that is very issue-specific we summarize it in the ethical and morality frame. This is also an ambivalent frame with no clear positions.
The public accountability frame (Dahinden, 2002; Nisbet, 2009) addresses questions of regulation and governance, as well as responsibility (Semetko and Valkenburg, 2000). In the AI debate, this involves political or regulatory criticism (Sun et al., 2020) that calls for regulation due to possible uncertainties and threats coming with AI. It also involves other public responsibilities such as teaching digital skills and media literacy. This frame also has no systematic pro or contra positions.
3 Research questions and hypotheses
The main aim of this study is to use a theory-driven framing framework and bridge gaps between inductive (i.e., computational) and traditional manual content analyses. We compare the two approaches along the following research questions:
First, we want to find out, which actors have a voice in the AI debate in the news media:
RQ1: Which actors have standing in the mediated AI debate?
When it comes to actors, Brennen et al. (2018) have shown that economic actors are leading the AI debate in news media. Therefore, we hypothesize:
H1: In news media coverage on AI, it is mainly economic actors who comment on artificial intelligence, while scientific and political actors are represented less.
Second, we want to analyze, which framing is evident in news media coverage:
RQ2: Which frames of artificial intelligence can be found in news media coverage using a manual, deductive approach to content analysis?
The state of research shows that AI reporting tends to be positive and economy-focused, emphasizes, and predominantly containing positions portraying AI as an everyday aid or even as a panacea for a variety of problems (Brennen et al., 2018, 2022; Chuan et al., 2019; Cools et al., 2024; Köstler and Ossewaarde, 2022; Sun et al., 2020). Ethical aspects are discussed comparatively less (Chuan et al., 2019). This leads to the following hypotheses:
H2: In news media coverage of AI, the progress frame is most strongly represented.
H3: In news media coverage of AI, the ethics and morality frame plays a subordinate role.
H4: In news media coverage on AI, pro positions on AI predominate.
Since previous studies have only addressed the question of who comments on AI, we further pose the following exploratory research questions without hypothesizing about it:
RQ3: Which actors use which frames and hold which positions in the mediated AI debate?
Lastly, for our methodological contribution, we want to compare the findings of the manual and the automated content analysis. Our last, again exploratory, research question therefore is:
RQ4: To what extent do manual and automated content analyses yield different or similar results regarding standing and framing in the AI debate?
4 Methods
This article aims to detect frames in AI news coverage, link them to different actors contributing to the debate, and compare manual and automated content analysis. To address these research interests, we conducted a manual and an automated content analysis. Content analysis is one of the most used methods to analyze technology coverage (Gurr and Metag, 2023).
4.1 Sample
We analyzed media reports from November 14, 2020, to November 17, 2022. To be able to make comparisons to existing research, and because it was important that the manual coders fully understand the articles, we selected English and German-speaking media outlets for analysis. We selected the USA, UK, Germany, and Switzerland for variation. They all are highly industrialized and technologized countries that are among the most mentioned players when it comes to AI (Sun et al., 2020) and therefore are likely to be similar regarding AI reporting.
Relevant articles were identified using the keywords “artificial intelligence,” “künstliche* Intelligenz,” and “artifizielle* Intelligenz” using Dow Jones’ FACTIVA database. The abbreviations “AI” and “KI” were not included in the search inquiry because it resulted in too much noise in the sample (e.g., authors’ initials). One quality and one tabloid legacy newspaper with wide reach were selected for each country. To avoid duplicates, only print versions were included. For the US, these were the Wall Street Journal (quality) and the New York Post (tabloid), for Great Britain The Guardian (quality) and The Sun (tabloid), for Germany, Süddeutsche Zeitung (quality) and BILD (tabloid), and for Switzerland Tages Anzeiger (quality) and Blick (tabloid). For the defined period, this resulted in a total sample of N = 2,594 articles.
4.2 Manual coding and Intercoder reliability
Eleven trained coders coded content at the article (e.g., outlet, publication date), and frame level (Who speaks? What are the arguments and interpretations?). To increase reliability and validity, a first coder training with a following test coding was held. In a second training session, the codebook was slightly adapted based on emerging insecurities, which was again followed by another round of test coding. After the second test coding revealed that there were no more issues with the coding system, a third and final test coding was conducted. It was used for the reliability test.
Frames were the starting point for the coding. Coders were advised to code each frame they found in the article (see 4.3). Building on Gamson and Modigliani's (1989) argument that media discourse consists of a set of competing interpretative frame packages, we argue that multiple frames can coexist within a single article. A frame was defined as an interpretation of or a perspective on the topic of AI. If no frame was present in the article, the article was excluded. This was the case for articles mentioning AI but not containing a concrete storyline regarding AI (e.g., event tips or mere mention that a company is in the business of AI). This resulted in a final sample of 1,588 articles.
The reliability test included a total of 747 coded frames and a total of 110 articles. We conducted it using Nogrod (Wettstein, 2019), which is a text processing Python script built for complex content analyses that allows us to compare multiple coders and variables at the same time. We used Brennan and Prediger’s Kappa coefficient (Brennan and Prediger, 1981) which is a chance-corrected kappa coefficient more suitable for different distributions, unlikely categories, and multiple coders (Quarfoot and Levine, 2016). Intercoder reliability for the relevant constructs was satisfactory (see 4.4 for coefficients).
4.3 Automated coding
The goal of the automated coding was to mirror the manual approach as closely as possible. The automated content analysis consisted of three steps. First, the raw newspaper text along with meta-data was subjected to basic text pre-processing (changing words to lowercase, removing encoding issues, tokenization) and transformed into a document term matrix.
Second, key actors were extracted from the raw text using Named Entity Recognition (Nadeau and Sekine, 2007). Traditional NER has long been considered as “solving” the task of automated extraction of key places, objects, actors etc. (Marrero et al., 2013). Yet recent reformulations of NER models have further enhanced performance by leveraging Bidirectional Encoder Representations from Transformers (BERT) to understand words in their context, enabling the model to effectively capture the nuances of language, including both semantic and syntactic information (Devlin et al., 2019). We used a pre-trained BERT model for NER, implemented via Hugging Face’s infrastructure and accessed through the statistical software R. The BERT-based NER model learns to recognize entities based on the relationships and patterns present in the data, creating an end-to-end framework where the embeddings are used to classify entities directly (Souza et al., 2019; Hakala and Pyysalo, 2019). Of note, only named entities that were covered as grammatical subjects were retained to ensure their relevance as acting instances in the coverage. Two authors then manually classified the extracted entities into one of the actor types described in 4.4 (κ = 0.91).
Third, we conducted a reversed Joint Sentiment Topic model (rJST; Lin et al., 2012; Pipal et al., 2024) to identify latent topics in the corpus of news articles. As an extension of unsupervised traditional topic modeling techniques, rJST assumes that each news coverage article consists of thematic structures (“topics”) that can have varying sentiment attached to them (see Pipal et al., 2024; Lin and He, 2009). Traditional approaches to topic modeling look for semantic clusters regardless of sentiment. This is problematic, as it may falsely group together types of coverage that are quite different in tone, for example, euphoric reports of a cure for cancer and alarming reports of rising cancer rates. Choosing rJST remedies this problem by mirroring the theoretical distinction between favorable and unfavorable positions within frames (see Table 1). Empirically, rJST has been shown to outperform traditional dictionary-based approaches or Latent Dirichlet Allocation models for topic analysis with emphasis on sentiment, such as political speeches with varying ideological positions (i.e., varying sentiment; Pipal et al., 2024).
The model’s hyperparameters were chosen based on theoretical considerations. Specifically, we initially estimate a relatively large number of topics (K = 100) to be able to detect more fine-grained semantic structures in news articles that conceptually approximate frames (for a similar approach see Ort et al., 2023). We follow recommended practice (Griffiths and Steyvers, 2004) and set a rather symmetric Dirichlet prior (α = 50/K) to encourage sparser distributions. We choose a relatively low value for the smoothing parameter (β = 0.001) to allow for more concentrated word distributions within topics (i.e., more “specialized” topics with distinct word sets). Finally, we choose three sentiment categories (S = 3) to reflect the conceptual definition of frames as being either negative (contra), positive (pro), or neutral/ambivalent.
After the inductive generation of 100 topics, two authors aggregated the topics into frames by manually assigning each topic to one of the deductive frames (see Table 1), including positions (intercoder reliability: κ = 0.83). For every topic, the authors independently coded which of nine deductive frames best corresponded to the topic’s most representative 15 words, determined by their FREX scores (i.e., a topic metric balancing word frequency with exclusivity). For example, a topic with the top words “firm, investor, boom, venture, nvidia etc.” was coded as the economic optimism frame. As a second source of information, the chosen frame was then compared to the standardized mean weighted sentiment for each topic across the corpus as a conceptual validity check. For the same example, the economic optimism frame was associated with a very positive sentiment (M = 1.13), thus corroborating both the content of the frame (i.e., economic consequences) as well as the position (i.e., optimism).
4.4 Measures and analysis
Once the coders detected an interpretive storyline in an article, they assigned it to one of the six deductively derived frames and positions detailed in Table 1 (κ = 0.70). If none of the defined frames was suitable, they coded other and described the frame in an open text variable. A frame could thus occur not at all or multiple times within a news article in the manual coding. In the automated content analysis, the output of the rJST yields a probabilistic estimate of the prevalence of each frame for a newspaper article (ranging from 0 to 1). High estimates suggest that this frame is very likely to be present in a given article.
In manual coding, the speaker and actor type (κ = 0.72) were assigned to each frame (i.e., who does the framing?). We relied on journalists (i.e., authors of the articles), as a main source of news frames in event-driven debates (Hänggli and Trucco, 2022) as well as speakers of the areas of politics, science, industry, interest groups, non-scientific experts, and citizens, as these groups are relevant for technology coverage (Gurr and Metag, 2023). We also identified law and order as relevant speaker types (i.e., military and judiciary) because they proved to be important in the test coding. For some analyses (see 5.2. and 5.3.), we have combined citizens, non-scientific experts, and interest groups into a general group of civil society due to small case numbers. For the automated coding, the extracted actors were used as search strings which were then applied to each article. The result is a count variable of the number of occurrences of each actor type in each newspaper article—regardless of their link to a specific frame. Actors without an active voice (objects) were not coded in either content analytic approach.
Two types of analyses were conducted. On the one hand, the presence of actors and frames was calculated as shares (see Figures 1, 2). On the other hand, the associations of different actors to frames were quantified by means of ordinary least squares regression models. The prevalence of each frame was predicted in a separate model containing all actor types as predictors (see Figure 3). The resulting estimates are interpreted in terms of co-occurrence of a given actor type and frame in AI news coverage. Moreover, we included meta-data as control variables in all models, including the date and medium of publication as well as the number of words.
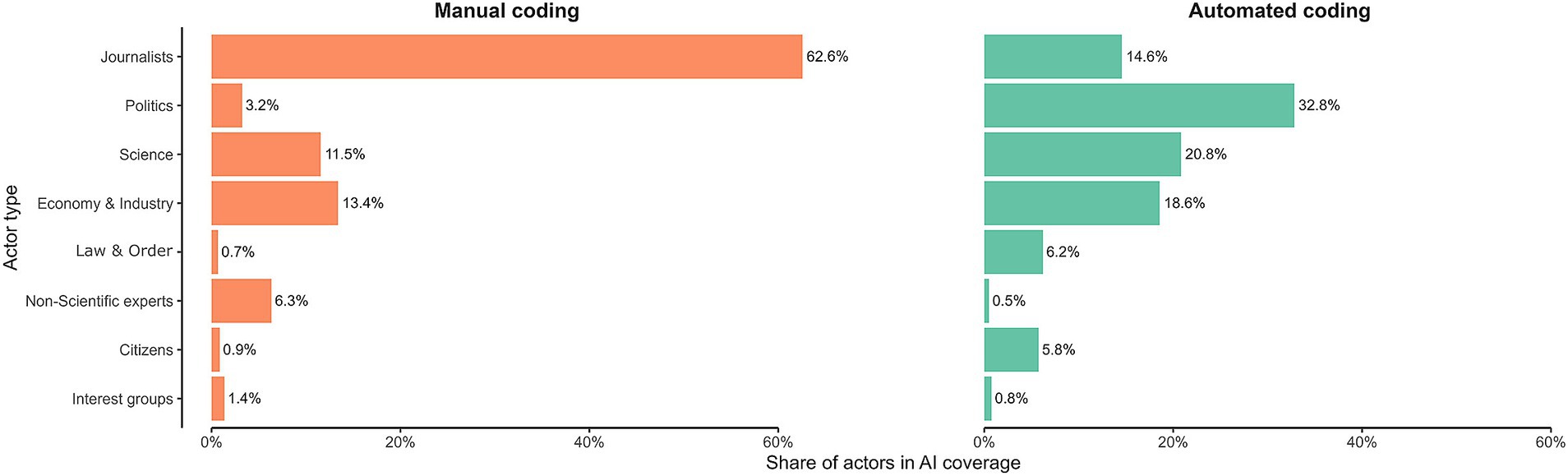
Figure 2. Share of actors in AI coverage based on manual (left panel) and automated (right panel) coding. The graph shows the share of each actor group in the AI debate. The manual coding only includes actors who are linked to a frame whereas the automated coding includes all actors who occur as subjects in news coverage (see methods for more details).
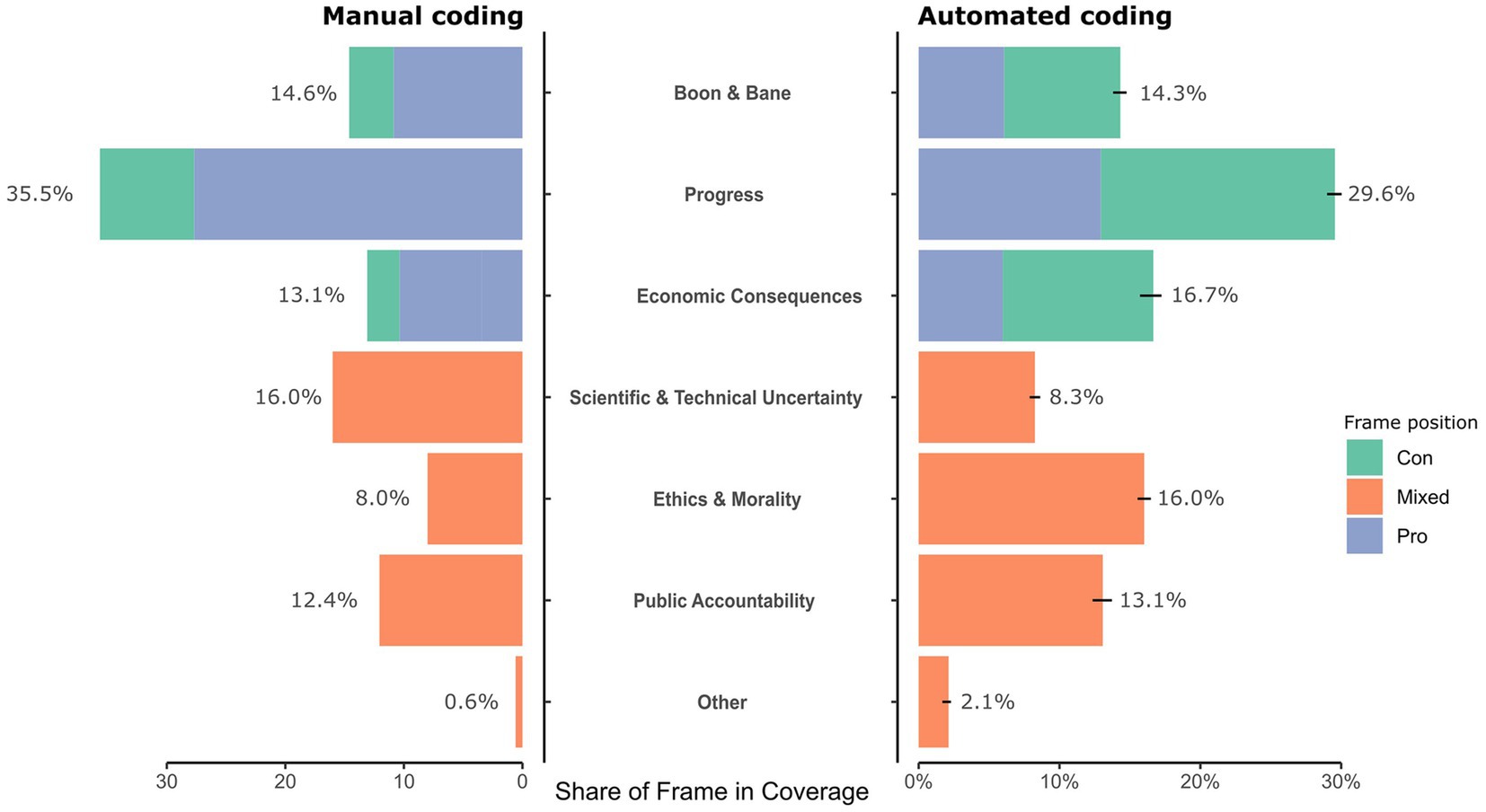
Figure 3. The share of frames and positions in AI coverage. The graph depicts the overall share of frames and positions in AI coverage for manual and automated content analysis. Values for manual coding (left panel) represent relative frequencies of frame occurrence; values for the automated coding (right panel) represent estimated mean frame prevalence with their 95% Confidence Intervals (bars).
5 Results
The results cover two parts. The first relates to the content of the articles and the second to the comparison between manual and automated content analysis. We will present the content-related results and the methodological comparison simultaneously for each research question, and we will present the findings for each method collectively (i.e., not comparing regions or outlets).
5.1 Actors shaping the AI debate
Figure 2 provides an overview of the share of the actors’ voices in the AI debate and shows a direct comparison of the manual and the automated content analysis. In the manual coding (see Figure 2, left-hand side), journalists prove to have the highest standing with almost two-thirds (62.6%) of the coded AI frames. This is followed by economic actors (13.4%), scientific actors (11.5%), non-scientific experts (6.3%), and political actors (3.2%). Interest groups, citizens, and law and order actors only reach a marginal share of voices in the AI debate. If we exclude journalists as authors of the articles, it becomes apparent that, according to manual coding, economic and scientific actors are leading the debate.
Based on the automated analysis (see Figure 2, right-hand side), political actors are the most frequent speakers in the AI debate, with almost one-third of all voices (32.8%). This is substantially more than in the manual analysis. Political actors are followed by scientific actors (20.8%), economic actors (18.6%), and journalists (14.6%). The latter were remarkably less recognized as speakers in the automated content analysis than in the manual one. With a share of less than 10%, the automated analysis shows that law and order actors (6.2%), as well as citizens (5.8%), have few voices in the AI debate. Here, interest groups and non-scientific experts have almost no standing. Note that a chi-square test of independence shows no significant association between actor groups and the data source, χ2(7, N = 6,841) = 56.2, p = 0.22.
5.2 Frames and positions in AI news coverage
Figure 3 depicts the share of each frame and their positions (if applicable). Overall, we see that the pro position of each frame is more frequent in the manual coding whereas the contra position is more frequent in the automated coding. The differences are due to a lack of semantic context in the rJST (see Discussion for further elaboration). The progress frame is most prevalent in both the manual (35.5%) and the automated analysis (29.6%). A proportion test shows that these two proportions are statistically different (χ2 = 114.3, p < 0.001; see Supplementary Table A1 for detailed results of the pairwise proportion tests). However, in the manual coding, pro positions of the progress frame predominate, while the automated analysis finds more contra positions. In manual coding, scientific and technical uncertainty is the second most common frame (16%). This frame has a lower share in the automated coding (8.3%; χ2 = 531.1, p < 0.001). In the automated analysis, economic consequences is the second most common frame (16.7%), which only reaches 13.1% in the manual coding (χ2 = 63.5, p < 0.001). Here, as with the progress frame, it becomes apparent that contra positions dominate in automated coding, while pro positions clearly prevail in manual coding. The boon and bane frame has a similar share in both analyses. However, pro positions are again substantially more present in the automated analysis. The public accountability frame also has similar shares in the manual and the automated coding. The same applies to the ethics and morality frame which is the least represented deductively derived frame in both analyses. A small part could not be clearly assigned to one of the frames (others), although this part was larger in the automated analysis and almost non-existent in the manual coding.
5.3 Association between actors and frames
Looking at the co-occurrence of frames and actors, some frames are more likely to be prevalent when certain actors are present as speakers. The results vary in clarity and differ in part depending on the method used. First, we want to focus on the clear and consistent results (i.e., we find the same effect using manual and automated coding). There is a link between the use of the public accountability frame and political actors. Political actors are also likely to co-occur with the economic consequences frame. Economic actors are also strongly linked to the economic consequences frame. The boon and bane frame, as well as the scientific and technical uncertainty frame co-occur with scientific actors. The ethics and morality and the progress frame are both linked to journalists and law and order actors. The progress frame is also used in the context of civil society actors.
The manual analysis further shows that the public accountability frame is likely to co-occur with scientific actors, law and order actors, and economy actors; the boon and bane frame with political actors, media, economy, and civil society; the economic consequences frame with scientific actors, and media; the ethics and morality frame and the progress frame with scientific actors, political actors, and economy; and the scientific and technical uncertainty frame with political actors, media, and economy.
The automated coding, on the other hand, finds unlikely co-occurrences between the public accountability frame and science, media, as well as economy; the boon and bane frame and politics, and economy; the economic consequences frame and science, media, law and order, and civil society; the ethics and morality frame and science, and economy; the progress frame and politics, and economy; and the scientific and technical uncertainty frame and politics, media, and economy. Figure 4 shows all the predictions of co-occurrence between actors and frames.
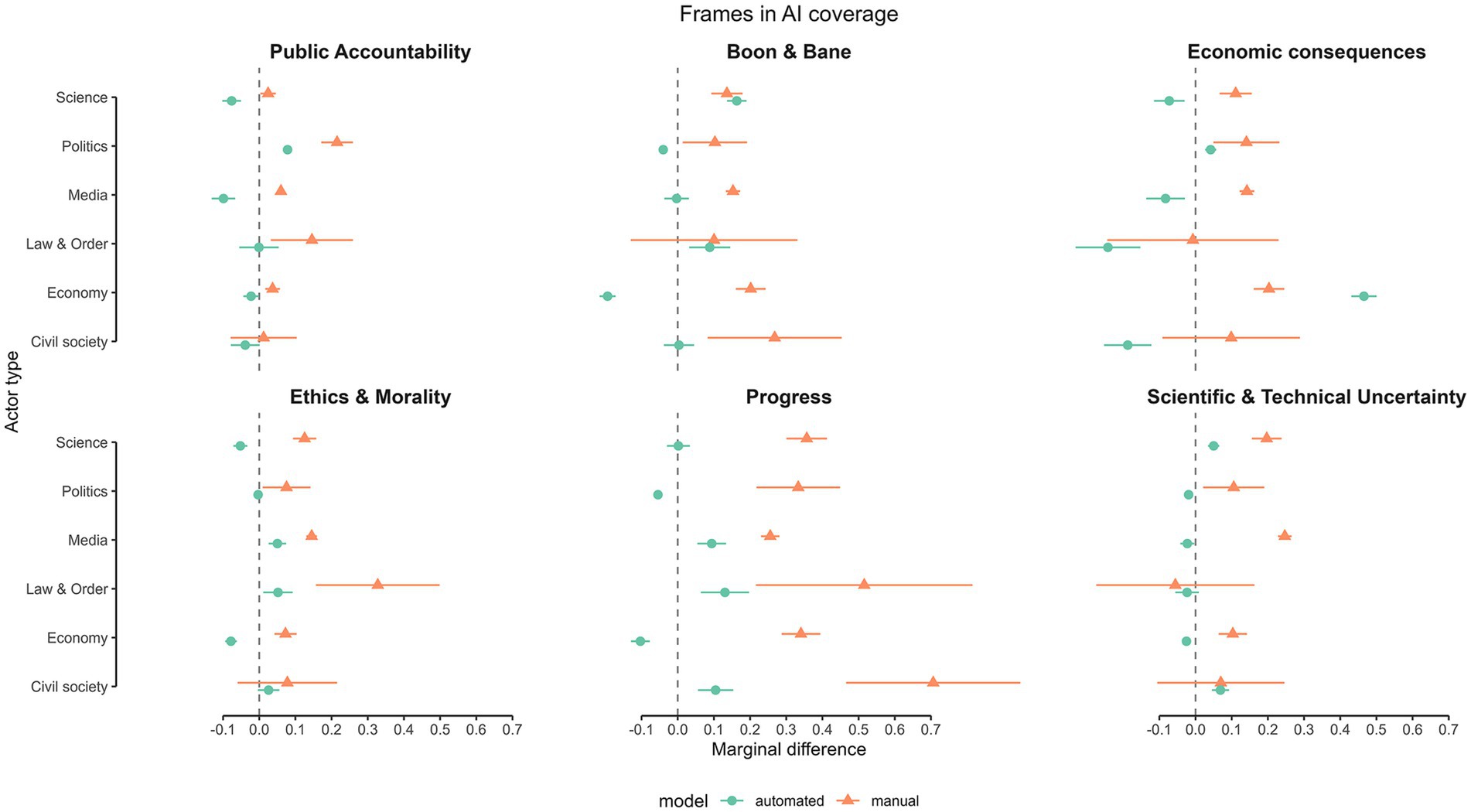
Figure 4. Predicting the prevalence of frames in AI coverage by actor type. The plots show predictions for co-occurrence of actor types and frames, both for automated (green/circles), and manual (orange/triangles) content analysis. Point estimates represent the marginal difference of the presence vs. absence of an actor type along with 95% Confidence intervals.
To understand which actors stand for which positions of these frames, we take a closer look at the frames with pro and contra positions of the manual content analysis. Due to the coding, the positions can be precisely assigned to individual actors, and we can calculate the exact frequencies. The automated analysis, on the other hand, only allows us to calculate co-occurrence within an article. A chi-square test of independence shows a significant association between the actor groups and the distribution of frames, χ2(30, N = 6,841) = 166.55, p < 0.001. The results (Table 2) indicate that for a large part of the frames with pro and contra positions, pro voices are more frequently represented throughout the different actors. Exceptions are civil society actors (i.e., non-scientific experts, interest groups, and citizens) holding a relatively high share of contra-positions of the boon and bane frame and thus providing a more apocalyptic than euphoric view on AI. Civil society actors are also most critical when it comes to economic consequences, even though pro positions slightly dominate. Another exception are law and order actors who use more contra positions in the progress and the boon and bane frame. However, the case numbers are very small here, which is why this should be interpreted with caution. It is also noteworthy that actors from politics and the economy are proportionately the most euphoric (boon and bane) when they speak and tend to represent an economically optimistic position. Among journalists, the proportion of pro-positions of the Progress Frame is also relatively high. Scientific actors also tend to speak more in favor of AI, although they are also positively associated with the ethics and morality frame and the scientific and technical uncertainty frame which can both also be more critical or relativizing (see Figure 4).
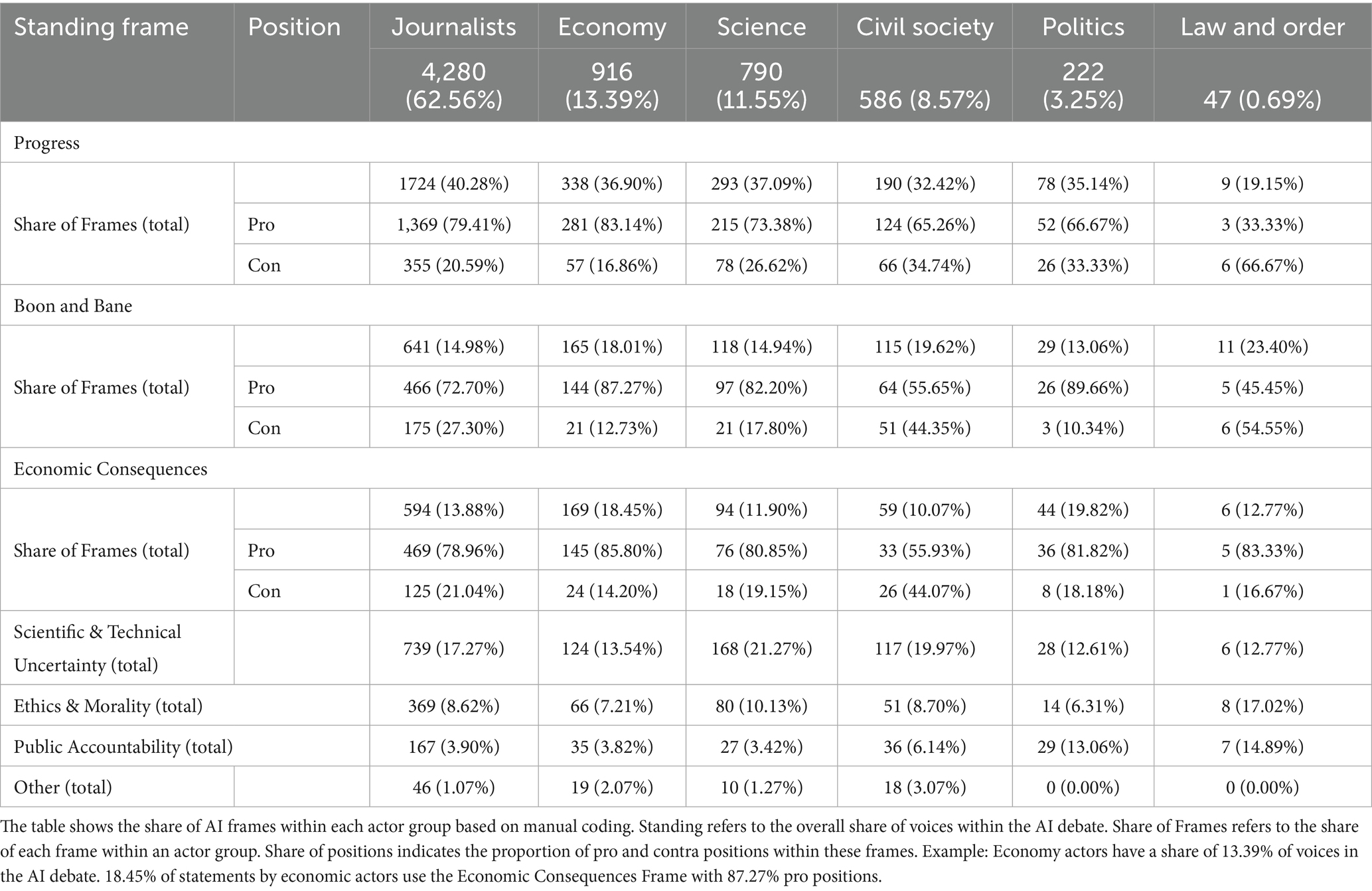
Table 2. Actors’ share of AI frames with pro and con positions (manual coding).
6 Discussion
Our first research aim was to see who has standing in the mediated AI debate (RQ1). We have mixed results on this question, depending on the method. The manual analysis showed a clear dominance of journalistic voices, indicating that the authors of articles are most often contextualizing AI themselves. The automated content analysis, on the other hand, found journalists to have way less standing and detected political actors as speakers with the highest standing in the debate. Possible methodological reasons for this are discussed later in this section. However, if we leave aside these contradictory findings, both methods show that business and economic actors have a high standing compared to all other groups. While this goes in line with previous findings showing that the AI debate is led by economic actors (Brennen et al., 2018), this finding also highlights the importance of scientific actors in the debate, as it is the case for other emerging technologies (e.g., Metag and Marcinkowski, 2014). Consequently, we also do not find support for our first hypothesis.
Secondly, we investigated how prominent the different AI frames are in news media coverage (RQ2). Here, the manual and the automated analysis both find a predominance of the progress frame. This is consistent with previous findings on AI reporting (e.g., Chuan et al., 2019; Cools et al., 2024; Sun et al., 2020) and supports our second hypothesis. A consistent result is also seen in the occurrence of the ethics and morality frame. It is least represented in both methods and therefore shows to play a subordinate role in the AI debate. Hence, the third hypothesis is also supported. We further hypothesized that pro positions predominate (H4). Our findings do not clearly support this hypothesis. Possible reasons for this difference will also be assessed in more detail later when comparing methods.
Our third research goal was to see which frames and positions are associated with which actors in the mediated AI debate (RQ3). We identify several actor-frame associations: political actors and the public accountability frame; economic actors and the economic consequences frame; scientific actors and the boon and bane frame as well as the scientific and technical uncertainty frame; and between journalists as well as law and order actors and the ethics and morality and the progress frame (Figure 4). These findings indicate that media reporting tends to link actors to frames that are consistent with their domain of expertise. For example, journalists draw from political actors to comment on regulatory issues, refer to economic actors to discuss economic issues and turn to scientific actors as the voice of scientific relativization. Noteworthy is also the association of scientific actors and the boon and bane frame, where pro positions seem to prevail based on the results of manual analysis. Scientists may frame technologies as breakthroughs or highly promising (e.g., AI bringing them a great step forward in decoding protein structures). At the same time, the prominence of the uncertainty frame indicates that such possible exaggerations are also routinely relativized (e.g., stating that AI technologies do not work reliably yet to decode protein structures). This could be because most of the scientific voices seem to come from computer science, likely emphasizing more technical aspects. However, based on our data, we cannot conclusively clarify which scientist, or disciplines bring in which perspectives. This should be subject to future research.
Another remarkable finding is about the ethics and morality frame. Despite its relevance for society, it is the least common frame. Literature on frame-building shows that it is the powerful, active and prominent actors that largely shape the debate (e.g., Hänggli, 2020). Journalists, being the actors with the highest standing, therefore have the potential to bring ethical and moral aspects more into the debate. They could either do this more themselves, which requires AI literacy, or include more other voices advocating for ethical AI. Our findings show that the ethics and morality frame is most likely to be brought up by scientists, or law and order actors. Such speakers could thus be integrated more into the AI debate by journalists, especially as law and order actors are currently little represented.
The results also show that civil society actors are the most critical. Actors speaking in the interest of citizens and the common-sense, such as non-scientific experts, are most strongly represented in this group. This includes, for example, NGOs advocating for human or digital rights. Political actors do not have high standing in the AI debate. If they speak, they mostly frame AI as positive progress bringing economic benefits or consider it a boon. As we see a similar pattern for economic actors, this might indicate a link between politics and economy.
Finally, we compared manual and automated content approaches for the analysis of technology frames in technology coverage. This addresses the current desideratum in framing research concerning the suitability of computational approaches for frame detection (Hase, 2023). The use of manual content analysis and Named Entity Recognition as well as rJST showed in our case of AI coverage some similarities and some differences. For the actors, manual content analysis found substantially more journalistic speakers than the automated coding did. This can be explained by the method of Named Entity Recognition. Journalists (i.e., the authors of the article) almost exclusively do not occur as named entities in the article (as there are rarely names as speaking subjects). If they occur as speakers and use a frame, it is way more subtle than it is the case for other actors such as politicians or economic actors. These actors are often marked via their function (e.g., MP, president, CEO) and are therefore more likely to be detected using Named Entity Recognition. This might lead to an overestimation of the political actors and an underestimation of journalistic actors. While this study’s use of NER identifies subjects, it does not distinguish between speakers and mentions. This might further explain why political actors are overestimated using NER.
While the overall shares of the frames are similar for both methods, rJST finds more contra positions than the manual coding. This may be because rJST only relies on the sentiment of certain word combinations but does not consider their semantic context. The results are a probabilistic estimate of the prevalence of each frame in an article whereas the manual coding provides actual frequencies. For the nuanced positions, this might also lead to different shares. Computational approaches that rely more heavily on transformer-based architectures or leverage large language models (LLM) could probably be used to partially overcome these limitations (Chew et al., 2023; Kuang et al., 2025). However, they would demand a very large amount of training data and would raise additional issues regarding the transparency of data processing. Of note, manual coding is not free of limitations, either. 11 coders were needed to code a large number of articles. Managing volume while ensuring reliability adds cost and workload. Automated coding, on the other hand, applies the exact same principle to all the articles in less time. Finally, we contrasted two computational techniques, NER and rJST, with manual coding. Future research would benefit from continued interest in comparing state-of-the-art computational and manual approaches to media framing research.
There are also some general limitations of this study. First, data was collected before the 2023 AI boom caused by generative AI such as ChatGPT (see Figure 1). Articles published during this period in which AI coverage increased even more were therefore not included in the sample. Further, we only included the general term of artificial intelligence for our search inquiry. Articles reporting on specific AI technologies and only including the abbreviation “AI” were not covered. Even though in many articles the term is first written out in full and then used with the abbreviation, it is therefore possible that not all relevant articles have been considered. Also, the selected news outlets do not represent the full coverage in each country. Outlets with different political positions have proven to report differently on AI with left-leaning media reporting more on ethics and right-leaning media reporting more on economics (Brennen et al., 2018). Due to the focus of this study, that is identifying relevant AI frames and speakers in the overall debate and comparing manual and automated analysis, the results were presented collectively. The study did not aim to compare outlets or regions. However, future research is invited to build on this and pursue corresponding comparative approaches.
7 Conclusion
This study set out to bring the disparate body of scholarship on media discourses around AI closer together in three ways. Conceptually, we revisited the framing literature and distilled existing approaches into six key frames that integrate different attitudinal positions. We also outlined how these frames connect to actor-oriented media analysis. Empirically, our study offers an important empirical update on media coverage of AI at a crucial time in public AI discourse. Methodologically, we propose and test novel operationalizations and procedures to track key AI media frames with both manual and automated content analysis. This hybrid and comparative approach serves as a point of reference in a field that is increasingly grappling with the integration of findings from computational and manual content-analytic approaches (see Hase, 2023).
The findings overall show support for the dominance of the progress frame that pragmatically presents AI as an everyday aid or also emphasizes possible dangers. In the manual coding, however, pro positions clearly predominated. Even if we can detect a certain economic orientation and euphoric future prospects, critical voices are also present. The scientific and technical uncertainty frame puts the potential of AI applications into perspective and points out possible limits. We also find a considerable proportion of the public accountability frame, which calls for regulation and responsible use of AI. The ethics and morality frame is comparatively little represented.
In the manual analysis, journalists prove to do most of the AI framing themselves. To enhance voices addressing ethical and moral issues coming with AI, journalists could involve more actors who are experts in this field such as social scientists, philosophers, or legal scholars. In addition, if the political players do not include the ethical aspects in the public debate, these aspects will not (or less likely) be included in legislation and will not be considered in any other way. We see this as problematic. Generally, the low occurrence of political actors in the manual analysis indicates that politics is not yet strongly engaged with the topic of AI, or that this has not yet entered the public debate. Due to the still increasing importance of AI, an increasing politicization of the topic could also emerge. Besides journalists, economic and scientific actors have the highest standing in the debate. Overall, they rather hold pro positions, even though scientific actors are also clearly associated with the scientific and technical uncertainty frame. Journalists could therefore include more critical voices from these areas to create a more balanced debate.
Methodologically, we showcase that computational approaches using rJST yield mostly similar results as manual content analysis when it comes to detecting topics. There are larger differences in the recognition of the framing regarding speakers and positions of these frames. This indicates that rJST may not be sufficiently attuned to the context of frames as they are conceptualized in communication theory (e.g., Druckman, 2001; Entman, 1993; Ferree et al., 2002; for an overview see Hänggli Fricker, 2025). In the case of actors, the automated analysis (NER) was not able to reliably distinguish between speaking subjects (somebody acts as a speaker) and non-speaking subjects (somebody is mentioned but does not speak). Further, our approach struggles to recognize latent or more implicit entities while overestimating clearly labelled entities, such as political actors. This also points to certain limits of automated methods in recognizing subtle contextual factors. Computational methods may therefore be more suitable for content analyses as a complement to manual coding, as far as contextual knowledge is required. But to shed further light on this, more research combining automated and manual analyses is needed.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found at: https://osf.io/cbzkh/?view_only=797e547d2fb74820a58c6add85730cd6.
Author contributions
FZ: Data curation, Conceptualization, Writing – review & editing, Methodology, Formal analysis, Writing – original draft, Investigation. TR: Writing – original draft, Writing – review & editing, Visualization, Formal analysis, Methodology, Data curation. RH: Investigation, Conceptualization, Writing – review & editing, Writing – original draft, Methodology.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Acknowledgments
The authors thank the student assistants for their highly valued contribution to the manual coding.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that Gen AI was used in the creation of this manuscript. Generative AI (ChatGPT, GPT-4, OpenAI) was used to assist in manuscript revision, including language editing, text condensation, and grammar correction. The AI-generated output was reviewed and revised by the authors to ensure accuracy and appropriateness.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fcomm.2025.1599854/full#supplementary-material
References
Arceneaux, N., and Schmitz Weiss, A. (2010). Seems stupid until you try it: press coverage of twitter, 2006-9. New Media Soc. 12, 1262–1279. doi: 10.1177/1461444809360773
Brennan, R. L., and Prediger, D. J. (1981). Coefficient kappa: some uses, misuses, and alternatives. Educ. Psychol. Meas. 41, 687–699. doi: 10.1177/001316448104100307
Brennen, J. S., Howard, P. N., and Nielsen, R. K. (2018). An industry-led debate: how UK media cover artificial intelligence. Reuters Institute for the Study of Journalism. Available online at: https://reutersinstitute.politics.ox.ac.uk/sites/default/files/2018-12/Brennen_UK_Media_Coverage_of_AI_FINAL.pdf (Accessed June 18, 2025).
Brennen, J. S., Howard, P. N., and Nielsen, R. K. (2022). What to expect when you’re expecting robots: futures, expectations, and pseudo-artificial general intelligence in UK news. Journal. 23, 22–38. doi: 10.1177/1464884920947535
Bunz, M., and Braghieri, M. (2022). The AI doctor will see you now: assessing the framing of AI in news coverage. AI & Soc. 37, 9–22. doi: 10.1007/s00146-021-01145-9
Chew, R., Bollenbacher, J., Wenger, M., Speer, J., and Kim, A. (2023). Llm-assisted content analysis: using large language models to support deductive coding. ArXiv (Cornell Univ.). doi: 10.48550/arXiv.2306.14924
Chuan, C.-H., Tsai, W.-H. S., and Cho, S. Y. (2019). Framing artificial intelligence in American newspapers. Proc. AAAI Conf. Artif. Intell., 339–344. doi: 10.1145/3306618.3314285
Cools, H., van Gorp, B., and Opgenhaffen, M. (2024). Where exactly between utopia and dystopia? A framing analysis of AI and automation in US newspapers. Journal. 25, 3–21. doi: 10.1177/14648849221122647
Dahinden, U. (2002). Biotechnology in Switzerland. Sci. Commun. 24, 184–197. doi: 10.1177/107554702237844
de Graaf, R., and van der Vossen, R. (2013). Bits versus brains in content analysis. Comparing the advantages and disadvantages of manual and automated methods for content analysis. Communications 38, 433–443. doi: 10.1515/commun-2013-0025
de Vreese, C. H. (2005). News framing: theory and typology. Inf. Des. J. 13, 51–62. doi: 10.1075/idjdd.13.1.06vre
Devlin, J., Chang, M. W., Lee, K., and Toutanova, K. (2019). Bert: pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 conference of the north American chapter of the association for computational linguistics: Human language technologies, volume 1 (long and short papers). pp. 4171–4186
Druckman, J. N. (2001). The implications of framing effects for citizen competence. Polit. Behav. 23, 225–256. doi: 10.1023/A:1015006907312
Durant, J., Bauer, M. W., and Gaskell, G. (1998). Biotechnology in the public sphere: A European sourcebook : Science Museum.
Entman, R. M. (1993). Framing: toward clarification of a fractured paradigm. J. Commun. 43, 51–58. doi: 10.1111/j.1460-2466.1993.tb01304.x
Fast, E., and Horvitz, E. (2017). Long-term trends in the public perception of artificial intelligence. Proc. AAAI Conf. Artif. Intell. 31. doi: 10.1609/aaai.v31i1.10635
Ferree, M. M., Gamson, W. A., Gerhards, J., and Rucht, D. (2002). Shaping abortion discourse: Democracy and the public sphere in Germany and the United States. Communication, society, and politics. Cambridge, UK: Cambridge University Press.
Fogel-Dror, Y., Shenhav, S. R., Sheafer, T., and van Atteveldt, W. (2019). Role-based association of verbs, actions, and sentiments with entities in political discourse. Commun. Methods Meas. 13, 69–82. doi: 10.1080/19312458.2018.1536973
Gamson, W. A., and Modigliani, A. (1989). Media discourse and public opinion on nuclear power: a constructionist approach. Am. J. Sociol. 95, 1–37. doi: 10.1086/229213
Griffiths, T. L., and Steyvers, M. (2004). Finding scientific topics. Proc. Natl. Acad. Sci. 101, 5228–5235. doi: 10.1073/pnas.0307752101
Gurr, G., and Metag, J. (2023). “Content analysis in the research field of technology coverage” in Standardisierte Inhaltsanalyse in der Kommunikationswissenschaft – Standardized content analysis in communication research: Ein Handbuch - a handbook. eds. F. Oehmer-Pedrazzi, S. H. Kessler, E. Humprecht, K. Sommer, and L. Castro. 1st ed (Wiesbaden, Germany: Springer Fachmedien Wiesbaden; Imprint Springer VS).
Hakala, K., and Pyysalo, S. (2019). Biomedical named entity recognition with multilingual BERT. In Proceedings of the 5th workshop on BioNLP open shared tasks, 56–61.
Hänggli, R. (2011). “Key factors in frame building” in Challenges to democracy in the 21st century. Political communication in direct democratic campaigns: Enlightening or manipulating? ed. H. Kriesi. 1st ed (London, UK: Palgrave Macmillan), 125–142.
Hänggli, R. (2020). The origin of dialogue in the news media. Challenges to democracy in the 21st century Ser : Springer International Publishing AG.
Hänggli Fricker, R. (2025). “Framing” in Elgar encyclopedia of political communication. eds. A. Nai, M. Grömping, and D. Wirz (Cheltenham, UK: Edward Elgar Publishing).
Hänggli Fricker, R., and Beck, D. (2024). A comparative analysis of reporting on Islam between 2018–2020: characteristics of institutionally and event-driven debates. Sage J. doi: 10.1177/14648849241266719
Hänggli, R., and Trucco, N. (2022). Bad guy or good guy? The framing of an imam. Stud. Commun. Sci., 1–20. doi: 10.24434/j.scoms.2022.03.2928
Hase, V. (2023). “Automated content analysis” in Standardisierte Inhaltsanalyse in der Kommunikationswissenschaft – Standardized content analysis in communication research: Ein Handbuch - a handbook. eds. F. Oehmer-Pedrazzi, S. H. Kessler, E. Humprecht, K. Sommer, and L. Castro. 1st ed (Wiesbaden, Germany: Springer Fachmedien Wiesbaden; Imprint Springer VS), 23–36.
Hase, V., Engelke, K. M., and Kieslich, K. (2020). The things we fear. Combining automated and manual content analysis to uncover themes, topics and threats in fear-related news. Journal. Stud. 21, 1384–1402. doi: 10.1080/1461670X.2020.1753092
Kitzinger, J., and Williams, C. (2005). Forecasting science futures: legitimising hope and calming fears in the embryo stem cell debate. Soc. Sci. Med. 61, 731–740. doi: 10.1016/j.socscimed.2005.03.018
Köstler, L., and Ossewaarde, R. (2022). The making of AI society: AI futures frames in German political and media discourses. AI & Soc. 37, 249–263. doi: 10.1007/s00146-021-01161-9
Kriesi, H., Bernhard, L., Fossati, F., and Hänggli, R. (2019). “Introduction” in Debating unemployment policy: Political communication and the labour market in Western Europe. eds. L. Bernhard, F. Fossati, R. Hänggli, and H. Kriesi (Cambridge, UK: Cambridge University Press), 3–28.
Kuang, X., Liu, J., Zhang, H., and Schweighofer, S. (2025). Towards algorithmic framing analysis: expanding the scope by using LLMs. J. Big Data 12:66. doi: 10.1186/s40537-025-01092-y
Lawrence, R. G. (2023). The politics of force: Media and the construction of police brutality (updated edition). Oxford scholarship online political science. New York, USA: Oxford University Press.
Lin, C., and He, Y. (2009). “Joint sentiment/topic model for sentiment analysis” in Proceedings of the 18th ACM conference on information and knowledge management, 375–384. doi: 10.1145/1645953.1646003
Lin, C., He, Y., Everson, R., and Ruger, S. (2012). Weakly supervised joint sentiment-topic detection from text. IEEE Trans. Knowl. Data Eng. 24, 1134–1145. doi: 10.1109/TKDE.2011.48
Livingston, S., and Bennett, W. L. (2003). Gatekeeping, indexing, and live-event news: is technology altering the construction of news? Polit. Commun. 20, 363–380. doi: 10.1080/10584600390244121
Marrero, M., Urbano, J., Sánchez-Cuadrado, S., Morato, J., and Gómez-Berbís, J. M. (2013). Named entity recognition: fallacies, challenges and opportunities. Comput. Stand. Inter. 35, 482–489. doi: 10.1016/j.csi.2012.09.004
Metag, J. (2019). “Technology coverage” in The wiley blackwell-ICA international encyclopedias of communication. The international encyclopedia of journalism studies. eds. T. P. Vos, F. Hanusch, D. Dimitrakopoulou, M. Geertsema-Sligh, and A. Sehl (Wiley-Blackwell), 1–5. doi: 10.1002/9781118841570.iejs0216
Metag, J., and Marcinkowski, F. (2014). Technophobia towards emerging technologies? A comparative analysis of the media coverage of nanotechnology in Austria, Switzerland and Germany. Sage J. 15, 463–481. doi: 10.1177/1464884913491045
Nadeau, D., and Sekine, S. (2007). Named entities: recognition, classification and use. Lingvist. Investig. 30, 3–26. doi: 10.1075/li.30.1.03nad
Nader, K., Toprac, P., Scott, S., and Baker, S. (2022). Public understanding of artificial intelligence through entertainment media. AI & Soc., 1–14. doi: 10.1007/s00146-022-01427-w
Nelson, L. K. (2019). To measure meaning in big data, don’t give me a map, give me transparency and reproducibility. Sociol. Methodol. 49, 139–143. doi: 10.1177/0081175019863783
Nguyen, D., and Hekman, E. (2024). The news framing of artificial intelligence: a critical exploration of how media discourses make sense of automation. AI & Soc. 39, 437–451. doi: 10.1007/s00146-022-01511-1
Nisbet, M. C. (2009). Communicating climate change: why frames matter for public engagement. Environ. Sci. Pol. 51, 12–23. doi: 10.3200/ENVT.51.2.12-23
Nisbet, M. C., and Lewenstein, B. V. (2002). Biotechnology and the American media: the policy process and the elite press, 1970 to 1999. Sci. Commun. 23, 359–391. doi: 10.1177/107554700202300401
Nisbet, M. C., and Scheufele, D. A. (2009). What’s next for science communication? Promising directions and lingering distractions. Am. J. Bot. 96, 1767–1778. doi: 10.3732/ajb.0900041
Ort, A., Rohrbach, T., Diviani, N., and Rubinelli, S. (2023). Covering the crisis: evolution of key topics and actors in COVID-19 news coverage in Switzerland. Int. J. Public Health 67:1605240. doi: 10.3389/ijph.2022.1605240
Ouchchy, L., Coin, A., and Dubljević, V. (2020). AI in the headlines: the portrayal of the ethical issues of artificial intelligence in the media. AI & Soc. 35, 927–936. doi: 10.1007/s00146-020-00965-5
Pipal, C., Schoonvelde, M., Schumacher, G., and Boiten, M. (2024). JST and rJST: joint estimation of sentiment and topics in textual data using a semi-supervised approach. Commun. Methods Meas., 1–19. doi: 10.1080/19312458.2024.2383453
Quarfoot, D., and Levine, R. A. (2016). How robust are multirater interrater reliability indices to changes in frequency distribution? Am. Stat. 70, 373–384. doi: 10.1080/00031305.2016.1141708
Scheufele, D. A., and Lewenstein, B. V. (2005). The public and nanotechnology: how citizens make sense of emerging technologies. J. Nanopart. Res. 7, 659–667. doi: 10.1007/s11051-005-7526-2
Semetko, H. A., and Valkenburg, P. M. V. (2000). Framing European politics: a content analysis of press and television news. J. Commun. 50, 93–109. doi: 10.1111/j.1460-2466.2000.tb02843.x
Souza, F., Nogueira, R., and Lotufo, R. (2019). Portuguese named entity recognition using BERT-CRF. arXiv preprint arXiv:1909.10649.
Sun, S., Zhai, Y., Shen, B., and Chen, Y. (2020). Newspaper coverage of artificial intelligence: a perspective of emerging technologies. Telematics Inform. 53:101433. doi: 10.1016/j.tele.2020.101433
Wettstein, M. (2019). Nogrod (version 1.1.2) [computer software]. Avalable online at: https://github.com/Tarlanc/Nogrod (Accessed June 18, 2025).
Keywords: artificial intelligence, framing, standing, public debate in the media, manual content analysis, automated content analysis
Citation: Zai F, Rohrbach T and Hänggli Fricker R (2025) Voices and media frames in the public debate on artificial intelligence: comparing results from manual and automated content analysis. Front. Commun. 10:1599854. doi: 10.3389/fcomm.2025.1599854
Edited by:
Arnau Gifreu-Castells, Autonomous University of Barcelona, SpainReviewed by:
Bartłomiej Łódzki, University of Wrocław, PolandClaudio Meneses, Universidad Católica del Norte, Chile
Copyright © 2025 Zai, Rohrbach and Hänggli Fricker. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Florin Zai, ZmxvcmluLnphaUB1bmlmci5jaA==