 Aref Smiley1
Aref Smiley1 David Villarreal-Zegarra1
David Villarreal-Zegarra1 C. Mahony Reategui-Rivera1
C. Mahony Reategui-Rivera1 Stefan Escobar-Agreda2
Stefan Escobar-Agreda2 Joseph Finkelstein1*
Joseph Finkelstein1*- 1Department of Biomedical Informatics, University of Utah, Salt Lake City, UT, United States
- 2Telehealth Unit, Universidad Nacional Mayor de San Marcos, Lima, Peru
This study aimed to evaluate the quality and transparency of reporting in studies using machine learning (ML) in oncology, focusing on adherence to the Consolidated Reporting Guidelines for Prognostic and Diagnostic Machine Learning Models (CREMLS), TRIPOD-AI (Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis), and PROBAST (Prediction Model Risk of Bias Assessment Tool). The literature search included primary studies published between February 1, 2024, and January 31, 2025, that developed or tested ML models for cancer diagnosis, treatment, or prognosis. To reflect the current state of the rapidly evolving landscape of ML applications in oncology, fifteen most recent articles in each category were selected for evaluation. Two independent reviewers screened studies and extracted data on study characteristics, reporting quality (CREMLS and TRIPOD+AI), risk of bias (PROBAST), and ML performance metrics. The most frequently studied cancer types were breast cancer (n=7/45; 15.6%), lung cancer (n=7/45; 15.6%), and liver cancer (n=5/45; 11.1%). The findings indicate several deficiencies in reporting quality, as assessed by CREMLS and TRIPOD+AI. These deficiencies primarily relate to sample size calculation, reporting on data quality, strategies for handling outliers, documentation of ML model predictors, access to training or validation data, and reporting on model performance heterogeneity. The methodological quality assessment using PROBAST revealed that 89% of the included studies exhibited a low overall risk of bias, and all studies have shown a low risk of bias in terms of applicability. Regarding the specific AI models identified as the best-performing, Random Forest (RF) and XGBoost were the most frequently reported, each used in 17.8% of the studies (n = 8). Additionally, our study outlines the specific areas where reporting is deficient, providing researchers with guidance to improve reporting quality in these sections and, consequently, reduce the risk of bias in their studies.
1 Introduction
Cancer is one of the leading causes of disease burden and mortality worldwide. Early detection is crucial for improving clinical outcomes, yet approximately 50% of cancers are diagnosed at an advanced stage (1). Artificial Intelligence (AI), particularly machine learning (ML) models, has shown great potential in cancer diagnosis, prognostic, and treatment, standing out for its high accuracy, sensitivity, and ability to integrate into clinical workflows (2). This progress has led to a significant increase in studies and publications dedicated to the development and evaluation of these models in recent years (3).
The quality of reporting in these studies is critical, as clear and comprehensive documentation allows for the validation of results and their replication in different contexts (2). However, growing concerns have emerged regarding the completeness and accuracy of reports in ML-based research. Indeed, a meta-review of fifty systematic reviews, revealed that most reports of primary diagnostic accuracy studies were incomplete, limiting their utility and reproducibility (4). Furthermore, systematic reviews on treatment response in cancer patients have identified high heterogeneity and reporting issues (5, 6).
In response to these deficiencies, specific guidelines, such as the Consolidated Reporting Guidelines for Prognostic and Diagnostic Machine Learning Models (CREMLS) and the Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis (TRIPOD+AI), have been developed to standardize the key aspects that should be included in ML study reports (7, 8). Nevertheless, the widespread adoption of these tools depends on their dissemination and proper training, which may delay their integration into recent scientific publications (9). In addition to ensuring the quality of reporting, assessing the risk of bias in studies using AI models for cancer patients is essential. The Prediction Model Risk of Bias Assessment Tool (PROBAST) is a tool designed to evaluate the risk of bias across four domains: participants, predictors, outcomes, and analysis (10).
Our study evaluated PubMed publications that applied ML for the diagnosis, treatment, and prognosis of cancer patients. We assessed reporting quality (CREMLS and TRIPOD+AI), risk of bias (PROBAST), and ML performance metrics.
2 Materials and methods
2.1 Eligibility criteria
We included primary studies that applied AI techniques to predict cancer diagnosis, treatment, and prognosis in patients. Studies were eligible regardless of participants’ age, sex, race, ethnicity, or other sociodemographic or clinical characteristics. Articles written in any language and employing observational or experimental study designs were considered. Reviews, viewpoints, and conference papers were excluded. Our study included research that evaluates the first case of a specific cancer, specific recurrent cancers, groups of cancers, or metastases.
2.2 Search strategy and sources
Our search strategy included terms related to oncology, AI, prognosis, diagnosis, and treatment. A search was conducted in PubMed, restricted to studies published between February 1, 2024, and January 31, 2025. The results were sorted by “most recent,” and the 15 most recent studies on prognosis, diagnosis, and treatment were selected, yielding a total of 45 articles. The most recent articles were chosen in order to reflect the current state of the rapidly evolving landscape of AI applications in oncology. Details of the search strategy are provided in Supplementary Material 1.
2.3 Selection process
The selection process was conducted using Rayyan (11). Two reviewers independently screened the title and abstract of each record identified to determine if the inclusion criteria were met. Subsequently, both reviewers independently evaluated the full text of records that passed the title and abstract screening. In cases of disagreement, a third reviewer made the final decision regarding inclusion.
2.4 Data collection process and data items
Data extraction was performed using a standardized Excel form. Two independent reviewers conducted the data collection process, and a third reviewer made the final decision in cases of disagreement. Each reviewer independently collected information using this form, which captured details such as the name of the first author, year of publication, article title, patient characteristics, type of AI tested or developed, clinical contexts, reported outcomes (AI performance metrics), reporting quality (CREMLS and TRIPOD+AI) (7, 8), and risk of bias (PROBAST) (10).
The extraction process was conducted in duplicate, and the level of agreement between independent evaluators was assessed in the first five included studies. The extracted information was highly consistent, achieving an agreement level above 80%.
2.5 Synthesis methods
2.5.1 Report quality
The TRIPOD+AI checklist consists of 27 key items designed to ensure the quality and transparency of reporting in prediction model studies (8). This updated version of TRIPOD extends the recommendations to include models developed using ML methods. The primary objective of TRIPOD+AI is to promote clear, comprehensive, and reproducible reporting in studies that develop or validate prediction models in healthcare. TRIPOD+AI results were categorized using the following response options: Yes, No/Not reported, or Not applicable.
The CREMLS guideline was developed to enhance the transparency and quality of reporting in ML studies for diagnostic and prognostic applications in healthcare (7). It comprises 37 items organized into five categories: study details, data, methodology, model evaluation, and model explainability. CREMLS results were assessed using the following response options: Yes, No/Not reported, or Not applicable.
Since our objective was to assess the reporting quality of studies using ML for diagnostic, prognostic, and treatment outcomes in cancer patients, no studies were excluded based on a negative evaluation of reporting quality.
2.5.2 Risk of bias
The PROBAST tool assessed the risk of bias (RoB) in studies on prediction models for diagnosis, prognosis, and treatment. PROBAST provides a structured framework for evaluating the internal and external validity of studies by identifying potential biases in participant selection, predictor and outcome measurement, analytical strategies, and data presentation (10).
The response options in PROBAST were: low RoB/low concern regarding applicability (+), high RoB/high concern regarding applicability (-), and unclear RoB/unclear concern regarding applicability (?).
2.5.3 AI performance metrics
The study presented the main metrics used to evaluate the performance of each AI model included in the analyzed articles across different phases (i.e., training, testing, validation). These metrics included sensitivity (also known as recall or true positive rate), specificity (true negative rate), overall accuracy (probability of correct classification), positive predictive value (precision), F1 score, and the area under the ROC curve (AUC).
2.6 Statistical analysis
All statistical analyses were performed using R. Our study employed a descriptive approach based on percentages and absolute frequencies of CREMLS, TRIPOD+AI, and PROBAST scores. No inferential approaches focused on hypothesis testing were used.
3 Results
3.1 Study selection
Our study searched PubMed for ML models related to diagnosis, treatment, and prognosis that met the inclusion criteria. To standardize selection, we included only the first 15 articles for each category: prognosis, diagnosis, and treatment. The screening process, which involved title and abstract review followed by full-text assessment, is shown in Figure 1.
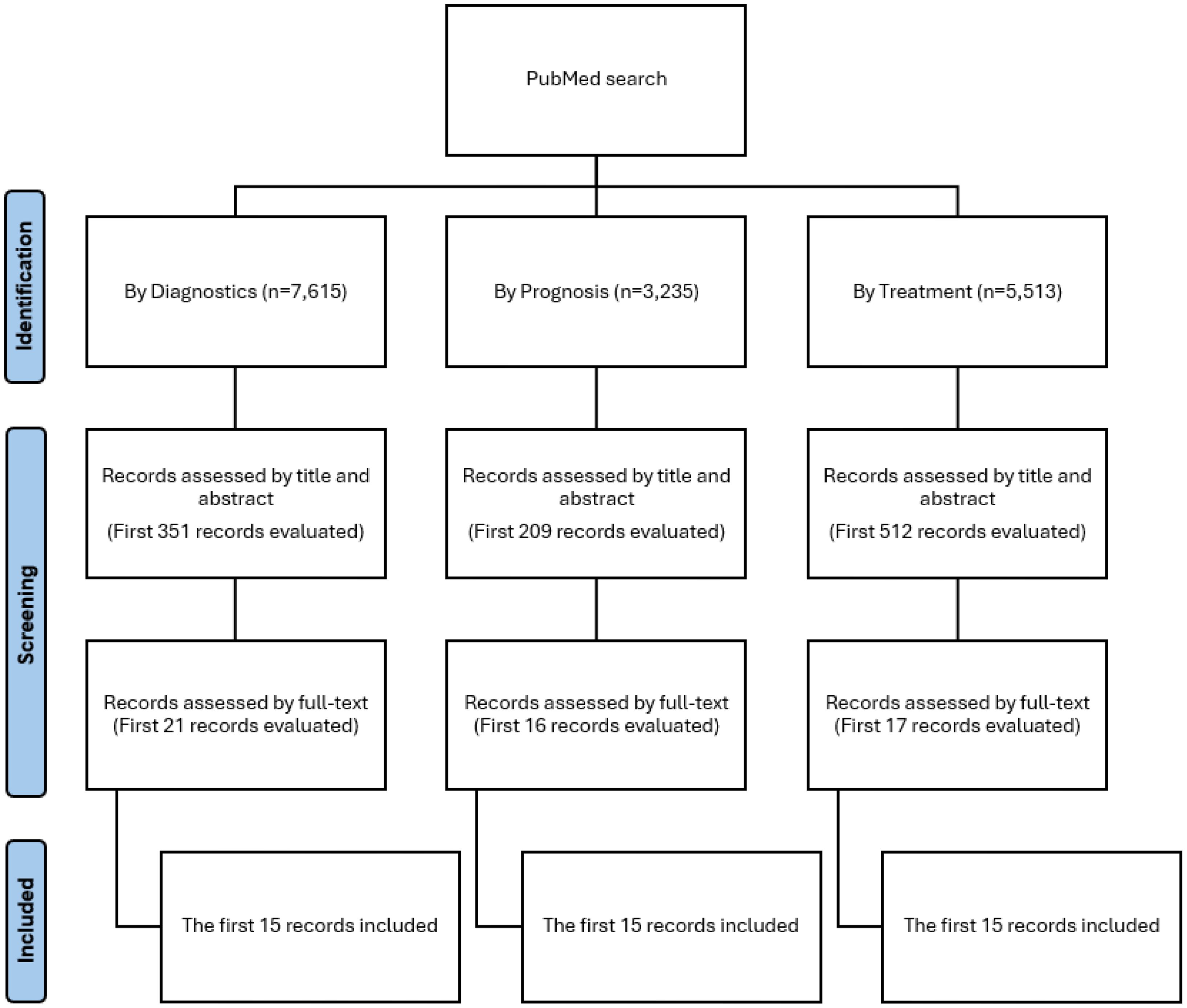
Figure 1. Flowchart.
3.2 Characteristics of the included studies
The first authors of the included studies were affiliated with institutions from 16 different countries. China had the highest number of publications (n=27/45; 60%), followed by Egypt (n=3/45; 6.7%). The most frequently studied cancer types were breast cancer (n=7/45; 15.6%), lung cancer (n=7/45; 15.6%), and liver cancer (n=5/45; 11.1%). More than half of the studies did not specify the source of funding (n=25/45; 55.6%). The individual characteristics of each study are summarized in Supplementary Table 1. The list of included articles is presented in Supplementary Table 2.
3.3 Report quality by CREMLS
Our study found that, in the study design section, all evaluated studies adequately reported the medical/clinical task of interest, research question, overall study design, and intended use of the ML model. However, only 51% of the studies provided information on whether existing model performance benchmarks for this task were considered.
In the data section, all studies reported information on methods of data collection and data characteristics. However, a large proportion did not report details on sample size calculation (98%), known quality issues with the data (69%), or bias introduced due to the data collection method used (62%).
In the methodology section, all studies reported the rationale for selecting the ML algorithm, and 98% described the method used to evaluate model performance during training. However, no studies reported strategies for handling outliers, and the majority did not provide information on strategies for model pre-training (92%) or data augmentation (79%).
In the evaluation section, nearly all studies reported some type of performance metrics used to evaluate the model (98%) and the results of internal validation (98%). However, no studies provided information on characteristics relevant for detecting data shift and drift, and 93% did not report or discuss the cost or consequences of errors.
In the explainability and transparency section, 82% of the studies reported the most important features and their relationship to the outcomes. Compliance with different criteria for each individual study is detailed in Figure 2.

Figure 2. CREMLS checklist. +, Yes; -, No/No reported/The report is not clear; NA, Not applicable.
3.4 Report quality by TRIPOD+AI
The included studies demonstrate high compliance with key reporting standards for predictive modeling. All studies (100%) clearly identified their nature as predictive modeling investigations, specified their objectives, and provided detailed descriptions of data sources and participant eligibility (Figure 3). Also, they precisely defined predictors and outcomes, justifying their selection and evaluation methodology. Data preparation and model validation were also well-documented, with comprehensive descriptions of analytical methods, including model type, hyperparameter tuning, and performance metrics. Furthermore, all studies addressed the interpretation of results and discussed limitations, biases, and generalizability. Ethical considerations were reported in most cases, with 96% of studies indicating approval from an ethics committee or an equivalent review process. The flow of participants and differences between development and evaluation datasets were also consistently documented.
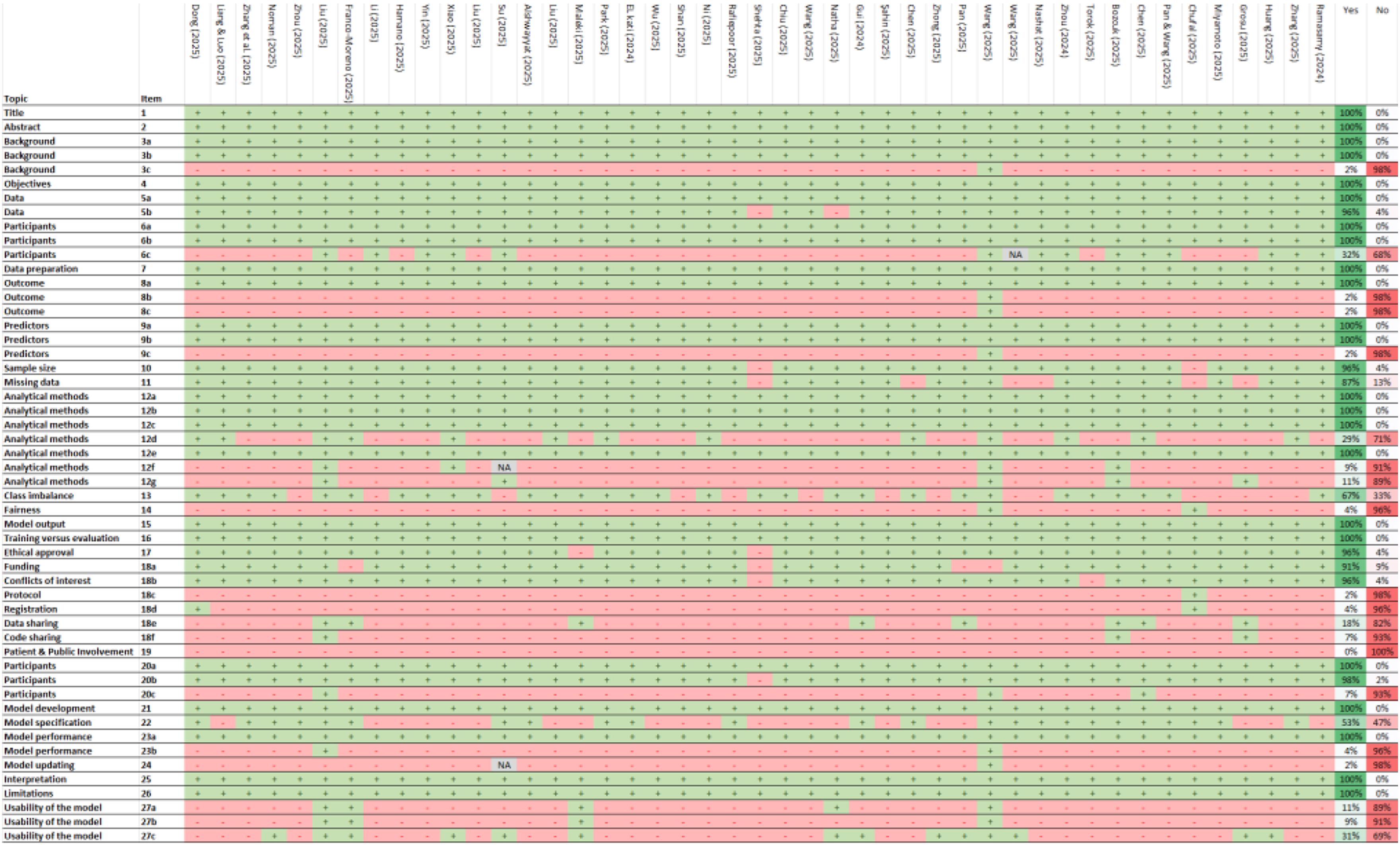
Figure 3. TRIPOD+AI checklist. +, Yes; -, No/No reported/The report is not clear; NA, Not applicable. 1) Identify the study as developing or evaluating the performance of a multivariable prediction model, the target population, and the outcome to be predicted. 2) See TRIPOD+AI for Abstracts checklist. 3a) Explain the healthcare context, rationale for developing or evaluating the prediction model, including references to existing models. 3b) Describe the target population and intended purpose of the prediction model, including intended users. 3c) Describe any known health inequalities between sociodemographic groups. 4) Specify the study objectives, including whether it describes development or validation of a prediction model. 5a) Describe sources of data separately for development and evaluation datasets, rationale for using these data. 5b) Specify dates of collected participant data, including start and end of participant accrual. 6a) Specify key elements of the study setting including number and location of centers. 6b) Describe the eligibility criteria for study participants. 6c) Give details of any treatments received and how they were handled during model development or evaluation. 7) Describe any data pre-processing and quality checking across sociodemographic groups. 8a) Clearly define the outcome being predicted, time horizon, and assessment method. 8b) Describe qualifications and demographic characteristics of the outcome assessors. 8c) Report any actions to blind assessment of the outcome. 9a) Describe the choice of initial predictors and any pre-selection before model building. 9b) Clearly define all predictors, including how and when measured. 9c) Describe qualifications and demographic characteristics of predictor assessors. 10) Explain how study size was determined, including sample size calculation. 11) Describe how missing data were handled and reasons for omitting data. 12a) Describe how data were used for development and evaluation of model performance. 12b) Describe how predictors were handled in the analyses. 12c) Specify model type, rationale, steps for building, hyperparameter tuning, and validation. 12d) Describe how heterogeneity in estimates and model performance was handled. 12e) Specify all measures and plots used to evaluate model performance. 12f) Describe any model updating arising from evaluation. 12g) Describe how model predictions were calculated. 13) Describe methods for handling class imbalance and recalibrating predictions. 14) Describe approaches used to address model fairness and their rationale. 15) Specify the output of the prediction model and rationale for classification thresholds. 16) Identify differences between development and evaluation data. 17) Name the ethics committee that approved the study and describe consent procedures. 18a) Give the source of funding and role of the funders. 18b) Declare any conflicts of interest and financial disclosures. 18c) Indicate where the study protocol can be accessed or state if unavailable. 18d) Provide registration information or state if not registered. 18e) Provide details of data availability. 18f) Provide details of analytical code availability. 19) Provide details of patient and public involvement or state no involvement. 20a) Describe the flow of participants through the study, including follow-up time. 20b) Report characteristics overall and by data source, including key demographics. 20c) Compare development data with evaluation data for key predictors. 21) Specify the number of participants and outcome events in each analysis. 22) Provide full details of the prediction model, including accessibility. 23a) Report model performance estimates with confidence intervals. 23b) Report results of heterogeneity in model performance. 24) Report results from model updating, including updated model. 25) Provide overall interpretation of results, including fairness. 26) Discuss study limitations, biases, and generalizability. 27a) Describe handling of poor-quality or unavailable input data. 27b) Specify required user interaction and expertise. 27c) Discuss future research steps and generalizability.
Despite strong adherence to several TRIPOD+AI criteria, significant reporting gaps were identified. 98% of studies did not report potential health inequalities among sociodemographic groups or describe the demographic characteristics and qualifications of outcome and predictor assessors. Additionally, 98% of studies failed to indicate where the study protocol could be accessed, and 96% did not provide information on study registration or describe methods to address model equity or justify their approach. The availability of analytical code was also limited, with 93% of studies not providing details on access. A critical issue was the complete absence of patient and public involvement in study development (100%). Furthermore, 93% of studies did not compare development and evaluation data for key predictors, while 96% did not report heterogeneity in model performance. Lastly, 98% of studies did not present results on model updating, and 91% did not specify the level of user interaction or expertise required for model implementation.
3.5 Risk of bias by PROBAST
The methodological quality assessment using PROBAST revealed that 89% of the included studies exhibited a low overall risk of bias, suggesting adequate internal validity in most evaluated studies (see Table 1). Additionally, all studies demonstrated a low risk of bias in terms of applicability, indicating that the assessed predictive models are potentially transferable to real-world clinical settings.
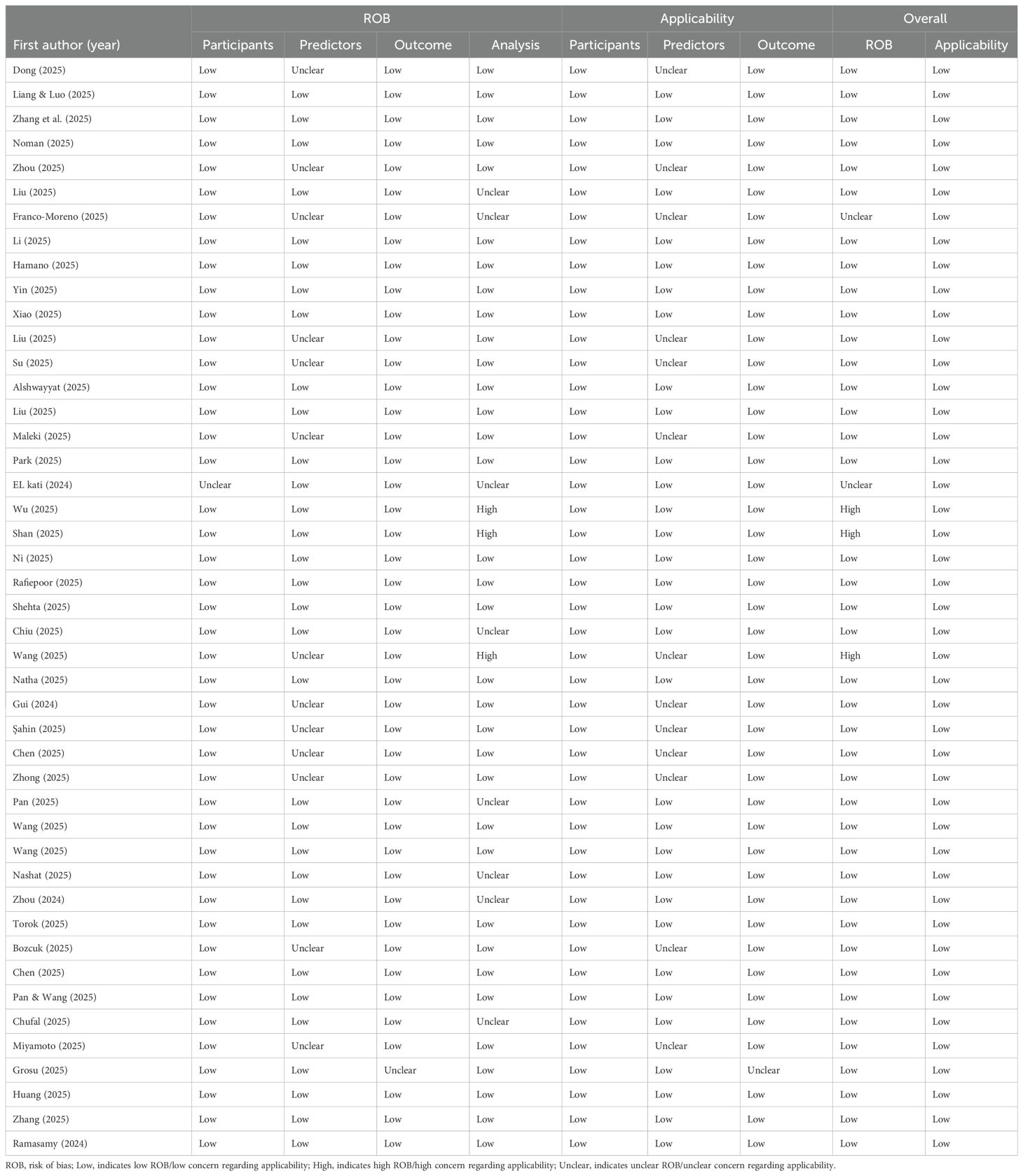
Table 1. Risk of Bias by PROBAST.
At the domain level, the risk of bias in the participant and outcome domains was minimal, with 98% of the studies showing a low risk of bias in these areas. Regarding applicability, 100% of the studies reported low concern for the applicability of participants, while 98% indicated low concern for the applicability of outcomes.
However, the predictor domain showed an unclear risk of bias in 29% of the studies, both in terms of bias risk assessment and applicability. Furthermore, in the analysis domain, only 76% of the studies exhibited a low risk of bias, suggesting that a significant proportion may have employed methodological practices that compromise the validity of their findings. Issues such as handling of missing data, predictor selection, and correction for overfitting require further attention to enhance the robustness of predictive models in future studies.
3.6 AI performance metrics
In terms of the AI model family used, 73.3% of the studies employed Supervised ML models (n = 33), while 24.4% used Deep Learning models (n = 11). Regarding the specific AI models identified as the best-performing, Random Forest (RF) and XGBoost were the most frequently reported, each used in 17.8% of the studies (n = 8). The performance metrics for each study are presented in Table 2.
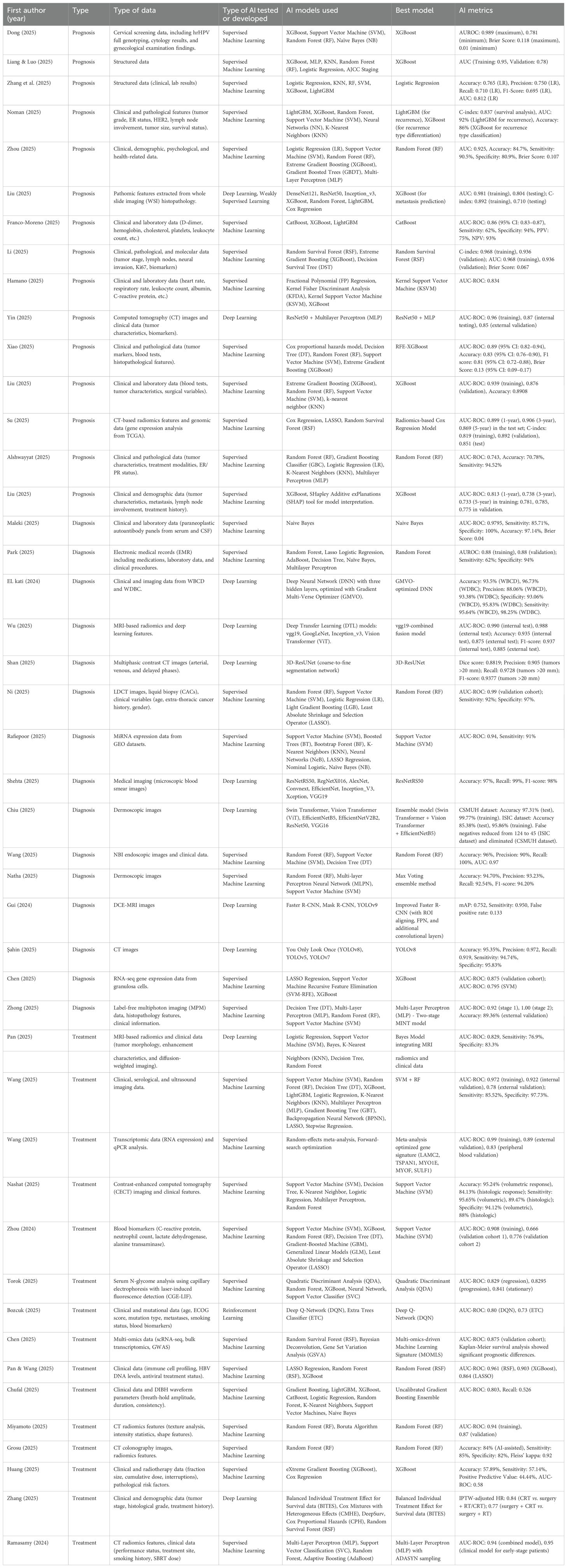
Table 2. AI performance metrics by study.
4 Discussion
Our study included 45 studies that employed ML models for diagnostic, prognostic, and treatment outcomes in cancer patients. The findings indicate several deficiencies in reporting quality, as assessed by CREMLS and TRIPOD+AI. These deficiencies primarily relate to sample size calculation, reporting on data quality, strategies for handling outliers, documentation of ML model predictors, access to training or validation data, and reporting on model performance heterogeneity.
These reporting limitations align with the PROBAST risk of bias assessment, which identified unclear risk of bias in the predictors and analysis domains in approximately one in four included studies. Therefore, it is plausible to conclude that reporting quality is most limited in sections related to methodology, analysis, and elements that support study reproducibility (e.g., code and datasets). These limitations may introduce a higher risk of bias.
Our study aligns with previous research identifying significant issues in the quality of reporting in studies employing AI techniques to develop clinical prediction models, including the presence of “spin” practices and poor reporting standards (12). Moreover, another systematic review concluded that most studies are at high risk of bias, citing issues such as small sample sizes, inadequate handling of missing data, and lack of external validation (13). These problems are not limited to predictive models for cancer but also extend to other disciplines within clinical diagnostics, for instance, cardiology or mental health (14, 15).
The potential of AI models to predict cancer diagnoses, prognosis, and treatment are substantial, representing an opportunity to enhance healthcare access (16). While some studies have demonstrated that the diagnostic accuracy of AI models for detecting neoplasms is remarkably high, particularly in cases such as upper gastrointestinal tract cancers (17), the methodological quality of these studies remains low, with a high risk of selection bias. Additionally, other review studies evaluating the use of AI for predicting treatment and prognostic outcomes in cancer patients have also identified reporting issues and highly restricted access to data necessary for study replication (18, 19). Regarding performance metrics, the evidence highlights the need to standardize the reporting of metrics in studies due to variability in the parameters used and the inconsistent reporting of performance outcomes (20, 21).
Currently, several initiatives aim to promote the responsible use of AI models in oncology patients, such as the American Society of Clinical Oncology’s transparency principles for AI. These principles seek to enhance transparency in AI models within oncology, potentially improving their real-world application and supporting clinical decision-making (22). However, a recent review published in a journal of this scientific society found that adherence to these principles remains limited, highlighting the need to promote their implementation (23). Nevertheless, this issue does not appear to be exclusive to oncology. A systematic review identified risks of bias and reporting quality issues in ML models across various healthcare contexts, not just oncology (13). Therefore, poor reporting quality seems to be a broader issue affecting health-related disciplines in general.
Incorporating cost-related information into AI model evaluations is essential for their real-world applicability. Understanding both direct and indirect costs would facilitate the integration of these models into clinical practice by providing a clearer assessment of the financial requirements for infrastructure, staff training, and implementation logistics (24). One of the key reporting limitations identified in the included studies was the lack of information on costs and the consequences of classification errors. This may be because most studies focus primarily on accuracy and effectiveness while overlooking the associated costs, despite evidence suggesting that AI can reduce the costs of cancer diagnosis and treatment (25). Additionally, assessing the economic impact of classification errors could help balance model performance with cost-effectiveness, ensuring that AI-driven tools provide both clinical and economic value. Future studies should integrate cost analyses alongside model performance metrics to enhance the feasibility and adoption of AI in oncology.
The analysis of AI model data must be transparent, as improper handling of missing data, outliers, participant imbalance, or dimensionality reduction can introduce biases into the model. For instance, internal biases and errors during model training may lead to misclassifications, potentially resulting in biased clinical decision-making if the model is implemented in real-world settings (26). Therefore, it is essential for AI models to ensure transparency throughout this process by sharing data, code, and any other materials that enable replication (22).
The main strength of our study lies in the detailed assessment of reporting quality using the CREMLS checklist and TRIPOD+AI checklist, and the risk of bias evaluation with PROBAST. However, an important limitation of our study is that it is not a systematic review encompassing all available evidence from multiple databases, resulting in limited representativeness.
5 Conclusion
Our study, using CREMLS and TRIPOD+AI, identified that AI models in oncology exhibit reporting limitations, particularly in the methodology sections related to predictors and the analysis plan. These findings align with an unclear risk of bias in one out of every four included studies, as indicated by PROBAST in the Predictors and Analysis domains. Additionally, our study outlines the specific areas where reporting is deficient, providing researchers with guidance to improve reporting quality in these sections and, consequently, reduce the risk of bias in their studies.
Author contributions
AS: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Project administration, Supervision, Validation, Writing – review & editing. DV-Z: Conceptualization, Data curation, Formal Analysis, Investigation, Methodology, Software, Validation, Visualization, Writing – original draft. CMR-R: Data curation, Investigation, Writing – review & editing. SE-A: Conceptualization, Data curation, Investigation, Methodology, Visualization, Writing – review & editing. JF: Conceptualization, Data curation, Formal Analysis, Funding acquisition, Investigation, Methodology, Resources, Software, Supervision, Validation, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This study has been in part supported by the contract HT9425-24-1-0264-P00001 from the Congressionally Directed Medical Research Program.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fonc.2025.1555247/full#supplementary-material
Supplementary Material 1 | Search strategy.
Supplementary Table 1 | Characteristics of the included studies.
Supplementary Table 2 | List of records included.
Abbreviations
AI, Artificial Intelligence; ML, Machine Learning; TRIPOD+AI, Transparent Reporting of a Multivariable Prediction Model for Individual Prognosis or Diagnosis – Artificial Intelligence extension; CREMLS, Checklist for REporting Machine Learning Studies; PROBAST, Prediction Model Risk of Bias Assessment Tool.
References
1. Crosby D, Bhatia S, Brindle KM, Coussens LM, Dive C, Emberton M, et al. Early detection of cancer. Science. (2022) 375:eaay9040. doi: 10.1126/science.aay9040
2. Maiter A, Salehi M, Swift AJ, Alabed S. How should studies using AI be reported? lessons from a systematic review in cardiac MRI. Front Radiol. (2023) 3:1112841. doi: 10.3389/fradi.2023.1112841
3. Maulana FI, Adi PDP, Lestari D, Ariyanto SV, Purnomo A. (2023). The scientific progress and prospects of artificial intelligence for cancer detection: A bibliometric analysis, in: 2023 International Seminar on Intelligent Technology and Its Applications (ISITIA), . pp. 638–42. doi: 10.1109/ISITIA59021.2023.10221162
4. Jayakumar S, Sounderajah V, Normahani P, Harling L, Markar SR, Ashrafian H, et al. Quality assessment standards in artificial intelligence diagnostic accuracy systematic reviews: a meta-research study. NPJ Digit Med. (2022) 5:11. doi: 10.1038/s41746-021-00544-y
5. Gurumurthy G, Gurumurthy J, Gurumurthy S. Machine learning in paediatric haematological Malignancies: a systematic review of prognosis, toxicity and treatment response models. Pediatr Res. (2024). doi: 10.1038/s41390-024-03494-9
6. Moharrami M, Azimian Zavareh P, Watson E, Singhal S, Johnson AEW, Hosni A, et al. Prognosing post-treatment outcomes of head and neck cancer using structured data and machine learning: A systematic review. PloS One. (2024) 19:e0307531. doi: 10.1371/journal.pone.0307531
7. El Emam K, Leung TI, Malin B, Klement W, Eysenbach G. Consolidated reporting guidelines for prognostic and diagnostic machine learning models (CREMLS). J Med Internet Res. (2024) 26:e52508. doi: 10.2196/52508
8. Collins GS, Moons KGM, Dhiman P, Riley RD, Beam AL, Van Calster B, et al. TRIPOD+AI statement: updated guidance for reporting clinical prediction models that use regression or machine learning methods. BMJ. (2024) 385:e078378. doi: 10.1136/bmj-2023-078378
9. Simera I, Moher D, Hirst A, Hoey J, Schulz KF, Altman DG. Transparent and accurate reporting increases reliability, utility, and impact of your research: reporting guidelines and the EQUATOR Network. BMC Med. (2010) 8:24. doi: 10.1186/1741-7015-8-24
10. Wolff RF, Moons KGM, Riley RD, Whiting PF, Westwood M, Collins GS, et al. PROBAST: A tool to assess the risk of bias and applicability of prediction model studies. Ann Intern Med. (2019) 170:51–8. doi: 10.7326/M18-1376
11. Ouzzani M, Hammady H, Fedorowicz Z, Elmagarmid A. Rayyan-a web and mobile app for systematic reviews. Systematic Rev. (2016) 5. doi: 10.1186/s13643-016-0384-4
12. Andaur Navarro CL, Damen JAA, Takada T, Nijman SWJ, Dhiman P, Ma J, et al. Systematic review finds “spin” practices and poor reporting standards in studies on machine learning-based prediction models. J Clin Epidemiol. (2023) 158:99–110. doi: 10.1016/j.jclinepi.2023.03.024
13. Andaur Navarro CL, Damen JAA, Takada T, Nijman SWJ, Dhiman P, Ma J, et al. Risk of bias in studies on prediction models developed using supervised machine learning techniques: systematic review. BMJ. (2021) 375:n2281. doi: 10.1136/bmj.n2281
14. Cai Y, Cai Y-Q, Tang L-Y, Wang Y-H, Gong M, Jing T-C, et al. Artificial intelligence in the risk prediction models of cardiovascular disease and development of an independent validation screening tool: a systematic review. BMC Med. (2024) 22:56. doi: 10.1186/s12916-024-03273-7
15. Chen Z, Liu X, Yang Q, Wang Y-J, Miao K, Gong Z, et al. Evaluation of risk of bias in neuroimaging-based artificial intelligence models for psychiatric diagnosis: A systematic review. JAMA Netw Open. (2023) 6:e231671. doi: 10.1001/jamanetworkopen.2023.1671
16. Kapoor DU, Saini PK, Sharma N, Singh A, Prajapati BG, Elossaily GM, et al. AI illuminates paths in oral cancer: transformative insights, diagnostic precision, and personalized strategies. EXCLI J. (2024) 23:1091–116. doi: 10.17179/excli2024-7253
17. Arribas J, Antonelli G, Frazzoni L, Fuccio L, Ebigbo A, van der Sommen F, et al. Standalone performance of artificial intelligence for upper GI neoplasia: a meta-analysis. Gut. (2020) 70:1458–68. doi: 10.1136/gutjnl-2020-321922
18. Corti C, Cobanaj M, Marian F, Dee EC, Lloyd MR, Marcu S, et al. Artificial intelligence for prediction of treatment outcomes in breast cancer: Systematic review of design, reporting standards, and bias. Cancer Treat Rev. (2022) 108:102410. doi: 10.1016/j.ctrv.2022.102410
19. Dhiman P, Ma J, Navarro CA, Speich B, Bullock G, Damen JA, et al. Reporting of prognostic clinical prediction models based on machine learning methods in oncology needs to be improved. J Clin Epidemiol. (2021) 138:60–72. doi: 10.1016/j.jclinepi.2021.06.024
20. Kanan M, Alharbi H, Alotaibi N, Almasuood L, Aljoaid S, Alharbi T, et al. AI-driven models for diagnosing and predicting outcomes in lung cancer: A systematic review and meta-analysis. Cancers (Basel). (2024) 16:674. doi: 10.3390/cancers16030674
21. Kumar Y, Gupta S, Singla R, Hu Y-C. A systematic review of artificial intelligence techniques in cancer prediction and diagnosis. Arch Comput Methods Eng. (2022) 29:2043–70. doi: 10.1007/s11831-021-09648-w
22. American Society of Clinical Oncology. Principles for the responsible use of artificial intelligence in oncology (2024). Available online at: https://society.asco.org/sites/new-www.asco.org/files/ASCO-AI-Principles-2024.pdf (Accessed October 4, 2024).
23. Smiley A, Reategui-Rivera CM, Villarreal-Zegarra D, Escobar-Agreda S, Finkelstein J. Exploring artificial intelligence biases in predictive models for cancer diagnosis. Cancers (Basel). (2025) 17:407. doi: 10.3390/cancers17030407
24. Wolff J, Pauling J, Keck A, Baumbach J. The economic impact of artificial intelligence in health care: systematic review. J Med Internet Res. (2020) 22:e16866. doi: 10.2196/16866
25. Kacew AJ, Strohbehn GW, Saulsberry L, Laiteerapong N, Cipriani NA, Kather JN, et al. Artificial intelligence can cut costs while maintaining accuracy in colorectal cancer genotyping. Front Oncol. (2021) 11:630953. doi: 10.3389/fonc.2021.630953
26. Corti C, Cobanaj M, Dee EC, Criscitiello C, Tolaney SM, Celi LA, et al. Artificial intelligence in cancer research and precision medicine: Applications, limitations and priorities to drive transformation in the delivery of equitable and unbiased care. Cancer Treat Rev. (2023) 112:102498. doi: 10.1016/j.ctrv.2022.102498
Keywords: cancer, artificial intelligence, diagnosis, prognosis, therapy
Citation: Smiley A, Villarreal-Zegarra D, Reategui-Rivera CM, Escobar-Agreda S and Finkelstein J (2025) Methodological and reporting quality of machine learning studies on cancer diagnosis, treatment, and prognosis. Front. Oncol. 15:1555247. doi: 10.3389/fonc.2025.1555247
Received: 03 January 2025; Accepted: 18 March 2025;
Published: 14 April 2025.
Edited by:
Sharon R. Pine, University of Colorado Anschutz Medical Campus, United StatesReviewed by:
Devesh U. Kapoor, Gujarat Technological University, IndiaMiaomiao Yang, Yantai Yuhuangding Hospital, China
Copyright © 2025 Smiley, Villarreal-Zegarra, Reategui-Rivera, Escobar-Agreda and Finkelstein. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Joseph Finkelstein, am9zZXBoLmZpbmtlbHN0aW5AdXRhaC5lZHU=