 Katharina Hagmann
Katharina Hagmann Anja Hellings-Kuß
Anja Hellings-Kuß Julian Klodmann
Julian Klodmann Rebecca Richter
Rebecca Richter Freek Stulp
Freek Stulp Daniel Leidner
Daniel Leidner- German Aerospace Center (DLR), Institute of Robotics and Mechatronics Center, Weßling, Germany
Minimally invasive robotic surgery copes with some disadvantages for the surgeon of minimally invasive surgery while preserving the advantages for the patient. Most commercially available robotic systems are telemanipulated with haptic input devices. The exploitation of the haptics channel, e.g., by means of Virtual Fixtures, would allow for an individualized enhancement of surgical performance with contextual assistance. However, it remains an open field of research as it is non-trivial to estimate the task context itself during a surgery. In contrast, surgical training allows to abstract away from a real operation and thus makes it possible to model the task accurately. The presented approach exploits this fact to parameterize Virtual Fixtures during surgical training, proposing a Shared Control Parametrization Engine that retrieves procedural context information from a Digital Twin. This approach accelerates a proficient use of the robotic system for novice surgeons by augmenting the surgeon’s performance through haptic assistance. With this our aim is to reduce the required skill level and cognitive load of a surgeon performing minimally invasive robotic surgery. A pilot study is performed on the DLR MiroSurge system to evaluate the presented approach. The participants are tasked with two benchmark scenarios of surgical training. The execution of the benchmark scenarios requires basic skills as pick, place and path following. The evaluation of the pilot study shows the promising trend that novel users profit from the haptic augmentation during training of certain tasks.
1 Introduction
In the last 30 years, Minimally Invasive Robotic Surgery (MIRS) has become an important technology in modern medicine. It leverages the advantages of minimal invasive surgery, such as shorter recovery times for patients, and avoids several of its disadvantages for the surgeons, such as the interrupted hand-eye coordination and the loss of Degrees of Freedom (DoF) inside the patient’s body (Klodmann et al., 2020). Consequently, MIRS decreases the physical and cognitive load once it has been mastered by the surgeon. However, providing individualized and contextual assistance to enhance surgical performance even further remains an open research topic.
Exploitation of commonly used haptic input devices, for instance by means of Virtual Fixtures (VFs), is one possibility in which the surgeon’s performance can be further augmented. However, VFs have to be parameterized according to the context of the task at hand in order to provide reasonable assistance. Due to the unstructured dynamic environment inside the patient’s body, automatic perception of the procedural context in a real surgery remains challenging (van Amsterdam et al., 2021). Surgical training, in turn, offers a well-defined environment. Herein, abstracted training tasks as visualized in Figure 1, are utilized to train key surgical skills.
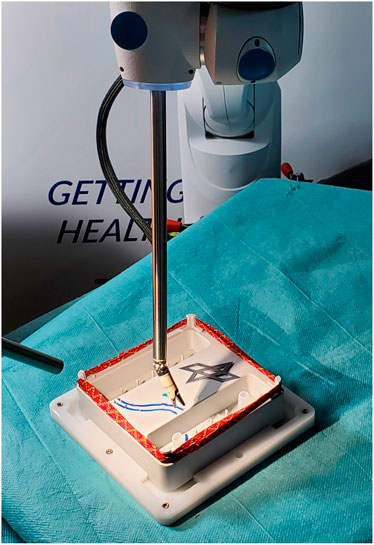
FIGURE 1. The Nylon Twist training pad from Lübecker Toolbox (LLC, 2021) is performed with the DLR MiroSurge system to train the hand-eye-coordination, bi-manual work, and working over cross.
Our approach introduces a Digital Twin (DT) to monitor procedural context information during training. Based on this, we propose a novel concept for the on-line parametrization of haptically rendered assistance functions using VFs. This preserves the dexterity of the surgeon and adds an additional feedback channel to the visual one. We hypothesize that training with our approach enables a novice surgeon to realize a task faster, more accurately and with less cognitive load. The main contributions of this article are 1) an approach to estimate geometric and semantic task states using a DT that mirrors the real robotic system, 2) a novel way to flexibly parameterize assistance functions online based on the estimation of the current semantic task states, 3) the combination of both methods to assist in training for MIRS using multi-modal support, and 4) an evaluation in a proof-of-concept experiment in surgical training.
This work is divided into the following sections. Section 2 further motivates our work based on the current state of the art. The methods used in our approach are explained in Section 3 followed by the description of the pilot study and its results in Section 4. Section 5 presents the conclusions and an outlook.
2 State of The Art
Surgical training tasks such as the Lübecker Toolbox (LLC, 2021) offer various training scenarios that are relevant for real operations, as shown in Figure 1. They are designed to train preparation, resection and reconstruction skills. This sequence maps in parts to a cholecystectomy (removal of the gall bladder) as it requires the surgeons to expose critical structures consisting of the cystic duct and the cystic artery by removing surrounding tissue, followed by inserting multiple clips at the correct locations to stop the fluid flow in these structures so they can be cut to free the gall bladder. Even though modern training curricula for MIRS (Thornblade and Fong, 2021) extend traditional surgical training (Sealy, 1999), it is still cumbersome to acquire the required motor skill level to control a surgical robot for the use in MIRS.
Increased autonomy of surgical robots could decrease the required skill level. Haidegger (2019) introduces a scale to classify the level of autonomy in robotic surgery ranging from no autonomy to full autonomy. Commercially available surgical robotic systems assisting in laprascopy fulfill the criteria for level 1 named robot assistance, whereas prototypes of surgical robots reach task-level autonomy (level 2). Robotic systems in other surgical domains that tackle tasks like autonomously taking blood samples reach up to level 4, high-level autonomy. A great challenge of laparascopic surgery consist of the development of perception algorithms, that extract information from the unpredictable environment containing soft tissue. Therefore, autonomous navigation in MIRS is still challenging (Nagy and Haidegger, 2019).
The introduction of assistance functions by means of shared control (Endsley, 1999) offers a possible solution to support surgeon training for MIRS. As a subsequent step the assistance could transfer to real OR situations. Therefore, shared control could be seen as an intermediate step towards the increase to task-level autonomy. Assistance functions may range from displaying relevant data using mixed reality (Qian et al., 2019), over tremor filtering and scaling of input movements (Weber et al., 2013) to the automation of certain steps of a task under the supervision of the surgeon (Nagy and Haidegger, 2019). VFs as described in Rosenberg (1993), Abbott et al. (2007), and Bowyer et al. (2014) represent a different type of shared control which enables haptic augmentation. They comprise of attractive VFs that haptically guide the user towards a goal structure as in Selvaggio et al. (2018), repulsive VFs protecting him or her from entering in prohibited zones as in Li et al. (2020), and automated scaling of the user input compared to the instrument tip’s movement as in Zhang et al. (2018). Ovur et al. (2019) show that haptic guidance during training in simulation for simple and complex path-following tasks improves performance. Enayati et al. (2018) assess the specific competences and the overall skill level of novice and expert users during training of a path-following task and adapt the strength of assistance functions according to the competence level.
It is essential that assistance functions are represented such that they can be rapidly adjusted to the ongoing task and the dynamically changing environment. In cholecystectomy for instance, critical structures are first exposed, and it is crucial not to harm them during this step. But in later phases, they are manipulated and even cut. Task-dependent shared control functions are required to account for such drastic change of the task context. The problem of adapting shared-control functions online to a changing environment is stated in Selvaggio et al. (2018) and tackled by an human-in-the-loop approach using VFs. The surgeon can generate attractive VFs and adapt their position and geometry by recording interaction points. Fontanelli et al. (2018) design a vision-free pipeline to support surgeons during suturing. A state machine defines the task. The transitions between states are based on predefined gestures and are, therefore, controlled by the surgeons. Different controllers with varying degree of autonomy and VFs are applied. Maier et al. (2019) develop a training simulator for orthopedic hand surgery in virtual reality generating haptic impressions similar to bone cutting for the surgeon using VFs. A state machine is used to switch between different implementations of VFs according to the task state. All environment states are pre-known due to the virtual reality approach.
Human-in-the-loop approaches for the positioning and parametrization of VF add to the surgeon’s workload. Ideally, the parametrization of VFs should be done automatically by robotic system based on semantic knowledge about the task phases and context, i.e., an abstract knowledge representation, about the environment and the state of the system. A DT approach offers the possibility to derive semantic knowledge from fused data obtained by different sources. A robotic system provides diverse data about its poses and control states. Laaki et al. (2019) design a DT of a simplified surgical environment containing one robotic arm that is controlled in a virtual reality environment by a HTC vive system. The hand movements of the user control the DT in virtual reality and are additionally projected to a robot arm in real-time. Modern machine learning frameworks may eventually be able to segment semantic information of endoscopic images as stated by Scheikl et al. (2020); however, Ahmed and Devoto (2020) consider the modeling of tissue with deformations and movement as the main limitation of DT technologies in surgical robotics. Nevertheless DT-based assistance functions may very well be able to assist in training surgeons where the environment is well-defined by abstracted training pads. In other domains we have shown that physics simulations are able to yield semantic information about the environment as seen in Bauer et al. (2018).
3 Methods
The approach described in this work consists of three modules as visualized in Figure 2. That is, a parameterizable concept for Virtual Fixtures (VFs), the Shared Control Parametrization Engine (SCOPE), and a Digital Twin (DT) that provides the required semantic state information. The three modules are introduced in the following and explained on the basis of the benchmark scenarios for in the pilot study. The benchmark scenarios consist of two variations of a pick and place task. They are designed to act on the Nylon Twist training pad as introduced in Figure 1 and are conducted using the DLR MiroSurge surgical robotic platform (Schlenk et al., 2018; Seibold et al., 2018).
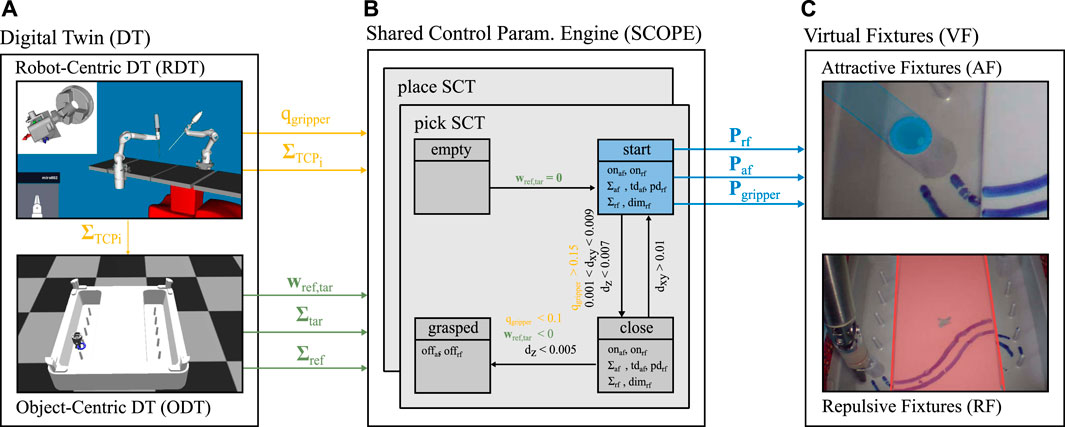
FIGURE 2. Overview of the three core components and their interaction within the proposed concept. Virtual fixtures (A) are introduced in Section 3.1. The parameters are determined by SCOPE (B), which is described in Section 3.2. SCOPE requires the task context, which is provided by the digital twin DT, (C), as described in Section 3.3.
For this work one 7-DoF light weight robotic arm called MIRO is mounted on the left standard side rail of the operating room table. The MIRO carries a wristed surgical instrument i whose additional 2-DoFs are actuated by a MICA drive unit. The pose of the instrument’s Tool-Center Point (TCP)ΣTCP is telemanipulated by a Force Dimension’s sigma.7, a 6-DoF input device with an additional gripping DoF, offering the possibility to haptically render forces (Dimension, 2021). A second MIRO is mounted on the right side of the operating room table holding a stereo endoscope. In telemanipulation mode, a software layer integrates multiple avatar robots and maps the motion of up to two input devices to
3.1 Virtual Fixtures
In the following paragraphs, some general design principles of VFs for a surgical robotic platform are explained followed by the description of the implemented VFs, which are divided into system related and parameterizable, task related VF.
VF generate a virtual wrench wPOI = [fPOI; mPOI], comprising the forces fPOI and torques mPOI, which act on the Pose of Interest (POI) ΣPOI. A virtual proxy Σproxy mirrors ΣPOI. The motion of Σproxy is restricted by the virtual object that describes the geometries of the VF, i.e. Σproxy stays on the surface of the virtual object while ΣPOI penetrates it. Σproxy is linked to ΣPOI by a six DoF spring damper system as explained by Caccavale et al. (1999). The displacement between ΣPOI and Σproxy generates wPOI depending on the stiffness K and the damping D. D is scaled by a function taking into account the distance between ΣPOI and Σproxy to avoid an abrupt increase of the damping wrench when a displacement occurs.
The resulting wPOI is rendered to the input device. If
Considering an 8-DoF robot (6-DoF robotic arm and a 2-DoF instrument) Ja is invertible, so an unique mapping between the joint torques τ and the Cartesian wrench
With this general implementation several VFs can be realized and haptically rendered to the input device.
3.1.1 System Related VF
System related VFs are defined and parametrized by the restrictions that come with the robotic system e.g. the length of the instrument’s shaft or workspace limits of the hardware (in Cartesian and Joint space). For the pilot experiments a Cartesian workspace limit on the x-axis is set to the bottom of the trainings pad as visualized in Figure 3. According to Nitsch et al. (2012) the intuitiveness is enhanced when haptically guiding the user to avoid such limits by rendering the restrictions to the input devices.
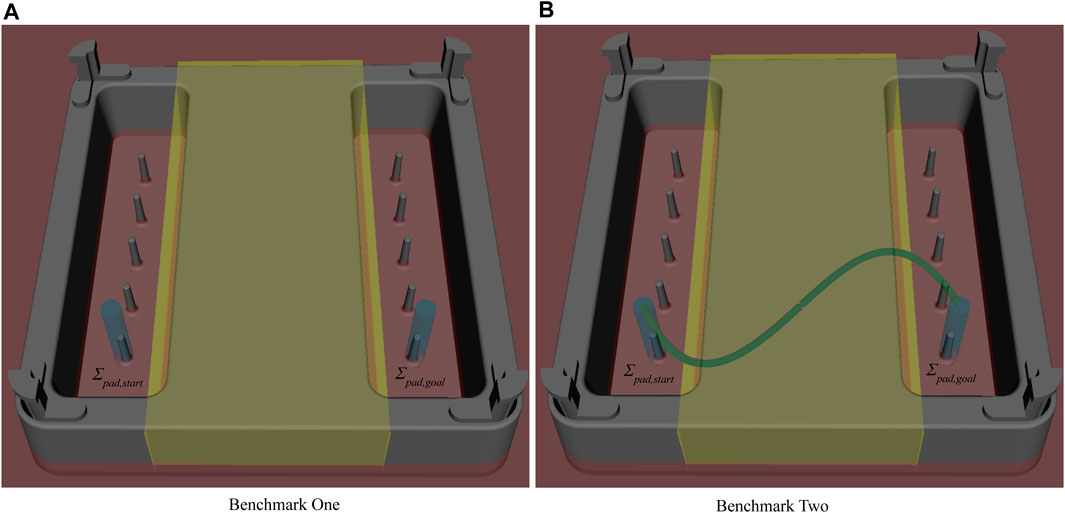
FIGURE 3. The training pad used for the benchmark scenarios is shown. Σpad,start is the initial pose of the ring and Σpad,goal its goal pose. The blue cylinders depict the AFs. The yellow box depicts the RF and the red area visualizes the Cartesian workspace limit in z-axis. Together they help avoid collisions between the instrument and the trainings pad. (A) depicts the first benchmark scenario consisting of an unconstrained pick and place task. (B) displays the second benchmark scenario. The constrained pick and place task is realized by an sinus-shaped AF for the follow_path SCT. It is shown by the green curve.
3.1.2 Task Related VF
Repulsive VFs (RF) inside the workspace prevent the user from hitting a forbidden region. RFs are implemented using geometrical primitives e.g., virtual boxes as depicted on the right lower side in Figure 2. Their corresponding parameters Prf are displayed in Table 1. When ΣPOI penetrates the virtual box, the Σproxy stays on the surface. Depending on the instrument and the obstacle geometry multiple ΣPOI can be defined along the instrument structure. For the pick skill RFs in the form of virtual boxes are implemented with
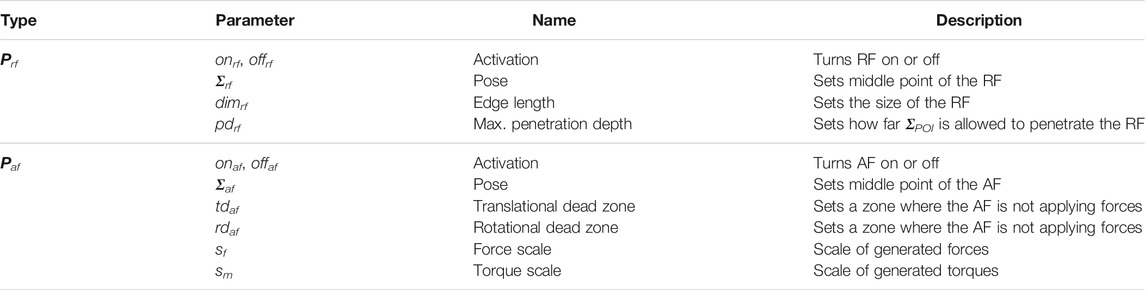
TABLE 1. This table displays the corresponding parameters of RF and AF.
Attractive VFs (AF) guide the user towards or along a certain predefined path or target as visualized on the right upper side in Figure 2. AFs are implemented by a cylindrical geometry around the attractive pose Σaf, where Σproxy is free to move along the z-axis. Along the remaining axes Σproxy is limited by a given radius, which is encoded in the translational dead zone tdaf. The rotation of Σproxy is fixed to guide the orientation of ΣPOI with a parameterizable rotational dead zone rdaf. Table 1 presents an overview of the parameters of AFs Paf. The pick skill sets Σaf to the middle point of a ring with tdaf equal to the ring radius to align
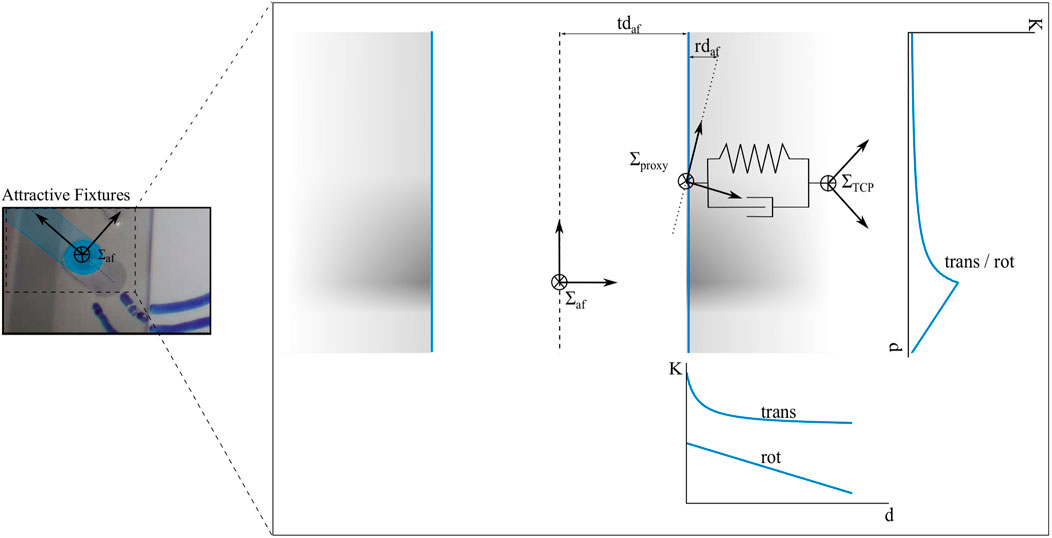
FIGURE 4. The profile of the cylindrical AF at ΣAF is displayed. ΣTCP entered the cylinder, Σproxy stayed at its surface and a virtual spring damper system is spanned in between. The blue lines denote the shape of the stiffness K depending on the distance d along axial and radial axes of the cylinder. The gray areas depict the blending of the scaling functions.
The second benchmark scenario implements the follow path skill. It restricts the translation from the left side of the trainings pad to the right side by the shape of a polynomial function. The path following AF is implemented by updating Σaf in every time step to slide along the predefined path. Σaf is defined as the projection of ΣPOI onto the path with the smallest distance. sm = 0 is set to let the user control the rotation of ΣPOI.
A virtual wall introduced at the gripping DoF of the input device assists the grasping of objects. The user feels a small opposing force at the point where the gripper of the instrument closes forcelessly. The user overcomes it by pressing slightly against it and the gripper closes firmly applying force on the grasped tissue. The grasp is loosened applying the same principle.
Different phases of a task may require distinct VF. Parameterizable VFs offer an interface to activate them and to adapt their parameters at run time. In the presented work the switching is realized by gradually fading down the initial wrench difference the involved VFs have at the time of switching. Switching between VFs may cause instabilities. While in practice instabilities aren’t observed, a time domain passivity controller as introduced in Hannaford and Ryu (2002) and further developed in Hertkorn et al. (2010), Ryu et al. (2005), and Hulin et al. (2021) is to be integrated into the presented approach in the future, to guarantee a safe operation for arbitrary tasks in all circumstances. Switching between VFs and their parametrization allows the flexible application of various VFs depending on the required task.
3.2 Shared Control Parametrization Engine
SCOPE provides a framework to parametrize VFs depending on the current task state. The SCOPE concept builds on our former work on Shared Control Templates (SCTs) (Quere et al., 2020). SCTs represent robot skills as a sequence of states leading to a certain goal state as depicted in the center of Figure 2. One SCT may encode different phases in order to guide the user through different phases of a task. In each phase different parameters can be set and different transition conditions apply (e.g., the distance between the end-effector and the target object).
In Quere et al. (2020), SCTs have been implemented to assist in tasks like pick and place, pouring, drinking, or opening doors and drawers. In this work, the portfolio is extended for MIRS tasks required to solve the Nylon Twist training pad from Lübeck Toolbox (see Figure 1), i.e., pick, follow_path, and place. Each of these SCTs describes the interaction between a reference object or a robot component Oref and a target object Otar as it is listed in Table 2.
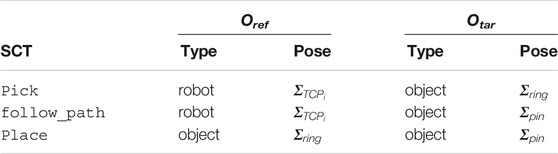
TABLE 2. Mapping of Oref and Otar for the individual SCTs implemented for MIRS assistance.
SCOPE progresses through the SCTs to parameterize haptically rendered assistance functionality as described in Algorithm 1. Until the goal state is reached SCOPE queries the actual state of the environment and the robot. It receives the current task context
Algorithm 1. Pseudocode of the SCOPE main loop to parse SCTs and parameterize VFs.
Input: The SCT encoding the current task.
Output: The algorithm terminates nominal as all states of the SCT are processed.
1 stateid ← 0
2 stategoal ← getGoal (SCT)
3 Oref, Otar ← getReferenceAndTarget (SCT)
4 whilestateid ≠ stategoaldo
5 getContextInformation (Oref, Otar)
6 statecurr ← getCurrentState (
7 ifstateid ≠ statecurrthen
8 Prf, Paf, Pgripper ← getParameter (statecurr)
9 parametrizeVF(Prf, Paf, Pgripper)
10 stateid ← statecurr
11 return True
The SCOPE approach relies on current updates of Σref, Σtar, wref,tar, and qgripper which are included in the task context getContextInformation. A physics-based state inference utilizing the proposed DT model is used to generate the information provided by getContextInformation. This extends the SCT approach which infers the required information through visual perception only.
3.3 Digital Twin
The DT approach offers the possibility to generate the required information about the world and the current task and to fuse it with data about the robot obtained by different sources. The DT is divided into a Robot-centric DT (RDT) and an Object-centric DT (ODT) which constantly exchange information as shown on the left in Figure 2.
The RDT mirrors the DLR Mirosurge system by interfacing its telemanipulation layer. It provides information about the interaction of the different robots. Each MIRO robot generates data at different granularity levels like sensor readings, joint angles and control states. Additionally, information about the relations of the different robots, their workspaces and the poses of their bases are gathered. The RDT offers an interface to select information needed for a task and to provide it for further processing. A middleware provides the infrastructure to query all this information in real time. A viewer displays all relevant information and, therefore, serves as a visualization of the RDT. In Figure 2 the RDT of the DLR MiroSurge system is displayed on the top left. For the pilot study it gathers information about
The ODT provides information about the world state. It makes use of the world state representation as presented in Leidner (2019), which provides an interface to instantiate the robot’s believe about the current state of the world and query this information. It has knowledge about the present objects and their poses. The objects’ poses Σo are dynamically updated. The information about Σo can be provided by an imaging system. However, reasoning about the current state of a task not only requires knowledge about the involved objects and their poses, but also about their interactions. Interactions between objects are encoded in semantic states. E.g. “ring is grasped by gripper” requires information about interaction wrenches between the ring and the gripper. In this work we use a physics simulation to keep track of Σo of the objects of interest as it gives us the possibility to generate interaction wrenches between
Pre-known information about a variety of objects is provided by the object database, presented in Leidner (2019), offering a hierarchical structure for objects with respect to their functionality. Physical objects are derived from high level abstract object definitions which provide not only information about the object but also about actions. These can be refined for certain types of the abstract objects. The physics simulation queries the meshes of present objects from the object database and receives their poses from the world state representation. Then it instantiates the objects that are currently present in the robot’s environment. Furthermore, it loads the instrument’s gripper and places it at
The proof-of-concept implementation uses AMBF physics simulation engine (Munawar et al., 2019) which integrates the Bullet Dynamics Engine (Coumans, 2015) as a dynamic solver and interfaces of CHAI-3D (Conti, 2003). This simulation framework was developed to meet the requests of closed-loop kinematic chains and redundant mechanisms as often used in surgical robotics.
This DT approach enables the implementation of the getContextInformation function as explained in Algorithm 2. It decides if Oref is an object or a robot component and returns the accumulated context information
Algorithm 2. Pseudocode of the getContextInformation function
Input: The reference object/robot Oref and the target object Otar.
Output: The algorithm returns context information
1 ifOref is robot then
2 qgripper, Σref ← getUpdateRDT (Oref)
3 Σtar, wref,tar ← getUpdateODT (Otar)
4
5 else
6 Σref, Σtar, wref,tar ← getUpdateODT (Oref, Otar)
7
8 return
4 Evaluation
The presented approach is evaluated in a pilot study. The experimental setup is described in subsection 4.1. The results are presented in subsection 4.2.
4.1 Experiment Setup
The evaluation is conducted by means of the Nylon Twist training introduced in Figure 1. Two benchmark scenarios are derived as visualized in Figure 4. First, an unconstrained pick and place task ([a]) and second, a constrained pick and place task ([b]). A ring is initially placed on the training pad at the start pose Σpad,start. The subjects are tasked to pick up this ring and place it on the goal pin located at Σpad,goal. In benchmark one, the transition between Σpad,start and Σpad,goal is not constrained as shown in 4 [a]. The benchmark scenario two restricts the transition from Σpad,start to Σpad,goal to a sine-shaped path as shown in 4 [b]. The predefined path is marked on the real training pad for visual guidance.
The gripper of the instrument is simulated in the ODT at
The proof-of-concept implementation of SCOPE provides three SCTs, namely pick, place, and follow_path as shown in Figure 5. References and targets are visualized in Table 2. The implemented AFs support the successful completion of the task. The Cartesian workspace limit and the RF prevent collisions between the instrument and the training pad. The pick SCT is visualized in Figure 5A with the transition requirements and the corresponding parameters. The state init is the entry point of the pick SCT. If there is no wrench close is constrained by the distance d, defined between grasped is reached if dz, the distance along the z-axis, is sufficiently small, the gripper is closed and place SCT is implemented very similar to the pick SCT and makes use of the same VFs. It is visualized in Figure 5B, but not described in more detail here. After successfully picking a ring the follow_path SCT is activated as depicted in Figure 5C. The first state of the SCT is grasped. If d fulfills all criteria the transfer state is reached and a path following AF (PF) is set. If dx indicates that at_target state is reached and the follow_path SCT finishes.
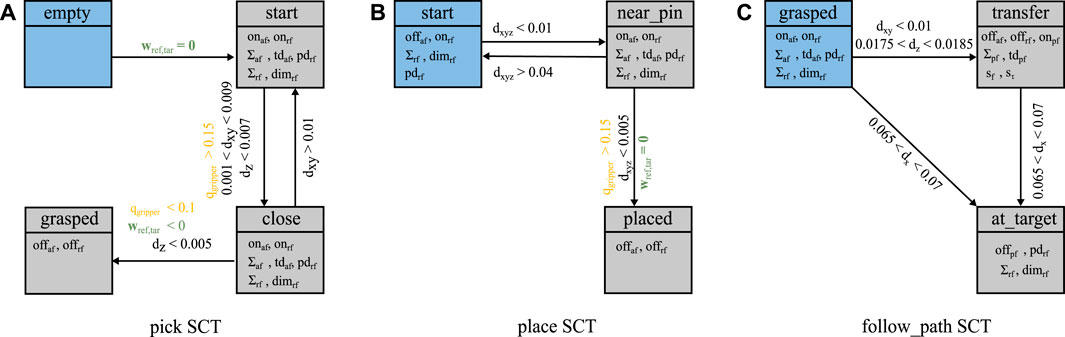
FIGURE 5. States, transitions and the respective parameters describing the pick SCT (A), the place SCT (B), and the follow_path SCT (C). The blue states indicate the starting states of the respective SCT. The yellow information are provided by the RDT, the green by the ODT and the black are computed as a combination of ODT and RDT.
Each of the two benchmark scenarios starts with the pick SCT as the gripper is initially empty. The first benchmark progresses with the place SCT, while the second benchmark transitions to the follow_path SCT after grasping the ring successfully. As the distance between Σring and Σpin becomes sufficiently small, the place SCT is activated as last task of both benchmark scenarios.
Six subjects performed both benchmark scenarios. They are split in two groups namely a test group and a control group. They have little to no experience with telemanipulation of the DLR MiroSurge System. Before starting with the benchmark scenarios a short introduction to the system is provided with a few introduction movements. The test group performed trials one and five of each benchmark scenario without assistance and the remaining trials with assistance. The control group performed each benchmark five times without assistance to investigate the hypothesis, that the proposed approach accelerates training. After each trial the participant is asked to rate the current workload based on the Overall Workload Scale (Vidulich and Tsang, 1987).
4.2 Results
To investigate the hypothesis that training with our approach enables a novice surgeon to realize a task faster, more accurately and with less cognitive load, the following metrics are presented: duration of a task Δt, translational and rotational deviations from the predefined pose Δp, consisting of Δptrans and Δprot, and the assessed workload. This section provides the pure results, a detailed interpretation of the results is provided in Section 4.3.
4.2.1 Pose Deviation
The activated AFs attract
The recorded wrenches are analyzed separately for each skill of the benchmark scenarios. Furthermore, the analysis splits wrenches into forces f and torques m. The absolute force ft measured in one time step is calculated from the forces along the x, y, z-axis by the euclidean norm. For each subject all ft measured during one skill of one trial are accumulated to fa. fa is normalized over all subjects and trials and over both benchmarks within one skill. Therefore, the results within one skill are comparable over both user groups and both benchmarks. Furthermore, the pick and place skills are normalized by the same value to make them comparable as well. The mean and standard deviation over all subjects’ normalized deviations is acquired separately for each of the trials. The recorded torques are processed equally. Figure 6 shows the processed deviations for both benchmark scenarios.
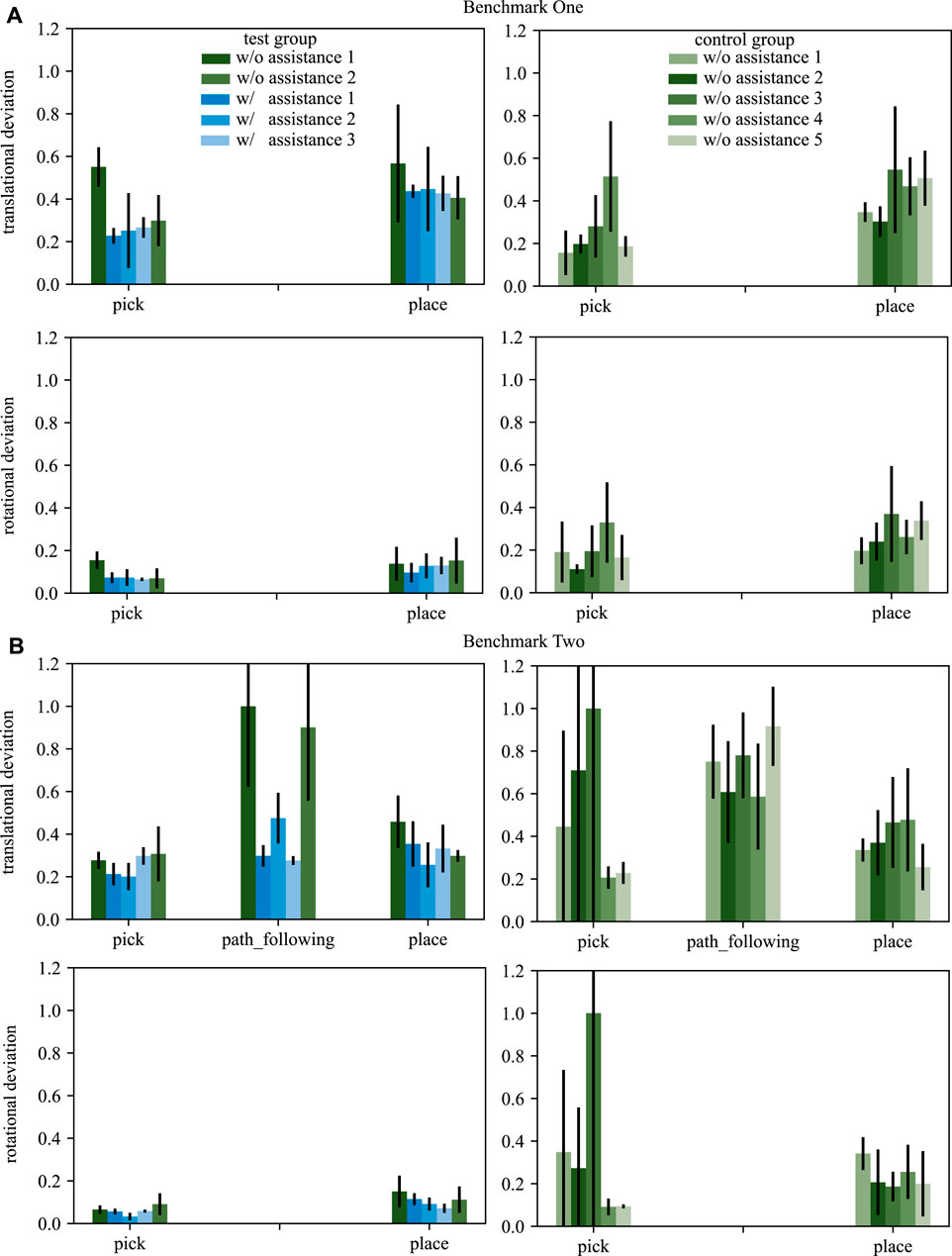
FIGURE 6. The translational and rotational deviations for benchmarks one (A) and two (B) are shown. The left column depicts results of the test group, the right column of the control group. Blue bars display trials with assistance, green ones trials without assistance. The standard deviation is depicted by black arrows.
4.2.2 Duration
The duration of completing a task is analyzed for each participant. Figure 7 shows the mean duration and standard deviation over all subjects for each trial for both benchmarks and both groups.
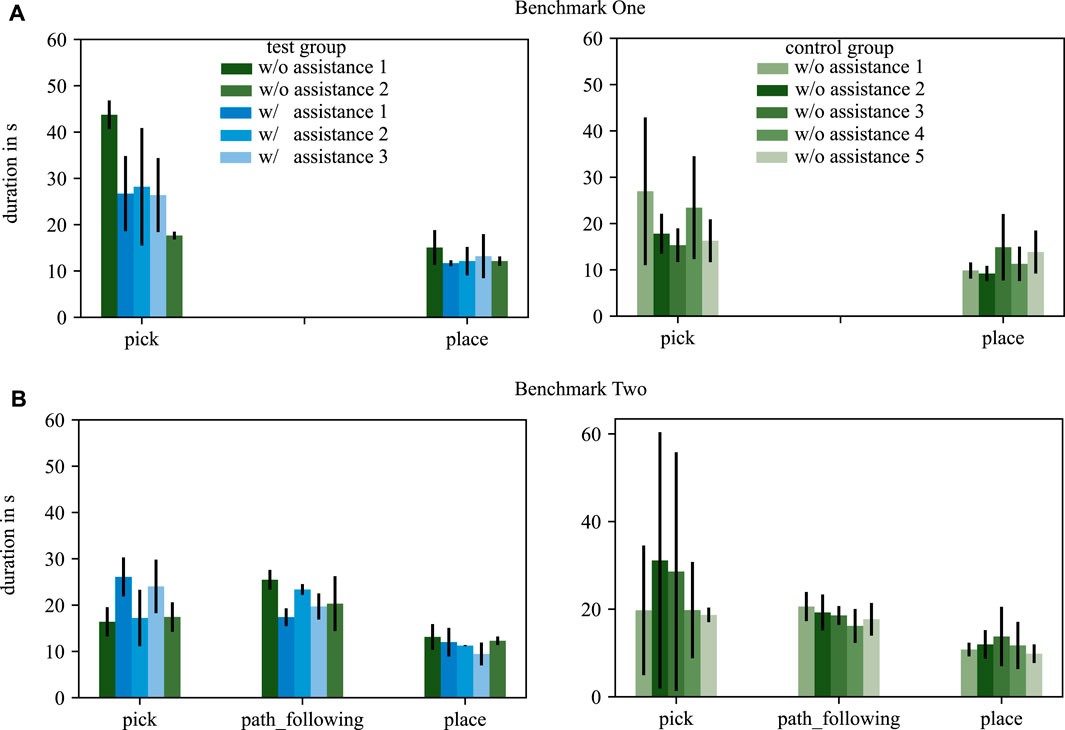
FIGURE 7. The duration of each tasks in benchmark scenario one (A) and benchmark scenario two (B) are depicted. The test group is displayed in the left column, the control group in the right column. Trials with assistance are shown in blue, trials without assistance in green. The standard deviation is depicted by black arrows.
4.2.3 Workload
The workload is assessed after each trail with the Overall Workload Scale. The subjects are asked to rate their workload on a scale from 0 (very low) to 20 (very high) after each trial. The evaluation of the different tasks of a benchmark scenario is combined into one value. The mean and standard deviation is acquired by averaging over all participants but separating the different trials of a benchmark scenario. Figure 8 shows the mean and standard deviation over all subjects for each trial of both benchmark scenarios and both groups.
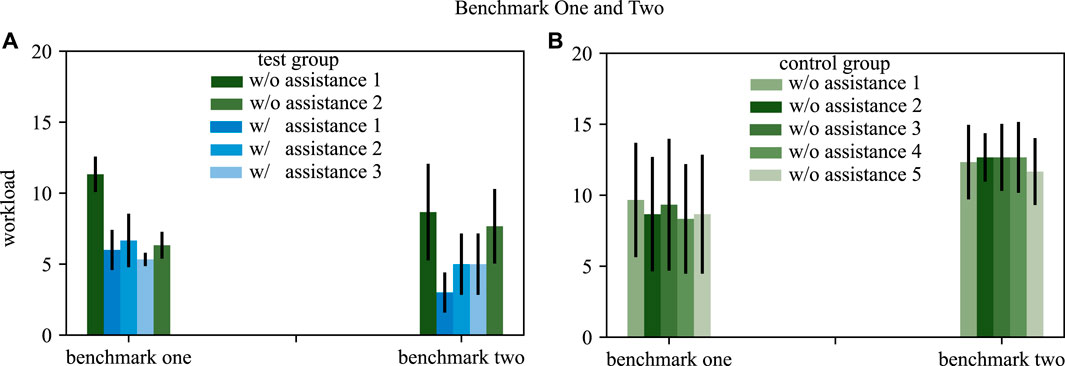
FIGURE 8. The workload for both benchmarks is depicted, comparing the test group (A) and the control group (B). Blue bars depict trials with assistance, green bars trials without assistance. The standard deviation is shown by black arrows.
4.3 Performance Analysis
The small number of subjects included in this pilot study allows us to identify trends in how the proposed approach influences pose deviation, duration until benchmark scenario completion, and subjective workload. As each of the involved groups include only three participants the trends are presented in the form of plots rather then with a statistical analysis of the significance levels. The pilot study therefore does not aim to draw statistically significant conclusions, but instead to provide an initial assessment of feasibility.
4.3.1 Pose Deviation
The analysis of the pose deviation aims to find trends investigating if our approach helps a novice surgeon to realize a task more accurately. The expected result is that after training with our approach the measured deviations of the predefined path are smaller than without such training represented by the control group. Figure 6 shows the processed deviations for both benchmark scenarios. The test group is depicted in the left column, the control group in the right.
In general, three main observations can be made. First, it is visible that the test group performs more accurate for some task if the assistance functions are activated (see trials with blue bars in Figure 6).
Second, the test group performs more accurate with respect to rotational deviation by means of absolute numbers, whereas the translational deviation is mostly comparable over all tasks. Third, comparing the performance (both translational and rotational) over all trials and all tasks of both benchmarks shows a clear trend: That is, for each task, the gradient on the mean deviation over the five trials is decreasing or constant for the test group, whereas it is increasing or constant for the control group.
Investigating the tasks individually, it is visible that especially the path_following SCT is providing assistance. For the trials in which the test group is assisted by means of haptic guidance, the accuracy is increased by 60%.
In addition, a learning effect can be observed for the test group, while the control group does not show a training effect. This training effect is further analyzed statistically by performing a two-sided related t-test comparing the first with the last trial for each task within each group. A two sided p-value p < 0.05 will be considered statistically significant. The resulting p reveal that the rotational deviation for the pick skill causes a statistically significant learning effect (p = 0.009). The remaining p are below the considered significance level. Considering that the statistical power of t-tests increases with the size of a data set, the result is deemed very promising and will be further investigated. The pick and place skills do not show a clear trend in the mean pose deviation. However, it is visible that the standard deviation is positively affected by the assistance functions for both tasks concerning translations and rotations.
In summary, the analysis of pose deviation shows that assistance functions have a certain impact on training for some tasks. Furthermore, the steady increase in pose deviation for some skills across both benchmarks for the control group shows that accuracy is further compromised as more repetitions are performed. This may already be an indication of increased workload, which will be discussed further at the end of this section.
4.3.2 Duration
The duration of task execution is evaluated to investigate if SCOPE supports a novice surgeon to complete a required task faster. In comparison to the pose deviation, no general observation can be made with respect to this hypothesis.
Nevertheless, Figure 7 reveals that the test group improved the duration to complete the pick task, both with respect to mean values but as well with respect to the standard deviation. The place and path_following skills do not show clear effects in duration for both groups.
4.3.3 Workload
The workload is assessed to investigate if SCOPE decreases the workload of a novice surgeon during task execution. The results shown in Figure 8 supports this hypothesis. In general, the analysis reveals that the perceived workload of the participants decreases when offering task dependent assistance functions. After training with our approach the execution of the required skills without assistance requires less workload then without training, which is also visible in detail when analyzing the two benchmark scenarios in detail.
Benchmark one shows that the workload decreases in the test group when repeating the same task multiple times. After some trials with assistance the workload for the trial without assistance is decreased compared to the first trial without assistance. The control group rates the workload for all trials in benchmark with a comparable value.
Benchmark two also shows that the trials with assistance for the test group are rated with less workload then the trials without assistance. The training effect is smaller comparing trial 1 and 5 without assistance. The control group rates do not show a learning effect in the workload for benchmark two.
5 Conclusion
This paper presents a novel approach to parameterize haptic assistance functions at run-time, entitled SCOPE. The procedural context to do so, is derived utilizing a DT approach. The concept is integrated into the DLR MiroSurge system and evaluated in a pilot study for surgical training. The experiments show a promising trend, that novel users profit from haptic augmentation during training of certain tasks, such that they perform a task faster, more accurately and with less cognitive load.
5.1 Scalability and Generalizability
Even though the pilot study is conducted with only a small amount of participants, it reveals promising trends with respect to the learning effect. In a next step, a follow-up user study will be conducted with partnering novice surgeons. This will allow the recording of a sufficiently large data set to analyze the statistical significance of the trends presented in this work.
As the portfolio of available skills in terms of SCTs is currently predefined by a technical expert, the amount of available skills is limited. The skill set will be extended by aligning the set of training tasks to established curricula (Ritter and Scott, 2007; Laubert et al., 2018; Chen et al., 2020), e.g., by introducing peg-transfer, cutting along resection lines, needle guidance and suturing. In addition, the available assistance functionality will be extended by parameterizable assistance functions such as motion scaling between input device and
The stiffness function parametrizing AF visualized in Figure 3 influences the surgeon’s haptic perception of the guidance. The preferred guidance mode might differ between surgeons and most likely influences training outcome. Therefore, we plan to automatically generate the stiffness function as extension to the empirically chosen function currently implemented for both benchmarks. Two approaches will be compared in the future improving different aspects of the haptic perception of VFs. First, the generation of the stiffness function will be based on trials performed by expert surgeons which describe the optimal stiffness. The second approach adapts the stiffness function on the surgeon’s preferences learned from previous trials.
The presented approach focuses on the task state estimation of a known task series. This approach could be extended by surgical gesture recognition inferring which task the surgeon aims to complete (van Amsterdam et al., 2021). This would allow for more flexible task series.
Furthermore it is crucial to note that the initial pose of all relevant objects in the scene is currently predefined. After initialization the objects’ poses are tracked by the physics simulation. The presented tasks consist of short sequences to prevent the divergence of the simulated scene from the real scene. Longer action sequences will require the integration of a vision pipeline to further prevent divergence of the simulated world and the real world. This includes object detection and tracking to allow for a more generic scene initialization and the update of the parameters, i.e., pose of the objects, used by the physics simulation. Additionally, the integration of a vision pipeline into our approach will enhance the flexibility of our setup.
5.2 Outlook
Based on the insights of this work, we argue that adaptable haptically augmented VFs explain a task more accurately than oral or visual explanations. In the future, the tasks to be trained could be learned from expert demonstrations (Steinmetz et al., 2019). To achieve this, an expert surgeon could perform a task first, allowing the abstraction of skills and corresponding support functions. A novice surgeon could then benefit from a haptically augmented training process that encodes the expert knowledge inherently.
As SCOPE allows the adaptable parametrization of VFs, it enables the personalization of VFs to the surgeons’ needs during the different phases of training. With increasing proficiency, the strength of the haptic guidance could be reduced to further train the novice surgeons’ ability follow the predefined path by their own (Enayati et al., 2018). According to Ovur et al. (2019) decreasing the strength of guidance and finally removing it doesn’t affect the achieved skill level. Furthermore, VFs could be parametrized according to the surgeon’s preferences observed by the robotic system.
At last, we envisage the possibility to train critical steps before surgery in virtual reality. Assistance functions could be predefined in virtual reality and applied during real surgery. However, the automatic perception of procedural context information in real surgery is still an open research question. Perceiving the procedural context would allow to integrate SCOPE into real surgical procedures.
This outlook leads to the final goal of supporting surgeons during MIRS with individualized contextual assistance and therefore enhancing surgical performance.
Data Availability Statement
The datasets presented in this study can be found using the following link: https://github.com/DLR-RM/Contextual-MIRS-Assistance.
Ethics Statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author Contributions
KH, AH, RR, JK, FS, and DL contributed to conception and design of the presented approach. KH, AH, and RR implemented the approach. KH, AH, JK, FS, and DL contributed to conception and design of the presented pilot study. KH evaluated the results. KH wrote the first draft of the article. KH, AH, JK, and DL wrote sections of the article. All authors contributed to article revision, read, and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The Authors would like to gratefully acknowledge the financial support and endorsement from the DLR Management Board Young Research Group Leader Program and the Executive Board Member for Space Research and Technology.
Footnotes
1For more details on the control of the system, please refer to Le Tien et al. (2007) and Le Tien et al. (2008) for the MIRO, to Thielmann et al. (2010) for the MICA drive unit and to Tobergte et al. (2009) and Seibold et al. (2018) for the overall system control.
References
Abbott, J. J., Marayong, P., and Okamura, A. M. (2007). “Haptic Virtual Fixtures for Robot-Assisted Manipulation,” in Robotics Research (Springer), 49–64.
Ahmed, H., and Devoto, L. (2020). The Potential of a Digital Twin in Surgery. Surg. Innov. 28, 509–510. doi:10.1177/1553350620975896
Bauer, A. S., Schmaus, P., Albu-Schäffer, A., and Leidner, D. (2018). “Inferring Semantic State Transitions during Telerobotic Manipulation,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 1–9. doi:10.1109/iros.2018.8594458
Bowyer, S. A., Davies, B. L., and Rodriguez y Baena, F. (2014). Active Constraints/Virtual Fixtures: A Survey. IEEE Trans. Robot. 30, 138–157. doi:10.1109/TRO.2013.2283410
Caccavale, F., Natale, C., Siciliano, B., and Villani, L. (1999). Six-dof Impedance Control Based on Angle/axis Representations. IEEE Trans. Robot. Automat. 15, 289–300. doi:10.1109/70.760350
Chen, R., Armijo, P. R., Rodrigues Armijo, P., Krause, C., Siu, K.-C., and Oleynikov, D. (2020). A Comprehensive Review of Robotic Surgery Curriculum and Training for Residents, Fellows, and Postgraduate Surgical Education. Surg. Endosc. 34, 361–367. doi:10.1007/s00464-019-06775-1
Coumans, E. (2015). Bullet Physics Simulation. ACM SIGGRAPH 2015 Courses 1. doi:10.1145/2776880.2792704
Dimension, F. (2021). Force Dimension sigma.7. Available at: https://www.forcedimension.com/products/sigma (Accessed 06 27, 2021).
Enayati, N., Ferrigno, G., and De Momi, E. (2018). Skill-based Human-Robot Cooperation in Tele-Operated Path Tracking. Auton. Robot 42, 997–1009. doi:10.1007/s10514-017-9675-4
Endsley, M. R., and Kaber, D. B. (1999). Level of Automation Effects on Performance, Situation Awareness and Workload in a Dynamic Control Task. Ergonomics 42, 462–492. doi:10.1080/001401399185595
Fontanelli, G. A., Yang, G.-Z., and Siciliano, B. (2018). “A Comparison of Assistive Methods for Suturing in MIRS,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) (Madrid: IEEE), 4389–4395. doi:10.1109/iros.2018.8593607
Haidegger, T. (2019). Autonomy for Surgical Robots: Concepts and Paradigms. IEEE Trans. Med. Robot. Bionics 1, 65–76. doi:10.1109/tmrb.2019.2913282
Hannaford, B., and Jee-Hwan Ryu, J.-H. (2002). Time-domain Passivity Control of Haptic Interfaces. IEEE Trans. Robot. Automat. 18, 1–10. doi:10.1109/70.988969
Hertkorn, K., Hulin, T., Kremer, P., Preusche, C., and Hirzinger, G. (2010). “Time Domain Passivity Control for Multi-Degree of freedom Haptic Devices with Time Delay,” in 2010 IEEE International Conference on Robotics and Automation (IEEE), 1313–1319. doi:10.1109/robot.2010.5509148
Hulin, T., Panzirsch, M., Singh, H., Balachandran, R., Coelho, A., Pereira, A., et al. (2021). Model-augmented Haptic Telemanipulation: Concept, Retrospective Overview and Current Use-Cases. Front. Robotics AI 8, 76. doi:10.3389/frobt.2021.611251
Jee-Hwan Ryu, J.-H., Preusche, C., Hannaford, B., and Hirzinger, G. (2005). Time Domain Passivity Control with Reference Energy Following. IEEE Trans. Contr. Syst. Technol. 13, 737–742. doi:10.1109/tcst.2005.847336
Klodmann, J., Schlenk, C., Borsdorf, S., Unterhinninghofen, R., Albu-Schäffer, A., and Hirzinger, G. (2020). Robotische Assistenzsysteme für die Chirurgie. Chirurg 91, 533–543. doi:10.1007/s00104-020-01205-8
Laaki, H., Miche, Y., and Tammi, K. (2019). Prototyping a Digital Twin for Real Time Remote Control over Mobile Networks: Application of Remote Surgery. IEEE Access 7, 12. doi:10.1109/access.2019.2897018
Laubert, T., Esnaashari, H., Auerswald, P., Höfer, A., Thomaschewski, M., Bruch, H. P., et al. (2018). Conception of the Lübeck Toolbox Curriculum for Basic Minimally Invasive Surgery Skills. Langenbecks Arch. Surg. 403, 271–278. doi:10.1007/s00423-017-1642-1
Le Tien, L., Albu-Schaffer, A., De Luca, A., and Hirzinger, G. (2008). “Friction Observer and Compensation for Control of Robots with Joint Torque Measurement,” in 2008 IEEE/RSJ International Conference on Intelligent Robots and Systems (IEEE), 3789–3795.
Le Tien, L., Schaffer, A. A., and Hirzinger, G. (2007). “Mimo State Feedback Controller for a Flexible Joint Robot with strong Joint Coupling,” in Proceedings 2007 IEEE International Conference on Robotics and Automation (IEEE), 3824–3830. doi:10.1109/robot.2007.364065
Li, Z., Gordon, A., Looi, T., Drake, J., Forrest, C., and Taylor, R. H. (2020). Anatomical Mesh-Based Virtual Fixtures for Surgical Robots. arXiv:2006.02415 [cs, eess].
Llc, M. M. (2021). Trainingsmodule Lübbecker Toolbox. Available at: http://www.luebeck-toolbox.com/training.html (Accessed 06 27, 2021).
Maier, J., Perret, J., Huber, M., Simon, M., Schmitt-Rüth, S., Wittenberg, T., et al. (2019). Force-feedback Assisted and Virtual Fixtures Based K-Wire Drilling Simulation. Comput. Biol. Med. 114, 103473. doi:10.1016/j.compbiomed.2019.103473
Munawar, A., Wang, Y., Gondokaryono, R., and Fischer, G. S. (2019). “A Real-Time Dynamic Simulator and an Associated Front-End Representation Format for Simulating Complex Robots and Environments,” in 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 1875–1882. doi:10.1109/iros40897.2019.8968568
Nagy, T. D., and Haidegger, T. (2019). A DVRK-Based Framework for Surgical Subtask Automation. Acta Polytechnica Hungarica 16, 18. doi:10.12700/aph.16.8.2019.8.5
Nitsch, V., Färber, B., Hellings, A., Jörg, S., Tobergte, A., and Konietschke, R. (2012). “Bi-modal Assistance Functions and Their Effect on User Perception and Movement Coordination with Telesurgery Systems,” in Proceedings of 2012 IEEE International Workshop on Haptic Audio Visual Environments and Games (HAVE 2012) (IEEE), 32–37. doi:10.1109/have.2012.6374427
Ovur, S. E., Cobanaj, M., Vantadori, L., De Momi, E., and Ferrigno, G. (2019). “Surgeon Training with Haptic Devices for Computer and Robot Assisted Surgery: An Experimental Study,” in Mediterranean Conference on Medical and Biological Engineering and Computing (Springer), 1526–1535. doi:10.1007/978-3-030-31635-8_189
Qian, L., Wu, J. Y., DiMaio, S. P., Navab, N., and Kazanzides, P. (2019). A Review of Augmented Reality in Robotic-Assisted Surgery. IEEE Trans. Med. Robotics Bionics 2, 1–16.
Quere, G., Hagengruber, A., Iskandar, M., Bustamante, S., Leidner, D., Stulp, F., et al. (2020). “Shared Control Templates for Assistive Robotics,” in 2020 IEEE International Conference on Robotics and Automation (ICRA), 1956–1962. doi:10.1109/icra40945.2020.9197041
Ritter, E. M., and Scott, D. J. (2007). Design of a Proficiency-Based Skills Training Curriculum for the Fundamentals of Laparoscopic Surgery. Surg. Innov. 14, 107–112. doi:10.1177/1553350607302329
Rosenberg, L. B. (1993). “Virtual Fixtures: Perceptual Tools for Telerobotic Manipulation,” in Proceedings of IEEE virtual reality annual international symposium (IEEE), 76–82. doi:10.1109/vrais.1993.380795
Scheikl, P. M., Laschewski, S., Kisilenko, A., Davitashvili, T., Müller, B., Capek, M., et al. (2020). Deep Learning for Semantic Segmentation of Organs and Tissues in Laparoscopic Surgery. Curr. Dir. Biomed. Eng. 6. doi:10.1515/cdbme-2020-0016
Schlenk, C., Bahls, T., Tarassenko, S., Klodmann, J., Bihler, M., and Wuesthoff, T. (2018). Robot Integrated User Interface for Physical Interaction with the DLR MIRO in Versatile Medical Procedures. J. Med. Robot. Res. 03, 1840006. doi:10.1142/S2424905X18400068
Sealy, W. C. (1999). Halsted Is Dead: Time for Change in Graduate Surgical Education. Curr. Surg. 56, 34–39. doi:10.1016/s0149-7944(99)00005-7
Seibold, U., Kübler, B., Bahls, T., Haslinger, R., and Steidle, F. (2018). “THE DLR MIROSURGE SURGICAL ROBOTIC DEMONSTRATOR,” in The Encyclopedia of Medical Robotics. Editor R. Patel, 111–142. doi:10.1142/9789813232266_0005
Selvaggio, M., Fontanelli, G. A., Ficuciello, F., Villani, L., and Siciliano, B. (2018). Passive Virtual Fixtures Adaptation in Minimally Invasive Robotic Surgery. IEEE Robot. Autom. Lett. 3, 3129–3136. doi:10.1109/LRA.2018.2849876
Siciliano, B., and Khatib, O. (2008). Springer Handbook of Robotics. Springer Science & Business Media.
Steidle, F., Hellings, A., Klodmann, J., Schlenk, C., Tarassenko, S., and Kübler, B. (2014). “Adaption of the DLR MiroSurge System’s Kinematics to Surgical Table Based Patient Repositioning in Minimally Invasive Surgery,” in Tagungsband der 13. Jahrestagung der Deutschen Gesellschaft für Computer-und Roboterassistierte Chirurgie (CURAC), 4.
Steinmetz, F., Nitsch, V., and Stulp, F. (2019). Intuitive Task-Level Programming by Demonstration through Semantic Skill Recognition. IEEE Robot. Autom. Lett. 4, 3742–3749. doi:10.1109/lra.2019.2928782
Thielmann, S., Seibold, U., Haslinger, R., Passig, G., Bahls, T., Jörg, S., et al. (2010). “Mica-a New Generation of Versatile Instruments in Robotic Surgery,” in 2010 IEEE/RSJ International Conference on Intelligent Robots and Systems (IEEE), 871–878. doi:10.1109/iros.2010.5649984
Thornblade, L. W., and Fong, Y. (2021). Simulation-based Training in Robotic Surgery: Contemporary and Future Methods. J. Laparoendoscopic Adv. Surg. Tech. 31, 556–560. doi:10.1089/lap.2021.0082
Tobergte, A., Konietschke, R., and Hirzinger, G. (2009). “Planning and Control of a Teleoperation System for Research in Minimally Invasive Robotic Surgery,” in 2009 IEEE International Conference on Robotics and Automation (IEEE), 4225–4232. doi:10.1109/robot.2009.5152512
Tobergte, A. (2010). MiroSurge-Advanced User Interaction Modalities in Minimally Invasive Robotic Surgery. Presence: Teleoperators and Virtual Environments 19, 400–414. doi:10.1162/pres_a_00022
van Amsterdam, B., Clarkson, M., and Stoyanov, D. (2021). Gesture Recognition in Robotic Surgery: a Review. IEEE Trans. Biomed. Eng. 99, 1. doi:10.1109/tbme.2021.3054828
Vidulich, M. A., and Tsang, P. S. (1987). Absolute Magnitude Estimation and Relative Judgement Approaches to Subjective Workload Assessment. Proc. Hum. Factors Soc. Annu. Meet. 31, 1057–1061. doi:10.1177/154193128703100930
Weber, B., Hellings, A., Tobergte, A., and Lohmann, M. (2013). “Human Performance and Workload Evaluation of Input Modalities for Telesurgery,” in Proceedings of the German Society of Ergonomics (GfA) Spring Congress (Dortmund: GfA Press).
Keywords: minimally invasive robotic surgery, shared control, digital twin, virtual fixtures, surgical robotics training
Citation: Hagmann K, Hellings-Kuß A, Klodmann J, Richter R, Stulp F and Leidner D (2021) A Digital Twin Approach for Contextual Assistance for Surgeons During Surgical Robotics Training. Front. Robot. AI 8:735566. doi: 10.3389/frobt.2021.735566
Received: 02 July 2021; Accepted: 06 September 2021;
Published: 21 September 2021.
Edited by:
Keng Peng Tee, Institute for Infocomm Research (A∗STAR), SingaporeReviewed by:
Mario Selvaggio, University of Naples Federico II, ItalyQilong Yuan, Institute for Infocomm Research (A∗STAR), Singapore
Copyright © 2021 Hagmann, Hellings-Kuß, Klodmann, Richter, Stulp and Leidner. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Katharina Hagmann, a2F0aGFyaW5hLmhhZ21hbm5AZGxyLmRl