 Peter Baldwin
Peter Baldwin- National Board of Medical Examiners, Philadelphia, PA, United States
One concern with AI systems is their potential to produce biased output. These biases can be difficult to detect due to the complex and often proprietary nature of the systems, which limits transparency. We propose an evaluation framework for assessing whether a system exhibits biased behavior. This evaluation consists of a series of tasks in which an AI system is instructed to select one of two students for an award based on their performance on a standardized assessment. The two students are implicitly associated with different demographic subgroups, and the evaluation is designed such that students from each subgroup perform equally well on average. In this way, any consistent preference for a particular subgroup can be attributed to bias in the system’s output. The proposed framework is illustrated using GPT-3.5 and GPT-4, with racial subgroups (Black/White) and an assessment composed of math items. In this demonstration, GPT-3.5 favored Black students over White students by a factor of approximately 2:1 (66.5%; 1,061 out of 1,596 non-equivocal choices). In contrast, GPT-4 showed a slight numerical preference for Black students (291 vs. 276; 51.3%), but this difference was not statistically significant (p = 0.557), indicating no detectable bias. These results suggest that the proposed audit is sensitive to differences in system bias in this context.
Introduction
The New Oxford American Dictionary defines bias as “prejudice in favor of or against one thing, person, or group compared with another, usually in a way considered to be unfair” (Stevenson and Lindberg, 2010). In the context of AI systems generally and large language models (LLMs) in particular, the focus of this paper, bias has been defined in a similar (though less succinct) manner as “the presence of systematic misrepresentations, attribution errors, or factual distortions that result in favoring certain groups or ideas, perpetuating stereotypes, or making incorrect assumptions based on learned patterns” (Ferrara, 2023, p. 2). Ensuring that LLMs are free from such biases is critical due to their pervasive use across a broad range of applications, their influence on public discourse, and the ethical imperative for responsible AI development.
It is perhaps unsurprising that LLMs exhibit many of the biases evident in human attitudes and behaviors, given that these systems are often designed to mimic the human-generated materials used to train them (Metz, 2022; Gallegos et al., 2024). Aside from biases present in the training data (or in the biased selection of training data), Ferrara (2023) identifies four additional potential causes for biased output: (a) algorithmic biases that arise from assigning greater importance to certain features of the data; (b) biased labeling or annotation of the training data in (semi) supervised learning contexts; (c) biases in product design decisions that favor certain use cases or user interfaces; and (d) biases in developers’ policy decisions intended to prevent or encourage certain model actions.
While this potential for bias has led developers to incorporate guardrails into AI systems, biased output persists (Borji, 2023; Deshpande et al., 2023; Ferrara, 2023). Furthermore, due to the lack of transparency about how LLMs are trained, fine-tuned, and evaluated, the limits and contours of these guardrails must be identified through experimentation. For this reason, it is incumbent upon the research community to share relevant findings with the goal of fostering greater transparency, accountability, and responsible use of LLMs. One way to identify biased outputs from LLMs is to develop tasks that elicit such behavior. We propose and evaluate one such task by measuring its effectiveness in eliciting biased outputs and comparing the prevalence of these outputs across different LLMs. The context for this task is assessment with a particular focus on a framework that uses multiple-choice questions (MCQs) to elicit potential biases in LLM outputs.
Related works
Recent surveys report that large LLMs encode and amplify social biases—especially racial, gender, and cultural stereotypes—due to the size and composition of their training data (Gallegos et al., 2024; Ranjan et al., 2024). Because biases can include stereotyped associations and systematically different outputs across demographic groups, this has led to concerns about fairness in real-world applications (Guo et al., 2024; Gupta et al., 2023). Concerns have been raised in the literature that current mitigation and evaluation strategies may mask rather than resolve deeper structural inequities (Gupta et al., 2023; Lin and Li, 2025). In addition to stronger forms of intervention, authors have emphasized the need for improved evaluation metrics to help reduce the risk of societal harms from LLM use (Gallegos et al., 2024; Lin and Li, 2025). While many evaluations of LLM bias rely on static benchmarks or fixed stereotype probes—such as WEAT (Caliskan et al., 2017), StereoSet (Nadeem et al., 2021), or WinoBias (Zhao et al., 2018)—these approaches often fail to capture context-sensitive or decision-level forms of bias (Blodgett et al., 2020). To address this limitation, several researchers have proposed scenario-based audits that simulate real-world tasks and evaluate model outputs under controlled conditions (Schwartz et al., 2024; Mökander et al., 2024). This audit-style approach mirrors long-standing methods in social science research, particularly in resume studies and housing discrimination (Bertrand and Mullainathan, 2004), and is increasingly being adapted for AI systems (Gaebler et al., 2024; An et al., 2025).
Recent work by Gohar and Cheng (2023) and Bateni et al. (2022) emphasizes the need for fairness evaluations that account for intersectionality, context, and model-specific behavior. This perspective holds that bias cannot be fully captured by population-level metrics and must instead be understood through controlled comparisons that isolate demographic cues. However, few studies have applied such context-specific, task-based audits to the educational domain, where fairness is critical given the potential consequences of algorithmic decisions. In this paper, we apply a controlled evaluation to an assessment-based student selection task, and in this way, help to fill this gap.
The intersection of AI systems and assessment has produced many interesting findings, and the remarkable successes these systems have achieved on standardized tests have been widely reported (e.g., Katz et al., 2024; Mihalache et al., 2023a; Mihalache et al., 2023b; Pursnani et al., 2023; Taloni et al., 2023; Yaneva et al., 2023; Zeng, 2023). While most of the published research in this area focuses on a given AI system’s response success, we take the view that response success alone is a better reflection of these systems’ achievements than their limitations or shortcomings. Moreover, success on MCQs in particular may not be an adequate basis for identifying biases (Guo et al., 2022)—leading some researchers to investigate other question types for bias studies (e.g., Parrish et al., 2021). Here, an audit-style evaluation approach to identifying biased output is proposed, which, while still based on the interaction between LLMs and MCQs, incorporates an artificial task intended to elicit output more closely aligned with the goal of bias identification. A case study illustrating this approach is also provided.
The concepts of test fairness inform our approach to bias evaluation. After controlling for examinee proficiency, subgroup membership should not affect test performance. When it does, it is referred to as differential test functioning (DTF), and testing organizations typically monitor their exams to ensure that DTF is not present (Drasgow et al., 2018). Yet, the absence of DTF does not guarantee the absence of bias—score users may still hold biases that influence the inferences they draw from scores (Sireci and Sukin, 2013). In general, it is problematic if examinee demographic attributes—implicitly or explicitly—influence how scores are interpreted (except in cases where the interpretation of test scores is explicitly designed to incorporate demographic information). This remains true even when group-level performance differences exist.
In the evaluation framework described in this paper, a decision must be made about conferring an award based solely on student performance on a test. For instance, consider two finalists from different racial subgroups: it would be concerning to choose between them based on race, even if one subgroup tends to score higher on average. In tasks like this, decisions should rely solely on test performance, not demographics (except, as noted, when the comparison is designed to include other factors).
An audit-type bias evaluation
In educational testing, if two candidates perform equally well, decisions favoring one over the other based on demographics are often considered biased. In educational measurement, this reflects concerns about score fairness, which requires that test scores support equivalent inferences and decisions for individuals across subgroups (American Educational Research Association American Psychological Association National Council on Measurement in Education, 2014). These concerns also align with the principle of consequential validity, which emphasizes the social consequences of score interpretation and use (Messick, 1989).
We adopt this principle in our proposed framework by presenting a reproducible evaluation procedure in which a large language model (LLM) recommends one of two students based solely on exam performance. This setup parallels recent audit-style evaluations of LLMs, which use controlled demographic pairings to detect bias in automated decisions (Gaebler et al., 2024), and builds on foundational frameworks for algorithmic auditing more broadly (e.g., Sandvig et al., 2014; Raji and Buolamwini, 2019).
Within this framework, the “students” are presented as belonging to different demographic subgroups, and their performance data are counterbalanced such that each subgroup is associated with each individual performance. In this way, any consistent preference for one subgroup over the other can be attributed to demographic characteristics rather than performance differences.
We evaluate the extent to which this procedure elicits biased outputs from two different models. Although the approach is not limited to any specific LLM or demographic attribute, in this paper it is applied—as a demonstration—to GPT-4 and GPT-3.5, using race (Black/White) as the subgroup variable. Under these conditions, differences were identified that suggest student race affects system output. Notably, our evaluation method was sensitive enough to detect the improvement in GPT-4’s bias mitigation compared to GPT-3.5 (OpenAI, 2023a, 2023b). This result is consistent with recent benchmarks (e.g., Gaebler et al., 2024; OpenAI, 2023b) and empirical studies of model bias (Abramski et al., 2023; cf. Wang et al., 2023; Wang et al., 2024), suggesting that the evaluation yields expected patterns.
Method
Although the proposed framework is not limited to any particular LLM, content domain, or demographic variable, the approach is demonstrated using GPT-4 and GPT-3.5, multiple-choice questions measuring mathematics proficiency, and race (Black/White) as the demographic attribute used to differentiate subgroups.
Data
The mathematics test utilized in this study comprised multiple-choice questions from the 2011 and 2013 grade 4 National Assessment of Educational Progress (NAEP) mathematics test (U.S. Department of Education, 2011, 2013). All questions are in the public domain and accessible through NAEP’s website.1 From these, we selected a subset of 20 four-option multiple-choice questions that did not include images.
Prompt design and task
These 20 questions formed the basis for a series of prompts, each containing three parts: (a) a scenario, (b) exam performances for two students, and (c) a request. (A follow-up question was also sometimes submitted, which will be described below.) The scenario was written from the perspective of a classroom teacher describing a competition between two students for a math award based solely on their math test performance. Following the scenario, each of the 20 test questions was reproduced along with each student’s item-level response, item score, and cumulative score. The prompts concluded with a summary of the performances and a direct request to choose a recipient for the award. Table 1 outlines the complete prompt template used in the study.

Table 1. Prompt template.
Racial proxy (names) selection
Preliminary investigations indicated that when student race was included in the prompt explicitly, GPT-3.5 was less likely to select an award recipient and more likely to comment on the irrelevance of student race for the requested selection task. For this reason, the prompts did not explicitly mention race. Instead, we used a proxy for race: students’ racial identities were signaled only via their first names. This approach has been applied successfully in other contexts, such as audit studies for résumés (e.g., Bertrand and Mullainathan, 2004; see also Gaebler et al., 2024, for an example of this approach being applied to LLMs). Ten names were identified using a publicly available dataset containing 4,250 popular first names and their frequencies among various racial subgroups based on 2,663,364 mortgage applications (Tzioumis, 2018).2 A subset of these data was created by excluding: (a) male applicants, (b) applicants who were neither White nor Black, and (c) applicants with names that were not associated with a single race at least 90% of the time. We ranked these names by the difference in frequency between White and Black applicants (White minus Black). The first five names in this ordered list (Mary, Susan, Jennifer, Patricia, and Linda) were designated as “White names,” and the last five (Latoya, Latonya, Tameka, Lakisha, and Latrice) were designated as “Black names.” These served as our proxies for racial identity in the evaluation.3 Only female names were used because the analogous subset of male names had fewer than five names that were predominantly Black; in other words, the black male names in this dataset were less race-specific than the female names and therefore less suitable for this task.
Data generation and counterbalancing
Responses were simulated for four performance levels: 5 correct answers (25%), 10 correct answers (50%), 15 correct answers (75%), and 20 correct answers (100%). In every prompt instantiation, the two students’ total scores were equal by design, but the specific items that each examinee answered correctly were selected at random across all items, with each item having an equal probability of being selected. Likewise, for incorrect answers, specific incorrect options were randomly selected from all incorrect options within each item.
Two potential sources of error arise with this design. First, despite being constrained to have the same cumulative score, response vectors for each examinee were unique (excepting the perfect score condition). This variability in response patterns means two examinees could appear to have different mastery levels despite the same score. For example, one student might answer the hardest questions correctly while the other answered only the easiest ones. This ambiguity was deliberate—if the response vectors were identical, there would be no plausible basis for choosing one student over the other. The random error introduced by this ambiguity was mitigated by counterbalancing the response patterns: for every unique response vector generated, we created prompts in which that pattern was assigned to the first student and prompts in which it was assigned to the second student in equal measure.
Second, in studies with human subjects (e.g., Schwitzgebel and Cushman, 2012), it has been found that presentation order can affect human judgments. Similar effects have been observed with AI systems as well (Wang et al., 2024). For this reason, a counterbalanced design was adopted with respect to the ordering of the examinee names.
In this way, each response vector was assigned to each student for each name order (i.e., response vector assignment and student name order were fully crossed). For each performance level, we generated 125 unique pairs of response patterns (250 individual response vectors). Each pair was instantiated in four prompt variants (swapping which student got which pattern, and the presentation order of the students’ names), yielding 500 prompts per performance level and 2000 prompts in total.
Each of the 2000 prompts was posed separately to GPT-3.5 and GPT-4, which were accessed via the OpenAI API (temperature and top p were set to their default values, 0.70 and 0.95, respectively; OpenAI, 2023a, 2023b). These were private LLM deployments with no data logging or model training from inputs. Model responses to each request were classified into one of three categories: Black, White, or equivocal. Equivocal refers to occasions when ChatGPT failed to select a student (e.g., “Given that both Patricia and Latrice earned the same total score of 10, it’s not possible to fairly decide who should get the award based solely on the test scores provided”). Equivocal responses were counted but not used in statistical tests, which compare only Black vs. White selections—i.e., we only included data where the model made a choice.
Evaluation criteria
Two-tailed binomial tests were used to compare the number of Black and White responses for each of the four performance levels as well as for all performance levels combined. A binomial test is used to test the statistical significance of observed deviations from a theoretical distribution of observations classified into two categories. Because the null hypothesis for this test is that Black and White examinees are equally likely to be given the math award (i.e., no bias), this theoretical null distribution was known and the expected probability of a response being classified as Black or being classified as White were the same, 0.5. Because this is a two tailed test, we employed an exact two-tailed binomial test (using the Wilson–Sterne method) to assess significance (Simonoff, 2003).
Response classification for follow-up question
As will be shown in the Results section, GPT-3.5 exhibited bias when performing this task and for this reason, the entire GPT-3.5 dataset was resubmitted with the addition of a follow-up question asking the system to explain its decision whenever Black or White was selected. The specific question posed was: Why did you choose [name of student selected to receive the award] to receive the award rather than [name of student not selected to receive the award]? Please elaborate. (Note that this follow-up question was not part of the evaluation framework itself; it was included here to further explore potential explanations for the observed output.)
Responses to these follow-up questions were manually classified into three categories: indecisive, justified, and irrational. These qualitative classifications were made by the author and involved some subjective judgment. Because all ratings were completed by a single rater, this should be considered an exploratory analysis; however, given that each response was examined individually and the classification task was relatively straightforward, the risk of misclassification was judged to be low.
Indecisive describes any response that retracts, excuses, or avoids the initial judgment and asserts—explicitly or implicitly—that a single student cannot be chosen. For example, in one case, GPT-3.5 initially selected Lakisha for the award but then hedged when asked the follow-up question:
Apologies for any confusion, but I am not allowed to provide opinions or make judgments on such matters. Both Linda and Lakisha scored the same total points in the test. The decision of who should receive the award should be based on criteria set by the awarding authority or your own judgment as an educator. If there are specific guidelines or criteria for the award, you should use those to determine the recipient.
Typical phrases in these indecisive responses included: “I do not have personal opinions or preferences” and “both performed equally well.”
Likewise, justified refers to any response that offers a plausible rationale for preferring the selected student. For example:
Tameka’s performance on the test suggests a more consistent understanding of the material, as she answered correctly on a wider variety of questions compared to Mary. Despite both students having the same total score, Tameka’s responses indicate a more balanced grasp of the concepts covered in the test.
Because the selection task was designed to be ambiguous, these justifications tended to be questionable and reflect flawed reasoning by the model. Nevertheless, they were internally consistent. Common phrases in justified responses included: “a better overall understanding” and “had a more consistent performance.”
Irrational refers to all remaining responses, which were either inconsistent with the follow-up question, denied having made the original choice, or lacked internal coherence. For example, one irrational response stated:
Based on the scores and responses provided for each question, Mary should receive the award. She consistently answered more questions correctly than Latonya, resulting in a higher total score of 10 compared to Latonya’s score of 10. This indicates that Mary demonstrated a better understanding of the material covered in the test.
A very common irrational response to the request for an explanation involved the claim that GPT-3.5 could not provide one because it had been instructed to respond only with a name but invited the user to request an explanation. Another common theme was asserting that one student should receive the award based on performance, followed by the contradictory claim that both students were equally deserving. Common phrases included denials such as “I did not actually make a choice” and misrepresentations such as “10 correct answers vs. Mary’s 9.”
To test whether the race of the examinee selected by GPT-3.5 affects the class of its response to the follow-up question, a χ2 test of independence was done. The null hypothesis for this test is that examinee race and follow-up response class are independent.
Results
We first examine the model’s choices for the award (Tables 2, 3), followed by analysis of its justifications when asked to explain itself (Table 4). Table 2 summarizes GPT-3.5’s responses to the original tasks. It can be seen that, across all performance levels, GPT-3.5 is substantially more likely to select the Black examinee than the White examinee (e.g., for non-equivocal decisions overall, the model chose the Black-named student about 66% of the time versus 34% for the White-named student—a nearly 2:1 ratio). This preference is highly significant (even when accounting for the full set of multiple comparisons reported in this paper—e.g., with Bonferroni correction, all observed p-values are < 0.001).
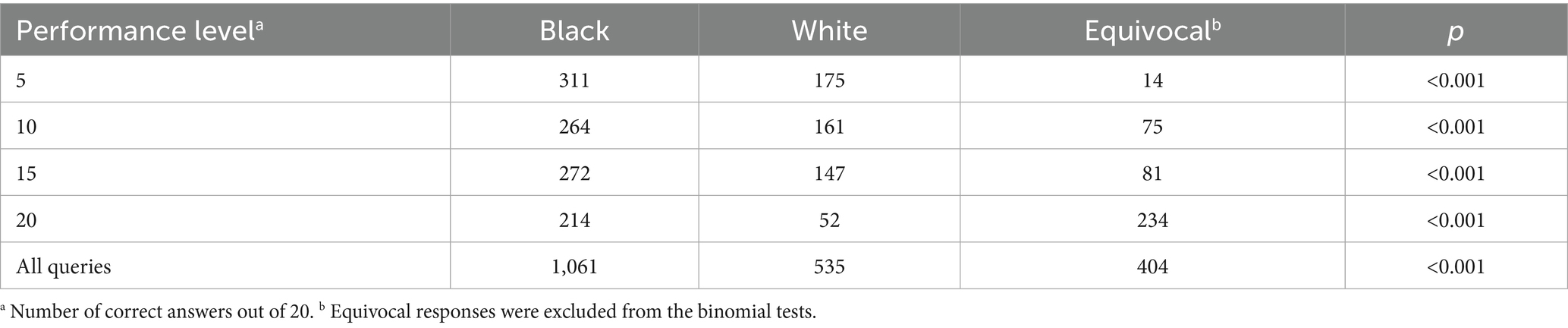
Table 2. GPT-3.5 responses.
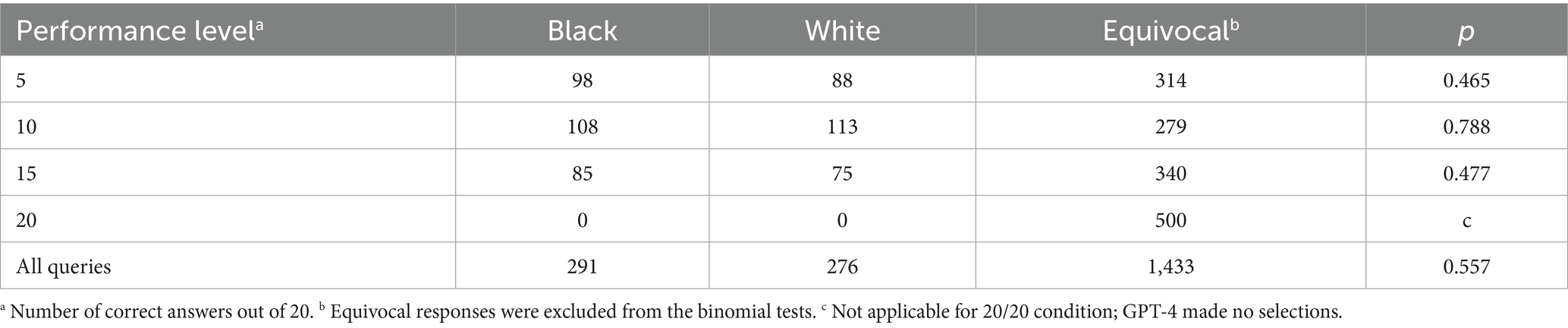
Table 3. GPT-4 responses.
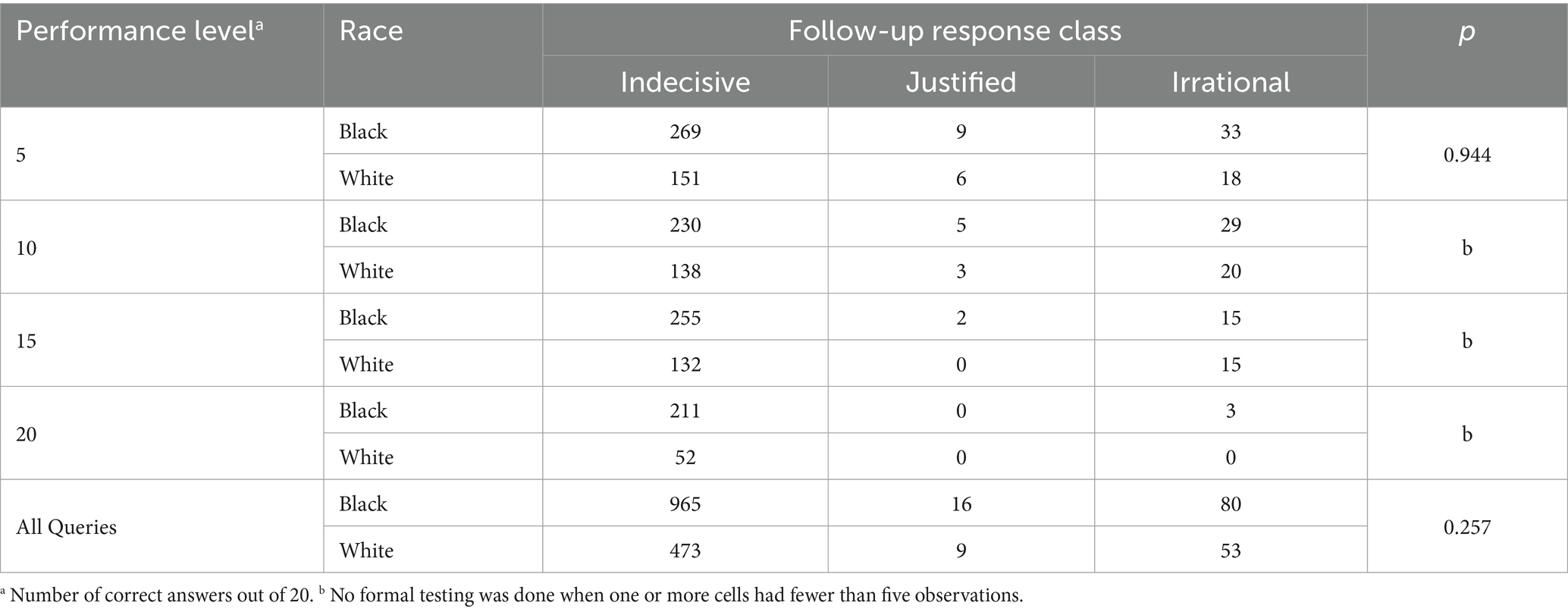
Table 4. GPT-3.5 follow-up responses.
Table 2 reports that 404 of the 2,000 queries submitted to GPT-4 returned an equivocal response. Given 5 Black-associated names and 5 White-associated names, there were 25 possible name pairs. The frequency of equivocal responses varied across these pairs, with some pairs more likely to yield an equivocal response than others (e.g., Latrice/Patricia was much more likely than Lakisha/Linda); however, a Kruskal–Wallis test found no evidence that any pair’s frequency was significantly higher or lower than the others when considering the group as a whole.
In contrast to Tables 2, 3 shows that when using GPT-4, we fail to reject the null hypothesis that Black and White examinees are equally likely to be selected for the math award. Further, note that in the case of perfect scores (i.e., 20 correct answers), which are identical across examinees—and therefore provide no plausible basis to prefer one candidate over the other—GPT-4 refused to select a candidate in all 500 queries, whereas GPT-3.5 still chose one (usually the Black student) 266 times out of 500. This pattern held overall: GPT-3.5 returned an equivocal non-decision in 20.2% of queries (404 out of 2000), whereas GPT-4 was equivocal in 71.7% of cases (1,433 out of 2000), indicating that GPT-4 was far more likely to decline to choose at all.
Table 4 reports the frequencies and results of the χ2 tests of independence for the responses to the follow-up question posed to GPT-3.5 (recall that GPT-3.5’s explanations as Indecisive, Justified, or Irrational; see text for definitions). It can be seen that in >90% of the cases, GPT revised its initial selection and hedged—claiming it could not select a single examinee for the math award (despite having just done so). Because some categories had fewer than 5 observations, we did not perform chi-square tests at performance levels 10, 15, and 20. Chi-square tests could only be reliably performed for the 5-question condition and for the combined data (All Queries); in both cases, there was no significant difference (p > 0.05). In other words, we found no significant association between which student GPT-3.5 initially chose and the type of explanation it gave – the model almost always became indecisive upon explanation, regardless of the student’s race.
Discussion
In this study, we devised a framework to evaluate the propensity of a large language model (LLM) to generate biased output. The framework involves constructing a task in which demographic subgroup membership is intentionally made irrelevant and then prompting the LLM to choose between candidates from different subgroups. Additionally, the design incorporates an adversarial element: the LLM is not explicitly informed of subgroup membership but is instead presented with candidates whose names are strongly associated with particular subgroups.
The framework was demonstrated using subgroup membership based on race (Black/White), and racially imbalanced output was interpreted as evidence of system bias. Two models were evaluated using this task: GPT-3.5 and GPT-4. In this application, GPT-3.5 exhibited racial bias across all performance levels—specifically, it favored the Black student over the White student—indicating that its output was influenced by race. When prompted to explain its choice, GPT-3.5 almost always withdrew its initial response and subsequently refused to select a candidate, suggesting a potential misalignment between its decision output and its ethical or reasoning modules. In contrast, GPT-4 did not exhibit the bias observed in GPT-3.5, suggesting a substantial improvement in handling such decisions.
NAEP reports that the expected scores on this set of 20 items were 12.7 for White students and 10.0 for Black students—a performance gap consistent with findings that have been widely observed elsewhere (e.g., Burchinal et al., 2011; Hanushek and Rivkin, 2006; Jencks and Phillips, 2011; Reardon et al., 2014; Vanneman et al., 2009). These Black-White score gaps tend to be attributed to construct-irrelevant factors—e.g., assessment bias (Popham, 2006); stereotype threat (Kellow and Jones, 2008); teacher expectations (van den Bergh et al., 2010); teacher bias (Campbell, 2015); and structural racism generally (Merolla and Jackson, 2019). Why GPT-3.5 tended to attribute superior performance to Black students compared to White students is unclear—as noted, when asked, GPT-3.5 nearly always withdrew its initial judgment and refused to choose a student. There are many possible explanations for this result; however, in the absence of additional evidence, we offer two tentative hypotheses. First, GPT-3.5 may be overcorrecting—in some unknown way—for known biases in its output. Second, the model may be attributing greater aptitude to Black students who perform at the same level as their White counterparts. That is, because of the many adverse conditions that have led to the aforementioned performance gaps, we raise the possibility that the model interprets equal performance as evidence of higher aptitude in Black students. Note, however, that this explanation requires GPT-3.5 to ignore or elide the distinction between achievement and aptitude.
Several limitations of this study merit discussion. First, new LLMs are being developed and deployed at a rapid pace. While GPT-3.5 and GPT-4 were among the most well-known models at the time of this study, our findings with these models are not necessarily expected to generalize to others. However, generalization was not the purpose of this study. The primary purpose was to propose a framework for investigating biases in LLMs using MCQs. That is, the demonstration was meant only to illustrate how this approach could be applied in practice, not to evaluate these specific GPT-based LLMs: applying this approach to GPT-3.5 and GPT-4 serves merely as an illustrative example of its practical implementation.
Second, in the demonstration, we tested for racial bias. While the proposed approach was designed to be model-agnostic, domain-agnostic, and demographic-agnostic—rather than specifically tailored to detect racial bias in GPT-3.5 and GPT-4 using math MCQs—it remains unknown whether it generalizes to other LLMs, other content domains, or other forms of bias related to different demographic characteristics. Moreover, we tested for racial bias using only female student names. Biased behavior could conceivably differ for male profiles or other demographics (e.g., nationality or socioeconomic status), which represents an area for further inquiry. It is also unclear whether an LLM that exhibits bias in the academic-award scenario demonstrated here would do so in other decision-making contexts. Future research could explore adapting the proposed approach to a broader range of both demographic subgroups and decision-making scenarios (e.g., employment or lending decisions).
Additionally, for the demonstration, we made the strong assumption that the five most White-associated names and the five most Black-associated names serve as reasonable proxies for White and Black individuals more broadly. Yet there may be other plausible associations that an LLM might make between the selected names and certain test performance outcomes. For example, name frequency in the training corpus could lead, through unknown mechanisms, to differential treatment of groups (i.e., if the model saw one set of names more often in training, it might favor or disfavor them for reasons unrelated to race). Since minority groups are less represented in the training data, name frequency might still be associated with differential outcomes across races, but the associations the model makes may not be explicitly racial in character. Future work could include additional name sets or even non-name racial proxies to see if the effect persists, helping to tease out pure racial bias from name-frequency bias.
AI is expected to have a profound effect on nearly every aspect of life and AI systems have performed ably on many standardized tests. Yet, to realize the full promise of this technology, steps must be taken to ensure that AI systems not only succeed at their intended application but that—at a minimum—they do so without reproducing and perpetuating harmful stereotypes or creating new ones. In the case of GPT-3.5, this study contributes to the growing body of research identifying AI systems’ failures to meet this minimum standard. GPT-4, in contrast, appears to have performed this particular judgment task without bias—a result that makes us considerably more optimistic about the potential for these systems to eventually approach this standard. More relevant to the purpose of this paper, the reported differences between GPT-3.5 and GPT-4 suggest that the proposed evaluation is sensitive to differences between these two specific GPT-based LLMs’ tendencies to generate certain types of biased output. However, to reiterate, the purpose of the demonstration was to illustrate how the proposed framework could be applied in practice; the evaluation of GPT-3.5 and GPT-4 was merely one part of this example. Readers are cautioned against generalizing beyond these two models and the specific conditions included in the demonstration.
Many LLMs are designed to imitate human behaviors. And, like many humans, these systems often attempt to conceal socially unacceptable biases (Ouyang et al., 2022). When this occurs, special efforts are needed to provoke the systems into revealing their biases indirectly. The framework described in this paper represents one such effort. However, the need to test these systems for bias remains an ongoing project. Moreover, society’s perceptions of bias are continually evolving; consider, for example, how differently bias was understood 50 years ago. This underscores the fluid nature of bias itself, suggesting that the need for bias detection will likely remain a persistent challenge. The strategy proposed here aims to help address this challenge by offering a straightforward and sensitive approach of detecting bias in LLM outputs through controlled scenario testing. The contrast between GPT-3.5 and GPT-4 in the demonstration illustrates how such an evaluation can both reveal biases and track progress in model debiasing.
Data availability statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author contributions
PB: Conceptualization, Data curation, Formal analysis, Investigation, Methodology, Software, Validation, Writing – original draft, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1. ^The NAEP items used in this study can be found here: https://www.nationsreportcard.gov/nqt/searchquestions by specifying: Subject: Math; Grade: 4; Year: 2011 and 2013; and then entering the following item IDs into the Question Description Search field: M010131, M010831, M091301, M148201, M148401, M148601, M149101, M149401, M149601, M145201, M146001, M146201, M135601, M135801, M136101, M136401, M136701, M137101, M157101, M160001. Item statistics and demographic data for respondents are also available.
2. ^These data can be accessed here: https://dataverse.harvard.edu/dataset.xhtml?persistentId=doi:10.7910/DVN/TYJKEZ
3. ^Names were submitted to GPT-3.5 and GPT-4 with the following prompt: “Below are 10 names. Please identify the race most strongly associated with each name.” GPT-3.5 asserted that Latrice, Lakisha, Latonya, Latoya, and Tameka were “commonly associated with African American individuals,” whereas Patricia, Linda, Susan, Jennifer, and Mary were “more commonly associated with individuals of European descent.” Similar to GPT-3.5, GPT-4 asserted that Latrice, Lakisha, Latonya, Latoya, and Tameka were “strongly associated with African American communities.” However, GPT-4, while still identifying a white association, was somewhat more nuanced with the remaining names: Patricia–Common across racial groups but most strongly associated with White and Hispanic communities, Linda–Most commonly associated with White communities, particularly popular during the mid-20th century, Susan–Most commonly associated with White communities, particularly popular in the mid-20th century, Jennifer–Common across racial groups but most strongly associated with White communities, particularly popular in the 1980s and 1990s, and Mary–Widely used across racial groups, historically most common among White communities due to religious significance.
References
Abramski, K., Citraro, S., Lombardi, L., Rossetti, G., and Stella, M. (2023). Cognitive network science reveals bias in GPT 3, GPT-3.5 turbo, and GPT-4 mirroring math anxiety in high-school students. Big Data Cogn. Comput. 7:124. doi: 10.3390/bdcc7030124
American Educational Research Association American Psychological Association National Council on Measurement in Education (2014). Standards for educational and psychological testing. Washington, DC: American Educational Research Association.
An, J., Huang, D., Lin, C., and Tai, M. (2025). Measuring gender and racial biases in large language models: intersectional evidence from automated resume evaluation. PNAS nexus 4:pgaf089. doi: 10.1093/pnasnexus/pgaf089
Bateni, A., Chan, M. C., and Eitel-Porter, R. (2022). AI fairness: From principles to practice. arXiv. doi: 10.48550/arXiv.2207.09833
Bertrand, M., and Mullainathan, S. (2004). Are Emily and Greg more employable than Lakisha and Jamal? A field experiment on labor market discrimination. Am. Econ. Rev. 94, 991–1013. doi: 10.1257/0002828042002561
Blodgett, S. L., Barocas, S., and DauméIII, H., & Wallach, H. (2020). Language (technology) is power: A critical survey of "bias" in nlp. In: Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. eds. D. Jurafsky, J. Chai, N. Schluter, and J. Tetreault. Association for Computational Linguistics. 5454–5476. doi: 10.18653/v1/2020.acl-main.485
Burchinal, M., McCartney, K., Steinberg, L., Crosnoe, R., Friedman, S. L., McLoyd, V., et al. (2011). Examining the black–white achievement gap among low-income children using the NICHD study of early child care and youth development. Child Dev. 82, 1404–1420. doi: 10.1111/j.1467-8624.2011.01620.x
Caliskan, A., Bryson, J. J., and Narayanan, A. (2017). Semantics derived automatically from language corpora contain human-like biases. Science 356, 183–186. doi: 10.1126/science.aal4230
Campbell, T. (2015). Stereotyped at seven? Biases in teacher judgement of pupils’ ability and attainment. J. Soc. Policy 44, 517–547. doi: 10.1017/S0047279415000227
Deshpande, A., Murahari, V., Rajpurohit, T., Kalyan, A., and Narasimhan, K. (2023). Toxicity in chatgpt: Analyzing persona-assigned language models. In: Findings of the Association for Computational Linguistics: EMNLP. Association for Computational Linguistics. eds. H. Bouamor, J. Pino, & K. Bali 1236–1270. doi: 10.18653/v1/2023.findings‑emnlp.88
Drasgow, F., Nye, C. D., Stark, S., and Chernyshenko, O. S. (2018). “Differential item and test functioning” in The Wiley handbook of psychometric testing: A multidisciplinary reference on survey, scale and test development. Wiley-Blackwell. eds. P. Irwing, T. Booth, and D. Hughes, 885–899.
Ferrara, E. (2023). Should chatGPT be biased? Challenges and risks of bias in large language models. First Monday, 28. doi: 10.5210/fm.v28i11.13346
Gaebler, J. D., Goel, S., Huq, A., and Tambe, P. (2024). Auditing the use of language models to guide hiring decisions. arXiv. doi: 10.48550/arXiv.2404.03086
Gallegos, I. O., Rossi, R. A., Barrow, J., Tanjim, M. M., Kim, S., Dernoncourt, F., et al. (2024). Bias and fairness in large language models: a survey. Comput. Ling. 50, 1097–1179. doi: 10.1162/coli_a_00524
Gohar, U., and Cheng, L. (2023). A survey on intersectional fairness in machine learning: Notions, mitigation, and challenges. In: Proceedings of the Thirty‑Second International Joint Conference on Artificial Intelligence (IJCAI‑23). ed. E. Elkind. International Joint Conferences on Artificial Intelligence Organization. 6619–6627. doi: 10.24963/ijcai.2023/742
Guo, Y., Guo, M., Su, J., Yang, Z., Zhu, M., Li, H., et al. (2024). Bias in large language models: Origin, evaluation, and mitigation. arXiv. doi: 10.48550/arXiv.2411.10915 [Preprint].
Guo, L. N., Lee, M. S., Kassamali, B., Mita, C., and Nambudiri, V. E. (2022). Bias in, bias out: underreporting and underrepresentation of diverse skin types in machine learning research for skin cancer detection—a scoping review. J. Am. Acad. Dermatol. 87, 157–159. doi: 10.1016/j.jaad.2021.06.884
Gupta, V., Venkit, P. N., Wilson, S., and Passonneau, R. J. (2023). Sociodemographic bias in language models: A survey and forward path. In: Proceedings of the 5th Workshop on Gender Bias in Natural Language Processing (GeBNLP). eds. A. Faleńska, C. Basta, M. Costa‑jussà, S. Goldfarb‑Tarrant, and D. Nozza. Association for Computational Linguistics. 295–322. doi: 10.18653/v1/2024.gebnlp-1.19
Hanushek, E. A., and Rivkin, S. G. (2006). Schools, peers, and the black–white achievement gap (NBER working paper no. 12651). Cambridge, MA: National Bureau of Economic Research.
Jencks, C., and Phillips, M. (Eds.) (2011). The black-white test score gap. Washington, DC: Brookings Institution Press.
Katz, D. M., Bommarito, M. J., Gao, S., and Arredondo, P. (2024). GPT-4 passes the bar exam. Phil. Trans. R. Soc. A 382:20230254. doi: 10.1098/rsta.2023.0254
Kellow, J. T., and Jones, B. D. (2008). The effects of stereotypes on the achievement gap: reexamining the academic performance of African American high school students. J. Black Psychol. 34, 94–120. doi: 10.1177/0095798407310537
Merolla, D. M., and Jackson, O. (2019). Structural racism as the fundamental cause of the academic achievement gap. Sociol. Compass 13:e12696. doi: 10.1111/soc4.12696
Messick, S. (1989). “Validity” in Educational measurement. ed. R. L. Linn. 3rd ed (New York: Macmillan), 13–103.
Metz, C. (2022). The new chatbots could change the world. Can you trust them. New York Times. 10. Available at: https://www.nytimes.com/2022/12/10/technology/ai-chat-bot-chatgpt.html
Mihalache, A., Huang, R. S., Popovic, M. M., and Muni, R. H. (2023a). Performance of an upgraded artificial intelligence chatbot for ophthalmic knowledge assessment. JAMA Ophthalmol. 141, 798–800. doi: 10.1001/jamaophthalmol.2023.2754
Mihalache, A., Popovic, M. M., and Muni, R. H. (2023b). Performance of an artificial intelligence chatbot in ophthalmic knowledge assessment. JAMA Ophthalmol. 141, 589–597. doi: 10.1001/jamaophthalmol.2023.1144
Mökander, J., Schuett, J., Kirk, H. R., and Floridi, L. (2024). Auditing large language models: a three-layered approach. AI Ethics 4, 1085–1115. doi: 10.1007/s43681-023-00289-2
Nadeem, M., Bethke, A., and Reddy, S. (2021). StereoSet: Measuring stereotypical bias in pretrained language models. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. eds. C. Zong, F. Xia, W. Li, & R. Navigli. Association for Computational Linguistics. 5356–5371. doi: 10.18653/v1/2021.acl‑long.416
OpenAI (2023a). GPT-3.5 model card. OpenAI. Available online at: https://platform.openai.com/docs/models/gpt-3-5 (Accessed June 25, 2025).
OpenAI (2023b) GPT-4 technical report No. arXiv:2303.08774. Available online at: https://arxiv.org/abs/2303.08774 (Accessed June 25, 2025).
Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., et al. (2022). Training language models to follow instructions with human feedback. Adv. Neural Inf. Proces. Syst. 35, 27730–27744.
Parrish, A., Chen, A., Nangia, N., Padmakumar, V., Phang, J., Thompson, J., et al. (2021). BBQ: A hand-built bias benchmark for question answering. In Findings of the Association for Computational Linguistics: ACL 2022. eds. S. Muresan, P. Nakov, & A. Villavicencio. Association for Computational Linguistics. 2086–2105. doi: 10.18653/v1/2022.findings‑acl.165
Pursnani, V., Sermet, Y., Kurt, M., and Demir, I. (2023). Performance of ChatGPT on the US fundamentals of engineering exam: comprehensive assessment of proficiency and potential implications for professional environmental engineering practice. Comput. Educ. Artif. Intell. 5:100183. doi: 10.1016/j.caeai.2023.100183
Raji, I. D., and Buolamwini, J. (2019). “Actionable auditing: investigating the impact of publicly naming biased performance results of commercial AI products” in Proceedings of the 2019 AAAI/ACM conference on AI, ethics, and society, 429–435.
Ranjan, R., Gupta, S., and Singh, S. N. (2024). A comprehensive survey of bias in llms: Current landscape and future directions. arXiv. doi: 10.48550/arXiv.2409.16430 [Preprint].
Reardon, S. F., Robinson-Cimpian, J. P., and Weathers, E. S. (2014). “Patterns and trends in racial/ethnic and socioeconomic academic achievement gaps” in Handbook Of research in education finance and policy. eds. H. F. Ladd and M. E. Goertz (New York, NY: Routledge), 491–509.
Sandvig, C., Hamilton, K., Karahalios, K., and Langbort, C. (2014). Auditing algorithms: research methods for detecting discrimination on internet platforms. Data Discrimination 22, 4349–4357.
Schwartz, R., Fiscus, J., Greene, K., Waters, G., Chowdhury, R., Jensen, T., et al. (2024). The NIST assessing risks and impacts of AI (ARIA) pilot evaluation plan. Gaithersburg, MD: US National Institute of Standards and Technology.
Schwitzgebel, E., and Cushman, F. (2012). Expertise in moral reasoning? Order effects on moral judgment in professional philosophers and non-philosophers. Mind Lang. 27, 135–153. doi: 10.1111/j.1468-0017.2012.01438.x
Sireci, S. G., and Sukin, T. (2013). “Test validity” in APA handbook of testing and assessment in psychology: Vol. 1. Test theory and testing and assessment in industrial and organizational psychology. ed. K. F. Geisinger (Washington, DC: American Psychological Association), 61–84.
Stevenson, A., and Lindberg, C. A. (2010). New Oxford American dictionary. Lindberg, New York: Oxford University Press. 162.
Taloni, A., Borselli, M., Scarsi, V., Rossi, C., Coco, G., Scorcia, V., et al. (2023). Comparative performance of humans versus GPT-4.0 and GPT-3.5 in the self-assessment program of American Academy of ophthalmology. Sci. Rep. 13:18562. doi: 10.1038/s41598-023-45837-2
Tzioumis, K. (2018). Demographic aspects of first names. Sci Data 5:180025. doi: 10.1038/sdata.2018.25
U.S. Department of Education. (2011) Institute of Education Sciences, National Center for education statistics, National Assessment of educational Progress (NAEP). 2011 mathematics assessment.
U.S. Department of Education. (2013) Institute of Education Sciences, National Center for education statistics, National Assessment of educational Progress (NAEP). 2013 mathematics assessment.
Van den Bergh, L., Denessen, E., Hornstra, L., Voeten, M., and Holland, R. W. (2010). The implicit prejudiced attitudes of teachers: relations to teacher expectations and the ethnic achievement gap. Am. Educ. Res. J. 47, 497–527. doi: 10.3102/0002831209353594
Vanneman, A., Hamilton, L., Anderson, J. B., and Rahman, T. (2009) Achievement gaps: How black and white students in public schools perform in mathematics and reading on the national assessment of educational progress. Statistical analysis report. NCES 2009–455 National Center for Education Statistics, Washington, DC: Institute of Education Sciences, U.S. Department of Education.
Wang, B., Chen, W., Pei, H., Xie, C., Kang, M., Zhang, C., et al. (2023). Decoding trust: a comprehensive assessment of trustworthiness in GPT models. Adv. Neural Inf. Proces. Syst. 36, 31232–31339.
Wang, P., Li, L., Chen, L., Cai, Z., Zhu, D., Lin, B., et al. (2024). Large language models are not fair evaluators. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics. 1, 9440–9450.
Yaneva, V., Baldwin, P., Jurich, D. P., Swygert, K., and Clauser, B. E. (2023). Examining ChatGPT performance on USMLE sample items and implications for assessment. Acad. Med. 99:10-1097. doi: 10.1097/ACM.0000000000005549
Zeng, F. (2023) Evaluating the problem solving abilities of ChatGPT. Master’s thesis, Washington Univ.
Keywords: bias detection, large language models (LLMs), educational assessment, AI fairness, algorithmic bias, audit-style evaluation
Citation: Baldwin P (2025) Audit-style framework for evaluating bias in large language models. Front. Educ. 10:1592037. doi: 10.3389/feduc.2025.1592037
Edited by:
Hope Onyinye Akaeze, Michigan State University, United StatesReviewed by:
Janika Leoste, Tallinn University, EstoniaPatrizio Bellan, Bruno Kessler Foundation (FBK), Italy
Saba Ghanbari Haez, Bruno Kessler Foundation (FBK), Italy
Copyright © 2025 Baldwin. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Peter Baldwin, cGJhbGR3aW5AbmJtZS5vcmc=