 Zhenao Sun
Zhenao Sun Yongshan Shen1
Yongshan Shen1 Zhe Chen
Zhe Chen- 1School of Electrical Engineering, Shenyang University of Technology, Shenyang, China
- 2Department of Energy Technology, Aalborg University, Aalborg, Denmark
- 3School of Electric Power, Shenyang Institute of Engineering, Shenyang, China
The interval prediction of wind speed is crucial for the economic and safe operation of wind farms. To overcome the probability density function parameter optimization and long-term correlation of time series problems in an interval prediction method, a hybrid model based on the beta distribution of an allele real-coded quantum evolutionary algorithm (ARQEA) and a shared weight long short-term memory (SWLSTM) neural network is proposed for predicting the interval of short-term wind speed, which is beta–ARQEA–SWLSTM. Input variables are determined via autocorrelation functions, and the shape and position parameters in the beta distribution function are optimized by the ARQEA algorithm. An interval-divided multi-distribution function aggregation is proposed to deal with the fluctuation of wind speed series. Lastly, case studies are provided to demonstrate the effectiveness of the proposed method.
1 Introduction
Wind power generation differs from traditional fossil power generation methods. The integration of wind power into a power grid is restricted by the uncertainty and intermittency of wind speed. Therefore, to maximize the use rate of wind power, more accurate wind speed prediction is crucial for the control strategy of wind farms (Li et al., 2019; Naik et al., 2019; Li et al., 2020; Gan et al., 2021). This process can simultaneously deal with the indetermination of wind farms and decrease the schedule deflection of power systems (Zhang YX. et al., 2016; Liang et al., 2017; Khosravi et al., 2018; Wang and Li, 2018). A precise wind speed prediction interval (PI) can assist policymakers to control deviations in transmission network planning and dispatching, risk evaluation, and reliability estimation. It is also a key factor to be considered in reducing peak loads, guaranteeing backup capacity, and increasing the safe performance of large-scale wind power generation systems (Wang et al., 2016).
In general, wind speed prediction methods can be divided into two types: point wind speed prediction (PWS) and PI of wind speed (PIWS). Compared with PWS, PIWS can obtain additional upper and lower bounds for the predicted wind speed, which can provide more predictive information. Traditional PWS methods include physical, statistical, and artificial intelligence models. A PWS prediction method is simple in construction and facile to implement in wind farms. However, it is usually difficult to obtain accurate prediction results with this method because of the randomness and intermittent nature of wind resources. Although a lot of studies focus on improving the preciseness of the PWS method and have made some progress, the impact of wind power uncertainty still cannot be solved. For instance, the inhomogeneous distribution of wind farms is affected by local terrain, the nonlinear vibration of wind generators, and machine halts outside the plan (Kiplangat et al., 2016; Li and Jin, 2018; Wang et al., 2018). Therefore, errors occur in wind power prediction, posing risks to grid dispatch. By contrast, PIWS can provide additional forecast information and reduce risks in grid dispatch (Yuan et al., 2017a; Peng et al., 2017); thus, it will improve the understanding of decision-makers on the indeterminacy of wind power fluctuations to avoid potential risks.
In recent years, many studies were conducted on the uncertainties of wind power generation, and PIWS has already been used for many actual items. There are two sorts divisions of the PIWS methods. The first one uses neural networks to directly obtain the upper and lower bounds of PIs. As an instance, the lower bound/upper bound estimation (LUBE) for forecasting wind speed time series is a significant breakthrough in PIWS (Zhang et al., 2016b). The method solves the problem of probability prediction by constructing PIs, wherein an interval is represented by upper and lower estimates. However, the LUBE cannot deal with the fluctuation as an indetermination in wind speed time series. Another interval prediction method involves estimating PIs on the basis of the probability density of a point prediction result. To determine the uncertainty of wind speed, it is necessary to construct the probability density curve of prediction results, which requires the probability density prediction method. This can provide accurate prediction information on power system operation through this curve.
The preciseness of the wind speed probability distribution function (PDF) is determined by the selected approaches and the prediction error level, because the key factor of PIWS estimation is the PDF of forecasting error (Allen et al., 2017; Naik et al., 2018; Zhao et al., 2018). A shared weight long short-term memory (SWLSTM) neural network can decrease the variable number that should be optimized (Zhang et al., 2019). It also exhibits the advantages of nonlinear prediction, fast convergence, and the capability to capture the long-term correlations of the time series. At present, the SWLSTM model has been applied for wind speed prediction. Previous studies have shown that wind speed time series demonstrate long-term memory characteristics. The present study adopts the SWLSTM model as the basis for wind speed prediction. In addition, normal or Laplace distribution functions and beta distribution functions are also widely used as PDFs in the field of PIWS. Among them, the beta distribution is more effective in estimating the PIWS than the normal distribution and Laplace distribution (Ren et al., 2016). The beta distribution is selected as the basis of the PIWS in the present study consequently.
In this study, to improve the accuracy of wind speed, a new hybrid method based on the SWLSTM model and beta–ARQEA algorithm is proposed, which combines methods of artificial intelligence and statistics. The main contributions are listed as follows in four parts:
1) The SWLSTM model is applied to wind speed prediction. The partial autocorrelation function is adopted to determine the input variables of the SWLSTM model to reduce the prediction error.
2) The real-coded quantum evolutionary algorithm (ARQEA) of alleles (Zhang et al., 2016c) is adopted to optimize the shape and position parameters in the beta distribution function for selecting the appropriate distribution function to fit the wind speed prediction error obtained by the SWLSTM model.
3) The entire wind speed time series are divided into plenty of intervals per error distribution to improve the prediction accuracy of PIWS methods.
4) The optimized parameters of different distribution functions are utilized to fit the prediction error of each wind speed interval, then confirm the confidence interval of the wind speed series, and superimpose them to get the PI of the entire wind speed. The PIWS based on beta–ARQEA–SWLSTM achieves higher reliability and narrower interval bandwidth.
Eventually, the PI of the entire wind speed series is acquired by superimposing the confidence interval of each wind speed level. Therefore, the PIWS based on beta–ARQEA–SWLSTM achieves higher reliability and narrower interval bandwidth.
The rest part of this study is as follows: a review of the principle of an SWLSTM neural network is shown in Section 2. Section 3 presents the key theory of ARQEA optimization parameters based on beta distribution and discusses how to use it to calculate confidence intervals. The PIWS process with the beta–ARQEA−SWLSTM model is introduced in section 4. Section 5 contains a case study and result analysis. Section 6 provides the conclusion drawn from the study.
2 SWLSTM Neural Network
The SWLSTM model is a special artificial intelligence model. It keeps the characteristics of the recurrent neural network model, which can make use of a series of memory cells to deal with the arbitrary input data and enhance the learning process of the time series. In addition, the SWLSTM model can capture the long-term dependence of the input data to prevent the gradient disappearing from information transmission, which enhances its capacity to capture the dynamic changes of the time series.
In SWLSTM, a new type of shared gate is proposed, which is composed of input, output, and forget gate. The network structure is shown in Figure 1. SWLSTM does not change the gate structure of the standard long short-term memory (LSTM), but shares the weight and bias of the gate structure. The advantages of SWLSTM are reducing the number of variables that must be optimized and shortening the training time (Zhang et al., 2019).
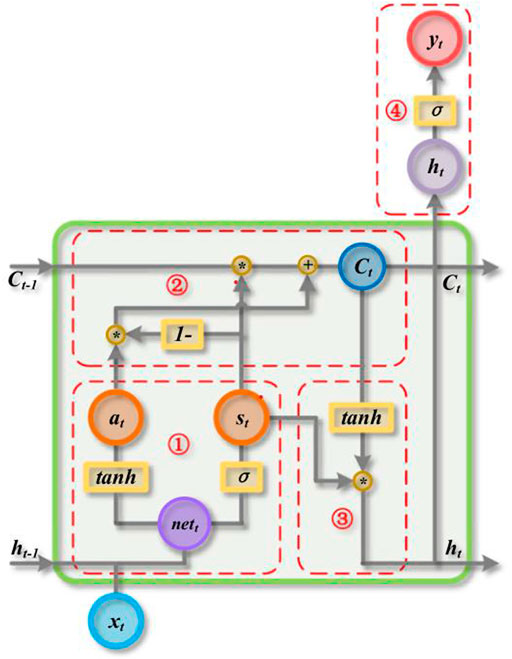
FIGURE 1. Schematic of the SWLSTM network structure.
As shown in Figure 1, the shared gate in the SWLSTM model has an inherent relationship with the time series, of which the purpose is to ensure that the training results often tend to be the new input information. Hence, training the time series model by the SWLSTM model has some advantages.
The hyperparameters of the SWLSTM model are shown in Table 1.
TABLE 1. Hyperparameters of the SWLSTM model.
In Figure 1,
SWLSTM has two stages: forward propagation and back-propagation. The process of forward propagation of SWLSTM in the tth cycle is discussed as follows.
1) Calculate the shared gate state and calculate the information gate state:
2) Update the cell state:
3) Calculate the output of the hidden layer:
4) Output predicted value of the output layer:
In the preceding formula and figure, t represents the current cycle,
The process of error back-propagation in the tth cycle of the SWLSTM is discussed as follows.
1) Use the squared error function as the optimization objective:
2) Calculate the error of variables in the output layer:
3) Calculate the error of variables in the hidden layer:
The shared gates in SWLSTM reserve the functions of the three gates in the LSTM and still have the ability to discard useless historical information and keep current useful information. Coupling the input and forget gates simplified the LSTM without significantly decreasing the performance. Activation functions Sigmoid and tanh are retained in the SWLSTM. These two points indicate that the SWLSTM does not significantly reduce the prediction accuracy.
3 Estimation of Random Samples Based on the Beta–ARQEA Model
Considering the optimization problem of probability density function parameters in interval prediction methods, to find the appropriate distribution function for fitting prediction errors of wind speed obtained by the SWLSTM model, the present study uses random sample estimation based on the beta–ARQEA model. The position parameters in the beta distribution function are optimized by using ARQEA. The beta distribution is expressed for a random sample
where
Using ARQEA to find the optimal parameters of the beta distribution function can further improve the precision of the beta distribution model.
Allele real-coding for beta position parameters is as follows (Zhang YX. et al., 2016):
where
1) The “better gene”
where
2) For the “poor gene”
where
The “better gene” and the “poor gene” perform local search and global search, respectively. A hybrid evolution strategy is developed when the two genes are transformed into each other, enhancing the balance between the local search and global search of the algorithm.
To evaluate the performance of the beta distribution model, the approximate index
where
According to Eq. 18, the fitness function of the beta distribution optimization model and its constraints can be obtained as follows:
where
To obtain the PDF of beta–ARQEA, we calculate the histogram of the frequency distribution of the sample
After obtaining the PDF, the distribution function
Presume the confidence level is
Then, we can obtain the confidence interval
4 PIWS Estimation Based on the Beta–ARQEA–SWLSTM Model
Since the SWLSTM’s point prediction accuracy is high and beta–ARQEA’s probability prediction results are reliable, SWLSTM and beta–ARQEA are combined to obtain high-precision point prediction, high-reliability interval prediction, and probability prediction. The wind speed PI implementation process based on the beta–ARQEA–SWLSTM model can be shown as follows:
Step 1: Divide the wind speed historical data into training dataset
Step 2:
Step 3: The PACF of
Step 4:
Step 5:
Step 6: The errors between
Step 7: The predicted data
Step 8: Wind speed prediction values and their forecasting errors under each wind speed level are statistics. The values and errors are denoted as
Step 9: Input
Step 10: The wind speed series PI of every level, which can be represented as
Step 11: The entire wind speed series PI consists of each wind speed level.
Wind speed PI implementation based on the beta–ARQEA–SWLSTM is shown in Figure 2.
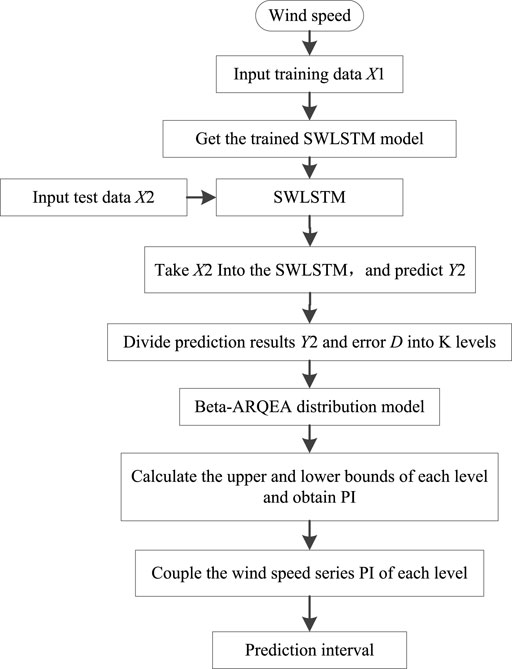
FIGURE 2. Wind speed PI implementation based on beta–ARQEA–SWLSTM.
5 Case Study
5.1 Wind Speed Series Data
In the current study, the wind speed series data of a wind farm in Jilin, China, are used. The wind speed series data in April 2018 were selected, which were measured and recorded by the wind tower. The step of wind speed series data is 15 min. The model of the wind turbine used in the wind farm is S82–1.5, the rated wind speed is 13 m/s, and the cut-in wind speed and the cut-out wind speed are 4 m/s and 20 m/s, respectively. To verify the performance of the model, four datasets are selected for testing, one of which is shown in Figure 3. Each dataset uses a data length of 7 days consisting of 672 wind speed time series. Take approximately 80% of the data from every set as a training set and take the remaining portion as a validation set. The training set is used to calibrate the parameters of the beta–ARQEA–SWLSTM model and the validation set is used to verify the performance of the beta–ARQEA–SWLSTM model for the prediction interval of wind speed.
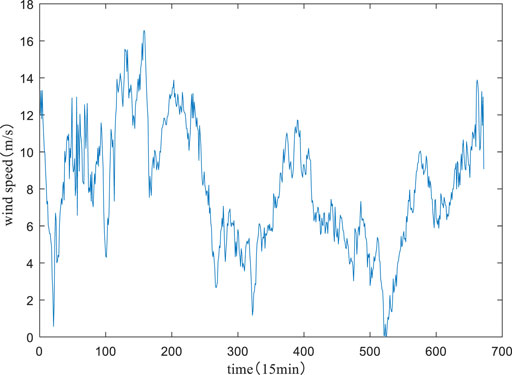
FIGURE 3. Dataset of wind speed.
5.2 Evaluation Criteria
5.2.1 Evaluation Criteria of PIWS
To evaluate the performance of different models, these indicators are selected to verify the effectiveness of the PI model: PI coverage probability (
To clarify the definition, the ith measured value is represented by
where
The average bandwidth
At the same confidence level, a smaller
If the interval width
The
In accordance with the concept of sharpness, the quality of the PI opposite to
Here, sharpness
Here, a smaller
5.2.2 Probability Prediction Evaluation Indicator
To verify the certainty, ensemble, and probability prediction, the comprehensive evaluation indicator of prediction performance, namely the continuous sorting probability score (
where
5.2.3 Reliability Evaluation Indicator
Reliability is the statistical consistency between forecasting and observations. Probabilistic integral transformation (
To check whether the
5.3 Results and Analysis
To verify the effectiveness of the method proposed in this research, beta–ARQEA–SWLSTM is compared with other wind speed prediction methods in terms of point prediction accuracy, PI suitability, and probability prediction comprehensive performance. Then, the reliability of beta–ARQEA–SWLSTM is verified.
1) Point prediction results of wind speed.
To test the point forecasting accuracy of the method, the beta–ARQEA–SWLSTM model is applied for wind speed forecasts. The results are shown in Figure 4.
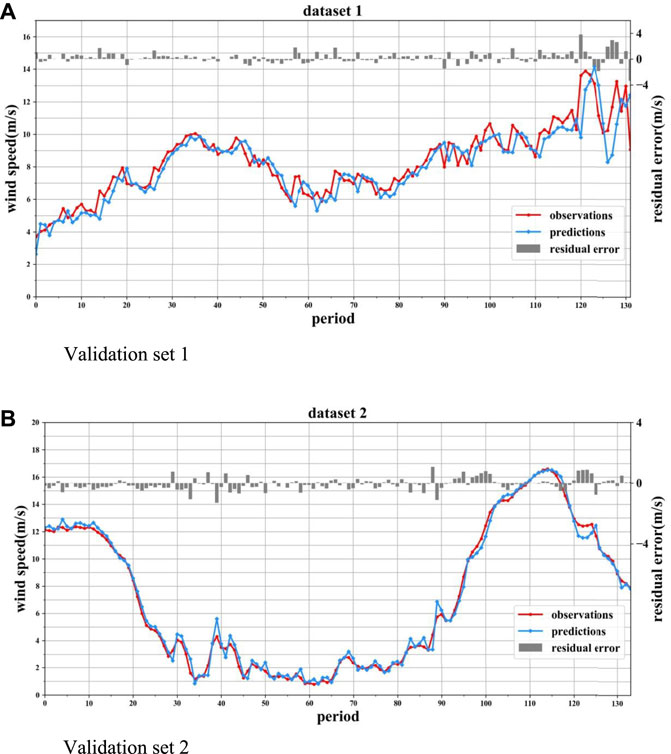
FIGURE 4. Wind speed prediction results for validation sets 1 and 2. (A) Validation set 1. (B) Validation set 2.
It can be seen from Figure 4 that the wind speed forecasted values of the SWLSTM model is near the observed values. The PDF is difficult to fit all the wind speed forecasting errors, so we partition the wind speed into 10 wind speed grades following the predicted value. The grade gap of wind speed is 0.1

TABLE 2. Fitting indicators in each wind speed grade of the four models.
When the results of each distribution model in Table 2 are compared with that of the beta–ARQEA distribution model, the fitting indicator
2) Interval estimation of wind speed.
The interval estimation of wind speed is to verify the suitability of beta–ARQEA–SWLSTM. The wind speed PI results obtained from beta–ARQEA–SWLSTM are shown in Figure 5.
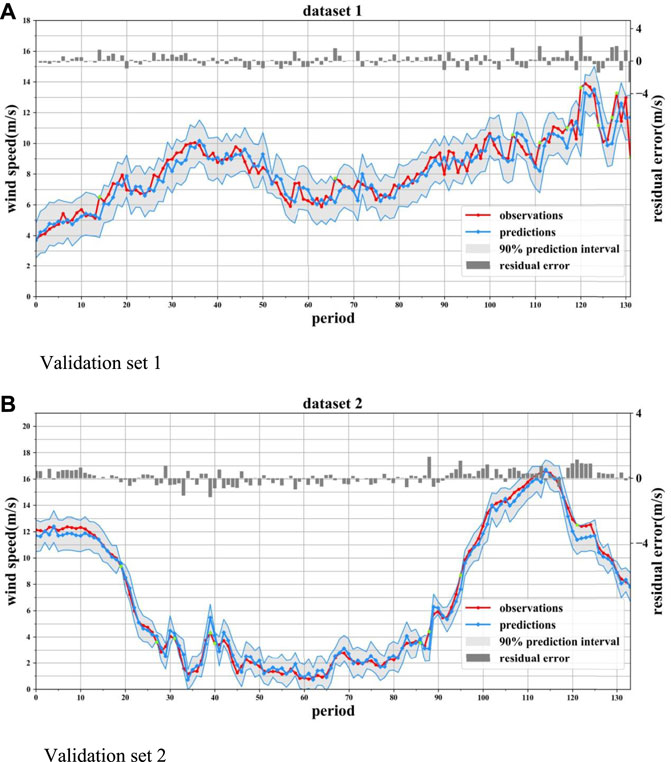
FIGURE 5. Wind speed PI at 90% confidence level. (A) Validation set 1. (B) Validation set 2.
It can be seen from Figure 5 that the PI adopting the beta–ARQEA–SWLSTM model basically contains all the actual wind speed data. The little green dots in Figure 5 are the points at which the observation exceeds the prediction interval of beta–AEQEA–SWLSTM. The performance indicators of four models are computed and compared to verify the superiority of the beta–ARQEA–SWLSTM model. The results are shown in Table 3.
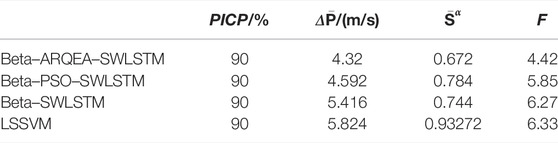
TABLE 3. Performance of the compared PIWS models.
As indicated in Table 3, the coverage rate of each model reached 90%. When the coverage rate reaches the standard, the interval width is represented by
3) Probability prediction results.
To verify the entire performance of the PDF of each model, probability prediction evaluation is applied. The
4) Verification of beta–ARQEA–SWLSTM reliability.
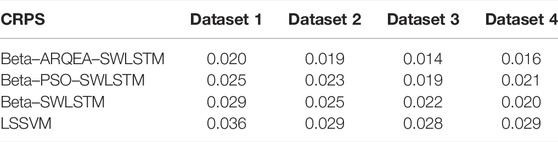
TABLE 4. Probability prediction metrics in each dataset.
To guarantee that the prediction results of beta–ARQEA–SWLSTM are convincing, the reliability evaluation is essential. If the prediction results are reliable, then the

FIGURE 6. Reliability test of beta–ARQEA–SWLSTM. (A) Validation set 1. (B) Validation set 2.
As can be seen from Figure 6, the
To summarize, compared with other models, the proposed hybrid model has higher accuracy, coverage rate and reliability in wind speed point prediction, interval estimation, probability prediction and reliability evaluation, and can provide higher quality wind speed prediction interval and more accurate results.
6 Conclusion
To achieve the goal of “carbon peaking, carbon neutralization,” clean and renewable wind energy is very important. Accurate wind speed prediction is crucial for the smooth operation of wind turbines and improving their connection to grids. A new hybrid method based on the ARQEA algorithm and beta–SWLSTM model is proposed to improve the accuracy of wind speed prediction and the convergence speed. Compared with the traditional PIWS method, the hybrid model retains functionality while being able to capture the long-term correlations of the time series. The intervals of the wind speed time series are divided by the error distribution, which enables the hybrid model to obtain a PDF with higher reliability and narrower interval bandwidth.
The proposed method is applied on a wind farm in Jilin, China, to verify its effectiveness on wind speed forecasting. In order to accurately verify the applicability of point prediction, interval prediction, and the reliability of probability prediction, six reference indexes of
The beta distribution is considered in the proposed model. However, for the wind power prediction problem, other distributions such as the Gaussian distribution may have a better performance for different scenarios. In future, more wind farms in different geographical conditions and more probability distribution hypotheses will be testified.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material; further inquiries can be directed to the corresponding author.
Author Contributions
ZS was responsible for the specific work of this manuscript. XQ and YS carried out some of the calculation work. ZC and YT guided the work of this manuscript.
Funding
The authors acknowledge the funding of the National Key Research and Development Plan (2017YFB0902100).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors, and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Alessandrini, S., Delle Monache, L., Sperati, S., and Cervone, G. (2015). An Analog Ensemble for Short-Term Probabilistic Solar Power Forecast. Appl. Energy 157, 95–110. doi:10.1016/j.apenergy.2015.08.011
Allen, D. J., Tomlin, A. S., Bale, C. S. E., Skea, A., Vosper, S., and Gallani, M. L. (2017). A Boundary Layer Scaling Technique for Estimating Near-Surface Wind Energy Using Numerical Weather Prediction and Wind Map Data. Appl. Energy 208, 1246–1257. doi:10.1016/j.apenergy.2017.09.029
Gan, Z., Li, C., Zhou, J., and Tang, G. (2021). Temporal Convolutional Networks Interval Prediction Model for Wind Speed Forecasting. Electr. Power Syst. Res. 191. doi:10.1016/j.epsr.2020.106865
Khosravi, A., Koury, R. N. N., Machado, L., and Pabon, J. J. G. (2018). Prediction of Wind Speed and Wind Direction Using Artificial Neural Network, Support Vector Regression and Adaptive Neuro-Fuzzy Inference System. Sustain. Energy Technol. Assessments 25, 146–160. doi:10.1016/j.seta.2018.01.001
Kiplangat, D. C., Asokan, K., and Kumar, K. S. (2016). Improved Week-Ahead Predictions of Wind Speed Using Simple Linear Models with Wavelet Decomposition. Renew. Energy 93, 38–44. doi:10.1016/j.renene.2016.02.054
Li, C., Tang, G., Xue, X., Saeed, A., and Hu, X. (2020). Short-Term Wind Speed Interval Prediction Based on Ensemble GRU Model. IEEE Trans. Sustain. Energy 11 (3), 1370–1380. doi:10.1109/tste.2019.2926147
Li, F., Ren, G., and Lee, J. (2019). Multi-step Wind Speed Prediction Based on Turbulence Intensity and Hybrid Deep Neural Networks. Energy Convers. Manag. 186, 306–322. doi:10.1016/j.enconman.2019.02.045
Li, R., and Jin, Y. (2018). A Wind Speed Interval Prediction System Based on Multi-Objective Optimization for Machine Learning Method. Appl. Energy 228, 2207–2220. doi:10.1016/j.apenergy.2018.07.032
Liang, J., Yuan, X., Yuan, Y., Chen, Z., and Li, Y. (2017). Nonlinear Dynamic Analysis and Robust Controller Design for Francis Hydraulic Turbine Regulating System with a Straight-Tube Surge Tank. Mech. Syst. Signal Process. 85, 927–946. doi:10.1016/j.ymssp.2016.09.026
Liu, Y., Ye, L., Qin, H., Hong, X., Ye, J., and Yin, X. (2018). Monthly Streamflow Forecasting Based on Hidden Markov Model and Gaussian Mixture Regression. J. Hydrology 561, 146–159. doi:10.1016/j.jhydrol.2018.03.057
Naik, J., Dash, P. K., and Dhar, S. (2019). A Multi-Objective Wind Speed and Wind Power Prediction Interval Forecasting Using Variational Modes Decomposition Based Multi-Kernel Robust Ridge Regression. Renew. Energy 136, 701–731. doi:10.1016/j.renene.2019.01.006
Naik, J., Dash, S., Dash, P. K., and Bisoi, R. (2018). Short Term Wind Power Forecasting Using Hybrid Variational Mode Decomposition and Multi-Kernel Regularized Pseudo Inverse Neural Network. Renew. Energy 118, 180–212. doi:10.1016/j.renene.2017.10.111
Peng, T., Zhou, J., Zhang, C., and Zheng, Y. (2017). Multi-step Ahead Wind Speed Forecasting Using a Hybrid Model Based on Two-Stage Decomposition Technique and AdaBoost-Extreme Learning Machine. Energy Convers. Manag. 153, 589–602. doi:10.1016/j.enconman.2017.10.021
Ren, Y., Suganthan, P. N., and Srikanth, N. (2016). A Novel Empirical Mode Decomposition with Support Vector Regression for Wind Speed Forecasting. IEEE Trans. Neural Netw. Learn. Syst. 27, 1793–1798. doi:10.1109/tnnls.2014.2351391
Tang, G., Wu, Y., Li, C., Wong, P. K., Xiao, Z., and An, X. (2020). A Novel Wind Speed Interval Prediction Based on Error Prediction Method. IEEE Trans. Ind. Inf. 16 (11), 6806–6815. doi:10.1109/tii.2020.2973413
Tasnim, S., Rahman, A., Oo, A. M. T., and Haque, M. E. (2018). Wind Power Prediction in New Stations Based on Knowledge of Existing Stations: a Cluster Based Multi Source Domain Adaptation Approach. Knowledge-Based Syst. 145, 15–24. doi:10.1016/j.knosys.2017.12.036
Wang, J., and Li, Y. (2018). Multi-step Ahead Wind Speed Prediction Based on Optimal Feature Extraction, Long Short Term Memory Neural Network and Error Correction Strategy. Appl. Energy 230, 429–443. doi:10.1016/j.apenergy.2018.08.114
Wang, J., Song, Y., Liu, F., and Hou, R. (2016). Analysis and Application of Forecasting Models in Wind Power Integration: A Review of Multi-Step-Ahead Wind Speed Forecasting Models. Renew. Sustain. Energy Rev. 60, 960–981. doi:10.1016/j.rser.2016.01.114
Wang, L., Li, X., and Bai, Y. (2018). Short-term Wind Speed Prediction Using an Extreme Learning Machine Model with Error Correction. Energy Convers. Manag. 162, 239–250. doi:10.1016/j.enconman.2018.02.015
Yu, X., Zhang, W., and Zang, H. (2018). Wind Power Interval Forecasting Based on Confidence Interval Optimization. Energies 11 (12), 33–36. doi:10.3390/en11123336
Yuan, X., Chen, C., Jiang, M., and Yuan, Y. (2019). Prediction Interval of Wind Power Using Parameter Optimized Beta Distribution Based LSTM Model. Appl. Soft Comput. 82, 105550. doi:10.1016/j.asoc.2019.105550
Yuan, X., Tan, Q., Lei, X., Yuan, Y., and Wu, X. (2017a). Wind Power Prediction Using Hybrid Autoregressive Fractionally Integrated Moving Average and Least Square Support Vector Machine. Energy 129, 122–137. doi:10.1016/j.energy.2017.04.094
Yuan, X., Tan, Q., Lei, X., Yuan, Y., and Wu, X. (2017b). Wind Power Prediction Using Hybrid Autoregressive Fractionally Integrated Moving Average and Least Square Support Vector Machine. Energy 129, 122–137. doi:10.1016/j.energy.2017.04.094
Zhang, C., Wei, H., Zhao, J., Liu, T., Zhu, T., and Zhang, K. (2016b). Short-term Wind Speed Forecasting Using Empirical Mode Decomposition and Feature Selection. Renew. Energy 96, 727–737. doi:10.1016/j.renene.2016.05.023
Zhang, C., Wei, H., Zhao, X., Liu, T., and Zhang, K. (2016c). A Gaussian Process Regression Based Hybrid Approach for Short-Term Wind Speed Prediction. Energy Convers. Manag. 126, 1084–1092. doi:10.1016/j.enconman.2016.08.086
Zhang, Y. X., Qian, X. Y., Peng, H. D., and Wang, J. H. (2016a). An Allele Real-Coded Quantum Evolutionary Algorithm Based on Hybrid Updating Strategy. Comput. Intell. Neurosci. 2016, 9891382. doi:10.1155/2016/9891382
Zhang, Y., Zhao, Y., Pan, G., and Zhang, J. (2020). Wind Speed Interval Prediction Based on Lorenz Disturbance Distribution. IEEE Trans. Sustain. Energy 11 (2), 807–816. doi:10.1109/tste.2019.2907699
Zhang, Z., Ye, L., Qin, H., Liu, Y., Wang, C., Yu, X., et al. (2019). Wind Speed Prediction Method Using Shared Weight Long Short-Term Memory Network and Gaussian Process Regression. Appl. Energy 247 (AUG.1), 270–284. doi:10.1016/j.apenergy.2019.04.047
Keywords: wind speed, interval prediction, SWLSTM, beta distribution, ARQEA optimization
Citation: Sun Z, Shen Y, Chen Z, Teng Y and Qian X (2022) Interval Prediction Method for Wind Speed Based on ARQEA Optimized by Beta Distribution and SWLSTM. Front. Energy Res. 10:927260. doi: 10.3389/fenrg.2022.927260
Received: 24 April 2022; Accepted: 27 May 2022;
Published: 05 July 2022.
Edited by:
Jun Liu, Xi’an Jiaotong University, ChinaReviewed by:
Xing Lu, Texas A&M University, United StatesGiuseppe Ciaburro, Università della Campania, Italy
Copyright © 2022 Sun, Shen, Chen, Teng and Qian. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhenao Sun, c3phX2RrQDE2My5jb20=