
 Gilles Paradis2,3,4
Gilles Paradis2,3,4
- 1University Hospital Center, Institute of Social and Preventive Medicine (IUMSP), University of Lausanne, Lausanne, Switzerland
- 2Department of Epidemiology, Biostatistics, and Occupational Health, McGill University, Montreal, QC, Canada
- 3McGill University Health Center Research Institute, Montreal, QC, Canada
- 4Public Health Institute of Quebec, Montreal, QC, Canada
Analyzing the relationship between the baseline value and subsequent change of a continuous variable is a frequent matter of inquiry in cohort studies. These analyses are surprisingly complex, particularly if only two waves of data are available. It is unclear for non-biostatisticians where the complexity of this analysis lies and which statistical method is adequate. With the help of simulated longitudinal data of body mass index in children, we review statistical methods for the analysis of the association between the baseline value and subsequent change, assuming linear growth with time. Key issues in such analyses are mathematical coupling, measurement error, variability of change between individuals, and regression to the mean. Ideally, it is better to rely on multiple repeated measurements at different times and a linear random effects model is a standard approach if more than two waves of data are available. If only two waves of data are available, our simulations show that Blomqvist’s method – which consists in adjusting for measurement error variance the estimated regression coefficient of observed change on baseline value – provides accurate estimates. The adequacy of the methods to assess the relationship between the baseline value and subsequent change depends on the number of data waves, the availability of information on measurement error, and the variability of change between individuals.
Introduction
Analyzing the relationship between the baseline value and subsequent change of a continuous variable is a frequent matter of inquiry in cohort studies. For instance, researchers may want to estimate what is the average expected body mass index (BMI) change in children considering their initial BMI: if BMI is elevated, will the subsequent change in BMI be larger or smaller than if BMI is initially low? Is there a differential baseline effect on change (1– 3)? Baseline BMI is typically positively associated with subsequent change in BMI in children from age 5 and above (4). In the study of such relationship, the fundamental goal is to estimate the association between the true initial value of the variable of interest and true subsequent change (5, 6). However, the observed values may not correspond to the true (unobservable) values and observed change may not correspond to true change. How can the relationship be properly assessed with minimum bias using observed values?
It is important here to distinguish two questions: one is how to estimate to which extent change is related to the initial value; the other is how to estimate change in a variable of interest in relation to other variables, given the initial value of the variable of interest. The latter question has been extensively addressed in previous reviews (7– 10). In this tutorial style paper, our aim is to address the former question. Previous reviews on this topic were quite technical and sometimes highly conflicting in their conclusions (1, 2, 11– 16). As a result, it remains often unclear for non-biostatisticians where the complexity of this analysis lies and which statistical method is adequate to properly address this question, especially when only two waves of data are available. Therefore, with the help of simulated longitudinal data of BMI in children, we review methods for the analysis of the association between baseline value and change of a continuous variable in cohort studies.
The Problem
Let’s suppose a cohort of subjects for whom the continuous random variable Y has been measured twice during follow-up. Y1 and Y2 are the true values of Y at initial and follow-up time, respectively. Due to within-subject short-term biological variability and imperfect measurement methods, there is some measurement error in the estimate of Y1 and Y2 (see Glossary). Hence, U1 and U2 are the observed value of Y1 and Y2: U1 = Y1 + E1 and U2 = Y2 + E2, where E1 and E2 are independent random measurement errors. The observed change is U2 − U1.
It appears trivial to estimate the association between the baseline value and subsequent change, e.g., by the regression of U2 − U1 on U1 or by the correlation between U2 − U1 and U1. However, these methods result in a negatively biased estimate (1, 11– 16). For instance, a strong and inverse association between the initial BP level and subsequent BP change was reported in many trials of antihypertensive drugs, leading to conclusion that drugs were more potent among patients with very high level of BP (15). The inverse association disappeared when apparently appropriate statistical analyses were used (15).
Assessing the genuine association between baseline value and subsequent change of a continuous variable is complex, especially if only two waves of data are available. Mathematical coupling, measurement error, variability of change between individuals, and regression to the mean are interrelated concepts which need to be addressed to better understand issues at stake in such analyses (see Glossary) (17– 22).
The observed correlation between the initial value (U1) and change (U2 − U1) results in part from the mathematical coupling between the two terms (2, 23– 25). Mathematical coupling occurs when one variable is part of another (24, 25). It is a common problem in physiology where correlations are assessed between variables that are calculated using a common set of measured variables (22, 24). The calculated variables share a common source of variation which introduces a relation between the variables that has no physiological basis (22, 23). A separated problem is that any error in the measurement of the shared component creates a coupling of errors between the coupled variables (23).
In our case, U1 and U2 − U1 share the common variable U1. If we suppose that U1 and U2 are two independent random variables with identical variance, it can be shown that the observed correlation between U1 and U2 − U1 is −1/√2 (13) (for the derivation, see Appendix). In this case, Y1 and Y2 are not correlated. In general and in the simulations below, Y1 and Y2 are not independent variables and are correlated. The correlation is often positive, between 0 and 1, but rarely attains 1 because perfect correlation would only occur if every individual underwent exactly the same (true) change, which is not the case in general (2). Indeed, there is some variability of true change between individuals. Regression to the mean is the expression of imperfect correlation between repeated measures (19– 21) (see Glossary). The lower the correlation between Y1 and Y2, the larger is the effect of mathematical coupling (25), the greater is the amount of regression to the mean, and the larger is the impact on the correlation between U1 and U2 − U1. Error in the measurement of Y1 and Y2 is also associated with a low correlation between U1 and U2 and has an impact on the correlation between U1 and U2 − U1.
How to Assess the Association between the Baseline Value and Subsequent Change?
If more than two measures per individual are available, the linear random effects model or individual growth curve modeling (see Glossary) is a standard method to assess the relationship between change in a continuous variable and its correlates, including the baseline level (28, 35, 36).
Linear random effects model cannot be used with two waves of data. In such a case, the pattern of changes in the spread of the data during follow-up may help to reveal the existence of an association between the baseline value and subsequent change (1, 13, 26, 27). The variance may not change if there is no association between baseline and change (Figure 1A). If there is an association, the variance may either increase (positive association, increasing spread of the data) or decrease (negative association, decreasing spread of the data) (Figures 1B,C). For example, the increasing spread of BMI during childhood may suggest that having a high BMI early in childhood is associated with a larger BMI gain in the following years (4, 28). The pattern of individual time paths showing positive correlation between initial value and subsequent change is called fan spread (29). A variance ratio test exists to test for the equivalence of variance between two correlated variables (30). While comparing variance is intuitively appealing, it is misleading in many situations. For instance, if there are large between-individual differences in change of the variable of interest during follow-up, variance can increase even if there is no association between baseline and subsequent change (Figure 1D) (29).
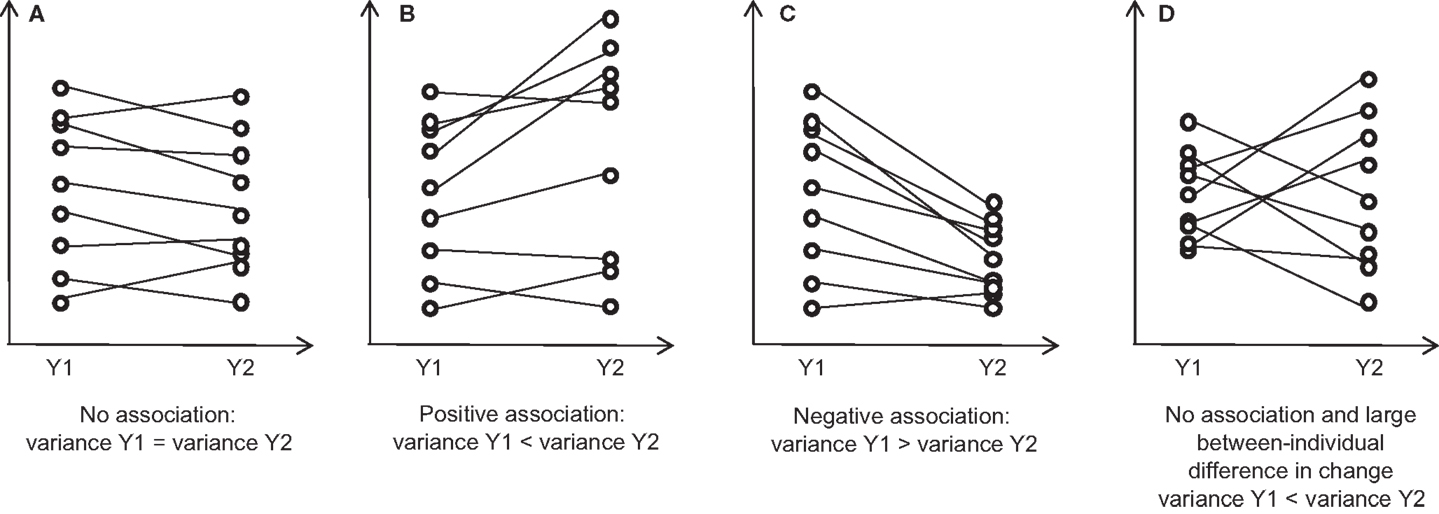
Figure 1. Each panel shows the spread (to illustrate the variance) of a continuous variable Y measured at initial (Y1) and follow-up (Y2) times under various assumptions. “True” values are shown (without measurement error). (A) If there is no association between Y1 and subsequent change (Y2 − Y1), the spread may remain constant during follow-up; (B) If there is a positive association, the spread may increase during follow-up; (C) If there is a negative association, the spread may decrease during follow-up; (D) If there is no association and a large between-individual difference in change, the spread may increase during follow-up.
Oldham proposed more than 50 years ago assessing the association between U2 − U1 and the average (U1 + U2)/2, rather than between U2 − U1 and U1 (31, 32). Due to random error, the initial measure U1 is merely an imperfect surrogate for an unobservable true baseline level Y1 and the average may be a better indicator of the true level of Y. Furthermore, the difference in the random errors of U1 and U2 is uncorrelated with their average. Nevertheless, this method allows the unbiased estimation of a different statistic, that is, of the correlation between change and the value at the mid-time point between Y1 and Y2, but not of the correlation between change and the value at baseline.
To avoid correlated errors due the mathematical coupling between U1 and U2 − U1, one may assess the association between U2 − U1 and another measure obtained relatively close in time to U1 (16), e.g., a repeated measure U1bis. While this method avoids some bias inherent to the estimate obtained by the crude association, the estimate tends to be biased toward the null due to the measurement error on U1bis, i.e., a regression dilution bias (see Glossary) (33).
Blomqvist proposed another method which consists in adjusting the estimated regression coefficient of change on baseline value accounting directly for measurement error (5, 6, 34). This method requires accurate information on the variance of measurement error: the ratio of measurement error variance to total variance is used to make a correction of the crude estimate of the regression or correlation coefficient [adjusted regression coefficient = (crude regression coefficient + k)/(1 − k), with k = variance of measurement error/total variance; see also below].
These methods listed in Table 1 can result in different estimates of the association between baseline value and subsequent change, and they cannot be used in all contexts. To assess the strengths and weaknesses of these methods, we applied each of them to examine the association between baseline value and subsequent change of BMI to simulated data of a cohort of children.

Table 1. Methods to assess the association between the baseline value and subsequent changes of a continuous variable.
Simulations
Scenarios
We simulated a cohort study of 500 children randomly selected from the general population who underwent BMI measurement each year between the ages of 5 and 10. We assumed that each child’s true BMI followed an individual linear growth with time with a specific initial true BMI (intercept) at the age of 5 and a specific rate of change (slope) between the ages of 5 and 10. At the population level, intercept and slope are random variables. Their distribution reflects between-individual variability in the true initial BMI and true change.
First, we simulated data following a “realistic” scenario, i.e., with BMI changes throughout time close to what would be observed in real life (4, 28). At the initial time (age 5), the mean true BMI was 15.0 kg/m2 (SD: 1.2) (normal distribution). True BMI changed at a mean rate of +0.4 kg/m2 per year between the ages of 5 and 10. The true BMI change varied between children (SD of yearly change: 0.2) and was positively associated with baseline level (correlation: +0.6). Using these parameters in a linear random effects regression model (Glossary), we simulated true BMI values at ages 5, 6, 7, 8, 9, and 10. Observed BMI values were computed by adding a relatively small random measurement error (SD of error: 0.3) to the true BMI values. Because error occurs at random, the means of errors are zero and the means of observed values are close to the mean of true values. Second, we simulated data along alternative scenarios, including a larger measurement error (SD: 1.2) and a larger between-individual variability in true yearly change (SD of yearly change: 0.4). Each simulation was repeated 1000 times.
Analyses
We first compared changes in the spread (SD) of measured BMI at the beginning of follow-up at age 5 (initial value: U1) and at the end of the follow-up at age 10 (U2) for each scenario. Second, we estimated the association between baseline (Y1) and change (Y2 − Y1) using the methods described in Table 1 including:
(1) Linear random effects modeling method (29, 35): we fitted a linear random effects regression model of BMI on age using all available data, i.e., measured BMI at ages 5, 6, 7, 8, 9, and 10. We assessed the correlation rrandom between the random coefficient of the slope and the random coefficient of the intercept;
(2) Crude method: we assessed the correlation rcrude between U2 − U1 (at initial time and at age 10) and U1 (at initial time);
(3) Oldham’s method (31): we assessed the correlation rOldham between U2 − U1 (at initial time and at age 10) and (U1 + U2)/2;
(4) Repeated measurement method (16): we assessed the correlation rrepeated between U2 − U1 (at initial time and at age 10) and U1bis (at initial time), which is a simulated repeated measurement of Y at the initial time;
(5) Blomqvist’s method (32, 34): first, we assessed the regression coefficient bcrude of U2 − U1 (at initial time and at age 10) on U1 (at initial time). Second, we computed the regression coefficient bBlomqvist adjusted for measurement error as bBlomqvist = (bcrude + k)/(1−k), with k = variance of measurement error/total variance = 1 – intra-class correlation (ICC) between (short-term) repeated measurements (Glossary). The corresponding correlation rBlomqvist was estimated. We compared estimates assuming that the information on the variance of measurement error (to compute k) was accurate, underestimated, or overestimated.
Simulations and analyses were conducted using the statistical package R 2.10.1 (R Project for Statistical Computing; http://www.r-project.org/).
Results of the Simulations
Assuming a relatively low measurement error and small between individual variability of change, the observed mean BMI and standard deviation (SD) of a simulated cohort of 500 children are shown as an illustration in Table 2. Mean BMI increased linearly with age during that period. The SD also increased indicating an increase in the variance. Such a data pattern is typically observed if there is a positive correlation between initial value and subsequent change and is named fan spread (29).
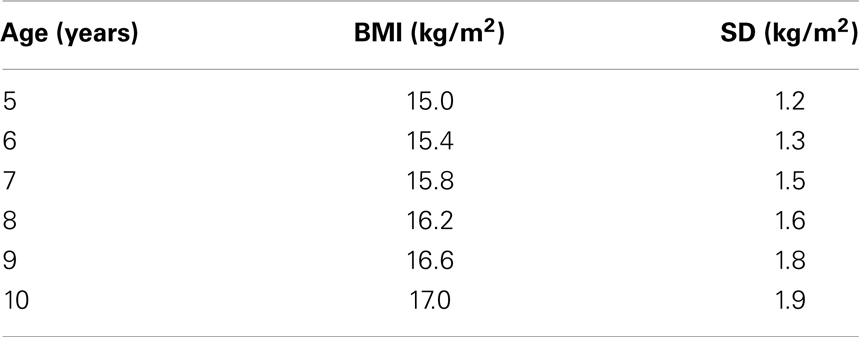
Table 2. Measured body mass index (BMI) and standard deviation (SD) of the 500 children followed-up annually between the ages of 5 and 10.
Estimates of the correlation between the baseline and change are shown in the Figures 2A,B assuming a relatively small variability in BMI change between individuals (true yearly change SD: 0.2) and Figures 2C,D assuming a relatively large variability in BMI change between individuals (true yearly change SD: 0.4), respectively.
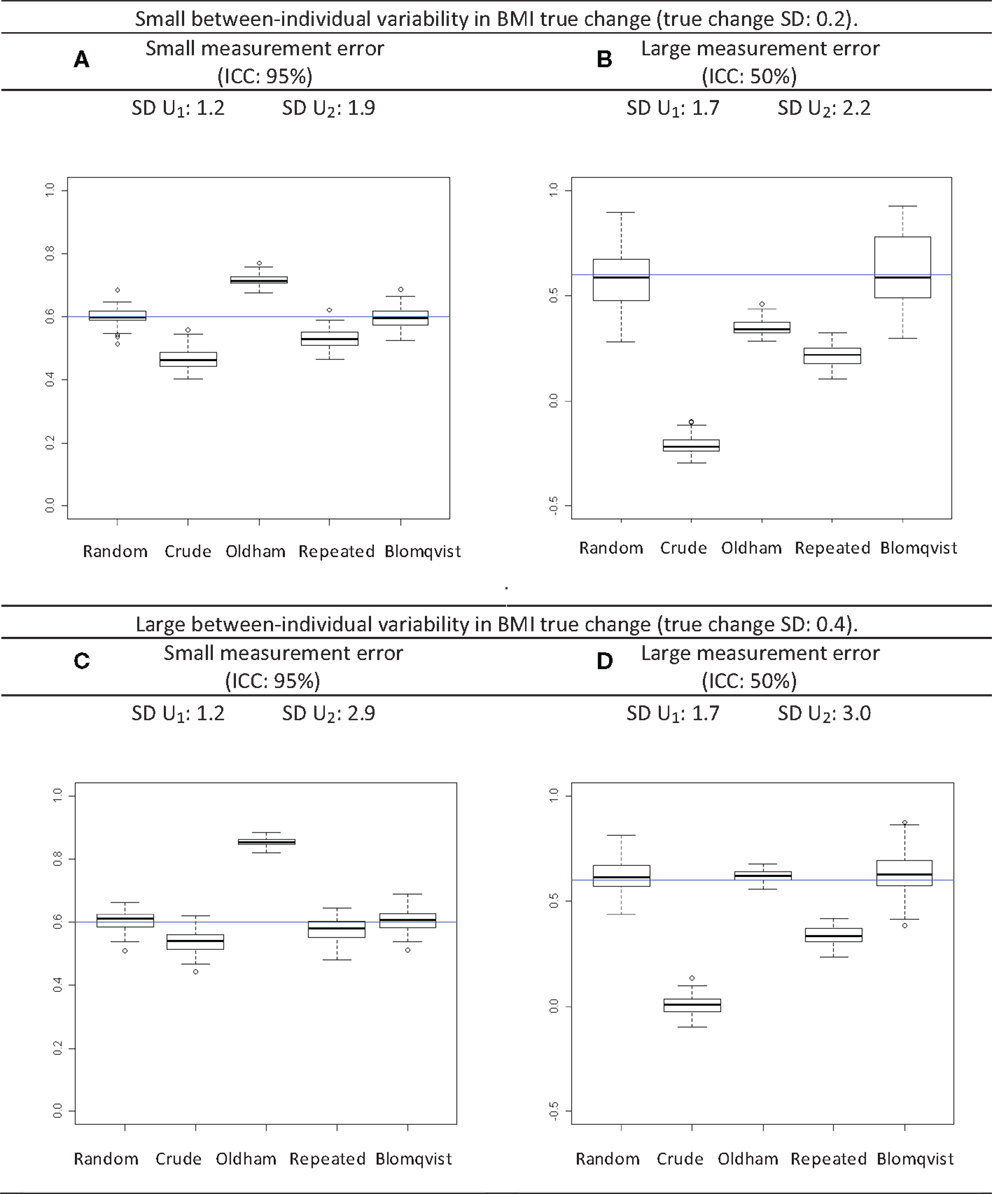
Figure 2. Distribution of the estimates of correlation coefficients between change and initial value following different scenarios. The standard deviation (SD) of measured BMI at age 5 (initial time; U1) and at age 10 (follow-up time; U2) are reported. The horizontal line is the expected correlation. The box plot shows the mean and the 25th and 75th percentile, and the whiskers extend to 1.5 times the interquartile range from the box. Random: estimate using a linear random effects model; Crude: crude correlation between initial value and change; Oldham: estimates using Oldham’s method; Repeated: estimates using repeated measurement method; Blomqvist: estimates using Blomqvist’s method. (A) Results in case of small between-individual variability in BMI true change and of small measurement error. (B) Results in case of small between-individual variability in BMI true change and of large measurement error. (C) Results in case of large between-individual variability in BMI true change and of small measurement error. (D) Results in case of large between-individual variability in BMI true change and of large measurement error.
Relatively small change variability between individuals
Assuming a relatively low measurement error variance (ICC of 95%) (Figure 2A), the average estimate based on the linear random effects regression model rrandom was +0.6 as expected. The crude estimate rcrude was slightly negatively biased, rOldham was slightly positively biased, and rrepeated was slightly negatively biased. The estimated correlation rBlomqvist was on average equal to the expected correlation rrandom. SD increased from 1.2 to 1.9 kg/m2 during follow-up. If the measurement error variance was relatively large (ICC: 50%) (Figure 2B), rcrude and rrepeated were more negatively biased than if measurement error was small, rOldham was negatively biased and closer to the null value. rBlomqvist was on average equal to the expected correlation. The SD increase was less important than in (Figure 2A).
Relatively large variability in change between individuals
Similar patterns for rcrude, rrepeated, and rBlomqvist were observed for large compared to small change variability between individuals. However, rOldham was more biased when measurement error variance was small (Figure 2C) and less biased when measurement error variance was large (Figure 2D). SD increased systematically and the amount of SD increase during follow-up was much larger in most cases with large than with small change variability between individuals (Figures 2C,D).
Blomqvist’s method with variance of measurement error under or overestimated
If the variance of measurement error was underestimated, rBlomqvist was negatively biased (data not shown). Conversely, if the variance of measurement error was overestimated, rBlomqvist was biased away from the null: the correlation was overestimated if the true correlation was positive and underestimated if the true correlation was negative.
Discussion
Different methods exist to assess the association between the baseline and subsequent change in the value of a continuous variable (Table 1). Our simulation study indicates that the crude correlation was systematically negatively biased. In some cases, analyzing the pattern of change in the spread of data helped identify the existence of an association. In most scenarios, Oldham’s method did not allow estimating the correlation. Using the repeated measurement method, the correlation was biased toward the null. Using Blomqvist’s method, the estimated correlation was on average equal to the true correlation, assuming an accurate estimate of the measurement error variance. As expected, the estimated correlation using linear random effects modeling method was equal to the true correlation.
The linear random effects model (or individual growth curve modeling) has received common acceptance to analyze change in a continuous variable and its correlates, including the baseline level (1, 28, 30, 33). However, this method requires multiple measurements and cannot be used if only two waves of data are available. Some of the other listed methods (Table 1) can be used with two waves of data, but with caution. In fact, assumptions have to be made either on the amount of measurement error or on the amount of between individuals variability of (true) change to properly interpret estimates with any of these methods, and it may be difficult to check the validity of these assumptions. For instance, analyzing the variance offers insights only if there is a priori a small variability of change between individual. Blomqvist’s method provides accurate estimates and this method is in fact an application of the linear random effects model [see Edland (32) for an in depth explanation]. However, Blomqvist’s method requires having an accurate estimate of the variance of measurement error, based on short-term repeated measurements or from external sources (e.g., previous studies). Some authors have argued that Blomqvist’s method does not correct for regression to the mean caused by between-individual variability of change (2) but our simulation indicates that this method provides accurate estimate of the relation between initial value and change assuming different levels of variability of change between individuals.
The estimate of the correlation was biased in many cases with Oldham’s method. While this method has been used extensively (15, 31), it has been criticized notably because it is difficult to understand why we should assess the relation between (U1 + U2)/2 and U2 − U1 if the aim is to estimate the relation between Y1 and Y2 − Y1. Indeed, this method allows the unbiased estimation of a different statistic, that is, of the correlation between change and the value at the mid-time point between Y1 and Y2, but not of the correlation between change and the value at baseline. Repeated measurement method may be satisfactory if measurement error is small: in that case, the estimate is slightly biased toward the null, due to the regression dilution bias (33). However, measurement errors of U1 and U1bis (a repeated measurement of Y at the initial time) may be correlated. If this is the case, the association between U2 − U1 and U1bis will still be affected by regression to the mean and will be negatively biased. A correlation between errors is difficult to ascertain but will be likely if the initial value (U1) and the repeated measure (U1bis) are gathered close in time. Furthermore, since a third measure is required to use repeated measurement method, random effect modeling should be preferred in this circumstance.
The linear random effects method and Blomqvist’s method account for random intra-individual variability. Intra-individual variability has two components, one due to imperfect measurement methods and another due to the (short-term) biological variability (33) but, in practice, one component cannot most often be separated from the other. Measurement error is typically assessed by the variability of repeated measurements over a short period of time. Such a method may be insufficient to capture the whole biological variability. For example, assessing BP a few times at one visit may not capture the full random individual variability of BP (37, 38). Consequently, with limited numbers of measurements or limited information on the variance of measurement error, the linear random effects method and Blomqvist’s method may not capture the genuine association between baseline value and subsequent change of a continuous variable.
We simulated a cohort of 500 subjects examined at the same ages to simplify our illustration. Linear random effects model as well as Blomqvist’s method can be used with data collected at different spacing (in our case different ages) (32, 35). Random variability in the estimates would have been greater for all methods with a smaller cohort size, potentially blurring the difference between the methods. No confounding factor was taken into account in the simulations. Linear random effects model can directly take account of confounding factors. Furthermore, we assumed in our simulation a linear growth with time. While this may be approximately true over short periods of time, such a model is not realistic over a long interval for most biologic variables. More complex non-linear patterns of growth over time can be analyzed by random effects models if enough measurements are available (32, 35). However, in case of non-linear growth, the question of whether change depends on baseline value or not becomes highly complex. If only two waves of data are available and a linear approximation of growth is not realistic, there is no satisfactory method. Other methods have been proposed to assess the association between the initial value and subsequent change, e.g., generalization of Blomqvist’s method by Edland (32) or structural regression and multilevel modeling (13, 39).
Finally, it is important to underscore that the assessment of the true association between the baseline value and subsequent change (or between level and slope) is easily misinterpreted. At best, such assessment helps predict the expected future change of a variable given previous (true) level. However, while it is tempting, no simple etiological inference can be made in most cases (32). When modeling progressive conditions (such as elevated BMI), it is important to consider that differential progression prior to the initial measurement can induce an association between level at any time and change (32). Actually, the association between initial level and subsequent change can be explained by changes prior to the initial measurement, a so-called “horse racing effect” in case of positive association between level and change (4, 40), and the strength of the association will depend on the timing at which initial and follow-up values were measured (1).
Summary
To assess the genuine association between the baseline value of a continuous variable and subsequent change, assuming a linear growth with time:
• In general, it is better to rely on multiple measurements at different times to account for the variability of changes between individual and for measurement error.
• If only two waves of data and accurate estimation of the variance of measurement error are available, our simulation shows that Blomqvist’s method provides accurate estimation.
• If more than two waves of data are available, a linear random effects model provides accurate estimation.
• In all cases, researchers should be cautious on causal interpretations of the relationship between baseline value and subsequent change.
Glossary
Measurement error: Short-term within-subject variability. It has two components: (1) an error due to the measurement method itself and (2) a short-term biological variability. The error occurs at random if it fluctuates in an unpredictable manner around the true value (which is estimated by the mean of repeated measurements) (33).
Mathematical coupling: Because the initial value (Y1) and the change from initial value (Y2 − Y1) share a common variable, there is a mathematical coupling between Y1 and Y2 − Y1 (2, 23– 25). This coupling induces a correlation between Y1 and Y2 − Y1.
Intra-class correlation (ICC): ICC is the proportion of variability due to the between-subject variability. It is the ratio of between-subject variance to total variance, the latter being the sum of between-subject variance and (short-term) within-subject variance. The within-subject variance is the measurement error variance and can be estimated in longitudinal studies by repeated measurements over a short period of time. ICC is also called the reliability coefficient.
Regression to the mean (RTM): RTM (also called regression effect, regression paradox, or regression fallacy) affects any variable measured with some random error. It is the expression of imperfect correlation between repeated measures and results from some selection process. For example, if the initial measure U1 is elevated, the probability of having a lower second measure U2 is – strictly by chance – greater than having a higher measure. The reverse is true if U1 is initially low: the probability of having a higher follow-up measure U2 is greater than having a lower measure. Whatever the initial measure, the following one is – on average- closer to the mean of multiple measures: it has regressed to the mean. The further away is the initial measure from the mean, the greater – on average – is the amount of RTM (19– 21). RTM is what produces the correlation between initial value and subsequent change (1). RTM also manifests at group level when subjects are sampled based on their extremeness, i.e., above or below a given threshold, or due to random sampling variability. Due to RTM, the change observed in this group cannot be used as an estimate of the average change in the population.
Regression dilution bias: Occurs in the presence of random measurement error in the exposure: it biases toward the null the estimate of the relationship between the exposure (in our case, the initial value) and the outcome (in our case, the change) (33).
Linear random effects regression model (LREM): Used to model repeated longitudinal measures of a given variable Y throughout time, also called individual growth modeling (35). Y is assumed to follow a linear trajectory over time (or age) which differs from one individual to the other; Y is thus modeled for an individual i at timeij as E(yij) = β0 + b0 i + β1 × timeij + b1 i × timeij where b0 i and b1 i are random coefficients for the intercept β0 and the slope β1, respectively. The regression of b1 i on b0 i or the correlation between b1 i and b0 i are indicators of the relationship between change in the level of a variable and its initial value (32, 35). Two-wave longitudinal data cannot be used to fit such model; additional measures are required.
Appendix
The correlation r between U1 and U2 − U1 can be written as:
If we assume that that E1 and E2 are random variables with identical variance and that the covariance (Y1,Y2) is null (no correlation between Y1 and Y2), the equation can be simplified as
Authors’ Contributions
Arnaud Chiolero and James A. Hanley had the original idea for this work, which was developed with Gilles Paradis and Benjamin Rich. Arnaud Chiolero drafted the manuscript. Arnaud Chiolero and Benjamin Rich carried out the simulation under the supervision of James A. Hanley. Gilles Paradis, Benjamin Rich, and James A. Hanley revised the manuscript. All authors read and approved the final manuscript.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
Arnaud Chiolero is supported by the Canadian Institutes of Health Research (CIHR). Gilles Paradis holds a CIHR Applied Public Health Research Chair.
References
1. Rogosa DR. The analysis of change. In: Gottman JM editor. Myths and Methods: “Myths About Longitudinal Research,” Plus Supplemental Questions. Hillsdale, NJ: Erlbaum (1995). p. 3–65.
2. Blance A, Tu YK, Gilthorpe MS. A multilevel modeling solution to mathematical coupling. Stat Methods Med Res (2005) 14:553–65. doi:10.1191/0962280205sm418oa
3. Hofman A, Valkenburg HA. Determinants of change in blood pressure during childhood. Am J Epidemiol (1983) 117:735–43.
4. Cole TJ. Children grow and horses race: is the adiposity rebound a critical period for later obesity? BMC Pediatr (2004) 4:6. doi:10.1186/1471-2431-4-6
5. Svärdsudd K, Blomqvist N. A new method for investigating the relation between change and initial value in longitudinal blood pressure data. I. Description and application of the method. Scand J Soc Med (1978) 6:85–95.
6. Blomqvist N, Svärdsudd K. A new method for investigating the relation between change and initial value in longitudinal blood pressure data. II. Comparison with other methods. Scand J Soc Med (1978) 6:125–9.
7. Senn S. Methods for assessing difference between groups in change when initial measurement is subject to intra-individual variation. Stat Med (1994) 13:2280–5. doi:10.1002/sim.4780132110
8. Vickers AJ, Altman DG. Statistics notes: analysing controlled trials with baseline and follow up measurements. BMJ (2001) 323:1123–4. doi:10.1136/bmj.323.7321.1123
9. Chan SF, Macaskill P, Irwig L, Walter SD. Adjustment for baseline measurement error in randomized controlled trials induces bias. Control Clin Trials (2004) 25:408–16. doi:10.1016/j.cct.2004.06.001
10. Glymour MM, Weuve J, Berkman LF, Kawachi I, Robins JM. When is baseline adjustment useful in analyses of change? An example with education and cognitive change. Am J Epidemiol (2005) 162(3): 267–78. doi:10.1093/aje/kwi187
11. Hayes RJ. Methods for assessing whether change depends on initial value. Stat Med (1988) 7:915–27. doi:10.1002/sim.4780070903
12. Twisk JWR. Longitudinal studies with two measurements: the definition and analysis of change. Applied Longitudinal Data Analysis for Epidemiology: A Practical Guide, Chap. 8, Cambridge: Cambridge University Press (2003). p. 167–78.
13. Tu YK, Gilthorpe MS. Revisiting the relation between change and initial value: a review and evaluation. Stat Med (2007) 26:443–57. doi:10.1002/sim.2538
14. Jin P. Toward a reconceptualization of the law of initial value. Psychol Bull (1992) 111:176–84. doi:10.1037/0033-2909.111.1.176
15. Gill JS, Zezulka AV, Beevers DG, Davies P. Relation between initial blood pressure and its fall with treatment. Lancet (1985) 1:567–9. doi:10.1016/S0140-6736(85)91219-X
16. Wu M, Ware JH, Feinleib M. On the relation between blood pressure change and initial value. J Chronic Dis (1980) 33:637–44. doi:10.1016/0021-9681(80)90006-5
19. Yudkin PL, Stratton IM. How to deal with regression to the mean in intervention studies. Lancet (1996) 347:241–3. doi:10.1016/S0140-6736(96)90410-9
20. Stigler SM. Regression towards the mean, historically considered. Stat Methods Med Res (1997) 6:103–14. doi:10.1191/096228097676361431
21. Barnett AG, van der Pols JC, Dobson AJ. Regression to the mean: what it is and how to deal with it. Int J Epidemiol (2005) 34:215–20. doi:10.1093/ije/dyh299
22. Moreno LF, Stratton HH, Newell JC, Feustel PJ. Mathematical coupling of data: correction of a common error for linear calculations. J Appl Physiol (1986) 60:335–43.
23. Squara P. Mathematic coupling of data: a frequently misused concept. Intensive Care Med (2008) 34:1916–21. doi:10.1007/s00134-008-1178-5
24. Archie JP Jr. Mathematic coupling of data: a common source of error. Ann Surg (1981) 193(3): 296–303. doi:10.1097/00000658-198103000-00008
25. Tu YK, Nelson-Moon ZL, Gilthorpe MS. Misuses of correlation and regression analyses in orthodontic research: the problem of mathematical coupling. Am J Orthod Dentofacial Orthop (2006) 130(1): 62–8. doi:10.1016/j.ajodo.2004.12.022
26. Bland JM, Altman DG. Statistical methods for assessing agreement between two methods of clinical measurement. Lancet (1986) 1:307–10. doi:10.1016/S0140-6736(86)90837-8
27. Bland JM, Altman DG. Comparing methods of measurement: why plotting difference against standard method is misleading. Lancet (1995) 346:1085–7. doi:10.1016/S0140-6736(95)91748-9
28. Cole TJ, Bellizzi MC, Flegal KM, Dietz WH. Establishing a standard definition for child overweight and obesity worldwide: international survey. BMJ (2000) 320:1240–3. doi:10.1136/bmj.320.7244.1240
29. Rogosa D, Brandt D, Zimowski M. A growth curve approach to the measurement of change. Psychol Bull (1982) 92:726–48. doi:10.1037/0033-2909.92.3.726
30. Geenen R, van de Vijver FJ. A simple test of the Law of Initial Values. Psychophysiology (1993) 30:525–30. doi:10.1111/j.1469-8986.1993.tb02076.x
31. Oldham PD. A note on the analysis of repeated measurements of the same subjects. J Chronic Dis (1962) 15:969–77. doi:10.1016/0021-9681(62)90116-9
32. Edland SD. Blomqvist revisited: how and when to test the relationship between level and longitudinal rate of change. Stat Med (2000) 19:1441–52. doi:10.1002/(SICI)1097-0258(20000615/30)19:11/12<1441::AID-SIM436>3.0.CO;2-H
33. Hutcheon J, Chiolero A, Hanley J. Random measurement error and regression dilution bias. BMJ (2001) 340:c2289. doi:10.1136/bmj.c2289
34. Blomqvist N. On the relation between change and initial value. J Am Stat Assoc (1977) 72:746–9. doi:10.2307/2286454
35. Singer J, Willet JB. Applied Longitudinal Data Analysis: Modeling Change and Event Occurrence. New York: Oxford University Press (2003).
36. Byth K, Cox DR. On the relation between initial value and slope. Biostatistics (2005) 6:395–403. doi:10.1093/biostatistics/kxi017
37. Gillman MW, Cook NR, Rosner B, Beckett LA, Evans DA, Keough ME, et al. Childhood blood pressure tracking correlations corrected for within-person variability. Stat Med (1992) 11:1187–94. doi:10.1002/sim.4780110905
38. Chiolero A, Cachat F, Burnier M, Paccaud F, Bovet P. Prevalence of hypertension in schoolchildren based on repeated measurements and association with overweight. J Hypertens (2007) 25:2209–17. doi:10.1097/HJH.0b013e3282ef48b2
39. Myrtek M, Foerster F. The law of initial value: a rare exception. Biol Psychol (1986) 22:227–37. doi:10.1016/0301-0511(86)90032-3
Keywords: baseline value, change, measurement error, regression to the mean, mathematical coupling
Citation: Chiolero A, Paradis G, Rich B and Hanley JA (2013) Assessing the relationship between the baseline value of a continuous variable and subsequent change over time. Front. Public Health 1:29. doi: 10.3389/fpubh.2013.00029
Received: 28 May 2013; Accepted: 06 August 2013;
Published online: 23 August 2013.
Edited by:
ClarLynda Williams-DeVane, North Carolina Central University, USAReviewed by:
Luigino Dal Maso, Centro Riferimento Oncologico di Aviano, ItalyJuan Carlos Vivar, NCCU, USA
Copyright: © 2013 Chiolero, Paradis, Rich and Hanley. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Arnaud Chiolero, University Hospital Center, Institute of Social and Preventive Medicine (IUMSP), University of Lausanne, 10 route de la Corniche, 1010 Lausanne, Switzerland e-mail:YXJuYXVkLmNoaW9sZXJvQGNodXYuY2g=