 Clarisse Lins de Lima1
Clarisse Lins de Lima1 Cecilia Cordeiro da Silva2
Cecilia Cordeiro da Silva2 Ana Clara Gomes da Silva3Eduardo Luiz Silva2Gabriel Souza Marques2Lucas Job Brito de Araújo2Luiz Antônio Albuquerque Júnior2Samuel Barbosa Jatobá de Souza2
Ana Clara Gomes da Silva3Eduardo Luiz Silva2Gabriel Souza Marques2Lucas Job Brito de Araújo2Luiz Antônio Albuquerque Júnior2Samuel Barbosa Jatobá de Souza2 Maíra Araújo de Santana1
Maíra Araújo de Santana1 Juliana Carneiro Gomes1Valter Augusto de Freitas Barbosa3
Juliana Carneiro Gomes1Valter Augusto de Freitas Barbosa3 Anwar Musah4
Anwar Musah4 Patty Kostkova4
Patty Kostkova4 Wellington Pinheiro dos Santos3*Abel Guilhermino da Silva Filho2
Wellington Pinheiro dos Santos3*Abel Guilhermino da Silva Filho2- 1Polytechnique School of the University of Pernambuco, Poli-UPE, Recife, Brazil
- 2Center for Informatics, Federal University of Pernambuco, Recife, Brazil
- 3Department of Biomedical Engineering, Federal University of Pernambuco, Recife, Brazil
- 4Institute for Risk and Disaster Reduction, University College London, London, United Kingdom
Background: The global burden of the new coronavirus SARS-CoV-2 is increasing at an unprecedented rate. The current spread of Covid-19 in Brazil is problematic causing a huge public health burden to its population and national health-care service. To evaluate strategies for alleviating such problems, it is necessary to forecast the number of cases and deaths in order to aid the stakeholders in the process of making decisions against the disease. We propose a novel system for real-time forecast of the cumulative cases of Covid-19 in Brazil.
Methods: We developed the novel COVID-SGIS application for the real-time surveillance, forecast and spatial visualization of Covid-19 for Brazil. This system captures routinely reported Covid-19 information from 27 federative units from the Brazil.io database. It utilizes all Covid-19 confirmed case data that have been notified through the National Notification System, from March to May 2020. Time series ARIMA models were integrated for the forecast of cumulative number of Covid-19 cases and deaths. These include 6-days forecasts as graphical outputs for each federative unit in Brazil, separately, with its corresponding 95% CI for statistical significance. In addition, a worst and best scenarios are presented.
Results: The following federative units (out of 27) were flagged by our ARIMA models showing statistically significant increasing temporal patterns of Covid-19 cases during the specified day-to-day period: Bahia, Maranhão, Piauí, Rio Grande do Norte, Amapá, Rondônia, where their day-to-day forecasts were within the 95% CI limits. Equally, the same findings were observed for Espírito Santo, Minas Gerais, Paraná, and Santa Catarina. The overall percentage error between the forecasted values and the actual values varied between 2.56 and 6.50%. For the days when the forecasts fell outside the forecast interval, the percentage errors in relation to the worst case scenario were below 5%.
Conclusion: The proposed method for dynamic forecasting may be used to guide social policies and plan direct interventions in a cost-effective, concise, and robust manner. This novel tools can play an important role for guiding the course of action against the Covid-19 pandemic for Brazil and country neighbors in South America.
1. Introduction
The world faces a new pandemic that is spreading at an alarming rate. The ongoing outbreak is caused by an acute infectious disease known as severe acute respiratory syndrome coronavirus (SARS-CoV-2) which is responsible for the current coronavirus disease 2019 (Covid-19) pandemic. The probable origins of SARS-CoV-2 are from the Pangolins, a mammalian animal of the order Pholidota (1). The SARS-CoV-2 has a high transmission rate, within a short time period between December 2019 and May 2020, more than 4.7 million people were infected in 216 countries (2). The acute symptoms for Covid-19 includes fever, cough, sore throat, fatigue, and shortness of breath (3); however, in some cases if the symptoms are not managed, it can develop into severe pneumonia which, in turn, leads to critical conditions, such as sepsis or acute respiratory distress syndrome which can be fatal. As of May 2020, the Covid-19 has claim more than 317,000 lives and this figure shall continue to rise in the coming months (2).
The gold standard test for diagnosing Covid-19 is the Reverse Transcription Polymerase Chain Reaction (RT-PCR) with DNA sequencing and identification (4). Nevertheless, the RT-PCR needs several hours to return a result (4). While the RT-PCR identifies directly the presence or absence of the virus, on the other hand, the rapid test may sometimes be non-specific. They detect the serological evidence of recent infection based on the presence of antibodies. However, the production of antibodies starts after some days, or even weeks after the infection (5). Besides that, this kind of tests could recognize antigens of other viruses; for example, influenza and other coronaviruses (6). What compromise the test's accuracy; for example, are tests based on IgM/IgG antibodies which were realized in samples collected in the first week of the illness have 18.8% sensitivity and 77.8% specificity (7).
Currently, there is no vaccine nor a specific treatment for curing Covid-19. In a home or hospital settings, one can only ease the symptoms through the course of the infection until s/he recovers. The best strategy to decrease its transmission within a population is to quarantine those infected with Covid-19, and to encourage the practice of social and physical distancing on a mass scale. This course of action provides a much safer and practical approach for limiting contact between the infected and those at risk of infection (8). This course of action, and in addition to, the cancellation or postponement of large public events as well as deferment of non-essential activities on a mass scale has significantly helped in controlling the spread of the virus as observed in China and elsewhere. Social isolation and quarantine also prevents people with asymptomatic infection from spreading the virus (8, 9). Other works also show positive results in the reduction of its transmission with social isolation in effect in countries, such as Italy (9), Switzerland (10), and Brazil (11).
One of the approaches used to combat diseases include the forecast of the number of cases based on the behavior of past events. In the case of arboviruses, for example, the time series of the number of cases and climatic variables are used to forecast future behaviors (12–14). Considering the SARS-CoV-2, forecasting the pandemic trends could be crucial to avoid the virus spreading. Many mathematical models, such as Susceptible-Infected-Removed (SIR) and its variations have being used to forecast Covid-19 pandemic trends (15–20).
Therefore, the main goal of this research is to present a methodology for monitoring and to provide forecasts of cases and deaths of Covid-19 for each federative units of Brazil. This research relies on an interdisciplinary approach that brings together digital health, statistical modeling, GIS and computer sciences to create a system which comprise of a dynamic web application interfaced with multiple databases reporting incident cases (and deaths) of Covid-19 in Brazil. This tool will churn the information to provide forecasts on a national and state-level. The Autoregressive Integrated Moving Average (ARIMA) method (21) was utilized for this purpose. The reasons for choosing the ARIMA model: (1) it provides the user with dynamic forecasts for a daily basis through model training (per day with a maximum window of 3 days); and (2) its flexibility and robustness in terms of providing user three important outputs [i.e., the forecasted number future cases with their corresponding 95% confidence interval (CI) as well as both best and worst case scenarios].
This paper is organized as follows: in section 2, we provide a brief discussion about previous studies that used mathematical models to forecast trends of Covid-19 pandemic. In section 3, we describe our proposed method and review its theoretical concepts. In section 4, we present the analysis of the data and the results. Discussions are delivered in section 5, and finally, conclusions are drawn in section 6.
2. Related Works
Several forecasting models for Covid-19 have emerged around the world. Due to many uncertainties surrounding the behavior of the virus, these models have guided the development of public health strategies and the application of policies that promote social isolation. Given this scenario, several studies have sought to adapt conventional epidemiological models to forecast this pandemic trend (15); for instance, an extended Susceptible-Infected-Removed (eSIR) model was used to forecast epidemics trends in Italy and compared with Hunan (China) due to its similarity in population size and structure. The eSIR model is a version of the classical Susceptible-Infected-Removed (SIR) model. The SIR model uses three different compartments: Susceptible (S), Infected (I), and Recovered (R). This model was presented by Kermack and McKendrick (22), by Britton (23) in his book entitled “Essential Mathematical Biology,” and by Brauer et al. (24) in the book “Mathematical Epidemiology.” The SIR model is used to investigate diseases, such as measles and chickenpox. This model is represented by the following equations:
where S(t) is the population of susceptible individuals, I(t) is the symptomatic infected individuals, R(t) is the recovered individuals with immunity, β is the contact rate between susceptible and infected individuals, and γ is the transfer rate from I to R. The diagram in Figure 1A illustrates the compartments of the SIR model.
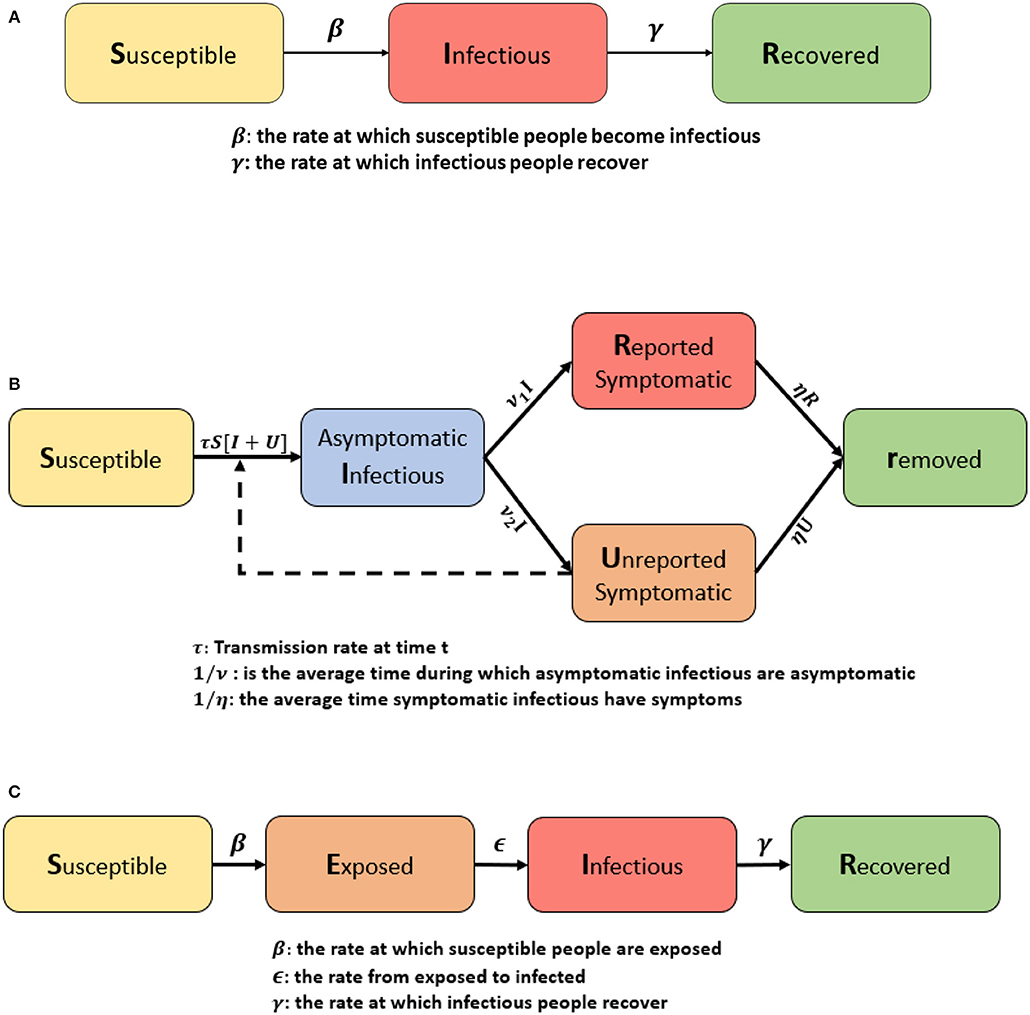
Figure 1. (A) Flow chart of the SIR model. The classic SIR model considers three classes: Susceptible, Infectious, and Recovered. β means the rate at which susceptible people can become infectious, and γ is the rate at which infectious people recover. (B) Model flow chart adapted from Liu et al. (17). They proposed a modified SIR model by adding asymptomatic infectous people and by dividing symptomatic cases into two classes: reported and unreported. (C) Flow chart of the SEIR model. It is composed by four individual classes: Susceptible, Exposed to the virus, Infected and Removed. In contrast to the SIR model, β is the rate at which susceptible people become exposed, ϵ is the rate from exposed to infected, and γ is the rate at which infectious people recover.
It should be noteworthy that while a SIR model uses a constant transmission rate. The eSIR can account for time-varying transmission rates in the population, and in addition, use time-varying parameters for isolation measures. Wangping et al. (15) used the eSIR forecast the reproduction number (R0) for Covid-19 in Hunan and Italy which was estimated as 3.15 (95% CI: 1.71–5.21) and 4.10 (95% CI: 2.15–6.77), respectively. Due to the discrepancy between these two R0 values, the authors concluded that the results needs to be confirmed in further studies.
In a similar manner, other models, like Bastos and Cajueiro (16), that are akin to SIR have been developed purposefully for forecasting the evolution of Covid-19 in Brazil from February 25, 2020 to March 30, 2020. Data were provided by the Brazilian Ministry of Health. For this purpose, the authors used a modified SIR model in order to create two versions: (1) SID (Susceptible-Infected-Dead) and (2) SIASD (Susceptible-Infected-Asymptomatic-Symptomatic-Dead). In the first version, the authors modified the original model in order to estimate the proportion of individuals who dies from Covid-19. This new parameter also changes the total number of individuals in the population. On the other hand, the second version seeks to improve the SID model. It considers that a relevant part of the population is infected, but asymptomatic. In the SIASD model, the variable of infecteds is divided into two groups accordingly—symptomatic and asymptomatic. In addition, the authors modified the transmission factor which takes into account the effects of the social distancing policies adopted during the selected period. Additionally, this parameter allows the model to evaluate the effectiveness of the measures adopted. In order to estimate the parameters of the models, the work sought to minimize the quadratic error between the real data and the estimated values. The curves were constructed with a 95% confidence interval (95% CI). The authors also considered the underreporting of cases, due to the lack of tests and the government's recommendation to test only patients with severe symptoms. Finally, both models indicated that social distancing policies were able to minimize contagion. It was also possible to conclude that the policies adopted for a short period bought sometime to postpone the peak of the pandemic. Thus, the authors indicated the dates considered to be the optimal for ending the quarantine period. In particular, the SIASD model forecasted a greater number of infections than the SID model. It also indicated a lower peak for symptomatic patients who, in turn, are need of urgent medical attention.
A recent study from China proposed a modified SIR model to forecast the cumulative number of cases of Covid-19 (17). In this example, the model defined by series of five differential equations depicted in a flowchart shown in Figure 1B.
This model formation represents the following: S(t) is the number of individuals susceptible to infection at time t, I(t) is the number of asymptomatic infectious individuals at time t, R(t) is the number of reported symptomatic infectious individuals at time t, U(t) is the number of unreported symptomatic infectious individuals at time t, τ(t) is the transmission rate at time t, is the average time during which asymptomatic infectious are asymptomatic, and is the average time symptomatic infectious have symptoms.
This model provides information on the number of both asymptomatic and symptomatic infected individuals. It estimates the amount of reported and unreported cases from the symptomatic group. From this study, the authors found that the estimation of unreported cases is extremely important to understand the severity of Covid-19. They also showed the importance of considering the asymptomatic infectious cases for the estimation of disease transmission rate. In these findings, the authors demonstrated the merits of implementing strict control measures by the government, and tighten them so as to decrease the transmission burden.
Similar research utilize a Susceptible-Infectious-Recovered-Dead (SIRD) model to forecast the basic reproduction number (R0) of SARS-Cov-2 and the daily rates of infection mortality and recovery (18). The R0 measures the average number of secondary cases that has resulted from an index infectious case. From the R0 value, a system may forecast the spreadability of an infectious disease. This approach was based on the daily available data of new confirmed cases in Hubei province, China, and was described by the following equations:
The model formation for the above equations are represented as follows: S(t) is the number of susceptible individuals at time t, I(t) is the number of infected individuals at time t, R(t) is the number of recovered individuals at time t, D(t) is the number of dead individuals at time t, α is the estimation of the infection rate, β is the estimation of the recovery rate, γ is the estimation of the mortality rate, and N is the population size.
This model fits the behavior of Covid-19 in Hubei which enables the estimation of key epidemiological parameters. The approach was successful in forecasting the spread of Covid-19 in China. Nevertheless, the SIRD model has some limitations in terms of its inability to include important factors that impacts disease dynamics, such as the effect of the incubation period, demographical characteristics of the population and the effects of restrictive policies. The authors acknowledge point the urgent need for using data in their derived from validated tests. The inclusion of these factors are crucial for building a more accurate and robust forecast models—since they are the key for limiting any residual confounding that may arise from the results, as well as building a more realistic picture for a deterministic point of view.
On the other hand, as proposed by Yang et al. (19) who use a modified Susceptible-Exposed-Infectious-Removed (SEIR) model jointly with the Artificial Intelligence method known as the Long-Short-Term-Memory (LSTM), to forecast epidemics trend of Covid-19 in China under public health interventions. SEIR model is another conventional forecast model, which is composed of four individual classes: Susceptible, Exposed to the virus or in the latent period, Infected and Removed. This model was first introduced by Kermack and McKendrick (22) and is used to understand illnesses like influenza. SEIR model uses the following equation system:
where S(t) is the population susceptible individuals, E(t) represents the individuals exposed to the disease or in a latent period, I(t) is the symptomatic infected individuals, R(t) is the recovered individuals with immunity, β is the contact rate between susceptible and exposed, ϵ is the transfer rate from class E to I, and γ is the transfer rate from I to R. The diagram in Figure 1C explains the SEIR model.
Yang et al. (19) modified the SEIR model by including the parameters: move-in, move-out, and the contact rate before and after the implementation of control policies. They used the recurrent neural network Long-Short-Term-Memory (LSTM) to corroborate their model forecasts. LSTM was trained on the 2003 SARS epidemic statistics, with available cases between April and June of 2003. They forecasted that the disease in China will peak in late February and end in late April by a combination of their methods. However, using a deep network like LSTM can trigger challenges. The main one is the high memory consumption, since it stores past states, thus making a multi-user application unfeasible (25). In this sense, LSTM is not suitable for client-server applications, such as the one proposed in this study.
In contrast to previous works (20), the authors made a comparative analysis of machine learning (ML) techniques for forecasting the coronavirus outbreak. The authors argue that more traditional models, such as SIR and SEIR, are insufficient to model the pandemic. The reasons are the quarantine and social distance policies applied by many governments in an iterative way, and the lack of data that reveals the real scenario, since the reported data do not actually correspond to the number of infected people. These factors impose great limits on the generalization ability of these conventional models. Thus, the work explores ML techniques to find the best model that estimates time-series data. Data were collected on the worldometers website in five countries: Italy, Germany, Iran, USA and China, corresponding to a period of 30 days. Initially, simple mathematical models were tested (i.e., Logistic, Logarithmic, Quaddratic, Compound, Power, and exponential). In order to estimate the parameters, three optimization algorithms were tested: Genetic Algorithm (GA), Particle Swarm Optimization (PSO), and the Gray Wolf (GWO) optimizer. Considering the processing time, the Root Mean Standard Error (RMSE) and the correlation coefficient as evaluation metrics, the GWO optimizer presented the best results, while the logistic model showed the smallest errors in the forecast of the Covid-19 outbreak for the five countries. However, these models showed low accuracy and low generalization capacity which lacked the ability to properly extrapolate the data beyond 30 days. In the following, two ML methods were introduced for time-series forecast: MultiLayer Perceptron (MLP) and adaptive network-based fuzzy inference system (ANFIS). Both were tested in two different scenarios: Scenario 1 with the data processed weekly; and Scenario 2, with daily sampling of consecutive days. In the case of MLP, they tested 8, 12, and 16 neurons. For ANFIS, the membership function types were Tri, Trap, and Gauss. The comparison between analytical and intelligent models indicated that MLP presented better results in both scenarios, being able to achieve a good approximation with the real data. Long-term data (up to 150 days) were also extrapolated, which reported an outbreak progression. Finally, the authors concluded that ML techniques can be useful in forecasting the Covid-19 pandemic, being able to overcome challenges found in traditional models.
Although the works presented in this section have shown good results, the models using equations require that we estimate a certain number of parameters. It can be a bias for the construction of the model. Moreover, mathematical models are insufficient to analyze the randomness of epidemics and they are also difficult to generalize (26). In addition, as each state has its own dynamics, it makes difficult to implement these models in the proposed tool. ARIMA models, in turn, are good tools for modeling time series because they can capture their changing trends, periodic changes and random distortions in time series. Besides, ARIMA models have been applied in several areas of health due to its simplicity and fast applicability. According to the survey carried out by Ceylan (26), ARIMA models have been used to forecast epidemics, such as dengue, tuberculosis, and hemorrhagic fever, for example.
3. Materials and Methods
3.1. Proposed Method
In this work, we proposed a system for real-time forecast of the cumulative cases of Covid-19 in Brazil, and for each of its 27 federative units (or state). The system operates as follows: Each Brazilian state feeds a database of Covid-19 notifications. All of this information is gathered in a general database, the Brazil.io. Then, our developed software, the COVID-SGIS, captures Covid-19 data which is made readily available by the Brasil.io portal (https://brasil.io/home/) on a daily basis through the SGIS web crawler. This accumulated data are collated into a comma separated value (.csv) file. We can in turn, derive training datasets from this data for which models are created for the accumulated number of confirmed and reported deaths of Covid-19. With the generated models, 6-days forecasts are reported with their corresponding 95% CI. The forecasted graphs of the accumulated confirmed cases and deaths caused by Covid-19 are available for Brazil and for each of its federative units, separately. In addition to the forecasts, the worst and best scenarios are presented for the number of confirmed cases as well as the number of deaths by Covid-19. Figure 2 shows the general schematic of this solution.
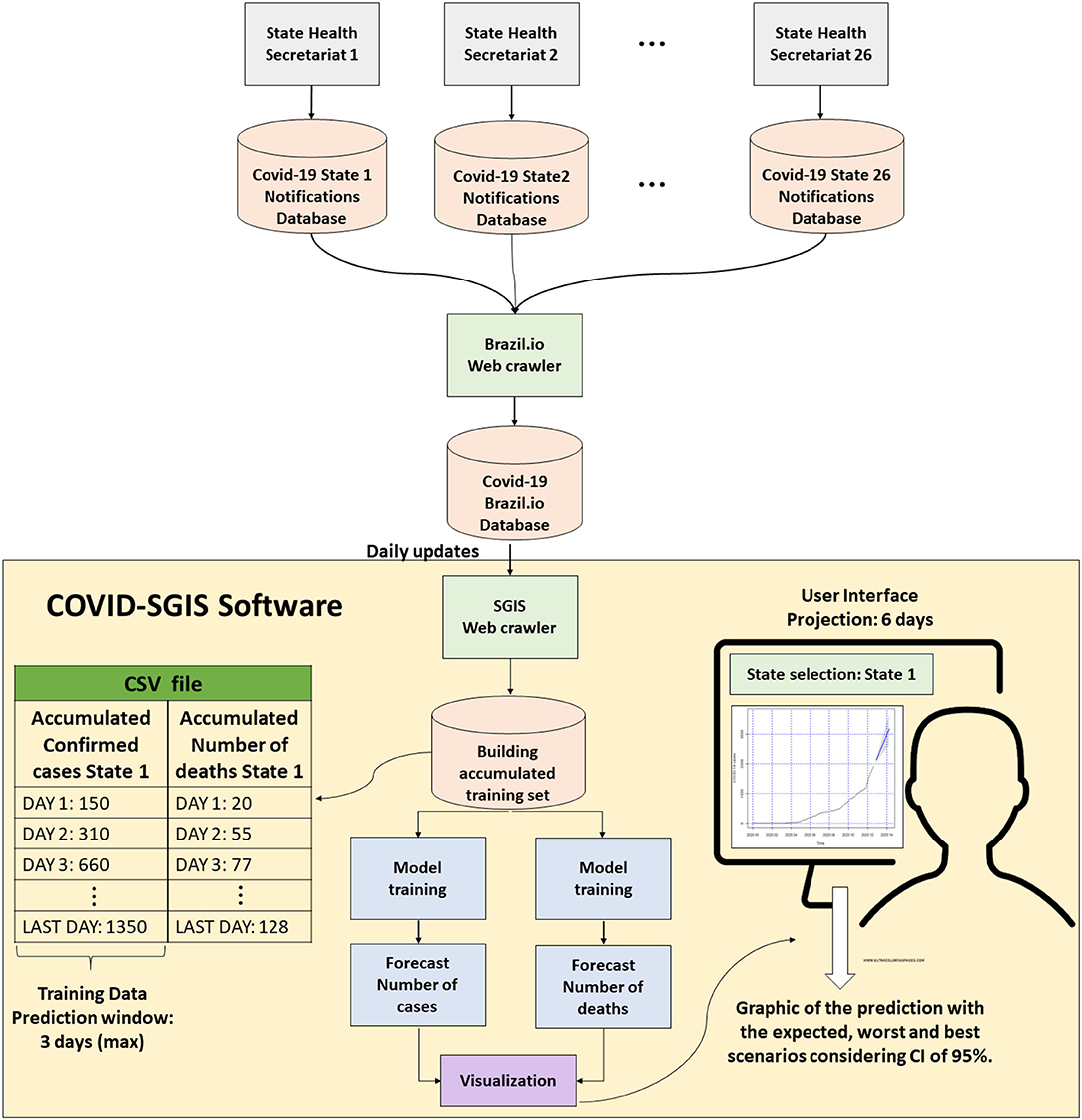
Figure 2. Proposed method: Each of the Health Secretariat of the 26 Brazilian states plus the Distrito Federal (the autonomous district in which is inserted the national capital) is responsible for feeding a notification base. All of this information is available on Brazil.io. Our Covid-SGIS software is updated daily with data from Brazil.io. A file in CSV format is organized with the accumulated data. From them, training sets of the model can be formed. After the ARIMA model training, the user can view the forecast of the number of cases and deaths for each of the states, with a 6-days projection.
3.2. Confirmed Cases Database
We used the data referring to confirmed cases available in the Brasil.io portal1 in our temporal forecast approach. Brasil.io portal provides the records of confirmed cases and deaths obtained through the bulletins of the State Health Secretariats. In this work, we selected data related to confirmed cases of Covid-19 for all Brazilian federative units. For each federative unit (out of 27), the records is from the first date of confirmation of the disease until the last update on May 5, 2020.
3.3. ARIMA Model
ARIMA models are classic models widely used to forecast future behaviors of stationary time series. ARIMA's acronym indicates the combination of autoregressive (AR) and moving average (MA) models. The “I” which stands for “integrated,” this indicates the model's original undifferenced series, which was differenced d times until it became a stationary series before fitting the ARMA(p,q) process. In the ARIMA(p, d, q) model, p and q correspond to the orders of the AR and MA models, respectively, while the d corresponds to the level of differencing. Equation (17) represents the mathematical expression of the model, where yt is the differenced series, c and ϕ are the parameters of the model and ε is the random error in time t (27, 28).
The construction of the ARIMA model (p, d, q) occurs according to the following steps (27, 28):
1. Evaluate the stationarity of the series (if it is not stationary, the differencing is applied until the stationarity is achieved). The results of the Dickey-Fuller test are shown in Table 1.
2. Estimate the p and q parameters based on the autocorrelation function (ACF) and the partial autocorrelation function (PACF) plots.
3. Evaluate the best fitted forecasting model using Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC).
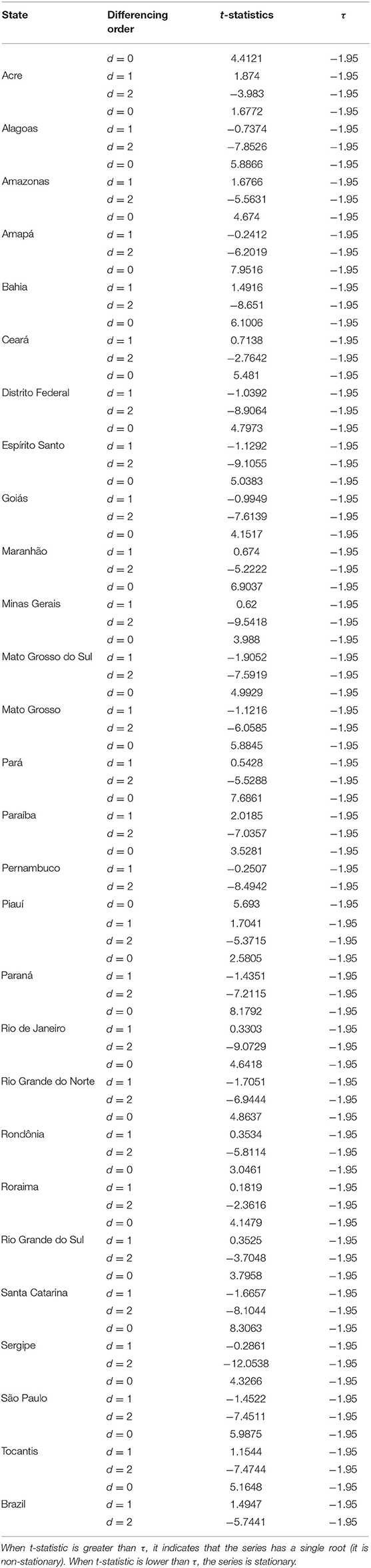
Table 1. Results of the Dickey-Fuller tests of the historical series of the accumulated number of cases of covid-19 in Brazil and in its 27 federative units.
The function auto.arima() in the forecast package in R, automatically calculates the p, d and q parameters and returns a fitted model. The forecast() function of this same package can be used to forecast based on the model adjusted by the auto.arima() function (21). In this context, from the data collected regarding the accumulated number of confirmed cases by state, we created a database corresponding to the historical series of accumulated confirmed cases of Covid-19 for Brazil and each of its federative units. We considered the period from the first notification date of the disease until May 5, 2020. From this historical series of accumulated cases of Covid-19. To this end, we built three types of ARIMA models: (1) one which was stratified by each state; (2) another stratified by Distrito Federal; and lastly, (3) one for the overall Brazil. To reiterate, these models were generated using the function auto.arima() from forecast package in R (version 3.6.3)2. Each model built was used to carry out the projection of the accumulated cases of the disease for 6 days, with a confidence interval of 95%. In order to evaluate the performance of the forecasts, we used accumulated data from May 6 to 11, which were updated on May 13.
3.4. Metrics
We selected two metrics to evaluate the models: the correlation coefficient and the Relative Quadratic Error (RMSE percentage). The correlation coefficient is a statistical measure between expected and forecasted values. This value varies from −1 to 1. When it approaches 1, it indicates a strong positive correlation. Conversely, when the correlation coefficient is close to −1, it indicates that the variables have a strong negative correlation. Of course, when the correlation coefficient is close to zero, it indicates that there is no correlation between the variables (29). The value of the correlation coefficient serves as the global evaluator for the model—thus, it is possible to obtain a high correlation coefficient as well as at the same time obtain high values for local errors. For this reason, it cannot be the only metric for assessing model performance. In order to avoid a superficial evaluation of the regressors, we therefore chose the RMSE (%) as an evaluation metric. Equation (18) shows the expression of the calculation of the relative quadratic error, where p is the forecasted value and a is the actual value.
In addition to the RMSE(%), we also calculated the Root Mean Square Error (RMSE), the Mean Absolute Error (MAE), the Mean Absolute Percentage Error (MAPE), and the Mean Percentage Error (MPE) (Equations 19–22):
where, f is the forecasted value, a is the actual value and e is the difference between the actual value and the forecasted value.
4. Results
In Figures 3–6 we can see the forecasts (6 days) of the number of Covid-19 cases for all Brazilian States and the whole country (from 06-05-2020 to 11-05-2020).
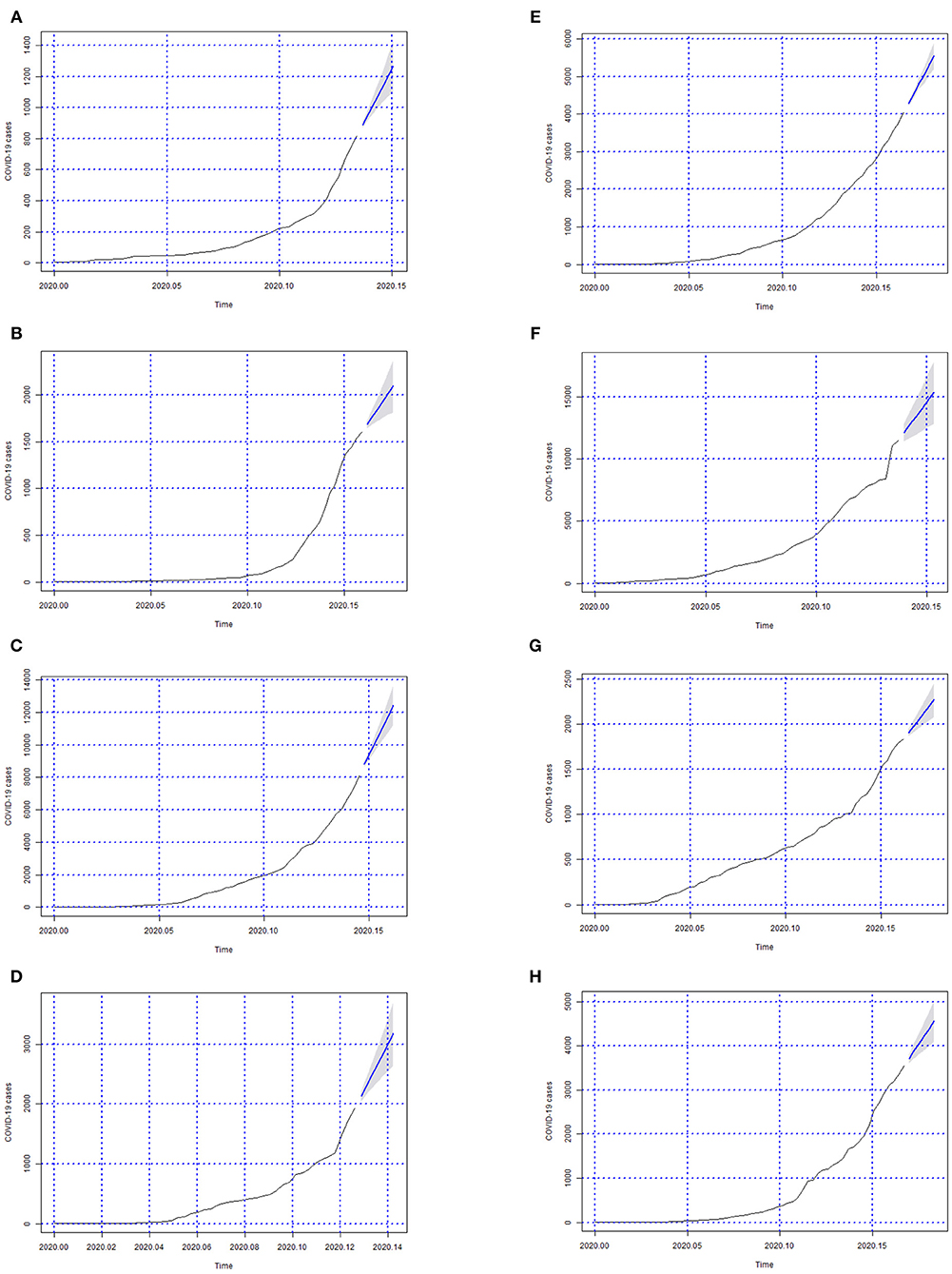
Figure 3. Forecasts of the number of Covid-19 cases from 06-05-2020 to 11-05-2020 for states (A) Acre, (B) Alagoas, (C) Amazonas, (D) Amapá, (E) Bahia, (F) Ceará, (G) Distrito Federal, and (H) Espírito Santo.
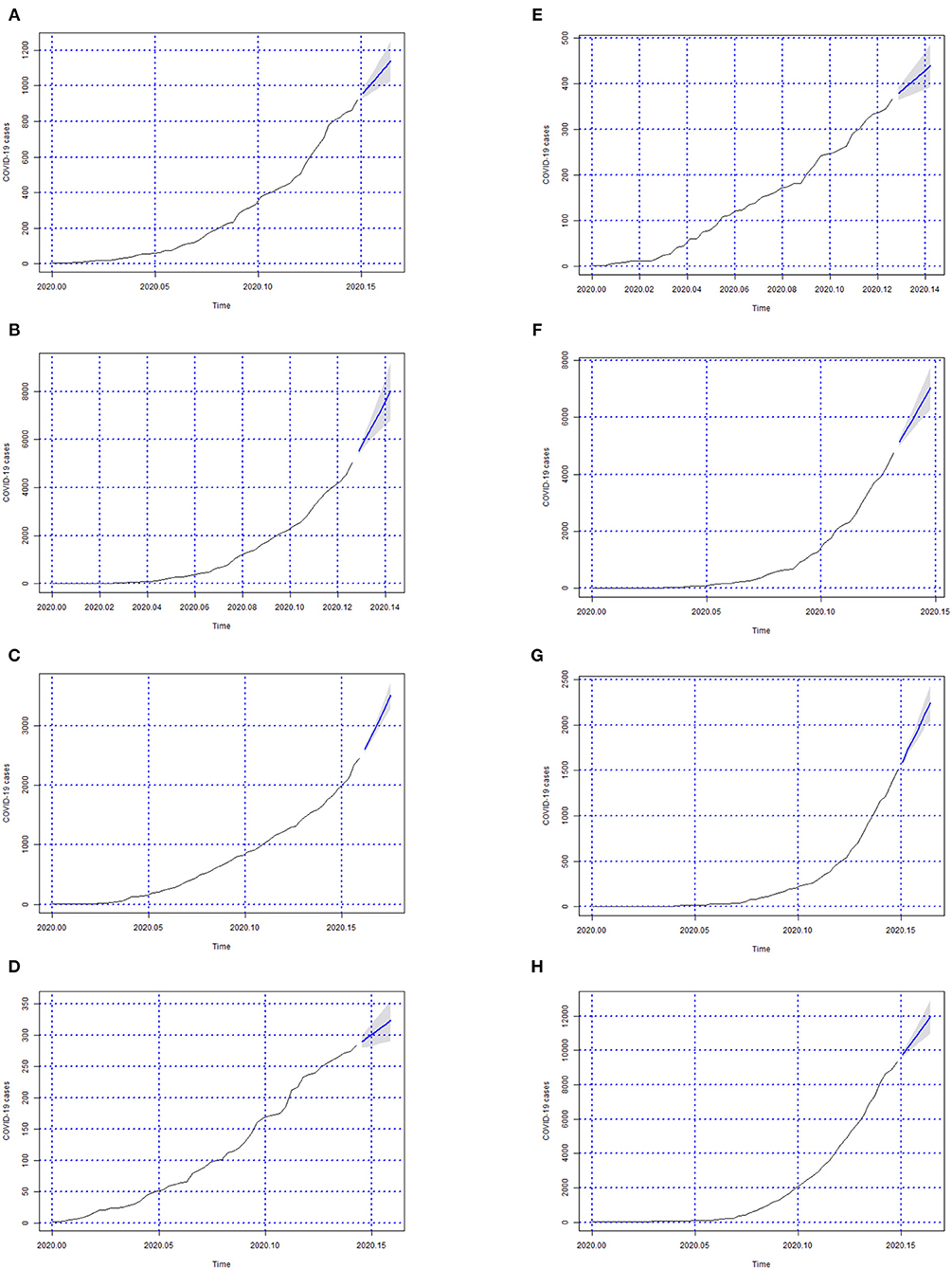
Figure 4. Forecasts of the number of Covid-19 cases from 06-05-2020 to 11-05-2020 for states (A) Goiás, (B) Maranhão, (C) Minas Gerais, (D) Mato Grosso do Sul, (E) Mato Grosso, (F) Pará, (G) Paraíba, and (H) Pernambuco.
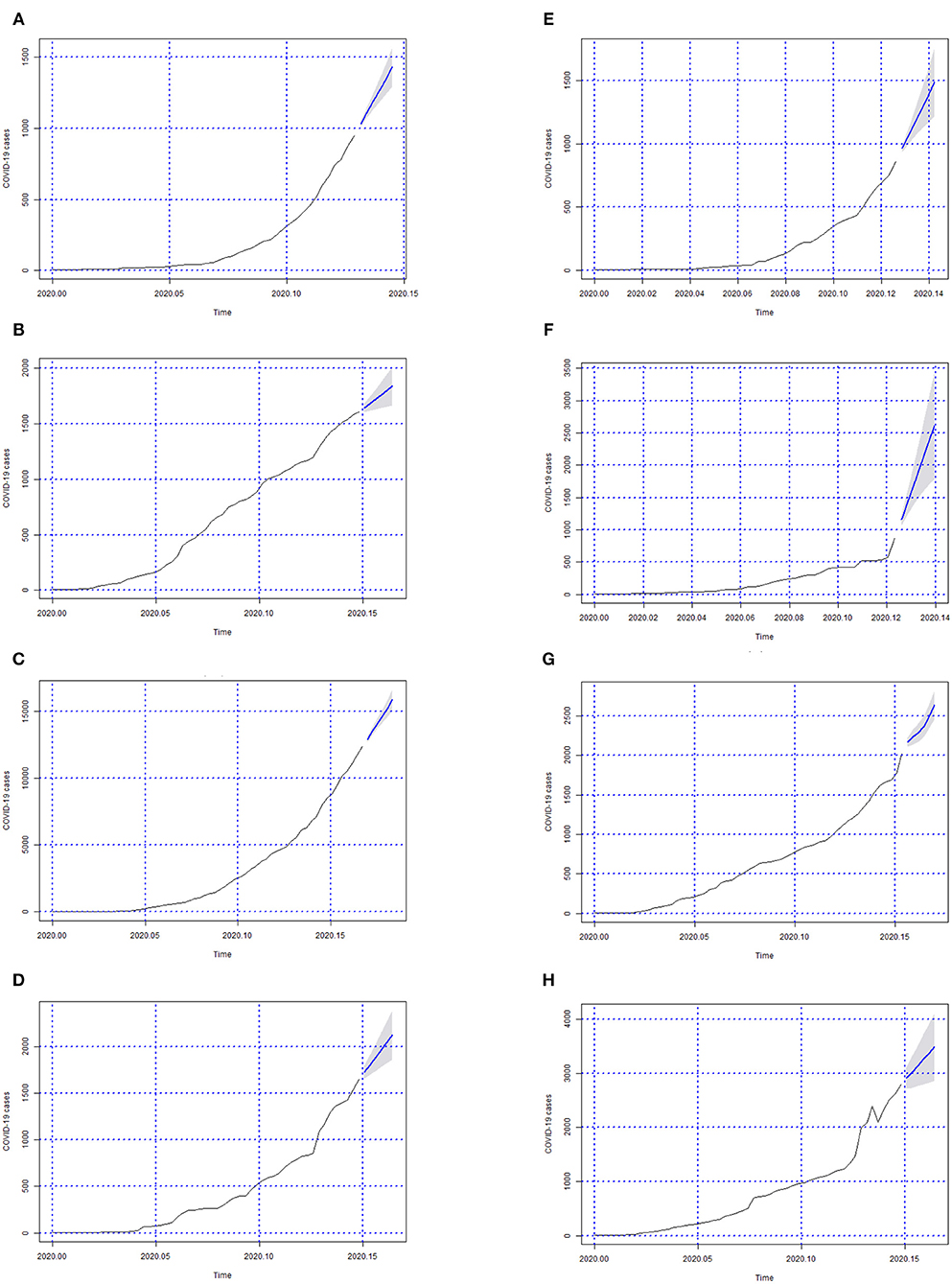
Figure 5. Forecasts of the number of Covid-19 cases from 06-05-2020 to 11-05-2020 for states (A) Piauí, (B) Paraná, (C) Rio de Janeiro, (D) Rio Grande do Norte, (E) Rondônia, (F) Roraima, (G) Rio Grande do Sul, and (H) Santa Catarina.
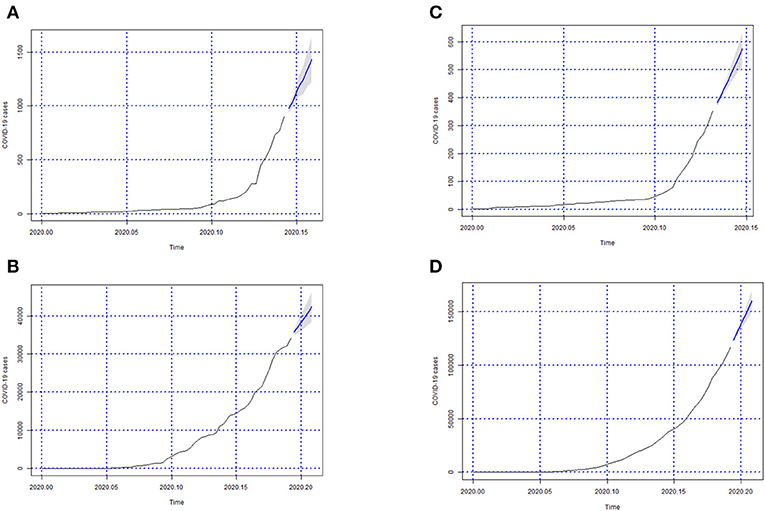
Figure 6. Forecasts of the number of Covid-19 cases from 06-05-2020 to 11-05-2020 for states (A) Sergipe, (B) São Paulo, (C) Tocantins, and (D) the whole country.
4.1. ARIMA Forecasting
The models built were evaluated by taking into account, as global quality, the correlation coefficients of Pearson, Spearman, and Kendall. The RMSE (%) was used with a local quality metric. In this work, a high correlation coefficient is considered to be above 0.9 and a low RMSE below 5%. Table 2 shows the evaluation metrics of the results for the models using ARIMA.
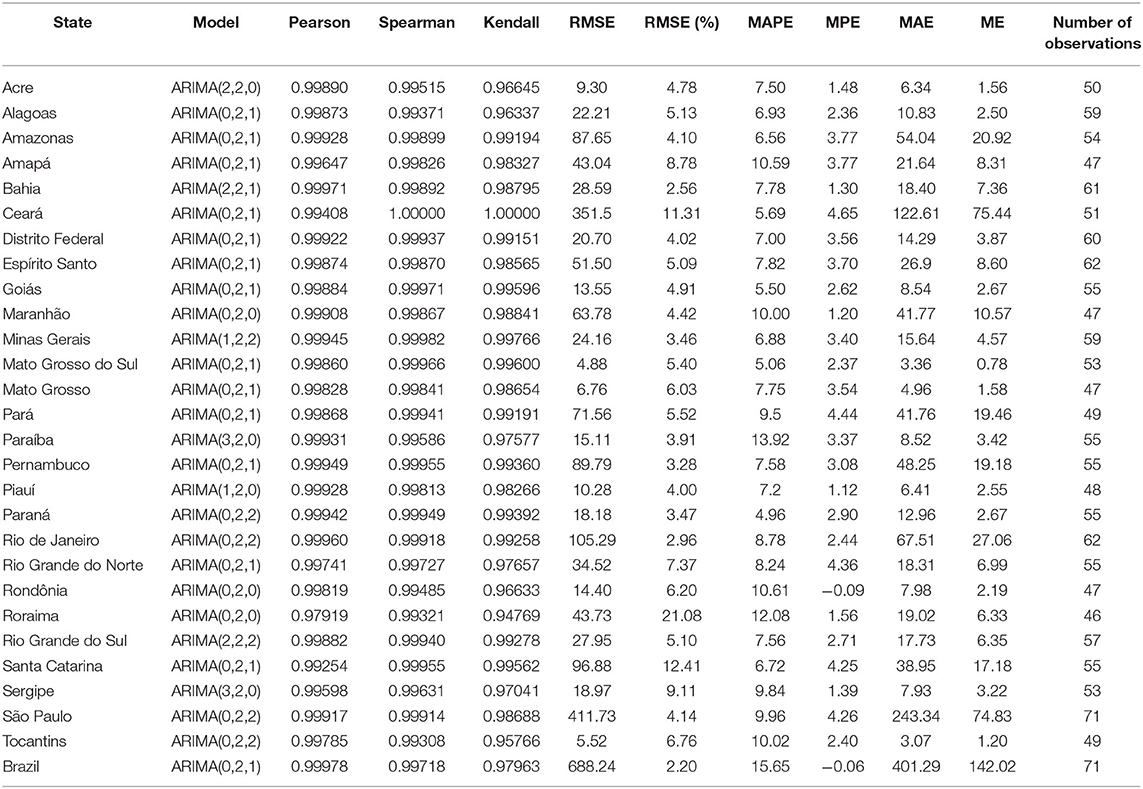
Table 2. Results of the correlation coefficients of Pearson, Spearman, and Kendall, and of the RMSE% for the ARIMA models built for Brazil and its 27 federative units.
Tables 3–7, present the results for the forecast using the ARIMA models for Brazil and each of its 27 federative units. The performance of the models was evaluated by taking into account erro quadrático médio de between the forecasted values and the actual cases of the accumulated cases of Covid-19, as well as the absolute error between the actual cases and the lower or limit of the forecast. The values highlighted in red represent the situations in which the value of the actual cases are outside of the forecasted interval and the absolute error in between the lower or upper limit is <5%.
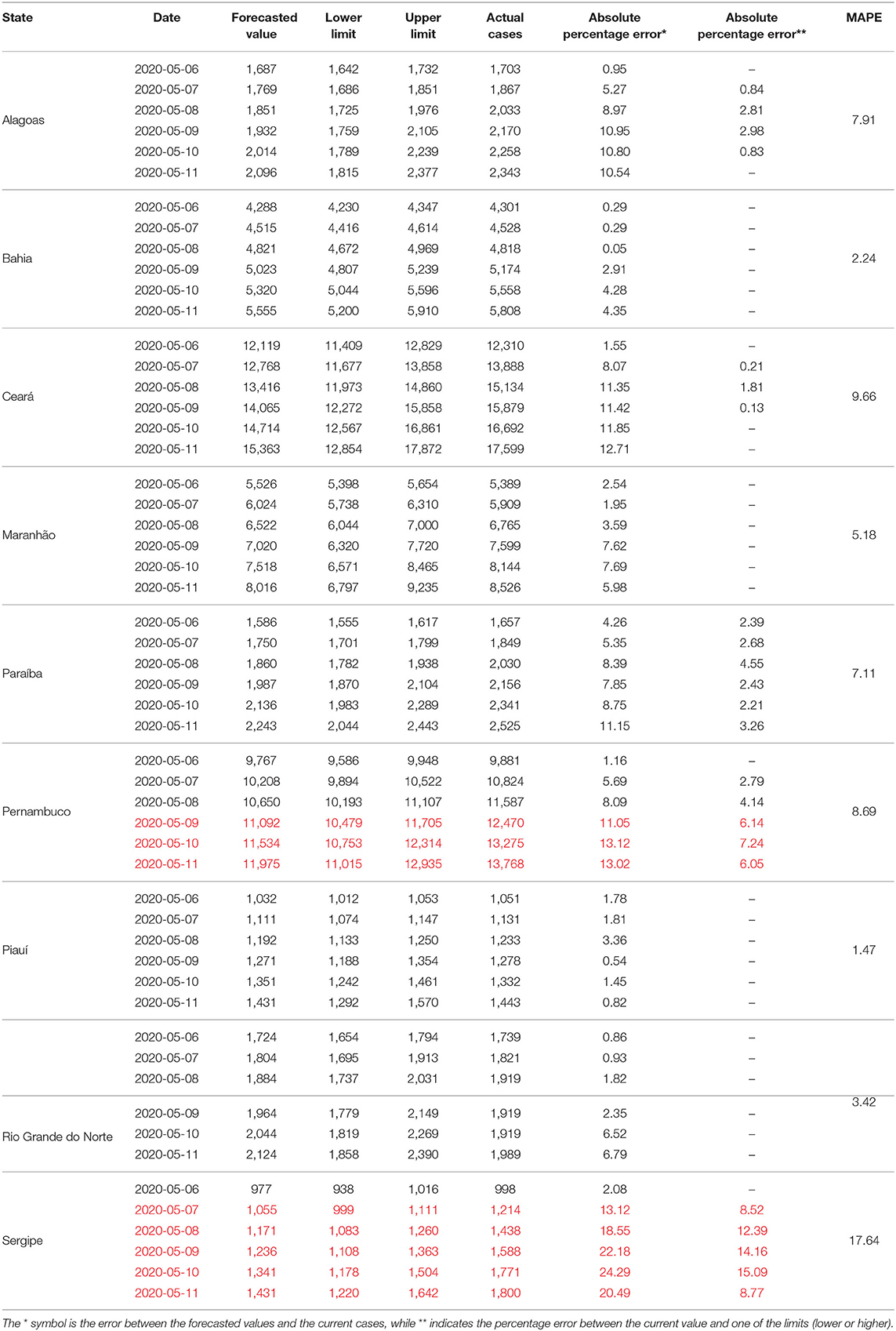
Table 3. Results of projections of confirmed cases of Covid-19 between May 6 and 11, 2020 for the states of the Northeast Region.
The findings in Table 3 show the resulting outputs from the ARIMA models for the Northeast Region of Brazil. For the states of Bahia, Maranhão, Piauí, and Rio Grande do Norte, the actual cases were within the range of the forecast limits from 06 to 11 May. The ARIMA model for the State of Piauí showed the best performance. The errors obtained for actual and estimated cases substantially varied from 0.54 to 3.36%. On the other hand, the model that had the worst performance for this region was the State of Sergipe. For that state in particular and from its 6 days of forecast, we observed that the cases estimated for May 6 were within the forecast interval. On the remaining days, we found that the actual cases accumulated for Covid-19 exceeded the maximum limits of the projections, with errors of 8.52, 12.39, 14.16, 15.09, and 8.77% (see absolute percentage error of Sergipe in Table 2).
Table 4 show the forecasted findings for all states in the Brazilian Northern Region. The models that presented the best performance were the ones for the states of Amapá and Rondônia. For the 6 days of forecast, the actual cases were within the minimum and maximum limits. The worst performances were for the states of Roraima and Tocantins. For those states, the errors between the actual cases and the minimum and maximum limits, respectively, reached more than 55 and 25%.
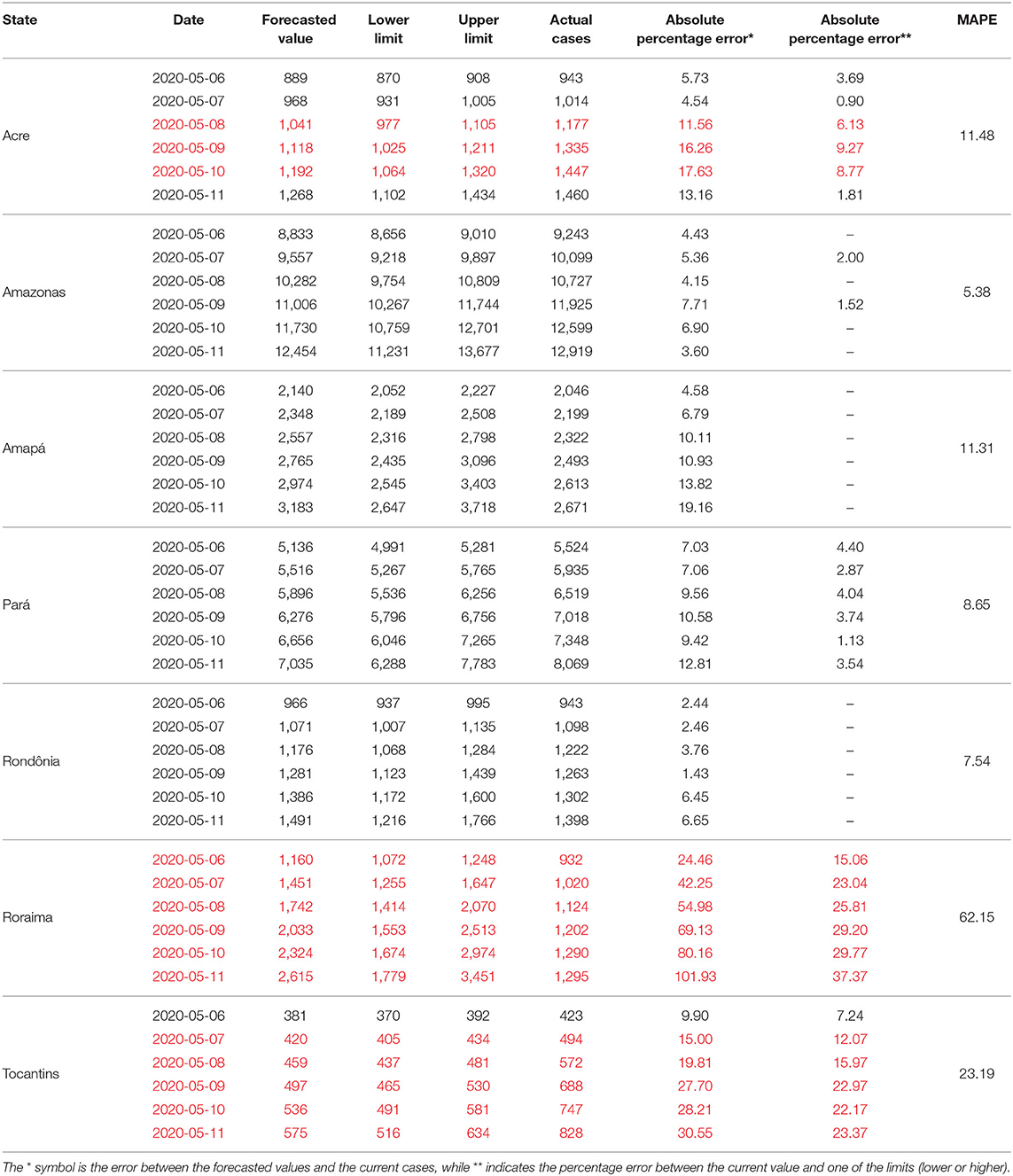
Table 4. Results of projections of confirmed cases of covid-19 between May 6 and 11, 2020 for the states of the Northern Region.
The forecasted findings for the states of the Midwest Region and the Distrito Federal are presented in Table 5. The models referring to the states of Mato Grosso do Sul and Goiás presented the best performances for the region. In the case of the State of Goiás, only the forecast for May 6 was not within the forecast's interval. However, the absolute percentage error between the actual cases and the upper limit did not exceed the 5% mark. In contrast, for the State of Mato Grosso do Sul, the cumulative sum of the actual cases of Covid-19 was not within the forecast's interval. However, the errors considering the actual cases and the upper limit were not <5%. Meanwhile, both models for the state of Mato Grosso and the Distrito Federal presented a low performance, with the latter showing to be the worst for the region. It should be noted that for the 6 days of forecast, all of them were outside the interval between the lower limit and the upper limit. Additionally, only the cumulative sum of the actual cases for May 6 obtained an error below 5% in relation to the upper limit.
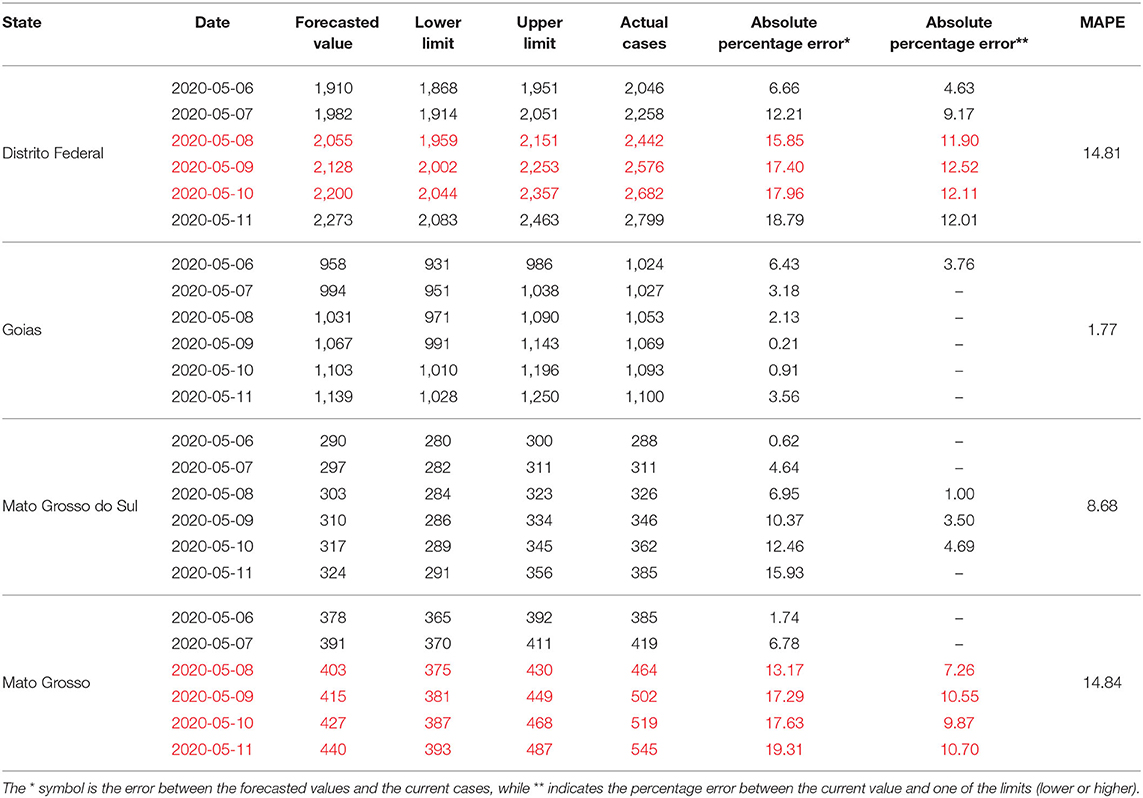
Table 5. Results of projections of confirmed cases of Covid-19 between May 6 and 11, 2020 for the states of the Midwest Region of Brazil and the Distrito Federal.
The results of the forecasts for the states of the Southeast Region are presented in Table 6. Among the four models generated, only the model from the State of Rio de Janeiro did not show a good performance. From the 6 days of forecast, only two met the criteria of a good performance. For the states of Espírito Santo and Minas Gerais, the forecasts for the 6 days were within the forecast interval. In these two states, the absolute percentage errors between the actual cases and the forecasted values varied between 0.10 and 5.36%, for the State of Espírito Santo, and between 0.03 and 5.74%, for the State of Minas Gerais. The actual cases for the State of São Paulo, for most of the forecast days, were outside the lower limit and upper limit interval. However, for those days (May 6th–10th), the errors between the actual cases and the upper limits ranged from 2.40 to 3.57%.
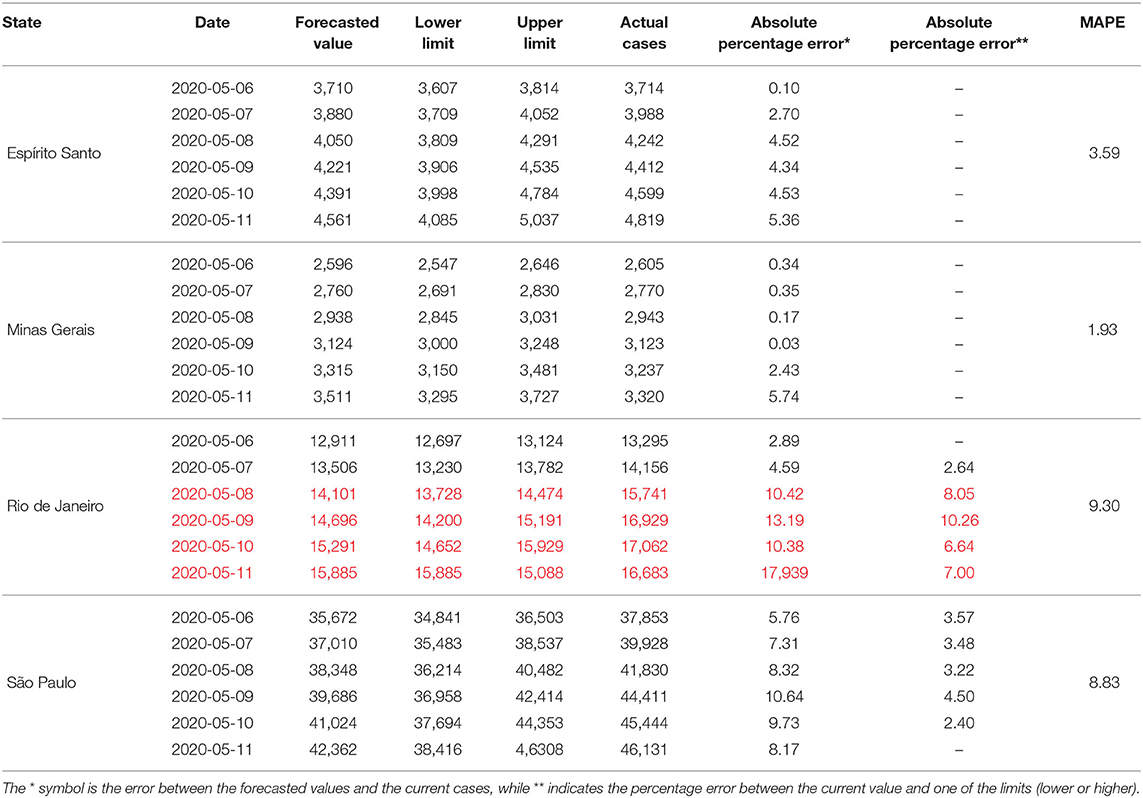
Table 6. Results of projections of confirmed cases of Covid-19 between May 6 and 11, 2020 for the states of the Southeast Region of Brazil.
The ARIMA models generated for the South Region, as shown in Table 7, obtained good results for the forecasts of the cumulative sum of Covid-19 cases for this region. For both the State of Santa Catarina and the State of Paraná, the actual cases were within the forecast interval and very close to the estimated values. The absolute percentage errors between the real cases of the Covid-19 accumulated cases for the two states varied between 0.26 and 3.21%, and 0.19 and 3.30%, respectively. In the case of the forecasts for Rio Grande do Sul, the actual cases of May 8 and 9 are outside the forecast interval range, however the errors between the actual case number and the upper limit were 3.17 and 1.66%, respectively.
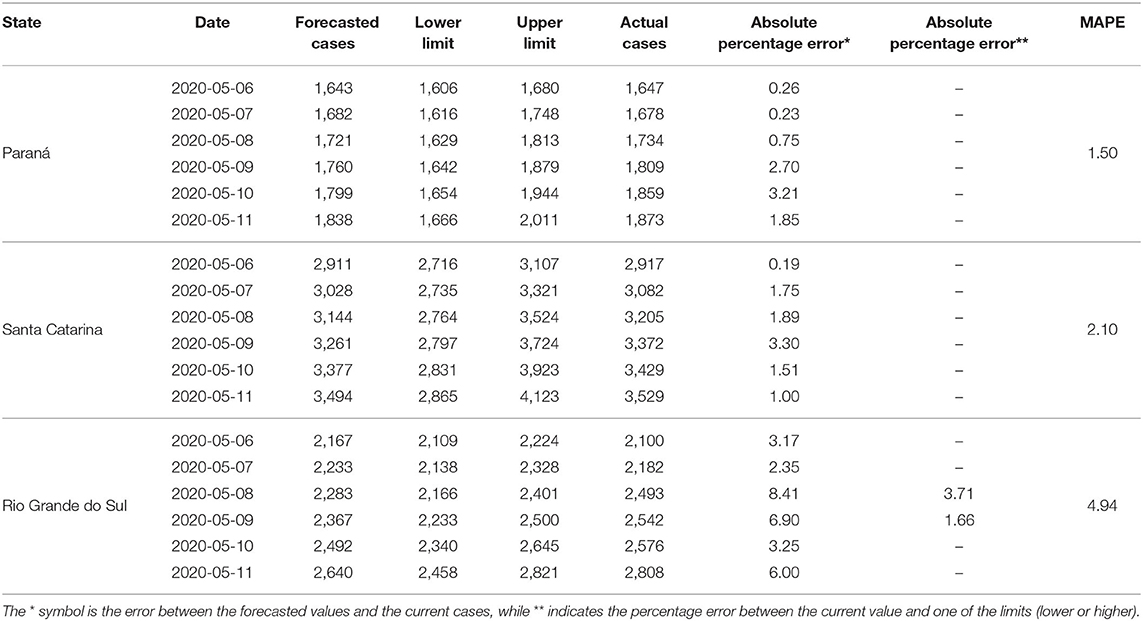
Table 7. Results of projections of confirmed cases of Covid-19 between May 6 and 11, 2020 for the states of the South Region of Brazil.
The results of the forecasts for Brazil are shown in Table 8. From May 6th to 10th, the actual cases were outside the forecast range (they were higher than the upper limit). However, the absolute percentage error between the upper limit and the actual cases did not exceed the 5% limit. On May 11, the value of the actual cases was within the forecast interval, showing an error of 5.63% between the forecasted value and the actual cases.
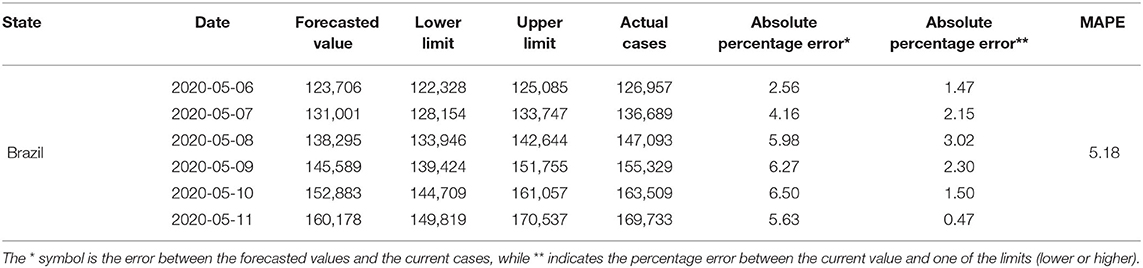
Table 8. Result of the projections of the accumulated confirmed cases of Covid-19 for Brazil between May 6th to 11th, 2020.
4.2. Web Application
The prototype of the developed system can be accessed by the link (https://www.cin.ufpe.br/covidsgis). On the home screen, it is possible to visualize information about spatial forecasts (Figure 7A). The projections of the cumulative cases of Covid-19 can be accessed in the “More information” option, in which the user will be directed to the page with the graphics. In this screen, graphs of the temporal forecasts (Figure 7B), as well as graphs referring to the distribution of daily cases and deaths in Brazil (Figure 7C) are also available. In addition, it is available daily and cumulative cases (Figure 7D), as well as daily and cumulative deaths (Figure 7E). For these graphs, the user can select from which state they wish to evaluate these information. The software's backend is freely available for non-commercial purpose on our Github repository: https://github.com/Biomedical-Computing-UFPE/Covid-SGIS.
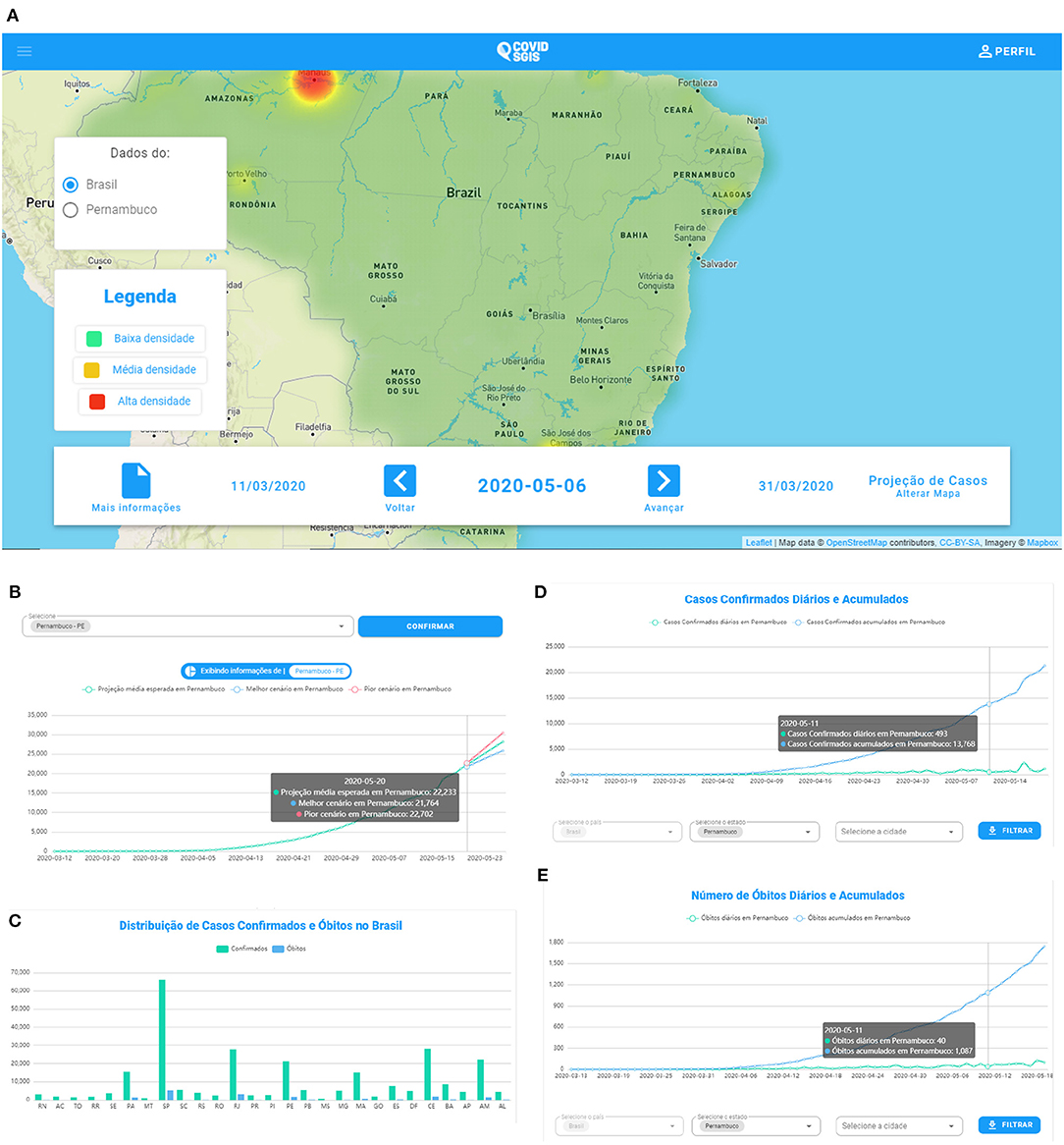
Figure 7. (A) COVID SGIS web application home screen. (B) Accumulated cases of Covid-19 forecast graph. The forecast with ARIMA is represented by the green line. The worst case scenario (indicated by the upper limit of the forecast) is represented by the line in red. The best scenario (indicated by the lower limit of the forecast) is represented by the blue line. (C) Screen of the graph of the distribution of confirmed cases and deaths by Covid-19. In this graph the user can have an overview of the accumulated confirmed cases and death cases in all states of Brazil and the Distrito Federal. In COVID SGIS, the user can follow the daily and accumulated confirmed cases (D) and deaths (E) of Covid-19 for each Brazilian state and the Distrito Federal, separately.
5. Discussion
In this study, we evaluated the forecast of the cumulative cases of Covid-19 for Brazil, and its 27 federative units in Brazil, using ARIMA models in the period between May 6 and 11. To our knowledge, this is the first study to integrate ARIMA models, GIS and data health sciences into a computerized system for the forecast and surveillance of Covid-19 within a Brazilian context. Our findings showed that the overall cases of Covid-19 in Brazil were on the rise during the observed periods, as shown in Figure 6D, whereby such rises were confirmed through the analyses of actual Covid-19 cases for the same time period as shown in Table 8 which shows evidence of the growth in the number of cases. Furthermore, our approach is able to detect the peaks of the disease within this period as shown in Table 8, which was not possible to observe in prior studies.
In Figures 3–6; the images show the forecasts' curves of Covid-19 cases for each of the states in those observed period and how they all tended to increase. This fact was confirmed with the results in the section 4. Both for Brazil and its federative units, the ARIMA(p, d, q) models managed to capture the trend patterns in the curves. This can be useful for health managers and governments in promoting public policies for combating the burden of Covid-19.
One of the limitations of this work is related to the fact that the ARIMA models analyze only univariate time series. Therefore, factors, such as population distribution, the influence of isolation policies and factors linked to population dynamics were not taken into account. Data related to the geographic space and climate of the federative units were also excluded from the model. The authors are aware that this may have contributed to the high errors in the states of Acre, Tocantins and Rondônia.
The low performance of the forecasts for some Brazilian states may be associated with the underreporting of cases. That is, the amount of tests for the diagnosis is not sufficient to meet the populational demand. Thus, people who are asymptomatic or have symptoms of the disease, but have not been tested, are not counted in the reported cases. This problem makes the data substantial underestimated. In addition to this problem linked to underreporting, the authors acknowledge that the forecasting from these models may potentially lack statistical power, a problem which is typically associated with lower sample size which is again due to the undocumented and/or underreported cases in some areas of Brazil.
Another factor that may be associated with higher errors in the forecasts is the time taken to update the databases from the Departments of Health. This directly affects the historical series of the states' accumulated cases, and also the time it takes for the models to process large volumes of data. Indeed, the ARIMA algorithm are quite computationally expensive in terms of time and power needed to crunch large stores of historical data in time series format, and thus such delay in updating the databases are inevitable which, in turn, directly affect the real-time forecasts. In addition, the high forecast errors can also be associated with the historical series itself. As the day of the first notification varies from state-to-state.
Using more features could contribute to improve the forecasts. However, since the main vectors for Covid-19 spreading are the human beings, we believe these new features should emerge from a population model complex enough to include the local population behavior due to economical needs, for instance, since the unemployed population has significantly increased since the beginning of the social distancing measures. Such a population model should be consistent with seasonal variations as well, since these aspects influence economical dynamics in a country as large as Brazil with large environmental diversity. However, since the construction of a sufficient population model to generate additional features for Covid-19 forecasting is out of the scope of this work, we preferred to keep ARIMA due to its computational advantages (essentially, low memory usage and no intensive processing) and relatively good forecasting results in most of cases as discussed above.
Brazil's Covid-19 epidemiological data are very likely to be underestimated. Since 2018, the country has been experiencing a real plague of false news that circulates freely on social networks, especially among people with lower education. This aspect, as well as the action of negationist movements, contributes to disorient the population regarding measures of social distancing and contamination prevention (30). Another important aspect is the high level of social inequality and the low sanitary conditions that affect the lowest income population. According to Prado (30) 13 million Brazilians live in Favelas (i.e., urban settlements which are under-developed and greatest levels of socioeconomic deprivation), where its widespread to see a single room inhabited by more than three people, and where access to clean water and security are precarious. These are factors which we were unable to include in our ARIMA models for Covid-19 due to such paucity of data also due to limitations of modeling with ARIMA. The authors therefore acknowledge the lack of these risk factors and its inclusion to the model may have led to some residual confounding in our analysis.
6. Conclusion
Several countries are greatly affected by the increased burden of Covid-19. With a high number of infected people and the public health systems operating at maximum capacity, the situation is becoming increasingly critical. For this reason, it is important to have a tool that performs the forecast of Covid-19 cases so as able support government officials, health managers, and general stakeholders to be informed to execute health policies and targeted interventions. Therefore, it is possible to make short-term decisions, develop public policies, and direct resources to health professionals and hospitals. In addition, the forecasting tool can assist governments in controlling measures of social isolation and lockdown. The evaluation of these forecasts allows to intensify the restrictions of social agglomerations, as well as to evaluate the effect of these measures in the contagion of the population.
With that in mind, our motivation is to provide a robust, flexible, and rapid forecasting method. Thus, we combined the ARIMA model for time series analysis with Artificial Intelligence techniques. ARIMA was an excellent choice for the purpose, being efficient in forecasting Covid-19, which has a rapid proliferation and changes to the daily scenarios. The method is capable of presenting the forecast if the context of the forecast moment remains constant, as well as presenting the best and worst scenarios, with their 95% confidence interval limits.
The developed models achieved good performance when taking into account their percentage errors. Among the 26 Brazilian states analyzed plus Distrito Federal, the majority presented satisfactory results, with low error rates. Some states, such as Roraima, Tocantins, and Distrito Federal showed higher errors. Some hypotheses can be raised for this: many cases of Covid-19 are not reported, as in cases of asymptomatic people or who remained in isolation at home; in addition, database updates can be slow, directly affecting the forecast of the following days. This fact becomes even worse when taking into account the measures of the Brazilian Ministry of Health to limit testing to severe cases attested by clinical diagnosis.
Besides that, some specific issues in Brazil directly affected the course of the pandemic. One fundamental challenge resides on the strong social inequality in the country (31), and the lack of government planning to deal with this reality (32). Many Brazilian citizens do not have a fixed income and a formal job (33). Furthermore, the impact of the pandemic on income-generating activities is most severe for unprotected workers and for the most vulnerable groups in the informal economy (33, 34). Although the Federal Government has been providing monthly aid to the most financially affected families, there are several difficulties in accessing this aid. In addition, in many cases, it is not enough to guarantee basic survival needs. It is also important to highlight the lack of access to hygiene information and basic protection items, such as masks and alcohol, by the less favored population (35). As a consequence, these people need to work and thus break the imposed social isolation policies. In this way, there is a considerable portion of the population circulating on the streets, increasing the population susceptible to contamination by SARS-CoV-2.
Despite this, our method provides a possibility of dynamic forecasting: the proposed model is retrained and adapted to the real scenario in a daily basis. The proposed model is trained everyday with a maximum window of 3 days, achieving low errors in most forecasts, and acceptable errors (inside the confidence interval) in the worst scenarios. This forecasting window is dynamic, since it is chosen by automatic ARIMA models. Another advantage of our proposal is the use of multiple databases. In this way, several countries can benefit from this solution, adapting the model to their databases, incorporating dedicated web crawlers, for instance. Our system can be an important tool to guide the course of this pandemic.
The scope of our proposal comprises the forecast of Covid-19 cases in real time. As a case study, the tool developed, COVID-SGIS, was applied to the forecast of cases in Brazil, in each of the 27 units of the Federation, and in each of the 5,570 municipalities. Brazil is a continental country, with a population of 209.5 million people and involving an area larger than that of Western Europe. Every 24 h, the proposed system collects information from the state health departments for each federative unit and each municipality. And every day the model is retrained with all the data obtained since the official start of the pandemic in the country: March 2020. Thus, a model that could provide good accuracy at a low computational cost of training, with a low demand for memory and processing, is a prerequisite for this problem. Among the low computational cost models investigated, the standard ARIMA has met this prerequisite with an accuracy that can be considered very good or acceptable in most cases.
The situation at Covid-19 is somewhat different from that of other diseases. In arboviruses, for example, vectors and population must be modeled as completely different entities. In addition, the epidemiological dynamics is also influenced by climatic and environmental factors, in addition to socioeconomic factors. In these models, population modeling can help increase accuracy. In the case of Covid-19, we believe that it is quite reasonable to assume that geographic location and the number of cases is the most relevant factors, given that Covid-19 spreads very quickly and that climatic and environmental factors are unrelated to the disease. In Covid-19, the vector and the population coincide, given that the contamination occurs from human to human. The good results obtained by the model we propose show that our hypothesis of focusing on the number of cases, given that the predictors have each municipality and each federative unit as a reference, is correct. Thus, if we wanted to increase the model's accuracy by increasing the number of attributes, these attributes could emerge from a population model. This would be a reasonably complex model, one that could be able to deal with socioeconomic differences that lead to increasing the mobility of low-income populations and to violating social distancing measures. However, there is no guarantee that such a model could contribute to increased accuracy, although this would be an interesting point for future works.
Data Availability Statement
The datasets referring to confirmed cases of Covid-19 can be found in the Brasil.io website (https://brasil.io/home/). The software's back-end is available on our Github repository: https://github.com/Biomedical-Computing-UFPE/Covid-SGIS.
Author Contributions
CdL: responsible for the design of forecasting models using machine learning and models' implementation in R code. CdS: responsible for the design of forecasting models using machine learning. AdS, MdS, JG, and VdF: responsible for models' implementation in R code. ES, GM, LdA, LAA, and SSd: front-end and back-end developers. AM, PK, WdS, and AdS: associate researchers and supervisors. All authors contributed to the article and approved the submitted version.
Funding
This study was funded by the Federal University of Pernambuco, the Brazilian research agencies FACEPE, CAPES, and CNPq, and the University College London held UKRI research grant number NE/T013664/1.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This manuscript has been released as a pre-print at medRxiv (36).
The authors were grateful to the Brazilian research agencies FACEPE, CAPES, and CNPq, for the partial financial support of this research.
Footnotes
References
1. Zhang T, Wu Q, Zhang Z. Probable pangolin origin of SARS-CoV-2 associated with the COVID-19 outbreak. Curr Biol. (2020) 30:1346–51.e2. doi: 10.1016/j.cub.2020.03.022
2. WHO. Coronavirus Disease (COVID-19) Pandemic. (2020). Available online at: www.who.int/emergencies/diseases/novel-coronavirus-2019 (accessed May 20, 2020).
3. Guo YR, Cao QD, Hong ZS, Tan YY, Chen SD, Jin HJ, et al. The origin, transmission and clinical therapies on coronavirus disease 2019 (COVID-19) outbreak-an update on the status. Milit Med Res. (2020) 7:1–10. doi: 10.1186/s40779-020-00240-0
4. Döhla M, Boesecke C, Schulte B, Diegmann C, Sib E, Richter E, et al. Rapid point-of-care testing for SARS-CoV-2 in a community screening setting shows low sensitivity. Public Health. (2020) 182:170–2. doi: 10.1016/j.puhe.2020.04.009
5. Okba NM, Muller MA, Li W, Wang C, GeurtsvanKessel CH, Corman VM, et al. SARS-CoV-2 specific antibody responses in COVID-19 patients. medRxiv. (2020) 2020. doi: 10.1101/2020.03.18.20038059
6. Li Z, Yi Y, Luo X, Xiong N, Liu Y, Li S, et al. Development and clinical application of a rapid IgM-IgG combined antibody test for SARS-CoV-2 infection diagnosis. J Med Virol. (2020) 92:1518–24. doi: 10.1002/jmv.25727
7. Liu Y, Liu Y, Diao B, Ren F, Wang Y, Ding J, et al. Diagnostic indexes of a rapid IgG/IgM combined antibody test for SARS-CoV-2. medRxiv. (2020) 2020. doi: 10.1101/2020.03.26.20044883
8. Chen S, Yang J, Yang W, Wang C, Bärnighausen T. COVID-19 control in China during mass population movements at New Year. Lancet. (2020) 395:764–6. doi: 10.1016/S0140-6736(20)30421-9
9. Day M. Covid-19: identifying and isolating asymptomatic people helped eliminate virus in Italian village. BMJ. (2020) 368:m1165. doi: 10.1136/bmj.m1165
10. Salathé M, Althaus CL, Neher R, Stringhini S, Hodcroft E, Fellay J, et al. COVID-19 epidemic in Switzerland: on the importance of testing, contact tracing and isolation. Swiss Med Wkly. (2020) 150:w20225. doi: 10.4414/smw.2020.20225
11. Oliveira WKd, Duarte E, França GVAd, Garcia LP. How Brazil can hold back Covid-19. Epidemiol Serv Saúde. (2020) 29:e2020044. doi: 10.5123/S1679-49742020000200023
12. Guo P, Liu T, Zhang Q, Wang L, Xiao J, Zhang Q, et al. Developing a dengue forecast model using machine learning: a case study in China. PLoS Negl Trop Dis. (2017) 11:1–22. doi: 10.1371/journal.pntd.0005973
13. Siriyasatien P, Chadsuthi S, Jampachaisri K, Kesorn K. Dengue epidemics prediction: a survey of the state-of-the-art based on data science processes. IEEE Access. (2018) 6:53757–95. doi: 10.1109/ACCESS.2018.2871241
14. Baquero OS, Santana LMR, Chiaravalloti-Neto F. Dengue forecasting in São Paulo city with generalized additive models, artificial neural networks and seasonal autoregressive integrated moving average models. PLoS ONE. (2018) 13:e0195065. doi: 10.1371/journal.pone.0195065
15. Wangping J, Ke H, Yang S, Wenzhe C, Shengshu W, Shanshan Y, et al. Extended SIR prediction of the epidemics trend of COVID-19 in Italy and compared with Hunan, China. Front Med. (2020) 7:169. doi: 10.3389/fmed.2020.00169
16. Bastos S, Cajueiro D. Modeling and forecasting the early evolution of the Covid-19 pandemic in Brazil. arXiv. (2020) 200314288.
17. Liu Z, Magal P, Seydi O, Webb G. Predicting the cumulative number of cases for the COVID-19 epidemic in China from early data. Math Biosci Eng. (2020) 17:3040–51. doi: 10.20944/preprints202002.0365.v1
18. Anastassopoulou C, Russo L, Tsakris A, Siettos C. Data-based analysis, modelling and forecasting of the COVID-19 outbreak. PLoS ONE. (2020) 15:e0230405. doi: 10.1371/journal.pone.0230405
19. Yang Z, Zeng Z, Wang K, Wong SS, Liang W, Zanin M, et al. Modified SEIR and AI prediction of the epidemics trend of COVID-19 in China under public health interventions. J Thorac Dis. (2020) 12:165. doi: 10.21037/jtd.2020.02.64
20. Ardabili SF, Mosavi A, Ghamisi P, Ferdinand F, Varkonyi-Koczy AR, Reuter U, et al. COVID-19 outbreak prediction with machine learning. medRxiv. (2020). doi: 10.31234/osf.io/5dyfc
21. Hyndman RJ, Khandakar. Automatic time series forecasting: the forecast package for R. J Stat Softw. (2008) 27:1–22. doi: 10.18637/jss.v027.i03
22. Kermack W, McKendrick A. A contribution to the mathematical theory of epidemics. R Soc Lond A Math Phys Sci A. (1927) 115:700–21. doi: 10.1098/rspa.1927.0118
23. Britton NF. Essencial Mathematical Biology. London: Springer Undergraduate Mathematics Series (2003).
25. Ma Y, Principe JC. A taxonomy for neural memory networks. IEEE Trans Neural Netw Learn Syst. (2020) 31:1780–93. doi: 10.1109/TNNLS.2019.2926466
26. Ceylan Z. Estimation of COVID-19 prevalence in Italy, Spain, and France. Sci Total Environ. (2020) 729:138817. doi: 10.1016/j.scitotenv.2020.138817
27. Chakraborty T, Gosh I. Real-time forecasts and risk assessment of novel coronavirus (COVID-19) cases: a data-driven analysis. Chaos Solit Fract. (2020) 135:109850. doi: 10.1016/j.chaos.2020.109850
29. Witten IH, Frank E. Data Mining: Practial Machine Learning Tools and Technique. San Francisco, CA: Morgan Kaufmann Publishers (2005).
30. Prado B. COVID-19 in Brazil: “so what?”. Lancet. (2020) 395:1461. doi: 10.1016/S0140-6736(20)31095-3
31. Santos JAF. COVID-19, fundamental causes, social class and territory. Trabalho Educ Saúde. (2020) 18:1–7. doi: 10.1590/1981-7746-sol00280
32. Ortega F, Orsini M. Governing COVID-19 without government in Brazil: ignorance, neoliberal authoritarianism, and the collapse of public health leadership. Glob Public Health. (2020) 15:1257–7. doi: 10.1080/17441692.2020.1795223
33. Costa SdS. Pandemia e desemprego no Brasil. Rev Admin Públ. (2020) 54:969–78. doi: 10.1590/0034-761220200170
34. Nicola M, Alsafi Z, Sohrabi C, Kerwan A, Al-Jabir A, Iosifidis C, et al. The socio-economic implications of the coronavirus and COVID-19 pandemic: a review. Int J Surg. (2020) 78:185–93. doi: 10.1016/j.ijsu.2020.04.018
35. Natividade MdS, Bernardes K, Pereira M, Miranda SS, Bertoldo J, Teixeira MdG, et al. Social distancing and living conditions in the pandemic COVID-19 in Salvador-Bahia, Brazil. Ciênc Saúde Coletiva. (2020) 25:3385–92. doi: 10.1590/1413-81232020259.22142020
Keywords: SARS-CoV-2 spread forecast, intelligent forecasting systems, infectious diseases, dynamic forecasting systems, Covid-19 forecasting
Citation: de Lima CL, da Silva CC, da Silva ACG, Luiz Silva E, Marques GS, de Araújo LJB, Albuquerque Júnior LA, de Souza SBJ, de Santana MA, Gomes JC, de Freitas Barbosa VA, Musah A, Kostkova P, dos Santos WP and da Silva Filho AG (2020) COVID-SGIS: A Smart Tool for Dynamic Monitoring and Temporal Forecasting of Covid-19. Front. Public Health 8:580815. doi: 10.3389/fpubh.2020.580815
Received: 07 July 2020; Accepted: 19 October 2020;
Published: 17 November 2020.
Edited by:
Nilufar Baghaei, Massey University, New ZealandReviewed by:
Robertas Damasevicius, Silesian University of Technology, PolandFarhad Mehdipour, Otago Polytechnic Auckland, New Zealand
Copyright © 2020 de Lima, da Silva, da Silva, Luiz Silva, Marques, de Araújo, Albuquerque Júnior, de Souza, de Santana, Gomes, de Freitas Barbosa, Musah, Kostkova, dos Santos and da Silva Filho. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wellington Pinheiro dos Santos, d2VsbGluZ3Rvbi5zYW50b3NAdWZwZS5icg==