 Eric Appiah Mantey1*†
Eric Appiah Mantey1*† Conghua Zhou1*†
Conghua Zhou1*† Joseph Henry Anajemba2†
Joseph Henry Anajemba2† Izuchukwu M. Okpalaoguchi3†Onyeachonam Dominic-Mario Chiadika4†
Izuchukwu M. Okpalaoguchi3†Onyeachonam Dominic-Mario Chiadika4†- 1School of Computer Science & Comm. Engineering, Jiangsu University, Zhenjiang, China
- 2Department of Communication Engineering, Hohai University, Changzhou, China
- 3Department of Computer Science, Nnamdi Azikiwe University, Awka, Nigeria
- 4Electronic and Computer Engineering, Brunel University, London, United Kingdom
Recommender systems offer several advantages to hospital data management units and patients with special needs. These systems are more dependent on the extreme subtle hospital-patient data. Thus, disregarding the confidentiality of patients with special needs is not an option. In recent times, several proposed techniques failed to cryptographically guarantee the data privacy of the patients with special needs in the diet recommender systems (RSs) deployment. In order to tackle this pitfall, this paper incorporates a blockchain privacy system (BPS) into deep learning for a diet recommendation system for patients with special needs. Our proposed technique allows patients to get notifications about recommended treatments and medications based on their personalized data without revealing their confidential information. Additionally, the paper implemented machine and deep learning algorithms such as RNN, Logistic Regression, MLP, etc., on an Internet of Medical Things (IoMT) dataset acquired via the internet and hospitals that comprises the data of 50 patients with 13 features of various diseases and 1,000 products. The product section has a set of eight features. The IoMT data features were analyzed with BPS and further encoded prior to the application of deep and machine learning-based frameworks. The performance of the different machine and deep learning methods were carried out and the results verify that the long short-term memory (LSTM) technique is more effective than other schemes regarding prediction accuracy, precision, F1-measures, and recall in a secured blockchain privacy system. Results showed that 97.74% accuracy utilizing the LSTM deep learning model was attained. The precision of 98%, recall, and F1-measure of 99% each for the allowed class was also attained. For the disallowed class, the scores were 89, 73, and 80% for precision, recall, and F1-measure, respectively. The performance of our proposed BPS is subdivided into two categories: the secured communication channel of the recommendation system and an enhanced deep learning approach using health base medical dataset that spontaneously identifies what food a patient with special needs should have based on their disease and certain features including gender, weight, age, etc. The proposed system is outstanding as none of the earlier revised works of literature described a recommender system of this kind.
Introduction
The idea of a secured recommendation system has been proposed in recent times due to the nature of diseases and dietary effects suffered by patients with unique conditions that inhibit their ability to receive routine diet recommendation care. This system which is incorporated with a blockchain privacy mechanism is advantageous to both the hospital data management unit and the patients with special needs in terms of privacy violation protection, scandals, and longevity of the patients. In (1), the authors gave a comprehensive explanation, including their history and basic concepts of networks and how they could be applied in the field of pharmaceutical sciences as an option instead of just traditional methodology. The authors of (2) discussed the various ways Artificial Neural Networks (ANNs) can be applied to resolve challenges in the pharmaceutical field. Similarly, in (3), the authors discussed how ANNs can be used in diverse ways in medicine such as in the delivery of drugs, classification of cancer, research in pharmaceutics and others. The authors of (4) proposed an algorithm to solve the issue of classification, analysis, and summarization of document analytics. Experimental results showed the efficiency of the algorithm regarding its precision and implementation time. In (5), the authors proposed a solution based on deep learning for medical datasets which identifies what kind of food a patient should be fed based on factors like the nature of diseases, gender, age, and weight, among others. Their framework made use of machine learning and deep learning algorithms. Experimental results showed its efficiency and accuracy.
The motivation of this study is to enhance, secure, and analyze the performance of an expansive nutritional theory into the Internet of Medical Things (IoMT) using a blockchain privacy system and deep learning algorithms.
The contributions of this study are stated below:
• To propose and incorporate a reliable blockchain privacy system (BPS) for a secured diet recommendation system for patients with special needs.
• To investigate and perform analysis of machine learning, deep learning system previously used on IoMT such as Naive Bayes and logistic regression, recurrent neural network (RNN), gated recurrent unit (GRU), and long short-term memory (LSTM).
• To design an all-inclusive diet recommendation model which can be applied for patient special needs products and disease specifications.
• To analyze the behavior of our Enhanced Artificial Intelligence (AI) and deep learning mechanisms and how it is administered.
• The result showcased the Enhanced Machine Learning and deep learning for patients with special needs and for treating varied patient diseases with varied recommender evidence that is secured using a blockchain privacy system.
Structure
The remaining part of the study laid out on this paper is organized as follows. Several literature are revised and detailed in the related works section. Introduced in section System Model are the methods and materials of the system, including its execution utilizing AI. Summarized in section Experiments and Results are the findings of the conducted experiment in this study. Finally, the conclusions of the study are discussed in section Conclusion and Future Work.
Related Works
Blockchain is one of the most recent subjects currently under-studied and has been recently incorporated into several societal, industrial and academic scenarios (6). One of the areas that have extensively incorporated the BPS is the hospital and patient recommender systems. The authors in (7) proposed research for customizing a service for the recommendation of diet for its customers which prevents and manages heart diseases in the area of healthcare. It provides this service by putting into consideration factors like family history of illnesses, preferences of food, vital signs, etc., of the customers with the issue of heart diseases. This service can aid customers to change their living habits to healthier ones. The study conducted by the authors of (8) proposed a framework for nourishment recommendation where input is retrieved from children and analyzed, which results in output that provides for a better and healthier diet plan. Its goal is to provide kids from the age of eight to their early teens with a healthier eating lifestyle which varies according to their age, gender, and other related factors. The study of the authors in (9) suggested a platform that smartly plans the meals of users according to their health conditions. This platform makes use of machine learning algorithms to function. The authors of (10) studied the impact of various factors which influence the adoption and use of a user of online health facilities, specifically in Ukraine and China. The authors in (11) proposed a framework that recommends healthy diet plans to patients that have hypertension. It utilizes machine learning algorithms and considers factors such as allergies, food preferences, age, and blood pressure, among others. The study conducted by the authors of (12) discussed how blockchain technology in conjunction with the Internet of Things (IoT) could be used to monitor the supply chain efficiently. The \ study of the authors in (13) proposed a system that recommends healthier diets specifically for American Indians with diabetes, by studying the profile of the user with clinical regulations and guidelines. The system makes customized recommendations based on various factors for the AI patient. The authors of (14) used a neural network deep learning method to explain how big data analytics could be utilized in the execution of an efficient system for health recommendation, and demonstrates how the industry of healthcare could evolve from a customary system to a more customized one in the online health environment.
The authors in (15) examined the ways for calculating and measuring the similarities of users in health websites. The recommendation of similar users to customers aids in the support search, whether emotional or not in a more efficient way. The study conducted by the authors of (16) presented an overview of the literature that examines how machine learning algorithms are used in recommender systems and also pinpoints opportunities for research in the software engineering field. It concluded that the algorithms are used because they are not complex. The study of the authors in (17) proposed a method for recognizing parameters that influence processes and suggests a framework for machines by executing a device that can collect a large amount of data and integrate them into the Cloud for more studies. The authors of (18) identified various ways big data analytics could be utilized and gave its benefits regarding IT framework in strategic areas. They also suggested tactics for organizations concerned with healthcare to adopt big data analytics. The authors in (19) proposed a recommendation of threads to health communities' online users by making use of diverse healthcare information network mining. The study conducted by the authors of (20) proposed a scheme to improve the efficacy of recommender systems and preserve privacy, as long as the data collected are examined efficiently. The study of the author in (21) provided an exhaustive review of all research regarding and related to recommender systems that are based on deep learning technology. The authors of (22) proposed a model that is based on fog deep learning that acquires data from people and forecasts their fitness statistics and abnormalities making use of a model that is based on a neural network that is capable of handling diverse and large amounts of data.
The authors in (23) proposed a recommender system that delivers accommodative nutrition information to extend and improve the lives of people with diet-related illnesses, as well as healthy people. The system recommends nutrition according to the health profile of the user. The study conducted by the authors of (24) proposed an architecture that collects and collates data from different primary indicators of performance in healthcare communities, as well as predicts possible values of these principal performance indicators. The study of the authors in (25) proposed a system that utilizes customized features concerning nutrition that aids users in the change of their attitude toward healthier food choices and diets. The authors of (26) conducted a review to determine if dieted and nutritional products are issues often left out in shortages research. The authors in (27) proposed a framework for the recommendation of everyday meals while also managing preference-inclusive and nutritional information. The study conducted by the authors of (28) proposed a recommender system making use of analysis of food clustering for patients with diabetes. The study of the authors in (29) reviewed numerous existing works of literature and discovered lacunas in the existing systems of diet management. The authors of (30) in their study concentrated on developing a recommender system that integrates Artificial Intelligence methods and creates a base of knowledge following the appropriate and lawful guidelines and regulations concerning diabetes. The recommended menu is according to the preferences and conditions of the patients.
The authors in (31) presented a recommender system that is based on the pathology report of the user. This system utilizes the ant colony algorithm to create a menu and suggests appropriate food in line with the values of the pathology report of the user. The study conducted by the authors of (32–34) discussed error sources regarding nutrition, as well as possible solutions to tackle those challenges for future systems. They also discussed the incorporation of nutritional propositions into information systems. The study of the authors in (35) proposed a management system to aid in the preparation of a proper and healthy diet for children. The authors of (36) studied the shifts in obesity and its various kinds from the richer to the less fortunate across an era of economic growth in a developing country (Malaysia). They concluded that as the country develops, the risk of obesity among the less fortunate should be expected. The authors in (37) proposed a customized recommender system fashioned to meet the nutritional restrictions, preferences, and expectations of the user. The conducted by the authors of (38) recommended a diet plan to patients with jaundice using a hierarchy process that considers vital nutrients to determine the best choice for meals for all times of the day. The study of the authors in (39) discussed the uses and benefits of deep learning methods and ANNs in the advancement of the medical field in areas such as electroencephalography and the collation of physiological data. On the other hand, the authors in (40) presented a review of recommendation methods for people and groups to eat healthier foods. They also studied the existing recommender systems and challenges regarding research of recommendation technology. The study of the authors in (41) presented a Privacy-Preserving and Secure Framework (PPSF) for IoT-driven smart cities. The proposed PPSF is subject to two key schemes: a two-level privacy mechanism and an intrusion detection mechanism. Finally, the potentials of blockchain-enabled edge-of-Things (BEoT) by Prabadevi et al. in (42) was designed to provide security and services which comprises trust management, attack detection, data privacy preservation and access authentication.
System Model
The methodology used in this study is explained in the following discussions. The objective of this study is for the recommendation of diet to various patients with special needs with a BPS utilizing machine and deep learning classifiers for the health-based medical dataset which will spontaneously identify what kind of food a patient with special needs should have, based on their disease and other factors such as weight, gender, and age, among others. For this reason, we have incorporated a BPS utilizing various deep and machine learning classifiers. A random forest classifier was utilized to know what feature has a greater effect on the dataset.
Dataset
The dataset utilized in this study comprises about a thousand products and 50 patients collated using IoT and cloud methods. The products experimented on various disease patients. The dataset possesses over 13 features and has stored in it almost 17,000 records. The features of the products are listed in Table 1, the features of the patient are listed in Table 2, while Table 3 is the Training accuracy of models after BPS.
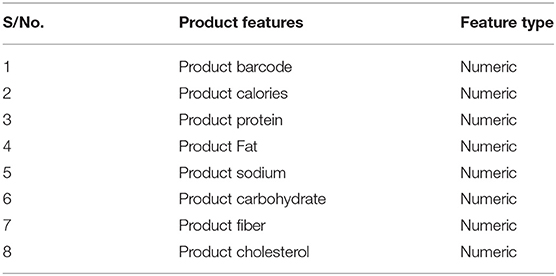
Table 1. Number of features in the product.
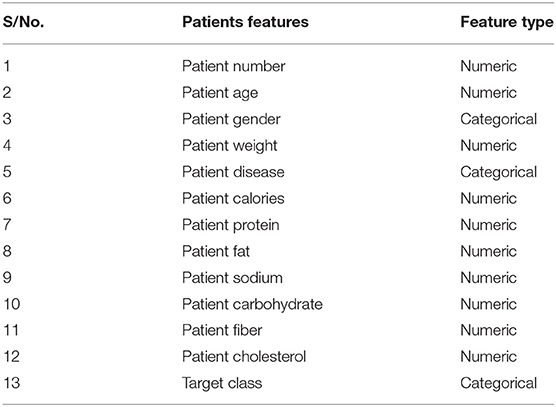
Table 2. Features of patients.

Table 3. Training accuracy of models after BPS.
Data Preservation and Protection
The proposed BPS can be used by patients to store and preserve their personal data which are applicable to recommender systems. Example of such data includes diagnosed illness, treatment status, demographic attributes, prescribed medications, and response performance, among others. The BPS stores and fully encrypts this set of data, such that, accessing them without permission is almost impossible. Other related data, such as health history, diets of the patients, and more, which illustrates the actual treatment performance that is vital for the recommender systems are classically gathered by the hospital database system (HDS). These user-sensitive data are transmitted and stored in the BPS instead of the database of the hospitals, as illustrated in Figure 1, in order to enhance privacy by preventing attacks of the eavesdroppers, hacker attacks, and other intruding vulnerabilities. On the other hand, the BPS grants adequate permission to the patients to access these data in a very secured and trusted format. In case of a recommendation, prescription, check-ups, or emergencies, the BPS also sends a prompt notification to the registered smart device of the patient. This ensures adequate transparency about the data collection events of the hospitals for the patients (users).
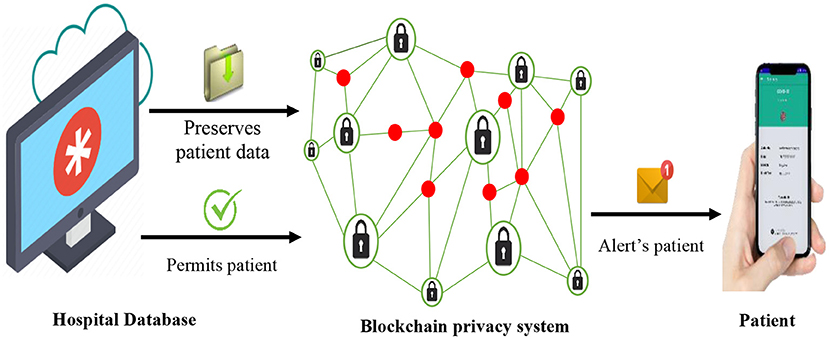
Figure 1. BPS-based data storage and patient alert preservation system.
Cooperative Filtering
One of the major advantages of the BPS over other existing privacy technology is its ability to perform efficient data computations while keeping all input data confidential. As illustrated in Figure 2, the hospital is notified each time the patient (user) attempts to obtain a recommendation for their confidential medical details. Because the hospital runs a multi-user system with several of its patients, their individual data are employed as input variables for the cooperative filtering algorithm of the recommender systems to sort and locate the best recommendations for each enquiring patient. Meanwhile, the hospital database manager can only view basic information of the patient as the rest of the sensitive data and computations are performed at the BPS. In conclusion, the patient gets a notification alert and receives secure permission to access the subsequent recommendations.
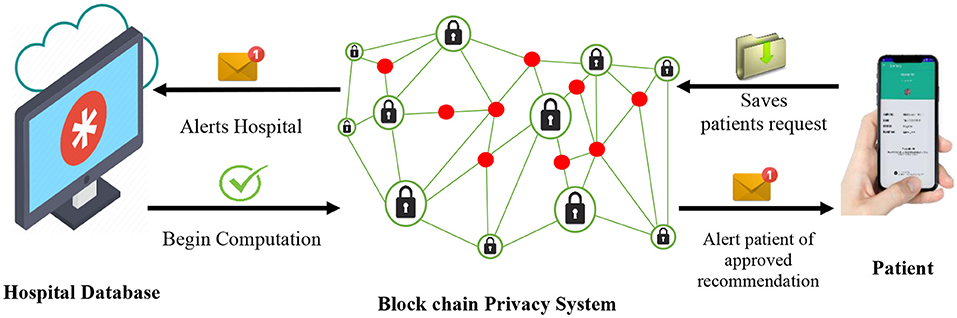
Figure 2. BPS-based data storage, hospital management and preservation system.
Data Processing
Data Normalization
Functions of data cleaning are carried out to get rid of noise and regularize the features after choosing a dataset. The aim of regularization is for the dataset to be scaled into a single range. This is done because the dataset has varied scale values. They can be one-digit, two-digit, or three-digit values so every value is brought into one scale so that the machine learning models perform more effectively. For this reason, we carried out min-max normalization. In this study, min-max scaling normalizes values within the scope of [0, 1] and is illustrated in Equation (1) below.
where y = (C1, C2… Cn) are the number of features. Ci is the feature to be normalized and Ni stands for the features that have been formalized. As a result of doing this, all the features now have identical weights, and they are all in a single scope.
Data Encoding
While this research was carried out, values that were duplicated and inconsistent were eliminated from the dataset before data encoding was performed. Subsequently, the nominal features are transformed into arithmetic values. The objective of this is to ensure that the backend functions of the machine learning models are performed using arithmetic values prior to their implementation. In this study, non-arithmetic data was transformed to arithmetic data prior to the performance of data encoding. Machine learning (ML) algorithms backend computations were also carried out on arithmetic values before data was passed to the suggested model.
Optimal Feature Visualization
A Product calorie has an important percentage of 48% in the dataset. Product fat has a significance percentage of 12%. Product protein and carbohydrates have significance percentages of 8%. Product sodium has an important percentage of 6%. The user number has an important percentage of 5%. Furthermore, product fiber, user fat, and protein have significance percentages of 2% each. Age, user weight and calories, disease, product barcode, and user carbohydrate have important percentages of 1% each in the dataset. Random Forest is a combination of decision trees. For the prediction to be correct, it integrates all the decision trees and gives more precise results. It is used not just for regression and classification, but also in the application of the best features in the dataset. Its best attribute is that regression and classification can be performed using it. When classifying Random Forest, the majority vote was utilized in the prediction of the target. However, for the evaluation of regression, Random Forest takes the average value of all the decision trees and predicts it as a threshold as stipulated for each node. Subsequently, there is a performance of splitting based on that threshold. The threshold is stipulated by computing gain-index and entropy. Their various equations are shown below.
where b1, b2…bs stands for the probabilities of the class labels.
Deep Learning Classifiers
Multilayer Perception
There exist various kinds of neural networks created and developed previously. All the existing ANNs may be distinguished by their processing unit (PE) transfer functions. Their techniques of learning and by the link equations. Processing unit is a basic constituent of ANN. It collects numerous signals that are weighted from other existing processing units. The framework of forwarding ANN is like this. The first layer has its input units. There are hidden layers in the middle. Finally, the last layer comprises output units. The function of the input unit is the provision of data from outside sources. Next, the data that is collected is transported to concealed layers where it is amplified with weights. Finally, it is passed to the output layer to initiate the final signals. The classification capacity of ANN is based completely on concealed layers. These concealed layers are linked by the synapses with the neighbor's layers. If there are p input data points (b1, b2… bp), we call it p number of features in the data. In the ANN framework, all the features are amplified with weights (e1, e2…ep) and then added as is stated in Equation (4) below.
where “p” represents the total amount of features present in the dataset given as input B to the input layer. While “e” stands for the weights of all the features amplified with its weight. It is referred to as the dot product too. The addition of the bias function is done next in the dot product function. It will lead to Equation (5) stated below.
In Equation (5), a denotes the activation function f (a). In this manner, we will obtain the output for the first neuron and the first hidden layer. This procedure will be repeated until the last weight and the last input is seen.
Recurrent Neural Network
Recurrent Neural Network is a kind of ANN where node-to-node links create a graph administered along with a corporeal order which makes provision for the display of dynamic behavior. It is a type of new ANN that has memory cycles that are directed.
Long Short-Term Memory
This is a framework that carries out a memory augmentation for the RNN. In this study, 3 layers of LSTM with a batch size of 32, as well as the sigmoid function is used to activate it. The Adam function is utilized for optimization. Binary cross-entropy is used to compute function loss.
Gated Recurrent Units
The principle of the GRU is more current than the LSTM. Basically, it functions more effectively. It is quicker in the training of models as opposed to the LSTM. The model can be modified and manipulated easily. However, LSTM performs better than the GRU if a longer memory is needed. Eventually, the comparison of performance depends on the kind of dataset being used. The frameworks LSTM and GRU are somewhat similar, but there are some important differences stated below:
• The GRU comprises two gates, but the LSTM has three.
• Gated recurrent units do not have internal memory that is opposed to the detectable hidden form. The output gate which is embedded in LSTMs is also not present in the GRUs.
• There is no application of second non-linearity when calculating GRU output as opposed to the LSTMs.
Machine Learning Classifiers
Logistic Regression
This is a popular classification algorithm utilized in machine learning. Basically, a bipartite result is acquired with it. Its purpose is to find a link connecting the possibility of a particular outcome and its features. A logit (odds) function is utilized in this algorithm. In Equation (6), the algorithm is described as seen below:
In the equation above, the logit function is and the odd function is . The odds show the probability proportion of insertion of the feature to the likelihood of failure or lack of features. Output is normally done in this algorithm subsequent to the mapping of inputs to log-odds in a straight blend. Now, the contrary of the function stated above would be;
Equation (7) is referred to as a sigmoid function which is a mathematical function that has an “S”—shaped curve characteristic, which converts the values between the range 0 and 1. As long as the probability value is initiated within the range of 0 < R < 1, then we chose the variables in the logarithm in a manner to expand the likelihood of scrutinizing sample values.
Naive Bayes
This is a collation of algorithms that have a joint where all the pairs of the features are unconstrained. Two hypotheses are considered in the algorithm which are as follows:
1. All the functions are separate.
2. The texts need to be translated into arithmetic values in the instance of features in text format. Bayes' Theorem is shown in Equation (8) below:
where G and H events, R (G) is the prior probability posterior probability. Now, Bayes' theorem can be implemented by Equation (9) as seen below:
where B represents the dependent feature vector and v is the class variable, B is of size n so, B = (B1, B2, B3 …, Bn). For evidence to be split into unconstrained categories for events G and H: R (G, H) = R (G) R (H). The results then become:
It can be expressed as Equation (11) below:
Because the denominator is continuous for input, so in Equation (12) below:
For a classifier model to be produced, the input probabilities for v must be determined and the output with the highest probability has to be taken. Hence, in Equation (13) below:
Finally, what is left for calculation is which is the initial probability and R (v) which represents the contrast of the logit function.
Evaluation Metrics
Various metrics are utilized in the evaluation of the performance of our suggested model. These are stated below:
The objective of precision is to examine the True Positive (AZ) units in connection to False Positive (CZ) units.
The objective of recall is to examine True Positive (AZ) units in connection to False Negative (CN) units that are not classified. The arithmetic arrangement of recall is stated in Equation (16) below:
Sometimes, assessment of performance may not be very efficient with recall and accuracy. For example, if a mining algorithm has high precision but low recall, then another algorithm is needed. Then comes the question of which algorithm is more effective. This challenge is solved utilizing F1-measure that gives a mean recall and precision. F1-measure can be calculated as follows:
Software Analysis
A Colab software installed on a Core-i7 computer system is employed in performing the Deep Learning experiments. The system is fully equipped with 16GB RAM, 4 CPUs, a 1.7 GHz processor, and about 20GB obtained from Google Colab laboratory. The overall dataset was partitioned into three segments which includes training segment, cross-validation segment, and testing segments. Constituting 80% of the dataset was utilized in the research as the training set, 20% was used as the testing set, while K-Fold Cross-validation was employed and is applicable to both the training and testing sets.
The study employed both machine and deep learning classifiers in this research and their training accuracies are presented in Table 4. Using a 32-batch sized 3-layer LSTM with sigmoid activation function, it is established that the LSTM classifier ranked maximum with 95.45% training accuracy, while MLP ranked as the least at 86.5%. The training accuracies for the rest classifiers which are GRU, RNN, Logistic regression [LR], and Naive Bayes were at 94.6, 92.3, 88.5, and 87.2% training accuracies, respectively.

Table 4. Performance of training score accuracy for selected classifiers.
Experiments and Results
The training and validation scores of Naive Bayes, LR, and MLP classifiers are presented in Figures 2, 4, 5, respectively. For all the figures, the training scores are denoted with a blue line/curve while the red curve represents the scores of cross-validations. For Naive Bayes in Figure 3, it is observed that the training and cross-validation scores merged at 87.2%. The cross-validation score of the logistic regression in Figure 4 remained stable and linear while the training score increases up to 93.8%, stabilizes, and further decreases. The validation and training scores of the MLP classifier is illustrated in Figure 5. The experiment shows that both the training and validation scores of the MLP classifier training scores increase at some point and ultimately decreased.
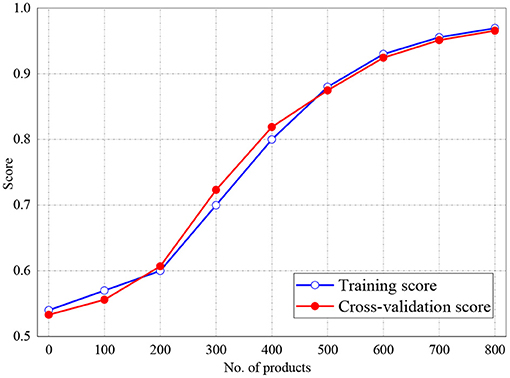
Figure 3. Result for Training and Cross-Validation of Naive Bayes classifier.
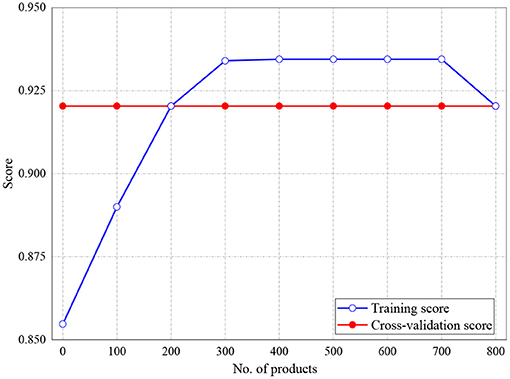
Figure 4. Result for Training and Cross-Validation Scores of Logistic Regression classifier.
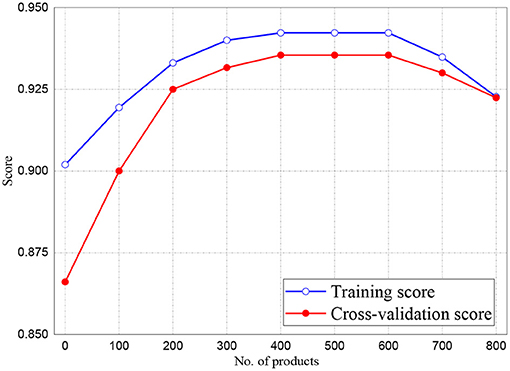
Figure 5. Result for Training and Cross-Validation of MLP classifier.
The test accuracies of the MLP classifiers are presented in Table 5. The result shows that the LSTM classifier realized a maximum of 99.5% test accuracy, while the MLP classifier achieved the least score of 90.3% test accuracy. The rest classifiers which are GRU, Naive Bayes, RNN, and LR all attain 98.8, 95.6, 95.5, and 90.8% testing accuracies, respectively.

Table 5. Performance of testing score accuracy for selected classifiers.
Figures 6, 7 represent the testing accuracies and cross-validation scores of both Naive Bayes and LR models, respectively, it is observed that the testing accuracies and validation scores for both models merged at 94 and 94.28%, respectively. Similarly, Figure 8 shows that the validation and testing scores for MLP merged at 93.81 and 92.85%, respectively.
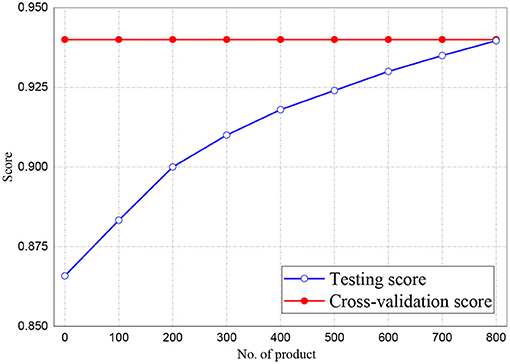
Figure 6. Result for Testing and Cross-Validation of Naive Bayes classifier.
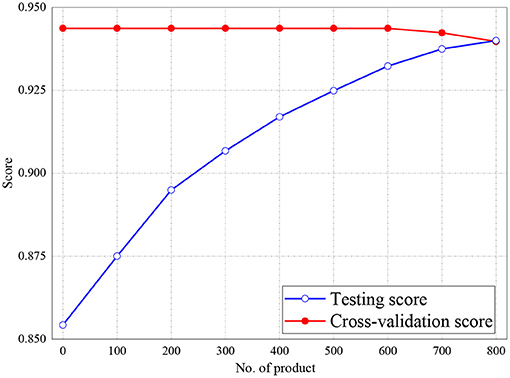
Figure 7. Result for Testing and Cross-Validation of Logistic Regression.
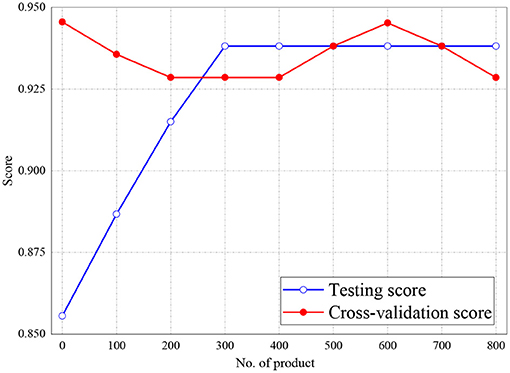
Figure 8. Result of Testing and Cross-Validation for MLP classifier.
The study further investigated the accuracies and loss performance of training scores against the testing scores for all the models. The results of these investigations are presented in Figures 9–11. The red curves denote the training scores, while the blue curves denote the testing scores for both the accuracy and loss performances. Figure 9A represents the performance accuracy of the training and testing scores for the GRU classifier. It is observed that the performance started from 87.5% and remained stable until after about 45 epochs. It further witnessed instabilities till it achieved an apex of 93% at 96.6 epoch. Similarly, the blue curve which represents the testing score started and remains stable at 85.5%, witnessed several instabilities but attained its apex of 90.2% at 100 epochs.
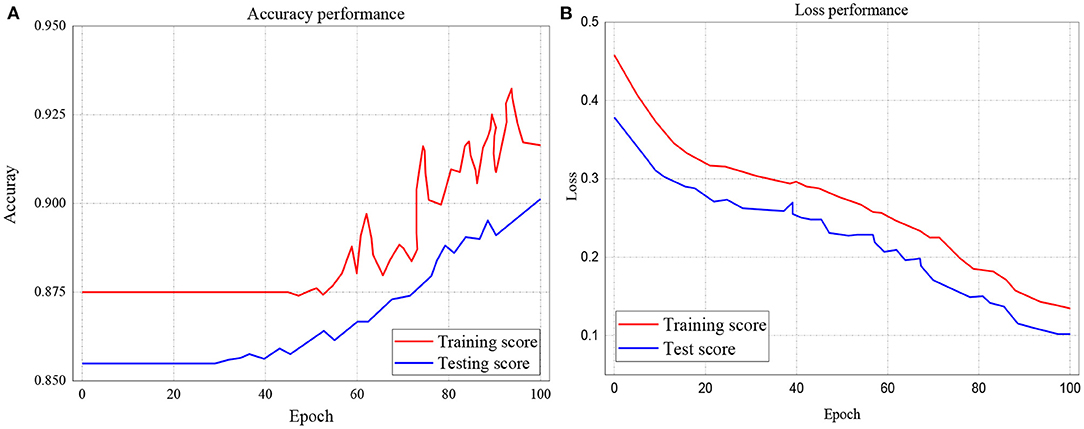
Figure 9. (A,B) Performance accuracy and loss of Training and Testing Scores for GRU classifier.
On the other hand, the loss performance of the training and testing scores for the GRU classifier is represented in Figure 9B. The figure indicates that the loss performance of the training score began from 0.45 and decreased to 0.14. In the same way, testing loss performance commenced from 0.38 down to 0.102.
The training and testing scores accuracy for LSTM is presented in Figure 10A, while the loss performance for the same model is illustrated in Figure 10B. Considering Figure 10A, the experiment shows that for accuracy, the training score started from 92.1%, with the least performance of 86.8% and peak performance of 94.3%. Likewise, for testing score accuracy, the performance began from 90.4% to a peak of 92.8% with the least performance of 90.1%. On the other hand, the training and testing loss performance of the LSTM classifier is illustrated in Figure 10B. The performance indicates that the training loss score commenced from 0.46 and declines to 0.14 after 100 epochs. The testing loss performance shows that the reading also started from 0.46 but decreased down to 0.1 after 100 epochs.
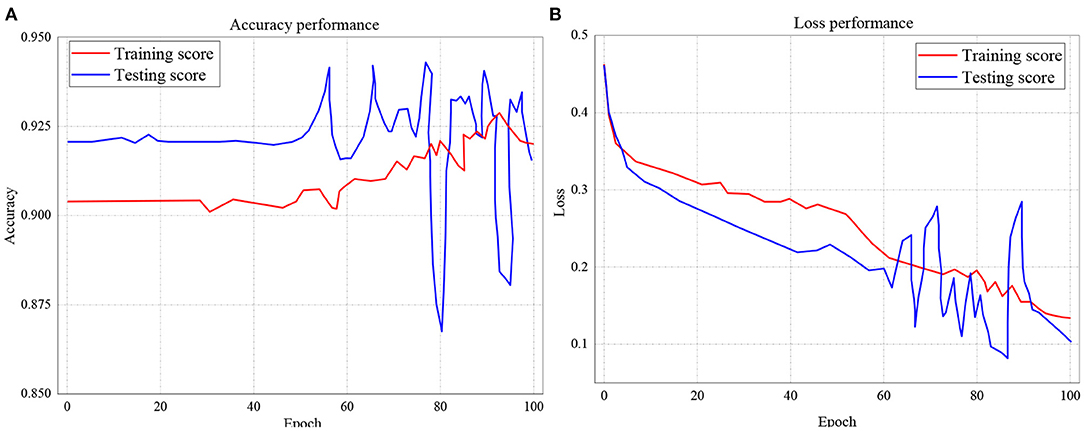
Figure 10. (A,B) Performance accuracy and loss of Training and Testing Scores for LSTM.
In Figure 11A, the testing and training scores accuracy for the RNN model is presented, while the loss performance for the same model is illustrated in Figure 11B. With respect to Figure 11A, the experiment shows that for accuracy, the training score started from 89.5% and also records as the least performance with a peak performance of 92.9% after 100 epochs. Also, for testing score accuracy, the performance began from 91.3% to a peak of 91.5% with the least performance of 85.8%. On the other hand, the training and testing loss performance of the RNN classifier is illustrated in Figure 11B. The performance indicates that the training loss score commenced from 0.435 and declines to 0.185 after 100 epochs. The testing loss performance shows that the reading also started from 0.435 but decreased down to 0.12 after 100 epochs.
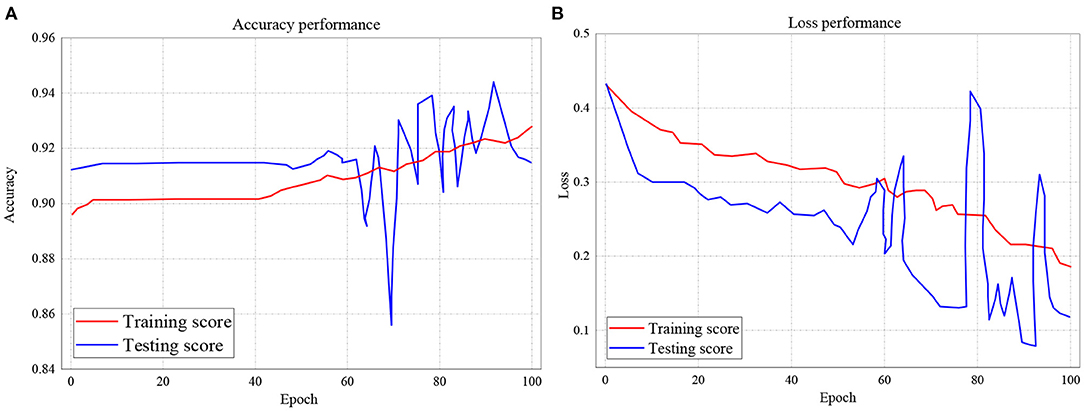
Figure 11. (A,B) Performance accuracy and loss of Training and Testing Scores for RNN.
The classification further recorded the deep learning and machine learning classifiers which are presented in Figure 12. The result indicates that the LSTM classifier outperforms the rest of the tested classifiers with reference to recall, F1-measure, and precision. The experiment is divided into allowed and not allowed classes. The performance of the LSTM classifier for the allowed class is measured at 99, 100, and 99% for recall, precision and F1-measure accordingly. Meanwhile, the disallowed class performance of the LSTM classifier measure at 90, 80, and 45%, for recall, precision, and F1-measure, respectively. The rest of the experimented models performs well in terms of the allowed class. However, they did not perform well with the disallowed class.
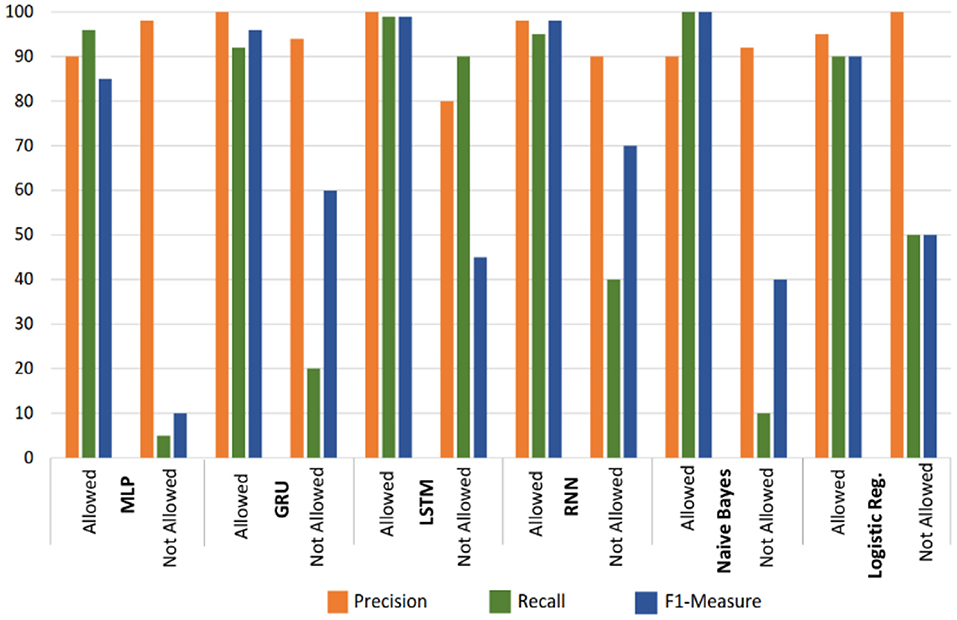
Figure 12. Result of the Classification for Deep and Machine Learning classifiers.
Conclusion and Future Work
The analysis of collected automated medical data has been established to have the potential in providing adequate recommendations for the improvement and management of patients with special needs in the hospitals through different algorithm developments and knowledge discovery. However, several medical facilities and special care patients are yet to grasp the usage and intent of secured recommender systems. One of the reasons for not embracing the systems is due to fear of data Privacy Breach. This research proposes a secure deep learning-based recommender system that estimates and issues basic treatment and diet recommendations to patients with special needs without revealing their sensitive health details. The system automatically issues exact recommendations to ailing patients based on their basic demography, diet, health history and other related data. The deep learning classifiers considered in this research include LSTM, MLP, GRU, RNN, Naive Bayes, and LR. The results of the performed experiments show that LSTM and GRU outperform every other classifier with reference to their recall, precision, and F-1 measures for both the allowed and not allowed classes. The performance of the LSTM classifier for the allowed class is measured at 100, 99, and 99% for precision, F1-measure, and recall, respectively. Meanwhile, the disallowed class performance of the LSTM classifier measures 90, 80, and 45% for recall, precision, and F1-measure, respectively. In the future, we shall incorporate the concept of multidimensionality in the secured diet recommender systems, where patients with special needs will maintain privacy after the whole process.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
All authors listed have made a substantial, direct and intellectual contribution to the work, and approved it for publication.
Funding
This paper was supported by the key research and development plan (social development) projects BE2016630 and BE2017628 of Jiangsu province, the scientific research project Z201603 of Wuxi health and family planning commission.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Bourquin J, Schmidli H, Van Hoogevest P, Leuenberger H. Basic concepts of artificial neural networks (ANN) modeling in the application to pharmaceutical development. Pharm DevTechnol. (1997) 2:95–109.
2. Agatonovic-Kustrin S, Beresford R. Basic concepts of artificial neural network (ANN) modeling and its application in pharmaceutical research. J Pharm Biomed Anal. (2000) 22:717–27. doi: 10.1016/S0731-7085(99)00272-1
3. Puri M, Pathak Y, Sutariya VK, Tipparaju S, Moreno W. Introduction to artificial neural network (ANN) as a predictive tool for drug design discovery. In: Delivery and Disposition: Basic Concepts and Modeling. New York, NY: Academic Press (2016). p. 3–13.
4. Iwendi C, Suresh P, Revathi M, Srinivasan K, Chang C-Y. An efficient and unique TF/IDF algorithmic model-based data analysis for handling applications with big data streaming. Electronics. (2019) 8:1331. doi: 10.3390/electronics8111331
5. Iwendi C, Khan S, Anajemba JH, Bashir AK, Noor F. Realizing an efficient IoMT-assisted patient diet recommendation system through machine learning model. IEEE Access. (2020) 8:28462–74. doi: 10.1109/ACCESS.2020.2968537
6. Srivastava G, Dhar S, Dwivedi AD, Crichigno J. Blockchain education. In: 2019 IEEE Canadian Conference of Electrical and Computer Engineering (CCECE). (2019). p. 1–5.
7. Kim J-H, Lee J-H, Park J-S, Lee Y-H, Rim K-W. Design of diet recommendation system for healthcare service based on user information. In: Proceedings of the Fourth International Conference on Computer Sciences and Convergence Information Technology. Seoul: IEEE (2009). p. 516–8.
8. Banerjee A, Nigar N. Nourishment recommendation framework for children using machine learning and matching algorithm. In: Proceedings of the International Conference on Computer Communication and Informatics (ICCCI). Coimbatore: IEEE (2019). p. 1–6.
9. Miranda R, Ferreira D, Abelha A, Machado J. Intelligent nutrition in healthcare and continuous care. In: Proceedings of the International Conference in Engineering Applications (ICEA). Sao Miguel: IEEE (2019). p. 1–6.
10. Kutia S, Chauhdary SH, Iwendi C, Liu L, Yong W, Bashir AK. Socio-technological factors affecting user's adoption of eHealth functionalities: a case study of China and Ukraine eHealth systems. IEEE Access. (2019) 7:90777–88. doi: 10.1109/ACCESS.2019.2924584
11. Sookrah R, Dhowtal JD, Nagowah SD. A DASH diet recommendation system for hypertensive patients using machine learning. In: Proceedings of the 7th International Conference on Information and Communication Technology (ICoICT). (2019). p. 1–6.
12. Madumidha S, Ranjani PS, Varsinee SS, Sundari P. Transparency and traceability: In food supply chain system using blockchain technology with Internet of Things. In: Proceedings of the 3rd International Conference on Trends in Electronics and Informatics (ICOEI). (2019). p. 983–7.
13. Alian S, Li J, Pandey V. A personalized recommendation system to support diabetes self-management for American Indians. IEEE Access. (2018) 6:73041–51. doi: 10.1109/ACCESS.2018.2882138
14. Sahoo AK, Pradhan C, Barik RK, Dubey H. DeepReco: deep learning-based health recommender system using collaborative filtering. Computation. (2019) 7:25. doi: 10.3390/computation7020025
15. Jiang L, Yang CC. User recommendation in healthcare social media by assessing user similarity in heterogeneous network. Artif Intell Med. (2017) 81:63–77. doi: 10.1016/j.artmed.2017.03.002
16. Portugal I, Alencar P, Cowan D. The use of machine learning algorithms in recommender systems: a systematic review. Expert Syst Appl. (2018) 97:205–27. doi: 10.1016/j.eswa.2017.12.020
17. Panda SK, Blome A, Wisniewski L, Meyer A. IoT retrofitting approach for the food industry. In: Proceedings of the 24th IEEE International Conference on Emerging Technologies and Factory Automation (ETFA). Zaragoza: IEEE (2019). p. 1639–42.
18. Wang Y, Kung L, Byrd TA. Big data analytics: understanding its capabilities and potential benefits for healthcare organizations. Technol Forecasting Social Change. (2018) 126:3–13. doi: 10.1016/j.techfore.2015.12.019
19. Yang CC, Jiang L. Enriching user experience in online health communities through thread recommendations and heterogeneous information network mining. IEEE Trans Comput Soc Syst. (2018) 5:1049–60. doi: 10.1109/TCSS.2018.2879044
20. Kaur H, Kumar N, Batra S. An efficient multi-party scheme for privacy preserving collaborative filtering for healthcare recommender system. Future Gener Comput Syst. (2018) 86:297–307. doi: 10.1016/j.future.2018.03.017
21. Mu R. A survey of recommender systems based on deep learning. IEEE Access. (2018) 6:69009–22. doi: 10.1109/ACCESS.2018.2880197
22. Priyadarshini R, Barik R, Dubey H. DeepFog: Fog computing-based deep neural architecture for prediction of stress types diabetes and hypertension attacks. Computation. (2018) 6:62. doi: 10.3390/computation6040062
23. Agapito G, Calabrese B, Guzzi PH, Cannataro M, Simeoni M, Care I, et al. DIETOS: a recommender system for adaptive diet monitoring and personalized food suggestion. In: Proceedings of the IEEE 12th International Conference on Wireless and Mobile Computing, Networking and Communications (WiMob). New York, NY: IEEE (2016). p. 1-8.
24. Baldominos Gomez, Rada F, Saez Y. DataCare: big data analytics solution for intelligent healthcare management. Int J Interact Multimedia Artif Intell. (2017) 4:13. doi: 10.9781/ijimai.2017.03.002
25. Leipold N, Lurz M, Bohm M. Nutrilize a personalized nutrition recommender system: an enable study. HealthRecSys. (2018) 3:4–10.
26. Jenzer H, Busser S, Scheidegger-Balmer F. Nutrition and dietetic product shortages are a neglected issue in alerting systems and in registries. J Clin Nutr. (2016) 2:15. doi: 10.4172/2472-1921.100022
27. Yera Toledo R, Alzahrani AA, Martinez L. A food recommender system considering nutritional information and user preferences. IEEE Access. (2019) 7:96695—711. doi: 10.1109/ACCESS.2019.2929413
28. Maiyaporn P, Phathrajarin P, Suphakant P. Food recommendation system using clustering analysis for diabetic patients. In: Proceedings of the International Conference on Information Science and Applications, Vol. 6. Seoul: IEEE (2010). p. 5–14.
29. Iwendi C, Anajemba JH, Biamba C, Ngabo D. Security of things intrusion detection system for smart healthcare. Electronics. (2021) 10:1375. doi: 10.3390/electronics10121375
30. Norouzi S, Ghalibaf AK, Sistani S. A mobile application for managing diabetic patients' nutrition: a food recommender system. Arch Iranian Med. (2018) 21:466–72.
31. Rehman F, Khalid O, Haq N, Khan AR, Sajjad KB. Diet-right: a smart food recommendation system. KSII Trans Internet Inf Syst. (2017) 11:2910–25.
32. Anajemba JH, Iwendi C, Mittal M, Yue T. Improved advance encryption standard with a privacy database structure for IoT nodes. In: 2020 IEEE 9th International Conference on Communication Systems and Network Technologies (CSNT). Gwalior (2020). p. 201–6.
33. Schäfer H, Elahi M, Elsweiler D, Groh G, Harvey M, Ludwig B, et al. User nutrition modelling and recommendation: balancing simplicity and complexity. In: Proceedings of the Adjunct Publication of the 25th Conference on USER MODELING, Adaptation and Personalization (UMAP). (2017). p. 9–12.
34. Kale A, Auti N. Automated menu planning algorithm for children: food recommendation by dietary management system using ID3 for Indian food database. Procedia Comput Sci. (2015) 50:197–202. doi: 10.1016/j.procs.2015.04.070
35. Anajemba JH, Yue T, Iwendi C, Alenezi M, Mittal M. Optimal cooperative offloading scheme for energy efficient multi-access edge computation. IEEE Access. (2020) 8:53931–41. doi: 10.1109/ACCESS.2020.2980196
36. Yang L, Hsieh C-K, Yang H, Pollak JP, Dell N, Belongie S, et al. Yum-Me: a personalized nutrient-based meal recommender system. ACM Trans Inf Syst. (2017) 36:1–31. doi: 10.1145/3072614
37. Anajemba JH, Tang Y, Iwendi C, Ohwoekevwo A, Srivastava G, Jo O. Realizing efficient security and privacy in IoT networks. Sensors. (2020) 20:2609. doi: 10.3390/s20092609
38. Saini S, Dubey SK. Recommendation of diet to jaundice patient on the basis of nutrients using AHP and fuzzy AHP technique. Int J Intell Eng Syst. (2017) 10:91–9. doi: 10.22266/ijies2017.0831.10
39. Chensi C, Feng L, Hai T, Deshou S, Wenjie S, Weizhong L, et al. Deep learning and its applications in biomedicine. Genomics Proteomics Bioinf. (2018) 16:17–32. doi: 10.1016/j.gpb.2017.07.003
40. Trang Tran TN, Atas M, Felfernig A, Stettinger M. An overview of recommender systems in the healthy food domain. J Intell Inf Syst. (2018) 50:501–26. doi: 10.1007/s10844-017-0469-0
41. Kumar P, Kumar R, Srivastava G, Gupta GP, Tripathi R, Gadekallu TR, et al. PPSF: a privacy-preserving and secure framework using blockchain-based machine-learning for IoT-driven smart cities. In: IEEE Transactions on Network Science and Engineering.
Keywords: blockchain privacy system, deep learning, machine learning, IOMT, artificial intelligence
Citation: Mantey EA, Zhou C, Anajemba JH, Okpalaoguchi IM and Chiadika OD-M (2021) Blockchain-Secured Recommender System for Special Need Patients Using Deep Learning. Front. Public Health 9:737269. doi: 10.3389/fpubh.2021.737269
Received: 06 July 2021; Accepted: 03 August 2021;
Published: 20 September 2021.
Edited by:
Thippa Reddy Gadekallu, VIT University, IndiaReviewed by:
Praveen Kumar, VIT University, IndiaEbuka Ibeke, Robert Gordon University, United Kingdom
Gautam Srivastava, Brandon University, Canada
Copyright © 2021 Mantey, Zhou, Anajemba, Okpalaoguchi and Chiadika. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Conghua Zhou, Y2h6aG91QHVqcy5lZHUuY24=; Eric Appiah Mantey, ZXJpY3BoZEB5YWhvby5jb20=
†These authors have contributed equally to this work and share first authorship