 Jingguo Chen1
Jingguo Chen1 Hao Mi2
Hao Mi2 Jinyu Fu2
Jinyu Fu2 Haitian Zheng3Hongyue Zhao4
Haitian Zheng3Hongyue Zhao4 Rui Yuan4Hanwei Guo2Kang Zhu1
Rui Yuan4Hanwei Guo2Kang Zhu1 Ya Zhang1Hui Lyu1Yitong Zhang1Ningning She1
Ya Zhang1Hui Lyu1Yitong Zhang1Ningning She1 Xiaoyong Ren1*
Xiaoyong Ren1*- 1Department of Otorhinolaryngology-Head and Neck Surgery, The Second Affiliated Hospital of Xi'an Jiaotong University, Xi'an, China
- 2School of Computer Science and Technology, Xi'an Jiaotong University, Xi'an, China
- 3School of Mathematics and Statistics, Xi'an Jiaotong University, Xi'an, China
- 4Health Science Center, Xi'an Jiaotong University, Xi'an, China
Aim: To explore the role of smell and taste changes in preventing and controlling the COVID-19 pandemic, we aimed to build a forecast model for trends in COVID-19 prediction based on Google Trends data for smell and taste loss.
Methods: Data on confirmed COVID-19 cases from 6 January 2020 to 26 December 2021 were collected from the World Health Organization (WHO) website. The keywords “loss of smell” and “loss of taste” were used to search the Google Trends platform. We constructed a transfer function model for multivariate time-series analysis and to forecast confirmed cases.
Results: From 6 January 2020 to 28 November 2021, a total of 99 weeks of data were analyzed. When the delay period was set from 1 to 3 weeks, the input sequence (Google Trends of loss of smell and taste data) and response sequence (number of new confirmed COVID-19 cases per week) were significantly correlated (P < 0.01). The transfer function model showed that worldwide and in India, the absolute error of the model in predicting the number of newly diagnosed COVID-19 cases in the following 3 weeks ranged from 0.08 to 3.10 (maximum value 100; the same below). In the United States, the absolute error of forecasts for the following 3 weeks ranged from 9.19 to 16.99, and the forecast effect was relatively accurate. For global data, the results showed that when the last point of the response sequence was at the midpoint of the uptrend or downtrend (25 July 2021; 21 November 2021; 23 May 2021; and 12 September 2021), the absolute error of the model forecast value for the following 4 weeks ranged from 0.15 to 5.77. When the last point of the response sequence was at the extreme point (2 May 2021; 29 August 2021; 20 June 2021; and 17 October 2021), the model could accurately forecast the trend in the number of confirmed cases after the extreme points. Our developed model could successfully predict the development trends of COVID-19.
Conclusion: Google Trends for loss of smell and taste could be used to accurately forecast the development trend of COVID-19 cases 1–3 weeks in advance.
Introduction
COVID-19 has ravaged countries worldwide, seriously threatening human life and health and causing severe damage to the social order and economic development (1). Governments in all countries attach great importance to pandemic prevention and control, and pandemic trend forecasting is critical to this end.
Big data from the Internet played an essential role in pandemic monitoring and prevention, disease source tracing, drug screening, medical treatment, product recovery, and other applications (2–4). Based on Internet big data, such as Google Trends and Baidu Trends, the occurrence and development of infectious disease trends can be predicted (5, 6). Previous studies have confirmed a significant positive correlation between Google Trends data for smell and taste loss and the daily number of confirmed COVID-19 cases (7–10).
Previous studies have found that loss of smell and taste is an early symptom of COVID-19 infection and can serve as a reliable indicator in COVID-19 diagnosis (11, 12). Most clinical symptoms in patients with COVID-19 who have olfactory and gustatory disorders are not serious, so these patients are difficult to diagnose in a timely fashion, raising the risk for the spread of infection. However, patients with olfactory and gustatory disorders usually search for information and methods to deal with smell and taste loss online. Therefore, analysis of big data for information on smell and taste loss retrieved from the Internet can likely provide an essential reference for pandemic prevention and control. By analyzing billions of Google search results worldwide, Google Trends displays the search volume and relevant statistical data for each keyword entered into Google, which can reflect the scale, timeliness, accuracy, and intuitiveness of the data. In this study, we used Google Trends data on smell and taste loss, as well as the daily pandemic statistics reported by the World Health Organization (WHO), to build a COVID-19 global pandemic trend forecast model. Our study can provide an essential scientific basis for the prevention and control of COVID-19.
Research data and methods
Raw data
Number of confirmed COVID-19 cases
Using the WHO official website (https://covid19.who.int/info), we downloaded daily data on newly confirmed cases of COVID-19 infection from 6 January 2020 to 26 December 2021 in the data module. We then aggregated these to obtain the weekly number of new confirmed cases worldwide, in the United States (US), and in India.
Google Trends data on smell and taste loss
Using the Google Trends platform (https://trends.google.com), we used “loss of smell” and “loss of taste” as keywords to obtain Google Trends data on loss of smell and taste worldwide, in the United States, and in India from 6 January 2020 to 26 December 2021.
Data preprocessing
Normalization of confirmed case data
Because the maximum retrieval volume defined by Google Trends is 100, we normalized the maximum number of weekly new cases to 100 such that the weekly confirmed cases data were distributed within the range of 0–100.
Outliers
Due to the potential influence of media reports or other factors, there may be abnormal changes in the Google Trends data for individual weeks, which would adversely affect the analysis of the overall trend for loss of smell and taste; therefore, we defined outliers.
For the detection of outliers, the following judgment principles were used:
For a given time series {Nt}, if
This means that Nt+1 is not an outlier. Otherwise, it can be concluded that Nt+1 is an outlier.
For some outliers, we used the linearization method for modification. Assuming Ni, Ni+1, ⋯ , Ni+k−2, Ni+k−1were k adjacent outlier points, we first calculated a straight line through two points (i−1, Ni−1), (i+k, Ni+k) and then replaced the k outlier points with corresponding equally spaced points on the straight line.
Calculation of cross-correlation function (CCF) between the input sequence and response sequence
We analyzed the CCF of input sequences (Google Trends data for loss of smell and Google Trends data for loss of taste) and response sequences (number of new confirmed cases per week during the COVID-19 pandemic) to determine the lag effect of Google Trends on the development trend of the COVID-19 pandemic.
The calculation method of the CCF was as follows.
For the sample {Ut, t = 1, 2, ⋯ , n}, {Vt, t = 1, 2, ⋯ , n} of time series {Ut}, {Vt}, we calculated the interaction covariance function of the sample as an estimate of the interaction covariance function of {Ut}, {Vt}:
Similarly, the sample CCF can be regarded as follows:
where Su is the sample standard deviation of Ut; Sv is the sample standard deviation of Vt.
Transfer function model fitting
We adopted the Box–Jenkins iterative three-stage modeling approach, namely, identification, estimation, and diagnostic checking.
(1) Structure of the model
We denoted the Google Trends search volume for “loss of smell” or “loss of taste” in 1 week as Xt and the number of newly diagnosed COVID-19 cases (normalized) as Yt; then, the structure of the transfer function model is given as follows:
where B is the backshift operator, ,
φ(B) is the autoregressive polynomial,
θ(B) is the moving average polynomial,
at is the white noise process, and b is the lag period of Xt.
(2) Identification of the model
Because both Xt and Yt are non-stationary sequences, and regressions with non-stationary series are spurious and the analyses are not valid, we applied the first-order difference transformation to obtain the stationary sequences.
Some cases are shown in Figures 1, 2.
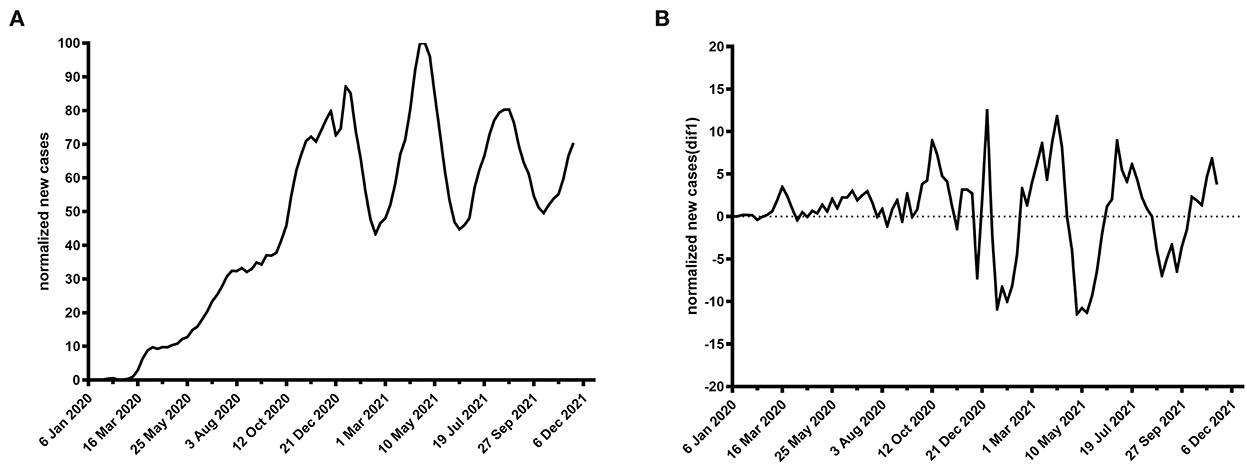
Figure 1. Time plot of normalized newly confirmed COVID-19 cases per week worldwide. (A) Raw data, (B) first-order difference.
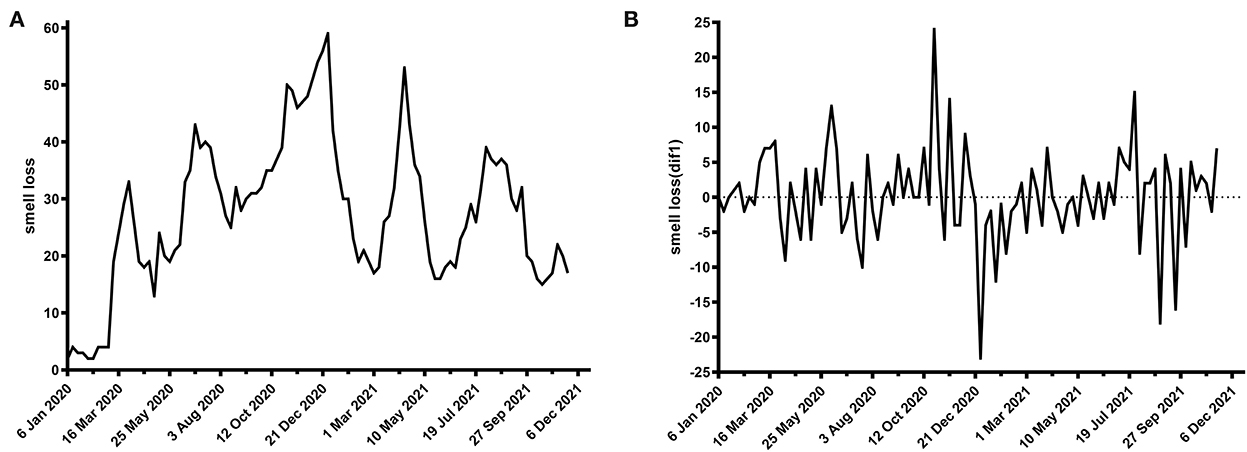
Figure 2. Time plot of Google Trends for smell loss per week worldwide. (A) Raw data, (B) first-order difference.
Therefore, the structure of the model can be transformed into the following equation:
Then, we conducted pre-white noise processing on and Zt. Next, by observing the features of a CCF diagram of and Zt, the values b, s, r could be determined, and then, w(B) and δ(B) could be calculated. After that, it is necessary to identify the white noise property of the residual. If the residual is a white noise sequence, meaning that there is no useful information to further extract, the transfer function model has been established; otherwise, if the residual is a non-white noise sequence, the autoregressive integrated moving average (ARIMA) model should be used to extract the information. The orders of AR and MA parameters can be identified by examining the autocorrelation and partial autocorrelation function; then, θ(B)and φ(B) are calculated to obtain the transfer function model.
(3) Parameter estimation: Parameters were estimated using the non-linear least-squares method.
(4) Model diagnosis was done using the following:
① Significance test of parameters.
② Autocorrelation check of residuals.
③ Cross-correlation check of residuals with the input sequence.
Results
Lag effect of Google Trends for smell and taste loss during the COVID-19 pandemic
First, we selected the Google Trends data for anosmia and ageusia worldwide from 6 January 2020 to 28 November 2021 as the input sequence and the weekly new confirmed cases during the same period as the response sequence. Then, by calculating the CCF between the input sequence and response sequence when the former lagged in different weeks, we could analyze the lag effect of the input sequence on the response sequence. The results are shown in Figure 3.
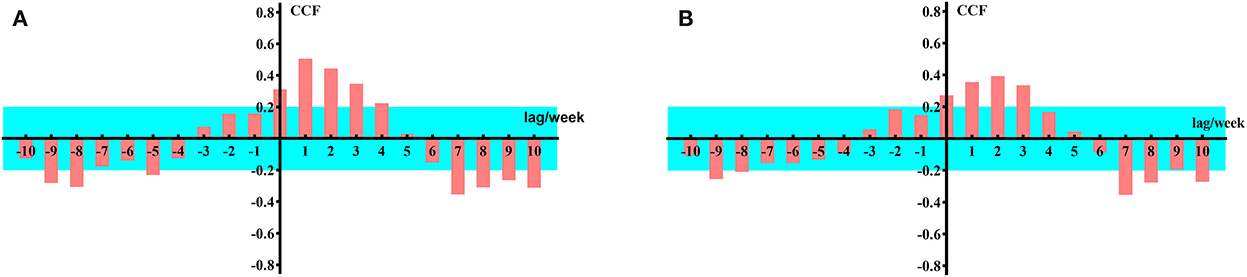
Figure 3. Cross-correlation function values for global data. (A) Google Trends data for loss of smell worldwide as the input sequence. (B) Google Trends data for loss of taste worldwide as the input sequence.
The unit of the horizontal axis in the figure is 1 week, which represents the number of lag periods of the input sequence; the vertical axis represents the CCF. The blue background represents a two-standard error interval. If the CCF is outside the two-standard errors when the input sequence is lagged by k weeks, it can be concluded that the CCF is significantly changed (P < 0.001), which means that the input sequence {Ut} and response sequence {Vt+k} are significantly correlated (P < 0.05).
From Figure 3, it can be concluded that when k = 1–3, the input sequence is significantly correlated with the response sequence; therefore, on a global scale, the impact of Google Trends for anosmia and ageusia on the weekly number of newly confirmed cases of COVID-19 lags by 1–3 weeks. Similarly, we can draw the same conclusion from data from the United States and India (Figure 4).
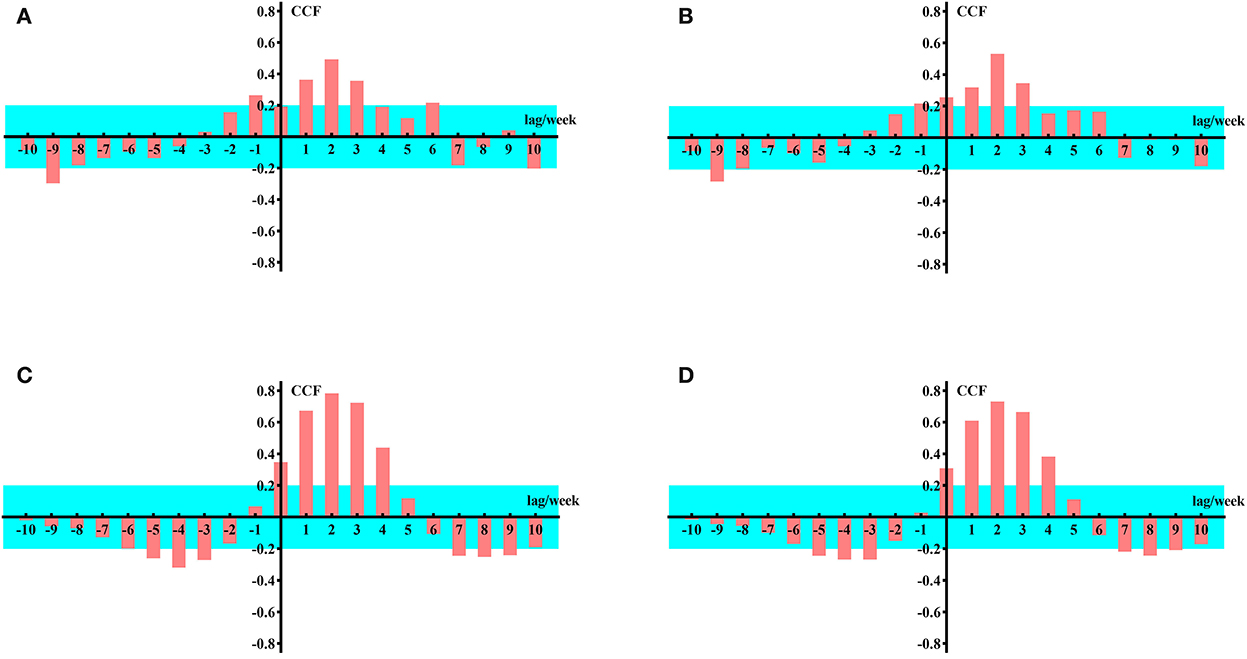
Figure 4. Cross-correlation function values for data from the United States and India. (A) Google Trends data for United State loss of smell as the input sequence. (B) Google Trends data for United State loss of taste as the input sequence. (C) Google Trends data for loss of smell in India as the input sequence. (D) Google Trends data for loss of taste in India as the input sequence.
The CCF of the input and response sequence with a lag of 1–3 weeks is shown in Table 1.
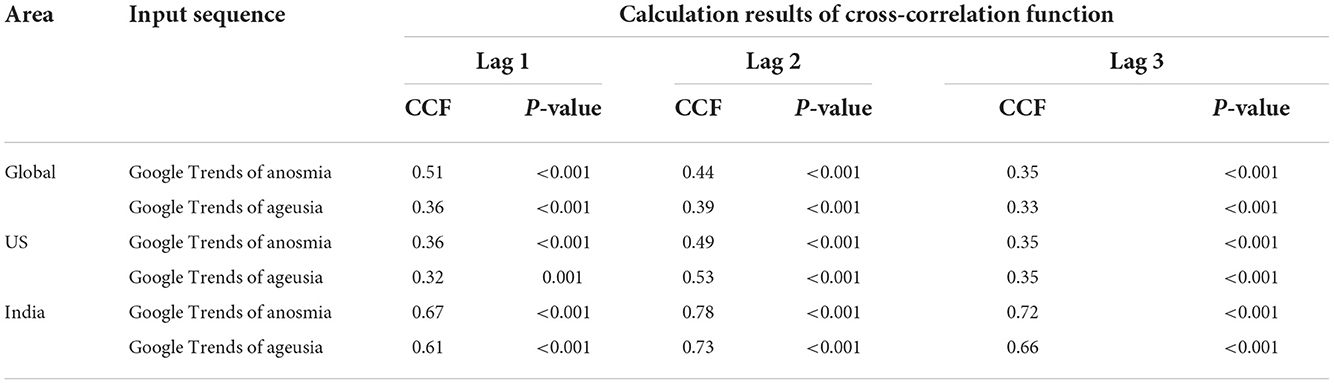
Table 1. Results of cross-correlation function analysis.
Construction and accuracy test of the COVID-19 forecast model
Construction of the transfer function model
We selected 99 weeks of data from 6 January 2020 to 28 November 2021 with a focus on the whole world, the United States, and India as the raw data for modeling. Taking the weekly number of newly confirmed COVID-19 cases (normalized) in the corresponding region as the response sequence and Google Trends data for anosmia and ageusia as the input sequence, we established the corresponding transfer function models and calculated the parameters in the models. Model construction and parameter calculation were implemented using SAS 9.4 (SAS Institute Inc., Cary, NC, USA). The results are shown in Table 2.

Table 2. Transfer function models for different areas and different input sequences.
Forecast results
First, using the transfer function model established above, we calculated the weekly number of newly confirmed COVID-19 cases (normalized) from 6 January 2020 to 28 November 2021 globally and in the United States and India. Second, we used the model to calculate the weekly number of new confirmed cases from 29 November 2021 to 26 December 2021, as the forecast of the response sequence for the following 4 weeks. Finally, the 95% confidence interval of the forecast was calculated. The results are shown in Table 3.
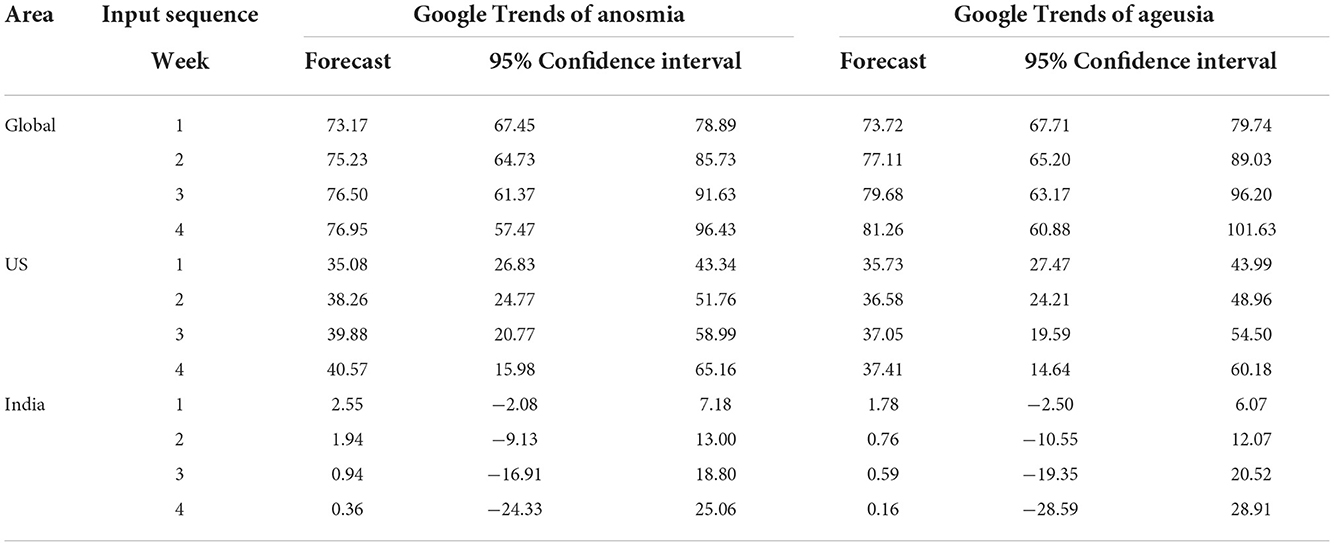
Table 3. Forecast values and 95% confidence interval for the following 4 weeks.
The timing diagram of the actual data and forecast value was plotted using GraphPad Prism 8.0 (GraphPad Software, Inc., San Diego, CA, USA) for data visualization (Figure 5).
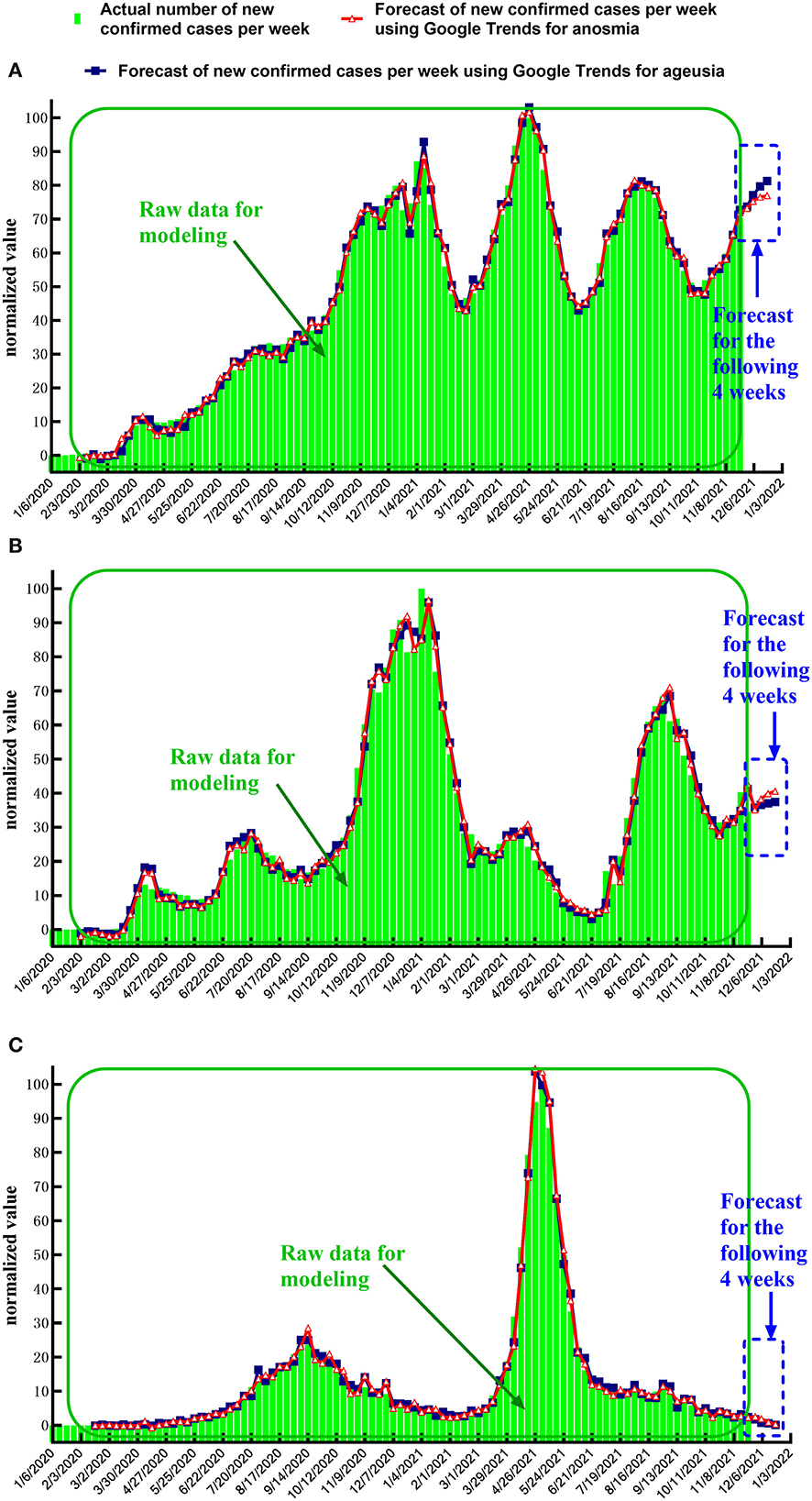
Figure 5. Timing diagram of actual value and forecast value for weekly new cases. (A) Global, (B) United States, and (C) India.
Accuracy test of the transfer function model
From Figure 5, it can be preliminarily considered that the forecast results are ideal. To test the accuracy of the model, we downloaded the daily number of newly confirmed COVID-19 cases from 29 November 2021 to 26 December 2021 from the official WHO website and aggregated these to obtain the weekly number of new confirmed cases. We then normalized the data to obtain the actual value of the response sequence in the following 4 weeks. Finally, model accuracy was tested by calculating the absolute error between the forecast value and the actual value in the following 4 weeks. The results are shown in Table 4.
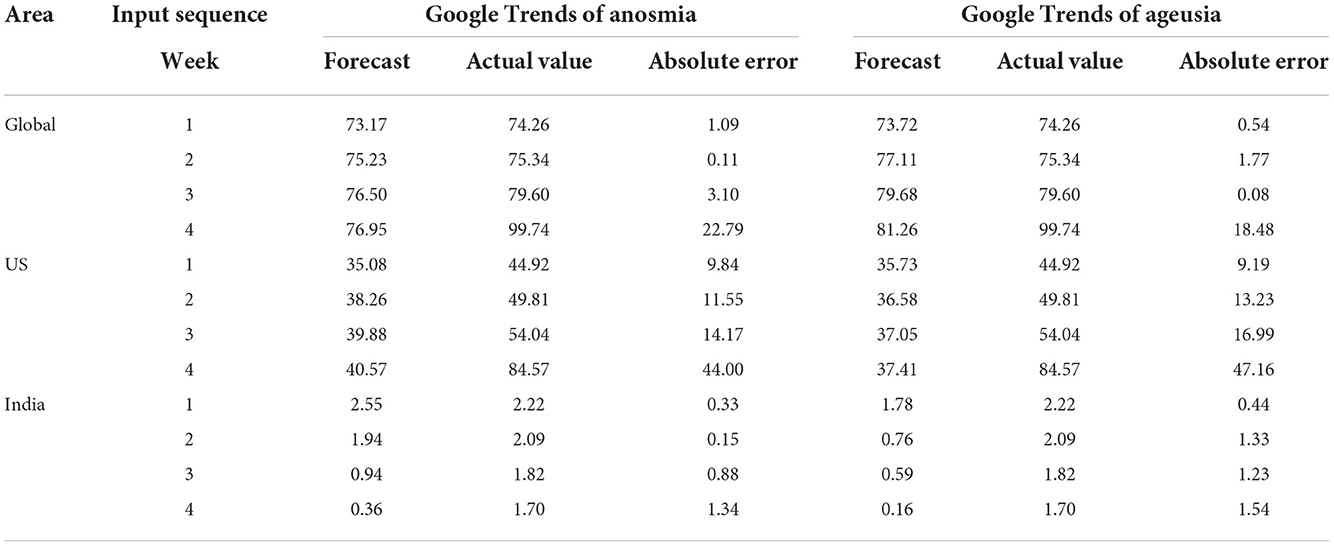
Table 4. Absolute error between forecast values and actual values for the following 4 weeks.
It can be concluded from Table 4 that when the forecast week is 1–3, the absolute error (normalized) between the forecast value and the actual value is not >16.99 (it should be noted that the normalized absolute error is distributed between 0 and 100; the same applies below). When the region scope of the data is global or India-based, the absolute error between the forecast value and the actual value is not >3.10. Therefore, it can be considered that the transfer function model has high accuracy in forecasting the development trend of the COVID-19 pandemic.
Analysis of forecast accuracy of the transfer function model with changes in the last point of the response sequence
Selection of the last point
Considering that the forecast accuracy of the model will be affected by changes in the position of the last point of the response sequence, we selected two midpoints of the upward trend, two midpoints of the downward trend, two maximum points, and two minimum points in the timing diagram of weekly new confirmed cases of COVID-19 worldwide as the last point (Figure 6). Then, using Google Trends of anosmia worldwide as the input sequence, we established different transfer function models for the data before different last points and forecasted the weekly number of newly confirmed cases in the following 4 weeks after the last points. Considering that the difference between the last points will lead to a change in the amount of raw data for modeling, to reduce the influence of this factor on the forecast accuracy, the dates of the eight last points are relatively close to each other.
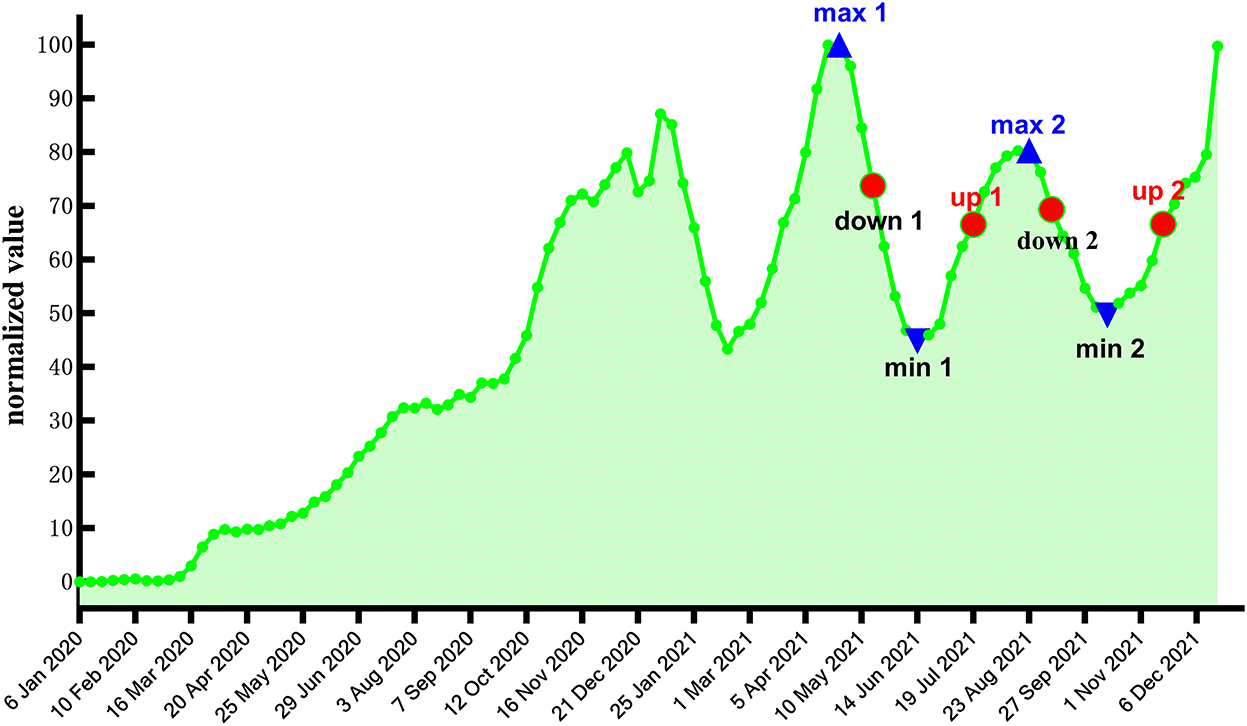
Figure 6. Timing diagram of weekly new confirmed cases worldwide.
Analysis of forecast accuracy when the last point is at the midpoint of the upward trend or downtrend
In this study, the number of new confirmed cases during the week of 25 July 2021 and the week of 21 November 2021 were selected as the last points, which were at the midpoint of the upward trend. Then, we used data before the cutoff date as the raw data to build the transfer function model for forecasting. The forecast results and absolute error are shown in Table 5.
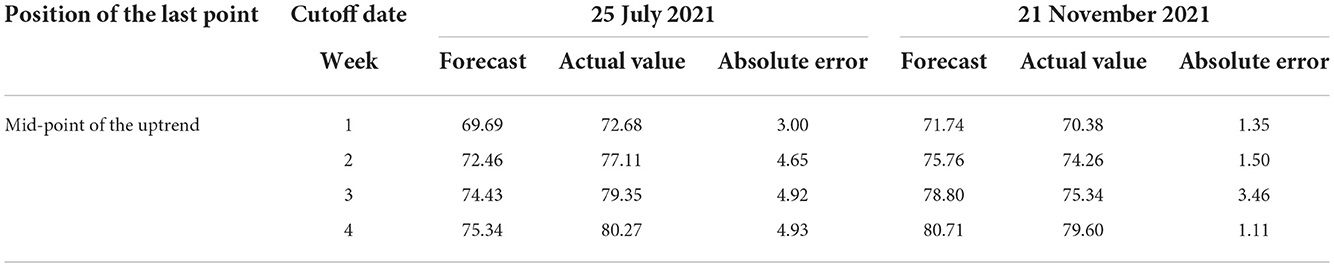
Table 5. Forecast result when the last point is at the midpoint of the upward trend.
The number of newly confirmed COVID-19 cases during the week of 23 May 2021 and the week of 12 September 2021 were selected as the last points, which were at the midpoint of the downtrend. Then, we used the data before the cutoff date as the raw data to build the transfer function model for forecasting. The forecast results and absolute error are shown in Table 6.

Table 6. Forecast result when the last point is at the midpoint of the downward trend.
The timing diagram of actual data and forecast value was plotted using GraphPad Prism 8.0 for data visualization (Figure 7).
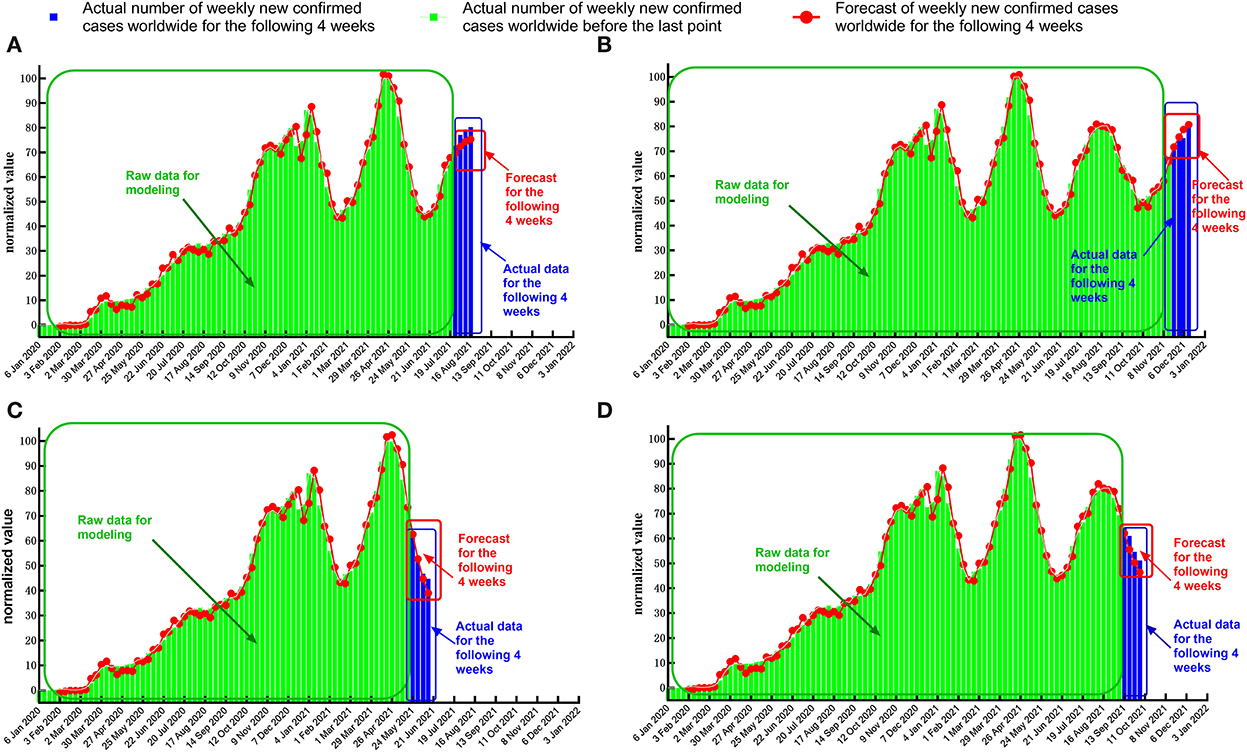
Figure 7. Timing diagram of forecasts and actual values when the last point of the response sequence is at the midpoint of the upward trend or downtrend. (A) Date of the last point: 25 July 2021 (upward trend 1). (B) Date of the last point: 21 November 2021 (upward trend 2). (C) Date of the last point: 23 May 2021 (downtrend 1). (D) Date of the last point: 12 September 2021 (downtrend 2).
Analysis of the forecast accuracy when the last point is at the maximum point or minimum point
In this study, the number of newly confirmed COVID-19 cases during the week of 2 May 2021 and the week of 29 August 2021 were selected as the last points, which were at the maximum points in the response sequence. Then, we used the data before the cutoff date as the raw data to build the transfer function model for forecasting. The forecast results and absolute error are shown in Table 7.

Table 7. Forecast result when the last point is at the maximum point.
The number of new confirmed cases in the week of 20 June 2021 and the week of 17 October 2021 were selected as the last points, which were the minimum points in the response sequence. Then, we used the data before the cutoff date as the raw data to build the transfer function model for forecasting. The forecast results and absolute error are shown in Table 8.

Table 8. Forecast result when the last point is at the minimum point.
The timing diagram of actual data and forecast value was plotted using GraphPad Prism 8.0 for data visualization (Figure 8).
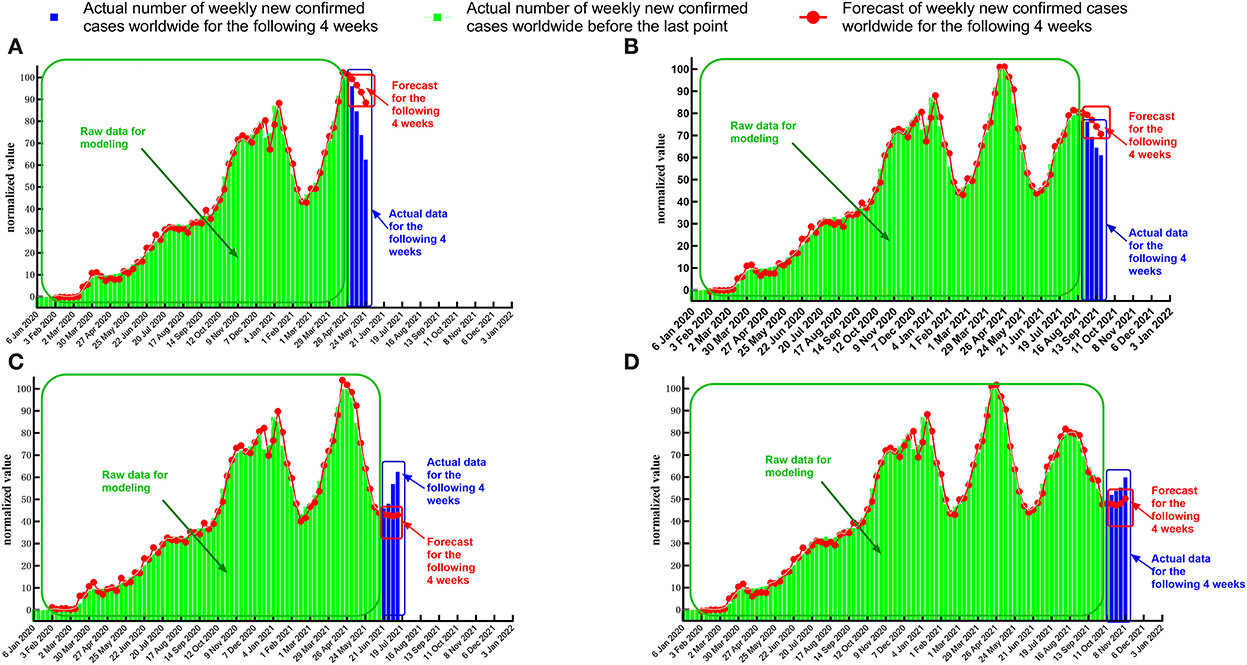
Figure 8. Timing diagram of forecasts and actual values when the last point of the response sequence is at the maximum or minimum point. (A) Date of the last point: 2 May 2021 (maximum 1). (B) Date of the last point: 29 August 2021 (maximum 2). (C) Date of the last point: 20 June 2021 (minimum 1). (D) Date of the last point: 17 October 2021 (minimum 2).
When the last point for the response sequence is at the extreme point, the standard error between the forecast value and the actual normalized data (Tables 7, 8) is more significant than in the case where the last point is at the midpoint of the uptrend or downtrend (Tables 5, 6). In some test cases (Figure 8A), the absolute error increases relatively rapidly as the number of forecast periods increases.
We found that in most test cases (Figures 8A,B,D), the transfer function model could accurately forecast the date of the inflection point of the pandemic and the trend of the response sequence in the future. Specifically, when we set the last point of the response sequence as 2 May 2021 and 29 August 2021, the transfer function model successfully forecasted that there would be a maximum point for the number of newly confirmed COVID-19 cases, which means that the intensity of the pandemic will ease after a few weeks. When we set the last point of the response sequence as 17 October 2021, the transfer function model successfully forecasted that there would be a minimum point for the number of newly confirmed cases, which means that the intensity of the pandemic will rise after a few weeks.
In summary, when the last point of the response sequence is at the extreme point, although the forecast value of the transfer function model deviates slightly from the actual value, the turning point of the pandemic can be forecasted relatively accurately. Therefore, this forecast method is of great guiding importance for accurate judgment about future trends in the COVID-19 pandemic and the deployment and adjustment of governmental prevention and control policies.
Sensitivity analysis of the search term
To further test the prediction accuracy of the trans function model when the search term of Google Trends changed, we used “smell loss” instead of “loss of smell” as a keyword to obtain Google Trends data from 6 January 2020 to 28 November 2021 worldwide, the United States, and India. Then, we used these data as the input sequences of the model to forecast the new confirmed cases for the next 4 weeks. The prediction results and absolute errors are shown in Table 9, which showed that absolute errors were very similar to that in Table 4, which indicates that the precise forecast results we can also get when the search term was changed to “smell loss.” In conclusion, the prediction method proposed in this paper has good stability for different search terms.
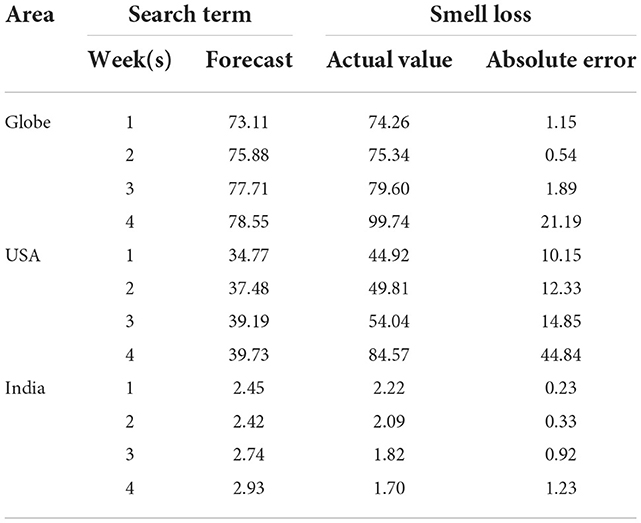
Table 9. Prediction results and absolute errors when the search term changed to “smell loss.”
Discussion
Summary of the study and comparison with contemporaneous studies
Through multivariate time-series analysis, the transfer function models forecast the development trend of COVID-19, which is of great importance in pandemic prevention and control. A few researchers have used Google Trends data to forecast trends in the development of diseases, including COVID-19 (13–15). Mavragani and Gkillas (16) applied regression analysis to Google search data on COVID-19 in the United States and found a statistically significant correlation between Google Trends and COVID-19 data. In those publications, various methods were used for analysis, including long short-term memory, random forest regression, AdaBoost algorithm, neural network autoregression, and vector error correction modeling. The conclusions indicated that the use of Google Trends data could be beneficial for forecasting and surveillance of COVID-19 spread in most countries.
However, few researchers established a forecast model using Google Trends data on smell or taste loss worldwide. Walker et al. (7) found a positive correlation between Google Trends data with loss of smell and taste using Spearman's grade correlation analysis. Henry et al. (17) used Google searches for loss of smell, taste, and fever to forecast the number of new cases of COVID-19 in Poland using linear regression. Ahmed et al. (18) used data from Pakistan to establish a linear regression model and concluded that patients' loss of smell and taste occurred roughly 2–3 weeks earlier than the time the case was diagnosed. Although relevant research has been carried out, due to the complex relationship between the number of confirmed cases and Google Trends search volume, there are still many shortcomings in linear regression. Our study improved on these by using a transfer function model in a multivariate time-series analysis, a combination of multiple regression, and time-series analysis. As a result, the accuracy of the forecast is effectively improved.
Explanation of the regional scope of the source data selected in this study
In this study, we selected data from the United States and India, based on extensive data analysis. First, the United States and India have had many confirmed cases since the COVID-19 outbreak. Second, the Google search engine is the most widely used in the United States, India, and worldwide. Therefore, the Google Trends data from the United States and India used in this study have strong representativeness and reliability. With the popularization and improvement of Internet technology, big Internet data can be used to monitor infectious diseases earlier in many countries to prevent problems before they occur (19–21).
In the course of pandemic prevention and control in China, Internet big data has played an important role in monitoring and early warning, virus source tracking, etc. (2, 22). We have also tried to add analysis on the search volume of Chinese smell and taste keywords, but we finally concluded that there were no valid data on the loss of smell and taste in China. First, Baidu is the search engine commonly used by most netizens in China, but in the Baidu search engine, related keywords such as “loss of smell” and “loss of taste” are not included in the Baidu Index entries. According to the Baidu Index data acquisition rules, “Keywords that do not meet the inclusion criteria can be added to the Baidu Index by purchasing the right to add words. For new words created on the day, the system starts calculating and providing data services the next day and does not backtrack historical data.” According to this rule, we could not obtain online search data for keywords such as “loss of smell” and “loss of taste” during the most severe period of the pandemic in China. Second, in most cases, users use Google to search in English, Google has withdrawn from the Chinese market, and there is no relevant valid data about the pandemic in China. Based on the consideration of big data analysis, the study selected the United States and India as regions to examine.
Explanation of error calculation in the accuracy test
In this study, we evaluated the forecast accuracy of the model by calculating the absolute error between the forecast value and the actual normalized value (abbreviated as the normalized absolute error).
First, the absolute error reflects the difference between the number of newly confirmed cases during the COVID-19 pandemic per week and the number of confirmed cases forecasted by the model. The advantage is that the error is not affected by the confirmed cases, which enables the forecast accuracy of the same model in other weeks to have a unified measurement standard.
Second, the normalized absolute error can limit the range of absolute error to 0 and 100. The advantage of this is that the error can be more intuitive for researchers in analysis. At the same time, comparing the forecast accuracies of models in different regions eliminates the effect of differences in the populations of different regions in error comparisons, which enables the forecast accuracy of the different models in different regions to have a unified measurement standard.
In summary, we used the normalized absolute error to judge model forecast accuracy.
Discussion about the media converge
As we all know, the popularity of media coverage had a certain correlation with the search volume of Google Trends, which might affect the number of online searches in a certain period of time (21, 23), but from the overall time point of view, it could not change the overall development trend of online search volume, nor would it affect the development trend of pandemic situation. Taking India as an example, after the media reported the symptoms of COVID-19 including loss of smell and taste (around mid-March 2020), its network retrieval volume was still at a low level (data from Media Cloud). On the contrary, the media coverage had different effects on Google Trends search volume in different countries and different time periods, and it was difficult to quantify it by setting an indicator. Due to the above considerations, we did not include the impact of media coverage on the data in the calculation of the model.
Overview of advantages and disadvantages of this study
The present study has many advantages and innovations in the selection of source data and the consideration of research methods. First, in terms of source data selection, the data from Google Trends have been widely used as raw data for infectious disease research, so its accuracy has been confirmed (24–26). Second, the time duration of the data collected in this study was sufficiently long to cover many critical and peak periods of the pandemic. The cumulative number of confirmed cases reached 180 million, and the spread regions covered nearly the whole world. Third, although media reports and public opinion have a slight impact on the retrieval volume of entries (21), these cannot significantly influence the overall increase or decrease trend of data over a long period. Therefore, the accuracy of the data still could be guaranteed. In terms of research methods, we established a transfer function model for data from different regions at different periods and tested the stability and accuracy of the model from various perspectives. Regardless of the current pandemic situation, the error in the forecast was within a smaller interval without influences on the trend of COVID-19. In addition, the turning points of the pandemic could be forecasted relatively accurately, which is of importance for the deployment and adjustment of governmental prevention and control policies.
There are also some shortcomings of this study. First, we only considered time-series analysis in this study, and the only independent variable was anosmia or ageusia according to Google Trends. Compared with some mature forecast models, this model may be somewhat simple, but the results proved that this model has sufficient forecast accuracy. Our study provides a heuristic idea to which researchers can add the variables of loss of smell or taste based on an existing mature forecast system to further improve forecast accuracy. Second, the study findings only provide a forecast but do not specify how to promptly deploy and adjust pandemic prevention and control policies.
Conclusion
Google Trends data for smell and taste loss can help with the advanced forecasting of trends in COVID-19 infection. Worldwide, in the United States, and India, the weekly numbers of newly confirmed cases of COVID-19 lag Google Trends by 1–3 weeks, suggesting that Google Trends regarding loss of smell or taste could forecast the trend in COVID-19 infection up to 3 weeks in advance.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author/s.
Author contributions
JC and XR conceived and designed the initial experiments. JC, HM, JF, HZhe, HZha, RY, HG, YaZ, and KZ finalized the design of the study and performed the experiments. HM, JF, HZhe, HL, YiZ, and NS analyzed the data. JC and HM coordinated the writing of this manuscript with the contribution of JF, HZhe, HZha, and XR. All authors contributed to the article and approved the submitted version.
Funding
This study was supported by the National Natural Scientific Foundation of China (82000960), the Fundamental Research Funds for the Central Universities (xzy012020046), and the Shaanxi Provincial Natural Science Foundation Research Program for Youth (S2021-JQ-418).
Acknowledgments
We thank LetPub (www.letpub.com) for its linguistic assistance during the preparation of this manuscript.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Tsang HF, Chan LWC, Cho WCS, Yu ACS, Yim AKY, Chan AKC, et al. An update on COVID-19 pandemic: the epidemiology, pathogenesis, prevention and treatment strategies. Expert Rev Anti Infect Ther. (2021) 19:877–88. doi: 10.1080/14787210.2021.1863146
2. Wu J, Wang J, Nicholas S, Maitland E, Fan Q. Application of big data technology for COVID-19 prevention and control in China: lessons and recommendations. J Med Internet Res. (2020) 22:e21980. doi: 10.2196/21980
3. Corsi A, de Souza FF, Pagani RN, Kovaleski JL. Big data analytics as a tool for fighting pandemics: a systematic review of literature. J Ambient Intell Humaniz Comput. (2021) 12:9163–80. doi: 10.1007/s12652-020-02617-4
4. Biswas R. Outlining big data analytics in health sector with special reference to Covid-19. Wirel Pers Commun. (2022) 124:2097–108. doi: 10.1007/s11277-021-09446-4
5. Zhao C, Yang Y, Wu S, Wu W, Xue H, An K, et al. Search trends and prediction of human brucellosis using Baidu index data from 2011 to 2018 in China. Sci Rep. (2020) 10:5896. doi: 10.1038/s41598-020-62517-7
6. Li K, Liu M, Feng Y, Ning C, Ou W, Sun J, et al. Using Baidu search engine to monitor AIDS epidemics inform for targeted intervention of HIV/AIDS in China. Sci Rep. (2019) 9:320. doi: 10.1038/s41598-018-35685-w
7. Walker A, Hopkins C, Surda P. Use of Google trends to investigate loss-of-smell-related searches during the COVID-19 outbreak. Int Forum Allergy Rhinol. (2020) 10:839–47. doi: 10.1002/alr.22580
8. Cherry G, Rocke J, Chu M, Liu J, Lechner M, Lund VJ, et al. Loss of smell and taste: a new marker of COVID-19? tracking reduced sense of smell during the coronavirus pandemic using search trends. Expert Rev Anti Infect Ther. (2020) 18:1165–70. doi: 10.1080/14787210.2020.1792289
9. Panuganti BA, Jafari A, MacDonald B, DeConde AS. Predicting COVID-19 incidence using anosmia and other COVID-19 symptomatology: preliminary analysis using Google and twitter. Otolaryngol Head Neck Surg. (2020) 163:491–7. doi: 10.1177/0194599820932128
10. Higgins TS, Wu AW, Sharma D, Illing EA, Rubel K, Ting JY. Correlations of online search engine trends with coronavirus disease (COVID-19) incidence: infodemiology study. JMIR Public Health Surveill. (2020) 6:e19702. doi: 10.2196/19702
11. Callejon-Leblic MA, Moreno-Luna R, Del Cuvillo A, Reyes-Tejero IM, Garcia-Villaran MA, Santos-Pena M, et al. Loss of smell and taste can accurately predict COVID-19 infection: a machine-learning approach. J Clin Med. (2021) 10:570. doi: 10.3390/jcm10040570
12. Gerkin RC, Ohla K, Veldhuizen MG, Joseph PV, Kelly CE, Bakke AJ, et al. Recent smell loss is the best predictor of COVID-19 among individuals with recent respiratory symptoms. Chem Senses. (2021) 46:bjaa081. doi: 10.1093/chemse/bjaa081
13. Amusa LB, Twinomurinzi H, Okonkwo CW. Modeling COVID-19 incidence with Google trends. Front Res Metr Anal. (2022) 7:1003972. doi: 10.3389/frma.2022.1003972
14. Saegner T, Austys D. Forecasting and surveillance of COVID-19 spread using Google trends: literature review. Int J Environ Res Public Health. (2022) 19:12394. doi: 10.3390/ijerph191912394
15. Lippi G, Mattiuzzi C, Cervellin G. Google search volume predicts the emergence of COVID-19 outbreaks. Acta Biomed. (2020) 91:e2020006. doi: 10.23750/abm.v91i3.10030
16. Mavragani A, Gkillas K. COVID-19 predictability in the United States using Google Trends time series. Sci Rep. (2020) 10:20693. doi: 10.1038/s41598-020-77275-9
17. Henry BM, Szergyuk I, De Oliveira MS, Lippi G, Juszczyk G, Mikos M. Utility of Google Trends in anticipating COVID-19 outbreaks in Poland. Pol Arch Intern Med. (2021) 131:389–92. doi: 10.20452/pamw.15894
18. Ahmed S, Abid MA, de Oliveira MHS, Ahmed ZA, Siddiqui A, Siddiqui I, et al. Ups and downs of COVID-19: can we predict the future? local analysis with Google trends for forecasting the burden of COVID-19 in Pakistan. EJIFCC. (2021) 32:421–31.
19. Mayo-Yáñez M, Calvo Henríquez C, Chiesa-Estomba C, Lechien JR, González-Torres L. Google Trends application for the study of information search behaviour on oropharyngeal cancer in Spain. Eur Arch Otorhinolaryngol. (2021) 278:2569–75. doi: 10.1007/s00405-020-06494-7
20. Luers JC, Rokohl AC, Loreck N, Wawer Matos PA, Augustin M, Dewald F, et al. Olfactory and gustatory dysfunction in coronavirus disease 2019 (COVID-19). Clin Infect Dis. (2020) 71:2262–4. doi: 10.1093/cid/ciaa525
21. Sousa-Pinto B, Anto A, Czarlewski W, Anto JM, Fonseca JA, Bousquet J. Assessment of the impact of media coverage on COVID-19-related Google trends data: infodemiology study. J Med Internet Res. (2020) 22:e19611. doi: 10.2196/19611
22. Qiu HJ, Yuan LX, Wu QW, Zhou YQ, Zheng R, Huang XK, et al. Using the internet search data to investigate symptom characteristics of COVID-19: a big data study. World J Otorhinolaryngol Head Neck Surg. (2020) 6:S40–8. doi: 10.1016/j.wjorl.2020.05.003
23. Jung JH, Shin JI. Big data analysis of media reports related to COVID-19. Int J Environ Res Public Health. (2020) 17:5688. doi: 10.3390/ijerph17165688
24. Rovetta A. Bhagavathula AS. Global infodemiology of COVID-19: analysis of Google web searches and Instagram hashtags. J Med Internet Res. (2020) 22:e20673. doi: 10.2196/20673
25. Pierron D, Pereda-Loth V, Mantel M, Moranges M, Bignon E, Alva O, et al. Smell and taste changes are early indicators of the COVID-19 pandemic and political decision effectiveness. (2020) 11:5152. doi: 10.1038/s41467-020-18963-y
Keywords: COVID-19, big data, smell, taste, prediction
Citation: Chen J, Mi H, Fu J, Zheng H, Zhao H, Yuan R, Guo H, Zhu K, Zhang Y, Lyu H, Zhang Y, She N and Ren X (2022) Construction and validation of a COVID-19 pandemic trend forecast model based on Google Trends data for smell and taste loss. Front. Public Health 10:1025658. doi: 10.3389/fpubh.2022.1025658
Received: 23 August 2022; Accepted: 03 November 2022;
Published: 01 December 2022.
Edited by:
Reza Lashgari, Shahid Beheshti University, IranReviewed by:
Ana Clara Gomes da Silva, Universidade de Pernambuco, BrazilZixin Hu, Fudan University, China
Copyright © 2022 Chen, Mi, Fu, Zheng, Zhao, Yuan, Guo, Zhu, Zhang, Lyu, Zhang, She and Ren. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiaoyong Ren, cmVueGlhb3lvbmdAdmlwLnNpbmEuY29t