 Liyi Dai
Liyi Dai- Computing Sciences Division, U.S. Army Research Office, Research Triangle Park, NC, USA
The compressive sensing framework finds a wide range of applications in signal processing, data analysis, and fusion. Within this framework, various methods have been proposed to find a sparse solution x from a linear measurement model y = Ax. In practice, the linear model is often an approximation. One basic issue is the robustness of the solution in the presence of uncertainties. In this paper, we are interested in compressive sensing solutions under a general form of measurement y = (A + B)x + v in which B and v describe modeling and measurement inaccuracies, respectively. We analyze the sensitivity of solutions to infinitesimal modeling error B or measurement inaccuracy v. Exact solutions are obtained. Specifically, the existence of sensitivity is established and the equation governing the sensitivity is obtained. Worst-case sensitivity bounds are derived. The bounds indicate that sensitivity is linear to measurement inaccuracy due to the linearity of the measurement model, and roughly proportional to the solution for modeling error. An approach to sensitivity reduction is subsequently proposed.
1. Introduction
Consider the following minimization problem from perfect measurements
where y ∈ Rm is a vector of measurements, x ∈ Rn is the vector to be solved, A ∈ Rm×n is a matrix, and l0 denotes the l0 norm, i.e., the number of non-zero entries. In the compressive sensing framework, the number of measurements available is far smaller than the dimension of the solution x, i.e., m ≪ n. Because the l0 norm is not convex, equation (1) is a combinatorial optimization problem, solving, which directly is computationally intensive and often prohibitive for problems of practical interest. Therefore, equation (1) is replaced with the following l1 minimization problem
where the l1 norm is defined as . Note that the matrix A in equations (1) or (2) is assumed to be known exactly and that y is free from measurement inaccuracy. In practice, the problem formulation equation (2) is often an approximation because there may exist modeling errors in A and measurement inaccuracies in y. Therefore, a realistic measurement equation would be
where θ = [θj] ∈ Rp is a vector of unknown parameters, B(θ) ∈ Rm×n is a matrix describing modeling errors, and v(θ) ∈ Rm is measurement noise. One appealing feature of the measurement form equation (3) is that it can incorporate prior knowledge of the inaccuracies. For example, we may have
where Bj and vj are known matrices or vectors of appropriate dimensions from prior knowledge. When no prior knowledge is available, Bj and vj can be chosen as the entry indicator matrix or vector, e.g., vj has 1 for the j-th entry of v(θ) and 0 everywhere else. The form equation (3) can be used to describe a wide range of inaccuracies. In equation (4), θj is the unknown magnitude of inaccuracy. Another interpretation of the measurement form equation (3) is that it represents structured uncertainties and can be used to describe the characteristics of inaccuracies for different measurements. For example, in multi-spectrum imaging, the noise characteristics are different for different spectrum. Images taken from different views or at different times may exhibit different noise characteristics. In the setting of a sensor network, a particular sensor may produce bad data due to malfunctioning, which likely leads to different characteristics of inaccuracy compared with other functioning sensors. Without loss of generality, it is assumed that the nominal value of θ is 0, which corresponds to the case with perfect modeling and measurements. Under measurement equation (3), the problem equation (2) can be recast as
A natural question is how sensitive is the solution of equation (5) to small perturbations at θ, without loss of generality, particularly around θ = 0? Because equation (2) is often only an approximation for problems of practical interest, such sensitivity characterizes the robustness of the solution to modeling or measurement inaccuracies. Among the vast literature on compressive sensing, there has been significant interest in analyzing the robustness of compressive sensing solutions in the presence of measurement inaccuracies. One widely adopted approach, such as those in Candes et al. (2006) and Candes (2008), is to reformulate the problem equation (2) as
in which ϵ is a tolerable bound of solution inaccuracy, and the l2 norm is defined as . Existing literature on equation (6) is extensive. Interested readers are referred to Donoho (2006), Candes and Wakin (2008), and Eldar and Kutyniok (2012) for a comprehensive treatment and literature review. Of particular relevance to this paper, Donoho et al. (2011) (Donoho and Reevew, 2012) analyzed sensitivity of signal recovery solutions to the relaxation of sparsity under the Least Absolute Shrinkage and Selection Operator (LASSO) problem formulation and obtained asymptotic performance bounds in terms of underlying parameters in the methods of finding the solutions. Herman and Strohmer (2010) derived l2 bounds between the solutions of equations (2) and (5) in terms of perturbation bounds of unknown B(θ) and v(θ). Only the magnitudes (i.e., bounds) of B(θ) and v(θ) are assumed known. Chi et al. (2011) analyzed solution bounds to modeling errors of unknown B(θ) and v(θ). The goal was to investigate the effects of basis mismatch since the matrix A is also known as the basis matrix in compressive sensing. Upper bounds of solution deviation were obtained. The treatments in those papers considered both strictly sparse signals and compressible signals, i.e., the ordered entries of the signal vector decay exponentially fast. The bounds are of the following form Upper bounds of solutions are obtained (Candes et al., 2006; Candes, 2008)
where C1 and C2 are constants dependent of A, k is the sparsity of x, and xk is x with all but the k-largest entries set to zero. Recent publications (Arias-Castro and Eldar, 2011; Davenport et al., 2012; Tang et al., 2013) analyzed the statistical bounds when measurement inaccuracies are modeled as Gaussian noises. A recent publication (Moghadam et al., 2014) after this paper was written-derived sensitivity bounds while this paper seeks exact solutions to sensitivity.
The objective of this paper is to analyze the sensitivity of compressive sensing solutions to perturbations (inaccuracies) in matrix A and measurement y, i.e., the sensitivity of solutions to equation (5) to the unknown parameter θ at θ = 0. Such sensitivity characterizes the effects of infinitesimal perturbations in modeling and measurements. Deterministic problem setting is adopted, and the true solution is assumed to be k-sparse. The sensitivity is local at θ = 0. Exact expressions of the sensitivity are derived. The results of this paper provide complementary insights regarding the effects of modeling and measurement inaccuracies on compressive sensing solutions.
The rest of the paper is arranged as the follows: in Section 2, we examine the continuity of the solution x(θ) at θ = 0. In Section 3, we establish the existence, finiteness, and equation for the sensitivity of x(θ) at θ = 0. Bounds for worst-case infinitesimal perturbations are derived in Section 4. An approach to sensitivity reduction is proposed in Section 5. A numerical example is provided in Section 6 to illustrate the sensitivity reduction algorithms. Finally, concluding remarks are provided in Section 7.
In this paper, we use lower case letters to denote column vectors, upper case letters to denote matrices. For parameterized vectors, the following notational conventions, if exist, will be adopted.
Consequently, for a vector x ∈ Rn independent of θ,
For notational consistence, the l2 norm of a matrix A = [ai,j] is defined as the Frobenius norm, .
2. Solution Continuity
Let x(θ) denote the solution to equation (5). Without confusion, we reserve x = x(0) to denote a solution to the unperturbed problem equation (2). In this section, we examine the continuity of x(θ) in the neighborhood of θ = 0. A vector x ∈ Rn is said to be k-sparse, k ≪ n, if it has at most k non-zero entries (Candes et al., 2006). In the compressive sensing framework, we are interested in k-sparse solutions.
Without further assumption, the existence of a (sparse) solution to the optimization problem equation (5) is not sufficient in guaranteeing the continuity of x(θ) near θ = 0. To illustrate this issue, consider the following example.
Example 2.1. Consider the problem equation (5) with
near θ = 0. Then the minimum is achieved by
It’s clear that the solution x(θ) is not continuous at θ = 0.
In Example 2.1, the solution is not unique at θ = 0. It turns out that the uniqueness of the solution is critical in guaranteeing the continuity of the solution near θ = 0.
One popular approach to finding the solution to equation (5) is to solve the following LASSO problem.
which τ > 0 is a weighting parameter.
Theorem 2.1. Assume that both B(θ) and v(θ) are continuous at θ = 0, B(0) = 0, v(0) = 0, AAT is positive definite, and that the solution x(θ) to equation (7) is unique at θ = 0. Then, x(θ) is continuous at θ = 0, i.e.,
where x is the solution of equation (7) at θ = 0.
Proof. Consider
Then is the Moore–Penrose pseudoinverse solution to . Under the assumptions that AAT is positive definite and that both B(θ) and v(θ) are continuous at θ = 0 with B(0) = 0, v(0) = 0, we know that is continuous and uniformly bounded in a small neighborhood of θ = 0, i.e., there exist c > 0, δ > 0 such that for all . Because x(θ) is the optimal solution to equation (7) while may not, we have
or
for all . Therefore, x(θ) is uniformly bounded for all .
We next prove equation (8) by contradiction. Assume that equation (8) is not true. Because x(θ) is uniformly bound for all , there exists a sequence θi, i = 1, 2,…, such that
Note that x(θ) is the unique solution to equation (7). It must be that
By setting i → ∞, also noting the continuity of B(θ) and v(θ) at θ = 0, we obtain
Therefore, we must have because the solution to equation (7) at θ = 0 is unique, which contradicts equation (9). The contradiction establishes equation (8). ■
Note that the number of rows of A is far smaller than the number of columns, m = n. The positive definiteness of AAT is equivalent to that all measurements y are not redundant, which is technical and mild. Theorem 2.1 states that the solution to equation (7) is continuous if it is unique at θ = 0. Similarly, we can establish the continuity of the solution to equation (5). The proof is similar to that for Theorem 2.1 and omitted to avoid repetitiveness.
Theorem 2.2. Assume that both B(θ) and v(θ) are continuous at θ = 0, B(0) = 0, v(0) = 0, AAT is positive definite, and that the solution x(θ) to equation (5) is unique at θ = 0. Then x(θ) is continuous at θ = 0, i.e.,
We introduce the following concept, which is a one-sided relaxation of the Restricted Isometry Property (RIP) (Candes et al., 2006).
Definition 2.1. A matrix A ∈ Rm×n is said to be k-sparse positive definite if there exists a constant c > 0 such that
for any k-sparse vector x ∈ Rn.
The 2k-sparse positive definiteness is a sufficient condition for guaranteeing the uniqueness of the optimal solution to equation (5) (Candes, 2008).
3. Solution Sensitivity
In this section, we are interested in the gradient information
which, if exists, is an n × p matrix in Rn×p.
The next theorem establishes the existence of the gradient equation (12).
Theorem 3.1. Consider problem equation (5). Assume that both B(θ) and v(θ) are differentiable at θ = 0, B(0) = 0, v(0) = 0, and that there exists a δ > 0 such that A is 3k-sparse positive definite for all . Then at θ = 0, the gradient ▽x(θ) exists, is finite, and satisfies
where
and x is the solution to equation (2).
Proof. For the sake of simple notations, we only prove the theorem for scalar θ. The proof can be extended component wisely to the vector case.
We first establish the existence of ▽x(θ). Let h(θ) = θ−1[x(θ) − x] where x(θ) and x are solutions to the optimization problems equations (5) and (2), respectively.
Under the continuity of B(θ), A + B(θ) is 3k-sparse positive definite with a constant independent of θ in a small neighborhood of θ = 0 if A is. Therefore,
or
By assumption, B(θ) and v(θ) are differentiable at θ = 0. The previous inequality shows that h(θ) is uniformly bounded in a small neighborhood of θ = 0. Consequently, there exists a sequence θ(i) → 0 such that
exists and is finite. Recall that
and
Their difference gives
or
Since A is 3k-sparse positive definite, there exists a constant c > 0 such that
Consequently,
The right hand side of equation (16) goes to zero as θ → 0, i → ∞. Therefore,
Or equivalently,
which establishes that ▽x(θ) exists at θ = 0 and is finite.
Finally, the fact that x(θ) and x are the solutions to problems equations (5) and (2), respectively, gives
Denote which exists and is finite. By setting θ → 0 in the above equation, we obtain
which is equation (13). This completes the proof of the theorem. ■
Since the solution x(θ) is k-sparse for all θ in a small neighborhood of θ = 0, by focusing on the non-zero entries of x and x(θ), the proof of Theorem 3.1 also shows that each column of Z is k-sparse. The support of Z is the same as that of x.
Equation (13) indicates that only those perturbations in E that corresponds to non-zero entries of x contribute to the sensitivity.
A note is needed regarding the requirement of the 3k-sparse positive definiteness in Theorem 3.1. It has been known in the literature [e.g., Candes (2008) in the form of the Restricted Isometry Property] that 2k-sparse positive definiteness is needed for guaranteeing the uniqueness of a k-sparse solution. The 3k-sparse positive definiteness is needed for ensuring the differentiability of the solution, a higher order property. This is a sufficient condition, and its relaxation is a subject of current effort.
4. Sensitivity Analysis
Equation (13) gives an explicit expression of the sensitivity ▽x(θ) at θ = 0. Theorem 3.1 shows that the k-sparse solution Z is unique for given x, E, and W. In this section, we consider the worst-case perturbations, i.e., the value(s) of E and W that maximizes . It’s obvious that the sensitivity increases when either or increases. We analyze the sensitivity based on normalized perturbations. Specifically, we consider the following
Lemma 4.1. The sensitivity Z satisfies the following relationship
Proof. According to equation (13), Z satisfies
Next we consider each of the three cases.
Case I: W = 0. In this case,
Recall that
By applying the Cauchy-Schwarz inequality we obtain
Therefore,
Next, we prove that the upper bound is achievable for a specifically chosen E. Let
Then
and
For this , we have
or equivalently
The combination of equations (21) and (22) gives (18).
Case II: E = 0. In case,
from which equation (19) follows.
Case III: In general,
where
and Wj is the j-th column of W. By following the proof of Case I, we know that
which establishes equation (20). ■
Equations (18)–(20) show that the worst-case is a constant for measurement noise but proportional to the solution vector for modeling error E.
Theorem 4.1. Under the assumptions in Theorem 3.1, the sensitivity Z satisfies the following bounds
in which σmin(A) > 0 is the minimal singular value of A.
Proof. Without loss of generality, assume θ is a scalar. Let S be the collection of indices of possibly non-zero entries of Z, ZS ∈ R|S| be the vector of non-zero entries of Z corresponding to the indices in S, and AS be the matrix consisting of corresponding columns of A. Then, AS is of full column rank if it is k-sparse positive definite, σmin(AS) ≥ σmin(A), and
Consider the matrix AZ,
which gives
The rest follows from combining the previous inequality with equations (18)–(20) in Lemma 4.1. ■
If σmin(A) is achieved over k columns of A that correspond to the k-sparse signal to be recovered, then the equality in equation (26) holds and the bounds in Theorem 4.1 could be tight. The bounds are not tight in general because the k columns of A corresponding to the indices in S are unknown a priori.
5. Sensitivity Reduction
One natural way of reducing the sensitivity of compressive sensing solutions is to carefully select the basis matrix A so that Z is as small as possible. There has been extensive research on how to select A (Donoho et al., 2006). The general idea is to improve the incoherence of the matrix A, for example, by making A as close as possible to the identity matrix in terms of the RIP property. The problem could be difficult because selecting the correct columns of A from available choices is a combinatorial optimization problem. In this section, we consider an alternative. We assume that the matrix A is given. The objective is to find a solution x that is least sensitive to perturbations B and v. One example where this problem arises is in pattern recognition where each column of A represents a vector in a feature space. The issue is how to classify the pattern based on features of the training data so that the solution is robust to potential perturbations (i.e., noise in data).
We consider to improve the robustness of a signal recovery solution by reducing its sensitivity to model error and measurement inaccuracy. Toward that goal, we reformulate the l1 optimization problem equation (5) by including a term to penalize high sensitivity. This approach offers an alternative to the conventional approach of basis matrix selection and could be performed after the matrix A is selected.
Solution robustness can be improved by reducing the magnitude of sensitivity. The l∞ norm is a natural choice because it characterizes the largest entry of a vector or a matrix. Therefore, we consider the following optimization problem.
where λ > 0 is a penalizing weight and the l∞ norm is defined as . Note that Z ∈ Rn×p is a matrix. We convert Z into a vector by defining
where for each j, 1 ≤ j ≤ p, zj is the j-th column of Z. Then problem equation (27) can be re-written as
in which
and wj is the j-th column of W, 1 ≤ j ≤ p.
Several methods are available to solve the optimization problem equation (28), one of which is the Alternating Direction Method of Multipliers (ADMM) (Boyd et al., 2011). In fact, equation (28) is in the standard form of the ADMM problem formulation. There is a trade-off in selecting the method or algorithm to solve the optimization problem equation (28) in terms of accuracy, efficiency, and reliability. We adopt the gradient projection algorithms proposed by Figueiredo et al. (2007) for solving LASSO problems. Toward that end, we consider two modifications: The first modification is to replace the l∞ norm with the lv norm defined as where zj(i) is the ith entry of zj-the jth column of Z. It is known that . So a large v is chosen. To ensure the smoothness of the objective function, v is chosen as an even number. The second modification is to reformulate equation (28) as a modified LASSO problem so that the efficient gradient projection algorithms are applicable with minimum modifications. Finally, it is noted that for each j, zj(i) = 0 for all i not in the support of x. Consequently, we consider the following optimization problem for sensitivity reduction.
where v > 1 is a large even number, τ > 0 and λ > 0 are user-selected weights, S(x) is the set of indices corresponding to possibly non-zero entries of a sparse vector x, i.e., the support of x.
We next provide the algorithmic details of implementing the gradient projection method. First, the problem equation (29) is equivalent to the following constrained optimization problem (Figueiredo et al., 2007).
in which e is the vector of all ones, u = [uj] ≥ 0 (or r = [rj] ≥ 0) denotes uj ≥ 0 (or rj ≥ 0, respectively) for all j = 1, 2,…, n. The sparse solution x is given by
and thus S(r − u) = S(x) in equation (30). The gradient of the objective function in equation (30) is
where
in which for .
The gradient projection algorithms proposed in Figueiredo et al. (2007) find the optimal solutions iteratively. Let denote the values of at the ith iteration. Then, at the (i + 1)th iteration, are updated according to
where η(i) ∈ [0,1] is a weighting factor, and the transition values are gradient projection updates
In equations (33)–(35), α(i) > 0 is the step-size of the gradient algorithm, C+ = {u = [uj] ∈ Rn|uj ≥ 0,j = 1,2,…n} is the non-negative subspace, S(x) is the support of x as defined in equation (29), and ΠC(u) is the projection operator that projects u onto the subspace C. Because x = 1/2(r − u), the subspace S[r(i+1) − u(i+1)] in equation (35) is the subspace of x at the (i + 1)th iteration. To increase the efficiency of the algorithm, the step-size α(i) is selected according to the Armijo rule, i.e., in which α0 is the initial step-size, β ∈ (0,1), and i0 is the first number in the sequence of α0, αβ, αβ2, αβ3, … that achieves
in which the values of ▽F are evaluated at . Note that the projection of onto the support of x in equation (35) is unique to solving the optimization problem equation (30).
The value of x at the ith iteration is given by .
The dimension of z is np which could be high for large p since n typically is a large number. However, the matrix multiplications in updating the gradient equation (31) could be done offline. Updating equations (32)–(35) is straightforward.
The algorithm described by equations (32)–(35) has been observed with fast convergence for the numerical example in Section 6. It is nevertheless a basic version of the gradient projection algorithms. Our purpose is to illustrate the incorporation sensitivity information in improving the robustness of compressive sensing solutions through sensitivity reduction. Readers interested in the gradient projection approach are referred to Figueiredo et al. (2007) for a comprehensive treatment and improvements.
6. A Numerical Example
The goal of this section is to illustrate the performance of the sensitivity reduction algorithm described in Section 5 through a numerical example. In this example, the matrix A and measurement y are taken from the numerical example described in the software package accompanying (Candes and Romberg, 2005). In this example, n = 1024, m = 512. The matrix A and measurement y are, respectively, a random matrix and vector drawn from uniform distributions. Sparsity factor k = 102, about 10% of the entries of x. The sparse solution x is shown in Figure 1.
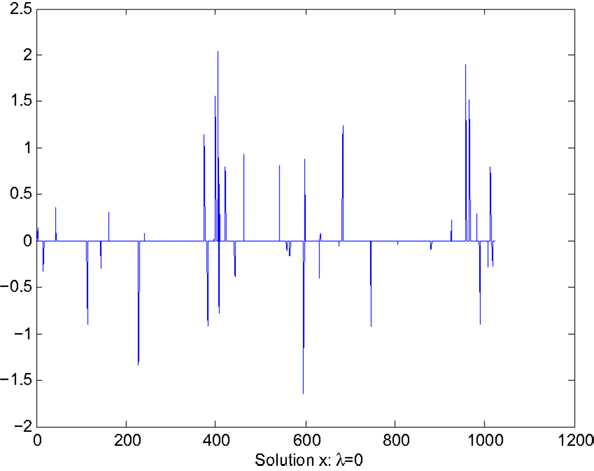
Figure 1. Solution x without sensitivity reduction: λ = 0.
We consider the sensitivity analysis and reduction for the following perturbation
where i0 = 959, is the i0-th column of A. Note that θ is a scalar, thus p = 1. Perturbation equation (36) leads to a spike in sensitivity as shown in Figure 2. For pattern classification, each column of A represents a feature vector of a training data point. The choice of B implies that we are interested in the sensitivity of a bad training data point and seek the reduction of its effects to pattern classification. Other user-selected parameters are v = 50, τ = 0.85, η(i) = 0.4 for all i, α0 = 0.9, and β = 0.8. For comparison, we show the sparse solution x and the corresponding sensitivity for two cases.
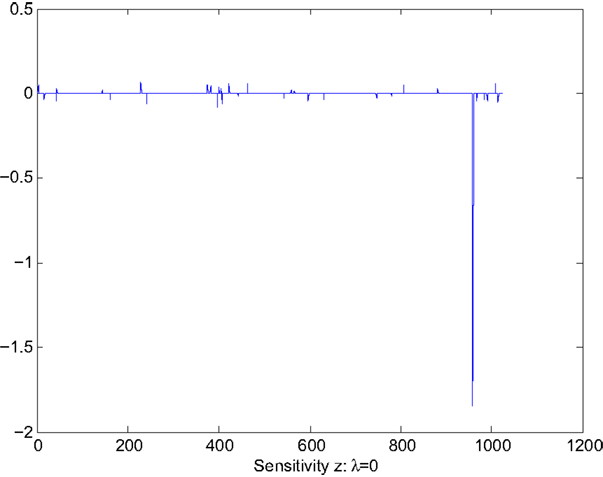
Figure 2. Sensitivity Z without sensitivity reduction: λ = 0.
Case 1: λ = 0. This case corresponds to the sparse solution to the following LASSO optimization:
Figure 1 shows the values of the solution x, which clearly indicates the sparseness of the solution. Figure 2 shows the sensitivity, Z displayed in the vector form , of x with respect to the parameter θ. The largest value of sensitivity is , which corresponds to x(i0) = x(959). The largest value of sensitivity is orders of magnitude larger than the rest of sensitivity values, which indicates the solution x is sensitive to the value of the i0th column of A.
Case 2: λ = 1.0. This case corresponds to the sparse solution with sensitivity reduction through the gradient projection algorithm described in Section 5. The values of x and are shown in Figures 3 and 4. Figure 3 indicates that x(i0) is now set to 0 to remove the effect of the i0th column of A. For pattern classification, this would mean that the feature vector corresponding to the i0 column of A is sensitive to noise and thus is removed for this particular case. Such feature vector may be resulted from biased data or incorrect choice, depending on the particular problem of concern or scenario. The largest value of sensitivity is , which represents orders of magnitude reduction from .
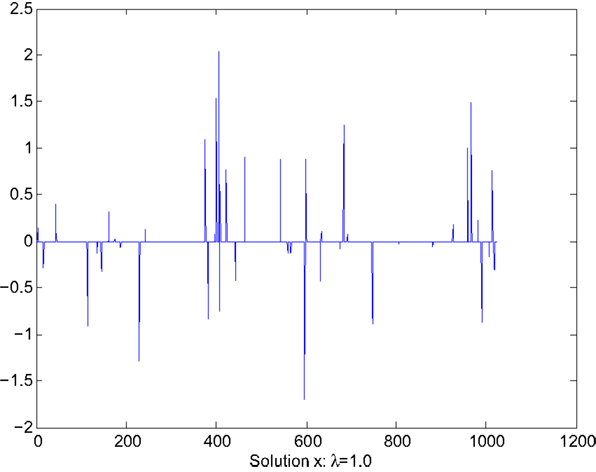
Figure 3. Solution x with sensitivity reduction: λ = 1.0.
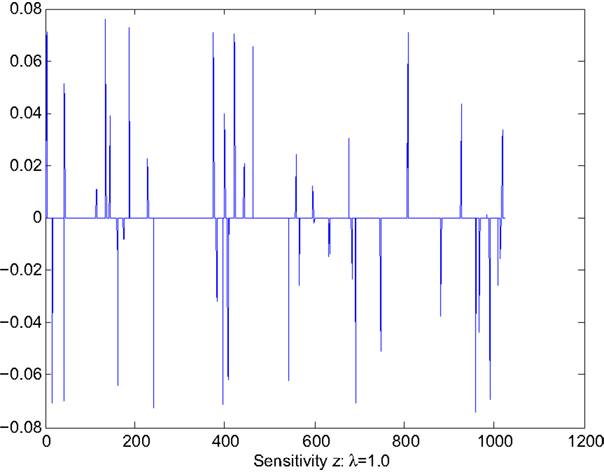
Figure 4. Sensitivity Z with sensitivity reduction: λ = 1.0.
7. Conclusion
Robustness of compressive sensing solutions has attracted extensive interest. Existing efforts have been focused on obtaining analytical bounds between the solutions of the perturbed and unperturbed linear measurement models. The perturbation is unknown but finite with a known upper bound. In this paper, we consider solution sensitivity to infinitesimal perturbations, the “other” side of perturbation has opposed to finite perturbations. The problem formulation enables the derivation of exact solutions. The results show that solution sensitivity is linear to measurement noise and proportional to the solution. We have also demonstrated how the sensitivity information can be incorporated in problem formulation to improve solution robustness. The new problem formulation provides a trade-off (i.e., by adjusting the parameter λ) between accuracy and robustness of compressive sensing solutions. One future research direction would be using the sensitivity information to adaptive optimization of parameterized compressive sensing problems. In computer vision, it is well recognized that the performance, e.g., the probability of detection, of object recognition is sensitive to feature selection and training data. The sensitivity information may be used to reduce such sensitivity, for example, in compressive sensing-based approaches to object recognition.
Conflict of Interest Statement
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work is part of the author’s staff research at the North Carolina State University. The author would like to thank Prof. Dror Baron, Jin Tan, and Nikhil Krishnan for their helpful comments and constructive suggestions. Their comments lead to the correction of an error in Lemma 3.1 in an earlier version. This work is supported in part by the U.S. Army Research Office under agreement W911NF-04-D-0003.
References
Arias-Castro, E., and Eldar, Y. C. (2011). Noise folding in compressed sensing. IEEE Signal Process. Lett. 18, 478–481. doi: 10.1109/LSP.2011.2159837
Boyd, S., Parikh, N., Chu, E., Peleato, B., and Eckstein, J. (2011). Distributed optimization and statistical learning via the alternating direction method of multipliers. Found. Trends Mach. Learn. 3, 1–122. doi:10.1561/2200000016
Candes, E. J. (2008). The restricted isometry property and its implications for compressed sensing. C.R. Acad. Sci. Ser. I 346, 589–592. doi:10.1016/j.crma.2008.03.014
Candes, E. J., and Romberg, J. (2005). l1-MAGIC: Recovery of Sparse Signals via Convex Programming. Available at: http://users.ece.gatech.edu/~justin/l1magic/
Candes, E. J., Romberg, J., and Tao, T. (2006). Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. 59, 1207–1223. doi:10.1002/cpa.20124
Candes, E. J., and Wakin, M. B. (2008). An introduction to compressive sampling. IEEE Signal Process. Mag. 25, 21–30. doi:10.1109/MSP.2007.914731
Chi, Y., Scharf, L. L., Pezeshki, A., and Calderbank, A. R. (2011). Sensitivity to basis mismatch in compressed sensing. IEEE Trans. Signal Process. 59, 2182–2195. doi:10.1109/TSP.2011.2112650
Davenport, M. A., Laska, J. N., Treichler, J. R., and Baraniuk, R. G. (2012). The pros and cons of compressive sensing for wideband signal acquisition: noise folding versus dynamic range. IEEE Trans. Signal Process. 60, 4628–4642. doi:10.1109/TSP.2012.2201149
Donoho, D., and Reevew, G. (2012). “The sensitivity of compressed sensing performance to relaxation of sparsity,” in Proceedings of the 2012 IEEE International Symposium on Information Theory (Cambridge, MA: IEEE Conference Publications), 2211–2215. doi:10.1109/ISIT.2012.6283846
Donoho, D. L. (2006). Compressed sensing. IEEE Trans. Inf. Theory 52, 1289–1306. doi:10.1109/TIT.2006.871582
Donoho, D. L., Elad, M., and Temlyakov, V. (2006). Stable recovery of sparse overcomplete representations in the presence of noise. IEEE Trans. Inf. Theory 52, 6–18. doi:10.1109/TIT.2005.860430
Donoho, D. L., Maleki, A., and Montanari, A. (2011). The noise-sensitivity phase transition in compressed sensing. IEEE Trans. Inf. Theory 57, 6920–6941. doi:10.1109/TIT.2011.2165823
Eldar, Y. C., and Kutyniok, G. (2012). Compressed Sensing: Theory and Applications. New York: Cambridge University Press.
Figueiredo, M. A. T., Nowak, R. D., and Wright, S. J. (2007). Gradient projection for sparse reconstruction: application to compressed sensing and other inverse problems. IEEE J. Sel. Top. Signal Process. 1, 586–597. doi:10.1109/JSTSP.2007.910281
Herman, M. A., and Strohmer, T. (2010). General deviants: an analysis of perturbations in compressed sensing. IEEE J. Sel. Top. Signal Process. 4, 342–349. doi:10.1109/JSTSP.2009.2039170
Moghadam, A. A., Aghagolzadeh, M., and Radha, H. (2014). “Sensitivity analysis in RIPless compressed sensing,” in 2014 52nd Annual Allerton Conference on Communication, Control, and Computing (Allerton) (Monticello, IL: IEEE Conference Publications), 881–888. doi:10.1109/ALLERTON.2014.7028547
Keywords: compressive sensing, sparse solutions, sensitivity analysis, robustness, gradient method
Citation: Dai L (2015) Sensitivity analysis of compressive sensing solutions. Front. Robot. AI 2:16. doi: 10.3389/frobt.2015.00016
Received: 09 March 2015; Accepted: 18 June 2015;
Published: 03 July 2015
Edited by:
Soumik Sarkar, Iowa State University, USAReviewed by:
Soumalya Sarkar, Pennsylvania State University, USAHan Guo, Iowa State University, USA
Copyright: © 2015 Dai. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Liyi Dai, Computing Sciences Division, U.S. Army Research Office, 4300 S. Miami Blvd, Research Triangle Park, NC 27703, USA,bGl5aS5kYWkuY2l2QG1haWwubWls