 Benjamin Rosenbaum
Benjamin Rosenbaum Michael Raatz3†
Michael Raatz3† Guntram Weithoff
Guntram Weithoff- 1German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Leipzig, Germany
- 2Institute of Biodiversity, Friedrich Schiller University Jena, Jena, Germany
- 3Institute of Biochemistry and Biology, University of Potsdam, Potsdam, Germany
- 4Department of Biology, McGill University, Montreal, QC, Canada
Empirical time series of interacting entities, e.g., species abundances, are highly useful to study ecological mechanisms. Mathematical models are valuable tools to further elucidate those mechanisms and underlying processes. However, obtaining an agreement between model predictions and experimental observations remains a demanding task. As models always abstract from reality one parameter often summarizes several properties. Parameter measurements are performed in additional experiments independent of the ones delivering the time series. Transferring these parameter values to different settings may result in incorrect parametrizations. On top of that, the properties of organisms and thus the respective parameter values may vary considerably. These issues limit the use of a priori model parametrizations. In this study, we present a method suited for a direct estimation of model parameters and their variability from experimental time series data. We combine numerical simulations of a continuous-time dynamical population model with Bayesian inference, using a hierarchical framework that allows for variability of individual parameters. The method is applied to a comprehensive set of time series from a laboratory predator-prey system that features both steady states and cyclic population dynamics. Our model predictions are able to reproduce both steady states and cyclic dynamics of the data. Additionally to the direct estimates of the parameter values, the Bayesian approach also provides their uncertainties. We found that fitting cyclic population dynamics, which contain more information on the process rates than steady states, yields more precise parameter estimates. We detected significant variability among parameters of different time series and identified the variation in the maximum growth rate of the prey as a source for the transition from steady states to cyclic dynamics. By lending more flexibility to the model, our approach facilitates parametrizations and shows more easily which patterns in time series can be explained also by simple models. Applying Bayesian inference and dynamical population models in conjunction may help to quantify the profound variability in organismal properties in nature.
1. Introduction
Trophic interactions provide the elementary link in all food webs. Long-term data sets of such interactions become increasingly available, both from field observations, and highly controlled large-scale and laboratory experiments (Fussmann et al., 2000; Tirok and Gaedke, 2007; Becks et al., 2010, 2012; Magurran et al., 2010; Weigelt et al., 2010; Boit and Gaedke, 2014). To mechanistically understand these trophic interactions, models are employed with the goal of reproducing the observed population dynamics, which can either settle to a steady state, or include more complex patterns like limit cycles or chaos (Fussmann et al., 2000; Boit et al., 2012; Becks and Arndt, 2013; Barraquand et al., 2017). Obtaining an agreement of such non-static experimental observations and modeled time series remains a demanding task. Often, modelers are faced with situations where they can reproduce basic features of the dynamics, but not on the right time scales or not on biomass levels close to the data. One logical reaction would be to refine the model structure and include a higher level of biological detail. However, another reason for such disagreements between model and data may be a generally valid model structure but an incorrect parametrization. In this study, we present a method to obtain the relevant model parameters directly from the experimental data by applying Bayesian inference to a comprehensive set of time series data for a laboratory predator-prey system that features both steady states and cyclic population dynamics.
Incorrect parametrizations can arise for different reasons. Firstly, a model always has to abstract from reality. This implies that individual model parameters summarize a multitude of different ecological processes. The impact of these processes on the model parameter likely changes over time. Due to these non-modeled processes a one-to-one relationship between empirically determined parameter values and model parameters is impossible. For example, typical predator-prey models consider a conversion efficiency by which prey biomass is converted into predator growth. Among others this efficiency depends on the variable prey abundance (S. Schälicke in prep.) and the relative importance of basal and activity respiration (Kath et al., 2018). Secondly, model parameters are often obtained experimentally under slightly different settings than the actually observed population dynamics. An example would be to measure the prey's population growth rate in batch experiments and then use this parameter in a chemostat model. By design, growth conditions in batch and chemostat cultures differ in some aspects, such as the dynamics of nutrient limitation or the selection pressure, e.g., for higher nutrient affinities vs. maximum growth rates. Therefore, the parameters that were obtained for one experimental setting might be of limited value for a different one.
It is more and more recognized that the functional traits of organisms that determine trophic interactions comprise a considerable variability (Litchman and Klausmeier, 2008; Bolnick et al., 2011; Violle et al., 2012; Bolius et al., 2017; Gaedke and Klauschies, 2017). This trait variability can have far-reaching consequences both at the population level (Abrams, 1999; Post and Palkovacs, 2009; Becks et al., 2010; Ehrlich et al., 2017; Raatz et al., 2017; Cortez, 2018) and at the community level (McGill et al., 2006; Hillebrand and Matthiessen, 2009). In such cases, employing just one parametrization for different time series of the same system may be insufficient and hamper the agreement of experimental and modeled population dynamics. Instead, the model will potentially support parts of the data or comprise certain general features, but will fail to reproduce its entire behavior. Our Bayesian framework allows to retrieve information on such parameter-related uncertainties directly from the time series data, which might even become apparent as between-replicate differences, and provide individual parameter estimates for each data set.
Dynamical population models have traditionally been fitted to time series data by least squares or maximum likelihood methods (Costantino et al., 2005; Cao et al., 2008; DeLong et al., 2014; Rall and Latz, 2016; Curtsdotter et al., 2018), see Bolker (2008) and Aster et al. (2012) for a general introduction. While they offer point estimates for unknown parameters, their confidence intervals rely on a local approximation and a normality assumption of the likelihood function (Bolker, 2008, Chap. 6.5).
Bayesian methods, on the other hand, quantify uncertainty more precisely by globally exploring the parameters' posterior probability distribution using Markov chain Monte Carlo (MCMC) sampling. They allow, for instance, direct inference on sought parameters and derived quantities, utilizing prior information, defining hierachical levels among parameters, and recovering unobserved system states (Kindsvater et al., 2018).
For discrete-time population dynamics, Bayesian methods have received growing attention over the last years (Almaraz and Oro, 2011; Elderd and Miller, 2015; Wittwer et al., 2015; Compagnoni et al., 2016; Robinson et al., 2017). In a discrete setup, state-space models (SSM) are feasible and allow, e.g., the separation of process and observation error (Hefley et al., 2013), recovering latent states (Hosack et al., 2012), incorporating age-structure (Taboadai and Anadón, 2016), adding environmental covariates (Almaraz et al., 2012; Koons et al., 2015), or spatially explicit models (Iijima et al., 2013). These advances were facilitated by the probabilistic programming environments BUGS (Lunn et al., 2009) and JAGS (Plummer, 2003).
The implementation of continuous-time population dynamics (described by ordinary differential equations, ODEs) is available in BUGS but not in JAGS. Until recently, modelers often combined numerical simulations of ODEs manually with MCMC routines (Gilioli et al., 2008; Toni et al., 2009; Johnson et al., 2013; Smith et al., 2015; Papanikolaou et al., 2016; Boersch-Supan et al., 2017). Like BUGS, the probabilistic programming language Stan (Carpenter et al., 2017) offers an integrated solution for ODEs. It comes with a built-in numerical ODE solver, interfaces to R, Python, Matlab and more, and a Hamiltonian Monte Carlo (HMC) sampler (Monnahan et al., 2017). Thus, it supports fitting dynamical population models to time series data in a Bayesian framework, see Fussmann et al. (2017) and Carpenter (2018) for recent applications.
In this study, we will apply Bayesian inference in Stan to a set of time series of a predator-prey system in a chemostat, i.e., a continuous flow-through culture (Novick and Szilard, 1950). The parameters of a well-established continuous-time chemostat ODE model will be estimated yielding posterior distributions for the parameters, which allow also to quantify their uncertainties. By comparing the posteriors for the individual time series we can deduce a variability among them that manifests in different types of population dynamics and pin-point to specific parameters that seem to determine this variability.
2. Materials and Methods
2.1. Data Collection
Chemostat experiments were performed to obtain predator-prey time series at a high temporal resolution in a highly controlled environment (Weithoff et al., unpublished) resulting in a large collection of long-term time series with several different species. From these we selected a subset of 13 experiments, which were replicates in the sense that the same species were used at the same inflow nutrient concentration and dilution rate, and daily counts of prey and predators are available. The experiments were conducted with a metazoan predator, the rotifer Brachionus calyciflorus s.s.(Michaloudi et al., 2018; Paraskevopoulou et al., 2018), and its prey Monoraphidium minutum, a unicellular green alga. The algae grew on nitrogen-limited medium. However, daily nitrogen concentrations are not available. The experiments were performed within a time span of 7 years, with some individual experiments lasting longer than 1 year. They yielded time series which differed with respect to the degree that they exhibited more or less regular cyclic dynamics, or more or less constant predator and prey densities. From these 13 replicates we selected all shorter time series that showed either clear and pronounced predator-prey cycles or steady-state equilibria, and excluded pronounced initial transient phases. We chose a minimum sample length of 20 days which would typically allow for at least two predator-prey cycles in this system. This process resulted in a set of 18 samples, 10 of which featured a steady state and eight contained cyclic dynamics.
2.2. Dynamical Population Model
The continuous-time population dynamics of a predator-prey system in a chemostat with nitrogen S, algae A and rotifers R are described by the equations:
This formulation represents a slightly simplified version of the one originally presented by Fussmann et al. (2000) and neglects age structure of the predator. δ is the system's inflow and outflow rate, and the concentration of nutrients in the inflow is given by S*. The factors cA and cR define the conversion of nutrients into algal biomass and algal into rotifer biomass, respectively. The growth rate of algae is described by Monod kinetics . fA is the maximum growth rate and hA is the half-saturation constant (the resource density at which the growth rate equals half of the maximum growth rate). The same applies to the resource-dependent growth rate of rotifers feeding on algae , which is described by a type II functional response (Real, 1977). The maximum growth rates fA[d−1], fR[d−1] and the conversion factors cA[cells μmol−1], cR[ind cells−1] are free parameters, which are estimated as described in the next section. We used constant values for the following parameters from a similar system which instead used Chlorella vulgaris as the prey species: S* = 80 μmol l−1 and δ = 0.55 d−1, as they were carefully controlled in the experiments, and hA = 4.3 μmol l−1 and hR = 7.5 · 108 cells l−1 (Fussmann et al., 2000). These values for the half-saturation constants were in the range of our predicted and observed resource states S and A, respectively (cf. Figures 2, 3).
We chose to not use half-saturation constants hA (or hR) as free parameters, since the estimates can be highly correlated with maximum growth rates fA (or fR). Their combined effects on the resource-dependent growth rate (or ) can only be disentangled if the data cover a large range in the resource states S (or A) (Rosenbaum and Rall, 2018), which is not the case for the present chemostat experiments.
2.3. Model Fitting and Inference
We combined numerical simulations of the deterministic dynamical population model (Equations 1–3) with Bayesian parameter estimation by drawing samples from the posterior probability distribution P(θ|y) of the free parameters θ given the data y, based on the likelihood P(y|θ) and the prior distribution P(θ). We used Hamiltonian Monte Carlo sampling in Stan, accessed via the RStan R-package (Stan Development Team, 2018). The Stan software comes with a built-in Runge-Kutta ODE solver with adaptive stepsize control for generating predictions .
The likelihood calculation P(y|θ) is carried out automatically by the software when provided with predictions and the distribution of residuals . The predictions are defined by the numerical solutions of the ODE and , evaluated at times ti, for a given parameter combination θ. We chose a log-normal distribution of the residuals, i.e., and , with scale parameters σA and σR. This trajectory matching method technically corresponds to treating the model deterministically and to assuming pure observation errors in the data without any process error (Bolker, 2008, Chap. 11). Note that, even without data for the concentration nitrogen S, it is possible to fit the ODE model by including the initial densities of the predictions , and as free parameters (Carpenter, 2018). However, one-step-ahead fitting (i.e., assuming pure process error) would only be possible for this ODE model if data for all state variables S, A and R was available. We did not consider full state-space models accounting for both process and observation error.
We fitted the maximum growth rates fA and fR and the conversion factors cA and cR on their logarithmic scale (see model code, Supporting Information). The dynamics and the statistical model are equivalent to fitting them on their original scale. But since they differ by several orders of magnitude, we found that log-transforming the parameter search space makes the iterative MCMC routine more robust.
We used a hierarchical model for the maximum growth rates fA and fR and for the conversion factors cA and cR by using time series identity j = 1, …, m as a random effect. This means that every time series j is fitted with its individual set of parameters , while each of these four parameters originates from a joint distribution across all m time series replicates. Thus, some information is shared across the individual replicates via the joint distribution, therefore this technique is also known as partial pooling. In a Bayesian framework, this can be modeled via hierarchical dependencies in the prior distributions. Including logarithmic scaling, they read
where μln(θ) are the overall means and σln(θ) the standard deviations across all m time series. μln(θ) and σln(θ) are also free parameters with their own prior distribution (see Table 1 for a full description of the priors).
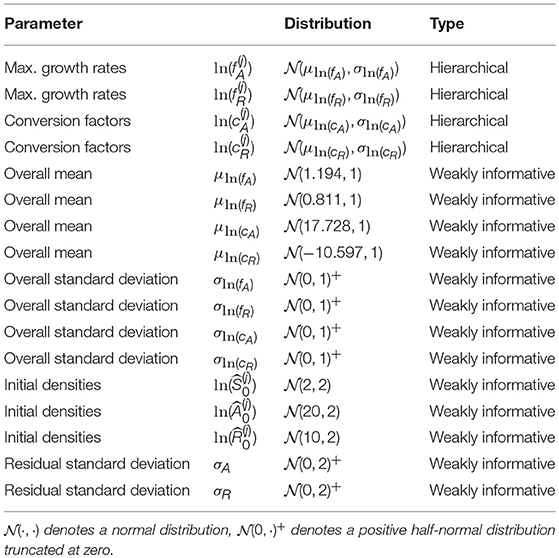
Table 1. Free parameters and their prior distributions.
We tested for variation in the dynamics of the different time series by uncovering differences in parameters. For each parameter θ = fA, fR, cA, cR, pairwise contrasts θ(j)−θ(k) between two time series j and k were inferred. I.e., we generated posterior probabilities that quantify these differences. These quantities Pjk are directly computed from the posterior distribution by dividing the number of samples featuring θ(j) > θ(k) by the total number of samples.
To further investigate the importance of variation among the parameter estimates for different time series, we also fitted the ODE model (Equations 1–3) using a single set of parameters {fA, fR, cA, cR} for all 18 time series as a null model. In contrast to the hierarchical (partial pooling) model above, this is also known as complete pooling, since all information across individual replicates is combined. Only for the initial states we allowed distinct values for each of the time series j = 1, …, 18.
We briefly comment on numerical issues that can arise when combining numerical solutions of ODEs with MCMC sampling. When the MCMC sampler explores the parameter space, points can be sampled that make the computation of the likelihood by numerical simulation of the ODE infeasible (e.g., by requiring an immensely small integration step-size or simply by divergent state variables). Still, the sampling algorithm requires the computation of the likelihood to proceed with the iterations. To prevent the sampler from entering regions of the parameter space where, over a whole range of values, the likelihood is not available, we used two strategies. First, we implemented a numerical condition which prevents the numerical ODE solution from diverging or crossing the lower boundary of zero by setting the right-hand-side of the ODE to zero if one of the state variables exceeds a reasonable range of [10−6, 1016] (see model code in Supporting Information). Second, we used weakly informative priors on the overall mean parameters μln(θ) based on measured values from Fussmann et al. (2000): μln(fA) ~ (ln(3.3), 1), μln(fR) ~ (ln(2.25), 1), , (see also Table 1). We used the same priors for the complete pooling model.
2.4. Simulation Study
Before fitting the presented models to the experimental chemostat data, we first validated our modeling approach in a simulation study. By fitting the hierarchical model to simulated time series, which were generated by known parameters, we tested the identifiability of model parameters. These parameters , , and were drawn randomly from lognormal distributions using the measured values from above (Fussmann et al., 2000) as means and a standard deviation of 0.5. Initial states of the time series were also assigned randomly according to Table 1. We numerically simulated ODE trajectories of Equations 1–3 for 100 days and chose 10 time series that settled to different steady states and 10 time series that featured cyclic dynamics of different frequencies and amplitudes. We used the observations of algal and rotifer states of the last 20 days (leaving out nitrogen states as in the experimental data) and added a random error with zero mean and standard deviation of 0.1 on the ln-scale (see also Figures A1, A2, Supporting Information).
3. Results
3.1. Model Convergence
We fitted all models (hierarchical model in simulation study; hierarchical model and complete pooling model for experimental chemostat data) by running 10 individual MCMC chains in parallel with an adaptation phase of 1,000 iterations and a sampling phase of 5,000 samples each, summing up to 50,000 samples of the posterior distribution. The runtime was approximately 7 days on a 2.2 GHz Intel Xeon server architecture. Visual inspection of the trace plots and density plots showed a good mixture of the chains. Gelman-Rubin statistics of and an adequate effective sample size neff (i.e., the estimated number of independent samples) verified convergence (Gelman and Hill, 2007). See Supporting Information (Tables A1–A4) for a full list of parameter estimates and their statistics.
3.2. Identifiability of Parameters
We used the simulation study to assess if known parameters can be recovered accurately by fitting the hierarchical model to a synthetic set of 10 steady-states and 10 cyclic time series (cf. Figures A1, A2, Supporting Information). Figure 1 shows the posterior error distributions (distributions of estimated parameter values minus true values on ln-scale) of maximum growth rates and and conversion factors, and of prey and predators, respectively. We found that all parameters of cyclic time series 11–20 were accurately identifiable. The posterior medians generally did not deviate more than 0.05 from the true parameters and all estimates featured a low uncertainty (posterior standard deviations smaller than 0.04).
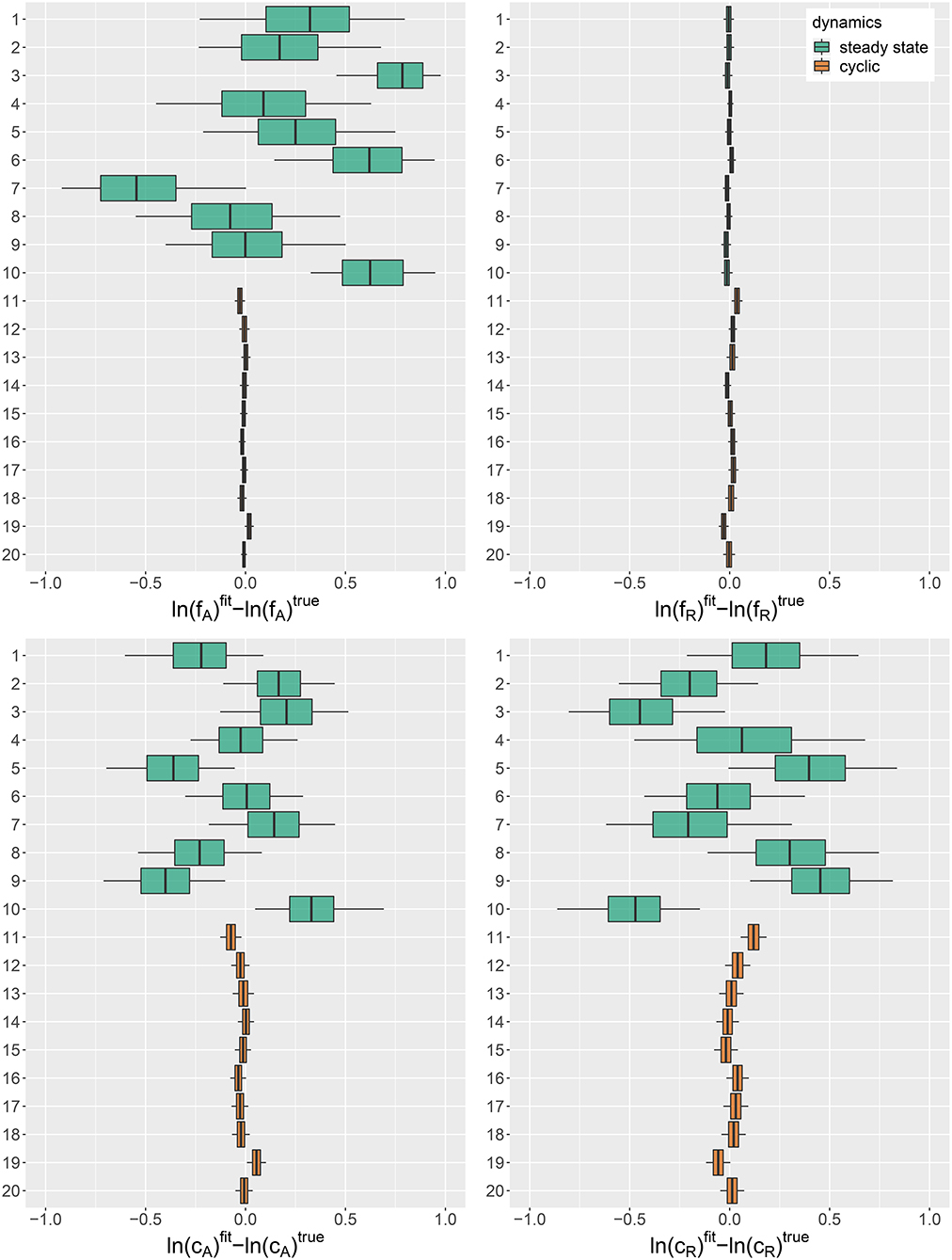
Figure 1. Posterior error distributions of maximum growth rates , and conversion factors for fitting simulated time series (j = 1, …, 20). Simulated trajectories 1–10 featured a steady-state equilibrium (green), while simulated trajectories 11–20 featured cyclic behavior (orange). Vertical lines represent medians, boxes represent 50% highest density intervals (HDIs) and horizontal lines represent 95% HDIs.
For steady-state time series 1–10, however, posterior distributions of algal maximum growth rates showed relatively high uncertainties (posterior medians deviating up to 0.8 from true values with posterior standard deviations up to 0.34). We assume that, in combination with the lack of nitrogen data S, steady-state time series, which cover a smaller range in the state space, contain less information about the resource density-dependent growth rates of algae feeding on nitrogen than cyclic time series. Estimates for rotifer maximum growth rates , on the other hand, were highly accurate just as for cyclic time series. In contrast to fA, the data seem to provide enough information on the growth rates of rotifers feeding on algae even in steady-state time series, since observations for both involved trophic levels are available. The estimates for conversion factors and were also less accurate for steady-state time series 1–10 than for cyclic time series 11–20 (posterior medians deviate up to 0.47 from true parameters, with an uncertainty of posterior standard deviations up to 0.37). We assume that steady-state data is not as informative as cyclic data on the conversion factors, as we also observe a high correlation between the posterior of and for every steady-state time series (cf. Supporting Information, Figure A3). Note that correlation per se does not imply unidentifiability. We observed correlations between the posteriors of cyclic time series parameters as well (cf. Supporting Information, Figure A4), while these parameters are estimated with a high accuracy.
3.3. Posterior Predictions
After assessing the identifiability of the hierarchical model in a simulation study, we investigated its performance with the experimental chemostat data. We generated posterior predictions by numerical simulations of the ODE system (Equations 1–3) with all samples of the posterior distribution (Figures 2, 3). After a short transient phase, the median predicted trajectories feature either a steady-state equilibrium (time series 1–9), cyclic behavior (time series 13–18); or the posterior distribution includes parameter samples producing steady states as well as cyclic trajectories (time series 10–12). Correspondingly, we found multimodalities in the posterior distributions of time series 10–12 (see Supporting Information, Figures A6, A7).
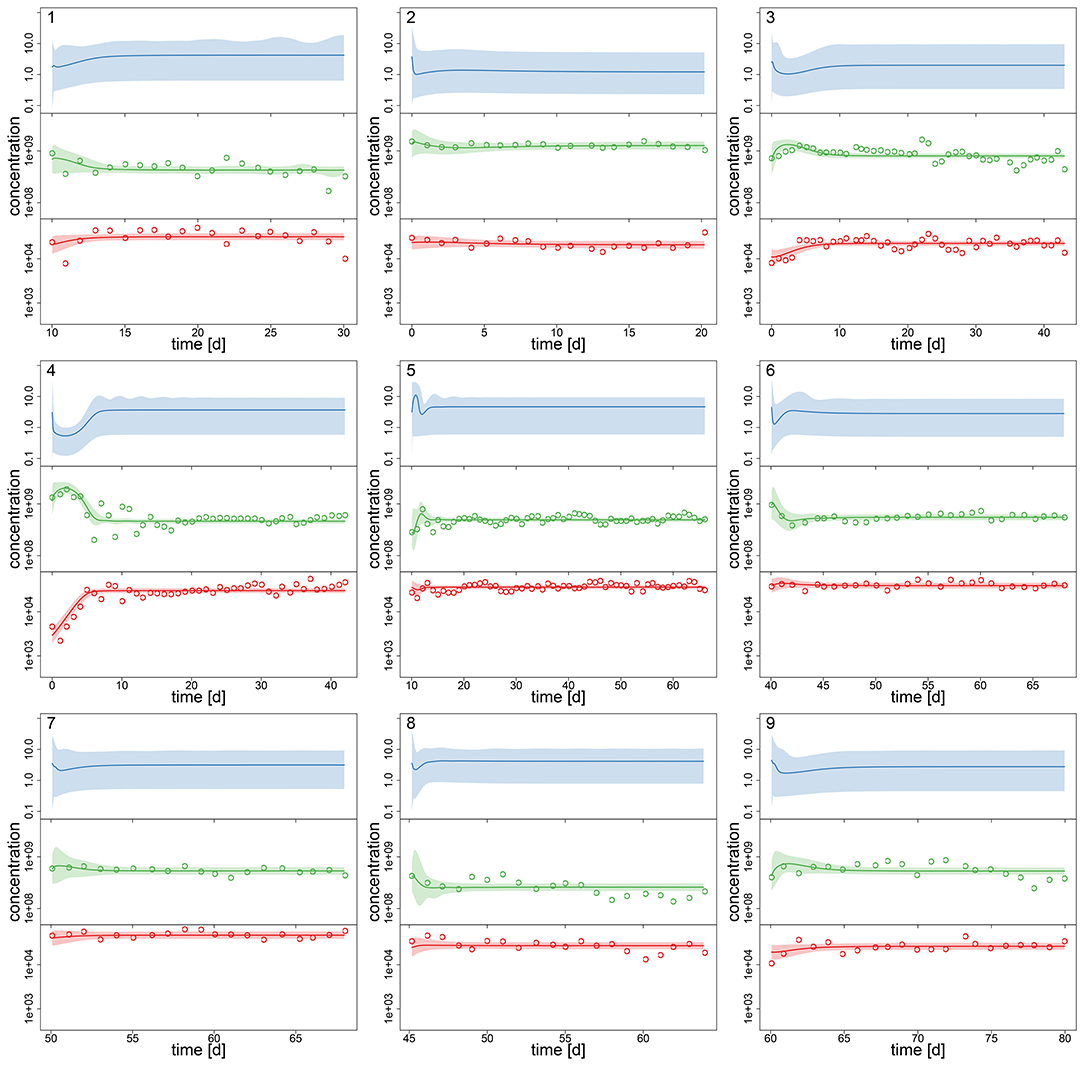
Figure 2. Experimental time series 1–9 of 18, data (dots) and posterior predictions of hierarchical model for nitrogen [μmol l−1] (blue), algae [cells l−1] (green) and rotifers [ind l−1] (red). Solid lines represent median predictions, shaded areas depict 95% highest density intervals of the predictions. Predicted trajectories 1–9 featured a steady-state equilibrium.
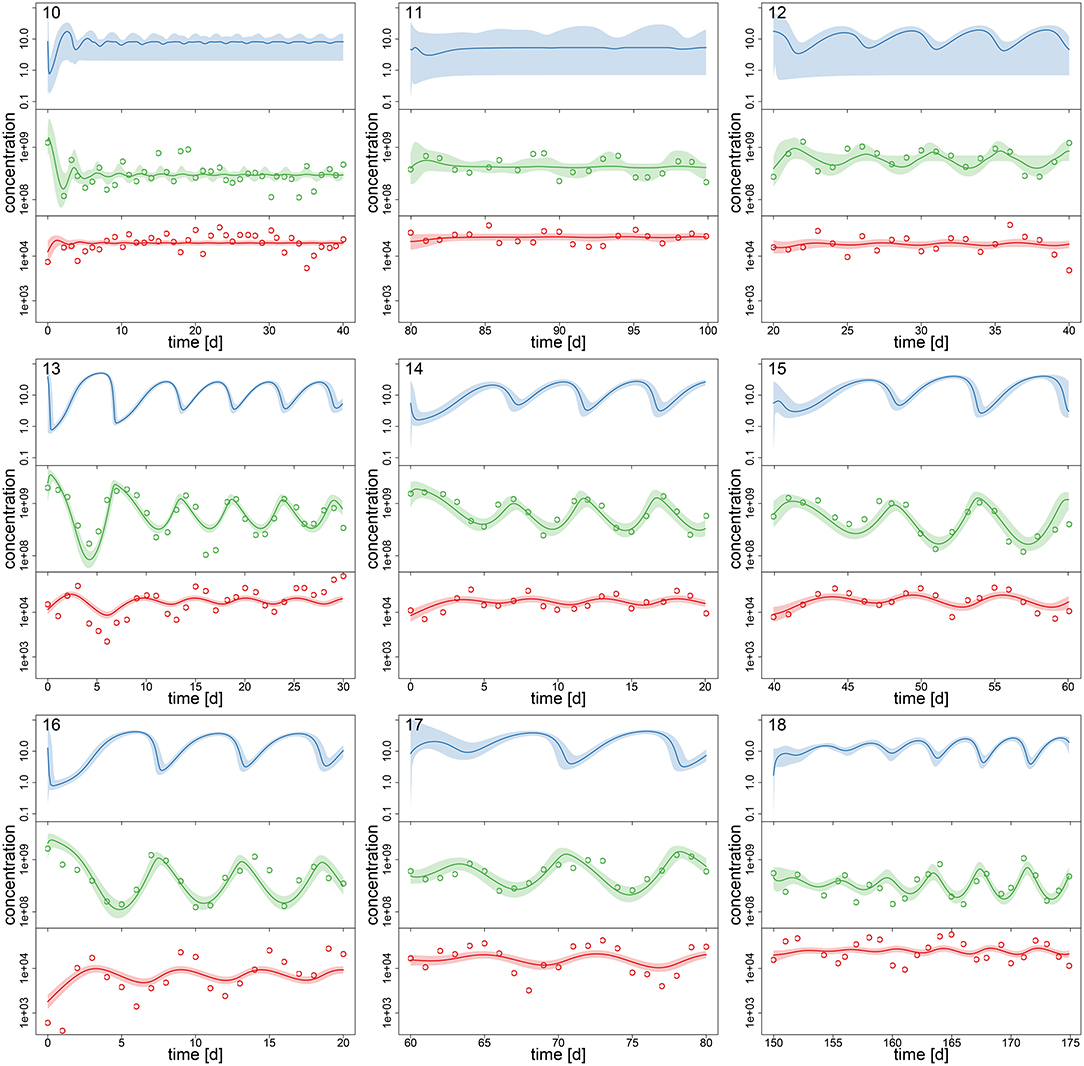
Figure 3. Experimental time series 10–18 of 18, data (dots) and posterior predictions of fitted model for nitrogen [μmol l−1] (blue), algae [cells l−1] (green) and rotifers [ind l−1] (red). Solid lines represent median predictions, shaded areas depict 95% highest density intervals of the predictions. Predicted trajectories 13–18 featured cyclic behavior. Time series 10–12 featured multimodalities in the posterior distribution and the predictions did not exhibit a clear tendency toward a steady state or cycles.
Interestingly, the relative uncertainty of the predictions (quantified by 95% confidence intervals) for all state variables is substantially reduced in time series 13–18 where the predictions feature cyclic behavior compared to other time series (Figures 2, 3). We measured the predictive accuracy in the univariate time series by normalized root mean-square-errors (cf. Figure A7, Supporting Information). Here we see that the error distributions are shifted to smaller values and become more narrow for cyclic dynamics, also indicating a better fit. Again, this may be explained by acknowledging that steady-state data, which covers a smaller range in the state space than cyclic data, contains less information about the process rates and hence the parameters.
As no data constrains the predictions for nitrogen, the uncertainty is even higher here than in algae or rotifers in time series 1–9 (this was also observed for steady-state time series in the simulation study, cf. Supporting Information Figure A1). Also, we found that our ODE model is able to predict the full amplitude of cycles in algal states better than in rotifer states (Figures 2, 3). We further validated this by calculating predictive accuracies (normalized root-mean-square error, Figure A7, Supporting Information) and posterior predictive checks (comparing observations and replicated predictions drawn from the posterior and , Figures A8, A9, Supporting Information). This is likely caused by a higher regularity in the algal data, which covers a larger amplitude decreasing the relative counting error. Also, algae feature a less complex life cycle than rotifers and their dynamics should thus be less variable.
3.4. Variation Among Time Series
For assessing the variation in the parameters across the experimental chemostat time series (j = 1, …, 18), we plotted the marginal (i.e., one-dimensional projections of the multivariate) posterior probability distributions of the logarithmic maximum growth rates and and the logarithmic conversion factors, and of prey and predators, respectively (Figure 4). We also computed probabilities of pairwise contrasts for a more detailed examination of the differences across time series (θ = fA, fR, cA, cR, Tables 2–5). Values close to one or close to zero indicate significant pairwise differences. Note that the tables are symmetrical in the sense of Pjk = 1−Pkj.
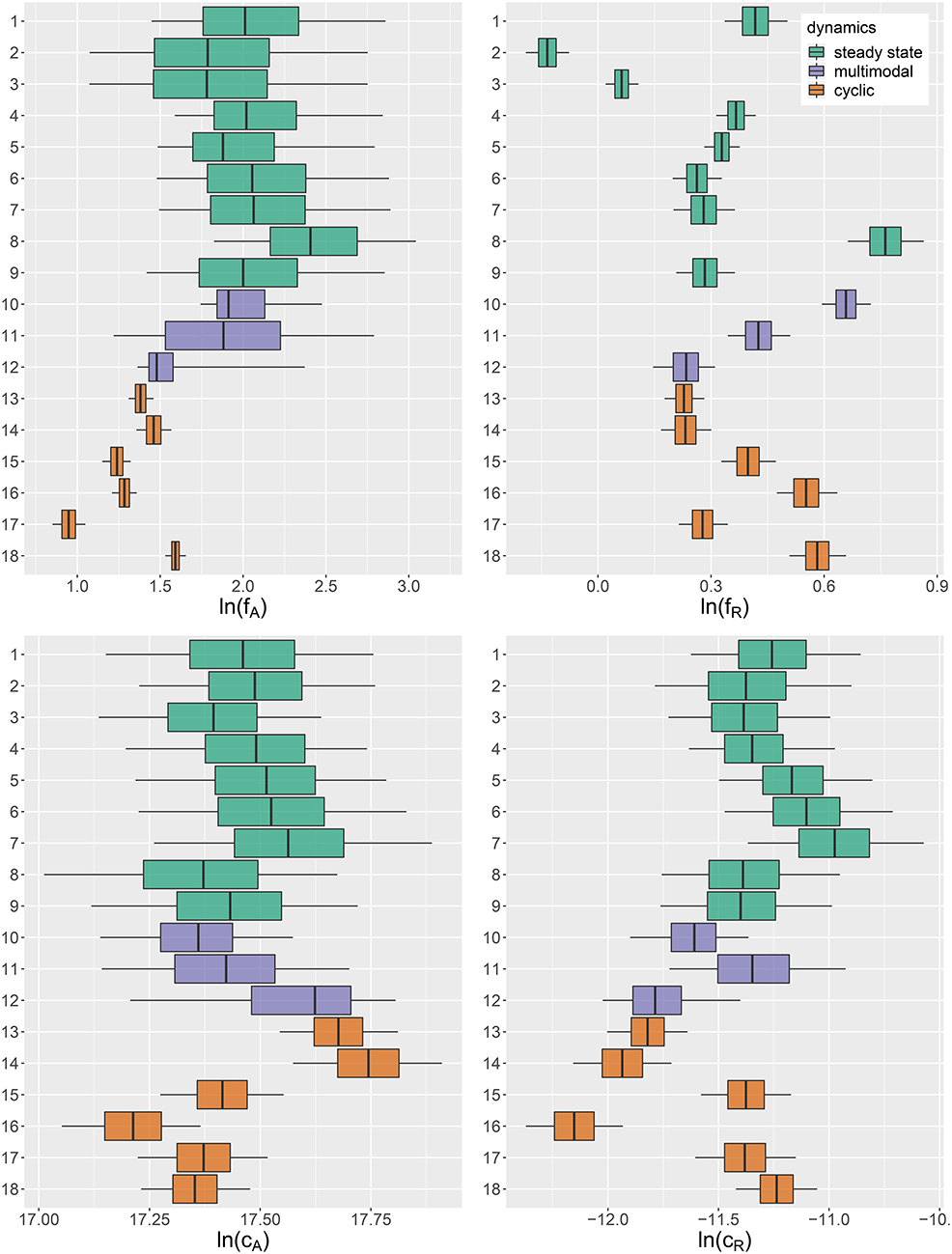
Figure 4. Marginal posterior distributions of maximum growth rates , and conversion factors for fitting experimental time series (j = 1, …, 18). Predicted trajectories 1–9 featured a steady-state equilibrium (green), while predicted trajectories 13–18 featured cyclic behavior (orange). Time series 10–12 (purple) featured multimodalities in the posterior distribution and the predictions did not exhibit a clear tendency toward a steady state or cycles. Vertical lines represent medians, boxes represent 50% highest density intervals (HDIs) and horizontal lines represent 95% HDIs.
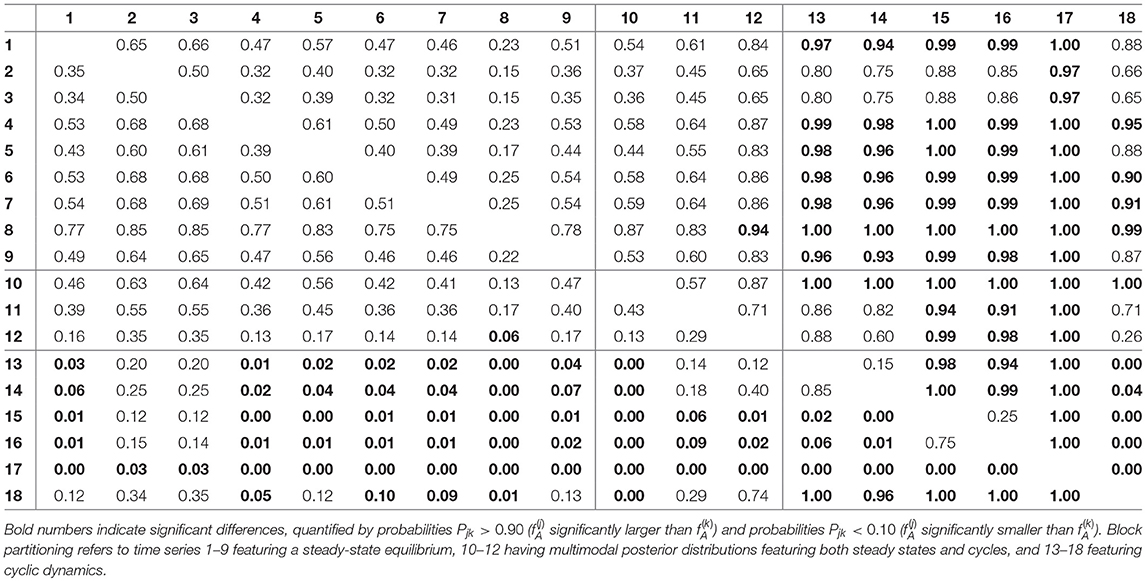
Table 2. Pairwise contrasts of maximum growth rates fA.
We found that time series with predicted steady states feature systematically higher values of fA than time series with cyclic dynamics (Figure 4A; Table 2, top right and bottom left blocks). While in cyclic time series 13–18 values of fA differ among each other (bottom right block), no evidence was found for differences among steady-state time series 1–9 (top left block). Steady-state time series also exhibit a high uncertainty in fA estimates with confidence intervals spanning from 2.43 d-1 to 40.85 d-1 when transformed back to a linear scale (Figure 4A, see also Supporting Information, Table A1). This uncertainty is substantially reduced in cyclic time series 13–18 with confidence intervals spanning from 2.29 d-1 to 5.31 d-1. Here, the predicted parameter values are close to the published value in Fussmann et al. (2000), which however was published for Chlorella instead of Monoraphidium, but should be in the same range.
For the rates fR we found pairwise differences across all time series (Figure 4B, Table 3). No systematic effect of cyclic or steady-state time series was observed (i.e., fR estimates for cyclic time series are not systematically smaller than estimates for steady-state time series or vice versa). In contrast to the rates fA, even steady-state data provide enough information on rates fR (with consumer and resource data available), resulting in a low uncertainty in estimation just as for cyclic time series.
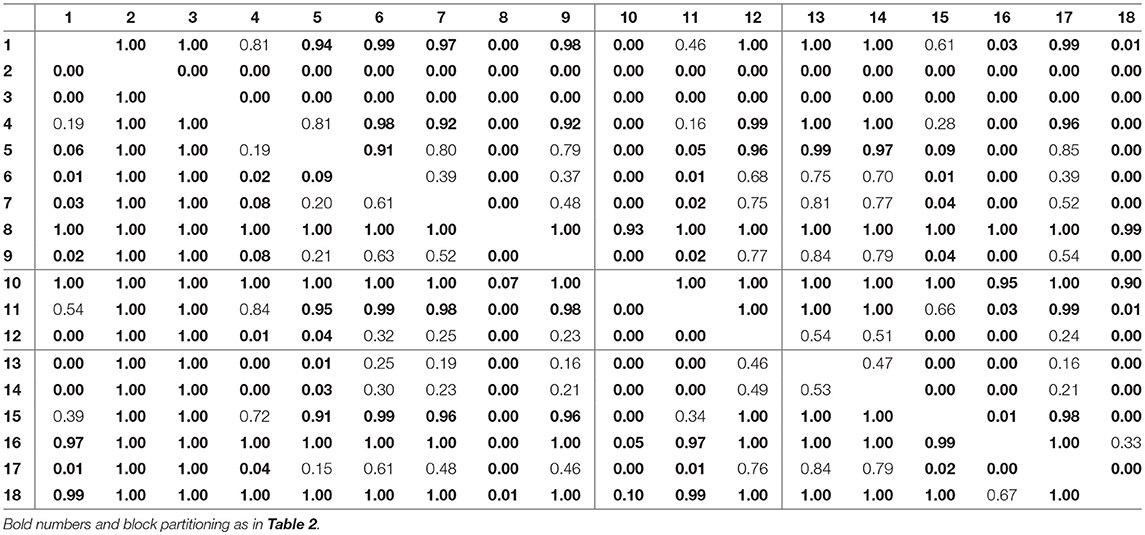
Table 3. Pairwise contrasts of maximum growth rates fR.
The conversion factors cA and cR did not show significant pairwise differences for steady-state time series 1–9 (Figures 4C,D; Tables 4, 5, top left blocks; with few exceptions for cR). Some pairwise differences among cyclic time series 13–18 (bottom right blocks) and to steady-state time series (top right and bottom left blocks) were observed, without being as systematic as in fA. The uncertainty in parameter estimates is slightly larger in steady-state time series than in cycles time series, but the effect is not as prominent as in fA estimates (see also full tables of estimates, Tables A1–A4, Supporting Information). All findings of this section regarding uncertainties in the parameter estimation were in accordance to the simulation study's results.
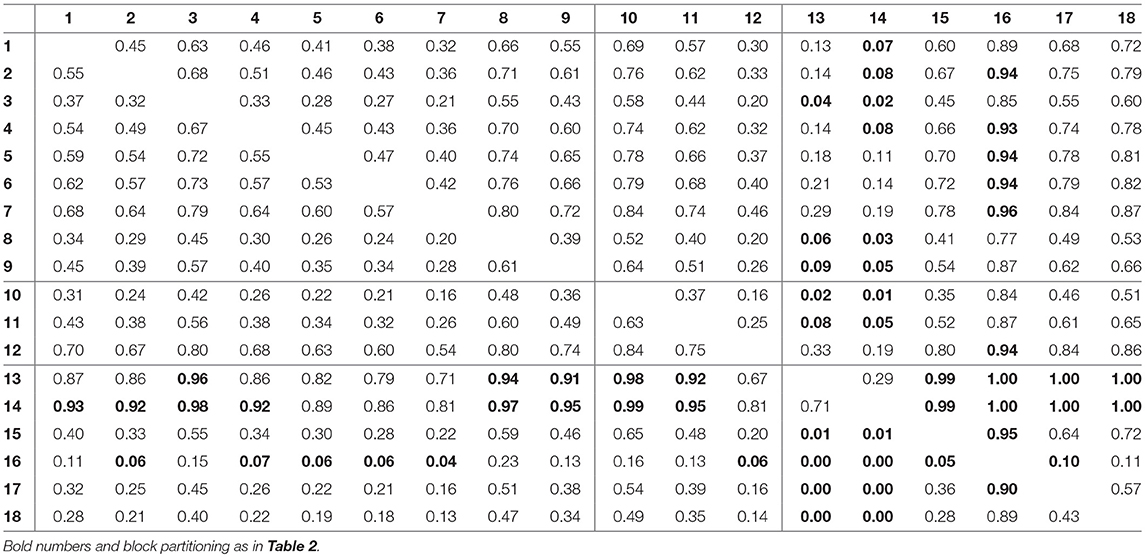
Table 4. Pairwise contrasts of conversion factors cA.
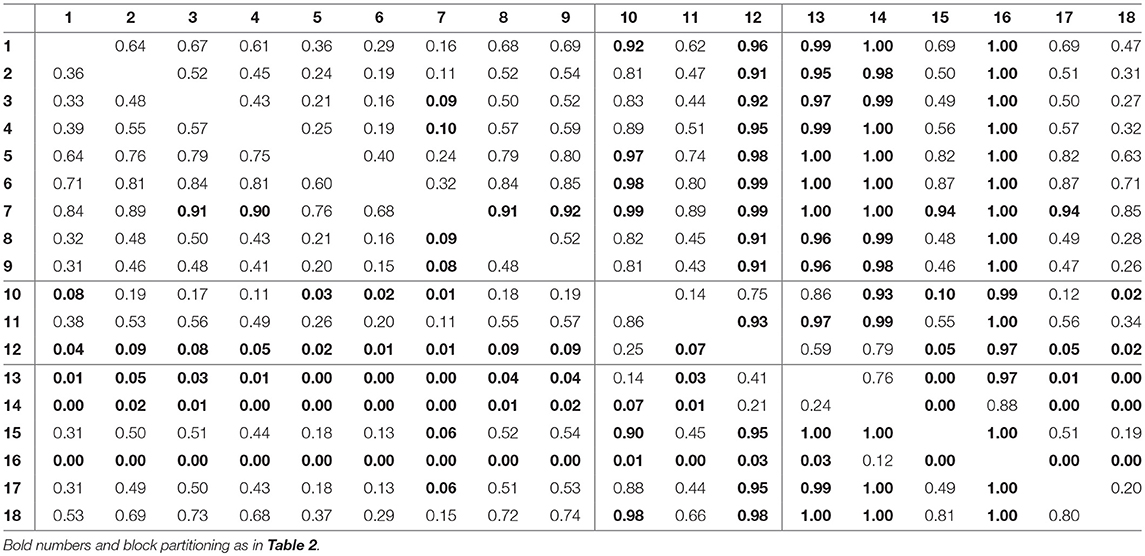
Table 5. Pairwise contrasts of conversion factors cR.
3.5. Comparison to Complete Pooling Model Fitting
To further support the importance of variation among the parameter estimates, we also fitted the complete pooling model using a single set of parameters {fA, fR, cA, cR} for all 18 time series as a null model. We used the same priors and model fitting specifications as above. Although a formal model comparison via information criteria is generally available for Bayesian statistics (Vehtari et al., 2018), it is not applicable to our dynamical model, since predictions (and therefore residuals) are correlated along time. Hence, we compare the complete pooling and the partial pooling (hierarchical) model qualitatively and quantitatively via their predictions. In contrast to the previous hierarchical model, the complete pooling model produces transient and steady-state predictions for all time series. Cyclic dynamics can not be reproduced (Supporting Information, Figures A10, A11). Also, the predicted equilibrium fails to reproduce the correct level of algae and rotifer states in some cases. This corresponds to a generally lower predictive accuracy when fitting algal and rotifers time series with the complete pooling model as compared to the hierachical model (Supporting Information, Figure A7). The effect is highest for cyclic time series 13–18, but also pronounced in time series 2, 3, 8, and 10, where the equilibrium states are not reproduced correctly.
3.6. Transition From Cyclic Dynamics to Steady States
To support the observation that low maximum growth rates fA cause cyclic dynamics while high maximum growth rates yield a steady-state equilibrium (Figure 4), we performed a simulation study. We numerically simulated the chemostat model (Equations 1–3) while systematically varying growth rates fA between 1 d-1 and 7.389 d-1 (corresponding to parameter values ln(fA) between 0 and 2). The maximum growth rate of the predator and the conversion factors were held constant at their estimated overall means exp(μln(θ)) across the 18 time series (fR = 1.419 d−1, cA = 3.865 · 107 cell μmol−1, cR = 1.065 · 10−5 ind cell−1). The bifurcation diagram (Figure 5) shows system states of simulations over 200 days after discarding the first 100 days and clearly indicates cycles for low growth rates and steady states for high growth rates, with the Hopf bifurcation located in fA = 4.446 d−1.
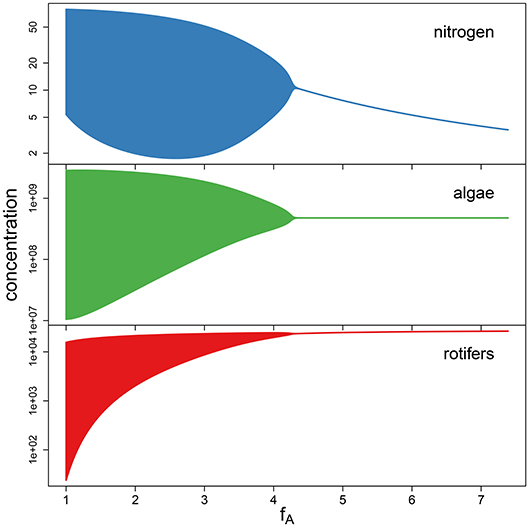
Figure 5. Bifurcation diagram for simulations with varying maximum growth rate fA, while keeping the remaining parameters constant at the fitted overall means. A Hopf bifurcation occurs at fA = 4.446.
4. Discussion
In this study we presented how a differential equations model can be fitted to observed time series data of species abundances, taking predator-prey dynamics as an example. Next to obtaining key model parameters in situ, this method allows to decipher variability in the outcomes among replicates and to point toward probable sources of this variability.
The comparison of choosing the time series identity as a random effect (partial pooling) to a model using only a single set of parameters (complete pooling) shows that allowing for such a variability in the parameters between replicates can be crucial to see whether time series data agree with a model. Especially if a certain parameter is close to a bifurcation, as it seems to be the case in our system for the maximum growth rate of the algae fA, minor deviations in this parameter result in different predictions for the system dynamics. In such cases, in-situ parameter estimation allows the detection of parameter sets for both steady states and cyclic dynamics, which can be separated by a multi-dimensional bifurcation boundary in models with a high number of parameters. Thereby, the chosen model structure may be accepted for all replicates, even if their dynamics differ, without increasing the model complexity. Instead, more than one parameter set might be needed to cover the whole diversity of possible and observable patterns in population dynamics.
Of course, this method requires that the model structure used for fitting the data applies sufficiently well to the mechanisms acting in the system delivering the data. Also, the data quality has to be high enough. We see that the dynamics of the prey are fitted better than those of the predator, which may be explained by different mechanisms: (i) The densities of the prey in the data are much larger than those of the predator. Assuming that the relative experimental error of counting decreases with larger individual numbers, this error should be smaller for the prey than for the predator. This increases the regularity of the dynamical patterns and simplifies the fitting of the prey time series. (ii) Rotifers, as metazoan animals, possess a more complex life-cycle than algae. Their dynamics may be affected by age-structure, variable resource co-limitation and other factors, which, for simplicity, were not included in the model. These non-modeled processes obviously decrease the goodness of fit. (iii) As no data was available for the resource of the prey, the parameters of the prey were confined only by the prey data, leaving more flexibility to improve the fitting in the prey's states. Contrarily, the parameters of the predator were more restricted, as both prey and predator data was available, leaving less flexibility for fitting the predator's states.
Interestingly, the type of population dynamics affects the quality of the inference as well. Population cycles contain a higher degree of information on the system than steady states, as also rates of change are apparent, additional to the biomasses of the trophic levels. This manifests in more narrow parameter estimates (Figure 4) and leads to more certain predictions (Figures 2, 3). Also, steady-state fits give rather (and partially unrealistically) high estimates for algal growth rates, whereas those from cyclic population dynamics are estimated close to published values. These findings were also confirmed in a simulation study by fitting the model to synthetic data generated by known parameters (Figure 1).
Variability in key parameters suggests a heterogeneity in the traits that are encoded by these parameters. Heterogeneous traits imply intra-specific variability which may enable populations to escape perturbations and to persist in the presence of strong stressors (Reusch et al., 2005; Bell and Gonzalez, 2009; Chevin et al., 2010). Bayesian parameter inference provides uncertainty estimates on key parameters and thereby allows to detect such variability in experiments. We propose that this technique may also help to quantify the presence of trait heterogeneity in nature.
Author Contributions
BR, UG, and MR conceived the ideas, GW and GF contributed the data, BR developed the methods, BR and MR led the writing of the manuscript. All authors contributed critically to the drafts and gave final approval for publication.
Funding
BR gratefully acknowledges the support of the German Centre for integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig funded by the German Research Foundation (FZT 118). MR was supported by German Research Foundation within the Priority Programme 1704 (DynaTrait) by grants WA 2445/11-1 and GA 401/26-1.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
We thank Bernd Blasius for his contribution to the acquisition and provision of the data.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fevo.2018.00234/full#supplementary-material
References
Abrams, P. A. (1999). Is predator-mediated coexistence possible in unstable systems? Ecology 80, 608–621. doi: 10.2307/176639
Almaraz, P., Green, A. J., Aguilera, E., Rendón, M. A., and Bustamante, J. (2012). Estimating partial observability and nonlinear climate effects on stochastic community dynamics of migratory waterfowl. J. Anim. Ecol. 81, 1113–1125. doi: 10.1111/j.1365-2656.2012.01972.x
Almaraz, P., and Oro, D. (2011). Size-mediated non-trophic interactions and stochastic predation drive assembly and dynamics in a seabird community. Ecology 92, 1948–1958. doi: 10.1890/11-0181.1
Aster, R. C., Borchers, B., and Thurber, C. H. (2012). Parameter Estimation and Inverse Problems, 2nd Edn. Oxford: Academic Press.
Barraquand, F., Louca, S., Abbott, K. C., Cobbold, C. A., Cordoleani, F., DeAngelis, D. L., et al. (2017). Moving forward in circles: challenges and opportunities in modelling population cycles. Ecol. Lett. 20, 1074–1092. doi: 10.1111/ele.12789
Becks, L., and Arndt, H. (2013). Different types of synchrony in chaotic and cyclic communities. Nat. Commun. 4:1359. doi: 10.1038/ncomms2355
Becks, L., Ellner, S. P., Jones, L. E., and Hairston, N. G. (2012). The functional genomics of an eco-evolutionary feedback loop: linking gene expression, trait evolution, and community dynamics. Ecol. Lett. 15, 492–501. doi: 10.1111/j.1461-0248.2012.01763.x
Becks, L., Ellner, S. P., Jones, L. E., and Hairston, N. G. Jr. (2010). Reduction of adaptive genetic diversity radically alters eco-evolutionary community dynamics. Ecol. Lett. 13, 989–997. doi: 10.1111/j.1461-0248.2010.01490.x
Bell, G., and Gonzalez, A. (2009). Evolutionary rescue can prevent extinction following environmental change. Ecol. Lett. 12, 942–948. doi: 10.1111/j.1461-0248.2009.01350.x
Boersch-Supan, P. H., Ryan, S. J., and Johnson, L. R. (2017). deBInfer: Bayesian inference for dynamical models of biological systems in R. Methods Ecol. Evol. 8, 511–518. doi: 10.1111/2041-210X.12679
Boit, A., and Gaedke, U. (2014). Benchmarking successional progress in a quantitative food eb. PLoS ONE 9:e90404. doi: 10.1371/journal.pone.0090404
Boit, A., Martinez, N. D., Williams, R. J., and Gaedke, U. (2012). Mechanistic theory and modelling of complex food-web dynamics in Lake Constance. Ecol. Lett. 15, 594–602. doi: 10.1111/j.1461-0248.2012.01777.x
Bolius, S., Wiedner, C., and Weithoff, G. (2017). High local trait variability in a globally invasive cyanobacterium. Freshw. Biol. 62, 1879–1890. doi: 10.1111/fwb.13028
Bolnick, D. I., Amarasekare, P., Araújo, M. S., Bürger, R., Levine, J. M., Novak, M., et al. (2011). Why intraspecific trait variation matters in community ecology. Trends Ecol. Evol. 26, 183–192. doi: 10.1016/j.tree.2011.01.009
Cao, J., Fussmann, G. F., and Ramsay, J. O. (2008). Estimating a predator-prey dynamical model with the parameter cascades method. Biometrics 64, 959–967. doi: 10.1111/j.1541-0420.2007.00942.x
Carpenter, B. (2018). Predator-Prey Population Dynamics: The Lotka-Volterra Model in Stan. Available online at: http://mc-stan.org/users/documentation/case-studies/lotka-volterra-predator-prey.html (accessed August 13, 2018).
Carpenter, B., Gelman, A., Hoffman, M., Lee, D., Goodrich, B., Betancourt, M., et al. (2017). Stan: a probabilistic programming language. J. Stat. Softw. 76, 1–32. doi: 10.18637/jss.v076.i01
Chevin, L. M., Lande, R., and Mace, G. M. (2010). Adaptation, plasticity, and extinction in a changing environment: towards a predictive theory. PLoS Biol. 8:e1000357. doi: 10.1371/journal.pbio.1000357
Compagnoni, A., Bibian, A. J., Ochocki, B. M., Rogers, H. S., Schultz, E. L., Sneck, M. E., et al. (2016). The effect of demographic correlations on the stochastic population dynamics of perennial plants. Ecol. Monogr. 86, 480–494. doi: 10.1002/ecm.1228
Cortez, M. H. (2018). Genetic variation determines which feedbacks drive and alter predator-prey eco-evolutionary cycles. Ecol. Monogr. 88, 353–371. doi: 10.1002/ecm.1304
Costantino, R. F., Desharnais, R. A., Cushing, J. M., Dennis, B., Henson, S. M., and King, A. A. (2005). “Nonlinear stochastic population dynamics: the flour beetle tribolium as an effective tool of discovery,” in Population Dynamics and Laboratory Ecology, Volume 37 of Advances in Ecological Research, ed R. A. Desharnais (London, Oxford, Boston, MA; New York, NY; San Diego, CA: Academic Press), 101–141.
Curtsdotter, A., Banks, H. T., Banks, J. E., Jonsson, M., Jonsson, T., Laubmeier, A. N., et al. (2018). Ecosystem function in predator-prey food webs-confronting dynamic models with empirical data. J. Anim. Ecol. 1–15. doi: 10.1111/1365-2656.12892
DeLong, J. P., Hanley, T. C., and Vasseur, D. A. (2014). Predator–prey dynamics and the plasticity of predator body size. Funct. Ecol. 28, 487–493. doi: 10.1111/1365-2435.12199
Ehrlich, E., Becks, L., and Gaedke, U. (2017). Trait–fitness relationships determine how trade-off shapes affect species coexistence. Ecology 98, 3188–3198. doi: 10.1002/ecy.2047
Elderd, B. D., and Miller, T. E. X. (2015). Quantifying demographic uncertainty: Bayesian methods for Integral Projection Models (IPMs). Ecol. Monogr. 86, 15–1526.1. doi: 10.1890/15-1526.1
Fussmann, G. F., Ellner, S. P., Shertzer, K. W., and Hairston, N. G. (2000). Crossing the Hopf bifurcation in a live predator-prey system. Science 290, 1358–1360. doi: 10.1126/science.290.5495.1358
Fussmann, K. E., Rosenbaum, B., Brose, U., and Rall, B. C. (2017). Interactive effects of shifting body size and feeding adaptation drive interaction strengths of protist predators under warming. bioRxiv. Available online at: https://www.biorxiv.org/content/early/2017/01/20/101675.full.pdf
Gaedke, U., and Klauschies, T. (2017). Analyzing the shape of observed trait distributions enables a data-based moment closure of aggregate models. Limnol. Oceanogr. Methods 15, 979–994. doi: 10.1002/lom3.10218
Gelman, A., and Hill, J. (2007). Data Analysis Using Regression and Multilevel/Hierarchical Models. Cambridge: Cambridge University Press.
Gilioli, G., Pasquali, S., and Ruggeri, F. (2008). Bayesian inference for functional response in a stochastic predator-prey system. Bull. Math. Biol. 70, 358–381. doi: 10.1007/s11538-007-9256-3
Hefley, T. J., Tyre, A. J., and Blankenship, E. E. (2013). Fitting population growth models in the presence of measurement and detection error. Ecol. Modell. 263, 244–250. doi: 10.1016/j.ecolmodel.2013.05.003
Hillebrand, H., and Matthiessen, B. (2009). Biodiversity in a complex world: consolidation and progress in functional biodiversity research. Ecol. Lett. 12, 1405–1419. doi: 10.1111/j.1461-0248.2009.01388.x
Hosack, G. R., Peters, G. W., and Hayes, K. R. (2012). Estimating density dependence and latent population trajectories with unknown observation error: estimating unknown observation error. Methods Ecol. Evol. 3, 1028–1038. doi: 10.1111/j.2041-210X.2012.00218.x
Iijima, H., Nagaike, T., and Honda, T. (2013). Estimation of deer population dynamics using a bayesian state-space model with multiple abundance indices. J. Wild. Mgmt. 77, 1038–1047. doi: 10.1002/jwmg.556
Johnson, L. R., Pecquerie, L., and Nisbet, R. M. (2013). Bayesian inference for bioenergetic models. Ecology 94, 882–894. doi: 10.1890/12-0650.1
Kath, N. J., Boit, A., Guill, C., and Gaedke, U. (2018). Accounting for activity respiration results in realistic trophic transfer efficiencies in allometric trophic network (ATN) models. Theor. Ecol. 11, 453–463. doi: 10.1007/s12080-018-0378-z
Kindsvater, H. K., Dulvy, N. K., Horswill, C., Juan-Jordá, M. J., Mangel, M., and Matthiopoulos, J. (2018). Overcoming the data crisis in biodiversity conservation. Trends Ecol. Evol. 33, 676–688. doi: 10.1016/j.tree.2018.06.004
Koons, D. N., Colchero, F., Hersey, K., and Gimenez, O. (2015). Disentangling the effects of climate, density dependence, and harvest on an iconic large herbivore's population dynamics. Ecol. Appl. 25, 956–967. doi: 10.1890/14-0932.1
Litchman, E., and Klausmeier, C. A. (2008). Trait-based community ecology of phytoplankton. Annu. Rev. Ecol. Evol. Syst. 39, 615–639. doi: 10.1146/annurev.ecolsys.39.110707.173549
Lunn, D., Spiegelhalter, D., Thomas, A., and Best, N. (2009). The BUGS project: evolution, critique and future directions. Stat. Medi. 28, 3049–3067. doi: 10.1002/sim.3680
Magurran, A. E., Baillie, S. R., Buckland, S. T., Dick, J. M., Elston, D. A., Scott, E. M., et al. (2010). Long-term datasets in biodiversity research and monitoring: assessing change in ecological communities through time. Trends Ecol. Evol. 25, 574–582. doi: 10.1016/j.tree.2010.06.016
McGill, B. J., Enquist, B. J., Weiher, E., and Westoby, M. (2006). Rebuilding community ecology from functional traits. Trends Ecol. Evol. 21, 178–185. doi: 10.1016/j.tree.2006.02.002
Michaloudi, E., Papakostas, S., Stamou, G., Neděla, V., Tihlaríková, E., Zhang, W., et al. (2018). Reverse taxonomy applied to the Brachionus calyciflorus cryptic species complex: morphometric analysis confirms species delimitations revealed by molecular phylogenetic analysis and allows the (re)description of four species. PLoS ONE 13:e0203168. doi: 10.1371/journal.pone.0203168
Monnahan, C. C., Thorson, J. T., and Branch, T. A. (2017). Faster estimation of bayesian models in ecology using hamiltonian monte carlo. Methods Ecol. Evol. 8, 339–348. doi: 10.1111/2041-210X.12681
Novick, A., and Szilard, L. (1950). Description of the chemostat. Science 112, 715–716. doi: 10.1126/science.112.2920.715
Papanikolaou, N. E., Williams, H., Demiris, N., Preston, S. P., Milonas, P. G., and Kypraios, T. (2016). Bayesian inference and model choice for holling's disc equation: a case study on an insect predator-prey system. Commun. Ecol. 17, 71–78. doi: 10.1556/168.2016.17.1.9
Paraskevopoulou, S., Tiedemann, R., and Weithoff, G. (2018). Differential response to heat stress among evolutionary lineages of an aquatic invertebrate species complex. Biol. Lett. 14:20180498. doi: 10.1098/rsbl.2018.0498
Plummer, M. (2003). JAGS: a program for analysis of bayesian graphical models using gibbs sampling, in Proceedings of the 3rd International Workshop on Distributed Statistical Computing (DSC), eds K. Hornik, F. Leisch, and A. Zeileis (Vienna).
Post, D. M., and Palkovacs, E. P. (2009). Eco-evolutionary feedbacks in community and ecosystem ecology: interactions between the ecological theatre and the evolutionary play. Philos. Trans. R. Soc. B Biol. Sci. 364, 1629–1640. doi: 10.1098/rstb.2009.0012
Raatz, M., Gaedke, U., and Wacker, A. (2017). High food quality of prey lowers its risk of extinction. Oikos 126, 1501–1510. doi: 10.1111/oik.03863
Rall, B. C., and Latz, E. (2016). Analyzing pathogen suppressiveness in bioassays with natural soils using integrative maximum likelihood methods in R. PeerJ 4:e2615. doi: 10.7717/peerj.2615
Reusch, T. B., Ehlers, A., Hammerli, A., and Worm, B. (2005). Ecosystem recovery after climatic extremes enhanced by genotypic diversity. Proc. Natl. Acad. Sci. U.S.A. 102, 2826–2831. doi: 10.1073/pnas.0500008102
Robinson, O. J., McGowan, C. P., and Devers, P. K. (2017). Disentangling density-dependent dynamics using full annual cycle models and bayesian model weight updating. J. Appl. Ecol. 54, 670–678. doi: 10.1111/1365-2664.12761
Rosenbaum, B., and Rall, B. C. (2018). Fitting functional responses: direct parameter estimation by simulating differential equations. Methods Ecol. Evol. 9, 2076–2090. doi: 10.1111/2041-210X.13039
Smith, M. J., Tittensor, D. P., Lyutsarev, V., and Murphy, E. (2015). Inferred support for disturbance-recovery hypothesis of north atlantic phytoplankton blooms. J. Geophys. Res. C 120, 7067–7090. doi: 10.1002/2015JC011080
Taboadai, F. G., and Anadón, R. (2016). Determining the causes behind the collapse of a small pelagic fishery using bayesian population modeling. Ecol. Appl. 26, 886–898. doi: 10.1890/15-0006
Tirok, K., and Gaedke, U. (2007). Regulation of planktonic ciliate dynamics and functional composition during spring in Lake Constance. Aquat. Microb. Ecol. 49, 87–100. doi: 10.3354/ame01127
Toni, T., Welch, D., Strelkowa, N., Ipsen, A., and Stumpf, M. P. (2009). Approximate bayesian computation scheme for parameter inference and model selection in dynamical systems. J. R. Soc. Interface 6, 187–202. doi: 10.1098/rsif.2008.0172
Vehtari, A., Gabry, J., Yao, Y., and Gelman, A. (2018). loo: efficient leave-one-out cross-validation and waic for bayesian models. R package version 2.0.0.
Violle, C., Enquist, B. J., McGill, B. J., Jiang, L., Albert, C. H., Hulshof, C., et al. (2012). The return of the variance: intraspecific variability in community ecology. Trends Ecol. Evol. 27, 244–252. doi: 10.1016/j.tree.2011.11.014
Weigelt, A., Marquard, E., Temperton, V. M., Roscher, C., Scherber, C., Mwangi, P. N., et al. (2010). The Jena Experiment: six years of data from a grassland biodiversity experiment. Ecology 91, 930–931. doi: 10.1890/09-0863.1
Keywords: Bayesian inference, chemostat experiments, ordinary differential equation, parameter estimation, population dynamics, predator prey, time series analysis, trait variability
Citation: Rosenbaum B, Raatz M, Weithoff G, Fussmann GF and Gaedke U (2019) Estimating Parameters From Multiple Time Series of Population Dynamics Using Bayesian Inference. Front. Ecol. Evol. 6:234. doi: 10.3389/fevo.2018.00234
Received: 07 September 2018; Accepted: 18 December 2018;
Published: 22 January 2019.
Edited by:
Mauricio Lima, Pontificia Universidad Católica de Chile, ChileReviewed by:
Pablo Almaraz, Institute of Marine Sciences of Andalusia (ICMAN), SpainRobert Brian O'Hara, Norwegian University of Science and Technology, Norway
Copyright © 2019 Rosenbaum, Raatz, Weithoff, Fussmann and Gaedke. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Benjamin Rosenbaum, YmVuamFtaW4ucm9zZW5iYXVtQGlkaXYuZGU=
†These authors have contributed equally to this work