 Tao He
Tao He Wei Liu2
Wei Liu2- 1State Grid Anhui Electric Power Co., Ltd., Ma’anshan Power Supply Company, Anhui, China
- 2State Grid Anhui Electric Power Research Institute, Anhui, China
Reliable fault detection is essential for ensuring the safe and efficient operation of electrochemical energy storage systems, including lithium-ion batteries and transformer. However, the performance of machine learning-based fault diagnosis models is often degraded in practice due to label noise in training data, caused by sensor inaccuracies, ambiguous fault transitions, and imperfect labeling processes. This paper proposes a lightweight and effective kernel-based data rectification framework to improve the robustness of fault detection under noisy label conditions. The method identifies and discards low-density data points that are statistically more likely to be mislabeled, using kernel density estimation and a tunable data discarding strategy. The approach is computationally efficient, classifier-agnostic, and easily applicable to existing fault diagnosis pipelines. We evaluate the proposed method on two datasets: simulated lithium-ion battery voltage data under various fault scenarios, and transformer winding oscillation wave data under multiple winding fault conditions. The results demonstrate that the rectification framework significantly improves classification accuracy across both Support Vector Machine (SVM) and Extreme Learning Machine (ELM) classifiers. Furthermore, the choice of discarding ratio is shown to be critical, with optimal performance achieved when the ratio is tuned close to the underlying noise level. These results highlight the potential of the proposed method to enhance the reliability of fault diagnosis in electrochemical energy storage systems. Future work will explore adaptive strategies to automatically optimize the rectification strength without requiring prior knowledge of the noise rate, and extend the framework to multi-sensor and multi-modal monitoring scenarios.
1 Introduction
Ensuring the safe and reliable operation of electrochemical energy storage systems is of critical importance across a wide range of industrial, transportation, and grid applications. Among these systems, lithium-ion batteries and transformer windings represent two key components with extensive deployments. Lithium-ion batteries are widely used in electric vehicles (Şen et al., 2024), renewable energy storage systems (Wali et al., 2024; Hasan et al., 2025), and portable electronics (Zubi et al., 2018), while power transformers are essential assets for stable and efficient electric power transmission and distribution (??). Faults in lithium-ion batteries, such as short circuits, overcharging, and over-discharging, can cause severe performance degradation, accelerate aging, and in extreme cases, trigger thermal runaway and fire hazards (Wang et al., 2024; Tahir and Tenbohlen, 2023). Likewise, transformer winding faults, including axial displacement, local buckling, inter-disc short circuits, and inter-turn short circuits, can compromise insulation integrity and lead to catastrophic transformer failures (Pei et al., 2023). Therefore, timely and accurate fault detection is a crucial function to ensure the safety, reliability, and longevity of these electrochemical energy storage systems in practical applications.
Recent advances in data-driven fault diagnosis leverage sensor measurements and machine learning techniques to automatically classify the states of electrochemical energy storage systems, including lithium-ion batteries and transformer windings (Kouhestani et al., 2023; Abdolrasol et al., 2024; Wang et al., 2024; Tahir and Tenbohlen, 2023; Pei et al., 2023; Deng et al., 2023; Hong et al., 2021). However, in practical applications, the quality of labeled training data is often compromised. Sensor noise, ambiguous fault transitions, and manual or heuristic labeling processes introduce label noise, where a significant fraction of training labels may be incorrect or inconsistent (Fan et al., 2025). Such label noise severely degrades the performance and reliability of supervised learning models (Goodfellow et al., 2016), posing a major obstacle to deploying robust fault detection frameworks in real-world energy storage systems. In the case of lithium-ion batteries, mislabeling may arise from overlapping voltage patterns during early-stage faults or human annotation errors. Likewise, for transformer windings, data-driven classifiers trained on frequency response analysis (FRA) or vibration signals are also vulnerable to labeling errors, given the subtle and complex nature of winding deformation and short-circuit phenomena. These challenges motivate the development of robust fault detection methods that can tolerate mislabeled data and preserve high diagnostic accuracy.
Although various robust learning techniques have been developed in the machine learning literature to address label noise, many of these approaches suffer from high computational complexity or require prior knowledge of the noise rate (Zhang et al., 2021; Han et al., 2018a; Goldberger and Ben-Reuven, 2017; Yao et al., 2020; Shen et al., 2024), which is typically unknown in practice. Moreover, these methods are often difficult to tune and deploy in resource-constrained hardware for battery or transformer winding fault detection (Wu et al., 2025).
In this paper, we propose a simple and efficient kernel-based data rectification framework for robust battery fault detection under noisy label conditions. Our method leverages kernel density estimation (KDE) to identify and discard data points located in low-density regions of the feature space, where noisy labels are statistically more likely to occur. The approach is computationally lightweight, classifier-agnostic.
We conduct comprehensive experiments on both simulated lithium-ion battery voltage data and transformer winding fault data, covering normal and various fault scenarios, with different synthetic label noise patterns. Our results demonstrate that the proposed rectification method consistently improves classification accuracy across both Support Vector Machine (SVM) and Extreme Learning Machine (ELM) classifiers. Furthermore, we analyze the sensitivity of the method to the rectification strength (controlled by a discarding ratio
2 Methods
2.1 Challenging issue of fault diagnosis with noisy labels
Formally, let
denote a dataset comprising sensor readings
Here,
However, in practical deployments, the fault labels
As a result, the dataset may contain noisy labels, i.e.,
Using
which may result in poor predictive accuracy and weak generalization due to overfitting the noisy labels. Consequently, the resulting classification model is unreliable in safety-critical applications such as system fault detection. The above-described problem and issue are summarized in an intuitive way presented in Figure 1. To address this challenge, it is necessary to propose a robust classification framework that aims to learn accurate decision boundaries despite the presence of label noise.
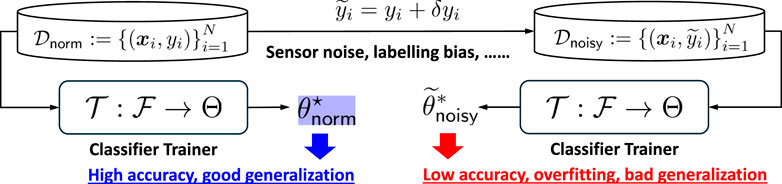
Figure 1. Intuitive explanation of the challenging issue by the label noises.
2.2 Framework of the proposed robust fault diagnosis
As shown in Figure 2, instead of directly using the noisy-labeled dataset

Figure 2. Framework of the proposed method.
The following subsections provide detailed explanations of the key components of our proposed framework:
2.3 Kernel-based rectification
2.3.1 Preliminary assumption
Let
Note that
This assumption states that, within the noisy dataset, the density of inputs
2.3.2 Kernel-based data cleaning
Note that the normal dataset
Consequently, the dataset
Specifically,
where
The bandwidth parameter
where
where
For any given density threshold
where
This paper adopts the following binary search procedure to determine the density threshold
and evaluate
After a fixed number of iterations, the binary search converges to a threshold
2.4 Robust fault detection algorithm
We summarize the method in the way of giving the algorithm in this subsection. To mitigate the adverse impact of label noise and enhance the reliability of fault diagnosis, we propose a robust classification framework that incorporates a data rectification step prior to model training. The core idea is to leverage kernel density estimation (KDE) (Botev et al., 2010) to identify and discard samples likely to be mislabeled, based on the observation that true labeled data tends to concentrate in high-density regions of the feature space. The procedure of Robust Fault Detection Algorithm is summarized in Algorithm 1.

Algorithm 1. Robust Fault Detection Algorithm.
3 Results
3.1 Validation scenario and data acquisition
3.1.1 Dataset for LIB battery
Voltage data for both healthy and faulty conditions were collected from simulation models developed in the MATLAB/Simulink environment. The simulation utilizes the LIB battery pack system designed for two-wheel electric vehicles, operating under both normal and fault-induced driving conditions. Data were acquired from voltage sensors installed within the battery pack, capturing system behavior under various scenarios. Faulty conditions were simulated by introducing short-circuit, overcharge, and over-discharge faults using the thermal resistive fault block. These faults were triggered at 0.2 s under different resistive load settings. The collected dataset includes multiple parameters such as state of charge (SOC), temperature, voltage, and current. In this study, only voltage data from both normal and faulty conditions were used, with the objective of contributing to the prevention of fire hazards in lithium-ion battery systems.
3.1.2 Fault detections in transformer windings
In addition to the lithium-ion battery dataset, a second dataset was considered for evaluating fault detection in transformer windings. This dataset was acquired via Oscillating Wave Testing (OWT), a non-invasive diagnostic technique that captures high-voltage oscillation signals to characterize winding deformations (Wu et al., 2020). This dataset originates from a 10 kV transformer winding fault simulation platform, where four types of winding faults—axial displacement, local buckling, inter-disc short circuit, and inter-turn short circuit were systematically considered. Each fault scenario was labeled based on the known fault type and its severity, as defined during the experimental setup, and repeated under controlled conditions to ensure labeling consistency. The resulting classification dataset includes labeled oscillation wave measurements for these four fault types as well as healthy conditions, enabling evaluation of the proposed robust classification framework in more applications in energy storage systems.
3.1.3 Methods for label noise
To evaluate the robustness of the proposed method under realistic noise conditions, we consider the following label noise generation strategies:
The above three types comprehensively represent a range of practically relevant label noise patterns in electrochemical energy storage systems’ fault diagnosis. In this study, we consider noise rates of
3.2 Benchmark algorithms
To evaluate the effectiveness of the proposed robust battery fault detection algorithm, we compare its performance with several baseline and benchmark methods. In particular, we systematically examine how different levels of kernel-based data cleaning affect the performance of two representative classifiers: Support Vector Machine (SVM) and Extreme Learning Machine (ELM).
The following benchmark algorithms are considered:
This experimental design enables a comprehensive analysis of the robustness and accuracy gains provided by the proposed data rectification framework across different classification models and varying levels of data cleaning. By comparing the Direct and Clean variants of both ELM and SVM, we can clearly assess the practical benefits of incorporating the rectification step into the battery fault diagnosis pipeline.
3.3 Performance metric
This section provides an overview of the performance metric used to evaluate the effectiveness of the proposed model. The selected evaluation metric is the classification accuracy, defined as:
where
3.4 Validation results of LIB battery fault detection
Figures 3, 4 present the classification accuracy results of ELM and SVM models trained either directly on the noisy dataset or on the rectified dataset obtained using different discarding ratios
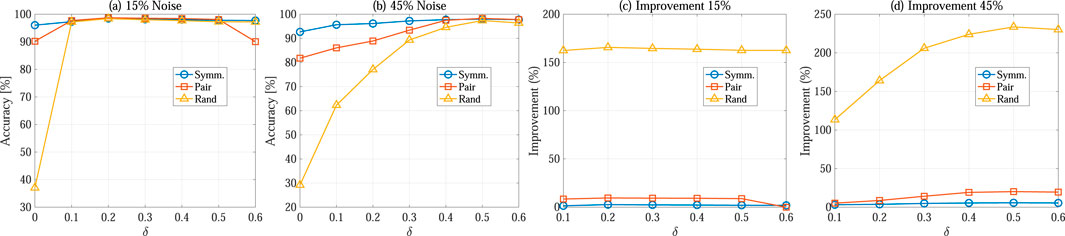
Figure 3. Classification accuracy of ELM. Mean value of 1,000 trials is reported. (A) Accuracy at
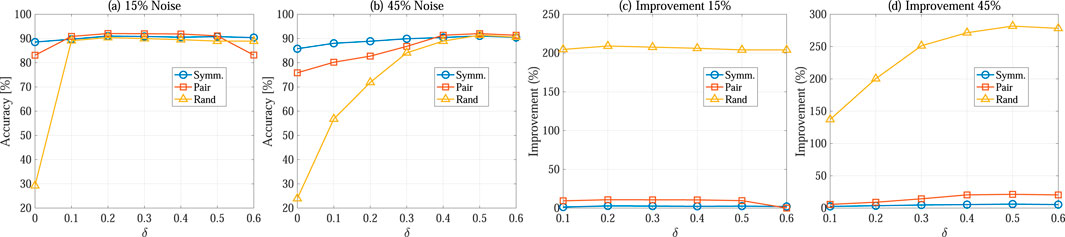
Figure 4. Classification accuracy of SVM. Mean value of 1,000 trials is reported. (A) Accuracy at
3.5 Validation results of transformer winding fault detection
In addition to the battery fault detection experiments, the proposed kernel-based rectification method was validated on transformer winding fault detection tasks, with four representative fault types: axial displacement (AD), local buckling (LB), inter-disc short circuit (IDSC), and inter-turn short circuit (ITSC). Figure 5 provides visual evidence of the discriminative oscillating wave signatures used in our fault diagnosis framework. The high-voltage oscillating wave test (OWT) captures these transient responses by applying a damped AC voltage pulse to the transformer winding and recording the resulting oscillation decay profile. These physically interpretable patterns form the basis of the feature vectors processed by our kernel-based rectification framework. The signal preprocessing pipeline, including noise suppression via wavelet thresholding and feature extraction through resonance frequency analysis, follows the methodology established in Wu et al. (2025). Consistent with the battery case study, setting the discarding ratio
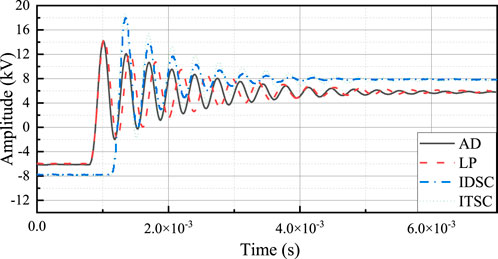
Figure 5. Representative oscillating wave signals under four fault conditions (axial displacement, local buckling, inter-disc short circuit, inter-turn short circuit).
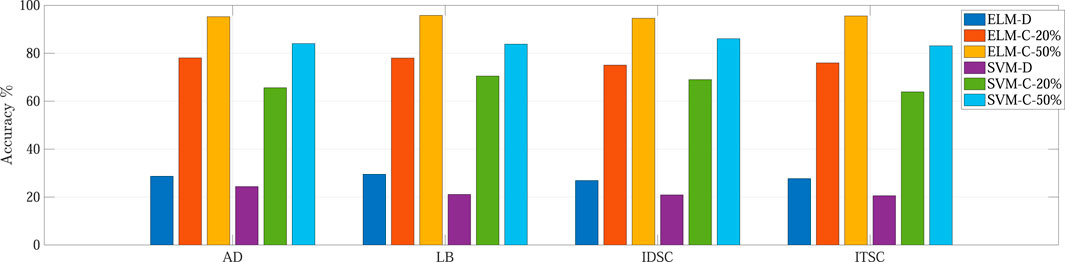
Figure 6. Classification accuracy for transformer winding fault detection. Mean value of 1,000 trials is reported.
3.6 Computational considerations
In terms of computational cost, the proposed kernel-based rectification framework was implemented in MATLAB on a standard laptop (Intel Core i7 processor), where the average runtime of the KDE-based data cleaning step was measured at approximately 15 ms per dataset partition containing 1,000 samples. Although we have not yet ported the algorithm to an embedded hardware platform, this processing time is well within the capabilities of modern embedded processors, especially considering that fault diagnosis generally operates on time scales of seconds to minutes. This supports our description of the method as computationally lightweight, while acknowledging that future work will further validate its runtime characteristics in actual embedded environments.
4 Discussion
This study presents a robust fault detection framework for electrochemical energy storage systems, integrating a kernel-based data rectification process into the standard classifier training pipeline. The motivation stems from the observation that real-world fault diagnosis systems often face label noise due to measurement errors, labeling inconsistencies, and the gradual nature of certain fault phenomena. Our method systematically addresses this challenge by discarding data points located in low-density regions of the feature space, where mislabeled samples are more likely to occur. Through comprehensive experiments on simulated lithium-ion battery voltage data as well as transformer winding fault data with synthetic label noise, we demonstrate that both ELM and SVM classifiers trained directly on noisy data suffer from substantial accuracy degradation. In contrast, applying the proposed kernel-based rectification step prior to training significantly improves classification performance across various noise scenarios and classifier types. Our results further indicate that tuning the discarding ratio
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
TH: Conceptualization, Formal Analysis, Investigation, Methodology, Validation, Writing – original draft, Writing – review and editing. WL: Formal Analysis, Methodology, Validation, Visualization, Writing – original draft, Writing – review and editing. XW: Formal Analysis, Validation, Writing – original draft, Writing – review and editing. YW: Validation, Writing – original draft, Writing – review and editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the State Grid Company Ltd. Science and Technology Program under Grant SGAHMA00YJJS2400635.
Conflict of interest
Authors TH, XW, and YW were employed by State Grid Anhui Electric Power Co., Ltd., Ma’anshan Power Supply Company.
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The authors declare that this study received funding from State Grid Company Ltd.. The funder had the following involvement in the study: data collection and analysis.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
1
References
Abdolrasol, M. G. M., Ayob, A., Lipu, M. S. H., Ansari, S., Kiong, T. S., Saad, M. H. M., et al. (2024). Advanced data-driven fault diagnosis in lithium-ion battery management systems for electric vehicles: progress, challenges, and future perspectives. eTransportation 22, 100374. doi:10.1016/j.etran.2024.100374
Botev, Z. I., Grotowski, J. F., and Kroese, D. P. (2010). Kernel density estimation via diffusion. Ann. Statistics 38, 2916–2957. doi:10.1214/10-AOS799
Deng, X., Zhang, Z., Zhu, H., and Yan, K. (2023). Early fault diagnosis of transformer winding based on leakage magnetic field and dsan learning method. Front. Energy Res. 10, 1058378. doi:10.3389/fenrg.2022.1058378
Fan, Y., Huang, Z., Li, H., Yuan, W., Yan, L., Liu, Y., et al. (2025). Fault detection for li-ion batteries of electric vehicles with feature-augmented attentional autoencoder. Sci. Rep. 15, 18534. doi:10.1038/s41598-025-03227-w
Goldberger, J., and Ben-Reuven, E. (2017). “Training deep neural networks using a noise adaption layer,” in Proceedings International Conference on Learning Representations.
Goodfellow, I., Bengio, Y., Courville, A., and Bengio, Y. (2016). Deep learning. Cambridge, Massachusetts: MIT press Cambridge.
Han, B., Yao, J., Niu, G., Zhou, M., Tsang, I., Zhang, Y., et al. (2018a). “Masking: a new perspective of noisy supervision,” in Advances in neural information processing systems, 5835–5846.
Han, B., Yao, Q., Yu, X., Niu, G., Xu, M., Hu, W., et al. (2018b). “Co-teaching: robust training of deep neural networks with extremely noisy labels,” in Advances in neural information processing systems, 8527–8537.
Hasan, M. M., Haque, R., Jahirul, M. I., Rasul, M. G., Fattah, I. M. R., Hassan, N. M. S., et al. (2025). Advancing energy storage: the future trajectory of lithium-ion battery technologies. J. Energy Storage 120, 116511. doi:10.1016/j.est.2025.116511
Hong, K., Jin, M., and Huang, H. (2021). Transformer winding fault diagnosis using vibration image and deep learning. IEEE Trans. Power Deliv. 36, 676–685. doi:10.1109/TPWRD.2020.2988820
Kouhestani, H. S., Liu, L., Wang, R., and Chandra, A. (2023). Data-driven prognosis of failure detection and prediction of lithium-ion batteries. J. Energy Storage 70, 108045. doi:10.1016/j.est.2023.108045
Patrini, G., Rozza, A., Menon, A. K., Nock, R., and Qu, L. (2017). “Making deep neural networks robust to label noise: a loss correction approach,” in Proceedings IEEE Conference on Computer Vision and Pattern Recognition, 1944–1952.
Pei, X., Han, S., Bao, Y., Chen, W., and Li, H. (2023). Fault diagnosis of transformer winding short circuit based on wkpca-wm and ipoa-cnn. Front. Energy Res. 11, 1151612. doi:10.3389/fenrg.2023.1151612
Şen, M., Özcan, M., and Eker, Y. R. (2024). A review on the lithium-ion battery problems used in electric vehicles. Next Sustain. 3, 100036. doi:10.1016/j.nxsust.2024.100036
Shen, X., Luo, Z., Li, Y., Ouyang, T., and Wu, Y. (2024). Chance-constrained abnormal data cleaning for robust classification with noisy labels. IEEE Trans. Emerg. Top. Comput. Intell., 1–8. doi:10.1109/tetci.2024.3375518
Tahir, M., and Tenbohlen, S. (2023). Transformer winding fault classification and condition assessment based on random forest using fra. Energies 16, 3714. doi:10.3390/en16093714
Wali, S. B., Hannan, M. A., Ker, P. J., Rahman, S. A., Le, K. N., Begum, R. A., et al. (2024). Grid-connected lithium-ion battery energy storage system towards sustainable energy: a patent landscape analysis and technology updates. J. Energy Storage 77, 109986. doi:10.1016/j.est.2023.109986
Wang, G., Qiu, S., Xie, F., Luo, T., Song, Y., and Wang, S. (2024). Diagnosing fault types and degrees of transformer winding combining fra method with soa-kelm. IEEE Access 12, 50287–50299. doi:10.1109/access.2024.3385229
Wu, Z., Zhou, L., Lin, T., Zhou, X., Wang, D., Gao, S., et al. (2020). A new testing method for the diagnosis of winding faults in transformer. IEEE Trans. Instrum. Meas. 69, 9203–9214. doi:10.1109/tim.2020.2998877
Wu, Z., Tao, J., Liu, Y., He, T., and Lu, S. (2025). Detection of structure deformation and insulation condition for transformer windings based on high-voltage oscillating wave. IEEE Trans. Instrum. Meas. 74, 1–12. doi:10.1109/tim.2025.3545720
Yao, Y., Liu, T., Han, B., Gong, M., Deng, J., Niu, G., et al. (2020). Dual t: reducing estimation error for transition matrix in label-noise learning. in Advances in neural information processing systems.
Zhang, Y., Niu, G., and Sugiyama, M. (2021). “Learning noise transition matrix from only noisy labels via total variation regularization,” in Proceedings International Conference on Machine Learning.
Keywords: fault diagnosis, robust classification, kernel density estimation, label noise, lithium-ion batteries, transformer windings
Citation: He T, Liu W, Wu X and Wei Y (2025) Robust fault detection in electrochemical energy storage systems under label noise: applications to lithium-ion batteries and transformer windings. Front. Energy Res. 13:1647197. doi: 10.3389/fenrg.2025.1647197
Received: 15 June 2025; Accepted: 16 July 2025;
Published: 22 August 2025.
Edited by:
Shuang Zhao, Hefei University of Technology, ChinaReviewed by:
Jin Zhang, Anhui University, ChinaLonglei Bai, Harbin Engineering University, China
Junfei Jiang, Guangdong Electric Power Design and Research Institute, China
Copyright © 2025 He, Liu, Wu and Wei. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tao He, MTY1MDU3ODIxMEBxcS5jb20=