 Zi-Ang Xie
Zi-Ang Xie Chee-Onn Chow
Chee-Onn Chow Joon Huang Chuah
Joon Huang Chuah Wong Jee Keen Raymond
Wong Jee Keen Raymond- 1Department of Electrical Engineering, Universiti Malaya, Kuala Lumpur, Malaysia
- 2Faculty of Engineering and Information Technology, Southern University College, Skudai, Malaysia
Introduction: Accurate multi-pollutant forecasting is vital for urban governance and public health. Existing deep models struggle to capture multi-scale temporal dynamics and synergistic cross-pollutant relations.
Methods: We propose an Enhanced Bidirectional Attention Multi-scale Temporal Network (EBAMTN) that combines a multi-scale TCN with linear attention, a two-layer BiLSTM augmented by multi-head self-attention, and a gated fusion layer. Under a multi-task paradigm, the backbone jointly learns shared temporal representations and outputs PM2.5 and PM10 via task-specific heads.
Results: Using hourly data from Guangzhou, Beijing, and Chengdu, EBAMTN achieved R2 > 0.94 for both pollutants while maintaining low errors (e.g., PM2.5 MAE≈2.03, RMSE≈2.94; PM10 MAE≈3.44, RMSE≈4.99). Confidence-interval analyses and scatter plots indicate strong trend tracking and robustness, with remaining challenges mainly at sharp peaks.
Discussion: The integration of multi-scale convolutions, bidirectional memory, attention, and gated fusion improves accuracy, interpretability, and generalization. The lightweight design (≈2.1M parameters; ∼ 13.2 ms/sample) supports real-time and edge deployment. Overall, EBAMTN offers a scalable, interpretable solution for multi-pollutant forecasting in complex urban settings.
1 Introduction
In recent years, with the rapid advancement of urbanization and industrialization, air pollution has emerged as an increasingly severe public health concern on a global scale. Fine particulate matter
Early air quality forecasting approaches primarily include numerical models, statistical techniques, and traditional machine learning methods. Numerical models, akin to weather forecasting systems, divide temporal and spatial domains into grids based on atmospheric physical and chemical principles, using computer simulations to predict meteorological and pollutant data. Common models include CMAQ, CAMx, and NAQPMS (Appel et al., 2021; Pouyaei et al., 2021; Liu H. et al., 2021; Qi et al., 2022; Cheng et al., 2022). Statistical models generally assume linearity and stationarity, using curve fitting and parameter estimation to model air quality. Typical examples include ARMA, ARIMA, MLR, and time series regression (Zhou et al., 2020; Liu B. et al., 2021; Lai and Dzombak, 2020; Kumari and Singh, 2023; Gong et al., 2022). For instance, ARIMA achieves good performance in low volatility
With the rapid advancement of deep learning, an increasing number of studies have applied these techniques to air quality time series forecasting. Depending on architecture, models are commonly classified into CNN-based, RNN-based, and attention-based approaches. Convolutional neural networks (CNNs) are widely used due to their strength in extracting local spatial features (Wang et al., 2024). As standard CNNs operate on regular grids, hybrid models are often adopted. For instance, Zhang and Li (2022) implemented a CNN-LSTM model for air quality prediction in Beijing. To enhance accuracy, Duan et al. (2023) proposed an ARIMA-BiLSTM model, which improved performance by approximately 10%. Among RNN variants, long short-term memory (LSTM) networks are the most prominent. Compared with CNNs, LSTMs are better at modeling long-term temporal dependencies and integrating with other modules. Seng et al. (2021) predicted
In recent years, recurrent neural network models such as RNNs and LSTMs have achieved strong performance across a wide range of tasks. However, due to their inherently sequential structure, they encounter difficulties in parallelizing the training process. Consequently, batch processing of long-term sequences often leads to memory limitations. Inspired by the human visual attention mechanism, attention-based models have been proposed to address these issues (Niu et al., 2021). Compared with recurrent models, attention mechanisms offer greater flexibility in handling inputs of varying shapes and help mitigate the problem of unbalanced computational resource allocation. As a result, attention-based architectures have gained widespread adoption and become one of the most prominent deep learning paradigms. Zhang et al. proposed a lightweight deep learning approach based on sparse attention mechanisms within Transformer Networks (Zhang et al., 2023), aimed at capturing long-term dependencies and complex feature relationships from input data. Iskandaryan et al. employed graph neural networks (GNNs) to predict air quality in Madrid (Iskandaryan et al., 2023). Their model integrates attention mechanisms, gated recurrent units (GRUs), and graph convolutional networks (GCNs). Experimental results show that the proposed method outperforms other approaches, including Time Graph Convolutional Networks (TGCNs), LSTM, and GRU models. Based on these research advances, incorporating attention mechanisms into other air quality forecasting models emerges as a promising direction for improving prediction accuracy and enhancing model interpretability (Ma et al., 2024).
Although deep learning-based models have achieved considerable progress in air quality forecasting, several key challenges remain. First, many existing models focus solely on single-scale temporal features, overlooking the multi-scale nature of pollutant concentration variations. This limitation hinders the model’s ability to jointly capture short-term fluctuations and long-term trends. Second, most models adopt a single task learning architecture, which fails to exploit the inherent correlations and synergistic relationships between multiple pollutants (e.g.,
1. A novel deep learning model named Enhanced Bidirectional Attention Multi-scale Temporal Network (EBAMTN) which is introduced to capture dynamic patterns across multiple temporal scales, which integrates a multi-scale attention Temporal Convolutional Network with an enhanced bidirectional attention LSTM. By employing parallel multi-scale convolutional branches, the model effectively captures temporal features across different receptive fields, thereby improving its capability to model multi-scale dynamic patterns in air quality data.
2. A cross-branch attention mechanism and a temporal attention mechanism are introduced to dynamically fuse multi-scale features and enhance feature responses at critical time steps, respectively. These mechanisms improve both the expressive capacity and interpretability of the model.
3. A multi-task prediction framework is designed to enable the joint modeling of
The remainder of this paper is organized as follows. Section 2 (Materials and Methods) provides a comprehensive review of related work and introduces the structure of the proposed EBAMTN model, including detailed algorithmic components. Section 3 (Results and Analysis) presents experimental settings, performance comparisons, and visualized results across three cities. Section 4 (Conclusion) summarizes key contributions and outlines potential directions for future enhancement.
2 Materials and methods
2.1 Related work
2.1.1 Temporal Convolutional Network
The Temporal Convolutional Network (TCN) is a convolutional neural network architecture specifically designed for sequence modeling tasks (Bednarski et al., 2022). Unlike traditional recurrent neural networks (RNNs) and their variants such as LSTM and GRU, TCNs utilize causal and dilated convolutions to capture temporal dependencies while enabling high degrees of parallelism and ensuring stable gradient propagation. TCNs have demonstrated strong performance across various sequential tasks, including time series forecasting, speech synthesis, and natural language understanding (Chen et al., 2020). A complete TCN architecture consists of three main components: causal convolution, dilated convolution, and residual connections between inputs and outputs (denoted as X and Y). These components are described in detail below:
Key formulations for the TCN components are summarized in Equations 1–7.
2.1.1.1 Causal convolution
To ensure temporal consistency and prevent information leakage from future time steps, the TCN employs causal convolution. In this design, the output at time step
In a causal one-dimensional convolution, the output
where
2.1.1.2 Dilated convolution
The second component is dilated convolution, which is employed in TCNs to expand the receptive field without significantly increasing model depth or computational cost. Dilated convolution introduces a fixed interval, known as the dilation factor, between input elements, allowing the model to efficiently capture long-range temporal dependencies. When used across multiple layers with exponentially increasing dilation factors, the model can simultaneously learn both short-term fluctuations and long-term trends. To expand the receptive field in causal convolution, the dilation factor
where
where
2.1.1.3 Residual connections
TCN incorporates residual connections, where each residual block consists of two dilated convolutional layers, each followed by weight normalization, ReLU activation, and dropout for regularization. These residual links are crucial for facilitating gradient flow and mitigating degradation in deep networks. When the input and output dimensions differ, a 1
where
This residual structure helps stabilize training and enables the construction of deeper TCN models.
2.1.2 Long short-term memory
Long Short-Term Memory (LSTM) networks have been widely used for sequence modeling due to their ability to capture long-range temporal dependencies. In this study, we adopt LSTM as one of the baseline models. Its structure and mathematical formulation can be found in prior works (Hochreiter and Schmidhuber, 1997). The detailed description is omitted here for brevity, as our focus lies in the proposed architectures.
2.2 Method
2.2.1 Problem formulation
The air quality forecasting task is formalized as a multi-task series prediction problem. Let the historical input sequence be
where f
2.2.2 Enhanced bidirectional attention multi-scale temporal network (EBAMTN)
To effectively model the complex temporal evolution of air pollutant concentrations, this paper proposes a multi-module synergistic deep hybrid architecture. The overall architecture is illustrated in Figure 1 and comprises four key sub-modules: 1) a Multi-Scale Temporal Convolution Module with Linear Attention, 2) an Enhanced Bidirectional LSTM with Muti-Head Attention, 3) a Feature Fusion Module with Gating, 4) Multi-Task Output Heads. This integrated design enables the model to capture both short-term fluctuations and long-term trends in air quality data. Moreover, it demonstrates strong generalization capability and supports simultaneous multi-target forecasting.
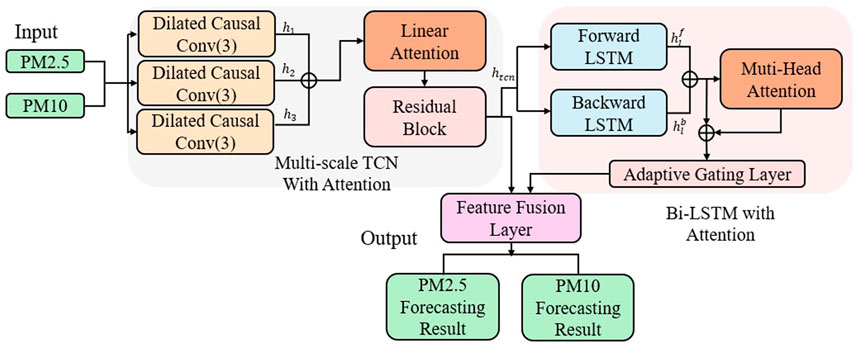
Figure 1. Architecture of the EBAMTN model.
2.2.2.1 Multi-scale TCN with attention
Air quality data are inherently nonlinear and non-stationary, often exhibiting multi-frequency and multi-periodic temporal patterns. These patterns arise from a variety of real-world factors, such as morning and evening traffic congestion, diurnal temperature fluctuations, seasonal monsoon cycles, and changes in human mobility during holidays (Zhang and Zhang, 2023). Such multi-scale temporal variations are reflected not only in short-term abrupt changes but also in long-term evolving trends. Therefore, developing a temporal modeling structure that can simultaneously perceive short-term fluctuations and long-term dependencies is essential for achieving high-accuracy air quality forecasting. To this end, we propose a Multi-Scale Temporal Convolutional Network (Multi-Scale TCN) module that integrates three key components: (1) parallel dilated convolution branches, (2) a lightweight channel-wise attention-based fusion mechanism, and (3) a stacked dilated convolutional structure with skip connections. This design enables the model to effectively capture air quality dynamics at multiple temporal resolutions.
First, the preprocessed input features are fed into three parallel Dilated Causal Convolutional branches, each using a different kernel size (3, 5, and 7) with fixed dilation. These branches are designed to capture temporal dependencies at local, intermediate, and broader scales, respectively. Through parallel multi-scale modeling, the network can simultaneously detect fine-grained variations and overarching temporal trends. Next, to enhance the flexibility and adaptiveness of multi-scale feature integration, a channel-wise attention fusion module is introduced. This mechanism applies global average pooling to the output of each convolutional branch to generate scale-specific descriptor vectors, followed by a linear attention mechanism to compute the importance weights for each scale. This dynamic weighting allows the model to emphasize informative branches and achieve adaptive scale-aware feature fusion. The resulting fused representation exhibits both strong temporal perception and scale discrimination capabilities. Finally, to extract deeper hierarchical temporal features, the fused output is passed through a stack of causal convolution layers with exponentially increasing dilation factors (e.g., d = 1, 2, 4, 8, …). Each layer incorporates skip connections to enhance feature propagation and stabilize gradient flow. The outputs from all skip connections are aggregated to produce the final representation of the multi-scale convolution module.
In summary, the proposed module demonstrates strong capabilities in temporal feature extraction and dynamic fusion. By leveraging the dilation mechanism to effectively expand the receptive field, the model significantly improves its performance and generalization in multi-scale air quality modeling tasks. Let the input tensor be
To fuse multi-scale features, we first apply global average pooling over the temporal dimension to obtain descriptor vectors:
An attention mechanism then computes scale-aware weights:
where we are learnable weight vectors. The final fused output is the weighted sum of branch outputs:
To capture deeper temporal dependencies, the fused representation is passed through a stack of dilated convolution layers with exponentially increasing dilation factors
followed by a skip connection:
The final output of the module aggregates all skip outputs:
The multi-scale attention TCN is formally defined in Equations 9–15.

Algorithm 1.Multi-scale TCN with Attention.
The overall procedure is summarized in Algorithm 1.
2.2.2.2 Bi-LSTM with attention
The concentration sequences of air pollutants exhibit pronounced temporal dependencies, particularly under complex meteorological conditions such as cross-day lag and persistent high-pressure accumulation (Ziernicka-Wojtaszek et al., 2024). Traditional unidirectional recurrent models often fail to comprehensively capture the bidirectional flow of information in time series. To address this limitation, we incorporate a two-layer bidirectional Long Short-Term Memory (BiLSTM) network into the model, with 64 hidden units per direction. This structure is capable of modeling both forward and backward temporal dependencies, thereby facilitating the learning of pollutant accumulation, propagation, and feedback mechanisms over time. As a result, it significantly enhances the model’s ability to capture the evolving trends in air pollution dynamics. To further strengthen the model’s capacity to identify critical temporal segments, especially in cases of sudden pollution bursts, non-stationary fluctuations, or structural regime shifts (Dong et al., 2024). We introduce a multi-head self-attention mechanism following the BiLSTM outputs. This mechanism computes relevance scores between time steps using a Query–Key–Value structure and learns multiple types of dependencies in parallel subspaces. Conceptually, it constructs a soft “global memory” over the sequence, allowing the model to dynamically focus on salient moments and better capture non-local interactions within the temporal context.
However, LSTM and attention modules produce feature representations of different nature (Khan and Hossni, 2025). Simply concatenating or summing their outputs may result in redundancy, representational conflict, or even degradation in generalization. To alleviate such issues, we further introduce a gating mechanism to adaptively fuse the outputs from the LSTM and attention layers. This mechanism employs a learnable gate to generate dynamic weights based on the joint input, thereby regulating the flow and contribution of each representation and ensuring a more coherent integration. Formally, let the input sequence to the module be:
where B is the batch size, T is the number of time steps, and D is the input feature dimension. The sequence is first passed through a two-layer BiLSTM, producing forward and backward hidden states concatenated as:
This output is then used as Query, Key, and Value in the multi-head self-attention mechanism, defined as:
The resulting attention-enhanced representation is
where
The BiLSTM-attention module and gating are given in Equations 16–20.
Finally, the fused representation

Algorithm 2.Bi-LSTM with Attention.
The steps of the BiLSTM-attention module are provided in Algorithm 2.
2.2.2.3 Fusion and prediction
Following the TCN and BiLSTM modules, the model concatenates the two output representations along the last dimension and applies a gated fusion network dynamically integrate temporal and contextual information. This fusion module adopts a fully connected layer followed by ReLU activation and dropout, enabling nonlinear feature transformation while suppressing redundant information. The fused representation from the TCN and BiLSTM modules is computed as:
where
The time-aware representation is obtained by element-wise multiplication:
At the final stage, two parallel output heads are employed to predict
where
The fusion, temporal weighting, task heads and loss follow Equations 21–25.where

Algorithm 3.Fusion and Multi-Task Output Module.
The rationale behind the architectural design of EBAMTN is further summarized below, emphasizing its effectiveness and explainability: The design of the EBAMTN architecture is motivated by the need to effectively model both fine-grained temporal dynamics and inter-pollutant interactions in real-world air quality forecasting scenarios. The use of parallel multi-scale convolutional branches enables the model to simultaneously capture short-term fluctuations and long-term periodic trends. The bidirectional LSTM component models sequential dependencies from both past and future directions, while the multi-head attention mechanism selectively focuses on informative time steps, improving interpretability. Moreover, the gated fusion mechanism adaptively balances contextual information from different modules, preventing feature redundancy and enhancing robustness. By jointly modeling
Fusion and multi-task output are detailed in Algorithm 3.
2.3 Experiments
2.3.1 Dataset and preprocessing
In this study, air quality monitoring data from three cities in China (Guangzhou, Chengdu and Beijing. For each city, data from a single central monitoring site was used to ensure consistency and avoid spatial heterogeneity.) are used to validate the effectiveness of the proposed model. The dataset contains hourly observations of two key pollutants,

Table 1. List of predictor variables used in the model.
2.3.2 Implementation details
To ensure the reproducibility of all experiments, a fixed random seed (seed = 42) was used for data partitioning and model initialization. All experiments were conducted on a single workstation equipped with an NVIDIA GeForce RTX 3090 Laptop GPU, an 11th Gen Intel(R) Core (TM) i7-11800H CPU, 8 GB of dedicated GPU memory, and 16 GB of system RAM. The model was implemented using the PyTorch 1.9.0 deep learning framework. Model performance was comprehensively evaluated using three standard metrics: Mean Squared Error (MSE), Mean Absolute Error (MAE), and the Coefficient of Determination (R2). The model was trained using a mini-batch size of 128, and parameters were updated using the Adam optimizer, with an initial learning rate of 0.001 and a weight decay coefficient of 0.0001. A cosine annealing learning rate scheduler was adopted with a cycle length of 100 epochs to improve convergence. Additionally, gradient clipping with a threshold of 1.0 was applied to prevent gradient explosion. An early stopping strategy was used to prevent overfitting, whereby training was terminated if the validation loss did not improve for 10 consecutive epochs. To enhance model robustness, Gaussian noise with a noise factor of 0.05 was added to the input data during training.
The proposed model adopts a novel hybrid architecture that integrates multi-scale Temporal Convolutional Networks (TCN) and an enhanced Bidirectional LSTM. The multi-scale TCN module contains three parallel convolutional branches with kernel sizes of 3, 5, and 7, and corresponding output channel sizes of 32, 64, and 128, respectively. Each branch is followed by batch normalization, a ReLU activation function, and a dropout layer with a dropout rate of 0.1. The outputs of these branches are dynamically weighted and fused using a lightweight channel-wise attention mechanism, implemented via a linear transformation followed by a softmax function. The enhanced LSTM module employs a two-layer bidirectional LSTM with a hidden size of 64 and integrates a multi-head self-attention mechanism to strengthen the model’s capacity for capturing long-range temporal dependencies. To effectively merge the outputs of the TCN and LSTM modules, a gated fusion mechanism is adopted. This mechanism uses a sigmoid-activated gating network to compute the importance of each representation and leverages residual connections to stabilize gradient propagation and mitigate vanishing gradients. At the output stage, the model adopts a multi-task prediction structure, where
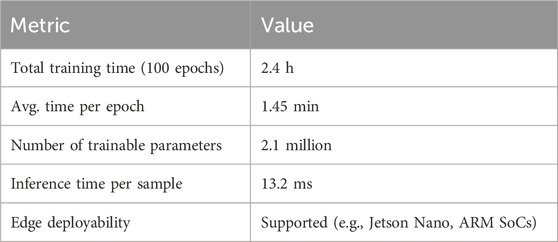
Table 2. Computational efficiency and deployment feasibility of EBAMTN.
Through a combination of multi-scale feature extraction, attention-enhanced sequence modeling, and adaptive feature fusion, the proposed model achieves significantly improved prediction accuracy while maintaining computational efficiency. Detailed quantitative results and comparisons with baseline methods are presented in the following section.
3 Results and Analysis
3.1 Results performance
From Table 3, it can be concluded that for
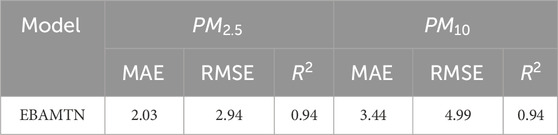
Table 3. Prediction performance of the EBAMTN model for
Figure 2 illustrates the effectiveness of the proposed model in long-term time-series forecasting of
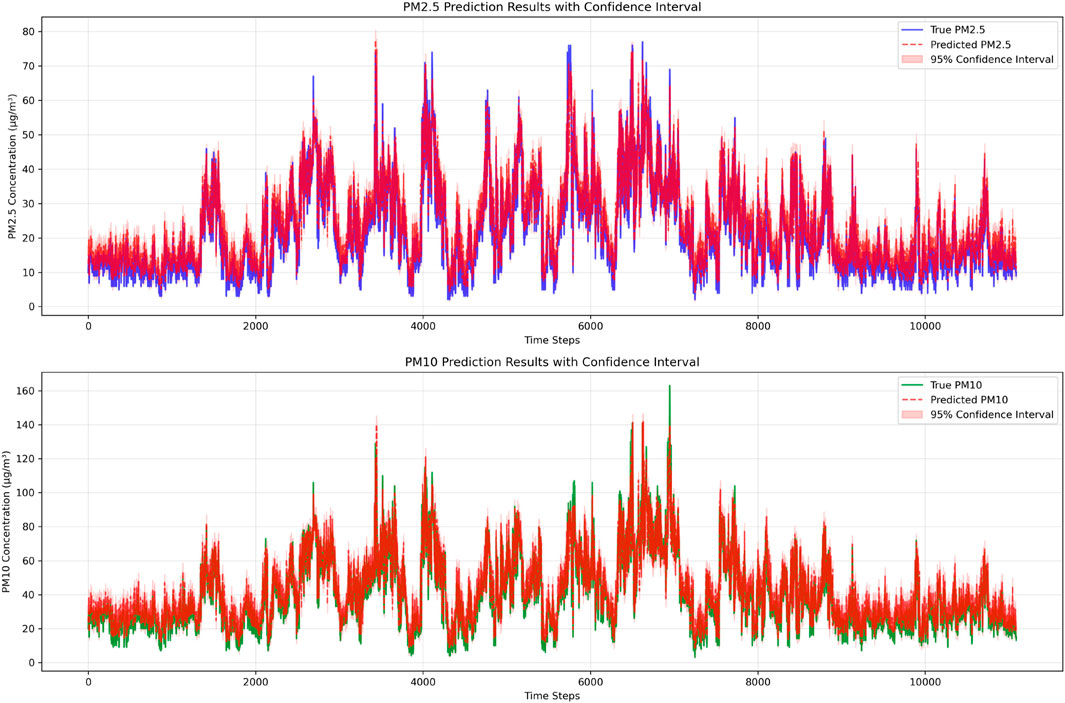
Figure 2. Prediction results for
Figure 3 illustrates the predicted concentrations of
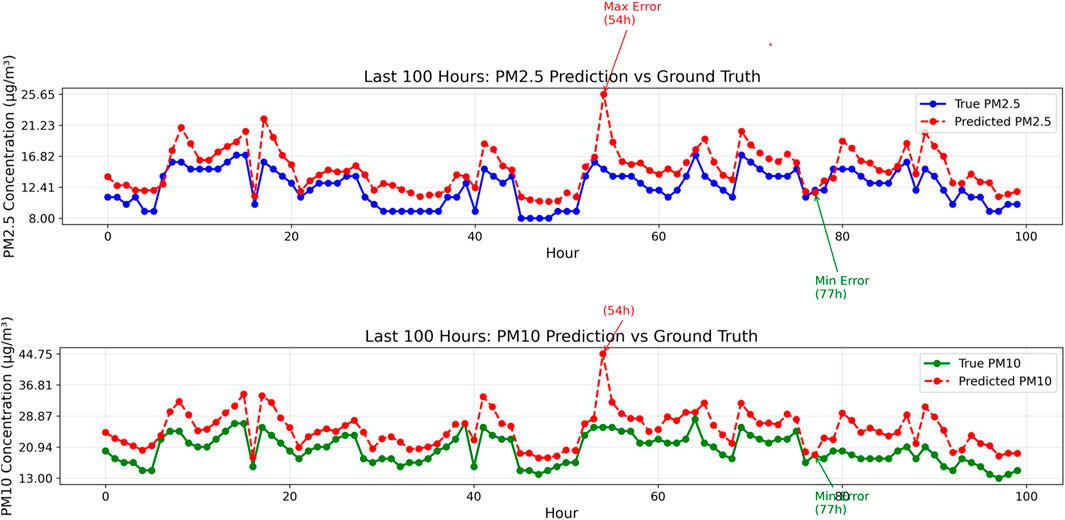
Figure 3. Comparison of predicted and actual values for
Overall, the model shows promising results in modeling the temporal dynamics and variability of both
The scatter plots provided (as shown in Figure 4) illustrate the regression analysis comparing the observed and predicted values of
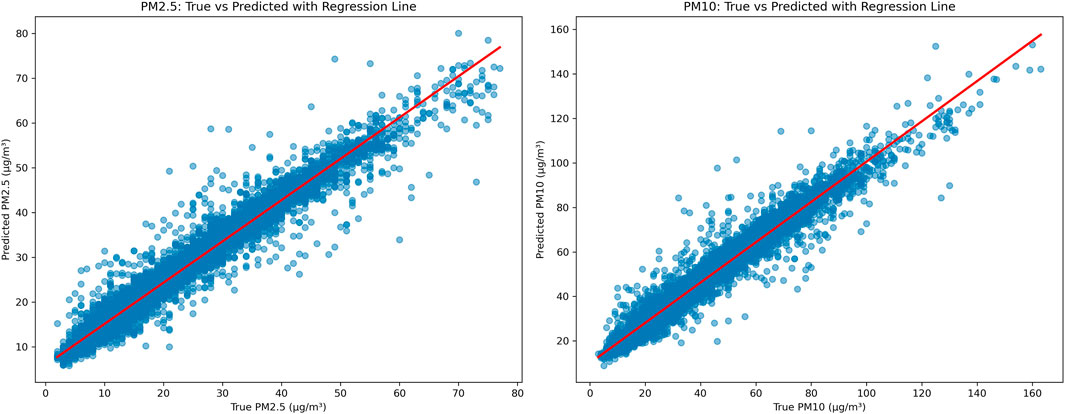
Figure 4. Regression plots of true vs. predicted concentrations for
Overall, the regression analysis confirms the model’s strong predictive capability under normal pollution levels, while also highlighting areas for potential improvement under high-pollution scenarios. These limitations could be addressed through targeted model enhancements such as rebalancing the training data, introducing adaptive loss functions, or applying data augmentation strategies specifically designed to emphasize extreme value learning.
3.2 Comparison study
Based on the comparison table provided, the prediction performance of various models for air quality forecasting is comprehensively analyzed as shown in Table 4. Traditional machine learning models such as Random Forest (RF) and Support Vector Regression (SVR) exhibit relatively poor performance, with R2 values for both
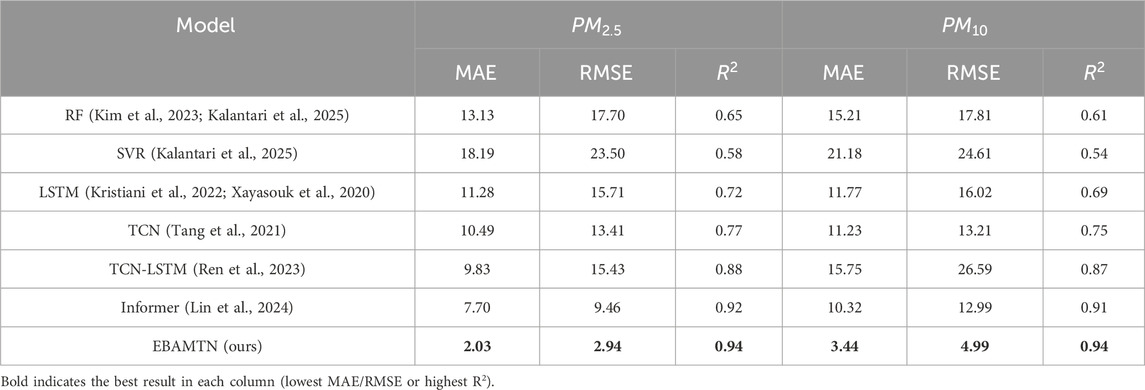
Table 4. Performance comparison of different models for
Finally, the proposed EBAMTN model achieves the best overall performance across all metrics. It reduces the MAE and RMSE for
The subsequent analysis focuses on the performance of the proposed EBAMTN model across different urban environments. Table 5 presents the prediction outcomes for
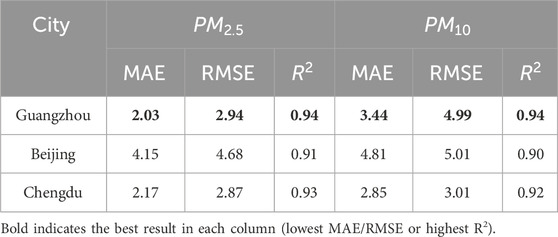
Table 5. Prediction performance of EBAMTN across three Cities for
In summary, the proposed EBAMTN model exhibits good cross-regional generalization and maintains stable performance across diverse urban environments. However, further refinement may be needed to enhance its responsiveness under northern seasonal extremes and pollution surge scenarios. To further support the superiority of the proposed model, we highlight that EBAMTN achieves better temporal alignment with the actual pollutant concentration trends across different urban environments. As illustrated in Figures 3, 4, the predicted values not only capture the overall fluctuations but also track the turning points more effectively than baseline methods. This indicates stronger trend generalization and dynamic adaptation capabilities.
4 Conclusion
This paper presents a multi-task air quality forecasting framework named Enhanced Bidirectional Attention Multi-Scale Temporal Network (EBAMTN), which integrates multi-scale Temporal Convolutional Networks (TCNs), enhanced BiLSTM, and linear/multi-head attention mechanisms to jointly improve forecasting accuracy and temporal representation learning. The proposed model demonstrates significant improvements in capturing both short-term fluctuations and long-term trends across multiple urban environments. By combining parallel multi-Scale TCNs with linear attention, the model effectively captures temporal dependencies at various resolutions while maintaining computational efficiency. The incorporation of multi-head attention in the BiLSTM module enhances the model’s ability to detect salient time intervals and bidirectional dependencies, improving interpretability and sequence modeling depth. The multi-task learning architecture further leverages inter-pollutant correlations to achieve superior accuracy compared to single-task models, with experiments showing R2 values exceeding 0.94 for both
EBAMTN is well-suited for practical applications in real-time air quality monitoring and early warning systems. Its lightweight and modular design allows deployment on resource-constrained devices, while its strong generalization ability ensures robust performance across diverse urban regions. The dual benefits of accuracy and efficiency offer valuable decision support for environmental authorities.
Future work may focus on refining the attention mechanism to enhance responsiveness to sudden pollution spikes, introducing adaptive loss functions or importance-weighted sampling to improve performance on rare events, and extending the model to include more pollutants such as
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: https://archive.ics.uci.edu/dataset/501/beijing+multi+site+air+quality+data.
Author contributions
Z-AX: Conceptualization, Investigation, Data curation, Writing – original draft, Methodology, Formal Analysis. C-OC: Validation, Methodology, Writing – review and editing, Supervision, Conceptualization. JC: Writing – review and editing, Supervision. WR: Writing – review and editing, Validation, Supervision.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that Generative AI was used in the creation of this manuscript. During the preparation of this work the authors used ChatGPT to improve the language and readability. After using this tool, the authors reviewed and edited the content as needed and take full responsibility for the content of the publication.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Ansari, M., and Ehrampoush, M. H. (2019). Meteorological correlates and airq+ health risk assessment of ambient fine particulate matter in Tehran, Iran. Environ. Res. 170, 141–150. doi:10.1016/j.envres.2018.11.046
Appel, K. W., Bash, J. O., Fahey, K. M., Foley, K. M., Gilliam, R. C., Hogrefe, C., et al. (2021). The community multiscale air quality (cmaq) model versions 5.3 and 5.3. 1: system updates and evaluation. Geosci. Model Dev. Discuss. 2020, 1–41. doi:10.5194/gmd-14-2867-2021
Bednarski, B. P., Singh, A. D., Zhang, W., Jones, W. M., Naeim, A., and Ramezani, R. (2022). Temporal convolutional networks and data rebalancing for clinical length of stay and mortality prediction. Sci. Rep. 12, 21247. doi:10.1038/s41598-022-25472-z
Box, G. E., Jenkins, G. M., Reinsel, G. C., and Ljung, G. M. (2015). Time series analysis: forecasting and control. John Wiley & Sons.
Chen, Y., Kang, Y., Chen, Y., and Wang, Z. (2020). Probabilistic forecasting with temporal convolutional neural network. Neurocomputing 399, 491–501. doi:10.1016/j.neucom.2020.03.011
Cheng, M., Fang, F., Navon, I. M., Zheng, J., Tang, X., Zhu, J., et al. (2022). Spatio-temporal hourly and daily ozone forecasting in China using a hybrid machine learning model: autoencoder and generative adversarial networks. J. Adv. Model. Earth Syst. 14, e2021MS002806. doi:10.1029/2021ms002806
Dong, J., Zhang, Y., and Hu, J. (2024). Short-term air quality prediction based on emd-transformer-bilstm. Sci. Rep. 14, 20513. doi:10.1038/s41598-024-67626-1
Duan, J., Gong, Y., Luo, J., and Zhao, Z. (2023). Air-quality prediction based on the arima-cnn-lstm combination model optimized by dung beetle optimizer. Sci. Rep. 13, 12127. doi:10.1038/s41598-023-36620-4
Gong, S., Zhang, L., Liu, C., Lu, S., Pan, W., and Zhang, Y. (2022). Multi-scale analysis of the impacts of meteorology and emissions on pm2. 5 and o3 trends at various regions in China from 2013 to 2020 2. Key weather elements and emissions. Sci. Total Environ. 824, 153847. doi:10.1016/j.scitotenv.2022.153847
Hochreiter, S., and Schmidhuber, J. (1997). Long short-term memory. Neural Comput. 9, 1735–1780. doi:10.1162/neco.1997.9.8.1735
Iskandaryan, D., Ramos, F., and Trilles, S. (2023). Graph neural network for air quality prediction: a case study in Madrid. IEEE Access 11, 2729–2742. doi:10.1109/access.2023.3234214
Jin, N., Zeng, Y., Yan, K., and Ji, Z. (2021). Multivariate air quality forecasting with nested long short term memory neural network. IEEE Trans. Industrial Inf. 17, 8514–8522. doi:10.1109/tii.2021.3065425
Kalantari, E., Gholami, H., Malakooti, H., Kaskaoutis, D. G., and Saneei, P. (2025). An integrated feature selection and machine learning framework for pm10 concentration prediction. Atmos. Pollut. Res. 16, 102456. doi:10.1016/j.apr.2025.102456
Karimian, H., Li, Q., Wu, C., Qi, Y., Mo, Y., Chen, G., et al. (2019). Evaluation of different machine learning approaches to forecasting pm2. 5 mass concentrations. Aerosol Air Qual. Res. 19, 1400–1410. doi:10.4209/aaqr.2018.12.0450
Khan, M., and Hossni, Y. (2025). A comparative analysis of lstm models aided with attention and squeeze and excitation blocks for activity recognition. Sci. Rep. 15, 3858. doi:10.1038/s41598-025-88378-6
Kim, B., Kim, E., Jung, S., Kim, M., Kim, J., and Kim, S. (2023). Pm2. 5 concentration forecasting using weighted bi-lstm and random forest feature importance-based feature selection. Atmosphere 14, 968. doi:10.3390/atmos14060968
Kristiani, E., Lin, H., Lin, J.-R., Chuang, Y.-H., Huang, C.-Y., and Yang, C.-T. (2022). Short-term prediction of pm2. 5 using lstm deep learning methods. Sustainability 14, 2068. doi:10.3390/su14042068
Kumari, S., and Singh, S. K. (2023). Machine learning-based time series models for effective co2 emission prediction in India. Environ. Sci. Pollut. Res. 30, 116601–116616. doi:10.1007/s11356-022-21723-8
Lai, Y., and Dzombak, D. A. (2020). Use of the autoregressive integrated moving average (arima) model to forecast near-term regional temperature and precipitation. Weather Forecast. 35, 959–976. doi:10.1175/waf-d-19-0158.1
Lelieveld, J., Klingmüller, K., Pozzer, A., Burnett, R., Haines, A., and Ramanathan, V. (2019). Effects of fossil fuel and total anthropogenic emission removal on public health and climate. Proc. Natl. Acad. Sci. 116, 7192–7197. doi:10.1073/pnas.1819989116
Lin, S., Zhang, Y., Liu, X., Mei, Q., Zhi, X., and Fei, X. (2024). Incorporating the third law of geography with spatial attention module–convolutional neural network–transformer for fine-grained non-stationary air quality predictive learning. Mathematics 12, 1457. doi:10.3390/math12101457
Liu, B., Jin, Y., and Li, C. (2021a). Analysis and prediction of air quality in nanjing from autumn 2018 to summer 2019 using pcr–svr–arma combined model. Sci. Rep. 11, 348. doi:10.1038/s41598-020-79462-0
Liu, H., Yan, G., Duan, Z., and Chen, C. (2021b). Intelligent modeling strategies for forecasting air quality time series: a review. Appl. Soft Comput. 102, 106957. doi:10.1016/j.asoc.2020.106957
Luo, J., and Gong, Y. (2023). Air pollutant prediction based on arima-woa-lstm model. Atmos. Pollut. Res. 14, 101761. doi:10.1016/j.apr.2023.101761
Ma, Z., Wang, B., Luo, W., Jiang, J., Liu, D., Wei, H., et al. (2024). Air pollutant prediction model based on transfer learning two-stage attention mechanism. Sci. Rep. 14, 7385. doi:10.1038/s41598-024-57784-7
Niu, Z., Zhong, G., and Yu, H. (2021). A review on the attention mechanism of deep learning. Neurocomputing 452, 48–62. doi:10.1016/j.neucom.2021.03.091
Pouyaei, A., Sadeghi, B., Choi, Y., Jung, J., Souri, A. H., Zhao, C., et al. (2021). Development and implementation of a physics-based convective mixing scheme in the community multiscale air quality modeling framework. J. Adv. Model. Earth Syst. 13, e2021MS002475. doi:10.1029/2021ms002475
Qi, H., Ma, S., Chen, J., Sun, J., Wang, L., Wang, N., et al. (2022). Multi-model evaluation and Bayesian model averaging in quantitative air quality forecasting in central China. Aerosol Air Qual. Res. 22, 210247. doi:10.4209/aaqr.210247
Ren, Y., Wang, S., and Xia, B. (2023). Deep learning coupled model based on tcn-lstm for particulate matter concentration prediction. Atmos. Pollut. Res. 14, 101703. doi:10.1016/j.apr.2023.101703
Seng, D., Zhang, Q., Zhang, X., Chen, G., and Chen, X. (2021). Spatiotemporal prediction of air quality based on LSTM neural network. Alexandria Eng. J. 60, 2021–2032. doi:10.1016/j.aej.2020.12.009
Tang, X., Wang, Y., Wang, Y., and Li, Y. (2021). Forecasting hourly pm2.5 based on deep temporal convolutional network. Appl. Soft Comput. 112, 107751. doi:10.1016/j.asoc.2021.107751
Tao, Q., Liu, F., Li, Y., and Sidorov, D. (2019). Air pollution forecasting using a deep learning model based on 1d convnets and bidirectional gru. IEEE access 7, 76690–76698. doi:10.1109/access.2019.2921578
Tran, H. D., Huang, H.-Y., Yu, J.-Y., and Wang, S.-H. (2023). Forecasting hourly pm2. 5 concentration with an optimized lstm model. Atmos. Environ. 315, 120161. doi:10.1016/j.atmosenv.2023.120161
Wang, C., Zhan, C., Lu, B., Yang, W., Zhang, Y., Wang, G., et al. (2024). Ssfan: a compact and efficient spectral-spatial feature extraction and attention-based neural network for hyperspectral image classification. Remote Sens. 16, 4202. doi:10.3390/rs16224202
Xayasouk, T., Lee, H., and Lee, G. (2020). Air pollution prediction using long short-term memory (lstm) and deep autoencoder (Dae) models. Sustainability 12, 2570. doi:10.3390/su12062570
Zhang, J., and Li, S. (2022). Air quality index forecast in beijing based on cnn-lstm multi-model. Chemosphere 308, 136180. doi:10.1016/j.chemosphere.2022.136180
Zhang, Z., and Zhang, S. (2023). Modeling air quality pm2. 5 forecasting using deep sparse attention-based transformer networks. Int. J. Environ. Sci. Technol. 20, 13535–13550. doi:10.1007/s13762-023-04900-1
Zhang, Y., Liu, H., Zhao, X., and Wang, L. (2023). Sparse attention mechanism in transformer networks for time series forecasting. IEEE Access 11, 45678–45689. doi:10.1007/s13762-023-04900-1
Zhao, L., Li, Z., and Qu, L. (2022). Forecasting of beijing PM2.5 with a hybrid ARIMA model based on integrated AIC and improved GS fixed-order methods and seasonal decomposition. Heliyon 8, e12239. doi:10.1016/j.heliyon.2022.e12239
Zhou, C., Fang, Z., Xu, X., Zhang, X., Ding, Y., Jiang, X., et al. (2020). Using long short-term memory networks to predict energy consumption of air-conditioning systems. Sustain. Cities Soc. 55, 102000. doi:10.1016/j.scs.2019.102000
Keywords: deep learning, multi-task learning, air quality forecasting, temporal convolutional network, long short-term memory, linear attention, multi-head attention
Citation: Xie Z-A, Chow C-O, Chuah JH and Raymond WJK (2025) Multi-pollutant air quality forecasting using bidirectional attention and multi-scale temporal networks. Front. Environ. Sci. 13:1623630. doi: 10.3389/fenvs.2025.1623630
Received: 06 May 2025; Accepted: 11 August 2025;
Published: 09 September 2025.
Edited by:
Manousos-Ioannis Manousakas, National Centre of Scientific Research Demokritos, GreeceReviewed by:
Prakash Rao Ragiri, Netaji Subhas University of Technology, IndiaMengfan Teng, Jiangxi University of Science and Technology, China
Copyright © 2025 Xie, Chow, Chuah and Raymond. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Chee-Onn Chow, Y29jaG93QHVtLmVkdS5teQ==