 Qian Liu
Qian Liu Daryl L. X. Fung
Daryl L. X. Fung Leann Lac
Leann Lac Pingzhao Hu
Pingzhao Hu- 1Department of Biochemistry and Medical Genetics, University of Manitoba, Winnipeg, MB, Canada
- 2Department of Computer Science, University of Manitoba, Winnipeg, MB, Canada
- 3Department of Statistics, University of Manitoba, Winnipeg, MB, Canada
Background: The outbreak of the novel coronavirus disease 2019 (COVID-19) has been raging around the world for more than 1 year. Analysis of previous COVID-19 data is useful to explore its epidemic patterns. Utilizing data mining and machine learning methods for COVID-19 forecasting might provide a better insight into the trends of COVID-19 cases. This study aims to model the COVID-19 cases and perform forecasting of three important indicators of COVID-19 in the United States of America (USA), which are the adjusted percentage of daily admitted hospitalized COVID-19 cases (hospital admission), the number of daily confirmed COVID-19 cases (confirmed cases), and the number of daily death cases caused by COVID-19 (death cases).
Materials and Methods: The actual COVID-19 data from March 1, 2020 to August 5, 2021 were obtained from Carnegie Mellon University Delphi Research Group. A novel forecasting algorithm was proposed to model and predict the three indicators. This algorithm is a hybrid of an unsupervised time series anomaly detection technique called matrix profile and an attention-based long short-term memory (LSTM) model. Several classic statistical models and the baseline recurrent neural network (RNN) models were used as the baseline models. All models were evaluated using a repeated holdout training and test strategy.
Results: The proposed matrix profile-assisted attention-based LSTM model performed the best among all the compared models, which has the root mean square error (RMSE) = 1.23, 31612.81, 467.17, mean absolute error (MAE) = 0.95, 26259.55, 364.02, and mean absolute percentage error (MAPE) = 0.25, 1.06, 0.55, for hospital admission, confirmed cases, and death cases, respectively.
Conclusion: The proposed model is more powerful in forecasting COVID-19 cases. It can potentially aid policymakers in making prevention plans and guide health care managers to allocate health care resources reasonably.
Background
It has been more than 1 year since the first case of the novel coronavirus disease (COVID-19) came to light in December 2019 (1). According to the interactive COVID-19 dashboard created and maintained by Johns Hopkins Center for Systems Science and Engineering (JHU-CSSE), COVID-19 has spread to 191 counties and caused 4,370,447 global deaths out of more than 207 million diagnosed cases by August 16, 2021 (2). COVID-19 was confirmed to be caused by severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2) as defined by the International Committee on Taxonomy of Viruses (ICTV) (3). SARS-CoV-2 coronavirus is a type of β-coronavirus with many potential hosts, leading to difficulties in prevention and treatment (4, 5).
As COVID-19 is rapidly spreading and putting the world under a very distressing situation, the WHO declared COVID-19 as a global pandemic in March 2020 (6). Since a whole year's data are now available, some epidemic patterns of COVID-19 have been observed. COVID-19 follows the dynamic transmission of an epidemic, with different magnitudes in terms of time, region, season, and weather, and exhibited as a non-linear relationship. Since new case prevention and healthcare resource management have become critical for every country, good time series forecasting tools for COVID-19 are extremely important and necessary for estimating the number of cases in the coming days.
There is a classic time series forecasting algorithm called autoregressive integrated moving average (ARIMA) (7), which is widely applied for infectious disease prediction in public health (8, 9). ARIMA has been applied to COVID-19 forecasting as early as February 2020 (10). Ceylan et al. used ARIMA to predict the prevalence of COVID-19 for confirmed and deceased cases in Italy, Spain, and France from February 21, 2020 to April 15, 2020 (11). Chintalapudi et al. have forecasted the number of registered and recovered cases after a 60-day lockdown in Italy by ARIMA with an accuracy rate of more than 80% (12). Researchers have also widely applied ARIMA in comparison with other approaches for COVID-19 forecasting (13–18). Since the trend of COVID-19 cases follows a seasonal pattern, and ARIMA is not able to capture seasonal patterns well, an improved variant of the ARIMA called Seasonal ARIMA (SARIMA) (19) was proposed to model the seasonality of time series data.
However, SARIMA is still considered to be too simple to recognize complex patterns in the data. In principle, more complex models, which could include other significant observed or hidden variables/factors in disease prevalence, could be considered when we design the forecasting framework. For example, unsupervised data-driven time series anomaly detection algorithms could find significant abnormal patterns within the time series data (20). If we could incorporate the anomaly information into the forecasting models, the performance may be increased. Matrix profile is one of such algorithms proposed by Keogh et al. (19). A matrix profile consists of two components: a distance vector and a profile index vector. The distance vector contains the minimum Euclidean distances among the patterns within the time series data. The indexes of the nearest neighbors are stored in the profile index vector. The idea is that if a part of the time series data is far different from its nearest neighbors, then it is likely an anomaly. Keogh and his team further developed a series of algorithms to calculate the matrix profile to express the abnormal patterns within time-series data (21–25).
Some machine learning algorithms, such as echo state network (ESN) (26), gated recurrent unit (GRU) (27), and long short-term memory (LSTM) (28), have also been widely applied in time series forecasting. They all belong to a recurrent neural network (RNN), which is a family of neural network technologies with internal memory (state) to process sequences of inputs. With the memory mechanism in the RNN, the standard RNN can handle the time series data very well. However, if a time series is very long, it will be difficult to pass information from the earlier timesteps to the later ones. This problem is called the vanishing gradient problem (29). The ESN does not suffer from this vanishing gradient problem because the hidden neurons in an ESN are very sparsely connected to form a network reservoir. The weights of the reservoir are randomly assigned and not trainable. The information of the earlier time points is randomly passed to the last points. Due to the untrainable random hidden state, the ESN has high computational efficiency, but the untrainable random hidden state reduces the complexity of the model thus reduces the power (30). While the GRU and the LSTM reduce the vanishing gradient problem by making it easier to pass previous information throughout the state sequences. They all use gates to regulate the information flow (28). The difference is that the LSTM has three gates and a cell state while the GRU has only two gates. Therefore, the LSTM may have more flexible control of the information flow. Previous studies have tested the performance of GRU, LSTM, and several variants of LSTM models for predicting COVID-19 cases across different counties and confirmed their accuracy and robustness (31–34).
However, these models cannot detect which time point is the important one for future prediction. Recently, the attention mechanism in machine learning was developed to overcome this limitation (35). This is achieved by keeping the intermediate information from the LSTM units, training the model to pay selective attention to the inputs, and relating them to the items in the output time series (36). The attention mechanism increases the computational burden but results in a more targeted model with better performance. In addition, the model is also able to show how attention is paid to the input time series when predicting the output. It can increase the explainability of the LSTM model, which is an essential characteristic of gaining trust from end users.
Although great advancements have been made in the theories and applications of both the matrix profile and the LSTM, limited efforts have been made to investigate the combination of the two approaches and explore the applications of this combined approach to time series data forecasting (such as COVID-19 cases). In this study, we aim to propose a novel framework, which is a hybrid of the unsupervised matrix profile to detect a potential time series anomaly and an attention-based LSTM model, to model and forecast COVID-19 cases in the United States of America (USA). We aim to achieve a more accurate COVID-19 forecasting model to support decision-making and guide future advanced model building.
Materials and Methods
Data Source
We considered the USA COVID-19 data from March 1, 2020 to August 5, 2021, which were obtained from the website of Carnegie Mellon University Delphi Research Group (37). We focused on three indicators: the adjusted percentage of daily admitted hospitalized COVID-19 cases (hospital admission), the number of daily confirmed COVID-19 cases (confirmed cases), and the number of daily death cases caused by COVID-19 (death cases). The hospital admission is the estimated percentage of new hospital admissions with COVID-19. It is based on insurance claims data from health system partners and smoothed using a Gaussian linear smoother.
Methods
Data Pre-processing and Remapping
To improve model performance and consider the consistency in evaluating model performance between statistical and machine learning approaches, pre-processing raw data by normalization is necessary. We applied z-normalization or standardization to the data. The formulation to transform the observed raw data into z-score is Zi = (Yi-Ȳ)/s, where Ȳ and s are the sample mean and standard deviation. Yi is the observed raw data at time point i. After building a forecasting model and obtaining the predicted value Zj, we remapped these values to the observed raw data scale by applying the formula: Yj = s*Zj + Ȳ. Here, Yj is the predicted data with raw data scale at time point j.
Matrix Profile for Time Series Data Analysis
Matrix profile compares snippets of the time series by computing the distance between each pair of snippets. A matrix profile consists of two components: a distance profile and a profile index vector. The distance profile contains the minimum Euclidean distances among the sub-snippets within the time series. If the minimum distance of a certain sub-snippet is very large, it is probably that this sub-snippet is an anomaly because it is very different from its nearest neighbor. The indexes of the nearest neighbors are stored in the profile index vector. Matrix profiles of the three COVID-19 indicators were calculated using the Python package “matrixprofile” (38). Several algorithms are provided by the package for computing the matrix profile, such as Scalable Time series Anytime Matrix Profile (STAMP) and Scalable Time series Ordered-search Matrix Profile (STOMP). We selected the STOMP function since it is faster. The window size was set as 7 (weekly anomaly). After the matrix profiles were calculated, top 10 discords (the top 10 sub-snippets with larger Euclidean distances with their nearest neighbors) were highlighted for the visualization. In addition to the distance profile, we also considered the index profile vector. The index profile vector stores the global index of the closest neighbor of each snippet. For instance, if the most similar snippet of the current snippet is at the 15th location, the global position of the current snippet will be 15. The relative position is the relative index of the closest neighbor of the current snippet. It can be calculated using the index profile vector. If the current snippet is at the 10th location and the nearest neighbor of the current snippet is at the 15th location, then the relative position will have a value of +5. In the remaining parts of the report, we mainly focus on the distance profile and the relative position, which are passed together with the normalized observed raw data into the LSTM for forecasting the COVID-19 cases.
Baseline Models
ARIMA Model for Seasonal Data (SARIMA)
Non-seasonal ARIMA is a generalized form of the autoregressive moving average (ARMA) model. The ARMA is a combination of the auto regression (AR) model of order p, and moving average (MA) model of order q.
Let yt denote the dth difference of Yt, and Yt refer to the observation at time t, the general equation of the ARIMA (p, d, q) model is as follows.
where ϕ = [ϕ1, ϕ2, …, ϕp] and θ = [θ1, θ2, …θq] are coefficients of AR and MA parts of the model, respectively. Here, c is a constant and εt is the residual assumed to be uncorrelated in the final selected ARIMA model.
The ARIMA is not capable of modeling seasonal data. Therefore, the SARIMA model includes the additional seasonal term (p, d, q)m where m is the number of observations per year. To estimate the coefficients in the SARIMA, the maximum likelihood estimation (MLE) and the least square estimation (LSE) were used (7). R function auto.arima() in the “forecast” package (39) was utilized to execute SARIMA.
Standard RNN Model
Vanilla RNN has backward-linking connections. It can be computed as follows:
which can also be described as: at a given timestep t, each recurrent layer receives the input xt and the output from the previous timestep yt−1, then outputs the non-linearly processed yt. The non-linearity comes from the activation function σ. Wx and Wy are the input weights and output weights. bt is the bias.
ESN Model
The simple ESN model can be computed as follows:
Where xt, ht, yt are the input, hidden state, and output at time point t, respectively. σ is the activation function. Wx and Wr weight matrices are randomly initialized and fixed in the training step, and only the output weight Wy is trainable.
GRU Model
The GRU model has a reset gate (rt), a cell state (ht), and an output gate (yt) to control the information flow.
where [ht−1, xt] is the concatenation between the hidden state of the previous timestep, ht−1, and the input of the current timestep, xt. bo, bt, bC are the bias of each gate.
Matrix Profile-Guided Attention LSTM Models
LSTM Without Attention
The LSTM model contains a forget gate (ft), an input gate (it), and an output gate (yt). The forget gate receives the hidden state from the previous timestep (ht−1), and concatenates them with the input in the current timestep, then passes them into a linear layer with a sigmoid activation.
Wf is the weight of the forget gate.
The input gate controls how much new information will be passed into the current timestep, which can be formulated as follows:
is used to update the cell state (Ct) of the current timestep.
The output gate controls and filters the information from the cell state. The equation is:
Convolutional Neural Network LSTM
The convolutional neural network LSTM (CNN-LSTM) is a model that uses a combination of CNN (40) to extract the features of the input and pass the extracted features as an input to the LSTM model. A CNN extracts features from a group of inputs based on the kernel size. The equation for convolutional operations is:
Where is the weights in layer l at row i and column j of the kernel, ll−1 is the output from the previous layer, and bl is the bias in layer l. We kept the kernel size 2. With kernel size 2, the sequence length of the input will be reduced by 1 after every layer. In order to maintain the sequence length for the LSTM, we used a transposed CNN to expand the sequence length to the original length. The output of the CNN is fed as input to the LSTM.
LSTM With Attention
We added an attention mechanism to our LSTM model. The proposed overall workflow can be found in Figure 1. As there are outliers in the forecasted values, the attention mechanism can help LSTM models to focus on important parts of the time series to prevent getting skewed values. We utilized multiheaded attention where there are several heads and each head contains a query, a key, and a value. Multiheaded attention has been shown to be beneficial with different learned linear projections (25). The equation for the attention is:
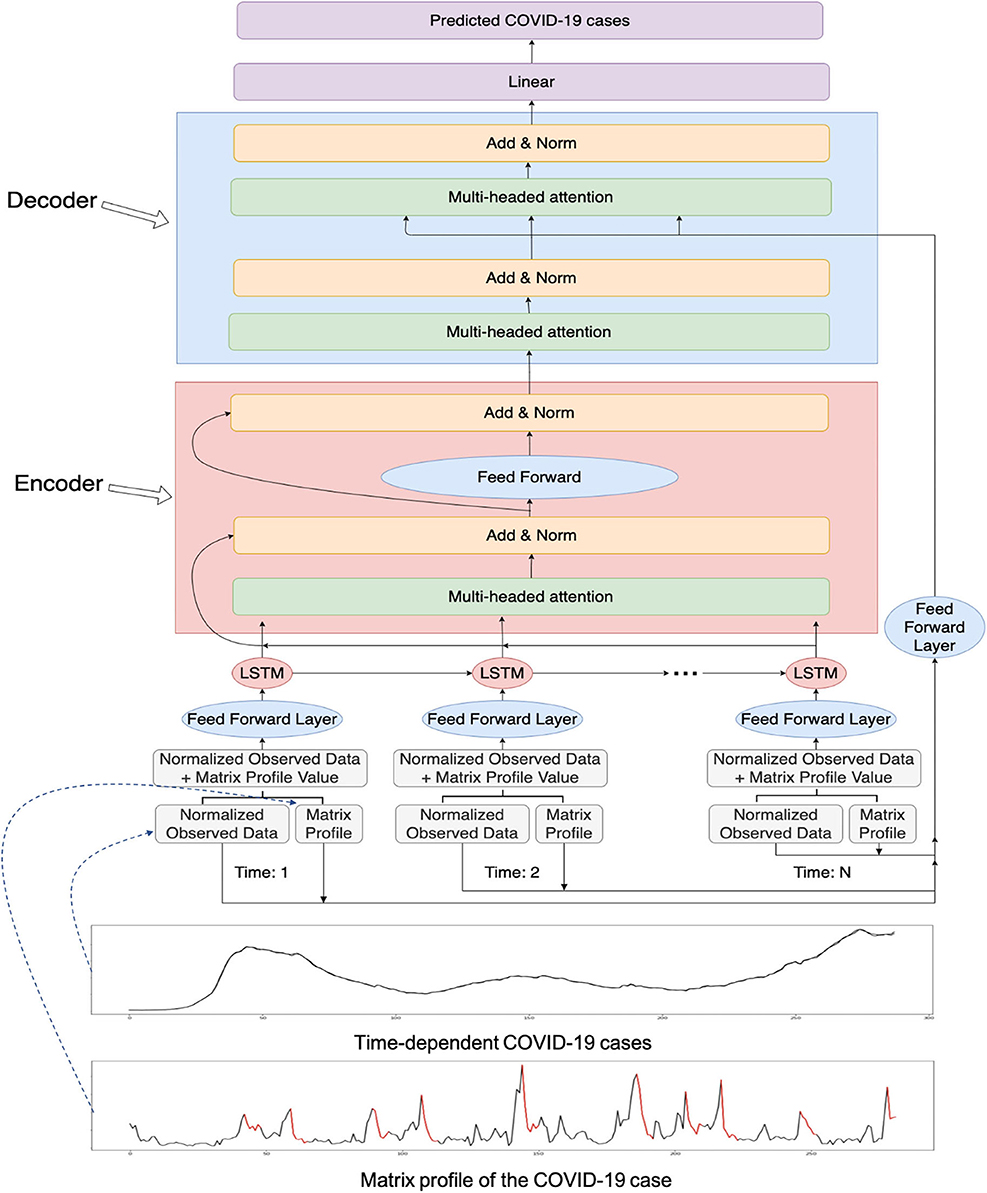
Figure 1. The overall workflow of the proposed novel matrix profile-guided attention LSTM algorithm. Matrix profile feature could be the distance profile (the LSTM-MatAtt model) or the relative position profile (the LSTM-RelAtt). The matrix profile feature concatenated with the normalized observed data of the COVID-19 indicators are first input into the LSTM unit, then passed to the later steps of the encoder-decoder attention process. The final output is the predicted future values of the COVID-19 indicators.
where Q is the query, K is the key, and V is the value. dk is the dimension of the current layer. Q = [Qt−p, Qt−p+1, …, Qt], K = [Kt−p, Kt−p+1, …, Kt], V = [Vt−p, Vt−p+1, …, Vt]. p is the attention span. The attention span would look at the previous p timesteps, so the model attends to them. t is the current timestep. Each head contains the attention equation:
Qt, Kt, Vt are obtained by passing the hidden outputs from the LSTM into a linear layer:
The multiheaded attention concatenates the attentions of the heads and outputs the combination of the attentions of the head, which can be formulated as:
Furthermore, we incorporate an encoder-decoder architecture for the LSTM with an attention model (Figure 1). The output of the LSTM is fed into the encoder. The attention architecture in the encoder undergoes multiheaded attention on its own input to determine which timestep the model should focus more on. It then passes its learned features to the decoder. The decoder receives the input from the output of the encoder. To aid in more guidance for the attention stage in the decoder, the matrix profile input is fed into the attention stage in the decoder in addition to the hidden features of the decoder. The decoder outputs its learned features and passes them into a linear layer to output the predicted value. The overall procedure of the matrix profile-guided attention LSTM model is summarized in Algorithm 1.

Algorithm 1: LSTM with attention
Given the combination of the normalized observed raw data, matrix profiles, and the attention mechanism, we evaluated different LSTM models for each of the three COVID-19 indicators used in the study, which include the following LSTM-related models:
1) LSTM: using only the normalized observed raw data.
2) CNN-LSTM: using only the normalized observed raw data with convolutional LSTM network.
3) LSTM-Att: using only the normalized observed raw data with attention mechanism in LSTM.
4) LSTM-MatAtt: using the normalized observed raw data and the distance profile fed into the attention-based LSTM network.
5) LSTM-RelAtt: using the normalized observed raw data and the relative position matrix profile feature fed into the attention-based LSTM network.
Hyperparameter Tuning
The number of reservoirs of ESN was tuned manually, ranging from 50 to 300, the best one was 200. GRU and simple RNN have one hidden unit, thus, there is no need to tune the number of hidden layers. The step size of the input time series was set as 12 for ESN, GRU, simple RNN, and all LSTM models with and without attention or matrix profile. Epochs were tuned separately for different models to achieve the best losses. The additional hyperparameters that we tuned for the LSTM networks, such as hidden dimensions, dropout, and feedforward dimensions, can be found in Table 1. These hyperparameters were tuned separately for different models with and without the addition of attention and the matrix profile to achieve the best convergence.
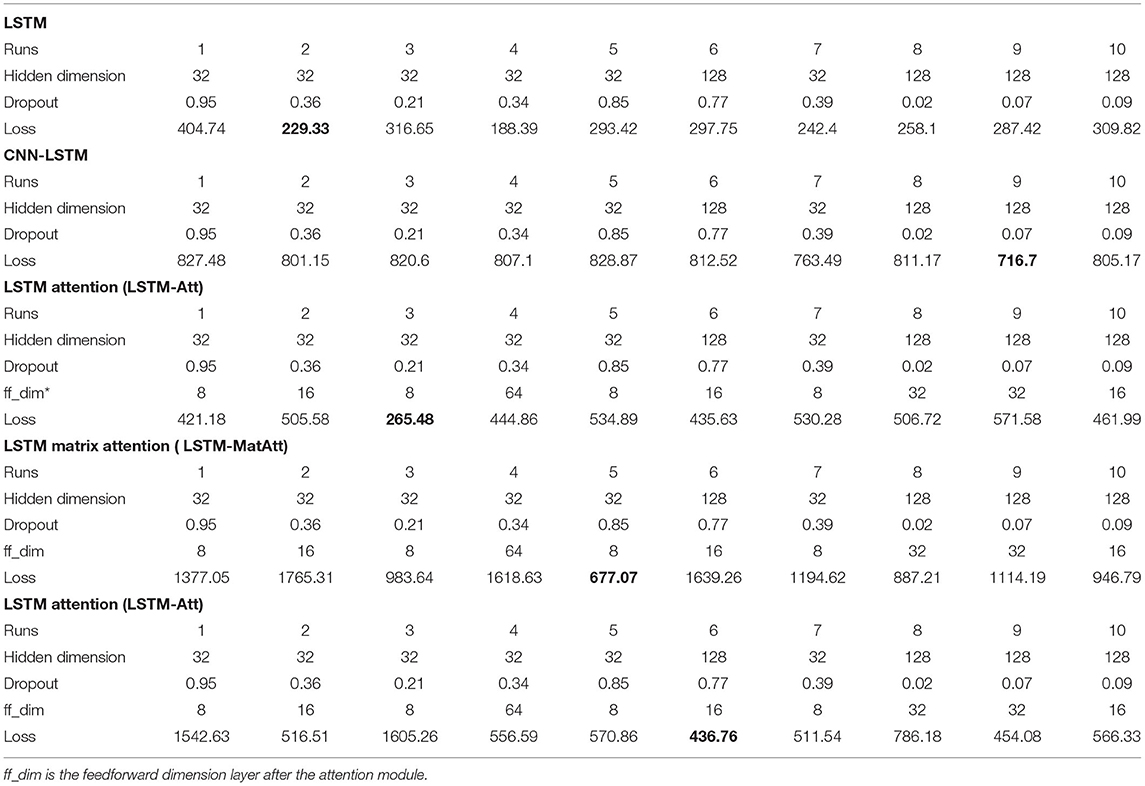
Table 1. Parameters tuning of LSTM models.
Performance Evaluation
After building the models for each indicator, it is important to evaluate the prediction accuracy and compare the forecasting performance to other proposed models in forecasting the number of COVID-19 cases. Traditional K-fold cross-validation is designated for independent data. However, time-series data are considered as dependent data in which we use past events to forecast the future ones. Therefore, we consider a rep-holdout cross-validation method. In this method, we divided the time series data into training and testing sets by ascending time order. To conduct the model performance evaluation, we applied the rep-holdout strategy, in which the test sets are the last (most recent) 10, 20, 30, 40, and 50 percentage of all time points (Figure 2). We measured the forecasting accuracy by root mean square error (RMSE), mean absolute error (MAE), and mean absolute percentage error (MAPE) using the test set.
where n is the sample size for each testing set, yt is the actual data, is the predicted data.
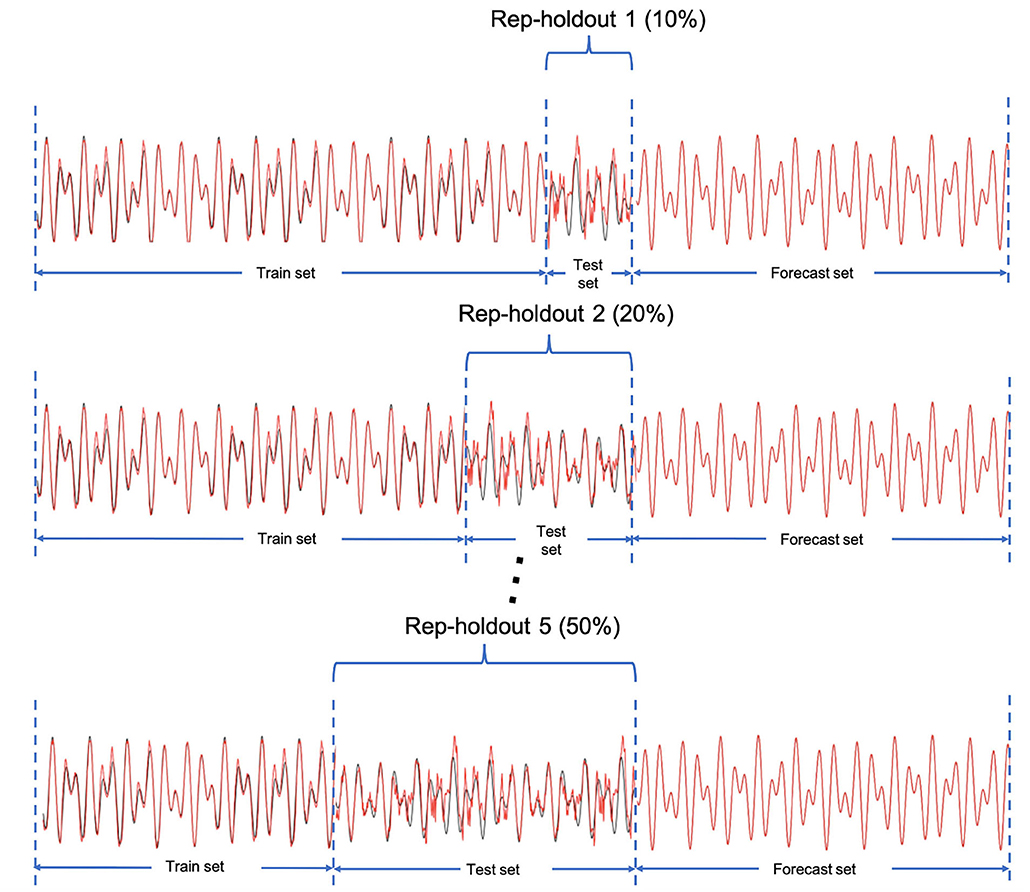
Figure 2. The rep-holdout strategy for model training and validation. The X axis is the time points.
Results
Matrix Profiles
The observed signals of the three indicators and their matrix profiles can be found in Figure 3. The trends of the hospital admission and death cases showed two peaks in April 2020 and January 2021 (top panels of Figures 3A,C). In addition, some minor decreasing and increasing trends were also observed. Matrix profiles of these two indicators were able to detect these ups and downs (bottom panels of Figures 3A,C). It should be noted that the beginning of the death cases time series was also detected as an anomaly because the death cases were pretty low at the first few days. The confirmed cases time series was stable overall until around November 2020 (top panel of Figure 3B). The top 1 anomaly in its matrix profile was located in around November 2020, which is consistent with the visual observation (bottom panel of Figure 3B). Overall, the data-driven unsupervised matrix profile successfully detected the intrinsic anomalous data in the time series of the three indicators.
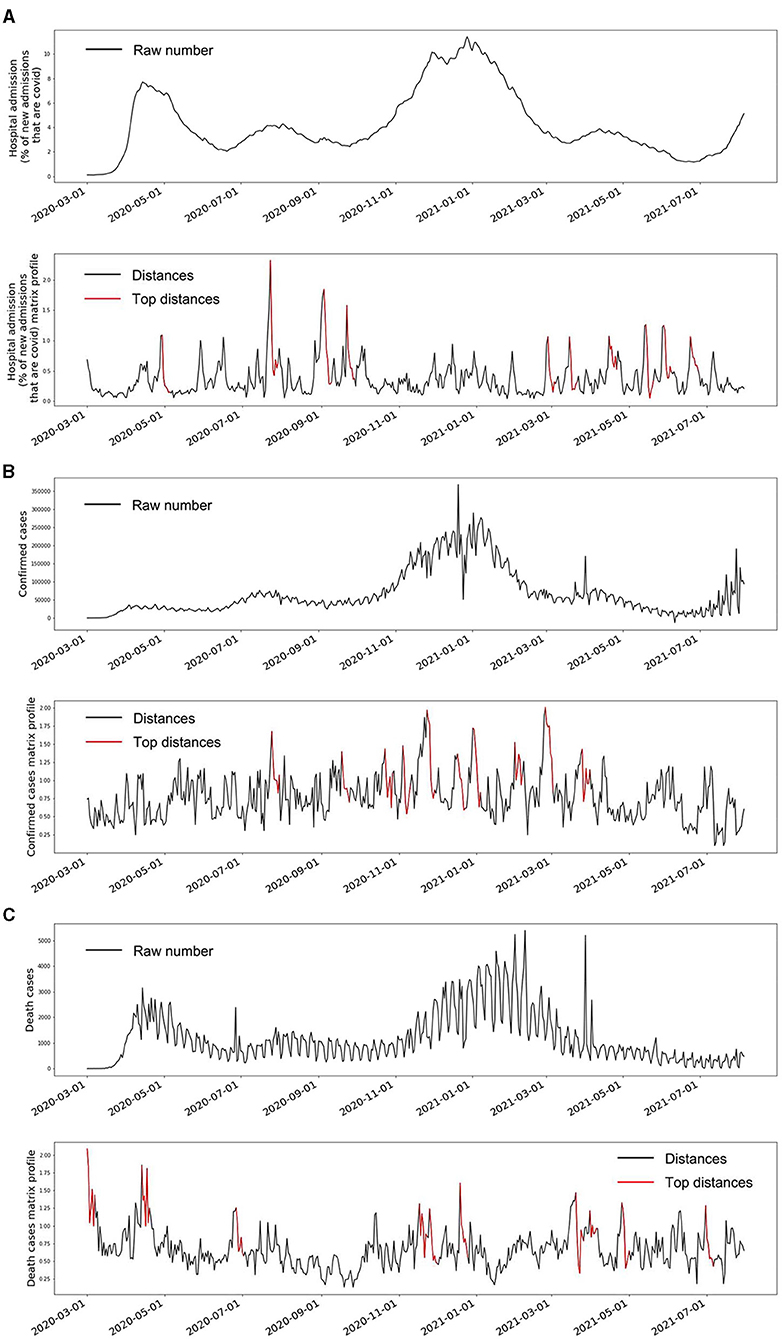
Figure 3. The raw time series and the matrix profile of the three indicators. (A) is the time series of COVID-19 hospital admissions and its matrix profile. (B) is the time series of the daily confirmed COVID-19 cases and its matrix profile. (C) is the time series of the daily death cases caused by COVID-19 and its matrix profile. The red segments in the matrix profile plots indicate the corresponding weeks that have large Euclidean distances to their nearest neighbor compared to all the other weeks, which also means these weeks marked as red are the top anomalies within the whole time series.
Seasonal ARIMA
The performance of the SARIMA is summarized in Table 2. Overall, SARIMA had a decent average performance of predicting the three indicators. Rep-holdout 1 (last 10% of time points as a testing set) did not always have best performance in predicting the three indicators among all other rep-holdout, and rep-holdout 5 (last 50% of time points as a testing set) was not the worst strategy, which indicates that the performance of the SARIMA model was not linearly related with the size of the training data. This is also applied to other models.
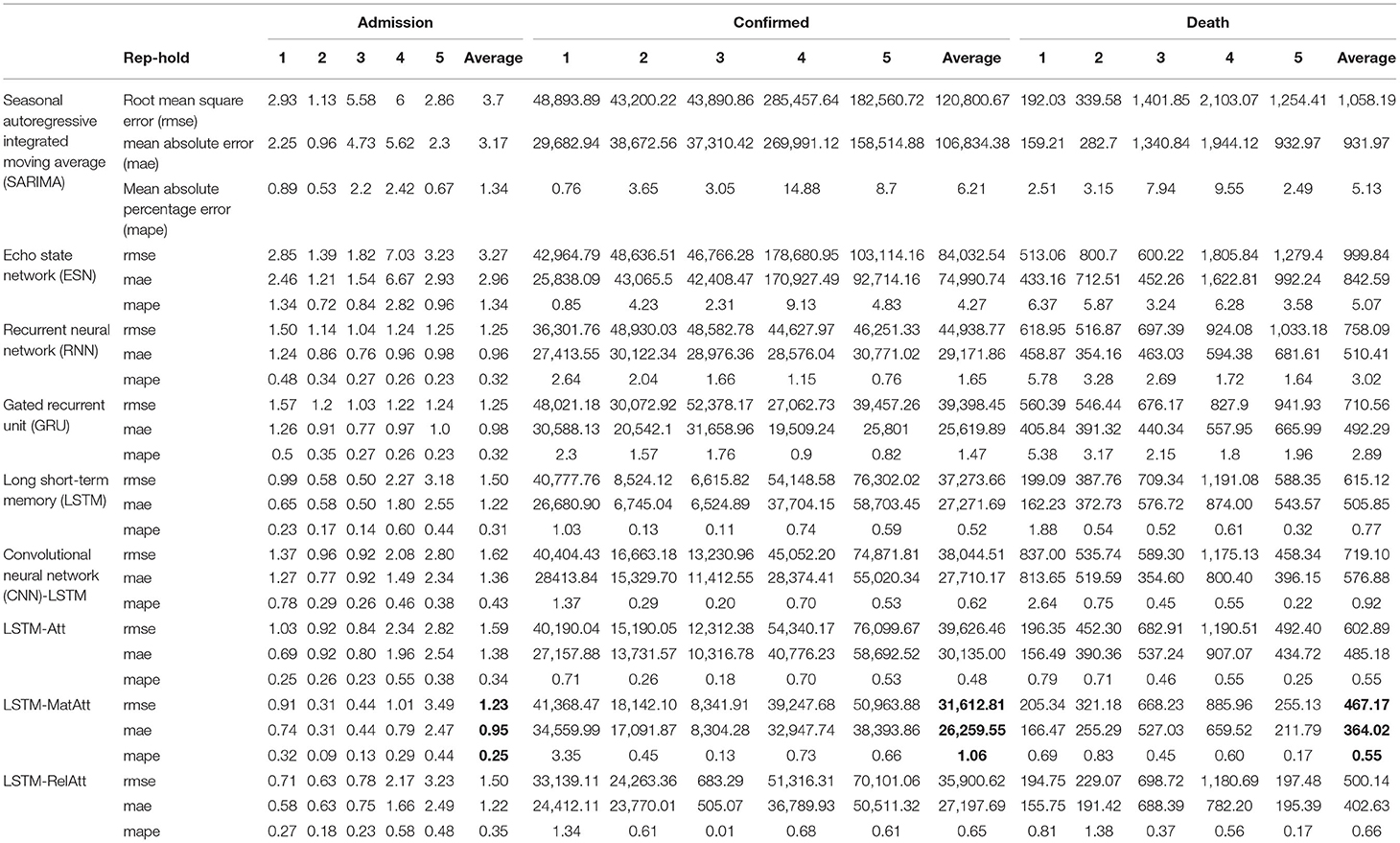
Table 2. Model performance.
RNN Models
The results of the simple RNN, ESN, and GRU models can be found in Table 2. The simple RNN and GRU achieved similar overall performance in predicting the three indicators, but their performances were better than that of the ESN model. The ESN performed slightly better than the SARIMA, while the simple RNN and GRU were much better than the SARIMA.
LSTM Models
The LSTM model with attention mechanism and matrix profile (Model: LSTM-MatAtt) has achieved better-averaged performance in predicting the three indicators (Table 2). Furthermore, the LSTM-MatAtt model with rep-holdout 3 was the best model in predicting hospital admission (RMSE = 1.23, MAE = 0.95, MAPE = 0.25). This performance was far better than other models we tested, no matter if they were classic statistic models or any other RNN models (Table 2).
Overall, the LSTM models with attention mechanism fed together with the matrix profile outperformed the classic statistic models, the other RNN models, and the LSTM models without the attention mechanism as well as the matrix profile assistance in predicting the three indicators. Different models may need to be equipped with different rep-holdouts.
COVID-19 Case Forecasting
After the performances of the models were evaluated and the hyperparameters were fine-tuned using the rep-holdout strategy, the final forecasting for the three indicators was performed based on the whole data (March 1, 2020 to August 5, 2021). We let the selected and well-trained models run freely to forecast the future data between August 6, 2021 and October 31, 2021 (Figure 4). Note: We can only access the data up to August 5, 2021 at the time we submit the report.
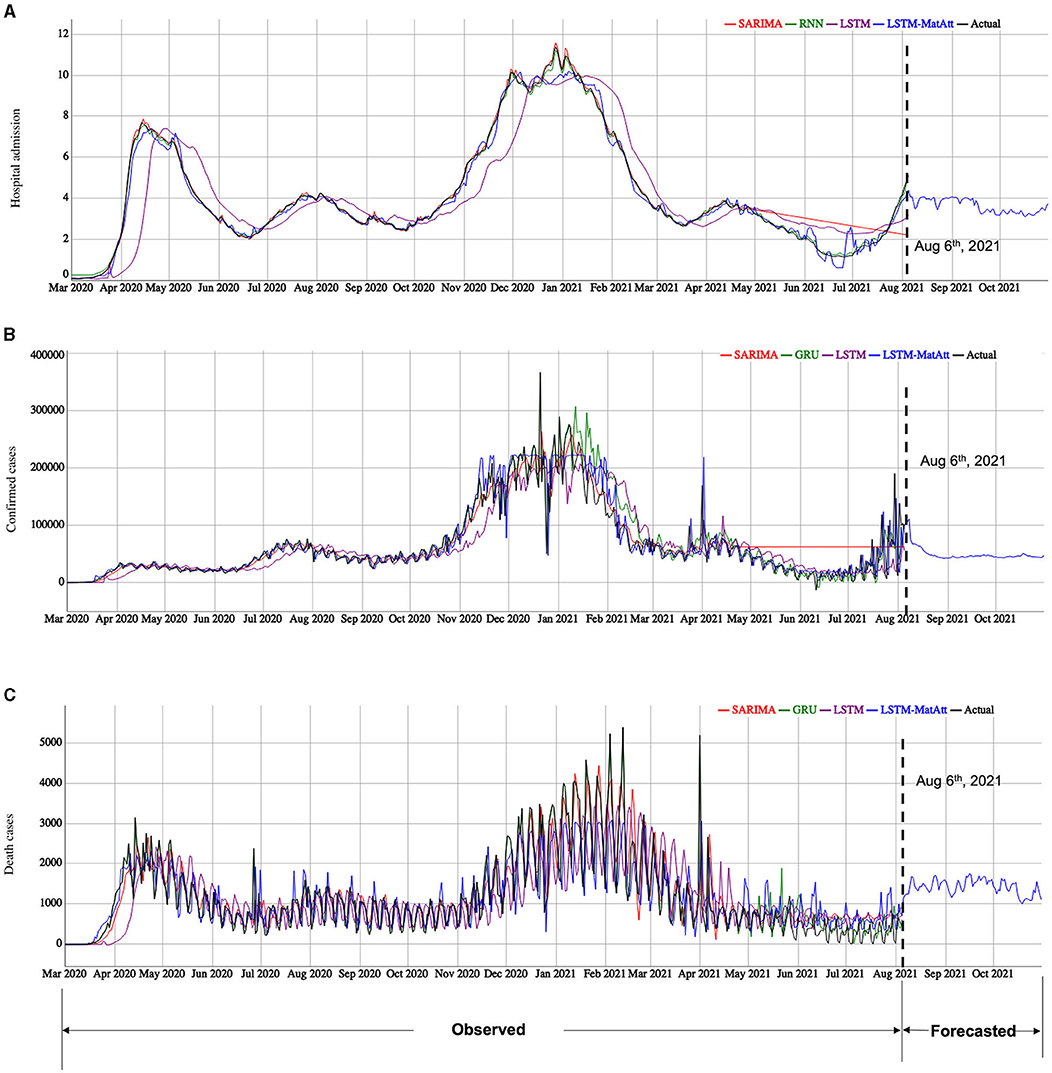
Figure 4. The model fitting and forecasting results of the three COVID-19 indicators by the selected models. (A) is the results for hospital admission, (B) is the results for confirmed cases, and (C) is the results for death cases. We showed the model fitting results based on the observed data from March 1, 2020 to August 5, 2021. The selected models are based on the performance shown in Table 2 for the categories of traditional statistical models, RNN-based models, and the family of the LSTM models, including our proposed LSTM-based models. The model forecasting results are based on the best model among the proposed and the compared models for each indicator.
Using the best models show in Table 2, we forecasted the cases of hospital admission, confirmed cases, and death cases using the trained LSTM-MatAtt models for the period from August 6, 2021 to October 31, 2021 (Figure 4). The forecasting results of hospital admission show a significant rise between July 2021 and October 2021. The confirmed cases and death cases indicate a relatively stable trend in the next few months, but they have significantly decreased from the peaks in January–February in 2021.
Discussions and Conclusions
Classic statistic time series forecasting models and the baseline RNN models, which are the benchmarks of this study, are able to achieve descent predictions of the three indicators of COVID-19. The proposed novel LSTM models combining matrix profile and attention mechanism achieved the overall best performance. A different number of time points was assigned to the training set according to the rep-holdout strategy. According to Table 1, the model performances were not associated with the size of the training sets, which means a larger training set may not guarantee a better performance. Careful selection of a proper training strategy could potentially increase the performance.
There are some limitations in this study. First, although the proposed models were selected through a five rep-holdout strategy, it was not validated in another totally independent dataset. Second, forecasting future cases is often not accurate while its uncertainty is seriously underestimated. One such example is the case of SARS, where the fear of becoming a pandemic was overblown, resulting in overspending and the application of restrictive measures to be taken that turned out to be unnecessary. Due to the uncertain measures taken, mathematical models overpredicted the number of cases. This calls us to fully take these potential uncertain factors into account when we build the forecasting models. In our modeling strategy, we used an indirect approach to first detect anomalies existing in the history data, which may be related to these uncertain measures. Despite the inaccuracies associated with the predictions, forecasting is still useful in allowing us to better understand the current situation and make plans.
In conclusion, a novel unsupervised matrix profile combined with an attention-based LSTM algorithm was proposed. Our experiments showed that the proposed algorithm has the best ability to forecast COVID-19 cases than the classical statistic methods and the baseline RNN models. The forecasted data may provide potentially useful information to help decision-makers to control the consequences of COVID-19.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://cmu-delphi.github.io/delphi-epidata/.
Author Contributions
QL and DF were responsible for the conceptualization, development of methodologies and writing, and editing the manuscript. LL performed data analysis and wrote the manuscript. PH provided advice on data analysis and critically reviewed the manuscript and was also involved in supervision and project administration. All authors had full access to all of the data in the study and can take responsibility for the integrity of the data and the accuracy of the data analysis.
Funding
This work was supported in part by the Natural Sciences and Engineering Research Council of Canada and the University of Manitoba. PH is the holder of the Manitoba Medical Services Foundation (MMSF) Allen Rouse Basic Science Career Development Research Award.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
Data were downloaded from the website of Carnegie Mellon University Delphi Research Group.
References
1. Disease outbreak news. WHO | Novel Coronavirus – China. WHO (2020). Available online at: https://www.who.int/csr/don/12-january-2020-novel-coronavirus-china/en/ (accessed Sep 22, 2020).
2. Dong E, Du H, Gardner L. An interactive web-based dashboard to track COVID-19 in real time. Lancet Infect Dis. (2020) 20:533–4. doi: 10.1016/S1473-3099(20)30120-1
3. Gorbalenya AE, Baker SC, Baric RS, Groot RJ De, Gulyaeva AA, Haagmans BL, et al. The species Severe acute respiratory syndrome-related coronavirus: classifying 2019-nCoV and naming it SARS-CoV-2. Nature microbiology (2020) 536.
4. Vellingiri B, Jayaramayya K, Iyer M, Narayanasamy A, Govindasamy V, Giridharan B, et al. COVID-19: a promising cure for the global panic. Sci Total Environ. (2020) 725:138277. doi: 10.1016/j.scitotenv.2020.138277
5. Abd El-Aziz TM, Stockand JD. Recent progress and challenges in drug development against COVID-19 coronavirus (SARS-CoV-2) - an update on the status. Infect Genet Evol. (2020) 83:104327. doi: 10.1016/j.meegid.2020.104327
6. Cucinotta D, Vanelli M. WHO declares COVID-19 a pandemic. Acta Biomed. (2020) 91:157–160. doi: 10.23750/abm.v91i1.9397
7. Box GEP, Jenkins GM, Reinsel GC. Time series analysis: forecasting and control. J Market Res. (1977) 14:269. doi: 10.2307/3150485
8. Heisterkamp SH, Dekkers ALM, Heijne JCM. Automated detection of infectious disease outbreaks: hierarchical time series models. Stat Med. (2006) 25:4179–96. doi: 10.1002/sim.2674
9. Choi K, thacker SB. An evaluation of influenza mortality surveillance, 1962–1979. Am J Epidemiol. (1981) 113:215–26. doi: 10.1093/oxfordjournals.aje.a113090
10. Benvenuto D, Giovanetti M, Vassallo L, Angeletti S, Ciccozzi M. Application of the ARIMA model on the COVID-2019 epidemic dataset. Data Brief. (2020) 29:105340. doi: 10.1016/j.dib.2020.105340
11. Ceylan Z. Estimation of COVID-19 prevalence in Italy, Spain, and France. Sci Total Environ. (2020) 729:138817. doi: 10.1016/j.scitotenv.2020.138817
12. Chintalapudi N, Battineni G, Amenta F. COVID-19 virus outbreak forecasting of registered and recovered cases after sixty day lockdown in Italy: a data driven model approach. J Microbiol Immunol Infect. (2020) 53:396–403. doi: 10.1016/j.jmii.2020.04.004
13. Alzahrani SI, Aljamaan IA, Al-Fakih EA. Forecasting the spread of the COVID-19 pandemic in Saudi Arabia using ARIMA prediction model under current public health interventions. J Infect Public Health. (2020) 13:914–9. doi: 10.1016/j.jiph.2020.06.001
14. Chaurasia V, Pal S. COVID-19 Pandemic: ARIMA and Regression Model-Based Worldwide Death Cases predictions. SN Comput Sci. (2020) 1:288. doi: 10.1007/s42979-020-00298-6
15. Chaurasia V, Pal S. Application of machine learning time series analysis for prediction COVID-19 pandemic. Res Biomed Eng. (2020) 24:1–13. doi: 10.1007/s42600-020-00105-4
16. Hernandez-Matamoros A, Fujita H, Hayashi T, Perez-Meana H. Forecasting of COVID19 per regions using ARIMA models and polynomial functions. Appl Soft Comput J. (2020) 96:106610. doi: 10.1016/j.asoc.2020.106610
17. Sahai AK, Rath N, Sood V, Singh MP. ARIMA modelling & forecasting of COVID-19 in top five affected countries. Diabetes Metab Syndrome Clin Res Rev. (2020) 14:1419–27. doi: 10.1016/j.dsx.2020.07.042
18. Wang Y, Xu C, Yao S, Zhao Y. Forecasting the epidemiological trends of COVID-19 prevalence and mortality using the advanced α-Sutte Indicator. Epidemiol Infect. (2020) 148: doi: 10.1017/S095026882000237X
19. M. WB, A. HL. Modeling and forecasting vehicular traffic flow as a seasonal ARIMA process: theoretical basis and empirical results. J Transport Eng. (2003) 129:664–72. doi: 10.1061/(ASCE)0733-947X(2003)129:6(664)
20. Chandola V, Banerjee A, Kumar V. Anomaly detection: a survey. ACM Comput Surveys. (2009) 41:1–58. doi: 10.1145/1541880.1541882
21. Yeh C-CM, Zhu Y, Ulanova L, Begum N, Ding Y, Dau HA, et al. Matrix profile I: all pairs similarity joins for time series: a unifying view that includes motifs, discords and shapelets. In: 2016 IEEE 16th International Conference on Data Mining (ICDM). Barcelona: Institute of Electrical and Electronics Engineers (IEEE) (2016). p. 1317–22.
22. Zhu Y, Zimmerman Z, Senobari NS, Yeh C-CM, Funning G, Mueen A, et al. Matrix profile II: exploiting a novel algorithm and gpus to break the one hundred million barrier for time series motifs and joins. In: 2016 IEEE 16th International Conference on Data Mining (ICDM). Barcelona: Institute of Electrical and Electronics Engineers (IEEE) (2016),739–48.
23. Yeh C-CM, Herle H, Van, Keogh E. Matrix profile III: the matrix profile allows visualization of salient subsequences in massive time series. In: : 2016 IEEE 16th International Conference on Data Mining (ICDM). Barcelona: Institute of Electrical and Electronics Engineers (IEEE).p. 579–88.
24. Yeh CCM, Zhu Y, Ulanova L, Begum N, Ding Y, Anh H, et al. Time series joins, motifs, discords and shapelets: a unifying view that exploits the matrix profile. Data Mining Knowl Discov. (2018) 32:83–123. doi: 10.1007/s10618-017-0519-9
25. Yeh CCM, Kavantzas N, Keogh E. Matrix profile IV: using weakly labeled time series to predict outcomes. Proc VLDB Endow. (2017) 10:1802–12. doi: 10.14778/3137765.3137784
26. Jaeger H, Haas H. Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. Science. (2004) 304:78–80. doi: 10.1126/science.1091277
27. Cho K, Van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation. In: EMNLP 2014 - 2014 Conference on Empirical Methods in Natural Language Processing, Proceedings of the Conference. Doha, Qatar, Association for Computational Linguistics (2014). p. 1724–34. doi: 10.3115/v1/D14-1179
28. Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput. (1997) 9:1735–80. doi: 10.1162/neco.1997.9.8.1735
29. Hochreiter S. The vanishing gradient problem during learning recurrent neural nets and problem solutions. Int J Uncertain Fuzziness Knowl Based Syst. (1998) 6:107–16. doi: 10.1142/S0218488598000094
30. Oztuik MC, Xu D, Principe JC. Analysis and design of echo state networks. Neural Comput. (2007) 19:111–38. doi: 10.1162/neco.2007.19.1.111
31. Shahid F, Zameer A, Muneeb M. Predictions for COVID-19 with deep learning models of LSTM, GRU and Bi-LSTM. Chaos Solitons Fractals. (2020) 140:110212. doi: 10.1016/j.chaos.2020.110212
32. Chimmula VKR, Zhang L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals. (2020) 135:109864. doi: 10.1016/j.chaos.2020.109864
33. Barman A. Time series analysis and forecasting of COVID-19 cases using LSTM and ARIMA models[J]. (2020). arXiv [Preprint]. arXiv 2006.13852
34. Shastri S, Singh K, Kumar S, Kour P, Mansotra V. Time series forecasting of Covid-19 using deep learning models: India-USA comparative case study. Chaos Solitons Fractals. (2020) 140:110227. doi: 10.1016/j.chaos.2020.110227
35. Wang Y, Huang M, Zhao L, Zhu X. Attention-based LSTM for aspect-level sentiment classification. In: EMNLP 2016 - Conference on Empirical Methods in Natural Language Processing, Proceedings. Austin, Texas, Association for Computational Linguistics (2016). p. 606–15. doi: 10.18653/v1/D16-1058
36. Xu J, Yao T, Zhang Y, Mei T. Learning multimodal attention LSTM networks for video captioning. In: MM 2017 - Proceedings of the 2017 ACM Multimedia Conference. New York, United States, Association for Computing Machinery (2017). p. 537–45. doi: 10.1145/3123266.3123448
37. Farrow DC, Brooks LC, Rumack A, Tibshirani RJ, Rosenfeld R. Delphi Epidata API. Delphi Research Group at Carnegie Mellon University, Available online at: cmu-delphi.github.io/delphi-epidata/api/covidcast.html (2021).
38. Van Benschoten A, Ouyang A, Bischoff F, Marrs T. MPA: a novel cross-language API for time series analysis. J Open Source Softw. (2020) 5:2179. doi: 10.21105/joss.02179
39. Hyndman RJ, Khandakar Y. Automatic time series forecasting: the forecast package for R. J Stat Softw. (2008) 27:1–22. doi: 10.18637/jss.v027.i03
Keywords: COVID-19 forecasting, LSTM models, matrix profile, attention mechanism, epidemiological indicators
Citation: Liu Q, Fung DLX, Lac L and Hu P (2021) A Novel Matrix Profile-Guided Attention LSTM Model for Forecasting COVID-19 Cases in USA. Front. Public Health 9:741030. doi: 10.3389/fpubh.2021.741030
Received: 26 July 2021; Accepted: 02 September 2021;
Published: 07 October 2021.
Edited by:
Reza Lashgari, Shahid Beheshti University, IranReviewed by:
Tarek Mohamed Abd El-Aziz, The University of Texas Health Science Center at San Antonio, United StatesArko Barman, Rice University, United States
Copyright © 2021 Liu, Fung, Lac and Hu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Pingzhao Hu, cGluZ3poYW8uaHVAdW1hbml0b2JhLmNh
†These authors share first authorship