 Hengyan Liu
Hengyan Liu Yang Leng
Yang Leng Yik-Chung Wu
Yik-Chung Wu Pui Hing Chau
Pui Hing Chau Thomas Wai Hung Chung3
Thomas Wai Hung Chung3 Daniel Yee Tak Fong
Daniel Yee Tak Fong- 1School of Nursing, The University of Hong Kong, Pokfulam, Hong Kong SAR, China
- 2Department of Electrical and Electronic Engineering, The University of Hong Kong, Pokfulam, Hong Kong SAR, China
- 3Family and Student Health Branch, Department of Health, Kwun Tong, Kowloon, Hong Kong SAR, China
Background: Early identification of high-risk individuals for weight problems in children and adolescents is crucial for implementing timely preventive measures. While machine learning (ML) techniques have shown promise in addressing this complex challenge with high-dimensional data, feature selection is vital for identifying the key predictors that can facilitate effective and targeted interventions. This study aims to utilize feature selection process to identify a robust and minimal set of predictors that can aid in the early prediction of short- and long-term weight problems in children and adolescents.
Methods: We utilized demographic, physical, and psychological wellbeing predictors to model weight status (normal, underweight, overweight, and obese) for 1-, 3-, and 5-year periods. To select the most influential features, we employed four feature selection methods: (1) Chi-Square test; (2) Information Gain; (3) Random Forest; (4) eXtreme Gradient Boosting (XGBoost) with six ML approaches. The stability of the feature selection methods was assessed by Jaccard's index, Spearman's rank correlation and Pearson's correlation. Model evaluation was performed by various accuracy metrics.
Results: With 3,862,820 million student-visits were included in this population-based study, the mean age of 11.6 (SD = 3.64) for the training set and 10.8 years (SD = 3.50) for the temporal test set. From the initial set of 38 predictors, we identified 6, 9, and 13 features for 1-, 3-, and 5-year predictions, respectively, by the best performed feature selection method of Chi-Square test in XGBoost models. These feature sets demonstrated excellent stability and achieved prediction accuracies of 0.82, 0.73, and 0.70; macro-AUCs of 0.94, 0.86, and 0.83; micro-AUCs of 0.96, 0.93, and 0.92 for different prediction windows, respectively. Weight, height, sex, total score of self-esteem, and age were consistently the most influential predictors across all prediction windows. Additionally, several psychological and social wellbeing predictors showed relatively high importance in long-term weight status prediction.
Conclusions: We demonstrate the potential of ML in identifying key predictors of weight status in children and adolescents. While traditional anthropometric measures remain important, psychological and social wellbeing factors also emerge as crucial predictors, potentially informing targeted interventions to address childhood and adolescence weight problems.
1 Introduction
The prevalence of weight problems, particularly among younger children, has been steadily increasing, raising significant concerns for public health (1). Overweight and obesity in children are strongly associated with major non-communicable diseases and can have detrimental effects on physical health (2). Additionally, children who are overweight or obese may face social challenges, including difficulties in making friends and being teasing by peers (3). Furthermore, these weight problems tend to persist into adulthood (4), thereby increasing the risk of long-term health complications. The prevalence of overweight and obesity has been on the rise in Hong Kong (5). Survey reported that about one in five primary students were overweight or obese for 2018/2019 school year, with a further surge to 24.1% reported during the COVID-19 pandemic in 2020 (6, 7). Being underweight is another weight problem that cannot be ignored, as it has been linked to psychiatric disorders, osteoporosis, scoliosis, and delayed pubertal development (8). In Hong Kong, the prevalence of underweight and severely underweight among primary 1 (P1, equivalent to United States Grade 1) students, was found to be 11.3 and 5.4% in boys, and 16.4 and 5.9% in girls, respectively, in 2006–2007 (9). The proportion of underweight children among all primary school students was reported to be 6.7% for boys and 11.9% for girls in 2014 (10). Given the urgent need to address weight problems in childhood and adolescence, early intervention is crucial (11). Consequently, accurate predictive models that can classify a child's future weight status would be valuable tools for early intervention.
The rapid advancements in data storage and capture capabilities have led to abundance of data in healthcare (12). Feature selection is a common approach to address the challenge of excessive data and unnecessary features (13, 14). By selecting the most relevant features, effective feature selection can reduce computing time (15), improve the overall performance of machine learning (ML) algorithms (16), and potentially insights into underlying biological processes (17). Previous studies among pediatric population have explored feature reduction in binary prediction of obesity and (or) overweight, primarily using features related to birth, infant, or parental measurements for early childhood or short-term predictions (18–23). One study has utilized laboratory measurements for long-term prediction (24). However, laboratory tests are less viable and cost-effective for the general population, limiting their clinical applicability. In addition, previous studies often reported the most important variables without thoroughly discussing predictive improvement and clinical application. Moreover, the use of single feature method in previous studies may overlook the importance of comparing different feature selection methods and evaluating the stability of the identified features. High stability is equally important as high prediction accuracy (25, 26).
To address the current gaps, we aimed to identify robust predictors for short- and long-term weight status in children and adolescents. We would use multiclass ML models to analyze various demographic, physical and psychological wellbeing features to determine which predictors contribute most significantly. By identifying the robust predictors, we can provide clinicians and health providers with a simplified and effective approach to predict future weight status in pediatric populations. This may ultimately improve clinical decision-making and inform interventions to prevent and treat childhood weight problems.
2 Materials and methods
2.1 Study design and setting
This was a population-based retrospective cohort study of students enrolled from P1 to secondary 6 (S6, equivalent to United States Grade 12) in Hong Kong during the academic cohorts of 1995/1996 to 2019/2020. Data were sourced from the Student Health Service (SHS) of the Department of Health, which has been providing annual voluntary health assessments to primary and secondary students across Hong Kong since the academic year of 1995/1996. To be included, students had to have participated in the SHS measurement for at least 2 years. We included all grades from 1995/1996 to 2014/2015 to allow for at least 1 year of follow-up, as the student lifestyle assessment questionnaire was updated in 2015/2016. More details about SHS health assessment program can be found elsewhere (27).
2.2 Data collection
We collected 38 predictors from the SHS data, including demographic information (age, sex), socioeconomic status indicators (housing type, home and school district, parental occupation and education levels), physical examination data (weight, height), and biennial records of physical and psychosocial measurements (details in Supplementary Table 1) (28–34).
2.3 Prediction outcome
Weight status was classified as underweight, normal weight, overweight, or obese based on the age- and sex-specific body mass index (BMI, expressed in kg/m2) reference standards developed by the International Obesity Task Force (IOTF). The IOTF provided a comprehensive set of BMI cut-off values for classifying weight status in children and adolescents aged 2–18 years, with cut-offs specified for each sex at 6-month age intervals (35, 36).
2.4 Data preparation
To prepare the data for analysis, we first removed responses from students with a lie self-esteem score ≤ 2, which was designed to assess reliability. We then ordered the categorical socioeconomic status variables based on Hong Kong median monthly domestic household income statistics and used one-hot encoding for the sex variable.
To ensure robustness of our analysis, the data sets for training and temporal test phases were partitioned according to students' enrollment academic years. Specifically, we used the academic cohorts of 1995/96 to 2009/10 for the training phase, and the academic cohorts of 2010/11 to 2014/15 for the temporal test phase. For each of these training and temporal test data sets, we examined the 1-, 3-, and 5-year prediction on children with the corresponding measurements available.
The missing data in our study was primarily due to the biennial nature of the physical and psychological measurements collected through the SHS questionnaires. To ensure complete data for ML analysis, we applied the k-Nearest Neighbor (k-NN) imputation method to fill the gaps in the missing years. The k-NN imputation approach uses the information from the nearest data points to estimate the missing values, effectively handling both continuous and categorical variables (37). We initially selected only the visit records without missing questionnaire data to perform the feature selection process. We then compared the results with those from data imputed using the k-NN method with different k-values (k =3 and 5). The feature rankings remained largely unchanged. Thus, we have taken k = 3 with lower computing intensity. The detailed results are presented in Supplementary Table 2. The imputation was implemented using the “KNNImputer” module from the scikit-learn library in Python.
All the data were standardized to a 0–1 scale to facilitate comparisons and eliminate scale-related biases.
2.5 Feature selection
2.5.1 Feature selection methods
To identify the most relevant features for predicting short- and long-term weight status, we attempted several feature selection methods. Feature selection methods can be broadly categorized into: Filter, Wrapper, and Embedded. Filter methods evaluate the relevance of features based on their statistical properties. They can be filter-univariate and filter-multivariate, with the latter being more computationally intensive and not as scalable as filter-univariate (38). Wrapper methods evaluate different feature subsets and select the one that performs best. Thus, they are also computationally expensive and time-consuming (14). Embedded methods integrate the feature selection process during the model development, allowing the model to select the most relevant features (39). Therefore, to allow efficient feature selection, we opted for filter-univariate and embedded methods.
Among the filter-univariate methods, we adopted the Chi-Square test and Information Gain (40, 41). The Chi-Square test evaluates the relationship between a feature and the target variable while Information Gain measures the reduction in entropy (or uncertainty) about the target variable achieved by knowing the value of a feature (39, 40). These approaches can effectively capture both linear and non-linear relationships between features and the target variable and are less sensitive to outliers (41). For the embedded feature selection techniques, we employed the Random Forest (RF) and eXtreme Gradient Boosting (XGBoost) (38). These are tree-based algorithms that provide built-in measures of feature importance, which are calculated based on the decrease in impurity (Gini importance) for RF (42), and the gain in predictive performance for XGBoost (43), when a feature is used for tree splitting. The inclusion of these embedded methods allowed us to leverage the model-specific knowledge to further refine the feature subset.
2.5.2 Feature selection analysis
Due to the high computational intensity of model using the entire sets, we randomly selected 10% of the subjects from the training subsets 10 times, without replacement, creating 10 sub-training samples for each of the 1-, 3-, and 5-year prediction periods.
For each sub-training sample, we applied the four feature selection methods to obtain four lists of features, from 1 to 38. To assess the stability of each feature list, we calculated three stability indices: (1) Jaccard's index, which measured stability by subset and was calculated by the amount of overlap between the overall subset of selected features; (2) Spearman's rank correlation coefficient, which measured stability by features' importance rank; and (3) Pearson's correlation coefficient, which measured stability by features' importance value (provided as “weight”) (14). We then obtained the average stability indices across the 10 sub-training samples for each fixed number of features.
The Synthetic Minority Oversampling Technique (SMOTE) was employed to handle imbalanced data structure to the training set within each cross-validation fold before model development (44). SMOTE generates synthetic examples of the minority classes by interpolating between existing minority class samples. This helps to balance the class distributions and improve the model's ability to learn from the minority classes (45). SMOTE was implemented using the default parameters in the “imbalanced-learn” and scikit-learn libraries in Python.
We attempted several multiclass ML prediction approaches for each of the random sub-training sample to predict weight status at 1, 3, and 5 years. The ML models included decision tree (DT) (46), RF (43), Support Vector Machine (SVM) (47), k-NN (48), XGBoost (49), and logistic regression (LR). To optimize the performance of these models, we conducted a grid search-based hyperparameter tuning procedure within a 10-fold cross-validation framework. The averaged correct classification rate, accuracy, macro- Area Under the Receiver Operating Characteristic Curve (macro-AUC), and micro-AUC were used to compare the performance of the tuned models for each prediction period. Macro-AUC, which calculates the AUC for each class individual and gives the equal importance. Micro-AUC combines the true positives, false positives, true negatives, and false negatives across all classes to calculate a single AUC value, which more influenced by the performance on the majority class.
During the temporal test phase, we evaluated the predictive performance of the top-performing ML models using the 10 feature sets identified during the preceding training phase, for each fixed number of features. The best performing hyperparameter values were determined through 10-fold cross-validation. The specific hyperparameters tuned for each ML model are detailed in Supplementary Table 3. We calculated the overall performance metrics by averaging the accuracy, macro-AUC, and micro-AUC across the folds. Additionally, we averaged the precision, recall, and F1-score for the abnormal weight status predictions, as these metrics provide complementary insights into the model's performance. The precision and recall are conceptually equivalent to the sensitivity and positive predictive value, and the F1 score is the harmonic mean of precision and recall. The optimal number of features for each ML approach were determined by a sequential process: (1) Identify the minimal number of features such that adding more features would not substantially improve the averaged value of accuracy, micro-AUC, and macro-AUC (defined as a change < 0.05); and (2) Increase the number of features, if needed, until additional features would not substantially increase the three stability indices.
All above feature selection methods and ML models were performed using the scikit-learn and “xgboost” libraries in Python software (version 3.10).
3 Results
3.1 Participants characteristics
During the study period, 3,862,820 student-visits were included for weight status prediction and feature selection. Their disposition and details of the study design are displayed in Figure 1. Of these, 3,727,390 student-visits were assigned to the training set, with a mean age of 11.6 years (Standard Deviation, SD = 3.64), and 135,430 student-visits were assigned to the temporal test set, with a mean age of 10.8 years (SD = 3.50). In the training set, 1,953,152 (52.4%) were male, while in the temporal test set, 65,684 (48.5%) were male. The prevalence of underweight, overweight, and obese in the training set was 18.5, 11.7, and 2.9%, respectively. In the temporal test set, the prevalence was 13.7, 11.7, and 2.0%, respectively. We identified 3,093,734 (83.0%), 1,155,491 (31.0%), and 782,752 (21.0%) student visit-pairs in the training set for 1-, 3-, and 5-year predictions, and 122,228 (90.3%), 56,970 (42.1%), and 10,699 (7.9%) student visit-pairs, respectively, in temporal test set. Table 1 presents the characteristics of all cohorts and displays the baseline characteristics of the training and temporal test sets. Supplementary Table 4 shows the baseline socioeconomic characteristics of training and temporal test sets.
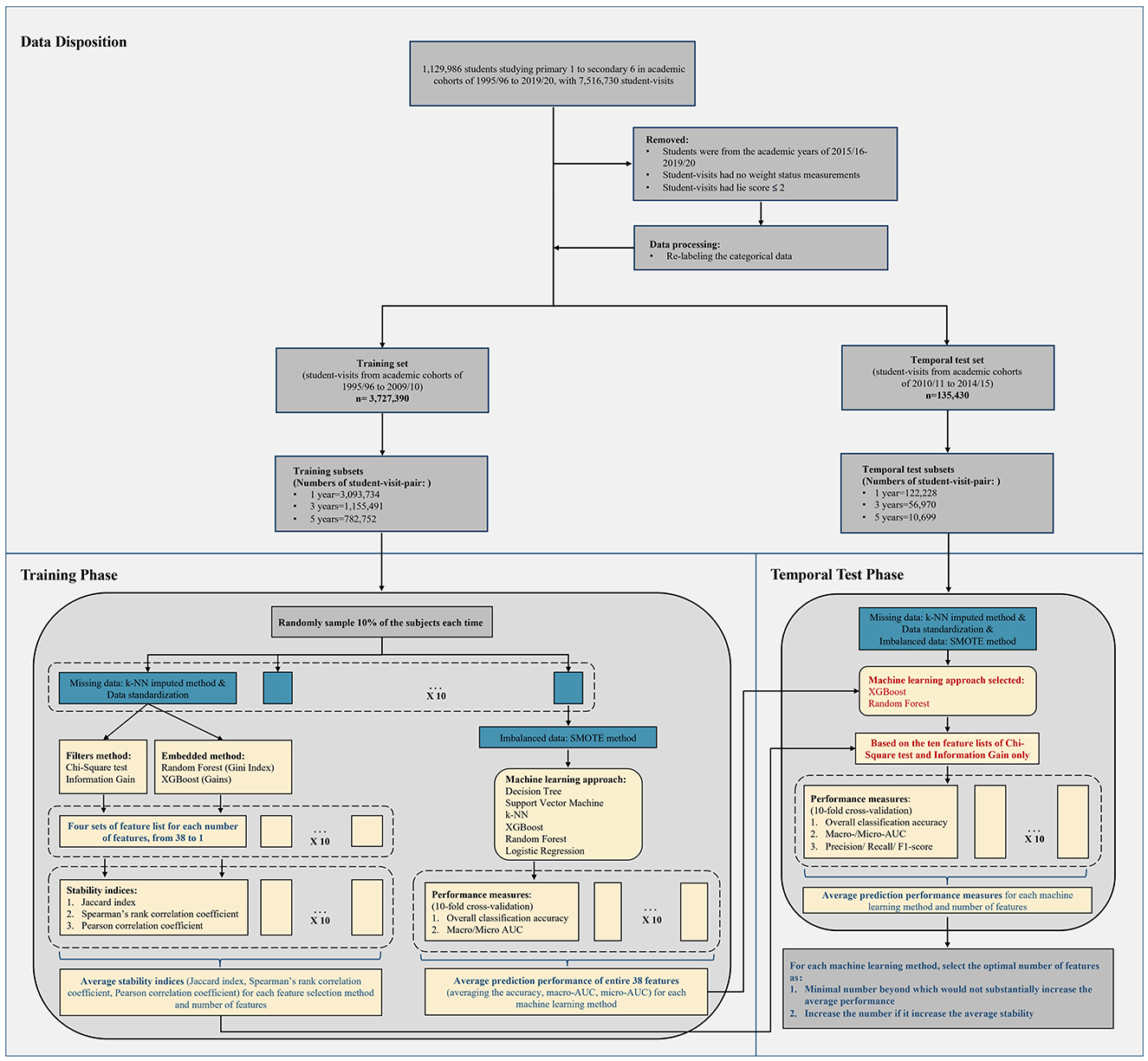
Figure 1. Flow chart of the study design.

Table 1. Characteristics of baseline training and temporal test sets.
3.2 Features selected for prediction
Figure 2 presents the averaged stability indices of the features selected using the Chi-Square test, Information Gain, RF, and XGBoost feature selection methods. The Pearson's correlation coefficient, which measured the stability of weight, consistently showed high values approaching 1 across all methods, and was not presented in the plots. All feature selection methods exhibited a nearly “U-shape” stability of rank as the feature size increased, indicating that the top and tail features were more robust. The Chi-Square test had less stable training results for the 3-year prediction. Overall, the Chi-Square test and Information Gain produced more stable feature subsets and ranks for all 1-, 3-, and 5-year weight status prediction. The features lists obtained from the Chi-Square Test and Information Gain were more stable than those from the RF and XGBoost, and thus only considered them in the temporal test phase.
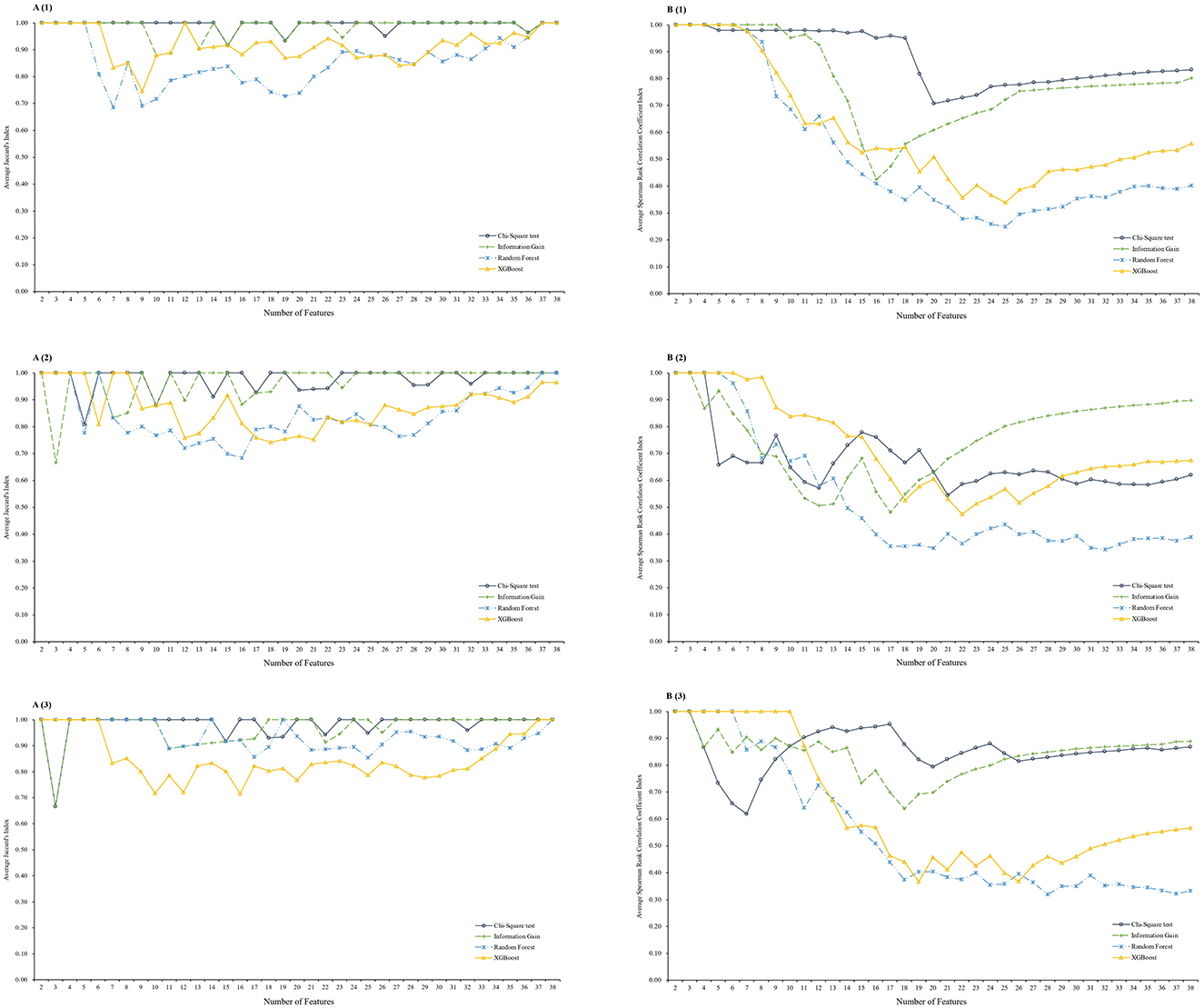
Figure 2. Average stability indices for different prediction windows. (A) Average Jaccard's Index for stability by subset, (B) Average Spearman's rank correlation coefficient Index for stability by rank; (1) on 1 year prediction window, (2) on 3-year prediction window, and (3) on 5-year prediction window; XGBoost, eXtreme Gradient Boosting feature selection method.
Figure 3 shows the averaged accuracy, macro- and micro-AUC of each prediction ML model and the conventional statistic method by LR. For the 1-year prediction, XGBoost achieved an overall accuracy of 0.84, a macro-AUC of 0.96, and a micro-AUC of 0.97. The 3-year prediction results showed XGBoost's accuracy at 0.77, macro-AUC at 0.89, and micro-AUC at 0.94. The 5-year prediction performance of XGBoost was consistently excellent, with an accuracy of 0.75, macro-AUC of 0.86, and micro-AUC of 0.93. RF attained accurate prediction, with 1-year accuracies of 0.83, macro-AUC of 0.95, and micro-AUC of 0.96. For the 3- and 5-year predictions, RF achieved accuracies of 0.76 and 0.74, macro-AUCs of 0.86 and 0.82, and micro-AUCs of 0.93 and 0.92, respectively. In contrast, the performance of LR was relatively lower, with 1-year accuracies of 0.73, macro-AUC of 0.87, and micro-AUC of 0.88. The 3- and 5-year predictions by LR had accuracies of 0.62 and 0.57, macro-AUCs of 0.84 and 0.81, and micro-AUCs of 0.83 and 0.81, respectively.

Figure 3. Prediction performance of different machine learning methods using 38 features. XGBoost, eXtreme Gradient Boosting, k-NN, k-Nearest Neighbors; AUC, Area Under the Receiver Operating Characteristic Curve. (A) 1-year prediction. (B) 3-year prediction. (C) 5-year prediction.
Figure 4 displays the XGBoost and RF models' performance at varying numbers of features. Feature lists obtained by Chi-Square test help the models consistently outperformed for all prediction windows. Based on the feature number determination strategies, we selected several minimized feature subsets for further comparison. For 1-year weight status prediction, we selected 6 features with good model performance and stability indices. For 3-year weight status prediction, we initially selected 7 features and then extended it to 9. For 5-year prediction, we initially selected 6 features and then extended it to 13. The Jaccard's index was nearly equal to 1 for the selected subsets, so Spearman's Rank Correlation Coefficient and test accuracy were considered.
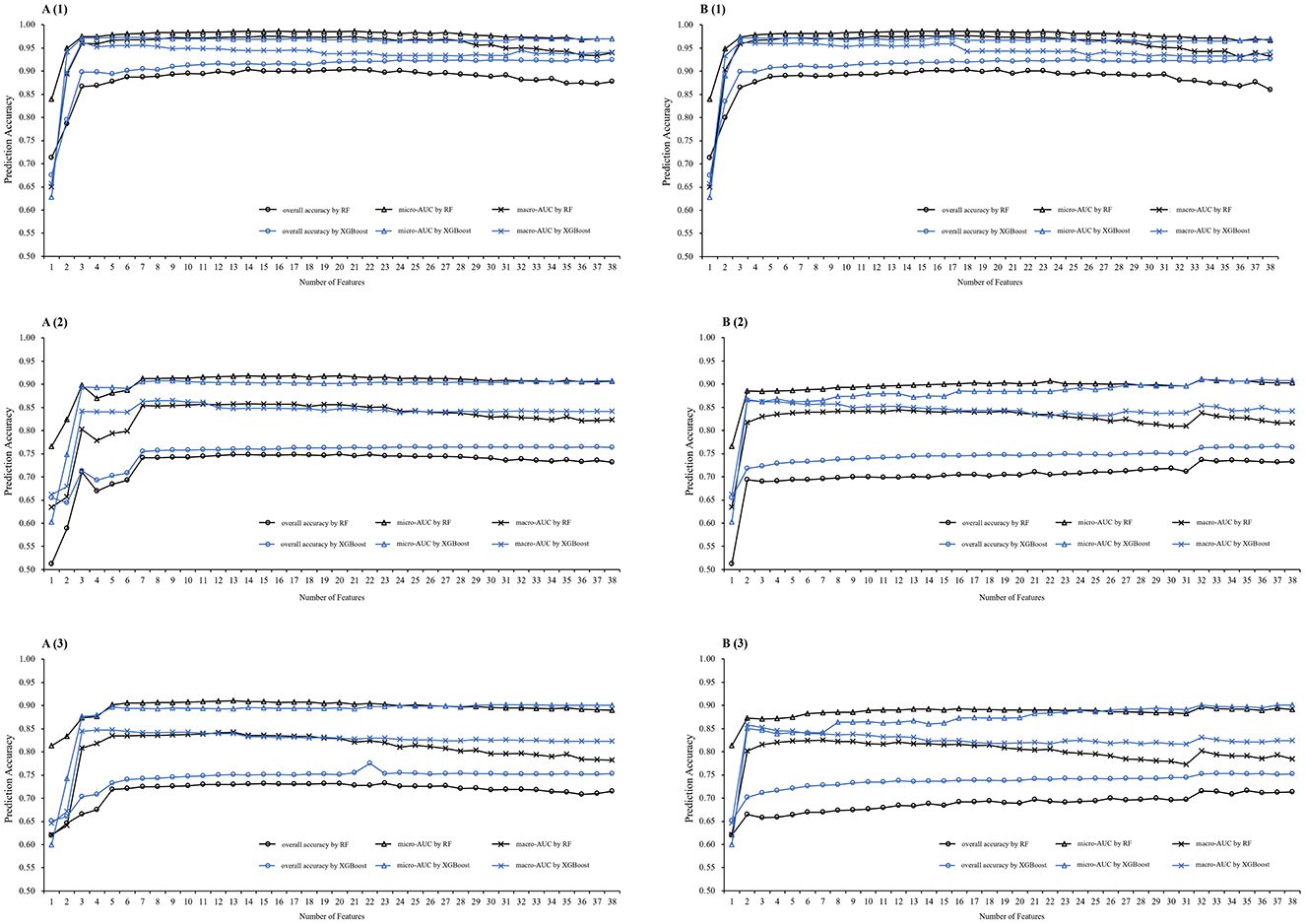
Figure 4. Model prediction performance at varying number of features. Model performance comparisons were conducted in the temporal test phase on different prediction windows. (A) By Chi-Square test feature selection method, (B) by Information Gain feature selection method; (1) on 1 year prediction window, (2) on 3-year prediction window, (3) on 5-year prediction window; RF, Random Forest model, XGBoost, eXtreme Gradient Boosting model; AUC, Area Under the Receiver Operating Characteristic Curve.
Figure 5 shows the feature selection stability and their ML accuracy of the selected data subsets. We finally selected 6, 9, and 13 features for 1-, 3-, and 5-year weight status prediction, respectively. These final selected features enabled the classifiers of XGBoost and RF to achieve their best performance, and detailed prediction performance is presented in Table 2. Overall, XGBoost provided the higher accurate prediction with the same number of features for short- and long-term weight status and yielded the best estimates for the four weight status categories across different prediction windows. The accuracies of XGBoost were 0.82, 0.73, and 0.70; the macro-AUCs were 0.94, 0.86, and 0.83; and the macro-AUCs were 0.96, 0.93, and 0.82 for 1-, 3-, and 5-year predictions, respectively. Table 3 summarizes the most frequent features selected across all prediction windows. The final selected feature lists were consistent in each of the ten repeated training sessions. Interestingly, the 13 features selected for 5-year prediction included almost all the same features as for 1- and 3-year weight status prediction. Weight, sex, height, total score of SEI, and age were the commonly key predictors.
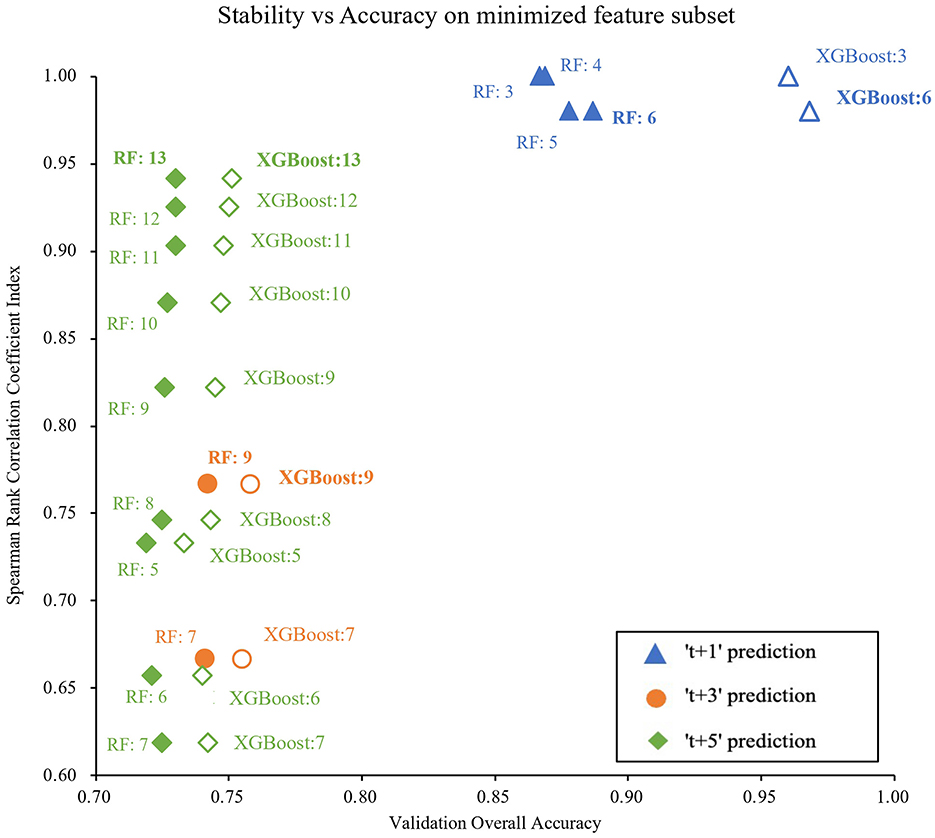
Figure 5. Plot of stability against overall accuracy when the Chi-Square test is used for feature selection. In the plot, each point shows with its applied model and the numbers of feature. RF, Random Forest model, XGBoost, eXtreme Gradient Boosting model.

Table 2. Performance evaluations for machine learning models based on 10-fold cross-validation.
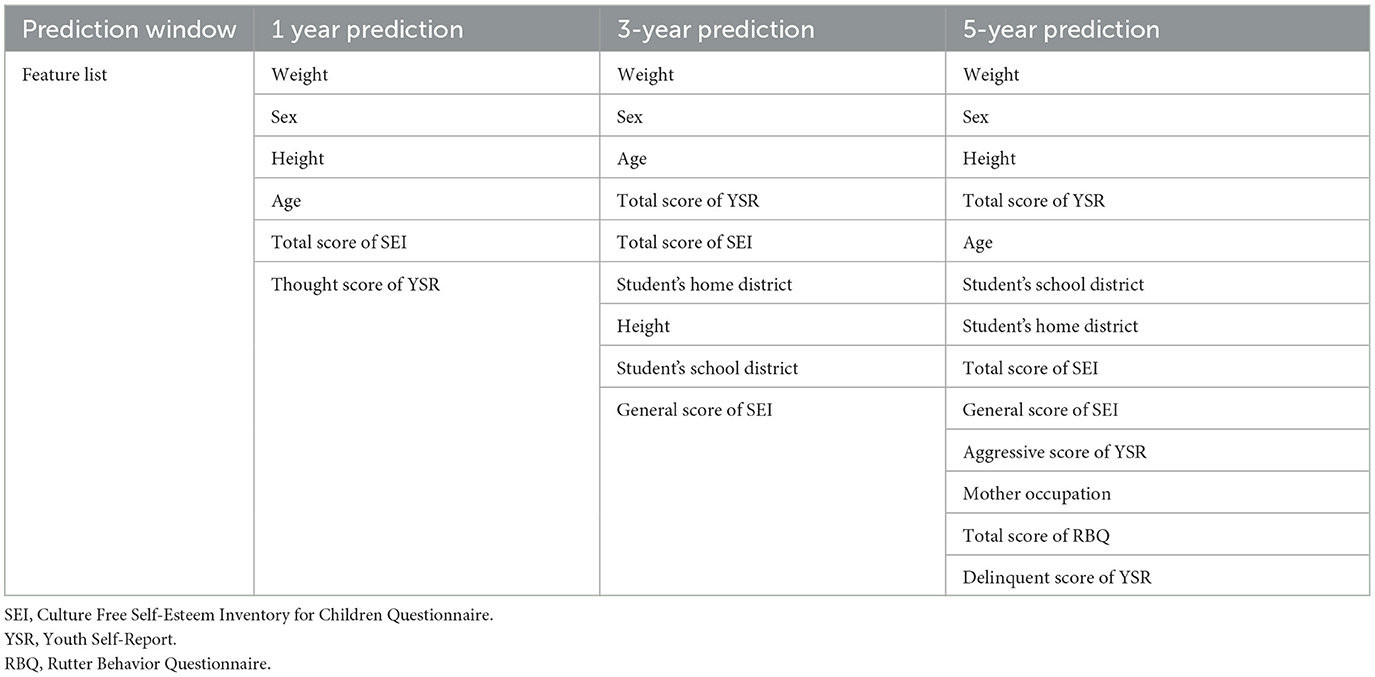
Table 3. Most frequently selected features ranking for each prediction window among the 10 times samples.
4 Discussion
Our study, which utilized a large population-based cohort of children and adolescents, is unique in its thorough feature selection process to identify robust sets of predictors for short- and long-term weight status prediction. The selected easily accessible features not only offer valuable insights into the influential factors of weight problems in children and adolescents but also provide a useful tool for self-screening assessment. By identifying a small set of readily available predictors, healthcare providers, schools, and families can implement effective and targeted interventions to promote healthier behaviors and mitigate the development of long-term weight problems.
4.1 Key predictors identification
We selected 6, 9, and 13 out of 38 features for 1-, 3-, and 5-year weight status prediction, respectively, indicating a substantial decrease in the computational burden for further analysis. The top five features: weight, height, sex, total score of SEI, and age, were consistently ranked highly across repeated feature selections and different prediction time intervals. This consistency suggests that these variables are crucial predictors of weight problems. However, the accuracy of multiclass models decreased significantly when only the top four predictors were used, indicating the need for additional predictors from different aspects to enhance early weight problem prediction.
The results highlight the importance of psychological and emotion behavior factors in weight status prediction. The total score of SEI, reflecting a child's self-esteem, consistently demonstrated a high influence on weight status prediction. Previous epidemiological research has established an association between low self-esteem and weight problems (50–52). Moreover, longitudinal studies have also found that low baseline self-esteem and decreases in global self-esteem levels significantly predicted increased BMI over time in school children (52). Low self-esteem may be a significant predisposing factor, as individuals with low self-esteem may be more prone to engage in unhealthy behaviors such as overeating and avoiding physical activities (50). These findings underscore the need for early intervention in children and adolescents with low self-esteem to prevent or manage weight problems.
Our study identified several unconventional features contributed to short-term prediction accuracy. One of these, the “thought score of YSR,” which reflects thought problems such as disorganized ideas, delusions, and hallucinations, has been found to be associated with increased sleep problems, which, in turn, can lead to uncontrolled weight gain (53). Indeed, clinical evidence has shown that insufficient sleep or sleep difficulties are linked to higher levels of the hormone ghrelin, which increases appetite, and lower levels of hormone leptin, leading to decreased feelings of fullness, resulting in weight gain (54). In addition, the general score of SEI, total score of RBQ, and total score of YSR, especially “aggressive behavior” and “delinquent behavior” of YSR showed increased accuracy in predicting weight status over a 5-year period. Adolescents with emotional and behavioral problems are more susceptible to losing behavioral control, disordered eating, and sedentary behaviors, leading to poor weight management (55). A population-based study has revealed significant relationships between adolescent aggressive and delinquent behavior problems with low self-esteem, parental and peer rejection, and low emotion warmth (56). It is important to note that new adjustments always happen as students grow older, such as the transition from primary to secondary school, which may cause new anxiety and emotional problems (57). These changes can affect weight status in children and adolescents. Our findings suggest the importance of considering psychological and emotional factors in weight status prediction and prevention.
Our feature selection analysis revealed the significant impact of socioeconomics factors, such as the location of students' residence and school, as well as the occupation of their mothers, on predicting long-term weight status. The geographical area where children live can greatly influenced their outdoor activities and the amount of time they spend on physical exercise. Moreover, environmental pollution has been linked to childhood weight problems. A systematic review has reported compelling evidence linking air pollution to a substantially increased risk of childhood obesity (58). Additionally, the role of mothers in Chinese family structure and parenting can impact the amount of time and attention devoted to a child's growth and development (59). These socio-economic factors have the potential to inspire new public health concerns and contribute to the prediction of long-term weight status.
4.2 Method selection and feature stability
Accurate and stable feature selection is crucial for obtaining a fixed set of common features while avoiding overfitting and ensuring a well predictive model. Previous studies have employed various feature selection techniques, but often without a comprehensive assessment of the stability and robustness of the selected features. One study conducted in Malaysia compared several methods to find the minimum number of features for predicting childhood obesity at 12 years old but did not validate the prediction results (21). Rehkopf et al. used a single method to get the relative importance of predictors for girls aged 9 or 10 years in BMI percentile changes (22). Gupta et al. also adopted a single feature selection approach to identify the top 20 important features without evaluating the stability of the feature set (24).
We opted for filter-univariate and embedded feature selection techniques, as they offer an effective and efficient feature selection process. The filter-univariate techniques, Chi-Square test and Information Gain, are more robust to outliers and can better handle mixed data types (categorical and numerical), compared to methods like ANOVA that rely on stricter data distribution assumptions. Furthermore, filter-univariate techniques are better able to capture non-linear relationships between features and the target variable, which is an important consideration in complex real-world datasets, compared to simpler techniques like Pearson correlation. While Wrapper feature selection methods fully consider feature dependencies, they are computationally expensive and time-consuming, as they require iteratively testing new feature subsets.
In the current study, we also conducted a comprehensive evaluation of the stability of our feature selection process, as this is often overlooked in previous studies. We assessed the robustness of the selected feature subsets using Jaccard's index, which measures the similarity of feature subsets across different iterations. Additionally, we examined the stability of the feature importance rankings and values using Spearman's rank correlation and Pearson's correlation, respectively. High values across these stability indices increase confidence in the identified predictors and ensure the generalizability of the developed predictive models (25).
In our study, XGBoost and RF models, utilizing a total of 38 features, outperformed the other ML approaches and LR in accurately predicting short- and long-term weight status. Moreover, XGBoost models using a stable and reduced set of features identified by the Chi-Square test demonstrated the better prediction performance in the multiclass models. Our large population-based study enabled us to make multiclass predictions for different years, by having an adequate number of children and adolescents in each weight status category. To the best of our knowledge, no other prediction models have been developed for temporal prediction of multiclass weight status in children and adolescents.
4.3 Limitations
This study has several limitations. First, the features collected from the SHS dataset did not capture all potentially relevant predictors of weight status in children and adolescents, such as family history of obesity, parental smoking, and lifestyle habits. Future research may incorporate these additional variables to enhance the predictive accuracy of weight status. Second, we had not tested our model's predictive performance in an external dataset. Evaluating the performance of the models on an independent dataset would be highly desirable to further assess the reliability and generalizability of the findings. Third, this study was conducted exclusively within the specific geographical context of Hong Kong, which has a relatively homogeneous Chinese population, accounting for over 91% of the sample. As such, the results may not fully represent the diverse populations and cultural contexts found in other regions. Additional research is needed to examine the transferability of the predictive models to more heterogeneous settings and populations with different cultural background.
5 Conclusions
We applied multiple feature selection frameworks to identify robust and minimal sets of features for predicting weight status in Hong Kong children and adolescents. The Chi-Square test method, combined with the XGBoost algorithm, provided the most robust and accurate results, with 6, 9, 13 features identified for 1-, 3-, and 5-year predictions, respectively. Weight, sex, height, total score of SEI, and age consistently emerged as key predictors across all short- and long-term predictions. Our study provides a comprehensive and robust list of predictors for weight status in children and adolescents in Hong Kong. This prediction model can be utilized by children, parents, and healthcare providers for early detection of weight problems, enabling timely intervention and prevention efforts.
Data availability statement
The datasets presented in this article are not readily available. The data supporting the conclusions of this study are available from the Student Health Services, Department of Health, Hong Kong SAR, but restrictions apply to the availability of these data, which were used under agreement for the current study, and so are not publicly available. Data are however available from the authors upon reasonable request and with permission of the Student Health Service, Department of Health, Hong Kong SAR. Requests to access the datasets should be directed to Thomas Wai Hung Chung, dHdoY2h1bmdAZGguZ292Lmhr.
Ethics statement
The studies involving humans were approved by the Institutional Review Board of the University of Hong Kong/Hospital Authority Hong Kong West Cluster (Reference number: UW19-796) and the Department of Health Ethics Committees (Reference number: L/M 44/2021). The studies were conducted in accordance with the local legislation and institutional requirements. All the participants' legal guardians/next of kin gave written informed consent each year to enroll in the annual SHS health assessments, including use of the participants' data for research.
Author contributions
HL: Conceptualization, Data curation, Formal analysis, Methodology, Software, Validation, Visualization, Writing – original draft, Writing – review & editing. YL: Formal analysis, Software, Writing – review & editing. Y-CW: Writing – review & editing. PHC: Writing – review & editing. TWHC: Data curation, Project administration, Resources, Writing – review & editing. DYTF: Funding acquisition, Methodology, Resources, Supervision, Writing – review & editing.
Funding
The author(s) declare that no financial support was received for the research, authorship, and/or publication of this article.
Acknowledgments
We thank all colleagues and staff at the Student Health Service of the Department of Health for their assistance and collaboration.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2024.1414046/full#supplementary-material
References
1. Sahoo K, Sahoo B, Choudhury AK, Sofi NY, Kumar R, Bhadoria AS. Childhood obesity: causes and consequences. J Fam Med Prim Care. (2015) 4:187–92. doi: 10.4103/2249-4863.154628
2. Tabarés Seisdedos R. Health effects of overweight and obesity in 195 countries over 25 years. N Engl J Med. (2017) 377:13–27. doi: 10.1056/NEJMoa1614362
3. Gunnarsdottir T, Njardvik U, Olafsdottir AS, Craighead LW, Bjarnason R. Teasing and social rejection among obese children enrolling in family-based behavioural treatment: effects on psychological adjustment and academic competencies. Int J Obes. (2012) 36:35–44. doi: 10.1038/ijo.2011.181
4. Simmonds M, Llewellyn A, Owen CG, Woolacott N. Predicting adult obesity from childhood obesity: a systematic review and meta-analysis. Obes Rev. (2016) 17:95–107. doi: 10.1111/obr.12334
5. Gong WJ, Fong DY, Wang MP, Lam TH, Chung TW, Ho SY. Increasing socioeconomic disparities in sedentary behaviors in Chinese children. BMC Publ Health. (2019) 19:1–0. doi: 10.1186/s12889-019-7092-7
6. Department of Health. Obesity Among Hong Kong Children Increased During Coronavirus Pandemic Due to Unhealthy Lifestyle, Survey Shows. (2022). Available at: https://www.scmp.com/news/hongkong/health-environment/article/3182782/obesity-among-hong-kong-children-increased-during (accessed June 23, 2022).
7. Leisure and Culture Services Department. Healthy Exercise for All Campaign Leisure and Culture Services Department Fitness Programmes for Children. (2023). Available at: https://www.lcsdgovhk/en/healthy/fitness/overhtml (accessed January 23, 2023).
8. Mak KK, Tan SH. Underweight problems in Asian children and adolescents. Eur J Pediatr. (2012) 171:779–85. doi: 10.1007/s00431-012-1685-9
9. Knowles G, Ling FC, Thomas GN, Adab P, McManus AM. Body size dissatisfaction among young Chinese children in Hong Kong: a cross-sectional study. Public Health Nutr. (2015) 18:1067–74. doi: 10.1017/S1368980014000810
10. Benjamin Neelon SE, Østbye T, Hales D, Vaughn A, Ward DS. Preventing childhood obesity in early care and education settings: lessons from two intervention studies. Child Care Health Dev. (2016) 42:351–8. doi: 10.1111/cch.12329
11. Hashem IA, Yaqoob I, Anuar NB, Mokhtar S, Gani A, Khan SU. The rise of “big data” on cloud computing: Review and open research issues. Inf Syst. (2015) 47:98–115. doi: 10.1016/j.is.2014.07.006
12. Jain D, Singh V. Feature selection and classification systems for chronic disease prediction: a review. Egyptian Informatics Journal. (2018) 19:179–89. doi: 10.1016/j.eij.2018.03.002
13. Huang C. Feature selection and feature stability measurement method for high-dimensional small sample data based on big data technology. Comput Intell Neurosci. (2021) 2021:3597051. doi: 10.1155/2021/3597051
14. Chandrashekar G, Sahin F. A survey on feature selection methods. Comput Electr Eng. (2014) 40:16–28. doi: 10.1016/j.compeleceng.2013.11.024
15. Cueto-López N, García-Ordás MT, Dávila-Batista V, Moreno V, Aragonés N, Alaiz-Rodríguez R, et al. comparative study on feature selection for a risk prediction model for colorectal cancer. Comput Methods Programs Biomed. (2019) 177:219–29. doi: 10.1016/j.cmpb.2019.06.001
16. Zhang S, Tjortjis C, Zeng X, Qiao H, Buchan I, Keane J. Comparing data mining methods with logistic regression in childhood obesity prediction. Inform. Syst. Front. (2009) 11:449–60. doi: 10.1007/s10796-009-9157-0
17. Hammond R, Athanasiadou R, Curado S, Aphinyanaphongs Y, Abrams C, Messito MJ, et al. Predicting childhood obesity using electronic health records and publicly available data. PLoS ONE. (2019) 14:e0215571. doi: 10.1371/journal.pone.0215571
18. Lee I, Bang KS, Moon H, Kim J. Risk factors for obesity among children aged 24 to 80 months in Korea: a decision tree analysis. J Pediatr Nurs. (2019) 46:e15–23. doi: 10.1016/j.pedn.2019.02.004
19. Pang X, Forrest CB, Lê-Scherban F, Masino AJ. “Understanding early childhood obesity via interpretation of machine learning model predictions,” in 2019 18th IEEE International Conference On Machine Learning And Applications (ICMLA). Boca Raton, FL: IEEE (2019). p. 1438–43.
20. Dugan TM, Mukhopadhyay S, Carroll A, Downs S. Machine learning techniques for prediction of early childhood obesity. Appl Clin Inform. (2015) 6:506–20. doi: 10.4338/ACI-2015-03-RA-0036
21. Abdullah FS, Manan NS, Ahmad A, Wafa SW, Shahril MR, Zulaily N, et al. “Data mining techniques for classification of childhood obesity among year 6 school children,” in Recent Advances on Soft Computing and Data Mining: The Second International Conference on Soft Computing and Data Mining (SCDM-2016), Bandung, Indonesia, August 18-20, 2016 Proceedings Second 2017 (Cham: Springer International Publishing), 465–474.
22. Rehkopf DH, Laraia BA, Segal M, Braithwaite D, Epel L. The relative importance of predictors of body mass index change, overweight and obesity in adolescent girls. Int J Pediatr Obes. (2011) 6:e233–242. doi: 10.3109/17477166.2010.545410
23. Colmenarejo G. Machine learning models to predict childhood and adolescent obesity: a review. Nutrients. (2020) 12:2466. doi: 10.3390/nu12082466
24. Gupta M, Phan TL, Bunnell HT, Beheshti R. Obesity Prediction with EHR data: a deep learning approach with interpretable elements. ACM Trans Comput Healthc. (2022) 3:1–9. doi: 10.1145/3506719
25. Khaire UM, Dhanalakshmi R. Stability of feature selection algorithm: a review. J King Saud Univ Comput Inform Sci. (2022) 34:1060–73. doi: 10.1016/j.jksuci.2019.06.012
26. Raudys S. “Feature over-selection,” in Structural, Syntactic, and Statistical Pattern Recognition: Joint IAPR International Workshops, SSPR 2006 and SPR 2006, Hong Kong, China, August 17-19, 2006. Proceedings 2006 (Berlin; Heidelberg: Springer). p. 622–31.
27. Student Health Service. Enrolment Forms and Related Information. Department of Health, The Government of Hong Kong SAR, China (2022). Available at: https://www.studenthealth.gov.hk/english/resources/resources_forms/resources_forms.html (accessed June 29, 2022).
29. Chan YH. The Normative Data and Factor Structure of the Culture-Free Self-Esteem Inventory-Form a-in Hong Kong Adolescents. HKU Theses Online (HKUTO). University of Hong Kong, Pokfulam, Hong Kong SAR (2002). doi: 10.5353/th_b2974025
30. Ivanova MY, Achenbach TM, Rescorla LA, Dumenci L, Almqvist F, Bilenberg N, et al. The generalizability of the Youth Self-Report syndrome structure in 23 societies. J Consult Clin Psychol. (2007) 75:729. doi: 10.1037/0022-006X.75.5.729
31. Leung PW, Kwong SL, Tang CP, Ho TP, Hung SF, Lee CC, et al. Test-retest reliability and criterion validity of the Chinese version of CBCL, TRF, and YSR. J Child Psychol Psychiat. (2006) 47:970–3. doi: 10.1111/j.1469-7610.2005.01570.x
32. Leung PW TP H, Hung SF, Lee CC, Tang CP. CBCL/6-18 Profiles for Hong Kong Boys/Girls. Sha Tin: Chinese University of Hong Kong, Department of Psychology (1998).
33. Rutter M. A children's behaviour questionnaire for completion by teachers: preliminary findings. Child Psychol Psychiat Allied Discipl. (1967). doi: 10.1111/j.1469-7610.1967.tb02175.x
34. Liu H, Wu YC, Chau PH, Chung TW, Fong DY. Prediction of adolescent weight status by machine learning: a population-based study. BMC Publ Health. (2024) 24:1351. doi: 10.1186/s12889-024-18830-1
35. Cole TJ, Bellizzi MC, Flegal KM, Dietz WH. Establishing a standard definition for child overweight and obesity worldwide: international survey. Br Med J. (2000) 320:1240. doi: 10.1136/bmj.320.7244.1240
36. Cole TJ, Flegal KM, Nicholls D, Jackson AA. Body mass index cut offs to define thinness in children and adolescents: international survey. Br Med J. (2007) 335:194. doi: 10.1136/bmj.39238.399444.55
37. Beretta L, Santaniello A. Nearest neighbor imputation algorithms: a critical evaluation. BMC Med Inform Decis Mak. (2016) 16:197–208. doi: 10.1186/s12911-016-0318-z
38. Hira ZM, Gillies DF. A review of feature selection and feature extraction methods applied on microarray data. Adv Bioinform. (2015) 2015:198363. doi: 10.1155/2015/198363
39. Tang J, Alelyani S, Liu H. Feature Selection for Classification: A Review. Data Classification: Algorithms and Applications. (2014). p. 37.
40. Saeys Y II, Larrañaga P. A review of feature selection techniques in bioinformatics. Bioinformatics. (2007) 19:2507–17. doi: 10.1093/bioinformatics/btm344
41. Noshad M, Choi J, Sun Y, Hero III A, Dinov ID. A data value metric for quantifying information content and utility. J Big Data. (2021) 8:82. doi: 10.1186/s40537-021-00446-6
42. Nembrini S, König IR, Wright MN. The revival of the Gini importance? Bioinformatics. (2018) 34:3711–8. doi: 10.1093/bioinformatics/bty373
44. Chawla NV, Bowyer KW, Hall LO, Kegelmeyer WP. SMOTE synthetic minority over-sampling technique. J Artif Intell Res. (2002) 16:321–57. doi: 10.1613/jair.953
45. Elreedy D, Atiya AF, Kamalov F. A theoretical distribution analysis of synthetic minority oversampling technique (SMOTE) for imbalanced learning. Mach Learn. (2024) 113:4903–23. doi: 10.1007/s10994-022-06296-4
47. Cristianini N, Shawe-Taylor J. An Introduction to Support Vector Machines and Other Kernel-Based Learning Methods. Cambridge: Cambridge University Press (2000).
48. Altman NS. An introduction to kernel and nearest-neighbor nonparametric regression. Am Stat. (1992) 46:175–85. doi: 10.1080/00031305.1992.10475879
49. Chen TQ, Guestrin C. “XGBoost,” in Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. New York, NY: ACM Press (2016). p. 785–94.
50. Byth S, Frijters P, Beatton T. The relationship between obesity and self-esteem: longitudinal evidence from Australian adults. Oxf Open Econ. (2022) 1:odac009. doi: 10.1093/ooec/odac009
51. Heatherton TF, Baumeister RF. Binge eating as escape from self-awareness. Psychol Bull. (1991) 110:86. doi: 10.1037//0033-2909.110.1.86
52. Aggarwal H. Self-Esteem and Obesity: A Longitudinal Analysis Among Children and Adolescents in Niagara, Canada. Brock University. Available at: http://hdl.handle.net/10464/14109
53. Thompson EC, Fox KA, Lapomardo A, Hunt JI, Wolff JC. Youth self-report thought problems and sleep difficulties are linked to suicidal ideation among psychiatrically hospitalized adolescents. J Child Adolesc Psychopharmacol. (2020) 30:522–5. doi: 10.1089/cap.2019.0160
54. Tasali E, Wroblewski K, Kahn E, Kilkus J, Schoeller DA. Effect of sleep extension on objectively assessed energy intake among adults with overweight in real-life settings: a randomized clinical trial. J Am Med Assoc Intern Med. (2022) 182:365–74. doi: 10.1001/jamainternmed.2021.8098
55. Ternouth A, Collier D, Maughan B. Childhood emotional problems and self-perceptions predict weight gain in a longitudinal regression model. BMC Med. (2009) 7:1–9. doi: 10.1186/1741-7015-7-46
56. Barnow S, Lucht M, Freyberger HJ. Correlates of aggressive and delinquent conduct problems in adolescence. Aggress Behav. (2005) 31:24–39. doi: 10.1002/ab.20033
57. Nowland R, Qualter P. Influence of social anxiety and emotional self-efficacy on pre-transition concerns, social threat sensitivity, and social adaptation to secondary school. Br J Educ Psychol. (2020) 90:227–44. doi: 10.1111/bjep.12276
58. Parasin N, Amnuaylojaroen T, Saokaew S. Effect of air pollution on obesity in children: a systematic review and meta-analysis. Children. (2021) 8:327. doi: 10.3390/children8050327
Keywords: child, obesity, machine learning, feature selection, feature stability
Citation: Liu H, Leng Y, Wu Y-C, Chau PH, Chung TWH and Fong DYT (2024) Robust identification key predictors of short- and long-term weight status in children and adolescents by machine learning. Front. Public Health 12:1414046. doi: 10.3389/fpubh.2024.1414046
Received: 08 April 2024; Accepted: 03 September 2024;
Published: 24 September 2024.
Edited by:
Marco Bilucaglia, Università IULM, ItalyReviewed by:
Khan Md Hasib, Bangladesh University of Business and Technology, BangladeshChibueze Ogbonnaya, University College London, United Kingdom
Copyright © 2024 Liu, Leng, Wu, Chau, Chung and Fong. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daniel Yee Tak Fong, ZHl0Zm9uZ0Boa3UuaGs=