 Wei Gong1,2,3
Wei Gong1,2,3 Peng Sun
Peng Sun- 1Public Health School, Ningxia Medical University, Yinchuan, China
- 2Key Laboratory of Environmental Factors and Chronic Disease Control, Yinchuan, China
- 3School of Medical Information and Engineering, Ningxia Medical University, Yinchuan, China
- 4School of Nursing, Ningxia Medical University, Yinchuan, China
- 5Institute of Medical Science and Technology, Ningxia Medical University, Yinchuan, China
Background: Multimorbidity is increasingly prevalent among older adults and poses significant challenges to public health systems. While previous studies have highlighted the role of individual behaviors, the complex interaction between lifestyle factors and socioeconomic status (SES) in multimorbidity remains unclear.
Methods: Using nationally representative data from the China Health and Retirement Longitudinal Study (CHARLS), we developed predictive models to identify key determinants of multimorbidity among individuals aged ≥60 years. A total of 34,755 participants were included, and 17 features related to demographics, SES, and lifestyle were selected via LASSO regression. Eight machine learning algorithms including logistic regression, decision tree, naive Bayes, neural network, support vector machine, random forest, XGBoost and Bayesian Ridge Regression were applied to build predictive models. Model performance was evaluated using AUC, accuracy, precision, recall, F1-score, RMSE, and decision curve analysis (DCA). SHapley Additive exPlanations (SHAP) were used to interpret model outputs.
Results: XGBoost achieved the best predictive performance (AUC = 0.788 on the test set), outperforming both linear and non-linear models across most evaluation metrics. SHAP analysis revealed that education level, activities of daily living (ADL), work status, self-assessed health status, and per capita income were the top factors associated with of multimorbidity. Subgroup analyses showed variated associations by age and sex, with psychological and geographic factors playing a larger role among those aged ≥80.
Conclusion: This study demonstrated the feasibility and interpretability of using machine learning to model complex risk patterns of multimorbidity. Socioeconomic and functional variables were dominant factors associated with multimorbidity, suggesting structural roots of health inequality. These findings offered empirical and theoretical support for early risk stratification and targeted public health interventions aimed at mitigating multimorbidity in aging populations.
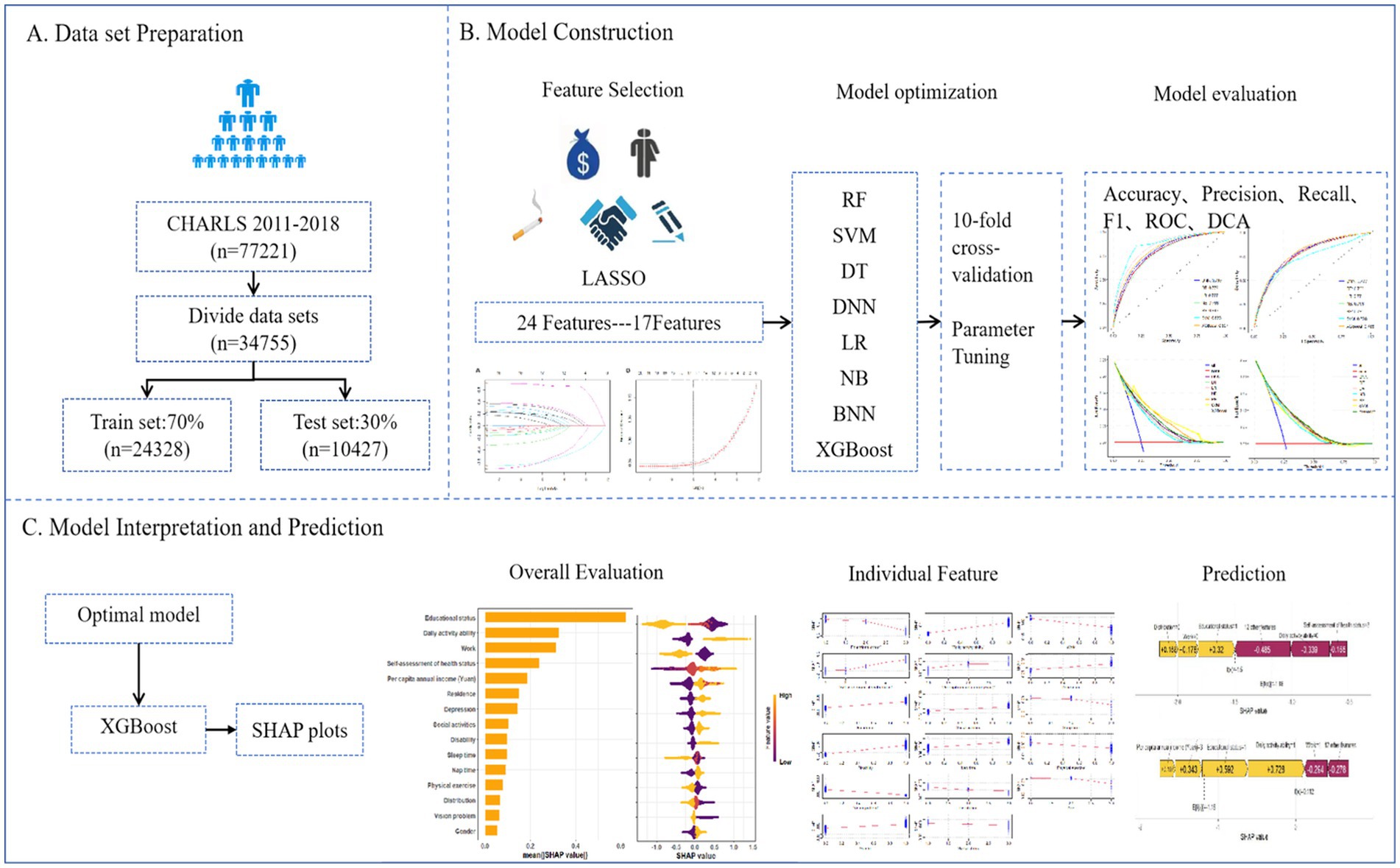
Graphical Abstract.
1 Introduction
With the acceleration of global population aging and profound shifts in lifestyle, multimorbidity, the coexistence of two or more chronic conditions has become increasingly prevalent, especially among older adults. It now poses a major challenge for global public health systems (1, 2). Multimorbidity prevalence rates as high as 55–98% among those aged 60 and above (3). It accelerates physical decline and increases the risk of mental health issues and mortality (4, 5). Therefore, identifying high-risk populations and designing effective intervention strategies are critical for improving health equity in aging populations.
Multimorbidity is shaped not only by biomedical factors but also by broader social determinants, including lifestyle behaviors, environmental exposures, and social structures (5, 6). Currently, China is in the process of urbanization, where socioeconomic status differences lead to health disparities among the older adult, with a weaker socioeconomic status negatively impacting older adult health (7, 8). Lifestyle, public services, and social psychological factors can mitigate the direct impact of socioeconomic status on older adult health to some extent. Previous studies on lifestyle and chronic diseases have often focused on individual-level factors (9–11), overlooking the broader social context in which healthy behaviors occur. Key socioeconomic status (SES) indicators, such as education level, occupational status, and income are crucial (12, 13). However, how these factors interact within China’s unique social transformation remains underexplored.
While previous studies have identified demographic and clinical predictors of multimorbidity (14, 15), few have integrated sociological theory to examine how macro-level social change interacts with individual health behaviors. ML offers new analytical pathways by capturing non-linear, multidimensional relationships between social structure and health outcomes, enabling deeper insights into the social roots of chronic disease. Traditional statistical methods used in prior studies often fall short in capturing non-linear relationships and complex interactions among variables. In contrast, machine learning (ML) has emerged as a powerful tool for addressing complex problems and has been increasingly applied in healthcare research (16–19). To enhance interpretability and policy relevance, Shapley Additive Explanations (SHAP) are increasingly used to visualize and explain contributions of variables in machine learning models (20–23).
Drawing on data from the China Health and Retirement Longitudinal Study (CHARLS), this study integrated variables related to socioeconomic status, lifestyle, and self-reported health, and applied a suite of machine learning algorithms to construct interpretable predictive models. Our aim was to systematically identify key social and behavioral determinants of multimorbidity in older Chinese adults. This research contributed to the growing literature by providing theoretical and empirical insights for early identification of high-risk groups and offered actionable evidence for the development of more targeted and equitable health policies in the context of population aging in China.
2 Materials and methods
2.1 Data source
This study is based on national data from the China Health and Retirement Longitudinal Survey (CHARLS) conducted by the National Development Research Institute of Peking University1. This study is an ongoing community-based cohort study of a nationally representative sample of Chinese residents aged 45 and older. To ensure best practice and internationally comparable results, CHARLS is coordinated with leading international research in the Health and Retirement Research (HRS) model. A stratified multi-stage random sampling strategy was adopted. Follow-up visits have been conducted every 2 years since 2011, with the most recent follow-up in 2020, and comprehensive and detailed information on demographics, socioeconomic status, biomedical measurements, health status, and functioning were collected. To ensure sample representativeness, the CHARLS baseline survey covers 150 countries/regions and 450 villages/urban communities across the country, involving 10,257 households with 17,708 people, and reflects the middle-aged and older adult in China (24).
In this study, we included 77,221 participants from the 2011–2018 study waves, of whom 34,755 were eligible for model development and internal validation. Inclusion criteria: (1) participants aged ≥60 years; exclusion criteria: (1) participants aged <60 years; (2) participants without missing data for chronic disease and depression. The detailed inclusion and exclusion process was shown in Figure 1.
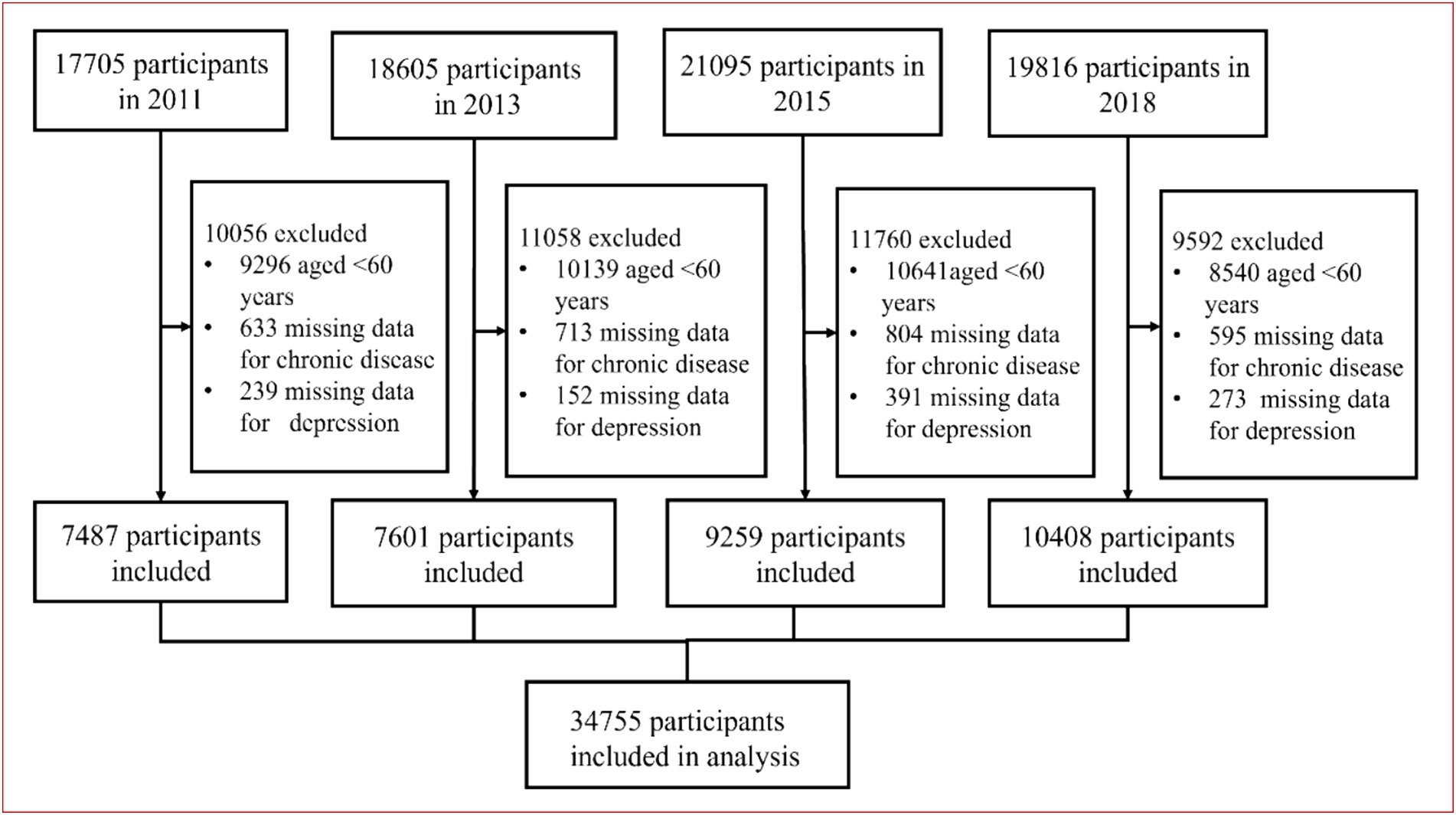
Figure 1. Flowchart of study participant selection.
2.2 Variable selection and definition
2.2.1 Dependent variable
In the questionnaire, each follow-up visit was asked about new diagnoses by doctors of a set of chronic diseases and the timing of diagnoses of specific conditions, where relevant, current medications and treatments for each specific condition. The survey content of chronic diseases in CHARLS. “have you been diagnosed with [conditions listed below] by a doctor?,” with diseases including hypertension; dyslipidemia (elevation of low-density lipoprotein, triglycerides, and total cholesterol, or a low high-density lipoprotein level); diabetes or high blood sugar; cancer or malignant tumor (excluding minor skin cancers); chronic lung diseases (such as chronic bronchitis or emphysema, excluding tumors or cancers); liver disease (except fatty liver, tumors, and cancer); heart attack (including coronary heart disease, angina, congestive heart failure, or other heart problems); stroke; kidney disease (except for tumor or cancer); stomach or other digestive diseases (except for tumor or cancer); emotional, nervous, or psychiatric problems; memory-related disease (such as dementia, brain atrophy, and Parkinson’s disease); arthritis or rheumatism and asthma (24). We divided multimorbidity into two categories: (1) no multimorbidity (0 ≤ chronic diseases ≤1) and (2) multimorbidity (chronic diseases ≥ 2).
2.2.2 Predictor variables
A preliminary evaluation of predictors related to multimorbidity based on clinical significance and scientific knowledge identified 24 variables as candidate predictors. Specifically, it includes: (1) Demographic characteristics (age, gender, marital status, residence, geographical distribution); (2) Lifestyle (smoking, drinking, disability, vision problem, hearing problem, sleep time, nap time, depression, activities of daily living (ADL), instrumental activities of daily living (IADL), self-assessment of health, physical exercise, physical pain condition, social activities); (3) Socioeconomic variables [educational status, Per capita annual income (Yuan), work, medical insurance, endowment insurance], specific variables are described in Supplementary Table S1.
2.3 Statistical methods
2.3.1 Data collection and preprocessing
Variables with missing data exceeding 30% were excluded prior to imputation to avoid introducing excessive bias through imputation (25). For the remaining variables with missing data (<30%), mean imputation using regression models was employed. This method was selected for its computational efficiency and relative stability compared to simpler methods, especially given the large sample size (26, 27). Regression-based mean imputation utilizes the relationships observed in the non-missing data to estimate missing values more accurately than a simple overall mean (28), while remaining less computationally intensive than multiple imputation methods for this high-dimensional dataset (25, 29, 30). The preprocessing steps involved duplicate checking, outlier detection, and standardized variable encoding, all conducted in Python 3.7. The cleaned dataset was randomly split into a training set (70%) and a testing set (30%), ensuring no significant differences in baseline characteristics between the two groups (p > 0.05). The training set was used to develop the models, while the test set was reserved for hyperparameter tuning and performance evaluation. To reduce dimensionality and enhance model generalizability, we applied the Least Absolute Shrinkage and Selection Operator (LASSO) method with 10-fold cross-validation to identify the optimal penalty parameter (λ), selecting the most predictive features from 22 candidates by minimizing binomial deviance.
2.3.2 Model construction and evaluation
We constructed predictive models using eight machine learning algorithms, each with distinct advantages and limitations. Logistic Regression (LR) is a linear probabilistic model that employs the sigmoid function to estimate binary outcomes; it is computationally efficient and interpretable but limited in modeling non-linear relationships. Random Forest (RF), an ensemble method based on bootstrapped aggregation of decision trees, is robust to overfitting and effective for high-dimensional data, though computationally demanding. Extreme Gradient Boosting (XGBoost) is a scalable and regularized gradient boosting framework that delivers high accuracy and supports parallel computation, but it requires careful hyperparameter tuning. Support Vector Machine (SVM) constructs optimal hyperplanes to maximize class separation, performing well with small samples and non-linear kernels, yet it is sensitive to noise and missing values. Naive Bayes (NB) is a probabilistic classifier grounded in Bayes’ theorem with an assumption of conditional independence among features; it is efficient for high-dimensional sparse data, although performance may decline when this assumption is violated. Decision Tree (DT) models recursively partition data based on criteria such as information gain or Gini index; they are easy to interpret but prone to overfitting. Deep Neural Networks (DNN) can learn complex non-linear relationships through backpropagation and are highly powerful given large datasets, but they require considerable computational resources and are less interpretable. Bayesian Ridge Regression (BRR) applies L2 regularization within a Bayesian framework by introducing a Gamma prior on the coefficients, optimizing hyperparameters via marginal likelihood to automatically control model complexity and avoid overfitting. It produces probabilistic predictions and is suitable for small datasets, yet its applicability is restricted to linear relationships, it is sensitive to prior assumptions, and it has relatively low computational efficiency (31).
All models were trained using 10-fold cross-validation and grid search to optimize hyperparameters, with the primary objective of maximizing the Area Under the ROC Curve (AUC) while controlling model complexity. To evaluate model performance, we applied multiple metrics: Accuracy, Precision, Recall, F1-score, Brier Score, Log Loss. AUC-ROC curves assessed the trade-off between true positive rate (TPR) and false positive rate (FPR). Decision Curve Analysis (DCA) used to estimate the net benefit of each model at various threshold probabilities.
2.3.3 Model interpretability
To enhance interpretability, we employed SHapley Additive exPlanations (SHAP) on the best-performing model (XGBoost). SHAP values quantified the contribution of each feature to individual predictions, while summary plots ranked overall feature importance (32). SHAP dependence plots illustrated non-linear effects and interaction patterns, and force plots were used to explain individual-level predictions, facilitating clinical understanding.
The eight algorithms differ significantly in terms of model assumptions, capacity to handle non-linear relationships and feature interactions, interpretability and transparency, sensitivity to data quality and missingness, computational cost and scalability. By comparing these models, our study aimed to identify the most suitable approach for predicting multimorbidity risk among older adult individuals in China. Figure 2 showed the workflow of study.
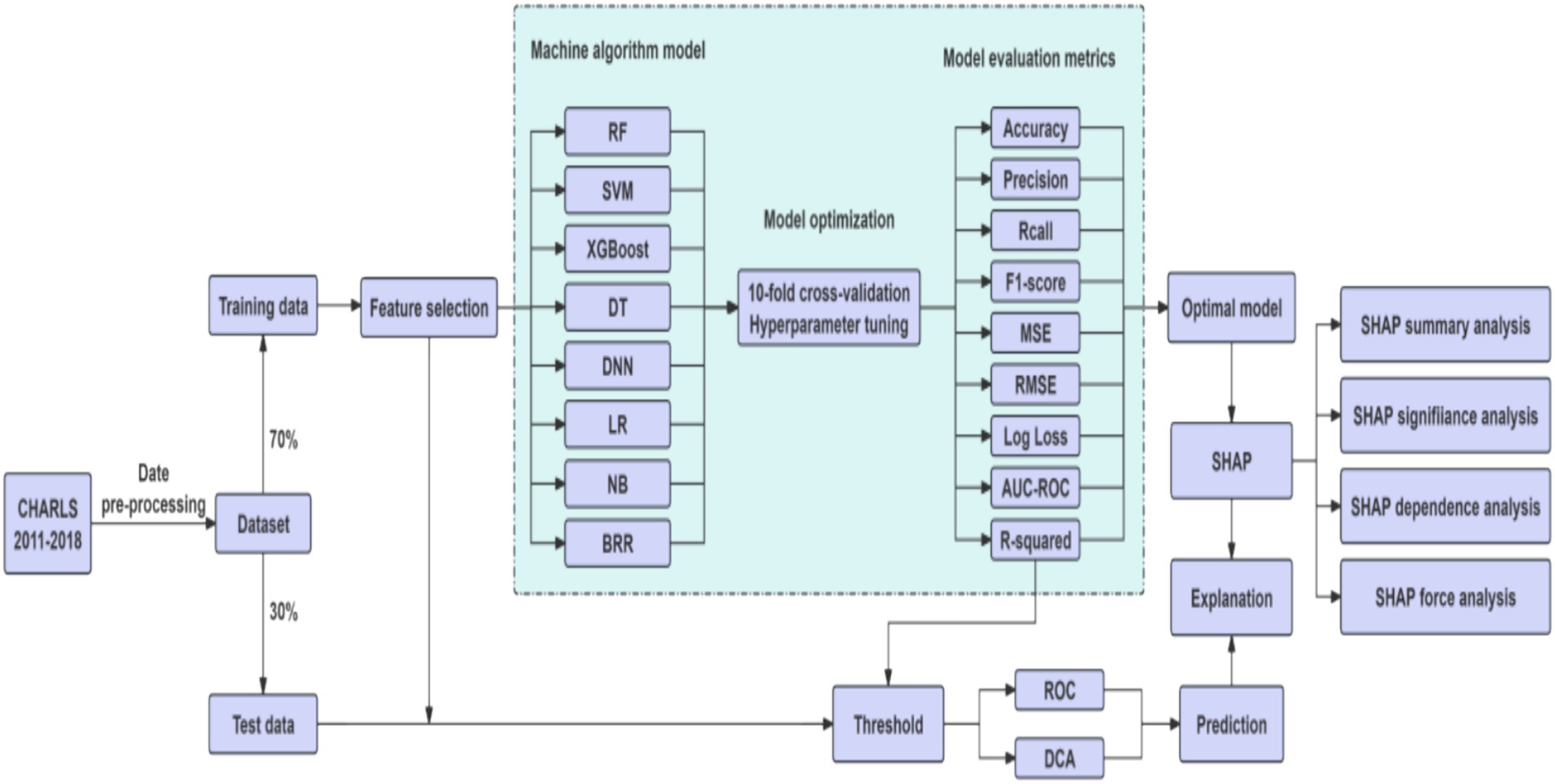
Figure 2. The workflow of study.
3 Results
3.1 Demographic characteristics
A total of 34,755 older adult were included in this study, 8,728 of whom had multimorbidity, and the multimorbidity rate of chronic diseases was 25.1%. Among them, 4,584 are male and 4,144 are female. There were 5,066 people aged 60–69 years old suffering from multimorbidity, 2,892 aged 70–79 years old, and 770 aged over 80 years old. The data were split according to a ratio of 7:3. The training set contained 24,328 cases, of which 6,056 had multimorbidity. The test set contained 10,427 cases, of which 2,672 had multimorbidity. The final demographic characteristics baseline data are as shown in Table 1. Except for hearing problem and medical insurance, there were no statistically significant differences in baseline characteristics between the two groups (p > 0.05).
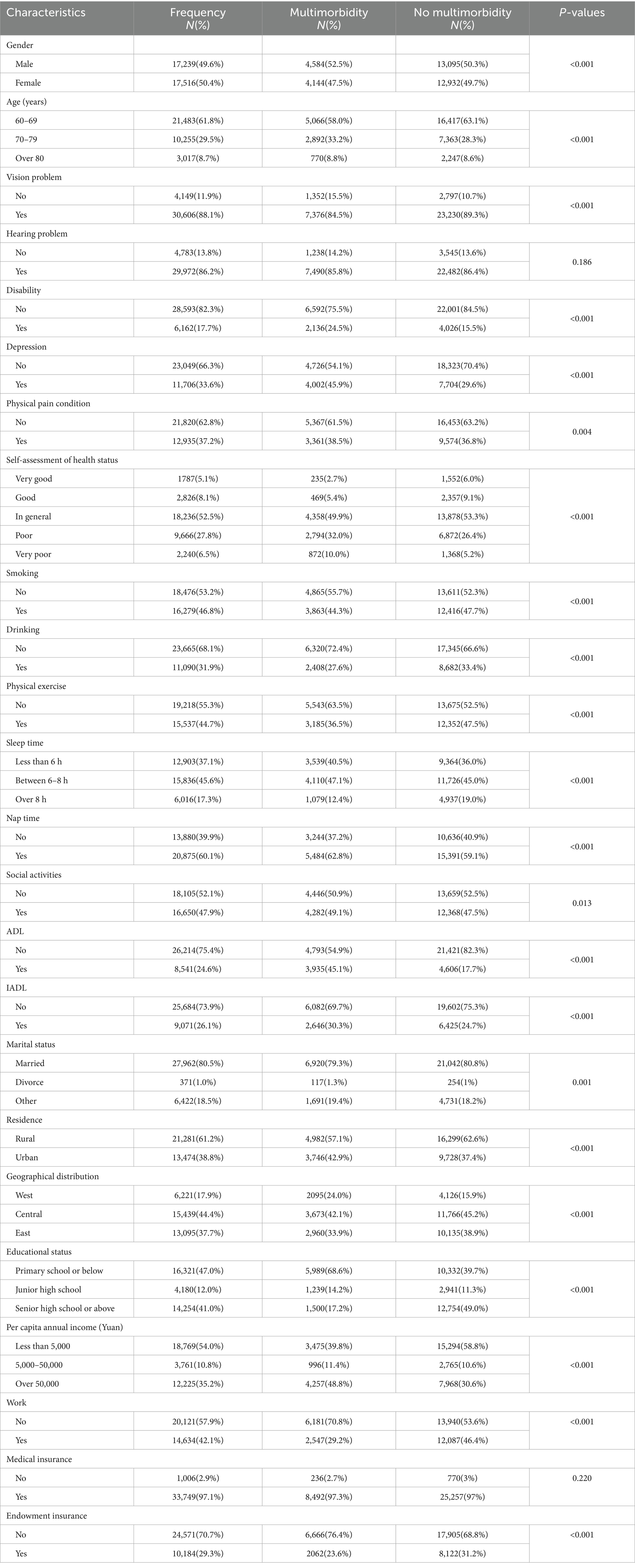
Table 1. Characteristics of study population.
3.2 Feature selection
We used LASSO regression for parameter screening, and the changing characteristics of the coefficients of the variables are shown in Figure 3A. The 10-fold cross-validation method was used for iterative analysis. When λ = 0.0068 (Log λ = −4.99), a model with excellent performance and the smallest number of variables was obtained (Figure 3B). Finally, we combined gender, age, vision, disability, self-assessed health status, depression, physical exercise, sleep time at night, nap status, daily activity ability, marital status, geographical distribution, urban and rural distribution, education level, working status, per capita annual income. A total of 17 features were used as predictor variables to develop the machine learning model.
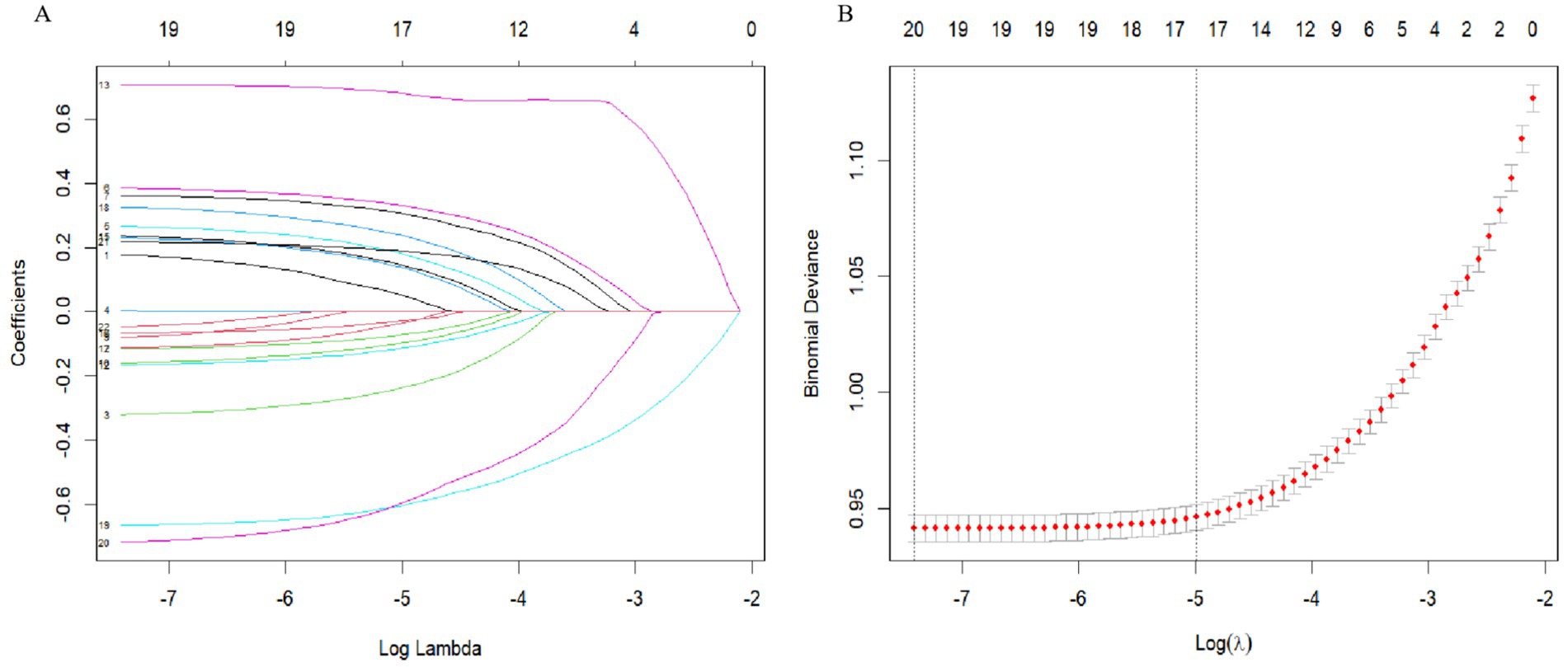
Figure 3. Variable screening based on Lasso regression model. (A) The changing characteristics of variable coefficients. (B) The selection process of the optimal value of parameter λ in the Lasso regression model by cross-validation method.
3.3 Model evaluation and comparison
Based on the features selected by the LASSO algorithm, we constructed predictive models using eight widely adopted machine learning algorithms: RF, SVM, XGBoost, DT, DNN, LR, NB, and BRR. Model performance was evaluated on both the training and test datasets using a comprehensive set of metrics, including accuracy, precision, recall, F1-score, MSE, RMSE, log loss, AUC-ROC, and R-squared.
Among all models, the XGBoost algorithm demonstrated the most favorable overall performance. It achieved the highest AUC values on both the training set (0.807) and the test set (0.788), indicating superior discriminative ability. In terms of classification metrics, XGBoost maintained competitive accuracy (training: 0.817; test: 0.780), precision (training: 0.805; test: 0.755), recall (training: 0.817; test: 0.775), and F1-score (training: 0.803; test: 0.758), outperforming most other models across these indicators. While the RF and SVM models also exhibited relatively high AUCs (training: 0.843 and 0.863, respectively), their test performance in accuracy and other metrics was slightly lower than that of XGBoost, suggesting potential overfitting or reduced generalizability. Notably, although BRR achieved acceptable accuracy (training: 0.776; test: 0.771) and AUC (training: 0.775; test: 0.768), its recall (training: 0.254; test: 0.255) and F1-score (training: 0.361; test: 0.364) were significantly lower than those of other models, indicating poor sensitivity and suboptimal classification balance, as shown in Figures 4A,B.
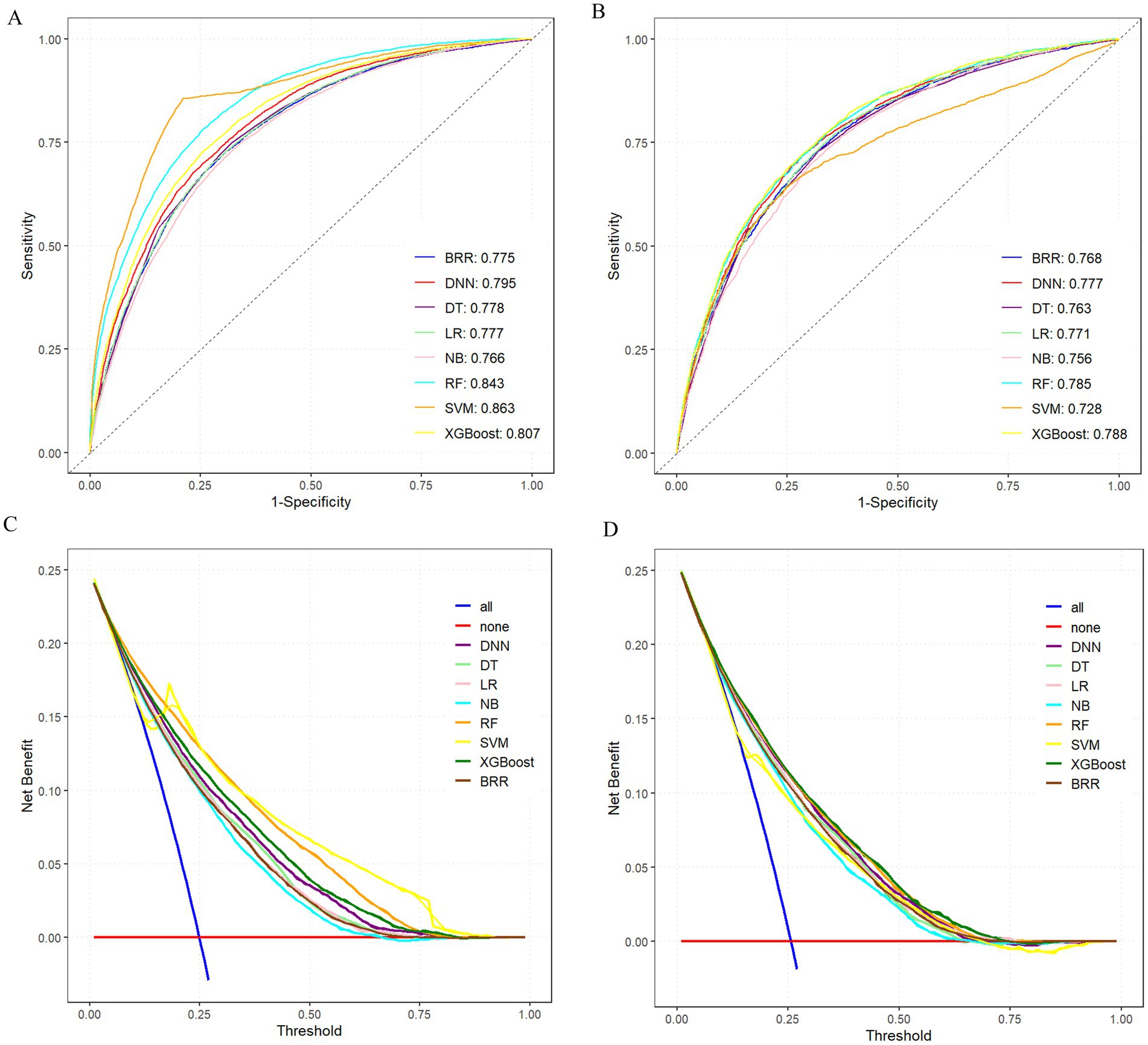
Figure 4. Comprehensive evaluation of machine learning models. (A) ROC and AUC of the training set. (B) ROC and AUC of the test set. (C) DCA of the training set. (D) DCA of the test set; where the all curve in the DCA curve represents all situations with intervention. The benefit rate, while the none curve represents the benefit rate in all cases without intervention. The remaining curves represent various models.
To further compare the practical utility of each model, we performed DCA on both the training and test datasets. As shown in Figures 4C,D, XGBoost consistently yielded the highest net benefit across a wide range of threshold probabilities, further supporting its superior clinical applicability. Specific model parameters for each algorithm are detailed in Table 2.
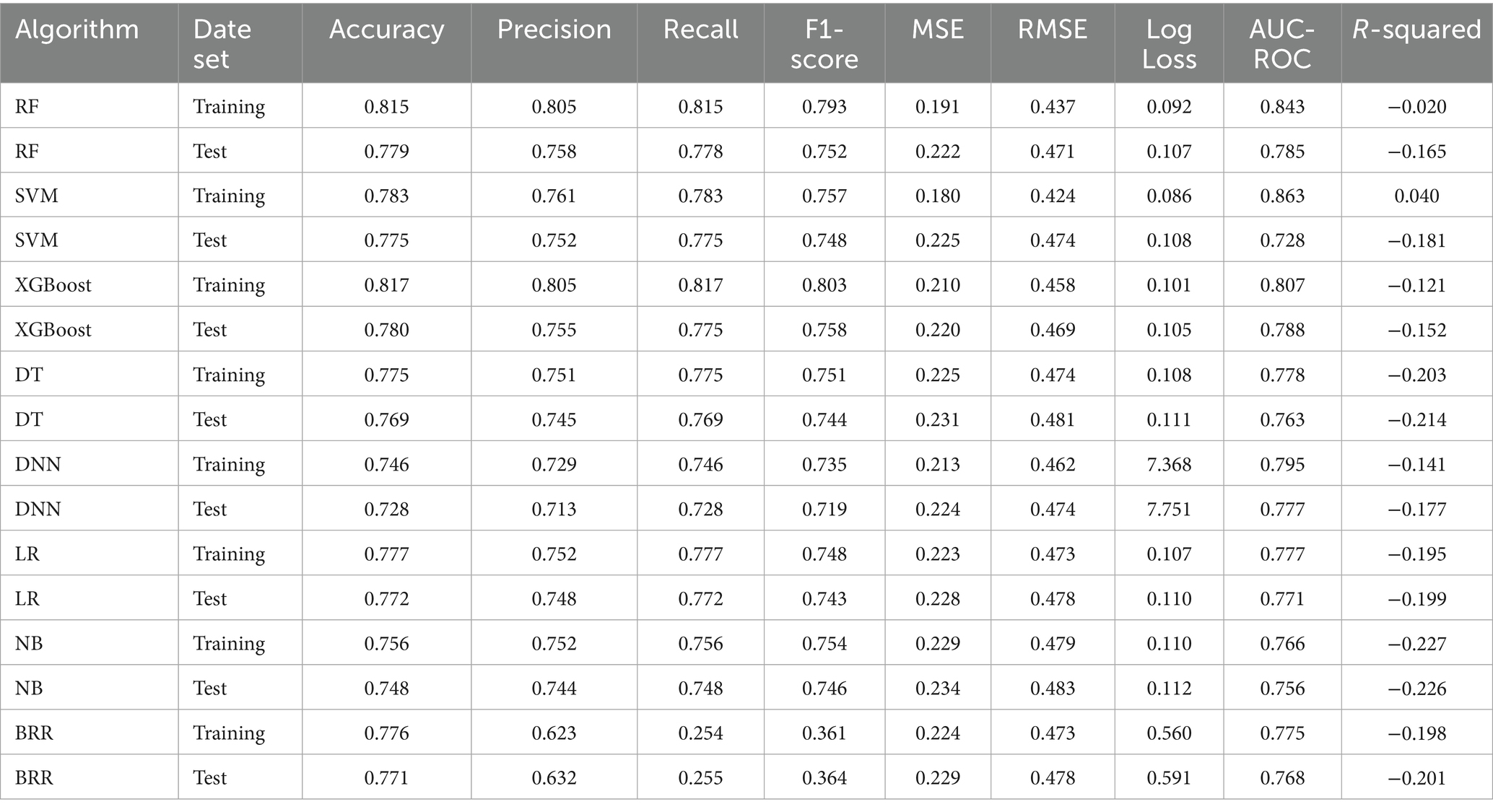
Table 2. Evaluates the performance of eight algorithms.
Collectively, these findings indicated that the XGBoost model offers the best balance of predictive accuracy, robustness, and clinical utility, and thus represented the optimal choice for risk prediction in this study.
3.4 Mode explanation
To better understand the relationship between the model and the data, we used SHAP to provide an intuitive interpretation of the XGBoost model to illustrate how these variables affect the risk of multimorbidity in the model. Figure 5A showed the important features in the model, and the ranking of features on the y-axis indicates their importance to the predictive model. The results showed that education level, ADL, working status, self-assessed health status, and per capita annual income were highly correlated with the risk of multimorbidity. Figure 5B illustrated the positive or negative effects of the 15 features affected by XGBoost through SHAP values. The x-axis represents the Shapley value, and each feature has positive and negative associations. For example, higher educational level associated negatively to multimorbidity, whereas higher ability to perform daily activities associated positively to multimorbidity. The SHAP dependency diagram can help understand the association of a single feature on the output of the XGBoost prediction model (Figure 5C). For example, lower self-evaluation of health has a negative association to multimorbidity, while having a job has a positive association to multimorbidity. In addition, we provide two typical examples, one predicting participants without multimorbidity (Figure 5D) and the other predicting participants with multimorbidity (Figure 5E). In the prediction of the risk of multimorbidity without chronic disease, education, ADL, work status, and other factors were the main associations, while in the prediction of the risk of multimorbidity with chronic disease, ADL, education status, self-assessment health status, and work status were the main associations. All yellow bars on the left side of the figure represent features that had a positive association deviating from the base value, while red bars on the right side represented features that had a negative association deviating from the base value. The length of the bar chart showed the association of the features, further demonstrating the interpretability of the model.
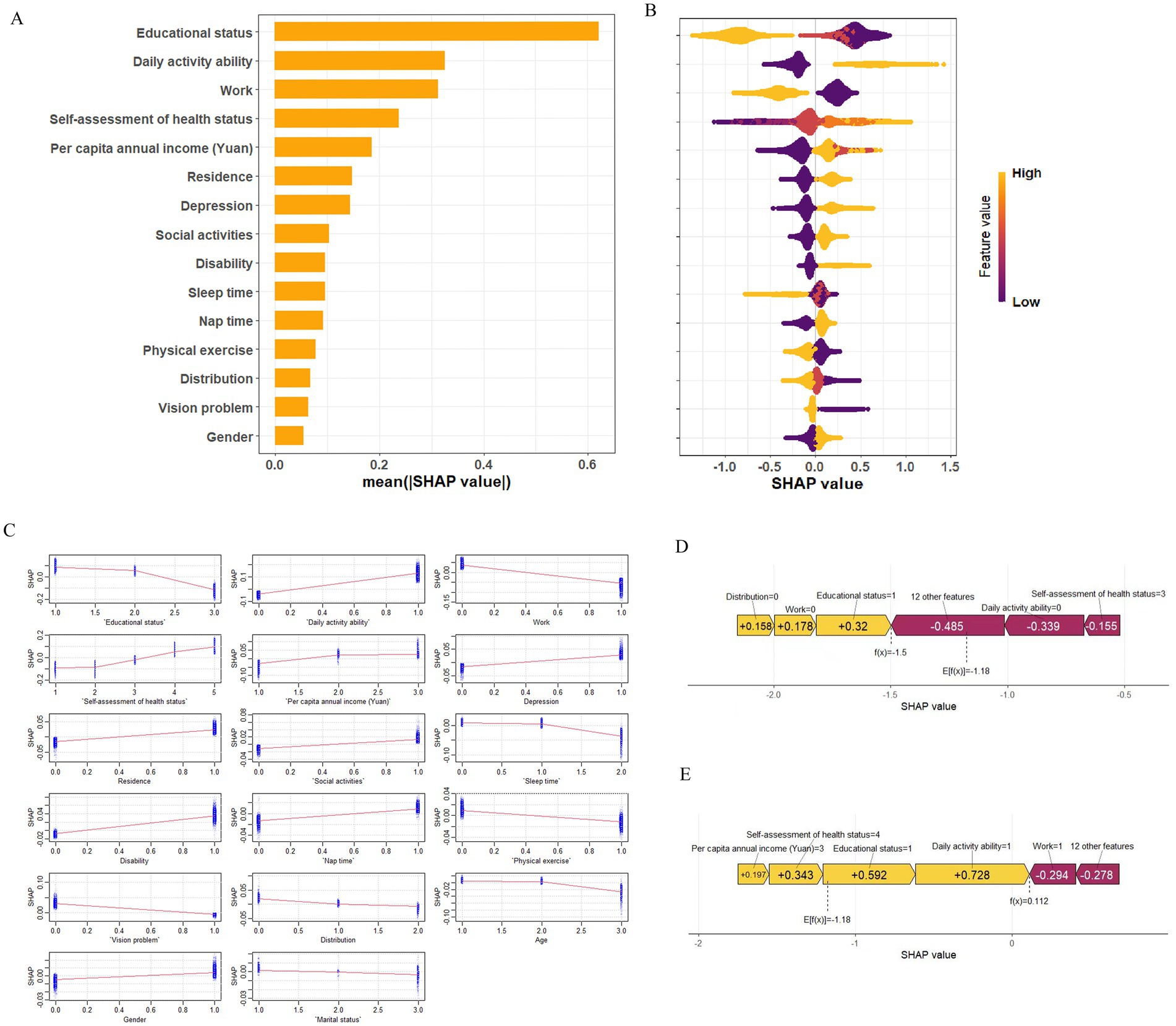
Figure 5. SHAP explains the model. (A) Ranking of variable importance based on mean of XGBoost model. (B) SHAP honeycomb plot. (C) SHAP dependency graph of XGBoost model. (D) SHAP prediction for samples without multimorbidity. (E) SHAP prediction for multimorbidity samples. Yellow arrowed indicate higher risk of multimorbidity, while red arrows indicated lower risk of multimorbidity. The length of the arrow helped visualize the predicted impact, with longer arrows indicating a more significant effect.
The results showed that for the age-based subgroups, the top five influencing factors were highly consistent between the 60–69 and 70–79 age groups. These included education status, ADL, work status, self-assessment health status, and per capita annual income, with test set AUCs of 0.796 and 0.790, respectively. In contrast, for individuals aged ≥80 years, the top factors were education status, per capita annual income, residence, depression, and ADL, yielding a slightly lower AUC of 0.728 (Supplementary Figures S1–S4). This suggested a rising influence of psychological and geographic factors in the oldest age group.
For the sex-based subgroups, the key factors for males were education status, work status, ADL, self-assessment health status, and per capita annual income (AUC = 0.790). For females, the main factors were education status, ADL, self-assessment health status, work status, and residence (AUC = 0.792) (Supplementary Figures S5, S6).
4 Discussion
This study integrated multiple machine learning algorithms with interpretable analysis techniques (SHAP) to construct a predictive model for multimorbidity risk among the older adult in China. The results indicated that the XGBoost model outperformed others in predictive performance.
SHAP analysis further highlighted the strong association of socioeconomic status (e.g., education level, income, work status) and lifestyle (e.g., ADL, self-assessment health status) in the formation of multimorbidity. These findings aligned closely with theories of social stratification and health lifestyles, supporting the significant association of socioeconomic factors on health outcomes and revealing significant behavioral differences across social strata.
Previous research has shown that individuals with lower socioeconomic status tend to bear a heavier disease burden, face higher rates of chronic illness, and have worse health outcomes (33–35). In China, this issue is particularly complex due to the dual urban–rural structure, regional disparities in development, and differences in social welfare systems, all of which exacerbate health inequality (36). Studies have demonstrated that rural residents are experiencing significantly higher growth rates of obesity, hypertension, and diabetes compared to urban residents (37, 38), largely due to lower education levels, poor health awareness, and limited access to medical resources (33–35). Our findings are consistent, showing that higher education levels are strongly associated with reduced multimorbidity risk.
Education, representing cultural capital, is associated with enhanced health literacy and self-management capabilities (39, 40). The high multimorbidity rate among rural older adult further confirmed the existence of a “health gradient,” where social class shaped health trajectories through access to economic resources, occupational conditions, and health behavior choices (41, 42). Additionally, this study found that reduced ADL and poor self-assessment health status were significant predictors of multimorbidity, indicating that maintaining physical function is associated with a lower risk of delaying the onset of multiple chronic diseases. The U. S. NHATS study found significant associations between multimorbidity and IADL ability, where individuals with five or more chronic conditions exhibited substantial limitations in daily functioning (43). Self-assessment health status, as a multidimensional indicator, reflected not only physical functioning but also psychological well-being and social support (44). In our study, poorer self-assessment health status was significantly associated with a higher risk of multimorbidity, supporting findings from the Italian centenarian study (45), which demonstrated that subjective health perception is driven by emotional well-being and functional ability, while indirectly influenced by socioeconomic status. Thus, self-assessment health status could serve as a practical screening tool for identifying high-risk older adult individuals, especially in resource-limited rural areas (46, 47). Individuals aged ≤79 were mainly influenced by economic and behavioral factors, while those aged ≥80 showed stronger associations with psychological health and geographic location (48). Males were more influenced by occupational and economic security, whereas females appeared more sensitive to living environment and perceived health. These subgroup differences suggested potential avenues for more tailored interventions. The prominence of economic and functional factors (education, work, ADL, income, self-rated health) in the younger older adult (60–79 years) underscored the importance of socioeconomic support and maintaining functional capacity during the earlier stages of aging to potentially mitigate multimorbidity development (49–51). In contrast, the increased relative importance of psychological well-being (depression) and geographic location (residence) among the oldest old (≥80 years) (52–55) highlighted the need to integrate mental health support and address potential barriers related to location (e.g., access to care, social isolation) in interventions. The finding that males appeared more sensitive to occupational and economic security factors, while females were more sensitive to living environment and perceived health (56–58), suggested that gender-specific approaches considering these distinct sensitivities might enhance intervention effectiveness (59). For instance, programs for older adult men might benefit from components addressing financial security or retirement transition, while programs for women might place greater emphasis on improving living conditions and self-efficacy in health management.
Using the LASSO method, this study identified 17 key variables encompassing demographic characteristics, socioeconomic factors, and lifestyle behaviors, underscoring their substantial predictive value and clinical relevance in identifying individuals at risk for multimorbidity (60, 61). The predictive performance of the eight machine learning algorithms evaluated in this study was generally robust, with AUC values ranging from 0.728 to 0.788. Among them, the XGBoost model consistently achieved the highest AUC in both the training and test sets, demonstrating superior discrimination ability. To assess the clinical applicability of each model, we conducted DCA, which revealed that XGBoost provided the greatest net benefit across a wide range of threshold probabilities, reinforcing its potential as a practical tool for early identification of high-risk individuals (62).
From a methodological perspective, non-linear models generally outperformed linear models across multiple evaluation metrics, including accuracy, F1-score, RMSE, and log loss. In particular, XGBoost, which integrates a gradient boosting framework with regularization techniques, demonstrated enhanced ability to model complex, non-linear interactions among predictors. This advantage is especially important in the context of multimorbidity, where the interplay between socioeconomic status, demographic profiles, and lifestyle risk factors is often intricate and multidimensional (63). In contrast, linear models such as logistic regression and Bayesian ridge regression, while offering interpretability and computational efficiency, are inherently limited in their capacity to capture non-linear associations. Consequently, they may underestimate the effects of key predictors or fail to detect higher-order interactions that are clinically meaningful (64). Taken together, these findings suggest that non-linear ensemble models, particularly XGBoost, provide a more accurate and clinically useful approach for multimorbidity risk prediction in population-based datasets. Future studies should explore the integration of model explainability techniques, such as SHAP values, to enhance interpretability without compromising predictive performance, thereby facilitating real-world implementation in preventive healthcare settings.
SHAP analysis visually demonstrated the impact of each feature on prediction outcomes. For instance, higher education levels were associated with negative SHAP values, indicating a protective effect against multimorbidity. Other key variables, ADL, work status, self-assessment health status, and per capita annual income also had significant impacts on predictions. SHAP summary and dependence plots further illustrated how these features contributed to individual risk predictions and how the presence of chronic diseases modulated feature importance, thereby enhancing model interpretability.
These findings not only supported the optimization of predictive models but also underscored the importance of addressing the structural roots of medical issues. Policymakers should increase investment in health education, particularly for low-SES groups, and work to improve the equitable distribution of medical resources. Based on the key features identified, early risk assessment tools for multimorbidity could be developed to optimize intervention strategies and clinical trial design, improving resource efficiency and targeting.
Despite the significance of these findings, this study has several limitations. Firstly, this study is the reliance solely on Chinese data from the CHARLS cohort for model development and validation. While CHARLS provides a nationally representative sample of the Chinese older adult population, the unique socioeconomic transitions, healthcare system structure of China may not directly translate to populations in other countries. External validation using datasets from diverse international cohorts is essential to assess the generalizability and potential applicability of our findings and the XGBoost model. Secondly, this study was a cross-sectional design. Although our analysis identified robust associations between socio-economic factors, lifestyle variables and the risk of chronic disease comorbidity, it was not possible to make causal inferences. Future longitudinal studies or intervention studies are needed to determine the causal relationship.
5 Conclusion
By applying machine learning techniques alongside interpretability tools (SHAP) to a large, nationally representative dataset, this study robustly identified key socioeconomic, functional, and lifestyle factors associated with multimorbidity among older adults in China. Integrating machine learning with sociological theory, the study constructed an interpretable model that highlighted variables such as education level, ADL, work status, self-rated health, and income serve as effective predictive factors and reflect deep associations linked to the broader social determinants of health. These findings offer both theoretical insights and practical implications for understanding the underlying mechanisms of multimorbidity, enhancing model interpretability, and informing targeted public health strategies. Future studies incorporating external validation datasets from diverse populations are needed to confirm the applicability of our models.
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found: https://charls.pku.edu.cn/en/.
Ethics statement
The studies involving humans were approved by Peking University’s Institutional Review Board, approval number: IRB00001052-11015. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
WG: Conceptualization, Data curation, Formal analysis, Funding acquisition, Writing – original draft. XH: Data curation, Writing – original draft. HC: Software, Writing – original draft. YZ: Methodology, Software, Writing – original draft. HL: Formal analysis, Methodology, Writing – original draft. PS: Conceptualization, Data curation, Funding acquisition, Writing – review & editing. JY: Conceptualization, Funding acquisition, Supervision, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the National Natural Science Foundation of China (No. 82060597), Key Research and Development Project in Ningxia (2021BEG03031), Ningxia Natural Science Foundation Project (2024AAC03240).
Acknowledgments
We would like to express our sincere gratitude to Peking University for providing data of CHARLS and to those involved in data collection and management.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The authors declare that no Gen AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2025.1586091/full#supplementary-material
Footnotes
References
1. Makovski, TT, Schmitz, S, Zeegers, MP, Stranges, S, and van den Akker, M. Multimorbidity and quality of life: systematic literature review and meta-analysis. Ageing Res Rev. (2019) 53:100903. doi: 10.1016/j.arr.2019.04.005
2. Psaltopoulou, T, Hatzis, G, Papageorgiou, N, Androulakis, E, Briasoulis, A, and Tousoulis, D. Socioeconomic status and risk factors for cardiovascular disease: impact of dietary mediators. Hell J Cardiol. (2017) 58:32–42. doi: 10.1016/j.hjc.2017.01.022
3. Nguyen, H, Manolova, G, Daskalopoulou, C, Vitoratou, S, Prince, M, and Prina, AM. Prevalence of multimorbidity in community settings: a systematic review and meta-analysis of observational studies. J Comorb. (2019) 9:2235042x19870934. doi: 10.1177/2235042X19870934
4. Guo, M, Yu, Y, Wen, T, Zhang, X, Liu, B, Zhang, J, et al. Analysis of disease comorbidity patterns in a large-scale China population. BMC Med Genet. (2019) 12:177. doi: 10.1186/s12920-019-0629-x
5. Skou, ST, Mair, FS, Fortin, M, Guthrie, B, Nunes, BP, Miranda, JJ, et al. Multimorbidity. Nat Rev Dis Primers. (2022) 8:48. doi: 10.1038/s41572-022-00376-4
6. Langenberg, C, Hingorani, AD, and Whitty, CJM. Biological and functional multimorbidity—from mechanisms to management. Nat Med. (2023) 29:1649–57. doi: 10.1038/s41591-023-02420-6
7. Gong, P, Liang, S, Carlton, EJ, Jiang, Q, Wu, J, Wang, L, et al. Urbanisation and health in China. Lancet. (2012) 379:843–52. doi: 10.1016/S0140-6736(11)61878-3
8. Bai, X, and Shi, P. China’s urbanization at a turning point—challenges and opportunities. Science. (2025) 388:eadw3443. doi: 10.1126/science.adw3443
9. Dayoub, E, and Jena, AB. Chronic disease prevalence and healthy lifestyle behaviors among US health care professionals. Mayo Clin Proc. (2015) 90:1659–62. doi: 10.1016/j.mayocp.2015.08.002
10. Anderson, AR, and Fowers, BJ. Lifestyle behaviors, psychological distress, and well-being: a daily diary study. Soc Sci Med. (2020) 263:113263. doi: 10.1016/j.socscimed.2020.113263
11. Vajdi, M, Nikniaz, L, Pour Asl, AM, and Abbasalizad Farhangi, M. Lifestyle patterns and their nutritional, socio-demographic and psychological determinants in a community-based study: a mixed approach of latent class and factor analyses. PLoS One. (2020) 15:e0236242. doi: 10.1371/journal.pone.0236242
12. Navarro-Carrillo, G, Alonso-Ferres, M, Moya, M, and Valor-Segura, I. Socioeconomic status and psychological well-being: revisiting the role of subjective socioeconomic status. Front Psychol. (2020) 11:1303. doi: 10.3389/fpsyg.2020.01303
13. McCoy, CA, Johnston, E, and Hogan, C. The impact of socioeconomic status on health practices via health lifestyles: results of qualitative interviews with Americans from diverse socioeconomic backgrounds. Soc Sci Med. (2024) 344:116618. doi: 10.1016/j.socscimed.2024.116618
14. Heindl, B, Howard, G, Clarkson, S, Kamin Mukaz, D, Lackland, D, Muntner, P, et al. Urban-rural differences in hypertension prevalence, blood pressure control, and systolic blood pressure levels. J Hum Hypertens. (2023) 37:1112–8. doi: 10.1038/s41371-023-00842-w
15. Chaturvedi, A, Zhu, A, Gadela, NV, Prabhakaran, D, and Jafar, TH. Social determinants of health and disparities in hypertension and cardiovascular diseases. Hypertension. (2024) 81:387–99. doi: 10.1161/HYPERTENSIONAHA.123.21354
16. Gomes, S, von Schantz, M, and Leocadio-Miguel, M. Predicting depressive symptoms in middle-aged and elderly adults using sleep data and clinical health markers: a machine learning approach. Sleep Med. (2023) 102:123–31. doi: 10.1016/j.sleep.2023.01.002
17. Koops, J. Machine learning in an elderly man with heart failure. Int Med Case Rep J. (2021) 14:497–502. doi: 10.2147/IMCRJ.S322827
18. Battineni, G, Sagaro, GG, Chinatalapudi, N, and Amenta, F. Applications of machine learning predictive models in the chronic disease diagnosis. J Pers Med. (2020) 10:21. doi: 10.3390/jpm10020021
19. Swanson, K, Wu, E, Zhang, A, Alizadeh, AA, and Zou, J. From patterns to patients: advances in clinical machine learning for cancer diagnosis, prognosis, and treatment. Cell. (2023) 186:1772–91. doi: 10.1016/j.cell.2023.01.035
20. Rudin, C. Stop explaining black box machine learning models for high stakes decisions and use interpretable models instead. Nat Mach Intell. (2019) 1:206–15. doi: 10.1038/s42256-019-0048-x
21. Lee, Y-G, Oh, J-Y, Kim, D, and Kim, G. Shap value-based feature importance analysis for short-term load forecasting. J Electr Eng Technol. (2023) 18:579–88. doi: 10.1007/s42835-022-01161-9
22. Wang, K, Tian, J, Zheng, C, Yang, H, Ren, J, Liu, Y, et al. Interpretable prediction of 3-year all-cause mortality in patients with heart failure caused by coronary heart disease based on machine learning and SHAP. Comput Biol Med. (2021) 137:104813. doi: 10.1016/j.compbiomed.2021.104813
23. Yi, F, Yang, H, Chen, D, Qin, Y, Han, H, Cui, J, et al. XGBoost-SHAP-based interpretable diagnostic framework for Alzheimer's disease. BMC Med Inform Decis Mak. (2023) 23:137. doi: 10.1186/s12911-023-02238-9
24. Zhao, Y, Hu, Y, Smith, JP, Strauss, J, and Yang, G. Cohort profile: the China health and retirement longitudinal study (CHARLS). Int J Epidemiol. (2014) 43:61–8. doi: 10.1093/ije/dys203
25. Ren, L, Wang, T, Sekhari Seklouli, A, Zhang, H, and Bouras, A. A review on missing values for main challenges and methods. Inf Syst. (2023) 119:102268. doi: 10.1016/j.is.2023.102268
26. Haneuse, S, Arterburn, D, and Daniels, MJ. Assessing missing data assumptions in EHR-based studies: a complex and underappreciated task. JAMA Netw Open. (2021) 4:e210184. doi: 10.1001/jamanetworkopen.2021.0184
27. Templeton, GF, Kang, M, and Tahmasbi, N. Regression imputation optimizing sample size and emulation: demonstrations and comparisons to prominent methods. Decis Support Syst. (2021) 151:113624. doi: 10.1016/j.dss.2021.113624
28. Zhang, Z. Missing data imputation: focusing on single imputation. Ann Transl Med. (2016) 4:9. doi: 10.3978/j.issn.2305-5839.2015.12.38
29. Azur, MJ, Stuart, EA, Frangakis, C, and Leaf, PJ. Multiple imputation by chained equations: what is it and how does it work? Int J Methods Psychiatr Res. (2011) 20:40–9. doi: 10.1002/mpr.329
30. Saffari, SE, Volovici, V, Ong, MEH, Goldstein, BA, Vaughan, R, Dammers, R, et al. Proper use of multiple imputation and dealing with missing covariate data. World Neurosurg. (2022) 161:284–90. doi: 10.1016/j.wneu.2021.10.090
31. Bhattacharyya, A, Pal, S, Mitra, R, and Rai, S. Applications of Bayesian shrinkage prior models in clinical research with categorical responses. BMC Med Res Methodol. (2022) 22:126. doi: 10.1186/s12874-022-01560-6
32. Aas, K, Jullum, M, and Løland, A. Explaining individual predictions when features are dependent: more accurate approximations to Shapley values. Artif Intell. (2021) 298:103502. doi: 10.1016/j.artint.2021.103502
33. Schultz, WM, Kelli, HM, Lisko, JC, Varghese, T, Shen, J, Sandesara, P, et al. Socioeconomic status and cardiovascular outcomes: challenges and interventions. Circulation. (2018) 137:2166–78. doi: 10.1161/CIRCULATIONAHA.117.029652
34. Mair, FS, and Jani, BD. Emerging trends and future research on the role of socioeconomic status in chronic illness and multimorbidity. Lancet Public Health. (2020) 5:e128–9. doi: 10.1016/S2468-2667(20)30001-3
35. Powell-Wiley, TM, Baumer, Y, Baah, FO, Baez, AS, Farmer, N, Mahlobo, CT, et al. Social determinants of cardiovascular disease. Circ Res. (2022) 130:782–99. doi: 10.1161/CIRCRESAHA.121.319811
36. Pan, W, Wang, J, Li, Y, Chen, S, and Lu, Z. Spatial pattern of urban-rural integration in China and the impact of geography. Geogr Sustain. (2023) 4:404–13. doi: 10.1016/j.geosus.2023.08.001
37. Peng, W, Chen, S, Chen, X, Ma, Y, Wang, T, Sun, X, et al. Trends in major non-communicable diseases and related risk factors in China 2002–2019: an analysis of nationally representative survey data. Lancet Regional Health Western Pacific. (2023):100809. doi: 10.1016/j.lanwpc.2023.100809
38. Su, B, Li, D, Xie, J, Wang, Y, Wu, X, Li, J, et al. Chronic disease in China: geographic and socioeconomic determinants among persons aged 60 and older. J Am Med Dir Assoc. (2023) 24:206–212.e5. doi: 10.1016/j.jamda.2022.10.002
39. Magnani, JW, Ning, H, Wilkins, JT, Lloyd-Jones, DM, and Allen, NB. Educational attainment and lifetime risk of cardiovascular disease. JAMA Cardiol. (2024) 9:45–54. doi: 10.1001/jamacardio.2023.3990
40. Contador, I, Stern, Y, Bermejo-Pareja, F, Sanchez-Ferro, A, and Benito-Leon, J. Is educational attainment associated with increased risk of mortality in people with dementia? A population-based study. Curr Alzheimer Res. (2017) 14:571–6. doi: 10.2174/1567205013666161201200209
41. Vu, HM, Tang, HT, Hai, BVM, Nguyen, CD, Nguyen, MH, Le, HTK, et al. Comorbidities and health-related quality of life among rural older community-dwellers in Vietnam. PLoS One. (2025) 20:e0321267. doi: 10.1371/journal.pone.0321267
42. Che, Y, Xin, H, Gu, Y, Ma, X, Xiang, Z, and He, C. Associated factors of frailty among community-dwelling older adults with multimorbidity from a health ecological perspective: a cross-sectional study. BMC Geriatr. (2025) 25:172. doi: 10.1186/s12877-025-05777-0
43. Klinedinst, TC, Terhorst, L, and Rodakowski, J. Multimorbidity groups based on numbers of chronic conditions are associated with daily activity. Chronic Illn. (2022) 18:634–42. doi: 10.1177/17423953211023964
44. Strozza, C, Egidi, V, Vannetti, F, Cecchi, F, Macchi, C, and Pasqualetti, P. Self-assessment of health: how socioeconomic, functional, and emotional dimensions influence self-rated health among Italian nonagenarians. Qual Quant. (2024) 58:5257–73. doi: 10.1007/s11135-023-01724-6
45. Wang, J, and Geng, L. Effects of socioeconomic status on physical and psychological health: lifestyle as a mediator. Int J Environ Res Public Health. (2019) 16:281. doi: 10.3390/ijerph16020281
46. Zhang, L, Ding, D, Fethney, J, Neubeck, L, and Gallagher, R. Tools to measure health literacy among Chinese speakers: a systematic review. Patient Educ Couns. (2020) 103:888–97. doi: 10.1016/j.pec.2019.11.028
47. Gong, W, and Cheng, KK. Challenges in screening and general health checks in China. Lancet Public Health. (2022) 7:e989–90. doi: 10.1016/S2468-2667(22)00207-9
48. Zhang, CQ, Chung, PK, Zhang, R, and Schüz, B. Socioeconomic inequalities in older adults' health: the roles of neighborhood and individual-level psychosocial and behavioral resources. Front Public Health. (2019) 7:318. doi: 10.3389/fpubh.2019.00318
49. Cai, J, Coyte, PC, and Zhao, H. Determinants of and socio-economic disparities in self-rated health in China. Int J Equity Health. (2017) 16:7. doi: 10.1186/s12939-016-0496-4
50. Barakat, C, and Konstantinidis, T. A review of the relationship between socioeconomic status change and health. Int J Environ Res Public Health. (2023) 20:6249. doi: 10.3390/ijerph20136249
51. Sulander, T, Heinonen, H, Pajunen, T, Karisto, A, Pohjolainen, P, and Fogelholm, M. Longitudinal changes in functional capacity: effects of socio-economic position among ageing adults. Int J Equity Health. (2012) 11:78. doi: 10.1186/1475-9276-11-78
52. Knutson, D, Irgens, MS, Flynn, KC, Norvilitis, JM, Bauer, LM, Berkessel, JB, et al. Associations between primary residence and mental health in global marginalized populations. Community Ment Health J. (2023) 59:1083–96. doi: 10.1007/s10597-023-01088-z
53. Griffith, GJ, and Jones, K. When does geography matter most? Age-specific geographical effects in the patterning of, and relationship between, mental wellbeing and mental illness. Health Place. (2020) 64:102401. doi: 10.1016/j.healthplace.2020.102401
54. Cai, J, Gao, Y, Hu, T, Zhou, L, and Jiang, H. Impact of lifestyle and psychological resilience on survival among the oldest-old in China: a cohort study. Front Public Health. (2023) 11:1329885. doi: 10.3389/fpubh.2023.1329885
55. Hajek, A, and König, HH. Determinants of psychosocial factors among the oldest old – evidence from the representative "survey on quality of life and subjective well-being of the very old in North Rhine-Westphalia (NRW80+)". Int J Geriatr Psychiatry. (2023) 38:e6031. doi: 10.1002/gps.6031
56. Davey, J, Holden, CA, and Smith, BJ. The correlates of chronic disease-related health literacy and its components among men: a systematic review. BMC Public Health. (2015) 15:589. doi: 10.1186/s12889-015-1900-5
57. Temkin, SM, Barr, E, Moore, H, Caviston, JP, Regensteiner, JG, and Clayton, JA. Chronic conditions in women: the development of a National Institutes of health framework. BMC Womens Health. (2023) 23:162. doi: 10.1186/s12905-023-02319-x
58. Schlünssen, V, and Jones, RM. Gender aspects in occupational exposure and health studies. Ann Work Expo Health. (2023) 67:1023–1026. doi: 10.1093/annweh/wxad063
59. Patwardhan, V, Gil, GF, Arrieta, A, Cagney, J, DeGraw, E, Herbert, ME, et al. Differences across the lifespan between females and males in the top 20 causes of disease burden globally: a systematic analysis of the global burden of disease study 2021. Lancet Public Health. (2024) 9:e282–94. doi: 10.1016/S2468-2667(24)00053-7
60. Chen, X, Wang, X, Gan, M, Li, L, Chen, F, Pan, J, et al. MRI-based radiomics model for distinguishing endometrial carcinoma from benign mimics: a multicenter study. Eur J Radiol. (2022) 146:110072. doi: 10.1016/j.ejrad.2021.110072
61. Ding, R, Chen, T, Zhang, Y, Chen, X, Zhuang, L, and Yang, Z. HMGCS2 in metabolic pathways was associated with overall survival in hepatocellular carcinoma: a LASSO-derived study. Sci Prog. (2021) 104:368504211031749. doi: 10.1177/00368504211031749
62. Muschelli, J. ROC and AUC with a binary predictor: a potentially misleading metric. J Classif. (2020) 37:696–708. doi: 10.1007/s00357-019-09345-1
63. Raihan, MJ, Khan, MA, Kee, SH, and Nahid, AA. Detection of the chronic kidney disease using XGBoost classifier and explaining the influence of the attributes on the model using SHAP. Sci Rep. (2023) 13:6263. doi: 10.1038/s41598-023-33525-0
Keywords: machine learning, multimorbidity, Chinese older adult, XGBoost, SHAP, predictive model
Citation: Gong W, Hu X, Cui H, Zhao Y, Lin H, Sun P and Yang J (2025) Socioeconomic status and lifestyle as factors of multimorbidity among older adults in China: results from the China Health and Retirement Longitudinal Survey. Front. Public Health. 13:1586091. doi: 10.3389/fpubh.2025.1586091
Edited by:
Surapati Pramanik, Nandalal Ghosh B.T. College, IndiaReviewed by:
Arinjita Bhattacharyya, University of Louisville, United StatesOlga Vasiliauskiene, Lithuanian University of Health Sciences, Lithuania
Copyright © 2025 Gong, Hu, Cui, Zhao, Lin, Sun and Yang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jianjun Yang, eWFuZ2pqQG54bXUuZWR1LmNu; Peng Sun, c3VucGVuZ0BueG11LmVkdS5jbg==