 Qin Zeng
Qin Zeng Xi Huang
Xi Huang Jun Zhu
Jun Zhu Shaoyu Su1,2
Shaoyu Su1,2- 1Department of Pediatrics Nursing, West China Second University Hospital, Sichuan University, Chengdu, China
- 2Key Laboratory of Birth Defects and Related Diseases of Women and Children, Sichuan University, Ministry of Education, Chengdu, China
- 3Department of Neonatology Nursing, West China Second University Hospital, Sichuan University, Chengdu, China
- 4Department of Pediatrics, National Office for Maternal and Child Health Surveillance of China, National Center for Birth Defect Surveillance of China, West China Second University Hospital, Chengdu, China
Aim: This study aimed to explore the formation mechanism of artificial intelligence (AI) usage intention among nurses in public hospitals in Beijing, Sichuan, and Yunnan, China, analyzing the influence of AI literacy on usage intention through AI self-efficacy and general attitudes.
Methods: A multi-center cross-sectional design was adopted, surveying 901 registered nurses via the Wenjuanxing platform from December 26, 2024, to February 25, 2025, with 878 valid questionnaires returned (effective rate 97.45%). Data were collected using the AI Literacy Scale (AILS), General Attitudes toward AI Scale (GAAIS), AI Self-Efficacy Scale (AISES), and AI Usage Intention Scale. Descriptive statistics, correlation analysis, and structural equation modeling (SEM) analysis were conducted using SPSS 26.0 and AMOS 26.0, with case weighting adjustments based on the total number of nurses in each region.
Results: Of the respondents, females accounted for 94.08%, those aged 40 and below accounted for 84.03%, and only 14.24% of nurses had received AI training. The average scores for GAAIS, AILS, and AISES were 69.33 ± 10.31, 56.27 ± 8.60, and 107.92 ± 22.35, respectively, with higher scores observed among nurses with master’s degrees or above, preceptors, and those in Beijing. GAAIS showed strong positive correlations with AILS (r = 0.549), GAAIS with AISES (r = 0.567), and AILS with AISES (r = 0.684, p < 0.001), and AI usage intention was closely correlated with all three (p < 0.001). Structural equation modeling analysis indicated that the direct effect of AI literacy on usage intention accounted for 30.51%, with indirect effects through AI self-efficacy (21.41%) and general attitudes (14.58%), resulting in a total effect of 0.967 (p < 0.001).
Conclusion: AI literacy effectively promotes nurses’ AI usage intention by enhancing their self-efficacy and improving their attitudes toward AI, with self-efficacy being particularly crucial. This mechanism, combining both direct and indirect effects, suggests that enhancing confidence and knowledge is key to promoting AI acceptance. Given the low training participation rate (14.24%) and regional disparities (Beijing outperforming Yunnan), it is recommended that hospitals implement systematic AI training, prioritizing groups with low training exposure and underdeveloped regions, while simultaneously improving attitudes through promotional activities to advance the widespread adoption of AI in nursing and elevate patient care standards.
1 Introduction
With the rapid development of artificial intelligence (AI) technology in healthcare, its potential to enhance nursing quality and efficiency has become increasingly evident. Systematic and scoping reviews indicate that AI technologies, such as intelligent diagnostic systems, nursing robots, and electronic health record management, have been widely applied in clinical practice, providing nurses with efficient decision-making support and patient management tools (1–4). For instance, recent studies have proposed a predictive framework for IoT-based smart healthcare systems, leveraging predictive analytics to accurately estimate child mortality rates, providing real-time intervention support in resource-limited regions (5). Furthermore, AI technologies can optimize nursing processes and improve patient outcomes (6), particularly in the security of smart IoT devices, such as intrusion detection systems for people with disabilities, which have shown significant application potential (7). However, these reviews consistently highlight challenges faced by nurses, including low technology acceptance, insufficient AI-related knowledge, and a lack of confidence, which significantly hinder the adoption of AI in nursing practice (2, 4). As a core component of the healthcare system, nurses play a critical role in the implementation and application of AI technologies, with their attitudes and willingness to use AI directly impacting its effective integration into clinical practice (8). Therefore, systematically exploring the factors influencing nurses’ AI adoption intentions and their underlying mechanisms is essential for promoting AI applications in nursing and providing theoretical and practical insights to enhance care quality.
In China, AI technologies are gradually being integrated into the healthcare system, particularly in smart medical devices and data-driven nursing management (9). Comprehensive literature suggests that research on AI applications in nursing is predominantly focused on Western countries, with limited attention to the unique characteristics of China’ s healthcare system, cultural context, and technological resources (2, 4). A cross-sectional study of Chinese nursing professionals found that only 57% of respondents had a basic understanding of AI, 64.7% had little knowledge of its specific applications in nursing, and 13.4% were completely unaware of AI in nursing, despite generally holding positive attitudes toward AI (8). Furthermore, significant disparities in medical resources and technological levels exist across different regions in China. For instance, Beijing, as a technologically advanced municipality, boasts sophisticated medical facilities and greater opportunities for AI technology adoption, whereas Sichuan and Yunnan, constrained by economic and technological limitations, offer nurses fewer opportunities to engage with AI (3, 9). Recent studies have analyzed infant mortality rates in Pakistan and Ethiopia using data mining models, revealing the impact of regional differences on nursing data analysis (10), which resonates to some extent with the regional challenges faced by Chinese nurses. However, existing research rarely addresses regional variations in Chinese nurses’ willingness to adopt AI, particularly in applications for child health prediction and nursing data management (5, 10).
This study constructs a theoretical framework based on the Technology Acceptance Model (TAM) and the Theory of Planned Behavior (TPB) to explore the formation mechanism of nurses’ AI usage intention. The Technology Acceptance Model (TAM) posits that perceived usefulness and perceived ease of use influence behavioral intentions through attitudes, while the Theory of Planned Behavior (TPB) further emphasizes the critical role of self-efficacy (perceived behavioral control) in shaping behavioral intentions (11–13). Extensive research indicates that individuals’ attitudes toward technology reflect their overall cognitive and emotional orientations, while self-efficacy measures their confidence in using technology, which is particularly crucial in AI technology applications (14, 15). Systematic reviews further suggest that positive AI attitudes and high self-efficacy significantly enhance technology adoption intentions (2, 4). Moreover, AI literacy, as a foundational variable, may indirectly influence adoption intentions by enhancing attitudes and self-efficacy (8, 16). Recent studies have also explored the application of multimodal generative AI and autoregressive large language models (LLMs) in human motion understanding and generation, demonstrating how AI can enhance the contextual relevance of nursing-related tasks through semantic alignment (17). This offers new perspectives for improving nurses’ AI literacy. However, existing studies have rarely systematically explored the mediating mechanisms among AI literacy, attitudes, and self-efficacy, particularly within the context of Chinese nurses.
Research on AI applications in nursing has made some progress, but systematic reviews reveal several shortcomings (1, 2, 4). Firstly, most studies focus on single variables (such as attitudes or self-efficacy), lacking systematic analysis of the mediating mechanisms among AI literacy, attitudes, and self-efficacy. Second, empirical studies targeting Chinese nurses are scarce, especially those considering regional differences (e.g., Sichuan, Yunnan, and Beijing). Finally, research on AI applications in nursing predominantly centers on Western countries, with the unique characteristics of Chinese nurses—such as healthcare system, cultural background, and technological resources—remaining underexplored. Thus, investigating how AI literacy affects AI usage intention through self-efficacy and attitude pathways among nurses in Sichuan, Yunnan, and Beijing holds significant research value. Recent studies have proposed a lightweight multistage holographic attention network for image super-resolution, demonstrating AI’s optimization potential in resource-constrained environments (18), which is highly relevant to the current state of nursing technology applications in some regions of China. Additionally, the use of unified large language models to detect misinformation in low-resource languages (19) offers new insights for information management in nursing, indirectly supporting nurses’ trust and adoption of AI tools.
This study targets nurses in Sichuan, Yunnan, and Beijing, China, to examine the mechanisms by which AI literacy influences AI usage intention through self-efficacy and general AI attitudes. We propose the following hypothetical: (1) H1: AI literacy directly affects usage intention by enhancing self-efficacy; (2) H2: AI literacy indirectly influences usage intention by improving general AI attitudes; (3) H3: AI literacy further impacts attitudes via self-efficacy, subsequently affecting usage intention. Employing a cross-sectional survey method, this study uses multidimensional scales (General Attitudes toward AI Scale, AI Literacy Scale, AI Self-Efficacy Scale) to assess nurses’ related variables, with structural equation modeling (SEM) applied to validate these mediating pathways.
Theoretically, this study validates the mediating effects of AI literacy on usage intention through self-efficacy and attitude pathways, enriching the application of TAM and TPB in nursing. Existing reviews indicate that the formation mechanisms of AI adoption intentions remain underexplored in non-Western contexts (2, 4). This study aims to fill the gap in research on regional differences and mediating mechanisms among Chinese nurses. Practically, the findings can provide a basis for hospital administrators to develop targeted AI training programs. For instance, in regions with limited technological resources, such as Sichuan and Yunnan, enhancing AI literacy and self-efficacy can boost adoption intentions, while in technologically advanced Beijing, optimizing AI attitude training can facilitate technology implementation (3, 20). Moreover, the findings offer policymakers guidance to promote the widespread application of AI in nursing practice, ultimately improving nursing quality and patient care outcomes (Figure 1).
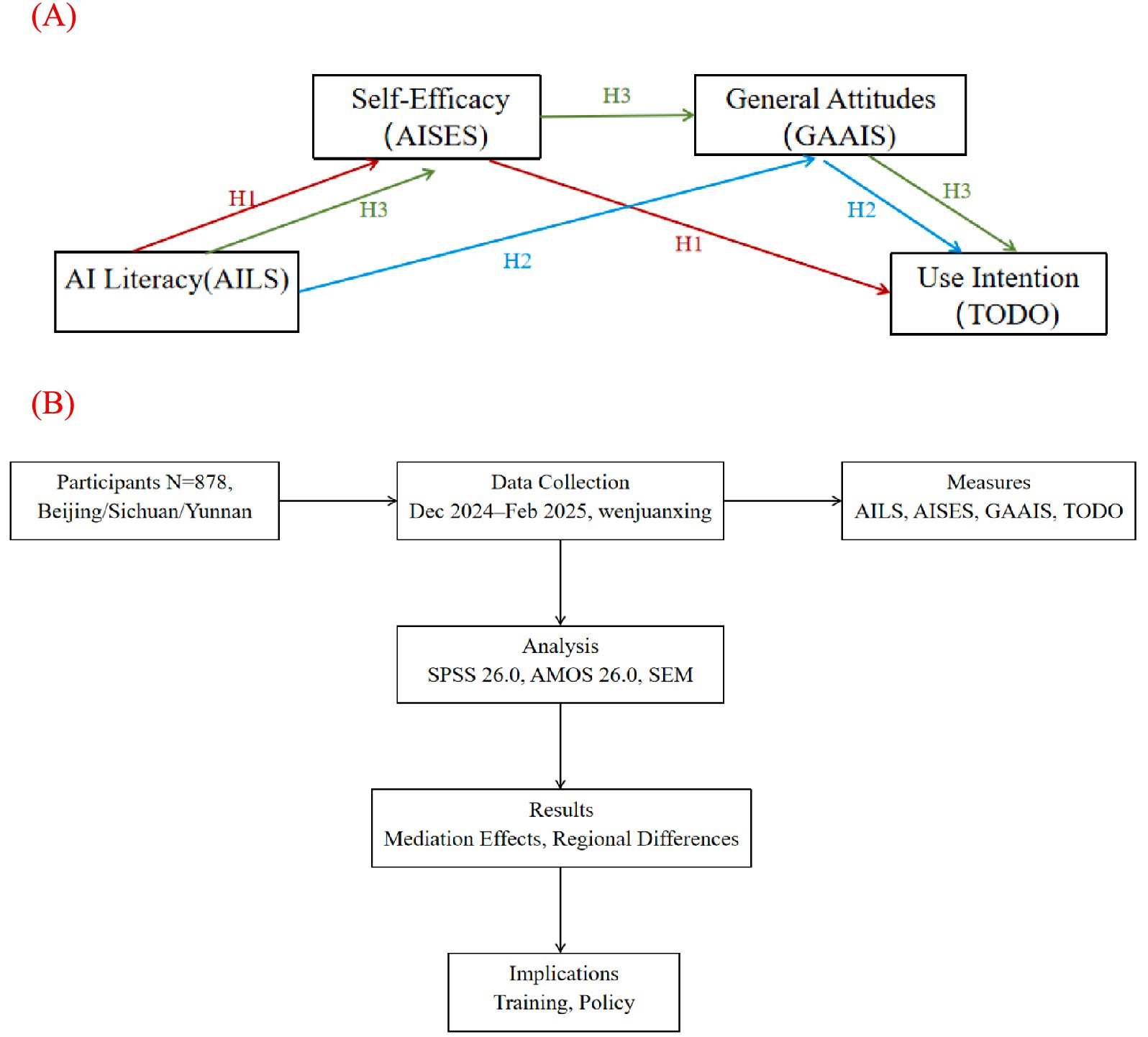
Figure 1. Framework of the study. (A) Theoretical model illustrating the mediating pathways from AI literacy (AILS) to AI use intention (TODO) via AI self-efficacy (AISES) and general attitudes (GAAIS). (B) Research process, including participant selection, data collection, measurement tools, and analytical methods.
2 Participants and methods
2.1 Study participants
This study targeted registered nurses from public hospitals in Beijing, Sichuan, and Yunnan, China, aiming to explore the roles of AI literacy, self-efficacy, and attitudes in the formation mechanism of nurses’ artificial intelligence (AI) usage intention, with a particular focus on the mediating effect of AI literacy through the pathway of self-efficacy to attitudes. Considering the potential demand for AI technologies in nursing services, eligible registered nurses were recruited through the Chinese Nursing Association. A preliminary literature review indicated insufficient prior data on AI usage intention and related mediating mechanisms among nurses in these regions to provide an a priori proportion. Thus, the expected proportion of nurses’ attitudes and usage intention toward AI was assumed to be 50% (p = 0.50). Based on the sample size calculation formula for cross-sectional studies, with a margin of error set at 5% (E = 0.05) and a confidence level of 95% (Z = 1.96), the minimum required sample size for simple random sampling was calculated as 385 participants. Accounting for a 15% non-response rate (based on empirical data from similar studies), the adjusted sample size was 453 participants (385 ÷ 0.85). According to the China Statistical Yearbook 2023, the number of nurses in public hospitals in Beijing, Sichuan, and Yunnan was 126,111, 318,267, and 189,852, respectively. Based on proportional weighting , the sample required at least 90 participants from Beijing , 227 from Sichuan , and 136 from Yunnan Due to the use of convenience sampling within hospitals in three provinces, there may be intra-cluster correlations among nurses from the same province in terms of cognition or attitudes. Therefore, a clustered sampling structure was considered in the sample design. Using provinces (Beijing, Sichuan, and Yunnan) as the clustering units, the average sample size per province was 151. Based on commonly reported intraclass correlation coefficient (ICC) values in social science and health research (typically ranging from 0.01 to 0.05) (21), an ICC of 0.03 was conservatively assumed. Accordingly, the design effect (DEFF) was estimated as: DEFF = 1 + (151–1) × 0.03 = 5.5. Although full compensation for the design effect would theoretically require a much larger sample, a pragmatic approach was adopted considering fieldwork constraints and the use of robust structural equation modeling techniques. Thus, the sample size was conservatively inflated by a factor of 1.5 to enhance representativeness and reduce sampling error while maintaining analytical precision. The final minimum target sample size was set at 680 participants (453 × 1.5). A total of 901 questionnaires were distributed, with 878 valid responses collected, yielding a response rate of 97.45%. Among these, 91 participants were from Beijing (planned minimum: 90), 549 from Sichuan (planned minimum: 227), and 238 from Yunnan (planned minimum: 136), all meeting or exceeding the planned sample sizes and satisfying regional representativeness requirements. All participants signed an electronic informed consent form prior to participation, fully understanding the study’ s purpose and content.
2.2 Methods and quality control
This study adopted a multi-center cross-sectional survey design, collecting data through convenience sampling. Data collection was coordinated by the Chinese Nursing Association. The director of the nursing department at the researcher’ s hospital distributed questionnaires to national committee members of the association, who then forwarded them to nursing department directors and head nurses in public hospitals in Beijing, Sichuan, and Yunnan, ultimately distributing them to registered nurses for completion. The questionnaires were administered electronically via the Wenjuanxing platform1 from December 26, 2024 to February 25, 2025, with nurses completing them anonymously online by scanning a QR code. To ensure completeness, all questions were set as mandatory, and each device was restricted to submitting only one response. To maintain data quality, based on pre-survey results (average response time of 362.24 s), questionnaires completed in <120 s were excluded. Additionally, collected data underwent logical consistency checks to eliminate responses with obvious contradictions. This study received approval from the Medical Research Ethics Committee of the researcher’ s institution [Ethics approval number: medical research 2024 ethics approval no. (202)]. Prior to participation, all respondents were required to review an electronic informed consent form on the questionnaire’ s homepage, which detailed the study’ s purpose, content, and privacy protection measures, and could proceed to complete the questionnaire only after providing consent. All data were anonymized to ensure the confidentiality and security of participants’ personal information and responses.
2.3 Survey instruments
2.3.1 General information questionnaire
This study utilized a self-designed questionnaire to collect nurses’ general information, including gender, age group, ethnicity, marital status, educational level, professional title, years of work experience, work department, job content, whether they serve as a preceptor, AI-related training experience, province of the workplace, hospital type, hospital level, and whether the hospital is a teaching hospital. To further assess nurses’ intention to use AI, two additional questions were included: “Are you willing to use AI to assist in learning and work?”(USE) and “Are you willing to receive training on AI-related knowledge?”(LEA) These questions were scored using a 10-point Likert-type scale, where 0 represents “completely unwilling” and 10 represents “completely willing.” The average score of the two items was used to construct the “AI Usage Intention”(TODO as a custom code) variable for subsequent analysis. The internal consistency of this variable was high (Cronbach’s α = 0.924).
2.3.2 General attitudes toward artificial intelligence scale (GAAIS)
The General Attitudes toward Artificial Intelligence Scale (GAAIS), developed by Schepman and Rodway (22), has been validated as an effective tool for measuring individuals’ positive and negative attitudes toward AI and has been successfully applied to assess attitudes among nurses (23). The scale comprises two subscales—positive attitudes and negative attitudes—with a total of 20 items, scored on a 5-point Likert-type scale. Items in the positive attitude subscale are scored directly (1 = strongly disagree, 5 = strongly agree), while items in the negative attitude subscale are reverse-scored (5 = strongly disagree, 1 = strongly agree). The total score ranges from 20 to 100, with higher scores indicating more positive attitudes. In this study, the Cronbach’ s α for the overall GAAIS was 0.903, with values of 0.952 and 0.955 for the positive and negative attitude subscales, respectively. Additionally, the scale’ s Kaiser-Meyer-Olkin (KMO) value was 0.945, and Bartlett’ s test of sphericity showed a significance level of <0.001, indicating excellent internal consistency and structural validity for the adapted Chinese version, making it suitable for this study.
2.3.3 Artificial intelligence literacy scale (AILS)
The Artificial Intelligence Literacy Scale (AILS), developed by Wang et al. (24), is considered one of the ideal tools for assessing AI literacy due to its proposed four-dimensional structural model, encompassing awareness, usage, evaluation, and ethical capability. The scale aims to quantify core competencies of general users in the AI domain and has been validated and applied in groups such as students, teachers, and nurses (25–27). The AILS consists of four subscales—awareness, usage, evaluation, and ethics—with a total of 12 items, scored on a 7-point Likert-type scale (1 = strongly disagree, 7 = strongly agree). Three items are reverse-scored, and the total score ranges from 12 to 84, with higher scores indicating greater AI literacy. In this study, the overall Cronbach’s α for the AILS was 0.829, with a Kaiser-Meyer-Olkin (KMO) value of 0.894 and a Bartlett’s test of sphericity significance level <0.001, demonstrating good internal consistency and structural validity, making the scale suitable for this study.
2.3.4 Artificial intelligence self-efficacy scale (AISES)
The Artificial Intelligence Self-Efficacy Scale (AISES), developed by Wang and Chuang (28), is designed to assess individuals’ perceived self-efficacy regarding specific features of AI technology. The scale has been widely applied and validated in groups such as students and educators (29). The AISES comprises 22 items, divided into four dimensions: Assistance, Anthropomorphic Interaction, Comfort with AI, and Technological Skills, scored on a 7-point Likert-type scale (1 = strongly disagree, 7 = strongly agree). The total score ranges from 22 to 154, with higher scores indicating stronger self-efficacy in using AI technologies/products. In this study, the overall Cronbach’ s α for the AISES was 0.980, with Cronbach’ s α values for the subscales (Assistance, Anthropomorphic Interaction, Comfort with AI, and Technological Skills) being 0.972, 0.937, 0.975, and 0.943, respectively. The scale’ s KMO value was 0.968, and Bartlett’ s test of sphericity showed a significance level <0.001, indicating excellent internal consistency and structural validity, making the scale suitable for this study.
2.4 Statistical analysis
This study utilized Epidata 3.1 for double data entry and logical checks to ensure data accuracy and consistency, with data analysis conducted using SPSS 26.0. To assess potential common method bias, Harman’ s single-factor test was applied to the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), and Artificial Intelligence Self-Efficacy Scale (AISES). Participants’ demographic characteristics and scale scores were presented through descriptive statistical analysis: demographic characteristics were expressed as frequencies and percentages (%), while continuous variables, such as scale scores, were assessed for normality. If normally distributed, they were described using mean ± standard deviation (x̄ ± s); otherwise, median and interquartile range [M (Q1, Q3)] were used. To correct for uneven regional sample distribution, case weighting adjustments were applied based on the total number of nurses in Beijing (126,111), Sichuan (318,267), and Yunnan (189,852) as reported in the China Statistical Yearbook 2023, and the actual sample sizes (91, 549, and 238, respectively). The weighting variable was entered into AMOS using the “sample weight” function and applied in the subsequent structural equation modeling analysis. The weight data were processed in SPSS, and AMOS successfully implemented the weighting.
For group comparisons of continuous variables, appropriate methods were selected based on normality and homogeneity of variance tests: for two-group comparisons, independent samples t-tests were used if normality and homogeneity of variance were satisfied; otherwise, Mann–Whitney U tests were employed. For comparisons involving three or more groups, one-way analysis of variance (ANOVA) with post-hoc multiple comparisons was used if normality and homogeneity of variance were met; otherwise, non-parametric tests were applied. Pearson correlation analysis was used to evaluate the relationships among GAAIS, AILS, and AISES scores, with correlation coefficients ranging from −1 to +1; values closer to 1 indicate stronger correlations, and 0 indicates no correlation. Structural equation modeling (SEM) was performed using AMOS 26.0 to analyze the path relationships among general attitudes toward AI, AI literacy, AI self-efficacy, and usage intention. In this study, we decided to use composite scores to simplify the analysis process. We recognize that using composite scores may introduce some bias, as it may obscure the independent contributions of each item. To minimize this bias, we ensured that the three scales used are well-established and validated, with strong internal consistency. While item-level modeling could theoretically provide more detailed analysis, the complexity of the models could lead to overly complicated results, especially when there are many items in each scale, and the items are highly correlated. This approach is consistent with prior research and widely accepted in the field. All statistical tests adopted a two-tailed significance level of α = 0.05.
3 Results
3.1 General characteristics of participants
This study distributed 901 questionnaires, of which 2 respondents declined participation, and 21 questionnaires were excluded due to completion times of <120 s. Ultimately, 878 valid questionnaires were collected, yielding an effective response rate of 97.45%. Among the respondents, females accounted for 94.08% (n = 826), those aged 40 and below comprised 84.03% (n = 738), Han ethnicity represented 92.71% (n = 814), and married individuals made up 70.62% (n = 620). The majority had a bachelor’ s degree or undergraduate education (75.74%, n = 665), and those with junior or intermediate professional titles accounted for 82.92% (n = 728). Years of work experience were relatively evenly distributed. The predominant work department was pediatrics (49.32%, n = 433), with 92.37% (n = 811) engaged in clinical nursing. Preceptors comprised 56.04% (n = 492), and only 14.24% (n = 125) had received professional AI-related training. Regarding workplace, specialty hospitals and general hospitals accounted for 49.66% (n = 436) and 50.34% (n = 442), respectively; 57.52% (n = 505) of respondents were from Grade IIIA hospitals, and 71.53% (n = 628) worked in teaching hospitals. The mean score of the “AI Usage Intention” variable was 8.40 ± 1.92, indicating a generally high level of willingness to use AI among participants. Detailed information is presented in Table 1.
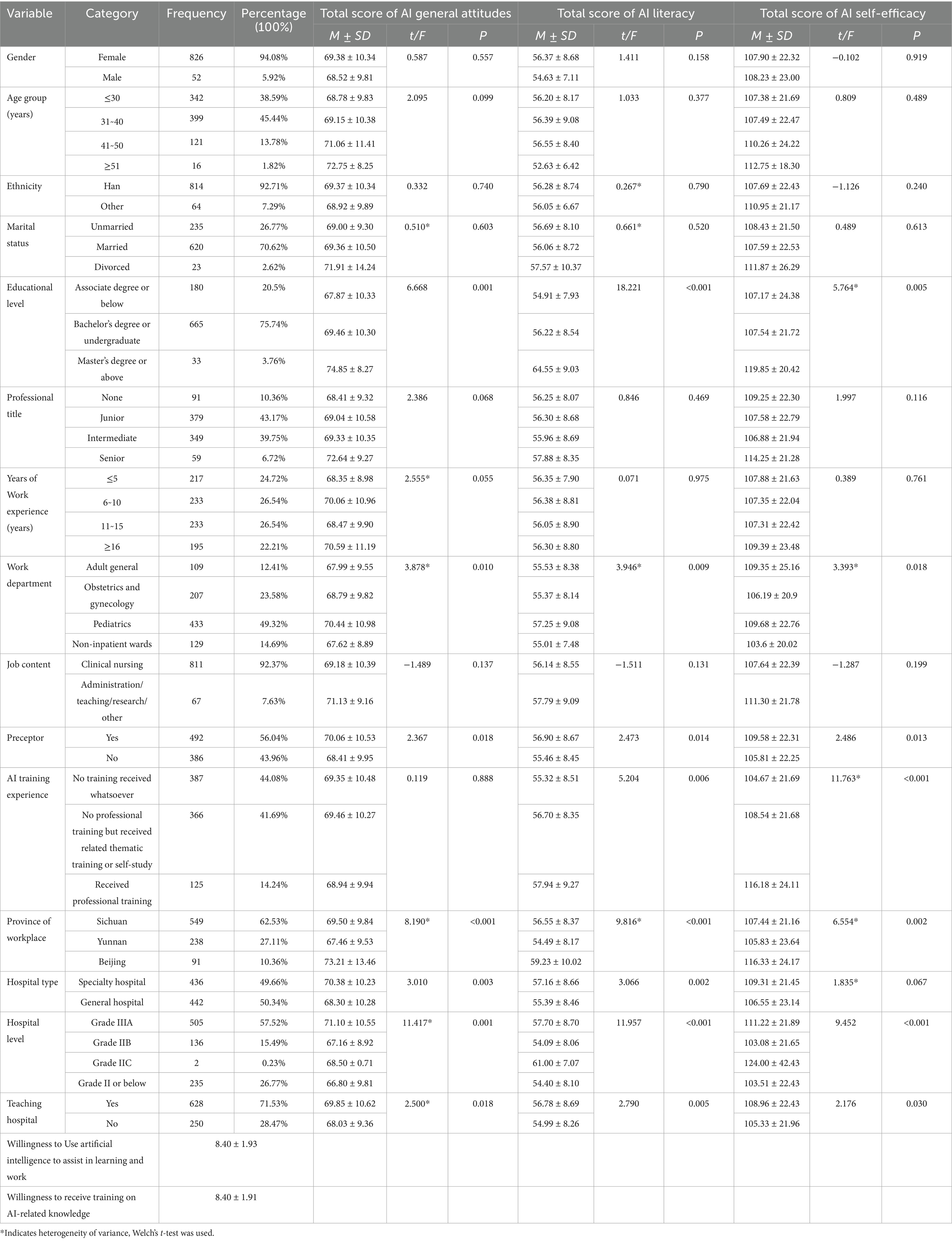
Table 1. Differences in AI general attitudes, AI literacy, and AI self-efficacy across general characteristics of participants (N = 878).
3.2 Scores and influencing factors of AI general attitudes, AI literacy, and AI self-efficacy
The mean scores for the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), and Artificial Intelligence Self-Efficacy Scale (AISES) were 69.33 ± 10.31, 56.27 ± 8.60, and 107.92 ± 22.35, respectively. Analysis of demographic characteristics revealed significant differences in scale scores across different groups (Table 1).
AI general attitude scores: significant differences were observed based on educational level (p = 0.001), work department (p = 0.010), preceptor status (p = 0.018), province of workplace (p < 0.001), hospital type (p = 0.003), hospital level (p = 0.001), and teaching hospital status (p = 0.018).
AI literacy scores: significant differences were found based on educational level (p < 0.001), work department (p = 0.009), preceptor status (p = 0.014), AI-related training experience (p = 0.006), province of workplace (p < 0.001), hospital type (p = 0.002), hospital level (p < 0.001), and teaching hospital status (p = 0.005).
AI self-efficacy scores: significant differences were identified based on educational level (p = 0.005), work department (p = 0.018), preceptor status (p = 0.013), AI-related training experience (p < 0.001), province of workplace (p = 0.002), hospital level (p < 0.001), and teaching hospital status (p = 0.005).
3.3 Common method Bias test
This study employed Harman’ s single-factor test to assess common method bias. The results showed five factors with eigenvalues >1, with the first factor accounting for 20.62% of the variance and the cumulative variance of the top five factors explaining 73.53%. Since the variance explained by the first factor was well below the critical threshold of 50%, it indicates that no single factor accounted for the majority of the variance, suggesting that common method bias was not significant in this study.
3.4 Group differences analysis of AI general attitudes, AI literacy, and AI self-efficacy
T-tests, Mann–Whitney U tests, or one-way analysis of variance (ANOVA) were used to examine differences in scores of the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), and Artificial Intelligence Self-Efficacy Scale (AISES) across various demographic characteristics (Table 1). The results indicated that preceptors had significantly higher total scores for GAAIS, AILS, and AISES compared to non-preceptors (p < 0.05), and nurses in teaching hospitals scored significantly higher than those in non-teaching hospitals (p < 0.05). By hospital type, nurses in specialty hospitals had higher GAAIS and AILS total scores than those in general hospitals (p < 0.05), but no statistically significant difference was found in AISES scores (p > 0.05).
For data with equal variances, the LSD method is used for post-hoc multiple comparisons, and Cohen’s d is supplemented to measure the effect size. For data with unequal sample sizes and unequal variances, the Games-Howell method is used for post-hoc multiple comparisons, and Glass’ Delta based on the control group’ s standard deviation is supplemented to calculate the effect size. All statistical tests adopted a two-tailed significance level of α = 0.05. The results of multiple comparisons are detailed in Table 2.
1. Educational level: the GAAIS, AILS, and AISES scores of the master’ s degree or above group were significantly higher than those of the associate degree or below group and the bachelor’ s degree or undergraduate group (p < 0.05). No statistically significant differences were observed between the associate degree or below group and the bachelor’s degree or undergraduate group (p > 0.05).
2. Work department: significant differences were found in GAAIS, AILS, and AISES scores between pediatric nurses and nurses in non-inpatient wards (p < 0.05). Pairwise comparisons among other departments showed no statistically significant differences (p > 0.05).
3. Province of workplace: after case weighting adjustments based on the total number of nurses and actual sample sizes in Beijing, Sichuan, and Yunnan, Beijing nurses’ GAAIS, AILS, and AISES scores were significantly higher than those of Sichuan nurses (p < 0.05), and Sichuan nurses’ scores were significantly higher than those of Yunnan nurses (p < 0.05).
4. Hospital level: nurses in Grade IIIA hospitals had significantly higher GAAIS, AILS, and AISES scores than nurses in other hospital levels (p < 0.05). No statistically significant differences were found among nurses in other hospital levels (p > 0.05).
5. AI-related training experience: nurses who received AI-related training (including self-study or professional training) had significantly higher AILS scores than those without any training (p < 0.05), but no significant differences were found between the self-study and professional training groups (p > 0.05). For AISES scores, nurses who received professional training scored significantly higher than those with self-study or only related thematic training (p < 0.05), and the latter group scored significantly higher than those without any training (p < 0.05).
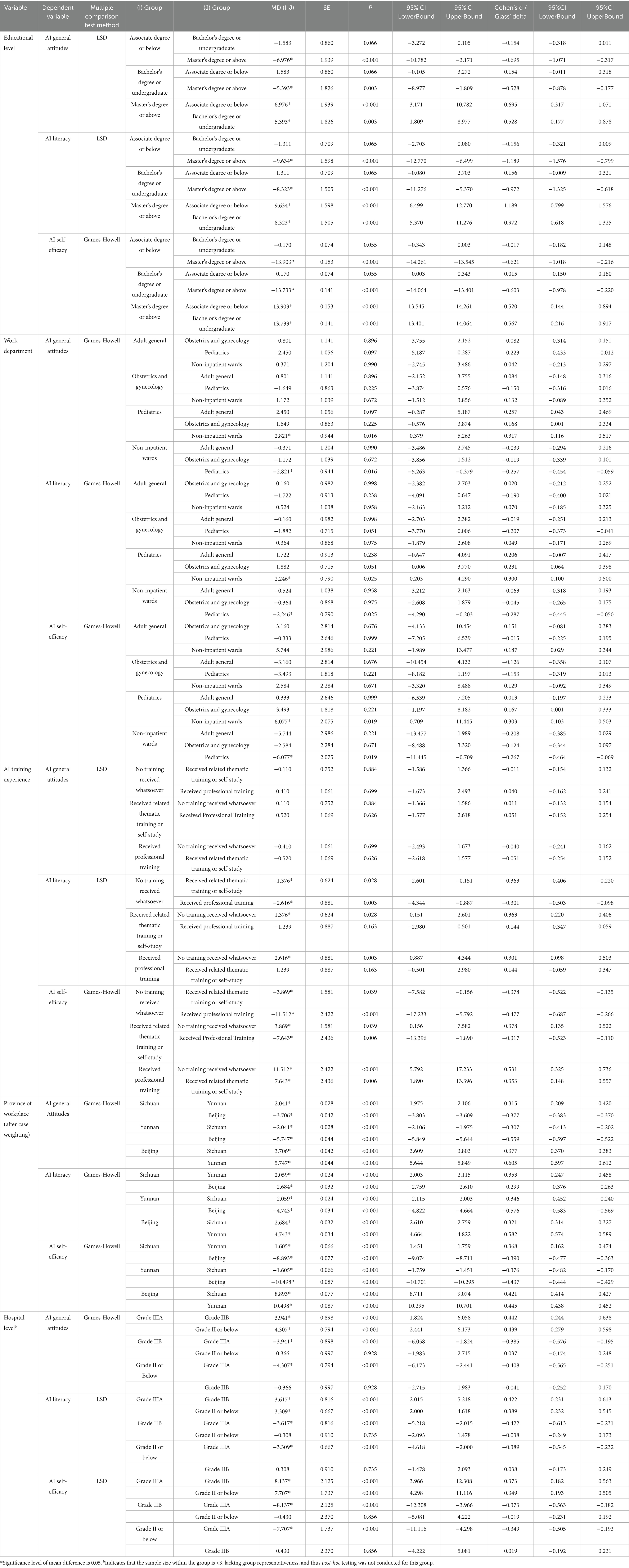
Table 2. Multiple comparisons of AI general attitudes, AI literacy, and AI self-efficacy across general characteristics of participants (N = 878).
3.5 Correlation analysis of AI general attitudes, AI literacy, AI self-efficacy, and usage intention
After applying case weighting adjustments for the province of the workplace, partial correlation analysis was conducted to control for the effects of variables including educational level, work department, preceptor status, AI-related training experience, province of workplace, hospital type, hospital level, and teaching hospital status. This analysis examined the correlations among the total scores of the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), Artificial Intelligence Self-Efficacy Scale (AISES), and AI usage intention (Table 3). The results showed significant positive correlations between GAAIS total scores and AILS total scores (r = 0.549, p < 0.001) and AISES total scores (r = 0.567, p < 0.001). AILS total scores were also significantly positively correlated with AISES total scores (r = 0.684, p < 0.001). Additionally, AI usage intention exhibited significant positive correlations with the total scores of GAAIS, AILS, and AISES (p < 0.001).
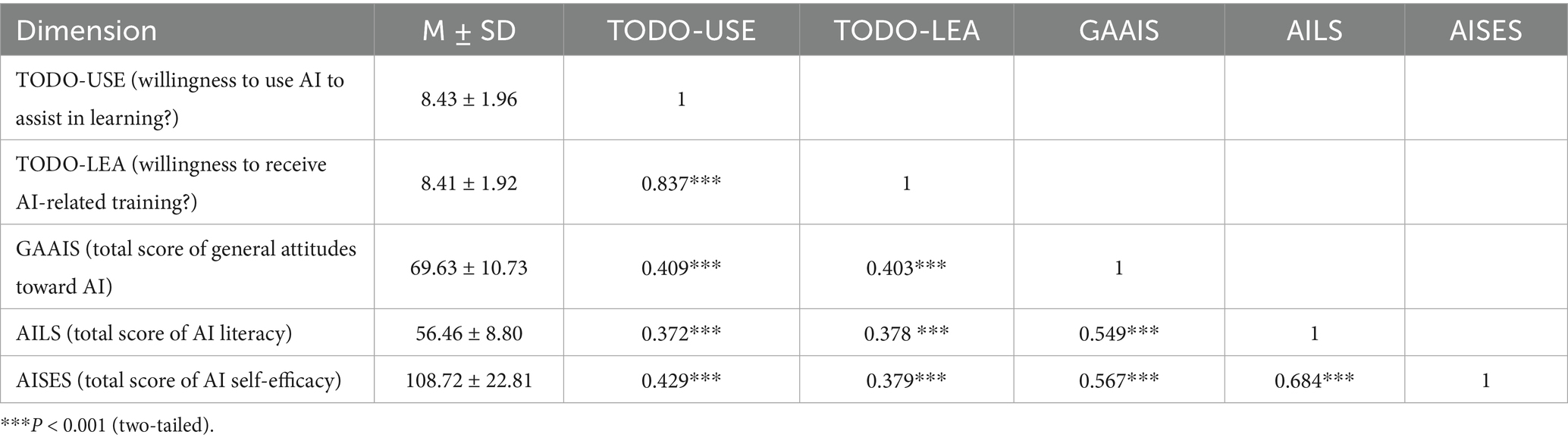
Table 3. Correlation analysis of AI general attitudes, AI literacy, AI self-efficacy, and usage intention (n = 878).
3.6 Mediating effect analysis of AI general attitudes, AI literacy, AI self-efficacy, and usage intention
Using AI usage intention (TODO) as the dependent variable, AI Literacy Scale (AILS) scores as the independent variable, and AI Self-Efficacy Scale (AISES) scores and General Attitudes toward Artificial Intelligence Scale (GAAIS) scores as mediating variables, a structural equation model (SEM) was constructed using AMOS 26.0 to analyze mediating effects. The model fit results were as follows: χ2/df = 4.581, RMSEA = 0.0824, TLI = 0.901, CFI = 0.940, SRMR < 0.049. Compared to the fit criteria (χ2/df < 5, RMSEA < 0.08, TLI and CFI > 0.90, SRMR < 0.08), the χ2/df and RMSEA values are slightly above the ideal threshold, possibly due to the large sample size (n = 878). However, CFI, TLI, and SRMR met the criteria for good fit, indicating that the overall model fit was adequate (Figure 2).
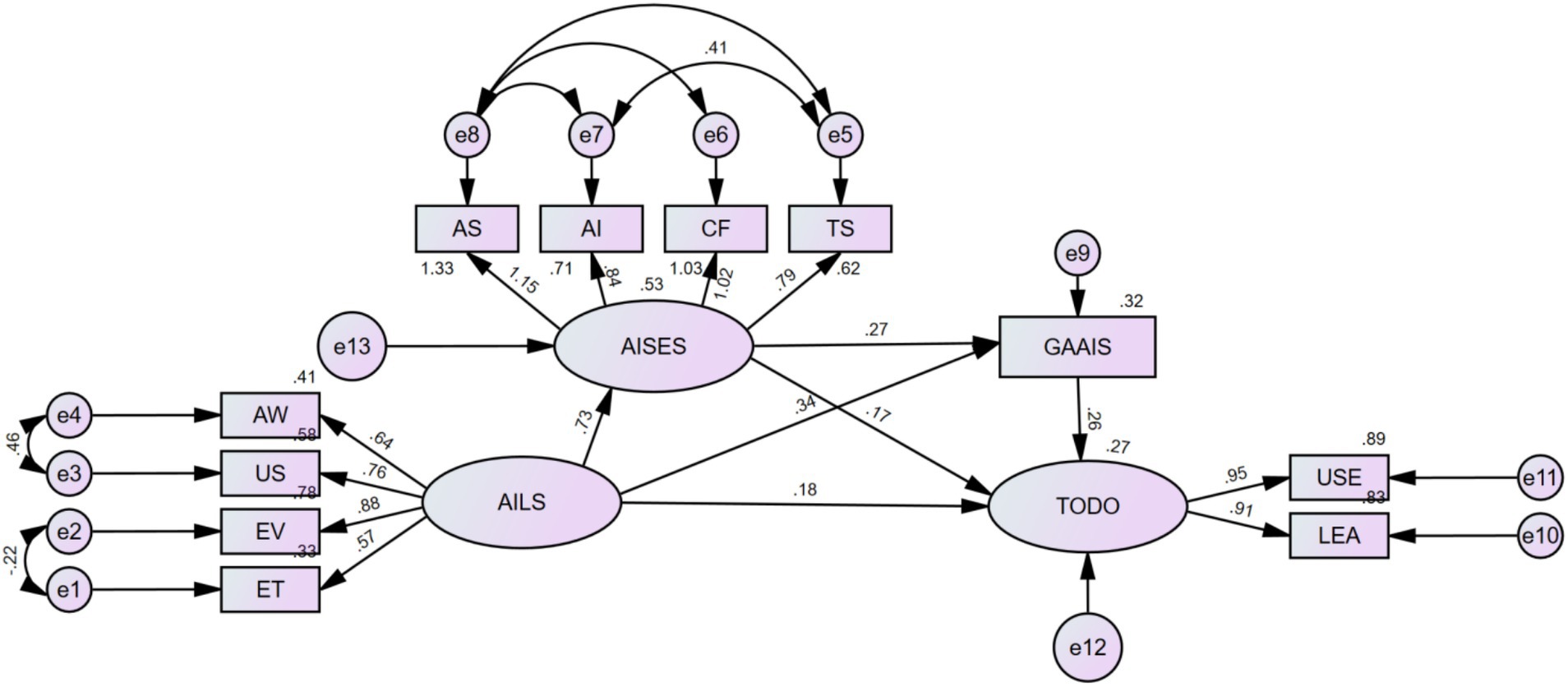
Figure 2. Mediation effect analysis of AI general attitudes, AI literacy, AI self-efficacy, and usage intention.
The path coefficient analysis of the SEM revealed the following (Table 4): the path coefficient from AILS to AISES was 0.728, from AILS to GAAIS was 0.343, and from AILS to TODO was 0.180; the path coefficient from AISES to GAAIS was 0.274 and from AISES to TODO was 0.172; the path coefficient from GAAIS to TODO was 0.261. All path coefficients were statistically significant (p < 0.001), indicating significant direct effects among the variables.
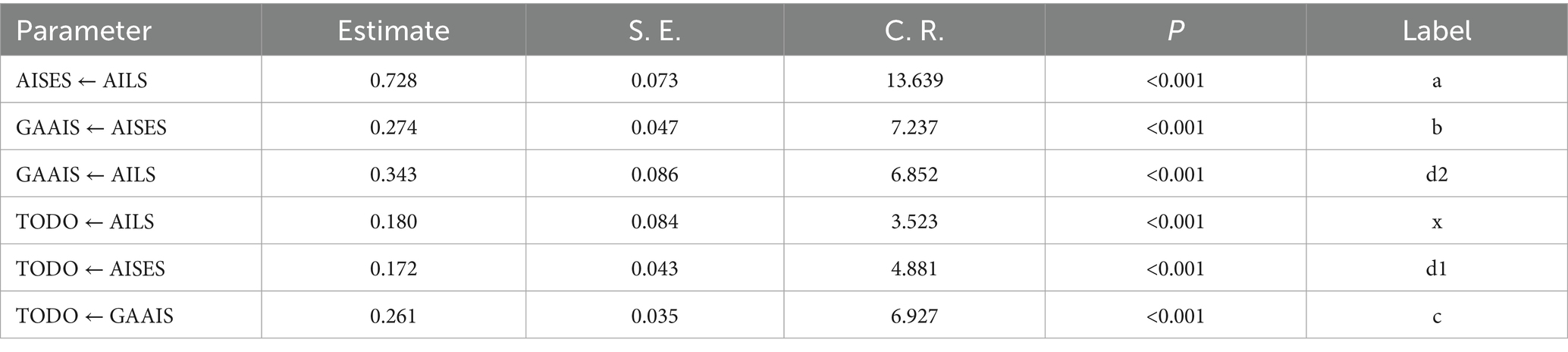
Table 4. Mediation effect analysis of AI general attitudes, AI literacy, AI self-efficacy, and usage intention (n = 878).
The Bootstrap method (5,000 resamples) was used to test the mediation effects, with results as follows (Table 5):
1. Path 1: AILS → AISES → TODO: The mediation effect value was 0.207.
2. (95% CI: 0.125–0.327, p < 0.001), accounting for 21.41% of the total effect.
3. Path 2: AILS → AISES → GAAIS → TODO: The mediation effect value was 0.082 (95% CI: 0.046–0.145, p < 0.001), accounting for 8.48% of the total effect.
4. Path 3: AILS → GAAIS → TODO: The mediation effect value was 0.141 (95% CI: 0.090–0.215, p < 0.001), accounting for 14.58% of the total effect.
5. Direct effect: AILS → TODO: The effect value was 0.295 (95% CI: 0.148–0.442, p = 0.002), accounting for 30.51% of the total effect.
6. Direct effect: GAAIS → TODO: The effect value was 0.242 (95% CI: 0.187–0.315, p < 0.001), accounting for 25.03% of the total effect.
7. Total effect: the total effect value was 0.967 (95% CI: 0.828–1.143, p < 0.001).
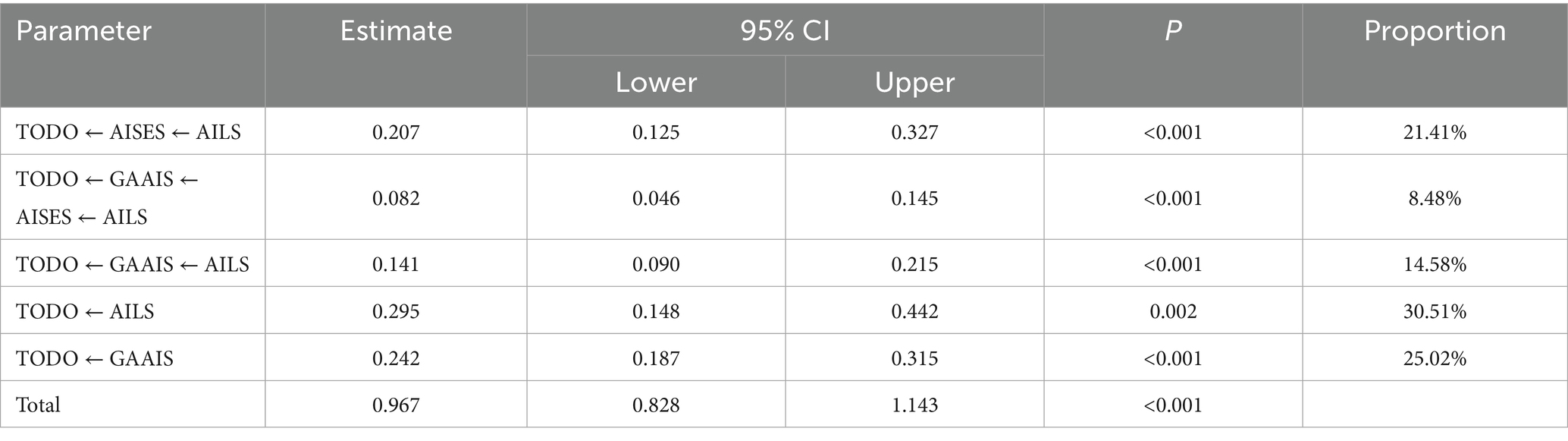
Table 5. Decomposition table of mediation effects for AI general attitudes, AI literacy, AI self-efficacy, and usage intention (n = 878).
The 95% confidence intervals for all mediation effects did not include 0, indicating that the mediation effects were significant. The influence pathways of AI literacy on usage intention through AI self-efficacy and general AI attitudes were both confirmed, with the direct effect (30.51%) and the mediation effect through AI self-efficacy (21.41%) accounting for the largest proportions.
4 Discussion
4.1 Influence of demographic characteristics on AI general attitudes, AI literacy, and AI self-efficacy
4.1.1 Influence of hospital type and level
This study found that nurses in specialty hospitals had significantly higher scores on the General Attitudes toward Artificial Intelligence Scale (GAAIS) and the Artificial Intelligence Literacy Scale (AILS) compared to those in general hospitals (p < 0.05), but no significant differences were observed in Artificial Intelligence Self-Efficacy Scale (AISES) scores. Nurses in Grade IIIA hospitals scored significantly higher on GAAIS, AILS, and AISES than those in other hospital levels (p < 0.05), with no significant differences among other hospital levels.
The higher GAAIS and AILS scores among specialty hospital nurses may be attributed to their frequent use of specific AI tools (e.g., clinical decision support systems or imaging analysis), which increases familiarity and positive attitudes toward AI. However, the lack of significant differences in AISES scores suggests that self-efficacy may depend more on individual training than hospital environment. Lambert et al. (30) indicated that the frequency of AI tool usage in hospitals significantly influences healthcare professionals’ technology acceptance, but confidence enhancement requires training. General hospitals, due to their broad service scope, may rely less on specific AI tools, resulting in lower scores. The highest scores among Grade IIIA hospital nurses reflect their technological resources and training opportunities. As top-tier medical institutions in China, Grade IIIA hospitals often lead in adopting AI technologies (e.g., intelligent monitoring systems) and provide more learning opportunities, enhancing nurses’ literacy, attitudes, and confidence. Maleki Varnosfaderani et al. (31) noted that advanced hospitals, with robust technological infrastructure, are more likely to promote AI application in clinical settings. Other hospital levels, limited by resources, show less AI integration and no significant score differences. This suggests that specialty hospitals should strengthen AI applications to improve attitudes and literacy, general hospitals need increased exposure to technology, and Grade IIIA hospitals can support lower-level hospitals through training and technological assistance to bridge the gap.
4.1.2 Score differences between preceptors and teaching hospital nurses
This study found that preceptors had significantly higher total scores on the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), and Artificial Intelligence Self-Efficacy Scale (AISES) compared to non-preceptors, and nurses in teaching hospitals scored significantly higher than those in non-teaching hospitals (p < 0.05).
The higher scores among preceptors may be attributed to their teaching responsibilities, which require mastering AI technologies, such as intelligent monitoring systems or data analysis tools, thereby enhancing their AI literacy and positive attitudes (AILS and GAAIS). Additionally, practical experience and feedback gained during teaching may bolster their confidence in using AI (AISES). Bandura’s (32) self-efficacy theory posits that mastery experiences and vicarious experiences (e.g., guiding others) significantly enhance self-efficacy. The higher scores of teaching hospital nurses reflect the technological and educational advantages of their environment. Teaching hospitals, often affiliated with medical schools, are equipped with advanced AI technologies (e.g., intelligent diagnostic systems or robotic-assisted nursing) and offer more training opportunities. These conditions likely increase nurses’ understanding and familiarity with AI (AILS), improve their attitudes (GAAIS), and enhance confidence through practice (AISES). Lambert et al. (30) found that teaching hospitals, with abundant resources and frequent technology exposure, exhibit higher AI acceptance among healthcare professionals, whereas non-teaching hospitals, constrained by limited resources, restrict nurses’ AI cognition. This aligns with Goldfarb et al.’s (33) perspective on the advantages of teaching hospitals in AI adoption. Practically, hospitals can leverage preceptors to promote AI knowledge and attitudes, and teaching hospitals should support non-teaching hospitals through training to bridge the gap.
4.1.3 Influence of educational level
This study found that nurses with a master’s degree or above had significantly higher scores on the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), and Artificial Intelligence Self-Efficacy Scale (AISES) compared to those with an associate degree or below and those with a bachelor’s degree or undergraduate education (p < 0.05). No significant differences were observed between the associate degree or below group and the bachelor’s degree or undergraduate group.
The higher scores among nurses with a master’s degree or above may be attributed to higher education providing more AI-related knowledge and skills training, such as courses on data analysis or intelligent healthcare systems, which enhance AI literacy (AILS) and positive attitudes (GAAIS). Additionally, research or practical opportunities may bolster their confidence in using AI (AISES). Dumić-Čule et al. (34) study indicated that higher education significantly improves healthcare professionals’ AI cognition and capabilities, particularly in understanding and applying intelligent healthcare systems. The lack of significant differences between the associate degree or below and bachelor’s degree groups may be due to the limited AI-related content in basic nursing education, which fails to distinctly differentiate the AI cognition of these two groups. This aligns with the Technology Acceptance Model (TAM), which posits that educational level influences perceived ease of use and usefulness, thereby enhancing attitudes and capabilities (11). Practically, nursing education should strengthen AI-related curricula, particularly for nurses with bachelor’s degrees or below, to improve their AI literacy and confidence.
4.1.4 Differences by work department
This study found significant differences in scores on the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), and Artificial Intelligence Self-Efficacy Scale (AISES) between pediatric nurses and nurses in non-inpatient wards (p < 0.05), while pairwise comparisons among other departments showed no significant differences.
The higher scores among pediatric nurses may be attributed to the greater demand for AI technologies in their work. Pediatrics frequently employs intelligent monitoring systems or disease prediction models to monitor children’s conditions, and the frequent use of these tools likely enhances nurses’ familiarity with AI (AILS) and positive attitudes (GAAIS). Additionally, hands-on experience may strengthen their confidence in using AI (AISES). Karaarslan et al.’s (35) study indicated that the high usage rate of AI tools in pediatric nursing significantly improves healthcare professionals’ technology acceptance and capabilities. Non-inpatient ward nurses (e.g., outpatient or community nurses) primarily engage in health education or basic nursing tasks, where AI integration is limited, resulting in lower scores. Other departments (e.g., internal medicine, surgery) showed no significant differences, possibly due to relatively balanced levels of AI application. This aligns with the Technology Acceptance Model (TAM), which posits that the frequency of technology exposure influences perceived usefulness and attitudes (11). Practically, hospitals should increase AI application opportunities in non-inpatient departments to enhance nurses’ AI literacy and confidence.
4.1.5 Influence of regional differences
This study, after applying case weighting adjustments by province, found that Beijing nurses had significantly higher scores on the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), and Artificial Intelligence Self-Efficacy Scale (AISES) compared to Sichuan nurses, and Sichuan nurses scored significantly higher than Yunnan nurses (p < 0.05).
Regional differences may stem from disparities in economic development levels and the distribution of medical technology resources. As an economic hub, Beijing boasts advanced healthcare systems and abundant AI resources, such as intelligent diagnostic systems and robotic nursing, which increase nurses’ exposure opportunities, enhancing AI literacy (AILS) and positive attitudes (GAAIS). Training and practical experience further bolster their confidence (AISES). Sichuan, with a relatively developed economy, exhibits moderate technology integration, while Yunnan, due to resource scarcity, has limited AI applications and training, resulting in the lowest scores. Amin et al. (36) indicated that regional medical technology levels significantly influence nurses’ AI acceptance, with urban areas demonstrating higher capabilities and confidence due to concentrated resources and robust technical support. Similarly, Lambert et al. (30) noted that urban hospitals, with frequent AI tool usage, show significantly higher acceptance and technical capabilities among healthcare professionals, whereas rural areas exhibit lower acceptance due to technological disparities. This aligns with the Technology Acceptance Model (TAM), which posits that technology availability influences perceived usefulness and attitudes (11). Practically, policies should increase AI investment in underdeveloped regions like Yunnan, providing equipment and training support. Remote education or collaborations with advanced hospitals in regions like Beijing can establish technology-sharing mechanisms, reducing regional disparities and promoting balanced AI application.
4.1.6 Influence of training experience
This study found that nurses who received self-study or professional training had significantly higher Artificial Intelligence Literacy Scale (AILS) scores compared to those without any training (p < 0.05), with no significant differences between the self-study and professional training groups. For Artificial Intelligence Self-Efficacy Scale (AISES) scores, the professional training group scored significantly higher than the group with related thematic training or self-study, which in turn scored significantly higher than the no-training group, with all pairwise comparisons showing statistical significance (p < 0.05).
The improvement in AILS scores through training indicates that both self-study and professional training effectively enhance AI knowledge, such as skills in using intelligent healthcare tools. The lack of significant differences between self-study and professional training may be because both provide core knowledge, but professional training further enhances AISES through hands-on practice and guidance. Bandura (32) noted that mastery experiences, such as those gained through practical training, directly strengthen individuals’ confidence in their abilities via successful experiences. Amin et al. (36) found that professional training significantly boosts nurses’ confidence in AI through structured learning and feedback mechanisms, as evidenced by higher self-efficacy and usage intention, while self-study yields lesser effects. The no-training group’s lowest scores reflect the absence of exposure as a barrier to improving AI capabilities. Practically, hospitals should promote professional training to enhance nurses’ AI literacy and confidence while supporting self-study as a supplement to ensure all nurses have access to AI knowledge.
4.2 Correlation of AI general attitudes, AI literacy, and AI self-efficacy
This study found significant positive correlations among the total scores of the General Attitudes toward Artificial Intelligence Scale (GAAIS), Artificial Intelligence Literacy Scale (AILS), and Artificial Intelligence Self-Efficacy Scale (AISES), with correlation coefficients of GAAIS with AILS (r = 0.549, p < 0.001), GAAIS with AISES (r = 0.567, p < 0.001), and AILS with AISES (r = 0.684, p < 0.001). Additionally, AI usage intention showed significant positive correlations with the total scores of GAAIS, AILS, and AISES (p < 0.001).
These positive correlations suggest that the three factors form a mutually reinforcing positive cycle. Positive AI attitudes (GAAIS) may stimulate nurses’ motivation to learn, such as proactively exploring intelligent diagnostics or robotic nursing technologies, thereby enhancing AI literacy (AILS). Higher literacy, by increasing understanding and mastery of AI, further strengthens confidence in its use (AISES). Conversely, increased confidence and knowledge may reinforce positive evaluations of AI, creating a virtuous cycle. The high correlation between AILS and AISES (r = 0.684) is particularly notable, indicating that knowledge accumulation serves as the foundation for confidence. Wang and Chuang (28) found that AI self-efficacy is significantly positively correlated with literacy and attitudes, with knowledge and confidence jointly driving technology acceptance. Amin et al. (36) further noted that nurses’ positive attitudes toward AI are closely linked to their technical capabilities, supporting the positive cycle mechanism observed in this study. This aligns with the Technology Acceptance Model (TAM), which posits that perceived usefulness (attitudes) and ease of use (literacy) influence behavioral intention (11). The positive correlations of AI usage intention with all three factors suggest that positive attitudes, robust knowledge, and high confidence collectively promote nurses’ acceptance of AI. Practically, hospitals can enhance nurses’ literacy and self-efficacy through AI training while improving attitudes through promotional efforts, fostering a positive cycle to strengthen AI usage intention, which will facilitate the widespread application of AI in nursing.
4.3 Mediating roles of AI self-efficacy and AI general attitudes in the relationship between AI literacy and usage intention
This study, through structural equation modeling (SEM), revealed that AI self-efficacy (AISES) and general attitudes toward AI (GAAIS) play significant mediating roles between AI literacy (AILS) and AI usage intention (TODO). The mediation effects were as follows: AILS → AISES → TODO (0.207, accounting for 21.41% of the total effect), AILS → AISES → GAAIS → TODO (0.082, 8.48%), and AILS → GAAIS → TODO (0.141, 14.58%), with all paths significant at p < 0.001. The direct effect (AILS → TODO) was 0.295 (30.51%), and the total effect was 0.967, 95% CI [0.828–1.143].
Compared with findings from systematic and scoping reviews, this study’s effect sizes offer new insights. O’Connor et al.’s (4) systematic review indicates that nurses’ self-efficacy and positive attitudes are key drivers of AI adoption, but it does not provide specific mediation effect sizes. Similarly, Ng et al.’s (2) scoping review emphasizes that insufficient AI literacy and low technology acceptance limit AI application in nursing, with self-efficacy and attitudes playing significant roles in promoting adoption intentions. This study’s mediation effects (AISES: 21.41%; GAAIS: 14.58%) align with the qualitative conclusions of these reviews, quantifying the strength of AI literacy’s influence through confidence and attitudes. In contrast, Kwak et al. (37) reported a mediation effect of AI literacy on nursing students’ usage intentions through self-efficacy (path coefficients approximately 0.15–0.20), slightly lower than this study’s AISES path (0.207). This difference may stem from this study’s focus on Chinese nurses, whose unfamiliarity with AI likely amplifies the role of self-efficacy.
AI literacy indirectly promotes usage intentions by enhancing nurses’ confidence (AISES) and positive attitudes (GAAIS). The mediation effect of AISES is the strongest (21.41%), with path coefficients (AILS → AISES = 0.728, AISES → TODO = 0.172) indicating that AI literacy significantly boosts self-efficacy, which in turn drives usage intentions. This may be because AI knowledge (e.g., skills in intelligent monitoring systems or data analysis) enables nurses to feel confident in handling AI tasks, aligning with Bandura’s self-efficacy theory (32), which posits that mastery experiences (e.g., technical training) influence behavior through confidence. The mediation effect of GAAIS (14.58%) and the secondary path (8.48%) show that AI literacy improves attitudes (AILS → GAAIS = 0.343), which subsequently motivates usage (GAAIS → TODO = 0.261). The dual mediation path (AILS → AISES → GAAIS → TODO) has the smallest effect (8.48%), possibly due to the heterogeneous impact of attitudes on usage intentions across different regions (e.g., Sichuan and Yunnan vs. Beijing). Amin et al. (36) found that nurses’ positive attitudes and confidence significantly promote AI usage intentions, particularly in contexts where training enhances confidence. Wang and Chuang (28) highlighted the central role of self-efficacy in AI acceptance but did not deeply explore the interaction between attitudes and confidence. This study addresses this gap by elucidating the dual mediation path.
Contextual heterogeneity further explains the uniqueness of this study’ s findings. O′ Connor et al. (4) noted that the roles of self-efficacy and attitudes vary across cultural backgrounds and work environments, with Western nurses potentially exhibiting stronger direct effects (AILS → TODO) due to greater technological resources and widespread training. In contrast, Chinese nurses face regional disparities: limited technological resources in Sichuan and Yunnan may weaken the direct effect of AI literacy (30.51%), making AISES (21.41%) a more critical mediating pathway, as confidence compensates for reduced technology exposure. Conversely, Beijing’ s advanced technological environment may enhance the role of GAAIS (14.58%), as nurses are more likely to develop positive attitudes. This aligns with lower trust in new technologies in Chinese culture, where training should prioritize boosting confidence (2). Secinaro et al. (38) support that training and experience with AI tools enhance healthcare professionals’ acceptance, particularly in resource-limited regions. These findings are consistent with the Technology Acceptance Model (TAM), which posits that perceived ease of use (literacy) and attitudes drive behavioral intentions (11).
Practically, this study underscores the central role of AISES and recommends that hospitals implement structured training to enhance AI literacy and self-efficacy. In Sichuan and Yunnan, training should focus on foundational AI skills (e.g., operating intelligent devices) to bolster nurses’ confidence in AI tasks. In Beijing, promotional efforts and case studies can improve AI attitudes, facilitating technology adoption. Policymakers should account for regional resource disparities and develop tiered training strategies to support the widespread application of AI in nursing practice, ultimately improving care quality and patient outcomes.
5 Practical implications and policy recommendations
This study elucidated the mechanism by which AI literacy (AILS) influences nurses’ AI usage intention through AI self-efficacy (AISES) and general attitudes toward AI (GAAIS), providing significant insights for nursing practice and policy. The results indicate that AISES (21.41%) and GAAIS (14.58%) significantly facilitate usage intention as mediators, with the direct effect (30.51%) underscoring the critical role of literacy.
Practically, hospitals should design structured AI training programs, such as those focusing on intelligent monitoring systems and data analysis skills, to enhance nurses’ AI literacy and self-efficacy. Given that only 14.24% of nurses have received AI training, priority should be given to non-teaching hospitals and lower-level hospitals to bridge the technological gap. Preceptors, who scored higher, can serve as pioneers in AI promotion, disseminating knowledge and positive attitudes through teaching. Amin et al. (36) emphasized that training significantly boosts nurses’ confidence and acceptance. At the policy level, the government should address regional disparities (e.g., Beijing outperforming Yunnan) by providing subsidies or remote education to support AI resources and technology in underdeveloped regions. Secinaro et al. (38) suggested that policies should balance technology allocation to elevate overall healthcare standards. Additionally, hospitals can improve nurses’ attitudes toward AI through promotional activities, fostering a positive cycle of literacy, confidence, and attitudes to enhance usage intention. This will promote the widespread adoption of AI in nursing, ultimately improving patient care quality.
6 Limitations and future directions
Although this study provides empirical support for the application of AI in nursing, it has certain limitations. First, the sample was limited to public hospitals in Beijing, Sichuan, and Yunnan, and convenience sampling was employed, which may restrict the generalizability of the results to the national level or other healthcare institutions. Second, reliance on self-reported questionnaires to measure AI literacy, attitudes, and self-efficacy may be subject to social desirability bias, failing to reflect actual usage behavior. Additionally, the cross-sectional design cannot establish causality, and the SEM model fit was adequate (χ2/df = 4.581, RMSEA = 0.0824) but did not reach the ideal level (χ2/df < 3), possibly influenced by the large sample size (n = 878).
Future research could employ random sampling to expand the sample scope, covering more regions and hospital types to enhance representativeness. Incorporating objective indicators (e.g., frequency of AI tool usage) to validate self-reported results would help reduce bias. Longitudinal designs or intervention experiments could be used to track the dynamic impact of training on AI literacy and usage intention, clarifying causal relationships. Furthermore, optimizing the model structure by including variables such as organizational support or technology availability could refine the formation mechanism of AI usage intention. These improvements will help refine the theoretical framework and promote the application of AI in nursing practice.
Data availability statement
The data analyzed in this study is subject to the following licenses/restrictions: given the sensitive nature of the data, the de-identified dataset and surveys are not publicly accessible. However, reasonable requests for data access may be considered upon discussion with the research team. Requests to access these datasets should be directed to XZ, MTYyMzEzMTQ2OEBxcS5jb20=.
Ethics statement
The studies involving humans were approved by the Ethics Committee of West China Second University Hospital, Sichuan University [ethics approval number: medical research 2024 ethics approval no. (202)]. The studies were conducted in accordance with the local legislation and institutional requirements. The participants provided their written informed consent to participate in this study.
Author contributions
QZ: Project administration, Data curation, Conceptualization, Funding acquisition, Writing – original draft, Investigation. XH: Investigation, Supervision, Software, Data curation, Writing – original draft. JZ: Writing – original draft, Resources, Conceptualization. SS: Writing – original draft, Investigation, Resources, Funding acquisition. YH: Validation, Investigation, Supervision, Writing – review & editing. XZ: Software, Formal analysis, Validation, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This study was supported by the 2022 Sichuan University New Era Medical Education Innovation and Development Research Project (Project No. SCUYM10) and the Higher Education Teaching Reform Project (11th Phase) of Sichuan University (Project No. SCU1199).
Acknowledgments
We sincerely thank Dingxi Bai from Chengdu University of Traditional Chinese Medicine, Ying Duan from North Sichuan Medical College, and Qin Yang from Beijing Children’ s Hospital for their assistance in data collection. Their support was instrumental in ensuring the smooth progress of this study.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The authors declare that no Gen AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Footnotes
References
1. Seibert, K, Domhoff, D, Bruch, D, Schulte-Althoff, M, Fürstenau, D, Biessmann, F, et al. Application scenarios for artificial intelligence in nursing care: rapid review. J Med Internet Res. (2021) 23:e26522. doi: 10.2196/26522
2. Ng, ZQP, Ling, LYJ, Chew, HSJ, and Lau, Y. The role of artificial intelligence in enhancing clinical nursing care: a scoping review. J Nurs Manag. (2022) 30:3654–74. doi: 10.1111/jonm.13425
3. von Gerich, H, Moen, H, Block, LJ, Chu, CH, DeForest, H, Hobensack, M, et al. Artificial intelligence-based technologies in nursing: a scoping literature review of the evidence. Int J Nurs Stud. (2022) 127:104153. doi: 10.1016/j.ijnurstu.2021.104153
4. O'Connor, S, Yan, Y, Thilo, FJS, Felzmann, H, Dowding, D, and Lee, JJ. Artificial intelligence in nursing and midwifery: a systematic review. J Clin Nurs. (2023) 32:2951–68. doi: 10.1111/jocn.16478
5. Islam, M, Usman, M, Mahmood, A, Abbasi, AA, and Song, O-Y. Predictive analytics framework for accurate estimation of child mortality rates for internet of things enabled smart healthcare systems. Int J Distrib Sens Networks. (2020) 16:155014772092889. doi: 10.1177/1550147720928897
6. Pailaha, AD. The impact and issues of artificial intelligence in nursing science and healthcare settings. SAGE Open Nurs. (2023) 9:23779608231196847. doi: 10.1177/23779608231196847
7. Naveed, M, Usman, SM, Islam, M, Aleshaiker, S, and Anwar, A. “Intrusion detection in smart IoT devices for people with disabilities,” in 2022 IEEE International Smart Cities Conference (ISC2). IEEE. (2022): 1–5.
8. Wang, X, Fei, F, Wei, J, Huang, M, Xiang, F, Tu, J, et al. Knowledge and attitudes toward artificial intelligence in nursing among various categories of professionals in China: a cross-sectional study. Front Public Health. (2024) 12:1433252. doi: 10.3389/fpubh.2024.1433252
9. Jiang, Y. Artificial intelligence in nursing education: challenges and opportunities in the Chinese context. Open J Soc Sci. (2024) 12:55–66. doi: 10.4236/jss.2024.1211004
10. Islam, M, Ali, MW, Irshad, A, and Shah, MA. Studying infant mortality: a demographic analysis based on data mining models. Open Life Sci. (2023) 18:20220643. doi: 10.1515/biol-2022-0643
11. Davis, FD. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. (1989) 13:319–40. doi: 10.2307/249008
12. Ajzen, I. The theory of planned behavior. Organ Behav Hum Decis Process. (1991) 50:179–211. doi: 10.1016/0749-5978(91)90020-T
13. Venkatesh, V, Morris, MG, Davis, GB, and Davis, FD. User acceptance of information technology: toward a unified view. MIS Q. (2003) 27:425–78. doi: 10.2307/30036540
14. Wang, B, Liu, YK, and Parker, SK. How does the use of information communication technology affect individuals? A work design perspective. Acad Manage Ann. (2020) 14:695–725. doi: 10.5465/annals.2018.0127
15. Bandura, A. Self-efficacy: The exercise of control. New York, NY: W H Freeman/Times Books/Henry Holt & Co. (1997).
16. Chai, CS, Lin, P-Y, Jong, MS-Y, Dai, Y, Chiu, TKF, and Qin, J. Perceptions of and behavioral intentions towards learning artificial intelligence in primary school students. J Educ Technol Soc. (2021) 24:89–101. Available at: https://webofscience.clarivate.cn/wos/alldb/full-record/WOS:000669522300007
17. Islam, M, Huang, T, Ahn, E, and Naseem, U. Multimodal Generative AI with Autoregressive LLMs for Human Motion Understanding and Generation: A Way Forward. arXiv:2506.03191 [cs.CV]. (2025). doi: 10.48550/arXiv.2506.03191
18. ABE, G, A, F, and Islam, M. Lightweight multi-stage holistic attention-based network for image super-resolution. IET Image Process. (2025) 19:e70013. doi: 10.1049/ipr2.70013
19. Islam, M, Khan, JA, Abaker, M, Daud, A, and Irshad, A. Unified large language models for misinformation detection in low-resource linguistic settings (2025).
20. Wei, Q, Pan, S, Liu, X, Hong, M, Nong, C, and Zhang, W. The integration of AI in nursing: addressing current applications, challenges, and future directions. Front Med. (2025) 12:1545420. doi: 10.3389/fmed.2025.1545420
21. Campbell, MK, Piaggio, G, Elbourne, DR, and Altman, DGCONSORT Group. Consort 2010 statement: extension to cluster randomised trials. BMJ. (2012) 345:e5661. doi: 10.1136/bmj.e5661
22. Schepman, A, and Rodway, P. Initial validation of the general attitudes towards artificial intelligence scale. Comput Hum Behav Rep. (2020) 1:100014. doi: 10.1016/j.chbr.2020.100014
23. Tuncer, GZ, and Tuncer, M. Investigation of nurses' general attitudes toward artificial intelligence and their perceptions of ChatGPT usage and influencing factors. Digit Health. (2024) 10:20552076241277025. doi: 10.1177/20552076241277025
24. Wang, B, Rau, PLP, and Yuan, T. Measuring user competence in using artificial intelligence: validity and reliability of artificial intelligence literacy scale. Behav Inf Technol. (2023) 42:1324–37. doi: 10.1080/0144929X.2022.2072768
25. Kahraman, H, Akutay, S, Yüceler Kaçmaz, H, and Taşci, S. Artificial intelligence literacy levels of perioperative nurses: the case of Türkiye. Nurs Health Sci. (2025) 27:e70059. doi: 10.1111/nhs.70059
26. Ng, DTK, Leung, JKL, Chu, SKW, and Qiao, MS. Conceptualizing AI literacy: an exploratory review. Comput Educ Artif Intell. (2021) 2:100041. doi: 10.1016/j.caeai.2021.100041
27. Celik, I. Towards intelligent-TPACK: an empirical study on teachers’ professional knowledge to ethically integrate artificial intelligence (AI)-based tools into education. Comput Human Behav. (2023) 138:107468. doi: 10.1016/j.chb.2022.107468
28. Wang, YY, and Chuang, YW. Artificial intelligence self-efficacy: scale development and validation. Educ Inf Technol. (2024) 29:4785–808. doi: 10.1007/s10639-023-12015-w
29. Morales-García, WC, Sairitupa-Sanchez, LZ, Morales-García, SB, and Morales-García, M. Adaptation and psychometric properties of a brief version of the general self-efficacy scale for use with artificial intelligence (GSE-6AI) among university students. Front Educ. (2024) 9:1293437. doi: 10.3389/feduc.2024.1293437
30. Lambert, SI, Madi, M, Sopka, S, Lenes, A, Stange, H, Buszello, CP, et al. An integrative review on the acceptance of artificial intelligence among healthcare professionals in hospitals. NPJ Digit Med. (2023) 6:111. doi: 10.1038/s41746-023-00852-5
31. Maleki Varnosfaderani, S, and Forouzanfar, M. The role of AI in hospitals and clinics: transforming healthcare in the 21st century. Bioengineering. (2024) 11:337. doi: 10.3390/bioengineering11040337
32. Bandura, A. Self-efficacy: toward a unifying theory of behavioral change. Psychol Rev. (1977) 84:191–215. doi: 10.1037/0033-295X.84.2.191
33. Goldfarb, A, and Teodoridis, F. Why is AI adoption in health care lagging? Washington, DC: Brookings Institution (2022).
34. Dumić-Čule, I, Orešković, T, Brkljačić, B, Kujundžić Tiljak, M, and Orešković, S. The importance of introducing artificial intelligence to the medical curriculum - assessing practitioners' perspectives. Croat Med J. (2020) 61:457–64. doi: 10.3325/cmj.2020.61.457
35. Karaarslan, D, Kahraman, A, and Ergin, E. How does training given to pediatric nurses about artificial intelligence and robot nurses affect their opinions and attitude levels? A quasi-experimental study. J Pediatr Nurs. (2024) 77:e211–7. doi: 10.1016/j.pedn.2024.04.031
36. Amin, SM, El-Gazar, HE, Zoromba, MA, El-Sayed, MM, and Atta, MHR. Sentiment of nurses towards artificial intelligence and resistance to change in healthcare organisations: a mixed-method study. J Adv Nurs. (2025) 81:2087–98. doi: 10.1111/jan.16435
37. Kwak, Y, Ahn, JW, and Seo, YH. Influence of AI ethics awareness, attitude, anxiety, and self-efficacy on nursing students’ behavioral intentions. BMC Nurs. (2022) 21:267. doi: 10.1186/s12912-022-01048-0
Keywords: artificial intelligence, literacy, self-efficacy, attitude, usage intention, nursing, China
Citation: Zeng Q, Huang X, Zhu J, Su S, Hu Y and Zhang X (2025) Mechanisms of nurses’ AI use intention formation in Sichuan, Yunnan, and Beijing, China: mediating effects of AI literacy via self-efficacy-to-attitude pathways. Front. Public Health. 13:1622802. doi: 10.3389/fpubh.2025.1622802
Edited by:
Shikha Kukreti, National Cheng Kung University, TaiwanReviewed by:
Rabie Adel El Arab, Almoosa College of Health Sciences, Saudi ArabiaMuhammad Islam, James Cook University, Australia
Copyright © 2025 Zeng, Huang, Zhu, Su, Hu and Zhang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yanling Hu, aHV5YW5saW5nMDcyNUBzY3UuZWR1LmNu Xiujuan Zhang, MTYyMzEzMTQ2OEBxcS5jb20=
†These authors have contributed equally to this work and share first authorship