 Edel Rafael Rodea-Montero
Edel Rafael Rodea-Montero Brenda Jesús Rodríguez-Alcántar2
Brenda Jesús Rodríguez-Alcántar2- 1INFOTEC Centro de Investigación e Innovación en Tecnologías de la Información y Comunicación, Aguascalientes, Mexico
- 2Department of Research, Hospital Regional de Alta Especialidad del Bajío (HRAEB), Instituto Mexicano del Seguro Social para el Bienestar (IMSS-BIENESTAR), Leon, Mexico
- 3SECIHTI Secretaría de Ciencia, Humanidades, Tecnología e Innovación, Mexico City, Mexico
Purpose: To describe the pre- and post-admission characteristics of hospitalized patients in a tertiary care hospital and to adjust machine learning models capable of predicting and identifying the factors that are associated with and have a greater prognostic value for in-hospital death.
Materials and methods: This was a retrospective study based on data from patients who were discharged from a Mexican tertiary care hospital during its first 10 years of operation (2007–2016). Preadmission characteristics were analyzed using descriptive statistics. Comparison tests (Mann–Whitney U) and association tests (chi-square) were applied according to the absence or presence of in-hospital death. Multivariate models (logistic regression, random forest and XGBoost) were fitted. Their ROC curves were compared using the DeLong test, and performance metrics were evaluated.
Results: In total, 55,253 hospital discharges were considered, only 45,011 (0–101 years) had complete data, and the rate of in-hospital death was 4.17%. In total, 70% of the data were used for training and 30% for testing. Two-to-two comparisons between areas under the curve (AUCs) revealed that XGBoost (AUC = 0.9162) outperformed logistic regression (AUC = 0.9036) and random forest (AUC = 0.8978) (p-value < 0.001 in both cases). XGBoost had a sensitivity of 87%, specificity of 81.3% and balanced efficiency of 84.2%. The most relevant predictive factors were medical service that performed the admission, number of conditions, origin of the outpatient consultation of the hospital, and the main condition diagnosed at admission according to the ICD-10, age, month of admission, and day of the week of admission.
Conclusions: Owing to its ability to capture complex patterns, the XGBoost model makes it possible to identify patients with a relatively high risk of in-hospital death using the data available at hospital admission. This constitutes a support tool for decision-making, helping to determine which patients require closer monitoring and follow-up during their hospital stay to improve the quality of medical care.
1 Introduction
A hospital discharge occurs when a patient's hospitalization period ends and a hospital bed is vacated, either because of medical discharge or death. Data on hospital discharge by death can be valuable resources for hospital planning and management (1). In Mexico, the General Directorate of Health Information (DGIS, acronym in Spanish) is the operational body of the Ministry of Health (SSA, acronym in Spanish) that is responsible for generating statistics on health. Among the information subsystems that it manages is the Automated Hospital Discharge System (SAEH, acronym in Spanish) (2), which contains an accumulation of public data of approximately three million records per year (with at most 140 variables captured for each record) of patients who are hospitalized in a hospital unit of the Ministry of Health of Mexico (3, 4).
During the hospital stay of a patient, that is, from admission to discharge from the hospital, various adverse events may occur, among which death (also known as in-hospital death) stands out. The importance of this adverse event has been reflected in the international arena, where measures have been implemented for monitoring and analysis. For example, since 1986, the Health Care Financing Administration (HCFA) has incorporated the percentage of hospital mortality as a quantitative indicator to compare American hospitals (5). Hospital mortality is a widely used indicator of the quality of medical care (6), and the quantification of in-hospital deaths can be considered a measure of the effectiveness of hospital intervention (7). A high percentage of in-hospital deaths are associated with deficiencies in the quality of hospital care (8, 9).
The number of hospital discharges, both in general and with respect to those corresponding to deaths, varies according to hospital conditions and procedures. From the perspective of the analysis of data on hospital discharge, in Mexico, there are descriptive reports on hospital discharge at the national level (2) or at the regional level (10) that provide details on discharges due to deaths; these reports are similar to those described in the international literature (11–14). It is estimated that between 2% and 3% of hospital discharges result in death (3, 6). Identifying the factors that affect the likelihood of in-hospital death is essential for the construction of predictive models. There is evidence of factors that can increase the risk of in-hospital death, such as hospital admission during weekends (15, 16), increases in the number of hospitalized patients (17, 18) and increases in the volume of surgical patients (19, 20).
With respect to the prediction of the likelihood of in-hospital death during hospitalization, multivariate logistic regression models that are validated by an analysis of the area under the receiver operating characteristic (ROC) curve, are typically constructed (21). Then, a confusion matrix is created to evaluate the performance of the model by calculating various efficiency metrics, such as sensitivity, specificity, balanced efficiency, positive predictive value, negative predictive value, precision, recall and F1 score. The implementation of multivariate logistic regression models (22) to predict in-hospital death has allowed the identification of predictive factors such as the age of the patient (23–25), the sex of the patient (25, 26), whether the patient is a clinical or surgical patient (24), the patient's diagnosis (26), the type of disease (25, 26) and the presence of hypotension (27).
Today, the prediction of the in-hospital death of patients can be approached as a machine learning problem. This approach is considered an indispensable tool for revealing answers to complex questions in medicine (28). This is especially the case through the use of supervised machine learning, which is based on data labeled as the presence or absence of in-hospital death. With the current computing power, it is possible to implement prediction techniques using complex algorithms, whose predictive capacity has been shown to be superior to that resulting from logistic regression. These predictive algorithms include decision trees (29), random forest (30), neural networks (31), naive Bayes (32), vector support machines (33), and XGBoost (34).
At a global level, various machine learning–based risk prediction models have been developed and compared to predict in-hospital death across diverse populations and clinical settings, including the United States (35), Europe (36), Asia (37), Oceania (38), and Africa (39). These studies highlight the widespread adoption and effectiveness of supervised algorithms for early risk stratification at hospital admission, while also illustrating the variability of performance across healthcare systems and patient populations. In contrast, there is little to no evidence of similar models being applied or systematically evaluated in Latin American healthcare systems.
While previous studies have used machine learning to predict in-hospital mortality, few have specifically focused on the Mexican or Latin American healthcare context; strictly based on administrative and preliminary diagnostic data available at the point of admission, which is crucial for early, low-cost risk stratification; and systematically compared a range of advanced models, including XGBoost, on such a large, decade-long cohort.
The aim of this study was to describe the pre- and post-admission characteristics of hospitalized patients in a tertiary care hospital and to develop a risk prediction model for in-hospital death based on machine learning. By systematically comparing algorithms such as logistic regression, random forest, and XGBoost, the study identified the best-performing model and proposed it as a robust risk index tailored to the Mexican healthcare context, which provides a foundation for future integration into clinical workflows as a decision-support tool.
2 Materials and methods
2.1 Patients
We conducted a retrospective study of all the records of patients (n = 55,253) who were discharged from a Mexican tertiary care hospital (HRAEB) during its first 10 years of operation (April 2007 to December 2016). The dataset constitutes a secondary base and was obtained from the national registries of the Automated Subsystem of Hospital Expenditures (SAEH, acronym in Spanish) operated by the General Directorate of Health Information of the Secretary of Health of Mexico (DGIS, acronym in Spanish) (3). The SAEH is a system that compiles data on hospital discharges from Mexican hospitals as a primary source. The data included 16 preadmission characteristics of the patients (age, sex, state of residence, municipality of residence, has healthcare entitlement, day of the week of admission, month of admission, first hospitalization, origin of outpatient consultation of the Hospital, presence of injury, initial preadmission reference diagnoses according to the ICD-10, medical service that performed the admission, main condition diagnosed at admission according to the ICD-10, initial preadmission reference diagnoses equal to the main condition diagnosed at admission, the ICD-10 group of initial preadmission reference diagnoses equal to the ICD-10 group of the main condition diagnosed at admission, and number of comorbidities) that were collected.
In addition, data on 12 post-admission characteristics of the patients (number of diagnostic, surgical or therapeutic procedures performed, number of procedures under general anesthesia, length of stay (days), length of stay > 48 h, length of stay ≥7 days, length of stay ≥14 days, nosocomial infection, day of the week of discharge, month of discharge, medical service that performed the discharge, discharge service equal to admission service, and in-hospital death) were collected.
For the analysis, only the dataset of patients with complete records (n = 45,011) was considered, among whom 4.17% (1,879/45,011) experienced in-hospital death. The dataset was divided into two parts by using the train_test_split function of the R statistical package “rsample: General Resampling Infrastructure” (40). With 70% of the records (n = 31,507), a set was formed for the construction of models (training dataset), and with 30% of the records (n = 13,504), a set was formed to evaluate the models (test dataset).
2.2 Statistical analysis
All the data were analyzed using the R programming language (version 4.3.3, R Core Team, Vienna, Austria) (41). Initially, hospital discharges were counted in general and by reason of in-hospital death per year. Next, considering the dataset of the patients with complete records, descriptive statistics of the preadmission and post-admission characteristics of the patients in general were calculated and grouped by the absence or presence of in-hospital death. These characteristics were subjected to a comparison or association search via Mann–Whitney U tests (42) or chi–square tests (43), depending on the type of variable being analyzed. To predict in-hospital death and through the use of the training dataset, multivariate models were fitted [logistic regression (22), random forest (30) and XGBoost (44)] considering the preadmission characteristics of the patients as predictive variables, and the importance of the variables for each model was determined. All this was accomplished with the statistical packages R “caret: Classification and Regression Training” (45), “RandomForest: Breiman and Cutler's Random Forests for Classification and Regression” (46), and “xgboost: Extreme Gradient Boosting” (47).
For each case, the fit of the model was evaluated using the Hosmer–Lemeshow test (48). The coefficient of determination [Nagelkerke's R2 (49)] or the analysis of the area under the ROC curve (21) and optimal cutoff points were estimated, as were efficiency metrics (specificity, sensitivity, balanced accuracy, negative predictive value, positive predictive value, precision, recall and F1 score) on the basis of the confusion matrices generated with each model for both the training and test datasets. The optimal cutoff point in each case was calculated as the minimum value of the square root of [(1-sensitivity)2 + (1-specificity)2], which reflects a better accuracy due to a smaller distance to the point (0, 1) of the respective ROC curve in each case (50). The ROC curves of each multivariate model that resulted when the test dataset was considered were compared two by two through the implementation of DeLong tests (51). In all cases, 95% confidence intervals were constructed, and a level of significance of alpha = 0.05 was used in all tests. This study is consistent with “the Transparent Reporting of Multivariate Predictive Models for Individual Prognosis or Diagnosis (TRIPOD): TRIPOD statement” (52).
3 Results
3.1 Hospital discharges and in-hospital deaths
From 2007 to 2016 in the Automated Hospital Discharge System of Mexico, a total of 27,426,516 hospital discharges were registered, and when all the hospitals of the Ministry of Health were considered, the percentage of in-hospital deaths was 2.15% (588,710/27,426,516). Among all hospital discharges, only 55,253 were from the selected tertiary care hospital, where 3.66% (2,025/55,253) were due to in-hospital death. Data on the total number of hospital discharges and the number of discharges due to in-hospital death at both the national and hospital selected levels per year are shown in Table 1.
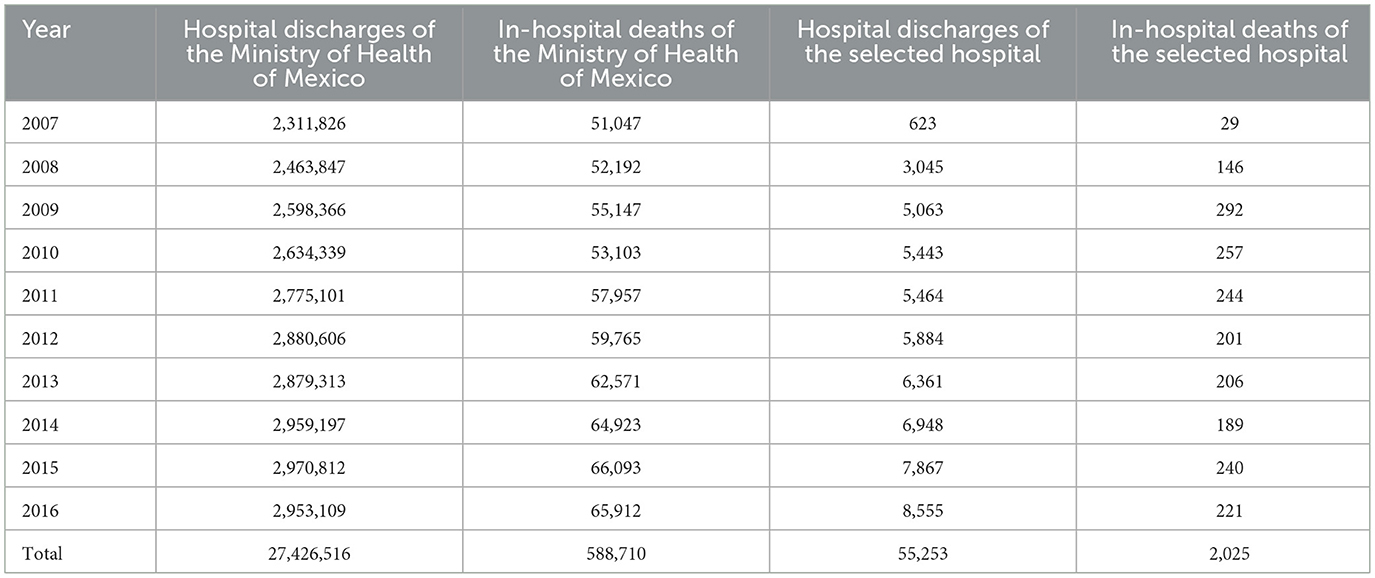
Table 1. Hospital discharges from all hospitals of the Ministry of Health of Mexico registered in the Automated Hospital Discharge System per year from 2007 to 2016.
Of the 55,253 hospital discharges, 10,242 (18.54%) were excluded due to incomplete data in at least one of the 28 variables analyzed (16 pre-admission and 12 post-admission). Most variables (23 of 28) were fully complete; the five with missing data had completeness rates of 99.998% (55,252/55,253) for age, 99.982% (55,243/55,253) for sex, 99.929% (55,214/55,253) for first hospitalization, 87.069% (48,108/55,253) for medical service that performed the admission, and 94.4% (52,170/55,253) for nosocomial infection.
Among the 10,242 excluded records, 146 (1.43%) resulted in-hospital dead, indicating that data loss was not concentrated among patients with adverse outcomes. No systematic pattern of missingness related to patient characteristics or illness severity was identified, minimizing potential selection bias.
3.2 Preadmission characteristics
The final analysis included the data of 45,011 patients with complete records, namely, 21,580 (47.94%) women and 23,431 (52.06%) men, hospitalized in the selected hospital during the study period. The mean age (±standard deviation) of all patients at hospital admission was 33.72 ± 24.64 years, with the ages ranging from < 1 to 101 years. In terms of hospitalization, 32,374/45,011 (71.92%) patients were first-time hospitalization cases. In addition, 40,964/45,011 (91.01%) of the hospitalized patients, originated from outpatient consultations at the hospital, and 1,879/45,011 (4.17%) of the hospital discharges were in-hospital deaths.
Data on the preadmission characteristics of the patients hospitalized during the study period in general and grouped by the absence or presence of in-hospital death are detailed in Table 2. An intergroup comparison using the Mann–Whitney U test revealed that the age of the patients who died was significantly higher than that of those who were discharged alive (42.62 vs. 33.33 years, p < 0.001). Additionally, after data analysis with the chi-square test, associations between the variable presence or absence of in-hospital death and the following variables were identified: age group, residence in the state where the hospital is located, residence in the municipality where the hospital is located, has healthcare entitlement, day of the week of admission, origin of outpatient consultation of the Hospital, presence of injury (p < 0.001 in all cases), month of admission (p = 0.024) and first hospitalization (p = 0.027).
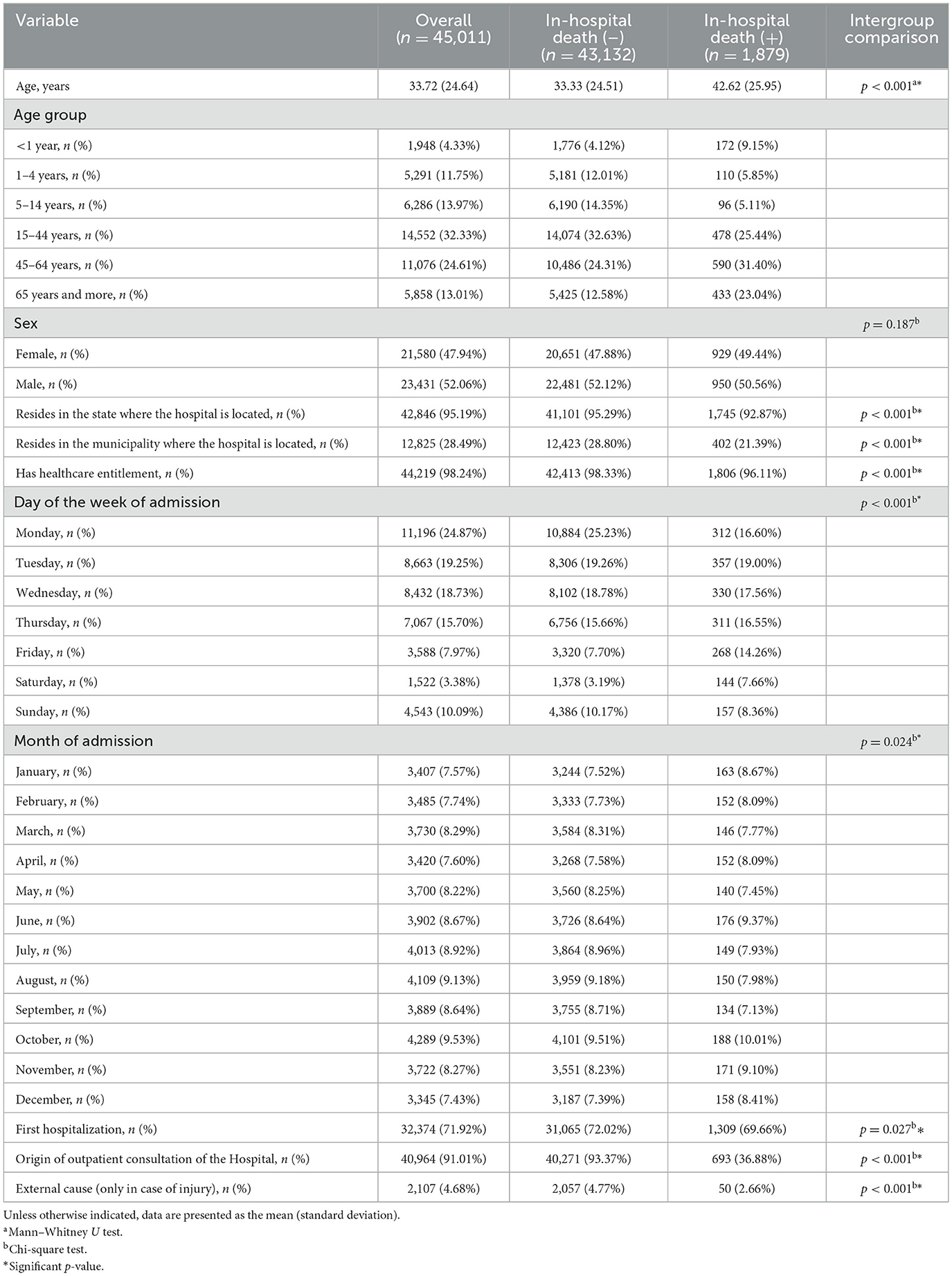
Table 2. Preadmission characteristics of hospitalized patients in the selected hospital from 2007 to 2016.
Table 3 shows the initial preadmission reference diagnoses according to the ICD-10 group of patients hospitalized during the study period in general and grouped by the absence or presence of in-hospital death, highlighting that the four main preadmission reference ICD-10 diagnosis groups in a descending order (approximately 60% total) were as follows: [C00-D48] Neoplasms 14,245/45,011 (31.65%), [R00-R99] Symptoms, signs and abnormal clinical findings and laboratory findings, not elsewhere classified 5,549/45,011 (12.33%), [Q00-Q99] Congenital malformations, deformities and chromosomal abnormalities 4,475/45,011 (9.94%), and [N00-N99] Diseases of the genitourinary tract 4,182/45,011 (9.29%). In addition, an association between the preadmission reference ICD-10 diagnosis group and the absence or presence of in-hospital death was identified (p < 0.001).
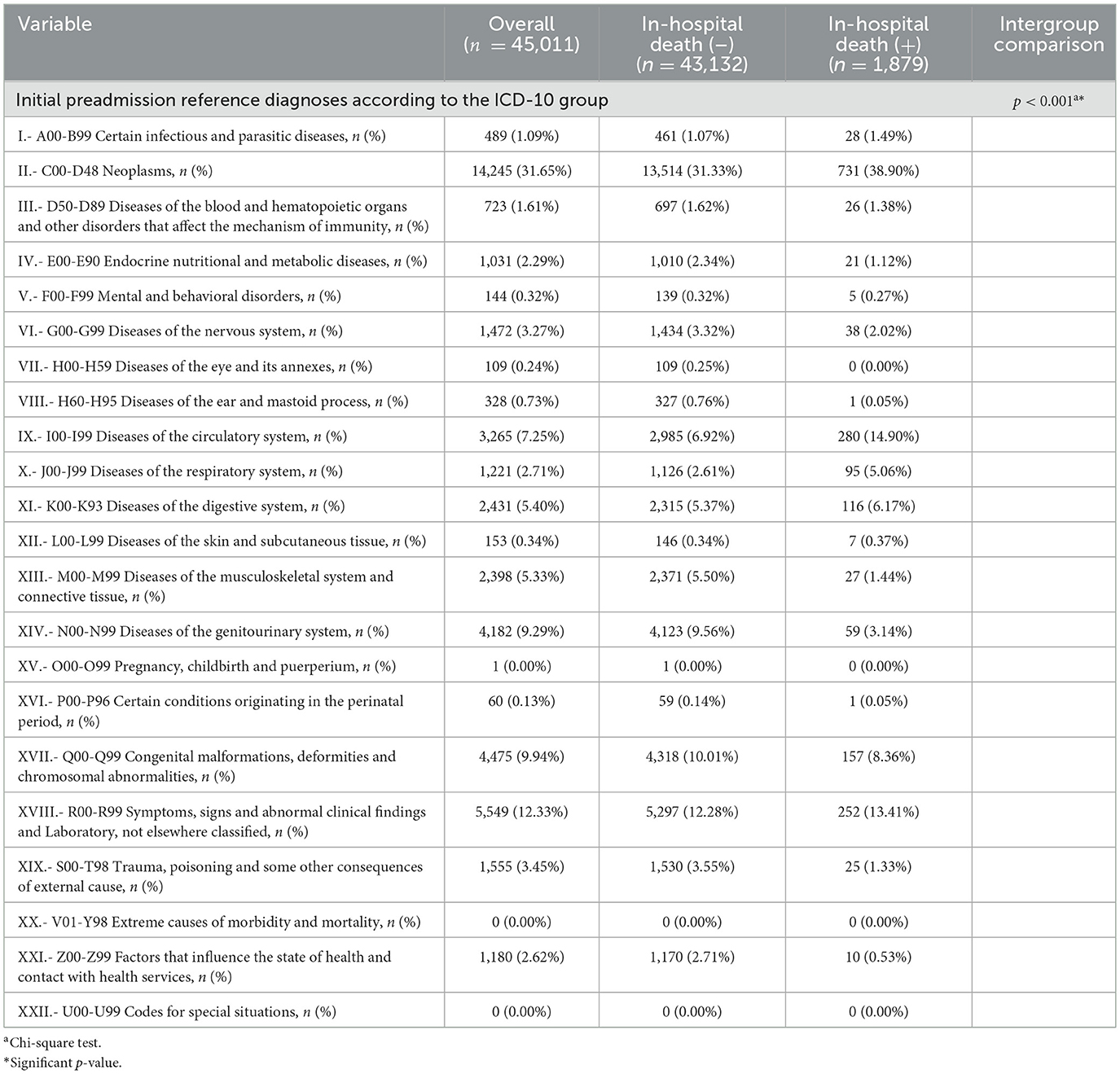
Table 3. Initial preadmission reference diagnoses according to the ICD-10 group of patients hospitalized in the selected hospital from 2007 to 2016.
As shown in Table 4, the medical services that performed the admission of patients in general are detailed and grouped according to the absence or presence of in-hospital death, highlighting that the services that contributed to at least 5.00% of the admissions were the following in a descending order: oncology, 8,107/45,011 (18.01%); urology, 2,729/45,011 (6.06%); neurosurgery, 2,605/45,011 (5.79%); pediatric oncology, 2,548/45,011 (5.66%); traumatology, 2,389/45,011 (5.31%); and cardiology, 2,275/45,011 (5.05%). In addition, an association between the medical service that performed the admission and the absence or presence of in-hospital death was identified (p < 0.001). The five medical services that accounted for approximately half of the in-hospital deaths (926/1,879) were oncology, 398/1,879 (21.18%); hematology, 179/1,879 (9.53%); internal medicine 173/1,879 (9.21%); neurosurgery 90/1,879 (4.79%); and cardiology, 86/1,879 (4.58%).
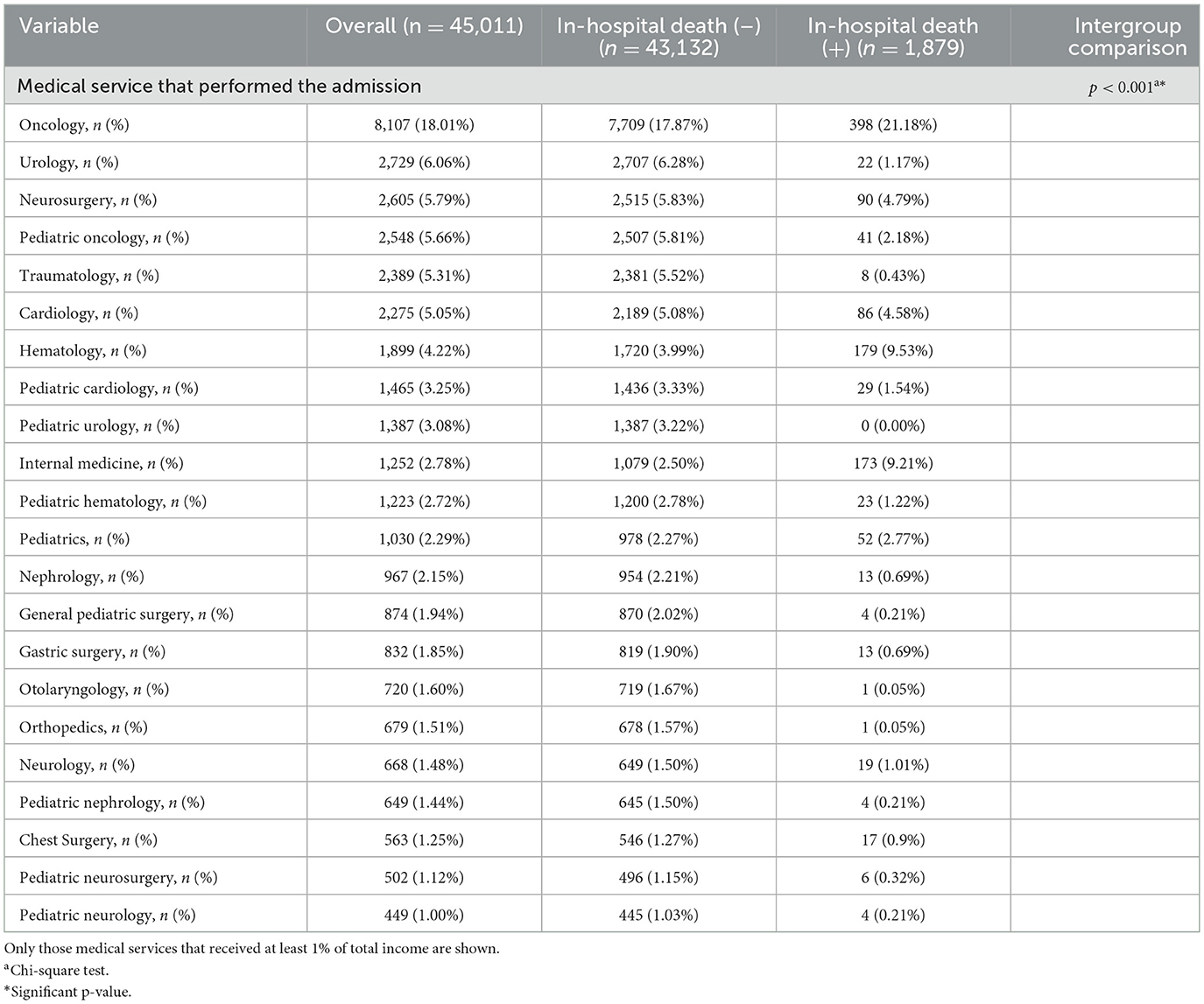
Table 4. Medical services that performed the admission of patients in the selected hospital from 2007 to 2016.
The main conditions diagnosed at admission according to the ICD-10 group of patients hospitalized during the study period in general and grouped by the absence or presence of in-hospital death are listed in Table 5. The results highlight that the four main ICD-10 main conditions diagnosed at admission groups (approximately 70% total) were, in descending order, [C00-D48] neoplasms, 16,710/45,011 (37.12%); [I00–I99] diseases of the circulatory system 3,625/45,011 (8.05%); [N00-N99] diseases of the genitourinary system 4,773/45,011 (10.60%); and [Q00-Q99] congenital malformations, deformities and chromosomal abnormalities 5,125/45,011 (11.39%). In addition, an association between the group with the main condition diagnosed at admission according to ICD-10 group and the absence or presence of in-hospital death was identified (p < 0.001).
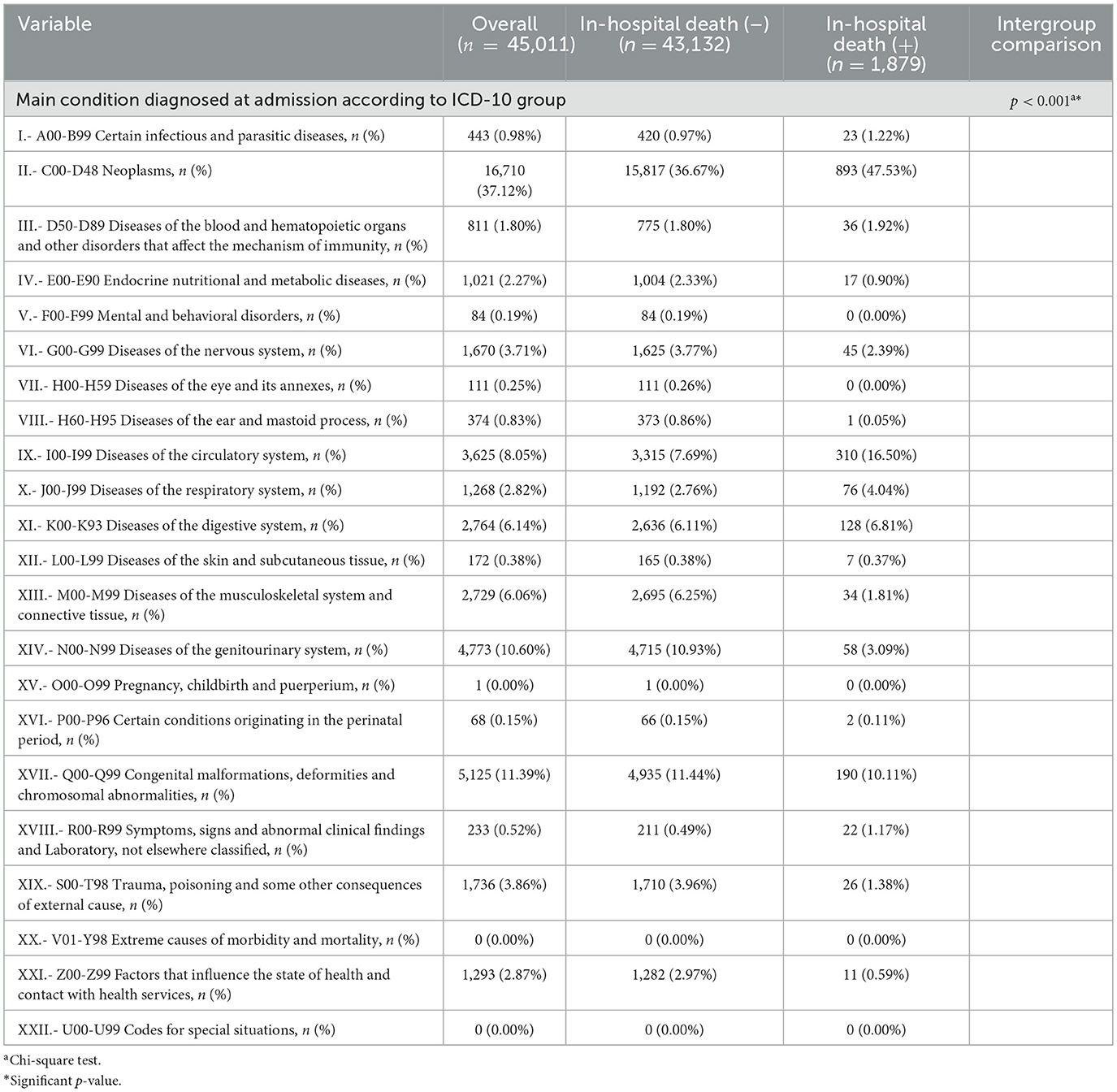
Table 5. Main conditions diagnosed at admission according to the ICD-10 group of patients hospitalized in the selected hospital from 2007 to 2016.
The characteristics of the conditions of the patients hospitalized during the study period in general and grouped by the absence or presence of in-hospital death are listed in Table 6. In all hospitalized patients, the main condition diagnosed at admission was equal to the initial preadmission reference diagnosis at 37,412/45,011 (83.12%). Similarly, there was equality in ICD-10 groups of the main condition diagnosed at admission and the baseline diagnosis at 38,295/45,011 (85.08%). A total of 35,753/45,011 (79.43%) of patients did not present with comorbidities. An intergroup comparison using the Mann–Whitney U test revealed that the number of comorbidities (1.07 vs. 0.33; p < 0.001) was significantly higher in patients who died than in those who did not. Additionally, in the chi-square test, associations between the variable presence or absence of in-hospital death and the following variables were identified: equality in the main condition diagnosed at admission and the initial reference diagnosis, in general and grouped by ICD-10, as well as the presence of comorbidities (p < 0.001 in all cases).
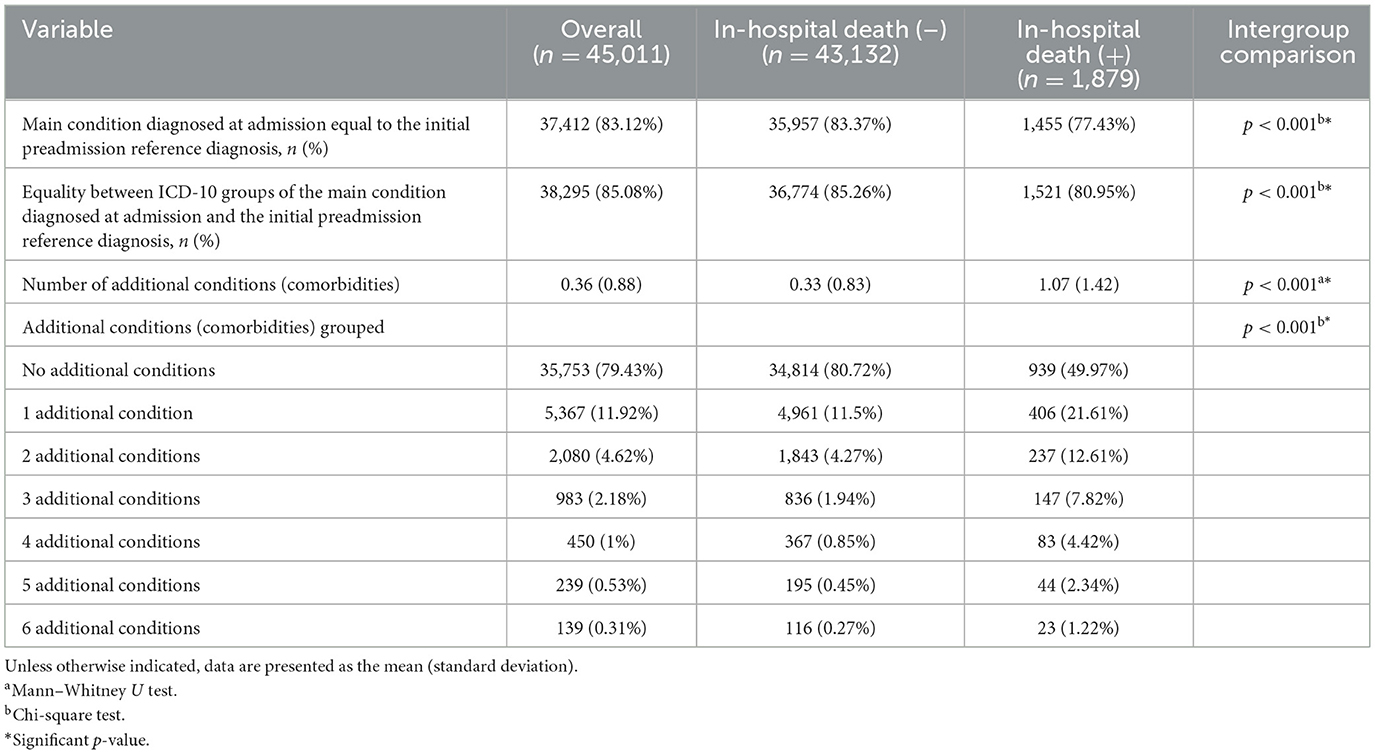
Table 6. Characteristics of the conditions of hospitalized patients in the selected hospital from 2007 to 2016.
3.3 Post-admission characteristics
In general, the patients underwent a mean (±standard deviation) of 1.08 ± 0.65 procedures (diagnostic, surgical or therapeutic). The mean ± standard deviation of the number of days of hospital stay was 6.25 ± 10.8; 28,223/45,011 (62.70%) had a stay of > 48 h, 12,293/45,011 (27.31%) had a stay of ≥7 days, and 4,706/45,011 (10.46%) had a stay of ≥14 days. Notably, 1,816/45,011 (4.03%) patients developed nosocomial infections; 1,454/43,132 (3.37%) patients presented with infection and did not die, and 362/1,879 (19.27%) patients presented with infection and died. In addition, in 44,646/45,011 (99.19%) of the patients, the medical service at discharge was equal to that at admission.
The post-admission characteristics of the patients hospitalized during the study period in general and grouped by the absence or presence of in-hospital death are detailed in Table 7. On the basis of the intergroup comparison by means of the Mann-Whitney U test, the number of procedures (1.11 vs. 1.08; p < 0.001), the number of procedures under general anesthesia (0.54 vs. 0.53; p = 0.002) and the length of stay in days (11.74 vs. 6.01; p < 0.001) were significantly higher in those patients who died. Additionally, analysis with the chi-square test revealed an association between the presence or absence of in-hospital death and the following variables: stay >48 h, stay ≥7 days, stay ≥14 days, presence of nosocomial infection, day of the week of discharge (p < 0.001 in all cases), month of discharge (p = 0.064), and equality between the service of admission and that of discharge (p = 0.086).
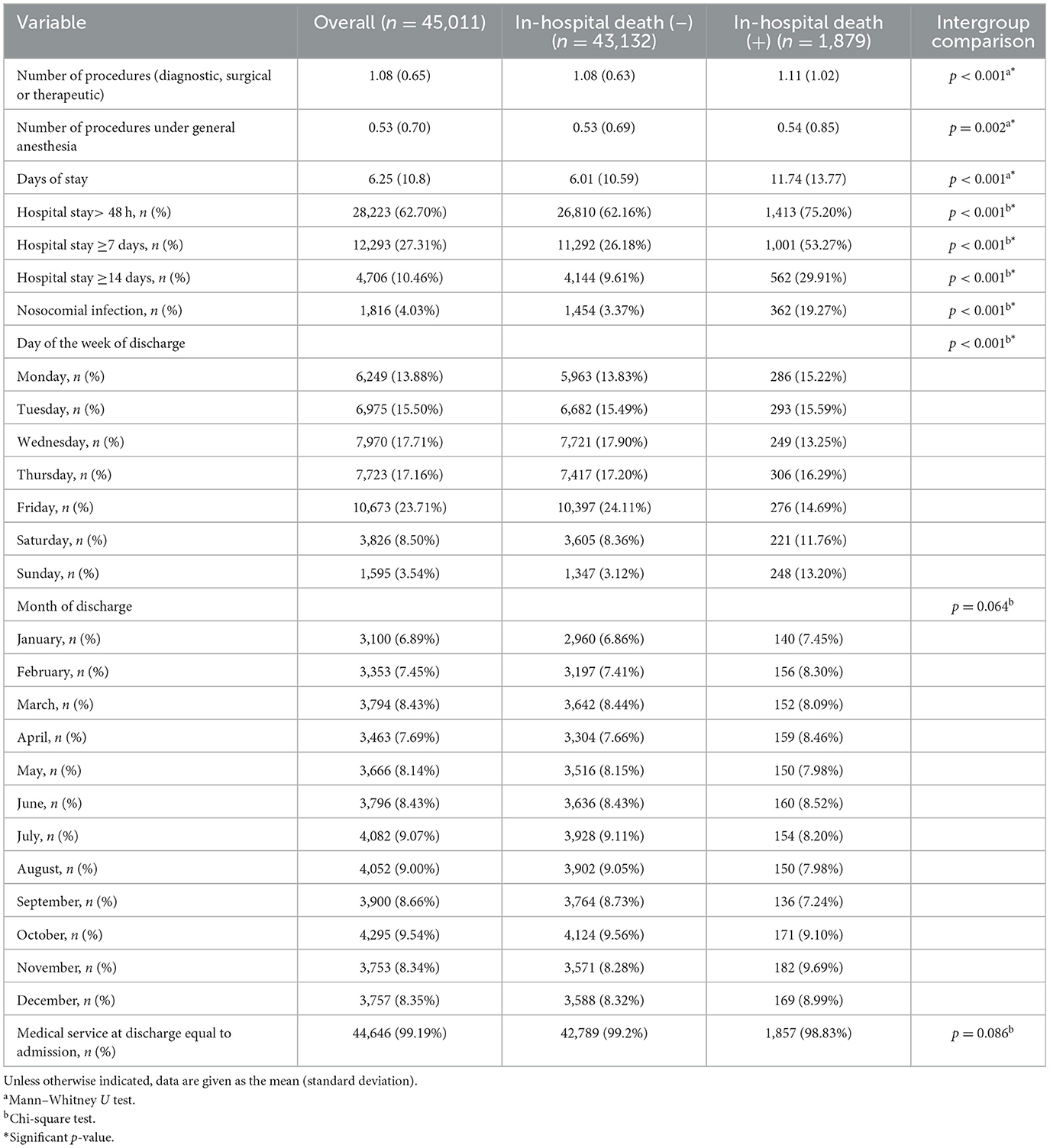
Table 7. Post-admission characteristics of hospitalized patients in the selected hospital from 2007 to 2016.
3.4 Model fitting and performance evaluation
3.4.1 Modeling approach
To fit the machine learning models, the dataset (n = 45,011; 1,879 in-hospital deaths) was randomly divided into a training set (70% of the data, n = 31,507; 1,293 in-hospital deaths) and a test set (30% of the data, n = 13,504; 586 in-hospital deaths). The scheme for fitting the in-hospital death predictive models is shown in Figure 1. The training set was divided into five parts, with which each model was cross-validated.
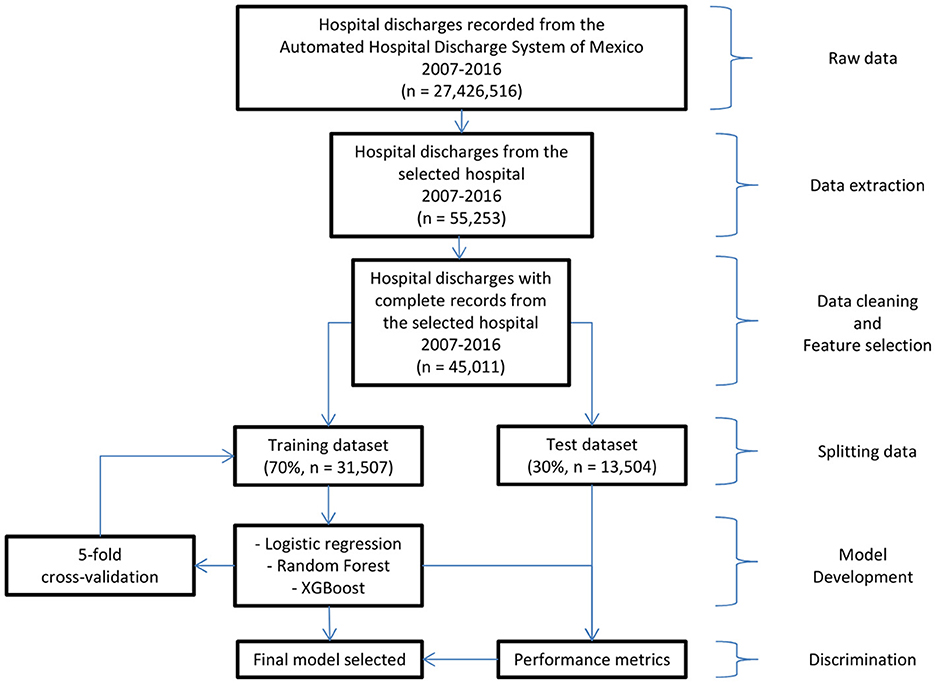
Figure 1. Workflow diagram for model development and evaluation.
3.4.2 Model training
Based on the training set, the best fitted multivariate model (higher AUC) of each type (logistic regression, random, forest and XGBoost) that resulted from considering the 16 preadmission characteristics of the patients as predictor variables are detailed below. For the case of logistic regression, the best model was the one that included the 16 characteristics, which generated a Nagelkerke R2 = 0.443, a p = 0.447 associated with the Hosmer and Lemshov test and an AUC = 0.9237 with a CI of 95% (0.9162–0.9312). In the case of the random forest, the best model included the 16 characteristics and considered the following parameters: the number of characteristics used to divide each node (mtry = 4) and the number of trees (ntree = 1000), which generated an AUC = 0.9892 with a 95% CI (0.9853–0.9931). For XGBoost, the best model included the 16 characteristics and considered the following parameters: number of iterations (nrounds = 1,000), maximum depth per tree (max.depth = 6) and learning rate (eta = 0.01), which generated an AUC = 0.9563 with a 95% CI (0.9512–0.9614).
3.4.3 Variable importance
The importance of each of the preadmission variables that predict in-hospital death in descending order for each model is shown in Figure 2. In the case of logistic regression, the most important variables are the origin of the hospital outpatient consultation and the medical service that performed the admission. For the random forest model, the variables that are the most important are the origin of the hospital outpatient consultation, the medical service that performed the admission, the month of admission and the day of the week of admission. In the XGBoost model, the most important variables are the medical service that performed the admission, the number of conditions, the origin of the hospital outpatient consultation and the main condition diagnosed upon admission according to the ICD-10.

Figure 2. Variable importance for predicting in-hospital death across modeling approaches. (A) Logistic regression. (B) Random forest. (C) XGBoost.
3.4.4 Model comparison
The confusion matrices, as well as the areas under the curve (AUCs), with their respective 95% confidence intervals for each of the models fitted with preadmission variables for the prediction of in-hospital death on the basis of the SAEH-HRAEB 2007–2016 data, both in the training set and in the test set is shown in Figure 3. In all cases, a cutoff point equal to 0.5 was considered. Notably, on the basis of the test set and when two-to-two comparisons of the AUCs (using Delong tests) between the three models were performed, a higher AUC was detected in the model built with XGBoost AUC = 0.9162 (0.9047–0.9277) than in those constructed using logistic regression AUC = 0.9036 (0.8902–0.9170) and random forest AUC = 0.8978 (0.8829–0.9126) (p-value < 0.001 in both cases), which suggests that the performance of the constructed model via XGBoost is better. In addition, the ROC curves constructed based on the test set for each of the models (logistic regression, random forest and XGBoost) are shown in Figure 4.
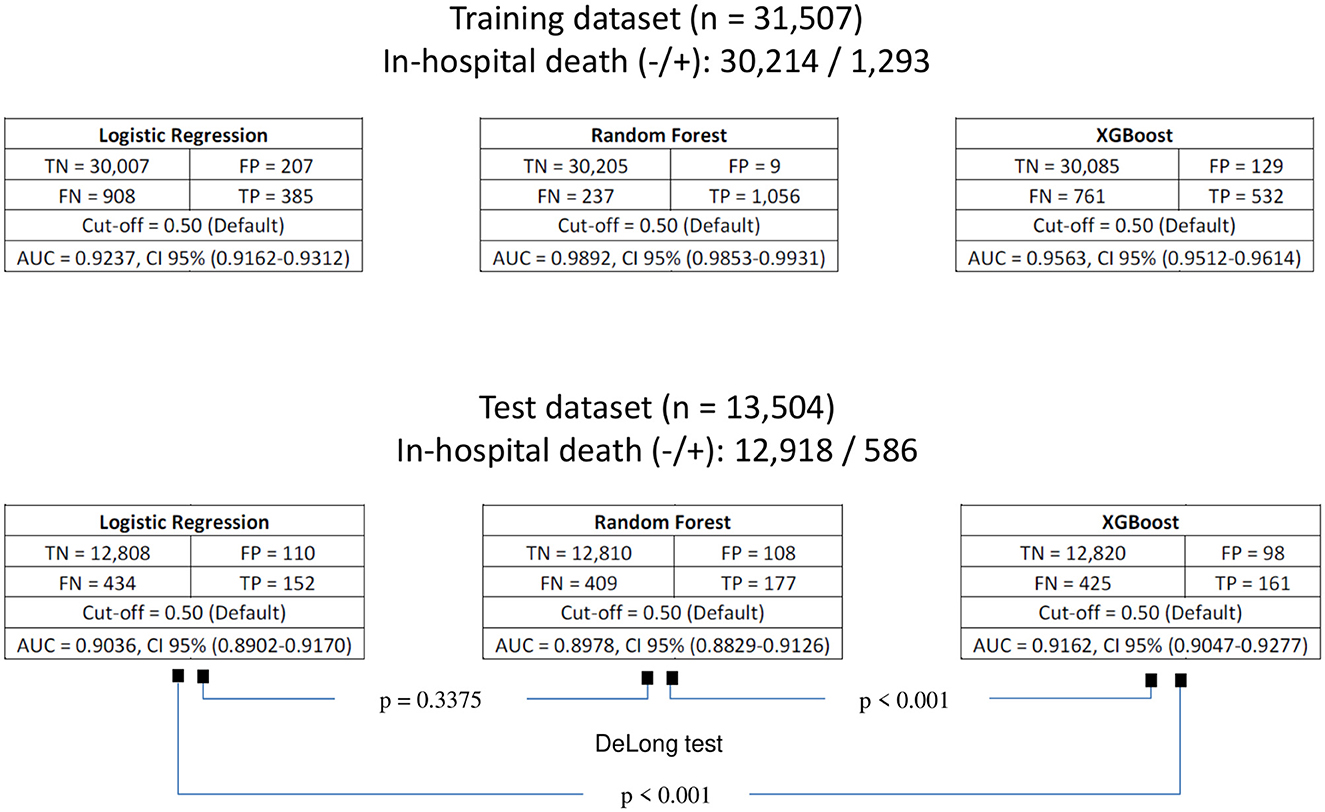
Figure 3. Confusion matrices of the fitted models for predicting in-hospital death for both training and test datasets. TN, true negative; FP, false positive; FN, false negative; TP, true positive; AUC, area under curve; CI, confidence interval.
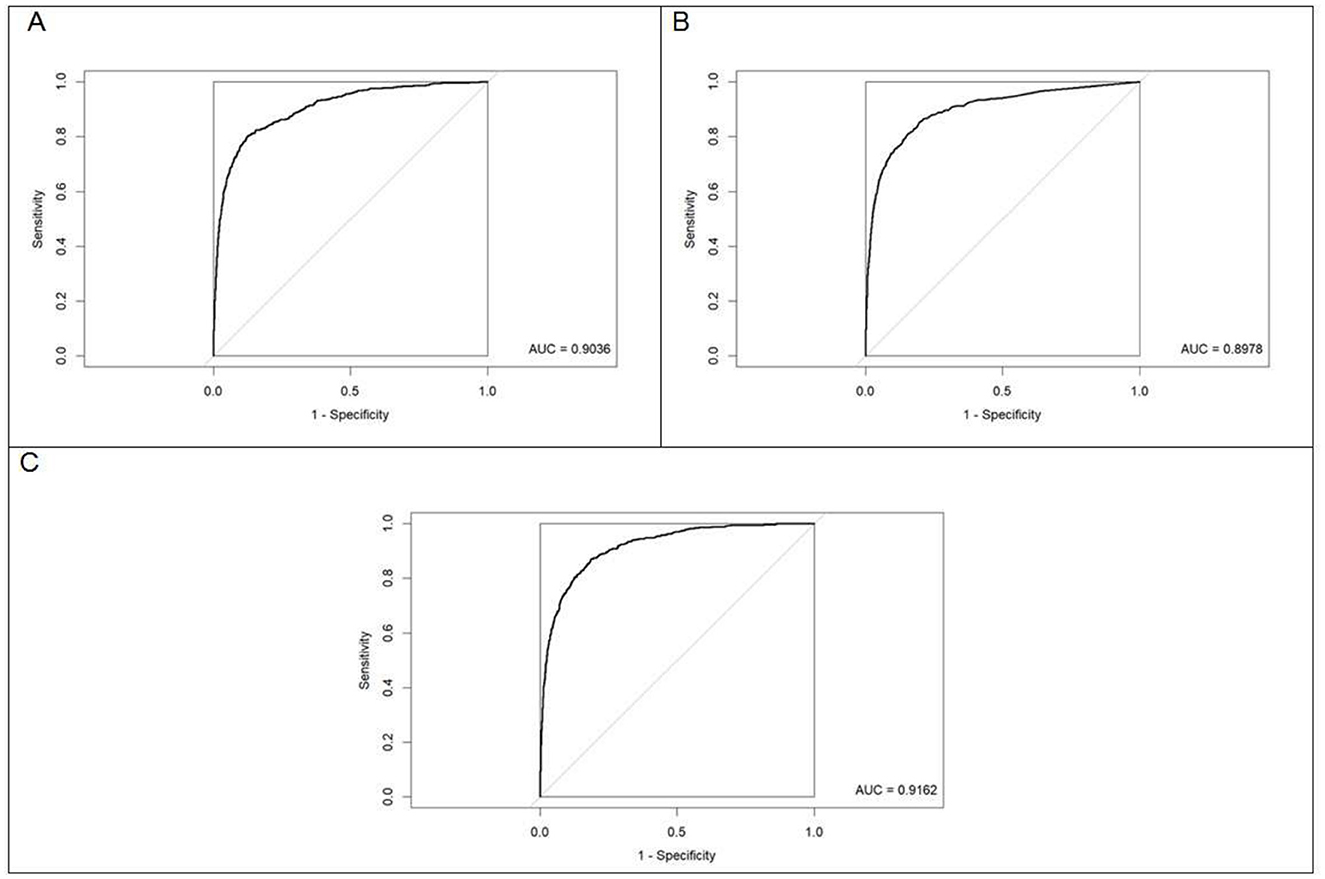
Figure 4. Receiver operating characteristic (ROC) curves for the fitted models evaluated on the test dataset. (A) Logistic regression. (B) Random forest. (C) XGBoost. The diagonal line indicates the performance of a random classifier (reference line, AUC = 0.50).
3.4.5 Model performance metrics
Based on the test set, when exploring the optimal cutoff points in the construction of ROC curves (criterion of the point closest to [0,1] of the ROC curve), as shown in Table 8, these cutoff points are detailed as follows as the efficiency metrics of the models to predict in-hospital death considering 16 preadmission variables. The logistic regression model generated an AUC = 0.904 (0.890–0.917), a cutoff point equal to 0.040, a sensitivity of 80.5%, a specificity of 87.2% and a balanced efficiency of 83.9%. The random forest model generated an AUC = 0.898 (0.883–0.912), a cutoff point equal to 0.037, a sensitivity of 85.3%, a specificity of 80.3% and a balanced efficiency of 82.8%. The XGBoost model generated an AUC = 0.916 (0.905–0.928), a cutoff point equal to 0.023, a sensitivity of 87.0%, a specificity of 81.3% and a balanced efficiency of 84.2%. The DeLong test revealed that the area under the curve of the XGBoost model was greater than that of the logistic regression and random forest models (p-value < 0.001 in both cases).
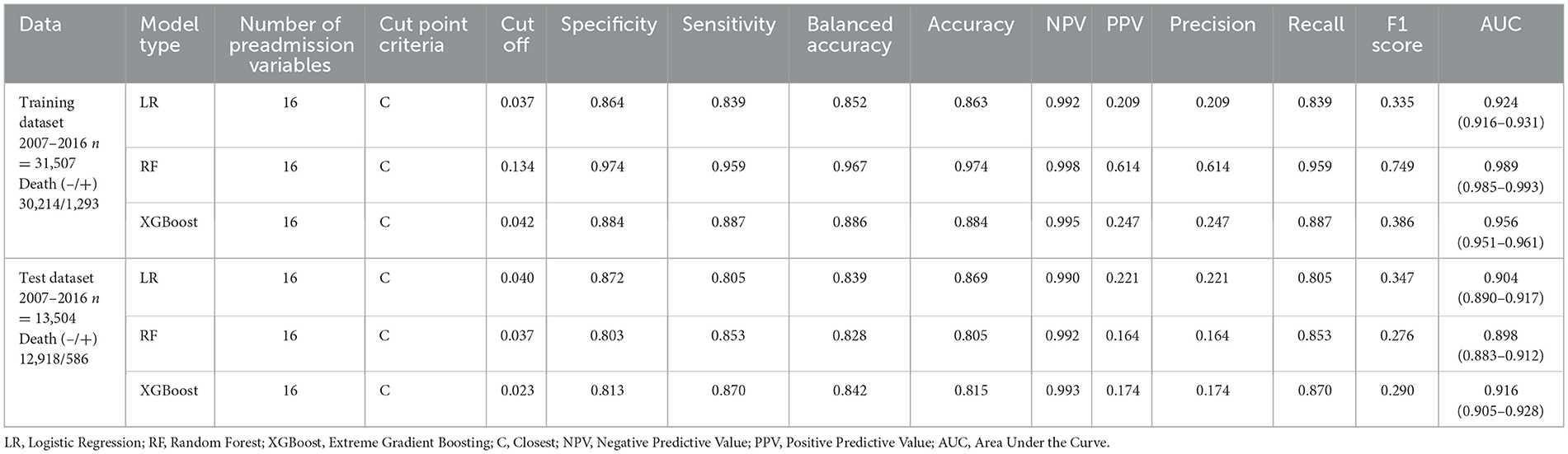
Table 8. Performance metrics of the machine learning models fitted for the prediction of in-hospital death.
Finally, the confusion matrices for all models evaluated on the test set, along with their respective optimal cut-off points, are presented in Figure 5. Notably, for the best-performing model for predicting in-hospital death was XGBoost. When evaluated on the test set (n = 13,504; 586 in-hospital deaths), this model identified 10,502 true negatives, 76 false negatives, 2,416 false positives, and 510 true positives. This result in a ratio of 4.7 to 1 for patients predicted to die in-hospital who ultimately survived, compared those who actually died.
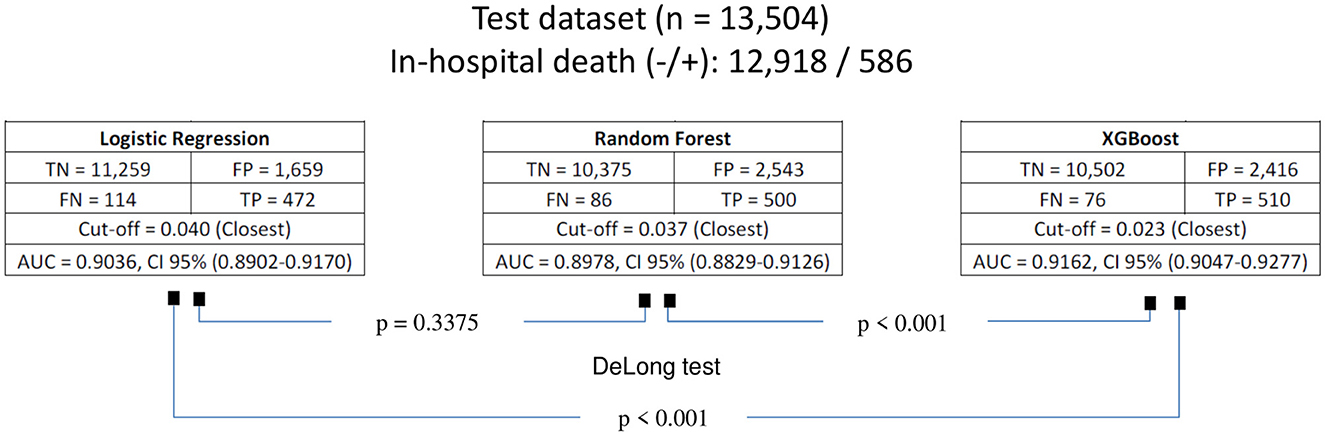
Figure 5. Confusion matrices of the models for predicting in-hospital death, evaluated on the test dataset using the optimal cut-off points, defined by the closest to [0,1] criterion on the ROC curve. TN, true negative; FP, false positive; FN, false negative; TP, true positive; AUC, area under curve; CI, confidence interval.
4 Discussion
Hospital mortality is a multidimensional indicator widely used to evaluate the quality and effectiveness of medical care (6, 7). Identifying the factors associated with in-hospital death that facilitate the construction of robust predictive models is essential. The current computing power allows the implementation of complex algorithms that exceed the capabilities of traditional logistic regression. Among these predictive models, approaches such as random forest (30) and XGBoost (34), stand out, as they are able to identify complex patterns between the data.
The identification of factors with high prognostic value for in-hospital death is crucial in the hospital setting since it provides the opportunity to carry out closer monitoring of patients at risk, helping to reduce the frequency of adverse events and therefore improving the quality of hospital care. This study seeks to adjust machine learning models to predict and identify the preadmission factors with the highest prognostic value for in-hospital death.
4.1 In-hospital mortality and preadmission characteristics
In our study, in which the hospital discharge records of 45,011 patients in a third-level Mexican hospital during its first 10 years of operation were analyzed, an in-hospital mortality of 4.17% was observed. This figure is similar to that reported by Le Guen and Tobin (53), who reported a mortality of 3.62% in 44,297 patients discharged from an Australian tertiary care hospital over a period of 5 years. However, it is higher than the 2.15% registered nationally in Mexican hospitals in the same 10-year period of our study (3). This could be attributed to the greater complexity of the pathologies treated in tertiary care hospitals.
Additionally, the mean age of the patients who died in the hospital was significantly higher than that of patients who survived, a finding that is consistent with that reported by Clark et al. (24) in a multicenter study in which 10,743 hospital admissions were considered and patients younger than 60 years were reported to have a risk of in-hospital death that was up to three times lower than that of patients older than 60 years. Likewise, a significant association was found between in-hospital death and the day of the week of admission, which is consistent with the findings of Mohammed et al. (16) in a multicenter study that included approximately 1.5 million hospital admissions, hospital admission on the weekend was a risk factor for in-hospital death, and the risk was more pronounced in elective admissions than in emergency admissions.
On the other hand, the month of admission was also associated with in-hospital death. This phenomenon could be explained in terms of seasonal variability in mortality, as reported by Achebak et al. (54), who, in their analysis of approximately 1.7 million hospital admissions, reported that although the number of hospitalizations for respiratory diseases increases during cold months, in-hospital mortality peaks during months of high temperatures, probably because of the additional effect of heat on the vulnerability of patients with chronic respiratory diseases.
Regarding other associated factors, the first hospitalization, coming from the outpatient clinic, as well as the equality between the main condition diagnosed at admission and the reference diagnosis, was associated with lower in-hospital mortality. In this sense, in 83.12% of the 45,011 hospital discharges, the main condition diagnosed at admission coincided with the reference diagnosis.
In contrast, factors such as the reference diagnosis, the main condition diagnosed at admission, the medical service that performed the admission, the presence of comorbidities and a higher number of comorbidities were associated with higher in-hospital mortality. Among the 45,011 hospital discharges, the main ICD-10 diagnostic groups at admission were neoplasms (37.12%), genitourinary diseases (10.60%), congenital malformations (11.39%) and diseases of the circulatory system (8.05%), accounting for approximately 70% of the total. In addition, approximately half of the 1,879 in-hospital deaths were patients admitted by one of the following five services: oncology (21.18%), hematology (9.53%), internal medicine (9.21%), neurosurgery (4.79%) and cardiology (4.58%). Notably, 79.43% of the 45,011 hospital discharges did not present comorbidities.
Our findings suggest that patients with in-hospital death tend to enter a worse clinical state and have less prior information about their medical condition, either because of a late diagnosis or the presence of a serious acute illness. In addition, those without contact prior to outpatient care do not have a known clinical history or a history of response to previous treatments, which makes their management difficult. This clinical context limits the capacity for therapeutic response and increases the risk of fatal outcomes. These findings are consistent with those proposed by models such as the HOMR (Hospital Patient One-year Mortality Risk), built on the basis of 640,022 hospital admissions (55), which identifies the admission diagnosis, the admission medical service and the number of comorbidities as key predictors of hospital mortality (55).
4.2 Model performance and interpretability
To fit the three types of supervised machine learning models (logistic, random forest and XGBoost) considered for predicting in-hospital death on the basis of preadmission characteristics, our 45,011 hospital discharges were randomly divided into two subsets: 70% for training and 30% for testing. This proportion has been used in studies such as the one by Wen et al. (56), in which eight types of machine learning models were evaluated to predict 28-day mortality in patients with sepsis. In other studies, such as that by Cao et al. (57), an 80% ratio for training was used, and a 20% ratio was used for testing when an XGBoost model was developed to predict in-hospital mortality in a cohort of 545,388 patients with severe traumatic brain injury. These variations reflect that the data partition can be adapted to the sample size, but in all cases, a balance between model fit and generalizability is sought.
In addition, the inclusion of multiple models allows us to compare not only their precision but also their ability to identify clinically relevant factors with prognostic value. In our study, machine learning methods were shown to be effective in predicting in-hospital mortality using only data available at the time of admission.
Through the test set and the implementation of the DeLong test, the XGBoost model outperformed logistic regression (AUC = 0.9036, 95% CI: 0.8902–0.9170) and random forest (AUC = 0.8978, 95% CI: 0.8829–0.9126), with a p-value < 0.001 in both cases.
Overfitting, which arises when a model fits the training data too closely and loses generalizability (58), was evident in the Random Forest model, with near-perfect discrimination on the training set (AUC = 0.989) but reduced discriminatory ability on the test set (AUC = 0.898). In contrast, XGBoost showed only a mild decrease in discrimination for training (AUC = 0.956) to test data (AUC = 0.916), which can be attributed to the explicit regularization mechanisms (e.g., learning rate and depth control) that limit model complexity.
The XGBoost model reached an AUC = 0.916, 95% CI: 0.905–0.928, with an optimal cutoff point of 0.023 (according to the criterion of the point closest to [0.1] on the ROC curve), a sensitivity of 87.0%, a specificity of 81.3%, and a balanced efficiency of 84.2%. These values indicate that the model has high discrimination and an adequate balance between false positives and negatives in real clinical conditions.
With respect to interpretability, the models identified variables with greater predictive importance. In logistic regression, the origin of the outpatient consultation of the hospital and the medical service that performed the admission stood out. In the random forest model, there was a coincidence with logistic regression, but the month of admission and the day of the week of admission were added. Finally, in XGBoost, the most relevant variables were medical service that performed the admission, number of conditions, origin of the outpatient consultation of the Hospital, the main condition diagnosed at admission according to the ICD-10, age, month of admission, and day of the week of admission. These differences in the variables with greater predictive importance highlight the ability of complex models to detect nonlinear interactions and hidden relationships between predictors.
Notably, “medical service that performed the admission” emerged as the single strongest predictor of in-hospital death in the XGBoost model, likely serving as a proxy for critical clinical factors such as disease severity, case-mix complexity, and variations in admission or treatment practices. In our cohort, oncology (21.18%, 398/1,879), hematology (9.53%, 179/1,879), and internal medicine (9.21%, 173/1,879) contributed the largest shares of in-hospital deaths, reflecting known high-risk patient populations: oncology patients frequently present with advanced or metastatic disease (53), hematology patients mainly with various types of leukemia receiving chemotherapy regimens that carry high treatment-related risks including infections and complications (59), and internal medicine patients often present with complex or undifferentiated conditions, which may delay definitive diagnosis and timely intervention (60). The predictive prominence of this variable thus captures critical aspects of patient complexity at admission, highlighting its practical value for early risk stratification and targeted preventive interventions.
Our best fitted model to predict in-hospital death results with XGBoost AUC = 0.916 (0.905–0.928), when evaluated in the test set (n = 13,504; 586 in-hospital deaths), allows us to identify 10,502 true negatives, 76 false-negatives, 2,416 false positives and 510 true positives, which generates a ratio of 4.7 to 1 of false positives for every true positive. Although this alert rate may appear high, in the clinical setting, it could be considered reasonable since it is based solely on preadmission characteristics and allows timely detection of patients at risk, facilitating early preventive interventions.
Similar findings were reported by Soffer et al. (61). In particular, when XGBoost was applied to a cohort of 118,262 hospitalized patients (6,311 in-hospital deaths), an AUC of 0.924 (95% CI: 0.917–0.930) and a ratio of 5.9 to 1 of false positives for each true positive were achieved on the basis of preadmission characteristics and comorbidities, together with data on laboratory tests and initial treatment. This concordance supports the clinical potential of the XGBoost model as a useful tool for identifying patients at high risk of in-hospital mortality, especially when it is based on patient data available at hospital admission.
In the clinical practice, the integration of the model into the electronic health record as a decision-support alert would enable admitting physicians to identify high-risk patients early (62), guiding timely preventive actions while minimizing alert fatigue and clinician burden. Rather than functioning as a hard stop, the model could serve as a first-line screening tool, prompting secondary evaluations, such as targeted laboratory tests, imaging studies, or enhanced monitoring, to refine risk stratification. This approach aligns with prior studies demonstrating the practical application of AI-based risk prediction systems in daily medical practice (63–65), where models produce probabilities or scores that inform, rather than dictate, clinical decision-making.
In summary, our results show that the use of advanced algorithms such as XGBoost allows not only improvement of the accuracy of the prediction but also optimization of the identification of clinically relevant risk factors, offering a solid basis for the development of early warning systems for mortality in high-complexity hospitals.
4.3 Limitations, strengths, and future directions
Our study has certain limitations. First, since it is a cross-sectional study, it does not allow us to infer causality. Second, the results are based on a single-center study that uses data from a secondary base, which may contain some inherent capture errors at the source. Third, predictive models of in-hospital death were not constructed on the basis of medical services at admission or specific pathologies. Fourth, 18.54% of discharge records were excluded due to incomplete data; although most variables were nearly complete and missingness was not systematically associated with patient characteristics or adverse outcomes, the excluded records included only 146 in-hospital deaths (1.43%, 146/10,242), which may still introduce potential selection bias and affect model performance and variable importance. Finally, the lack of a preadmission biochemical or imaging characterization of patients limits the possibility of exploring potential associations and the predictive capacity of various biomarkers that could generate more robust models to predict in-hospital mortality.
Despite these limitations, our study has notable strengths, such as the evaluation of preadmission characteristics in a large sample (n = 45,011) of patients corresponding to a long period of time and the first 10 years of operation at a third-level care hospital. In addition, it was not restricted to the use of logistic regression but rather incorporated advanced machine learning techniques capable of identifying complex relationships between the predictor variables. This allowed identification of the factors that induce a greater propensity to present in-hospital death, improving the predictive capacity and understanding of the associated risks.
Finally, given the limitations identified, it is recommended that multicenter and longitudinal studies that include biochemical and imaging characteristics from hospital admission be carried out. In addition, it would be useful to develop specific models for different admission medical services, such as medical, surgical, and pediatric, including high-risk services like oncology and hematology, as well as specific pathologies. This approach would allow for greater precision in the identification of patients at high risk of in-hospital death, ideally externally validated and providing more context-specific estimates.
5 Conclusion
The XGBoost model, owing to its ability to capture complex patterns, makes it possible to identify patients with a higher risk of in-hospital death from the data available at hospital admission. This study provides a support tool for clinical decision-making and helps in the early identification of patients who require closer monitoring and follow-up during their hospital stay. This approach not only helps prioritize resources efficiently but also optimizes intervention strategies, significantly contributing to reducing in-hospital mortality and ultimately improving quality and comprehensive care in the hospital setting.
Author disclosure
The authors confirm that only an abstract (fewer than 350 words) was presented as a poster at the 20th Congreso de Investigación en Salud Pública (20th Public Health Research Congress) and the VIII Congreso Latinoamericano y del Caribe de Salud Global (VIII Latin American and Caribbean Congress on Global Health), both conferences held in Cuernavaca, Mexico, in March 2025. These conferences were organized by the Instituto Nacional de Salud Pública (INSP, National Institute of Public Health of Mexico) and the Alianza Latinoamericana de Salud Global (ALASAG, Latin American Alliance for Global Health).
Data availability statement
Publicly available datasets were analyzed in this study. This data can be found here: http://www.dgis.salud.gob.mx/contenidos/basesdedatos/da_egresoshosp_gobmx.html.
Ethics statement
The studies involving humans were approved by Research and Research-Ethics committees of the Hospital Regional de Alta Especialidad del Bajío (registration numbers: CI-HRAEB 037-2022 and CEI-023-2022). The studies were conducted in accordance with the local legislation and institutional requirements. The ethics committee/institutional review board waived the requirement of written informed consent for participation from the participants or the participants' legal guardians/next of kin because the retrospective nature of the study.
Author contributions
ER-M: Data curation, Validation, Conceptualization, Methodology, Formal analysis, Supervision, Writing – review & editing, Project administration, Writing – original draft, Software. BR-A: Conceptualization, Data curation, Writing – review & editing, Writing – original draft, Formal analysis, Software. DA-M: Supervision, Writing – review & editing, Methodology, Software, Conceptualization, Writing – original draft, Formal analysis, Project administration, Data curation, Validation.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. Open Access funding for this article was supported by Servicios de Salud del Instituto Mexicano del Seguro Social para el Bienestar (IMSS-BIENESTAR).
Acknowledgments
The present work was carried out within the framework of the Servicios de Salud del Instituto Mexicano del Seguro Social para el Bienestar (IMSS-BIENESTAR). We thank the Instituto Mexicano del Seguro Social para el Bienestar (IMSS-BIENESTAR) for the support and resources provided.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher's note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Segura-Benedicto A. El análisis de la mortalidad hospitalaria como una medida de efectividad. Med Clin. (1988) 91:139–41.
2. Estadística de. egresos hospitalarios de la secretaría de salud, 1999. Salud Publica Mex. (2000) 42:456–70. doi: 10.1590/S0036-36342000000500012
3. DGIS. Bases de datos sobre egresos hospitalarios (2020). Available online at: http://www.dgis.salud.gob.mx/contenidos/basesdedatos/da_egresoshosp_gobmx.html (Accessed January 15, 2023).
4. DGIS. Guía de intercambio de información sobre Reporte de información de egresos hospitalarios a la Secretaría De Salud (2015). Available online at: http://www.dgis.salud.gob.mx/contenidos/intercambio/gegresos_gobmx.html (Accessed January 15, 2023).
5. Agency for Healthcare Research and Quality. AHRQ Quality Indicators —Guide to Inpatient Quality Indicators: Quality of Care in Hospitals— Volume, Mortality, and Utilization. Revision 4. Rockville, MD: Agency for Healthcare Research and Quality (2002).
6. García Ortega C, Almenara Barrios J GOJ. Tasas específicas de mortalidad en el Hospital de Algeciras durante el periodo 1995-1996. Rev Esp Salud Pública. (1997) 71:305–15. doi: 10.1590/S1135-57271997000300009
7. Jiménez Paneque RE. Indicadores de calidad y eficiencia de los servicios hospitalarios: una mirada actual. Rev Cuba salud pública. (2004) 30.
8. Nosocomial infection rates for interhospital comparison: limitations and possible solutions. A Report from the National Nosocomial Infections Surveillance (NNIS) System. Infect Control Hosp Epidemiol. (1991) 12:609–21. doi: 10.1086/646250
9. Andrews RM, Russo C a, Pancholi M. Trends in hospital risk-adjusted mortality for select diagnoses and procedures, 1994-2004: statistical brief #38. Healthc Cost Util Proj Stat Briefs. (2006) 1–7. http://www.ncbi.nlm.nih.gov/pubmed/21850773
10. Secretaría de Salud de Aguascalientes. Egresos Hospitalarios 2010 - 2014. Available online at: http://www.issea.gob.mx/egresos.asp (Accessed January 15, 2023).
11. Rodríguez-Salgado MRS. Frecuencia de infecciones asociadas a la atención de la salud en los principales sistemas de información de México. Boletín CONAMED. (2018) 3:16–20.
12. Ponce De León S, Rangel-Frausto MS, Elías-López JI, Romero-Oliveros C, Huertas-Jiménez M. Infecciones nosocomiales: tendencias seculares de un programa de control en Mexico. Salud Publica Mex. (1999) 41:5–11. doi: 10.1590/S0036-36341999000700003
13. Zamudio I, Espinoza-Vital G, Rodriguez R, Gomez J MM. Infecciones nosocomiales Tendencia durante 12 años en un hospital pediátrico. Rev Med Inst Mex Seguro Soc. (2014) S38:38–43.
14. Torres D, Núñez N, Villalobos R, Durán M. Características de las infecciones asociadas con la atención de la salud en un hospital de tercer nivel de Yucatán, México Characteristics of health care-associated infections in a high specialty hospital of Yucatan, Mexico. Med Int Méx. (2020) 36:451–9. doi: 10.24245/mim.v36i4.3188
15. Clarke MS, Wills RA, Bowman RV, Zimmerman PV, Fong KM, Coory MD, et al. Exploratory study of the “weekend effect” for acute medical admissions to public hospitals in Queensland, Australia. Intern Med J. (2010) 40:777–83. doi: 10.1111/j.1445-5994.2009.02067.x
16. Mohammed MA, Sidhu KS, Rudge G, Stevens AJ. Weekend admission to hospital has a higher risk of death in the elective setting than in the emergency setting : a retrospective database study of national health service hospitals in England. BMC Health Serv Res. (2012) 12:87. doi: 10.1186/1472-6963-12-87
17. Taylor HD, Dennis DA, Crane HS. Relationship between mortality rates and hospital patient volume for medicare patients undergoing major orthopaedic surgery of the hip, knee, spine, and femur. J Arthroplasty. (1997) 12:235–42. doi: 10.1016/S0883-5403(97)90018-8
18. Tucker J, UK Neonatal Staffing Study Group. Patient volume, staffing, and workload in relation to risk- adjusted outcomes in a random stratified sample of UK neonatal intensive care units : a prospective evaluation. Lancet. (2002) 359:99–107. doi: 10.1016/S0140-6736(02)07366-X
19. Mcphee JT, Iii PR, Eslami MH, Arous EJ, Messina LM, Schanzer A. Surgeon case volume, not institution case volume, is the primary determinant of in-hospital mortality after elective open abdominal aortic aneurysm repair. YMVA. (2007) 53:591–9.e2. doi: 10.1016/j.jvs.2010.09.063
20. Ghaferi AA, Birkmeyer JD, Dimick JB. Variation in hospital mortality associated with inpatient surgery. N Engl J Med. (2009) 361:1368–75. doi: 10.1056/NEJMsa0903048
21. Tanner WP, Swets JA. A decision-making theory of visual detection. Psychol Rev. (1954) 61:401–9. doi: 10.1037/h0058700
22. Cox DR. The regression analysis of binary sequences. J R Stat Soc Ser B Stat Methodol. (1958) 20:215–32. doi: 10.1111/j.2517-6161.1958.tb00292.x
23. Rosenthal GE, Kaboli PJ, Barnett MJ, Sirio CA. Age and the risk of in-hospital death: insights from a multihospital study of intensive care patients. J Am Geriatr Soc. (2002) 50:1205–12. doi: 10.1046/j.1532-5415.2002.50306.x
24. Clark D, Armstrong M, Allan A, Graham F, Carnon A, Isles C. Imminence of death among hospital inpatients: prevalent cohort study. Palliat Med. (2014) 28:474–9. doi: 10.1177/0269216314526443
25. Aylin P, Bottle A, Majeed A. Use of administrative data or clinical databases as predictors of risk of death in hospital: comparison of models. Br Med J. (2007) 334:1044–7. doi: 10.1136/bmj.39168.496366.55
26. Gordon HS, Rosenthal GE. The relationship of gender and in-hospital death: increased risk of death in men. Med Care. (1999) 37:318–24. doi: 10.1097/00005650-199903000-00011
27. Buist M, Bernard S, Nguyen T V, Moore G, Anderson J. Association between clinically abnormal observations and subsequent in-hospital mortality: a prospective study. Resuscitation. (2004) 62:137–41. doi: 10.1016/j.resuscitation.2004.03.005
28. Obermeyer Z, Emanuel EJ. Predicting the future—big data, machine learning, and clinical medicine. N Engl J Med. (2016) 375:1216. doi: 10.1056/NEJMp1606181
29. Charbuty B, Abdulazeez A. Classification based on decision tree algorithm for machine learning. J Appl Sci Technol Trends. (2021) 2:20–8. doi: 10.38094/jastt20165
31. Patel J, Goyal R. Applications of artificial neural networks in medical science. Curr Clin Pharmacol. (2008) 2:217–26. doi: 10.2174/157488407781668811
32. Langarizadeh M, Moghbeli F. Applying naive bayesian networks to disease prediction: a systematic review. Acta Inform Medica. (2016) 24:364–9. doi: 10.5455/aim.2016.24.364-369
33. Stoean R, Stoean C. Modeling medical decision making by support vector machines, explaining by rules of evolutionary algorithms with feature selection. Expert Syst Appl. (2013) 40:2677–86. doi: 10.1016/j.eswa.2012.11.007
34. Zelli V, Manno A, Compagnoni C, Ibraheem RO, Zazzeroni F, Alesse E, et al. Classification of tumor types using XGBoost machine learning model: a vector space transformation of genomic alterations. J Transl Med. (2023) 21:1–14. doi: 10.1186/s12967-023-04720-4
35. Brajer N, Cozzi B, Gao M, Nichols M, Revoir M, Balu S, et al. Prospective and external evaluation of a machine learning model to predict in-hospital mortality of adults at time of admission. JAMA Netw Open. (2020) 3:1–14. doi: 10.1001/jamanetworkopen.2019.20733
36. Allyn J, Allou N, Augustin P, Philip I, Martinet O, Belghiti M, et al. comparison of a machine learning model with EuroSCORE II in predicting mortality after elective cardiac surgery: a decision curve analysis. PLoS ONE. (2017) 12:1–12. doi: 10.1371/journal.pone.0169772
37. Kasim S, Malek S, Song C, Ahmad WAW, Fong A, Ibrahim KS, et al. In-hospital mortality risk stratification of Asian ACS patients with artificial intelligence algorithm. PLoS ONE. (2022) 17:1–28. doi: 10.1038/s41598-022-18839-9
38. Trentino KM, Schwarzbauer K, Mitterecker A, Hofmann A, Lloyd A, Leahy MF, et al. Machine learning–based mortality prediction of patients at risk during hospital admission. J Patient Saf. (2022) 18:494–8. doi: 10.1097/PTS.0000000000000957
39. Mpanya D, Celik T, Klug E, Ntsinjana H. Predicting in-hospital all-cause mortality in heart failure using machine learning. Front Cardiovasc Med. (2023) 9:1032524. doi: 10.3389/fcvm.2022.1032524
40. Frick H, Chow F, Kuhn M, Mahoney M, Silge J, Wickham H. rsample: General Resampling Infrastructure. R package (2025).
41. R Core Team. R: A Language and Environment for Statistical Computing (2024). Available online at: https://www.r-project.org (Accessed March 15, 2024).
42. Mann HB, Whitney DR. On a test of whether one of two random variables is stochastically larger than the other. Ann Math Stat. (1947) 18:50–60. doi: 10.1214/aoms/1177730491
43. Pearson K. On the criterion that a given system of deviations from the probable in the case of a correlated system of variables is such that it can be reasonbly supposed to have arisen from random sampling. Lond Edinburgh Dublin Philos Magaz J Sci. (1900) 50:157–75. doi: 10.1080/14786440009463897
44. Chen T, Guestrin C. XGBoost: a scalable tree boosting system. In: Proc ACM SIGKDD Int Conf Knowl Discov Data Min. New York, NY: Association for Computing Machinery (ACM). (2016). p. 13–7. doi: 10.1145/2939672.2939785
45. Kuhn M, Wing J, Weston S, Williams A, Keefer C, Engelhardt A, et al. Package ‘caret.' R J (2020) 223.
46. RColorBrewer S, Liaw MA. Package ‘randomforest.' Univ California, Berkeley Berkeley, CA, USA (2018)
48. Hosmer Jr DW, Lemeshow S, Sturdivant RX. Applied Logistic Regression. Hoboken, NJ: John Wiley & Sons (2013). doi: 10.1002/9781118548387
49. Nagelkerke NJD, A. note on a general definition of the coefficient of determination. Biometrika. (1991) 78:691–2. doi: 10.1093/biomet/78.3.691
50. Pepe MS. The Statistical Evaluation of Medical Tests for Classification and Prediction. Oxford: Oxford University Press (2003). doi: 10.1093/oso/9780198509844.001.0001
51. DeLong ER, DeLong DM, Clarke-Pearson DL. Comparing the areas under two or more correlated receiver operating characteristic curves: a nonparametric approach. Biometrics. (1988) 44:837–845. doi: 10.2307/2531595
52. Collins GS, Reitsma JB, Altman DG, Moons KGM. Transparent reporting of a multivariable prediction model for individual prognosis or diagnosis (TRIPOD): the TRIPOD statement. BMJ. (2015) 350:1. doi: 10.1186/s12916-014-0241-z
53. Le Guen M, Tobin A. Epidemiology of in-hospital mortality in acute patients admitted to a tertiary-level hospital. Intern Med J. (2016) 46:457–64. doi: 10.1111/imj.13019
54. Achebak H, Garcia-Aymerich J, Rey G, Chen Z, Méndez-Turrubiates RF, Ballester J. Ambient temperature and seasonal variation in inpatient mortality from respiratory diseases: a retrospective observational study. Lancet Reg Heal - Eur. (2023) 35:100757. doi: 10.1016/j.lanepe.2023.100757
55. Van Walraven C. The Hospital-patient One-year Mortality Risk score accurately predicted long-term death risk in hospitalized patients. J Clin Epidemiol. (2014) 67:1025–34. doi: 10.1016/j.jclinepi.2014.05.003
56. Wen C, Zhang X, Li Y, Xiao W, Hu Q, Lei X, et al. An interpretable machine learning model for predicting 28-day mortality in patients with sepsis-associated liver injury. PLoS ONE. (2024) 19:e0303469. doi: 10.1371/journal.pone.0303469
57. Cao Y, Forssten MP, Sarani B, Montgomery S, Mohseni S. Development and validation of an xgboost-algorithm-powered survival model for predicting in-hospital mortality based on 545,388 isolated severe traumatic brain injury patients from the TQIP database. J Pers Med (2023) 13:1401. doi: 10.3390/jpm13091401
58. Montesinos López OA, Montesinos López A, Crossa J. Overfitting, model tuning, and evaluation of prediction performance. In: Multivariate Statistical Machine Learning Methods for Genomic Prediction. Dordrecht, NL: Springer (2022). p. 109–39 doi: 10.1007/978-3-030-89010-0_4
59. Biard L, Darmon M, Lemiale V, Mokart D, Chevret S, Azoulay E, et al. Center effects in hospital mortality of critically ill patients with hematologic malignancies. Crit Care Med. (2019) 47:809–16. doi: 10.1097/CCM.0000000000003717
60. Verma AA, Guo Y, Kwan JL, Lapointe-Shaw L, Rawal S, Tang T, et al. Patient characteristics, resource use and outcomes associated with general internal medicine hospital care: the General Medicine Inpatient Initiative (GEMINI) retrospective cohort study. C Open. (2017) 5:E842–9. doi: 10.9778/cmajo.20170097
61. Soffer S, Klang E, Barash Y, Grossman E, Zimlichman E. Predicting in-hospital mortality at admission to the medical ward: a big-data machine learning model. Am J Med. (2021) 134:227–34.e4. doi: 10.1016/j.amjmed.2020.07.014
62. Miller DD, Brown EW. Artificial intelligence in medical practice: the question to the answer? Am J Med. (2018) 131:129–33. doi: 10.1016/j.amjmed.2017.10.035
63. Delahanty RJ, Kaufman D, Jones SS. Development and evaluation of an automated machine learning algorithm for in-hospital mortality risk adjustment among critical care patients. Crit Care Med. (2018) 46:E481–8. doi: 10.1097/CCM.0000000000003011
64. Gao Y, Cai GY, Fang W, Li HY, Wang SY, Chen L, et al. Machine learning based early warning system enables accurate mortality risk prediction for COVID-19. Nat Commun. (2020) 11:1–10. doi: 10.1038/s41467-020-18684-2
Keywords: in-hospital death, logistic regression, prediction, random forest, XGBoost
Citation: Rodea-Montero ER, Rodríguez-Alcántar BJ and Armenta-Medina D (2025) Prediction of in-hospital death among patients admitted to a tertiary care hospital over the first 10 years: a machine learning approach. Front. Public Health 13:1635708. doi: 10.3389/fpubh.2025.1635708
Received: 30 May 2025; Accepted: 05 September 2025;
Published: 06 October 2025.
Edited by:
Wasan Katip, Chiang Mai University, ThailandReviewed by:
Jiangtao Sheng, Shantou University, ChinaImaobong Chinedozi, Johns Hopkins University, United States
Copyright © 2025 Rodea-Montero, Rodríguez-Alcántar and Armenta-Medina. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Dagoberto Armenta-Medina, ZGFnb2JlcnRvLmFybWVudGFAaW5mb3RlYy5teA==