 Lanshan Zhang1,2†
Lanshan Zhang1,2† Jingyi Yang
Jingyi Yang Gege Fang
Gege Fang- 1School of Digital Media and Design Arts, Beijing University of Posts and Telecommunications, Beijing, China
- 2New Media and Creative Center at the Beijing Key Laboratory of Internet Systems and Network Culture, Beijing, China
Introduction: This study examines the drivers behind healthcare professionals’ and patients’ acceptance of medical AI chat assistants in China.
Methods: A nationwide online survey was conducted from March 10 to April 28, 2024, using quota sampling to collect 500 valid responses, and data were analyzed via structural equation modeling.
Results: Performance expectancy, perceived cost, digital access, and digital competence all positively predicted intention to use, whereas patient age and consultation frequency—rather than socioeconomic status—directly influenced actual usage behavior.
Discussion: Findings validate an extended UTAUT model in digital-health contexts, highlight cultural moderators of technology acceptance, and inform age-friendly AI design and equitable health-informatization policies in aging societies.
1 Introduction
As a populous nation with an outsized demand for healthcare, China recorded 9.54 billion outpatient visits in 2023—an average of seven encounters per capita (1). Although Artificial Intelligence-Generated Content technologies have been integrated into clinical workflows, longstanding asymmetries in resource allocation and persistent supply–demand imbalances remain significant (2). Despite incremental advances under the Healthy China 2030 agenda, the structural tension between service supply and population need endures.
The rapid maturation of artificial intelligence has catalyzed the emergence of “AI+Healthcare,” deepening algorithmic penetration across the care continuum and offering novel pathways to redress shortages and maldistribution of medical resources. Industry forecasts project that China’s AI application market will reach US$127 billion by 2025, with the medical AI segment accounting for one-fifth of the total value (3). AI systems are increasingly positioned as “second brains” for clinicians, assuming partial responsibility for resource provision and bearing the societal expectation of alleviating systemic strain.
The November 2022 release of ChatGPT accelerated the development of Chinese medical large language models and facilitated the rollout of AI-empowered conversational agents. In May 2023, MedLink unveiled MedGPT, its proprietary medical chatbot, which achieved a 96 percent concordance rate with face-to-face initial diagnoses in a controlled experiment (4). In October 2023, Huatuo GPT successfully passed the National Medical Licensing Examination and nearly all other medical credentialing tests. By November, the system had already served several hundred thousand users (5). These milestones underscore the substantial value and latent potential of AI chatbots within China’s health ecosystem.
However, technological breakthroughs have not been accompanied by commensurate adoption. In 2023, the urban AI adoption rate was only 6.3 percent, with fewer than 1 million AI-assisted consultations per day—an overall penetration rate below 4 percent. To meet the target set in the 14th Five-Year Plan for National Health Informatization—namely, achieving a 50 percent utilization rate of intelligent diagnostic aids in tertiary hospitals by 2025—a compound annual growth rate exceeding 35 percent is required over the next 24 months (6). This supply–demand asymmetry foregrounds the urgency of identifying the drivers of AI adoption.
Echoing Chen et al.’s systematic review, extant scholarship on AI in healthcare predominantly privileges technical dimensions or single-stakeholder perspectives—either patients or clinicians—thereby neglecting systematic analyses of acceptance gaps across the dyadic doctor–patient relationship (7). Moreover, most studies rely on the original Technology Acceptance Model (TAM) or the Unified Theory of Acceptance and Use of Technology (UTAUT) without incorporating context-specific variables pertinent to China’s medical environment (8). By extending UTAUT to incorporate Digital Access, Digital Competence, and patients’ Socio-Economic Status, this research offers a theoretically grounded and empirically nuanced account of the factors shaping the acceptance and use of AI-enabled chatbots among both clinicians and patients, ultimately informing policy and practice aimed at enhancing service delivery and doctor-patient relations.
2 Literature review
2.1 Application and effects of medical AI chat assistants
2.1.1 Application status and ethical risks
Medical AI chat assistants represent a new form of healthcare technology developed within the context of large language models. These assistants enable patients to provide information such as their age, symptoms, and medical history through conversation, in exchange for receiving a diagnosis and treatment plan. Healthcare professionals can use these AI-generated assessments to validate or assist their own diagnostic and treatment decisions.
In terms of application, Nov et al. conducted a survey to explore respondents’ ability to recognize and trust medical advice provided by ChatGPT compared to human doctors. The findings indicated that ChatGPT’s accuracy in addressing patients’ medical questions ranged from 49 to 85%, with a minimal distinction rate between human and machine feedback (65.5% for humans vs. 65.1% for machines) (9). Moreover, the trust in ChatGPT’s medical responses was moderately positive. Additionally, Ayesha et al. investigated the potential of medical artificial intelligence in assisting healthcare professionals with diagnosing and treating cardiovascular diseases through an experimental approach. They posed 10 hypothetical clinical cardiovascular disease questions to ChatGPT and had the medical feedback evaluated by human medical experts. The results showed that eight of ChatGPT’s responses were accurate diagnoses, while the other two, although not entirely incorrect, had some discrepancies from the actual diagnostic procedures (10).
In terms of ethical risks, Liu highlighted significant concerns regarding the “technological black box” and the autonomous learning capabilities of medical AI. These risks include challenges in regulating the protection of medical data and difficulties in assigning accountability when medical harm occurs (11). On the other hand, Starke et al. developed a trust model based on research into human-machine interaction. They argued that despite the risks, medical AI can be considered trustworthy by focusing on its reliability, capability, and intent. They called for the cultivation of reasonable trust in medical AI (12).
2.1.2 Impact on doctor-patient relationships and treatment outcomes
The impact of medical AI chat assistants on doctor-patient relationships has elicited mixed views within the academic community. Some scholars argue that medical AI chat assistants have a positive influence on doctor-patient relationships. Margam suggests that ChatGPT provides medical professionals with extensive medical knowledge, which helps them make more informed decisions and reduces administrative burdens, enabling them to focus on delivering compassionate and effective patient care (13). Similarly, Lu et al., based on evidence-based medicine principles, argue that AI can offer precise recommendations for clinical diagnosis and treatment. This facilitates discussions between patients and doctors about personalized treatment plans, thereby enhancing shared decision-making (SDM) and improving doctor-patient relationships. However, other scholars express concerns about potential negative effects (14). Dey notes that excessive reliance on medical AI by some patients could lead to detachment from professional doctors, potentially worsening doctor-patient relationships (15). Feng highlights a growing distrust among some patients toward medical AI, which may further damage doctor-patient relationships and increase conflicts (16).
The impact of medical AI chat assistants on treatment outcomes also shows varied perspectives. Kong et al. argue that the machine learning capabilities of medical AI can expand the range of medical resources and accelerate care, which is crucial for addressing issues of insufficient and unevenly distributed medical resources (17). Dey found that integrating ChatGPT into diabetes care enables patients to receive personalized medical guidance and enhances their involvement in managing their condition (15). Conversely, Shaw et al. point out the limitations of AI in healthcare, including potential issues with data quality and privacy, which could lead to incorrect guidance or privacy breaches (18). Triberti et al. discuss the “third-order effect” in psychological terms, where AI involvement in health decisions may lead to decision delays or paralysis, confusion in doctor-patient communication, and ambiguity in responsibility (19).
2.2 Application and effects of medical AI chat assistants
2.2.1 Application status and ethical risks
Medical AI chat assistants represent a new form of healthcare technology developed within the context of large language models. These assistants enable patients to provide information such as their age, symptoms, and medical history through conversation, in exchange for receiving a diagnosis and treatment plan. Healthcare professionals can use these AI-generated assessments to validate or assist their own diagnostic and treatment decisions.
In terms of application, Nov et al. conducted a survey to explore respondents’ ability to recognize and trust medical advice provided by ChatGPT compared to human doctors. The findings indicated that ChatGPT’s accuracy in addressing patients’ medical questions ranged from 49 to 85%, with a minimal distinction rate between human and machine feedback (65.5% for humans vs. 65.1% for machines) (9). Moreover, the trust in ChatGPT’s medical responses was moderately positive. Additionally, Ayesha et al. investigated the potential of medical artificial intelligence in assisting healthcare professionals with diagnosing and treating cardiovascular diseases through an experimental approach. They posed 10 hypothetical clinical cardiovascular disease questions to ChatGPT and had the medical feedback evaluated by human medical experts. The results showed that eight of ChatGPT’s responses were accurate diagnoses, while the other two, although not entirely incorrect, had some discrepancies from the actual diagnostic procedures (10).
In terms of ethical risks, Liu highlighted significant concerns regarding the “technological black box” and the autonomous learning capabilities of medical AI. These risks include challenges in regulating the protection of medical data and difficulties in assigning accountability when medical harm occurs (11). On the other hand, Starke et al. developed a trust model based on research into human-machine interaction. They argued that despite the risks, medical AI can be considered trustworthy by focusing on its reliability, capability, and intent. They called for the cultivation of reasonable trust in medical AI (12).
2.2.2 Impact on doctor-patient relationships and treatment outcomes
The impact of medical AI chat assistants on doctor-patient relationships has elicited mixed views within the academic community. Some scholars argue that medical AI chat assistants have a positive influence on doctor-patient relationships. Margam suggests that ChatGPT provides medical professionals with extensive medical knowledge, which helps them make more informed decisions and reduces administrative burdens, enabling them to focus on delivering compassionate and effective patient care (13). Similarly, Lu et al., based on evidence-based medicine principles, argue that AI can offer precise recommendations for clinical diagnosis and treatment. This facilitates discussions between patients and doctors about personalized treatment plans, thereby enhancing shared decision-making (SDM) and improving doctor-patient relationships. However, other scholars express concerns about potential negative effects (14). Dey notes that excessive reliance on medical AI by some patients could lead to detachment from professional doctors, potentially worsening doctor-patient relationships (15). Feng highlights a growing distrust among some patients toward medical AI, which may further damage doctor-patient relationships and increase conflicts (16).
The impact of medical AI chat assistants on treatment outcomes also shows varied perspectives. Kong et al. argue that the machine learning capabilities of medical AI can expand the range of medical resources and accelerate care, which is crucial for addressing issues of insufficient and unevenly distributed medical resources (17). Dey found that integrating ChatGPT into diabetes care allows patients to receive personalized medical guidance and enhances their involvement in managing their condition (15). Conversely, Shaw et al. point out the limitations of AI in healthcare, such as potential issues with data quality and privacy, which could lead to incorrect guidance or privacy breaches (18). Triberti et al. discuss the “third-order effect” in psychological terms, where AI involvement in health decisions might lead to decision delays or paralysis, confusion in doctor-patient communication, and ambiguity in responsibility (19).
2.3 Development of the UTAUT model
2.3.1 Application of UTAUT in communication studies
Research on user technology acceptance behavior is extensive, with researchers often building on previous work by incorporating other relevant theories to design various extended new theoretical models for specific application scenarios. The relatively mature technology acceptance models that have been empirically tested include the Technology Acceptance Model 2 (TAM2), the Decomposed Theory of Planned Behavior (DTPB), and the Unified Theory of Acceptance and Use of Technology (UTAUT).
The Technology Acceptance Model 2 (TAM2) extends the original Technology Acceptance Model (TAM). TAM, proposed by Davis, suggests that the attitude toward use (AU) influences behavioral intention to use, which in turn affects actual usage behavior. This attitude is determined by two core variables: perceived usefulness (PU) and perceived ease of use (PEU) (20). Venkatesh and Davis expanded this model to form TAM2 by introducing social influence (SI) and cognitive instrumental processes (CI) as additional variables affecting PU and usage intentions. TAM2 explains 60% of user technology acceptance behavior (21).
The Decomposed Theory of Planned Behavior (DTPB) was developed by Taylor and Todd by expanding upon the Technology Acceptance Model (TAM), Theory of Planned Behavior (TPB), and Theory of Reasoned Action (TRA). The researchers decomposed attitude, subjective norm, and perceived behavioral control from the original models, which clarifies the relationships between factors, making it easier to understand what influences technology usage. DTPB explains 60% of user intention to use, outperforming TAM and TPB (22).
The Unified Theory of Acceptance and Use of Technology (UTAUT) was developed by Venkatesh et al. by integrating key factors from eight user acceptance-related theoretical models, including TAM, TPB, and Innovation Diffusion Theory (IDT). UTAUT posits that four direct factors—Performance Expectancy (PE), Effort Expectancy (EE), Social Influence (SI), and Facilitating Conditions (FC)—determine user acceptance and usage behavior (23). In 2012, Venkatesh et al. refined the model by including Hedonic Motivation, Price Value, and Habit as core variables (24). UTAUT explains 69% of technology adoption intentions and behaviors and is broadly applicable, making it suitable for this study on healthcare professionals’ and patients’ acceptance of medical AI chat assistants.
In the field of health communication, the UTAUT model has been utilized to explain the factors and motivations underlying the adoption of medical products or technologies. For instance, Wang et al. combined UTAUT with the Health Belief Model to establish a model for mask acceptance during the COVID-19 pandemic. Against the backdrop of the COVID-19 pandemic, the researchers employed an extended UTAUT model to validate university students’ adoption behavior and psychological mechanisms toward Learning Management Systems (LMS) across five Asian countries (25).
The study found that social influence, perceived susceptibility, hedonic motivation, and communication barriers significantly impacted the willingness of Chinese people to wear masks. Researchers have noted variations in the impact of UTAUT’s core variables across different scenarios (26). Cao et al. expanded the UTAUT model using Protection Motivation Theory to explain Japanese youth’s acceptance of mobile health (mHealth), finding that Performance Expectancy directly influences behavioral intentions to use mobile health services (27). Conversely, Arfi et al. employed the UTAUT model to investigate factors influencing patients’ use of electronic medical services via the Internet of Things, and found that Performance Expectancy did not significantly affect patients’ intentions to use electronic medical services. Therefore, this study will adapt and extend the UTAUT model based on specific application contexts to identify targeted user intention factors (28).
2.3.2 Integration of artificial intelligence into daily life: acceptance of AI agents
Artificial intelligence agents have emerged across various industries and contexts, and academic research has begun to explore how audiences receive these virtual intelligent agents. Wölker et al. examined the impact of news-writing robots on the journalism industry. Their experimental study investigated readers’ ability to distinguish and trust automated news production, revealing that European readers exhibited equal trust in news articles produced by robots and those produced through traditional methods, with even higher trust in robot-generated sports news. Additionally, trust did not significantly influence readers’ decisions to read or avoid news articles (29).
Building on the Unified Theory of Acceptance and Use of Technology (UTAUT) model, Wang et al. incorporated the “Computers Are Social Actors” (CASA) paradigm, adding variables such as perceived credibility, perceived anthropomorphism, and perceived agency to refine the measurement model (30). They used a questionnaire survey to explore user attitudes and acceptance levels of AI news anchors in the news industry.
Balakrishnan et al. focused on virtual chatbots in the service industry, extending the UTAUT model by incorporating user, system, and social perception factors. Their study found that this extended model provided a better explanation of users’ behavioral intentions under these conditions (31).
In summary, there is currently limited academic attention to the acceptance of medical AI chat assistants as artificial intelligence agents, and research on the acceptance of large language models in the medical field remains scarce.
2.4 Conjectural framework and hypotheses development
It is worth noting that the present study undertakes a context-sensitive reduction of the original UTAUT framework. In the high-stakes domain of medical practice—where diagnostic accuracy rather than operational ease is the overriding concern—Effort Expectancy is expected to yield limited explanatory power for adoption intention. Within China’s hospital milieu, policy mandates and departmental protocols exert a far stronger influence on technology uptake than peer pressure; consequently, Social Influence is provisionally omitted. Moreover, Facilitating Conditions are largely institutionally provisioned after initial deployment and are therefore deemed peripheral to first-time use intention, leading to their exclusion from the current model.
2.4.1 Performance expectancy
Building on Venkatesh et al., Performance Expectancy denotes an individual’s perception that using a technology will enhance the attainment of valued outcomes; it is consistently identified as a primary determinant of behavioral intention. In the context of smart healthcare promotion, Alam et al. further demonstrated that patients are more likely to adopt mobile health services when they perceive such technologies as instrumental in improving efficiency (32). Consequently, this study conceptualizes Performance Expectancy as “healthcare professionals’ and patients’ perceived usefulness and anticipated outcomes of medical AI chat assistants,” and posits the following hypothesis:
H1: Performance Expectancy (PE) significantly positively influences the Intention to Use medical AI chat assistants (IU).
2.4.2 Perceived cost
Economic barriers are widely recognized as primary obstacles to the diffusion of technologies and services. Park et al. define Perceived Cost as an individual’s tendency to weigh the anticipated benefits of a technology or service against its consumption costs (33). Similarly, Singer et al. demonstrate that patients base their healthcare decisions on the perceived benefits and costs of medical services, underscoring the critical influence of perceived cost on technology adoption (34). Accordingly, this study operationalizes Perceived Cost as “the cost burden associated with using medical AI chat assistants” and formulates the following hypothesis:
H2: Perceived Cost (PC) significantly negatively influences the Intention to Use medical AI chat assistants (IU).
2.4.3 Digital access
Fridsma et al. identify digital access as a determinant of a healthy society (35). Yet the digital divide engenders inequities in patients’ digital access and constrains the availability of certain telehealth technologies. Eruchalu et al. note that although the effect of digital-access disparities on COVID-19 mitigation has not been quantitatively examined, unequal digital access in New York City widened gaps in pneumonia-treatment availability (36). These findings underscore the critical influence of digital access on users’ ability to engage with medical technologies and utilize healthcare services. Consequently, this study proposes the following hypothesis:
H3: Digital Access (DA) significantly positively influences the Intention to Use medical AI chat assistants (IU).
2.4.4 Digital competence
Zhao et al. conceptualize digital competence as the capacity to acquire and apply knowledge, skills, and cognitive orientations necessary for living and working in the digital realm, which can be progressively developed through sustained social engagement (37). Adopting a market perspective, Malchenko et al. further demonstrate that consumers’ digital competence facilitates their acceptance and utilization of technologies, as well as their participation in value co-creation (38). Accordingly, this study advances the following hypothesis:
H4: Digital Competence (DC) has a significantly positive influence on the Intention to Use medical AI chat assistants (IU).
2.4.5 Socioeconomic status and age
Drawing on Ren, socioeconomic status (SES) in the Chinese context is conceived as an aggregate evaluation of an individual’s or household’s economic and social standing, with income, educational attainment, and occupational prestige as its core constituents. SES is calculated here via a simple additive index (see Formula 1). Okunrintemi et al. demonstrate that economic income exerts a direct influence on individuals’ utilization of healthcare technologies: patients with higher incomes enjoy superior medical care and service quality, whereas those with lower incomes report markedly poorer healthcare experiences (39). Age is also a salient determinant; Alameraw et al. employed a modified UTAUT-2 model to demonstrate that younger healthcare professionals exhibit greater openness to remote-monitoring technologies (40, 41). Consequently, this study advances the following hypotheses:
H5: Socioeconomic Status (SES) significantly positively influences the Actual Usage Behavior of medical AI chat assistants (AUB).
H6: Age (A) significantly negatively influences the Actual Usage Behavior of medical AI chat assistants (AUB).
Formula 1 SES Calculation Method.
2.4.6 Consultation frequency
Ridd et al. operationalize consultation frequency as the number of physician visits within a specified period; this metric gages patients’ demand for healthcare services and serves as an indicator of disease-management effectiveness and treatment outcomes (42). Given heterogeneity in patients’ medical preferences and needs, the influence of consultation frequency on the utilization of alternative consultation modalities remains indeterminate. Given the current low penetration of medical AI chat assistants, higher consultation frequencies may reduce reliance on these tools. Consequently, the impact of consultation frequency on the actual usage behavior of medical AI chat assistants warrants investigation; accordingly, this study advances the following hypothesis:
H7: Consultation Frequency (CF) significantly negatively influences the Actual Usage Behavior of medical AI chat assistants (AUB).
2.4.7 Intention to use
Many technology acceptance theories, such as TAM and UTAUT, have validated the relationship between Intention to Use (IU) and Actual Usage Behavior (AUB). Subsequent studies have also confirmed this relationship. For instance, Chen et al. employed an improved UTAUT model to measure factors affecting the use of wearable devices among older adults, hypothesizing that intention to use has a significant positive impact on actual usage behavior (43). Thus, the following hypothesis is proposed:
H8: Intention to Use (IU) significantly positively influences the Actual Usage Behavior of medical AI chat assistants (AUB).
In summary, this paper proposes eight hypotheses, where H1, H2, H3, and H4 are related to factors influencing the use of medical AI chat assistants, H5, H6, and H7 pertain to patient characteristics, and H8 concerns the impact of intention to use on the actual usage behavior of medical AI chat assistants (Figure 1).
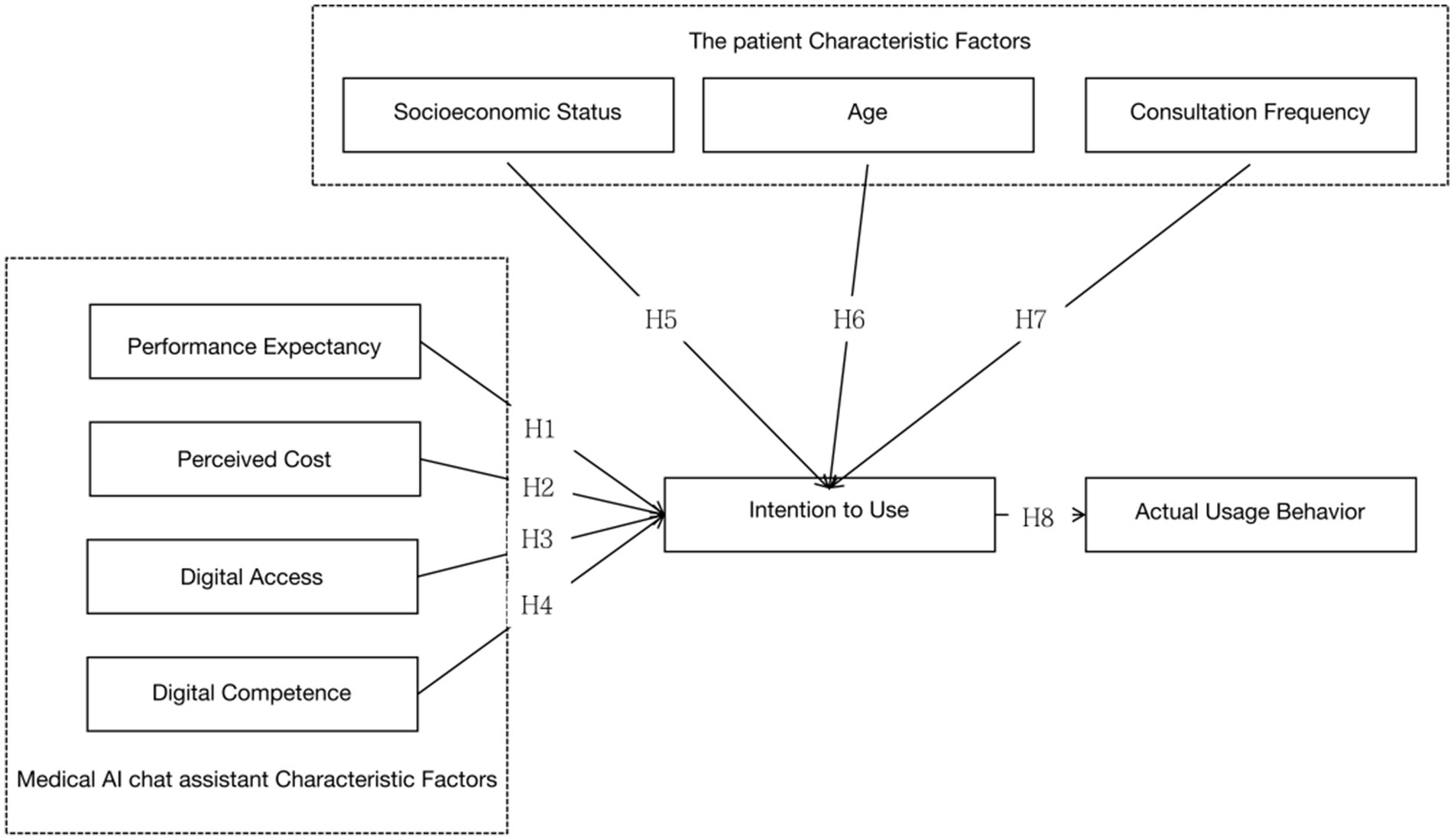
Figure 1. Proposed improved UTAUT in the present study.
Hypotheses Related to Factors Influencing the Use of Medical AI Chat Assistants:
H1: Performance Expectancy (PE) positively influences the intention to use (IU) medical AI chat assistants.
H2: Perceived Cost (PC) negatively influences the intention to use (IU) medical AI chat assistants.
H3: Digital Access (DA) positively influences the intention to use (IU) medical AI chat assistants.
H4: Digital Competence (DC) positively influences the intention to use (IU) medical AI chat assistants.
Hypotheses Related to Patient Characteristics:
H5: Patients’ Socioeconomic Status (SES) positively influences the actual usage behavior (AUB) of medical AI chat assistants.
H6: Patients’ Age (A) negatively influences the actual usage behavior (AUB) of medical AI chat assistants.
H7: Consultation Frequency (CF) negatively influences the actual usage behavior (AUB) of medical AI chat assistants.
H8: Intention to Use (IU) positively influences the actual usage behavior (AUB) of medical AI chat assistants.
3 Research methodology
3.1 Research design
Anchored in the extended Unified Theory of Acceptance and Use of Technology (UTAUT), this study employs a cross-sectional survey design to capture the differential acceptance logics of medical AI chatbots among Chinese physicians and patients within a single temporal slice.
3.2 Measurement instruments
The questionnaire is bifurcated into two segments. Section A elicits demographic attributes—region, age, and outpatient-visit frequency—while Section B operationalizes six reflective constructs: performance expectancy (PE; 4 items), perceived cost (PC; 3 items), digital access (DA; 4 items), digital competence (DC; 4 items), intention to use (IU; 3 items), and actual use behavior (UB; 2 items). All items are measured on a five-point Likert continuum (1 = strongly disagree, 5 = strongly agree). Adapted from canonical scales advanced by Venkatesh et al. (23), Dehghani et al. (44), Guo (45), Chen (46), and Mariani et al. (47), the measures underwent bilingual back-translation and cultural decentering to ensure semantic equivalence in the Chinese healthcare context. The complete item battery is presented in Appendix A. A pilot test (n = 34) yielded Cronbach’s α = 0.943 and KMO = 0.743 (p < 0.001), attesting to internal consistency and sampling adequacy.
3.3 Sampling frame
The target population consists of mainland Chinese residents aged 15 or older who have engaged with a medical AI chatbot at least once within the preceding 12 months.
3.4 Sampling strategy
Quota sampling was deployed along six demographic vectors calibrated to national benchmarks: gender (male 51%, female 49%), residence (urban 66%, rural 34%), age (≤15 1.8%, 16–59 61%, ≥60 21%), education (primary or below 5%, junior high 7%, senior high 3%, university or above 3%), income (five equal quintiles), and region (eastern 40%, central 26%, western 27%, northeastern 7%). The first five quotas align with the 2023 National Economic Performance release (48); the regional quotas are derived from the Third Communique of the Seventh National Population Census (49).
3.5 Data collection procedure
Fieldwork was commissioned to the professional agency “Survey Factory” and executed from March 10 to April 28, 2024, via a hybrid online-offline protocol. Invalid cases were identified and expunged through attention-check items and response latency thresholds, resulting in 500 valid responses. The achieved sample exhibits proportional congruence with the predefined demographic quotas; 77% of respondents reported 1–5 outpatient visits in the past year, while 2% reported more than 10 visits.
3.6 Estimation techniques
Reliability and validity diagnostics, together with correlational and difference tests, will be performed in SPSS 29.0. A covariance-based structural equation model (SEM) will be estimated in AMOS 28.0 to assess the nomological validity of the extended UTAUT framework across the physician-patient dyad.
4 Results
4.1 Reliability and validity testing
Reliability reflects the consistency of measurement results. The reliability was assessed using Cronbach’s alpha, which yielded a value of 0.927 (>0.8), indicating that the research results are reliable. Validity reflects the accuracy of the measurement results. To test the structural validity of the questionnaire scales, exploratory factor analysis was conducted. The Kaiser-Meyer-Olkin (KMO) measure of sampling adequacy was 0.939 (>0.5), and Bartlett’s test of sphericity showed a p-value <0.001 (<0.05), indicating good structural validity.
4.2 Correlation analysis
Table 1 summarizes the correlations between Performance Expectancy, Perceived Cost, Digital Access, Digital Competence, and Intention to Use, as well as the correlation between Socioeconomic Status, Intention to Use, and Actual Usage Behavior. Pearson correlation analysis was used to measure the strength of these correlations. The analysis shows that Performance Expectancy, Perceived Cost, Digital Access, and Digital Competence are all significantly correlated with Intention to Use, with p-values < 0.001 (p < 0.05). The correlation coefficients are 0.532, 0.540, 0.495, and 0.497, respectively, indicating positive correlations between these factors and Intention to Use. Additionally, Intention to Use is a significant factor influencing Actual Usage Behavior, with a p-value < 0.001 (p < 0.05) and a correlation coefficient of 0.522, which is greater than 0, indicating a positive correlation between Intention to Use and Actual Usage Behavior. Socioeconomic Status (p = 0.42 > 0.05) does not have a significant correlation with Actual Usage Behavior.

Table 1. Correlations analysis.
Table 2 summarizes the correlations between Patient Age, Consultation Frequency, Income Level, Education Level, and Occupation Status with Actual Usage Behavior, using Spearman’s rank correlation analysis to measure the strength of these correlations. The analysis shows that Patient Age and Consultation Frequency are significant factors affecting Actual Usage Behavior, with p-values < 0.05. The correlation coefficients are 0.120 and 0.143, respectively, indicating positive correlations between these factors and Actual Usage Behavior. Income Level, Education Level, and Occupation Status (p = 0.097 > 0.05; p = 0.067 > 0.05; p = 0.284 > 0.05) do not have significant correlations with Actual Usage Behavior.

Table 2. Correlations analysis.
4.3 Confirmatory factor analysis
Confirmatory factor analysis was conducted through structural equation modeling to assess the aggregation of items within variables. Post-hoc power analysis (G*Power 3.1.9.7) indicated that, assuming α = 0.05, f2 = 0.10, 1-β = 0.90, and six predictors, a minimum of 119 participants was required. Our sample of 500 exceeds this threshold, safeguarding the stability of parameter estimates and the interpretive fidelity of the structural model. As shown in Table 3, the model fit indices including CMIN/DF (1.558 < 3), RMSEA (0.033 < 0.08), GFI (0.950 > 0.9), NFI (0.950 > 0.9), TLI (0.977 > 0.9), and CFI (0.981 > 0.9) all met the evaluation criteria for model fitting, indicating a good fit of the model. In this model, the p-value of the significant variables (0.000) is less than 0.05, indicating significant correlations between manifest variables and latent variables, and suggesting that these manifest variables can explain their corresponding latent variables. As shown in Table 4, the Average Variance Extracted (AVE) values of latent variables are greater than 0.5, and the composite reliability values are greater than 0.8, indicating that the scale has good composite reliability.

Table 3. Model fit test.

Table 4. Convergence validity and composite reliability of the scale dimensions.
Furthermore, the discrimination between variables is effective when the correlation coefficients between variables are less than the square root of their average variance. According to Table 5, the correlation coefficients of the main variables are less than their respective average variance square roots. Therefore, it can be determined that there is good discriminant validity between different latent variables. The specific confirmatory factor analysis model for variable items is shown in Figure 2.

Table 5. Discrimination validity of the scales.
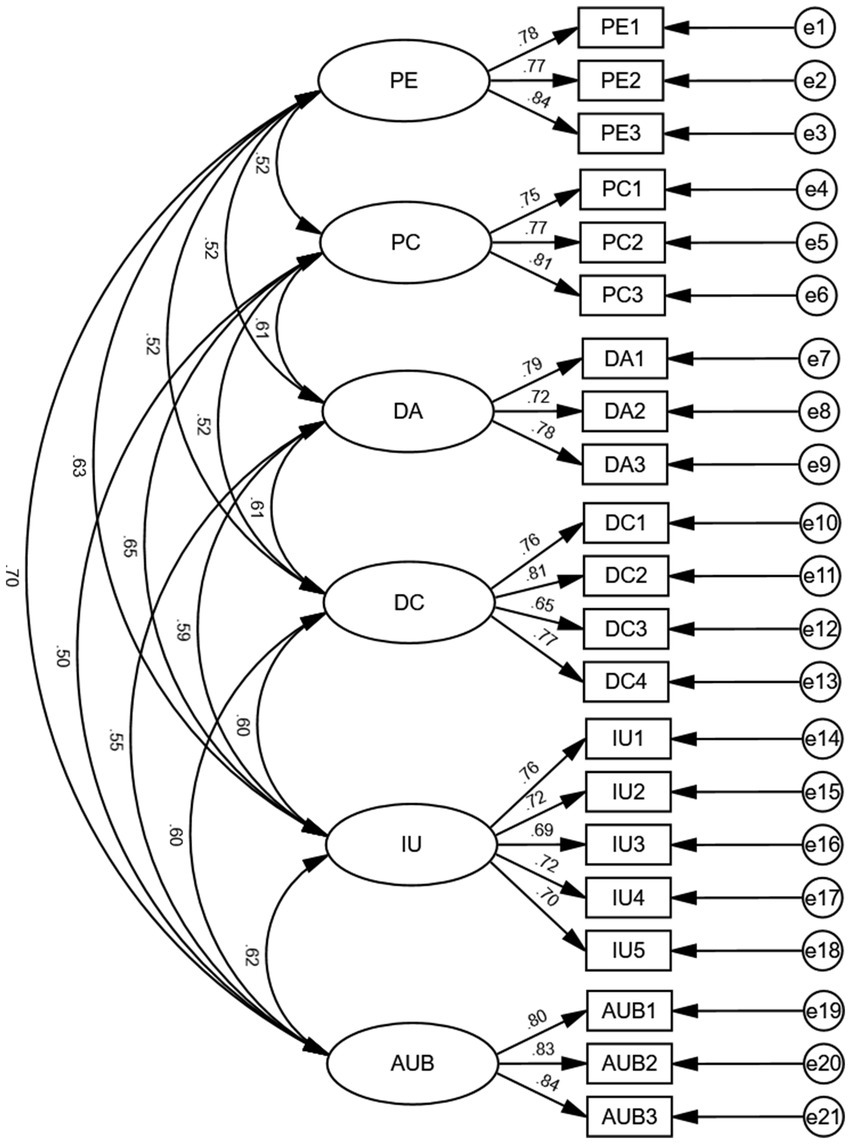
Figure 2. Confirmatory factor analysis model diagram.
4.4 Hypothesis testing
4.4.1 Model fitting
This study aims to discuss the mechanisms of influence factors on the usage intentions and behaviors of medical AI chat assistants. Therefore, a structural equation model was constructed using Amos software to examine the path relationships among Performance Expectancy, Perceived Cost, Digital Access, and Digital Competence. According to Table 6, the model fit indices—CMIN/DF (2.074 < 3), RMSEA (0.046 < 0.08), GFI (0.933 > 0.9), NFI (0.932 > 0.9), TLI (0.956 > 0.9), CFI (0.963 > 0.9)—all met the criteria, with the p-value of significant variables (0.000) being less than 0.05. Therefore, the model demonstrates good absolute fit and is reliable.

Table 6. The fit of the structural equation model.
4.4.2 Testing the effects of path relationships
The results of testing the effects of path relationships with Amos are displayed in Table 7, and the structural equation model is illustrated in Figure 3. Performance Expectancy, Perceived Cost, Digital Access, and Digital Competence have significant positive effects on the intention to use medical AI chat assistants (β = 0.354, p < 0.05; β = 0.286, p < 0.05; β = 0.120, p < 0.05; β = 0.239, p < 0.05). These results confirm Hypotheses H1, H3, and H4, while Hypothesis H2 is not supported; the actual direction of the impact of Perceived Cost on the intention to use medical AI chat assistants contradicts the hypothesis. The intention to use has a significant positive impact on the usage behavior of medical AI chat assistants (β = 0.699, p < 0.05), thereby validating Hypothesis H8.

Table 7. Analysis and test of acting path.
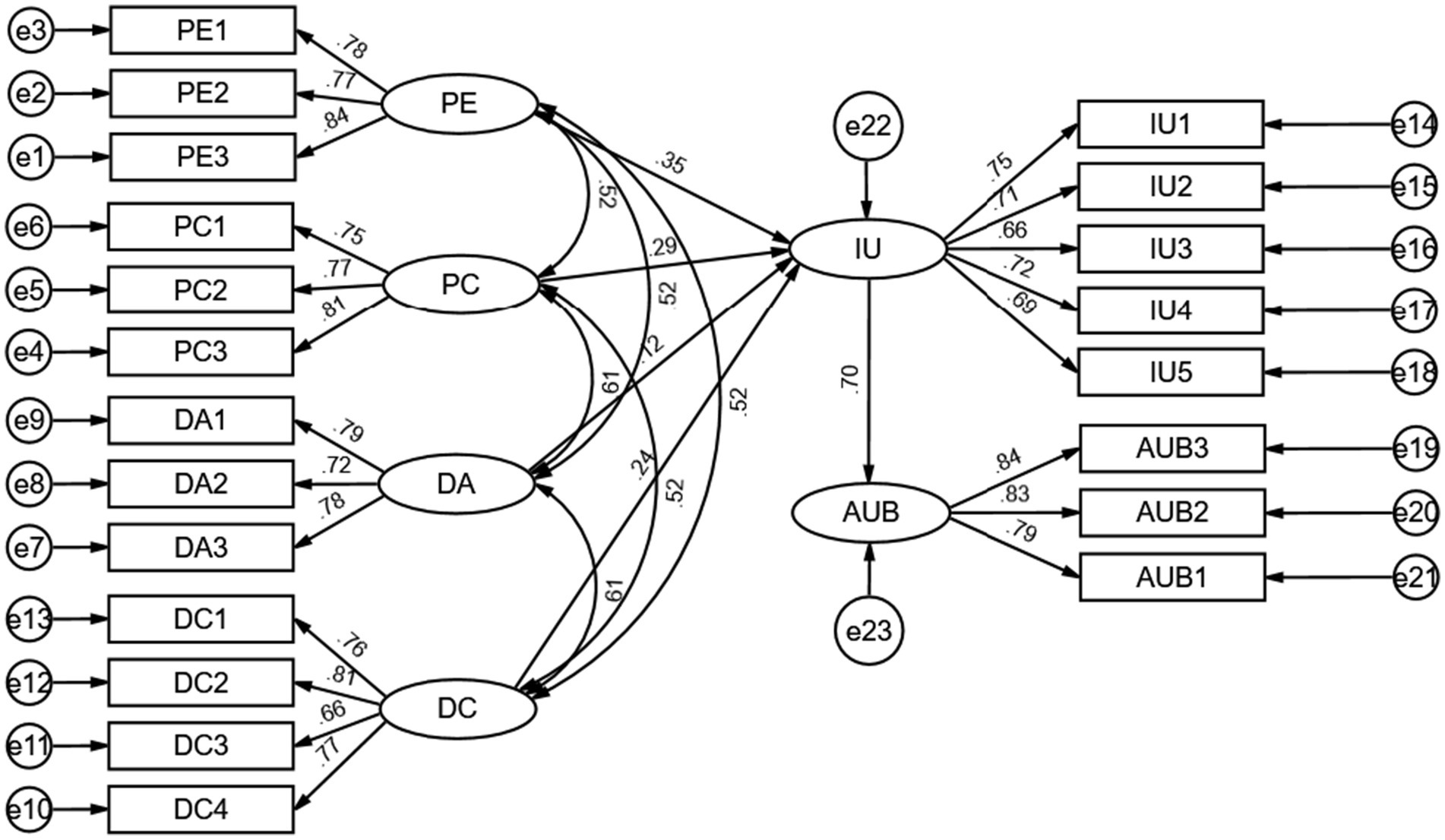
Figure 3. Structural equation model.
4.5 Analysis of variance
A one-way ANOVA was conducted to analyze the differences in usage behavior of medical AI chat assistants among patients of different ages. The test for homogeneity of variances was passed (see Appendix 2). The results of the ANOVA are presented in Table 8, indicating significant differences in usage behavior across different age groups (F = 3.296, p < 0.05). This suggests that there are significant age-related differences in usage behavior. Further multiple comparisons (see Appendix 2) revealed that patients aged 16–30 are the least likely to engage in usage behavior compared to other age groups.

Table 8. Analysis of variance.
A one-way ANOVA was conducted to analyze differences in the usage behavior of medical AI chat assistants based on the consultation frequency. The test for homogeneity of variances was not passed (see Appendix 3), so a non-parametric test was employed for the analysis. The analysis was conducted using the Kruskal-Wallis test, and the results are shown in Table 9, indicating a Kruskal-Wallis H statistic of 12.157, with p = 0.007 < 0.05. This indicates significant differences in usage behavior among patients with different consultation frequencies. Further pairwise comparisons (see Appendix 3) revealed differences in the usage behavior of medical AI chat assistants among groups with 0–10 visits. It was found that as the consultation frequency increases, patients are more likely to engage in usage behavior.

Table 9. Kruskal-Wallis H test.
5 Discussion
This study finds that performance expectancy, perceived cost, digital access, and digital competence positively influence the intention to use medical AI chat assistants, whereas patient age, consultation frequency, and intention positively affect actual usage behavior. In addition, socioeconomic status is not correlated with usage behavior. The hypothesis testing results are shown in Table 10.

Table 10. Results of hypothesis testing.
First, this study confirms that performance expectancy, digital access, and digital competence are positively associated with the intention of physicians and patients to use medical AI chat assistants. Moreover, the intention to use these assistants has a positive impact on actual usage behavior. Among these, the positive effect of performance expectancy on intention is consistent with previous findings (23), indicating that the perceived usefulness and functional value of medical AI chat assistants are key determinants of willingness to use.
Second, Park et al. suggest that patients make medical decisions based on perceived benefits and costs, with lower expected costs leading to a stronger intention (33). However, physicians and patients in this study exhibit the opposite attitude toward the expected cost burden of using medical AI chat assistants, showing that as expected costs increase, intention to adopt also increases. One reason is that Chinese physicians and patients generally hold a high level of agreement that more expensive medical products are more effective. Wang et al. found that 82.08% of patients believe that higher-priced medical products are superior to lower-priced ones, associating price level with product quality and interpreting high prices as symbols of advanced technology and quality assurance (50). In addition, current mainstream medical AI chatbots in China commonly adopt a “basic free + premium paid” pricing strategy, making it difficult for users to perceive the true marginal cost. Due to information asymmetry, users equate “high price” with “high value” and no longer view perceived cost as an economic burden but as an external signal of technological credibility. These conditions result in a positive correlation between willingness to use and perceived cost.
Third, this study points out the development potential of medical AI chat assistants in an aging society. Results confirm a positive correlation between patient age and consultation frequency, as well as intention to use medical AI chat assistants. Li et al. found that as patient age increases and offline consultation frequency rises, the intention to use medical technology products decreases (51). However, this study finds that medical AI chat assistants are more attractive to older patients and those who frequently visit offline. These findings align with those of Zhang et al., who showed that as age increases, Chinese patients place greater emphasis on convenience and service attitude in healthcare (52).
Finally, this study refutes the common assumption in technology diffusion literature that patients’ socioeconomic status is positively correlated with healthcare behavior. Zhang et al. found that generally income and education levels positively influence healthcare behavior (52). However, this study finds no significant impact of socioeconomic status on the intention to use medical AI chat assistants, and factors such as income and educational level are not correlated with this intention.
6 Implications
Theoretically, this study extends the applicability of the Unified Theory of Acceptance and Use of Technology (UTAUT) within digital-health contexts. By integrating perceived cost, digital access, digital competence, and consultation frequency into the original framework, we provide an expanded model that clarifies the mechanisms underlying intention and behavior toward medical AI chat assistants.
Practically, as these tools rely on web or mobile APIs and H5 interfaces, designers should prioritize usability and cognitive load reduction to deliver low-threshold, age-friendly products (53). Pricing policies should align with China’s medical-service pricing mechanisms, avoid excessive charges, and undergo regular cost accounting to ensure market-appropriate fees (54).
Policy-wise, governments should narrow the digital divide by offering data-fee exemptions for health apps, embedding “AI health literacy” modules within national essential public-health services, deploying “silver-age digital coaches,” and including compliant AI consultations in the medical reimbursement catalog to lower economic barriers and incentivize sustained use.
7 Conclusion
The integration of artificial intelligence into healthcare is reshaping physicians’ workflows and patients’ care experiences. This study confirms that performance expectancy, perceived cost, digital access, and digital competence serve as critical antecedents to the adoption of medical AI chat assistants by both doctors and patients, while age, consultation frequency, and intention directly drive actual usage. The extended UTAUT framework effectively explains these mechanisms and offers an actionable theoretical and empirical pathway for the equitable diffusion of AI medical technologies in aging societies.
Notably, the findings reveal the unique downward compatibility of medical AI chat assistants: they provide high-quality consultation and diagnostic services at low cost, proving particularly effective for minor ailments and chronic disease management. For developing countries like China, the widespread deployment of these assistants can help mitigate geographical and wealth-based disparities in healthcare resources, reduce the caseload pressure on offline medical institutions, and rebalance the supply and demand within the healthcare system. Moreover, as population aging accelerates, AI assistants offer older adults a more convenient and accessible channel for seeking care, helping them navigate age-related functional limitations and ensuring timely medical support.
8 Limitations and potential areas of future studies
Despite revealing significant findings, this study has limitations. First, the influence of the Chinese and Western medical systems should be considered in the scope of factors affecting medical AI chat assistants; however, this is limited by the lack of comprehensive digital resources for traditional Chinese medicine, which leaves current large medical models predominantly Western. Second, the empathic capabilities of medical AI chat assistants should be measured. Empathic communication in doctor-patient interactions can encourage patients to discuss their conditions more openly, improving both the relationship and the quality of medical care (55). In interactions between medical AI chat assistants and patients, patients’ emotions and behaviors can be dynamically perceived and immediately responded to, thus potentially enhancing patients’ willingness to use through empathic communication (56). This aspect was not covered in the current study and needs further development. Looking forward, we invite extensions that enrich the utilitarian core of UTAUT with relational constructs salient to human–AI interaction in clinical settings. Specifically, agent trust and social presence—anchored in the Computers Are Social Actors (CASA) paradigm—promise to illuminate the socio-emotional circuitry that complements instrumental drivers of technology acceptance. The development of large medical AI models is a global endeavor, and implementing this technology in practice requires consideration of different national healthcare systems and policies. Future research should continue to center on developing countries, integrating qualitative data and real-world usage indicators—such as patient satisfaction, diagnostic accuracy, and service trust—to examine how large-scale AI models can advance patient experience within diverse healthcare systems.
Data availability statement
The datasets presented in this study can be found in online repositories. The dataset is available in the Harvard Dataverse repository under DOI 10.7910/DVN/SLWWAG.
Ethics statement
This study was conducted on human participants and did not involve any animal experiments. This study was reviewed and approved by the Biomedical Ethics Committee of Beijing University of Posts and Telecommunications (Protocol No. BUPT-P-2025019).
Author contributions
LZ: Writing – review & editing, Funding acquisition. JY: Writing – original draft. GF: Writing – review & editing, Data curation, Methodology.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported in part by Industry-University-Research Innovation Fund of China University under grant 2021ITA07005.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2025.1637270/full#supplementary-material
References
1. Zhang, X. D., Chen, X. Y., and Shu, T. (2020). China Medical Artificial Intelligence Development Report. Beijing: Social Sciences Academic Press, pp. 424–449.
2. Wang, Z, Liu, Y, Li, Y, Li, C, and Ma, Z. Spatio-temporal pattern, matching level and prediction of ageing and medical resources in China. BMC Public Health. (2023) 23:1155. doi: 10.1186/s12889-023-15842-2
3. Rui, X. W., Li, S. F., and Gong, X. D. China internet health and medical development report. (2019) Beijing: Social Sciences Academic Press, pp. 166–185.
4. MedLink. MedGPT: China’s first medical large language model released and validated for consistency with West China hospital. Baidu Baike. (2023). Available online at: https://www.medlinker.com/index/xinwenzhongxin/1199.html
5. The Chinese University of Hong Kong, Shenzhen & Shenzhen Institute of Data Science. (2023). HuatuoGPT-II passes the 2023 national licensed pharmacist examination and serves hundreds of thousands of users. CUHK-SZ News. Available online at: https://www.cuhk.edu.cn/zh-hans/article/9783 (Accessed December 5, 2023).
6. National Health Commission of the People’s Republic of China. (2023). China health statistics yearbook 2023. Available online at: https://www.nhc.gov.cn/guihuaxxs/c100133/202408/0c53d04ede9e4079afff912d71b5131c.shtml (Accessed on August 10, 2024)
7. Chen, MY, Zhang, B, Cai, ZT, Zhang, XM, and Wang, XY. Acceptance of clinical artificial intelligence among physicians and medical students: a systematic review with cross-sectional survey. Front Med. (2022) 9:Article 990604. doi: 10.3389/fmed.2022.990604
8. Wang, R, and Zhang, L. Technology acceptance model (TAM) key antecedents analysis. J Inf Resour Manage. (2020) 10:48–59.
9. Nov, O, Singh, N, and Mann, D. Putting ChatGPT’s medical advice to the (Turing) test: survey study. JMIR Med Educ. (2023) 9:e46939. doi: 10.2196/46939
10. Rizwan, A, and Sadiq, T. The use of AI in diagnosing diseases and providing management plans: a consultation on cardiovascular disorders with ChatGPT. Cureus. (2023) 15:e43106. doi: 10.7759/cureus.43106
11. Liu, JL. Legal challenges and responses to the clinical application of medical artificial intelligence. East Leg Stud. (2019) 5:133–9. doi: 10.19404/j.cnki.dffx.20190808.001
12. Starke, G, Van Den Brule, R, and Elger, BS. Intentional machines: a defense of trust in medical artificial intelligence. Bioethics. (2022) 36:154–61. doi: 10.1111/bioe.12891
13. Margam, R. ChatGPT: the silent partner in healthcare. Rev Contemp Scientific Academic Stud. (2023) 3:10.55454. doi: 10.55454/rcsas.3.10.2023.005
14. Lu, Y, Liu, JN, Wang, M, Huang, J, Han, B, and Sun, M. The application of artificial intelligence in shared decision-making between doctors and patients. Union Med J. (2023) 15:661–667. doi: 10.12290/xhyxzz.2023-0209
15. Dey, AK. ChatGPT in diabetes care: an overview of the evolution and potential of generative artificial intelligence model like ChatGPT in augmenting clinical and patient outcomes in the management of diabetes. Int J Diabetes Technol. (2023) 2:66–72. doi: 10.4103/ijdt.ijdt_31_23
16. Feng, JY. The trust issues and avoidance paths of medical artificial intelligence. Yuejiang Acad J. (2023) 15:85–94. doi: 10.13878/j.cnki.yjxk.2023.05.007
17. Kong, X, Ai, B, Kong, Y, Su, L, Ning, Y, Howard, N, et al. Artificial intelligence: A key to relieve China’s insufficient and unequally-distributed medical resources. Am J Transl Res. (2019) 11:2632. Available online at: https://pubmed.ncbi.nlm.nih.gov/31217843
18. Shaw, J, Rudzicz, F, Jamieson, T, and Goldfarb, A. Artificial intelligence and the implementation challenge. J Med Internet Res. (2019) 21:e13659. doi: 10.2196/13659
19. Triberti, S, Durosini, I, and Pravettoni, G. A “third wheel” effect in health decision making involving artificial entities: a psychological perspective. Front Public Health. (2020) 8:117. doi: 10.3389/fpubh.2020.00117
20. Davis, FD. Perceived usefulness, perceived ease of use, and user acceptance of information technology. MIS Q. (1989) 13:319–40.
21. Venkatesh, V, and Davis, FD. A theoretical extension of the technology acceptance model: four longitudinal field studies. Manag Sci. (2000) 46:186–204. doi: 10.1287/mnsc.46.2.186.11926
22. Taylor, S, and Todd, P. Assessing IT usage: the role of prior experience. MIS Q. (1995) 19:561–70.
23. Venkatesh, V, Morris, M, Davis, G, and Davis, FD. User acceptance of information technology: toward a unified view. MIS Q. (2003) 27:425–78. doi: 10.2307/30036540
24. Venkatesh, V, Thong, J, and Xu, X. Consumer acceptance and use of information technology: extending the unified theory of acceptance and use of technology. MIS Q. (2012) 36:157–78. doi: 10.2307/41410412
25. Ahmed, RR, Štreimikienė, D, and Štreimikis, J. The extended UTAUT model and learning management system during COVID-19: evidence from PLS-SEM and conditional process modeling. J Bus Econ Manag. (2022) 23:82–104. doi: 10.3846/jbem.2021.15664
26. Wang, M, Zhao, C, and Fan, J. To wear or not to wear: analysis of individuals’ tendency to wear masks during the COVID-19 pandemic in China. Int J Environ Res Public Health. (2021) 18:11298. doi: 10.3390/ijerph182111298
27. Cao, J, Kurata, K, Lim, Y, Sengoku, S, and Kodama, K. Social acceptance of mobile health among young adults in Japan: an extension of the UTAUT model. Int J Environ Res Public Health. (2022) 19:15156. doi: 10.3390/ijerph192215156
28. Arfi, WB, Nasr, IB, Kondrateva, G, and Hikkerova, L. The role of trust in intention to use the IoT in eHealth: application of the modified UTAUT in a consumer context. Technol Forecast Soc Change. (2021) 167:120688. doi: 10.1016/j.techfore.2021.120688
29. Wölker, A, and Powell, TE. Algorithms in the newsroom? News readers’ perceived credibility and selection of automated journalism. Journalism. (2021) 22:86–103. doi: 10.1177/1464884918757072
30. Wang, YX, Wu, FZ, and Wang, Z. Why are artificial intelligence news anchors accepted?: a dual perspective of new technology and social actors. Global J Media Stud. (2021) 8:86–102. doi: 10.16602/j.gjms.20210032
31. Balakrishnan, J, Abed, SS, and Jones, P. The role of meta-UTAUT factors, perceived anthropomorphism, perceived intelligence, and social self-efficacy in chatbot-based services? Technol Forecast Soc Change. (2022) 180:121692. doi: 10.1016/j.techfore.2022.121692
32. Alam, MZ, Hoque, MR, Hu, W, and Barua, Z. Factors influencing the adoption of mHealth services in a developing country: a patient-centric study. Int J Inf Manag. (2020) 50:128–43. doi: 10.1016/j.ijinfomgt.2019.04.016
33. Park, E. User acceptance of smart wearable devices: an expectation-confirmation model approach. Telemat Informatics. (2020) 47:101318. doi: 10.1016/j.tele.2019.101318
34. Singer, E, Couper, MP, Fagerlin, A, Fowler, FJ, Levin, CA, Ubel, PA, et al. The role of perceived benefits and costs in patients’ medical decisions. Health Expect. (2014) 17:4–14. doi: 10.1111/j.1369-7625.2011.00739.x
35. Fridsma, D. B. (2017). AMIA response to FCC notice on accelerating broadband health tech availability. Available online at: https://amia.org/public-policy/public-comments/amia-responds-fcc-notice-broadband-enabled-health-technology
36. Eruchalu, CN, Pichardo, MS, Bharadwaj, M, Rodriguez, CB, Rodriguez, JA, Bergmark, RW, et al. The expanding digital divide: Digital health access inequities during the COVID-19 pandemic in New York City. J Urban Health. (2021) 98:183–6. doi: 10.1007/s11524-020-00508-9
37. Zhao, Y, Zhang, T, Dasgupta, RK, and Xia, R. Narrowing the age-based digital divide: developing digital capability through social activities. Inf Syst J. (2023) 33:268–98. doi: 10.1111/isj.12400
38. Malchenko, Y, Gogua, M, Golovacheva, K, Smirnova, M, and Alkanova, O. A critical review of digital capability frameworks: a consumer perspective. Digit Policy Regul Gov. (2020) 22:269–88. doi: 10.1108/DPRG-02-2020-0028
39. Okunrintemi, V, Khera, R, Spatz, ES, Salami, JA, Valero-Elizondo, J, Warraich, HJ, et al. Association of income disparities with patient-reported healthcare experience. J Gen Intern Med. (2019) 34:884–92. doi: 10.1007/s11606-019-04848-4
40. Alameraw, TA, Asemahagn, MA, and Gashu, KD. Intention to use telemonitoring for chronic illness management and its associated factors among nurses and physicians at public hospitals in Bahir Dar. Northwest Ethiopia: Using modified UTAUT-2 model (2023).
41. Ren, CR. Measurement techniques of students’ family socioeconomic status (SES). J Educ. (2010) 6:77–82. doi: 10.14082/j.cnki.1673-1298.2010.05.010
42. Ridd, M, Shaw, A, Lewis, G, and Salisbury, C. The patient–doctor relationship: A synthesis of the qualitative literature on patients’ perspectives. Br J Gen Pract. (2009) 59:e116–33. doi: 10.3399/bjgp09X420248
43. Chen, J, Wang, T, Fang, Z, and Wang, H. Research on elderly users’ intentions to accept wearable devices based on the improved UTAUT model. Front Public Health. (2023) 10:1035398. doi: 10.3389/fpubh.2022.1035398
44. Dehghani, M, Kim, KJ, and Dangelico, RM. Will smartwatches last? Factors contributing to intention to keep using smart wearable technology. Telemat Informatics. (2018) 35:480–90. doi: 10.1016/j.tele.2018.01.007
45. Guo, J. The evolution of the digital divide: from internet access to cognitive engagement—a survey on college students’ online learning during the pandemic. J East China Normal University (Educ Sci). (2021) 39:16. doi: 10.16382/j.cnki.1000-5560.2021.07.002
46. Chen, DY. Digital acquisition: youth development based on digital capabilities and use. Chinese Youth Stud. (2021) 8:50–7. doi: 10.3969/j.issn.1002-9931.2021.08.007
47. Mariani, MM, Styven, ME, and Teulon, F. Explaining the intention to use digital personal data stores: an empirical study. Technol Forecast Soc Change. (2021) 166:120657. doi: 10.1016/j.techfore.2021.120657
48. State Council Information Office (2024) Press conference on the economic performance of the nation in 2023 Available online at: https://www.gov.cn/zhengce/202401/content_6926623.htm (Accessed January 17, 2024).
49. National Bureau of Statistics of China (2021) The seventh national population census bulletin (no. 3) Available online at: https://www.stats.gov.cn/sj/pcsj/rkpc/7rp/zk/html/fu03c.pdf (Accessed May 11, 2024).
50. Wang, P, Lin, XL, and Zhang, LM. A survey of medical behavior among different health insurance groups. Health Soft Sci. (1997) 5:42–3.
51. Li, M, Wang, ZZ, and Wang, LJ. Analysis of factors affecting the use of elderly care technology by elderly at home—based on surveys in Beijing, Nanjing, and Xianyang. Population Develop. (2017) 23:84–92. doi: 10.3969/j.issn.1674-1668.2017.03.009
52. Zhang, L, and Li, W. A study on the factors influencing medical behavior of urban and rural residents in Shandong Province. J Med Philosophy (A). (2016) 37:43–6. doi: 10.12014/j.issn.1002-0772.2016.12a.12
53. Lewis, JR, and Sauro, J. Usability and user experience: design and evaluation. In: G Salvendy and W Karwowski editors. Handbook of human factors and ergonomics (2021) 972–1015.
54. Jiang, S. (2018) Research on the pricing mechanism and pricing models of medical services in China [dissertation]. Huazhong University of Science and Technology.
55. Howick, J, Moscrop, A, Mebius, A, Fanshawe, TR, Lewith, G, Bishop, FL, et al. Effects of empathic and positive communication in healthcare consultations: A systematic review and meta-analysis. J R Soc Med. (2018) 111:240–52. doi: 10.1177/0141076818769477
Keywords: medical, AI chat assistant, UTAUT model, artificial intelligence, digital competence, technological acceptance, China
Citation: Zhang L, Yang J and Fang G (2025) Factors influencing the acceptance of medical AI chat assistants among healthcare professionals and patients: a survey-based study in China. Front. Public Health. 13:1637270. doi: 10.3389/fpubh.2025.1637270
Edited by:
Yanwu Xu, Baidu, ChinaReviewed by:
Rizwan Raheem Ahmed, Indus University, PakistanSo Ra Kang, Wonkwang University, Republic of Korea
Copyright © 2025 Zhang, Yang and Fang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Gege Fang, Z2VnZUBidXB0LmVkdS5jbg==; Jingyi Yang, ZXJpY2EwOTMweWp5QDE2My5jb20=
†These authors have contributed equally to this work and share first authorship