 Patrick Gögler
Patrick Gögler Magdalena Dorfner
Magdalena Dorfner Thomas Hamacher
Thomas Hamacher- Chair of Renewable and Sustainable Energy Systems, Department of Electrical and Computer Engineering, Technical University of Munich, Munich, Germany
As an attempt to reduce reliance on fossil fuels to satisfy electricity demand, the penetration of renewable sources like wind or solar power has experienced rapid growth in recent years. Due to their intermittent nature, the exact contribution of renewable sources to electricity supply is at least partly unknown. In order to be able to accommodate this uncertainty in real-time, sufficient capacities in the form of thermal and hydro power plants must be available. On that account, power system operators solve the so-called unit commitment problem after bidding in the day-ahead market closes to derive schedules for their power plants which can ensure system reliability at low costs. In literature, two approaches have mainly been studied in this context: Robust and stochastic unit commitment. Being a worst-case formulation, robust unit commitment puts its focus on reliability. A common drawback of this approach is that it tends to deliver over-conservative schedules. Stochastic unit commitment on the other hand creates more cost-effective schedules by preparing for the expected case, but either fails to guarantee system reliability or puts a high workload on the CPU. The limitations of known formulations have sparked interest in so-called hybrid approaches, which aim at combining the ideas of robust and stochastic unit commitment in a favorable way. This paper reports a novel hybrid approach to solve the unit commitment under uncertainty, which yields both robust and cost-efficient schedules. The new method respects the continuous nature of uncertainties and is thus in particular favorable for applications in power systems with high penetration of volatile renewable sources. By merging the ideas of robust and stochastic unit commitment, the proposed hybrid formulation minimizes the expected worst-case dispatch costs. Our method relies on partitioning the continuous range of the uncertainties into subsets. By means of the number of partitions, the solution can be adjusted between the conservative robust and the cost-efficient stochastic unit commitment in a user-friendly manner. A Benders decomposition algorithm is derived to solve the hybrid unit commitment efficiently. Finally, a case study confirms the superior performance of the proposed method.
1. Introduction
In an attempt to foster competition among different participants, today's electricity markets are frequently deregulated. In such markets, all participants must submit their generation bids at least one day in advance in the day-ahead market. Once the bidding window in the day-ahead market closes, power system operators solve the so-called unit commitment (UC) problem in order to select the winning bids. Typically, the UC problem is formulated so that schedules for the thermal and hydro power plants, which promise to maintain system reliability at the lowest possible costs, are obtained. On the next day, in the real-time market, the power outputs of the committed units are then adjusted in order to meet the demand in a cost-efficient way.
An integral part of UC formulations is proper uncertainty management. Nowadays, various sources of uncertainty can be identified in power systems. For instance, in recent years, the share of electricity generated from renewable sources has been increasing steadily. Encouraged by lawmakers, this trend is projected to continue in the near term. Along with this development, managing uncertainties in electricity generation issues a challenge to power system operators. Other sources of uncertainty include for example departures from the load forecast or equipment failures. Uncertainties affect system reliability significantly and might require committing additional expensive fast-start generators or incur penalties for load shedding. In order to be better prepared for departures from the expected system condition, it is common practice to schedule more power plants than actually necessary to meet the forecast demand. This excess capacity is called reserve and plays a key role in power systems. Whereas with too few reserves, system reliability might not be maintained in case of emergencies, holding too many units in reserve is not an economically sound strategy.
A traditional approach to handle uncertainties is to introduce reserve requirements to the UC formulation. Once the required amount of reserve has been determined, this method is easy to implement. Despite being current practice in power system operations, managing uncertainties implicitly by means of reserve requirements might not be the optimal approach from an economical point of view. To see this, notice that in order to keep the power system reliable, operators must be able to respond to extreme and unlikely events. Thus, reserve requirements are commonly chosen very conservatively, which in turn leads to a less cost-efficient operation.
In recent years, in order to enhance the process of decision-making in UC formulations under uncertainty, great attention has been given to approaches which take uncertain factors explicitly into account. Among these approaches, exploring ways to apply the principles of robust optimization and stochastic programming to the UC problem has sparked particular interest. In both cases, the UC is typically formulated as two-stage minimization problem as this structure reflects the current market structure with day-ahead and real-time operations best. In the first stage, commitment decisions determine the ON/OFF status of power plants. These decisions are made in the day-ahead market in a here-and-now manner, i.e., before the realization of uncertain parameters. In the second stage, wait-and-see decisions determine the economic dispatch amount of each committed unit as the recourse. These decisions take place in the real-time market after the uncertainties have become known.
Embedding the UC problem into the framework of stochastic programming gives the so-called Stochastic Unit Commitment (SUC) as published by Zheng et al. (2015) for example. Here, uncertain parameters are described by probability distributions which can for example be learned from historical data. SUC delivers satisfactory results in terms of costs as it minimizes the expected dispatch costs in the second stage. In large-scale power systems, where several uncertain factors come into play, SUC formulations reach their limit as determining the expected costs in the second stage becomes numerically intractable. A common remedy to this problem is to rely on sample average approximations. Such approximations can help keep numerical costs within bounds, but lead to reliability concerns since the solution to the SUC can only guarantee feasibility for the samples, but not for any realization of the uncertainty. This trade-off between computational costs and reliability is the culprit of SUC formulations and limits practical applications.
Approaches which use robust optimization to solve the UC under uncertainty are known as Robust Unit Commitment (RUC) in literature (see, An and Zeng, 2015 for example). Instead of considering a probability distribution to model uncertain factors, a deterministic set, the so-called uncertainty set, is employed to capture uncertainties. It is assumed that all outcomes of the uncertain factors lie within this set. The objective of RUC is to determine the least-cost schedule for the worst-case in the uncertainty set. Provided that the uncertainty set has been selected properly, RUC formulations take all possible future outcomes of the uncertainty into account and can thus guarantee system reliability. However, since this approach completely neglects any underlying probabilistic information, over-conservative schedules that protect against worst cases, which rarely happen, are frequently produced.
In order to address the shortcomings of robust optimization and stochastic programming, various approaches, which merge the ideas of RUC and SUC in a favorable way, have emerged in recent years. The resulting formulations are called Hybrid Unit Commitment (HUC) and aim at delivering low-cost solutions that can guarantee system reliability at the same time. In literature, the term HUC is ambiguous since various and essentially different hybrid formulations can be found. In an effort to assess their quality, four criteria are envisioned:
1. cost-efficiency: Does the HUC yield economically reasonable solutions? Since SUC has been shown to perform well from this point of view, cost-efficiency implies that the HUC must be able to get close to the SUC.
2. reliability: Can the solution to the HUC guarantee feasibility for all possible realizations of the uncertainty?
3. ease of use: Can the solution to the HUC be balanced between the conservative RUC and the cost-efficient SUC in a user-friendly manner?
4. tractability: Can the HUC model be solved numerically in a reasonable amount of time?
A first HUC formulation was proposed by Zhao and Guan (2013) with the so-called unified UC. Here, both the expected operating costs from the SUC and the worst-case operating costs from the RUC are taken into consideration in the objective function. Furthermore, a user-defined weight factor is introduced to balance the two cost terms. This approach can be solved by Benders decomposition and promises to yield more cost-efficient results as compared to RUC and more robust results as compared to SUC. When following this idea, the main challenge resides in finding a proper weight term to balance the cost terms. In order to avoid sub-optimal results, the weight term cannot be adjusted manually by the decision-maker, but must be determined heuristically.
When applying SUC, perfect knowledge of the underlying probability distribution is assumed. Contrary, RUC neglects potentially available distributional information completely. However, neither assumption reflects reality. As the probability distribution, which models the uncertainties, is often chosen as the one which fits historical data best, partial knowledge is available but it is uncertain itself to some extent. This observation has paved the way for various so-called distributionally robust UC formulations (see, Zhao and Guan, 2016; Duan et al., 2018 for example). Here, in order to account for the uncertainty due to the estimation, a family of possible distributions, commonly referred to as ambiguity set, is defined. Then, in the second stage, the expected costs under the worst-case distribution within the ambiguity set are minimized. As the computational costs of such formulations exceed the costs of SUC by far in general, applications in practice are currently greatly restricted.
More recently, another more user-friendly hybrid approach, which seeks to minimize the expected worst-case operating costs, was derived by Blanco and Morales (2017) with the so-called Robust Stochastic UC. This method relies on partitioning the uncertainty set into several subsets. By varying the number of partitions, the focus of this hybrid formulation can intuitively be shifted more toward reliability or cost-efficiency, depending on the decision maker's preferences. Additionally, it can be solved efficiently by applying the column-and-constraint generation algorithm as presented by Zeng and Zhao (2013). The fact that the solution to the robust stochastic UC can be adjusted manually instead of applying heuristics represents a clear advantage of this formulation over the unified UC proposed by Zhao and Guan (2013). The main culprit of the robust stochastic UC is that it is restricted to discrete sets as model for uncertainties. However, this assumption does not reflect reality, where uncertainties like generation from wind or solar farms in general take values in continuous sets. As a consequence, reliability cannot be ensured for such uncertainties.
Overcoming the weaknesses of RUC and SUC has attracted the attention of many researchers and motivated several HUC formulations. However, as discussed, existing hybrid approaches fail to ensure reliability, are not easy to use or suffer from high computational costs. Thus, no approach can be found which meets all of our requirements on HUC formulations. On that account, we seek to propose a novel HUC that can be handled in a user-friendly manner and leads to cost-efficient and reliable results in a reasonable amount of time. Our approach borrows and extends the model derived by Blanco and Morales (2017) by supporting continuous uncertainties. By partitioning the continuous range of uncertainties into subsets, our novel HUC minimizes the expected worst-case dispatch costs in the second stage. Based upon preferences, the considered number of partitions can be used to move this hybrid formulation more toward RUC or SUC. In essence, the main contributions of this paper read as follows.
1. By merging the ideas of RUC and SUC, the proposed hybrid formulation minimizes the expected worst-case dispatch costs. The new method respects the continuous nature of uncertainties and is thus in particular favorable for applications in power systems with high penetration of volatile renewable sources.
2. In comparison to traditional UC formulations, the proposed approach delivers a more cost-efficient solution than RUC and a more reliable solution than SUC.
3. In comparison to known HUC formulation, the proposed approach is more user-friendly than the unified UC by Zhao and Guan (2013), more reliable than the robust stochastic UC by Blanco and Morales (2017) and computationally cheaper than the distributionally robust UC by Zhao and Guan (2016) and Duan et al. (2018).
4. A modified Benders decomposition algorithm can be applied to solve the proposed formulation very efficiently. By means of the number of partitions, the decision maker can control computation time and balance the solution between RUC and SUC.
The remainder of this paper is structured as follows. In section 2, traditional RUC and SUC formulations are briefly recapped and limitations are pointed out to motivate hybrid approaches. Section 3 is dedicated to our novel HUC. We start off by introducing the mathematical problem statement. Using this model, the core benefits of applying our novel HUC are highlighted. In order to allow for practical implementations, the novel HUC is embedded into the framework of Benders decomposition. At the end of the section, an efficient algorithm is derived to partition the continuous uncertainty set into the desired number of subsets. In section 4, numerical results verify the superior performance of the proposed formulation as compared to previous approaches. Finally, section 5 wraps the paper up by drawing a conclusion of the main findings. Additionally, possible directions for future research are explored.
2. Review of Robust and Stochastic Unit Commitment
In order to derive schedules for the optimal operation of power plants, power system operators rely on the UC problem. In this paper, the UC is formulated in its traditional form as two-stage optimization problem with binary first-stage commitment variables x and continuous non-negative second-stage dispatch variables y. The costs incurred by commitment and dispatch decisions are described by deterministic vectors c and d.
Throughout this paper, a simplified power system, which is composed of thermal power plants and wind farms, is considered. In this context, the commitment decisions x describe the day-ahead scheduling of the thermal power plants and the dispatch decisions y describe the real-time operation of both thermal power plants and wind farms. However, it is important to note that the UC problem is not restricted to this setting. For instance, UC can as well be applied to hydro-thermal power systems (compare, Nguyen et al., 2018) and power systems with injection from solar farms (see, Chakraborty et al., 2011).
The first-stage commitment decisions often need to be made under uncertainty. In general, it is necessary to distinguish between discrete and continuous uncertainties. Typical sources of discrete uncertainties include for example unexpected equipment failures like outages of lines or generators. Renewable sources like wind or solar power on the other hand introduce uncertainties, which are continuous in nature, to the power system. In this paper, the uncertain factor u corresponds to the available wind power. This kind of uncertainty is continuous and keeps on gaining in importance with the penetration of wind farms increasing.
In this section, the two currently most popular approaches to handle such uncertainties in power system scheduling are recapped: RUC and SUC.
2.1. Robust Unit Commitment
In recent years, considerable effort has been made to improve the quality of wind power forecasts (see, Quan et al., 2013 and references therein for example). However, as no forecast is absolutely perfect, departures from the forecast wind power can still occur. As a direct consequence, the available wind power is at least in parts uncertain when making the commitment decisions after the day-ahead bidding window closes. RUC seeks to capture this uncertainty by a deterministic uncertainty set . A simple model is the box set, which is defined according to
Here is the set of wind farms and is the set of time periods. By analyzing historical data, the lower bound uw, t and the upper bound can be estimated. In order to avoid costly solutions, finding a tight set to represent the uncertainty is desirable. However, if the set is chosen too small, coverage of all possible outcomes of the uncertainty can no longer be guaranteed. Figure 1 illustrates this dilemma for a random day in Germany.
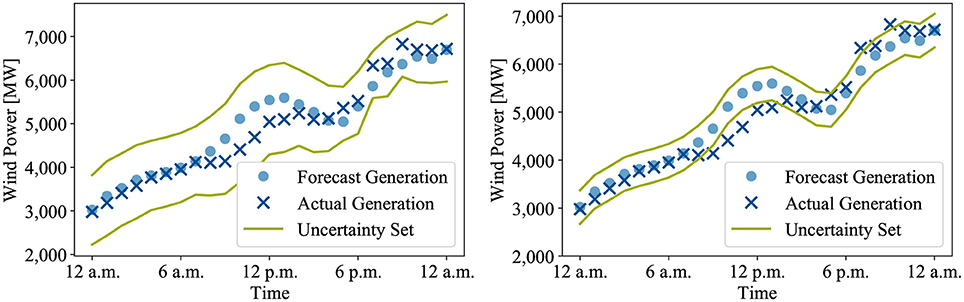
Figure 1. Possible uncertainty sets to model the available wind power: reliable but conservative (Left) and cost-efficient but risky (Right).
Box sets are easy to derive and promise to protect against uncertainties to a high degree. However, they do not consider correlations between adjacent nodes or consecutive time periods and are thus very conservative in general. The conservatism can be reduced by imposing budget constraints. This gives the frequently used ellipsoidal and polyhedral uncertainty sets. As we are going to see, our novel HUC does not require confining the uncertainty set to control conservatism. On that account, the discussion in this paper is limited to box sets.
As a matter of course, in the case of available wind power, strong spatio-temporal dependencies exist. Hence, the assumption of uncorrelated uncertain factors certainly does not hold in reality anymore. Nevertheless, in an effort to keep the following discussion as simple as possible, the correlations are neglected on purpose and the aforementioned box set (1) is used as model for uncertainties.
The traditional problem formulation of RUC reads as follows (e.g., Bertsimas et al., 2013).
Definition 1 (Robust Unit Commitment).
Constraint (3) contains commitment-related constraints like minimum up/down times or start-up/shut-down characteristics. Constraint (4), involving only dispatch variables, ensures load balance, i.e., that supply matches demand. Additionally, ramping-up/ramping-down and transmission capacity restrictions are included. Constraint (5) links commitment and dispatch variables and reflects generation capacities. Finally, Constraint (6) enforces that the dispatch of wind farms cannot exceed the available wind power. The dispatch decisions y are expressed as function of the uncertainty u, as the output of the generators depends on the available wind power. Since the commitment decisions x must be feasible for any realization in , RUC can guarantee system reliability. However, as the most cost-efficient schedule for the worst-case realization is determined, the resulting schedule tends to be too conservative and thus too expensive for most real-time outcomes of the uncertainty.
2.2. Stochastic Unit Commitment
SUC assumes that the uncertainty can be described by a probability distribution. Recalling that departures from the forecast are the cause of uncertainty, a probabilistic model of the uncertain available wind power u can be derived as follows. First, available historical data are exploited to determine the empirical distribution of the forecast errors. This is done by constructing a histogram. In this context, the forecast errors are given as the difference between forecast and actual generation. Then, by using maximum likelihood estimation, the parameters of different probability distributions are fit to the histogram and the distribution which matches best is selected as underlying probability distribution of the forecast errors. Centering this distribution around the forecast then gives a probabilistic model of the uncertain available wind power.
In literature, several distributions have been suggested to model forecast errors. Justified by the central limit theorem, the Gaussian distribution is a popular choice (c.f., Doherty and O'Malley, 2005) for example. Other distributions including Beta, hyperbolic and Weibull distribution have been examined as well (compare, Bludszuweit et al., 2008; Hodge et al., 2012; Osório et al., 2016). Using above propositions, historical data on forecast errors, which have been collected in Germany in 2017, have been analyzed in Figure 2. Since the hyperbolic distribution in essence corresponds to the Laplace distribution except that it allows asymmetry between its sides, the simpler Laplace distribution is taken into account instead of the hyperbolic distribution. Additionally, note that the support of the Beta distribution is limited to [0, 1]. Thus, in order to accommodate the Beta distribution, the forecast errors are normalized by the installed capacity and centered around 0.5.
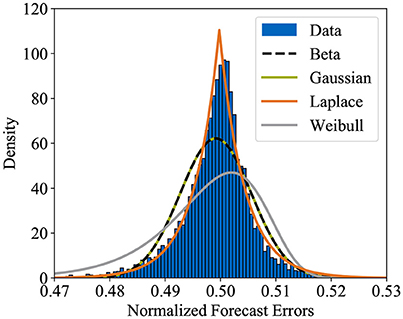
Figure 2. Probability distributions fit to histogram of forecast errors in Germany in 2017.
Among the considered distributions, the Laplace distribution is found to fit the data by far best and is thus selected to describe the wind power forecast error distribution. Shifting right by the forecast wind power then gives a probabilistic model of the uncertain available power at wind farm w at time t according to
with location parameter μw, t ∈ ℝ and scale parameter bw, t > 0. As correlations are neglected in this paper, the joint probability distribution of the uncertainties u reads as
The basic SUC is then given by (e.g., Zhao and Guan, 2016):
Definition 2 (Stochastic Unit Commitment).
Here, the expectation is calculated with respect to u. In theory, besides yielding cost-efficient solutions by finding the cheapest schedule for the expected case, SUC determines a commitment decision which is feasible for any outcome of the uncertainty. However, assuming continuous uncertainties, the expectation in the second stage corresponds to a multiple integral. Thus, in practice, in order to ensure numerical tractability, evaluating the expectation requires approximations such as sample averages. Since discrete sample sets can never represent all possible realizations of continuous uncertainties, feasibility of the commitment decisions can no longer be guaranteed. This necessary trade-off between computational costs and reliability is the major shortcoming of SUC approaches.
3. Novel Hybrid Robust/Stochastic Unit Commitment
Our novel HUC seeks to bring together reliability of RUC and cost-efficiency of SUC by taking advantage of both approaches. To this end, the continuous uncertainty set (1) is split into K disjoint subsets according to . Then, the worst-case, i.e., the realization which incurs the highest dispatch costs, is determined in each subset. Finally, the commitment decisions are made so that the expected costs of these worst cases are at a minimum.
3.1. Mathematical Formulation
In mathematical terms, our HUC formulation reads as follows.
Definition 3 (Continuous Hybrid Unit Commitment).
For the sake of brevity, a compact matrix-vector notation is used. A detailed formulation is presented in the Supplementary Material. In above definition, K corresponds to the number of partitions. The weight term pk is equal to the probability, that a realization of the uncertainty lies in the specific subset k:
Since a weighed sum of several worst cases is considered in the second stage of the objective function, the HUC minimizes the expected worst-case costs. Definition 3 allows us to highlight the two most appealing features of our novel HUC. First, in contrast to the RUC from Definition. 1, our novel HUC does not focus on one specific worst-case scenario and is thus expected to deliver less conservative, i.e., more cost-efficient results. Second, when making the commitment decisions, all realizations of the uncertainty are taken into consideration in the HUC. Thus, the solution remains feasible for any possible future outcome of the uncertainty in the uncertainty set. This crucial property clearly distinguishes our HUC from the SUC formulation from Definition. 2, which falls short of guaranteeing system reliability in the face of continuous uncertainties in practical implementations.
In terms of total costs, our novel HUC yields a solution that lies between RUC and SUC, i.e., . This inequality is obvious since the costs of covering worst cases from several subsets are always upper bounded by the costs of protecting against the worst-case from the entire uncertainty set as proposed in RUC and lower bounded by the costs of preparing for several random cases from the uncertainty set as proposed in SUC. With in creasing K, the subsets k become smaller and the influence of the max-operator starts to dwindle, making the HUC less conservative. Hence, varying the number of partitions allows for moving the HUC closer to RUC and SUC, respectively. In fact, by setting K = 1 and K → +∞, the HUC can actually be reduced to the purely robust and stochastic formulations from Definitions 1 and 2. This claim can be proven as follows. First, for K = 1, the uncertainty set is not split up at all. Thus, the summation in the objective (16) vanishes and the HUC coincides with the RUC. Letting the number of partitions approach toward infinity on the other hand, the max-operator in the objective (16) can be dropped as the subsets become small enough to approximate the worst-case in each subset by a random sample. As a result, the HUC corresponds to the SUC as the second stage in its objective function boils down to a sample average.
3.2. Benders Decomposition Algorithm
The structure of large-scale two-stage optimization problems like the UC formulations in Definitions 1–3 in general lends itself very naturally to solution by decomposition algorithms such as Benders decomposition (see, Rahmaniani et al., 2017), and column-and-constraint generation (see, Zeng and Zhao, 2013). Both approaches seek to derive a solution by considering a smaller optimization problem which is solved repeatedly. Despite their common goal, the two decomposition algorithms differ considerably in how they define the smaller optimization problem. Whereas in Benders decomposition, the reduction in size is achieved by taking a smaller constraint set into account, column-and-constraint generation confines the uncertainty set. Each reduced constraint and uncertainty set are iteratively extended until optimality is reached. In literature, both Benders decomposition and column-and-constraint generation have been applied to solve HUC formulations (see, Zhao and Guan, 2013; Blanco and Morales, 2017 for example). Recent studies suggest that column-and-constraint generation shows superior performance (compare, Zhao and Zeng, 2012). Nevertheless, in this paper, we follow the lead of Zhao and Guan (2013) and develop an algorithm based upon Benders decomposition to solve our novel HUC. This choice can be justified by the fact that in the case of continuous uncertainties, enlarging the uncertainty set until optimality is reached, as proposed in column-and-constraint generation, is no longer guaranteed to always be a finite procedure. In contrast, applying Benders decomposition is going to yield the optimal solution at latest once the entire constraint set has been restored, which is achieved in a finite number of iterations for sure.
The small-scale optimization problem which is solved recurrently, is called master problem (MP) within the context of Benders decomposition and can be obtained by replacing the second stage economic dispatch problems in Definition 3 by approximating variables θ1, …, θK. Thus, the MP is given by
As we are going to see, these variables act as lower bounds on the optimal value of the second stage. By means of feasibility and optimality cuts, information about the constraint set and the structure of the second stage in the original optimization problem from Definition 3 is gradually added to the MP. Note that these cuts improve the quality of the solutions to the MP, but lead to a increase in size at the same time and eventually are going to restore the original optimization problem. Hence, in order to benefit from Benders decomposition, the cuts need to be incorporated into the MP in such a way that the optimal solution to the original optimization problem is obtained after as few iterations as possible.
At each iteration, after solving the MP, optimal values for x and θ1, …, θK are received. The obtained values can be used to check, whether the optimal solution to the HUC from Definition 3 has already been reached. To this end, we attempt to solve the K second stage economic dispatch problems
Within the framework of Benders decomposition, the optimization problem above is referred to as k-th slave problem (SP). When evaluating the quality of the solution to the MP by means of the SPs, three possible situations arise:
• x is infeasible
• x is feasible but non-optimal
• x is feasible and optimal
In case of infeasibility or non-optimality, it can be ruled out that x is the optimal solution to the HUC from Definition 3. Then, in order to ensure that the same x is not chosen again in future iterations, additional constraints in the form of cuts are added to the MP. In the following, the specific design of these cuts is discussed in detail.
3.2.1. Feasibility Check
In order to be a possible solution to our novel HUC, all SPs must be feasible for the given MP solution x. Let 1 denote a vector of ones. Then, the feasibility check problem for the k-th SP and given u ∈ k reads as
The slack variables and can always be chosen such that the constraints (28)–(30) in the SPs are satisfied. Since the objective measures the overall constraint violation, the following equation is required for feasibility:
Instead of solving (31)–(35) for all u ∈ k, feasibility can equivalently be detected for given x by considering the following worst-case formulation:
We then have fk(x) = 0 for feasible x and fk(x) > 0 for infeasible x. To proceed, we write out the dual of (31)–(35) according to
where are the dual variables corresponding to constraints (32)–(34). Plugging into (37) allows for writing the feasibility check problem in the form of a single-stage maximization:
This is a disjointly constrained bilinear program, which is known to be NP-hard under general settings (see, Matsui, 1996 for example). Hence, in literature on UC, rather than trying to solve bilinear programs into optimality, it is common practice to apply a heuristic approach to obtain an approximate solution in a reasonable amount of time (compare, Bertsimas et al., 2013; Zhao and Guan, 2013). We follow this lead by sticking to the mountain-climbing procedure as presented by Konno (1976). Being a heuristic, this approach is not guaranteed to yield the optimal solution (see, Bennett and Mangasarian, 1993). However, numerical simulations carried out by Ahmed and Guan (2005) and Jiang et al. (2014) show that the optimality gap is negligible. In essence, by alternately fixing one of the variables in the bilinear term, the mountain-climbing approach defines two linear programs
and
Letting u* and denote the optimal solutions, the two linear programs are solved recurrently until . As is an approximate solution to the feasibility check problem (31)–(35), we have for feasible x and for infeasible x. To cut off infeasible solutions in future iterations, the feasibility cut
is added to the MP. The procedure described above is summarized in Algorithm 1. Since the variables and u are not coupled by any constraint, the optimal solution to the bilinear program (41)–(44) must lie on a corner point of the constraint set (cf., Konno, 1976). Hence, the algorithm can be accelerated by starting out with an arbitrary extreme point in k.

Algorithm 1. Feasibility Check for k-th SP
3.2.2. Optimality Check
After completing the feasibility check, the optimality of the solution to the MP can be tested. Note that at this point, x is guaranteed to be feasible for all SPs because otherwise feasibility cuts would have been generated. In order to check optimality, the SPs (27)–(30) need to be solved. However, due to their max-min structure, this is not a trivial task in general. On that account, we opt to transform the SPs into single-stage maximizations by taking the dual of the inner minimization. Then, the k-th SP can equivalently be stated as
Here, λ, μ, ν are the dual variables on constraints (28)–(30). Let u*, λ*, μ*, ν* denote the optimal solution. Being the point-wise maximum of affine functions, Qk(x) is piecewise linear and convex in x (compare, Boyd and Vandenberghe, 2004). Hence, it holds that
By placing the same lower bound on the approximation θk according to
an optimality cut, which can be fed into the MP, is obtained. As all constraints on θk in the MP have the same form as (56), θk is a lower bound on Qk(x). By means of the optimality cuts, the MP gains insight into the shape of the SPs. Hence, the more cuts are considered, the closer the approximation θk is going to be to the exact objective value Qk(x) of the SP. As soon as approximation and exact value coincide, the procedure can stop as x, the solution to the MP, is optimal in light of the HUC from Definition 3 as well.
Notice that computing Qk(x) requires optimizing a bilinear term ν⊺u. Similar to the feasibility check, this issue is addressed by applying the mountain-climbing approach. Then, the optimality check problem for given x boils down to two linear programs—one in terms of λ, μ, ν
and one in terms of u
which are solved iteratively until convergence is reached. The proposed scheme is summarized in Algorithm 2.

Algorithm 2. Optimality Check for k-th SP
3.2.3. Overall Algorithm
When speaking of Benders decomposition, we need to distinguish between uni-cut and multi-cut approaches. In uni-cut formulations, the MP increases slowly in size and can quickly be solved, since only one single cut is added at each iteration. The downside of this procedure is that a lot of iterations might be required until an optimal solution is obtained. Multi-cut schemes propose to introduce one cut for each of the SPs at each iteration. As a result, less iterations as compared to uni-cut formulations are necessary. However, since larger MPs need to be handled, computation time for each iteration increases. In this paper, we follow the multi-cut approach of Birge and Louveaux (1988), i.e., multiple optimality cuts are generated at each iteration. Putting above remarks and the results of the previous two sections together allows for formulating a Benders decomposition algorithm tailored to the HUC from Definition 3. In Figure 3, a flow chart summarizes our proposed algorithm.
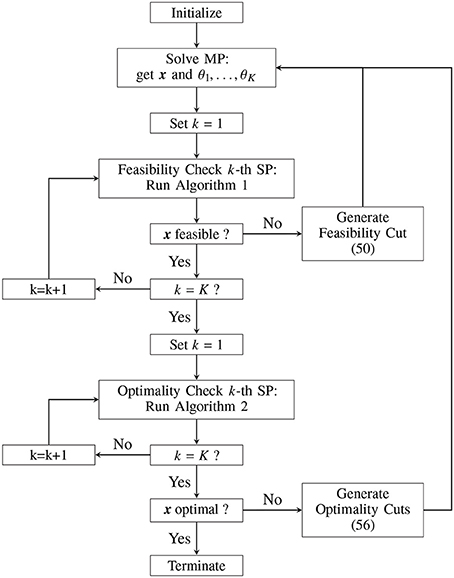
Figure 3. Benders decomposition algorithm to solve HUC from Definition 3.
3.3. On the Partitioning of Continuous Uncertainty Sets
The performance of our novel HUC stands or falls by the strategy that is employed to partition the continuous uncertainty set . Generally speaking, as the considered box uncertainty set (1) takes the form of a hyperrectangle in , any space partitioning algorithm can be envisioned to determine the hyperplanes which divide the uncertainty set. However, as the partitioning algorithm directly affects the ease of use and tractability of our formulation, the scheme to partition needs to be chosen deliberately.
Exploring ways to derive partitions of uncertainty sets has been the goal of previous studies as well. Assuming discrete uncertainty sets, the performance of different clustering techniques has been analyzed by Blanco and Morales (2017). Based upon numerical results, the authors conclude that hierarchical clustering, which determines the partitions by iteratively splitting the subset with the largest dissimilarity between two of its elements, yields the best results. Vayanos et al. (2011) and Büsing and D'Andreagiovanni (2012) have discussed the benefits of splitting the continuous uncertainty set in robust optimization and stochastic programming models, respectively. However, rather than providing a specific partitioning scheme, the partitions are assumed to be given. The partitioning of arbitrarily shaped continuous uncertainty sets has been the aim of the study conducted by Postek and den Hertog (2016). As a rule of thumb, the authors propose to divide the uncertainty set in such a way that critical scenarios, which have been identified beforehand, lie in different subsets. Finally, Bertsimas and Dunning (2016) have suggested the possibility to use Voronoi diagrams to split continuous uncertainty sets.
In the context of HUC, a user-friendly approach is characterized by the property that the conservatism of its solution can be controlled in a fairly obvious manner. In our novel HUC, we aim at allowing the decision maker to adjust the solution by varying the number of partitions of the uncertainty set. In particular, we seek to establish a one-to-one correspondence between the number of partitions and total system costs, i.e. an increase in the number of partitions is always accompanied by a decrease in total costs and vice versa. The partitioning algorithm must be able to yield partitions such that the HUC possesses this property.
In theory, it can be observed that taking an infinite number of partitions into consideration is necessary to obtain a result, which compares with SUC in terms of operational costs. Obviously, having to deal with infinitely many partitions is computationally challenging and has to be avoided by all means to ensure numerical tractability. Hence, in order to benefit from our novel HUC in practice, we strive to develop a partitioning algorithm such that considerably less partitions are required to approach the SUC. Moreover, bear in mind that prior to being able to actually solve the HUC, the partitions of the uncertainty set need to be determined by running a partitioning algorithm. Due to their complexity, space partitioning algorithms in general are time and storage consuming. On that account, the scheme used in our novel HUC should be kept as simple as possible in order not to jeopardize tractability of our HUC.
With the above remarks in mind, the partitioning algorithm can now be devised. In order to preserve the ease of use of our HUC, the proposed partitioning scheme establishes a hierarchy of partitions by dividing the uncertainty set iteratively. At each iteration, the number of partitions is increased by splitting one subset up into two subsets. This procedure is repeated until the desired number of partitions is reached. Adhering to this rule ensures that increasing the number of partitions provokes a decrease in total costs and thus moves the solution to the HUC farther from the RUC and closer to the SUC.
Secondly, it is important to keep an eye on numerical tractability. This implies that the number of partitions, which is required to get close to the SUC, has to be kept as low as possible. For that reason, we opt to use the Euclidian distance to measure the dissimilarity between two elements u1 and u2 in the same subset according to
The largest possible distance that needs to be covered to get from one element in a subset Uk to another element in the same subset is denoted as maximum dissimilarity and given by
In general, an UC solution is called conservative if the system conditions, which are assumed to derive the solution, differ significantly from normal operating conditions. Consequently, the worst-case of the subset with the largest maximum dissimilarity is expected to be particularly conservative. Splitting this set up into two subsets in a way such that the dissimilarity in the new subsets is smaller, promises a significant decrease in total system costs and limits the required number of partitions to approach the SUC. Since determining the maximum dissimilarity in subsets of random shape may be cumbersome, the subsets are restricted to boxes. Then, the maximum dissimilarity in a subset corresponds to the distance between two corner points that are not on the same face of the box. Recalling (1), this observation gives
In the following, assume that the subset with the largest maximum dissimilarity has been identified. Let w,t = [uw,t, uw,t] denote the interval that defines this subset along the (w, t)-th dimension. Furthermore, let
be its length. As we aim at reducing the maximum dissimilarity in the new subsets, but are restricted to box sets at the same time, it is necessary to split the longest interval. Using (65), this interval can be identified very easily. Finally, Figure 4 illustrates the basic procedure to derive partitions of the continuous uncertainty set (1).

Figure 4. Sketch of proposed partitioning algorithm.
In an effort to reduce the dissimilarity in the two new subsets to the greatest possible extent, we propose to split the box set with the largest maximum dissimilarity at the midpoint of its longest interval. However, this implicates that neither the subset with the largest maximum dissimilarity nor the longest interval of the selected subset are always uniquely identifiable. Taking the probabilistic knowledge of the uncertainty into account can remedy these problems. We first focus on selecting a subset when more than one subset exhibits the largest maximum dissimilarity. Revisiting the objective function (16) of the novel HUC formulation reveals that the worst-case costs of each subset are weighted with the probability that a realization of the uncertainty actually falls into this subset. Consequently, a subset that is linked to a small probability has little influence on the objective value. With regard to our objective to control the conservatism of the novel HUC with as few partitions as possible, splitting such a subset is of limited value. Hence, out of the subsets with the largest maximum dissimilarity, we propose to divide the subset that is most likely contain a realization of uncertainty, i.e., the subset with the largest weight term pk (22).
Once the subset with the largest maximum dissimilarity has been detected, we aim at deriving two subsets by dividing the longest interval into two parts of equal length. If the longest interval cannot clearly be identified, it is necessary to come up with another way to select an appropriate interval. To this end, the probabilistic knowledge is exploited once more. Again, let w,t = [uw,t, uw,t] denote the interval of the subset that needs to be divided. Apart from its length (65), the probability that a realization of the uncertainty uw, t lies in this interval, i.e.,
is another possibility to characterize . Using (66), the remarks from above paragraph apply and the interval which a realization of the uncertainty is most likely to lie in is chosen, i.e., the interval with the maximum ρw, t. Finally, our proposed partitioning scheme is summarized in Algorithm 3.

Algorithm 3. Partitioning of the Box Uncertainty Set U
4. Numerical Case Study
In this section, numerical results are reported to evaluate the performance of our proposed novel HUC formulation. A simple one-node model is considered which consists of two thermal power plants, one wind farm and one consumer. The uncertain available wind power is modeled as Laplacian-distributed random variable with location parameter μ = 120MW and scale parameter b = 2MW. Choosing the support of this random variable as deterministic uncertainty set gives = [106MW, 134MW]. In accordance with Bertsimas et al. (2013), the penalty costs for constraint violations are set to be 5000$/MW. The implementation is done in Python with GLPK as MILP solver running on a Windows 7 PC with four 2.3 GHz Intel cores and 6 GB RAM. In all experiments, both feasibility gap and optimality gap are set to 10−6. The MIP gap for the master problem in Benders decomposition is equal to the GLPK default gap.
4.1. Effects of Considered Number of Partitions
First, the relationship between the number of partitions K of the uncertainty set and the optimal value of the objective (16) is analyzed. To this end, the HUC from Definition 3 is solved for various K. The partitions are obtained by running Algorithm 3. In Figure 5, the results are depicted.
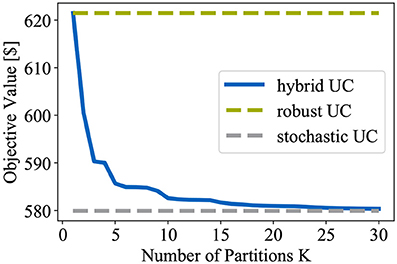
Figure 5. Comparison of solution to HUC with solutions to RUC and SUC.
As expected, it can be observed that with increasing number of partitions, the optimal objective value decreases since, by taking more subsets into account, the influence of unlikely worst cases gradually diminishes. For the sake of comparison, the objective values of the RUC from Definition 1 and the SUC from Definition 2 are shown as well. Note that, in order to solve the SUC, a sample average approximation with 5, 000 samples is used. Comparing the objectives, we first notice that the HUC is able to nicely fill in the gap between the solutions to RUC and SUC. In addition, by means of the number of partitions, the HUC can be adjusted very intuitively so as to approach the purely robust and stochastic formulations, respectively. Finally, the numerical results confirm our theoretical findings from section 3.1, where we have argued that only one partition is required to reduce our HUC to a traditional RUC formulation. In the same section, we have shown that, in general, an infinite number of partitions has to be considered in order to obtain a result that is as cost-efficient as the SUC solution. Luckily, our numerical simulation reveals that in practice, way less partitions may in fact be necessary to come very close to the SUC solution. This observation suggests that our novel HUC may actually serve as replacement for SUC formulations since taking a small number of worst cases instead of a large set of random samples into account promises considerable savings in computation time.
4.2. Evaluation of Proposed Partitioning Algorithm
The efficiency of the partitioning algorithm plays a key role in the overall performance of our novel HUC. To this end, we dedicate this section to analyzing our proposed scheme as given in Algorithm 3. In order to live up to our expectations, a proper method needs to satisfy two properties. First, increasing the number of partitions should always result in a decrease in total costs in order to ensure that the conservatism of the solution can be controlled in an obvious manner. Second, notice that the computational costs increase simultaneously with the considered number of partitions. Hence, the less partitions are required to balance the solution to the HUC between the respective solutions to RUC and SUC, the better from a computational viewpoint.
Keeping these requirements in mind, four different possibilities to construct partitions of the uncertainty set are raised. The first method (Max-Diss) corresponds to our proposed partitioning algorithm. Here, in summary, the partitions are determined by iteratively splitting the subset with the largest maximum dissimilarity into two subsets such that the maximum dissimilarity in the new subsets is at a minimum. The second scheme (Random) always starts from scratch and determines the desired K partitions by making K−1 random cuts. The third technique (Hierarchy) establishes a hierarchy, i.e. at each iteration, the number of subsets is increased by dividing one subset. However, the subset and the split point are still selected at random. The fourth and final approach (Max-Diss-Rand) coincides with our proposed partitioning algorithm (Max-Diss) except the fact that the subset with the largest maximum dissimilarity is split into two random subsets. For ease of understanding, Figure 6 summarizes the considered partitioning techniques.
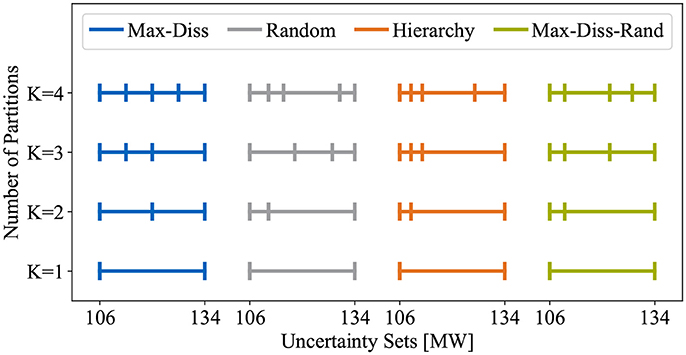
Figure 6. Partitions of the uncertainty set for four different partitioning schemes.
Employing these partitioning schemes, the optimal objective value (16) of our HUC formulation is plotted against the number of considered partitions in Figure 7.
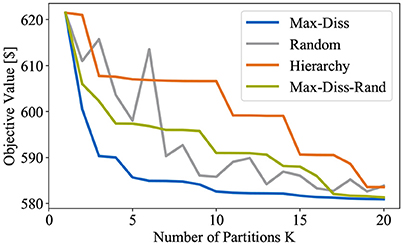
Figure 7. Comparison of solutions to HUC for four different partitioning schemes.
Most importantly, it can be observed that our proposed partitioning scheme (Max-Diss) clearly performs best since it yields a monotonically decreasing objective function and achieves the greatest reduction within the first few partitions. These two properties are key since they contribute to the ease of use and the numerical tractability of our HUC formulation. In contrast, the introduced reference algorithms perform significantly worse since they either exhibit unpredictable behavior or require a high number of partitions to remarkably decrease the optimal objective value (16). The unsatisfactory performance of the reference algorithms can be exploited to justify the design of our proposed partitioning scheme.
We start off with the random scheme (Random), where all partitions are calculated concurrently by making random splits. Comparing the objective values shows that this scheme comes close to our partitioning algorithm with increasing number of partitions. However, its non-hierarchical structure leads to undesirable peaks within the first few partitions. Hence, this method does not allow for controlling the objective value (16) by adjusting the number of partitions. Unlike the random scheme, the other two reference algorithms produce a hierarchy of partitions since, at each iteration, the number of subsets is increased by splitting one of the subsets from the previous iteration. Except for its hierarchical structure, the first of these two schemes (Hierarchy) coincides with the random scheme since both subset and split point are selected randomly at each iteration. As a result, the objective value decreases slowly but steadily with increasing number of partitions. The obvious downside of this approach is that remarkably more partitions as compared to our proposed partitioning method are required to control the objective value and thus the conservatism of the HUC. The second hierarchical reference algorithm (Max-Diss-Rand) is more sophisticated since it seeks to split the subset with the largest dissimilarity between two of its elements. What distinguishes this approach from our proposed partitioning scheme (Max-Diss) is that the selected subset is divided at a random point, i.e., the dissimilarity is only decreased but not minimized. Looking at Figure 7, aiming at minimizing the dissimilarity turns out to be crucial since reference scheme (Max-Diss-Rand) requires the most partitions to yield results, which are similar to the ones obtained by applying our proposed scheme. In conclusion, the limitations of the reference algorithms highlight the key properties of the proposed partitioning algorithm and demonstrate its superior performance.
4.3. Evaluation of Proposed Benders Decomposition Algorithm
To relieve the computational burden, a solution strategy based upon Benders decomposition has been proposed in section 3.2 to solve the novel HUC in an efficient manner. However, relying on decomposition schemes might not always be necessary. For instance, the assumed one-node model puts us in a position to derive an exact solution to our novel HUC, since only small-scale optimization problems need to be handled. This fact is exploited to verify that the proposed decomposition algorithm to solve the novel HUC works properly. In order to obtain the exact solution, the HUC is solved by applying exhaustive enumeration as follows (see, Sheble and Fahd, 1994; Padhy, 2004 for example). First, all possible combinations of the ON/OFF status of the thermal units are determined. Then, by solving the HUC for the enumerated values, a set of objective values is received. Finally, selecting the least-cost feasible solution gives the optimal solution to our HUC. In Figure 8, the results of solving the novel HUC by applying our proposed decomposition algorithm and exhaustive enumeration are compared. Note that the partitions are the result of running Algorithm 3.
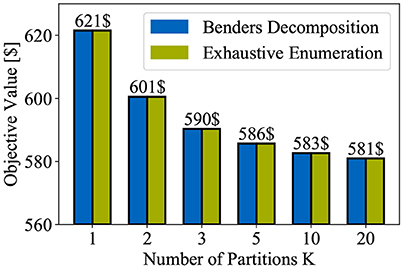
Figure 8. Comparison of solutions to HUC after applying Benders decomposition and exhaustive enumeration.
By analyzing the bar graph, it can be noticed that the decomposition approach is able to recover the exact solution as determined by the exhaustive search since the optimal objective values coincide (the optimality gap is found to lie below 10−12 for all instances). Hence, the numerical results confirm that the proposed decomposition algorithm is suitable for application to our novel HUC since it yields very close to optimal results.
4.4. Comparison With Robust Optimization Approach
In our discussion so far, we have argued that our novel HUC formulation is able to yield results similar to RUC and SUC, since the number of partitions can be adjusted such that the differences between the objectives vanish. However, in order to truly benefit from the novel formulation and to justify practical implementations, it is necessary to demonstrate that the novel approach is not limited to recover known results. On that account, we seek to show in the following that the novel HUC is as reliable but more cost-efficient than RUC and as cost-efficient but more reliable and computationally cheaper than SUC. In this section, our focus lies on the benefits of applying our novel HUC instead of RUC. Contrasting our novel approach with SUC is postponed until the next section.
In accordance with Bertsimas et al. (2013) and Zhao and Guan (2013), we proceed as follows. First, by solving the problem formulations from Definitions 1 and 3, the respective commitment decisions are obtained. In order to keep the computational costs of the HUC as low as possible, the number of partitions is fixed to be K = 2. Then, the received unit commitment policies are fixed and their performance is evaluated by carrying out Monte-Carlo simulation. To this end, the economic dispatch problem
is solved for Ns = 1, 000 randomly generated scenarios of the available wind power u. Note that the commitment decisions x in the above minimization problem correspond to the RUC and HUC solution, respectively. The computational results are collected in Table 1.
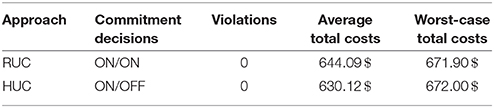
Table 1. Comparison between RUC and HUC.
The first column reports the unit commitment decisions for each approach. Here, we observe that RUC schedules more thermal units than the novel HUC approach. The second column counts the number of constraint violations in the economic dispatch problems. Since neither RUC nor HUC incur any violations, both unit commitment decisions are feasible for all samples. Hence, despite scheduling less thermal units, the HUC approach can ensure reliability. Summing up commitment related and dispatch related costs gives the total system costs
for given commitment decisions x and given sample of the available wind power u. By analyzing the average and the worst-case total costs, we can draw a comparison between the performance of RUC and HUC in terms of costs. In the third column, the average total system costs
are described. From this point of view, HUC performs better than RUC since it incurs considerably lower costs on average (around 2.2% savings in our small-scale one-node model). Finally, the fourth column contains the worst-case total system costs
Since in RUC, the commitment decisions are made so that the total costs in the worst-case are minimized, RUC leads to lower costs than HUC. However, the potential savings are negligible (less than 0.02%). In summary, the main findings of this section are
• the HUC solution is as robust as the RUC solution
• the HUC solution is more cost-efficient than the RUC solution.
4.5. Comparison With Stochastic Programming Approach
In this section, the novel HUC is compared with traditional SUC. We follow a procedure similar to that adopted in the previous section to carry out the simulation. First, the unit commitment decisions are obtained by solving the SUC and HUC formulations from Definitions 2 and 3. In the HUC, the number of partitions is again set to be K = 2. Following common practice, the expectation in the second stage of the objective in the SUC is approximated by a sample average. In order to evaluate the effect of the number of samples on the solution, the SUC is solved twice, once with 50 samples and once with 500 samples. Second, using the committed units, Monte-Carlo simulation is run by solving the economic dispatch problem (67)-(71) for a set of Ns = 1, 000 randomly generated scenarios of the available wind power. The numerical results are reported in Table 2.
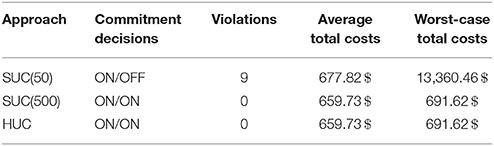
Table 2. Comparison between SUC and HUC.
The unit commitment decisions are summarized by the first column. The second column reports the number of infeasible scenarios by counting the constraint violations. The third and fourth column describe the average total costs (73) and worst-case total costs (74). We first draw a comparison between HUC and SUC with the smaller sample set SUC(50). Here, at first sight, the HUC is more conservative than the SUC as more thermal units are committed. However, considering the number of constraint violations of the SUC reveals that the more conservative scheduling approach of the HUC is justified since only the unit commitment plan provided by HUC can ensure feasibility for all outcomes of the available wind power. As violations are penalized at the rate of 5000$/MW, the potential savings of the SUC resulting from scheduling less thermal units are expected to be by far outweighed by the penalty related costs. To confirm this supposition, we first focus on the worst-case performance. Here, we notice that the total costs of the SUC solution are around 20 times the total costs of the HUC solution. This result illustrates vividly that applying HUC instead of SUC can help keep the costs in the worst-case under control. Regarding the average system operation, the differences in performance between HUC and SUC are less prominent but still existent as applying HUC in lieu of SUC leads to a decrease in average total costs by 2.7%. In summary, from an economical point of view, the HUC yields superior results as compared to SUC in both the expected case and the worst-case provided that penalty costs are included.
Above shortcomings can be remedied by incorporating more samples into the SUC in order not to miss critical realizations of the uncertainty. For instance, in our numerical case study, when applying SUC with 500 samples, the results of the HUC are recovered. However, since a large number of samples is required, this achievement comes at the expense of increased computational costs as compared to HUC, where considering K = 2 worst cases is sufficient to yield the same result. The main conclusions of the comparison between HUC and SUC read as follows.
1. SUC with small sample set
• the HUC solution is more robust than the SUC solution
• Including penalty terms, the HUC solution is more cost-efficient than the SUC solution
2. SUC with large sample set
• the HUC solution is as robust and as cost-efficient as the SUC solution
• the HUC solution is computationally cheaper than the SUC solution.
4.6. Comparison With Previous Hybrid Approaches
Finally, we seek to compare our novel HUC to previous HUC formulations that have appeared in literature. Recalling the introduction, the evaluation is based upon 4 criteria: 1. ease of use, 2. tractability, 3. reliability, and 4. cost-efficiency. The numerical results from the preceding sections verify that our novel HUC satisfies all of these properties since
1. the solution to the HUC can be adjusted between RUC and SUC in an obvious manner by varying the number of partitions of the uncertainty set, compare section 4.1
2. the proposed HUC formulation can efficiently be solved by applying Benders decomposition algorithm, compare section 4.3
3. the solution to the HUC does not incur any constraint violations and is thus as reliable as RUC, see section 4.4
4. the solution to the HUC is as cost-efficient as the SUC solution, compare section 4.5.
In the following, known HUC approaches are briefly reviewed. As the constraint set is given by (3)–(7) in all formulations, we restrict our discussion to the objective functions in the following. By pointing out the major shortcomings of each formulation, the superior performance of our novel HUC is demonstrated.
The unified stochastic and robust UC (UUC) by Zhao and Guan (2013) employs a weight term α ∈ [0, 1] to include both expected and worst-case dispatch costs in the second-stage:
As the weight term needs to be determined by applying heuristics in order to avoid sup-optimal results, the conservatism of the solution can not be controlled in an easy-to-use manner.
In accordance with our novel HUC, the idea behind the robust stochastic UC (RSUC) as presented by Blanco and Morales (2017) is to minimize the expected dispatch costs of several worst cases:
However, unlike our novel HUC, this formulation is limited to discrete uncertainties. Hence, in the face of continuous uncertainties such as the available wind power, reliability can no longer be ensured.
Finally, the distributionally robust UC (DRUC) formulations by Zhao and Guan (2016) and Duan et al. (2018) propose to minimize the dispatch costs under the worst-case distribution within a pre-defined ambiguity set :
Similarly to traditional SUC, such approaches require trade-offs between computational costs and reliability. The features of the considered HUC approaches are summarized in Table 3 for ease of reference.

Table 3. Comparison between novel HUC and previous HUC approaches.
We conclude that only our novel HUC satisfies all demanded properties.
5. Conclusion
Robust optimization and stochastic programming are the most prominent formulations to deal with uncertainty in the unit commitment problem. By protecting against the worst-case, RUC can guarantee reliability, but suffers from over-conservatism as the probability that the worst-case actually occurs is virtually nil. SUC yields better results from an economical viewpoint by preparing for the expected case, but commonly requires approximations which might in turn raise concerns about feasibility. In an attempt to address the shortcomings of purely robust and stochastic formulations, prior work has paid close attention to hybrid approaches in recent years. However, accommodating uncertain factors with continuous range such as the generation from wind or solar farms still remains an obstacle. On that account, known approaches either rely on discrete sample approximations or are computationally very demanding.
In this study, we propose a novel hybrid UC formulation which respects the continuous nature of uncertainties like wind power availability in its problem statement. By partitioning the continuous range of the uncertainty into subsets, the new approach seeks to minimize the expected worst-case costs. As continuous uncertainty sets are considered, the provided solution ensures system reliability for all possible future outcomes of the uncertainty. By means of the number of partitions, the conservatism of the solution can be controlled in a user-friendly manner. An efficient partitioning algorithm is derived such that the novel HUC achieves great reductions in conservatism within the first few partitions. This feature contributes to the tractability of our novel approach. A Benders decomposition algorithm is proposed to solve the HUC efficiently. Finally, a case study confirms that the presented HUC formulation delivers solutions that perform well in terms of both costs and reliability.
In comparison to RUC, the novel HUC yields results with reduced conservatism. Since the solution can still withstand any possible realization of the uncertainty, this benefit comes without sacrificing system reliability. Additionally, by applying our novel HUC, solutions which compare to SUC in terms of costs can be obtained. Contrary to SUC, no approximations which affect reliability are necessary. Indeed, similar remarks hold for various hybrid approaches. The key properties which differentiate our novel HUC from known formulations are listed in the following. Most notably, the novel HUC considers continuous uncertainties. This clearly distinguishes our formulation from the hybrid approach of Blanco and Morales (2017), where the discussion is restricted to discrete uncertainties. Consequently, in contrast to the approach therein, our novel formulation can ensure robustness in the face of continuous uncertainties. Moreover, our novel HUC offers to control conservatism by varying the number of partitions. Obviously, this approach is more intuitive than heuristically determining a proper weight term as suggested by Zhao and Guan (2013). Finally, the hybrid approaches by Duan et al. (2018) and Zhao and Guan (2016), which are based upon the principles of distributionally robust optimization, tend to impose a high computational complexity. Given limited computational resources in practice, the fact that the structure of our proposed hybrid formulation lends itself to solution by decomposition schemes such as Benders decomposition is another beneficial feature of our novel HUC. Being the main culprit of our novel HUC, system reliability stands or falls by the accuracy of the probabilistic model of uncertain factors. Hence, analyzing a sufficient amount of historical data in order to obtain an accurate representation is an integral preliminary step.
Current limitations of our formulation are possible targets of future research and thus worth mentioning. For instance, by assuming that the deterministic uncertainty set is given by a box set, spatio-temporal correlations have been neglected. Apparently, this simplistic assumption does not reflect reality, where obvious correlation patterns can be found. In order to be able to fully exploit such correlations, exploring ways to extend our novel HUC so that more sophisticated uncertainty sets are supported is an interesting aspect. As a natural consequence of loosening restrictions on the shape of the uncertainty set, more advanced algorithms are in line for determining the partitions of the uncertainty set. Recalling that in general any space partitioning algorithm can be envisioned, evaluating the effects of such algorithms on the performance of our novel HUC is another interesting direction of future research. Finally, we have pointed out the benefits from applying our hybrid approach provided that the sole source of uncertainty is the available wind power. Apart from wind power, solar power is going to play an essential role in future power systems as well. Hence, examining how our hybrid formulation adapts to this source of uncertainty is another possible target for future researchers.
Author Contributions
All authors contributed to the article. PG conducted the research as part of his master's thesis under the supervision of MD and TH. MD and TH discussed the approach in detail and revised the article.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This work was supported by the German Research Foundation (DFG) and the Technical University of Munich (TUM) in the framework of the Open Access Publishing Program.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fenrg.2018.00071/full#supplementary-material
References
Ahmed, S., and Guan, Y. (2005). The inverse optimal value problem. Math. Programming 102, 91–110. doi: 10.1007/s10107-004-0515-x
An, Y., and Zeng, B. (2015). Exploring the modeling capacity of two-stage robust optimization: Variants of robust unit commitment model. IEEE Trans. Power Syst. 30, 109–122. doi: 10.1109/TPWRS.2014.2320880
Bennett, K., and Mangasarian, O. (1993). Bilinear separation of two sets in n-space. Comput. Optim. Appl. 2, 207–227.
Bertsimas, D., and Dunning, I. (2016). Multistage robust mixed-integer optimization with adaptive partitions. Oper. Res. 64, 980–998. doi: 10.1287/opre.2016.1515
Bertsimas, D., Litvinov, E., Sun, X., Zhao, J., and Zheng, T. (2013). Adaptive robust optimization for the security constrained unit commitment problem. IEEE Trans. Power Syst. 28, 52–63. doi: 10.1109/TPWRS.2012.2205021
Birge, J., and Louveaux, F. (1988). A multicut algorithm for two-stage stochastic linear programs. Eur. J. Oper. Res. 34, 384–392.
Blanco, I., and Morales, J. (2017). An efficient robust solution to the two-stage stochastic unit commitment problem. IEEE Trans. Power Syst. 32, 4477–4488. doi: 10.1109/TPWRS.2017.2683263
Bludszuweit, H., Dominguez-Navarro, J., and Llombart, A. (2008). Statistical analysis of wind power forecast error. IEEE Trans. Power Syst. 23, 983–991. doi: 10.1109/TPWRS.2008.922526
Boyd, S., and Vandenberghe, L. (2004). Convex Optimization, Vol. 1. Cambridge: Cambridge University Press.
Büsing, C., and D'Andreagiovanni, F. (2012). “New results about multi-band uncertainty in robust optimization,” in International Symposium on Experimental Algorithms, Vol 1(Bordeaux), 63–74.
Chakraborty, S., Senjyu, T., Yona, A., and Funabashi, T. (2011). “Fuzzy quantum computation based thermal unit commitment strategy with solar-battery system injection,” in IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) (Taipei), 1–8.
Doherty, R., and O'Malley, M. (2005). A new approach to quantify reserve demand in systems with significant installed wind capacity. IEEE Trans. Power Syst. 20, 587–595. doi: 10.1109/TPWRS.2005.846206
Duan, C., Jiang, L., Fang, W., and Liu, J. (2018). Data-driven affinely adjustable distributionally robust unit commitment. IEEE Trans. Power Syst. 33, 1385–1398. doi: 10.1109/TPWRS.2017.2741506
Hodge, B., Florita, A., Orwig, K., Lew, D., and Milligan, M. (2012). “A comparison of wind power and load forecasting error distributions,” in World Renewable Energy Forum (Denver, CO. U.S. Department of Energy - Office of Scientific and Technical Information), 1–10.
Jiang, R., Zhang, M., Li, G., and Guan, Y. (2014). Two-stage network constrained robust unit commitment problem. Eur. J. Oper. Res. 234, 751–762. doi: 10.1016/j.ejor.2013.09.028
Konno, H. (1976). A cutting plane algorithm for solving bilinear programs. Math. Programming 11, 14–27.
Matsui, T. (1996). Np-hardness of linear multiplicative programming and related problems. J. Global Optimiz. 9, 113–119.
Nguyen, T., Quynh, N., Duong, M., and Dai, L. (2018). Modified differential evolution algorithm: a novel approach to optimize the operation of hydrothermal power systems while considering the different constraints and valve point loading effects. Energies 11:540. doi: 10.3390/en11030540
Osório, G., Lujano-Rojas, J., Matias, J., and CatalÃčo, J. (2016). “Wind power forecasting error distributions and probabilistic load dispatch,” in Power and Energy Society General Meeting (Boston, MA), 1–5.
Padhy, N. (2004). Unit commitment – a bibliographical survey. IEEE Trans. Power Syst. 19, 1196–1205. doi: 10.1109/TPWRS.2003.821611
Postek, K., and den Hertog, D. (2016). Multistage adjustable robust mixed-integer optimization via iterative splitting of the uncertainty set. INFORMS J. Comput. 28, 553–574. doi: 10.1287/ijoc.2016.0696
Quan, D., Ogliari, E., Grimaccia, F., Leva, S., and Mussetta, M. (2013). “Hybrid model for hourly forecast of photovoltaic and wind power,” in IEEE International Conference on Fuzzy Systems (FUZZ-IEEE) (Hyderabad), 1–6.
Rahmaniani, R., Crainic, T., Gendreau, M., and Rei, W. (2017). The benders decomposition algorithm: a literature review. Eur. J. Oper. Res. 259, 801–817. doi: 10.1016/j.ejor.2016.12.005
Sheble, G., and Fahd, G. (1994). Unit commitment literature synopsis. IEEE Trans. Power Syst. 9, 128–135.
Vayanos, P., Kuhn, D., and Rustem, B. (2011). “Decision rules for information discovery in multi-stage stochastic programming,” in 50th IEEE Conference on Decision and Control and European Control Conference (Orlando, FL), 7368–7373.
Zeng, B., and Zhao, L. (2013). Solving two-stage robust optimization problems using a column-and-constraint generation method. Oper. Res. Lett. 41, 457–461. doi: 10.1016/j.orl.2013.05.003
Zhao, C., and Guan, Y. (2013). Unified stochastic and robust unit commitment. IEEE Trans. Power Syst. 28, 3353–3361. doi: 10.1109/TPWRS.2013.2251916
Zhao, C., and Guan, Y. (2016). Data-driven stochastic unit commitment for integrating wind generation. IEEE Trans. Power Syst. 31, 2587–2596. doi: 10.1109/TPWRS.2015.2477311
Zhao, L., and Zeng, B. (2012). “Robust unit commitment problem with demand response and wind energy,” in IEEE Power and Energy Society General Meeting (San Diego, CA), 1–8.
Keywords: Benders decomposition, continuous uncertainty, robust optimization, stochastic programming, unit commitment
Citation: Gögler P, Dorfner M and Hamacher T (2018) Hybrid Robust/Stochastic Unit Commitment With Iterative Partitions of the Continuous Uncertainty Set. Front. Energy Res. 6:71. doi: 10.3389/fenrg.2018.00071
Received: 26 April 2018; Accepted: 29 June 2018;
Published: 20 July 2018.
Edited by:
Minh Quan Duong, Da Nang University of Technology, VietnamReviewed by:
Le Hong Lam, Politecnico di Milano, ItalyGabriela Nicoleta Sava, Politehnica University of Bucharest, Romania
Copyright © 2018 Gögler, Dorfner and Hamacher. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Patrick Gögler, cGF0cmljay5nb2VnbGVyQHR1bS5kZQ==
Magdalena Dorfner, bS5kb3JmbmVyQHR1bS5kZQ==