 David A. Barajas-Solano
David A. Barajas-Solano Francis J. Alexander2
Francis J. Alexander2 Marian Anghel
Marian Anghel Daniel M. Tartakovsky
Daniel M. Tartakovsky- 1Pacific Northwest National Laboratory, Computational Mathematics, Richland, WA, United States
- 2Brookhaven National Laboratory, Computational Science Initiative, Upton, NY, United States
- 3Los Alamos National Laboratory, Computer, Computational, and Statistical Sciences Division, Los Alamos, NM, United States
- 4Department of Energy Resources Engineering, Stanford University, Stanford, CA, United States
We present a generalized hybrid Monte Carlo (gHMC) method for fast, statistically optimal reconstruction of release histories of reactive contaminants. The approach is applicable to large-scale, strongly nonlinear systems with parametric uncertainties and data corrupted by measurement errors. The use of discrete adjoint equations facilitates numerical implementation of gHMC without putting any restrictions on the degree of nonlinearity of advection-dispersion-reaction equations that are used to describe contaminant transport in the subsurface. To demonstrate the salient features of the proposed algorithm, we identify the spatial extent of a distributed source of contamination from concentration measurements of a reactive solute.
1. Introduction
An accurate reconstruction of the release history of contaminants in geophysical systems is essential to regulatory and remedial efforts. These efforts rely on measurements of pollutant concentration to identify the sources and/or release history of a pollutant. Unfortunately, available concentration data are typically sparse in both space and time and are corrupted by measurement errors. Source identification and reconstruction of release history are further complicated by both spatial heterogeneity of model parameters and their insufficient characterization, although we do not consider these effects in the present work.
Detailed reviews of the historic developments and state-of-the-art in the field of inverse modeling as related to contaminant source identification are presented in Atmadja and Bagtzoglou (2001b) and Hutchinson et al. (2017). The existing approaches can be subdivided into two broad classes: deterministic and probabilistic. Deterministic approaches include, but are not limited to, Tikhonov regularization of convolution integrals (Liu and Ball, 1999; Ito and Jin, 2015), least-square estimation from analytical approximations (Butcher and Gauthier, 1994), least-square solution of an optimal control problem (Gugat, 2012), the method of quasi-reversibility (Skaggs and Kabala, 1995; Bagtzoglou and Atmadja, 2003), and the backward beam equation method (Atmadja and Bagtzoglou, 2001a; Bagtzoglou and Atmadja, 2003). These approaches provide estimates of the release history from a source of known locations and are not designed for quantifying the uncertainty associated with these estimates. The robustness of these methods is highly sensitive to measurement errors, and their mathematical formulations are often fundamentally ill-posed.
While existing probabilistic approaches, such as random walk particle tracking for the backward transport equation (Bagtzoglou et al., 1992), minimum relative entropy (Woodbury and Ulrych, 1996), and adjoint methods (e.g., Neupauer and Wilson, 1999), alleviate some of these problems, others remain. For example, these and similar methods do not take advantage of the regularizing nature of the measurement noise and, hence, are often ill-posed. Thus, the minimum relative entropy method treats concentration measurements as ensemble averages. Additionally, there are some outstanding issues with quantifying uncertainty (Neupauer et al., 2000) and the inability of many existing approaches to handle more than one observation point (Neupauer and Wilson, 2005).
Finally, most existing approaches to the reconstruction of release history are restricted to linear transport phenomena, that is, transport phenomena for which the transport equation is linear in the concentration, and thus are limited to migration of contaminants that are either conservative (all the references above) or exhibit first-order (linear) reaction rates (Neupauer and Wilson, 2003, 2004). This is because such approaches are based on either Green's functions (Skaggs and Kabala, 1994; Woodbury and Ulrych, 1996; Stanev et al., 2018) or analytically derived adjoint equations (Neupauer and Wilson, 1999, 2005). The use of Kalman filters for source identification (Herrera and Pinder, 2005) is formally limited to linear transport phenomena and Gaussian errors. While both limitations can be relaxed by employing various generalizations of the Kalman filter such as the extended and ensemble Kalman filter (e.g., Xu and Gömez-Hernández, 2016, 2018), these generalizations are known to fail if the nonlinearity is too strong. Bayesian optimization approaches (Pirot et al., 2019), accelerated by the use of Gaussian process models as surrogates, provide a promising alternative to the Kalman filter since they impose no linearity requirements.
Purely statistical approaches to history reconstruction, such as the geostatistical inversion with Bayesian updating (Snodgrass and Kitanidis, 1997) and various machine learning techniques (Vesselinov et al., 2018, 2019), are applicable to nonlinear transport. Since this is achieved by ignoring governing equations, the reconstructed release histories could have non-physical characteristics, including negative concentrations. These problems have been alleviated by introducing additional constraints into an optimization functional and requiring the reconstructed field to be Gaussian (Michalak and Kitanidis, 2003, 2004a). Combining these geostatistical approaches with analytically derived adjoint equations (Michalak and Kitanidis, 2004b; Shlomi and Michalak, 2007) however brings back the linearity requirement.
We present an optimal reconstruction of contaminant release history that fully utilizes all available information and requires neither the linearity of governing transport equations nor the Gaussianity of the underlying fields. In section 2 we formulate the problem of reconstructing the contaminant release history from noisy observations. Section 3 introduces our general computational framework, which is further implemented in section 4 for various examples.
2. Problem Formulation
2.1. Reconstruction of Contaminant Release History
We consider migration of a single chemically active contaminant in a porous medium Ω ⊂ ℝd, d ∈ [1, 3]. We assume that reactive transport is adequately described by the advection-dispersion-reaction equation with reaction term R(c):
together with corresponding boundary conditions. Here c = c(x, t) is the solute concentration at point x and time t, u is the average macroscopic pore velocity, D is the dispersion coefficient tensor, and r(x, t) is the source function. Both the location and duration of the contaminant release, i.e., the source function r(x, t), can be unknown, but only the former source of uncertainty is treated in the computational examples of section 4, that is, we assume that r(x, t) = r(x)δ(0).
Introducing the dimensionless quantities
and the normalized reaction term , we rewrite (1) in terms of dimensionless quantities,
The non-dimensionalization of the reaction term is specific to its functional form. The non-dimensionalization of a particular case employed in this manuscript is discussed in section 4. For all the following discussions we will consider the dimensionless Equation (2) and we will drop the prime notation for denoting dimensionless quantities.
For the remainder of this work we assume that u, D, and the boundary conditions are known, while the source function r(x, t) is unknown. Our goal is to reconstruct the release history r(x, t) from concentration data collected at points at times , and for known u, D, and boundary conditions.
Concentration measurements are corrupted by measurement errors. We assume that the measured concentrations differ from the true concentration by an additive measurement noise, so that
where the errors ϵmi are zero-mean Gaussian random variables with covariance 𝔼[ϵmiϵnj] = δijRmn, where 𝔼[·] is the expectation operator, δij denotes the Kroneker delta function, and the Rmn, m, n ∈ [1, M], are components of the spatial covariance matrix R ∈ ℝM×M of measurement errors. This treatment of measurement noise assumes that the measurements are well separated in time to neglect any temporal correlations, but the model can be easily extended to include temporal correlations. We use the additive error model (3) of Woodbury and Ulrych (1996) rather than the multiplicative error model of Skaggs and Kabala (1994) for the purpose of illustration only. Both models have similar effects on the accuracy of history reconstruction (Neupauer et al., 2000) and can be handled by our approach.
In a typical situation, one has prior information (or a belief) about potential sources of contamination (a region Ωc within the flow domain Ω) and a time period [Tl, Tu] during which the release has occurred. Examples of Ωc include spatially distributed zones of contamination (e.g., landfills) and a collection of point sources (e.g., localized/small industrial sites or storage facilities), some of which have contributed to contamination. The lower (Tl) and upper (Tu) bounds of the release interval might represent the time when a landfill became operational and the time when contamination has first been detected, respectively. In the absence of prior information about the release occurrence, one can assume a uniform random distribution of the release in [Tl, Tu] × Ω. We allow for an arbitrary number of measurement points and for either discrete or continuous-in-time measurements.
2.2. Likelihood Function
To simplify the exposition, we assume a spatially distributed chemical release at time t = 0 only, i.e., r(x, t) = c(x, 0)δ(t). Given the measurements and the noise model (3), our goal is to determine the likelihood of a given release configuration c(x, 0). Unfortunately, the measurements, generally taken at later times, do not estimate directly the likelihood of a release configuration. Nevertheless, because the transport Equation (2) is deterministic, we can implicitly assess the likelihood of a given release configuration, P[c(x, 0)], from the probability (likelihood) of a given (computed) concentration history c(x, t). This likelihood can be expressed as (Alexander et al., 2005)
where is the so-called “Hamiltonian” or log-likelihood function,
where , and R is the covariance matrix of measurement errors, as defined in section 2.1. Since (2) uniquely determines the evolution of the solute concentration from its initial state c(x, 0), the Hamiltonian (5) is a nonlinear functional of the initial conditions c(x, 0), i.e., .
This formulation assumes that the measurement errors ϵmi are Gaussian and uncorrelated with the state of the system. Other distributions of the measurement noise and the stochasticity of governing equations can be handled as well (Alexander et al., 2005). The Hamiltonian for stochastic systems, which can represent, e.g., uncertain hydraulic conductivity and flow velocity that are treated as random fields, can be reformulated to explicitly include the transport equation (Alexander et al., 2005; Archambeau et al., 2007).
The contribution of highly fluctuating or unphysical initial conditions is reduced by adding a regularization term Hreg[c(x, 0)] to the observation Hamiltonian (5) and replacing the likelihood function (4) with
where
and the weight γ > 0 is a tuning hyperparameter. The regularization term Hreg is equivalent to a Bayesian log-prior distribution on the initial condition. The selection of an appropriate regularization Hamiltonian is particularly important for problems in which the observation Hamiltonian does not specify a proper probability distribution for c(x, 0) due to a lack of measurements. For a one-dimensional source profile, the squared gradient of the initial spatial profile can play the role of the regularization Hamiltonian. In higher dimensions, one can use a thin-plate penalty functional (Wahba, 1990).
A conceptual difference between our approach and maximum likelihood methods is worth emphasizing. Rather than sampling the Gibbs distribution exp{−H[c(x, 0)]}, as we do here, maximum likelihood methods minimize the Hamiltonian (6b) over c(x, 0). While standard maximum likelihood methods determine the mode and variance of the posterior distribution under a Gaussian approximation, the approach described below can be used to determine the mean and higher-order statistics, and it is valid even when the posterior distribution is multi-modal.
3. Monte Carlo Sampling
In principle, one can sample the Gibbs distribution by using Markov-chain Monte Carlo (MCMC) (e.g., Michalak and Kitanidis, 2003). However, quite often, the disadvantage of local MCMC-based methods is their slow convergence. To improve convergence, we apply a Generalized Hybrid Monte Carlo (gHMC), which enables one to efficiently sample release configurations c(x, 0) with probability given by (6a).
3.1. Hybrid Monte Carlo (HMC)
Hybrid Monte Carlo (HMC) refers to a class of methods that combine Hamiltonian molecular dynamics with Metropolis-Hastings Monte Carlo simulations (see Neal, 1993 for an introductory survey). Specifically, a time-discretized integration of the molecular dynamics equations is used to propose a new configuration, which is then accepted or rejected by the standard Metropolis-Hastings Monte Carlo criteria. The change in total energy serves as the acceptance/rejection criteria.
In HMC one treats the log-likelihood function H in (6b) as the configurational Hamiltonian for a system of N “particles,” each of which has unit mass and generalized coordinates q1, q2, …, qN. Each of these generalized positions corresponds to the solute concentration c(x, t) at a space-time point (x, t). In the following, the particle positions correspond to the initial concentration at time t = 0, e.g., qi = c(xi, 0), xi = iL/(N − 1), i = 0, …, N − 1 for a contaminant release over the one-dimensional domain [0, L].
At any given time, the state of the system is completely described by (q, p), where and . Here, the momentum of the ith particle, pi, is dqi/dτ = pi, where τ is the fictitious time of the molecular dynamics. The kinetic energy of the system of N particles is given by
and the total Hamiltonian of the system is
It follows that the Hamiltonian dynamics are given by
where Fi is the force acting on the ith particle, that is to be computed from the governing transport equation. During the time interval Δτ, the system evolves from its current state (q, p) to a new state , which can be computed by discretizing the Hamiltonian dynamics (9). An example of such a discretization is the standard leapfrog method, which is written as
for i = 1, …, N. Multiple leapfrog steps, i.e., multiple applications of Equation (10), can be performed. For the hybrid Monte Carlo method, the number of leapfrog steps S is larger than one. For S = 1 we obtain the Langevin Monte Carlo method (Neal, 1993). This completes the “proposal part” of HMC.
The remaining part of HMC consists of deciding whether to accept or reject the new state . This is done by the Metropolis-Hastings sampling strategy, according to which the new state is accepted with probability
The momenta variables are resampled after each acceptance/rejection of the position variables according to a Gaussian distribution of independent variables ~ exp(−HK). The time-marching and acceptance/rejection process represents one step in the Markov chain, and therefore one Monte Carlo sample. It is important to note that the update from (q, p) to does not conserve energy as a result of the time discretization. The extent to which energy is not conserved is controlled by the time step Δτ. Detailed balance is achieved if the configuration obtained after evolving several steps is accepted with probability Q in (11). Thus, the Metropolis step corrects for time discretization errors.
As we have noted before, the method samples from the multivariate target distribution, ~ exp(−Ĥ), by computing a Markov chain. Sampling from this density allows us to estimate the mean state (reconstructed initial configuration) and its variance. Markov chain sampling from the posterior distribution involves a transient phase, in which we start from some initial state and simulate the Markov chain for a period long enough to reach its stationary density, followed by a sampling phase, in which we assume that the Markov chain visits states from this stationary density. If the chain has converged and the sampling phase is long enough to cover the entire posterior distribution, accurate inferences about any quantity of interest are made by computing the sample mean, variance, and other desired statistics (Landau and Binder, 2009).
3.2. Generalized Hybrid Monte Carlo (gHMC)
In many cases, the generalized hybrid Monte Carlo (gHMC) of Toral and Ferreira (1994) can improve the efficiency of standard HMC by means of the nonlocal sampling strategy described in some detail below. For q,p ∈ ℝN, gHMC replaces the Hamiltonian dynamics in (9) with a more general formulation,
where A is a linear operator represented by a ℝN×N matrix. The corresponding leapfrog discretization is then given by
The two formulations, (9) and (12), are identical if A is the identity matrix. The goal is to find a matrix A that leads to a significant reduction of the temporal correlations of the Markov chain without appreciably increasing the cost of the update due to matrix-vector multiplications.
In order to illustrate how the introduction of the matrix A can help to reduce the correlations of the Markov chain, consider the problem with q ∈ ℝN and Hamiltonian
so that the forcing is given by −Σ−1(q − μ). For the case A = I, it can be seen from (13) that the different components qi are updated at different rates, given by the covariance matrix Σ. For a given δτ, some components would be updated with long steps, while others would be updated with shorter steps.
The disadvantage of such a configuration is that too long of a step for a certain component might increase the total Hamiltonian enough to produce a rejection according to (11). If the rejection rate of the chain is too large, one would have to reduce δτ, which affects all components. The issue of the rejection rate would be addressed, but then some components would be updated with very short steps, increasing their correlation. To solve this issue, one can remove the appearance of Σ altogether by choosing A such that AA⊤Σ = I. If Σ is a valid covariance matrix, this is trivially accomplished by choosing A as the Cholesky factor of Σ. We therefore refer to A as the “acceleration” matrix.
Unfortunately, in general, the Hamiltonian (6b) for our problem does not have a simple bilinear form for which an appropriate selection of acceleration matrix A can be derived. Nevertheless, it stands to reason that one can build acceleration matrices for more complex systems to partially reduce the correlation of the Markov chain.
4. Numerical Experiments
In this section we illustrate how the framework outlined above can be applied to source identification problems. In the first case we study the implementation of HMC to contaminant transport problems with a nonlinear reaction term for different configurations of observations. In the second case we study a linear advection-dispersion problem and explore possible selections of the gHMC acceleration matrix.
4.1. Discrete in Space, Continuous in Time Measurements
We consider a one-dimensional transport with uniform velocity u and dispersion coefficient D. We employ as the regularization operator the ℓ2-norm of the gradient of the initial spatial distribution. Furthermore, we assume that the time of the contaminant release is precisely known and we impose no constraints on the total mass of the released contaminant. The measurements are taken continuously over the time interval (0, T) at a subset J of discrete locations in the spatial domain. We assume that the measurement errors are uncorrelated in space and time and have the same variance at every point. This setup represents observations of contaminant breakthrough curves at a number of sampling locations.
The Hamiltonian corresponding to this setup is
It is evaluated, together with its sensitivity with respect to the initial condition, by using a method-of-lines discretization of the concentration field c(x, t). Once the governing equation has been discretized into a system of ordinary differential equations (ODEs), one can compute the sensitivity ∇qH via the adjoint sensitivity method (Cao et al., 2003; Li and Petzold, 2004). The disadvantage of this approach is that it incurs two levels of numerical error: the integration error of the forward problem, which affects the initial condition of the adjoint problem, and the integration error of the backward problem. If these errors are significant, both the quality of the estimator and the rejection rate of the Markov chain can be compromised. Reducing the error requires one to decrease the time step used for integration in both directions, which would increase the computational cost per leapfrog step.
To partially alleviate this problem, we use a single-step ODE integration scheme for the forward problem and compute the sensitivity of H with respect to the initial condition via multiple applications of the chain rule (Daescu et al., 2000). Let ci (i = 0, …, I) be a vector of discretized states evaluated at time t = iT/I and be a vector of the measurements at time ti in the elements corresponding to the J measurements' locations and zeros in the other elements. Let C be a diagonal matrix with ones on the diagonal elements corresponding to the J subset of measurement locations and zeros in all other locations. We use this notation to rewrite the observation Hamiltonian and the sensitivity as
and
respectively, where dci/dq denotes the Jacobian of ci with respect to q. Using the chain rule, the sensitivity ∇qHobs can be rewritten as
This implies that the sensitivities can be evaluated by repeatedly computing products of the form (dci+1/dci)⊤u. If these products can be computed exactly, then this approach provides the exact sensitivity of the (space-time discretized) system, which is useful for problems with costly forward and backward solutions. The disadvantage of this approach is that it is highly application-specific and restricts the selection of ODE solvers to a specific family. Details of the implementation of this discrete sensitivity analysis approach are presented in Appendix.
We test this formulation on a one-dimensional transport problem defined in the domain [0, L], L = 1 with constant velocity u, dispersion coefficient D, and the reaction model (Lichtner and Tartakovsky, 2003)
corresponding to a nonlinear heterogeneous (precipitation/dissolution) reaction with equilibrium concentration ceq. Here k denotes the dimensionless kinetic rate constant normalized by porosity, given by , where is the kinetic rate constant normalized by porosity, with dimensions of inverse concentration times inverse time, and t0 and c0 are the time and concentration scales defined in section 2.1. The parameter values are set to D = 1.0, u = 50.0, ceq = 0.4, and k = 1.0. Boundary conditions are dc/dx = 0 at x = 0, L. The transport equation is discretized employing a finite-volumes scheme consisting of N = 128 cells of uniform size Δx. Concentration measurements are taken at the M = 3 spatial locations x = L/2, x = 3L/4, and x = L over the time period (0, 2.5 × 10−2) (Figure 1). The standard deviation of these measurements is set to σϵ = 0.02.
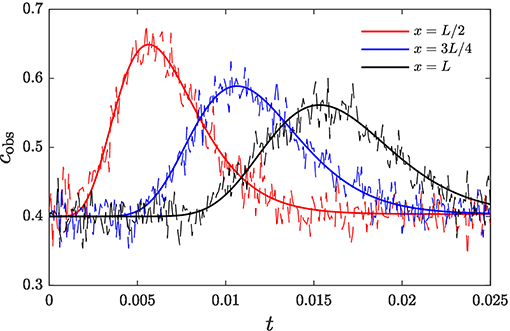
Figure 1. Breakthrough curves of contaminant at observation locations along the transport domain. Noisy measurements used for inference are shown in dashed.
The release configuration is inferred using the HMC scheme, carried out with hybrid timestep Δτ = 0.17, number of leapfrog steps S = 5, and regularizing parameter γ = 0.05. A total of 1 × 105 samples of the release profile were retained after the burn-in period, which are employed to compute the Monte Carlo estimates and of the posterior mean and standard deviation, respectively. These estimates are shown in Figure 2. In particular, Figure 2A shows the posterior mean estimate compared to the true release profile, c0. We also show the 95% confidence interval of the posterior mean estimate. It can be seen that the HMC scheme is able to infer the main features of the initial condition, namely the location of the release and the total mass of contaminant released. For comparison, we also compute the Bayesian maximum a posteriori (MAP) point estimate cMAP of the release profile, also presented in Figure 2A. The MAP is given by
where H[·] is the Hamiltonian given in (6b). MAP estimation is similar to the method of Bayesian global optimization (BGO) (Pirot et al., 2019) in that both aim to minimize the data misfit. BGO yields an estimate guaranteed to be the global minima over the search space, while MAP may converge toward local minima of the data misfit function. It can be seen that the MAP estimate and the posterior mean estimate are similar, although in general they need not coincide, as they correspond to different statistics. We note that, unlike MAP estimation and Bayesian global optimization, the HMC method is not limited to point estimates and can be used to quantify the uncertainty in the reconstruction. Nevertheless, MAP and Bayesian global optimization estimates are useful when quantifying uncertainty is not critical as their computational cost is smaller than that of HMC.
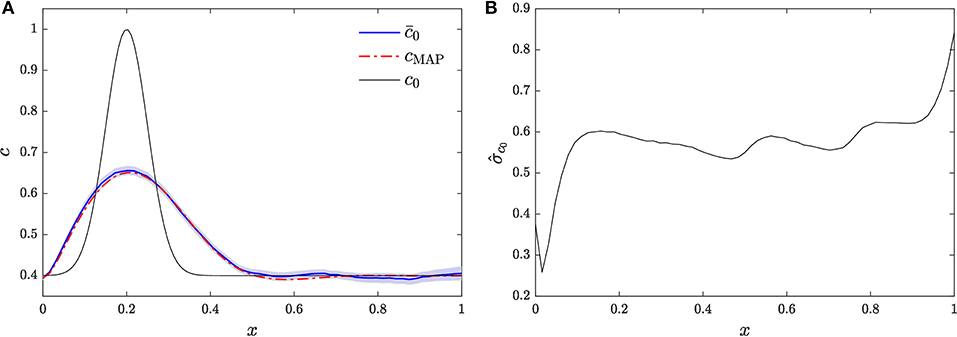
Figure 2. Reconstruction of release profile via HMC. (A) Posterior mean compared against MAP estimate cMAP and the actual release profile c0. (B) Posterior standard deviation.
Figure 2B shows the posterior standard deviation. It can be seen that the posterior standard deviation is large, which is due to the dearth of data available and the ill-posedness of the inversion problem. We also note that the posterior standard deviation is the largest for x = L. Due to the strong advective velocity together with the outflow boundary condition, c0(L) is only informed by the observations at x = L at early times.
4.2. Application of gHMC to Linear Transport
In order to study the construction of an acceleration matrix A appropriate for contaminant transport, we consider a 1-D advection-dispersion (no reaction) problem
with uniform coefficients u and D. This equation is subject to the periodic boundary condition
and (unknown) initial condition
Similar to the case studied in section 4.1, available concentration data consist of a set of measurements continuous in time on the interval (0, T) collected at a subset J of the discrete locations xj, cobs, j = cobs(xj, t). The measurements are subject to space-time uncorrelated additive errors of equal variance .
4.2.1. Observation Hamiltonian
The state variable c(x, t) is discretized into N functions cj(t) = c(xj, t), where xj = 2πj/N, j = 0, …, N − 1 are N equidistant nodes along the domain [0, 2π). We define the measurement Hamiltonian as
which defines the likelihood of the measurements given an initial release vector q with components qj = c0, j. The solution to (16)–(18) can be represented in terms of its discrete Fourier transform (DFT)
which defines the N Fourier modes ĉk. The backward or inverse transform is given by
Let c denote a vector of discrete values cj and denote its DFT. Then, (20) and (21) can be rewritten as
where is the DFT matrix whose elements are
and (·)* denotes the Hermitian adjoint. By projection, (16) is discretized into the set of uncoupled ODEs for the Fourier modes
with initial conditions , where the , k = −N/2, …N/2−1 are the components of , the DFT of q ≡ c(0). The solution to the ODEs is then given by
Substituting (22) and (24) into (19) yields the following expression for the measurement Hamiltonian:
where is the DFT of cobs(0), corresponds to the J columns of , B(t) is a diagonal matrix with elements , and is a Hermitian (semi)positive definite matrix. The measurement Hamiltonian specifies a multivariate normal distribution for , and given that q and are related via a linear transformation, it follows that the measurement Hamiltonian specifies a multivariate normal distribution for q.
If the measurements are available at every node of the computational domain, i.e., if , then and (25) simplifies to
which is equivalent to
where the coefficients ĝk are given by
Note that all coefficients ĝk are real, symmetric (ĝk = ĝ−k), and depend only on the dispersion coefficient D.
It follows from (25) that
where . That brings the forcing into the form F[q] = −Σ−1(q − μ) required by our analysis in section 3.2, which suggests a possibility of computing the acceleration matrices as . Unfortunately this is not generally feasible, because the matrix Gobs is singular unless the measurements are taken at every node of the domain. The singularity of Gobs implies the singularity of the multivariate normal distribution of given by Hobs, which means the distribution is concentrated in a r-dimensional subspace of ℂN, r < N. Since q results from a linear transformation of , the multivariate normal distribution of q is also degenerate. This implies that there is a linear subspace of configurations q for which Hobs does not assign a probability, and therefore cannot be identified.
An empirical study of the SVD decomposition of the matrix computed for the example of section 4.2.5 provides some insight into features of the degenerate distribution of q defined by the observations. Specifically, the vectors forming a basis for have negligible terms associated with the lower Fourier modes of q, i.e., |Vk, j| ≈ 0 for small |k| and . This implies that the lower frequency components of q fall mostly on the subspace of identifiable configurations. In general, |Vk, j| ≠ 0 for high |k| and , which implies that in general high frequency features cannot be identified.
4.2.2. Regularization Hamiltonian
The regularization Hamiltonian extends the distributions of q and in order to make them well-defined. After a real-space discretization, and accounting for the periodic boundary conditions (17), the ℓ2-norm regularization Hamiltonian takes the form
where γ is a regularization hyperparameter and Greg is the circulant matrix
or , where r = (2, −1, 0, …, 0, −1)⊤/Δx and Δx = 2π/N. The matrix Greg extends the probability distribution by assigning a high energy (low probability) to configurations with large high-frequency components. To demonstrate this, we rewrite Greg as
where is the DFT of r. The components of vector increase with frequency k, with the zeroth frequency giving rise to . The latter is to be expected since the regularization operator does not affect the observability of the zeroth frequency, which corresponds to the average of the initial release.
Note that a Fourier-space discretization of the regularization Hamiltonian leads to a similar bilinear form for Greg, with . Indeed, these have a similar asymptotic behavior as k → 0.
4.2.3. Acceleration Matrix
For the full Hamiltonian H = Hobs+Hreg, the forcing is given by
where and . This suggests that choosing the acceleration matrix A, such that , would reduce the correlation of the Markov chain. Since Gobs and Greg are Hermitian (semi)positive definite, their sum G = Gobs+Greg is at least Hermitian (semi)positive definite. In fact, G is a full rank matrix and thus can be factorized via a Cholesky decomposition G = S⊤S. The matrix A, defined by AA*G =I, is then given by
The added cost of computing the acceleration matrix A is the Cholesky factorization cost, and the leapfrog scheme for gHMC incurs four matrix-vector products. For dense matrices, these costs are and , respectively.
An advantage of the Cholesky factorization is that the vector of momenta p in (13) can be chosen as real and multivariate normal, with zero mean and identity covariance matrix. A drawback is its relatively high cost per step in the Markov chain. Moreover, the matrix G becomes more poorly conditioned as γ → 0, which affects the stability of the Cholesky decomposition.
A less computationally costly alternative for the construction of A is to employ the following heuristic: Instead of using the full correlation matrices in Fourier space, and , to define G, we approximate it as , where is the vector with components . This approximation allows one to factorize G as , where with the square root understood as element-wise. This argument suggests that the acceleration matrix A can be constructed as
which gives
Note that we have replaced the transpose of A with its Hermitian transpose due to the complex nature of the DFT. This implies that the transpose in (12) and (13) must be replaced with a Hermitian transpose, and that in order to guarantee that q ∈ ℝN we must generalize the momenta such that p ∈ ℂN. Once the acceleration matrix A in (30) is constructed, products of the form Ap and A*F can be computed using DFTs. The computational cost per leapfrog step is reduced from four matrix-vector products of cost to four of cost , and no Cholesky decomposition is necessary.
Since , the approximation (30) can be thought as building A from the diagonal of the Hessian of H with respect to (a similar heuristic is employed in Neal, 1995 for Bayesian learning). This observation begs the following question: Why do we take instead of , which would produce a similar acceleration matrix A without the Fourier transforms? The answer is that the matrix is more concentrated along its diagonal than G is. Hence, more information about the observation operator is conserved by taking the diagonal of than the diagonal of G.
4.2.4. Sampling of Momentum Vector
In order to retain the validity of the leapfrog method with generalized momenta, we require said momenta to be associated with a kinetic energy following a bilinear form. We achieve this by assuming that p ∈ ℂN has a general complex normal distribution with unit covariance Γ and
For given by (23),
where Ppq are the components of the permutation matrix P. Since D is diagonal and P is a permutation matrix (23), yields C = P.
Let p = X + iY with X,Y ∈ ℝN. The vector V⊤ = [X⊤Y⊤] is multivariate normal with zero mean. Given Γ and C, the cross-covariance matrix of this vector is
since both Γ and C are real. In other words, the real and imaginary parts of p are mutually uncorrelated. The covariance matrix of this vector is
It follows from (32) that only the components pk = Xk + iYk with k = −k are correlated. Their covariances are 𝔼[XkX−k] = 0.5, 𝔼[YkY−k] = −0.5. Since p must be complex-symmetric to guarantee that q remains real, we generate p as
Hence the vector p is generated with N independent identically distributed normal random variables.
4.2.5. Computational Example
We apply the gHMC algorithm to the model problem (16) with parameters D = 1.0, u = 10.0, N = 64, and σϵ = 0.02. Measurements are taken at locations xj, j ∈ J = {47, 63} over the time period (0, 6 × 10−1). The measurements are shown in Figure 3. To infer the release profile from the observations, we employ A = A1, S = 5 leapfrog steps, regularization parameter γ = 1 × 10−2, and hybrid timestep tuned to achieve a rejection rate of 30–35%. A total of 10 chains were generated, each with 2 × 104 samples retained after burn-in. These samples are employed to compute Monte Carlo estimates of the posterior mean and standard deviation, shown in Figure 4.
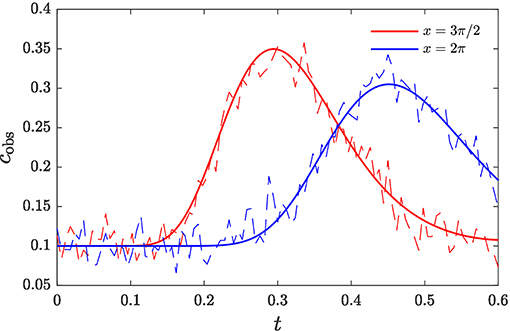
Figure 3. Breakthrough curves of contaminant at observation locations along the transport domain. Noisy measurements used for inference are shown in dashed lines.
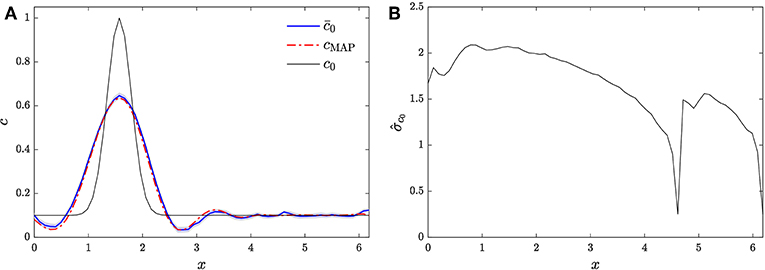
Figure 4. Reconstruction of release profile via gHMC and A = A1. (A) Posterior mean compared against MAP estimate cMAP and the actual release profile c0. (B) Posterior standard deviation.
Figure 4A compares the posterior mean estimate of the release profile, together with its 95% confidence interval, against the MAP estimate and the true release profile. It can be seen that the gHMC scheme is able to infer the main feature of the release profile. The gHMC estimate also compares favorably to the MAP estimate. Figure 4B shows the posterior standard deviation, which, as in section 4.1, is largely due to the relatively small number of observation locations, the relatively high measurement error, and the ill-posedness of the inverse problem.
Next, we study the effect of the choice of acceleration matrix A on the Markov chains produced by the gHMC algorithm and the Monte Carlo standard error of the posterior mean estimate. Three alternatives for A are considered: A = A1 in (29), A = A2 in (30), and A = I (no acceleration). The Monte Carlo standard error is given by , where is the posterior standard deviation of the inferred parameter, and neff denotes the MCMC effective sample size, given by neff ≡ n/η (Kass et al., 1998), where n is the number of MCMC samples, and η > 1 is a reduction factor due to the correlation between MCMC samples. This reduction factor is given by
where ρ(s) is the autocorrelation of the MCMC chain at lag s. We note that, after convergence, gHMC chains for different choices of A converge to the same posterior mean and standard deviation. The difference of performance between choices of A is in terms of the reduction factor η: Better-performing choices of acceleration matrix result in smaller values of η, so that fewer samples are necessary to achieve a certain target error in the estimation of the posterior mean.
We compute 10 gHMC chains for each choice of A and for two choices of regularization parameter γ, 1 × 10−2 and 1 × 10−3, and employ the samples to compute the autocorrelations ρ(s) and the effective sample size reduction ratios for each qj, j = 0, …, N − 1, except for j = 47, 63, which are included in the observations. Figure 5 presents the autocorrelations for γ = 1 × 10−3 and each choice of A. It can be seen that A = A1 produces highly uncorrelated chains for each of the qj studied, A = A2 produces more correlated chains, and A = I produces the most correlated chains. As expected, A2 provides a compromise between the low autocorrelation / high expense of the full Cholesky decomposition and the high autocorrelation / low cost of A = I.
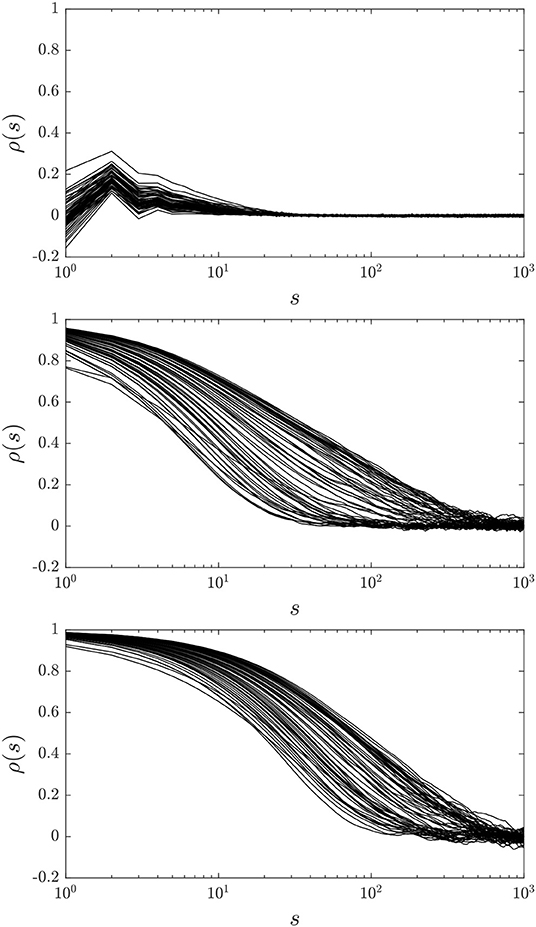
Figure 5. Autocorrelation functions for qj, j = {0, …, 63}\{47, 63}, and A = A1 (top), A = A2 (middle), and A = I (bottom).
The maximum effective sample size reduction ratio η for each choice of A and γ is shown in Table 1. It can be seen that, consistent with Figure 5, A = A1 produces highly uncorrelated chains, which leads to low values of η, and therefore to smaller standard errors. Similarly, A = I leads to the most correlated chains, the highest values of η, and the highest standard errors, while the choice A = A2 leads to values of η between those of A = A1 and A = I. We also note that the values of η for A = A2 and A = I increase significantly by going from γ = 1 × 10−2 to γ = 1 × 10−3, which is to be expected as the latter is a more challenging case due to weaker regularization. On the other hand, the value of η for A = A1 does not increase as dramatically when going from γ = 1 × 10−2 to γ = 1 × 10−3, which indicates that A1 is the best choice of acceleration matrix despite its higher computational cost per leapfrog step. We conclude that the gHMC scheme leads to a significant reduction in the estimation error over the use of HMC without an acceleration matrix.

Table 1. Effective sample size reduction ratio η for various choices of regularization parameter γ and acceleration matrix A.
For problems with reaction terms, the forcing F = −∇qH is not a linear function of q as in (28). In such cases, the selection of the acceleration matrix A is not straightforward. The challenge is to find an approximation to the forcing that is linear in q, i.e., preserves the form (28) with Gobs and Greg independent of q. This is required to guarantee the reversibility of the Hamiltonian dynamics.
Such an approximation can be obtained by disregarding the nonlinear reaction term and using Gobs in (25) and Greg in (27), which are functions only of the temporal and spatial domain properties and the hyperparameters and γ. This selection is equivalent to taking F ≈ −Glin(q − qobs), where Glin is the Hessian of the advection-diffusion (linear) portion of the Hamiltonian. It gives the acceleration matrix A1 of (29). This choice is justified for non-periodic boundary conditions if the contaminant plume does not reach the domain's boundaries during the simulation time. An alternative is to take only the diagonal portion of the Hessian of an advection-diffusion portion of the Hamiltonian. This would produce the acceleration matrix A2 in (30).
5. Conclusions and Further Work
We presented a computationally efficient and accurate algorithm for identification of sources and release histories of (geo)chemically active solutes. The algorithm is based on a generalized hybrid Monte Carlo approach, in which MC sampling is accelerated by the use of discrete adjoint equations. Some of the salient features of our approach are: (1) its ability to handle nonlinear systems, since it requires no linearizations, and (2) its compatibility with various regularization strategies.
The introduction of an acceleration matrix to the gHMC scheme was tested for an advection-dispersion problem. While the example presented was limited to one-dimensional domains, periodic boundary conditions, and homogeneous porous media, our analysis demonstrated that the proposed acceleration matrices improve upon basic HMC; therefore, we consider the proposed acceleration strategy to be promising. The generalization of these constructions to problems with nonlinear reaction terms, two- and three-dimensional, heterogeneous media, and non-periodic boundary conditions, will be the subject of future work.
Finally, we note the importance of considering the heterogeneity of flow and transport parameters, such as the hydraulic conductivity and dispersion coefficient tensors, for source identification tasks (Xu and Gömez-Hernández, 2018). Attempting to perform Bayesian inference when the values of these coefficients are assumed to be known but their values are erroneous may lead to model misspecification and consequently to posterior densities with little predictive value. Fortunately, the HMC and gHMC schemes presented in this work can accommodate the simultaneous identification of heterogeneous coefficients together with the release history by extending the state vector q to include the discretized heterogeneous coefficients. The calculation of the gradient of the data misfit with respect to the extended state vector can be accomplished via discrete adjoint sensitivity analysis (Zhang et al., 2017) for complex dynamical systems. The extension of the presented framework to the identification of heterogeneous parameters of geophysical models will be considered in future work.
Author Contributions
DB-S implemented the presented algorithms in MATLAB. All authors contributed equally to the preparation of this manuscript.
Funding
This work was supported in part by the Applied Mathematics Program within the U.S. Department of Energy Office of Advanced Scientific Computing Research Mathematical Multifaceted Integrated Capability Centers (MMICCS) project—AEOLUS—Advances in Experimental Design, Optimal Control, and Learning for Uncertain Complex Systems under award number DE-SC0019393, by the U.S. National Science Foundation under award number DMS-1802189, and by the U.S. Department of Energy Office of Basic Energy Research under award number DE-SC0019130. Pacific Northwest National Laboratory is operated by Battelle for the DOE under Contract DE-AC05-76RL01830.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
The handling editor is currently co-organizing a Research Topic with one of the authors DT, and confirms the absence of any other collaboration.
Acknowledgments
We thank N. Gulbahce and T. Bewley for fruitful discussions.
References
Alexander, F. J., Eyink, G. L., and Restrepo, J. M. (2005). Accelerated Monte Carlo for optimal estimation of time series. J. Stat. Phys. 119, 1331–1345. doi: 10.1007/s10955-005-3770-1
Archambeau, C., Opper, M., Shen, Y., Cornford, D., and Shawe-Taylor, J. (2007). “Variational inference for diffusion processes,” in Advances in Neural Information Processing Systems, Vol. 20, eds J. C. Platt, D. Koller, Y. Singer, and S. Roweis (Boston, MA: MIT Press), 1–8.
Atmadja, J., and Bagtzoglou, A. C. (2001a). Pollution source identification in heterogeneous porous media. Water Resour. Res. 37, 2113–2125. doi: 10.1029/2001WR000223
Atmadja, J., and Bagtzoglou, A. C. (2001b). State of the art report on mathematical methods for groundwater pollution source identification. Environ. Forensics 2, 205–214. doi: 10.1080/15275920127949
Bagtzoglou, A. C., and Atmadja, J. (2003). Marching-jury backward beam equation and quasi-reversibility methods for hydrologic inversion: application to contaminant plume spatial distribution recovery. Water Resour. Res. 39. doi: 10.1029/2001WR001021
Bagtzoglou, A. C., Dougherty, D. E., and Tompson, A. F. B. (1992). Application of particle methods to reliable identification of groundwater pollution sources. Water Resour. Manage. 6, 15–23. doi: 10.1007/BF00872184
Butcher, J. B., and Gauthier, T. D. (1994). Estimation of residual dense NAPL mass by inverse modeling. Ground Water 32, 71–78. doi: 10.1111/j.1745-6584.1994.tb00613.x
Cao, Y., Li, S., Petzold, L., and Serban, R. (2003). Adjoint sensitivity analysis for differential-algebraic equations: the adjoint DAE system and its numerical solution. SIAM J. Sci. Comput. 24, 1076–1089. doi: 10.1137/S1064827501380630
Daescu, D., Carmichael, G. R., and Sandu, A. (2000). Adjoint implementation of rosenbrock methods applied to variational data assimilation problems. J. Comput. Phys. 165, 496–510. doi: 10.1006/jcph.2000.6622
Gugat, M. (2012). Contamination source determination in water distribution networks. SIAM J. Appl. Math. 72, 1772–1791. doi: 10.1137/110859269
Herrera, G. S., and Pinder, G. F. (2005). Space-time optimization of groundwater quality sampling networks. Water Resour. Res. 41. doi: 10.1029/2004WR003626
Hutchinson, M., Eyink, G. L., and Restrepo, J. M. (2017). A review of source term estimation methods for atmospheric dispersion events using static or mobile sensors. Inf. Fusion 36, 130–148. doi: 10.1016/j.inffus.2016.11.010
Ito, K., and Jin, B. (2015). Inverse Problems: Tikhonov Theory and Algorithms, Vol. 22. Series in Applied Mathematics. Singapore: World Scientific.
Kass, R. E., Carlin, B. P., Gelman, A., and Neal, R. M. (1998). Markov chain Monte Carlo in practice: a roundtable discussion. Am. Stat. 52, 93–100. doi: 10.1080/00031305.1998.10480547
Landau, D. P., and Binder, K. (2009). A Guide to Monte Carlo Simulations in Statistical Physics. Cambridge, UK: Cambridge University Press.
Li, S., and Petzold, L. (2004). Adjoint sensitivity analysis for time-dependent partial differential equations with adaptive mesh refinement. J. Comput. Phys. 198, 310–325. doi: 10.1016/j.jcp.2003.01.001
Lichtner, P. C., and Tartakovsky, D. M. (2003). Upscaled effective rate constant for heterogeneous reactions. Stochas. Environ. Res. Risk Assess. 17, 419–429. doi: 10.1007/s00477-003-0163-3
Liu, C., and Ball, W. P. (1999). Application of inverse methods to contaminant source identification from aquitard diffusion profiles at Dover AFB, Delaware. Water Resour. Res. 35, 1975–1985. doi: 10.1029/1999WR900092
Michalak, A. M., and Kitanidis, P. K. (2003). A method for enforcing parameter nonnegativity in Bayesian inverse problems with an application to contaminant source identification. Water Resour. Res. 39. doi: 10.1029/2002WR001480
Michalak, A. M., and Kitanidis, P. K. (2004a). Application of geostatistical inverse modeling to contaminant source identification at Dover AFB, Delaware. J. Hydraul. Res. 42, 9–18. doi: 10.1080/00221680409500042
Michalak, A. M., and Kitanidis, P. K. (2004b). Estimation of historical groundwater contaminant distribution using the adjoint state method applied to geostatistical inverse modeling. Water Resour. Res. 40. doi: 10.1029/2004WR003214
Neal, R. M. (1993). Probabilistic Inference Using Markov Chain Monte Carlo Methods. Technical Report CRG-TR-93-1, University of Toronto.
Neal, R. M. (1995). Bayesian learning for neural networks (Ph.D. thesis). University of Toronto, Toronto, ON, Canada.
Neupauer, R. M., Borchers, B., and Wilson, J. L. (2000). Comparison of inverse methods for reconstructing the release history of a groundwater contamination source. Water Resour. Res. 36, 2469–2475. doi: 10.1029/2000WR900176
Neupauer, R. M., and Wilson, J. L. (1999). Adjoint method for obtaining backward-in-time location and travel time probabilities of a conservative groundwater contaminant. Water Resour. Res. 35, 3389–3398. doi: 10.1029/1999WR900190
Neupauer, R. M., and Wilson, J. L. (2003). Backward location and travel time probabilities for a decaying contaminant in an aquifer. J. Contam. Hydrol. 66, 39–58. doi: 10.1016/S0169-7722(03)00024-X
Neupauer, R. M., and Wilson, J. L. (2004). Forward and backward location probabilities for sorbing solutes in groundwater. Adv. Water Resour. 27, 689–705. doi: 10.1016/j.advwatres.2004.05.003
Neupauer, R. M., and Wilson, J. L. (2005). Backward probability model using multiple observations of contamination to identify groundwater contamination sources at the Massachusetts Military Reservation. Water Resour. Res. 41. doi: 10.1029/2003WR002974
Pirot, G., Krityakierne, T., Ginsbourger, D., and Renard, P. (2019). Contaminant source localization via Bayesian global optimization. Hydrol. Earth Sys. Sci. 23, 351–369. doi: 10.5194/hess-23-351-2019
Shlomi, S., and Michalak, A. M. (2007). A geostatistical framework for incorporating transport information in estimating the distribution of a groundwater contaminant plume. Water Resour. Res. 43. doi: 10.1029/2006WR005121
Skaggs, T. H., and Kabala, Z. J. (1994). Recovering the release history of a groundwater contaminant. Water Resour. Res. 30, 71–79. doi: 10.1029/93WR02656
Skaggs, T. H., and Kabala, Z. J. (1995). Recovering the history of a groundwater contaminant plume: method of quasi-reversibility. Water Resour. Res. 31, 2669–2673. doi: 10.1029/95WR02383
Snodgrass, M. F., and Kitanidis, P. K. (1997). A geostatistical approach to contaminant source identification. Water Resour. Res. 33, 537–546. doi: 10.1029/96WR03753
Stanev, V. G., Iliev, F. L., Hansen, S., Vesselinov, V. V., and Alexandrov, B. S. (2018). Identification of release sources in advection-diffusion system by machine learning combined with Green's function inverse method. Appl. Math. Model. 60, 64–76. doi: 10.1016/j.apm.2018.03.006
Toral, R., and Ferreira, A. (1994). “A general class of hybrid Monte Carlo methods,” in Proceedings of Physics Computing, Vol. 94, eds R. Gruber and M. Tomasi (New York, NY: EPS), 265–268.
Verwer, J. G., Spee, E. J., Blom, J. G., and Hundsdorfer, W. (1999). A second-order rosenbrock method applied to photochemical dispersion problems. SIAM J. Sci. Comput. 20, 1456–1480. doi: 10.1137/S1064827597326651
Vesselinov, V. V., Alexandrov, B. S., and O'Malley, D. (2018). Contaminant source identification using semi-supervised machine learning. J. Contam. Hydrol. 212, 134–142. doi: 10.1016/j.jconhyd.2017.11.002
Vesselinov, V. V., Alexandrov, B. S., and O'Malley, D. (2019). Nonnegative tensor factorization for contaminant source identification. J. Contam. Hydrol. 220, 66–97. doi: 10.1016/j.jconhyd.2018.11.010
Wahba, G. (1990). Spline Models for Observational Data, Vol. 59. Philadelphia, PA: Society for Industrial Mathematics (SIAM).
Woodbury, A. D., and Ulrych, T. J. (1996). Minimum relative entropy inversion: theory and application to recovering the release history of a groundwater contaminant. Water Resour. Res. 32, 2671–2681. doi: 10.1029/95WR03818
Xu, T., and Gömez-Hernández, J. J. (2016). Joint identification of contaminant source location, initial release time, and initial solute concentration in an aquifer via ensemble kalman filtering. Water Resour. Res. 52, 6587–6595. doi: 10.1002/2016WR019111
Xu, T., and Gömez-Hernández, J. J. (2018). Simultaneous identification of a contaminant source and hydraulic conductivity via the restart normal-score ensemble kalman filter. Adv. Water Resour. 112, 106–123. doi: 10.1016/j.advwatres.2017.12.011
Zhang, H., Abhyankar, S., Constantinescu, E., and Anitescu, M. (2017). Discrete adjoint sensitivity analysis of hybrid dynamical systems with switching. IEEE Trans. Circ. Syst. I 64, 1247–1259. doi: 10.1109/TCSI.2017.2651683
Appendix
Discrete Sensitivity Analysis
For the problem in section 4.1 we use the linearized Runge-Kutta (Rosenbrock) method ROS2 of Verwer et al. (1999) for time stepping of the forward ODE problem. The advantage of using this method is that it allows for a linear implicit treatment of the dispersion operator and a linearization of the reaction operator, while the advection operator is treated explicitly.
We assume that the advection-dispersion-reaction equation can be discretized into an autonomous system of ODEs
where c is the state vector, AD is the discretized linear dispersion operator, AA is the discretized linear advection operator, and R(c) is the reaction vector. Time stepping is performed via a scheme
where is the Jacobian of f with respect to the state. The coefficients θ and b are taken for this application as and b = 1/2, respectively. The left-hand side operators of (A2, A3) are approximated via approximate matrix factorization (AMF) to obtain the split form
The discussion in section 4.1 led us to conclude that it is necessary to compute products of the form (dci+1/dci)⊤u in order to apply the discrete sensitivity technique of Daescu et al. (2000). The formulae for the computation of these products are derived from the time-stepping scheme (A1-A3). In particular, differentiating (A1) with respect to the state and multiplying by a test vector u gives the single-step sensitivity product as
The next task is to derive formulas for the Jacobians of the stage derivatives k1 and k2. Let M be the AMF-ed left-hand-side matrix of (A2, A3). Differentiating (A2, A3) with respect to the state and multiplying by the test vector u gives the formulae
and
with , .
The computation of the products , i = 1, 2 is highly problem-specific. It depends on the structure of the second-order derivatives of the reaction vector with respect to the state. For the reaction model (15) and a method-of-lines discretization, the Jacobian Rc is diagonal, and so the computation of these products is straightforward. For different reaction models and more sophisticated discretization schemes the computation might be more involved.
Keywords: source identification, contaminant transport, Markov Chain Monte Carlo, hybrid Monte Carlo, inverse problems, uncertainty quantification
Citation: Barajas-Solano DA, Alexander FJ, Anghel M and Tartakovsky DM (2019) Efficient gHMC Reconstruction of Contaminant Release History. Front. Environ. Sci. 7:149. doi: 10.3389/fenvs.2019.00149
Received: 12 November 2018; Accepted: 17 September 2019;
Published: 11 October 2019.
Edited by:
Philippe Renard, Université de Neuchātel, SwitzerlandReviewed by:
Guillaume Pirot, Universität Lausanne, SwitzerlandRoseanna M. Neupauer, University of Colorado System, United States
Copyright © 2019 Barajas-Solano, Alexander, Anghel and Tartakovsky. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Daniel M. Tartakovsky, dGFydGFrb3Zza3lAc3RhbmZvcmQuZWR1