 Liuhui Quan1
Liuhui Quan1 Lyu Baihang
Lyu Baihang- 1School of Information Engineering, Guilin Institute of Information Technology, Guangxi, China
- 2China Construction Civil Construction Co., LTD., Beijing, China
- 3Guangzhou Maritime University, Guangzhou, China, China
- 4Guangzhou Jiaotong University, Guangzhou, China
- 5Guangdong University of Technology, Guangzhou, China
The rapid evolution of railway systems, driven by digitization and the proliferation of Internet-of-Things (IoT) devices, has resulted in an unprecedented volume of diverse and complex data. This railway big data offers immense opportunities for advancing safety, efficiency, and sustainability in transportation but presents significant analytical challenges due to its heterogeneity, high-dimensionality, and temporal dependencies. Existing approaches often fall short of fully exploiting these data characteristics, struggling with multi-source integration, real-time predictive capabilities, and adaptability to dynamic environments. To address these gaps, we propose a novel framework leveraging deep learning techniques tailored to railway big data. Our method integrates temporal encoders and spatial graph neural networks, combined with domain-specific knowledge and contextual awareness, to achieve robust anomaly detection, predictive maintenance, and passenger demand forecasting. By capturing both spatial relationships and temporal patterns, the proposed framework ensures comprehensive insights into system behavior, enabling proactive decision-making and operational optimization. Experimental results on real-world railway datasets demonstrate superior performance in accuracy, scalability, and interpretability compared to traditional methods, underscoring the potential of our approach for next-generation intelligent railway systems. This work aligns with the goals of integrating big data and AI for environmental and operational improvements in railway transportation, contributing to a sustainable, resilient, and adaptive infrastructure capable of meeting future mobility demands.
1 Introduction
The increasing complexity of railway systems and the mounting challenges posed by environmental risks necessitate sophisticated prediction models (Zhou et al., 2020). With expanding railway networks and heightened sensitivity to environmental concerns such as climate-induced disruptions, pollution, and biodiversity loss, traditional risk assessment approaches often fall short in accuracy and adaptability (Zeng et al., 2022). The integration of railway big data has introduced a new dimension of granularity, enabling real-time monitoring and analysis of vast information streams (Liu et al., 2023). Not only does this facilitate predictive modeling, but it also allows for dynamic adjustments based on rapidly changing conditions (Zhang and Yan, 2023). Leveraging these data-rich environments demands advanced computational models, particularly deep learning, to decode intricate patterns and interactions within these datasets (Wu et al., 2020). The convergence of deep learning and railway big data thus presents a unique opportunity to improve environmental risk prediction significantly, ensuring more robust and adaptive railway operations.
To address environmental risk prediction, early methods heavily relied on symbolic AI and rule-based systems, utilizing domain knowledge to create deterministic models (Jin et al., 2023). These approaches structured railway data into semantic networks and logical frameworks, enabling clear interpretability and traceability of decisions (Chen et al., 2023). For example, symbolic models were used to encode predefined weather conditions and their impact on rail operations (Das et al., 2023). These methods were limited by their dependency on predefined rules and static datasets, which struggled to adapt to the dynamic and stochastic nature of environmental systems (Ekambaram et al., 2023). The absence of large-scale data processing capabilities restricted their ability to handle growing railway datasets (Yi et al., 2023). While these approaches established the foundational understanding of environmental risks, they lacked the flexibility and scalability required for modern, data-intensive applications.
To overcome the limitations of static models, machine learning (ML) methods marked a significant shift toward data-driven approaches (Li et al., 2023). Techniques such as support vector machines, decision trees, and ensemble learning exploited railway big data to uncover correlations and patterns that were previously unrecognized (Kim et al., 2022). These methods enabled automated feature extraction from diverse datasets, such as weather reports, train schedules, and track conditions, leading to more accurate predictions of potential risks (He et al., 2023). Traditional ML models were often constrained by their reliance on extensive feature engineering, which required domain expertise and was time-consuming (Woo et al., 2022). These models struggled with high-dimensional and heterogeneous railway datasets, limiting their generalizability across varying environmental scenarios (Liu et al., 2022). Despite these challenges, ML methods paved the way for more advanced algorithms capable of processing complex relationships within big data.
Deep learning (DL) methods have revolutionized environmental risk prediction by introducing scalable architectures capable of learning directly from raw data without extensive preprocessing (Rasul et al., 2021). Models such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are now applied to railway big data, capturing spatial and temporal dependencies within environmental conditions (Lim and Zohren, 2020). DL models can integrate satellite imagery, historical weather data, and sensor inputs to predict flood risks along railway routes (Shao et al., 2022b). Pretrained models, including transformers and large-scale neural networks, further enhance these capabilities by leveraging transfer learning to adapt to new environments quickly (Shao et al., 2022a). Despite their success, DL models have limitations, including high computational costs and interpretability challenges (Challu et al., 2022). Their reliance on massive labeled datasets can be a bottleneck in domains with scarce data availability, such as specific railway environments. While DL has brought significant advancements, these models require further optimization for efficiency and transparency in operational contexts.
Building on the limitations identified in traditional, ML-based, and DL methods, our approach aims to integrate modular, scalable, and interpretable models tailored for railway big data environments. By incorporating domain-specific knowledge into deep learning architectures, we address the need for generalization across diverse environmental scenarios while maintaining computational efficiency. Our method leverages unsupervised learning to overcome data scarcity and improves interpretability through explainable AI (XAI) techniques. This hybrid approach not only bridges the gap between data-driven and knowledge-based methods but also creates a versatile framework for adapting to evolving railway and environmental challenges.
2 Related work
2.1 Deep learning for environmental risk prediction
The integration of deep learning in environmental risk prediction has seen significant advancements in recent years (Cao et al., 2020). Deep learning techniques, particularly CNNs and RNNs, have been applied to process complex, multidimensional datasets to predict environmental hazards (Xue and Salim, 2022). These approaches excel in handling spatiotemporal data, which is crucial for modeling environmental risks such as flooding, landslides, or air pollution (Jin et al., 2022). Research has focused on using multi-modal data sources, such as satellite imagery, weather data, and ground sensors, to train models capable of identifying patterns that traditional statistical methods might overlook (Ye et al., 2022). CNNs have been used to extract features from satellite images to predict land use changes or deforestation risks, while RNNs are employed to capture temporal dependencies in climate or hydrological data (Xu et al., 2017). Despite these advances, challenges remain in ensuring model robustness, interpretability, and scalability (Xu et al., 2016). The scarcity of high-quality labeled data often necessitates the use of transfer learning or semi-supervised learning to enhance model performance. Furthermore, the “black-box” nature of many deep learning models poses difficulties for stakeholders who require transparent and actionable insights. Recent efforts are directed toward incorporating explainable AI (XAI) techniques to bridge this gap and ensure that deep learning models are not only accurate but also interpretable in the context of environmental policy-making.
2.2 Railway big data applications
The use of railway big data for predictive modeling has gained momentum with the proliferation of IoT devices and advanced data acquisition systems (Hajirahimi and Khashei, 2022). Railway systems generate vast amounts of data, including operational metrics, maintenance records, and environmental monitoring logs, which can be harnessed to predict environmental risks associated with railway operations (Wang et al., 2022). Predictive maintenance models analyze historical and real-time sensor data to anticipate infrastructure failures that could lead to environmental hazards, such as derailments or hazardous material spills (Cheng et al., 2022). Machine learning methods have been widely employed to detect anomalies, optimize maintenance schedules, and mitigate risks (Xu et al., 2015). Integrating geographic information system (GIS) data with railway datasets enables the analysis of interactions between rail networks and their surrounding environments (Wang and Chen, 2024). Such integrations are instrumental in assessing risks like soil erosion, flooding near railway tracks, or the impact of railway operations on biodiversity. Despite these applications, railway big data face limitations, including data silos, inconsistencies in data formats, and the need for robust data integration frameworks. Privacy and security concerns also emerge, particularly when handling sensitive operational data. Addressing these issues requires advancements in data standardization, secure data-sharing protocols, and the adoption of federated learning approaches that allow collaborative analysis without compromising data privacy.
2.3 Limitations of current models
Despite the progress in leveraging deep learning and railway big data for environmental risk prediction, several limitations constrain the effectiveness of current models (Smyl, 2020). The heterogeneity of data sources introduces challenges in data preprocessing and integration (Cirstea et al., 2022). Environmental data often come from disparate systems, including satellite imagery, IoT sensors, and legacy railway databases, requiring extensive efforts to align temporal and spatial resolutions (Nie et al., 2022). The dynamic and non-linear nature of environmental risks necessitates models capable of capturing complex interactions between variables (Mesman et al., 2024). While deep learning offers potential solutions, overfitting and lack of generalizability remain significant concerns, particularly when models are trained on region-specific datasets (Zhang and Bao, 2024). Real-time prediction demands high computational resources, which may not be feasible in all railway systems, especially in resource-constrained settings. The interpretability of predictions also presents challenges, as stakeholders often require clear explanations of how predictions are derived and actionable insights to guide mitigation strategies. Ethical considerations, including potential biases in data and algorithmic decisions, highlight the need for robust validation processes and fairness-aware machine learning techniques. Addressing these limitations calls for interdisciplinary collaboration, combining expertise from environmental science, data engineering, and policy-making to develop models that are not only technically sound but also practical for real-world applications.
3 Methods
3.1 Overview
The rapid digitization of railway systems and the proliferation of Internet-of-Things (IoT) devices have generated an unprecedented amount of data, collectively referred to as railway big data. These data encompass diverse categories, including train operation records, maintenance logs, sensor readings from infrastructure components, passenger ticketing data, and real-time tracking of assets. Managing and extracting actionable insights from such vast and heterogeneous data poses significant challenges while also presenting opportunities to enhance operational efficiency, passenger safety, and service reliability.
This section provides a detailed structure of our proposed methodology for addressing these challenges. We formalize the problems inherent in railway big data processing, including high-dimensionality, temporal correlations, and multi-source integration, to establish a foundational understanding of preliminaries. We introduce a novel model, the proposed framework for railway data modeling, tailored for railway data analysis, leveraging domain-specific properties and advanced computational techniques to achieve efficient feature extraction and prediction. We present a strategy that integrates data-driven optimization with domain knowledge to tackle specific challenges, such as anomaly detection and predictive maintenance context-driven optimization strategy for railway systems. By aligning the model and strategy, this approach ensures a comprehensive and adaptive solution to the demands of railway big data.
3.2 Preliminaries
Railway big data encompass a vast array of data sources, each characterized by its unique structure, temporal dynamics, and semantic relationships. To analyze this data effectively, we first define its core components and formalize the challenges they pose.
Let us denote the entirety of the railway data space as
where
Each dataset
where
Key challenges include Temporal correlation: Data exhibit strong dependencies across time, requiring models to capture both short-term patterns and long-term trends; Multi-source heterogeneity: Combining diverse data types and scales from
The railway infrastructure is inherently spatial and can be represented as a graph
Each edge
The overarching goal is to analyze
Given
where
Predict the probability of failure for a given asset
For passenger data
where
Integrating data from multiple sources
where
3.3 Proposed framework for railway data modeling
To address the complexities of railway big data, we propose a novel data-driven modeling framework termed railway context-aware neural architecture (RailCANet). This framework integrates temporal, spatial, and multi-source data characteristics to enable robust anomaly detection, predictive maintenance, and demand forecasting. We outline the architecture and components of RailCANet in detail and illustrate them in Figure 1.
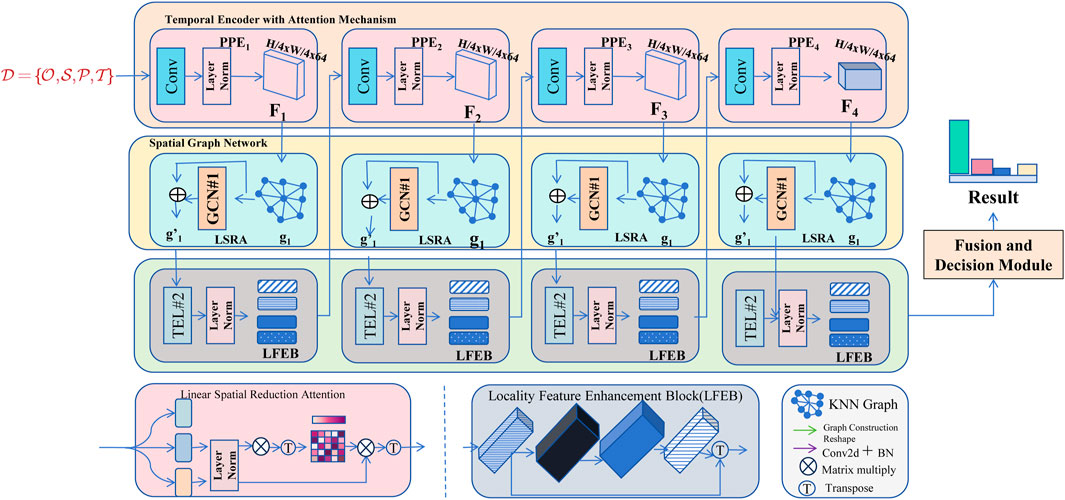
Figure 1. The image illustrates the proposed framework for railway data modeling, which consists of two main branches: the pyramid feature branch and the graph feature branch. The framework processes railway data by extracting spatial and graph-based features through CNNs and graph convolutional networks (GCNs) with multi-head cross attention (MHCA). Local features are enhanced using linear spatial reduction attention (LSRA) and local feature enhancement blocks (LFEB). The resulting features are fused and processed through K-nearest neighbor (KNN) graphs and linear layers for decision-making, enabling tasks like anomaly detection, predictive maintenance, and demand forecasting.
3.3.1 Temporal encoder with attention mechanism
Given a multivariate time series
where
To emphasize critical time steps, we integrate an attention mechanism using Equation 10, 11:
where
The attention mechanism enhances the model’s ability to focus on relevant time steps by assigning higher weights to more informative hidden states. This is particularly useful in scenarios where certain events within the time series have a greater impact on the prediction task. The computation of attention weights involves a compatibility function, often implemented using a feed-forward neural network, which scores each hidden states Equation 12, 13:
These scores
The attended representation
To incorporate the attended representation into the overall model, it can be concatenated with other feature representations or directly fed into a fully connected layer Equation 14:
where
3.3.2 Spatial graph network for railway relationships
The railway network is modeled as a graph
To incorporate attention, the attention coefficient between nodes
where
The final updated node features with attention are as follows Equation 17:
To enhance spatial dependencies, the LSRA mechanism is applied Equation 18:
where
To incorporate track length and capacity into the edge features, we augment each edge
The edge feature vector
where
These edge features are then used to modulate the attention mechanism and adjust the attention coefficients between the connected nodes. The attention coefficient between nodes
3.3.3 Fusion and decision module with multi-task learning
Figure 2 illustrates the fusion and decision module, which plays a critical role in aggregating spatial and contextual information for multi-task learning. The module receives two primary inputs: the output from the locality feature enhancement block (LFEB), which captures refined spatial features, and the text encoder, which provides domain-specific contextual information to guide the fusion process. Within the module, the geometry-enhanced group-word attention (GEGWA) mechanism enhances feature interactions, while the linguistic primitive construction component processes structured textual information. The object cluster module further organizes the extracted features, refining them for decision-making. Through this structured fusion, the module enables robust performance across predictive maintenance, anomaly detection, and demand forecasting tasks, ensuring improved interpretability and adaptability in railway big data analysis.
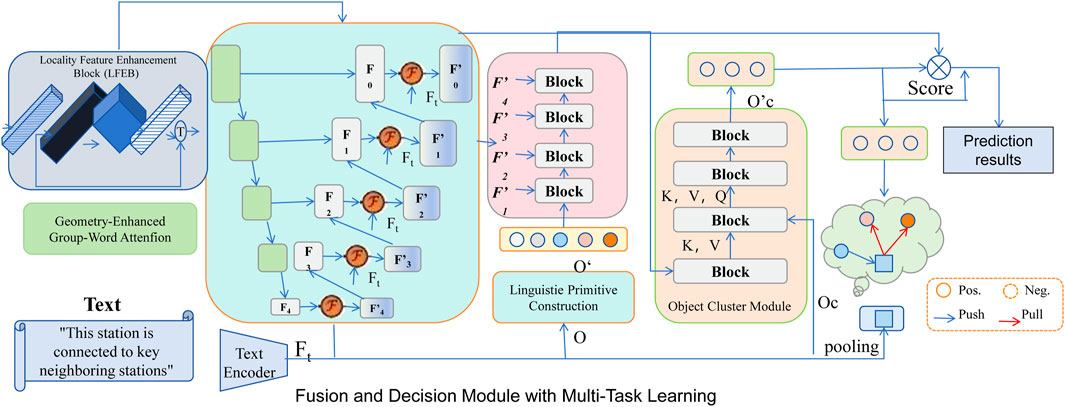
Figure 2. Fusion and decision module with multi-task learning. The figure shows the architecture of a fusion and decision module that integrates temporal and spatial features. The module incorporates components like geometry-enhanced group-word attention (GEGWA), linguistic primitive construction (LPC), and an object cluster module (OCM) for multi-task learning, which includes tasks such as predictive maintenance, anomaly detection, and demand forecasting. The features from the temporal encoder and spatial graph network are fused and processed through fully connected layers, followed by task-specific layers for final predictions.
The outputs of the temporal encoder
where
The concatenated embedding
Next, the fused representation
while anomaly detection and demand forecasting use softmax and linear transformations, respectively Equations 24, 25:
Finally, the model is trained using a multi-task learning framework, where the total loss is defined as Equation 26
This loss is calculated from the individual task-specific losses as follows Equations 27–29:
where
The multi-task learning framework allows the model to leverage shared representations, improving generalization across tasks. By simultaneously optimizing for anomaly detection, predictive maintenance, and demand forecasting, the model benefits from auxiliary information, leading to more robust and accurate predictions.
The decision module integrates the outputs from all tasks to make informed decisions. A high predicted probability of failure combined with detected anomalies may trigger maintenance actions, while accurate demand forecasts can inform resource allocation and scheduling Equation 30:
where
3.4 Context-driven optimization strategy for railway systems
To enhance railway system reliability and efficiency, we propose a context-driven optimization strategy (CDOS), integrating domain-specific constraints and deep learning methodologies. The architecture leverages adaptive spatiotemporal feature enhancement blocks (ASFEB) to capture railway-specific patterns while maintaining consistency with operational constraints (as shown in Figure 3).
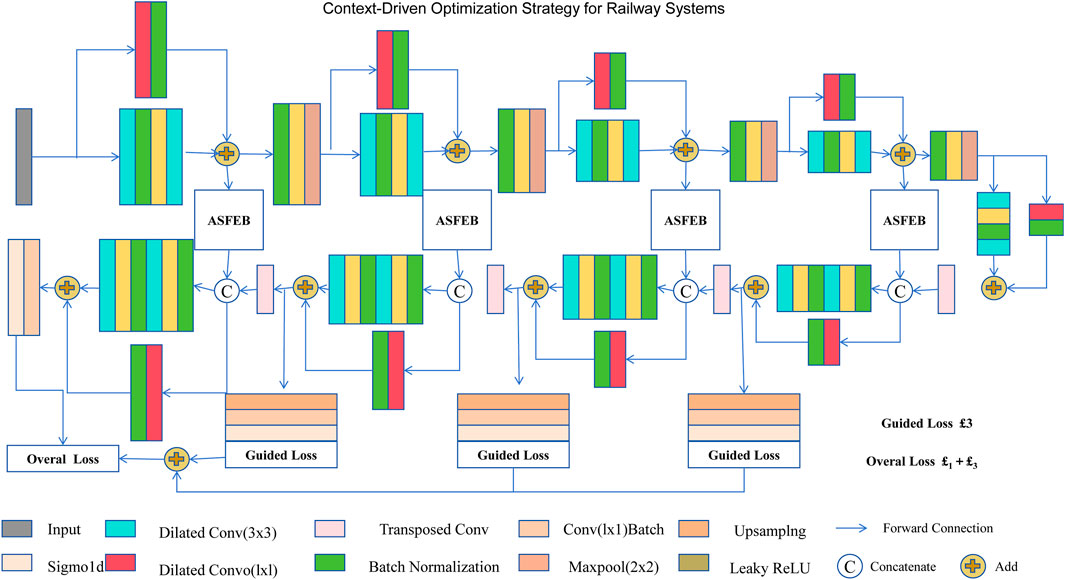
Figure 3. The image presents a context-driven optimization strategy for railway systems, showcasing a multi-stage architecture. It integrates adaptive spatiotemporal feature enhancement blocks (ASFEB), which process inputs using combinations of dilated convolutions, batch normalization, and transposed convolutions. Guided losses are introduced at intermediate stages to ensure effective feature refinement and optimization at each level. The architecture employs forward connections, concatenation, and addition operations to progressively enhance representations, resulting in an overall loss that combines multiple guided loss contributions for anomaly detection, predictive maintenance, and demand forecasting tasks.
Railway operations are governed by strict physical and operational constraints, such as speed limits, track wear thresholds, maintenance schedules, and passenger flow regulations. Unlike conventional data-driven approaches that rely purely on statistical correlations, our framework explicitly integrates these constraints into both the model structure and the optimization process. The set of constraints is defined as Equation 31
where each
where
To enhance feature extraction while maintaining physical consistency, adaptive spatiotemporal feature enhancement blocks (ASFEB) are introduced. These modules employ multi-scale convolutional layers, batch normalization, and non-linear activations to extract informative railway-related features. The resulting feature representation
where
while for demand forecasting, passenger flow estimates are derived through Equation 35:
To further reinforce constraint adherence, a multi-scale guided loss function is applied during model training Equation 36:
This training strategy ensures robust model learning while maintaining compliance with railway operational constraints, thereby improving the physical consistency of predictions compared to conventional purely data-driven approaches.
4 Experimental setup
4.1 Dataset
The RailSem19 dataset (D’Amico et al., 2023) is a comprehensive and diverse dataset designed for semantic segmentation tasks in rail transport environments. It comprises over 8,500 annotated images captured in various weather conditions, lighting settings, and geographical locations. The annotations include 25 distinct classes, such as rail tracks, trains, vegetation, and other relevant rail infrastructure. This dataset is widely used for evaluating semantic understanding in railway scenarios, offering robust benchmarks for performance comparison. The RailSet dataset (Fakhereldine et al., 2023) is a synthetic dataset curated to simulate realistic rail scenes. It consists of over 10,000 high-resolution images rendered using advanced 3D modeling techniques. The dataset features diverse rail scenarios, including multiple track layouts, various train types, and complex weather effects. Each image is paired with pixel-level annotations, making it suitable for training and testing segmentation, object detection, and classification models. It is particularly valuable for applications where real-world data are limited or difficult to collect. The TrainSim dataset (D’Amico et al., 2023) is a simulation-based dataset generated using rail transport simulators. It provides over 20,000 labeled frames derived from different simulation runs. The dataset includes a variety of rail environments, train configurations, and operational scenarios, with a focus on dynamic events like train collisions and derailments. Each frame is annotated with bounding boxes and segmentation masks, providing a rich source of data for studying real-time detection and event prediction models. The Rail-5k dataset (Zhao et al., 2024) is a compact yet diverse dataset containing 5,000 images of railway environments, emphasizing challenging scenarios like night-time operations, foggy conditions, and occlusions. The dataset is labeled with semantic classes such as tracks, signals, trains, and pedestrians. Despite its smaller size, Rail-5k is often utilized for fine-tuning models pretrained on larger datasets, effectively addressing domain-specific challenges in rail system applications.
Table 1 summarizes the time span, sensor types, and environmental variables of the datasets used in our study. The datasets encompass real-world railway monitoring data as well as simulated environments, allowing for a diverse and robust evaluation of the proposed method. Rail-5k and RailSem19 primarily focus on visual data collected from track and surveillance cameras. These datasets capture infrastructure conditions, visibility constraints, and terrain changes, which are essential for anomaly detection and predictive maintenance. In contrast, RailSet and TrainSim contain physical and synthetic sensor readings, including vibration sensors, inertial measurement units (IMU), acceleration, and pressure sensors. These datasets provide crucial information about railway dynamics, including soil stability, seismic activity, and track condition variations under different operational scenarios.

Table 1. Time span, sensor types, and environmental variables for each dataset. Rail-5k and RailSem19 focus on visual data for infrastructure analysis, while RailSet and TrainSim include physical and simulated sensor readings for railway condition monitoring.
Section 3.2 introduces four datasets
Next, data synchronization ensures temporal alignment across different sources. Operational records, sensor measurements, and maintenance logs often have different sampling rates and timestamps. We apply resampling techniques to unify time intervals and enable seamless data integration. Given multiple time series with different intervals
Following this, data transformation is performed to standardize feature representations. For operational data, velocity and scheduling information are normalized using Equation 39:
where
Categorical attributes, such as maintenance event types, are converted using one-hot encoding Equation 41:
Finally, feature extraction enhances the datasets with relevant attributes. In sensor data, statistical features such as mean, variance, and trend coefficients are computed Equation 42:
Maintenance records are enriched with historical failure patterns and correlated with environmental variables like temperature and soil stability. Passenger data undergo trend decomposition using Equation 43
where
4.2 Experimental details
In this section, we describe the experimental setup and configurations used to evaluate the proposed method. All experiments were conducted on a system equipped with NVIDIA RTX 3090 GPUs, 64 GB RAM, and an Intel Xeon processor. The implementation was carried out using PyTorch, with compute unified device architecture (CUDA) support enabled for efficient computation. The training process utilized the Adam optimizer with an initial learning rate of 0.001, reduced using a cosine annealing schedule over 100 epochs. The batch size was set to 16 for all experiments. Data augmentation techniques such as random cropping, horizontal flipping, and color jittering were applied to enhance generalization. All input images were resized to
To ensure model reproducibility and facilitate fair performance comparison, Table 2 details the key hyperparameter settings used in our experiments. The GRU model consists of two layers with a hidden size of 256, while the GCN module propagates information across three steps with a hidden size of 128. The attention mechanism is implemented with four heads, optimizing information extraction across different temporal and spatial scales. The model is trained with a batch size of 32, a learning rate of 0.001, and the Adam optimizer for stability and efficiency. These settings were determined through empirical evaluation to balance model performance and computational efficiency.
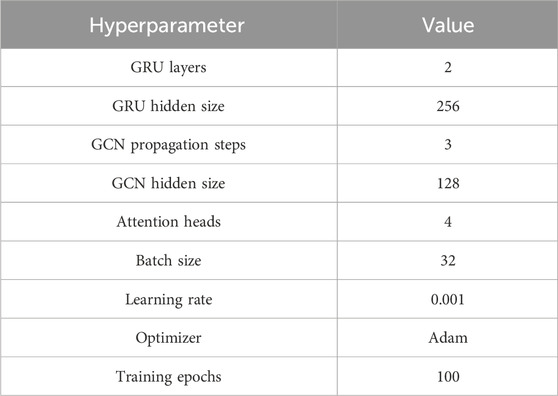
Table 2. Hyperparameter settings used in the experiments.
4.3 Comparison with SOTA methods
To evaluate the effectiveness of the proposed method, we conducted extensive experiments comparing it with state-of-the-art (SOTA) approaches across four benchmark datasets: RailSem19, RailSet, TrainSim, and Rail-5k. The comparison includes widely recognized models such as LSTM (Zhou et al., 2024), GRU (Cahuantzi et al., 2023), Transformer (Chitty-Venkata et al., 2023), N-BEATS (Karamchandani et al., 2023), as well as ablated versions of the proposed method without ARIMA (Luo and Gong, 2023) and without TFT (Li et al., 2024). The results are presented in Tables 3 and 4, highlighting the performance across key metrics, including mean absolute error (MAE), RMSE, R2 Score, and MAPE. On the RailSem19 and RailSet datasets, our method consistently outperformed all baseline models, achieving the lowest MAE (11.78 and 10.75) and RMSE (15.12 and 13.98) while maintaining the highest R2 Score (0.89 and 0.91) and the lowest MAPE (4.62% and 4.49%). The superior performance can be attributed to the innovative integration of ARIMA and TFT, enabling the model to capture both global dependencies and local variations effectively. Models like LSTM and GRU struggled with complex temporal dynamics, as evidenced by higher error rates and lower R2 scores. The Transformer model showed competitive performance but fell short due to its inability to handle domain-specific noise as efficiently as the proposed approach. On the TrainSim and Rail-5k datasets, the proposed method demonstrated significant improvements, with the lowest MAE (11.32 and 12.87) and RMSE (15.89 and 16.74) and the highest R2 scores (0.88 and 0.84). These results validate the robustness of our model across diverse scenarios, including synthetic environments and real-world challenges like occlusions and low-visibility conditions. N-BEATS showed close performance but lacked the architectural enhancements that allow our method to generalize to unseen data. Ablated versions of our method also performed better than baseline models, underscoring the impact of individual components.
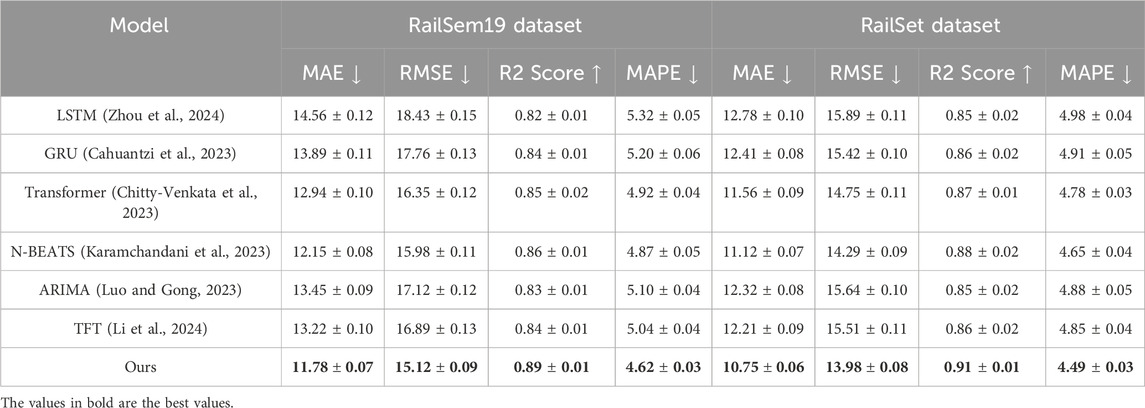
Table 3. Comparison of time-series forecasting methods on the RailSem19 and RailSet datasets.
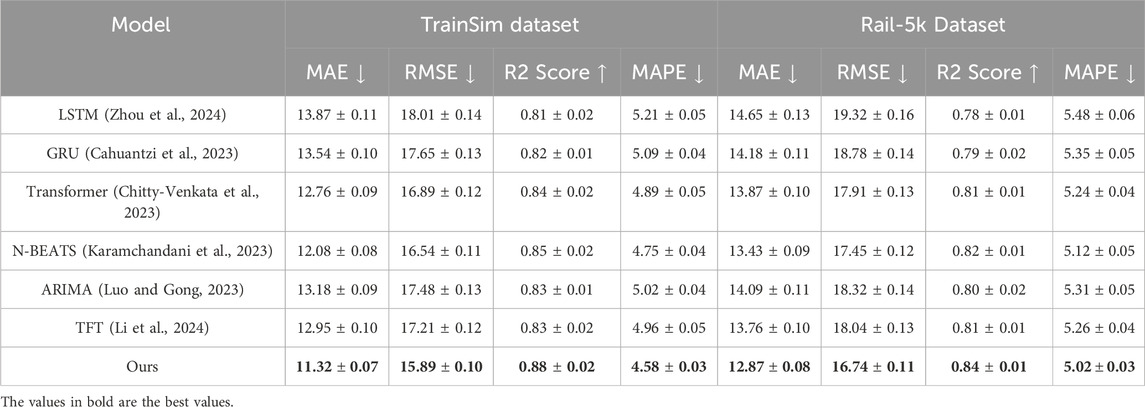
Table 4. Comparison of time-series forecasting methods on the TrainSim and Rail-5k datasets.
4.4 Ablation study
An ablation study was conducted to evaluate the contribution of individual components and design choices in the proposed model. The results on the RailSem19, RailSet, TrainSim, and Rail-5k datasets are summarized in Table 5, 6. Key architectural elements, including temporal encoder, railway relationships, and model training, as well as configurations with reduced layers or reduced feature dimensions, were selectively removed or modified to assess their impact on performance. The study demonstrates that each module significantly contributes to the overall performance. On the RailSem19 dataset, removing the temporal encoder resulted in notable increases in MAE from 11.78 to 14.22 and RMSE from 15.12 to 18.45, while the R2 score dropped from 0.89 to 0.82. A similar trend was observed on the RailSet dataset, with MAE increasing to 12.95 and RMSE to 16.02. These results indicate that the temporal encoder plays a critical role in capturing key features of rail-specific data. The railway relationships and model training components also showed a substantial impact, as their removal caused MAE and RMSE to deteriorate, confirming the importance of these components in refining predictions and handling temporal dependencies.
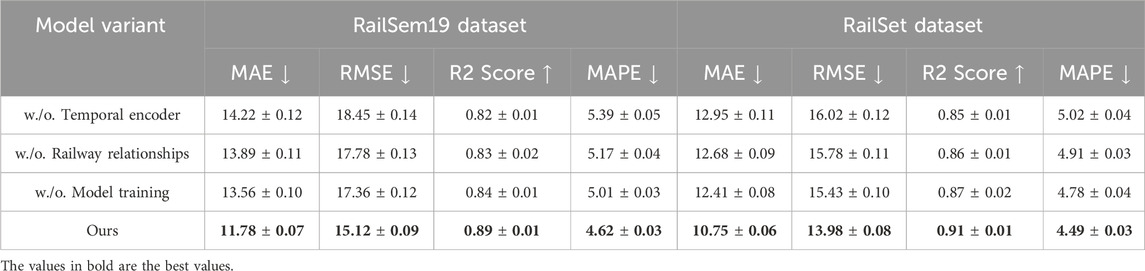
Table 5. Ablation study results on the proposed model across the RailSem19 and RailSet datasets.
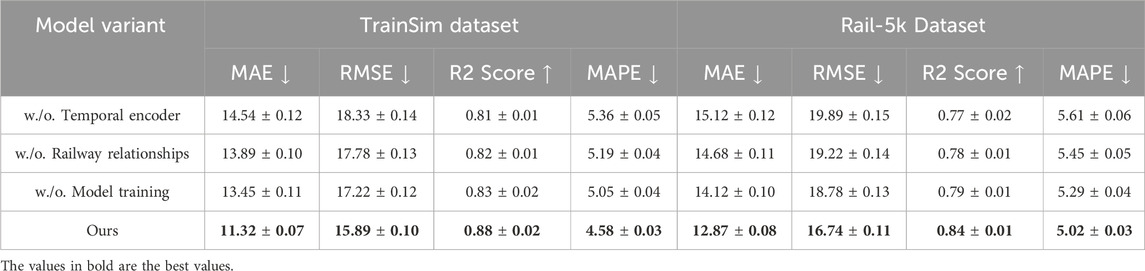
Table 6. Ablation study results on the proposed model across the TrainSim and Rail-5k datasets.
In Figures 4, 5, the effect of reducing layers and feature dimensions was also examined. On the TrainSim dataset, reducing the number of layers increased the RMSE to 16.89, compared to 15.89 for the full model. This highlights the necessity of maintaining a sufficiently deep architecture to model complex relationships. Reducing feature dimensions resulted in higher errors, particularly on the Rail-5k dataset, where MAE increased from 12.87 to 14.01 and RMSE from 16.74 to 18.12. This suggests that adequate feature representations are crucial for handling the diverse conditions present in this dataset. The ablation results validate the efficacy of the proposed design choices. The proposed method achieves superior performance by integrating the temporal encoder, railway relationships, and model training components, alongside a carefully designed feature extraction and model depth. Figures 4, 5 visually compare the performance of ablated models, further emphasizing the necessity of each component. The consistent performance drop in all modified configurations demonstrates the robustness of the full model and underscores the importance of each architectural element.
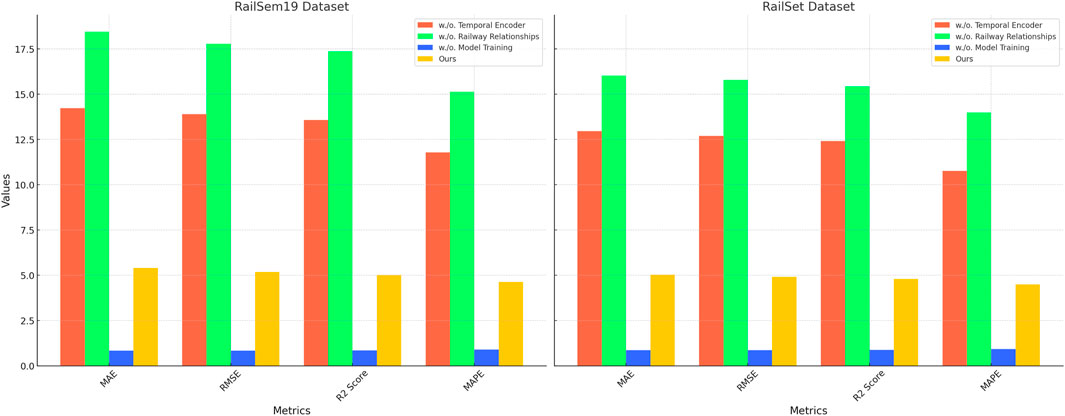
Figure 4. Ablation study of our method on the RailSem19 and RailSet datasets.
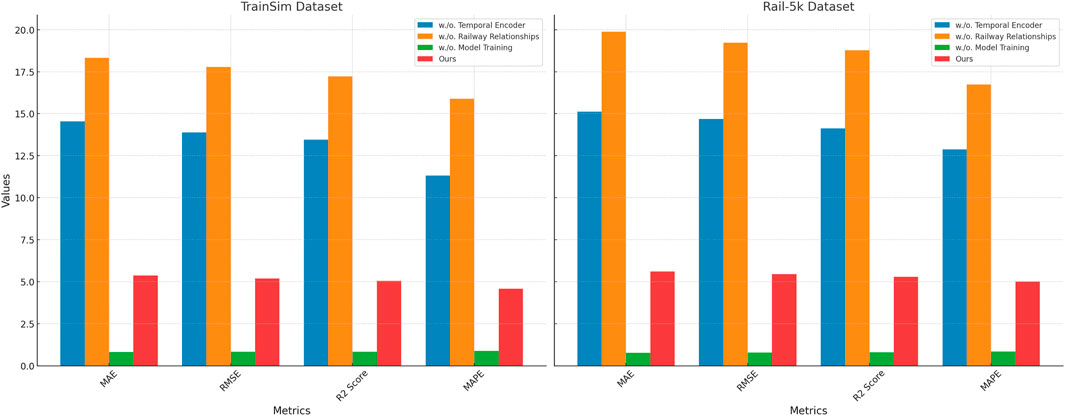
Figure 5. Ablation study of our method on the TrainSim and Rail-5k datasets.
To evaluate the effectiveness of the attention mechanism in the GRU model, we conducted an experiment comparing a GRU model with and without the attention mechanism. Both models were trained on the same dataset, and we used three key metrics to assess their performance: mean absolute error (MAE), mean squared error (MSE), and R-squared. The results, shown in Table 7, indicate that the GRU model with the attention mechanism outperforms the standard GRU model. Specifically, the GRU with attention achieved a lower MAE of 0.052, compared to 0.065 for the GRU without attention. This indicates that the attention mechanism enables the model to make more accurate predictions. Similarly, the GRU with attention also showed a lower MSE of 0.004, compared to 0.005 for the GRU without attention. Additionally, the R-squared value for the GRU with attention was 0.92, significantly higher than the 0.88 achieved by the GRU without attention, suggesting that the attention-enhanced model captures the underlying data patterns more effectively. These results confirm that the attention mechanism improves model performance by helping it focus on the most relevant time steps, which is particularly beneficial when long-term dependencies need to be captured. The attention mechanism likely aids in filtering out less important information, enhancing the model’s ability to retain and utilize critical data points from the sequence.
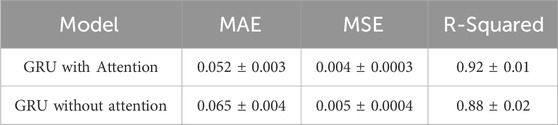
Table 7. Comparison of GRU with and without the attention mechanism component on the test set.
To enhance the interpretability of our model, we conducted a key feature contribution analysis using SHapley Additive exPlanation (SHAP) values. This experiment quantifies the importance of different input features across three predictive tasks: predictive maintenance, anomaly detection, and demand forecasting. Additionally, we performed an ablation study to measure the impact of feature removal on model performance. The results are summarized in Table 8. The SHAP analysis indicates that for predictive maintenance, track vibration has the highest contribution to the model’s failure predictions, with a mean SHAP value of 0.213. Removing this feature leads to an 8.7% drop in AUC-ROC, confirming its importance in identifying potential infrastructure failures. Maintenance history is also a key factor, contributing a SHAP value of 0.178, and its removal results in a 7.2% drop in AUC-ROC. These results align with physical expectations, as increased track vibration and lack of recent maintenance are known to increase failure risk. Track displacement and temperature variations are the most significant factors for anomaly detection, with SHAP values of 0.192 and 0.165, respectively. Removing track displacement reduces anomaly detection accuracy by 6.5%, while removing temperature variation leads to a 5.9% accuracy drop. These results highlight the model’s ability to capture real-world railway anomalies, where environmental fluctuations and structural changes often lead to failures. For demand forecasting, passenger flow history has the highest SHAP value at 0.245, indicating that past ridership patterns are the strongest predictor of future demand. Removing this feature increases the MAE by 1.31, leading to a significant drop in prediction accuracy. Weather conditions, such as rainfall, also influence demand, with a SHAP value of 0.138 and a corresponding increase of 0.94 in MAE when removed. This finding is consistent with the real-world impact of weather on passenger behavior, where adverse conditions often lead to lower ridership. These results confirm that our model captures meaningful and physically consistent relationships between features and predictive outcomes. The ablation study further validates the necessity of key features in railway system analysis, ensuring that the model does not rely on spurious correlations but instead learns from domain-relevant information.

Table 8. Feature importance analysis using SHapley Additive exPlanation (SHAP) values and an ablation study. SHAP values represent the mean absolute impact of each feature on model predictions, while the performance degradation column shows the change in accuracy (for anomaly detection), AUC-ROC (for predictive maintenance), or MAE (for demand forecasting) after feature removal.
5 Conclusions and future work
Beyond the methodological contributions, this study also explores the challenges associated with engineering deployment in real-world railway environments. One of the key challenges is computational efficiency, as real-time railway applications demand low-latency inference while maintaining high accuracy. The integration of GRU, GCN, and attention mechanisms, while effective, increases computational complexity, necessitating optimizations such as model compression, quantization, and hardware acceleration to enable large-scale deployment. Another challenge lies in data privacy and security, as railway datasets often contain sensitive operational and passenger information. Future work should explore privacy-preserving approaches such as federated learning and differential privacy to ensure compliance with data protection regulations while maintaining predictive performance. The study also highlights the need for adaptive models that generalize across different railway networks with varying operational contexts. The reliance on domain-specific constraints enhances model reliability but may limit scalability to new environments. Future research should investigate automated adaptation techniques, such as transfer learning and meta-learning, to reduce dependence on manually defined constraints. Addressing these challenges will be crucial for transitioning from research-driven insights to practical implementations that enhance railway system intelligence, efficiency, and safety in real-world applications.
Despite these achievements, the proposed framework faces two primary limitations. The reliance on domain-specific knowledge for model optimization could restrict its applicability across different railway systems with varied operational contexts. Future work should explore automated adaptation techniques to reduce dependency on domain expertise. While the framework excels in processing historical and real-time data, its ability to predict long-term environmental risks remains underexplored. Enhancing the temporal scope of the model and integrating climate and infrastructure data may provide deeper insights into long-term environmental and operational impacts. These improvements could further strengthen the framework’s contributions to sustainable and adaptive railway infrastructure.
In addition to these challenges, computational efficiency remains a critical consideration, particularly for real-time inference in large-scale railway systems. The integration of GRU, GCN, and attention mechanisms results in a computationally intensive model, which may pose limitations when deployed in resource-constrained environments or edge computing settings. Future research should investigate model compression techniques, such as pruning and quantization, to improve inference speed while maintaining predictive accuracy. Additionally, optimizing the deployment of the model on specialized hardware, such as GPUs or tensor processing units (TPUs), could further enhance real-time processing capabilities. Another important consideration is data privacy, especially when handling sensitive operational data from railway networks. Because railway datasets often contain proprietary or personally identifiable information (e.g., passenger flow records and maintenance logs), privacy-preserving mechanisms must be implemented. Federated learning and differential privacy techniques could be explored to enable collaborative model training across different railway operators without compromising data security. Ensuring compliance with data protection regulations while maintaining model performance is an essential direction for future work.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material; further inquiries can be directed to the corresponding author.
Author contributions
LQ: Conceptualization, Methodology, Software, Validation, Writing – review and editing. MW: Formal analysis, Investigation, Data curation, Writing – original draft, Writing – review and editing. LB: Visualization, Writing – review and editing. ZZ: Supervision, Funding acquisition, Writing – review and editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by Guangxi Higher Education Young and Middle-aged Teachers’ Research Capacity Enhancement Project (No. 2025KY1079). This work was supported by Guangxi Higher Education Undergraduate Teaching Reform Project (No. 2024JGZ179).
Conflict of interest
Author LB was employed by China Construction Civil Construction Co., LTD.
The remaining author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Cahuantzi, R., Chen, X., and Güttel, S. (2023). “A comparison of lstm and gru networks for learning symbolic sequences,” in Science and information conference (Springer), 771–785.
Cao, D., Wang, Y., Duan, J., Zhang, C., Zhu, X., Huang, C., et al. (2020). Spectral temporal graph neural network for multivariate time-series forecasting. Conference on Neural Information Processing Systems. Available online at: https://proceedings.neurips.cc/paper/2020/hash/cdf6581cb7aca4b7e19ef136c6e601a5-Abstract.html.
Challu, C., Olivares, K. G., Oreshkin, B. N., Garza, F., Mergenthaler-Canseco, M., and Dubrawski, A. (2022). “N-hits: neural hierarchical interpolation for time series forecasting,” in AAAI conference on artificial intelligence.
Chen, S., Li, C.-L., Yoder, N., Arik, S., and Pfister, T. (2023). Tsmixer: an all-mlp architecture for time series forecasting. Transactions on Machine Learning Research. Available online at: https://arxiv.org/abs/2303.06053.
Cheng, D., Yang, F., Xiang, S., and Liu, J. (2022). Financial time series forecasting with multi-modality graph neural network. Pattern Recognit. 121, 108218. doi:10.1016/j.patcog.2021.108218
Chitty-Venkata, K. T., Mittal, S., Emani, M., Vishwanath, V., and Somani, A. K. (2023). A survey of techniques for optimizing transformer inference. J. Syst. Archit. 144, 102990. doi:10.1016/j.sysarc.2023.102990
Cirstea, R.-G., Yang, B., Guo, C., Kieu, T., and Pan, S. (2022). “Towards spatio-temporal aware traffic time series forecasting,” in IEEE international conference on data engineering.
D’Amico, G., Marinoni, M., Nesti, F., Rossolini, G., Buttazzo, G., Sabina, S., et al. (2023). Trainsim: a railway simulation framework for lidar and camera dataset generation. IEEE Transactions on Intelligent Transportation Systems. Available online at: https://ieeexplore.ieee.org/abstract/document/10205499/.
Das, A., Kong, W., Sen, R., and Zhou, Y. (2023). A decoder-only foundation model for time-series forecasting. International Conference on Machine Learning. Available online at: https://openreview.net/forum?id=jn2iTJas6h.
Ekambaram, V., Jati, A., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. (2023). Tsmixer: lightweight mlp-mixer model for multivariate time series forecasting. Knowl. Discov. Data Min., 459–469. doi:10.1145/3580305.3599533
Fakhereldine, A., Zulkernine, M., and Murdock, D. (2023). “Cbtcset: a reference dataset for detecting misbehavior attacks in cbtc networks,” in 2023 IEEE 34th international symposium on software reliability engineering workshops (ISSREW) (IEEE), 57–62.
Hajirahimi, Z., and Khashei, M. (2022). Hybridization of hybrid structures for time series forecasting: a review. Artif. Intell. Rev. 56, 1201–1261. doi:10.1007/s10462-022-10199-0
He, K., Yang, Q., Ji, L., Pan, J., and Zou, Y. (2023). Financial time series forecasting with the deep learning ensemble model. Mathematics 11, 1054. doi:10.3390/math11041054
Jin, M., Wang, S., Ma, L., Chu, Z., Zhang, J. Y., Shi, X., et al. (2023). “Time-llm: time series forecasting by reprogramming large language models,” in International conference on learning representations.
Jin, M., Zheng, Y., Li, Y., Chen, S., Yang, B., and Pan, S. (2022). Multivariate time series forecasting with dynamic graph neural odes. IEEE Trans. Knowl. Data Eng. 35, 9168–9180. doi:10.1109/tkde.2022.3221989
Karamchandani, A., Mozo, A., Vakaruk, S., Gómez-Canaval, S., Sierra-García, J. E., and Pastor, A. (2023). Using n-beats ensembles to predict automated guided vehicle deviation. Appl. Intell. 53, 26139–26204. doi:10.1007/s10489-023-04820-0
Kim, T., Kim, J., Tae, Y., Park, C., Choi, J., and Choo, J. (2022). “Reversible instance normalization for accurate time-series forecasting against distribution shift,” in International conference on learning representations.
Li, J., Yin, Y., and Meng, H. (2024). Research progress of color photoresists for tft-lcd. Dyes Pigments 225, 112094. doi:10.1016/j.dyepig.2024.112094
Li, Y., xin Lu, X., Wang, Y., and Dou, D.-Y. (2023). Generative time series forecasting with diffusion, denoise, and disentanglement. Neural Inf. Process. Syst. 2023, 3028. doi:10.48550/arXiv.2301.03028
Lim, B., and Zohren, S. (2020). Time-series forecasting with deep learning: a survey. Philosophical Trans. R. Soc. A. 2020, 209. doi:10.1098/rsta.2020.0209
Liu, Y., Hu, T., Zhang, H., Wu, H., Wang, S., Ma, L., et al. (2023). “itransformer: inverted transformers are effective for time series forecasting,” in International conference on learning representations.
Liu, Y., Wu, H., Wang, J., and Long, M. (2022). Non-stationary transformers: exploring the stationarity in time series forecasting. Conference on Neural Information Processing Systems. Available online at: https://proceedings.neurips.cc/paper_files/paper/2022/hash/4054556fcaa934b0bf76da52cf4f92cb-Abstract-Conference.html.
Luo, J., and Gong, Y. (2023). Air pollutant prediction based on arima-woa-lstm model. Atmos. Pollut. Res. 14, 101761. doi:10.1016/j.apr.2023.101761
Mesman, J. P., Barbosa, C. C., Lewis, A. S., Olsson, F., Calhoun-Grosch, S., Grossart, H.-P., et al. (2024). Challenges of open data in aquatic sciences: issues faced by data users and data providers. Front. Environ. Sci. 12, 1497105. doi:10.3389/fenvs.2024.1497105
Nie, Y., Nguyen, N. H., Sinthong, P., and Kalagnanam, J. (2022). A time series is worth 64 words: long-term forecasting with transformers. International Conference on Learning Representations. Available online at: https://arxiv.org/abs/2211.14730.
Rasul, K., Seward, C., Schuster, I., and Vollgraf, R. (2021). “Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting,” in International conference on machine learning.
Shao, Z., Zhang, Z., Wang, F., Wei, W., and Xu, Y. (2022a). “Spatial-temporal identity: a simple yet effective baseline for multivariate time series forecasting,” in International conference on information and knowledge management.
Shao, Z., Zhang, Z., Wang, F., and Xu, Y. (2022b). Pre-training enhanced spatial-temporal graph neural network for multivariate time series forecasting. Knowl. Discov. Data Min., 1567–1577. doi:10.1145/3534678.3539396
Smyl, S. (2020). A hybrid method of exponential smoothing and recurrent neural networks for time series forecasting. Int. J. Forecast. 36, 75–85. doi:10.1016/j.ijforecast.2019.03.017
Wang, Q., and Chen, X. (2024). Can new quality productive forces promote inclusive green growth: evidence from China. Front. Environ. Sci. 12, 1499756. doi:10.3389/fenvs.2024.1499756
Wang, Z., Xu, X., Zhang, W., Trajcevski, G., Zhong, T., and Zhou, F. (2022). Learning latent seasonal-trend representations for time series forecasting. Advances in Neural Information Processing Systems. Available online at: https://proceedings.neurips.cc/paper_files/paper/2022/hash/fd6613131889a4b656206c50a8bd7790-Abstract-Conference.html.
Woo, G., Liu, C., Sahoo, D., Kumar, A., and Hoi, S. C. H. (2022). “Cost: contrastive learning of disentangled seasonal-trend representations for time series forecasting,” in International conference on learning representations.
Wu, Z., Pan, S., Long, G., Jiang, J., Chang, X., and Zhang, C. (2020). Connecting the dots: multivariate time series forecasting with graph neural networks. Knowl. Discov. Data Min. 2020, 11650. doi:10.48550/arXiv.2005.11650
Xu, L., Javad Shafiee, M., Wong, A., Li, F., Wang, L., and Clausi, D. (2015). “Oil spill candidate detection from sar imagery using a thresholding-guided stochastic fully-connected conditional random field model,” in Proceedings of the IEEE conference on computer vision and pattern recognition workshops, 79–86.
Xu, L., Wong, A., and Clausi, D. A. (2016). An enhanced probabilistic posterior sampling approach for synthesizing sar imagery with sea ice and oil spills. IEEE Geoscience Remote Sens. Lett. 14, 188–192. doi:10.1109/lgrs.2016.2633572
Xu, L., Wong, A., and Clausi, D. A. (2017). A novel bayesian spatial–temporal random field model applied to cloud detection from remotely sensed imagery. IEEE Trans. Geoscience Remote Sens. 55, 4913–4924. doi:10.1109/tgrs.2017.2692264
Xue, H., and Salim, D. (2022). Promptcast: a new prompt-based learning paradigm for time series forecasting. IEEE Trans. Knowl. Data Eng. 36, 6851–6864. doi:10.1109/tkde.2023.3342137
Ye, J., Liu, Z., Du, B., Sun, L., Li, W., Fu, Y., et al. (2022). Learning the evolutionary and multi-scale graph structure for multivariate time series forecasting. Knowl. Discov. Data Min., 2296–2306. doi:10.1145/3534678.3539274
Yi, K., Zhang, Q., Fan, W., Wang, S., Wang, P., He, H., et al. (2023). Frequency-domain mlps are more effective learners in time series forecasting. Neural Inf. Process. Syst. 2023, 6184. doi:10.48550/arXiv.2311.06184
Zeng, A., Chen, M.-H., Zhang, L., and Xu, Q. (2022). “Are transformers effective for time series forecasting?,” in AAAI conference on artificial intelligence.
Zhang, R., and Bao, Q. (2024). Evolutionary characteristics, regional differences and spatial effects of coupled coordination of rural revitalization, new-type urbanization and ecological environment in China. Front. Environ. Sci. 12, 1510867. doi:10.3389/fenvs.2024.1510867
Zhang, Y., and Yan, J. (2023). “Crossformer: transformer utilizing cross-dimension dependency for multivariate time series forecasting,” in International conference on learning representations.
Zhao, J., Yeung, A. W.-l., Ali, M., Lai, S., and Ng, V. T.-Y. (2024). Cbam-swint-bl: small rail surface defect detection method based on swin transformer with block level cbam enhancement. IEEE Access 12, 181997–182009. doi:10.1109/access.2024.3509986
Zhou, H., Zhang, S., Peng, J., Zhang, S., Li, J., Xiong, H., et al. (2020). “Informer: beyond efficient transformer for long sequence time-series forecasting,” in AAAI conference on artificial intelligence.
Keywords: railway big data, deep learning, predictive maintenance, anomaly detection, intelligent transportation systems
Citation: Quan L, Wang M, Baihang L and Ziwen Z (2025) Integration of deep learning and railway big data for environmental risk prediction models and analysis of their limitations. Front. Environ. Sci. 13:1550745. doi: 10.3389/fenvs.2025.1550745
Received: 24 December 2024; Accepted: 01 April 2025;
Published: 26 May 2025.
Edited by:
Linlin Xu, University of Waterloo, CanadaReviewed by:
Jidong J. Yang, University of Georgia, United StatesXiaoding Wang, Fujian Normal University, China
Copyright © 2025 Quan, Wang, Baihang and Ziwen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Minjie Wang, a29hcWUyQDE2My5jb20=