 Gang Yao
Gang Yao Ashwin Dani
Ashwin Dani- Department of Electrical and Computer Engineering, University of Connecticut, Storrs, CT, United States
An efficient iterative Earth Mover's Distance (iEMD) algorithm for visual tracking is proposed in this paper. The Earth Mover's Distance (EMD) is used as the similarity measure to search for the optimal template candidates in feature-spatial space in a video sequence. The local sparse representation is used as the appearance model for the iEMD tracker. The maximum-alignment-pooling method is used for constructing a sparse coding histogram which reduces the computational complexity of the EMD optimization. The template update algorithm based on the EMD is also presented. When the camera is mounted on a moving robot, e.g., a flying quadcopter, the camera could experience a sudden and rapid motion leading to large inter-frame movements. To ensure that the tracking algorithm converges, a gyro-aided extension of the iEMD tracker is presented, where synchronized gyroscope information is utilized to compensate for the rotation of the camera. The iEMD algorithm's performance is evaluated using eight publicly available videos from the CVPR 2013 dataset. The performance of the iEMD algorithm is compared with eight state-of-the-art tracking algorithms based on relative percentage overlap. Experimental results show that the iEMD algorithm performs robustly in the presence of illumination variation and deformation. The robustness of this algorithm for large inter-frame displacements is also illustrated.
1. Introduction
Visual tracking is an important problem for new robotics applications. The information generated from the sequence of images by the tracking algorithm can be utilized by vehicle navigation, human-robot interaction, and motion-based recognition algorithms (Dani et al., 2013; Ravichandar and Dani, 2015; Chwa et al., 2016). Visual tracking algorithms provide important information for visual simultaneous localization and mapping (SLAM), structure from motion (SfM), and vision-based control (Marchand and Chaumette, 2005; Marchand et al., 2005; Comport et al., 2006; Davison et al., 2007; Dani et al., 2012; Yang et al., 2015).
Image-based tracking algorithms are categorized as point tracking, kernel tracking, or silhouette tracking (Yilmaz et al., 2006). Distinguishing features, such as color, shape, and region are selected to identify objects for visual tracking. Modeling the object adapts to the slowly changing appearance is challenging, due to the illumination variants, object deformation, occlusion, motion blur, or background clutters. Supervised or unsupervised online learning algorithms are often used to robustly find and update the distinguishing features of the object, such as using variance ratios of the feature value's log likelihood (Collins et al., 2005), the online Ada-boost feature selection method (Grabner and Bischof, 2006), and incremental learning (Ross et al., 2008).
Approaches in visual tracking could be generally classified into two groups, either generative methods or discriminative methods. For generative methods, the tracked object is modeled based on the selected features, such as the color histogram, sparse coding representation, or kernels. Then, correspondence or similarity measurement between the target and the candidate across frames is constructed. Similarity measurements are derived through several methods, such as the Normalized Cross Correlation (NCC) (Bolme et al., 2010; Zhu et al., 2016), the Earth Mover's Distance (EMD) (Zhao et al., 2010; Karavasilis et al., 2011; Oron et al., 2012; Tahri et al., 2016), the Bhattacharyya Coefficient (BC) (Comaniciu et al., 2003) and point-to-set distance metric (Wang et al., 2015, 2016). Location of the candidate object in the consecutive frames is estimated by using the Kalman filter, particle filter or gradient descent method. Discriminative methods regard tracking as a classification problem and build a classifier or ensemble of classifiers to distinguish the object from the background. Representative classification tracking algorithms are the structured Support Vector Machine (SVM) (Hare et al., 2011), Convolutional Neural Nets (Li et al., 2016). Ensemble based algorithms such as ensemble tracking (Avidan, 2007), multiple instance learning (MIL) (Babenko et al., 2011), and online boosting tracker (Grabner and Bischof, 2006).
In order to robustly track moving objects in challenging situations, many tracking frameworks are proposed. Tracking algorithms with Bayesian filtering are developed to track moving objects. These algorithms can handle complete occlusion (Zivkovic et al., 2009). The non-adaptive methods, usually only model the object from the first frame. Although less error prone to occlusions and drift, they are hard to track the object undergoing appearance variations. However, adaptive meth ods are usually prone to drift because they rely on self updates of an online learning method. In order to deal with this problem, combining adaptive methods with the complementary tracking approaches leads to more stable results. For example, parallel robust online simple tracking (PROST) framework combines three different trackers (Santner et al., 2010): tracking-learning-detection (TLD) framework uses P-N experts to make the decision on the location of the moving object, based on the results from the Median-Flow tracker and detectors (Kalal et al., 2012), and online adaptive hidden Markov model for multi-tracker fusion (Vojir et al., 2016).
An EMD-based tracker using color histogram [iEMD(CH)] as an appearance model and its fusion with gyroscope information is presented in our prior related work (Yao et al., 2016; Yao and Dani, 2017). However, color histogram model is not robust to appearance changes. Also, the template update algorithm is not used in our prior related work. The sparse coding appearance model is based on a dictionary of templates consisting of the appearance variations of the target. The sparse coding appearance model has been used in literature and has shown robust performance in various tracking algorithms (Zhang et al., 2013). In this paper, we develop a generative tracking method using sparse coding appearance model along with EMD as a similarity measure. An adaptive template update algorithm is also developed to update the apprearance model during tracking to handle the appearance variations. Gyroscope information is used to aid the initialization of the EMD optimization. Specifically, the contributions of the paper are
• The maximum-alignment-pooling method for local sparse coding is used to build a histogram of appearance model. A template update algorithm is used to adaptively change the appearance model by an exponential rule based on EMD measure. An iEMD tracking algorithm is developed based on this local sparse coding representation of the appearance model. It is shown using videos from publicly available benchmark datasets that the iEMD tracker shows good performance in terms of percentage overlap compared to the state-of-the-art trackers available in literature.
• Gyro-measurements are used to compensate for the pan, tilt, and roll of the camera. Then the iEMD visual tracking algorithm is used to track the target after compensating for the movement of the camera. By this method, the convergence of the algorithm is ensured, thus providing a more robust tracker which is more capable of real-world tracking tasks.
The paper is organized as follows. Related work on the computation of the EMD and its application for visual tracking is illustrated in section 2. In section 3, the iEMD algorithm for visual tracking is developed. In section 4, the target is modeled as the sparse coding histogram. For the sparse coding histogram, the maximum-alignment-pooling method is proposed to represent the local image patches. In section 5, two extensions of the iEMD algorithm that includes the template update method, and the method of using the gyroscope data for ego-motion compensation are discussed. In section 6, the iEMD tracker is validated on eight publicly available datasets, and the comparisons with eight state-of-the-art trackers are shown. Experimental results using the gyro-aided iEMD algorithm are compared with tracking results without gyroscope information. The conclusions are given in section 7.
2. Related Work
Sparse coding has been successfully applied to model the target in visual tracking (Zhang et al., 2013). In sparse coding for visual tracking, the largest sum of the sparse coefficients or the smallest reconstruction error is used as the metric to find the target from the candidate templates using particle filter (Mei and Ling, 2009; Jia et al., 2016). The sparse coding process is usually the L1 norm minimization problem, which makes the sparse representation and dictionary learning computationally expensive. To reduce the computational complexity, the sparse representation as the appearance model is combined with the Mean-shift (Liu et al., 2011) or Mean-transform method (Zhang and Hong Wong, 2014). After a small number of iterations by these methods, the maximum value of the Bhattacharyya coefficient corresponding to the best candidate is obtained.
In real-world tracking applications, variations in appearance are a common phenomenon caused by illumination changes, moderate pose changes or partial occlusions. The Earth Mover's Distance (EMD) as a similarity measure, also known as 1-Wasserstein distance (Guerriero et al., 2010; Baum et al., 2015), is robust to these situations (Rubner et al., 2000). However, the major problem with the EMD is its computational complexity. Several algorithms for the efficient computation of the EMD are proposed. For example, the EMD-L1 algorithm is used for histogram comparison (Ling and Okada, 2007) and the EMDs are computed with the thresholded ground distances (Pele and Werman, 2009). In the context of visual tracking, although the EMD has the merit of being robust to moderate appearance variations, the efficiency of the computation is still a problem. Since solving the EMD is a transportation problem—a linear programming problem (Rubner et al., 2000), the direct differential method cannot be used. There are some efforts to employ the EMD for object tracking. The Differential Earth Mover's Distance (DEMD) algorithm (Zhao et al., 2010) is first proposed for visual tracking, which adopts the sensitivity analysis to approximate the derivative of the EMD. However, the selection of the basic variables and the process of identifying and deleting the redundant constraints still affect the efficiency of the algorithm (Zhao et al., 2010). The DEMD algorithm combined with the Gaussian Mixture Model (GMM), which has fewer parameters for EMD optimization, is proposed in Karavasilis et al. (2011). The EMD as the similarity measure combined with the particle filter for visual tracking is proposed in Oron et al. (2012). In this paper, the sparse coding is used along with EMD similarity measure for the visual tracking. To the best of our knowledge, this is the first work that combines sparse coding representation with the EMD similarity measure for visual tracking.
The success of the gradient descent based tracking algorithm depends on the assumption that the object motion is smooth and contains only small displacements (Yilmaz et al., 2006). However, in practice, this assumption is always violated due to the abrupt rotation and shaking movement of the camera mounted on a mobile robot, such as a flying quadcopter. Efforts have been made to combine the gyroscope data with tracking algorithms, such as the Kanade-Lucas-Tomasi (KLT) tracker or the MI tracker (Hwangbo et al., 2011; Park et al., 2013; Ravichandar and Dani, 2014). In our paper, to robustly track a static object using a moving camera, gyroscope data are directly utilized to estimate the initial location of the static object. When both the camera and the object being tracked are in motion, the gyroscope sensor data are utilized to compensate for the rotation of the camera, because rotation has a greater impact on the positional changes compared with the translation in video frames. Then, the iEMD tracking algorithm is applied to track the moving object. The robustness of the tracking algorithm is improved due to the compensation of the camera's ego-motion. Therefore, our method makes the EMD tracker more robust to this situation.
3. Iterative EMD Tracking Algorithm
In the context of visual tracking, first a feature space is chosen to characterize the object, then, the target model and the candidate model are built in the feature-spatial space. The probability density functions (histograms) representing the target model and the candidate model are (Comaniciu et al., 2003)
where is the weight of the uth bin of the target model , assuming the center of the template target is at (0, 0), is the weight of the vth bin of the candidate model , assuming the center of the template candidate is at y, NT and NC are the numbers of the bins.
Based on the target model and the candidate model, the dissimilarity function is denoted as . The optimization problem for tracking is to estimate the optimal displacement which gives the smallest value of . Thus, the optimization problem is formulated as
In (1), the center of the template target is assumed to be positioned at (0, 0), and the center of the template candidate is at y. The goal is to find the candidate model located at that gives the smallest value of the dissimilarity function . The differential tracking approaches are usually applied to solve this optimization problem, with the assumption that the displacement of the target between two consecutive frames is very small.
The optimization problem in (1) is solved using the iEMD algorithm as described in the following sub-sections. The iEMD algorithm iterates between finding the smallest EMD between template target and the template candidate based on the current position yk by the transportation-simplex method (see section 3.2 for details) and finding the best position yk+1 leading to the smallest EMD by gradient method (see section 3.3 for details).
3.1. EMD as a Similarity Measure
In this section, the EMD between the target model and the candidate model is used as the similarity measure. Solving the EMD is a transportation problem—a linear programming problem as shown in Figure 1. Intuitively, given the target model and the candidate model, each bin of both models are cross compared. The costs between the bins from two different models are predefined. Then the EMD is considered as the smallest overall cost of sending the weights of one bin from the target model to another bin of the candidate model. The EMD is defined as (Rubner et al., 2000)
subject to
where D⋆ is the optimal solution to this transportation problem, is the flow (weight) from the uth bin of to the vth bin of , duv is the ground distance (cost) between the uth and the vth bins, the subscript T denotes the object target and C is the object candidate, wT, u is the weight from the uth bin of , and wC, v is the weight from the vth bin of .
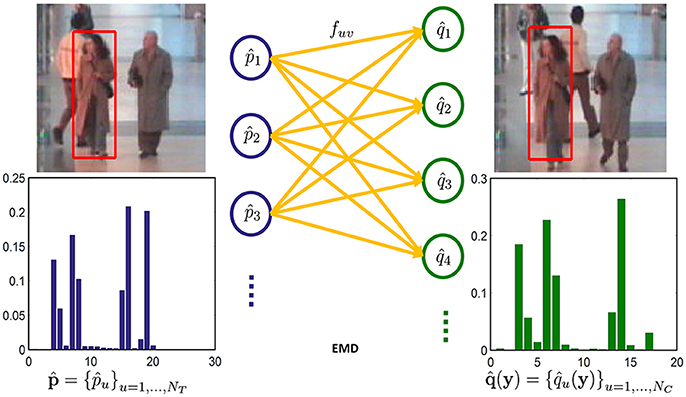
Figure 1. EMD comparison of the two templates (No permission is required from the copyright holders and/or the depicted individuals for the use of these images. The original images are obtained from the EC Funded CAVIAR project/IST 2001 37540, found at http://homepages.inf.ed.ac.uk/rbf/CAVIAR/).
3.2. EMD as a Function of Weights
Writing the above equation set (2–6) in a matrix form as
where the is the ground distance vector, is the flow vector, is the weight vector consisting of the weight vectors from and from , and is the matrix which consists of 0 and 1s.
In order to relate the EMD with the weight vector, the above primal problem in (7) is restated in its dual form as (Dantzig and Thapa, 2006)
where is a vector of variables to be optimized in the dual problem. By solving this dual problem in (8), the optimal solution D⋆ is calculated and directly represented as the linear equation of weights. However, considering the computation efficiency, the optimal solution (EMD) is first calculated from the primal problem in (7) using the transportation-simplex method, and then the EMD is represented as the function of the weights by the matrix transformation.
Using the transportation-simplex method (Rubner et al., 2000), the optimal solution to the EMD problem in (7) is calculated. The transportation-simplex method is a streamlined simplex algorithm, which is built on the special structure of the transportation problem. In order to reduce the number of iterations of the transportation-simplex method, the Russell's method is used to compute the initial basic feasible solution (Rubner et al., 2000; Ling and Okada, 2007).
The computation of the EMD is a transportation problem, which has exactly NT+NC−1 basic variables , and each constraint is a linear combination of the other NT+NC−1 constraints, which could be considered as redundant and discarded (Dantzig and Thapa, 2006). Based on the optimal solution to the linear programming problem, the flow vector is separated into basic variables and non-basic variables , and the ground distance vector d and H will be transformed as and , where , and . In order to derive the EMD as a function of the weights of the candidate model, the matrix transformation is performed. First, the last row of the constraint matrices (7) is deleted which is considered as the redundant constraint and then the matrices HB, H, and w are formulated as , and .
The problem in (7) is reformulated based on the optimal solution as
Left multiplying (10) with yields
Left multiplying (11) by and adding the resultant to (9) gives
where is a NC+NT−1-dimensional vector. Since fNB = 0NTNC−NT−NC+1, using (12) the EMD D⋆ is given by
3.3. Gradient Method to Find the Template Displacement
Based on the Equation (13), the gradient method is utilized to find the displacement y of the target candidate as
The optimal location of the template candidate is found by iteratively performing: (1) calculate the smallest EMD and reformulate it as (13); (2) search for the new location of the template candidate along the direction of (14). When the EMD no longer decreases, the iteration stops. By this method, the best match of the template target and the template candidate will be found. The EMD plays three roles in this algorithm: (1) it provides a metric of the matching between the template target and the template candidate; (2) it assigns more weights to the best matches between the histogram bins and assigns smaller weights or no weights to unmatched bins by linear optimization; (3) matched bins are used for finding the location of the template candidate, and the gradient vector of the EMD for searching the optimal displacement is calculated.
The pseudo-code for the iEMD tracking algorithm is given in Algorithm 1.

Algorithm 1: iEMD tracking algorithm.
4. Target Modeling Based on Histograms of Sparse Codes
Sparse codes histogram (SCH) has been widely used as feature descriptors in many fields (Zhang et al., 2013). Given the image set of the first L image templates from a video, a set of K overlapped local image patches are sampled by a sliding window of size m×n from each template to build a dictionary Φ∈ℝ(mn) × (LK). Each column of Φ is a basis vector, which is a vectorized local image patch extracted from the set of image templates. The basis vectors are overcomplete where mn < LK. Similarly, for a given image template target I, a set of overlapped local image patches are sampled by the same sliding window of size m×n with the step size of one pixel. Each image patch ϵr, which represents one fixed part of the target object, can be encoded as a linear combination of a few basis vectors of the dictionary Φ as follows
where is the coefficient vector which is sparse and n∈ℝ(mn) × 1 is the noise vector. The coefficient ar is computed by solving the following L1 norm minimization problem (Zhang et al., 2013; Mairal et al., 2014)
where is the sparse coefficients of the local patch, aij corresponds to the jth patch of the ith image template of the dictionary, and λ is the Lagrange multiplier.
Once a solution to (16) is obtained, the maximum-alignment-pooling method is used to construct the sparse coding histograms. Combining the coefficients corresponding to the dictionary patches that have the same locations in the template using (Jia et al., 2012), a new vector is formulated. The weight of the rth local image patch ϵr in the histogram of sparse codes is computed by using . The value corresponds to the uth image patch from . With J local image patches from the template target, the histogram is constructed as
In the spatial space, the Epanechnikov kernel is used to represent the template. The Epanechnikov kernel (Comaniciu et al., 2003) is an isotropic kernel with a convex profile which assigns smaller weights to pixels away from the center. Given the target histogram in (17), the isotropic kernel is applied to generate the histograms of target weighted by the spatial locations. The weights of the histogram of the target wT, u are computed using
where cr is the center of the rth image patch of the template target, h is template size and γ is the normalization constant. The candidate histogram is built in the same way as . An isotropic kernel is applied to the elements of the for generating the histogram of candidate with spatial locations. The weights of the candidate histogram wC, v(xi−y) are computed using
where y is the displacement of the rth image patch of the template candidate. The ground distance duv for the EMD in (2) is defined by
where α ∈ (0, 1) is the weighting coefficient, , are the vectors of the normalized pixel values of the image patch from the target and candidate templates, sampled in the same way as the image patches from the dictionary, and cu, cv are the corresponding centers of the image patches.
5. Extensions of The Tracking Algorithm
5.1. Template Update
In order to make the tracker robust to significant appearance variations during long video sequences, the outdated templates in the dictionary should be replaced with the recent ones. To adapt to the appearance variations of the target and alleviate the drift problem only the latest template in dictionary is replaced based on the weight ωi, which is computed by
where ωi is the weight associated with the template, γ0 is a constant, Δi is the time elapsed since the dictionary was last updated measured in terms of image index k and is the EMD value corresponding to the template Ik.
If the weight of the current template based on (21) is smaller than the weight of the latest template in the dictionary, the template is replaced with the current one. In order to avoid the errors and noises affecting the dictionary update algorithm, the reconstructed template is used to replace the one in the dictionary. Firstly, the following problem is solved in order to recompute the sparse code coefficients, ak,
where is a dictionary formed using the vectorized template image with the size m×n as columns, Imn×mn is the identity matrix, is the vector of the sparse coding coefficients, and λ is the Lagrange multiplier (cf., Jia et al., 2012). Then the reconstructed template is calculated using , where is computed using components of ak corresponding to the dictionary. The reconstructed template is used to replace the latest template in the dictionary. The detailed steps of the update scheme are given in Algorithm 2.

Algorithm 2: Template update procedure.
5.2. Gyroscope Data Fusion for Rotation Compensation
The general idea of the gyro-aided iEMD tracking algorithm is combining the image frames from the camera with the angular rate generated by the gyroscope for visual tracking. Synchronization of the camera and the gyroscope in time is required. The spatial relationship between the camera and the gyroscope must also be pre-calibrated. Then, the angular rate generated by the gyroscope is applied to compensate for the ego-motion of the camera. After the compensation of the ego-motion of the camera, the iEMD tracker is applied for tracking. In this section, details of the gyro-aided iEMD tracking algorithm are explained.
When a camera is mounted on a moving robot, the motion of the camera will cause a large displacement of the target between two consecutive frames. If the displacement is larger than the convergence region, the tracking algorithm will become susceptible to the large appearance changes and fail (Comaniciu et al., 2003; Hwangbo et al., 2011; Ravichandar and Dani, 2014). In order to improve the robustness of the tracking algorithm, the displacement caused by the camera rotation is estimated and compensated by fusing the data from the gyroscope, which is a commonly used sensor on flying robots. The rotation of the camera causes a larger displacement of the target compared with the translation movement in video-rate frames. Thus, the translation is neglected here.
The gyroscope provides the angular rate along three axes, which measure the pan, tilt, and roll of small time intervals Δt. In the case of pure rotation without translation, the angular rate ωy is obtained along three axes x, y and z. Let q(k), q(k+1)∈ℍ denote the quaternion of two frames k and k+1 during time Δt, the relationship between them is given as (cf. Spong et al., 2006)
where Ω(ω) is the skew-symmetric matrix of ω as
After the quaternion q(k+1) = m+ai+bj+ck is normalized and updated, the rotation matrix is calculated as
Thus, the estimated homography matrix between two templates is estimated by
where, K is the intrinsic camera calibration matrix that is accessed by calibrating the camera. The homography matrix is update d to the newest frame location , where (xc, yc) is the center point of the template, based on the following equations:
for the first frame, . This new location is then used as the initial guess of the object candidate.
The pseudo-code for gyro-aided iEMD algorithm is given in Algorithm 3.

Algorithm 3: Gyro-aided iEMD tracking algorithm.
6. Experiments
In this section, the iEMD algorithm is validated on real datasets. The algorithm is implemented in MATLAB R2015b, the C code in Rubner et al. (2000) is adopted for the EMD calculation, and the software in Mairal et al. (2014) is used for sparse modeling. The platform is Microsoft Windows 7 professional with Intel(R) Core(TM) i5-4590 CPU. Eight publicly available datasets are chosen to validate the iEMD tracking algorithm. The main attributes of the video sequences are summarized in Table 1. The Car2, Walking, Woman, Subway, Bolt2, Car4, Human8, and Walking2 sequences are from the visual tracker benchmark (Wu et al., 2013) (CVPR 2013, http://www.visual-tracking.net). The length of the sequences varies between 128 and 913 frames with one object being tracked in each frame.
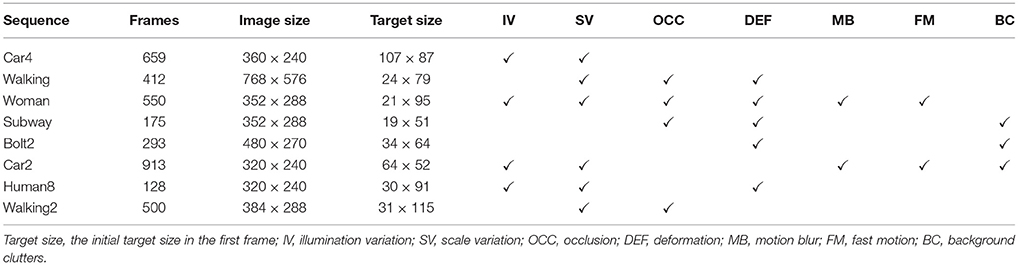
Table 1. The main attributes of the video sequences.
The tracker is initialized with the ground-truth bounding box of the target in the first frame. Then the tracking algorithm runs till the end of the sequence and generates a series of the tracked bounding boxes. Tracking results from consecutive frames are compared with the ground truth bounding boxes provided by this dataset. The relative overlap measure is used to evaluate this algorithm as (Wu et al., 2013)
where Rtr is the tracking result, represented by the estimated image region occupied by the tracked object, Rgt is the ground truth bounding box. Rtr∩Rgt is the intersection and Rtr∪Rgt is the union of the two regions. The range of the relative overlap is from 0 to 100%.
6.1. Results for the iEMD Tracker With Sparse Coding Histograms
In this subsection, the performance of the iEMD tracker with sparse coding histograms and the template update method is evaluated using the eight sequences. In our approach, the object windows are re-sized to 32 × 32 pixels for all the sequences, except for the Walking sequence, in which the object windows are resized to 64 × 32 pixels due to the smaller object size. The local patches in each object window are sampled with the size 16 × 16 pixels with step size 8 in sequences like Car4, Walking and Car2. For other sequences, the local patches in each object window are sampled with the size 8 × 8 pixels with step size 4. In the case of the abrupt motions of the object, 4 more particles are generated by moving the template in the surrounding area of the initial object position. For each particle, the template is enlarged and shrunk by 2% in case of the scale variations. Video 1 shows the comparisons of tracking methods on eight tracking video sequences (Supplementary Material section).
The performance of the proposed algorithm is compared with eight state-of-the-art tracking algorithms on eight video sequences. These state-of-the-art trackers include: ASLA (Jia et al., 2012), Frag (Adam et al., 2006), IVT (Ross et al., 2008), L1APG (Mei and Ling, 2011), LOT (Oron et al., 2012), MTT (Zhang et al., 2012), STRUCK (Hare et al., 2011), and iEMD(CH) (Yao et al., 2016; Yao and Dani, 2017). The source codes of the trackers are downloaded from the corresponding web pages and the default parameters are used. The average percentage overlap obtained by all the tracking algorithms on eight video sequences are reported in Table 2. The iEMD tracker achieves the highest average overlap over all the sequences. The iEMD tracker also achieves the second best tracking results on the 5 out of 8 sequences. In Figure 2, the tracking results of the eight video sequences are shown. The success plot shows the ratios of frames at the different thresholds of the relative overlap values varied from 0 to 1.
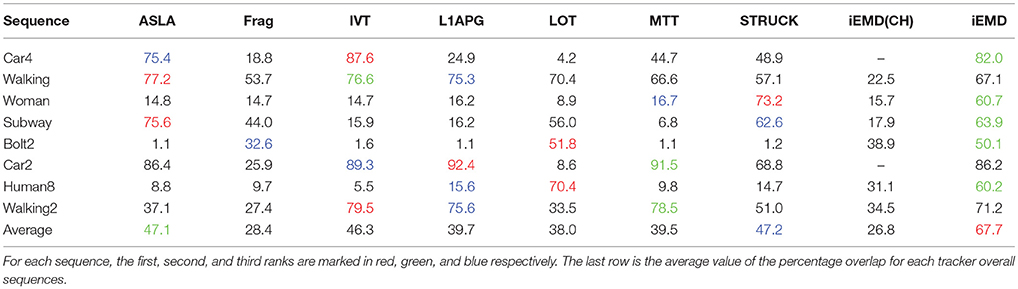
Table 2. The average overlap (in percentage) obtained by the tracking algorithms on eight datasets.
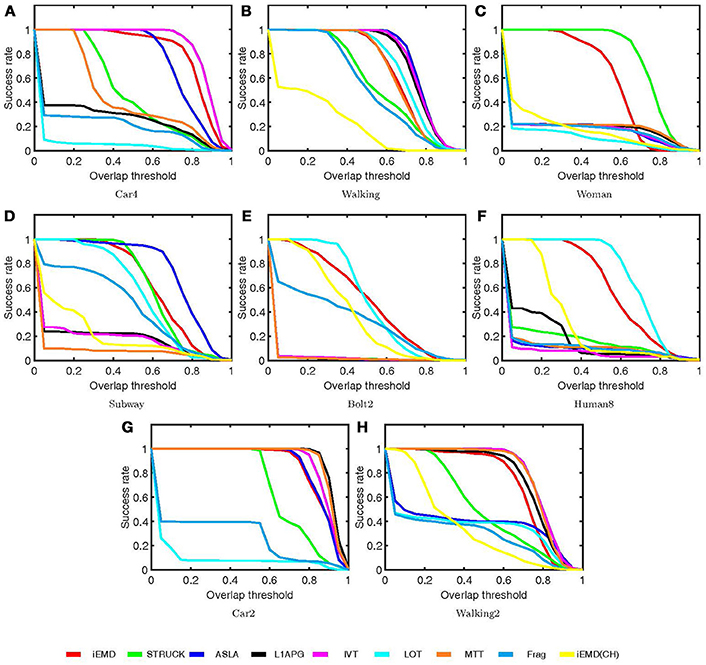
Figure 2. Success plots (A–H) for the nine tracking algorithms on the eight sequences.
Representative tracking results obtained by iEMD algorithm are shown in Figure 3. In the Human8 and Bolt2 sequences, the targets have significant illumination variations, and deformations, respectively. Only LOT, iEMD and iEMD(CH) trackers are able to track targets in all the frames. The size of the template estimated by the iEMD(CH) tracker is shrinked and not accurate. The LOT and iEMD trackers use the EMD as the similarity measure and their appearance models are based on local image patches, which make the trackers more robust to illumination changes and deformations (Rubner et al., 2000; Oron et al., 2012). In woman sequence, all the trackers start to drift away from the target in frame 124 except for the iEMD and STRUCK trackers. For the Car2 and Car4 sequences, there are significant illumination changes when the targets pass underneath the trees and the overpasses. The LOT and Frag trackers start drifting away from frame 72 in Car2 sequences. In Car4 sequence, the LOT tracker starts to lose the target from frame 15, and the Frag and L1APG trackers drift away when the car passes the overpass in frame 249. In Walking2 sequence, the LOT, Frag, and ASLA trackers start tracking the wrong target in frame 246, due to the similar colors of the clothes between the two people.

Figure 3. The visual tracking results obtained by the nine tracking algorithms on the eight video sequences (No permission is required from the copyright holders and/or the depicted individuals for the use of these images. The original images are obtained from the CVPR 2013 database: http://cvlab.hanyang.ac.kr/tracker_benchmark/datasets.html).
6.2. Results for The Gyro-Aided iEMD Tracking Algorithm
The test of the gyro-aided iEMD tracking algorithm is conducted using the sequence including 100 frames from the dataset provided by CMU (Hwangbo et al., 2011). The images are taken in front of a desk with motions, such as shaking and rotation. The frame sequences have a resolution of 640 × 480 at 30 frames per second (FPS). The gyroscope is carefully aligned with the camera and the tri-axial gyroscopic values are sampled at 11Hz in the range of ±200deg/sec (Hwangbo et al., 2011). Using the time stamps of the camera and the gyroscope, the angular rate data are synchronized with the frames captured by the camera.
The comparisons between the tracking results using the iEMD tracker with and without the gyroscope information are illustrated in Figure 4. The head of the eagle is chosen as the target and the ground truth is manually labeled in each frame. The magenta box indicates the estimated image region without using the gyroscope data, and the cyan box is the tracking results of the gyro-aided iEMD tracker. Without the gyroscope data, the tracker loses the target after the frame 15. However, the head of the eagle is successfully tracked with our gyro-aided iEMD tracking algorithm.

Figure 4. Results of the iEMD tracker in presence of rapid camera motion; the magenta boxes indicate the results of the iEMD tracker without the gyroscope information, and the cyan boxes indicate the results of the gyro-aided iEMD tracker (No permission is required from the copyright holders and/or the depicted individuals for the use of these images. The original images are obtained from the database: http://www.cs.cmu.edu/~myung/IMU_KLT/).
The performances of the iEMD tracker with and without the gyroscope information on the CMU sequence are summarized in Table 3. The value of the average overlap, the percentage of the total frame numbers of which the overlap is greater than 0 and 40% are reported. Gyroscope information provides a good initial position for the iEMD tracker to estimate the location of the target. Thus, the gyro-aided iEMD tracking algorithm is robust to the rapid movements of the camera.

Table 3. Evaluation results on the CMU dataset using the iEMD tracker with and without the gyroscope information.
7. Discussion
As a cross-bin metric for the comparison of the histograms, the advantages of the EMD are demonstrated in situations such as illumination variation, object deformation and partial occlusion. The iEMD algorithm uses the transportation-simplex method for calculating the EMD. The practical running time complexity of the transportation-simplex method is supercubic [a complexity in Ω(N3)⋂O(N4)] (Rubner et al., 2000), where N represents the number of the histogram bins. Other algorithms for calculating the EMD can be used to further reduce the running time (Ling and Okada, 2007; Pele and Werman, 2009). For our current impelementation in MATLAB, the average run time computed over the eight test sequences is 1.4 FPS. Compared to the algorithms used in Table 2, which has an average run time of 1 FPS or less (for algorithms implemented in MATLAB), iEMD algorithm performs better in terms of FPS (Wu et al., 2013). Furthermore, the experimental results, especially the Human8 and Bolt2 sequences, show that the iEMD tracker is robust to the appearance variations. The experimental results of Walking2 show that the iEMD tracker can discriminate the target from the surroundings with similar colors. The tracking results from Woman and Subway sequences demonstrate the robustness to partial occlusions. In Figures 2, 3 and Table 2, the tracking results of the iEMD(CH) (Yao et al., 2016; Yao and Dani, 2017) are also presented using six out of eight videos which has color images. The iEMD(CH) algorithm cannot be tested on Car2 and Car4 videos because they have gray images. Since the sparse coding histogram is used as the appearance model and the template update method is adopted to handle the appearance changes of the target, the performance of the iEMD with the sparse coding histogram is significantly better than our prior work using the iEMD(CH).
8. Conclusion and Future Work
This paper presents iEMD and gyro-aided iEMD visual tracking algorithms. The local sparse representation is used as the appearance model for the iEMD tracker. The maximum-alignment-pooling method is used for constructing a sparse coding histogram which reduces the computational complexity of the EMD optimization. The template update algorithm based on the EMD is also presented. The iEMD tracker is robust to variations in appearance of the target, deformations and partial occlusions. Experiments conducted on eight publicly available datasets show that the iEMD tracker is robust to the illumination changes, deformations and partial occlusions of the target. To validate the gyro-aided iEMD tracking algorithm, experimental results from the CMU dataset, which contains rapid camera motion are presented. Without the gyroscope measurements, the iEMD tracker fails on the CMU dataset. With the help of the gyroscope measurements, the iEMD algorithm is able to lock onto the target and track it successfully. The above experimental results show that the proposed iEMD tracking algorithm is robust to the appearance changes of the target as well as the ego-motion of the camera. As a gradient descent based dynamic model, the iEMD tracker, which provides good location prediction, can be further improved with more effective particle filters. The metrics used by sparse coding, such as the largest sum of the sparse coefficients or the smallest reconstruction error, can be combined with the EMD to make the tracker more discriminant. In future, an efficient impelementation of iEMD tracker in C/C++ will be pursued.
Author Contributions
GY: co-developed the algorithm and coded and validated the results. AD: co-developed the algorithm and verified the results.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The authors would like to thank Prof. Peter Willett, Iman Salehi, and Harish Ravichandar for their help.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/frobt.2018.00095/full#supplementary-material
Video 1. Comparisons of Tracking Methods.
References
Adam, A., Rivlin, E., and Shimshoni, I. (2006). “Robust fragments-based tracking using the integral histogram,” in IEEE Computer Society Conf. on Computer Vision and Pattern Recognition (New York, NY), 798–805.
Avidan, S. (2007). Ensemble tracking. IEEE Trans. Pattern Anal. Mach. Intell. 29, 261–271. doi: 10.1109/TPAMI.2007.35
Babenko, B., Yang, M. H., and Belongie, S. (2011). Robust object tracking with online multiple instance learning. IEEE Trans. Pattern Anal. Mach. Intell. 33, 1619–1632. doi: 10.1109/TPAMI.2010.226
Baum, M., Willett, P., and Hanebeck, U. D. (2015). On Wasserstein Barycenters and MMOSPA estimation. IEEE Signal Process. Lett. 22, 1511–1515. doi: 10.1109/LSP.2015.2410217
Bolme, D. S., Beveridge, J. R., Draper, B. A., and Lui, Y. M. (2010). “Visual object tracking using adaptive correlation filters,” in IEEE Conference on Computer Vision and Pattern Recognition (San Francisco, CA), 2544–2550.
Chwa, D., Dani, A. P., and Dixon, W. E. (2016). Range and motion estimation of a monocular camera using static and moving objects. IEEE Trans. Control Syst. Technol. 24, 1–10. doi: 10.1109/TCST.2015.2508001
Collins, R. T., Liu, Y., and Leordeanu, M. (2005). Online selection of discriminative tracking features. IEEE Trans. Pattern Anal. Mach. Intell. 27, 1631–1643. doi: 10.1109/TPAMI.2005.205
Comaniciu, D., Ramesh, V., and Meer, P. (2003). Kernel-based object tracking. IEEE Trans. Pattern Anal. Mach. Intell. 25, 564–577. doi: 10.1109/TPAMI.2003.1195991
Comport, A. I., Marchand, E., Pressigout, M., and Chaumette, F. (2006). Real-time markerless tracking for augmented reality: the virtual visual servoing framework. IEEE Trans. Visual. Comput. Graph. 12, 615–628. doi: 10.1109/TVCG.2006.78
Dani, A. P., Fischer, N. R., and Dixon, W. E. (2012). Single camera structure and motion. IEEE Trans. Automatic Control 57, 238–243. doi: 10.1109/TAC.2011.2162890
Dani, A. P., Panahandeh, G., Chung, S.-J., and Hutchinson, S. (2013). “Image moments for higher-level feature based navigation,” in IEEE/RSJ International Conference on Intelligent Robots and Systems (Tokyo), 602–609.
Dantzig, G. B., and Thapa, M. N. (2006). Linear Programming 1: Introduction. Berlin: Heidelberg; Springer-Verlag.
Davison, A. J., Reid, I. D., Molton, N. D., and Stasse, O. (2007). MonoSLAM: Real-time single camera SLAM. IEEE Trans. Pattern Anal. Mach. Intell. 29, 1052–1067. doi: 10.1109/TPAMI.2007.1049
Grabner, H., and Bischof, H. (2006). “On-line boosting and vision,” in IEEE Computer Society Conference on Computer Vision and Pattern Recognition (New York, NY), 260–267.
Guerriero, M., Svensson, L., Svensson, D., and Willett, P. (2010). “Shooting two birds with two bullets: how to find minimum mean OSPA estimates,” in International Conference on Information Fusion (Edinburgh), 1–8.
Hare, S., Saffari, A., and Torr, P. H. (2011). “STRUCK: structured output tracking with kernels,” in International Conference on Computer Vision (Barcelona), 263–270.
Hwangbo, M., Kim, J.-S., and Kanade, T. (2011). Gyro-aided feature tracking for a moving camera: fusion, auto-calibration and GPU implementation. Intl J. Robot. Res. 30, 1755–1774. doi: 10.1177/0278364911416391
Jia, X., Lu, H., and Yang, M.-H. (2012). “Visual tracking via adaptive structural local sparse appearance model,” in IEEE Conference on Computer Vision and Pattern Recognition (Providence, RI), 1822–1829.
Jia, X., Lu, H., and Yang, M. H. (2016). Visual tracking via coarse and fine structural local sparse appearance models. IEEE Trans. Image Process. 25, 4555–4564. doi: 10.1109/TIP.2016.2592701
Kalal, Z., Mikolajczyk, K., and Matas, J. (2012). Tracking-learning-detection. IEEE Trans. Pattern Anal. Mach. Intell. 34, 1409–1422. doi: 10.1109/TPAMI.2011.239
Karavasilis, V., Nikou, C., and Likas, A. (2011). Visual tracking using the earth mover's distance between gaussian mixtures and Kalman filtering. Image Vision Comput. 29, 295–305. doi: 10.1016/j.imavis.2010.12.002
Li, H., Li, Y., and Porikli, F. (2016). Convolutional neural net bagging for online visual tracking. Comp. Vision Image Understand. 153, 120–129. doi: 10.1016/j.cviu.2016.07.002
Ling, H., and Okada, K. (2007). An efficient earth mover's distance algorithm for robust histogram comparison. IEEE Trans. Pattern Anal. Mach. Intell. 29, 840–853. doi: 10.1109/TPAMI.2007.1058
Liu, B., Huang, J., Yang, L., and Kulikowsk, C. (2011). “Robust tracking using local sparse appearance model and K-selection,” in IEEE Conference on Computer Vision and Pattern Recognition (Colorado Springs, CO), 1313–1320.
Mairal, J., Bach, F., and Ponce, J. (2014). Sparse modeling for image and vision processing. Foundations Trends Comput. Graph. Vis. 8, 85–283. doi: 10.1561/0600000058
Marchand, É., and Chaumette, F. (2005). Feature tracking for visual servoing purposes. Robot. Auton. Syst. 52, 53–70. doi: 10.1016/j.robot.2005.03.009
Marchand, É., Spindler, F., and Chaumette, F. (2005). ViSP for visual servoing: a generic software platform with a wide class of robot control skills. IEEE Robot. Automation Mag. 12, 40–52. doi: 10.1109/MRA.2005.1577023
Mei, X., and Ling, H. (2009). “Robust visual tracking using L1 minimization,” in IEEE 12th International Conference on Computer Vision (Kyoto), 1436–1443.
Mei, X., and Ling, H. (2011). Robust visual tracking and vehicle classification via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 33, 2259–2272. doi: 10.1109/TPAMI.2011.66
Oron, S., Bar-Hillel, A., Levi, D., and Avidan, S. (2012). “Locally orderless tracking,” in IEEE Conference on Computer Vision and Pattern Recognition (Providence, RI), 1940–1947.
Park, J., Hwang, W., Kwon, H., and Kim, K. (2013). A novel line of sight control system for a robot vision tracking system, using vision feedback and motion-disturbance feedforward compensation. Robotica 31, 99–112. doi: 10.1017/S0263574712000124
Pele, O., and Werman, M. (2009). “Fast and robust earth mover's distances,” in IEEE International Conference on Computer Vision, 460–467.
Ravichandar, H. C., and Dani, A. P. (2014). “Gyro-aided image-based tracking using mutual information optimization and user inputs,” in IEEE International Conference on Systems, Man and Cybernetics (San Diego, CA), 858–863.
Ravichandar, H. C., and Dani, A. P. (2015). “Human intention inference through interacting multiple model filtering,” in IEEE Conference on Multisensor Fusion and Integration (San Diego, CA).
Ross, D. A., Lim, J., Lin, R.-S., and Yang, M.-H. (2008). Incremental learning for robust visual tracking. Intl. J. Comput. Vis. 77, 125–141. doi: 10.1007/s11263-007-0075-7
Rubner, Y., Tomasi, C., and Guibas, L. J. (2000). The earth mover's distance as a metric for image retrieval. Intl J. Comput. Vis. 40, 99–121. doi: 10.1023/A:1026543900054
Santner, J., Leistner, C., Saffari, A., Pock, T., and Bischof, H. (2010). “Prost: parallel robust online simple tracking,” in IEEE Conference on Computer Vision and Pattern Recognition (San Francisco, CA), 723–730.
Spong, M. W., Hutchinson, S., and Vidyasagar, M. (2006). Robot Modeling and Control, Vol 3. New York, NY: Wiley.
Tahri, O., Usman, M., Demonceaux, C., Fofi, D., and Hittawe, M. (2016). “Fast earth mover's distance computation for catadioptric image sequences,” in IEEE International Conference on Image Processing (Phoenix, AZ), 2485–2489.
Vojir, T., Matas, J., and Noskova, J. (2016). Online adaptive hidden markov model for multi-tracker fusion. Comput. Vis. Image Understand. 153, 109–119. doi: 10.1016/j.cviu.2016.05.007
Wang, J., Wang, H., and Zhao, W.-L. (2015). Affine hull based target representation for visual tracking. J. Vis. Commun. Image Represent. 30, 266–276. doi: 10.1016/j.jvcir.2015.04.014
Wang, J., Wang, Y., and Wang, H. (2016). “Adaptive appearance modeling with Point-to-Set metric learning for visual tracking,” in IEEE Transaction on Circuits and Systems for Video Technology. doi: 10.1109/TCSVT.2016.2556438
Wu, Y., Lim, J., and Yang, M.-H. (2013). “Online object tracking: a benchmark,” in IEEE Conference on Computer Vision and Pattern Recognition (CVPR) (Portland, OR).
Yang, J., Dani, A. P., Chung, S.-J., and Hutchinson, S. (2015). Vision-based localization and robot-centric mapping in riverine environments. J. Field Robot. 34, 429–450. doi: 10.1002/rob.21606
Yao, G., and Dani, A. (2017). Gyro-aided visual tracking using iterative Earth mover's distance. IEEE Aerospace Electron. Syst. Mag. 32, 52–55. doi: 10.1109/MAES.2017.160223
Yao, G., Williams, M., and Dani, A. (2016). “Gyro-aided visual tracking using iterative Earth mover's distance,” in 19th International Conference on Information Fusion (FUSION) (Heidelberg), 2317–2323.
Yilmaz, A., Javed, O., and Shah, M. (2006). Object tracking: a survey. ACM Comput. Surveys 38:13. doi: 10.1145/1177352.1177355
Zhang, S., Yao, H., Sun, X., and Lu, X. (2013). Sparse coding based visual tracking: review and experimental comparison. Pattern Recogn. 46, 1772–1788. doi: 10.1016/j.patcog.2012.10.006
Zhang, T., Ghanem, B., Liu, S., and Ahuja, N. (2012). “Robust visual tracking via multi-task sparse learning,” in IEEE Conference on Computer Vision and Pattern Recognition (Providence, RI), 2042–2049.
Zhang, Z., and Hong Wong, K. (2014). “Pyramid-based visual tracking using sparsity represented mean transform,” in Proc. of the IEEE Conf. on Computer Vision and Pattern Recognition (Columbus, OH), 1226–1233.
Zhao, Q., Yang, Z., and Tao, H. (2010). Differential earth mover's distance with its applications to visual tracking. IEEE Trans. Pattern Anal. Mach. Intell. 32, 274–287. doi: 10.1109/TPAMI.2008.299
Zhu, G., Wang, J., and Lu, H. (2016). Clustering based ensemble correlation tracking. Comp. Vis. Image Understand. 153, 55–63. doi: 10.1016/j.cviu.2016.05.006
Keywords: visual tracking, earth mover's distance, sparse coding, gyro-aided tracking, max-alignment pooling, template update
Citation: Yao G and Dani A (2018) Visual Tracking Using Sparse Coding and Earth Mover's Distance. Front. Robot. AI 5:95. doi: 10.3389/frobt.2018.00095
Received: 04 November 2017; Accepted: 27 July 2018;
Published: 22 August 2018.
Edited by:
David Fofi, Université de Bourgogne, FranceReviewed by:
Miguel Angel Olivares-Mendez, University of Luxembourg, LuxembourgAdlane Habed, UMR7357 Laboratoire des Sciences de l'Ingénieur, de l'Informatique et de l'Imagerie (ICube), France
Copyright © 2018 Yao and Dani. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ashwin Dani, YXNod2luLmRhbmlAdWNvbm4uZWR1