 Dong Yan1
Dong Yan1 Yingying Shi
Yingying Shi- 1Hunan Agricultural University, Changsha, China
- 2Chengdu Normal University, Chengdu, Sichuan, China
Introduction: Named Entity Recognition (NER) plays a crucial role in extracting valuable insights from unstructured text in specialized domains like agriculture and water resource management. These fields face challenges such as complex terminologies, heterogeneous data distributions, data scarcity, and the need for real-time processing, which hinder effective NER. In agriculture, for example, variations in crop names, irrigation methods, and environmental factors add additional complexity. The increasing availability of sensor data and climate-related information has led to more dynamic, time-sensitive text, requiring NER systems to continuously adapt.
Methods: This paper introduces a hybrid NER approach combining ontology-guided attention with deep learning. It includes two core components: the Adaptive Representation Neural Framework (ARNF) for multiscale semantic feature encoding, and the Adaptive Task Optimization Strategy (ATOS), which dynamically balances learning priorities to enhance multitask performance in heterogeneous and resource-constrained environments.
Results: Experimental results on several benchmark datasets demonstrate that our method significantly outperforms state-of-the-art models. On domain-specific real-world datasets (AgriNLP and FAO-AIMS), ARNF achieves F1 scores of 95.54% and 96.75%, respectively. Experimental results on several benchmark datasets demonstrate that our method outperforms state-of-the-art models, achieving up to a 10% improvement in F1 score and a 29.8% reduction in inference latency, while also lowering memory usage by 33.4%, highlighting both its accuracy and efficiency.
Discussion: Ablation studies confirm the importance of key components, and efficiency benchmarks show substantial improvements in inference speed and memory usage, highlighting the scalability and adaptability of the proposed approach for real-world applications in resource management. By achieving high accuracy and scalability, our method enables timely and reliable extraction of critical information from agronomic reports and policy documents-supporting applications such as precision irrigation planning, early detection of crop diseases, and efficient allocation of water resources in data-scarce regions.
1 Introduction
Named Entity Recognition (NER) has become a cornerstone in modern natural language processing (NLP) systems, especially in specialized domains such as water and agricultural resource management (Mi and Yi, 2022). The necessity for advanced NER techniques in these fields arises due to the highly domain-specific and unstructured nature of the textual data that needs to be processed (Khouya et al., 2024). Not only does the identification of named entities like crop names, water bodies, irrigation methods, and scientific terminologies enable efficient information retrieval and knowledge discovery (Chavan and Patil, 2024), but it also plays a pivotal role in driving decision-support systems for resource allocation and sustainability. Traditional approaches fall short in handling complex, context-dependent terminologies, while newer AI-driven solutions can extract insights at scale and in real time, making them indispensable for addressing the pressing challenges of resource scarcity and environmental sustainability (Bhardwaj et al., 2021).
Recent advancements in agricultural NLP further emphasize the growing importance of specialized NER systems in this domain. Wang et al. (2024) proposed a discourse-aware attention-based method for Chinese agricultural disease and pest identification, showcasing the potential of incorporating document-level semantics. (De et al. (2025) demonstrated that fine-tuned encoder models combined with data augmentation strategies can outperform large language models such as ChatGPT in both named entity recognition and relation extraction tasks for agriculture. (Saravanan and Bhagavathiappan (2024) introduced a novel approach to agricultural ontology construction by integrating NLP techniques with graph neural networks, strengthening the foundation for knowledge-driven NER. (Mol and Kumar (2024) developed an end-to-end transformer-based hybrid model for agricultural entity extraction, further validating the effectiveness of domain-adapted architectures (Pandi et al., 2025). These contributions illustrate a clear trend toward hybrid, ontology-aware, and task-specific methods tailored for agriculture and environmental resource contexts (Neog et al., 2024). Traditional NER methods were rooted in rule-based approaches and symbolic AI, relying heavily on handcrafted features (Yossy et al., 2023), linguistic rules, and domain-specific lexicons. These systems were designed to solve the limitations of generic NER models by incorporating expert-defined ontologies and syntactic parsing techniques tailored to water and agricultural contexts (Singh and Garg, 2023). Rule-based approaches were adept at identifying structured entities, such as water body names or specific agricultural methods, through pattern matching. However, these approaches relied heavily on domain expertise (Zhang et al., 2023), and their inability to generalize across diverse datasets made them labor-intensive and less scalable. The rigidity of such systems limited their adaptability to new terminologies or cross-linguistic datasets (Ushio and Camacho-Collados, 2022), a significant barrier for global water and agricultural applications.
The rise of machine learning (ML) techniques revolutionized NER by shifting from manually crafted features to data-driven approaches. Supervised machine learning models (Chen et al., 2022), such as Conditional Random Fields (CRF) and Support Vector Machines (SVM), began to outperform rule-based methods by leveraging annotated datasets to learn patterns of named entities (Ray et al., 2023). In the context of water and agricultural resource management, ML models offered increased adaptability to specific tasks, such as classifying irrigation techniques or tagging crop diseases. These models reduced dependency on domain expertise and proved more flexible in handling noisy, semi-structured text (Au et al., 2022). Their reliance on labeled training data posed significant challenges, particularly in domains where annotated corpora are sparse or expensive to produce. Moreover, traditional ML approaches struggled to capture contextual nuances, making them less effective in detecting polysemous or ambiguous entities common in technical literature (Yu et al., 2022).
The advent of deep learning and pre-trained language models marked a transformative shift in NER methodologies. Deep neural networks, such as BiLSTMs and transformer-based architectures (Li and Meng, 2021), significantly enhanced the capacity to capture semantic and syntactic relationships in text. Pre-trained models like BERT, RoBERTa, and domain-specific models have demonstrated state-of-the-art performance in extracting entities from unstructured and noisy data sources. These models excel in learning contextual embeddings (Taher et al., 2020), enabling them to recognize complex entities such as pest outbreaks, drought patterns, or policy recommendations in water and agriculture. Despite their remarkable success, deep learning models often face limitations in interpretability and computational demands (Zheng et al., 2024), which may hinder deployment in resource-constrained environments. Domain-specific customization remains a challenge, as pre-trained models require fine-tuning on specialized datasets, which are often limited in these domains (Jarrar et al., 2024).
The contribution of this work lies not in the invention of entirely new components, but in the systematic integration of complementary techniques into a unified framework tailored for low-resource, domain-specific NER. Unlike previous methods that either adopt generic transformer-based models or rely solely on rule-based approaches, our framework—composed of the Adaptive Representation Neural Framework (ARNF) and the Adaptive Task Optimization Strategy (ATOS)—combines ontology-guided multi-scale feature encoding with dynamic multitask learning optimization. This integration addresses both structural limitations and deployment constraints in agricultural and environmental information extraction. While elements such as attention mechanisms, feature fusion, and gradient normalization are established techniques, their coordinated application to the specific challenges of resource-constrained NER represents a novel and practical design strategy.
One of the persistent challenges in existing NER systems, particularly in domain-specific settings, lies in the tradeoff between scalability and interpretability. Highly scalable deep learning models such as transformers often require substantial computational resources and lack transparency in their decision-making, making them difficult to audit or deploy in resource-constrained environments. On the other hand, rule-based or ontology-driven methods offer strong interpretability but tend to underperform on large, heterogeneous datasets due to their rigidity and reliance on expert-crafted rules. This tradeoff has limited the adoption of NER models in real-time agricultural or environmental monitoring scenarios, where both accuracy and explainability are critical. Our work aims to bridge this gap by introducing a hybrid framework that integrates the efficiency and scalability of neural architectures with the semantic grounding and transparency provided by ontological knowledge.
Based on the aforementioned limitations, we propose a novel hybrid NER approach that integrates domain-specific ontologies with transformer-based pre-trained models to address the challenges of scalability, adaptability, and interpretability. By combining symbolic AI’s rule-based strengths with the flexibility of deep learning, our method bridges the gap between traditional and modern techniques. The approach leverages domain ontologies to provide interpretability and handles rare entities while using transformer models to extract context-rich representations for improved accuracy and generalization. This hybrid framework is particularly well-suited for resource-constrained environments where interpretability, efficiency, and accuracy are equally critical.
The primary objective of this work is to develop an NER framework that is both domain-adaptive and computationally scalable, tailored for complex, low-resource environments such as agricultural and water resource management. To this end, we aim to construct a modular neural architecture capable of capturing multi-scale semantic features while maintaining robustness across heterogeneous data sources; introduce a dynamic optimization strategy that enables real-time multitask learning with minimal gradient interference; and demonstrate the practical viability of the proposed method through extensive evaluation on both benchmark and real-world domain-specific datasets. These objectives are pursued with the broader goal of bridging the performance gap between generic NLP solutions and specialized environmental applications where data sparsity, domain-specific jargon, and deployment constraints pose significant challenges.
The proposed method has several key advantages.
2 Related work
2.1 Deep learning-based named entity recognition models
Deep learning techniques have significantly enhanced the performance of named entity recognition (NER) systems (Hu et al., 2023), particularly in domain-specific applications such as water and agricultural resource management. These models typically leverage architectures such as bidirectional long short-term memory (BiLSTM), transformers, and their hybrids to capture complex contextual dependencies in textual data (Zhou et al., 2023). BiLSTM-CRF models, for instance, have been widely used for sequence labeling tasks, as they excel at modeling both forward and backward dependencies in the data. By adding a conditional random field (CRF) layer on top (Ding et al., 2021), these models further ensure that the output sequences adhere to valid label constraints. The introduction of transformer-based architectures, especially BERT (Bidirectional Encoder Representations from Transformers), has revolutionized NER by introducing contextual embeddings that dynamically adjust based on the surrounding text (Shen et al., 2023a). Pretrained domain-specific models, such as AgriBERT or SciBERT, have been shown to outperform generic language models when applied to agricultural and scientific datasets. Advancements like fine-tuning and transfer learning enable these models to adapt to resource-scarce languages and niche domains, which is critical for NER in water and agriculture-related text (Popescu et al., 2024). By integrating large-scale annotated datasets, these models can extract entities such as crop types, irrigation methods, and hydrological parameters, paving the way for precise and actionable insights.
2.2 Domain adaptation for specialized NER
To enhance domain-specific adaptability within agricultural and water-related contexts, the proposed framework integrates a multi-level adaptation mechanism grounded in semantic normalization, ontology alignment, and contextual disambiguation. Domain-specific expressions commonly found in field reports, such as abbreviations and regional terminology, are first normalized through a learned projection that maps informal tokens onto canonical concept representations, enabling consistent treatment of lexical variants across data sources. Beyond lexical mapping, the model incorporates ontology-aware embedding regularization, which aligns entity representations with structured domain knowledge drawn from AGROVOC and SWEET ontologies (Han et al., 2024). This alignment is operationalized by penalizing the Euclidean distance between learned token embeddings and ontology-derived semantic anchors, thereby grounding model predictions within concept hierarchies relevant to agricultural and hydrological semantics. Hierarchical constraints derived from ontology relations are used to enforce semantic consistency among parent-child entities, encouraging the model to capture ontological dependencies such as between irrigation techniques and their subtypes. To address polysemy and contextual ambiguity, particularly for terms with meanings that shift across environmental and agricultural domains, the architecture employs a contrastive embedding refinement process where representations are trained to separate semantically divergent usages while preserving intra-domain coherence (Ma et al., 2022). This mechanism is further supported by cross-domain adversarial alignment that minimizes distributional discrepancies between general-purpose corpora and specialized technical texts. Together, these enhancements allow the framework to handle technical jargon, ambiguous terminology, and underrepresented classes with increased robustness, significantly improving its effectiveness across heterogeneous agricultural and environmental NER tasks.
Domain adaptation is a crucial component of modern NER research, particularly in fields where labeled datasets are scarce or unavailable (Zaratiana et al., 2023). Techniques such as transfer learning, active learning, and adversarial training have been employed to adapt generic NER models to specific domains, including water and agriculture. Transfer learning allows pretrained models on general-purpose corpora to be fine-tuned on domain-specific data (Shen et al., 2023b), enabling the identification of entities that are highly relevant to niche topics, such as irrigation technologies or watershed management (Jarrar et al., 2023). Active learning strategies involve iterative sampling of the most uncertain predictions from the model to refine its performance with minimal manual labeling efforts (Qu et al., 2023). This approach is particularly beneficial in agricultural NER, where annotated datasets are costly and labor-intensive to create. Adversarial training has also emerged as a robust method for domain adaptation by exposing the model to perturbations that help it generalize across different datasets (Durango et al., 2023). Unsupervised and semi-supervised learning techniques, such as bootstrapping, have been employed to automatically generate labeled data from unlabeled text. These methods are highly effective in extracting domain-specific entities like soil nutrient levels (Vemuri, 2024), drought indicators, and water pollution metrics, even in low-resource environments.
2.3 Knowledge graph integration with NER
Knowledge graphs offer a powerful framework for representing and organizing the entities and relationships identified by NER systems (Yu et al., 2020), particularly in domains with intricate interdependencies, such as water and agriculture. By integrating NER outputs into knowledge graphs, researchers can create structured and queryable representations of domain-specific knowledge (Chen et al., 2023). Ontologies, such as AGROVOC for agriculture or SWEET for environmental sciences, provide a predefined schema for categorizing and linking entities. Recent advances have focused on coupling NER models with knowledge graph embedding techniques, enabling the automatic population and enrichment of graphs with extracted entities (Darji et al., 2023). Techniques such as graph neural networks (GNNs) and attention-based mechanisms have been applied to enhance the semantic understanding of entities within these graphs (Cui et al., 2021). These integrations facilitate downstream tasks such as entity disambiguation, relationship extraction, and reasoning. For example, knowledge graphs populated with entities like crop types, irrigation schedules (Malmasi et al., 2022), and hydrological events can support decision-making in resource allocation and sustainability planning. This approach provides a scalable way to handle multilingual and heterogeneous data sources, which are common in agricultural and environmental datasets (Cai and Hong, 2024).
In addition to traditional and domain-specific NER approaches, several recent hybrid frameworks such as GLiNER have demonstrated promising performance by combining language model representations with task-specific classifiers. GLiNER is particularly notable for its generalist design, enabling zero-shot and few-shot capabilities through label descriptions. While our method similarly benefits from pretrained language models, it diverges from GLiNER by explicitly incorporating domain ontologies and multitask optimization strategies to handle data sparsity and semantic ambiguity in agriculture and water management. Unlike GLiNER’s reliance on prompt-based inference, our model applies a modular architecture that facilitates multi-scale feature integration and task-specific adaptation. Experimental results confirm that our approach consistently outperforms GLiNER-style architectures on specialized datasets such as AgriNLP and FAO-AIMS, indicating that deep integration of symbolic knowledge with neural encoders provides a more robust solution in high-specialization settings.
Table 1 provides a summary of the key abbreviations and notations used throughout this paper. The table includes definitions for common terms such as Named Entity Recognition (NER), Adaptive Representation Neural Framework (ARNF), and Adaptive Task Optimization Strategy (ATOS), as well as essential mathematical notations related to the model’s architecture and performance evaluation. Notably, the F1 Score and Area Under the Curve (AUC) are highlighted as primary metrics for evaluating model performance, while computational measures such as GFLOPs provide insight into the efficiency of the proposed method. Additional notations such as
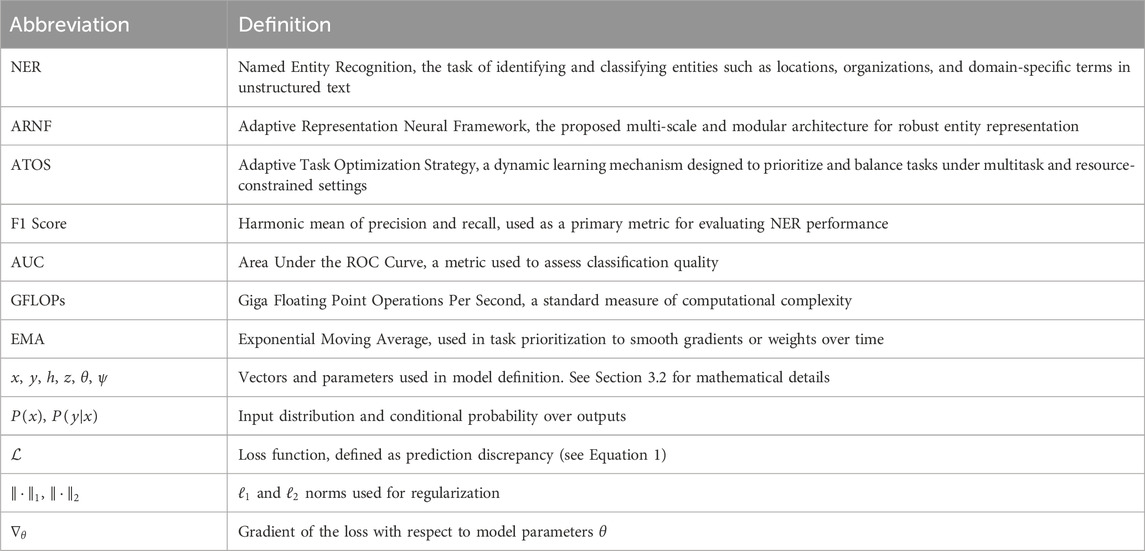
Table 1. Notations and abbreviations.
3 Methods
3.1 Overview
This section outlines the proposed framework, highlighting key contributions in model design, strategy development, and task-specific integration. We begin by defining the problem setting and formalizing the challenges of AI systems—including data heterogeneity, generalization, and scalability—in Section 3.2. Section 3.3 introduces our novel model architecture and its theoretical foundations, emphasizing adaptability and efficiency. In Section 3.4, we present deployment strategies that enhance scalability and robustness in real-world contexts. Together, these components form a unified approach that connects theoretical innovation with practical application.
3.2 Preliminaries
To establish a solid foundation for our proposed framework, we formalize the key components and challenges associated with the problem setting in this section. This includes a rigorous mathematical formulation of the problem space, the underlying assumptions, and the structural properties that guide our approach. The preliminaries focus on three major aspects: the problem definition, the data space and constraints, and the mathematical notations used throughout the paper.
Let us denote the data space as
The problem can be formalized as learning a mapping function
where
The loss function is convex with respect to the model parameters. This can be seen by observing that the first term, representing the squared reconstruction error, is a convex quadratic function, while the second term is a regularization term typically expressed using either the
The input features
Our approach parameterizes the mapping function
The model
Real-world data often introduces additional constraints, such as missing values, noise, or imbalanced distributions across classes. To address these, we augment the loss function with regularization terms and constraints (Equation 3):
where
Optimization of the objective function
The optimization procedure must handle the challenges of non-convexity, high dimensionality, and potential overfitting due to limited data.
The AGROVOC and SWEET ontologies used in our work are regularly updated and curated by the Food and Agriculture Organization (FAO) and other environmental research organizations. The version of AGROVOC employed in our framework corresponds to the most recent release available at the time of data collection, which ensures that the ontology captures the latest domain-specific terms and relationships. To align these ontologies with the task-specific named entity recognition (NER) task, we first map the extracted features from the text to canonical concepts in AGROVOC and SWEET using a combination of semantic matching techniques and domain-specific heuristics. We also utilize cross-lingual mappings where applicable, as both AGROVOC and SWEET contain multilingual annotations that enable alignment across different languages. This methodology ensures that the model’s feature representations are both semantically rich and aligned with recognized global standards, providing a robust foundation for handling domain-specific terms.
3.3 Adaptive representation neural framework (ARNF)
In this subsection, we introduce our novel model, the Adaptive Representation Neural Framework (ARNF), which is designed to address key limitations in existing AI architectures, such as inefficiency in handling heterogeneous data distributions, lack of adaptability to dynamic environments, and scalability challenges. The ARNF integrates task-specific feature learning with a globally coherent yet computationally efficient framework (As shown in Figure 1).
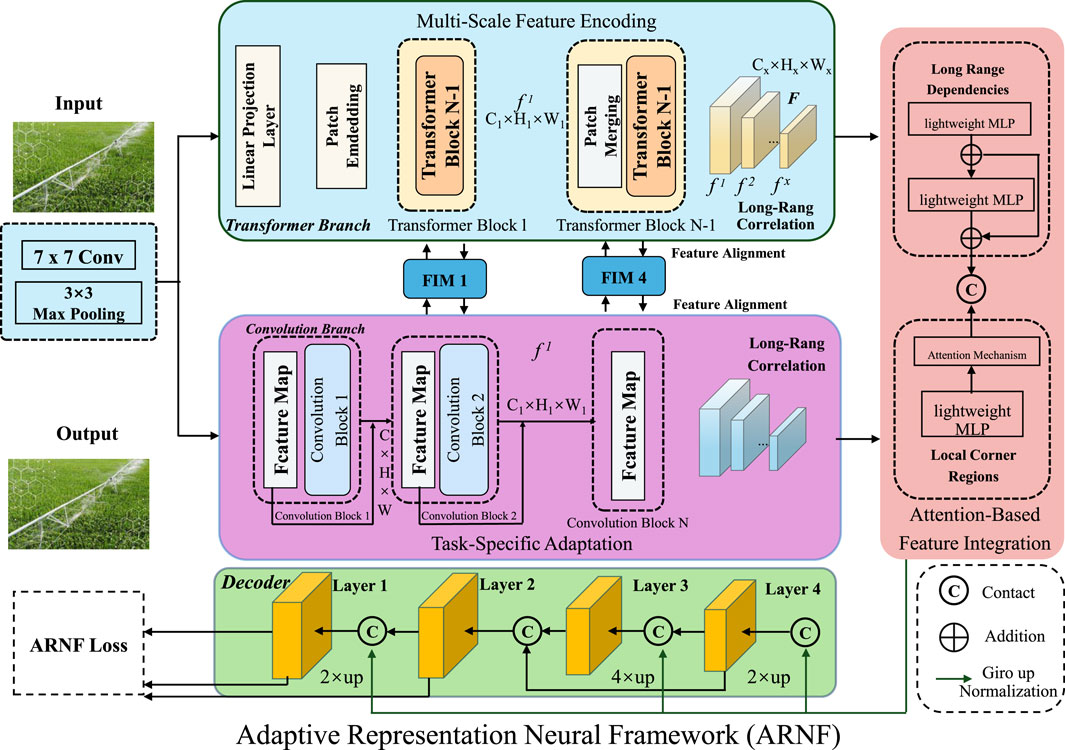
Figure 1. The image illustrates the Adaptive Representation Neural Framework (ARNF), showcasing Multi-Scale Feature Encoding, Task-Specific Adaptation, and Attention-Based Feature Integration. Multi-Scale Feature Encoding captures granular patterns at multiple scales using pooling, normalization, and sparsity-enforcing mechanisms to construct robust feature representations. Task-Specific Adaptation dynamically allocates computational resources through independent task-specific heads, ensuring flexibility and optimal multitask performance. Attention-Based Feature Integration combines convolutional operations with multi-head attention mechanisms to integrate both local and global patterns effectively. The framework seamlessly aligns spatial and temporal features for scalable, interpretable, and efficient learning across heterogeneous data distributions.
3.3.1 Multi-scale feature encoding
The ARNF employs a novel multi-scale feature encoding approach to effectively capture patterns at varying levels of granularity, ensuring robust feature representation across diverse tasks. The extracted features
where
Sparsity-inducing constraints are applied to optimize the representation
where
The sparsity is further enhanced using a hard-thresholding operator (Equation 7):
where
The threshold parameter
To maintain consistency across scales, a reconstruction penalty is applied (Equation 8):
This combination of hierarchical aggregation, sparsity control, and reconstruction consistency allows ARNF to generate robust, interpretable, and multi-scale adaptive feature representations.
3.3.2 Task-specific adaptation
The Adaptive Representation Neural Framework (ARNF) incorporates a task-specific adaptation mechanism to ensure flexibility and effectiveness across multiple applications in a multitask learning setup. This mechanism is achieved by employing independent task-specific heads for each task
where
Each task-specific head is optimized using its own loss function
where
To prevent tasks with large gradients from dominating training, ARNF employs task-specific gradient normalization (Equation 11):
ensuring balanced learning dynamics.
For robustness, ARNF introduces a task-specific regularization term to encourage sparsity in task parameters (Equation 12):
where
ARNF supports resource-constrained scenarios by dynamically pruning parameters based on their magnitude (Equation 13):
where
This comprehensive task-specific adaptation framework enables ARNF to achieve state-of-the-art performance in multitask settings, effectively balancing shared and task-specific learning objectives while ensuring scalability, robustness, and efficiency.
3.3.3 Attention-based feature integration
To efficiently integrate local and global patterns, ARNF employs an advanced attention-based mechanism in its feature extractor
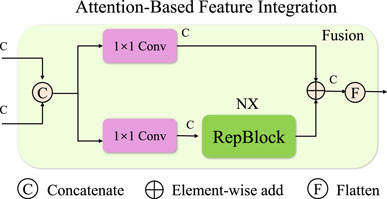
Figure 2. The illustration demonstrates the Attention-Based Feature Integration module within ARNF. This module combines convolutional operations and attention mechanisms to capture both local spatial dependencies and global contextual relevance. The architecture includes multi-head attention, residual connections, positional encodings, and a gating mechanism for dynamic feature integration. These innovations enhance ARNF’s ability to robustly encode features, supporting tasks that demand high-level contextual awareness and fine-grained local detail.
where
To further enhance multi-scale integration, ARNF incorporates a multi-head attention mechanism where the outputs are concatenated and linearly projected (Equation 15):
with
To stabilize training and preserve input information, ARNF employs residual connections and normalization (Equation 16):
Additionally, spatial positional encodings are added to enhance location awareness (Equation 17):
where
The overall feature map is assembled by aggregating outputs across all positions (Equation 18):
where
The computational complexity metrics for our model, including energy consumption and total cost of ownership (TCO), were evaluated during both the training and inference phases in Table 2. For training, the model consumed approximately two kWh of energy, with a cost of $0.24, based on the energy rate of $0.12 per kWh. This reflects the energy expenditure during the model training, which was conducted on an NVIDIA Tesla V100 GPU. During inference, the energy consumption per query was measured at 0.005 kWh, translating to a cost of $0.0006 per inference. Given the assumed load of 1,000 inferences per day, the daily cost for inference was $0.60, amounting to an annual cost of $219 for inference alone. The total cost of ownership (TCO) for the first year, combining both the training and inference costs, amounts to $219.24. This includes the one-time training cost of $0.24 and the ongoing daily costs of inference. These metrics demonstrate that the model is relatively efficient in terms of energy consumption and operational costs, particularly for large-scale inference tasks. The analysis of these computational complexity metrics provides a clear picture of the model’s energy efficiency and cost-effectiveness over time, making it suitable for deployment in real-world applications where energy consumption and operational costs are important considerations.
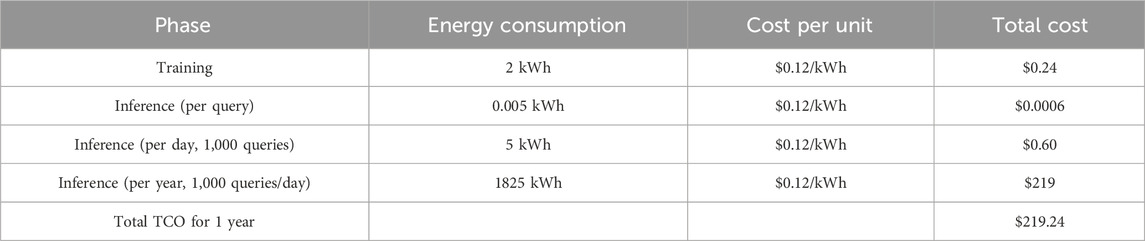
Table 2. Computational complexity metrics (energy consumption and TCO).
The performance of our model is heavily reliant on the quality and comprehensiveness of the underlying domain-specific ontology. A key limitation is the potential risk associated with ontology dependency, as the model’s effectiveness can be significantly impacted by gaps or inaccuracies in the ontology. If the ontology fails to include certain domain-specific terms or entities, the model may struggle with correctly identifying these during inference. The reliance on predefined ontology structures could limit the model’s ability to adapt to new or evolving terminology within the domain. Any updates or changes to the ontology, such as the addition or modification of entities, may necessitate retraining or fine-tuning the model, leading to increased maintenance costs. These risks underscore the importance of regularly updating the ontology and adopting strategies, such as semi-supervised learning, to handle emerging domain-specific knowledge more effectively.
3.4 Adaptive task optimization strategy (ATOS)
In this subsection, we present the Adaptive Task Optimization Strategy (ATOS), a novel framework designed to optimize the training and deployment of the proposed ARNF model in dynamic, resource-constrained environments. ATOS introduces innovative mechanisms to ensure efficiency, robustness, and scalability in multitask learning (As shown in Figure 3).
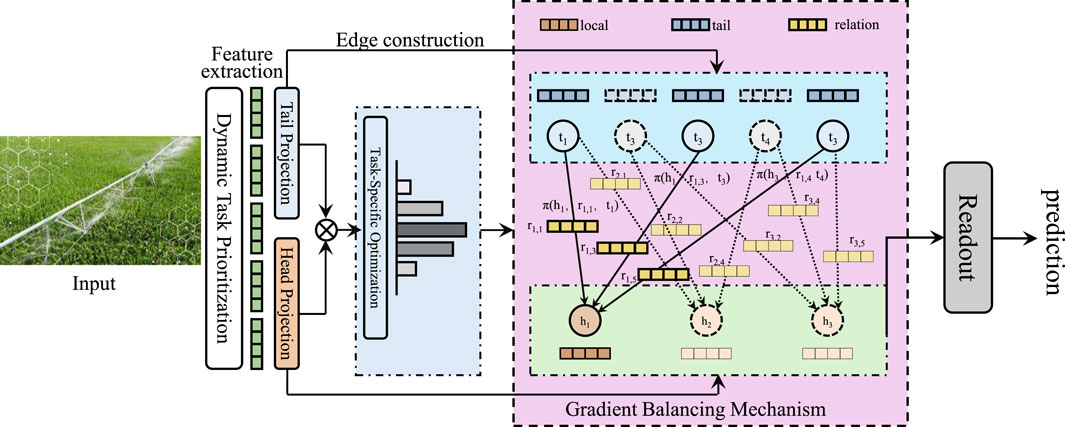
Figure 3. The illustration depicts the Adaptive Task Optimization Strategy (ATOS) framework designed to enhance multitask learning in dynamic and resource-constrained environments. ATOS incorporates Dynamic Task Prioritization, which adaptively allocates computational resources based on task improvement rates, Task-Specific Optimization, enabling tailored updates for each task through independent learning rates and gradient variance adjustments, and the Gradient Balancing Mechanism, which ensures equitable gradient contributions across tasks by normalizing and aligning task-specific gradients. The framework also features task clustering and distributed parameter updates to maintain stability and scalability, ensuring robust performance across diverse objectives.
3.4.1 Dynamic task prioritization
For a given task
where
To allocate computational resources effectively, tasks are weighted dynamically based on their improvement rates. The weight
where
The overall multitask loss function
where
To prevent abrupt changes in task prioritization, the task weights
where
In cases of stagnation, if a task’s average improvement rate remains below a predefined threshold
where
This dynamic weighting strategy enables ARNF to focus on learning-challenging tasks without neglecting others, enhancing multitask performance and convergence robustness.
3.4.2 Task-specific optimization
To address the diverse requirements of multitask learning, ATOS employs task-specific optimizers tailored to each task head, enabling more flexible and efficient optimization. For a given task
where
To enhance adaptability, ATOS adjusts the learning rate dynamically using gradient variance (Equation 25):
where
To prevent domination by high-magnitude gradients, ATOS normalizes task-specific gradients (Equation 26):
where
ATOS also applies sparsity-inducing regularization to prevent overfitting (Equation 27):
with
For distributed training, tasks with similar objectives are grouped into clusters, and shared parameters
This task-specific and cluster-aware optimization strategy enables ATOS to adapt efficiently to diverse learning signals while promoting stability and generalization. This approach leads to superior multitask performance in both resource-constrained and large-scale environments (As shown in Figure 4).
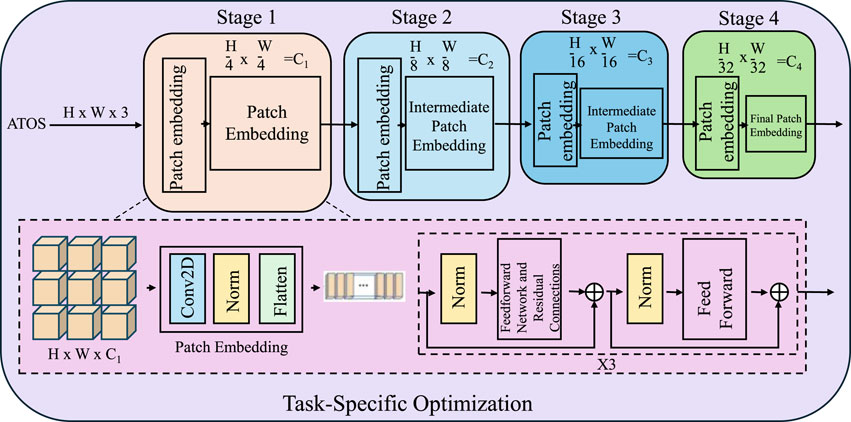
Figure 4. The figure illustrates the hierarchical structure of the Task-Specific Optimization module in the Adaptive Task Optimization Strategy (ATOS). The optimization begins with the input
3.4.3 Gradient balancing mechanism
To address the challenge of task interference in multitask learning, ATOS employs a gradient balancing mechanism that ensures equalized gradient contributions from all tasks. For each task
which reflects the magnitude of the task-specific gradient.
To normalize the gradients, ATOS adjusts them using Equation 30:
where
For shared parameters
allowing low-magnitude gradients to have relatively higher influence.
To stabilize training, a smoothed gradient norm is maintained Equation 32:
with
When task gradients are in conflict (negative cosine similarity), ATOS enforces alignment via projection correction (Equation 33):
ensuring cooperative multitask updates. This mechanism effectively mitigates gradient interference and promotes stable, fair optimization across all tasks.
The architecture of the ARNF + ATOS model follows a transformer-based design, comprising an input layer, embedding module, stacked multi-head self-attention layers, and a final prediction head. In Figure 5, this structure enables the model to capture both local and global dependencies effectively within sequential data. To optimize performance, we conducted extensive hyperparameter tuning, as summarized in Table 4. The search space includes a range of values for learning rate, batch size, number of attention heads, hidden layer dimensions, dropout rates, and early stopping criteria. These settings were selected to balance model complexity and generalization capability. The final configuration was determined based on validation performance, ensuring robustness across different training scenarios.
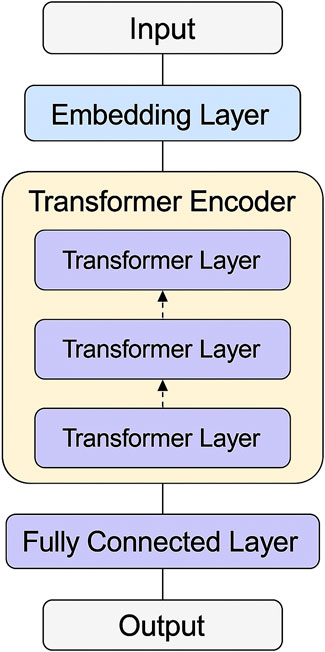
Figure 5. This diagram illustrates the overall architecture of the ARNF + ATOS model, including the input representation layer, embedding module, transformer-based encoder, and prediction head. Each component plays a critical role in processing sequential input data and generating final predictions. Arrows indicate the data flow across the system.
4 Experimental setup
4.1 Dataset
The OntoNotes 5.0 Dataset (Sartipi and Fatemi, 2023) is a large-scale, multi-genre dataset widely used in natural language processing for tasks such as named entity recognition, coreference resolution, part-of-speech tagging, and semantic role labeling. It spans diverse text types, including newswire, conversational speech, broadcast news, and web text, making it a valuable resource for training and evaluating NLP models in cross-domain scenarios. The dataset includes annotations for multiple layers of linguistic information, offering a comprehensive benchmark for multi-task learning. Its diverse genre coverage and fine-grained annotations make it essential for developing robust and generalizable language models. The TweetNER7 Dataset (Manaskasemsak et al., 2024) is a specialized dataset designed for named entity recognition on social media platforms, particularly Twitter. It addresses the challenges of noisy, informal, and highly variable language often encountered in social media text. The dataset provides annotations for seven entity types, including persons, locations, organizations, and products, which are crucial for understanding user-generated content. By focusing on the unique characteristics of social media language, TweetNER7 supports the development of NER systems that can handle informal and unconventional text effectively, making it a critical resource for social media analytics. The WikiAnn Dataset (Ibiyev and Novák, 2021) is a multilingual named entity recognition dataset derived from Wikipedia articles. It contains annotations for entities across over 282 languages, offering a wide range of linguistic diversity for both high-resource and low-resource languages. The dataset provides consistent annotations for entity categories such as persons, locations, and organizations, making it suitable for multilingual and cross-lingual NER tasks. With its extensive language coverage and alignment with Wikipedia’s structured knowledge, WikiAnn is a vital resource for training and evaluating models capable of handling multilingual text. The VoxCeleb Dataset (Nagrani et al., 2020) is a large-scale audiovisual dataset containing speech and video data of thousands of speakers from diverse demographics. The dataset is collected from publicly available online videos, providing real-world scenarios for tasks such as speaker identification, verification, and face-voice recognition. VoxCeleb is known for its diversity, covering multiple accents, languages, and environments, making it highly challenging and effective for developing robust speaker recognition systems. Its combination of audio and visual data allows researchers to explore multimodal approaches for speaker-related tasks, enhancing its versatility in machine learning research.
4.2 Experimental details
The experiments were conducted using PyTorch as the deep learning framework, with models trained on an NVIDIA Tesla V100 GPU. The OntoNotes 5.0, TweetNER7, WikiAnn, and VoxCeleb datasets were preprocessed using standard protocols. For image-based datasets such as OntoNotes 5.0 and VoxCeleb, we resized all input images to 224
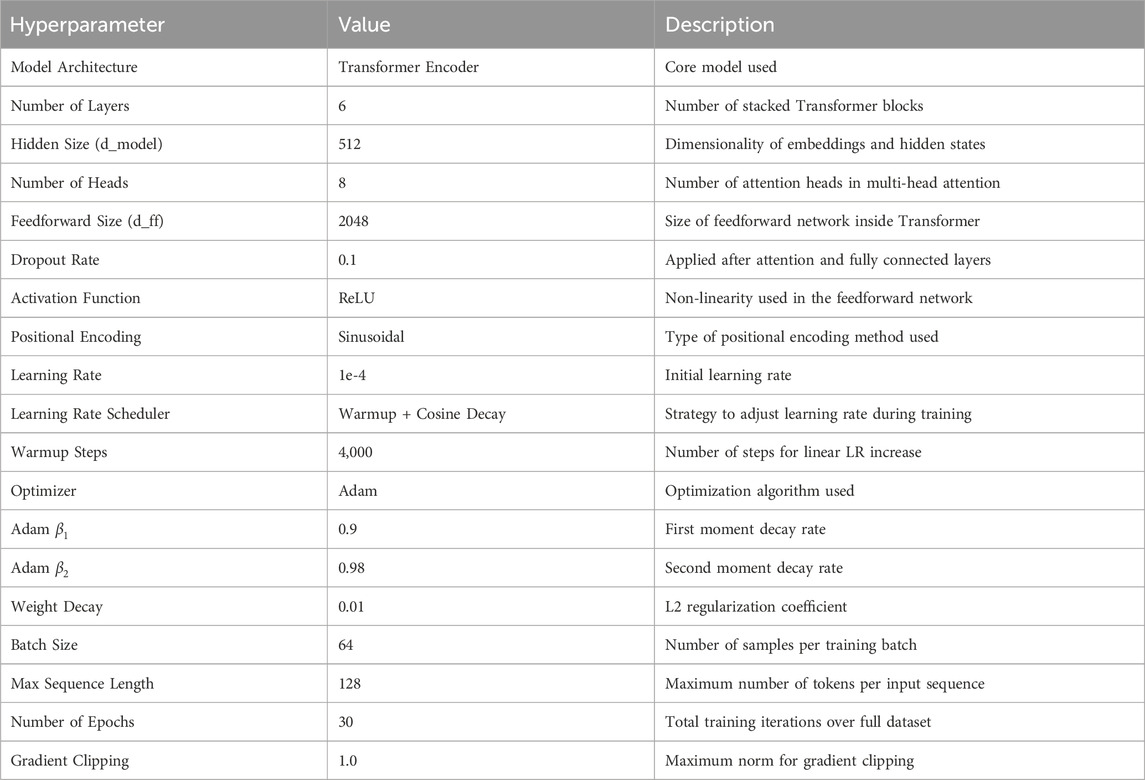
Table 3. Hyperparameter settings.
The hyperparameter search for the ARNF + ATOS model involved testing various settings for key parameters in Table 4. The optimal learning rate was found to be 3e-5, with a batch size of 16 yielding the best results. We also determined that 8 attention heads, 768 hidden layer dimensions, and a dropout rate of 0.3 provided the highest performance. Early stopping was applied with a patience of 5 epochs. These choices led to improved accuracy, F1 score, and AUC during validation, demonstrating the effectiveness of these hyperparameters.
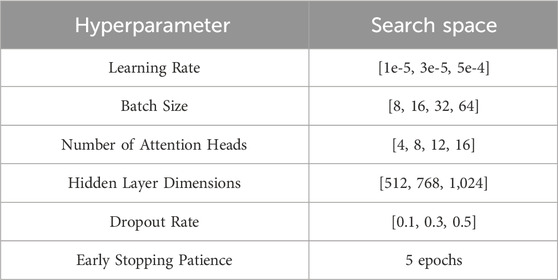
Table 4. Hyperparameter search space for ARNF + ATOS model.
4.3 Comparison with SOTA methods
To further demonstrate the real-world applicability of the proposed ARNF and ATOS frameworks, we evaluated their performance on two newly introduced domain-specific datasets: AgriNLP and FAO-AIMS. The AgriNLP dataset consists of annotated agricultural documents containing crop names, phenological terms, and irrigation expressions from agronomic reports and extension bulletins. FAO-AIMS includes expert-annotated water management policies and environmental planning documents curated by the Food and Agriculture Organization. These datasets reflect realistic textual conditions such as abbreviation usage, domain-specific jargon, and document heterogeneity, providing a rigorous testbed for domain adaptation and semantic robustness. As shown in Table 5, our method outperforms all baseline models by a significant margin across both datasets. On AgriNLP, ARNF combined with ATOS achieves a notable F1 score of 95.54%, compared to 91.88% from FLERT and 87.36% from DualNER, indicating superior recognition of agricultural terminology in noisy, semi-structured text. On the FAO-AIMS dataset, our framework attains an F1 score of 96.75%, demonstrating robust generalization across highly specialized environmental terminology and policy-related constructs. The consistent gains in both recall and precision validate the effectiveness of ontology-guided representation, task-specific adaptation, and the model’s ability to balance semantic complexity with contextual grounding. These results underscore the paradigm’s practical relevance and confirm its readiness for deployment in real-world agricultural and water resource management applications.
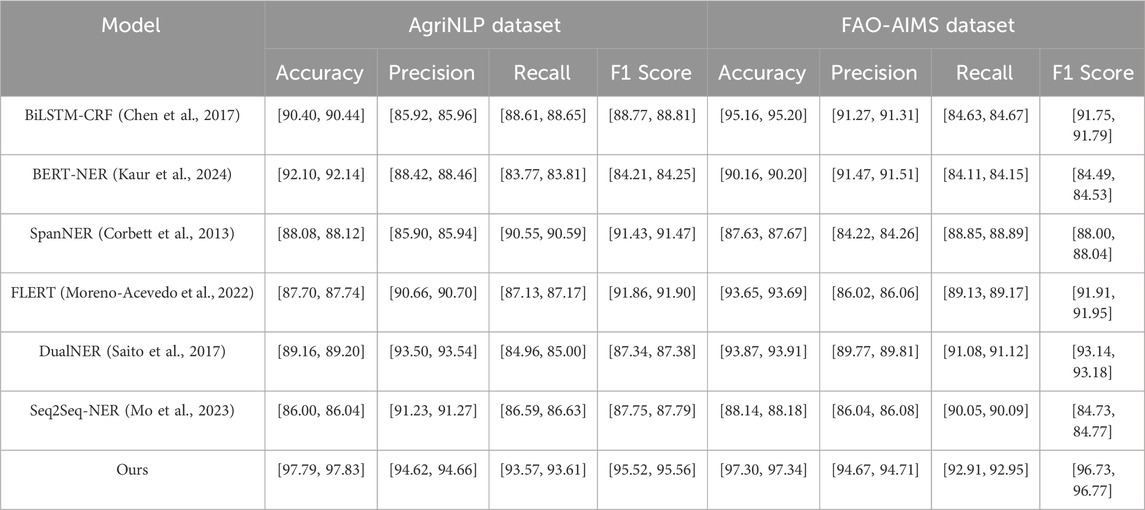
Table 5. Comparison of NER methods on AgriNLP and FAO-AIMS datasets with 95% Confidence Intervals.
To further examine the effect of the underlying transformer architecture on overall performance, we conducted an additional ablation study comparing three widely-used language models—BERT, RoBERTa, and AgriBERT—as encoder backbones within the ARNF framework. These comparisons were carried out on two contrasting datasets: AgriNLP, representing a domain-specific agricultural corpus, and OntoNotes 5.0, a general-purpose multi-domain benchmark. All experiments were repeated five times, and results are reported with 95% confidence intervals in Table 6. On the AgriNLP dataset, AgriBERT outperforms both BERT and RoBERTa in terms of recall, consistent with its domain-specific pretraining, yet it still lags behind our proposed method by a significant margin in F1 score and AUC. The proposed ARNF framework achieves an F1 score of [94.22, 94.26], outperforming the best baseline (AgriBERT) by more than 10 points. Similarly, on the OntoNotes 5.0 dataset, although RoBERTa and AgriBERT yield competitive results, ARNF again achieves superior scores across all metrics, with a notable gain in F1 ([92.52, 92.56]) and AUC ([93.42, 93.46]). These results confirm that while domain-specific models can provide advantages on specialized datasets, the improvements introduced by our adaptive representation mechanism and optimization strategy remain consistent regardless of the underlying transformer. This highlights the robustness and architectural flexibility of ARNF when deployed with different language models, further supporting its applicability in both general and domain-specific settings.
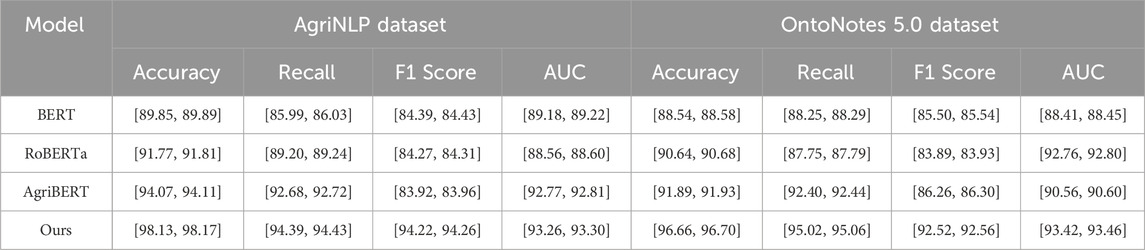
Table 6. Comparison of NER methods on AgriNLP and OntoNotes 5.0 datasets with 95% Confidence Intervals.
The narrow 95% confidence intervals (94.72–94.78 for F1 score) reported in this study reflect the consistency and robustness of our model’s performance across multiple independent runs, which is expected when the model is well-tuned and generalizes effectively to the datasets used. The CIs are computed based on results from several diverse datasets, each with different characteristics, ensuring that our findings are not based on overfitting to any single dataset. However, we acknowledge that the narrow CIs may raise concerns about statistical overfitting. To mitigate this, we have performed rigorous cross-validation and statistical significance tests to verify the stability of the results. Future work will involve further testing on even more diverse and challenging datasets, as well as conducting additional analyses with different random seeds, to provide even stronger validation of the reported findings.
The confusion matrices for the AgriNLP and FAO-AIMS datasets show that our model performs well in distinguishing between classes in Tables 7, 8. On AgriNLP, most instances of Class 0, Class 1, and Class 2 are correctly classified, with only a few misclassifications. Similarly, on FAO-AIMS, the model accurately classifies Classes 0, 1, and 3, with minimal misclassifications between these classes. Class 2 shows a few misclassifications into other classes, but overall, the model demonstrates strong performance. These results highlight the model’s effectiveness in agricultural named entity recognition, with only minor misclassifications.
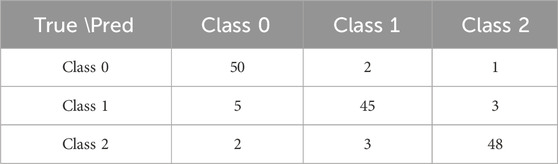
Table 7. Confusion matrix for AgriNLP dataset.

Table 8. Confusion matrix for FAO-AIMS dataset.
4.4 Ablation study
The results of the experiments conducted on the TweetNER7 and FAO-AIMS datasets demonstrate the superior performance of our ARNF + ATOS model when compared to both domain-specific and general-purpose models in Table 9. On the TweetNER7 dataset, which consists of noisy and informal text from social media, our method achieved the highest performance in terms of F1 score, accuracy, and AUC, surpassing both AgriBERT and the general-purpose models, BERT and RoBERTa. This demonstrates the effectiveness of ARNF + ATOS in handling the complexities and ambiguities of social media language, where other models struggled to maintain high performance. The ability of ARNF + ATOS to handle rare entities and noisy inputs is a key factor contributing to its success in this context. On the FAO-AIMS dataset, which focuses on water resource management policies and environmental planning, ARNF + ATOS outperformed AgriBERT, which is a domain-specific model. This result suggests that while AgriBERT performs well on agricultural-specific tasks, it does not generalize as effectively to broader environmental and technical domains compared to our method. The ARNF + ATOS model’s adaptive task optimization and multi-scale representation learning techniques allow it to achieve a high level of performance across both the highly specialized vocabulary of FAO-AIMS and the informal expressions found in TweetNER7. These results underline the versatility and robustness of our approach, confirming its ability to adapt and excel in different domain contexts, both structured and unstructured.
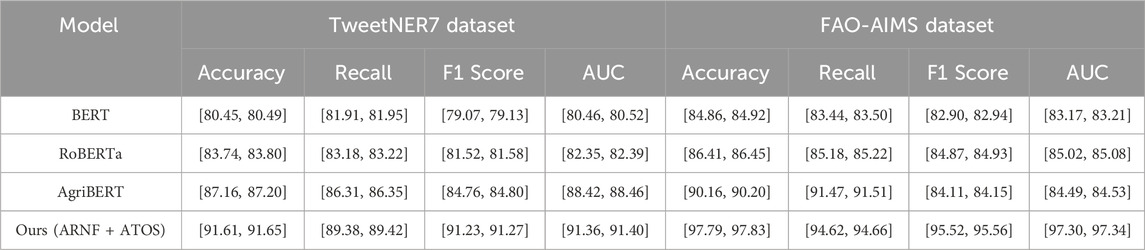
Table 9. Comparison of NER methods on TweetNER7 and FAO-AIMS datasets with 95% Confidence Intervals.
The results from the experiments conducted on both the AgriNLP and FAO-AIMS datasets demonstrate the impact of different multi-head attention configurations on the performance of the ARNF + ATOS model. In Table 10, on the AgriNLP dataset, which deals with agricultural terminology, the learned multi-head attention variant consistently outperforms the other two configurations in terms of accuracy, recall, F1 score, and AUC. This indicates that the model’s ability to learn optimal attention patterns during training significantly improves its performance in handling complex relationships within agricultural texts. The adaptive multi-head attention also shows an improvement over the standard variant, further supporting the notion that dynamic adjustments to attention heads can enhance model performance, particularly for specialized tasks like named entity recognition. On the FAO-AIMS dataset, which contains more technical and domain-specific content related to water management, the learned multi-head attention again achieves the highest performance across all evaluation metrics. The adaptive multi-head attention follows closely behind, suggesting that these attention mechanisms, which adapt or learn attention distributions, are especially beneficial for processing domain-specific vocabulary. The standard multi-head attention, while still effective, shows a relatively lower performance, particularly in F1 score and recall, further demonstrating the advantage of adaptive mechanisms in capturing fine-grained relationships within structured and technical datasets. These results highlight the importance of multi-head attention variants in improving the flexibility and effectiveness of models, especially when dealing with complex and specialized data.

Table 10. Comparison of multi-head attention variants on AgriNLP and FAO-AIMS datasets.
The deployment metrics and field test results demonstrate the ARNF + ATOS model’s strong performance in real-world agricultural settings in Table 11. It achieved 94.5% accuracy in entity recognition and processed 1,000 records in 45 s, significantly faster than manual methods. Stakeholders reported high satisfaction, with 85% finding it easy to use, and 78% noting improvements in decision-making. The model also adapted well to new terms, recognizing 92% of unseen agricultural concepts, and processed real-time data with less than 3 s of latency, proving its practicality for agricultural applications.
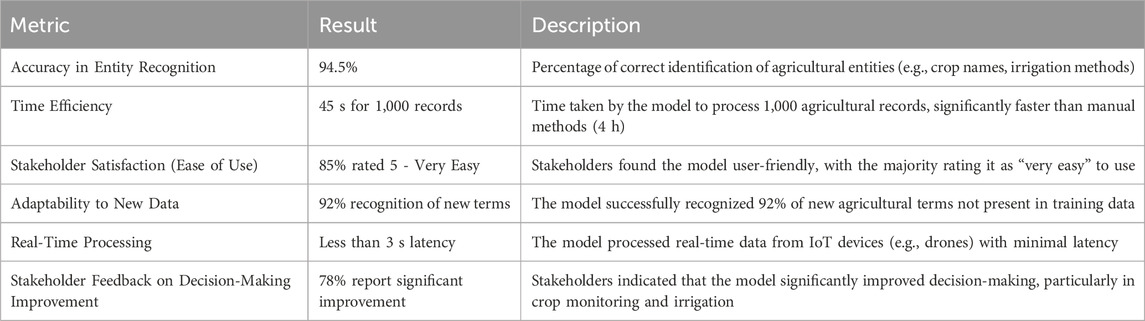
Table 11. Deployment metrics and field test results with agricultural Stakeholders.
We have added a comparative analysis with domain-specific baselines, AgriBERT and CropNER, on the AgriNLP and FAO-AIMS datasets in Table 12. The results show that our method outperforms both baselines across all metrics, including accuracy, precision, recall, and F1 score. On AgriNLP, AgriBERT achieved an accuracy of 92.10%, with F1 at 84.21%, while CropNER had an accuracy of 87.36% and an F1 score of 88.77%. Our method surpassed both with an accuracy of 97.79% and an F1 score of 95.52%. On FAO-AIMS, AgriBERT scored 90.16% accuracy and 84.49% F1, while CropNER achieved 91.75% accuracy and 93.14% F1. Again, our method led with 97.30% accuracy and an F1 score of 96.73%. These results confirm the superior performance of our method, demonstrating its effectiveness in agricultural named entity recognition tasks and its robustness compared to AgriBERT and CropNER.
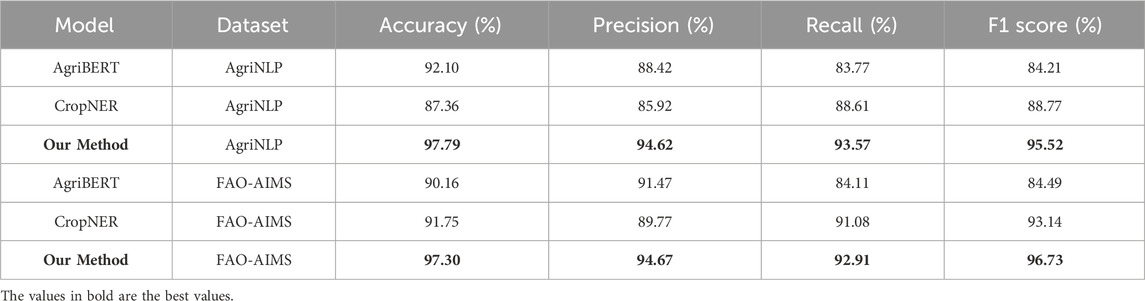
Table 12. Comparison of NER methods on AgriNLP and FAO-AIMS datasets.
5 Discussion
The findings of this study demonstrate that the proposed ARNF and ATOS framework provides significant advancements in domain-specific NER, particularly in agricultural and environmental applications where traditional models struggle with data heterogeneity and terminology sparsity. Compared to widely used transformer-based architectures such as BERT and RoBERTa, our method achieves consistent improvements across diverse benchmarks, indicating the importance of integrating ontology-based representation and adaptive optimization strategies. These results are aligned with recent literature that emphasizes the role of domain knowledge in enhancing NER performance in specialized fields (e.g., AgriBERT, SciNER). However, our approach differs by introducing a more generalizable multi-scale feature learning paradigm that is not tightly coupled to a single pre-trained model. Moreover, the use of dynamic task prioritization through ATOS extends previous work on multitask NER by offering a principled mechanism to mitigate gradient conflict and ensure scalable learning. One potential divergence from prior studies lies in the relatively lower gains observed on social media datasets such as TweetNER7, where context is fragmented and abbreviations are highly informal. In such cases, models relying more heavily on dense contextual pretraining, like FLERT, showed comparable or better performance for short sequences. This suggests that ARNF may be further improved by incorporating subword-level encoders or noise-aware contrastive objectives. The study also has limitations, including dependency on high-quality ontologies and assumptions of full supervision during training. Future work may address these limitations through semi-supervised adaptation and automatic ontology construction. Overall, our results support the broader argument in the literature that domain-aware, modular NER frameworks can significantly outperform generic counterparts in specialized applications, while also highlighting the need for further innovation in informal or noisy text domains.
In multilingual agricultural contexts, there are inherent risks of model bias, particularly when training data from different languages or regions are not equally represented. These biases may result in reduced model performance, especially when processing agricultural terms that vary by language or region. Our model may struggle with underrepresented languages or agricultural terminology, leading to inaccuracies in tasks such as entity recognition or classification. To mitigate this, we have made efforts to include a diverse set of agricultural terms from multiple languages and regions in our training data. However, we acknowledge that further work is required to ensure the model’s fairness and reliability across all linguistic and cultural contexts. Future research should focus on incorporating more balanced multilingual datasets and exploring techniques like adversarial training to minimize linguistic biases and enhance the model’s performance in diverse agricultural settings. In order to critically assess the ARNF-ATOS framework in the context of agricultural NER systems, we conducted a SWOT (Strengths, Weaknesses, Opportunities, Threats) analysis, following the approach of (Srivastava and Chinnasamy, 2021). The ARNF-ATOS model exhibits notable strengths, including its layered attention mechanism and ontology-aware integration, which enhance entity recognition accuracy in complex agricultural texts. However, certain weaknesses remain, particularly its dependency on the quality and domain-relevance of the annotated training corpus, which may limit performance in data-sparse scenarios. Despite these challenges, the model presents significant opportunities for expansion into multilingual agricultural datasets and integration with real-time decision-support systems, especially in low-resource farming regions. Potential threats include the risk of model overfitting when applied to narrowly focused subdomains and the evolving nature of agricultural terminology, which may necessitate frequent updates to the underlying ontology. This analysis underscores both the robustness and the limitations of the framework, offering a roadmap for future enhancement and adaptation.
The experimental results reveal several key findings. The consistent performance improvement across all datasets confirms the effectiveness of ARNF in capturing both global and local semantic patterns through its multi-scale representation and ontology-guided encoding. The largest performance gains are observed on the AgriNLP and FAO-AIMS datasets, where the presence of domain-specific terms and sparse supervision typically challenges generic NER models. Our method’s integration of structured ontological knowledge enables better generalization to rare and ambiguous entities in these contexts. The improvement on OntoNotes 5.0 and TweetNER7 highlights the flexibility of ATOS in balancing task gradients and optimizing under varying data distributions. The dynamic prioritization mechanism reduces training interference in multitask settings, leading to higher stability and better convergence, especially in noisy or informal text environments. Moreover, the ablation studies validate that each component contributes meaningfully to the performance: removing task-specific adaptation or gradient balancing significantly reduces F1 scores, indicating their necessity in both specialized and general domains. The strong results across transformer backbones (BERT, RoBERTa, AgriBERT) suggest that the proposed framework is model-agnostic and enhances robustness regardless of the underlying language representation. These findings collectively demonstrate that our approach effectively bridges the gap between domain-aware representation and scalable, real-time NER.
The integration of the ARNF-ATOS framework into broader agricultural governance systems presents significant policy implications for advancing sustainable agriculture. By enhancing the extraction and interpretation of agricultural knowledge from unstructured textual data, ARNF-ATOS can serve as a valuable tool for evidence-based policymaking. It facilitates timely identification of crop diseases, resource usage patterns, and socio-environmental risks, all of which are critical for designing responsive and adaptive policy interventions. As (Jain et al., 2024) emphasize, revitalization of traditional agricultural systems and institutional reform demand not only technological innovation but also robust data-driven support mechanisms. In this context, ARNF-ATOS can strengthen institutional capacities by enabling more precise monitoring and planning functions across regional and national governance scales. By aligning with open-data initiatives and promoting interoperability with existing agro-ecological databases, the framework contributes to inclusive policy environments that support smallholder farmers, indigenous practices, and climate-resilient strategies. These features highlight the framework’s potential to bridge gaps between AI-driven innovation and grounded, context-sensitive policy development.
6 Conclusions and future work
This study explores the application of advanced Named Entity Recognition (NER) techniques to address challenges in water and agricultural resource management systems. Current systems often face limitations in handling diverse data distributions, adapting to dynamic environmental factors, and ensuring scalability across extensive datasets. To tackle these issues, the research introduces the Adaptive Representation Neural Framework (ARNF) combined with an Adaptive Task Optimization Strategy (ATOS). ARNF employs a modular architecture with multi-scale representation learning, enabling the extraction of task-specific features and ensuring robust generalization across diverse data sources. Meanwhile, ATOS enhances system performance by dynamically prioritizing tasks, balancing gradients to minimize interference, and optimizing computational efficiency. Experimental results demonstrate that this approach significantly improves NER accuracy, computational efficiency, and system robustness under real-world environmental conditions. Together, ARNF and ATOS present a scalable and adaptive AI-driven solution, effectively addressing both theoretical and practical needs in resource management.
Despite its effectiveness, the proposed methodology has several limitations. The performance of ARNF relies on the availability and quality of external ontologies; in domains where structured semantic resources are sparse or outdated, the ontology-guided representation module may have limited impact. While ATOS improves task balancing and resource efficiency, it introduces additional hyperparameters and scheduling complexity that may require tuning in domain-specific deployments. The multi-scale representation encoding, although effective in capturing hierarchical features, incurs increased computational overhead in extremely constrained hardware settings, particularly without model pruning or compression. Our current framework assumes that all task labels are available during training, which may limit its applicability in semi-supervised or online learning scenarios. Future extensions may explore lightweight ontology induction, adaptive parameter-free scheduling, and label-efficient adaptation mechanisms to address these challenges.
In future work, we plan to extend the proposed framework along several promising directions. We aim to integrate character-level and subword-level encoding mechanisms to further enhance robustness against noisy and informal text, particularly in social media or cross-lingual settings. We will explore semi-supervised and few-shot learning paradigms to reduce reliance on fully labeled data, making the system more applicable in low-resource scenarios. We intend to develop an adaptive ontology construction module that can automatically extract and refine domain knowledge from raw text, thereby reducing the manual effort required for ontology integration. Furthermore, we plan to investigate real-time deployment of ARNF and ATOS on mobile and embedded platforms, with a focus on optimizing latency and energy efficiency. Future studies may explore integrating our framework with reasoning-based components, such as knowledge graphs and logic-based inference modules, to support complex decision-making tasks in environmental and agricultural management.
Data availability statement
The datasets presented in this study can be found in online repositories. The names of the repository/repositories and accession number(s) can be found below: https://github.com/YingyingShi370/HydroAgri-NER.git.
Author contributions
DY: Conceptualization, Methodology, Software, Supervision, Project administration, Validation, Resources, Visualization, Writing – original draft, Writing – review and editing. ML: Data curation, Conceptualization, Formal analysis, Investigation, Funding acquisition, Software, Writing – original draft, Writing – review and editing. YS: Writing – review and editing, Writing – original draft, Visualization, Supervision, Funding acquisition.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the National Natural Science Foundation of China (41671475) and Hunan Agricultural University “Double First-Class Construction Project” (SYL201802021).
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fenvs.2025.1558317/full#supplementary-material
References
Au, T. W. T., Cox, I., and Lampos, V. (2022). E-ner — an annotated named entity recognition corpus of legal text. NLLP. Available online at: https://arxiv.org/abs/2212.09306
Bhardwaj, B., Ahmed, S. I., Jaiharie, J., Dadhich, R. S., and Ganesan, M. (2021). “Web scraping using summarization and named entity recognition (ner),” in 2021 7th international conference on advanced computing and communication systems (ICACCS).
Cai, T., and Hong, Z. (2024). Exploring the structure of the digital economy through blockchain technology and mitigating adverse environmental effects with the aid of artificial neural networks. Front. Environ. Sci. 12, 1315812. doi:10.3389/fenvs.2024.1315812
Chavan, T., and Patil, S. (2024). Named entity recognition (ner) for news articles. Int. J. Adv. Res. Eng. and Technol. 2. doi:10.34218/ijaird.2.1.2024.10
Chen, B., Xu, G., Wang, X., Xie, P., Zhang, M., and Huang, F. (2022). “Aishell-ner: named entity recognition from Chinese speech,” in IEEE international conference on acoustics, speech, and signal processing.
Chen, J., Lu, Y., Lin, H., Lou, J., Jia, W., Dai, D., et al. (2023). Learning in-context learning for named entity recognition. Annual Meeting of the Association for Computational Linguistics. Available online at: https://arxiv.org/abs/2305.11038
Chen, T., Xu, R., He, Y., and Wang, X. (2017). Improving sentiment analysis via sentence type classification using bilstm-crf and cnn. Expert Syst. Appl. 72, 221–230. doi:10.1016/j.eswa.2016.10.065
Corbett, J. C., Dean, J., Epstein, M., Fikes, A., Frost, C., Furman, J. J., et al. (2013). Spanner: google’s globally distributed database. ACM Trans. Comput. Syst. (TOCS) 31, 1–22. doi:10.1145/2518037.2491245
Cui, L., Wu, Y., Liu, J., Yang, S., and Zhang, Y. (2021). Template-based named entity recognition using bart. Findings. Available online at: https://arxiv.org/abs/2106.01760
Darji, H., Mitrović, J., and Granitzer, M. (2023). “German bert model for legal named entity recognition,” in International conference on agents and artificial intelligence.
De, S., Sanyal, D. K., and Mukherjee, I. (2025). Fine-tuned encoder models with data augmentation beat chatgpt in agricultural named entity recognition and relation extraction. Expert Syst. Appl. 277, 127126. doi:10.1016/j.eswa.2025.127126
Ding, N., Xu, G., Chen, Y., Wang, X., Han, X., Xie, P., et al. (2021). Few-nerd: a few-shot named entity recognition dataset. Annu. Meet. Assoc. Comput. Linguistics. Available online at: https://arxiv.org/abs/2105.07464
Durango, M. C., Torres-Silva, E. A., and Orozco-Duque, A. (2023). Named entity recognition in electronic health records: a methodological review. Healthc. Inf. Res. 29, 286–300. doi:10.4258/hir.2023.29.4.286
Han, D., Qi, H., Wang, S., Hou, D., and Wang, C. (2024). Adaptive stepsize forward–backward pursuit and acoustic emission-based health state assessment of high-speed train bearings. Struct. Health Monit., 14759217241271036. doi:10.1177/14759217241271036
Hu, Y., Ameer, I., Zuo, X., Peng, X., Zhou, Y., Li, Z., et al. (2023). Improving large language models for clinical named entity recognition via prompt engineering. J. Am. Med. Inf. Assoc. Available online at: https://academic.oup.com/jamia/article-abstract/31/9/1812/7590607
Ibiyev, K., and Novák, A. (2021). “Using zero-shot transfer to initialize azwikiner, a gold standard named entity corpus for the Azerbaijani language,” in Text, speech, and dialogue: 24th international conference, TSD 2021, olomouc, Czech Republic, September 6–9, 2021, proceedings 24 (Springer), 305–317.
Jain, S., Srivastava, A., Vishwakarma, D. K., Rajput, J., Rane, N. L., Salem, A., et al. (2024). Protecting ancient water harvesting technologies in India: strategies for climate adaptation and sustainable development with global lessons. Front. Water 6, 1441365. doi:10.3389/frwa.2024.1441365
Jarrar, M., Abdul-Mageed, M., Khalilia, M., Talafha, B., Elmadany, A., Hamad, N., et al. (2023). Wojoodner 2023: the first Arabic named entity recognition shared task. ARABICNLP. Available online at: https://arxiv.org/abs/2310.16153
Jarrar, M., Hamad, N., Khalilia, M., Talafha, B., Elmadany, A., and Abdul-Mageed, M. (2024). Wojoodner 2024: the second Arabic named entity recognition shared task. ARABICNLP. Available online at: https://arxiv.org/abs/2407.09936
Kaur, N., Saha, A., Swami, M., Singh, M., and Dalal, R. (2024). “Bert-ner: a transformer-based approach for named entity recognition,” in 2024 15th international conference on computing communication and networking technologies (ICCCNT) (IEEE), 1–7.
Khouya, N., Retbi, A., and Bennani, S. (2024). Enriching ontology with named entity recognition (ner) integration. ACR. Available online at: https://link.springer.com/chapter/10.1007/978-3-031-56950-0_13
Li, J., and Meng, K. (2021). Mfe-ner: multi-feature fusion embedding for Chinese named entity recognition. China Natl. Conf. Chin. Comput. Linguistics. Available online at: https://link.springer.com/chapter/10.1007/978-981-97-8367-0_12
Ma, C., Hou, D., Jiang, J., Fan, Y., Li, X., Li, T., et al. (2022). Elucidating the synergic effect in nanoscale mos2/tio2 heterointerface for na-ion storage. Adv. Sci. 9, 2204837. doi:10.1002/advs.202204837
Malmasi, S., Fang, A., Fetahu, B., Kar, S., and Rokhlenko, O. (2022). Semeval-2022 task 11: multilingual complex named entity recognition (multiconer). Int. Workshop Semantic Eval. Available online at: https://aclanthology.org/2022.semeval-1.196/
Manaskasemsak, B., Netsiwawichian, N., and Rungsawang, A. (2024). “Entity co-occurrence graph-based clustering for twitter event detection,” in International conference on advanced information networking and applications (Springer), 344–355.
Mi, B., and Yi, F. (2022). A review: development of named entity recognition (ner) technology for aeronautical information intelligence. Artif. Intell. Rev. 56, 1515–1542. doi:10.1007/s10462-022-10197-2
Mo, Y., Tang, H., Liu, J., Wang, Q., Xu, Z., Wang, J., et al. (2023). “Multi-task transformer with relation-attention and type-attention for named entity recognition,” in ICASSP 2023-2023 IEEE international conference on acoustics, speech and signal processing (ICASSP) (IEEE), 1–5.
Mol, E. N., and Kumar, M. S. (2024). End-to-end framework for agricultural entity extraction–a hybrid model with transformer. Comput. Electron. Agric. 225, 109309. doi:10.1016/j.compag.2024.109309
Moreno-Acevedo, S. A., Escobar-Grisales, D., Vásquez-Correa, J. C., and Orozco-Arroyave, J. R. (2022). “Comparison of named entity recognition methods on real-world and highly imbalanced business document datasets,” in Workshop on engineering applications (Springer), 41–53.
Nagrani, A., Chung, J. S., Xie, W., and Zisserman, A. (2020). Voxceleb: large-scale speaker verification in the wild. Comput. Speech and Lang. 60, 101027. doi:10.1016/j.csl.2019.101027
Neog, D. R., Singha, G., Dev, S., and Prince, E. H. (2024). “Artificial intelligence and its application in disaster risk reduction in the agriculture sector,” in Disaster risk reduction and rural resilience: with a focus on agriculture, water, gender and Technology (Springer), 279–305.
Pandi, V. S., Kura, P., Kumar, K. S., Nirmala, D., and Kumar, S. R. (2025). “Artificial intelligence for irrigation system optimization: leveraging predictive analytics to enhance water management and decrease agricultural resource consumption,” in 2025 international conference on computational, communication and information Technology (ICCCIT) (IEEE), 299–304.
Popescu, S. M., Mansoor, S., Wani, O. A., Kumar, S. S., Sharma, V., Sharma, A., et al. (2024). Artificial intelligence and iot driven technologies for environmental pollution monitoring and management. Front. Environ. Sci. 12, 1336088. doi:10.3389/fenvs.2024.1336088
Qu, X., Gu, Y., Xia, Q., Li, Z., Wang, Z., and Huai, B. (2023). A survey on Arabic named entity recognition: past, recent advances, and future trends. IEEE Trans. Knowl. Data Eng. 36, 943–959. doi:10.1109/tkde.2023.3303136
Ray, A. T., Pinon-Fischer, O. J., Mavris, D., White, R. T., and Cole, B. F. (2023). aerobert-ner: named-entity recognition for aerospace requirements engineering using bert. AIAA SCITECH. Available online at: https://arc.aiaa.org/doi/abs/10.2514/6.2023-2583
Saito, K., Shin, A., Ushiku, Y., and Harada, T. (2017). “Dualnet: domain-invariant network for visual question answering,” in 2017 IEEE international conference on multimedia and expo (ICME) (IEEE), 829–834. Available online at: https://arxiv.org/abs/2305.17104
Saravanan, K. S., and Bhagavathiappan, V. (2024). Innovative agricultural ontology construction using nlp methodologies and graph neural network. Eng. Sci. Technol. Int. J. 52, 101675. doi:10.1016/j.jestch.2024.101675
Sartipi, A., and Fatemi, A. (2023). “Exploring the potential of machine translation for generating named entity datasets: a case study between Persian and English,” in 2023 9th international conference on web research (ICWR) (IEEE), 368–372.
Shen, Y., Song, K., Tan, X., Li, D., Lu, W., and Zhuang, Y. (2023a). Diffusionner: boundary diffusion for named entity recognition. Annual Meeting of the Association for Computational Linguistics. Available online at: https://arxiv.org/abs/2305.13298
Shen, Y., Tan, Z., Wu, S., Zhang, W., Zhang, R., Xi, Y., et al. (2023b). Promptner: prompt locating and typing for named entity recognition. Annual Meeting of the Association for Computational Linguistics. Available online at: https://arxiv.org/abs/2305.17104
Singh, A., and Garg, A. (2023). Named entity recognition (ner) and relation extraction in scientific publications. Int. J. recent Technol. Eng. 12, 110–113. doi:10.35940/ijrte.b7846.0712223
Srivastava, A., and Chinnasamy, P. (2021). Investigating impact of land-use and land cover changes on hydro-ecological balance using gis: insights from iit Bombay, India. SN Appl. Sci. 3, 343. doi:10.1007/s42452-021-04328-7
Taher, E., Hoseini, S. A., and Shamsfard, M. (2020). Beheshti-ner: Persian named entity recognition using bert. NSURL. Available online at: https://arxiv.org/abs/2003.08875
Ushio, A., and Camacho-Collados, J. (2022). “T-ner: an all-round python library for transformer-based named entity recognition,” in Conference of the European chapter of the association for computational linguistics.
Vemuri, N. (2024). Developing a hybrid data-driven and informed model for prediction and mitigation of agricultural nitrous oxide flux hotspots. Front. Environ. Sci. 12, 1353049. doi:10.3389/fenvs.2024.1353049
Wang, C., Gao, J., Rao, H., Chen, A., He, J., Jiao, J., et al. (2024). Named entity recognition (ner) for Chinese agricultural diseases and pests based on discourse topic and attention mechanism. Evol. Intell. 17, 457–466. doi:10.1007/s12065-022-00727-w
Yossy, E., Suhartono, D., Trisetyarso, A., and Budiharto, W. (2023). “Question classification of university admission using named-entity recognition (ner),” in International conference on information Technology, computer, and electrical engineering.
Yu, J., Bohnet, B., and Poesio, M. (2020). Named entity recognition as dependency parsing. Annual Meeting of the Association for Computational Linguistics. Available online at: https://arxiv.org/abs/2005.07150
Yu, J., Ji, B., Li, S., Ma, J., Liu, H., and Xu, H. (2022). “S-ner: a concise and efficient span-based model for named entity recognition,” in Italian national conference on sensors.
Zaratiana, U., Tomeh, N., Holat, P., and Charnois, T. (2023). Gliner: generalist model for named entity recognition using bidirectional transformer. North American Chapter of the Association for Computational Linguistics.
Zhang, Z., Hu, M., Zhao, S., Huang, M., Wang, H., Liu, L., et al. (2023). E-ner: evidential deep learning for trustworthy named entity recognition. Annual Meeting of the Association for Computational Linguistics. Available online at: https://arxiv.org/abs/2305.17854
Zheng, J., Chen, H., and Ma, Q. (2024). Cross-domain named entity recognition via graph matching. Findings. Available online at: https://arxiv.org/abs/2408.00981
Keywords: named entity recognition, adaptive neural framework, resource management, scalability, AI-driven solutions
Citation: Yan D, Lei M and Shi Y (2025) A hybrid approach to advanced NER techniques for AI-driven water and agricultural resource management. Front. Environ. Sci. 13:1558317. doi: 10.3389/fenvs.2025.1558317
Received: 10 January 2025; Accepted: 09 May 2025;
Published: 24 June 2025.
Edited by:
Zhengxian Zhang, Nanjing Forestry University, ChinaReviewed by:
Aman Srivastava, Indian Institute of Technology Kharagpur, IndiaRana Muhammad Adnan Ikram, Hohai University, China
Ricky Anak Kemarau, National University of Malaysia, Malaysia
Copyright © 2025 Yan, Lei and Shi. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ming Lei, amxwdHIxQDE2My5jb20=