 Wenxuan Fan
Wenxuan Fan Zhipeng Pi
Zhipeng Pi Keyu Kong
Keyu Kong Hua Qiao
Hua Qiao Minghao Jin1
Minghao Jin1 Yongyun Chang
Yongyun Chang Jingwei Zhang
Jingwei Zhang Huiwu Li
Huiwu Li- 1Shanghai Key Laboratory of Orthopaedic Implants, Department of Orthopaedic Surgery, Shanghai Ninth People’s Hospital, Shanghai Jiaotong University School of Medicine, Shanghai, China
- 2School of International Pharmaceutical Business, China Pharmaceutical University, Nanjing, China
Introduction: This investigation leverages advanced machine learning (ML) techniques to dissect the complex relationship between heavy metal exposure and its impacts on osteoarthritis (OA) and rheumatoid arthritis (RA). Utilizing a comprehensive dataset from the National Health and Nutrition Examination Survey (NHANES) spanning from 2003 to 2020, this study aims to elucidate the roles specific heavy metals play in the incidence and differentiation of OA and RA.
Methods: Employing a phased ML strategy that encompasses a range of methodologies, including LASSO regression and SHapley Additive exPlanations (SHAP), our analytical framework integrates demographic, laboratory, and questionnaire data. Thirteen distinct ML models were applied across seven methodologies to enhance the predictability and interpretability of clinical outcomes. Each phase of model development was meticulously designed to progressively refine the algorithm’s performance.
Results: The results reveal significant associations between certain heavy metals and an increased risk of arthritis. The phased ML approach enabled the precise identification of key predictors and their contributions to disease outcomes.
Discussion: These findings offer new insights into potential pathways for early detection, prevention, and management strategies for arthritis associated with environmental exposures. By improving the interpretability of ML models, this research provides a potent tool for clinicians and researchers, facilitating a deeper understanding of the environmental determinants of arthritis.
1 Introduction
Arthritis is a debilitating disease characterized by joint inflammation, synovial swelling, stiffness, and potential cartilage damage. It has two common types: osteoarthritis (OA) and rheumatoid arthritis (RA) (1). Arthritis represents a significant global health concern. In the United States alone, 54 million people suffer from arthritis, and projections indicate that by 2040, nearly half of the population (49%) will be affected by this condition (2). Globally, the age-standardized point prevalence rates for osteoarthritis (3) and rheumatoid arthritis (4) in 2017 were 3.75 and 0.25%, respectively.
In recent years, the potential contributory role of heavy metals (HMs) in the exacerbation of arthritic conditions, particularly RA, has garnered research interest. A growing body of evidence suggests that heavy metals, such as cadmium (Cd) and lead (Pb), may exacerbate oxidative stress, leading to sustained inflammation (5)—a recognized factor in the pathogenesis of RA (6). Several epidemiological studies have corroborated a positive correlation between cadmium exposure and the incidence of RA (7, 8). However, the investigation into OA, another subtype of arthritis, and its association with heavy metal exposure remains underexplored in population-based epidemiological studies. While limited research has suggested possible links between heavy metal levels and OA, these are often confounded by factors such as aging and body mass index (BMI). Although limited studies have suggested a potential link between heavy metal levels and OA, these studies have either relied on traditional statistical methods or chosen a limited sample size (9). Additionally, approaches based on machine learning have not focused on the interpretability of the models (10). Moreover, considering OA as a critical differential diagnosis from RA, there is a conspicuous absence of studies examining the differential impact of heavy metals on these two arthritic subtypes, an area that warrants comprehensive investigation.
Research into the correlation between heavy metals and arthritis remains nascent, and existing studies predominantly rely on traditional statistical methods (11). These conventional approaches often necessitate extensive data requirements, incorporate numerous presumptions, and are subject to stringent application constraints, which restricts their capacity to derive insights from voluminous datasets. However, the dawn of the big data era, coupled with the swift advancement of computational technologies, has paved the way for the burgeoning application of machine learning (ML) techniques across various domains, including medical research. Machine learning, in particular, holds immense promise for enhancing disease prediction, diagnosis, and treatment paradigms. By processing and analyzing large datasets, ML algorithms are adept at uncovering intricate patterns and relationships that might otherwise remain undetected, thereby bolstering medical decision-making and advancing clinical practices.
In our investigation, we utilized a dataset from the National Health and Nutrition Examination Survey (NHANES) spanning from 2003 to 2020 to examine the link between heavy metal exposure and the prevalence of OA and RA. We employed seven distinct ML techniques, designed to discern the presence of arthritis attributable to heavy metal exposure, and assessed the predictive performance of each model. Furthermore, our study integrates the use of SHapley Additive exPlanations (SHAP)-based methodologies (12) to quantify the contribution of individual heavy metals to the accurate detection of arthritis. This approach not only elucidates the impact of heavy metals on the disease but also opens avenues for early intervention strategies.
Due to the unresolved issues highlighted above, this article investigates whether machine learning methods can effectively identify arthritis patients and distinguish between OA and RA. Additionally, it explores the correlation between heavy metal exposure and the incidence of arthritis, as well as determining which heavy metals play a crucial role in differentiating between OA and RA patients.
2 Methods
2.1 Participants of study
The dataset for our study was sourced from the NHANES, which employs a combination of questionnaire administration and physical examinations to collect comprehensive health data from the US population. The methodologies pertaining to these survey strategies have been extensively delineated in prior literature (13). For the purposes of our analysis, we included data from eight consecutive cycles of NHANES, covering the period from 2003 to 2020, to ensure a robust longitudinal perspective of the association between heavy metal exposure and arthritis.
Our study established the following inclusion criteria:
(1) Participants must be at least 20 years old.
(2) Participants must have taken part in the NHANES sub-study focusing on heavy metal analysis through blood and urine tests.
(3) Participants must have confirmable arthritis status information derived from the NHANES questionnaire data.
Conversely, the exclusion criteria were:
(1) Participants with missing data for more than two heavy metals out of a panel of 19.
(2) Participants with an arthritis status coded as 7 or 9 according to the NHANES questionnaire, indicative of an uncertain arthritis diagnosis, where 7 represents “Refused” and 9 represents “Do not know” in response to the question about arthritis status in the questionnaire.
After applying these criteria, the final cohort for analysis comprised 14,319 participants.
2.2 Data collection
2.2.1 Demographic characteristics of the study participants
In our analysis, demographic and socioeconomic characteristics of the study participants were gleaned from the questionnaire data provided by NHANES. The collected characteristics encompass a broad spectrum, including gender, age, body mass index (BMI, expressed as kg/m2), racial/ethnic background (categorized broadly, including Hispanic and non-Hispanic classifications), educational attainment (categorized as college or above, high school or equivalent, and below high school), and the poverty income ratio (PIR), which was segmented into three groups for analytical purposes: below 1, between 1 to 4, and above 4. This diverse array of variables enables a comprehensive evaluation of the participants, facilitating a nuanced understanding of how demographic and socioeconomic factors may interact with heavy metal exposure to influence arthritis prevalence.
2.2.2 Heavy metals
In our study, we conducted an analysis of 19 heavy metals present in the blood and urine samples of participants. The quantification of heavy metal concentrations was performed at the National Center for Environmental Health Laboratory, utilizing the highly precise method of inductively coupled plasma dynamic reaction cell mass spectrometry (ICP-DRCMS) (14). This technique is renowned for its sensitivity and accuracy in detecting trace levels of metals in biological samples. The application of such rigorous analytical steps ensures the reliability of the heavy metal exposure data, forming a crucial foundation for subsequent analyses examining the association between heavy metal exposure and the incidence of arthritis.
2.2.3 Outcome ascertainment
In NHANES, the identification of arthritis among participants was based on self-reported data obtained from questionnaires. Initially, participants were asked to confirm whether they had been diagnosed with arthritis. Subsequently, for those who reported a diagnosis, the questionnaire data were used to ascertain the specific type of arthritis they had. This approach allowed for the differentiation between various forms of arthritis, such as RA, OA, and other subtypes, thereby facilitating a more nuanced analysis of the relationship between heavy metal exposure and specific arthritic conditions.
2.3 Pre-processing and extraction of ML features
The dataset underpinning our study comprised 25 features, with 21 being continuous variables and the remaining four categorized as categorical variables. To address missing values, we employed different strategies for each data type: median values were used to fill in missing continuous variables, while a nearest fill method was applied to categorical variables. This preparatory step ensured that the dataset was complete for subsequent analyses.
Our analysis leveraged the minimum absolute shrinkage and selection operator (LASSO) regression technique. LASSO (15) is particularly adept at handling datasets with numerous potential predictors, as it incorporates a penalty mechanism that reduces the regression coefficients of less significant variables towards zero. This feature of LASSO is instrumental in streamlining model complexity and mitigating the risk of overfitting, which is especially valuable when dealing with high-dimensional data. The intrinsic capability of LASSO to perform variable selection automatically is among its core strengths, enhancing both the model’s simplicity and its interpretive clarity while also potentially increasing prediction accuracy.
A crucial step in the application of LASSO regression in our study involved the standardization of variables (i.e., centralization and normalization), which is a prerequisite for the method to function optimally. Subsequently, the optimal penalty parameter, λ, was identified through a 5-fold cross-validation process. This approach to parameter tuning is critical for balancing the model’s complexity against its performance, ensuring that the selected variables are genuinely predictive of the study’s outcomes while minimizing the likelihood of incorporating spurious associations.
Through the application of LASSO regression analysis, our study has effectively pinpointed a suite of pivotal predictors. These key variables play an instrumental role in elucidating the underlying dynamics of our research phenomenon, thereby providing a solid foundation for both the formulation of subsequent experimental designs and the refinement of data analysis strategies. The process of identifying these predictors is critical, as it enables a focused investigation into the factors most relevant to the development of arthritis, ensuring that the research efforts are both efficient and directed towards areas of greatest potential impact.
The variables selected via the LASSO method were subsequently incorporated into a machine learning model. This step served a dual purpose: firstly, to validate the predictive power and relevance of these variables in the context of arthritis development, and secondly, to assess their contribution to the overall accuracy and performance of the predictive model. The integration of LASSO-selected variables into the machine learning framework not only confirms their significance but also enhances the model’s ability to make accurate predictions. This iterative process of variable selection and validation underscores the robustness of the methodology employed in our study, ensuring that the findings are both reliable and grounded in a rigorous analytical framework.
2.4 SMOTE sampling
In our study, we tackled the challenge of data imbalance—a common issue in medical datasets—using the synthetic minority oversampling technique (SMOTE) (16). This method is renowned for its effectiveness in addressing imbalances by artificially augmenting the size of the minority class through the generation of new instances. These instances are created via linear interpolation between existing minority class samples and their nearest neighbors, thus enriching the dataset without altering the majority class size. The application of SMOTE is not exclusive to our research; it has been extensively utilized across various medical studies, where it has consistently demonstrated its capability to enhance model performance by improving the recognition accuracy of underrepresented classes (17, 18).
The utility of SMOTE is particularly pronounced in our investigation into the development of arthritis, as it facilitates a more balanced distribution of classes within our dataset. By implementing SMOTE during the model’s training phase, we significantly boost the model’s ability to identify less prevalent categories. This improvement is pivotal for enhancing both the accuracy and the generalizability of our predictive model. It is important to note that SMOTE was exclusively applied to the training dataset to maintain the integrity and realism of the model evaluation process. The validation set was left in its original state, ensuring that the model’s performance could be accurately assessed on an untouched, representative sample of real-world data. This methodological choice underscores our commitment to ensuring the validity and reliability of our predictive model, enabling a faithful evaluation of its efficacy in novel contexts.
2.5 Machine learning strategy
In this study’s machine learning strategy, we employed the AutoGluon framework to construct and refine our predictive model through a phased approach. Initially, we developed 13 distinct machine learning models without leveraging advanced features such as auto-stacking, dynamic stacking, or hyperparameter optimization. As shown in Figure 1, these models included algorithms like K-Nearest Neighbors (KNN), RandomForest, ExtraTrees, LightGBM, CatBoost, XGBoost, and neural networks (19–24), each applied with various configurations and methodologies. This preliminary phase aimed to quickly generate a diverse set of models to explore the initial compatibility of our dataset with different machine learning algorithms.
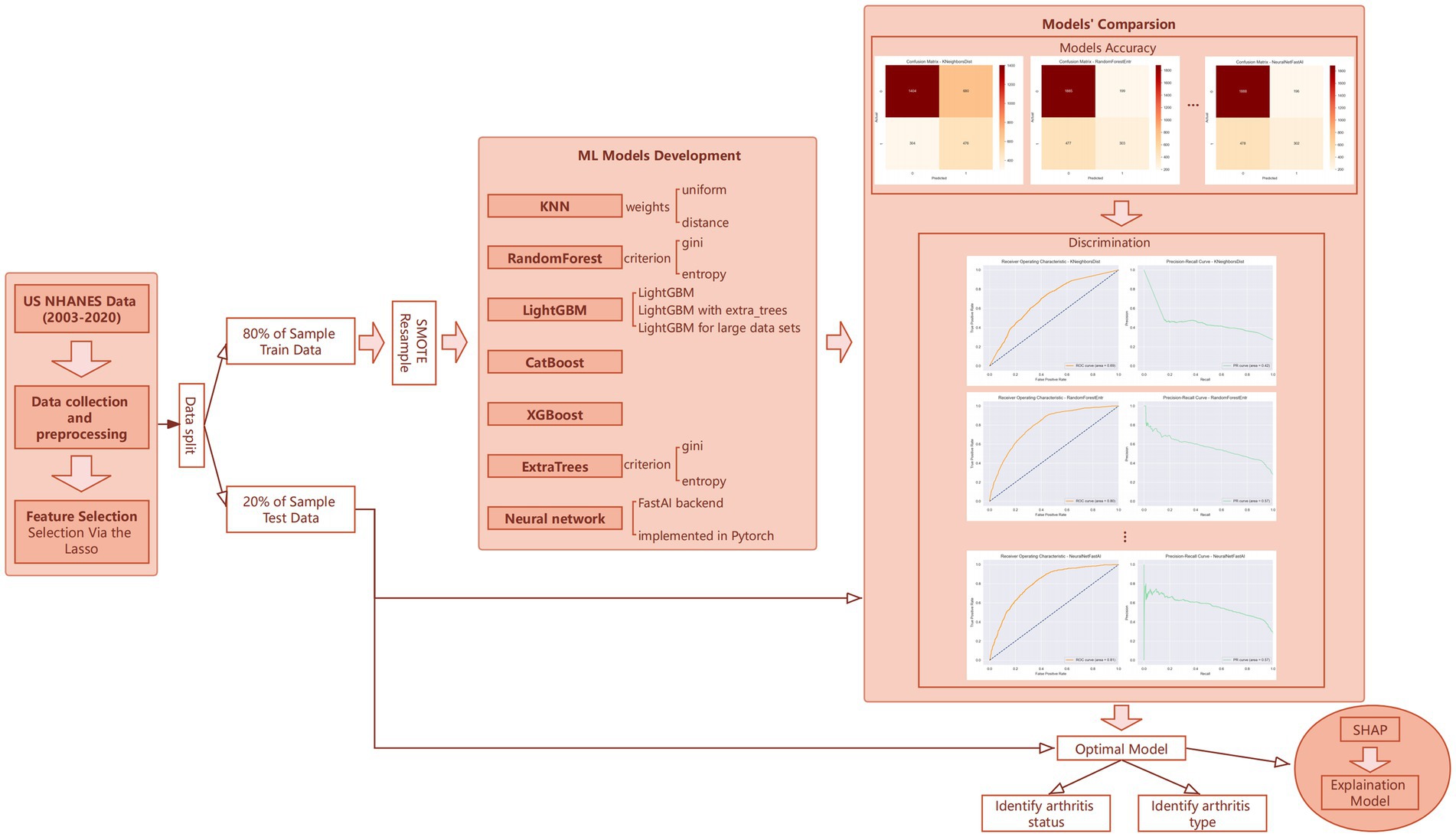
Figure 1. Overview plot.
Following the creation of these prototype models, we undertook a rigorous evaluation of their performance based on key metrics—accuracy, recall, and F1 score—using the validation set. Models exhibiting suboptimal performance were excluded from further consideration. For those models demonstrating promise, we then activated features such as auto-stacking, dynamic stacking, and engaged in hyperparameter optimization for retraining. Although this step entailed higher computational demands, the benefits in terms of enhanced prediction accuracy and model robustness were substantial, leading to the development of a suite of finely-tuned, high-quality machine learning models.
Ultimately, the model that showcased superior performance on the test set was selected as our predictive model. This process not only confirmed the model’s exceptional predictive accuracy but also validated the efficacy of our phased machine learning strategy. Through this methodical and iterative approach, we were able to systematically identify and optimize the most effective machine learning solution for predicting arthritis development, underscoring the strategic advantage of employing a phased methodology in machine learning projects.
2.6 Statistical analysis
In this study, we meticulously detailed the demographic characteristics of the participants. Continuous variables were summarized using the median and interquartile range, while categorical variables were presented as counts and percentages. To discern differences in characteristics based on arthritis status, we employed the Wilcoxon two-sample test for continuous variables and the chi-square test for categorical variables. Heavy metal exposure levels across eight NHANES data release cycles were reported using geometric mean and geometric standard deviation, with the Mann–Kendall test applied to assess trend significance over time.
The performance of our machine learning model was evaluated using several metrics, including the area under the curve (AUC) as described by Pruessner et al. (25), accuracy score, average precision score (APS), sensitivity/recall, and the F1 score. Given the imbalance in our dataset—marked by significant discrepancies in the prevalence of positive and negative samples—the average precision (AP) metric was deemed more appropriate for evaluating the binary classification model’s performance regarding arthritis status. The AP provides a nuanced measure of sensitivity and discriminative ability in unbalanced settings, hence its prioritization in our analysis. For the arthritis classification, which involves multiple classes, the F1 macro score was selected as the primary evaluation criterion due to its capacity to offer a balanced view of precision and recall rates across an unbalanced dataset.
Our analysis was conducted using Python version 3.9.18 and R version 4.3.2, provided by The R Foundation for Statistical Computing. Results achieving a p-value less than 0.05 were considered statistically significant. This methodological framework, as depicted in Figure 1, outlines our comprehensive approach to understanding the impact of heavy metal exposure on arthritis development, supported by robust statistical and machine learning analyses.
2.7 SHAP interpretation
SHAP (SHapley Additive exPlanations) (12) is an advanced model interpretation tool that draws upon the principles of cooperative game theory, specifically utilizing the concept of Shapley values, to elucidate the decision-making processes of machine learning models. The foundational theory behind SHAP posits that each feature within a model can be seen as a “player” in a cooperative game, where the “payout” or impact of each player is determined by their contribution to the predictive accuracy of the model. SHAP operates on the principle of “fair distribution,” akin to “more work, more gain,” ensuring that the contribution of each feature to the model’s prediction is accurately quantified and allocated.
This method demystifies the predictive judgments of complex models by detailing the exact contribution of each feature to the final prediction, thereby rendering the model’s decision-making process transparent. One of the hallmark characteristics of SHAP is its versatility and compatibility; it can be applied post hoc to virtually any machine learning model regardless of its underlying architecture. This is achieved by decomposing the model’s output into a linear sum of the individual contributions of all features. By converting the predicted value into the aggregated sum of these attributions, SHAP facilitates a deeper understanding of the model’s behavior, highlighting which features are most influential in driving predictions and providing insights into the dynamics underlying the model’s predictions.
3 Results
3.1 Population characteristics of the study participants
Table 1 in our study encapsulates the demographic and health-related characteristics of participants enrolled in the U.S. National Health and Nutrition Examination Survey (NHANES) between 2003 and 2020, focusing specifically on individuals with and without arthritis. The analysis included a cohort of 14,319 participants, with a gender distribution where 49% were male. The average age across the cohort was 49.0 years, with an interquartile range from 34.0 to 63.0 years. Within this population, a significant number, 3,900 participants, were identified as suffering from arthritis.
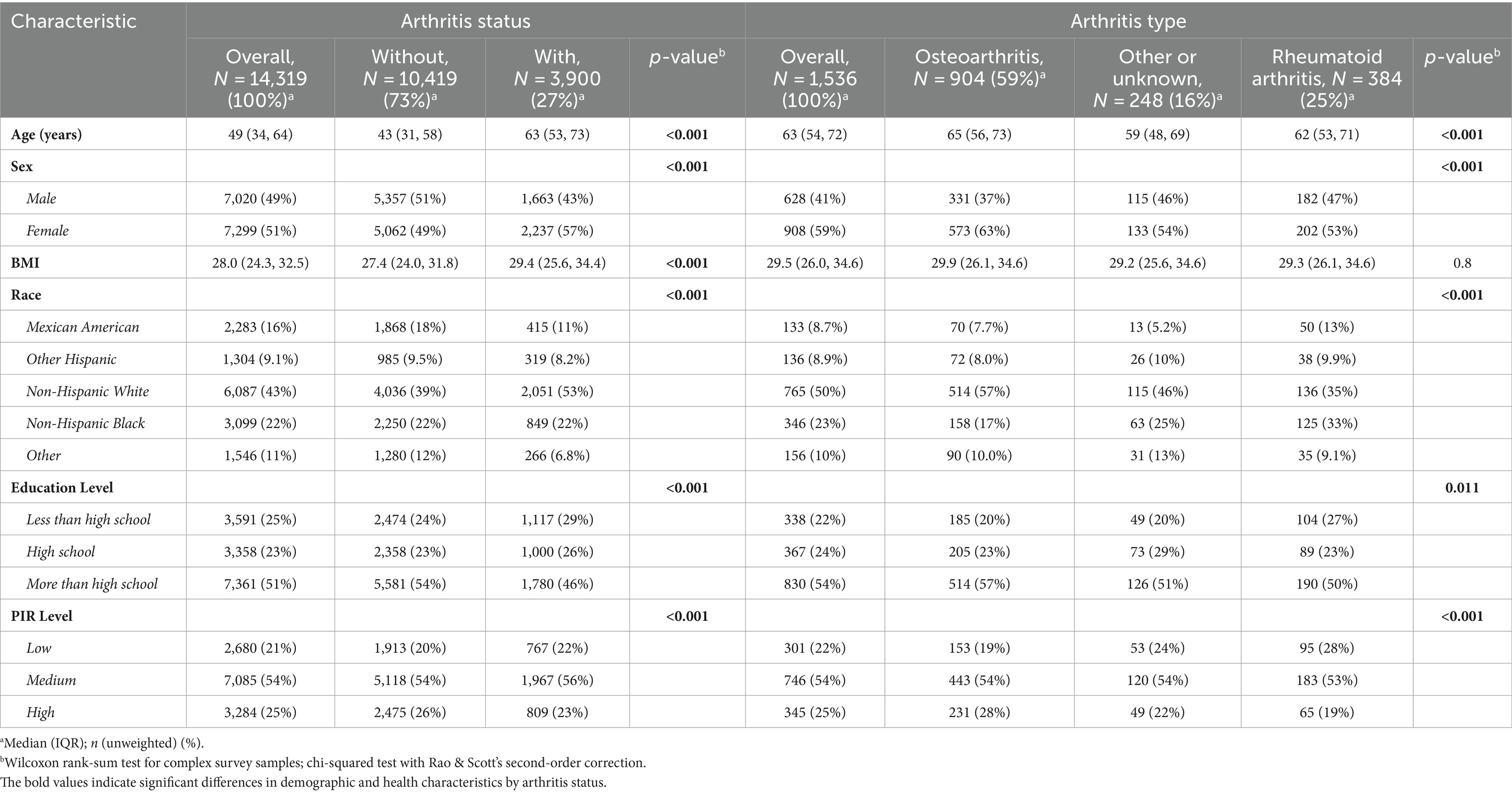
Table 1. Characteristics of the study participants from 2003–2020 in US NHANES.
The comparative analysis between participants with arthritis and those without highlighted several notable demographic and socioeconomic distinctions. Specifically, individuals diagnosed with arthritis were predominantly female, tended to be older, and were more likely to identify as non-Hispanic white. Additionally, this group was characterized by a moderate household income. These differences between the two groups were statistically significant, with all comparisons yielding a p-value of less than 0.05.
3.2 Data of heavy metal exposure
Table 2 in our study presents a detailed analysis of the concentrations of various heavy metals detected in urine or blood samples across each data release cycle from the U.S. National Health and Nutrition Examination Survey (NHANES). The heavy metals examined include total arsenic, arsenite, arsenic acid, dimethylarsinic acid, monomethylarsonic acid, barium, cadmium, lead, antimony, and tungsten, in addition to the specific analysis of cadmium and lead levels in blood samples.
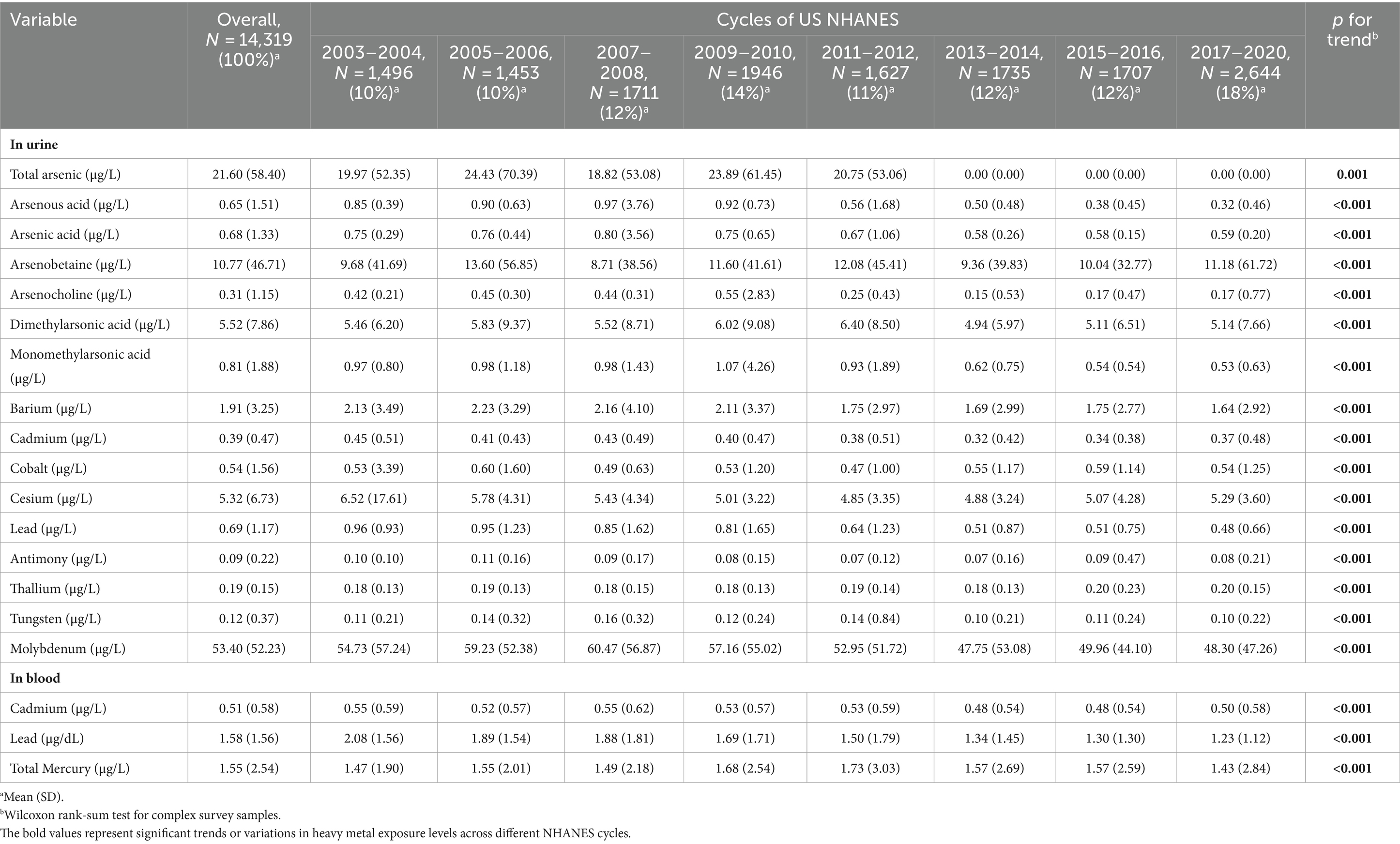
Table 2. Means and standard deviations of heavy metals by each cycle of US NHANES (2003–2020).
The analysis reveals a significant trend in the concentration levels of these heavy metals over the data release cycles, with a p-value of less than 0.05 indicating statistical significance. This suggests that there has been a consistent and noteworthy variation in the exposure levels to these metals among the U.S. population during the study period.
3.3 Training and testing of machine learning models
In the initial phase of our study, we focused on developing machine learning models capable of identifying the presence of arthritis. To refine the feature set for our machine learning (ML) models, we employed the LASSO regression technique for feature selection. This approach enabled us to identify 21 variables that exhibited non-zero coefficients after LASSO’s regularization process, indicating their significance in predicting arthritis.
The training outcomes of this first stage are documented in figures within the Supplementary material. Figure 2 illustrates the receiver operating characteristic (ROC) curves of the various ML models trained, plotted together for comparative analysis. It is important to note that certain models, such as K-nearest neighbors (KNN), demonstrated notably inferior performance in this specific task. As a result, models performing suboptimally were subsequently excluded from further analysis in favor of those that could be optimized with more effective settings.
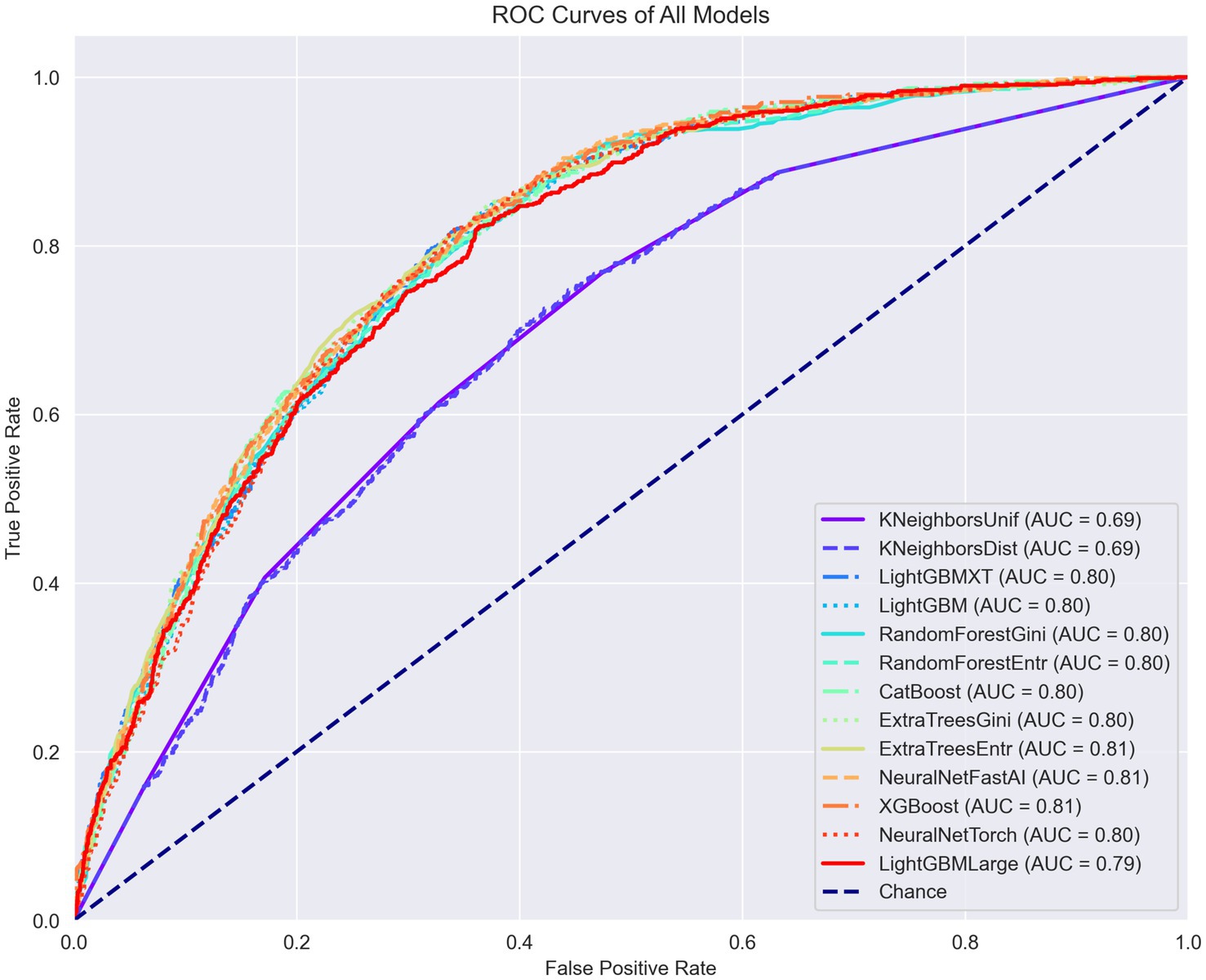
Figure 2. ROC curves, PR curves, and confusion matrices for each model in the binary classification task of diagnosing arthritis.
Among the various models evaluated, XGBoost emerged as particularly effective in predicting arthritis, showcasing an area under the curve (AUC) of 0.81, an accuracy of 0.77, an average precision score (APS) of 0.59, a precision of 0.61, a recall of 0.50, and an F1 score of 0.54. These results, depicted in Figure 3, underscore the superior performance of XGBoost in this context.
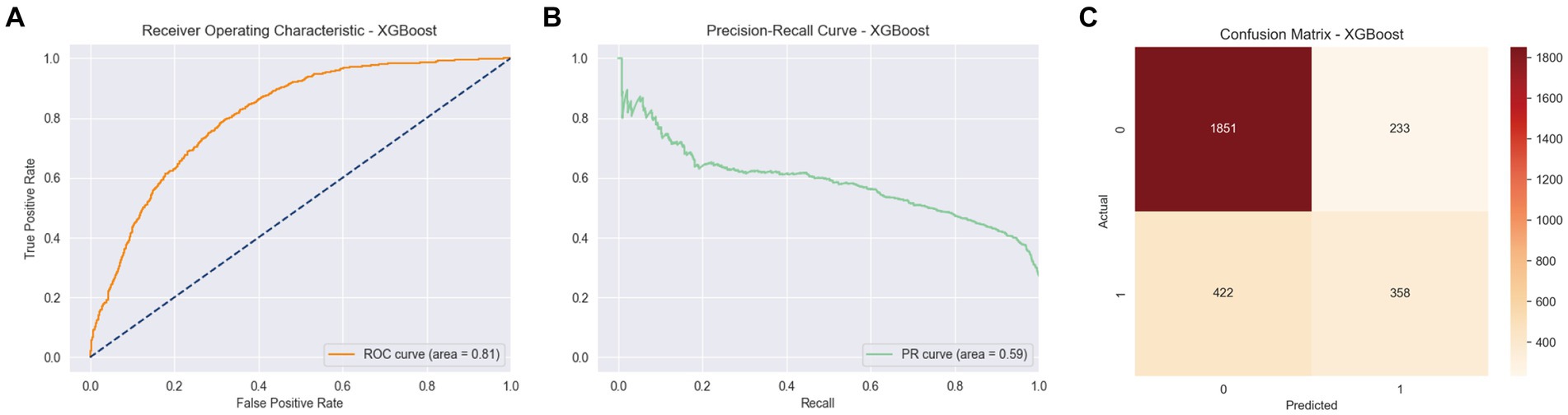
Figure 3. ROC curve, PR curve, confusion matrix of stage II XGBoost in the binary classification task of identifying arthritis. (A) ROC Curve for XGBoost model, showing the True Positive Rate against the False Positive Rate with an AUC of 0.81. (B) PR Curve for XGBoost model. (C) Confusion Matrix for XGBoost model, displaying the actual vs. predicted values.
Following the successful determination of arthritic status among participants, our study’s next objective was to differentiate between osteoarthritis (OA) and rheumatoid arthritis (RA) and to explore the specific influence of heavy metal exposure on these forms of arthritis. Leveraging the arthritis patient data initially selected, we proceeded with a similar two-stage machine learning model training approach. This process began with the extraction of relevant features from the dataset comprising identified arthritis patients, aiming to refine and select the most effective models through a rigorous two-stage training regimen. This strategy was designed to isolate the models that exhibited the strongest performance on the test set, with the ultimate goal of utilizing the optimized model to investigate the relationship between heavy metal exposure and the different types of arthritis. Such an approach not only aids in the precise categorization of arthritis types but also in understanding their potential associations with environmental factors.
In the final analysis, the LightGBM_Large model emerged as particularly effective for this task, achieving a macro area under the curve (AUC) of 0.76, an accuracy of 0.70, a balanced accuracy of 0.53, and a macro F1 score of 0.85. These outcomes are detailed in Figure 4.
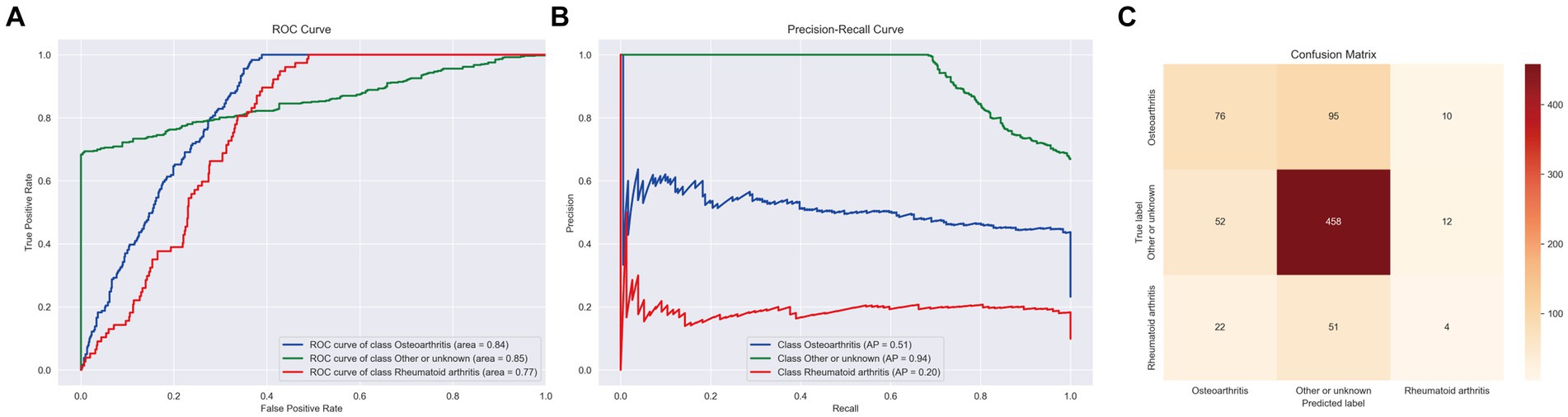
Figure 4. ROC curve, PR curve, confusion matrix of stage II LightGBM in the multi-classification task of identifying arthritis species. (A) ROC Curves for different classes. (B) PR Curves for different classes. (C) Confusion Matrix displaying the actual vs. predicted values for the different classes.
3.4 Feature importance visualization
In our study, we utilized SHAP (SHapley Additive exPlanations) to illuminate the impact of each variable within the XGBoost model on the status of arthritis in the test dataset. SHAP plots, including a decision map and a heatmap, visualize the model’s decision-making process and the distribution of SHAP values for each feature, respectively, as depicted in Figure 5. The analysis of SHAP values revealed that certain heavy metals significantly contribute to the model’s predictions. Specifically, tungsten (0.013) in urine and other metals such as cobalt (0.007), cadmium (0.007), antimony (0.005), total arsenic (0.002), and blood cadmium (0.005) showed positive contributions, indicating their association with an increased likelihood of arthritis diagnosis. Conversely, molybdenum in urine (−0.007), thallium (−0.004), lead (−0.003), and mercury (−0.004) in blood demonstrated negative contributions, suggesting their inverse relationship with arthritis risk.
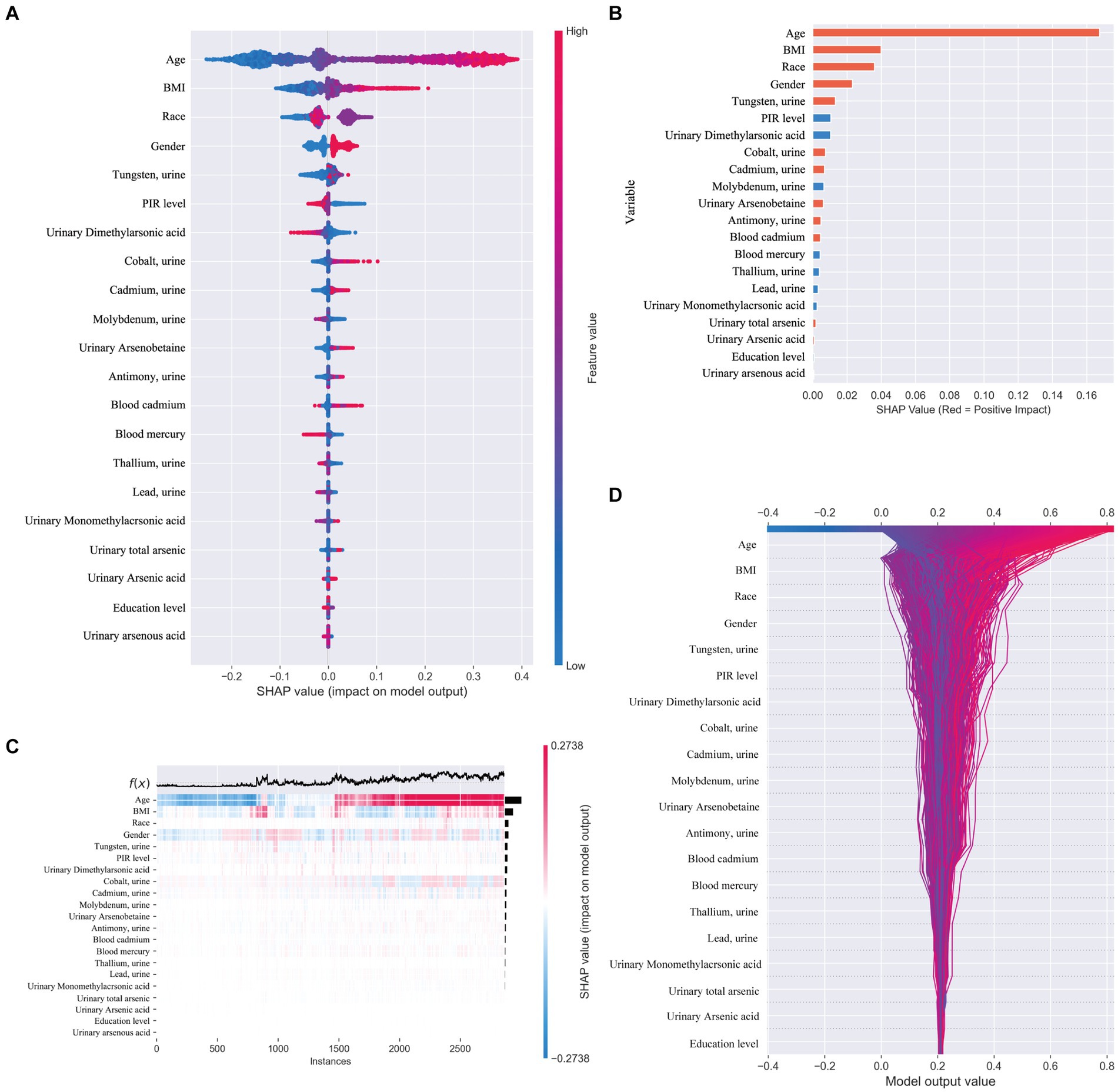
Figure 5. (A) SHAP plot. Top-to-bottom features are sorted by the average of the absolute shell values, that is, the vertical position shows the importance of the features. Each point in the figure represents the SHAP value for each sample, the color represents the feature value (the red high, the blue low), and the horizontal position shows whether the effect of this value leads to higher or lower predictions. (B) The features shown in red indicate positive contributions to the model, such as urinary tungsten (0.013), cobalt (0.007), cadmium (0.007), antimony (0.005), total arsenic (0.002), and cadmium in blood (0.005). The features shown in blue indicate a negative contribution to the model, such as molybdenum (−0.007) in urine, thallium (−0.004), lead (−0.003), and mercury in blood (−0.004). (C) SHAP heatmap. (D) SHAP decision diagram.
Beyond heavy metal exposure, demographic factors like gender, age, and ethnicity (non-Hispanic whites) were also identified as significant, with these groups showing a higher association with arthritis prevalence. This underscores the multifaceted nature of arthritis risk, encompassing both environmental and demographic influences.
When distinguishing between specific types of arthritis (OA, RA, or unspecified arthritis), the SHAP analysis for the multi-classification task did not yield as straightforward an interpretation as the binary classification model. Hence, we resorted to using feature importance based on permutation shuffling to ascertain the significance of heavy metal exposure in identifying OA and RA, with findings presented in Figure 6. Additionally, the development of RA was examined as a binary classification issue, exploring how the machine learning model discerns RA presence through SHAP values, detailed in Figure 7.
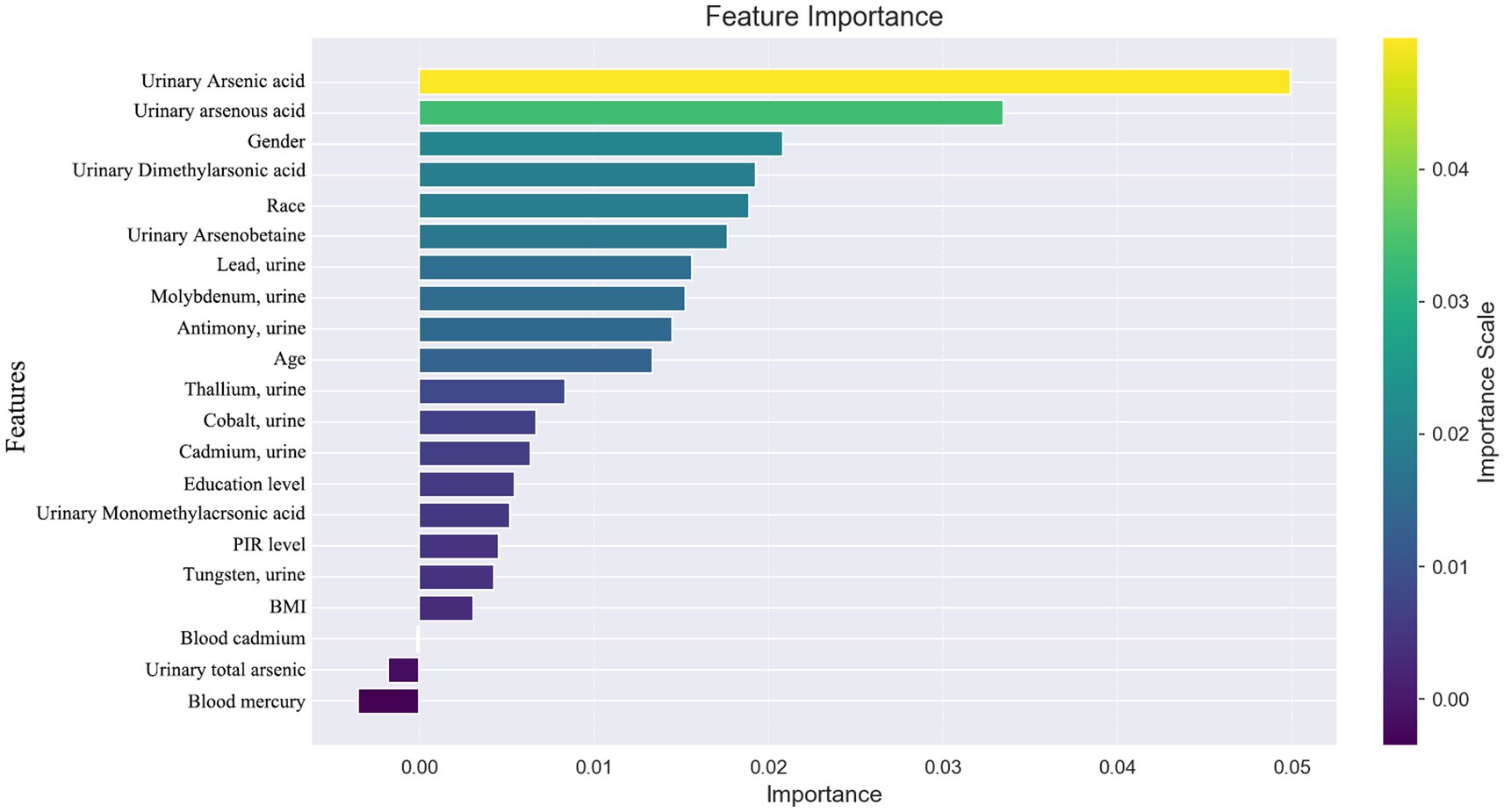
Figure 6. Feature importance based on permutation shuffling.
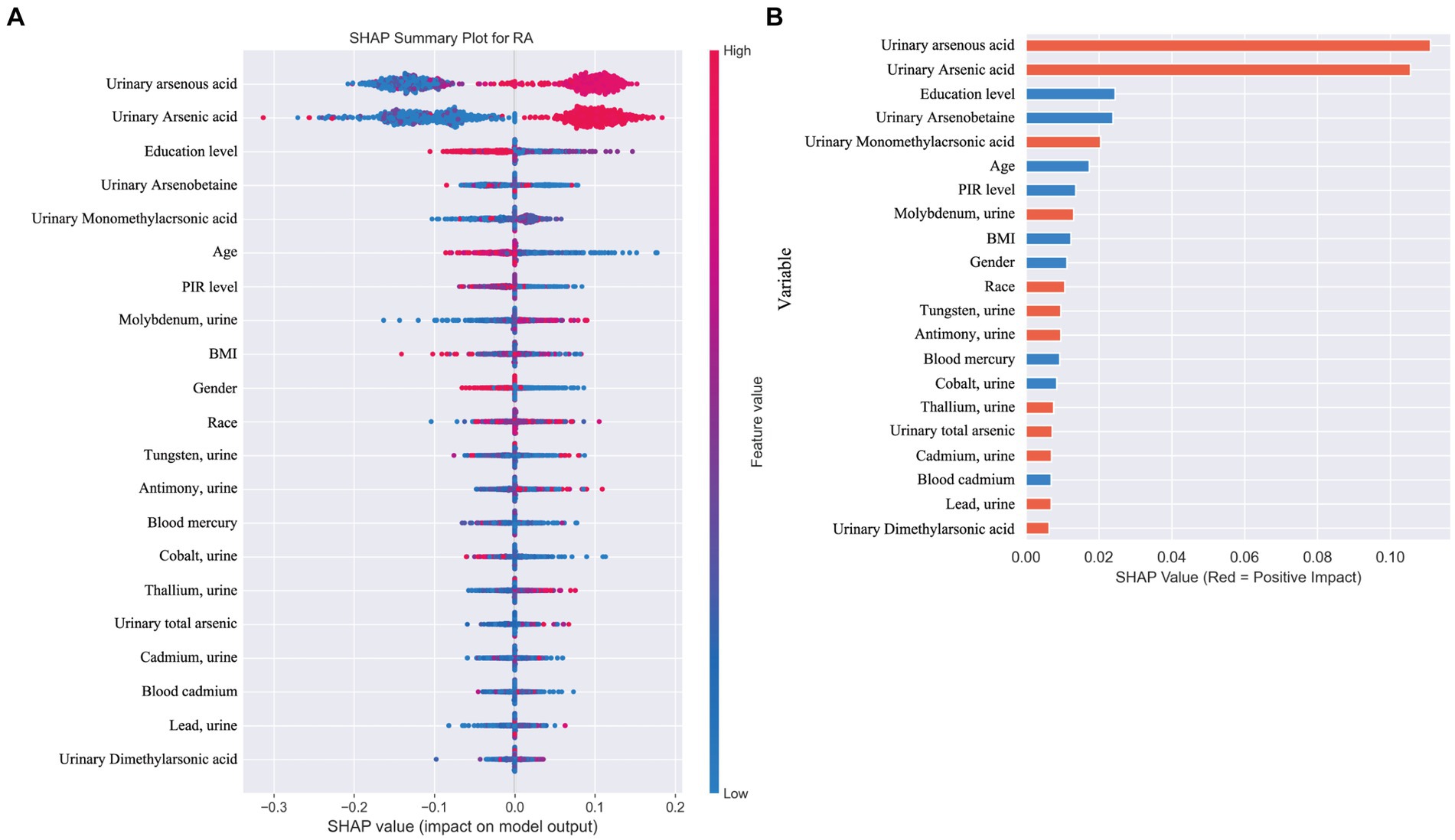
Figure 7. (A) SHAP plot. This figure illustrates the application of a machine learning model in a binary classification task for identifying the presence of rheumatoid arthritis (RA). (B) Positive (red) SHAP values indicate features that contribute to predicting RA presence, including arsenic metabolites (0.02), molybdenum (0.013), tungsten (0.009), antimony (0.009), and thallium (0.007). Negative (blue) SHAP values, such as for mercury (−0.009) and cobalt (−0.008), suggest these features are more associated with other types of arthritis or osteoarthritis (OA).
4 Discussion
In this investigation, we employed LASSO regression to efficiently delineate key variables and adopted explainable machine learning methodologies linked to heavy metal exposure. These techniques were implemented to ascertain the presence of arthritis within the NHANES database spanning 2003 to 2020. In our meticulous analysis of heavy metal exposure’s ramifications on OA and RA, the XGBoost and LightGBM algorithms demonstrated exceptional prowess in managing the complexities of the dataset, with XGBoost attaining an AUC of 0.81 and a precision rate of 77%, whereas LightGBM achieved an AUC of 0.76 and an accuracy of 70%. Both models were augmented by SHAP values, affording profound insights into how heavy metals modulate the risk trajectories for OA and RA, thereby enhancing the interpretability of our models and informing subsequent research trajectories.
ML, an intricate branch of artificial intelligence, leverages sophisticated mathematical algorithms to parse and categorize patterns across disparate datasets, thereby bolstering decision-making processes. Despite its efficacy, the opaque reasoning mechanisms of ML algorithms and the complexity inherent in their interpretability pose significant challenges to their practical application in medical decision-making (26). Our machine learning strategy boasted several distinctive features. Primarily, it circumvented the need for new data acquisition, instead exploiting demographic, laboratory, and questionnaire data from the NHANES, applying multi-source data to our machine learning models. Furthermore, our models underwent training and evaluation on an extensive dataset, with a particular emphasis on the blood levels of heavy metals in individual participants. Given that the annual average levels of heavy metal exposure among the study participants were not incorporated into the training data, the decreasing trends in metal content did not compromise model stability. Additionally, our phased machine learning strategy, which was congruent with NHANES’s questionnaire collection methodology, initially determined whether participants suffered from arthritis, subsequently classifying the type of arthritis. The AUC of XGBoost and LightGBM in these phased tasks stood at 0.81 and 0.76, respectively, indicative of robust model stability. In addition, our study implemented machine learning models configured with 13 distinct parameter settings, based on 7 different methodologies, to evaluate the efficacy of machine learning in our research context. The application of SHAP values to the XGBoost and LightGBM models was intended to more effectively illustrate the decision-making processes of the machine learning models. Positive SHAP values indicated a heightened risk of OA and RA during the 18-year survey period of the United States NHANES, whereas negative values suggested a reduced risk.
SHAP outcomes aligned with prior research, pinpointing exposures most closely linked with arthritis development as tungsten (0.013), cobalt (0.007), cadmium (0.007), antimony (0.005), and arsenic (0.002), significant as potential risk factors. In individuals diagnosed with arthritis, the presence of arsenic, lead, molybdenum, antimony, thallium, cobalt, cadmium, and tungsten significantly differentiated between OA and RA based on levels of heavy metal exposure.
Presently, studies on how tungsten, cobalt, and antimony catalyze the mechanisms that induce OA and RA remain sparse. Our findings offer valuable perspectives for future investigations into the impact of these heavy metals on the pathogenesis of arthritis. Cadmium (Cd), a known environmental contaminant causing renal damage and bone demineralization, has been demonstrated to promote the expression of enzymes linked to the breakdown of the extracellular matrix in joint cartilage and diminish the presence of glycosaminoglycans and proteoglycans through the generation of reactive oxygen species (27–29). Recent studies have highlighted arsenic as a contributory factor in the development of arthritis (29). In a mouse model integrated with surgery-induced joint instability (30), arsenic’s presence markedly intensified cartilage degradation, consistent with our findings. Prior studies correlated mercury with the onset of osteoarthritis, noting elevated mercury levels in the anterior cruciate ligaments of women under 65 with degenerative spinal conditions (31). The presence of mercury in bones may correlate with body mass index, anatomical differences, and sex (32). Our classification of the arthritis-affected populace reaffirmed the linkage between mercury and OA. Investigations by Grech (33) have shown that molybdenum could counteract iron-deficiency anemia by increasing enzyme quantities, revitalizing enzyme activity, and impeding inflammatory pathways, suggesting molybdenum’s role as a protective agent against arthritis, a finding corroborated by our analysis. Although certain studies have explored the relationship between blood lead levels and the prevalence and severity of knee osteoarthritis (34), our research did not substantiate this connection, likely due to the cross-sectional study design’s inherent limitations.
Moving forward, continuous monitoring and elucidation of selected features will yield invaluable insights for experts, enabling them to formulate well-founded conclusions instead of merely accepting the algorithm’s outputs. Furthermore, we intend to focus on validating the performance of the model by broadening the database and augmenting the interpretability of the interface between clinicians and the machine learning model.
This study has its limitations, including the absence of longitudinal follow-up for the same cohort and the current inability to access other datasets of similar scale for validation. We plan to address these issues in future research. Additionally, the inherent biases of cross-sectional studies, potential information bias from self-reported arthritis diagnoses, and biases resulting from imputing missing data are also limitations. Moreover, disparities in feature importance between permutation shuffling and SHAP, with the former concentrating on global explanations and the latter on individual prediction contributions, may impede replicability due to the complexity entailed in model interpretation.
5 Conclusion
Our study effectively utilized phased machine learning strategies to investigate the link between heavy metal exposure and arthritis prevalence among NHANES participants from 2003 to 2020. Employing SHAP enhanced our understanding of the predictive outcomes of these models, providing deep insights into the factors contributing to arthritis. This approach combines advanced analytics with improved interpretability, overcoming the typical “black box” issue in machine learning and enabling a more detailed exploration of the relationship between environmental exposures and health outcomes.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding authors.
Ethics statement
The studies involving humans were approved by the data analyzed in this study are from the National Health and Nutrition Examination Survey (NHANES), which received ethical approval from the Research Ethics Review Board (ERB) at the National Center for Health Statistics (NCHS), which is part of the Centers for Disease Control and Prevention (CDC). The studies were conducted in accordance with the local legislation and institutional requirements. Written informed consent for participation was not required from the participants or the participants’ legal guardians/next of kin in accordance with the national legislation and institutional requirements.
Author contributions
WF: Data curation, Formal analysis, Methodology, Validation, Visualization, Writing – original draft. ZP: Writing – review & editing, Data curation, Validation. KK: Writing – review & editing. HQ: Writing – review & editing. MJ: Writing – review & editing. YC: Writing – review & editing. JZ: Writing – review & editing. HL: Supervision, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. National Natural Science Foundation of China (82072397), Fundamental Research Funds for the Central Universities (YG2023ZD15), Program of Shanghai Academic/Technology Research Leader (22XD1434000), The Youth Talent Program from Shanghai Health System (2022YQ020), the Natural Science Foundation of Shanghai (23ZR1437300) and Natural Science Foundation of Inner Mongolia Autonomous Region (2024ZD32).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fnut.2024.1422617/full#supplementary-material
References
1. Tang, C-H . Research of pathogenesis and novel therapeutics in arthritis. Int J Mol Sci. (2019) 20:1646. doi: 10.3390/ijms20071646
2. Barbour, KE . Vital signs: prevalence of doctor-diagnosed arthritis and arthritis-attributable activity limitation—United States, 2013–2015. MMWR Morb Mortal Wkly Rep. (2017) 66:246–53. doi: 10.15585/mmwr.mm6609e1
3. Safiri, S, Kolahi, AA, Hoy, D, Smith, E, Bettampadi, D, Mansournia, MA, et al. Global, regional and national burden of rheumatoid arthritis 1990–2017: a systematic analysis of the Global Burden of Disease Study 2017. Ann Rheum Dis. (2019) 78:1463–71. doi: 10.1136/annrheumdis-2019-215920
4. Safiri, S, Kolahi, A-A, Smith, E, Hill, C, Bettampadi, D, Mansournia, MA, et al. Global, regional and national burden of osteoarthritis 1990–2017: a systematic analysis of the Global Burden of Disease Study 2017. Ann Rheum Dis. (2020) 79:819–28. doi: 10.1136/annrheumdis-2019-216515
5. Paithankar, JG, Saini, S, Dwivedi, S, Sharma, A, and Chowdhuri, DK. Heavy metal associated health hazards: an interplay of oxidative stress and signal transduction. Chemosphere. (2021) 262:128350. doi: 10.1016/j.chemosphere.2020.128350
6. Smallwood, MJ, Nissim, A, Knight, AR, Whiteman, M, Haigh, R, and Winyard, PG. Oxidative stress in autoimmune rheumatic diseases. Free Radic Biol Med. (2018) 125:3–14. doi: 10.1016/j.freeradbiomed.2018.05.086
7. Chen, L, Sun, Q, Peng, S, Tan, T, Mei, G, Chen, H, et al. Associations of blood and urinary heavy metals with rheumatoid arthritis risk among adults in NHANES, 1999–2018. Chemosphere. (2022) 289:133147. doi: 10.1016/j.chemosphere.2021.133147
8. Joo, SH, Lee, J, Hutchinson, D, and Song, YW. Prevalence of rheumatoid arthritis in relation to serum cadmium concentrations: cross-sectional study using Korean National Health and Nutrition Examination Survey (KNHANES) data. BMJ Open. (2019) 9:e023233. doi: 10.1136/bmjopen-2018-023233
9. Guan, T, Wu, Z, Xu, C, and Su, G. The association of trace elements with arthritis in US adults: NHANES 2013–2016. J Trace Elem Med Biol. (2023) 76:127122. doi: 10.1016/j.jtemb.2022.127122
10. Xia, F, Li, Q, Luo, X, and Wu, J. Identification for heavy metals exposure on osteoarthritis among aging people and machine learning for prediction: a study based on NHANES 2011–2020. Front Public Health. (2022) 10:906774. doi: 10.3389/fpubh.2022.906774
11. Fang, L, Zhao, H, Chen, Y, Ma, Y, Shanshan, X, Shenqian, X, et al. The combined effect of heavy metals and polycyclic aromatic hydrocarbons on arthritis, especially osteoarthritis, in the U.S. adult population. Chemosphere. (2023) 316:137870. doi: 10.1016/j.chemosphere.2023.137870
12. Lundberg, S M, and Lee, S-I. (2017). A unified approach to interpreting model predictions. Advances in Neural Information Processing Systems. Curran Associates, Inc.. Available at: https://proceedings.neurips.cc/paper/2017/hash/8a20a8621978632d76c43dfd28b67767-Abstract.html
13. National Center for Health Statistics . (2023). Surveys and data collection systems. Available at: https://www.cdc.gov/nchs/surveys.htm
14. National Center for Health Statistics . (2024). NHANES 2013–2014 laboratory methods. Available at: https://wwwn.cdc.gov/nchs/nhanes/ContinuousNhanes/LabMethods.aspx?BeginYear=2013. (Accessed March 30, 2024)
15. Tibshirani, R . Regression shrinkage and selection via the LASSO. J R Stat Soc B. (1996) 58:267–88. doi: 10.1111/j.2517-6161.1996.tb02080.x
16. Chawla, NV, Bowyer, KW, Hall, LO, and Kegelmeyer, WP. SMOTE: synthetic minority over-sampling technique. J Artif Intell Res. (2002) 16:321–57. doi: 10.1613/jair.953
17. López, V, Fernández, A, García, S, Palade, V, and Herrera, F. An insight into classification with imbalanced data: empirical results and current trends on using data intrinsic characteristics. Inf Sci. (2013) 250:113–41. doi: 10.1016/j.ins.2013.07.007
18. Sung, S-F, Hung, L-C, and Ya-Han, H. Developing a stroke alert trigger for clinical decision support at emergency triage using machine learning. Int J Med Inform. (2021) 152:104505. doi: 10.1016/j.ijmedinf.2021.104505
20. Geurts, P, Ernst, D, and Wehenkel, L. Extremely randomized trees. Mach Learn. (2006) 63:3–42. doi: 10.1007/s10994-006-6226-1
21. Ke, G, Meng, Q, Finley, T, Wang, T, Chen, W, Ma, W, et al. (2017). LightGBM: a highly efficient gradient boosting decision tree. Advances in Neural Information Processing Systems. Curran Associates, Inc.. Available at: https://papers.nips.cc/paper_files/paper/2017/hash/6449f44a102fde848669bdd9eb6b76fa-Abstract.html
22. Wikipedia . (2024). K-nearest neighbors algorithm. Wikipedia. Available at: https://en.wikipedia.org/w/index.php?title=K-nearest_neighbors_algorithm&oldid=1212348037
23. Prokhorenkova, L, Gusev, G, Vorobev, A, Dorogush, AV, and Gulin, A. (2019). CatBoost: unbiased boosting with categorical features. arXiv. Available at: https://doi.org/10.48550/arXiv.1706.09516. [Epub ahead of preprint]
24. Chen, T, and Guestrin, C. (2016). XGBoost: a scalable tree boosting system. Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 785–794
25. Pruessner, JC, Kirschbaum, C, Meinlschmid, G, and Hellhammer, DH. Two formulas for computation of the area under the curve represent measures of total hormone concentration versus time-dependent change. Psychoneuroendocrinology. (2003) 28:916–31. doi: 10.1016/S0306-4530(02)00108-7
26. de Souza, A, Alvaro, AP, Stubbs, DA, Baan, CC, and Boer, K. Cherry on top or real need? A review of explainable machine learning in kidney transplantation. Transplantation. (2024). doi: 10.1097/TP.0000000000005063
27. Frangos, T, and Maret, W. Zinc and cadmium in the aetiology and pathogenesis of osteoarthritis and rheumatoid arthritis. Nutrients. (2021) 13:53. doi: 10.3390/nu13010053
28. Liu, H, Liu, M, Qiao, L, Yang, Z, He, Y, Bao, M, et al. Association of blood cadmium levels and all-cause mortality among adults with rheumatoid arthritis: the NHANES cohort study. J Trace Elem Med Biol. (2024) 83:127406. doi: 10.1016/j.jtemb.2024.127406
29. Skalny, AV, Aschner, M, Zhang, F, Guo, X, Djordevic, AB, Sotnikova, TI, et al. Molecular mechanisms of environmental pollutant-induced cartilage damage: from developmental disorders to osteoarthritis. Arch Toxicol. (2024). doi: 10.1007/s00204-024-03772-9
30. Suminda, GG, Dinesh, YM, Ha, MW, Ghosh, M, Lee, D-S, and Son, Y-O. In vitro and in vivo investigations on arsenic-induced cartilage degeneration in osteoarthritis. J Hazard Mater. (2024) 461:132570. doi: 10.1016/j.jhazmat.2023.132570
31. Zioła-Frankowska, A, Dąbrowski, M, Kubaszewski, Ł, Rogala, P, Kowalski, A, and Frankowski, M. An analysis of factors affecting the mercury content in the human femoral bone. Environ Sci Pollut Res. (2017) 24:547–57. doi: 10.1007/s11356-016-7784-9
32. Pamphlett, R, and Jew, SK. Mercury is taken up selectively by cells involved in joint, bone, and connective tissue disorders. Front Med. (2019) 6:168. doi: 10.3389/fmed.2019.00168
33. Grech, BJ . Mechanistic insights into the treatment of iron-deficiency anemia and arthritis in humans with dietary molybdenum. Eur J Clin Nutr. (2021) 75:1170–5. doi: 10.1038/s41430-020-00845-7
34. Nelson, AE, Chaudhary, S, Kraus, VB, Fang, F, Chen, J-C, Schwartz, TA, et al. Whole blood lead levels are associated with biomarkers of joint tissue metabolism in African American and white men and women: the Johnston County Osteoarthritis Project. Environ Res. (2011) 111:1208–14. doi: 10.1016/j.envres.2011.08.002
Keywords: machine learning, heavy metal exposure, NHANES, SHAP (SHapley Additive exPlanation), osteoarthritis and rheumatoid arthritis, environmental health
Citation: Fan W, Pi Z, Kong K, Qiao H, Jin M, Chang Y, Zhang J and Li H (2024) Analyzing the impact of heavy metal exposure on osteoarthritis and rheumatoid arthritis: an approach based on interpretable machine learning. Front. Nutr. 11:1422617. doi: 10.3389/fnut.2024.1422617
Edited by:
Chenxi Huang, Xiamen University, ChinaReviewed by:
Barış Baydemir, Çanakkale Onsekiz Mart University, TürkiyeMehdi Pirooznia, Johnson & Johnson, United States
Copyright © 2024 Fan, Pi, Kong, Qiao, Jin, Chang, Zhang and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Jingwei Zhang, emp3X3lzQDE2My5jb20=; Huiwu Li, aHVpd3UxMjIzQDE2My5jb20=