 Zhucheng Zhang1,2†
Zhucheng Zhang1,2† Chenxi Peng3†Zhuo Li2Jiaqiang Li3Yan Li4Yuhang Pan1,2Ruihong Liu2*Xiangdong Chen1,4*
Chenxi Peng3†Zhuo Li2Jiaqiang Li3Yan Li4Yuhang Pan1,2Ruihong Liu2*Xiangdong Chen1,4*- 1Department of General Practice, Health Science Center, Shenzhen University, Shenzhen, China
- 2Department of Family Medicine, The University of Hong Kong-Shenzhen Hospital, Shenzhen, China
- 3Department of Biomedical Engineering, Health Science Center, Shenzhen University, Shenzhen, China
- 4Department of Otolaryngology-Head and Neck Surgery, Shenzhen University General Hospital, Shenzhen, China
Background and aim: Accelerated aging poses significant physical, psychological, and social health challenge to Chinese. Successful aging (SA) serves as a proactive approach to population aging, reflecting individual health status and quality of life, thereby enhancing the capacity for healthy living among the older adults. However, the complexity of SA measurement methods often hinders its application in community healthcare. Currently, there is a dearth of prediction model tailored for the older adults in community. This study aimed to develop and validate a prediction model for SA in Chinese community older adults.
Methods: Data were derived from the fifth wave of the China Health and Retirement Longitudinal Study (CHARLS), targeting community-dwelling older adults individuals over 60. Employing health ecology theory, we comprehensively utilized variables from community health records. The Shapley Additive exPlanation (SHAP) method identified key variables contributing to outcome prediction. An extreme gradient boosting machine learning method was used to construct the prediction model for SA in Chinese community older adults. The final model was obtained through hyperparameter adjustment via 8-fold cross-validation. The model’s performance was evaluated using area under the receiver operating characteristic curves (AUROC), discriminant slope, calibration curves, decision curves, SHAP-based risk factor analysis, and comparison with other methods to assess differentiation, calibration, interpretability, and clinical utility.
Results: The model incorporated variables available from community health records. SHAP indicated a robust importance ranking of variable features, with the most frequent top 16 features aligning with clinical practice, ensuring good interpretability and extensibility of the resulting prediction model. We used six machine learning methods to construct the prediction model. Among them, the extreme gradient boosting model demonstrated an AUROC of 0.78, a discrimination slope of 0.140, and a Brier score of 0.124. The proposed model is superior to other methods, and has outstanding discriminability and consistency. Decision curve analysis (DCA) indicated a higher clinical utility compared to other models.
Conclusion: We proposed a prediction model for SA in Chinese community older adults based on health ecology theory and machine learning, which demonstrate excellent prediction performance, interpretability, and extensibility. The prediction model can be applied to community older population health management, promoting SA within community older adults.
1 Introduction
In the 21st century, the global demographic landscape is witnessing a pivotal transformation, particularly in the form of accelerated population aging. China, with the world’s largest older population, is facing this challenge. By the end of 2022, the number of older individuals aged 60 and above in China soared to 280,04 million, constituting 19.8% of the total population, a figure that not only surpasses previous records but also indicates an escalating trend (1, 2). This demographic shift exerts great pressure on the nation’s social security and healthcare infrastructures (3). It is important to note that community-based primary healthcare providers, as the sentinels of public health, play a crucial role in swiftly assessing the physical and mental well-being of the older population (4, 5).
The concept of Successful Aging (SA) is initially introduced by Havighurst in 1961 and later refined by Rowe and Kahn in 1987. It serves as a pivotal metric for evaluating the aging status of individuals and populations (6, 7). SA incorporates low levels of disease and disability, preserved cognitive and physical functionality, and active social engagement (8). As the older population grows, the ability to maintain good health and social participation becomes increasingly significant. Assessing the prevalence of SA within community-dwelling older populations is essential for proactively addressing the aging demography (9). The factors influencing SA are complex, as highlighted by Bronfenbrenner’s health ecology theory, which underscores the intricate interplay of multiple environmental levels in shaping human health (10). This theory posits that the health status of community-dwelling older adults is not an isolated phenomenon but is embedded within a health ecosystem that spans from micro to macro levels. At present, the World Health Organization’s Active Ageing model emphasizes health, participation and safety as the pillars of aging, which is consistent with our multi-dimensional approach to successful aging (physical, psychological, cognitive and social dimensions) (11, 12). Furthermore, Baltes’ SOC model, which focuses on adaptive strategies for aging, can clarify from another perspective how our research can predict and intervene in successful aging through measurable health and lifestyle factors, complementing this model (13).
Despite the burgeoning integration of SA and machine learning to evaluate the older population, many studies are constrained by ambiguous theoretical frameworks and the constraints of sample data source (14–16). There are limitations in the development of SA models with broad applicability, high differentiation, and significant clinical benefits. This study aims to leverage large, representative cross-sectional data from China to explore predictive factors of SA suitable for the older population in Chinese communities. By constructing a SA prediction model with strong interpretability, ease of application, and potential for widespread promotion in community settings, we aim to provide a convenient instrument for community assessment of the older adults. This instrument will facilitate targeted intervention measures and enhance the health and well-being of the older population in communities.
2 Materials and methods
2.1 Data sources and sample
A cross-sectional study design was employed in our research, utilizing data sourced from the fifth wave of the China Longitudinal Study of Health and Retirement (CHARLS) which is conducted in 2020. The CHARLS constitutes a nationally representative longitudinal investigation into aging, which has followed participants biennially since its baseline survey in 2011 (17). This comprehensive survey has collected an extensive array of detailed information pertaining to the health status, familial structures, health behaviors, income, expenditures, and policy on older adults. The CHARLS surveys (including the 2020 wave) have been approved by the Peking University Institutional Review Board for Biomedical Research, with ethics approval number IRB00001052-11015. The specific details can be found in previous studies (18).
In our study, we followed to the definitions established by the United Nations and the World Health Organization (WHO), defined individuals aged 60 years and above as older adults (19, 20). Additionally, we utilized data from the CHARLS questionnaire, which includes inquiries about the respondents’ residential status to ascertain whether they reside within the community.
The original data from CHARLS2020 included a total of 19,395 respondents. Consequently, we excluded participants who were below the age of 60, residing in the community, as well as datasets that were deemed incomplete, characterized by more than 70% missing data for critical variables.
The final set of variables in our analysis was derived through imputation using the “MICE” package within R Studio 4.1.2. We employed the “missForest” algorithm, a multivariate iterative random forest method, which was iterated five times with 100 estimators per iteration. This approach was selected to generate imputed datasets that minimize variance relative to the original dataset, ensuring the robustness and reliability of our subsequent analyses.
After the data cleaning process, we retained 4,324 eligible samples for inclusion in the data analysis. Among these, 614 individuals (14.20%) were identified as successful aging.
2.2 Outcome variable: successful aging
Aging is a multifaceted process that affects physical, mental, and social functioning. Rowe and Kahn have proposed a conceptual model of aging that describes aging as “normal” and “successful” (6, 8). Based on recent studies, specific measurements of the 5 criteria including “No major disease,” “No disability,” “No depression,” “High cognitive function” and “Active social engagement” (21–23). The specific details of potential predictors in this research are presented in Table 1. The outcome variable in this study was binary, which means that irrespective of whether community older population is successful aging or normal aging.
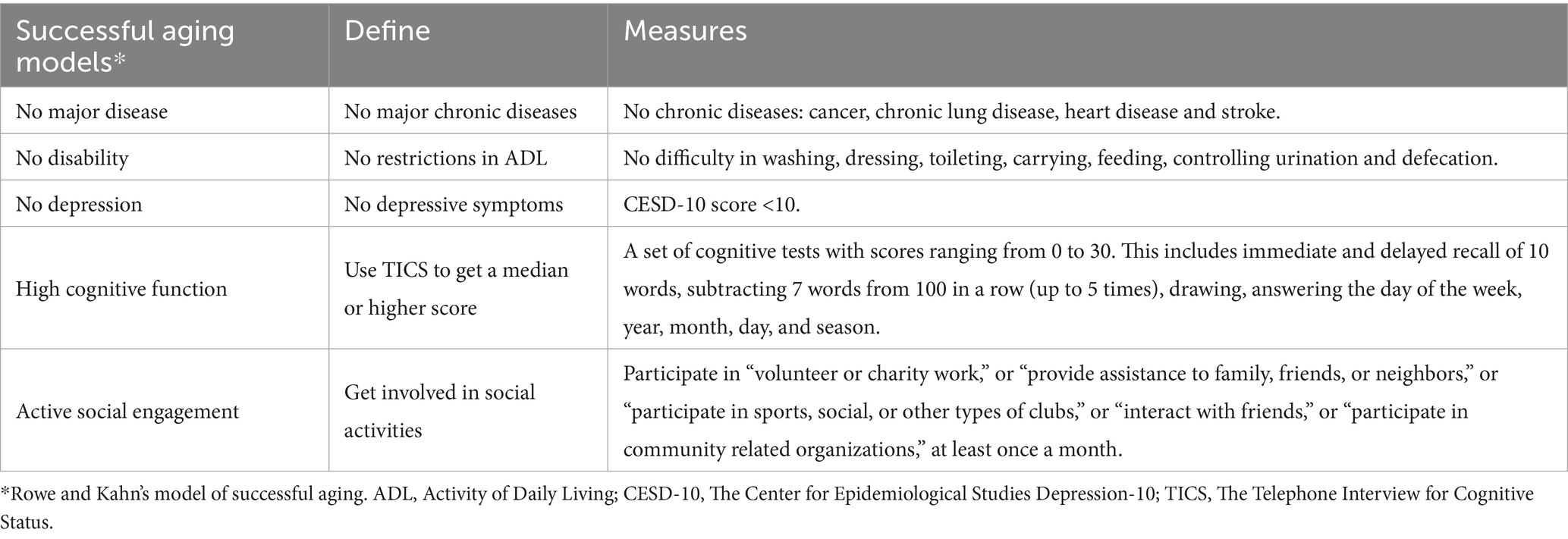
Table 1. Definition and measurement of successful aging.
2.3 Predictors and feature selection
Although the quantity of features plays a crucial role in model training, it is important to recognize that augmenting the number of features also escalates the level of difficulty and associated costs. Feature selection can be used to reduce the number of eliminate irrelevant or redundant features, thereby simplifying the final model and enhancing its efficiency (24).
Based on the health ecology theory and utilizing the health records of community residents that are employed by primary health care providers in China, we conducted a systematic review of pertinent studies to identify potential factors influencing successful aging in Figure 1 (25–28).
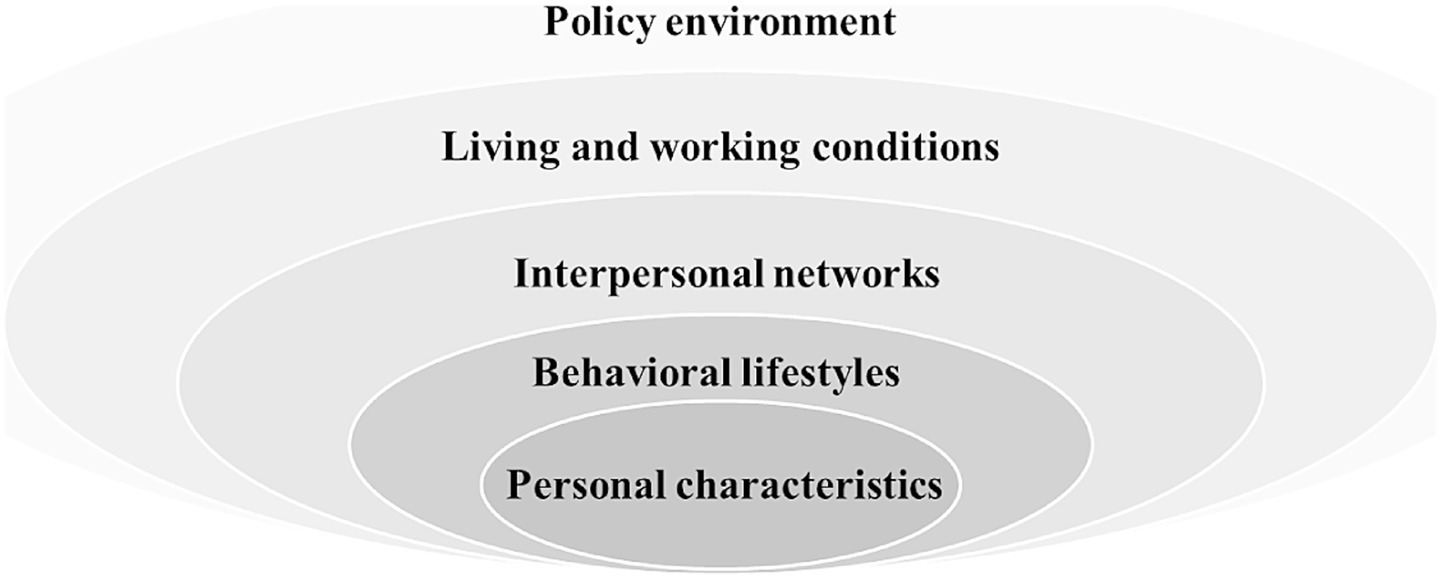
Figure 1. Model of health ecology theory.
Subsequently, we performed feature extraction and utilized the Shapley Additive explanation SHAP to compute the top 30 most significant features for the model based on their experimental result. To determine the feature factors included in the model training, we observed the model’s AUC performance and employed a reclassification method while considering various feature sets. After consulting with experts specializing in primary care, nursing, and gerontology, we finally selected 16 predictors that are indicative of potential SA within Chinese communities. The potential predictors of SA include five dimensions as outlined by the health ecology theory: personal characteristics, behavior and lifestyle, interpersonal network, living and working conditions, and policy environment. The specific details of potential predictors are presented in Table 2.
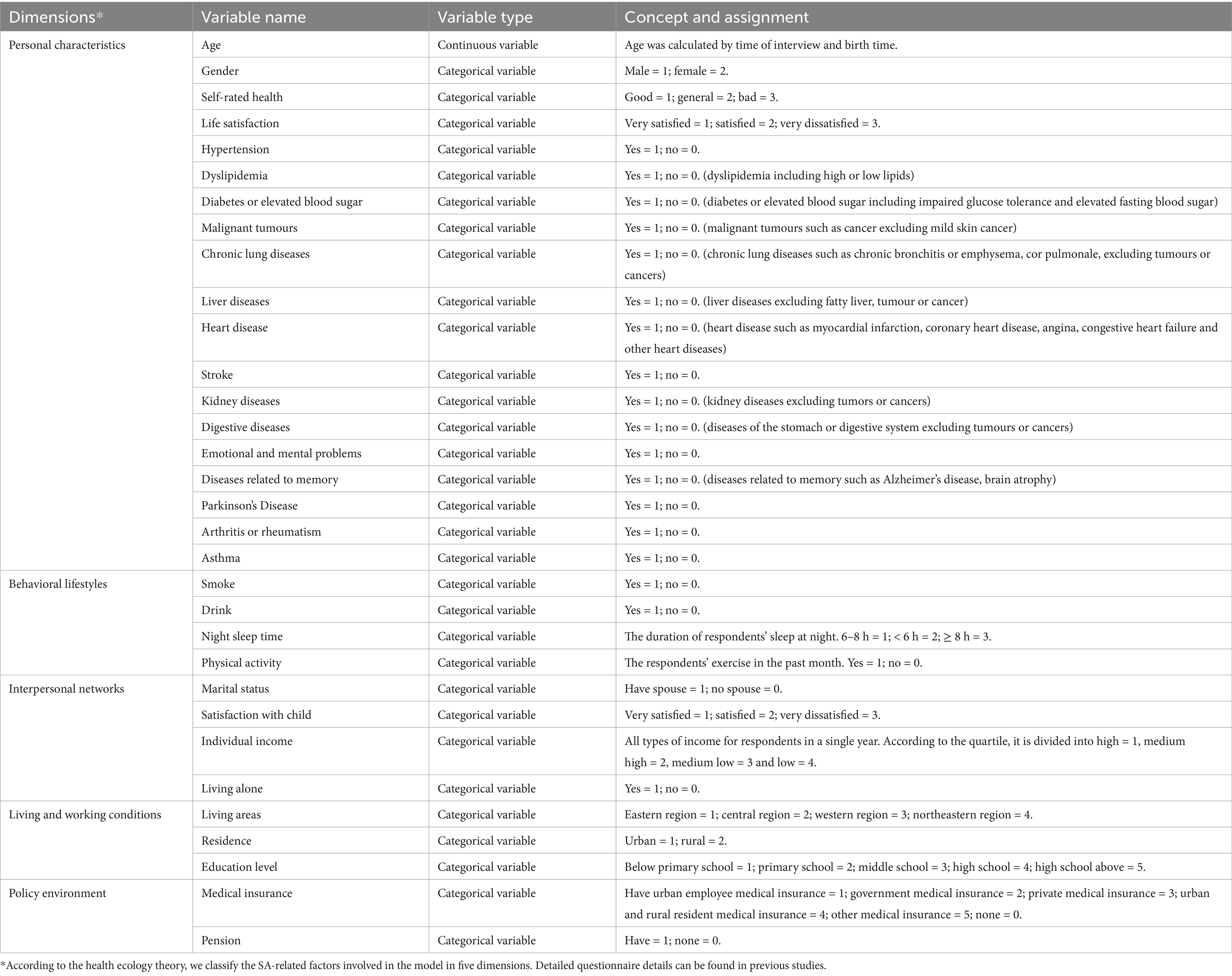
Table 2. Predictive factors about SA.
2.4 Model development
The research endeavor consists of a three-phased approach to model development: (1) construction of machine learning model, (2) model evaluation, and (3) model interpretation. The technical roadmap outlining this research methodology is depicted in Figure 2.
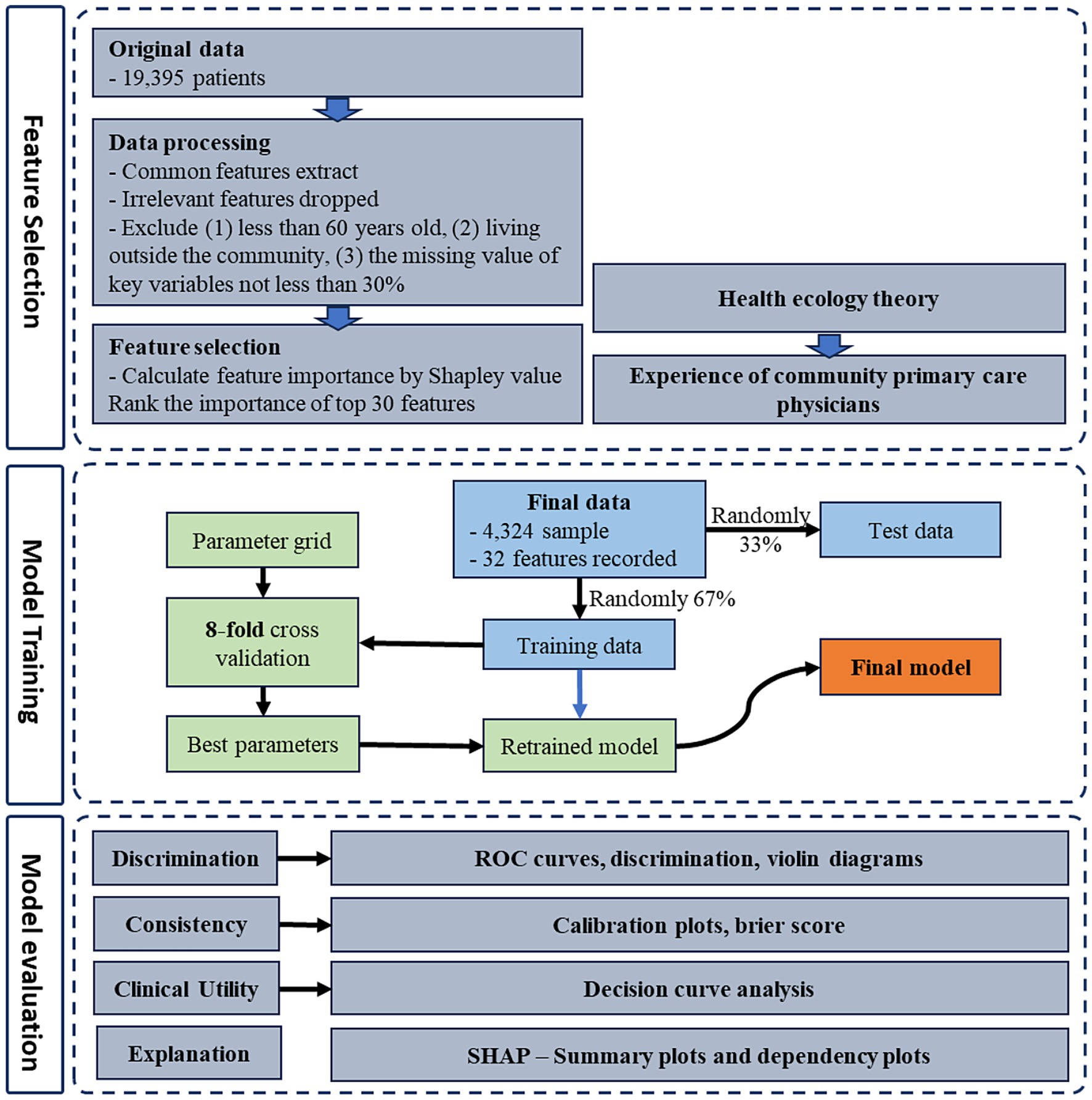
Figure 2. Technical roadmap for model development.
Prior to model construction, 67% of the samples were designated for the training set. The remaining 33% were allocated to the validation set.
In this study, we employed the scikit-learn Python library in conjunction with the XGBoost package for model construction and hyperparameter fine-tuning. To ensure consistent and comparable data, we applied a linear function normalization technique, specifically mapping the original data to the range [0,1]. This approach achieved proportional scaling, effectively mitigating any potential dimensional biases among the data features.
We applied six machine learning methods comprise (1) Logistic Regression (LR), (2) Random Forest (RF), (3) Light Gradient Boosting Machine (LGBM), (4) Gradient Boosting Decision Tree (GBDT), (5) K-Nearest Neighbors (KNN), (6) Extreme Gradient Boosting (XGBoost). These algorithms were compared to assess their performance in predicting SA among older individuals in the community.
2.4.1 Model construction
2.4.1.1 Logistic regression
Logistic Regression (LR), a type of general linear model, assumes that the outcomes adhere to a Bernoulli distribution, parameterized by p, which represents the likelihood of a positive outcome. In our study the positive outcome is the likelihood of SA among community-dwelling older adults. It is noteworthy that logistic regression imposes stringent requirements on the ratio of features to samples, necessitating a balance that ensures model generalizability across diverse populations. The parameters utilized in our study for logistic regression are set to their default values (29).
2.4.1.2 Random forest
Random Forest (RF), an ensemble method based on the Bagging principle, constructs multiple decision trees to enhance classification performance. Each tree draws a random subset of samples and features. The final classification is determined by a majority vote among the trees. The study used 1,000 trees with default settings to evaluate the model’s ability to predict successful aging. The RF algorithm’s effectiveness is attributed to its bagging technique, which reduces variance and improves accuracy by aggregating predictions (30, 31).
2.4.1.3 Light gradient boosting machine
Light Gradient Boosting Machine (LGBM) is a gradient boosting framework that leverages tree-based learning algorithms. It highlights two key techniques: Gradient-based One-Side Sampling (GOSS), which improves efficiency by focusing on data with substantial gradients during training, and Exclusive Feature Bundling (EFB), which simplifies the feature space by bundling exclusive features. These methods are crucial for enhancing the model’s ability to handle large-scale data and maintain accuracy (32).
2.4.1.4 Gradient boosting decision tree
Gradient Boosting Decision Tree (GBDT) begins with a single decision tree and iteratively adds trees to correct the errors of previous ones. The model uses a gradient-based approach to maximize loss reduction at each split point. Regularization techniques are employed to prevent overfitting, and the model’s complexity is managed through parameters that control the number and depth of tree leaves. The predictions from individual trees are aggregated for a final prediction, leveraging the ensemble’s collective wisdom to reduce variance and improve accuracy. Hyperparameter tuning, using grid search cross-validation, is crucial for achieving optimal GBT model performance by balancing bias and variance (33).
2.4.1.5 K-nearest neighbors
K-Nearest Neighbors (KNN) is a supervised learning technique used for classification tasks. The KNN algorithm determines the class of an unlabeled data point by finding the ‘K’ nearest labeled neighbors in the feature space and then assigning the class label based on the majority vote of these neighbors. The process hinges on three key aspects: a set of labeled training data, a distance metric to measure the proximity between data points, and the selection of the ‘K’ value. This method is particularly useful in biomedicine for tasks such as pattern recognition and classification, where understanding the proximity of data points can provide insights into complex relationships within the data (34).
2.4.1.6 Extreme gradient boosting
Extreme gradient boosting (XGBoost) is a gradient boosting framework known for its efficiency and scalability in machine learning. XGBoost was first proposed in 2011, optimizes prediction models by reducing the loss function through gradient descent. It stands out for its ability to integrate multiple weak models into a high-performance model, a process that enhances prediction accuracy and generalizes well across different datasets. The algorithm’s regularization features also help in preventing overfitting (35).
To enhance the classification performance of our XGBoost model, we implemented an 80% cross-validation strategy for hyperparameter optimization. This process focused on fine-tuning key hyperparameters. Through an iterative approach, we identified the most effective parameter combinations, which were subsequently integrated into our refined model.
2.4.2 Model evaluation
We had a rigorous evaluation of the proposed models, utilizing a suite of metrics to assess performance. The metrics encompass accuracy, precision, sensitivity, specificity, and the F1-measure. The formulas for calculating these metrics are delineated in Table 1. Additionally, we incorporated the area under the receiver operating characteristic curve (AUC-ROC) as a pivotal metric, quantifying the model’s ability to distinguish between different classes. The eightfold cross-validation approach was employed to ascertain the robustness of our algorithms.
To enhance the evaluative rigor of our model’s predictive capabilities, we incorporated decision curve analysis (DCA) (36). This method allowed us to scrutinize the model’s discriminatory power and diagnostic precision across a spectrum of subgroups, thereby enabling a nuanced comparison and targeted optimization of performance metrics. In parallel, we plotted a calibration curve to meticulously align predicted probabilities with actual outcomes. This visual representation is pivotal for a thorough evaluation of our model’s consistency and accuracy, ensuring that our predictive analytics not only perform well in theory but also align with empirical data in practice.
2.4.3 Model interpretation
The SHAP method serves as a technique for explaining individual predictions and providing global interpretation (37). By calculating the contribution of each feature, it indicates the model’s decision-making process, ultimately yielding meaningful interpretation results. The SHAP summary plot and dependence plot offer visualization that illustrate how diverse features impact prediction outcomes. In this study, the SHAP algorithm was employed to indicate the importance of features within the prediction model. SHAP values were computed to delineate the relationship between input factors and the output, specifically revealing the contribution of various feature factors to the prediction of successful aging among community-dwelling older adults.
2.5 Model development
Descriptive statistical analysis was conducted for all variables in the study. Continuous variables were summarized using the median with interquartile range (IQR) or the mean with standard deviation (SD), depending on their distribution. Categorical variables were described by their proportion within each category.
Kruskal-Walli’s rank sum test and Chi-square test were used to compare the continuity variables of non-normal distribution and categorical variables, respectively. p < 0.05 was considered statistically significant. In this study, Python scripting language (v3.9.13) and R (v4.3.1) were used for analysis.
3 Results
3.1 Characteristics of the sample
Following the data processing phase of our retrospective study, a total of 4,324 medical records were amassed, comprising 614 individuals with SA and 3,710 without SA. The demographic distribution included 2,207 males (51.00%) and 2,207 females (49.00%), with a median age of the participants being 67.6 years, as delineated by interquartile ranges A–B. The chi-square test was employed to ascertain the key factors significantly associated with SA, with the outcomes detailed in Table 3. Subsequently, variables that demonstrated a p-value of less than 0.05 in the univariant regression analysis were identified and are also presented in Table 3.
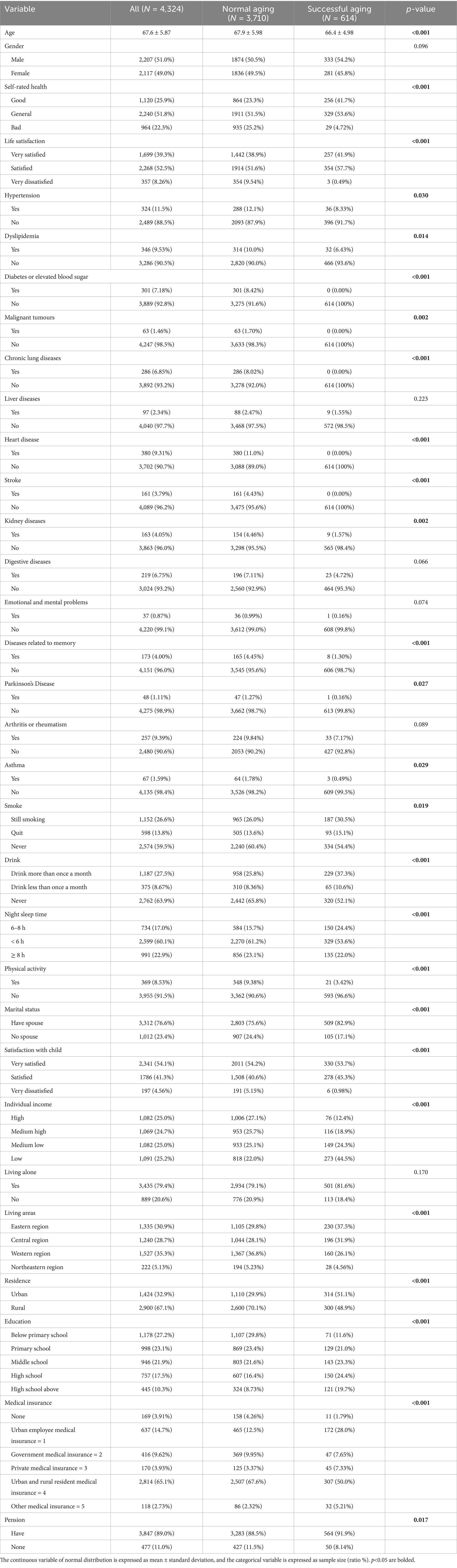
Table 3. Characteristics of the study population in the training set.
3.2 Feature selection for SA
In our study, patients were randomly allocated to the training and test sets in a 2: 1 ratio to ensure a robust evaluation framework. The training set encompassed 32 distinct features, which were subjected to calculate SHAP values to quantify their individual contributions to the model’s predictive accuracy. Each feature’s contribution was ranked, and this ranking process was iterated 300 times to ascertain the consistency and reliability of the results. We then tallied the frequency with which each feature appeared in the top 30 across these iterations. The resulting feature rankings, which are depicted in Figure 3A, reveal the most influential variables in our model (due to space limitations, only the top 30 features are displayed here). We also elucidate the distributional impact of each feature’s influence on the model output in Figure 3B. Prominent among these were life satisfaction, living area, medical insurance, self-rated health (SRH), smoke, education level, dyslipidemia, drank, residence, gender, night sleep duration, individual income, age, physical activity, and marital status, all of which demonstrate significant importance across all assessments.
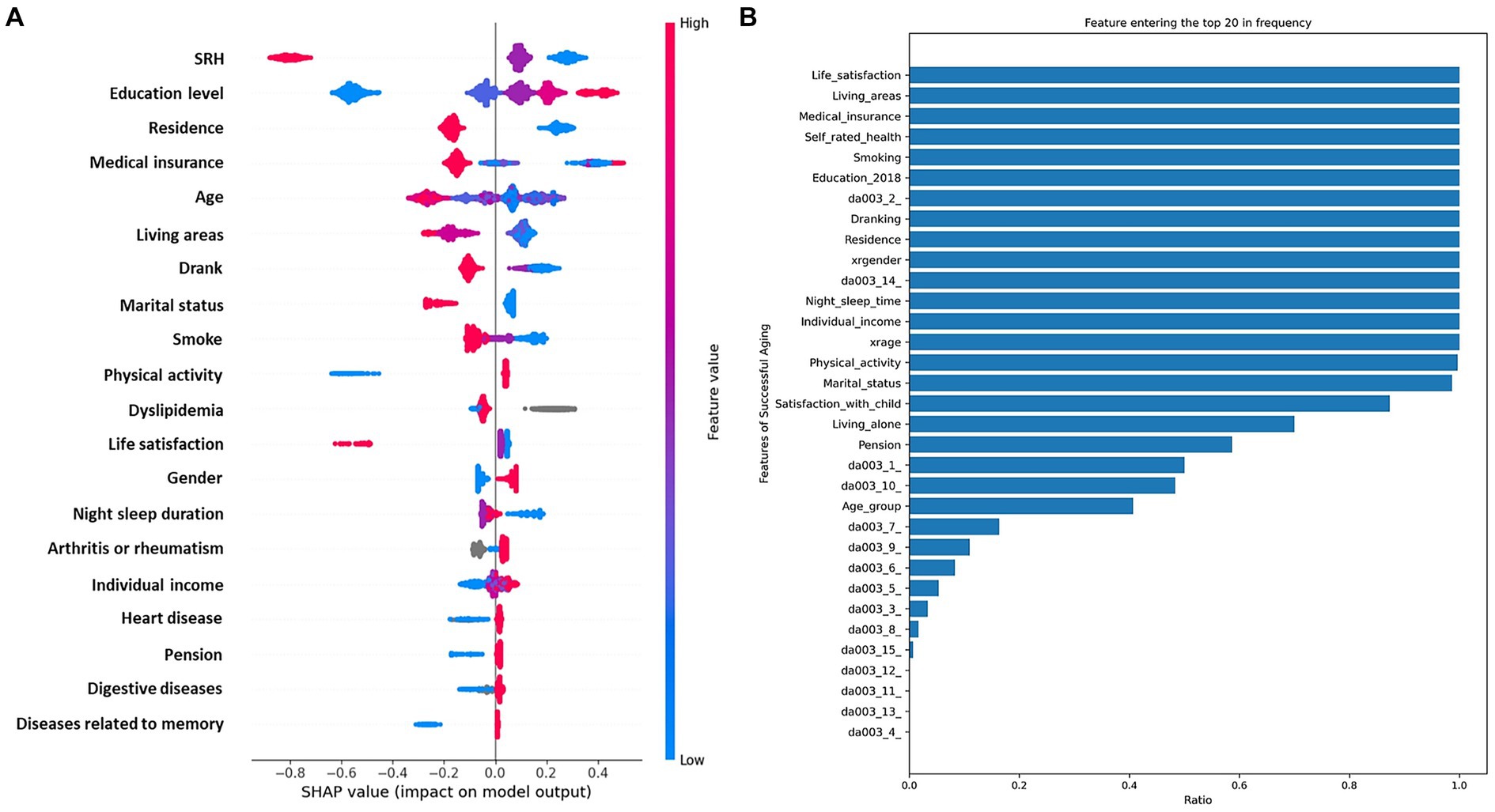
Figure 3. Integrated analysis of feature importance and impact distributions. (A), The prominence of top 30 features based on SHAP importance rankings. (B), The distribution of the impacts of each feature on the model output.
3.3 Performance comparison of different models
To optimize the predictive capabilities of our model, we employed six machine learning models for model development. A comparative analysis of their performance metrics revealed that the KNN model performed the least effectively. In contrast, the XGBoost model demonstrated superior performance compared to the other methods, achieving an accuracy of 82.82% and the area under the receiver operating characteristic (AUROC) of 78.60%. Detailed overview of the performance for each ML model is showed in Figure 4.
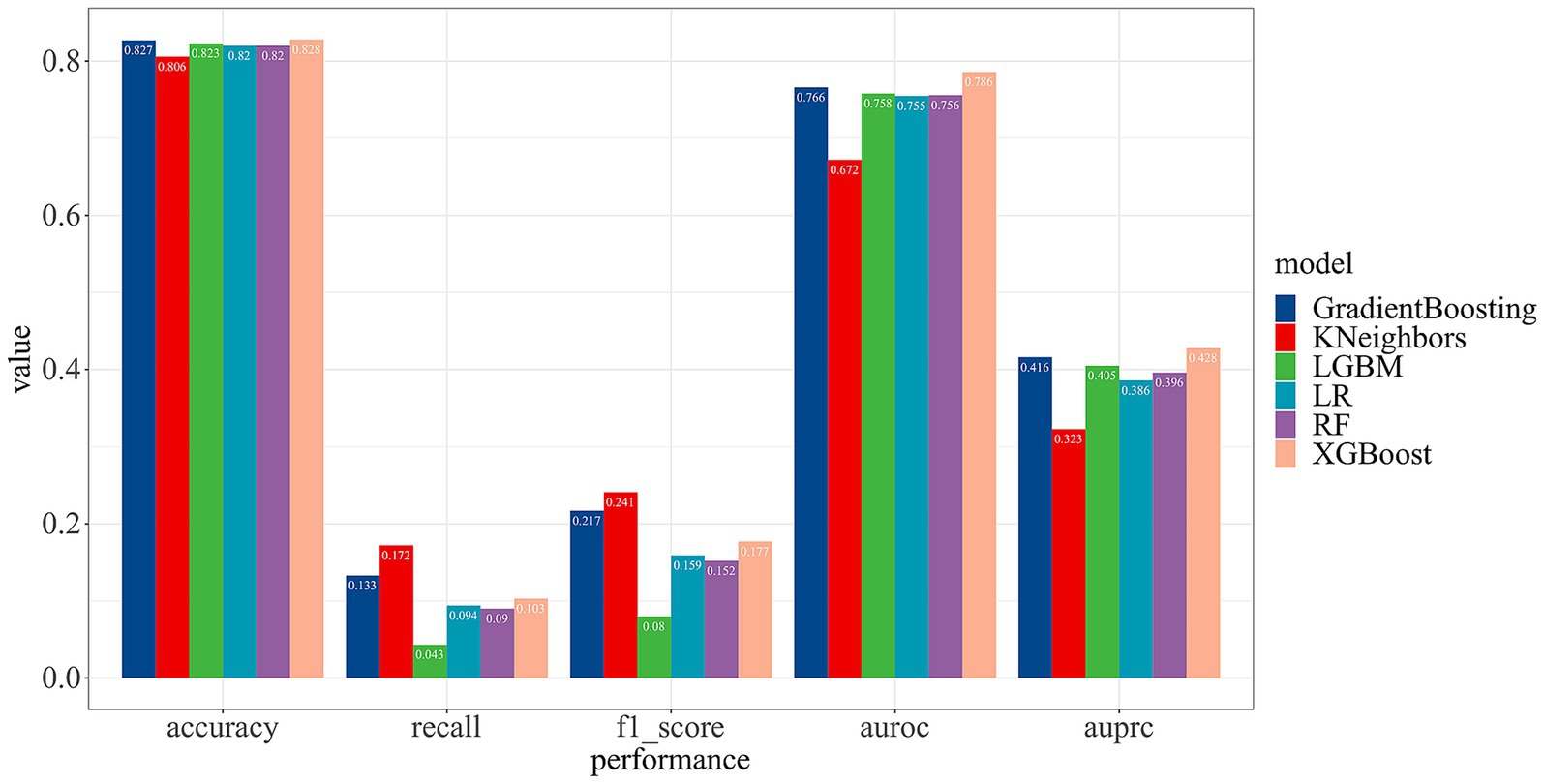
Figure 4. The performance comparison of different machine learning models.
3.4 Discrimination and consistency
After comparing of various machine learning models, we selected the XGBoost model to construct a prediction model for SA among community-dwelling older adults. Furthermore, this model was subjected to evaluate its discrimination ability and consistency.
Discrimination ability, a pivotal metric for gauging the model’s predictive prowess, pertains to its capacity to differentiate between individuals exhibiting successful aging within the community. We evaluated the model’s discriminative ability and consistency through AUROC and discriminant slope, which are critical benchmarks for assessing the reliability of our predictive outcomes.
Consistency denotes the alignment between the model’s predictive probabilities and the actual occurrence probabilities, visualized through a violin diagram. Meanwhile, we utilized the Brier score and calibration plots to conduct an exhaustive analysis of the model’s consistency. To bolster the study’s objectivity and applicability, we performed an in-depth evaluation of discrimination and consistency using models built with RF, LR, and XGBoost.
Figure 5A illustrates the model’s AUROC, demonstrating superior performance of the XGBoost model compared to RF and LR. Our model achieved a discriminant slope of 0.140. The violin diagram indicates the model’s proficiency in accurately predicting true negatives while sustaining the risk distribution stability of true positives in Figure 5B. The calibration plot reveals a strong concordance between our model’s predictions and actual outcomes in Figure 5C. With a Brier score of 0.124, below the threshold of 0.25, our model demonstrates high predictive accuracy within the dataset.
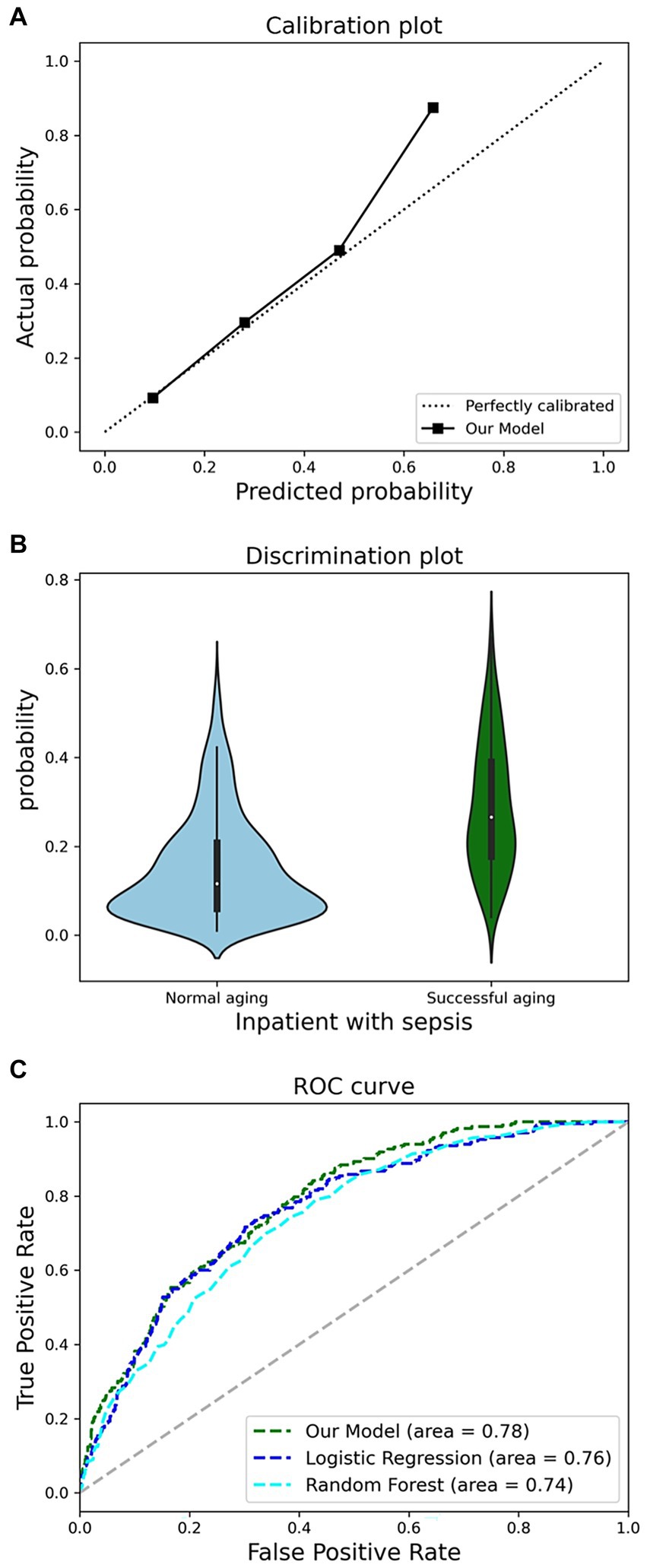
Figure 5. Comprehensive analysis of model performance metrics. (A), Receiver operating characteristic (ROC) analysis. (B), discrimination potentials of the prediction model in internal validation. (C), Calibration potentials of the prediction model in internal validation.
3.5 Decision curve analysis
To assess the model’s performance in a manner that is aligned with clinical decision-making, we employed Decision Curve Analysis (DCA) to evaluate the “net benefit” of our model across a range of clinical scenarios. The concept of “net benefit” encompasses both the advantages and disadvantages associated with false positive and false negative outcomes.
DCA’s fundamental principle is to measure the prediction model’s utility at a specific clinical decision threshold. The prediction model in our study demonstrates an outstanding clinical net benefit in Figure 6.
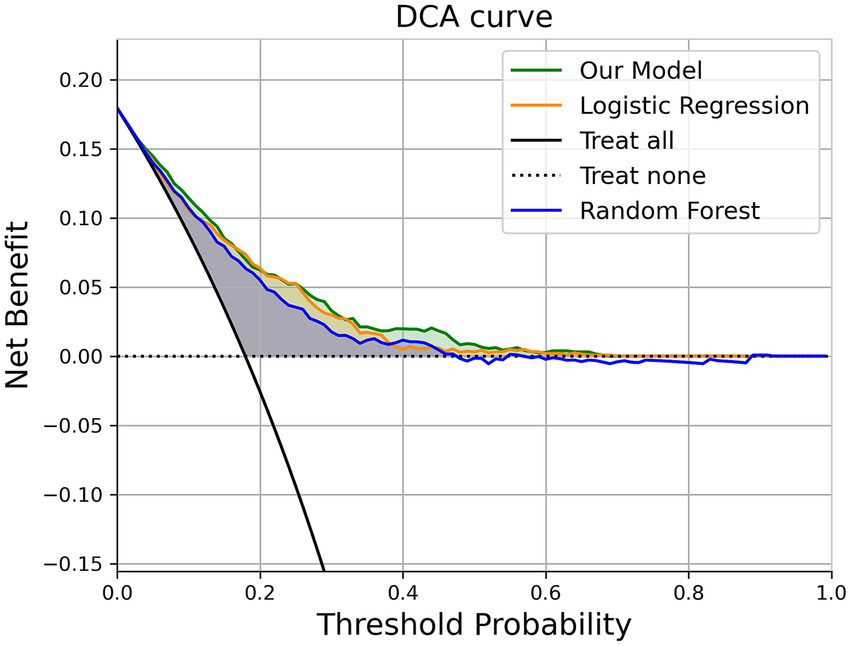
Figure 6. The decision curve analysis of the prediction model (XGBoost model).
3.6 Subgroup analysis
The model demonstrated varying performance across demographic subgroups in Table 4. Minimal disparity was observed, with nearly identical F1-scores (male: 0.484; female: 0.485). Performance declined in older adults (Age ≥70: F1 = 0.418, recall = 0.457) compared to younger counterparts (Age <70: F1 = 0.521, recall = 0.624), indicating higher false-negative rates. Significant income-based differences emerged, with the highest-income group achieving superior performance (F1 = 0.529) versus the lowest-income group (F1 = 0.318), which exhibited high false positives (precision = 0.182). Rural populations showed robust results (F1 = 0.597), while urban residents had notably lower recall (0.436), suggesting underdetection of positive cases.
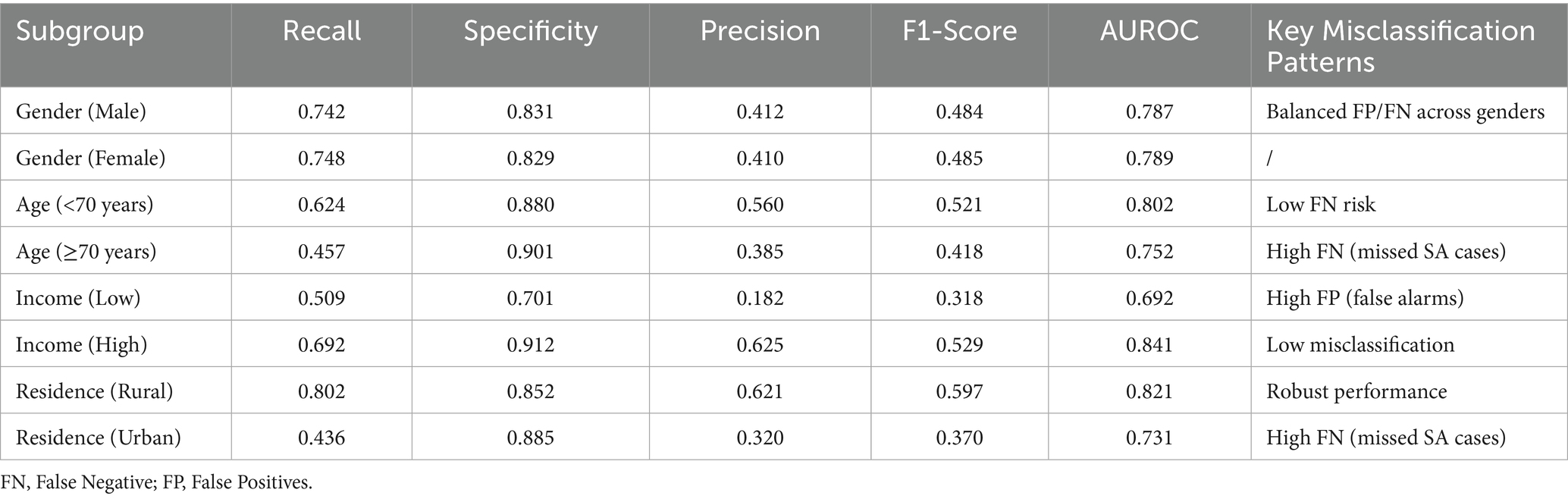
Table 4. Subgroup performance and fairness analysis.
4 Discussion
In our study, we employed the representative cross-sectional data from the CHARLS 2020 to identify predictive factors of SA within Chinese community-dwelling older populations. By employing SHAP values and variables from Chinese community health records, we selected the predictive factors. Subsequently, we engaged six different machine learning models to construct a prediction model. We assessed the differentiation, consistency, and clinical value of the model. Our efforts culminated in the development of a SA prediction model that not only possesses strong interpretability, but also promises ease of application and broad utility within community settings. Finally, a prediction model of SA among Chinese community-dwelling older population was constructed with strong interpretation, easy application and promotion.
Firstly, we employed Rowe and Kahn’s widely recognized model of SA, encompassing physiological, psychological, cognitive, and social dimensions. Previous research has utilized various machine learning models to construct SA prediction models, yet the lack of a unified definition of SA, leading to model heterogeneity and limited comparability (38, 39). Our approach aims to address this by leveraging a comprehensive dataset to enhance model generalizability and applicability.
Asghari Varzaneh et al. (38) utilized single-factor regression on Iranian older population cross-sectional data to identify characteristic variables, ultimately developing a KNN-based ensemble model with a 93% accuracy and 96.10% AUC, demonstrating robust performance and discrimination. Similarly, Yazdani et al. (39) conducted a retrospective analysis on Iranian older individuals, employing principal component analysis to extract features, and developed an ANFIS model based on fuzzy C-means, integrating neural networks and fuzzy reasoning systems, which showed promising capabilities. However, both studies omitted the psychological dimension of SA, and their single-center, retrospective nature limits the assessment of model predictive performance in community-dwelling older populations.
In addition, Cai et al. (40) developed four SA prediction models based on physical fitness tests using 3-year follow-up data from 3,657 older individuals in Nanchang, with the deep learning model exhibiting the best predictive performance (AUC 90.0%). However, the reliance on physical fitness tests presents practical challenges for using in community, given the resource-intensive nature of such assessments.
Through literature review, this study pioneers the use of a representative and high-confidence Chinese database to construct an SA prediction model for community-dwelling older populations, offering a valuable tool for health assessment in Chinese communities. Our focus on community application aligns with previous suggestions that ML models can directly serve clinical practice, with the potential to provide SA prediction services, which are crucial for proactively addressing population aging. By embedding prediction models within electronic medical records and extending their reach to mobile applications, we enhance their utility in community settings (41).
In variable selection, we prioritized clinically available variables, improving the model’s generalizability in community primary care. Community primary care physicians establish health records, assess the older adult’s health status and quality of life, and identify modifiable health factors, enabling more targeted health care and disease management recommendation (42, 43). Our approach to identifying SA predictors based on health ecology aids in understanding the multi-dimensional influencing factors of individual SA in community-dwelling older populations (44).
To bridge the gap between model development and clinical application, we have incorporated insights from recent studies on ML deployment in primary care. These works underscore critical challenges—data integration (e.g., interoperability between EHRs and predictive tools), scalability (e.g., adapting models to diverse clinic workflows), and clinician acceptance (e.g., addressing “black-box” skepticism through interpretability features)—which directly informed our implementation strategy. The introduction of the SHAP method in our study enhances model interpretability by assessing the importance and interrelationships of different variables, aligning the new model’s discriminant pathways and clinical variable thresholds with current community clinical practices (45, 46). Our DCA indicates the model’s good clinical benefits, suggesting its importance in primary care scenarios.
However, our study is not without limitations. The lack of a unified concept and measurement method for SA may introduce population bias due to regional and usage scenario differences. The database’s limitations precluded the inclusion of potential key variables, and as a retrospective study, data missing and input errors are inevitable. While our study improves model practicality through health ecology and initial screening of characteristic variables in primary care health records, potential differences in performance and discrimination across various primary care scenarios may exist, necessitating prospective validation in future research.
Our subgroup analysis revealed important disparities in model performance across demographic groups, with significant implications for clinical implementation. While demonstrating gender fairness, the model showed reduced accuracy among older adults (≥70 years; recall = 0.457), urban (recall = 0.436), and low-income populations (precision = 0.182), reflecting distinct error patterns with clinical consequences. The elevated false-positive rate in low-income groups risks unnecessary interventions, whereas the higher false-negative rates among older adults and urban residents could delay critical care - a particular concern given these populations’ healthcare access challenges. These findings underscore the necessity for subgroup-specific model calibration and highlight key ethical considerations for deploying predictive algorithms in real-world geriatric care settings, where equitable performance across vulnerable populations is paramount. Future iterations should prioritize feature engineering to address these identified gaps while maintaining the model’s overall predictive utility.
Future studies will track regular follow-up results from CHARLS, extract longitudinal data of older individuals in Chinese communities, further refine the SA prediction model, and deploy the model as an online resource, providing community physicians and geriatricians with a more accessible tool for older health assessment. Embedding SA predictions into routine health assessments (e.g., annual older population check-ups) via standardized application programming interfaces, with modifiable risk factors (e.g., smoking, physical inactivity) flagged for clinician review. Prospective validation will conduct for new patient data (e.g., third quarter of 2025), and indicators were adjusted according to real-world noise (for example, AUPRC for class imbalance). Subgroup-specific thresholds (e.g., lower probability cutoff for older adults) and feature engineering (e.g., neighborhood-level variables for urban residents) will reduce bias in future deployments. After the release of the follow-up CHARLS data in the future, we will actively refer to pioneering longitudinal studies (such as HRS in the United States and ELSA in the United Kingdom) and compare their methods, advantages, and limitations with ours to improve the cross-cultural and cross regional applicability of the model.
5 Conclusion
In this study, we developed a novel prediction model for successful aging in Chinese community-dwelling older adults using CHARLS 2020 data and various machine learning models, demonstrating outstanding predictive performance and clinical net benefits. The model is highly interpretable and generalizable, offering significant utility in community primary healthcare settings. It provides insights into the factors influencing successful aging and aids healthcare providers in making targeted interventions to develop the quality of life for the Chinese community-dwelling older adult.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary material, further inquiries can be directed to the corresponding author.
Ethics statement
Ethical review and approval was not required for the study on human participants in accordance with the local legislation and institutional requirements. Written informed consent from the [patients/participants or patients/participants legal guardian/next of kin] was not required to participate in this study in accordance with the national legislation and the institutional requirements.
Author contributions
ZZ: Conceptualization, Data curation, Formal analysis, Methodology, Supervision, Writing – original draft, Writing – review & editing. CP: Conceptualization, Formal analysis, Software, Writing – original draft, Writing – review & editing. ZL: Data curation, Investigation, Methodology, Writing – review & editing. JL: Data curation, Investigation, Methodology, Writing – review & editing. YL: Writing – original draft, Writing – review & editing, Methodology, Supervision, Formal analysis, Project administration, Validation. YP: Data curation, Methodology, Writing – review & editing. RL: Project administration, Supervision, Writing – review & editing. XC: Project administration, Supervision, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work is granted by the following: Basic Research Program of Science and Technology of Shenzhen (General Project), grant number is JCYJ20210324094802007.
Acknowledgments
The authors express their gratitude to the CHARLS participants and staff members for their valuable contributions to the data and its collection.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The authors declare that no Gen AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpubh.2025.1595540/full#supplementary-material
References
1. Chen, X, Giles, J, Yao, Y, Yip, W, Meng, Q, Berkman, L, et al. The path to healthy ageing in China: a Peking University-lancet commission. Lancet (London, England). (2022) 400:1967–2006. doi: 10.1016/s0140-6736(22)01546-x
2. National Health Commission NOoA. Communique on the development of the National Cause for aging in 2022. (2023). Available at: https://www.gov.cn/lianbo/bumen/202312/content_6920261.htm (Accessed September 1, 2025).
3. Wang, H, Qin, D, Fang, L, Liu, H, and Song, P. Addressing healthy aging in China: practices and prospects. Biosci Trends. (2024) 18:212–8. doi: 10.5582/bst.2024.01180
4. Li, X, Lu, J, Hu, S, Cheng, KK, De Maeseneer, J, Meng, Q, et al. The primary health-care system in China. Lancet (London, England). (2017) 390:2584–94. doi: 10.1016/s0140-6736(17)33109-4
5. Zhang, Q. Primary care and all-cause mortality in urban China: a mixed-level analysis. Fam Pract. (2021) 38:121–6. doi: 10.1093/fampra/cmaa095
6. Rowe, JW, and Kahn, RL. Human aging: usual and successful. Science (New York, NY). (1987) 237:143–9. doi: 10.1126/science.3299702
8. Rowe, JW, and Kahn, RL. Successful Aging. The Gerontologist. (1997) 37:433–40. doi: 10.1093/geront/37.4.433
9. Nakagawa, T, Cho, J, and Yeung, DY. Successful aging in East Asia: comparison among China, Korea, and Japan. J Gerontol B Psychol Sci Soc Sci. (2021) 76:S17–26. doi: 10.1093/geronb/gbaa042
11. Venkatapuram, S, and Amuthavalli Thiyagarajan, J. The capability approach and the WHO healthy ageing framework (for the un decade of healthy ageing). Age Ageing. (2023) 52:iv6–9. doi: 10.1093/ageing/afad126
12. Rudnicka, E, Napierała, P, Podfigurna, A, Męczekalski, B, Smolarczyk, R, and Grymowicz, M. The World Health Organization (who) approach to healthy ageing. Maturitas. (2020) 139:6–11. doi: 10.1016/j.maturitas.2020.05.018
13. Freund, AM, and Baltes, PB. Selection, optimization, and compensation as strategies of life management: correlations with subjective indicators of successful aging. Psychol Aging. (1998) 13:531–43. doi: 10.1037//0882-7974.13.4.531
14. Manierre, M. Successful present, successful future? Assessment of a nonbinary model of successful aging. The Gerontologist. (2019) 59:727–37. doi: 10.1093/geront/gnx198
15. Cosco, TD, Stephan, BC, and Brayne, C. Validation of an a priori, index model of successful aging in a population-based cohort study: the successful aging index. Int Psychogeriatr. (2015) 27:1971–7. doi: 10.1017/s1041610215000708
16. Depp, CA, and Jeste, DV. Definitions and predictors of successful aging: a comprehensive review of larger quantitative studies. Am J Geriatr Psychiatry. (2006) 14:6–20. doi: 10.1097/01.JGP.0000192501.03069.bc
17. Zhao, Y, Hu, Y, Smith, JP, Strauss, J, and Yang, G. Cohort profile: the China health and retirement longitudinal study (Charls). Int J Epidemiol. (2014) 43:61–8. doi: 10.1093/ije/dys203
18. Zhao, Y, Strauss, J, Chen, X, Wang, Y, Gong, J, Meng, Q, et al. China health and retire Ment longitudinal study wave 4 user’s guide National School of development, Peking University (2020). Available at: https://charls.pku.edu.cn/en/data/User2018.pdf (Accessed September 1, 2025).
19. Dixon, A. The United Nations decade of healthy ageing requires concerted global action. Nat Aging. (2021) 1:2. doi: 10.1038/s43587-020-00011-5
20. Nagarajan, NR, Teixeira, AAC, and Silva, ST. Ageing population: identifying the determinants of ageing in the least developed countries. Popul Res Policy Rev. (2021) 40:187–210. doi: 10.1007/s11113-020-09571-1
21. Lin, K, Ning, Y, Mumtaz, A, and Li, H. Exploring the relationships between four aging ideals: a bibliometric study. Front Public Health. (2021) 9:762591. doi: 10.3389/fpubh.2021.762591
22. Tian, L, Ding, P, Kuang, X, Ai, W, and Shi, H. The association between sleep duration trajectories and successful aging: a population-based cohort study. BMC Public Health. (2024) 24:3029. doi: 10.1186/s12889-024-20524-7
23. Zhu, X, Zhang, X, Ding, L, Tang, Y, Xu, A, Yang, F, et al. Associations of pain and sarcopenia with successful aging among older people in China: evidence from Charls. J Nutr Health Aging. (2023) 27:196–201. doi: 10.1007/s12603-023-1892-2
24. Zheng, A, and Casari, A. Feature engineering for machine learning: principles and techniques for data scientists. Sevastopol, California: O'Reilly Media, Inc. (2018).
25. McLeroy, KR, Bibeau, D, Steckler, A, and Glanz, K. An ecological perspective on health promotion programs. Health Educ Q. (1988) 15:351–77. doi: 10.1177/109019818801500401
26. Chang, H, Zhou, J, and Wang, Z. Multidimensional factors affecting successful aging among empty-nesters in China based on social-ecological system theory. Int J Environ Res Public Health. (2022) 19:11885. doi: 10.3390/ijerph191911885
27. Anton, SD, Woods, AJ, Ashizawa, T, Barb, D, Buford, TW, Carter, CS, et al. Successful aging: advancing the science of physical Independence in older adults. Ageing Res Rev. (2015) 24:304–27. doi: 10.1016/j.arr.2015.09.005
28. Rodrigues, CE, Grandt, CL, Alwafa, RA, Badrasawi, M, and Aleksandrova, K. Determinants and indicators of successful aging as a multidimensional outcome: a systematic review of longitudinal studies. Front Public Health. (2023) 11:1258280. doi: 10.3389/fpubh.2023.1258280
29. Meurer, WJ, and Tolles, J. Logistic regression diagnostics: understanding how well a model predicts outcomes. JAMA. (2017) 317:1068–9. doi: 10.1001/jama.2016.20441
30. Cutler, A, Cutler, DR, and Stevens, JR. Random forests. In: C Zhang and Y Ma, editors. Ensemble machine learning: methods and applications. New York, NY: Springer New York (2012). p. 157–75.
31. Biau, G. Analysis of a random forests model. J Mach Learn Res. (2012) 13:1063–95. doi: 10.1109/tase.2012.2183739
32. Ke, GL, Meng, Q, Finley, T, Wang, TF, Chen, W, and Ma, WD Lightgbm: a highly efficient gradient boosting decision tree. Advances in neural information processing systems 30 (NIPS 2017) (2017).
33. Zuo, D, Yang, L, Jin, Y, Qi, H, Liu, Y, and Ren, L. Machine learning-based models for the prediction of breast Cancer recurrence risk. BMC Med Inform Decis Mak. (2023) 23:276. doi: 10.1186/s12911-023-02377-z
34. Yuan, JD, Douzal-Chouakria, A, Yazdi, SV, and Wang, ZH. A large margin time series nearest neighbour classification under locally weighted time warps. Knowl Inf Syst. (2019) 59:117–35. doi: 10.1007/s10115-018-1184-z
35. Chen, T. Q., and Guestrin, C.Assoc Comp M. XGBoost: a scalable tree boosting system. Kdd'16: Proceedings of the 22nd ACM sigkdd international conference on knowledge discovery and data mining (2016). p. 785–94.
36. Van Calster, B, Wynants, L, Verbeek, JFM, Verbakel, JY, Christodoulou, E, Vickers, AJ, et al. Reporting and interpreting decision curve analysis: a guide for investigators. Eur Urol. (2018) 74:796–804. doi: 10.1016/j.eururo.2018.08.038
37. Su, PY, Wei, YC, Luo, H, Liu, CH, Huang, WY, Chen, KF, et al. Machine learning models for predicting influential factors of early outcomes in acute ischemic stroke: registry-based study. JMIR Med Inform. (2022) 10:e32508. doi: 10.2196/32508
38. Asghari Varzaneh, Z, Shanbehzadeh, M, and Kazemi-Arpanahi, H. Prediction of successful aging using ensemble machine learning algorithms. BMC Med Inform Decis Mak. (2022) 22:258. doi: 10.1186/s12911-022-02001-6
39. Yazdani, A, Shanbehzadeh, M, and Kazemi-Arpanahi, H. Using an adaptive network-based fuzzy inference system for prediction of successful aging: a comparison with common machine learning algorithms. BMC Med Inform Decis Mak. (2023) 23:229. doi: 10.1186/s12911-023-02335-9
40. Cai, T, Long, J, Kuang, J, You, F, Zou, T, and Wu, L. Applying machine learning methods to develop a successful aging maintenance prediction model based on physical fitness tests. Geriatr Gerontol Int. (2020) 20:637–42. doi: 10.1111/ggi.13926
41. Brothers, A, Kornadt, AE, Nehrkorn-Bailey, A, Wahl, HW, and Diehl, M. The effects of age stereotypes on physical and mental health are mediated by self-perceptions of aging. J Gerontol B Phychol Sci Soc Sci. (2021) 76:845–57. doi: 10.1093/geronb/gbaa176
42. Georgiev, K, Wang, Y, Conkie, A, Sinclair, A, Christodoulou, V, Seyedzadeh, S, et al. Predicting incident dementia in community-dwelling older adults using primary and secondary care data from electronic health records. Brain Commun. (2025) 7:fcae469. doi: 10.1093/braincomms/fcae469
43. Nguyen, OT, Kunta, AR, Katoju, S, Gheytasvand, S, Masoumi, N, Tavasolian, R, et al. Electronic health record nudges and health care quality and outcomes in primary care: a systematic review. JAMA Netw Open. (2024) 7:e2432760. doi: 10.1001/jamanetworkopen.2024.32760
44. Ko, PC, and Yeung, WJ. An ecological framework for active aging in China. J Aging Health. (2018) 30:1642–76. doi: 10.1177/0898264318795564
45. Niu, T, Cao, S, Cheng, J, Zhang, Y, Zhang, Z, Xue, R, et al. An explainable predictive model for anxiety symptoms risk among Chinese older adults with abdominal obesity using a machine learning and Shapley additive explanations approach. Front Psych. (2024) 15:1451703. doi: 10.3389/fpsyt.2024.1451703
Keywords: successful aging, prediction model, health ecology theory, machine learning, CHARLS
Citation: Zhang Z, Peng C, Li Z, Li J, Li Y, Pan Y, Liu R and Chen X (2025) Development and validation of a successful aging prediction model for older adults in China based on health ecology theory. Front. Public Health. 13:1595540. doi: 10.3389/fpubh.2025.1595540
Edited by:
Janaka Wijekoon, Victoria Institute of Technology, AustraliaReviewed by:
Lasith Gunawardena, University of Sri Jayewardenepura, Sri LankaDharshana Kasthurirathna, Sri Lanka Institute of Information Technology, Sri Lanka
Copyright © 2025 Zhang, Peng, Li, Li, Li, Pan, Liu and Chen. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ruihong Liu, aXVyaEBoa3Utc3poLm9yZw==; Xiangdong Chen, eGRjMTk4MUBzenUuZWR1LmNu
†These authors have contributed equally to this work and share first authorship