Abstract
This paper discusses techniques for solving discrete optimization problems using quantum annealing. Practical issues likely to affect the computation include precision limitations, finite temperature, bounded energy range, sparse connectivity, and small numbers of qubits. To address these concerns we propose a way of finding energy representations with large classical gaps between ground and first excited states, efficient algorithms for mapping non-compatible Ising models into the hardware, and the use of decomposition methods for problems that are too large to fit in hardware. We validate the approach by describing experiments with D-Wave quantum hardware for low density parity check decoding with up to 1000 variables.
1. Introduction
D-Wave Systems manufactures a device [1–4] that uses quantum annealing (QA) to minimize the dimensionless energy of an Ising model
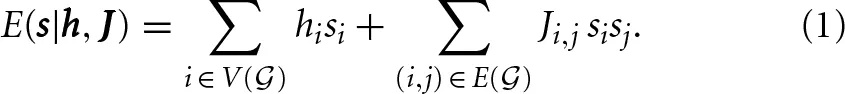
Here we have spin variables si ∈ {−1, 1} indexed by the vertices V(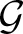 ) of a graph fixed by the device with allowed pairwise interactions given by the edges E() of this graph, and where the hi and Ji,j dimensionless coefficients are real-valued.
) of a graph fixed by the device with allowed pairwise interactions given by the edges E() of this graph, and where the hi and Ji,j dimensionless coefficients are real-valued.
QA was proposed in Finilla et al. [5] and Kadowaki and Nishimori [6] as a method to optimize discrete energy functions. More recently, similar ideas were generalized to full quantum computation [7, 8]. Here we explore practical implementation of QA. The quantum annealing process minimizes the Ising energy by evolving the ground state of an initial Hamiltonian 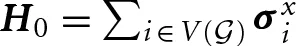 to the ground state of a problem Hamiltonian
to the ground state of a problem Hamiltonian 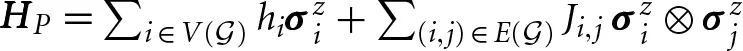 . The ground state of H0 is a superposition state in which all spin configurations are equally likely, while at the end of the process the spin configurations with smallest energy with respect to HP are most likely to be measured. The efficiency of QA is determined in part by the energy gap separating ground and excited states during evolution. However, different representations of the same optimization problem may give different quantum gaps, and it is very difficult to know this gap in advance.
. The ground state of H0 is a superposition state in which all spin configurations are equally likely, while at the end of the process the spin configurations with smallest energy with respect to HP are most likely to be measured. The efficiency of QA is determined in part by the energy gap separating ground and excited states during evolution. However, different representations of the same optimization problem may give different quantum gaps, and it is very difficult to know this gap in advance.
In this report, we focus not on problem representations giving rise to larger quantum gaps, but on representations ameliorating the limitations imposed by current experimental hardware. In particular, we observe that the following issues are detrimental for solving real world problems [
9]:
Limited precision/control error. Physical devices impose limitations on the precision to which the programmable parameters h, J can be specified. Moreover, since the Ising model is only an approximation to the underlying physics there may be systematic errors causing a discrepancy between programmed h, J and the effective Ising approximation. To maximize the performance of QA in hardware we seek problem representations that are insensitive to these control errors.
Limited energy range/finite temperature. Technological limitations restrict the range of energy scales of h, J relative to the thermal energy kB T. For problems having few ground states and exponentially many excited states within kB T a limited range makes the optimization challenging.
Sparse connectivity. It is difficult in hardware to realize all pairwise couplings as the number of couplings grows as n2, for an n-qubit system. Thus, QA hardware offering large numbers of variables is likely to offer only sparse connectivity. Figure 1 shows an example of the connectivity graph
for recent hardware supplied by D-Wave Systems. Optimization problems of practical interest require coupling significantly different from .Small numbers of qubits. While Ising problems may be difficult to minimize even at scales of several hundred variables, real-world problems are often significantly larger. Moreover, the translation of any optimization problem into sparse Ising form will almost always require additional ancillary variables thereby increasing the size of the problem.
Figure 1
The detrimental impact of hardware limitations (1) and (2) may be mitigated by finding problem representations in which there is a large (classical) gap between Ising ground and excited states. Notice that this does not guarantee that quantum gaps get any larger, though it seems unlikely they get worse. To deal with issue (3) we introduce additional variables to mediate arbitrary connectivity. For instance, ferromagnetically coupled spins can act as “wires” transporting long-range interactions; in general, the extra variables can take a more subtle role as ancillary variables. Finally, for issue (4), we demonstrate methods by which large problems may be solved through decomposition into smaller subproblems.
In addressing these practical limitations we focus on solving Constraint Satisfaction Problems (CSPs) involving a finite set of binary variables. That is, we have a set of variables si ∈ {−1, 1}, i = 1 … n, and a set of constraints, each corresponding to a non-empty subset Fj of {−1, 1}n (constituting the configurations allowed by the constraint), and we wish to find s ∈ ∩jFj. To represent such a problem using an Ising model, we construct an Ising-model penalty function for each constraint Fj. We write a penalty function as PenFj(z) = PenFj(s, a) where s are the “decision” variables upon which Fj depends and a are ancillary variables. This function should be represented in the Ising form (1) (with an additional constant offset for convenience) and must satisfy:
where g > 0. We call g the gap of the penalty function. While a decision variable may be involved in many different constraints, the sets of ancillary variables for different constraints are disjoint. In general, larger gaps make it more likely that the hardware will find a solution satisfying the constraints and offers protection against noise and precision limitations.
We add the penalty functions for each constraint to obtain an Ising model for our system of decision and ancillary variables. For any configuration of the decision variables that satisfies all the constraints, there will be some setting of the ancillary variables that makes all the penalty functions 0. On the other hand, any configuration of decision variables violating some constraint will have energy ≥ g. Thus, a ground state of the system solves the CSP if a solution exists.
We also address Constrained Optimization Problems (COPs), where in addition to the constraints Fj there is an objective to be minimized over the feasible configurations. This can be accomplished by adding more terms to the Hamiltonian expressing the objective in Ising form. The objective should be scaled so that it does not overcome the penalty functions, causing the appearance of ground states that do not satisfy the constraints. In this case also, a larger gap g allows for better scaling of the objective.
This report shows how CSPs and COPs can be represented to ameliorate the hardware limitations listed above. The techniques we present are applicable to any hardware device offering only sparse pairwise variable interaction. In Section 2.1, we consider how to construct a penalty function for a given constraint with the largest possible gap, subject to bounds on the h's and J's imposed by the hardware. We supply a novel algorithm which exploits the sparsity of the hardware graph . In Section 2.2, we consider how to fit a collection of penalty functions (and the corresponding graphs) onto a hardware graph of sparse connectivity. Generally, each variable participates in several constraints, necessitating the use of embedded chains of vertices of the hardware graph representing a single variable. We present a new heuristic embedding algorithm which scales well to large problems sizes. In Section 2.3, we consider how to deal with problems that are too large to be embedded in the hardware graph. We split the problem into subproblems small enough to embed, and coordinate solutions of the subproblems. We explore two coordination approaches: Belief Propagation (BP) and Dual Decomposition. Section 3 presents experimental results on using the D-Wave hardware to decode LDPC (low-density parity-check) codes [10, see Ch. 47]. Here, each constraint is a parity check on a small set of bits, and the objective is to minimize the Hamming distance to a received vector subject to satisfying all parity checks. Using the techniques presented in this paper on hardware very similar to Figure 1, we were able to decode problems with up to 1000 variables that were not correctly decoded by the standard BP decoding algorithm.
2. Methods
2.1. Mapping problems to Ising models
This section provides an algorithm to find Ising representations of constraints with large classical gaps. To emphasize the linear dependence of the Ising energy on its parameters we write Equation (1) as1
where 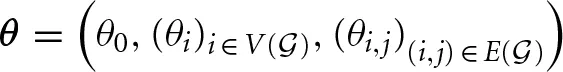 and
and 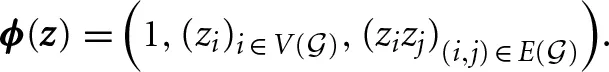 Here θi are the local fields hi, θi,j are the couplings Ji,j, and θ0 represents a constant energy offset. When z = (s, a), we implicitly identify certain nodes in V() as decision variables s, and other nodes as ancillary variables a. We assume there are n decision variables and na ancillary variables, and that the assignment of these variables to nodes (qubits) is given. The hardware's lower and upper bounds on the parameters are denoted by θ and θ respectively (e.g., for D-Wave hardware hi ∈ [−2, 2] and Ji,j ∈ [−1, 1]).
Here θi are the local fields hi, θi,j are the couplings Ji,j, and θ0 represents a constant energy offset. When z = (s, a), we implicitly identify certain nodes in V() as decision variables s, and other nodes as ancillary variables a. We assume there are n decision variables and na ancillary variables, and that the assignment of these variables to nodes (qubits) is given. The hardware's lower and upper bounds on the parameters are denoted by θ and θ respectively (e.g., for D-Wave hardware hi ∈ [−2, 2] and Ji,j ∈ [−1, 1]).
For the purpose of this section we will assume that the number of variables, n + na, is not too large, say less than 40. We will also require that the subgraph induced by the ancillary variables, a, has low treewidth. This assumption allows us to efficiently enumerate the smallest k energy states of any Ising model in a for, say, k ≤ 10000. The treewidth of the Chimera graph in Figure 1 that consists of N × N tiles of complete bipartite graphs K4,4 is 4N. In our experiments, we used up to 4 × 4 Chimera tiles, so the tree width of a was at most 16.
We maximize the penalty gap g separating s ∈ F from s ∉ F subject to the bounds on θ. This criterion gives rise to the following constrained optimization problem
Constraint (5) separates all s ∉ F, while constraints (4) and (6) make sure that the minimum penalty for s ∈ F is 0 [note that constraints (4)–(6) ensure (2)]. Here, constraint (6), involving the disjunction over a, makes this problem difficult since we do not know which of the ancillae settings gives zero energy for a particular feasible s, i.e., what is a*(s) at which 〈θ, ϕ(s, a*s))〉 = 0? However, we note that solving for θ given a*(s), for s ∈ F, is a linear programme, and can be made relatively scalable in spite of the exponential number of constraints (the low treewidth assumption makes cut generation tractable [11]). Using binary variables and linear constraints, it is straightforward to transform this optimization problem into a mixed integer linear programme (MILP). Commercial MILP solvers can typically solve this problem if |V()| is no larger than about 10. For larger problems these solvers may be ineffective, partly because the linear programme relaxations are typically weak. We propose a method which scales better than a MILP.
To address the disjunctive constraint it is easiest to encode a*(s) by introducing na|F| Boolean-valued (0/1) optimization variables β(s, i) for s ∈ F defined so that 2β(s, i) − 1 = a*i(s). The shorthand β(s) is used to indicate the vector of length na whose i-th component is β(s, i). Rather than directly maximizing g we have found empirically that it is faster to fix a g value and solve the following feasibility problem, FEAS(θ, β), to identify θ and β ≡ {β(s) | s ∈ F}:
Separately, we find the largest g for which FEAS(θ, β) is satisfiable. Notice that in this formulation we ground constraint (6) by considering all possible ancilla settings a. We solve FEAS(θ, β) with Satisfiability Modulo Theory (SMT) solvers. SMT [12] generalizes Boolean satisfiability by allowing some Boolean variables to represent equality/inequality predicates over additional continuous variables. As mentioned earlier, for any given setting of Boolean variables, finding the continuous variables θ is a linear programme. This linear programme can be solved using a variant of the simplex method [13] that can efficiently propagate new constraints and infer “nogoods” on the β variables. A number of solvers for SMT are available, and experiments here rely on the MathSat solver [14].
A naive representation of FEAS(θ, β) requires 2n + na inequality constraints, 2na|F| implication constraints and |V()| + |E()| bound constraints. However, we can significantly reduce the number of constraints by exploiting the fact that a has low treewidth. This allows us to solve any Ising model in a using dynamic programming, or more specifically, variable elimination (VE). VE exploits the observation that summation distributes over minimization, i.e., (a + b, a + c) = a + (b, c). Thus, to minimize a sum of local interactions we pick an ordering in which to minimize (eliminate) one ai variable at a time, and push minimizations as far to the right in the summation as possible. If we record these minimizations in tables then they can be reused in different contexts to save recomputation. Bucket elimination [15] is a convenient way to structure this memoization, and can be encoded nicely within our constraint model.
More concretely, we solve an Ising model in a by storing partial computations and spin states in tables as follows. Suppose that ancilla variables are eliminated in the order ana, ana − 1, …, a1. Let  na be the set of ancilla variables adjacent to ana in a. Clearly, for each setting of all variables in na we can deduce the optimal value of ana. This information is collected in
na be the set of ancilla variables adjacent to ana in a. Clearly, for each setting of all variables in na we can deduce the optimal value of ana. This information is collected in  na, a table of size 2|na|. This table is assigned to the variable of largest index in na (alternatively, one can think that the variables in na become induced neighbors of each other). In general, i consists of the neighbors of variable ai together with the variables on the tables assigned to ai but excluding ai itself (alternatively all its neighbors and induced neighbors). We then create i, a table of size 2|i|, for all possible values of variables in i. Notice that for each setting of the variables in i we can calculate the smallest contribution to the objective of variable ai by adding linear and quadratic local terms to values from previously generated tables. This information is stored in i and assigned to the variable of largest index in i (alternatively, the variables in i become induced neighbors of each other). In this way, after all variables have been eliminated we end up with one or more tables with a single entry (i.e., the corresponding i is empty). The sum over the values stored in these singleton tables is the value of the optimal solution of the Ising model. Notice that the storage necessary for the tables is O(∑nai = 12|i|). For our work here, the important observation is that one can easily find a variable elimination order for which maxi |i| is the treewidth of a using Gogate and Dechter [16]. In what follows, we assume that ancilla variables are ordered using this ordering.
na, a table of size 2|na|. This table is assigned to the variable of largest index in na (alternatively, one can think that the variables in na become induced neighbors of each other). In general, i consists of the neighbors of variable ai together with the variables on the tables assigned to ai but excluding ai itself (alternatively all its neighbors and induced neighbors). We then create i, a table of size 2|i|, for all possible values of variables in i. Notice that for each setting of the variables in i we can calculate the smallest contribution to the objective of variable ai by adding linear and quadratic local terms to values from previously generated tables. This information is stored in i and assigned to the variable of largest index in i (alternatively, the variables in i become induced neighbors of each other). In this way, after all variables have been eliminated we end up with one or more tables with a single entry (i.e., the corresponding i is empty). The sum over the values stored in these singleton tables is the value of the optimal solution of the Ising model. Notice that the storage necessary for the tables is O(∑nai = 12|i|). For our work here, the important observation is that one can easily find a variable elimination order for which maxi |i| is the treewidth of a using Gogate and Dechter [16]. In what follows, we assume that ancilla variables are ordered using this ordering.
In our case, the constraints are not as simple as just solving an Ising model in a, since some of the coefficients are themselves variables (entries of θ). Nevertheless, in this parametric Ising model, each table entry can be replaced by a continuous variable mi(vi|s) (a message conveying all required information from previously eliminated variables), indexed by the decision variable setting s and a setting vi of variables in i. Thus, the constraints on s Equations (4)–(6) become
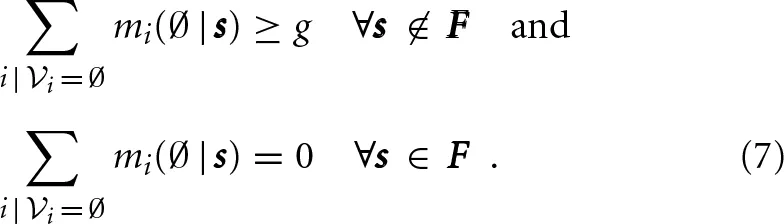
The purpose of message mi(vi|s) is to eliminate the ancilla setting of ai. Since in this case the Ising model is defined by variables θ, we do not know which setting of ai makes the contribution to the Ising model smallest. However, we can upper bound mi(vi|s) using the two possible values of ai, imposing two inequalities on mi(vi|s). This suffices for the case when s ∉ F because the messages will be themselves a lower bound on the value of the Ising model and we only require this value to be at least g in (7). When s ∈ F, we must make sure that the message takes the exact minimum value for the parametric Ising model. We impose these constraints by making sure that when ai corresponds to β(s, i), we lower bound the message so it takes the correct value.
2.1.1. Implementation concerns
For some problems many of the constraints arising from variable elimination are redundant, and many message variables can be shown to be equal. Eliminating such redundancies can dramatically shrink the size of FEAS(θ, β). Further consolidation can be obtained by exploiting automorphisms of , and gauge symmetries of the Ising energy 〈θ, ϕ(z)〉. Lastly, we note that the order in which constraints are presented to the SMT solver can significantly impact solving time. We have found that running multiple SMT solver instances each with a random shuffling of constraints often yields at least one solution quickly.
2.1.2. Scalability
FEAS(θ, β) can be very difficult to solve (particularly at larger g). Currently, we are limited to problems defined on graphs with at most 30–50 nodes, and up to |F| = 1000 feasible configurations. To scale to larger sizes requires heuristics which give suboptimal gaps. One approach to better scaling is through graph embedding. With embedding a problem is reduced to pairwise interactions without regard for the connectivity this reduction may generate. The connectivity is then mimicked in hardware with strong ferromagnetic interactions that slave qubits together: techniques for doing so are discussed in Section 2.2.
2.1.3. Examples
Consider the 3-bit parity check equation, that is, F is the set of four feasible solutions consisting of spin triplets with an even number of positive spins. Realizing this parity constraint as an Ising model requires at least one ancillary bit. The bound constraints are hi ∈ [−2, 2] for each i and Jij ∈ [−1, 1] for each edge (i,j). We assume first that is the complete graph on 4 nodes, K4. Then it is straightforward to verify that (s1 + s2 + s3 − 2a + 1)2/4 defines an optimal penalty function with gap 1. The same gap can be achieved if the hardware graph is the complete bipartite graph K3,3 and we identify two qubits on the right side of the partition with two on the left side using ferromagnetic couplings. The first two decision variables are mapped to these two pairs of coupled qubits, so that, s1 = a1 and s2 = a2, while the two remaining qubits are s3 and an additional ancilla a3. In this case, the Ising model is
However, using the MILP or SMT model we can obtain a gap of 2 by placing the decision qubits s1, s2, s3 on one side of K3,3, and all ancillary qubits a1, a2, a3 on the other:
As a more complex example consider the constraint (perhaps indicating one of 8 objects). This can be represented with the penalty (∑1≤i≤8si + 6)2 which couples all 8 variables. Embedding this penalty using the methods of Section 2.2.3 in the hardware graph of Figure 1 requires 24 qubits and gives a gap of 2/3.
However, using the SMT model we can accommodate the same constraint with only 16 qubits, and a gap of 4. The Ising models for these two penalties are shown in Figure 2.
Figure 2
2.2. Mapping Ising models to hardware
Using the techniques in Section 2.1, we realize the constraints {Fj | 1 ≤ j ≤ m} of a CSP as penalty Ising models {PenFj(s, a) | 1 ≤ j ≤ m}, where each PenFj is defined on a small subgraph j of the hardware graph . By choosing the subgraphs to be disjoint (or possibly intersecting at decision variables), we can solve all constraints simultaneously on the hardware. However, most variables si will appear in multiple constraints, and we require that all instances of a variable take the same value. To do this, we identify several connected qubits with the same variable, and apply a strong ferromagnetic connection between those qubits during the annealing process, ensuring that they obtain the same spin. A connected set of qubits representing the same variable is known as a chain. Notice that the variables in a chain connecting two variables which must assume the same value are ancillary variables enforcing the equality constraint. Chains are simply penalty functions enforcing equality constraints.
The problem of embedding the Ising model of a CSP into then consists of two parts: (1) choosing a placement of constraints onto disjoint subgraphs of , and (2) routing chains to represent variables that appear in multiple constraints. This “place and route” model of embedding has been used with great success and scalability in VLSI physical design [17, 18], where circuits with millions of variables may be mapped onto a single chip. Some of the techniques presented here have analogies in the VLSI literature. In this section, we describe techniques for placement and routing, as well as more general methods to map Ising models of arbitrary structure to .
2.2.1. Placement
We consider graphs
consisting of a repeating pattern of unit cells, and assume that constraints (like parity check on 3 variables) can be represented within a single unit cell. In mapping constraints to unit cells within
, we try to place constraints that share variables close to one another: a good choice of placement will make the routing process more tractable. The techniques presented here can be generalized, but for simplicity we assume that the hardware graph
consists of an
N×
Ngrid of
K4,4unit cells. Approaches to placement include:
Quadratic assignment: Define a flow Aj,j′ between two constraints Fj and Fj′ to be the number of variables they have in common. Define a distance Bu,u′ between two unit cells u and u' in
to be the length of the shortest path between them. Assuming two instances of a variable must be joined together by a path to create a chain, the quadratic assignment problem QAP(A, B) identifies a mapping from constraints to cells that roughly minimizes the sum of the chain lengths. (See [19] for background on QAP). Note that we do not require an optimal solution to the QAP problem in order to find a valid embedding; an approximate solution suffices.Simulated annealing: Simulated annealing updates an assignment of constraints to cells by swapping pairs of constraints. Swaps are chosen randomly and accepted or rejected as a function of the change in some cost function (the cost function used in QAP is one example). Provided that each constraint only shares variables with a small number of other constraints, changes in cost function can be evaluated quickly.
Recursive placement: As the hardware graph gets larger, both simulated annealing and quadratic assignment become computationally prohibitive. The cost can be reduced by recursively splitting the problem into pieces and then combining the solutions. First we partition the constraints into two regions such that the number of variables shared between regions is minimized, Then we partition the unit cells of
in two regions such that the number of edges between them is minimized. We continue to partition until the regions are small enough to be computationally tractable. Techniques for partitioning are discussed in Section 2.3.
2.2.2. Routing
Once constraints, and therefore variables, have been assigned to disjoint subgraphs of
, different instances of a variable must be joined together. The routing problem is formulated as follows: given
and a collection of disjoint terminal sets {
Ti⊆
V(
)) |
i= 1 …
m} representing the qubits on which variable
sihas already been placed, find a collection of disjoint chains {
Si}
mi= 1 such that
Sicontains
Ti. The performance of the D-Wave hardware is dependent on the choice of chains, so we would also like to minimize either the maximum size of any chain or the total number of qubits used. This routing problem differs from traditional VLSI routing only in the choice of objective function and the hardware graph
, so several VLSI methods apply with some modification:
Multicommodity flow: The problem of finding a tree S1 in
of minimal size containing a given terminal set T1 is known as the Steiner Tree problem on graphs and is NP-hard. For a given T1 = {z1, z2, …, zk1}, we can model a Steiner Tree for T1 as a network flow. Root vertex z1 is a source with k1 − 1 units of commodity, while each of {z2, …, zk1} is a sink requiring one unit of commodity. All other vertices of have a net-flow of zero. Then, a Steiner Tree S1 for T1 exists if and only if there is a feasible flow in this network. By adding binary variables that indicate whether or not a vertex of is in S1, we can easily formulate this problem as a mixed integer linear programme (MILP).The general case, when m > 1, can be formulated as a MILP using m commodities, one for each terminal set (see [20, Ch. 3.6] or [21] for background on multicommodity flows). We add the constraint that each vertex of
can be in at most one Steiner tree, and require that the flow of commodity i can only be routed through vertices in Steiner tree Si.Greedy Steiner Trees: We heuristically select a variable order and then greedily choose a Steiner Tree for each si from the subgraph
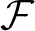 of unused qubits in . Several approximation algorithms for the Steiner tree problem are known, but perhaps the simplest is Kou et al. [22]: define a weighted complete graph
of unused qubits in . Several approximation algorithms for the Steiner tree problem are known, but perhaps the simplest is Kou et al. [22]: define a weighted complete graph 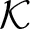 on V(), where the weight of an edge z1z2 is the shortest-path distance between z1 and z2 in . Choose a minimum spanning tree in , and then assign si to every vertex in on the paths representing edges in the minimum spanning tree. This creates a chain for si.
on V(), where the weight of an edge z1z2 is the shortest-path distance between z1 and z2 in . Choose a minimum spanning tree in , and then assign si to every vertex in on the paths representing edges in the minimum spanning tree. This creates a chain for si.- Rip-up routing
: Rip-up routing [
18,
23,
24] is a variation of the greedy Steiner Tree algorithm that temporarily allows chains of variables to overlap. For each variable
si, we maintain a chain
Sisuch that
Ti⊆
Si. Initially
Siis set to
Ti, but after the first iteration of the algorithm each
Siis connected, and by the end of the algorithm the chains are (hopefully) disjoint. The algorithm iteratively updates each chain
Sias follows:
For each vertex z in
, define a vertex weight wt(z) = α|{j ≠ i:z ∈ Sj}|, for some fixed α > 1.Using a Steiner Tree approximation algorithm, choose an approximately minimal vertex-weighted Steiner Tree Si for the terminal set Ti.
The algorithm terminates when all Si are disjoint or no improvements are found. By setting the weight of a vertex proportional to the number of variables it represents, the algorithm encourages chains to form on unused vertices whenever possible.
Multicommodity flow is an exact algorithm and therefore most successful when it is tractable (up to roughly 500 qubits). On the other hand Steiner tree approximation algorithms which are polynomial time can be used at much larger scales, and rip-up routing is usually more effective than greedy routing as it is less likely to get trapped in suboptimal local minima.
2.2.3. Global embedding techniques
For certain optimization problems it may be difficult or suboptimal to map individual constraints Fj to Ising models with the connectivity structure of . In these cases, we may instead map each Fj to an Ising model PenFj(z) of arbitrary structure (possibly using ancillary variables), and then attempt to map Pen(z) = ∑j PenFj(z) to directly. Because of the limited qubit connectivity, we will again require chains to represent variables. The techniques described here attempt to map a problem graph 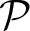 (in which zi and zj are adjacent if they have a non-zero interaction in Pen(z)) to without assuming or have any particular structure.
(in which zi and zj are adjacent if they have a non-zero interaction in Pen(z)) to without assuming or have any particular structure.
Constructing chains such that if two variables are adjacent in then there is at least one edge between their chains in is known as the minor-embedding problem [25]. Minor-embedding is NP-hard; the best known algorithm has running time O(2(2k + 1) log k|V()|2k 22|V()|2 |V()|), where k is the branchwidth of [26]. While there are deep theoretical results about minors in the theory developed by Robertson and Seymour [27], none of the known exact algorithms are even remotely practical for the scale of problems we are interested in. Nevertheless, heuristics can be effective provided that is not too large compared to . When is the Chimera graph in Figure 1, one strategy is to treat as a subgraph of a fixed complete graph. The ideal Chimera graph with 8N2 qubits was designed to have a minor-embedding of a complete graph on 4N + 1 variables [9, 25], and [28] provides algorithms for embedding complete graphs when qubits are missing. The heuristics described below, while slower, can embed much larger problems and also have more flexibility than constraint-based techniques. These heuristics may also be used to improve chain lengths of an embedding, regardless of how that embedding was found.
2.2.4. Shortest-path-based chains
This algorithm uses efficient shortest-path computations to construct a chain for each variable, based on the locations of its neighbors' chains. Chains are temporarily allowed to overlap, and each qubit is assigned a weight based on how many variables are currently assigned to it. Suppose we want to find a chain S0 for variable s0, and s0 is adjacent to s1, …, sk which already have chains S1, …, Sk respectively. By computing the weighted shortest path from each Si to every other qubit in , we can select a “root” qubit z* for S0 which minimizes the weight of the qubits needed to create a connection between s0 and each of s1, …, sk. We then take the union of the shortest paths from z* to each Sj as the chain for S0. The details of this algorithm can be found in Cai et al. [in preparation].
2.2.5. Simulated annealing
An alternative approach uses simulated annealing to attempt to improve partial embeddings. A partial embedding is an assignment of a chain
Sito each variable
si∈
V(
) such that all
Siare disjoint. An edge
si sjof
is unfulfilled if there is no edge in
joining
Siand
Sj. The partial embedding is assigned a score, consisting of the sum of the distances between
Siand
Sjfor unfulfilled edges
si sjplus a small positive constant times the sum of the squares of the cardinalities of all chains. We try to minimize the score by considering moves of the following types:
Given qubit z that is not in any chain, but is adjacent to a chain Si, adjoin z to Si.
Given qubit z in chain Si, remove z from Si (if Si\{z} is still a valid chain) and either leave it unassigned or adjoin it to a neighboring chain Sj.
Given two qubits in different chains, z1 ∈ Si and z2 ∈ Sj respectively, if z1 is adjacent to Sj and z2 is adjacent to Si, and Si\{z1} and Sj\{z2} are still valid chains, switch z1 from Si to Sj and z2 from Sj to Si.
Simulated annealing often produces better results than shortest-path-based chains but takes much longer.
2.3. Solving larger problems
The tools in Sections 2.1 and 2.2 allow for mapping of arbitrary CSPs to Ising models with connectivity constraints. However, it may be difficult to fit a given problem in the current D-Wave hardware due to its limited number of qubits. In this section we outline approaches to solving large problems by repeatedly calling QA hardware to optimize smaller subproblems.
One way of dealing with a large problem is to decompose it into regions. Smaller regional subproblems are then solved, and each region sends some form of feedback to its neighboring regions, which in turn modifies each regional subproblem. The process is repeated until all regions agree on shared variables or some stopping criteria is triggered.
Each region of a CSP is, essentially, a smaller CSP. When we partition a CSP into regions, each region should be as large as possible subject to being embeddable in the hardware graph. Partitions should be chosen so that regions have as few variables in common as possible to minimize the communication between regions.
To decompose the CSP in this way we may use graph and hypergraph partitioning techniques. One mechanism is the following: define a node for each constraint of the CSP and a weighted edge between two nodes counting the variables their constraints share. Then a min-cut balanced partition of the graph will produce similar regions with a minimal number of pairs of shared variables. The min-cut balanced partitioning problem is NP-hard in general, but the Kernighan-Lin algorithm [29] performs well in practice. It starts with a random partition and iteratively swaps sequences of vertices between regions based on improvements to the edge-weights. The software package Metis [30] has implemented a “multi-level” version of Kernighan-Lin that is scalable to tens of thousands of nodes. Since embedding in the hardware graph puts bounds on the number of variables, for regional decomposition to be effective the problem must exhibit some sparsity.
Decomposing the Ising model for the original CSP into 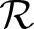 regions produces similar regional subproblems; a region R will have couplings ĥ(R) and ĵ(R) derived from (and often equal to) those of (1), yielding a problem
regions produces similar regional subproblems; a region R will have couplings ĥ(R) and ĵ(R) derived from (and often equal to) those of (1), yielding a problem
on a graph (R) = (V(R), E(R)) (where nR = |V(R)|). We assume the size and sparsity structure of this problem, defined by G(R), is compatible with the hardware. Next, we consider two approaches to coordinate the solutions of these regional subproblems produced by the decomposition. In our implementations, we chose the regions so that h(R)i splits hi evenly across regions R containing qubit i, but each edge ij ∈ E() belongs to exactly one region so that J(R)i,j = Ji,j. During the run of the algorithms, for each region R, only the linear terms were updated.
2.3.1. Belief propagation
Belief propagation (BP) [31] is an algorithm in which messages are passed between regions and variables. Messages represent beliefs about the minimal energy conditional on each possible value of a variable. In min-sum BP, messages from variables (i, j, …) to regions (R, S, …) are updated using the formula
where N(i) is the set of regions containing i. In the reverse direction, messages are updated as
where similarly N(R) is the set of variables in R.
Specifically, μi → R(zi) represents the aggregate of beliefs about zi from all regions excluding R, while μR → i(zi) is the minimum energy for R aggregating beliefs about all variables in R excluding i. These messages are iteratively passed between regions and variables until messages converge or another criterion is met when messages do not converge. BP is known to perform well for certain CSPs, and is a standard decoding algorithm for LDPC [32].
Two advantages of using hardware-sized regions, over performing BP in which each region is a single constraint, are (1) we can internalize within regions many of the short cycles of variable interactions, which are known to cause failure of BP, and (2) we need only pass messages for variables that appear in multiple regions, as variables appearing in a single region may be resolved after the BP algorithm terminates. Using min-cut heuristics to construct regions augments these benefits.
2.3.2. Dual decomposition
Dual decomposition (DD) uses Lagrangian relaxation methods, a standard approach for dealing with large scale optimization problems [11, 33, 34]. The Lagrangian relaxation of an Ising model (1) consists of a concave optimization problem of the form maxλ ∈ ΛL(λ) where
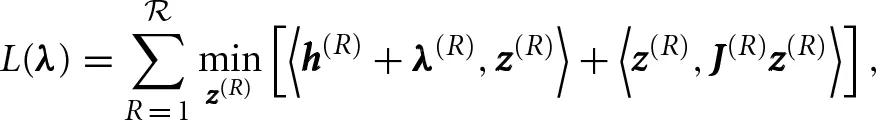
where for region R, h(R) = (h(R)i)i ∈ V((R)), J(R) = (J(R)i, j)(i,j) ∈ E()(R)). Valid multipliers λ must lie within 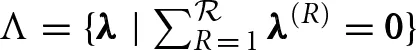 . As before the Ising models defined by h(R) and J(R) have sparsity structure (R) determined once after the partitioning, and the multipliers λ do not change the sparsity structure of J(R). Notice that evaluating L(λ) (and thus computing a supergradient) decomposes into independent regional subproblems of the form (8). The concave optimization problem that defines the relaxation can be solved using subgradient optimization methods (e.g., [33]).
. As before the Ising models defined by h(R) and J(R) have sparsity structure (R) determined once after the partitioning, and the multipliers λ do not change the sparsity structure of J(R). Notice that evaluating L(λ) (and thus computing a supergradient) decomposes into independent regional subproblems of the form (8). The concave optimization problem that defines the relaxation can be solved using subgradient optimization methods (e.g., [33]).
The Lagrangian relaxation is a lower bound on the optimal value of the original Ising model. In particular, if after solving the Lagrangian function L(λ) all the solutions z(R) agree at the regional boundaries, we have indeed solved the original problem. If the solutions z(R) differ at regional boundaries, a simple heuristic to try to derive a solution to the CSP is to use regional majority vote or randomized rounding to determine the values of the spins at the boundaries followed by a straightforward greedy descent procedure.
The Lagrangian relaxation can also be used to compute lower bounds in a branch-and-bound approach.
2.3.3. Large-neighborhood local search
Greedy descent or local search is an iterative optimization method that moves from one spin configuration z to another by flipping the spin that reduces the objective value of the Ising model the most. A straightforward variation of local search [35] is large-neighborhood local search (LNLS) (see [36]), in which many spins may be flipped simultaneously. In each iteration of LNLS, we select a subset of the spins that are allowed to change (the rest are fixed), and we optimize the subproblem over in hardware so as to minimize the overall objective value of the Ising model.
In contrast with the decomposition methods in Sections 2.3.1 and 2.3.2, LNLS does not rely on a single partitioning of the original problem: a new subproblem may be selected at each iteration. However, we must ensure that subproblems are embeddable in hardware. For instance, if we have an embedding of a complete graph Km, any subset of m variables can be optimized while keeping all the other spins fixed. An important consideration is the selection of the variables that are fixed at each iteration. One heuristic is to pick a variable at random and grow a breadth-first search tree to a fixed number of variables.
3. Results
In this section, we report results of our experiments using D-Wave hardware for solving LDPC problems. In our tests, an instance of LDPC consists of a parity check matrix G ∈ {0, 1}r × n, and a bit string (message) y ∈ {0, 1}n. A codeword x is any bit string whose parity check vector, Gx, is 0 modulo 2. The goal is to decode message y by finding the codeword x whose Hamming distance to y is as small as possible. The parity check matrix G is sparse. We chose G so that n was between 100 and 1000, r ≈ 0.70n, the number of non-zeros on each row was between 3 and 5, and the number of non-zeros in each column was between 2 and 4. The message y was chosen by first picking a random codeword x, and then flipping pn random bits, where p is the error rate. We tested instances for which p ∈ {8%, 10%, 12%, 14%}.
The standard decoding algorithm for LDPC uses belief propagation as described in Section 2.3.1, with each region defined to be a single parity check. We generated our instances at random, and, to get an indication of the potential usefulness of the hardware, considered only instances that had a unique optimal solution and for which standard belief propagation did not converge within 1000 iterations. Optimal solutions used to baseline hardware performance were obtained by dynamic programming applied to regional subproblems [16]. While dynamic programming is faster than hardware solution at these size subproblems, dynamic programming will not scale to much larger subproblems due to prohibitive memory requirements.
We solved the instances using D-Wave hardware (such as the one in Figure 1, for which hi ∈ [−2, 2] and Ji,j ∈ [−1, 1]) and the decomposition strategies of Section 2.3. Each region consisted of up to 20 parity checks from G and was mapped to the hardware in the following way. First we added ancillary variables so that each parity check involved exactly 3 variables2. Each of these checks was then placed in a cell using the techniques of Section 2.2.1. Inside a cell we used the two embeddings described in the example of Section 2.1.3, one with gap 2 (K3,3) and one with gap 1 (K4). We observed that the problems submitted to the hardware using K3,3-based embeddings had a significantly improved success probability as compared to the problems that used K4-based embeddings (see Figure 3). This in turn allowed for higher precision for the subproblems submitted to the hardware as required by the decomposition algorithms. Thus, in the following experiments we used K3,3-based embeddings.
Figure 3
We implemented both region-based Belief Propagation (BP) and Dual Decomposition (DD). We optimized each regional subproblem using up to 10 D-Wave hardware calls, in order to adjust the strength of the ferromagnetic couplings used to identify chains. Each hardware call took 10,000 samples with an annealing time of 20 μs (see [37] for more details on the hardware's operating specifications). In the case of DD, we used a standard subgradient algorithm once, and used a simple randomized rounding procedure and local search to try to produce codewords from the subproblems generated throughout the subgradient optimization.
We generated 18 random instances as described above. BP managed to solve all the instances, while DD solved 14 of 18, encountering difficulties for error rates p = 12% for instances with more than 600 bits. We attribute the higher reliability of BP to the fact that the problems sent to the hardware had lower precision than DD. On the other hand, typically DD required fewer hardware calls to converge. Among all the hardware samples we collected, 95% of them were within 4% of optimum (see Figure 3).
4. Conclusion
We have outlined a general approach for coping with intrinsic issues related to the practical use of quantum annealing. To address these issues we proposed methods for finding Ising problem representations that have a large classical gap between ground states and first excited states, practical methods for embedding Ising models that are not compatible with the hardware graph, and decomposition methods to solve problems that are larger than the hardware. As an application of our techniques, we described how we implemented LDPC decoding problems in D-Wave hardware. Our approach has enabled us to solve LDPC decoding problems of up to 1000 variables. The current hardware implementation of QA tested here is roughly as fast as an efficient implementation of simulated annealing, but these results offer the promise of hybrid quantum/classical algorithms that surpass purely classical solution as QA hardware matures.
As future work, we would like to improve upon the scalability of the current method for constructing penalty functions with large gaps. This would allow larger component subproblems and reduce the need for minor embedding between subproblems. Further, the methods we have described here for finding penalty functions assume an assignment of decision variables to qubits. Different assignment choices lead to different results and different hardware performance. We do not currently have an effective method for this assignment.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Statements
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Footnotes
1.^We indicate the energy as Pen, instead of E, to remind the reader this energy function represents a penalty function.
2.^Embedding 3-bit checks which fit within a unit cell and offer free qubits for routing is more efficient than embedding the penalties of 4- or 5-bit checks.
References
1.
BerkleyAJJohnsonMWBunykPHarrisRJohanssonJLantingTet al. A scalable readout system for a superconducting adiabatic quantum optimization system. Superconduct Sci Technol. (2010) 23:105014. 10.1088/0953-2048/23/10/105014
2.
DicksonNGJohnsonMWAminMHHarrisRAltomareFBerkleyAJet al. Thermally assisted quantum annealing of a 16-qubit problem. Nat Commun. (2013) 4:1903. 10.1038/ncomms2920
3.
HarrisRJohanssonJBerkleyAJJohnsonMWLantingTHanSet al. Experimental demonstration of a robust and scalable flux qubit. Phys Rev B (2010) 81:134510. 10.1103/PhysRevB.81.134510
4.
JohnsonMWAminMHSGildertSLantingTHamzeFDicksonNet al. Quantum annealing with manufactured spins. Nature (2011) 473:194–8. 10.1038/nature10012
5.
FinillaABGomezMASebenikCDollDJ.Quantum annealing: a new method for minimizing multidimensional functions. Chem Phys Lett. (1994) 219:343–348.
6.
KadowakiTNishimoriH.Quantum annealing in the transverse Ising model. Phys Rev E (1998) 58:5355. 10.1103/PhysRevE.58.5355
7.
ChildsAFarhiEPreskillJ.Robustness of adiabatic quantum computation. Phys Rev A (2001) 65:012322. 10.1103/PhysRevA.65.012322
8.
FarhiEGoldstoneJGutmannSSipserM.Quantum Computation by Adiabatic Evolution (2000). Available online at: http://arxiv.org/abs/quant-ph/0001106
9.
BunykPIHoskinsonEJohnsonMWTolkachevaEAltomareFBerkleyAJet al. Architectural Considerations in the Design of a Superconducting Quantum Annealing Processor (2014). Available online at: http://arxiv.org/abs/1401.5504
10.
MacKayDJC.Information Theory, Inference and Learning Algorithms. New York, NY: Cambridge University Press (2002).
11.
NemhauserGLWolseyLA.Integer and Combinatorial Optimization. New York, NY: Wiley-Interscience (1988). 10.1002/9781118627372
12.
de MouraLBjørnerN.Satisfiability modulo theories: introduction and applications. Commun ACM (2011) 54:69–77. 10.1145/1995376.1995394
13.
DutertreBde MouraL.A fast linear-arithmetic solver for DPLL(T). In: BallTJonesRB, editors. Computer Aided Verification. Vol. 4144 of Lecture Notes in Computer Science. Berlin; Heidelberg: Springer (2006). p. 81–94. 10.1007/11817963-11
14.
CimattiAGriggioASchaafsmaBSebastianiR.The MathSAT5 SMT solver. In: Piterman N, Smolka S, editors. Proceedings of TACAS. Vol. 7795 of LNCS. (Springer) (2013). Available online at: http://mathsat.fbk.eu/download.html
15.
DechterR.Bucket elimination: a unifying framework for reasoning. Artif Intell. (1999) 1–2:41–85. 10.1016/S0004-3702(99)00059-4
16.
GogateVDechterR.A complete anytime algorithm for Treewidth. In: Proceedings of the 20th Conference on Uncertainty in Artificial Intelligence. Arlington, VA: AUAI Press (2004). p. 201–8.
17.
GerezSH.Algorithms for VLSI Design Automation, 1st Edn. New York, NY: John Wiley and Sons, Inc. (1999).
18.
KahngABLienigJMarkovILHuJ.VLSI Physical Design - From Graph Partitioning to Timing Closure. New York, NY: Springer (2011). 10.1007/978-90-481-9591-6
19.
BurkardRDell'AmicoMMartelloS.Assignment Problems. Philadelphia, PA: Society for Industrial and Applied Mathematics (2009). 10.1137/1.9780898717754
20.
CookWJCunninghamWHPulleyblankWRSchrijverA.Combinatorial Optimization. New York, NY: John Wiley and Sons, Inc. (1998).
21.
ShragowitzEKeelS.A global router based on a multicommodity flow model. Integr VLSI J. (1987) 5:3–16. 10.1016/S0167-9260(87)80003-2
22.
KouLTMarkowskyGBermanL.A fast algorithm for steiner trees. Acta Inf. (1981) 15:141–5. 10.1007/BF00288961
23.
NairR.A simple yet effective technique for global wiring. Trans Comp-Aided Des Integ Cir Sys. (2006) 6:165–72. 10.1109/TCAD.1987.1270260
24.
TingBSBouNT.Routing techniques for gate array. Computer-Aided Design Integr Circ Syst IEEE Trans. (1983) 2:301–12. 10.1109/TCAD.1983.1270048
25.
ChoiV.Minor-embedding in adiabatic quantum computation: I. The parameter setting problem. Quantum Inf Process. (2008) 7:193–209. 10.1007/s11128-008-0082-9
26.
AdlerIDornFFominFVSauIThilikosDM.Faster parameterized algorithms for minor containment. Theor Comput Sci. (2011) 412:7018–28. 10.1016/j.tcs.2011.09.015
27.
RobertsonNSeymourPD.Graph minors XIII: the disjoint paths problem. J Comb Theory Ser B (1995) 63:65–110. 10.1006/jctb.1995.1006
28.
KlymkoCSullivanBDHumbleTS.Adiabatic quantum programming: minor embedding with hard faults. Quantum Inf Process. (2014) 13:709–29. 10.1007/s11128-013-0683-9
29.
KernighanBWLinS.An efficient heuristic procedure for partitioning graphs. Bell Syst Tec J. (1970) 49:291–307. 10.1002/j.1538-7305.1970.tb01770.x
30.
KarypisGKumarV.A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J Sci Comput. (1998) 20:359–92. 10.1137/S1064827595287997
31.
KschischangFRFreyBJLoeligerHA.Factor graphs and the sum-product algorithm. IEEE Trans Inf Theor. (2006) 47:498–519. 10.1109/18.910572
32.
McelieceRJMackayDJCChengJ.Turbo decoding as an instance of Pearls belief propagation algorithm. IEEE J Select Areas Commun. (1998) 16:140–52. 10.1109/49.661103
33.
BertsekasDP.Nonlinear Programming. Nashua, NH: Athena Scientific (1995).
34.
WolseyLA.Integer Programming. A Wiley-Interscience publication (1998).
35.
AartsELenstraJK editors. Local Search in Combinatorial Optimization. New York, NY: John Wiley and Sons, Inc. (1997).
36.
AhujaRKErgunOOrlinJBPunnenAP.A survey of very large-scale neighborhood search techniques. Dis Appl Math. (2002) 123:75–102. 10.1016/S0166-218X(01)00338-9
37.
LantingTPrzybyszAJSmirnovAYSpedalieriFMAminMHBerkleyAJet al. Entanglement in a quantum annealing processor. Phys Rev X (2014) 4:021041. 10.1103/PhysRevX.4.021041
Summary
Keywords
sparse Ising model, quantum annealing, discrete optimization, penalty functions
Citation
Bian Z, Chudak F, Israel R, Lackey B, Macready WG and Roy A (2014) Discrete optimization using quantum annealing on sparse Ising models. Front. Phys. 2:56. doi: 10.3389/fphy.2014.00056
Received
26 June 2014
Accepted
01 September 2014
Published
18 September 2014
Volume
2 - 2014
Edited by
Jacob Biamonte, ISI Foundation, Italy
Reviewed by
Mauro Faccin, ISI Foundation, Italy; Maria Kieferova, Slovak Academy of Sciences, Slovakia; Andrew Lucas, Harvard University, USA; Travis S. Humble, Oak Ridge National Laboratory, USA
Copyright
© 2014 Bian, Chudak, Israel, Lackey, Macready and Roy.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: William G. Macready, D-Wave Systems, 3033 Beta Ave, Burnaby, BC V5G 4M9, Canada e-mail: wgm@dwavesys.com
This article was submitted to Interdisciplinary Physics, a section of the journal Frontiers in Physics.
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.