Abstract
Hopfield networks are a variant of associative memory that recall patterns stored in the couplings of an Ising model. Stored memories are conventionally accessed as fixed points in the network dynamics that correspond to energetic minima of the spin state. We show that memories stored in a Hopfield network may also be recalled by energy minimization using adiabatic quantum optimization (AQO). Numerical simulations of the underlying quantum dynamics allow us to quantify AQO recall accuracy with respect to the number of stored memories and noise in the input key. We investigate AQO performance with respect to how memories are stored in the Ising model according to different learning rules. Our results demonstrate that AQO recall accuracy varies strongly with learning rule, a behavior that is attributed to differences in energy landscapes. Consequently, learning rules offer a family of methods for programming adiabatic quantum optimization that we expect to be useful for characterizing AQO performance.
1. Introduction
Content-addressable memory (CAM) is a form of associative memory that recalls information by value [1]. Given an exact or approximate input value, a CAM returns the closest matching key stored in memory. This is in contrast to random access memory (RAM), which returns the value stored at a provided key or address. CAMs are of particular interest for applications tasked to quickly search large databases including, for example, network switching, pattern matching, and machine vision [2]. An auto-associative CAM is a memory in which the key and value are the same and partial knowledge of the input value triggers complete recall of the key.
Auto-associative CAMs have proven of interest for modeling neural behavior and cognition [3]. This is due partly to their properties of operating in massively parallel mode and being robust to noisy input. These features motivated Hopfield to propose a model for an auto-associative CAM based on a network of computational neurons [1, 4]. The Hopfield neural network stores memories in the synaptic weights describing the connectivity between the neurons. An initial state of the neural network propagates discretely by updating each neuron based on the synapses and states of the other neurons. Hopfield showed that memories stored in the network become fixed point attractors under these Markov dynamics. The Hopfield network functions as an auto-associative CAM in which the initial network state represents the input value and the final state represents the recovered key or memory. The memory capacity for a Hopfield network depends strongly on how the synaptic weights are set [5–7].
The theoretical underpinning of the Hopfield network is a classical Ising model in which each binary neuron is mapped into a spin-1/2 system [3]. The synaptic weights define the couplings between these spins and the susceptibility for a neuron to become activated is set by the applied bias. The energy of the Ising model represents a Lyapunov function and stochastic dynamics guarantees convergence to a fixed point attractor in the asymptotic limit [1]. Conventionally, Hopfield networks are formulated in terms of an update rule governed by the Ising energy. However, finding stable points of this Lyapunov function can also be viewed as minimization of the network energy [8]. In the case of the Hopfield network, spin configurations that minimize the network energy are fixed point attractors representing stored memories.
A fundamental concern for accurate memory recall is the likelihood for the network dynamics to converge to the correct memory state. Although stored memories are guaranteed to reside at minima in the network energy, the number of stored memories greatly influences the radius of attraction for each stable point [9]. The radius of attraction determines how close (measured by Hamming distance) an initial network state must be in order to converge to a fixed point. As the number of stored memories increases, the radius of attraction for each fixed point decreases due to interference between memories [8]. The initial network state must then start closer to the sought after memory in order to accurately recall it. Conventional Hopfield networks rely on gradient descent to recover these stable fixed points. However, this method lacks any mechanism for escaping from the local minima that represent interfering memories [3].
In this work, we investigate the recall accuracy of an auto-associative CAM using methods of energy minimization by adiabatic quantum optimization (AQO). AQO represents a novel approach to optimization that leverages quantum computational primitives for minimizing the energy of a system of coupled spin states [10, 11]. In particular, AQO recovers the spin state that corresponds with the global minimum in energy. We formulate memory recall in terms of global energy minimization by AQO in order to avoid the local minima that undermine gradient descent in conventional Hopfield networks. We apply the promise that AQO returns the global network minimum by investigating how accurately a sought-after-memory can be recalled. As part of the broader adiabatic quantum computing model, AQO has also been investigated for a number of applications, including classification [12, 13], machine learning [14], graph theory [15–18], and protein folding [19, 20] among others [21–25]. In each of these representative applications, the respective problems require reduction first to a discrete optimization problem that is subsequently mapped into the AQO paradigm. By comparison, we show that memory recall within a Hopfield network is a direct application of AQO. Moreover, this task may be implemented using an Ising model in a transverse field with no reduction in the original problem required [26].
Our analysis is also directed at quantifying the influence that learning rules have on AQO recall accuracy. Although learning rules are well understood to influence memory capacity of Hopfield networks, these rules have not been applied to the study of AQO dynamics. Learning rules define the synaptic couplings that store memories and thus shape the energy landscape of the Ising model. It is an outstanding question to understand how the shape of the energy landscape determines the computational complexity of AQO, and we use these learning rules as a means of comparing performance between different AQO programs that implement the same recall task. This is possible due to the one-to-one correspondence between the Hopfield network and the Ising model. We ensure that the AQO dynamics are always adiabatic by using sufficiently long annealing times in our simulated networks. This enables us to focus on quantifying the relative recall accuracy of AQO under three different learning rules as opposed to questions about adiabaticity. We analyze changes in AQO recall accuracy with respect to the number of stored patterns and type of learning rule employed. We defer to future studies the question of how AQO performs relative to the absolute scaling of the minimum spectral gap. This question for Ising models in a traverse field is presently addressed by many others [27–30]. Our interest is in assessing how learning rules influence recall accuracy in the limit of sufficiently long annealing times. By guaranteeing the adiabatic condition, we avoid trapping in local minima but not interference between memories and the formation of spurious states. We use numerical simulations to quantify the conditions under which AQO may be useful for memory recall.
The use of AQO for performing memory recall in a Hopfield network has been investigated previously by Neigovzen et al. in the context of pattern recognition [31]. Specifically, they employed AQO to minimize the energy of a Hopfield network expressed as an Ising Hamiltonian. Neigovzen et al. performed an experimental demonstration of these ideas using a 2-neuron example in the context of NMR spin-based encoding. Their results confirmed that AQO provided accurate recall for that small network and invited questions as to how details of the Hopfield network influence performance. Our investigation addresses those questions by quantifying how different network parameters, including size, memories, and learning rules, influence recall accuracy.
Hopfield networks are tasked with finding an unknown value within an unsorted database, i.e., the network memory. There is a strong connection between this type of tagged search and Grover's search algorithm, which is formulated in terms of a quantum oracle. Previous work by Farhi et al. as well as Roland and Cerf using AQO to perform search tasks makes this point clear [32, 33]. Both have shown that Grover's search algorithm can be cast in terms of AQO by mapping the oracle operator to the terminal Hamiltonian. A Hopfield neural network using AQO for memory recall is equivalent to these implementations of Grover's search when the oracle expresses a one-memory network. However, a Hopfield network extends the search task to a more general context in which the oracle must discriminate between both tagged and untagged keys. This requires a more complex implementation of the oracle that we find plays a role in overall recall performance. This increase in oracle complexity likely undermine the optimal scaling reported by Roland and Cerf, i.e., 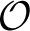 (2n/2), which stores only a single pattern in an n-qubit network. Our statistical analyses of multi-memory instances suggest that the optimal annealing schedule is dependent on both the learning rule and the number of stored memories.
(2n/2), which stores only a single pattern in an n-qubit network. Our statistical analyses of multi-memory instances suggest that the optimal annealing schedule is dependent on both the learning rule and the number of stored memories.
In Section 2, we define the task of memory recall using a conventional Hopfield network and describe the Hebb, Storkey, and projection learning rules for preparing the synaptic weights. In Section 4, we introduce adiabatic quantum optimization, its use for memory recall, and the basis for our numerical simulation studies. In Section 4, we present results for example instances of Hopfield networks that demonstrate the behavior of AQO for memory recall while in Section 5 we present calculations of the average recall success for an ensemble of different networks. We present final conclusions in Section 6.
2. Hopfield networks
We define a classical Hopfield network of n neurons with each neuron described by a bipolar spin state zj ∈ {±1}. Neurons i and j are symmetrically coupled by synaptic weights wij = wji while self-connections are not permitted, i.e., wii = 0, to ensure dynamic stability. Different choices for the weights are described below, but in all cases the energy of the network in a spin state z = (z1, z2, …, zn)T is
with θ = (θ1, θ2, …, θn)T and θi the real-valued activation threshold for the i-th neuron. This form for the energy represents a classical Ising model in which the spin configuration describes the orientation of the n-dimensional system. The dynamics of the Hopfield network are conventionally modeled by the discrete Markov process
where the state of the i-th neuron may be updated either in series (asynchronously) or in parallel (synchronously) with all other neurons in the network. The network is initialized in the input state zi = z0,i and subsequently updated under repeated application of Equation(2) until it reaches a steady state
Steady states of the Hopfield network represent fixed point attractors and are local minima in the energy landscape of Equations (1, 3). The stable fixed points are set by the choice of the synaptic couplings wij and the network converges to the memory state closest to the initial state z0. However, the network has a finite capacity to store memories and it is well known that the dynamics converge to a spurious mixture of memories when too many memories are stored [5–7]. The emergence of spurious states places a limit on the storage capacity of the Hopfield network that depends on both the interference or overlap between the memories and the learning rule used to set the synaptic weights.
2.1. Synaptic learning rules
Learning rules specify how memories are stored in the synaptic weights of a Hopfield network and they play an important role in determining the memory capacity. The capacity cn = p/n is the maximum number of patterns p that can be stored in a network of n neurons and then accurately recalled [9]. Different learning rules yield different capacities and we will be interested in understanding how these differences influence performance of the AQO algorithm. Setting the synaptic weights wij for a Hopfield network is done using a specific choice of learning rule that in turn generates a different Ising model. Learning rules represent a form of unsupervised learning in which the memories are stored in the network without any corrective back-action. We make use of three learning rules that have been found previously to yield different capacities for Hopfield networks in the classical setting.
2.1.1. Hebb rule
The Hebb learning rule defines the synaptic weights
for a set of p memories {ξ1, ξ2, …, ξp}, each of length n with bipolar elements ξμi ∈ {±1}. Geometrically, each summand corresponds to the projection of the neuron configuration into the μ-th memory subspace. These projections are orthogonal if all p patterns are mutually orthogonal. More generally, the Hebb rule maps non-orthogonal memory states into overlapping projections. This leads to interference during memory recall as two or more correlated memories may both be close to the input state. In the asymptotic limit for the number of neurons, the capacity of the Hebb rule is cn = n/2ln n under conditions of perfect recall, i.e., no errors in the retrieved state. By comparison, under conditions of imperfect recall the asymptotic capacity is cn ≈ 0.14 [5]. It is worth noting that the Hebb rule is incremental as it is a sum over individual patterns. The rule is also local since the synaptic weights depend only on the value of the adjacent neurons.
2.1.2. Storkey rule
The Storkey learning rule defines the synaptic weights in an iterative fashion as
where ξν is the memory to be learned in the ν-th iteration for ν = 1 to p and
is the local field at the i-th neuron [7]. The final synaptic weight storing p memories is given by wij = wpij. The Storkey rule is found to more evenly distribute the fixed points and increases the capacity of the network. The asymptotic Storkey capacity under perfect recall is , which represents an improvement over the Hebb rule. As with the Hebb rule, the Storkey rule is incremental and permits the addition of new memories.
2.1.3. Projection rule
The projection rule defines the synaptic weights for p memories as
where is the covariance matrix and C−1 is the inverse of C. This rule has a theoretical capacity of n for linearly independent patterns and approximately n/2 for interfering memories [6, 34]. The projection rule is neither local nor incremental as adding memories to the network requires resetting each element using knowledge of all other memories. In the limit of orthogonal memories, all three learning rules reduce to the Hebb rule.
3. Memory recall by adiabatic quantum optimization
The learning rules defined in Section 2.1 offer different methods for preparing the synaptic weights and the fixed points of a Hopfield network. Conventionally, the network finds those states that satisfy the equilibrium condition of Equation(3) by evolving under the discrete Markov process of Equation(2). However, the fixed points of a Hopfield network are also minima of the energy function known as stable fixed points. The stability of these solutions is due to the quadratic form of the energy function E(z; θ), which is a Lyapunov function that monotonically decreases under updates of network state [3]. As an example, consider that the k-th spin in the state z updates, i.e., zk → z′k. The relative change in unbiased energy is then
The sign of the summation always correlates with the change in the spin state, cf. Equation(2). Thus, network energy never increases with respect to updates in the state z. More importantly, the Lyapunov stability of the Hopfield network guarantees that the stochastic dynamics converge to fixed points representing stored memories.
As an alternative to fixed point convergence under stochastic update, we apply the principle of optimization for finding the global minima of the energy function and for recalling a stored memory. We are motivated by the stability analysis of the Ising model under Markov dynamics, which guarantees that memories represent fixed point attractors and, more importantly, energy minima. Our formulation uses the same synaptic weight matrix and underlying Ising model of a conventional Hopfield network. However, we set the activation thresholds θi in place of initializing the network to a known initial state z0. This feature casts recovery of an unknown memory in terms of minimizing the energy of the network. We formally define the energy minimization condition as
in which the vector θ represents the activation thresholds θi = Γ z0,i and Γ is an energy scale for the applied bias. The activation threshold θ serves as an energetic bias toward network states that best match the input z0. The behavior for a classical Hopfield network is recovered by initializing the state of all neurons to an indeterminate value, i.e., zi = 0, and using the first update to prepare the state z0.
In the absence of any bias, finding the global minima of E(z, 0) is equivalent to computing the lowest energy eigenstates of the synaptic weight matrix wij with the constraint zi ∈ {±1} (indeterminate values are not valid output states). Due to the symmetry of the unbiased energy, the complement of each memory is also an eigenstate. If the network stores p memories, then the ground state manifold is 2p degenerate subspace. However, the presence of a non-zero bias breaks this symmetry and leads to a lower energy for only one memory state relative to the other stored memories.
In the presence of bias, global minimization of E(z, θ) returns the spin configuration that encodes a recalled memory. The promise that the encoded memory is a global minimum depends on several factors. First, if the applied bias is too large then the input state itself becomes a fixed point and the global minimum becomes z0. This behavior is unwanted since it does not confirm whether the input or its closest match were part of the memory. This effect can be detected by decreasing Γ and monitoring changes in the recall. However, we can also compute an upper bound on Γ by comparing network energies of a memory state ξk with a non-memory state z0, e.g., for the projection rule
ensures that the network does not become over biased. In the limit that the memories are orthogonal to each other as well as the input key, this reduces to the result Γ < 1/(2n) previously noted by Neigovzen et al. [31].
Interference between memories prevents their discrimination when insufficient knowledge about the sought-after memory is provided. The number of memories stored in the network may also exceed the network capacity and lead to erroneous recall results. As an example, perfect recall is observed when using the Hebb rule in a classical network storing p orthogonal memories provided p ≤ n, since there is no interference in these non-overlapping states. However, the capacity for non-orthogonal memories is much lower and varies with learning rule, as described above. In our optimization paradigm, interference manifests as degeneracy in the ground state manifold. These degeneracies are formed from superpositions of stored memory states and the applied bias. These states are valid energetic minima that correspond to the aforementioned spurious states. Differences between learning rules seek to remove the presence of spurious states while also increasing the network capacity.
3.1. Adiabatic quantum optimization algorithm
Adiabatic quantum optimization (AQO) is based on the principle of adiabatically evolving the ground state of an initial well-known Hamiltonian to the unknown ground state of a final Hamiltonian. By defining the final Hamiltonian in terms of the Ising model representing a Hopfield network, we use AQO to recover the ground state expressing a stored memory. The Ising model for AQO will use the same synaptic weights and activation thresholds discussed in Section 2 for the Hopfield network. The recall operation begins by preparing a register of n spin-1/2 quantum systems (qubits) in a superposition of all possible network states and adiabatically evolving the register state toward the final Ising Hamiltonian. Assuming the adiabatic condition has remained satisfied, the qubit register is prepared in the ground state of the Ising Hamiltonian. Upon completion of the evolution, each qubit in the register is then measured and the resulting string of bits is interpreted as the network state.
Formally, we consider a time-dependent Hamiltonian
with piece-wise continuous annealing schedules A(t) and B(t) that satisfy A(0) = 1, B(0) = 0 and A(T) = 1, B(T) = 1. Together, the initial Hamiltonian
and the final Hamiltonian
represent an Ising model in a transverse field. In the latter equations, the Pauli Zi and Xi operators act on the i-th qubit while the constants hi and Jij denote the qubit bias and coupling, respectively. Of course, the latter quantities are exactly the activation threshold and synaptic weights of the Hopfield network, i.e., hi = θi and Jij = wij, and we use the symbols interchangeably. We choose the computational basis in terms of tensor product states of the +1 and −1 eigenstates of operators Zi denoted as |0〉 and |1〉, respectively. In this basis, the correspondence between the binary spin label si ∈ {0, 1} and the bipolar spin configuration label is zi = 2si − 1.
The quantum state of an n-qubit register is prepared at time t = 0 in the ground state of H0,
with |s〉 = |s1〉 ⊗ |s2〉 … ⊗ |sn〉 and
the binary expansion of the state label s. The register state ψ(t) evolves under the Schrodinger equation
from the initial time 0 to a final time T. We set ħ = 1. The time scale T is chosen so that changes in the register state ψ(t) are slow (adiabatic) relative to the inverse of the minimum energy gap of H(t), which has instantaneous eigenspectrum
where the i-th eigenstate φi has energy Ei. The minimum energy gap Δmin is defined as the smallest energy difference between the instantaneous ground state manifold and those excited states that do not terminate as a ground state. Provided the time scale T ≪ Δ−αmin for α = 2, 3, then the register typically remains in the ground state of the instantaneous Hamiltonian and evolution to the time T prepares the ground state of H(T) = H1. However, the exact scaling for the minimal T with respect to Ising model size and parametrization is an open question.
After preparation of the final register state ψ(T), each qubit is measured in the computational basis. Because the final Hamiltonian H1 is diagonal in the computational basis, measurement results represent the prepared (ground) state. The measurements may be directly related to a valid spin configuration of the Hopfield network. The state of the i-th qubit is measured in the Zi basis and the resulting label zi is the corresponding spin configuration for the i-th neuron.
Regarding execution time, the average-case time complexity for the AQO algorithm is currently observed to require T ≪ Δ−αmin with α = 2, 3 in order to recover the global minimum with negligible error. The scaling of energy gap Δmin with respect to n, however, is currently poorly understood except in a few cases. For example, some studies have found a gap that shrinks exponentially with increasing n [10], whereas others observe polynomial scaling [35]. By comparison, the algorithmic complexity for stochastic update in Equation(3) is dominated by the matrix-vector multiply. Assuming the classical operations are directly proportional to time, the execution time for stochastic update scales as O(n2). If Δmin scaled as 1/n, then AQO would at best have the same time scaling as stochastic update. Such weak scaling of the energy gap is unlikely for the average case, and it is far more likely that AQO provides a slowdown relative to gradient descent. This is because AQO makes a stronger promise than the stochastic update rule in Equation(3), i.e., the latter only finds a local stable fixed point.
3.2. AQO recall accuracy
The accuracy with which a memory is recalled using the AQO algorithm can be measured in terms of the probability that the correct (expected) network state is recovered. We define a measure of the probabilistic recall success as
where Pans is the probability to recover the correct memory and x ∈ [0, 1] is the threshold probability. Denoting the correct memory state as ϕans, the probability to recover the correct memory can be computed from the simulated register state as
We assume in this analysis that the register state is a pure state and therefore neglect sources of noise including finite temperature and external couplings.
From this definition for probabilistic success, we consider average success for an ensemble of N problem instances as
where fxi represents the probability for success of the i-th problem instance of n neurons storing p memories. This is a binomial distribution with variance 〈Δfx〉 = 〈fx〉 (1 − 〈fx〉). We use the statistic 〈fx〉 to characterize accuracy for the ensemble of simulated recall operations.
We use several tests of recall accuracy to characterize each learning rule. First, we quantify the recall success with respect to the applied bias when recalling a state known to be stored in the network. This removes any uncertainty (noise) in the input z0. Second, we quantify recall as the failure rate when the input z0 is noisy. This tests the ability for the network to discriminate noisy input from unknown memories. We quantify noise in terms of Hamming distance of the input state from the expected memory state. We perform these tests for all three learning rules and variable numbers of stored memories.
3.3. Numerical simulations of the AQO algorithm
We use numerical simulations of the time-dependent Schrodinger equation in Equation(6) to compute the register state ψ(T) prepared by the AQO algorithm. These simulations provide the information needed to calculate the probabilistic success fx as well as the average success with respect to network size and learning rule. Our methods are restricted to pure-state simulations, which provide an idealized environment for the AQO algorithm and permit our analysis to emphasize how learning rules influence success via changes to the Ising model.
Our numerical methods make use of a first-order Magnus expansion of the time-evolution operator
over the interval [tj, tj + 1] for j = 0 to jmax − 1. The use of a first-order approximation is justified by limiting our simulations to annealing times T that produce states well approximated by the ground state. We confirm this approximation by testing the convergence of the ground state population with respect to T, cf. Figure 11. Our simulations use a uniform time step Δt = tj + 1 − tj such that T = jmax Δt. Starting from the initial state Equation(14), an intermediate state is generated from the series of time evolution operators
In these calculations, the action of the jth time-evolution operator onto the appropriate state vector is calculated directly [36, 37]. The simulation code is available for download [38]. In our simulations, we use annealing schedules A(t) = 1 − t/T and B(t) = t/T, and we do not place any constraints on the qubit connectivity or the coupling precision. Simulated problem instances are detailed below but in general input parameters include the number of neurons n, the number of stored patterns p, the applied learning rule (Hebb, Storkey, or projection), the annealing time T, the applied bias Γ and the input key z0. The large number of parametrized simulations has limited our problem instances to only a few neurons.
4. Recall instances
We first present some example instances to demonstrate AQO behavior during memory recall for different learning rules. We begin by considering the case of p orthogonal memories. A convenient source of orthogonal bipolar states is the n-dimensional Hadamard matrix for n = 2k, whose unnormalized columns are orthogonal with respect to the usual inner product. We use these memories to prepare the synaptic weights and corresponding Ising Hamiltonians. Orthogonal memories are a special case for which all learning rules prepare the same synaptic weights. In the absence of any bias (θi = 0), we expect recall to recover each of the p encoded memories with uniform probability. The quadratic symmetry of the energy in Equation(1) also makes the complement of each memory state a valid fixed point. This implies a total ground state degeneracy of 2p in the absence of bias. An example of the time-dependent spectral behavior is shown in Figure 1 for the case p = n = 4, and all the eigenstates converge to a single ground state energy. The same case but with θ set to the first memory and Γ = 1 is shown in Figure 2. The presence of the bias removes the ground state degeneracy and, not apparent from the figure, the prepared ground state matches the biased input state.
Figure 1
Figure 2
We next consider an instance of non-orthogonal memories defined to have a non-zero inner product between pairs of memories. Interference is expected to cause failure during recall when the applied bias is insufficient to distinguish between similar states. With p = n = 4, we use the memory set
where columns 1, 2, and 3 overlap while columns 2 and 4 are orthogonal. We use an input state z0 = (1, −1, 1, −1) that most matches the first memory Σi,1. For these simulations, we found the annealing time T = 1000 was sufficiently long to yield convergence in the prepared quantum state. Both time and energy are expressed in arbitrary units since all calculated quantities are independent of the absolute energy scale of the Ising model.
Figure 3 through 6 plot the probability q = |〈φans|ψ〉|2 to successfully recall the answer state φans as a function of the applied bias Γ ∈ [0, 1]. The inset for each figure shows the semi-log plot of recall error under the same conditions. Recall probability q varies with input bias, number of memories, and learning rule. For p = 1, there is only one memory stored in the network and any non-zero bias distinguishes between the memory and its complement. Similarly, all three rules behave the same for the case of p = 2 in Figure 4. This is because there are not significant energetic differences between the rules using the first two memories above. The Hebb and Storkey rules coincide exactly, while the projection rule is identical only for the lowest energy eigenstate. However, for the case of p = 3 in Figure 5, there is a distinction between all three rules. The answer state probability using the projection rule is nearly the same as was observed for fewer memories while the Hebb rule shows a shift to larger bias. This shift is due to the added memory creating an energy basin that is lower than the unbiased answer state. Larger bias must be applied to lower the answer state below that of the new memory. In contrast, the Storkey shifts to smaller bias as a result of memory addition. This is because the Storkey rule attempts to mitigate interference by using the local field calculation. As shown in Figure 6 for p = 4, adding another memory makes the Hebb rule become more evenly distributed in energy across the degenerate memory states while the Storkey rule shows a slight shift to a larger bias and the projection rule remains unchanged. Differences in the recall errors are readily seen from the semi-log plots inset in the figures. The slopes of these lines highlight that each learning rule has a different sensitivity to Γ. Note that the inset plots show oscillations in the recall error when it is less than about 10−12; this is due to the finite precision of the numerical simulations.
Figure 3
Figure 4
Figure 5
Figure 6
5. Statistical recall behavior
Our results for recall success of individual Hopfield networks indicate a large degree of variability in performance with respect to the stored memory states. We have found it useful to average performance across a range of problem instances. Under these circumstances, we use the average success probability defined by Equation(20) to quantify the relative performance of each learning rule in terms of neurons n, memories p, and bias Γ. As noted earlier, these statistics correspond to a binomial distribution with parameter 〈fx〉.
We first investigate average AQO recall behavior with respect to the bias Γ. An ensemble of problem instances is constructed for n = 5 neurons in which each instance consists of p memories with elements sampled uniform random from {±1}. Among the p memories, one is selected as the answer state while all other memories are distinct from the answer state. The selected answer state is then chosen as the input state. This defines the activation threshold θ = Γ z0 for some choice of Γ. The simulation computes the full quantum state using an annealing time T = 1000. The probability to occupy the expected answer state is then computed using Equation(18) with a threshold x = 2/3. The exact value of x is not expected to be significant provided it is above the probability for a uniform superposition.
Figure 7 shows the average recall success for recovering the answer state as the bias Γ increases from 0 to 1. Each panel represents the results of a single learning rule and each line represents a network storing p = 1, 2, 3, 4, or 5 memories. We find that each learning rule exhibits a distinct behavior with respect to recall accuracy. For the Hebb rule there is a step-wise decrease in success as the number of memories increases, indicating greater interference during recall. A much weakened version of this dependency is seen for the Storkey rule at values of Γ below about 0.25. Above this threshold the Storkey rule recovers unit success for every memory set. The projection rule demonstrates a very different behavior; unit success is seen in every case for any non-zero value of Γ. Unlike the Hebb rule, there is a complete lack of interference during recall. The plots in Figure 7 indicate when the prepared ground state has greater than 2/3 probability to be in the answer state given an input that matches a memory. The better performance of both the Storkey and projection rules is a result of how they exploit correlations between memories. Both rules effectively raise the energy barrier between fixed stable points, while the Hebb rule preserves this interference. As the number of memories increases, so does the interference within the the typical problem instance. This behavior is underscored by the strong dependence of the Hebb rule on the number of stored memories p.
Figure 7
We also investigate AQO recall accuracy when a noisy input state is provided. As before, we construct an ensemble of problem instances for n = 5 neurons in which each instance consists of p memories with elements sampled uniform random from {±1}. We modify the procedure by selecting one memory as the answer state while creating all other memories at least Hamming distance 2 away from this answer state. We select an input state that is Hamming distance 1 away from the answer state by randomly flipping a bit in the answer state. This construction of the memory set ensures that the noisy input state is closest to the answer state. In Figure 8, the recall success for the noisy input test is plotted with respect to Γ and number of memories for each learning rule. For the Hebb rule, there is again a step-wise decrease in recall success as the number of stored memories is increased. This behavior indicates that the energy basin representing the answer state is not narrow with respect to the Hamming distance between spin configurations. As the stored memories increase, there is a greater chance that the applied bias lowers the energy of non-answer states. As the bias Γ increases beyond about 0.75, the input state is over biased. This leads to a recall accuracy of about 50% independent of stored memories. The Storkey rule exhibits a different behavior with respect to noisy input. Recall accuracy again decreases with the addition of new memories but much more weakly than was observed with the Hebb rule. The recall success also tends to vanish as the bias is increased. These differences underlie the fact that the Storkey rule distributes stored memories better than Hebb, such that an over-biased input is well separated from the expected answer state. Recall accuracy with the projection rule also vanishes for sufficiently strong bias due to the well-separated memory states. However, there is a much stronger dependence on recall accuracy with respect to the number of stored memories.
Figure 8
We have investigated further the influence on the network of over-biasing the input state. As noted previously, there are loose upper bounds on Γ based on the energetic analysis of the learning rules [31]. We have tested these bounds by attempting to recall a memory that is not stored in the network. These tests attempt to recall a stored memory using an input state that is guaranteed to be either Hamming distance 1 or 2 away from any stored memory. We would expect the failure rate for this test to increase as either the number of stored patterns or the bias Γ increases. This is because the biased state should eventually reach an energy lower than any stored memory. Figure 9 plots the average failure as the recall accuracy 〈fx〉. In these plots, the input state is not among the stored memories. As expected, the failure rate increases as Γ increases. For all the learning rules, there is a narrow range for Γ above which the network returns the input state. These thresholds mark that the system is over biased. It is notable, however, that each learning rules exhibit a different behavior from over biasing. Whereas the Hebb rule terminates at lower failure probability as the memories are increased, both the Storkey and projection rules reach unit failure with sufficiently large Γ. This is again due to the inability for the Hebb rule to discriminate between interfering memories. A similar plot is shown in Figure 10 for the case that the input is at least Hamming distance 2 from all the stored memories. The sensitivity to failure increases with the increase in Hamming distance as noted by the lower thresholds on Γ for over biasing.
Figure 9
Figure 10
Finally, we have investigated the role of the annealing time T on recall success. Because the state dynamics must be adiabatic relative to the minimum energy gap, the diversity of instances used for 〈fx〉 are also likely to support a diversity of Δmin. This implies that there may be some maximum T for the ensemble which ensures every instance is quasi-adiabatic. In Figure 11, we show a series of recall averages for different annealing times. For small values of T, the average success is low, especially as p approaches n. This suggests that many instances do not meet the x = 2/3 threshold for success. As T increases, the average success also increases but only up to a limit that depends on each learning rule. For the Storkey and projection rule, this limit is before T = 500, while for the Hebb rule the limit occurs before T = 50. Annealing times larger than these limits do not lead to significant changes in the average recall success (assuming a linear annealing schedule). Thus, the annealing time is not the limiting factor in recall success and the adiabatic condition has been met for these problem instances. Notably, the shortest annealing time is found for the Hebb rule but this rule also exhibits the most interference during memory recall. By contrast, the projection and Storkey rule require an order of magnitude increase in annealing time to ensure adiabaticity but these rules also exhibit greater accuracy during memory recall.
Figure 11
6. Conclusions
We have presented a theoretical formulation of auto-associative memory recall in terms of adiabatic quantum optimization. We have used numerical simulations to quantify the recall success with respect to three different learning rules (Hebb, Storkey, and projection) and we have accumulated statistics on recall accuracy and failure across an ensemble of different network instances. We have found that the probability to populate the expected ground state using AQO is sensitive to learning rule, number of memories, and size of the network. Our simulation studies have been limited in size, but for these small networks there are notable differences in both the success and failure rates across learning rules. These differences represent the strategies of each learning rule to manage memory interference and the sensitivity of the AQO algorithm to those different strategies.
The use of AQO for memory recall is closely related to its use for searching an unsorted database [32, 33]. Both Farhi et al. and Roland and Cerf have previously constructed the search problem using an oracle based on projection operators, which with an unbiased Hopfield network trained using the Hebb rule. Their previous work considered the task of recovering any valid memory from the network. We have used the activation threshold θ of the Hopfield network as the input key for a context-addressable memory. The activation threshold corresponds to the classical input to the oracle that identifies which memory is being sought. In this sense, the Hopfield network offers a robust implementation of Grover's search by permitting input to the task. However, this comes at the cost of a more complex oracle implementation. The three learning rules discussed here represent three different methods for oracle construction within the model of an Ising Hamiltonian. We have shown how choices in learning rule impact recall accuracy and we have observed that the projection rule seems to offer the most robust behavior. We have not attempted to optimize the annealing schedule associated with memory recall for each learning rule. It seems unlikely that the optimized annealing schedule recovered by Roland and Cerf for untagged search would extend to the current oracle implementations due to the influence of the variable activation threshold.
Recent work to assess the scaling of the spectral gap that determines the minimum AQO annealing time has underscored that the relative height of energy barriers play a fundamental role in determining which Ising Hamiltonians are challenging [27–30]. Historically, learning rules that provide well separated but broad energy basins have been the goal of classical Hopfield networks, as these landscapes favor methods like gradient descent [1, 6, 7]. We have found that the AQO recall accuracy and minimal annealing time also demonstrate a significant dependence on the learning rule. In particular, energy basins prepared by the projection rule are known to be better separated than by either the Hebb or Storkey rules. Consequently, the projection rule provides the best performance with respect to AQO recall accuracy. However, better performance is not due to the avoidance of local minima but rather to the reduced interference between the stored memories and the biased input. Because the shape of the energy basins also influence the spectral gap of the time-dependent Hamiltonian, we anticipate that learning rules can provide a form of energetic control over AQO scaling.
Conflict of interest statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Statements
Acknowledgments
Hadayat Seddiqi thanks the Department of Energy Science Undergraduate Laboratory Internship (SULI) program and Prof. Mark Edwards, Georgia Southern University, for use of computing resources. This manuscript has been authored by a contractor of the U.S. Government under Contract No. DE-AC05-00OR22725. Accordingly, the U.S. Government retains a non-exclusive, royalty-free license to publish or reproduce the published form of this contribution, or allow others to do so, for U.S. Government purposes.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1.
HopfieldJJ. Neural networks and physical systems with emergent collective computational abilities. Proc Natl Acad Sci USA. (1982) 79:2554–8. 10.1073/pnas.79.8.2554
2.
PagiamtzisKSheikholeslamiA. Content-addressable memory (CAM) circuits and architectures: a tutorial and survey. Solid State Circ IEEE J. (2006) 41:712–27. 10.1109/JSSC.2005.864128
3.
RojasR. Neural Networks. Berlin: Springer (1996).
4.
HopfieldJJTankDW. Computing with neural circuits-A model. Science (1986) 233:625–33. 10.1126/science.3755256
5.
AmitDJGutfreundHSompolinskyH. Spin-glass models of neural networks. Phys Rev A (1985) 32:1007–18. 10.1103/PhysRevA.32.1007
6.
PersonnazLGuyonIDreyfusG. Collective computational properties of neural networks: new learning mechanisms. Phys Rev A (1986) 34:4217–28. 10.1103/PhysRevA.34.4217
7.
StorkeyAJValabrgueR. The basins of attraction of a new Hopfield learning rule. Neural Netw. (1999) 12:869–76. 10.1016/S0893-6080(99)00038-6
8.
SchneiderJKirkpatrickS. Stochastic Optimization. Scientific Computation. Springer (2007). Available online at: http://books.google.com/books?id=myG_ueOaBDYC
9.
McElieceRJPosnerECRodemichERVenkateshSS. The capacity of the hopfield associative memory. IEEE Trans Inf Theor. (1987) 33:461–82. 10.1109/TIT.1987.1057328
10.
FarhiEGoldstoneJGutmannSLapanJLundgrenAPredaD. A quantum adiabatic evolution algorithm applied to random instances of an NP-complete problem. Science (2001) 292:472–6. 10.1126/science.1057726
11.
SantoroGEMartonakRTosattiECarR. Theory of quantum annealing of an ising spin glass. Science (2002) 295:2427–30. 10.1126/science.1068774
12.
NevenHRoseGMacreadyWG. Image recognition with an adiabatic quantum computer I. Mapping to quadratic unconstrained binary optimization. (2008) arXiv:0804.4457 [quant-ph]
13.
NevenHDenchevVSRoseGMacreadyWG. Training a binary classifier with the quantum adiabatic algorithm. (2008) arXiv:0811.0416 [quant-ph]
14.
PudenzKLidarD. Quantum adiabatic machine learning. Quantum Inform Process. (2013) 12:2027–70. 10.1007/s11128-012-0506-4
15.
GaitanFClarkL. Ramsey numbers and adiabatic quantum computing. Phys Rev Lett. (2012) 108:010501. 10.1103/PhysRevLett.108.010501
16.
HenIYoungAP. Solving the graph-isomorphism problem with a quantum annealer. Phys Rev A. (2012) 86:042310. 10.1103/PhysRevA.86.042310
17.
BianZChudakFMacreadyWGClarkLGaitanF. Experimental determination of ramsey numbers. Phys Rev Lett. (2013) 111:130505. 10.1103/PhysRevLett.111.130505
18.
GaitanFClarkL. Graph isomorphism and adiabatic quantum computing. Phys Rev A. (2014) 89:022342. 10.1103/PhysRevA.89.022342
19.
PerdomoATruncikCTubert-BrohmanIRoseGAspuru-GuzikA. Construction of model Hamiltonians for adiabatic quantum computation and its application to finding low-energy conformations of lattice protein models. Phys Rev A. (2008) 78:012320. 10.1103/PhysRevA.78.012320
20.
Perdomo-OrtizADicksonNDrew-BrookMRoseGAspuru-GuzikA. Finding low-energy conformations of lattice protein models by quantum annealing. Nat Sci Rep. (2012) 2:571. 10.1038/srep00571
21.
SmelyanskiyVNRieffelEGKnyshSIWilliamsCPJohnsonMWThomMCet al. A near-term quantum computing approach for hard computational problems in space exploration. (2012) arXiv:1204.2821 [quant-ph]
22.
LucasA. Ising formulations of many NP problems. Front Phys. (2014) 2:5. 10.3389/fphy.2014.00005
23.
VinciWMarkströmKBoixoSRoyASpedalieriFMWarburtonPAet al. Hearing the shape of the Ising model with a programmable superconducting-flux annealer. Sci Rep. (2014) 4:5703. 10.1038/srep05703
24.
Perdomo-OrtizAFluegemannJNarasimhanSBiswasRSmelyanskiyVN. A quantum annealing approach for fault detection and diagnosis of graph-based systems. (2014) arXiv:14067601 [quant-ph]
25.
O'GormanBPerdomo-OrtizABabbushRAspuru-GuzikASmelyanskiyV. Bayesian network structure learning using quantum annealing. (2014) arXiv:14073897
26.
JohnsonMWAminMHSGildertSLantingTHamzeFDicksonNet al. Quantum annealing with manufactured spins. Nature (2011) 473:194–8. 10.1038/nature10012
27.
BoixoSAlbashTSpedalieriFMChancellorNLidarDA. Experimental signature of programmable quantum annealing. (2012) arXiv:1212.1739 [quant-ph]
28.
KarimiKDicksonNHamzeFAminMHSDrew-BrookMChudakFet al. Investigating the performance of an adiabatic quantum optimization processor. Quantum Inf Process. (2012) 11:77–88. 10.1007/s11128-011-0235-0
29.
RønnowTFWangZJobJBoixoSIsakovSVWeckerDet al. Defining and detecting quantum speedup. (2014) arXiv:1401.2910 [quant-ph]
30.
KatzgraberHGHamzeFAndristRS. Glassy chimeras could be blind to quantum speedup: designing better benchmarks for quantum annealing machines. Phys Rev X. (2014) 4:021008. 10.1103/PhysRevX.4.021008
31.
NeigovzenRNevesJLSollacherRGlaserSJ. Quantum pattern recognition with liquid-state nuclear magnetic resonance. Phys Rev A. (2009) 79:042321. 10.1103/PhysRevA.79.042321
32.
FarhiEGoldstoneJGutmannSSipserM. Quantum computation by adiabatic evolution. (2000) arXiv:quant-ph/0001106
33.
RolandJCerfNJ. Quantum search by local adiabatic evolution. Phys Rev A. (2002) 65:042308. 10.1103/PhysRevA.65.042308
34.
KanterISompolinskyH. Associative recall of memory without errors. Phys Rev A. (1987) 35:380–92. 10.1103/PhysRevA.35.380
35.
YoungAPKnyshSSmelyanskiyVN. Size dependence of the minimum excitation gap in the quantum adiabatic algorithm. Phys Rev Lett. (2008) 101:170503. 10.1103/PhysRevLett.101.170503
36.
Al-MohyAHHighamNJ. Computing the action of the matrix exponential, with an application to exponential integrators. SIAM J Sci Comput. (2011) 33:488–511. 10.1137/100788860
37.
HighamNJAl-MohyAHComputing matrix functions. Acta Numer. (2010) 19:159–208. 10.1017/S0962492910000036
38.
AdiaQC. Accessed 2014-06-16. (2014) Available online at: https://github.com/hadsed/AdiaQC.
Summary
Keywords
quantum computing, adiabatic quantum optimization, associative memory, content-addressable memory, Hopfield networks
Citation
Seddiqi H and Humble TS (2014) Adiabatic quantum optimization for associative memory recall. Front. Phys. 2:79. doi: 10.3389/fphy.2014.00079
Received
07 July 2014
Accepted
04 December 2014
Published
22 December 2014
Volume
2 - 2014
Edited by
Jacob Biamonte, Institute for Scientific Interchange Foundation, Italy
Reviewed by
Faisal Shah Khan, Khalifa University, United Arab Emirates; Ryan Babbush, Harvard University, USA; Nicola Pancotti, La Sapienza, University of Rome, Italy
Copyright
© 2014 Seddiqi and Humble.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) or licensor are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Travis S. Humble, Oak Ridge National Laboratory, MS 6015, One Bethel Valley Road, Oak Ridge, TN 37831-6015, USA e-mail: humblets@ornl.gov
This article was submitted to Interdisciplinary Physics, a section of the journal Frontiers in Physics.
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.