 Wataru Souma
Wataru Souma- College of Science and Technology, Nihon University, Funabashi, Japan
The following methods are used to analyze correlations among stock returns. 1) The meaningful part of the correlation is obtained by applying random matrix theory to the equal-time cross-correlation matrix of assets returns. 2) Null-model randomness is implemented via rotational random shuffling. 3) Principal component analysis and Helmholtz-Hodge decomposition are used to extract leading and lagging relationships among assets from the complex correlation matrix constructed from the Hilbert-transformed data set of asset returns. These methods are applied to price data for 445 assets from the S&P 500 from 2010 to 2019 (2,510 business days). Additional analysis and discussion clarify key aspects of leading and lagging relationships among business sectors in the market. Numerical investigation of these dataset reveals the possibility that leading and lagging relationships among business sectors may depend on gross market conditions.
1 Introduction
The analysis of big data can reveal novel aspects of nature and society. However, data often contain noise, making it necessary to distinguish the signal from the noise. Principal component analysis (PCA), independent component analysis, machine learning, and other techniques have been applied to extract the meaningful components of various datasets. About 20 years ago, random matrix theory (RMT) was introduced to distinguish the components of a dataset from the noise. [1, 2] developed a “null-hypothesis” test based on RMT. In paticular, they compared the properties of empirical equal-time cross-correlation matrix to those of a random matrix and considered deviations from the random matrix case to suggest the presence of meaningful information. They compared the distribution of eigenvalues of this empirical cross-correlation matrix with the Marčenko-Pastur distribution [3], which is theoretically derived from so-called random Wishart matrices. They considered the eigenvector corresponding to the largest eigenvalue to represent the “market” itself. They also compared the distributions of the components of eigenvectors with the Porter-Thomas distribution [4], finding that the eigenvector corresponding to the largest eigenvalue differed remarkably from the Porter-Thomas distribution.
[5] confirmed the findings by [1, 2]; the meaningful part represents a market mode and group structures, such as industry categories and stocks with large market capitalization. [6] applied RMT to the equal-time cross-correlation matrix of assets listed on the first division of the Tokyo Stock Exchange (TSE). [7] clarified the structure of the meaningful part of the equal-time cross-correlation matrix of assets listed on the New York Stock Exchange (NYSE). [8] investigated the empirical equal-time cross-correlation matrix of stock price fluctuations on the National Stock Exchange of India, finding that this emerging market exhibited strong correlations in the movements of stock prices compared to developed markets such as the NYSE. [9] analyzed the empirical equal-time cross-correlation matrix of stock price fluctuations on the Tehran stock exchange and in the Dow Jones Industrial Average (DJIA), showing that the DJIA is more sensitive to global perturbations. [10] investigated the structures of networks constructed from principal components of the empirical equal-time cross-correlation matrices of stock price fluctuations on the Tehran stock exchange and in the DJIA. [11] constructed an autocorrelation matrix of a time series and analyzed it based on the random-matrix theory approach and fractional Gaussian noises.
[5] constructed a “filtered” cross-correlation matrix, from eigenvalues and eigenvectors outside the random matrix bound and applied this cross-correlation matrix to portfolio optimization [12]. The result they obtained shows that predicted risk was much closer to the realized risk than the traditional portofolio optimaization. [13] applied the portfolio optimization method to the stocks listed on the first division of the TSE and showed that the performance of the portfolio constructed by this method was usually better than that of market index such as TOPIX. [14] extended this portfolio optimization method to a case involving a short sale of stocks.
RMT is a powerful method for distinguishing meaningful components and noise in financial time-series data. The null hypothesis of randomness in this method assumes randomness in cross-correlation and autocorrelation. However, the autocorrelation of stock returns cannot be considered random (for example, see [15]. Thus, a new method is needed that preserves autocorrelation but randomizes cross-correlation. [16, 17] developed a method referred to as rotational random shuffling (RRS). In RRS, empirical time-series data are shuffled rotationally in the time direction with a periodic boundary condition imposed. Therefore, equal-time cross-correlation matrices constructed from RRS time series preserve almost all the autocorrelation information of each time series while randomizing cross-correlation. By comparing the distribution of eigenvalues of this RSS cross-correlation matrix with that of the empirical cross-correlation matrix, meaningful components and noise can be successfully distinguished.
It is natural to consider the application of RMT to different-time cross-correlation matrix. [18] introduced so-called complex Hilbert principal component analysis (CHPCA), in which the cross-correlation matrix is defined in the complex space. The components of eigenvectors of the complex cross-correlation matrix distribute in the complex plane, allowing the recognition of lead-lag relationships between components based on the difference in angle between them. [19] applied CHPCA to time-series data set for 483 assets representing the S&P 500 from 2008 to 2011 (1,009 business days) and constructed a correlation network in which pairs of assets with phase differences below a certain threshold were weighted based on correlation strength. [20] explored data from 1990 to 2012 for foreign exchanges and stock markets in 48 countries using CHPCA and extracted a significant lead-lag relationship between the markets. [21] applied CHPCA to a time-series data for assets listed on the NYSE from 2005 to 2014 and clarified lead-lag relationships among stocks, investment trusts, real estate investment trusts (REITs), and exchange traded funds (ETFs). [22, 23] applied CHPCA to the early warning indicators of financial crizes proposed by the Bank of Japan and explored changes in lead-lag relationships between indices before and after financial crizes.
When applying CHPCA to time series data, we need to explicitly extract the lead-lag relationship between the time series. [24, 25]; and [26] applied the Helmholtz-Hodge decomposition (HHD) to extract circular and gradient flows in a complex network. [27] applied CHPCA and HHD to monthly time series of 57 US macroeconomic indicators and five trade/money indexes, confirming statistically significant co-movements among these time series and identifying noteworthy economic events. [28] summarized CHPCA, RRS, and HHD and applied these methods to economic time-series data.
The purpose of the present paper is twofold. The first is to introduce a recently developed method to analyze stock return correlations. The second is to highlight a novel aspect of leading and lagging relations of business sectors in the market. In Section 2, log returns of stock prices are defined, and an empirical equal-time cross-correlation matrix is constructed for 445 assets from the S&P 500 from 2010 to 2019 (2,510 business days). A method is also presented for calculating the eigenvalues and eigenvectors of this cross-correlation matrix and applies RMT and RRS to distinguish the meaningful part from the noise. Furthermore, it is shown that the eigenvector corresponding to the largest eigenvalue represents the market mode and meaning components without the principal component represent group mode. In Section 3, the dataset is investigated using CHPCA, RRS, and HHD and lead-lag relationships among assets are discussed. In Section 4, an application of CHPCA to portfolio theory is sketched. Section 5 is devoted to summary and discussion.
2 Application of RMT and RRS
In this section, the equal-time cross-correlation matrix is defined. RMT is then applied to distinguish the meaningful components from the noise components. After that, RRS is introduced to distinguish the meaning components from the noise components.
2.1 Equal-Time Cross-Correlation Matrix
This paper investigates data for 445 assets from the S&P 500 for dates obtained 2010–2019 (2,510 business days). By denoting an opening price of stock n on day t as
where
A normalized log return of asset n is denoted as
Thus, a component of equal-time cross-correlation matrix is defined by
The left panel of Figure 1 depicts an equal-time cross-correlation matrix. In this figure, shade indicates the strength of the positive correlation. White color corresponds to
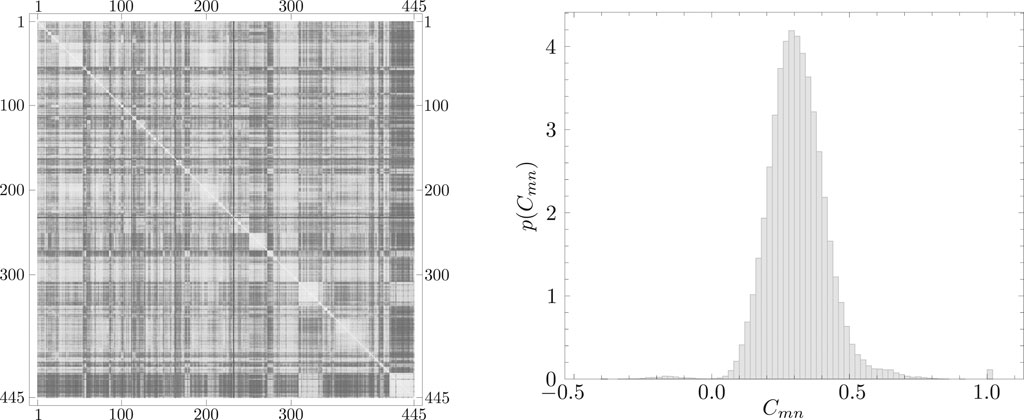
FIGURE 1. (Left) Visualization of the equal-time cross-correlation matrix for the data for 445 assets from S&P 500 from 2010 to 2019 (2,510 business days). The shade is proportional to correlation strength, with white color corresponding to
2.2 Application of RMT
Calculation of eigenvalues
where
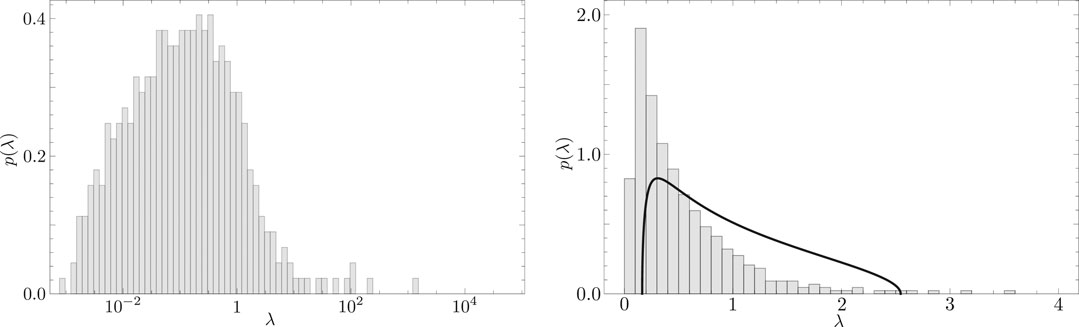
FIGURE 2. (Left) Distribution
In this paper,
In RMT extraction of the meaningful part of the correlation structure, empirical eigenvalues larger than
In traditional PCA, Monte Carlo simulations and so-called scree graphs are used to extract meaningful components. In the present method, the time series of each stock is randomly shuffled to generate an equal-time cross-correlation matrix. This manipulation breaks both the autocorrelation and the cross-correlation. It is derived from a similar concept as the application of RMT. If we construct the equal-time cross-correlation matrix from those randomly shuffled time series, we can obtain the histogram shown in the left panel of Figure 3. The solid line in this figure corresponds to the Marčenko-Pastur distribution given by Eq. 5. From this figure, we can recognize the equivalence between the traditional PCA and the application of RMT.
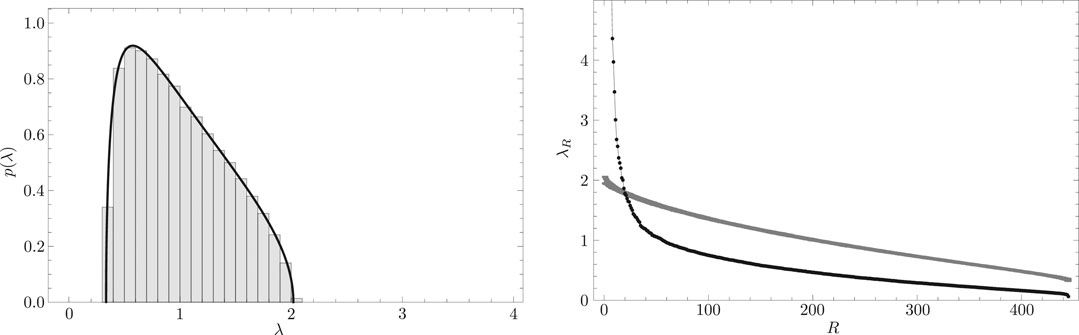
FIGURE 3. (Left) Distribution
The right panel of Figure 3 shows the scree graph. In this figure, the abscissa corresponds to the eigenvalue rankings and the ordinate corresponds to the magnitude of eigenvalues. The curve with error bars in this figure depicts the eigenvalue distribution of the randomly shuffled cross-correlation matrix. The thin line with filled circles in this figure depicts the distribution of eigenvalues of the empirical equal-time cross-correlation matrix. If we denote the upper bound of eigenvalue derived from the randomly shuffled cross-correlation matrix as
2.3 Application of the RRS
As stated above, when we make a randomly shuffled cross-correlation matrix, we break both the autocorrelation and the cross-correlation conditions. However, it has been reported that the stock price has an autocorrelation tendency. Thus, we need to develop a method that preserves autocorrelation but randomizes the crosscorrelation. [16, 17] developed a method referred to as RRS. In RRS, we shuffle the empirical time-series data rotationally in the time direction and impose the periodic boundary condition:
Here,
Such a rotationally randomly shuffled time series allows the cross-correlation matrix to be constructed and eigenvalues to be calculated. An example is shown in the histogram in the left panel of Figure 4. The solid line in this figure corresponds to the Marčenko-Pastur distribution given by Eq. 5. This figure shows that the distribution of eigenvalues is almost the same as the Marčenko-Pastur distribution based on RMT except for the large eigenvalue range.
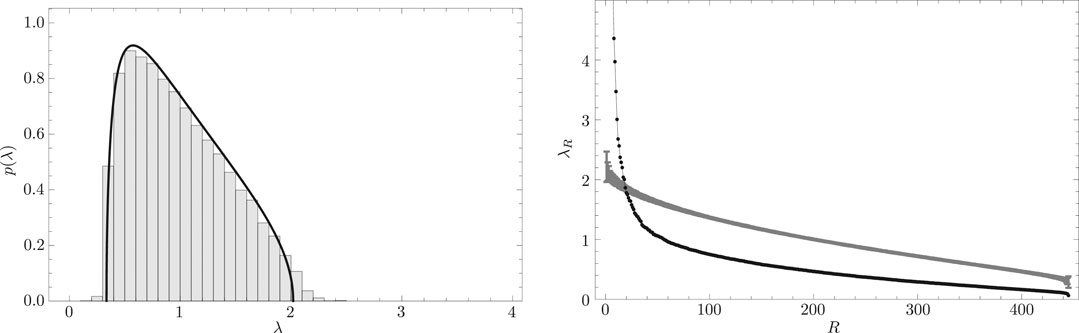
FIGURE 4. (Left) Distribution
The right panel of Figure 4 shows the scree graph. In this figure, the abscissa corresponds to eigenvalue rankings, and the ordinate corresponds to eigenvalue magnitude. The curve with error bars in this figure depicts the eigenvalue distribution of the RRS cross-correlation matrix. The thin line with filled circles in this figure depicts the distribution of eigenvalues of the empirical equal-time cross-correlation matrix. Again, if the upper bound of eigenvalues derived from the RRS cross-correlation matrix is denoted as
Figure 5 shows the distribution of components of the top 20 eigenvectors,
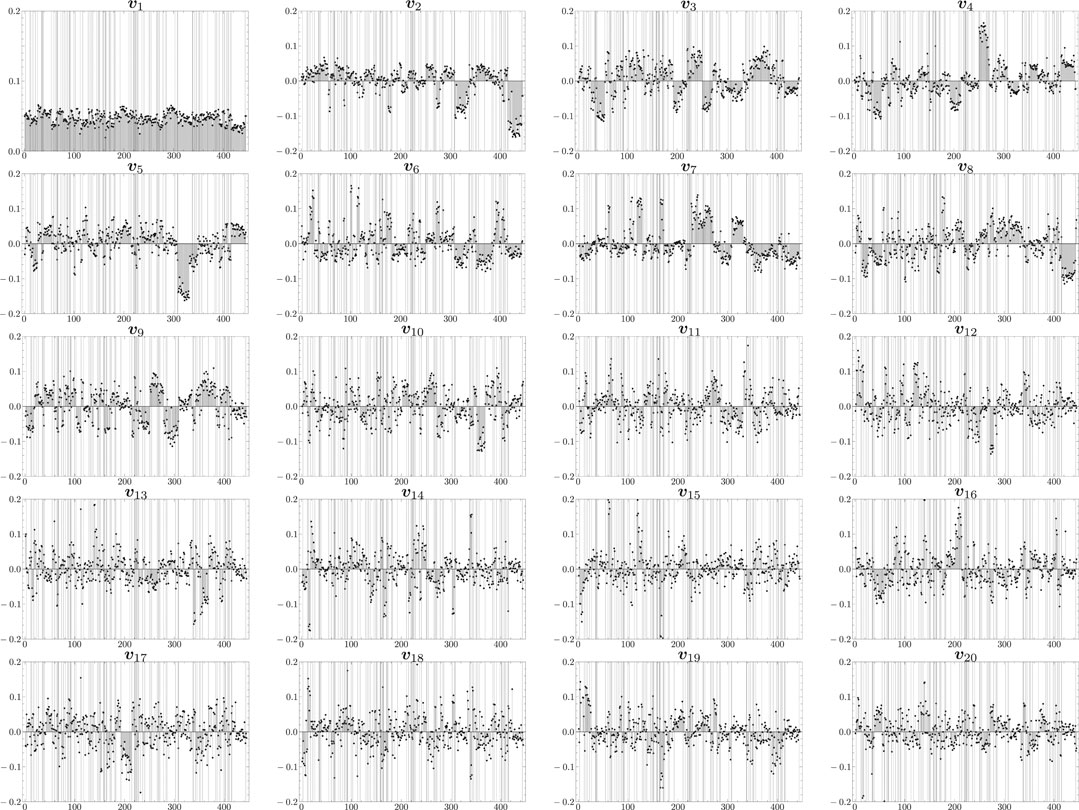
FIGURE 5. Distribution of components of the top 20 eigenvectors,
The first eigenvector
It is important to understand why the largest eigenvalue and the corresponding eigenvector are referred to as representing the market mode. The market index on day t is denoted as
i.e., weighting the average return with the weight given by the first eigenvector. On the other hand, the S&P 500 is used to characterize the entire market. The normalized log return on day t from open to close of the S&P 500 is denoted as
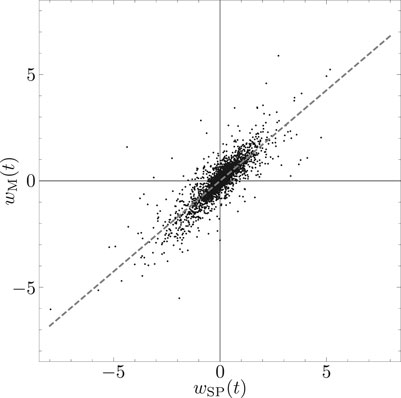
FIGURE 6. Scatter plot of the normalized S&P 500 index
3 Application of CHPCA and HHD
In this section, the complex correlation matrix is defined. RRT is then applied to distinguish the meaning components from the noise components, and CHPCA is introduced. After that, HHD is presented in order to clarify the lead-lag relationships among assets.
3.1 Complex Correlation Matrix
A simple definition of different-time correlation is given by
We consider the Fourier transform of the daily log returns of asset n as represented by
where
We define a complex log return
where i denotes an imaginary unit defined by
We define the normalized complex log return
Thus, the time-average of
Herein,
The elements of the complex correlation matrix distribute on the complex plane, as shown in the upper left panel of Figure 7. The lower left panel of Figure 7 shows the distribution of the real parts of the elements of the complex correlation matrix. This distribution is almost the same as for the case of the equal-time cross-correlation matrix shown in the right panel of Figure 1. The upper right panel of Figure 7 shows the distribution of the imaginary parts of the elements of the complex correlation matrix. This panel shows a symmetrical distribution.
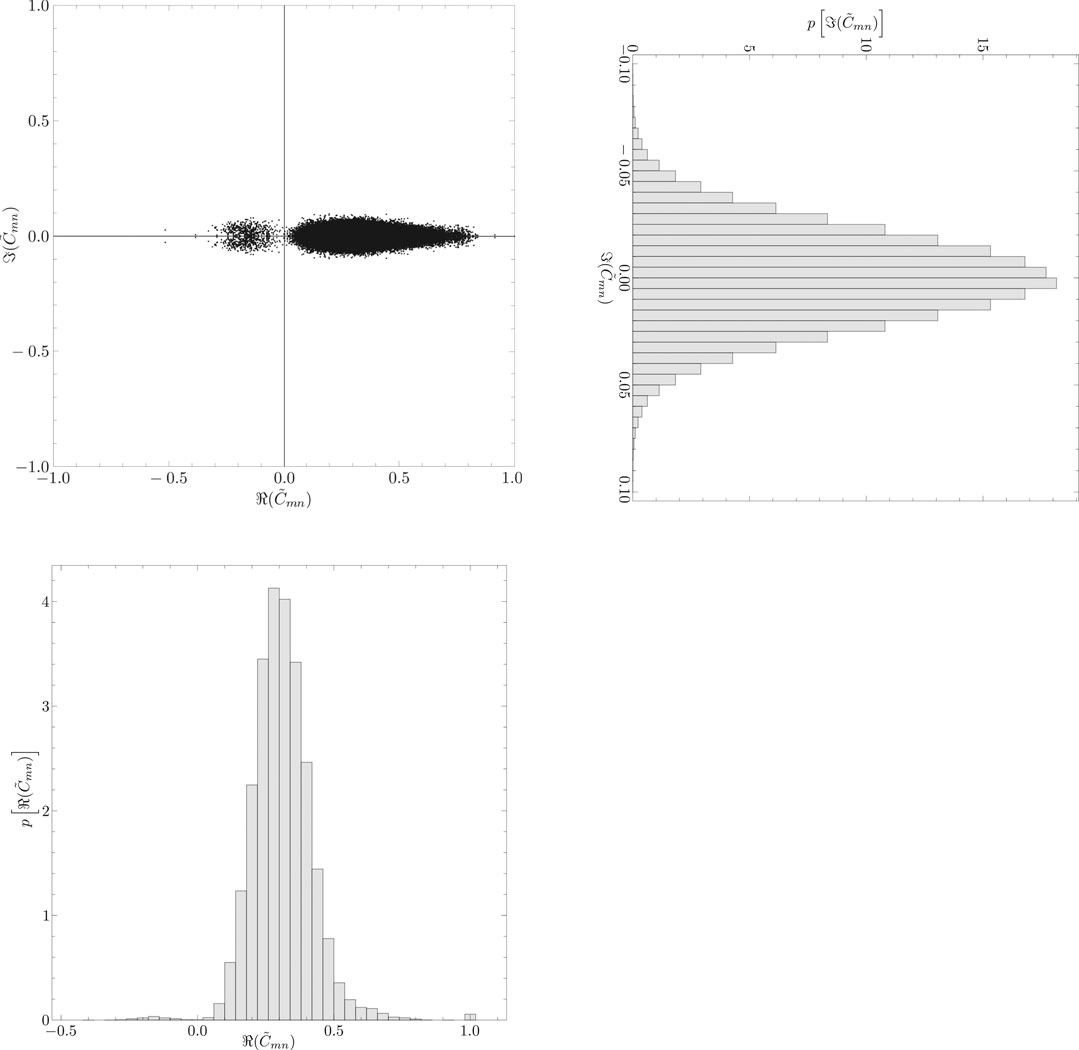
FIGURE 7. (Upper left) Distribution of the elements
3.2 Complex Hilbert Principal Component Analysis
Figure 8 is obtained by calculating the eigenvalues
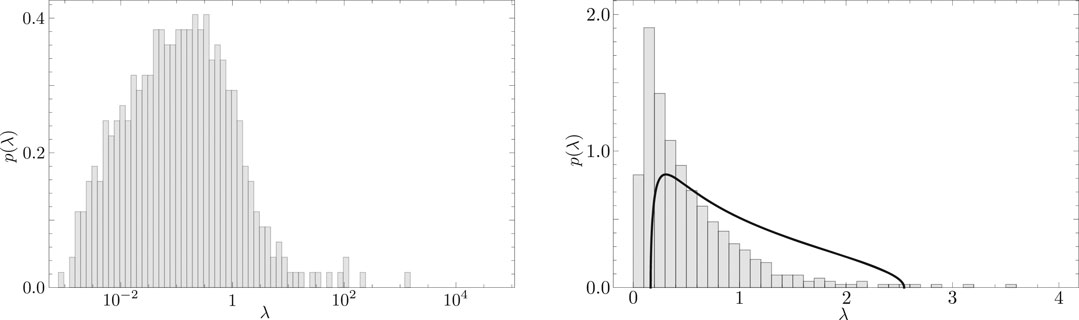
FIGURE 8. (Left) Distribution
Figure 9 shows the scree graph. In this figure, the abscissa corresponds to the eigenvalue rankings and the ordinate corresponds to eigenvalue magnitudes. The curve with error bars in this figure shows the eigenvalue distribution of the RRS complex correlation matrix. The thin line with filled circles in this figure depicts the distribution of eigenvalues of the empirical complex cross-correlation matrix. If we again denote the upper bound for eigenvalues derived from the RRS cross-correlation matrix as
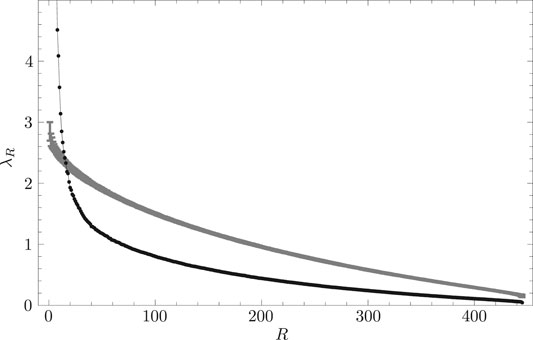
FIGURE 9. Scree graph of eigenvalues. The abscissa represents eigenvalue rankings R, while the ordinate represents empirically obtained eigenvalues
Figure 10 shows the distribution of each component for the top 16 eigenvectors
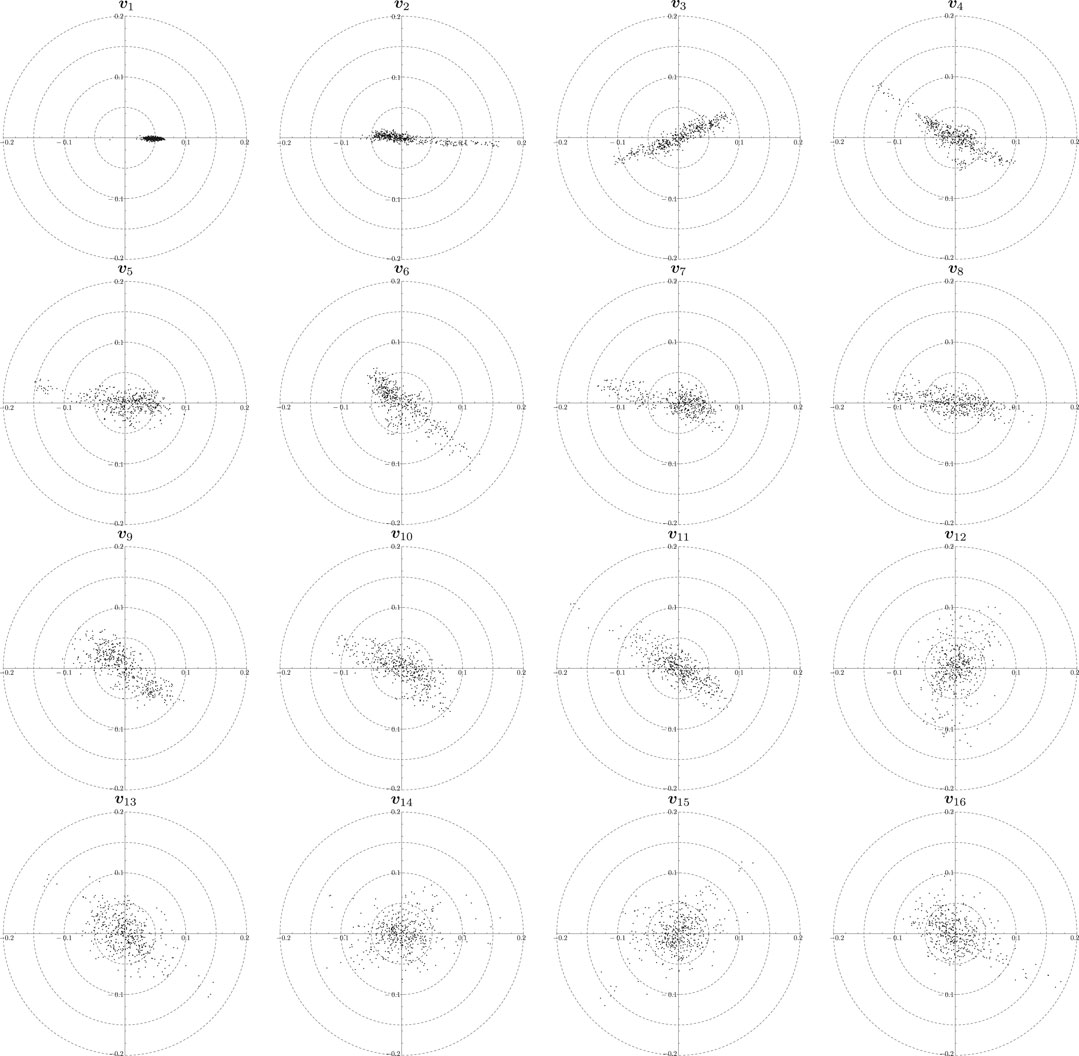
FIGURE 10. Distribution of components of the top 16 eigenvectors,
In the complex plane, we regard the clockwise direction from the positive real axis as corresponding to leading components, whereas the counterclockwise direction from the positive real axis corresponds to the lagging components. Components of the first eigenvector
3.3 Helmholtz-Hodge Decomposition
We decompose the complex correlation matrix into the meaningful part and the noise part as
where
where
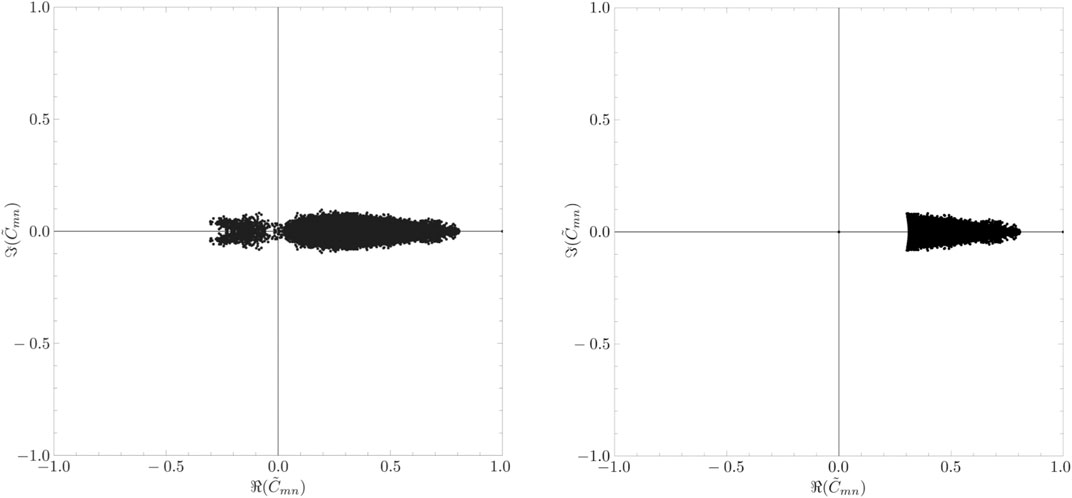
FIGURE 11. (Left) Distribution of the components of the meaningful part of the complex correlation matrix. (Right) Distribution of the components of the constrained meaningful part of the complex correlation matrix.
On the other hand,
Here,
By solving Eq. 18, we obtain the Helmholtz-Hodge potential shown in Figure 12. In this figure, the leading components show a small value of the Helmholtz-Hodge potential, while the lagging components show a large value.
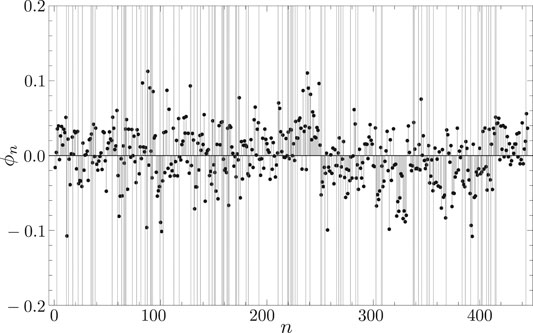
FIGURE 12. Distribution of Helmholtz-Hodge potential for each asset. The abscissa represents n, while the ordinate represents Helmholtz-Hodge potential
The average values
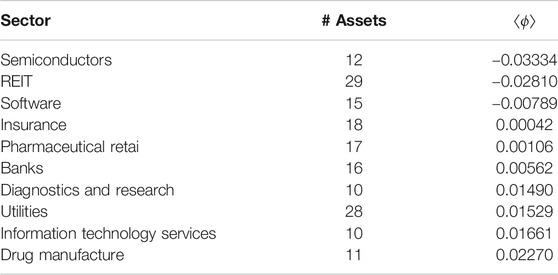
TABLE 1. Helmholtz-Hodge potentials
4 Application of CHPCA to the Portfolio Theory: A Sketch
As a problem for future study, we consider the application of CHPCA to construct a portfolio by following Markowitz’s portfolio theory [12]. We represent the fraction of wealth invested in asset n as
By using the complex log return of each asset
However, the portfolio return must be a real number, so we need to impose the following constraint:
The risk of the portfolio is defined by the variance:
Here again, the risk must be a real number, so we need to impose the following constraint:
Therefore, under the conditions given in Eqs 19, 21, 23, a portfolio can be created that minimizes risk under the assumed returns.
5 Conclusion
An analysis of price data for 445 assets from the S&P 500 from 2010 to 2019 (2,510 business days) provided the basis for an exploration of recent developments in distinguishing the meaningful part from the noise part in correlation structures in big data. Application of RMT to the equal-time cross-correlation matrix was found to be a useful method for obtaining the meaningful components of the correlation structure. However, the null hypothesis of randomness underlying RMT destroyed both real autocorrelation and real cross-correlation in the data. In order to preserve autocorrelation, we introduce RRS. In the case of this paper, the number of meaningful components for RMT and for RRS happened to be. We also introduced CHPCA for investigating the various different-time cross-correlations. By using both CHPCA and HHD, we clarified the lead-lag relationships for some major business sectors.
Data Availability Statement
Publicly available datasets were analyzed in this study. This data can be found here: https://en.wikipedia.org/wiki/List_of_S%26P_500_companies, https://github.com/datasets/s-and-p-500-companies.
Author Contributions
WS wrote this paper by himself.
Funding
This work was supported by JSPS KAKENHI Grant No. JP20228860 and National Bank Academic Research Promotion Foundation in 2019.
Conflict of Interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
The author would like to thank Hiroshi Iyetomi, Hideaki Aoyama, Yoshi Fujiwara, Yuichi Ikeda, Hiroshi Yoshikawa, and Irena Vodenska for useful discussions.
References
1. Laloux L, Cizeau P, Bouchaud J-P, Potters M. Noise dressing of financial correlation matrices. Phys Rev Lett (1999) 83:1467–70. doi:10.1103/physrevlett.83.1467
2. Plerou V, Gopikrishnan P, Rosenow B, Nunes Amaral LA, Stanley HE. Universal and nonuniversal properties of cross correlations in financial time series. Phys Rev Lett (1999) 83:1471–4. doi:10.1103/physrevlett.83.1471
3. Marčenko VA, Pastur LA. Distribution of eigenvalues for some sets of random matrices. Mathematics USSR-Sbornik (1967) 1:457–83. 10.1070.SM1967v001n04ABEH001994
4. Porter CE, Thomas RG. Fluctuations of nuclear reaction widths. Phys Rev (1956) 104:483–91. doi:10.1103/physrev.104.483
5. Plerou V, Gopikrishnan P, Rosenow B, Amaral LAN, Guhr T, Stanley HE. Random matrix approach to cross correlations in financial data. Phys Rev E, Stat Nonlinear, Soft Matter Phys (2002) 65:066126. doi:10.1103/physreve.65.066126
6. Utsugi A, Ino K, Oshikawa M. Random matrix theory analysis of cross correlations in financial markets. Phys Rev E, Stat Nonlinear, Soft Matter Phys (2004) 70:026110. doi:10.1103/physreve.70.026110
7. Kim D-H, Jeong H. Systematic analysis of group identification in stock markets. Phys Rev E Stat Nonlinear Soft Matter Phys (2005) 72:046133. doi:10.1103/physreve.72.046133
8. Pan RK, Sinha S. Collective behavior of stock price movements in an emerging market. Phys Rev E Stat Nonlinear Soft Matter Phys (2007) 76:046116. doi:10.1103/physreve.76.046116
9. Namaki A, Jafari GR, Raei R. Comparing the structure of an emerging market with a mature one under global perturbation. Physica A: Stat Mech its Appl (2011) 390:3020–5. doi:10.1016/j.physa.2011.04.004
10. Namaki A, Shirazi AH, Raei R, Jafari GR. Network analysis of a financial market based on genuine correlation and threshold method. Physica A: Stat Mech its Appl (2011) 390:3835–41. doi:10.1016/j.physa.2011.06.033
11. Jamali T, Jafari GR. Spectra of empirical autocorrelation matrices: a random-matrix-theory-inspired perspective. EPL (2015) 111:10001. doi:10.1209/0295-5075/111/10001
12. Markowitz H. Portfolio selection*. J Finance (1952) 7:77–91. doi:10.1111/j.1540-6261.1952.tb01525.x
13. Fujiwara Y, Souma W, Murasato H, Yoon H. Application of PCA and random matrix theory to passive fund management. in: H Takayasua, editors. Practical fruits of econophysics. Berlin, Germany: Springer (2006). p. 226–30.
14. Souma W. Toward a practical application of econophysics: an approach from random matrix theory (written in Japanese). Appl Math (2005) 15:45–59. doi:10.11540/bjsiam.15.3˙239
15. Lo AW, Craig MacKinlay A. An econometric analysis of nonsynchronous trading. J Econom (1990) 45:181–211. doi:10.1016/0304-4076(90)90098-e
16. Iyetomi H, Nakayama Y, Aoyama H, Fujiwara Y, Ikeda Y, Souma W. Fluctuation-dissipation theory of input-output interindustrial relations. Phys Rev E Stat Nonlinear Soft Matter Phys (2011a) 83:016103. doi:10.1103/physreve.83.016103
17. Iyetomi H, Nakayama Y, Yoshikawa H, Aoyama H, Fujiwara Y, Ikeda Y, et al. What causes business cycles? analysis of the Japanese industrial production data. J Jpn Int Economies (2011) 25:246–72. doi:10.1016/j.jjie.2011.06.002
18. Arai Y, Yoshikawa T, Iyetomi H. Complex principal component analysis of dynamic correlations in financial markets. Front Artif Intelligence Appl (2013) 255:111–9. doi:10.3233/978-1-61499-264-6-111
19. Arai Y, Yoshikawa T, Iyetomi H. Dynamic stock correlation network. Proced Comp Sci (2015) 60:1826–35. doi:10.1016/j.procs.2015.08.293
20. Vodenska I, Aoyama H, Fujiwara Y, Iyetomi H, Arai Y. Interdependencies and causalities in coupled financial networks. PLoS One (2016) 11:e0150994. doi:10.1371/journal.pone.0150994
21. Souma W, Aoyama H, Iyetomi H, Fujiwara Y, Vodenska I. Construction and application of new analytical methods for stock correlations: toward the construction of prediction model of the financial crisis (written in Japanese). JWEIN (2016) 1–8.
22. Souma W, Iyetomi H, Yoshikawa H. Application of complex Hilbert principal component analysis to financial data. in IEEE 41st Annual Computer Software and Applications Conference (COMPSAC); 2017 July 4–8; Turin, Italy. New York, NY: IEEE (2017) 2:391–4.
23. Souma W, Iyetomi H, Yoshikawa H. The leading and lagging structure of early warning indicators for detecting financial crises (written in Japanese). RIETI Pol Discussion Paper Ser 18-P-005 (2018). p. 1–26.
24. Kichikawa Y, Iyetomi H, Iino T, Inoue H. Hierarchical and circulating flow structure in an interfirm transaction network. Book of abstracts (2017) 12. Available from: https://core.ac.uk/download/pdf/148338502.pdf#page=27.
25. Iyetomi H, Ikeda Y, Mizuno T, Ohnishi T, Watanabe T. International trade relationship from a multilateral. Book of abstracts (2017) 253. Available from: https://core.ac.uk/download/pdf/148338502.pdf#page=27.
26. Kichikawa Y, Iyetomi H, Iino T, Inoue H. Community structure based on circular flow in a large-scale transaction network. Appl Netw Sci (2019) 4:92. doi:10.1007/s41109-019-0202-8
27. Iyetomi H, Aoyama H, Fujiwara Y, Souma W, Vodenska I, Yoshikawa H. Relationship between macroeconomic indicators and economic cycles in United States. Scientific Rep (2020) 10:1–12. doi:10.1038/s41598-020-70100-3
Keywords: S&P 500, stock return, cross-correlation matrix, random matrix theory, principal component, complex correlation matrix, complex hilbert principal component analysys, helmholtz-Hodge decomposition
Citation: Souma W (2021) Characteristics of Principal Components in Stock Price Correlation. Front. Phys. 9:602944. doi: 10.3389/fphy.2021.602944
Received: 04 September 2020; Accepted: 10 February 2021;
Published: 12 April 2021.
Edited by:
Wei-Xing Zhou, East China University of Science and Technology, ChinaReviewed by:
Gholamreza Jafari, Shahid Beheshti University, IranXiao Han, University of California, Davis, United States
Copyright © 2021 Souma. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wataru Souma, d2F0YXJ1LnNvbWFAZ21haWwuY29t