 Xiaohong Han1†
Xiaohong Han1† Mengfan Zhao
Mengfan Zhao- 1School of Information and Electrical Engineering, Hebei University of Engineering, Handan, China
- 2College of Intelligence and Computing, Tianjin University, Tianjin, China
- 3Science College, Shijiazhuang University, Shijiazhuang, China
The widespread rumors on social media seriously disturb the social order, and we urgently need practical methods to detect rumors. Most existing deep learning methods focus on mining news text content, user information, and propagation features but ignore the rumor diffusion structural features. Rumors spread in a vertical chain and diffusion in a horizontal network. Both are essential features of rumors. In addition, existing models need more effective methods to extract higher-order features of multiple resource information. To address these problems, we propose a multi-source information heterogeneous graph model in this paper, called jointly Multi-Source information and Local-Global relationship of heterogeneous network model named MSLG. It extracts multi-source information such as rumors content, user information, propagation, and diffusion structure. Firstly, we extract the higher order semantic representation of rumors content by graph convolution network and integrate local relational attention to strengthen the critical semantic. At the same time, we construct the rumors and users as heterogeneous graphs to capture the propagation and diffusion structure of the rumors. We are finally fusing global relational attention to measure submodules’ importance. Experiments on two real-world datasets show that the proposed method achieves state-of-the-art results in fake news detection.
1 Introduction
The convenience of social media provides an opportunity for the generation and propagation of fake news. When a public event happens, the public still has a limited understanding of it, so all rumors catering to public psychology take advantage of the space. Some users lack verification when retweeting news, which makes them helpful for rumor spreading. In the mobile Internet era, users can express their opinions freely. The concealment of information makes it easier for fake news and spread faster and harder to trace and control its source. The propagation of rumors not only brings trouble to the person concerned but also affects the order of the Internet and reduces the media’s credibility. Therefore, we urgently need an efficient method for rumor detection.
We classify existing rumor detection methods into five categories which are a knowledge-based method, rumor content-based method, propagation structure-based method, source-based method, and mixed method. When detecting fake news from a knowledge-based perspective, the aim is to verify the authenticity of the news by comparing the knowledge extracted from the news content with the known facts. The manual fact-checking method relies on domain experts to verify the authenticity of given news. This method is time-consuming, laborious, and inefficient. With the increased quantity of information, the scalability is extremely poor. Furthermore, because of people’s subjectivity, it is also highly subjective to judge the authenticity of the news. To address these problems, existing research has developed from manual verification methods to automated verification. Some researchers obtain existing knowledge from the open network and use knowledge triples to realize fake news detection [1, 2]. Knowledge-based methods mainly assess the veracity of a given news story, while style-based methods focus on analyzing the content features of rumors. They can assess news intent, i.e., whether they intentionally mislead the public [3]. It is helpful for us to detect rumors by mining features of rumors content. However, when users intentionally publish rumors for a specific purpose, they use ambiguous words to circumvent the conditions that the model determines as rumors. Therefore, content-based methods do not cover comprehensive information when detecting rumors, which limits the improvement of detection accuracy. The propagation-based methods start from the forwarding path of rumors and mining the features of rumor propagation by constructing tree structure [4, 5], graph structure [6, 7], or hierarchical structure [8, 9] to realize rumor detection. With the development of technology, some researchers have incorporated the source of rumors into their models. Here, we regard the source as a general concept, i.e., the source includes three aspects. Firstly, create sources of news stories, such as news writers. Secondly, the sources that publish news reports, such as news publishers or news publish platforms. Thirdly, the sources that spread the news, such as social media accounts [3]. Early news detection is achieved by detecting news sources to judge whether they are true or false. However, this detection method is one-sided, which seriously limits the effect of the model. Although these methods are effective for fake news detection, they cannot be used alone to improve detection accuracy further. Therefore, some hybrid methods [10, 11] come into being. By combining news content, propagation structure, social context, and source information for fake news detection, news features are fully characterized, greatly improving the detection effect. However, the hierarchical structure constructed by these hybrid methods cannot extract the higher-order feature representation of news, which is an urgent problem to be solved.
By investigating the spread of rumors on social media, we found differences in the propagation structure of true and false rumors. Consistent with previous research results [12], compared with true rumors, false rumors spread faster, cascade deeper, are more comprehensive, and are more popular. In fact, propagation and diffusion are two key characteristics of a rumor. The deep vertical propagation features represent the causal characteristics of rumors spread along the relationship chain, and reflect the interaction between users’ attention, comments and forwarding. The horizontal diffusion characteristics of rumors represent the structural characteristics of rumors in the community. It reflects the common relationship between users who forward or comment on the same news, but there is no direct interaction between these users. By observing the characteristics of users, we found that true and fake users and users with different preferences would present apparent cluster distribution. For example, for a user who often publishes or retweets rumors, the news that the user retweets again are likely to be fake. Users on social media tend to connect with like-minded people, so fake users form clusters, thus creating information cocoons. Figure 1 shows the propagation of rumors on social media. After the source user publishes a piece of news, different users will retweet or comment. We observe that users 1-5 are more interested in political news, users 6–10 are more interested in medical science, and users 11 and 12 are more interested in the medical and health fields. However, user13 participates in news forwarding in medical science and medical health, indicating that the two fields cover some similar news. For the news in the three fields, users who retweet or comment on this news show an apparent clustering phenomenon, which also conforms to our cognition. In order to improve the accuracy of rumor detection, many models extract rumor information by constructing a graph structure [13–15]. However, these models do not utilize the various information contained in rumors, the extracted information features are not comprehensive, and the excessive noise information contained limits the improvement of detection accuracy. To address these problems, we fully use all the information contained in rumors, such as content, propagation and user information, etc. Different from previous hierarchical models, we construct heterogeneous graphs for this multi-source information to extract higher-order features of rumors. Specifically, based on the constructed multi-source information heterogeneous graph, we design a semantic content feature module to extract higher-order content information of rumors. Moreover, we design a propagation diffusion feature module to extract higher-order structural features of rumor propagation and diffusion. Furthermore, a feature dynamic fusion module achieves a weighted fusion of two parts of features.
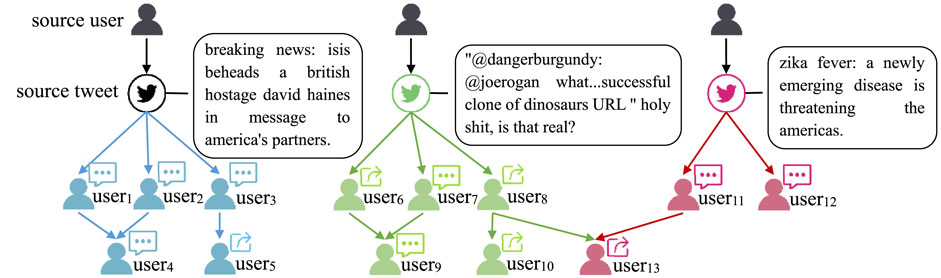
FIGURE 1. An example of news dissemination structures in social networks.
Users with the same color indicate that they share some common behavioral characteristics and are pulled close together in space.
In summary, the proposed model has the following contributions.
1) We build multi-source information into a heterogeneous graph, which enhances the representation ability of information and facilitates the model to learn comprehensive features in the future.
2) We design a content extraction module and a propagation extraction module to extract rumors’ content information and propagation structure. Furthermore, our model considers rumors’ vertical propagation structure and rumors’ horizontal diffusion structure, which effectively complements the deficiencies of current research.
3) Integrate the local and global attention mechanism to realize the adaptive dynamic fusion of features and reduce the influence of noise information.
4) Experiments on two real-world datasets demonstrate the effectiveness of the proposed model.
The remaining paper is structured as follows: Related work introduces the methods, defects, and research progress of rumor detection. The model describes the proposed model in detail. Experiments introduces our datasets, baselines, experimental results, ablation experiments, and rumor early detection. The conclusion summarizes our research results and discusses future research directions and emphasis.
2 Related work
2.1 Knowledge-based methods
In order to detect fake news with knowledge, it is necessary to construct a knowledge base or graph. Here, knowledge-based methods are divided into those that use external knowledge bases and those that do not. Using an external knowledge base needs to introduce an external knowledge base and use existing knowledge to assist rumor detection. The method that does not use an external knowledge base analyzes a rumor by extracting knowledge triples (subject, predicate, object) from the rumor content. Hu et al. [16] propose a new end-to-end graph neural model, which compares news with a knowledge base (KB) through entities to detect fake news. However, external knowledge graphs are often required in the limited work of knowledge-based fake news detection, which may bring additional problems. It is common for entities and relationships, especially new concepts, to be missing from existing knowledge graphs. Han et al. [17] research fake news detection without any external knowledge and transform the problem of fake news detection into a subgraph classification problem. Entities and relations are extracted from each news to form a knowledge graph, where a subgraph represents each news.
Introducing an external knowledge base in rumor detection has low time efficiency. It is difficult to be effectively promoted due to the need to search for knowledge from external web pages. When we do not use the external knowledge base to detect rumors, it is necessary to construct the content of rumor text into knowledge triples. However, due to rumors’ unstable writing style and incomplete subject-predicate, it is challenging to construct knowledge triples effectively.
2.2 Content-based methods
In the early stage of rumors detection, many researchers detected rumors by mining potential features in news content. According to research in forensic psychology [18], statements based on real experiences are very different from fictional statements in both content and quality. Przybyla P [19] designs a neural network and a model based on style features to distinguish true and false news by identifying sensational words. The emotions contained in the news can help us make judgments. Kumari R et al. [20] propose a deep multi-task learning model, which jointly performs novelty detection, emotion recognition, emotion prediction, and fake news detection, proving that these tasks are related.
Advances in fake news detection technology have, in turn, led to changes in the form of fake news. In order to achieve a specific purpose, many rumors will highly imitate real news to mislead the judgment of the model. Therefore, more than relying on news content alone is needed to improve the accuracy of fake news detection further.
2.3 Propagation-based methods
The propagation information of rumors can characterize the propagation path and cascade depth of rumors. For rumor detection, propagation features are critical. Bian et al. [4] capture the propagation structure features by constructing top-down and bottom-up propagation trees for rumors and using a bidirectional graph convolution network to learn the propagation patterns of rumors. Silva et al. [21] use the graph structure to predict the complete propagation network by embedding part of the propagation network and only use the propagation information of the news without using the news content features to realize the early detection of fake news. In order to understand the correlation between news propagation networks and fake news, Shu et al. [8] build a hierarchical propagation network for fake news and real news. Furthermore, comparing and analyzing the features of the propagation network between fake news and real news from the perspective of structure, temporal, and linguistics proves the potential of using these features to detect fake news.
Most existing propagation-based methods only dig the cascade propagation information of rumors, ignoring the diffusion characteristics of rumors and the cluster characteristics of users. In fact, rumors’ vertical propagation and diffusion characteristics are crucial, and the users’ follow-follower characteristics can help us detect rumors.
2.4 Source-based methods
Generally speaking, for users who often publish or retweet fake news, the news they publish or retweet again may also be fake. Similarly, for news publishers, platforms that routinely disseminate fake news are less credible than official media platforms, which proves that news sources can help us detect fake news. Karimi H et al. [22] introduce information from multiple sources and used a convolutional neural network (CNN) and long short-term memory network (LSTM) to realize fake news detection. Sitaula et al. [23] construct a news author collaboration network in which nodes represent the authors and edges indicate the two authors collaborate in writing one or more news articles, and fake news detection is carried out through the user homogeneity network.
Source-based methods follow a rule of thumb, so they can only play an auxiliary role and cannot replace the features of rumors themselves. Moreover, the detection methods are one-sided, and using them alone cannot improve detection accuracy.
2.5 Mixed methods
Recent studies have widely used mixed methods for rumor detection and demonstrated excellent performance. Lu et al. [24] predict the truth of news according to news content, user propagation sequence, and user profile. News content features are extracted by a graph convolution network (GCN), and news propagation features are captured by a convolutional neural network (CNN) and gate recurrent unit (GRU). Shu et al. [25] develop a sentence-comment co-attention network to exploit news content and user comments to jointly capture check-worthy sentences and user comments for fake news detection. Silva et al. [10] find that news records from different domains have significantly different word usage and propagation patterns. Therefore, the constructed model retains the knowledge of a specific domain to detect fake news from different domains effectively.
However, the hierarchical structure constructed by these hybrid methods cannot extract the higher-order feature representation of news, which is an urgent problem to be solved.
3 The proposed model
In this section, we will detail our constructed model MSLG. As shown in Figure 2, the model consists of four main parts. Firstly, we build the rich information in the dataset into a graph structure. Secondly, based on the constructed multi-source information heterogeneous graph, we can effectively extract the semantic information of news by semantic content feature extraction module. Then we use the feature extraction module of dissemination and diffusion to characterize the structure of news dissemination and diffusion. Finally, we design the weight measurement module for dynamic feature fusion to achieve accurate rumor classification.
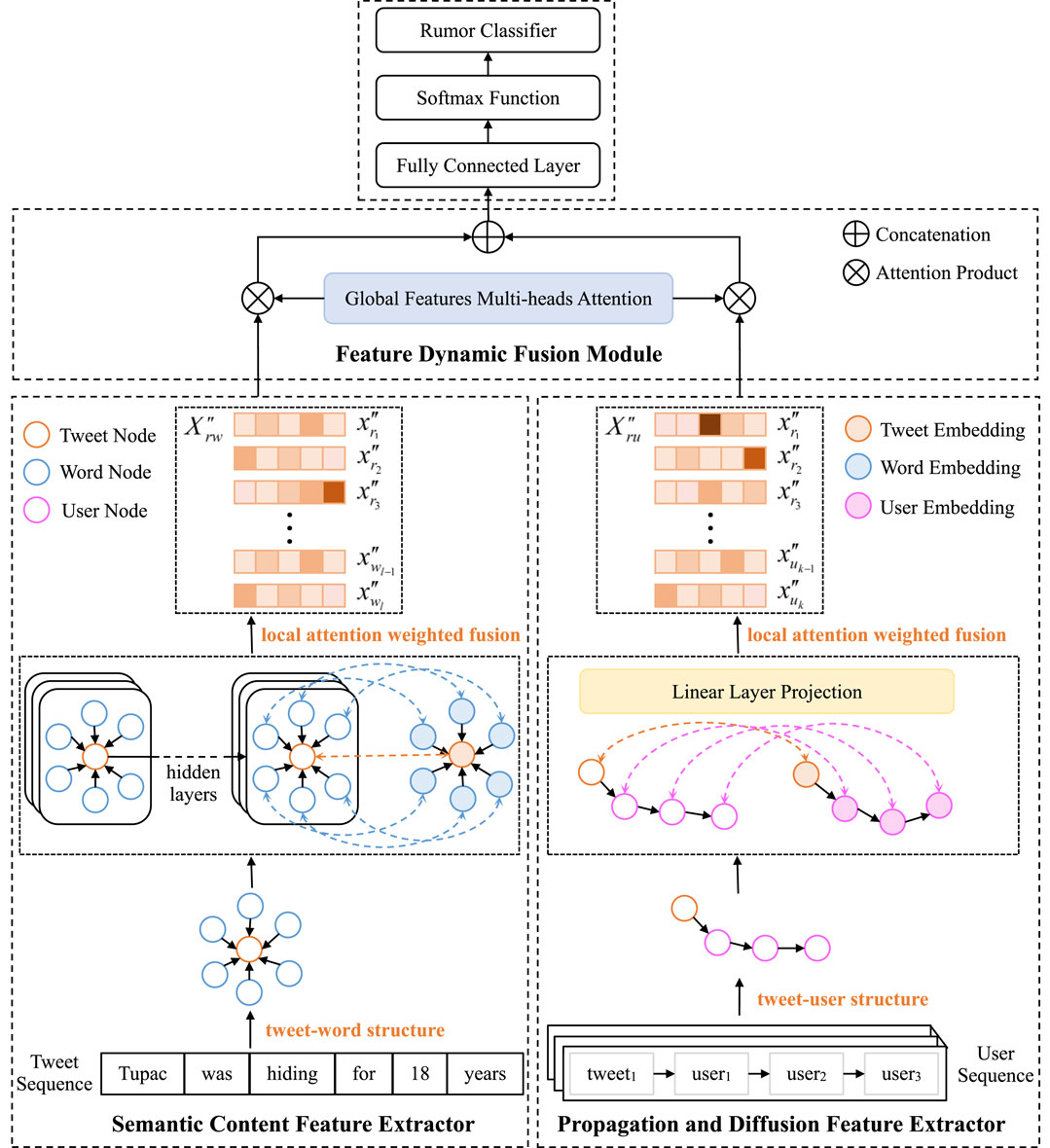
FIGURE 2. The architecture of the local-global attention model MSLG for rumor detection.
Our goal is to have the model learn a classification function that maps a rumor
3.1 Multi-information heterogeneous graph construction
We unify the dataset’s rumors, words, and users into the graph model. Specifically, given graph
For the constructed heterogeneous graph, we first initialize the weight matrix.
where
3.2 Semantic content feature extractor
The semantic content information of rumor itself is very important for rumor detection. Therefore, in the rumor-word heterogeneous graph, we first extract the initial feature vector of the rumor. The initial feature representation of the word set
where
In fact, different graph nodes have different contributions to the rumor detection task, which requires our model to be able to distinguish between important and unimportant nodes, and give high weight to important nodes. Here we introduce the attention mechanism [27] to measure the weight of different nodes. Given the node pair
Then we use the softmax function to normalize the weight coefficient and get the final attention coefficient
where
Next, we update the feature representation of node
In order to stabilize the learning process and get more accurate feature representation, we perform K transformations on the aggregation process, and then we can get the final output of each rumor:
We can obtain the final feature representation
3.3 Propagation and diffusion feature extractor
For a rumor, propagation and diffusion are two important structural features, which can play an auxiliary role in rumor detection. Therefore, in the rumor-user heterogeneous graph, we extract the initial features of the user as
where
At this point, we get the propagation diffusion structure feature expressed as
where
Next, we update the feature representation of the node by aggregating the neighbor nodes of node
In order to stabilize the learning process and get more accurate feature representation, we perform K transformations on the aggregation process, and then we can get the final output of each rumor:
Finally, we can get the final characteristic representation
3.4 Feature dynamic fusion module
After obtaining the semantic content features and propagation diffusion features of rumors, we need to fuse these two features. These two features have different contributions when judging the category of rumor. Therefore, we design the global attention to capture the feature of rumors. The learning process is as follows:
Specifically, firstly, we transform the feature representation of the nodes in the heterogeneous graph. Then we take the similarity between the transformed representation and the attention vector
where tanh (·) is a nonlinear transformation,
Finally, using the learned feature weights and joint graph node representation, we can obtain the final rumor representation:
where
Then we input the obtained rumor feature representation to the fully connected layer for rumor classification. The classification process is as follows:
where
To train the model parameters, we use the cross-entropy loss function for loss minimization, which can be formalized as follows:
where
4 Experiments
4.1 Datasets
To confirm the performance of MSLG in the rumor detection task, we conducted experiments on Twitter15 and Twitter16 datasets collected by Ma et al. [28]. The two datasets contained 1,490 and 818 rumors, respectively. Each rumor and its corresponding reply and retweet are provided as a spreading tree. Each news item is labeled as a true rumor, false rumor, non-rumor, unverified rumor. Since the original datasets do not include user information, nor do they contain all the text of retweets or comments, we call Twitter API to crawl the features of all users related to tweets. Furthermore, we crawl all the reply texts according to the reply IDs. To ensure the fairness of the comparison, we selected 10% of the datasets as the validation set. The remaining is divided into the training set and test set according to the ratio of 3:1. Detailed statistics for the two datasets are shown in Table 1.
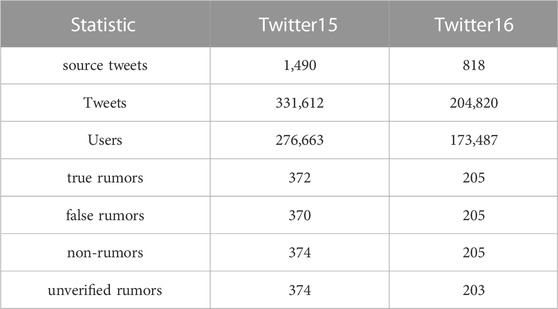
TABLE 1. Statistics of the datasets.
4.2 Confusion matrix and evaluation metrics
In essence, fake news detection is a classification task, so our evaluation metrics follow the existing research and use accuracy and F1 score in each category to evaluate the model’s performance. Since our task is a four-category problem, each category corresponds to a confusion matrix. According to the confusion matrix, we can calculate each category’s accuracy and F1 score. The confusion matrix is shown in Table 2. The calculation method of accuracy and F1 score is shown as follows.
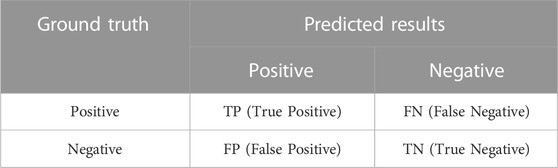
TABLE 2. Confusion matrix.
4.3 Baselines
We compare the proposed model with the following nine models, and we divide these baselines into three categories: traditional machine learning-based models, deep learning-based models, and graph neural networks-based models. Relevant models are introduced as follows:
Traditional machine learning-based models:
SVM-TK [28]: A kernel-based approach called propagation tree kernel captures high-order patterns that distinguish different types of rumors by evaluating the similarity between spread tree structures.
SVM-TS [29]: A method to capture the temporal characteristics of social background based on the time series of rumors’ lifecycle, which applies time series modeling techniques to integrate various social background information.
SVM-HK [30]: A hybrid SVM classifier based on graph kernel captures higher-order propagation patterns in addition to semantic features such as topics and sentiments.
Deep learning-based models:
PPC [31]: A time series classifier combining recurrent and convolutional networks for fake news detection by capturing global and local user feature changes along the propagation path, respectively.
PLAN [32]: A post-level attention model. This model uses the multi-head attention mechanism in a transformer network to model long-distance interactions between tweets.
PPA-WAE [33]: A lightweight propagation path aggregation neural network for rumor embedding and classification. Furthermore, the neural topic model in the Wasserstein autoencoder framework is used to capture the event-insensitive stance patterns that do not contain the source post in response propagation trees.
Graph neural networks-based models:
Bi-GCN [4]: A homogeneous bidirectional graph convolution network model explores these two propagation characteristics by operating top-down and bottom-up propagation of rumors.
GLAN [13]: A global-local attention network for rumor detection jointly encodes local semantic and global structural information.
HGATRD [14]: A meta-path-based heterogeneous graph attention network framework is used to capture the semantic relationship of text content and the structure information of source tweet propagation for rumor detection.
4.4 Results and analysis
Tables 3 and Tables 4 show that our model achieves state-of-the-art results on both datasets compared to other baseline models. As we observe from the results in the table, traditional machine learning methods have the worst performance, such as SVM-TS, SVM-HK, and SVM-TK. Moreover, the performance of deep learning models (such as PPC, PLAN, and PPA-WAE) has been improved to a certain extent. Graph neural network-based methods, such as Bi-GCN, GLAN, and HGATRD, have achieved better performance. These results are because the constructed graph structure can effectively capture the higher-order relations of news to obtain a more comprehensive feature representation.
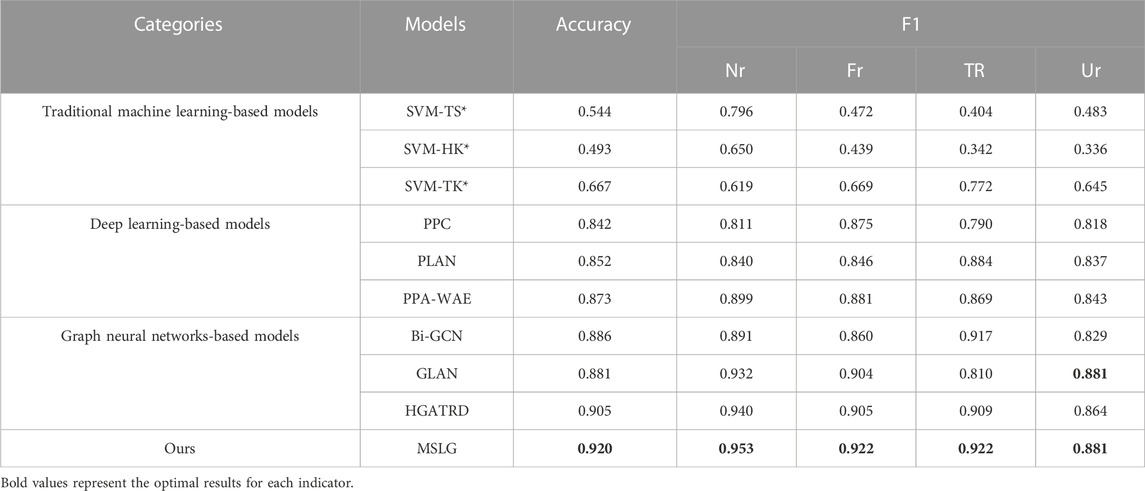
TABLE 3. Performance on Twitter15 dataset. The results indicated with * are obtained from [14] (NR: Non-Rumor; FR: False Rumor; TR: True Rumor; UR: Unverified Rumor).
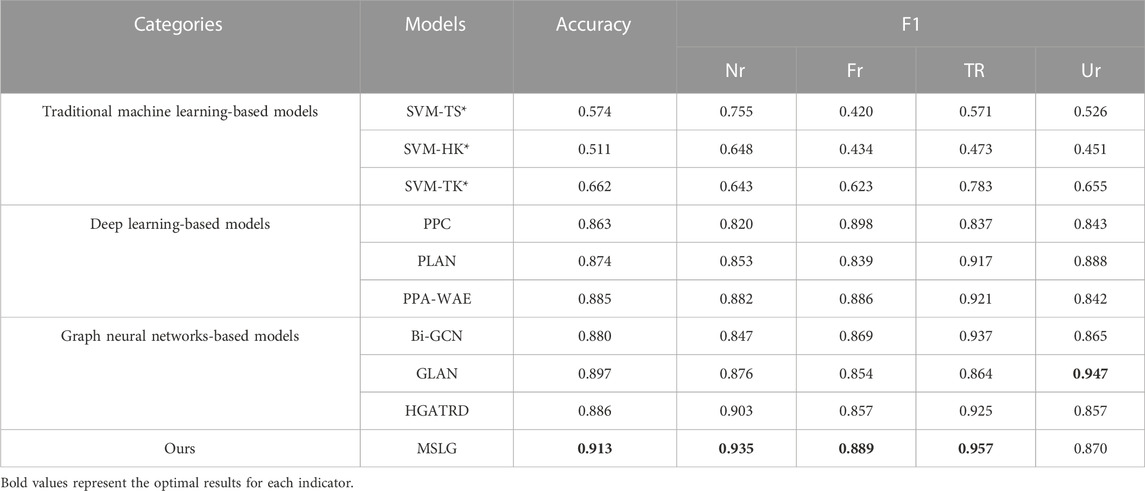
TABLE 4. Performance on Twitter16 dataset. The results indicated with * are obtained from [14] (NR: Non-Rumor; FR: False Rumor; TR: True Rumor; UR: Unverified Rumor).
The proposed model achieves 92.0% accuracy on the Twitter15 dataset, which is 2.5% higher than the best performance HGATRD model in baselines. This result is because the HGATRD model does not deeply extract the semantic features of news content, and the lack of semantic information extraction limits the performance improvement of the model. On the Twitter16 dataset, the best performance of all baseline models is GLAN, with an accuracy of 89.7%. The accuracy of our model is 91.3%, which is 1.6% higher than the model of GLAN. It is because our model not only extracts the global semantic information of rumors but also makes full use of the propagation structure information, thus achieving optimal performance.
Experimental results verify the effectiveness of our model in rumor detection. Our model’s heterogeneous graph fully represents the dataset’s information. The content information network we construct can extract the global semantic information of rumors. Through the propagation structure network, we extract information of high-order propagation and diffusion of rumors. Furthermore, the introduced node-level attention mechanism can enhance key nodes and networks’ features and reduce noise information’s weight. Finally, we fuse the two extracted features effectively to achieve high-quality rumor detection.
4.5 Ablation study
To verify the performance of each module of the model, we design two variants of the model MSLG, which are:
MSLG-nc: We delete the news content network from the model, and the model only uses the propagation structure information.
MSLG-ds: Deleting the propagation structure network in the model, and there is only news content information in the model.
Table 5 and Table 6 show the results of ablation experiments on the two datasets. Through the results in the table, we can observe that when we delete the news content network, model performance reduces rapidly. When we delete the propagation structure network, the model’s performance is also lower to a certain degree. This result indicates that for the fake news detection task, the semantic information of the news itself is more important. In contrast, other information only plays an auxiliary role to a certain extent.
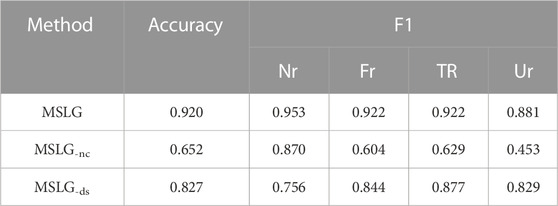
TABLE 5. Ablation experiment results on Twitter15 dataset.
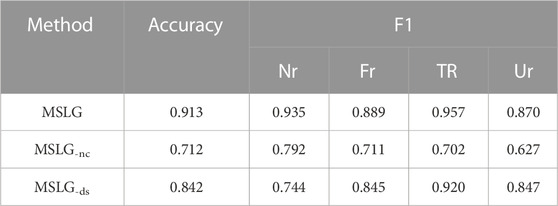
TABLE 6. Ablation experiment results on Twitter16 dataset.
We performed a four-class classification task on these two datasets. For the non-rumor class, when we remove the news content network, the model accuracy decreases by 8.3% and 14.3% on the Twitter15 and Twitter16 datasets, respectively. When we delete the propagation structure information, the model accuracy decreases by 19.7% and 19.1% on the two datasets, respectively. This result shows us that the propagation structural information is essential. In contrast, for the other three categories, content information is more critical. This result is because, compared with real users, fake users have more obvious cluster behavior and specific communication structure for news comments and forwarding information. The propagation structure network will pay more attention to fake users’ behavioral characteristics when we detect fake news. This result also conforms to our cognition.
4.6 Parameter analysis
This section analyzes the impact of different attention heads and dropout values on model performance. Figure 3 shows the visualized data results. As shown in Figure 3A, we can find that the model accuracy results show volatility when we use different attention heads. For the Twitter15 dataset, the model accuracy is highest when the number of attention heads is 6. For the Twitter16 dataset, the model has the highest accuracy when the number of attention heads is five or 6. As shown in Figure 3B, we can find that with different dropout values, the model performance is also different. We observe similar trends in both datasets when we apply different dropout values. The model’s overall performance shows a trend of rising and then falling. When the dropout value is 0.3, the model achieves the best performance. These results indicate that the attention head and dropout selection are critical to the model.
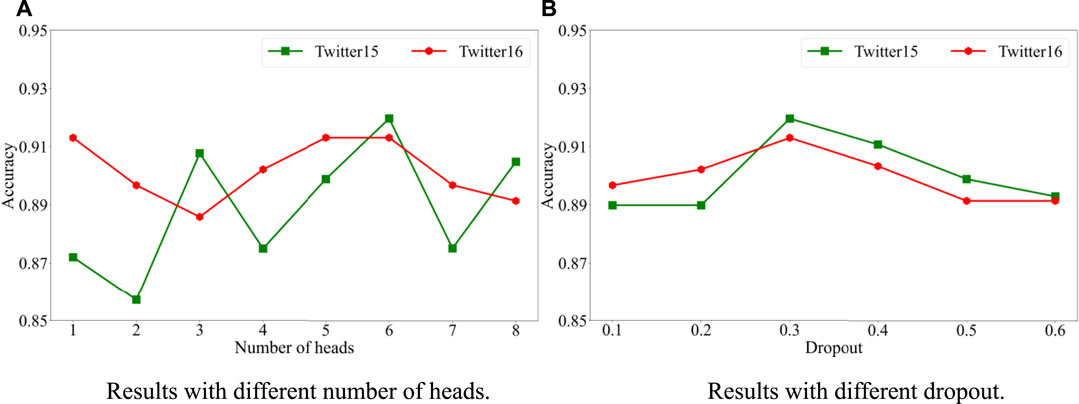
FIGURE 3. The performance of models with different parameters on two datasets.
4.7 Early detection of rumors
The early detection of rumors is a crucial goal of rumor detection. The longer it takes for a rumor to be published on social media, the more far-reaching its impact and the more difficult it is to dispel. Therefore, it is significant to realize the early detection of rumors. By studying the different propagation characteristics of real and fake news, Zhao et al. [34] realized fake news early detection is only based on the re-posting network topology between different users. However, there are only a few retweets or comments when a rumor is first published. At this time, we can only make full use of the text content of the source rumor for detection, which requires that the model constructed can fully extract the features of the text content of the rumor. To verify the performance of our model proposed in early rumor detection, we control the elapsed time after the source rumors have been published to represent different periods of rumor propagation. We reconstruct the semantic content feature extractor and propagation feature extractor by deleting comments and users after the deadline. Furthermore, we evaluate the performance of the different models. Figures 4A, B show the performance of each model on two datasets with different detection deadlines.
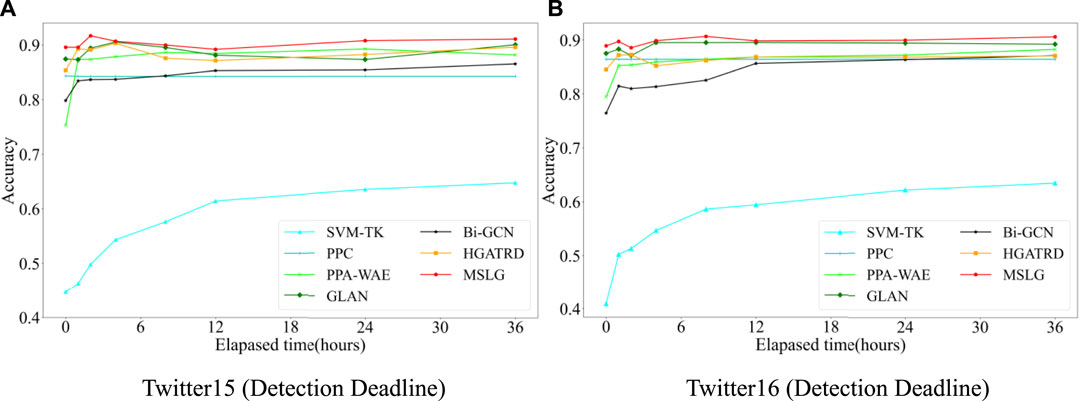
FIGURE 4. The performance of early rumor detection on two datasets.
Figures 4A, B show that our model MSLG achieves relatively high accuracy early after the rumor is published. It proves that the MSLG model can effectively extract the semantic content information of the rumor. In addition, with the increase of time after the rumor is published, the accuracy of each model is improved. Furthermore, the performance of MSLG is better than SVM-TK and Bi-GCN, which indicates that the fusion of multi-source information is beneficial for long-term rumor detection and early rumor debunking.
From Figure 4A, we find that when the detection deadline varies from 4 to 12 h, the performance of our model decreases slightly, but it is still better than other models. This is because, with the spread of rumors, there is more rumors’ semantic content and propagation structure, thus introducing noise information. As seen in Figure 4B, the performance of our model is always superior to other models, which indicates that the fusion of multi-source information is beneficial for long-term rumor detection and early rumor debunking. These results also indicate that our model is not sensitive to data and has good stability and robustness. In addition, semantic content and propagation information increased over time, increasing the accuracy of each model.
The experimental results on two real-world datasets prove that the proposed model can significantly improve the performance of rumor detection and realize the early detection of rumors.
5 Conclusion and future work
Most rumor detection methods based on graph neural networks have the problems of sparse features and excessive noise information. It is challenging to integrate complex multi-source information effectively. In addition, incomplete representation of the internal local relationship and external global relationship of rumors also limits the improvement of detection results. To address these problems, we extract various types of information from the dataset and design heterogeneous graph structures to represent the structure of multi-source information. Furthermore, we utilize a graph convolutional network to extract high-order feature representations of rumor content semantics and linear projection to extract propagation diffusion structure. Finally, we distinguish the importance of different nodes and different features by fusing local relational attention and global relational attention mechanisms, respectively. Experiments on two datasets verify the effectiveness of our method.
In future work, we consider designing a hypergraph structure to more comprehensively characterize rumors and further integrate user meta-attribute information to achieve fake news early detection. In addition, developing new datasets with pictures, audio, and video information is also a significant consideration. Fake news on social networks presents a multi-modal trend. A piece of news contains not only text information but also rich pictures and video information. This information is essential for fake news detection. Unfortunately, most of the datasets published so far only contain textual information. It results in many fake news detection methods being powerless in the face of multi-modal fake news.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
XH reviewed the manuscript. MZ designed the model and verified the experiment results. YZ revised the first draft of the paper. TZ collected the data and realized the visualization of the parameter analysis. All authors read and approved the final draft.
Funding
This work was supported by the Natural Science Foundation of Hebei Province (Grant No. 2020402003).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Ciampaglia GL, Shiralkar P, Rocha LM, Bollen J, Menczer F, Flammini A. Computational fact checking from knowledge networks. PLoS One (2015) 10:e0128193–13. doi:10.1371/journal.pone.0128193
2. Kang B, Deng Y. The maximum deng entropy. IEEE Access (2019) 7:120758–65. doi:10.1109/ACCESS.2019.2937679
3. Zhou X, Zafarani R. A survey of fake news: Fundamental theories, detection methods, and opportunities. Proc ACM Comput Surv (Csur) (2020) 53:1–40. doi:10.1145/3395046
4. Bian T, Xiao X, Xu T. Rumor detection on social media with bi-directional graph convolutional networks. In: Proceedings of the AAAI conference on artificial intelligence; 2020-04-03; New York, United States. Palo Alto, CA: AAAI Technical Track. 549–56. doi:10.1609/aaai.v34i01.5393
5. Ma J, Gao W, Wong K. Institutional knowledge at Singapore management university rumor detection on twitter with tree-structured recursive neural networks rumor detection on twitter with tree-structured recursive neural networks. In: Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics; Melbourne, Australia. Stroudsburg, PA: Association for Computational Linguistics (2018). 1980–9. doi:10.18653/v1/P18-1184
6. Zhou X, Zafarani R. Network-based Fake0 news detection: A pattern-driven approach. ACM SIGKDD Explor Newsl (2019) 21:48–60. Available at: http://arxiv.org/abs/1906.04210. doi:10.1145/3373464.3373473
7. Shu K, Wang S, Liu H. Beyond news contents: The role of social context for fake news detection. In: Proceedings of the 12th ACM International Conference on Web Search and Data Mining; 2019 Feb 11; Melbourne, Australia. 312–20. doi:10.1145/3289600.3290994
8. Shu K, Mahudeswaran D, Wang S, Liu H. Hierarchical propagation networks for fake news detection: Investigation and exploitation. In: Proceedings of the international AAAI conference on web and social media; Jun 8 2020-Jun 11 2020; Atlanta. AAAI Press. 626–37.
9. Jin Z, Cao J, Jiang YG, Zhang Y. News credibility evaluation on microblog with a hierarchical propagation model. In: Proceedings of the IEEE International Conference on Data Mining(ICDM); 14-17 December 2014; Shenzhen, China. IEEE. 230–9. doi:10.1109/ICDM.2014.91
10. Silva A, Luo L, Karunasekera S, Leckie C. Embracing domain differences in fake news: Cross-domain fake news detection using multi-modal data. In: Proceedings of the 35th AAAI Conference on Artificial Intelligence; 2021 Feb 2; Vancouver, Canada. 557–65. doi:10.1609/aaai.v35i1.16134
11. Zhang J, Dong B, Yu PS. FakeDetector: Effective fake news detection with deep diffusive neural network. In: Proceedings of the International Conference on Data Engineering; Washington, D.C. IEEE Computer Society (2020). 1826–9. doi:10.1109/ICDE48307.2020.00180
12. Vosoughi S, Roy D, Aral S. The spread of true and false news online. Science (2018) 359:1146–51. doi:10.1126/science.aap9559
13. Yuan C, Ma Q, Zhou W, Han J, Hu S. Jointly embedding the local and global relations of heterogeneous graph for rumor detection. In: Proceedings of the IEEE International Conference on Data Mining(ICDM); Washington, D.C. IEEE Computer Society (2019). p. 796–805. doi:10.1109/ICDM.2019.00090
14. Huang Q, Yu J, Wu J, Wang B. Heterogeneous graph attention networks for early detection of rumors on twitter. In: Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN); 19-24 July 2020; Glasgow, UK. IEEE. p. 1–8. doi:10.1109/IJCNN48605.2020.9207582
15. Ran H, Jia C, Zhang P, Li X. MGAT-ESM: Multi-channel graph attention neural network with event-sharing module for rumor detection. Inf Sci (Ny) (2022) 592:402–16. doi:10.1016/j.ins.2022.01.036
16. Hu L, Yang T, Zhang L, Zhong W, Tang D, Shi C, et al. Compare to the knowledge: Graph neural fake news detection with external knowledge. In: Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing; August 1–6; Pennsylvania. Association for Computational Linguistics (2021). 754–63.
17. Han Y, Silva A, Luo L, Karunasekera S, Leckie C. Knowledge enhanced multi-modal fake news detection. (2021) Available at: http://arxiv.org/abs/2108.04418.
19. Przybyła P. Capturing the style of fake news. In: Proceedings of the 34th AAAI conference on artificial intelligence; 2020-04-03, 34. AAAI Special Technical Track: AI for Social Impact. 490–7. doi:10.1609/aaai.v34i01.5386
20. Kumari R. A multitask learning approach for fake news detection: Novelty, emotion, and sentiment lend a helping hand. In: Proceedings of the 2021 International Joint Conference on Neural Networks; 18-22 July 2021; Shenzhen, China. IEEE. 1–8.
21. Silva A, Han Y, Luo L, Karunasekera S, Leckie C. Propagation2Vec: Embedding partial propagation networks for explainable fake news early detection. Inf Process Manag (2021) 58:102618. doi:10.1016/j.ipm.2021.102618
22. Karimi H, Roy PC, Saba-Sadiya S, Tang J. Multi-source multi-class fake news detection. In: Proceedings of the 27th international conference on computational linguistics; 2018 Jul 15; New Mexico, USA. Association for Computational Linguistics (2018). 1546–57.
23. Sitaula N, Mohan CK, Grygiel J, Zhou X, Zafarani R. Credibility-based fake news detection. In: Disinformation, misinformation, fake news soc media (2020). 163–82.
24. Lu Y-J, Li C-T. Gcan: Graph-Aware Co-attention networks for explainable fake news detection on social media. In: Proceedings of the Association for Computational Linguistics; 2020 Jul 4; Stroudsburg, Pennsylvania. Association for Computational Linguistics. 505–14.
25. Shu K, Cui L, Wang S, Lee D, Liu H. Defend: Explainable fake news detection. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 395–405. doi:10.1145/3292500.3330935
26. Zhang X, Zhang T, Zhao W, Cui Z, Yang J. Dual-attention graph convolutional network. In: Proceedings of Asian Conference on Pattern Recognition; 23 February 2020; New York City. Springer. 238–51. Available at: https://arxiv.org/pdf/1911.12486.pdf.
27. Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez NAKL. Attention is all you need. In: Proceedings of the 31th Conference on Neural Information Processing Systems; 2017 Dec 3; Palais des Congres de Montreal, Canada. Cambridge, MA: NeurIPS (2017).
28. Ma J, Gao W, Wong KF. Detect rumors in microblog posts using propagation structure via kernel learning. In: Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics; At: Vancouver, Canada (2017). 708–17.
29. Ma J, Gao W, Wei Z, Lu Y, Wong K-F. Detect rumors using time series of social context information on microblogging websites. In: Proceedings of the 24th ACM international on conference on information and knowledge management (2015). 1751–4.
30. Wu K, Yang S, Zhu KQ. False rumors detection on Sina Weibo by propagation structures. In: Proceedings of the 34th International Conference on Data Engineering; 13-17 April 2015; Seoul, Korea (South). IEEE (2015). 651–62. doi:10.1109/ICDE.2015.7113322
31. Liu Y, Wu YFB. Early detection of fake news on social media through propagation path classification with recurrent and convolutional networks. In: Proceedings of the AAAI conference on artificial intelligence; 2018-04-25; New Orleans, United States, 32 (2018). 354–61.
32. Khoo LMS, Chieu HL, Qian Z, Jiang J. Interpretable rumor detection in microblogs by attending to user interactions. In: Proceedings of the 34th AAAI Conference on Artificial Intelligence (2020). 8783–90. doi:10.1609/aaai.v34i05.6405
33. Zhang P, Ran H, Jia C, Li X, Han X. A lightweight propagation path aggregating network with neural topic model for rumor detection. Neurocomputing (2021) 458:468–77. doi:10.1016/j.neucom.2021.06.062
Keywords: multi-source information, propagation diffusion structure, attention mechanism, heterogeneous graph, rumor detection
Citation: Han X, Zhao M, Zhang Y and Zhao T (2023) Jointly multi-source information and local-global relations of heterogeneous network for rumor detection. Front. Phys. 10:1056207. doi: 10.3389/fphy.2022.1056207
Received: 28 September 2022; Accepted: 19 December 2022;
Published: 10 January 2023.
Edited by:
Jiang Zhu, Netskope Inc., United StatesReviewed by:
Xiu-Xiu Zhan, Hangzhou Normal University, ChinaYukie Sano, University of Tsukuba, Japan
Copyright © 2023 Han, Zhao, Zhang and Zhao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mengfan Zhao, emhhb21lbmdmYW5AdGp1LmVkdS5jbg==
†These authors share first authorship