Abstract
This paper presents an analytical framework for the physical environment of cities using fractal theory. The strength of the approach lies in its simplicity and precision. The equations presented in this article comprise: the number of occupied sites in an area; the population and the length of roads of a city; its fractal dimension; its number of average and maximum levels (floors per building); the average density of population and roads; what are the limits to growth as well as an analysis on some of the city’s scaling laws. These equations describe to a high level of precision the real values measured in the system of the United Kingdom, for every city above 5,000 people, which amounts to a sample size of 1,031 cities. This work will allow further research into the nature of cities, since it enables the creation of synthetic cities, and further analytical derivations that can arise from these building blocks. The paper shows as well how the same set of equations can be used to characterise the internal distribution of cities from the perspective of its growth as a possible example of an application of the framework.
Introduction
The field of urban studies is a continuous pursuit for regularities that expand our capacity to describe and understand cities. From its origins, the field has been intimately related to ideas and methodologies in the field of statistical physics, and an overarching summary of the path and main ideas of the application of statistical physics to urban environments is presented in [1].
We cannot claim that we understand how cities evolve as long as we do not have an exact set of equations that relate every variable to each other allowing us to understand the effects of population growth. This is paramount for a large number of fields, including research, urbanism and political/economical science. The aim of this work is to create an analytical framework for the analysis of the most important variables in a city from a geometrical standpoint.
This paper presents a theory of the physical aspect of the city using a fractal framework. Cities are defined by their occupation of space, and I show over the next sections that cities increase their fractal dimension as they grow in population, which is a fundamental property, and which was already noted in [2]. In fact, the study of cities as fractals has a long tradition in the scientific literature [2–8]. This view is fundamental to understand cities, since it commands the occupation of space for a given city, and therefore it is the only valid way to extract its geometric framework.
The work presented in this paper studies the population, the road network, the occupation of space, the fractal dimension of the city, the average heights, the maximum heights and the interactions or GDP of a city. I show how all these variables are related between each other and how they were derived. This work is not the first to attempt to produce a set of equations that describe the main variables of the city. Some previous work include [9, 10] which show how congestion influence the growth of cities, the aforementioned [2] that presents a theory of growth of cities based on scaling theory or several theories on the growth of cities [11–13].
This work delves as well into how this fractal framework affects and influence the scaling of a number of variables. Scaling theory [14–17] in urban science [18–23] study how allometric relations appear between variables such as the length of roads, the number of gas stations, the cost of maintaining a city’s infrastructure, its GDP and many other quantities to the size of the city in terms of population. In previous work [24], it was shown that those scaling exponents could be derived from a simplified and approximated version of the equations that governed those same variables. The current work presents an improvement on the calculation of the scaling exponents going beyond what was presented in [24], since we now account with better and more precise equations to describe length of roads, population and GDP.
The work also shows an application of the set of formulas to develop an approximation of the internal distribution of a city, derived from its growth. In order to do so, it assumes that the same formulas that describe a city in its current state have to remain meaningful to describe a city at any specific instant of its history, meaning that this growth is ergodic.
Framework
Cities begin to form with the construction of a single house, slowly other houses join, percolating space, and soon the city’s fractal dimension starts increasing. New occupied sites are incorporated with a certain probability of occupation over the territory that surrounds the city while the existing urban fabric gets densified. This probability of occupation tends to a constant value because of a self-optimization pattern. Going any lower would break the city apart into different clusters and expand the city over a long area, increasing travel times and decreasing economies of scale. Going higher would increase traffic and other problems derived from density, leading to an optimal solution in which the probability of occupation is as low as possible while still keeping the city as one single cluster. This probability is very close to the critical probability of a percolation over a squared lattice in two dimensions because the topology of cities is in average similar to that lattice.
In its first stages the city densifies its road network, subdividing the occupied sites which increases the density of occupation. At some point in its growth, the density of people that can live in a planar city saturates and in order to keep growing, the city needs to extend into the third dimension increasing its height, eventually pushing the fractal dimension of the population above 2. From its initial state, the density of population keeps on ever increasing as the city first densifies and later grows further into the third dimension.
The current section constructs the main framework of this work, presenting the derivation of its equations for several geometrical variables in a city. In order to simplify the equations and reasoning, I will use along this section an idealised system, in which I will avoid talking about multipliers or characteristic scales that need to be fitted in order to obtain realistic values, I will show how to calculate those multipliers in the last section of the paper, where I will adapt the equations to work with a real system and give the value for the constants in the specific case of the United Kingdom which will serve as an example throughout the paper.
As a city grows, the pre-existing city does not disappear, meaning that it must maintain a minimum of the current probability of occupation of sites where buildings are constructed. Considering a squared city with a linear dimension L, with a planar fractal dimension d and a certain number of occupied sites n = Ld (shown in Figure 1B) coming from a probability of occupation ρ over an area a = L2. Then we have ρa = n which in turn means that Ld−2 = ρ so:
FIGURE 1
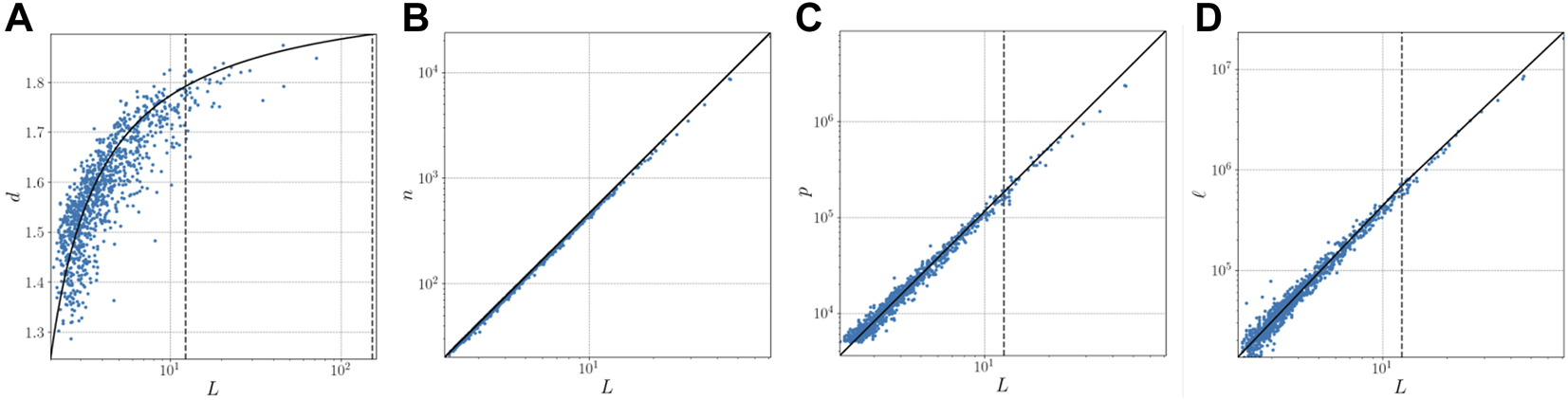
Comparison between real data and their corresponding equations. (A) fractal dimension as a function of linear dimension of the city. (B) number of occupied sites as a function of the linear dimension of the city, measured using GHS data [26]. (C) population as a function of the linear dimension of the city from GHS data. (D) total length of roads as a funcion of the linear dimension of the city taken from OSM data [28]. In blue real data, in black the equations derived with this approach. The vertical dotted line corresponds with the critical threshold.
This equation means that the fractal dimension of a city needs to increase as its linear dimension grows in order to avoid having its preexisting city disappear, this was already noted in [2]. Otherwise, if it were to remain constant (or decrease) we see that the only solution would be to decrease its probability of occupation, meaning that in order to occupy sites in its outskirts the city would need to vacate sites in its preexisting city. This explains the behaviour observed in real systems (Figure 1A) which shows a normal distribution of the error between the predicted and real value with mean −0.0142 and standard deviation of 0.0677.
Cities grow vertically above its two-dimensional footprint. In fact, population becomes a fractal volume, that starts below dimension 2 but as cities become larger it surpasses it. Furthermore, the population has always a larger fractal dimension than the footprint of a city. As it was shown on [24] the fractal dimension of the population (dp) can be obtained by adding a fractal vertical component η to the planar fractal dimension of sites d, that is dp = d + η and therefore the population (shown in Figure 1C) can be expressed as
Throughout its growth, a city starts densifying its street network increasing the quantity of people that can live within it, and at some threshold xc the density of population per site in a planar city saturates and cannot longer continue growing through this process. In order to keep on growing above that critical threshold xc it needs to start increasing its height. Therefore, the growth of people per site is absorbed either by the increase in average length of roads ⟨ℓ⟩ in a site of the space of the city or by the average number of vertical levels (floors) of the city ⟨h⟩. This means thatis a constant.
Numerically, at xc, the density of roads reaches its maximum value of 1 (understood as the probability of finding a road segment in a site) ⟨ℓ⟩c = 1 and the average number of levels of the city is also 1, ⟨h⟩c = 1, since it was 1 from the beginning of the growth of the city and it only starts increasing right after xc. So we have that:
We also have that since ρa = n,
This last equation means that at xc the population is proportional to the area since ⟨ℓ⟩c = 1 and ⟨h⟩c = 1 and k and ρ are constants. Therefore, the fractal dimension of the population at xc is the same as the fractal dimension of the area . In other terms, at the point in which the population starts growing into the third dimension is the threshold in which its fractal dimension grows above 2, as expected. We can see that since at xc, dc = 2 − η and using Eq. 1 we have that η isand since pc = L2 = ac and a/n = ρ−1 then , therefore, we can see that our constant in Eq. 4 is k = ρ−1 which means that,for any city size. This is a constant for any city, the limit of population density in each vertical floor belonging to a site per meter of road (how dense is the network, how subdivided is the system), the system cannot hold more people than this value per site, per level. Furthermore, Eq. 5 becomeswhich means that at the critical threshold xc, when saturation is reached and both the density of roads and the number of levels is 1, the population equals the area. Moreover, and as an indirect consequence of Eq. 6 we also have that the threshold xc is reached when the linear dimension of the city is Lc = ρ−1/η.
A city cannot grow without limit, the equations portrayed in this work show that its density would go to impossible amounts, the heights of its buildings would reach levels that are physically unattainable and a large number of other issues such as congestion and competition for space would arise. As we see in Eq. 7, ρ−1 is the density limit for the night time population, how many people can live in each site per level, and this is a hard limit, no city outgrows this. As cities grow further than this threshold (xc), the day-time population will spread over its area, people will walk down the parks, the plazas, the avenues and will of course be present in buildings. Since the area of the city cannot contain several levels, it means that at some point in its growth, the population spread over its area will also reach this same limit and the city will be completely collapsed. This is expectedly a hard limit for growth, and cities will not surpass it. In fact, using our equations and the multiplying factors measured for the United Kingdom, this only happens when the population of a city reaches 36.1 million people, and the largest city on Earth has a very similar level of population, of course, this is a numerical result that is highly dependent on the approximated value of η and ρ obtained through a genetic algorithm as explained in the next section, and very slight modifications to those values change greatly this specific value. We call this maximum threshold xm.
If at xm we have that ρpm = am and for all cities ρa = n, then which means that Lm = ρ−2/η and using Eq. 1, dm = 2 − η/2.
Regarding ⟨ℓ⟩ and ⟨h⟩ given that we know that both are complementary, since at xc both are 1, and one cannot exist in the numeric range of the other (one has to be less than 1 and the other more than 1) then we have that and given that ⟨ℓ⟩ is a probability and cannot go above the value 1:
which is shown in Figure 2D, and since then:portrayed in Figure 2B.
FIGURE 2
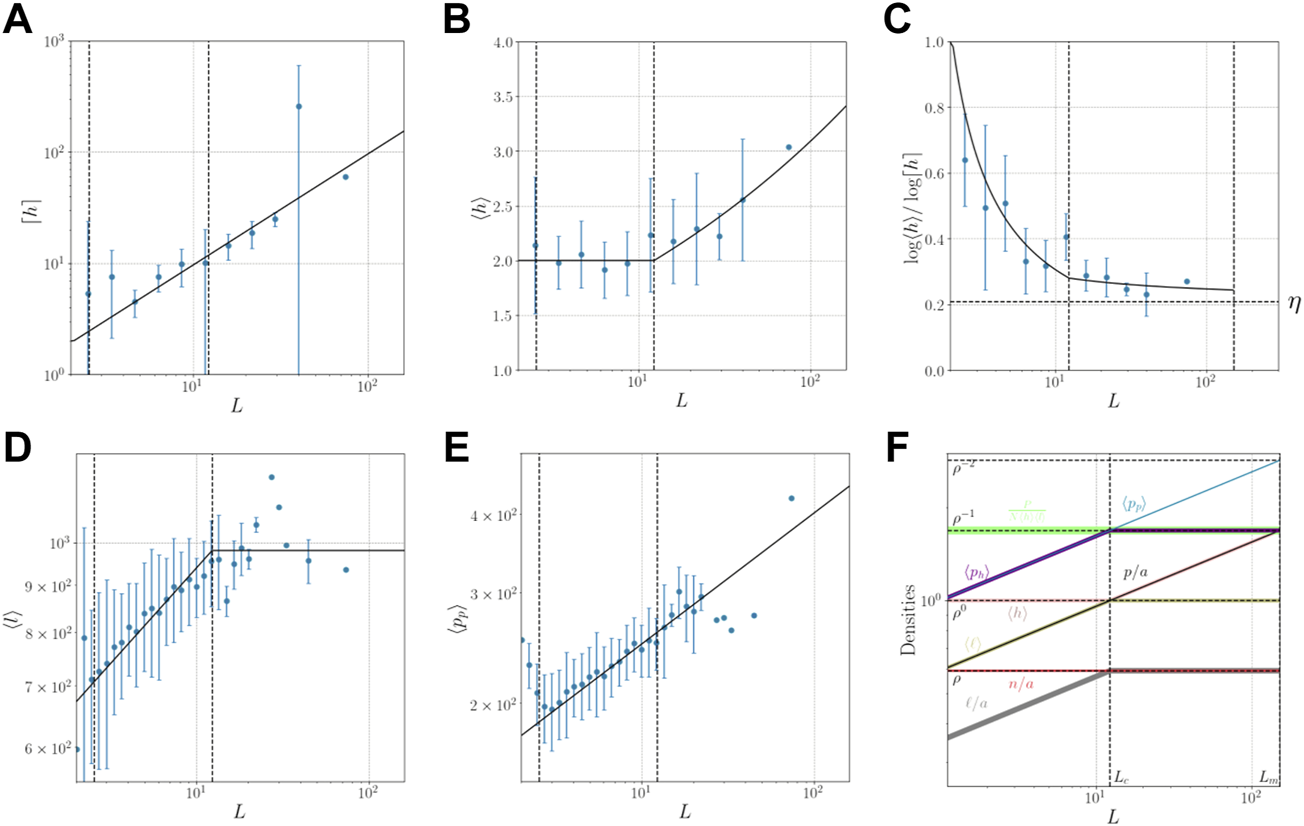
Comparison between number of levels and densities in the system with their respective equations. (A) maximum number of levels as a function of the linear dimension of the city. The number of levels is taken from data in Open Street Maps [28] (B) average number of levels as a function of the linear dimension of the city. (C) approximation of η using which as we can see works only above xc and will only reach exactly the same value as the true η (horizontal dotted line) at infinity. (D) average length of roads per site as a function of the linear dimension of a city. (E) planar density of the population per site as a function for the linear dimension of the city. (F) summary of how every density evolves as a function of the linear dimension of the city. In blue real data, in black the equations derived with this approach. The vertical dotted line corresponds with the critical threshold.
We can also obtain from Eq. 9 the total length of roads (shown in Figure 1D) which is:
In order to calculate the maximum number of levels of the city (⌈h⌉) we use an approximation from [24] where we obtained that using box counting analytically. Since this was only an approximation and meant to work above the critical threshold, we need to consider ⟨h⟩x = ρLη (without limiting its lower bound to 1). Doing so we have that (Figure 2C) which means that . Because of the approximated nature of the equation we can not obtain directly the value of kh and to calculate the true value of this multiplying constant we have to see that at the minimum possible linear dimension, when the city is composed of a single house, the average height and the maximum height should have the same value. This happens when d = 0, and since L = ρ1/(d−2) then Ld=0 = ρ−1/2, the average number of levels is and equating it to ⌈h⌉d=0 = khLd=0 = khρ−1/2 we obtain that kh = ρ1.5−η/2 therefore:which is shown in Figure 2A.
We can also obtain equations that describe the average number of population in a site projected to the floor (collapsing all levels) ⟨pp⟩ (Figure 2E), the average number of people per meter of road ⟨pℓ⟩ and the average number of people per site and per level ⟨ph⟩
Over the next sections I will show how to adapt this framework to real data and how to obtain the value of η and ρ to be able to get the final values of our exponents.
Scaling Theory
Originally a theory derived in the field of biology, scaling theory studies the allometric scaling of variables in a city as it they relate to its population growth. Some of those variables scale sub-linearly with the size of the city, meaning that the larger a city gets the slower that variable grows, this is the case for variables where economies of scale arise, such as the length of roads needed to cover the city, the number of gas stations, etc. Other variables grow linearly, because they correspond to some fixed value per person, such as the amount of water consumed. Finally, some other variables grow super-linearly, meaning that they grow faster than the population, usually these arise through feedback effects and include elements like traffic congestion, criminality, interactions or the GDP of a city. In [24] we showed that in fact, this relation to size was due to the fractal nature of cities, and calculated the expected exponents from the fractal scaling of the population and road network.
In that previous work [24] we reasoned that since the length of roads was proportional to Ld and the population was proportional to , the scaling exponent should be equal to . We now have an improved formulation that describe both quantities and no longer need to make any approximations we can just solve the scaling equation ℓ = pγ and calculate the exponent . This gives us that:this means that the previous reasoning still stands, but only for the largest cities (those above xc) but the small cities are better represented by a different γ. The resulting length of roads fits the data to a very high degree of precision (normal distribution of the differences between the logged real and predicted values with μ = 0.01466 and σ = 0.1618) as shown in Figure 3A where Figure 3C shows the value of γ.
FIGURE 3

Relations between some of the variables and the scaling equations presented in this paper. (A) length of roads as a function of the population and the sublinear exponent (ℓ = pγ). (B) GDP as a function of the population and the superlinear exponent . The GDP data was obtained from the Eurostat dataset [29] (C) values of both the sub-linear and super-linear exponents as calculated in this work. In blue real data, in black the equations derived using this approach. The vertical dotted line corresponds with the critical threshold.
In that same paper, we also reasoned that interactions occur when people go to the street and that therefore it should be proportional to the square of the quantity of people in the ground level, multiplied by the number of locations in which that were possible. In that work, the equations were approximated and we used ℓ ∼ n which gave us that i = (p/n) (p/n − 1)n, where i represents the total possible interactions, but since in this work we are distinguishing between the two values (ℓ and n), it is more precise to say that the people in the street interacts, and the number of possible locations is the length of the street network. therefore:
In order to obtain an approximation of the super-linear exponent of interaction , we need to drop the exact equation and approximate . Therefore the approximate value of the super-linear exponent is:
Similarly to what was done in [24], we assume that the GDP of a city is a direct consequence of the interactions between individuals, and use that quantity to showcase the validity of the formulation as shown in Figure 3B while the super-linear exponent is shown in Figure 3C.
Formulation, Constants and Units for Real Data
The current framework represents an idealised system, it is unitless because everything is divided by an implicit characteristic scale that we will make explicit in this section and there are not any multiplying constants for the sake of simplicity. This section completes the framework, by including those factors and thus creating the final set of equations for the system.
From this point on forward we will use the subindex r to refer to real variables as measured from the data.
To determine the side of our real square (in meters) we use the area of the city.
The characteristic scale for the length of the side of our squared area is called L0 and it is measured in meters.where for the United Kingdom L0 = 538.924 m. This value was calculated through measuring the fractal dimension for all cities and their areas. An approximation can be obtained through performing those measurements for the largest city (max (dr), max (Lr)) and calculating our theoretical max(L) = exp (ln(ρ)/(max (dr) − 2)), to find L0 = max (Lr)/max(L). Of course, for this we need to determine ρ, this can be done either through directly measuring occupied space (buildings and roads) against open spaces in the city (parks, and plazas) or assuming our theoretical value for ρ = 0.5991 taken from the next section. As an example, London has an approximated 40% surface occupied by parks, which means that its ρr = 0.60. I use this value for L0 as a starting guess and perform a least square estimate of L0 using the measured fractal dimension and area for all cities (I assumed the theoretical ρ to be valid). Notice that we cannot use Lr and d to directly calculate ρ because.
For completeness, we will show how to obtain the area as a function of the side of the square.where where for the United Kingdom p0 = 1,207 people, which was measured by adjusting the theoretical population to the real data measured until their differences were minimised.where for the United Kingdom n0 = 7.85 sites, measured against the real data.where for the United Kingdom ℓ0 = 7,700 m, measured against the real data.where for the United Kingdom h0 = 2 levels, measured against the real data.
The constant that limits growth becomes:
and the densities:
Regarding the scaling equations, we have that the real length of the road network as a function of the real population becomes:Notice that, the typical equation of a scaling is in fact , and since γ changes with the population size, the multiplying factor is not constant, as the equation assumes. The fact that both the exponent and the multiplying factor vary with size explains a lot of the problematic that exists around measuring precisely the scaling exponent, although much of the variability becomes negligible if we only use cities above xc.
For the GDP we have:where for the United Kingdom g0 = 2.3 ⋅ 107 euro, measured against the real data. This is an approximation, and from my perspective it is preferred to use the actual equation instead of an approximated scaling law, whenever possible, even though both equations look indistinguishable when presented against each other or the data. The equation for the interaction of population is:with a value i0 unknown, since there is no data to measure it. This factor i0 represents the probability that a potential interaction becomes a real one. Furthermore, if the assumption between proportionality of interactions and GDP stands:
One interesting side effect of this, is that given that L0, n0, p0, ℓ0 and h0 or even g0 are pure constants for a system of cities (the variability is absorbed through the rest of the equation), they are much better descriptors of a system, and when calculated for other systems, they will allow us to make comparisons with less noise between different countries.
The Value of ρ and η
To render this analytical approach useful we need to be able to obtain the values of our two constants η and ρ. My approach was to use a genetic algorithm, whose inputs were the area (ar, from where we obtain Lr), fractal dimension (dr) and population (pr) for each city and the parameters to be optimised are ηp and ρp. Using this, I apply a two steps approximation.
In the first step, in order to obtain the heuristic value for each individual, I calculate L0 using the parameter ρp given by the algorithm, and then after calculating the real density for each city, calculate an average density that mixes the parameter and the measured density, . I then calculate a theoretical fractal dimension and obtain the theoretical population for each city using it , where ηp is the second parameter to be fitted by the algorithm. Then obtain the linear fit between the theoretical population p and the real one pr = ap + b, discard b and return as the final heuristic the L1 norm between the logarithms of pr and ap. In this phase we obtain the value of η and an approximation of the value of ρ.
In the second step, we fix η and only optimize ρ, allowing the search only in the neighborhood of the approximated value we obtained in the first step. The only difference between the two, is that we no longer use the real ρr and instead use directly the parameter ρp at every step (to calculate L0 and d = 2 + ln (ρp)/ln (Lr/L0)). From this second step we obtain our constant ρ.
The values obtained were:were less significant digits were discarded. These values mean that dm = 2 − η/2 = 1.8954 and dc = 2 − η = 1.7908. The measurements of η and ρ were obtained from approximated processes and these measurements could be improved in the future.
This is surprisingly close to the values for a site percolation in a 2d-lattice given in the literature, were η = 0.2083 is the exponent for the function that controls the probability of two sites belonging to the same cluster as a function of distance, pc = 0.5927 is the critical probability, df = 1.8958 is the fractal dimension of the percolating cluster. Given that percolation has been tied in the literature [25] to the formation of cities, I expect that there exists a logical link between the two but the reasoning behind this numerical coincidence falls outside the scope of this paper and is left for future work.
Scaling studies have shown that different city systems across the world have very similar scaling exponents [18]. Following our derivation we see from Eq. 16, 18 that the scaling exponent depends on d and η. Since d is a function of the linear size of the city and ρ (Eq. 1) the scaling exponent is a function of ρ and η. If the scaling exponents are truly universal it would then mean that in fact ρ and η are universal and therefore these values should remain stable for different systems.
In the following section we show a possible application of the framework contained in this paper, in order to demonstrate its expressiveness.
Growth of a Single City
We can apply the same reasoning presented above to obtain the internal distribution of a single city, since at each stage of its growth, the city has to follow the equations presented for fractal dimension, population, number of sites, and length of roads if we consider urban growth to be an ergodic process.
Upon growth, the city increases from a current linear length L to L + dL. In this change of linear size, it modifies its fractal dimension from dL to dL+dL, and its population change is .
This population change will be partitioned between the stripe of land added to the city and the existing urban tissue. I assumed a simple formula for this, that uses a weight to balance the two, w. We then consider a value δ that is the density of population added at each step, which multiplied by the respective areas gives us the increase of population in the new area and the preexisting one. The basic formula for the population at a certain stage of its growth is then:
We can calculate pL+dL and pL using Eq. 1, 2 and their difference is the increment of population dp. So we can express δ as
where w is adjusted to fit the real distributions, in the modeling process w has been made dependent on the step size, so variations on the step size would not influence the final distribution, the adjusted value was , of course this can only be valid as long as w < 1, our step chosen for the model was dL = 1, the value used in the modeling was .
Of course, as we add new population, each city stripe must remain under the maximum possible population. This maximum possible population can be calculated from Eq. 8, where max(p) = max (a⟨ℓ⟩⟨h⟩) = a max ⟨ℓ⟩ max ⟨h⟩ and since max ⟨ℓ⟩ = 1 then max(p) = a⌈h⌉. So each stripe must remain below its area multiplied by the maximum height of the city for the current linear dimension.
When deciding where to locate in the city, a new inhabitant only cares on the distance to the center, in order to simulate this extent when distributing the population (δwL2) over the pre-existing city, we weight each strip by how many more people fit in it, divided by its perimeter, and use this factor to distribute the population on the existing city.
We can repeat the same steps for the number of sites and the length of roads, obtaining the most important variables. For number of sites, we choose a maximum possible density of 0.9 (being 1 complete occupation), this value was obtained from the data observed, while length of roads is limited by the number of sites. From it we can calculate the heights of buildings expected and the density of sites per area or of people per site.
The height of buildings for the real data is a direct measurement taken from the LIDAR available at the Copernicus site [27] and no transformation was applied other than dividing it by 3 m, which is taken as an average floor height, this is shown in Figure 4E. In order to calculate the density of a site, we calculate how many occupied sites (there exists population in that element of the grid using data from the GHS [26]) are in the surrounding area of each site (with a radius of 6.250 km) and divided it by the maximum possible number of sites in that circle, as shown in Figure 4F. The last comparison (population per site) is more complicated, and we need to think how this data was created. The population data is obtained from the Global Human Settlement layer [26], this data has been produced by taking the population in censal sections, determining the building footprints from satellite data and interpolating the population with the perceived density of buildings, also, most probably, since we do not see any clear cuts from the censal sections, a spatial interpolation averaging large discontinuities was performed. Both interpolations (and even the data aggregated to a censal section) reduce the peaks of population, softening the overall distribution. Therefore, in order to create a fair comparison, we performed similar steps to our results. In Figure 4C both the real distribution obtained (dotted points) and the distribution obtained after a process of clustering and interpolation is shown.
FIGURE 4

Internal growth of a city. (A) internal distribution of population per area of each stripe located at L distance from the center of the city. (B) number of levels per stripe at L distance from the center. (C) internal distribution of number of occupied sites per area of each stripe located at L distance from the center of the city. (D) comparison between expected population per site using our equations and the measured data from the GHS [26]. (E) comparison between the average number of levels obtained from our equations and measured LIDAR data from London taken from Copernicus data [27], which is divided by 3 m as an average floor height. (F) comparison between the expected density of sites and the measured data from the GHS. In blue real data, in black the equations derived with this approach.
The correspondence of the distributions obtained using the model with the real ones is fairly strong, indicating that this process could be a valid model for the internal growth of a city. However, and as we can notice in Figure 4B we can see that at the outskirts of the city there is a strange behaviour, where the height of buildings start growing again instead of decreasing, which means that there is still room for improvement. This problematic is created because the number of sites decreases faster than the population for that range.
Discussion
The analytical derivations that give rise to the equations portrayed in this work, makes them exact functional forms of many aspects of the city’s physical environment. This is of extreme importance, since every derivation made from them, every operation will still represent what they are meant to convey. As it is often said, we stand on the shoulder of giants, and approximated equations of similar quantities have been portrayed before in the literature, and while these brought light to a lot of issues they are of limited applicability, because of their approximated nature.
I believe that following this text, new ideas will become easier to test and derive, aiding the process of solving the puzzle of cities.
This work portrays the equations for fractal dimension, population, area, length of roads, different densities of population, average and maximum heights (levels) for a city, and interactions (or GDP). Moreover, it shows how using this framework we can study the internal distributions of those same variables within the city.
Data
The article uses population data from the Global Human Settlement Layer (GHS) [26], height data from the Copernicus satellite LIDAR data [27], height and road data from OpenStreetMap [28] and GDP data from Eurostat [29].
Statements
Data availability statement
The datasets used in this work fall under the umbrella of open data and are available at their respective websites as referenced in the bibliography.
Author contributions
The author confirms being the sole contributor of this work and has approved it for publication.
Conflict of interest
The author declares that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1.
BarthelemyM. The Statistical Physics of Cities. Nat Rev Phys (2019) 1(6):406–15. 10.1038/s42254-019-0054-2
2.
BattyMLongleyPA. Fractal-based Description of Urban Form. Environ Plann B (1987) 14(2):123–34. 10.1068/b140123
3.
MurcioRMasucciAPArcauteEBattyM. Multifractal to Monofractal Evolution of the london Street Network. Phys Rev E Stat Nonlin Soft Matter Phys (2015) 92(6):062130. 10.1103/PhysRevE.92.062130
4.
BattyMLongleyPA. Fractal Cities: A Geometry of Form and Function. Academic Press (1994).
5.
FrankhauserP, “Fractal Properties of Settlement Structures,” in First International Seminar on Structural Morphology, 1992.
6.
FrankhauserP. Aspects fractals des structures urbaines. spgeo (1990) 19(6):45–69. 10.3406/spgeo.1990.2943
7.
BattyMLongleyPA. Urban Shapes as Fractals. Area (1987) 215–21.
8.
TannierCPumainD. Fractals in Urban Geography: a Theoretical Outline and an Empirical Example. Cybergeo: Eur J Geogr (2005). 10.4000/CYBERGEO.3275
9.
LoufRBarthelemyM. How Congestion Shapes Cities: from Mobility Patterns to Scaling. Sci Rep (2014) 4:5561. 10.1038/srep05561
10.
LoufRBarthelemyM. Modeling the Polycentric Transition of Cities. Phys Rev Lett (2013) 111(19):198702. 10.1103/physrevlett.111.198702
11.
VerbavatzVBarthelemyM. The Growth Equation of Cities. Nature (2020) 587(7834):397–401. 10.1038/s41586-020-2900-x
12.
DurantonG.PugaD., “Chapter 5—the growth of cities,” in Handbook of Economic GrowthAghionP.DurlaufS. N., (2014) 2:781–853.10.1016/B978-0-444-53540-5.00005-7
13.
GabaixX. Zipf’s Law and the Growth of Cities. Am Econ Rev (1999) 89:129–32.
14.
Schmidt-NielsenK. Scaling in Biology: the Consequences of Size. J Exp Zoolog (1975) 194(1):287–307. 10.1002/jez.1401940120
15.
WestGBBrownJHEnquistBJ. A General Model for the Origin of Allometric Scaling Laws in Biology. Science (1997) 276(5309):122–6. 10.1126/science.276.5309.122
16.
WestGBBrownJHEnquistBJ. The Fourth Dimension of Life: Fractal Geometry and Allometric Scaling of Organisms. science (1999) 284(5420):1677–9. 10.1126/science.284.5420.1677
17.
WestGBBrownJHEnquistBJ. A General Model for Ontogenetic Growth. Nature (2001) 413(6856):628. 10.1038/35098076
18.
BettencourtLWestG. A Unified Theory of Urban Living. Nature (2010) 467(7318):912–3. 10.1038/467912a
19.
BettencourtLMLoboJHelbingDKühnertCWestGB. Growth, Innovation, Scaling, and the Pace of Life in Cities. Proc Natl Acad Sci U S A (2007) 104(17):7301–6. 10.1073/pnas.0610172104
20.
PumainDGueroisM. Scaling Laws in Urban Systems. SFI Working Papers. Santa Fe, NM: Santa Fe Institute (2004). p. 4.
21.
PumainDPaulusFVacchiani-MarcuzzoCLoboJ. An Evolutionary Theory for Interpreting Urban Scaling Laws. Cybergeo (2006) 2006:1278–3366. 10.4000/cybergeo.2519
22.
RibeiroFLMeirellesJFerreiraFFNetoCR. A Model of Urban Scaling Laws Based on Distance Dependent Interactions. R Soc open Sci (2017) 4(3):160926. 10.1098/rsos.160926
23.
RibeiroFLRybskiD. Mathematical Models to Explain the Origin of Urban Scaling Laws: A Synthetic Review (2021). arXiv preprint arXiv:2111.08365. 10.48550/arXiv.2111.08365
24.
MolineroCThurnerS. How the Geometry of Cities Determines Urban Scaling Laws. J R Soc Interf (2021) 18(176):20200705. 10.1098/rsif.2020.0705
25.
MakseHAAndradeJSBattyMHavlinSStanleyHEModeling Urban Growth Patterns with Correlated Percolation. Phys Rev E (1998) 58(6):7054. 10.1103/PhysRevE.58.7054
26.
European Commission. Global Human Settlement Layer. Population Grid, European Commission (2015). Availableat: http://ghsl.jrc.ec.europa.eu/ghs_pop.php (Accessed September 2019).
27.
European Commission. “Copernicus Urban Atlas (2012). Availableat: https://land.copernicus.eu/local/urban-atlas/building-height-2012 (Accessed September 2019).
28.
Planet OSM. OpenStreetMap Contributors, “Planet Dump (2017). Availableat: https://planet.osm.orghttps://www.openstreetmap.org (Accessed September 2019).
29.
Eurostat. Eurostat Gdp Data at Nuts-3 Level (2017). Availableat: https://ec.europa.eu/eurostat/web/rural-development/data (Accessed September 2019).
Summary
Keywords
fractal theory, urban growth, urban science, scaling theory, complexity science
Citation
Molinero C (2022) A Fractal Theory of Urban Growth. Front. Phys. 10:861678. doi: 10.3389/fphy.2022.861678
Received
25 January 2022
Accepted
21 April 2022
Published
09 June 2022
Volume
10 - 2022
Edited by
Haroldo V. Ribeiro, State University of Maringá, Brazil
Reviewed by
Luiz G. A. Alves, Northwestern University, United States
Satyam Mukherjee, Shiv Nadar University, Greater Noida, India
Updates
Copyright
© 2022 Molinero.
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: C. Molinero, c.molinero@ucl.ac.uk
This article was submitted to Social Physics, a section of the journal Frontiers in Physics
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.