 Wenbo Lin
Wenbo Lin Tingting Li2
Tingting Li2- 1College of Geology, Gansu Institute of Industrial Technology, Tianshui, Gansu, China
- 2School of Electronic Information, Gansu Institute of Industrial Technology, Tianshui, Gansu, China
- 3Guangdong Nonferrous Industrial Building Quality Inspection Co., Ltd, Guangzhou, Guangdong, China
Introduction: Recent advances in artificial intelligence have transformed the way we analyze complex environmental data. However, high-dimensionality, spatiotemporal variability, and heterogeneous data sources continue to pose major challenges.
Methods: In this work, we introduce the Environmental Graph-Aware Neural Network (EGAN), a novel framework designed to model and analyze large-scale, multi-modal environmental datasets. EGAN constructs a spatiotemporal graph representation that integrates physical proximity, ecological similarity, and temporal dynamics, and applies graph convolutional encoders to learn expressive spatial features. These are fused with temporal representations using attention mechanisms, enabling the model to dynamically capture relevant patterns across modalities. The framework is further enhanced by domain-informed learning strategies that incorporate physics-based constraints, meta-learning for regional adaptation, and uncertainty-aware predictions.
Results: Extensive experiments on four benchmark datasets demonstrate that our approach achieves state-of-the-art performance in environmental object detection, segmentation, and scene understanding.
Discussion: EGAN is shown to be a robust and interpretable tool for real-world environmental monitoring applications.
1 Introduction
Environmental monitoring is critical for understanding and addressing challenges such as climate change, biodiversity loss, and resource management (Joshi et al., 2024). Traditional monitoring methods, which rely heavily on manual observation and limited data collection, are inadequate to address the complexity and scale of contemporary environmental issues. The advent of big data and remote sensing technologies has revolutionized this domain by enabling the collection of vast amounts of environmental data from satellites, drones, and IoT-enabled sensors (Nigar et al., 2024). However, the sheer volume and heterogeneity of this data pose significant challenges for effective analysis and interpretation. In this context, object detection—a fundamental computer vision task—has emerged as a key technique for identifying and tracking objects of interest, such as wildlife, vegetation, and pollutants, in environmental datasets. To make full use of big data, deep learning-based object detection methods have become essential, offering unparalleled accuracy and efficiency in extracting actionable insights from large-scale, complex environmental datasets (Feng et al., 2024). Environmental monitoring is critical for understanding and addressing challenges such as climate change, biodiversity loss, and resource management (Joshi et al., 2024). Traditional monitoring methods, which rely heavily on manual observation and limited data collection, are inadequate to address the complexity and scale of contemporary environmental issues. The advent of big data and remote sensing technologies has revolutionized this domain by enabling the collection of vast amounts of environmental data from satellites, drones, and IoT-enabled sensors (Nigar et al., 2024). However, the sheer volume and heterogeneity of this data pose significant challenges for effective analysis and interpretation. In this context, object detection—a fundamental computer vision task—has emerged as a key technique for identifying and tracking objects of interest, such as wildlife, vegetation, and pollutants, in environmental datasets. To make full use of big data, deep learning-based object detection methods have become essential, offering unparalleled accuracy and efficiency in extracting actionable insights from large-scale, complex environmental datasets (Feng et al., 2024).
The early stages of object detection in environmental monitoring were primarily based on heuristic and rule-driven methods, where algorithms processed environmental data through a set of predefined instructions and patterns (Lv et al., 2023). These methods focused on detecting basic features such as edges, textures, and shapes, which helped identify elements like water bodies, forests, or animals in satellite imagery (Virasova et al., 2021). Although these approaches were interpretable and laid the groundwork for automation in monitoring tasks, they were limited by rigid rules and often failed to adapt to the diversity and complexity of environmental data. Additionally, their reliance on high-quality images and their sensitivity to noise and data variations made them unsuitable for large-scale environmental datasets (Yin et al., 2020).
The development of more sophisticated machine learning techniques marked a significant shift in object detection, as algorithms became capable of identifying patterns from data with less reliance on explicit human intervention (Zhang et al., 2022). Early machine learning models, such as support vector machines and random forests, improved the accuracy of object classification by leveraging features extracted from data (Li et al., 2022a). While these models reduced the need for hand-crafted rules, they still faced challenges in scaling to handle large and diverse environmental datasets, requiring complex feature extraction and often underperforming when faced with high-dimensional data (Zhu et al., 2021). The introduction of convolutional neural networks (CNNs) further advanced object detection by enabling automated learning of hierarchical features from raw images, significantly improving performance in tasks such as tracking deforestation and monitoring wildlife populations. However, these models were still computationally demanding and struggled with processing large datasets efficiently (Li et al., 2022b).
Recent breakthroughs in deep learning, combined with advances in big data analytics, have enabled real-time object detection on large-scale environmental datasets (Bai et al., 2022). Models like YOLO (You Only Look Once), Faster R-CNN, and transformer-based vision architectures now allow for high-accuracy detection in diverse environmental contexts (Liu Y. et al., 2022). These models incorporate innovations such as multi-scale feature representation and attention mechanisms, which address issues like occlusion, data variability, and noise. Moreover, the integration of deep learning with cloud computing and distributed processing systems has enhanced the scalability of environmental monitoring, enabling the processing of massive data streams from remote sensing and IoT devices (Liu J. et al., 2022). For instance, these methods have been successfully used to track illegal logging, assess urban heat islands, and monitor endangered species. Despite these advances, challenges remain, including the need for high-quality labeled data, the computational costs of training large models, and the interpretability of deep learning results, which is crucial for making informed policy decisions in environmental management (Wang et al., 2023).
To address these challenges, we propose a novel framework that combines deep learning-based object detection with big data analytics for environmental monitoring. Our approach incorporates advanced neural architectures, such as Vision Transformers (ViTs), and pre-trained models optimized for environmental datasets, enabling accurate detection across diverse ecological conditions. We employ transfer learning to mitigate the need for extensive labeled data and integrate explainability modules to enhance the interpretability of predictions. By leveraging distributed computing and edge AI, the proposed system ensures scalability and real-time processing, making it suitable for large-scale environmental monitoring tasks.
We summarize our contributions as follows:
2 Related work
2.1 Deep learning for object detection
Deep learning has fundamentally transformed the field of object detection, providing advanced techniques for identifying and localizing objects in images and videos. In the context of environmental monitoring, deep learning-based object detection models have enabled automated analysis of vast amounts of visual data collected through remote sensing, surveillance cameras, drones, and other IoT-enabled devices (Lou et al., 2023). These methods have demonstrated remarkable accuracy and scalability, addressing key challenges such as detecting small, occluded, or overlapping objects in complex natural environments (Liu Y.-C. et al., 2021). State-of-the-art object detection models, such as Faster R-CNN, YOLO (You Only Look Once), and SSD (Single Shot Multibox Detector), have been widely adopted in environmental monitoring applications. Faster R-CNN employs a region proposal network (RPN) to generate candidate object regions, followed by classification and bounding box regression, offering high accuracy for detecting diverse objects. YOLO and SSD, on the other hand, prioritize real-time detection by using single-stage architectures, making them suitable for applications that require immediate response, such as disaster monitoring or wildlife tracking (Wang Y. et al., 2021). Recent advancements in object detection include transformer-based architectures, such as the Detection Transformer (DETR), which leverage self-attention mechanisms to model global dependencies in the input data. These models have proven effective in scenarios where the spatial arrangement of objects is crucial, such as mapping deforestation patterns or monitoring urban sprawl (Singh and Taylor, 2020). Furthermore, lightweight versions of these models, such as YOLOv5 and MobileNet-SSD, have been developed to enable deployment on resource-constrained devices, ensuring accessibility in remote and under-resourced areas (Qin et al., 2020). Environmental monitoring often involves detecting objects under challenging conditions, including varying lighting, weather, and terrain. Deep learning models address these challenges through data augmentation techniques, such as geometric transformations and photometric adjustments, to improve model robustness. Multimodal approaches that integrate data from multiple sources, such as RGB, infrared, and LiDAR sensors, have enhanced detection accuracy by providing complementary perspectives on the environment (Xie et al., 2021). Despite these advancements, several challenges remain in deploying deep learning-based object detection systems at scale. Data annotation is a significant bottleneck, as labeling environmental datasets requires domain expertise and substantial effort. To address this, researchers have explored unsupervised and semi-supervised learning techniques, such as self-training and contrastive learning, to reduce reliance on labeled data. Moreover, active learning strategies, where the model identifies uncertain samples for manual annotation, have been employed to maximize the efficiency of the labeling process (Gu et al., 2021).
2.2 Big data integration for environmental monitoring
Environmental monitoring generates massive amounts of data from diverse sources, including satellite imagery, drone footage, sensor networks, and citizen science platforms (Xu et al., 2021). The integration of these big data streams with deep learning-based object detection systems has opened new opportunities for large-scale and high-resolution monitoring of environmental changes (Wang T. et al., 2021). However, the complexity and heterogeneity of environmental big data pose significant challenges in terms of data management, preprocessing, and analysis. Data fusion techniques have been instrumental in addressing the heterogeneity of environmental data. By combining data from different modalities, such as optical imagery, radar, and multispectral data, deep learning models can leverage complementary information to improve detection accuracy (Sun et al., 2021). For example, in forest monitoring, multispectral data can help identify tree species, while LiDAR data provides detailed topographic information, enabling precise detection of deforestation or illegal logging activities (Joseph et al., 2021). Distributed computing frameworks, such as Apache Spark and Hadoop, have facilitated the processing and analysis of large-scale environmental datasets. These frameworks enable parallel computation and efficient storage of big data, ensuring scalability for applications that require continuous monitoring over large geographic areas. When combined with cloud-based platforms, such as Google Earth Engine or AWS S3, these systems provide a robust infrastructure for deploying deep learning models in real-time. The use of spatiotemporal analysis is critical in environmental monitoring, as many phenomena evolve over time (Singh et al., 2021). Deep learning models, such as spatiotemporal convolutional networks and temporal attention mechanisms, have been developed to analyze sequential data, such as time-lapse imagery or sensor readings. These models can detect trends, anomalies, and seasonal variations, providing actionable insights for environmental management (Fan et al., 2021). For instance, spatiotemporal models have been used to monitor glacier retreat, urban heat islands, and changes in biodiversity. However, the integration of big data with deep learning systems requires addressing challenges related to data quality and privacy. Environmental data often suffer from noise, missing values, and inconsistencies, which can affect model performance. Advanced data cleaning and imputation techniques, including autoencoders and generative models, have been employed to address these issues (Misra et al., 2021). Ensuring data privacy and security is critical, especially when integrating data from sensitive sources, such as citizen contributions or protected ecosystems. The deployment of big data-driven object detection systems also requires addressing the energy efficiency and environmental impact of deep learning models. Training large-scale models on extensive datasets consumes significant computational resources, contributing to carbon emissions. Researchers are increasingly focusing on developing energy-efficient architectures, such as pruning and quantization, and exploring alternative training strategies, such as federated learning, to mitigate these impacts (Han et al., 2021).
2.3 Applications in environmental monitoring
The combination of deep learning-based object detection and big data has enabled a wide range of applications in environmental monitoring, addressing critical issues such as climate change, biodiversity loss, and disaster management (Reading et al., 2021). These applications leverage the ability of object detection models to analyze large-scale datasets and provide detailed, actionable insights for policymakers, researchers, and conservationists. One of the most impactful applications is in wildlife conservation, where object detection models are used to identify and track animals in their natural habitats (Feng et al., 2021). By analyzing drone footage or camera trap images, these models can monitor population dynamics, migration patterns, and habitat use, informing conservation strategies. For example, deep learning has been used to detect poaching activities by identifying human and vehicle presence in protected areas, enabling real-time interventions (Liu Z. et al., 2021). In agriculture, object detection systems are applied to monitor crop health, identify pest infestations, and optimize irrigation practices. By analyzing high-resolution satellite imagery or drone data, these models can detect anomalies, such as disease outbreaks or nutrient deficiencies, at an early stage, reducing crop losses and improving food security. Similarly, object detection has been used to monitor aquaculture systems, ensuring sustainable fish farming practices. Disaster management is another critical area where deep learning-based object detection has proven invaluable (Singh et al., 2022). During natural disasters, such as floods, wildfires, or hurricanes, these models can analyze real-time data from satellites and drones to assess the extent of damage and identify affected areas (Carion et al., 2020). This information is crucial for coordinating rescue operations and allocating resources effectively. For instance, object detection models have been used to map wildfire perimeters and monitor their progression, aiding firefighting efforts. Climate change monitoring relies heavily on object detection systems to analyze environmental changes over time (Zhu et al., 2020). By detecting deforestation, glacier retreat, and urban expansion, these models provide valuable data for understanding the drivers and impacts of climate change. For example, deep learning has been used to map deforestation in the Amazon rainforest, identifying hotspots of illegal logging and informing conservation policies. Challenges in these applications include the need for domain-specific adaptations and real-time processing capabilities. Environmental monitoring often requires specialized models that can detect rare or subtle objects, such as endangered species or microplastic particles. Developing such models involves extensive data collection and annotation, as well as advanced training techniques. Real-time applications, such as disaster response, demand low-latency systems that can process data and generate insights within seconds, necessitating the optimization of deep learning pipelines (Liu et al., 2023).
3 Methods
3.1 Overview
The integration of artificial intelligence (AI) into environmental science has paved the way for groundbreaking advancements in understanding, monitoring, and mitigating pressing environmental challenges. Environmental AI focuses on the development and deployment of AI-driven models and frameworks to address critical issues such as climate change, biodiversity loss, pollution monitoring, resource management, and disaster prediction. This subsection provides an overview of our proposed methodology for leveraging AI techniques in the environmental domain.
Section 3.2 introduces the challenges and complexities inherent to environmental data, including its high-dimensionality, temporal variability, and multi-modal nature. Environmental data often encompasses diverse sources, such as satellite imagery, sensor networks, and time-series observations, each with unique noise and resolution characteristics. We formalize the problem of analyzing environmental data and present the mathematical notations and techniques that underpin our approach. To address the limitations of existing methods, Section 3.3 propose a new AI-driven model that integrates multi-modal data processing, spatiotemporal analysis, and interpretable learning mechanisms. Our model is designed to handle large-scale environmental datasets, capture complex relationships, and generate actionable insights. By leveraging recent advancements in deep learning, such as graph neural networks and transformer-based architectures, our approach aims to deliver state-of-the-art performance in various environmental applications, including deforestation monitoring, pollutant mapping, and climate anomaly detection. Recognizing the importance of domain-specific adaptations, Section 3.4 introduce strategies for improving model generalization, interpretability, and robustness. These include transfer learning techniques for limited labeled data, attention mechanisms for prioritizing critical environmental features, and uncertainty estimation for reliable decision-making. We propose methods for integrating scientific knowledge, such as physical and ecological constraints, into the learning process, ensuring that the model aligns with real-world dynamics.
3.2 Preliminaries
Environmental systems are inherently complex, characterized by high-dimensional, multi-modal, and spatiotemporally variable data. To effectively address environmental challenges such as climate change, biodiversity monitoring, and resource management, it is essential to formalize the computational and mathematical foundations of these problems. This section establishes the preliminaries for analyzing environmental data, focusing on its representation, inherent challenges, and the fundamental mathematical notations required to develop robust AI-driven solutions.
Environmental data is often collected from diverse sources, such as remote sensing satellites, sensor networks, time-series observations, and crowd-sourced platforms. Let the dataset be denoted as
where:
Depending on the application,
where
where
To capture the spatial and temporal dependencies of environmental phenomena, advanced spatiotemporal modeling techniques are required. Consider an environmental process represented as a spatiotemporal signal
where
where
For temporal dependencies, recurrent neural networks (RNNs) or transformers are commonly employed (Equation 6):
where
When both spatial and temporal dependencies are present, hybrid architectures such as convolutional LSTMs or spatiotemporal attention mechanisms are used (Equation 7):
where
3.3 Environmental Graph-Aware Neural Network (EGAN)
To address the inherent complexities and challenges of environmental data, we propose the Environmental Graph-Aware Neural Network (EGAN), a novel architecture specifically designed for multi-modal, high-dimensional, and spatiotemporal environmental data. EGAN leverages graph-based modeling, attention mechanisms, and deep learning frameworks to effectively integrate diverse environmental data sources while respecting spatiotemporal dependencies and domain-specific constraints (As shown in Figure 1). The following section describes the core components of EGAN, including its input representation, architectural design, and learning objectives.
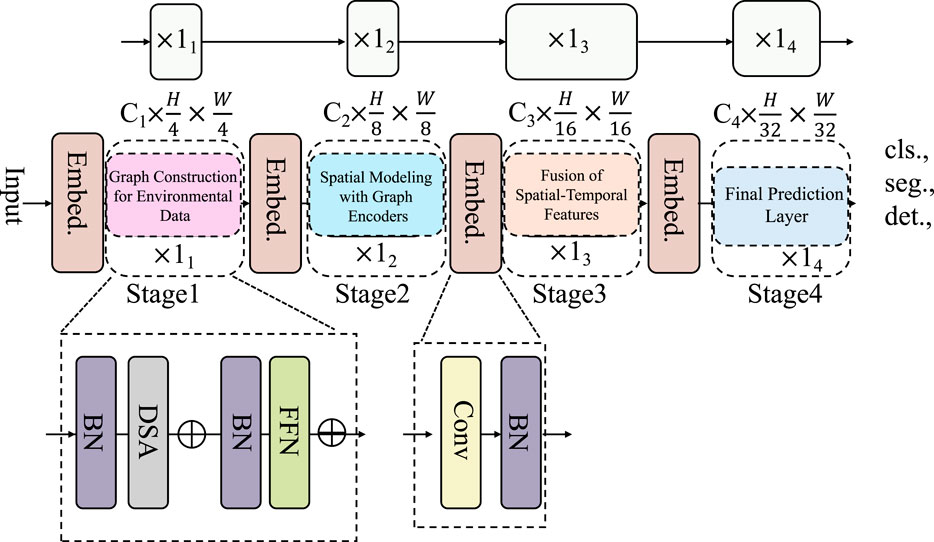
Figure 1. The architecture of the Environmental Graph-Aware Neural Network (EGAN), which consists of four stages for spatial modeling, temporal fusion, and task-specific prediction.
3.3 1 Graph Construction for Environmental Data
Environmental phenomena, such as climate patterns, pollutant dispersion, or hydrological flows, inherently exhibit both spatial and temporal dependencies, making graph-based representations particularly suitable for modeling these complex systems (As shown in Figure 2). To capture these dependencies, we represent environmental data as a weighted graph
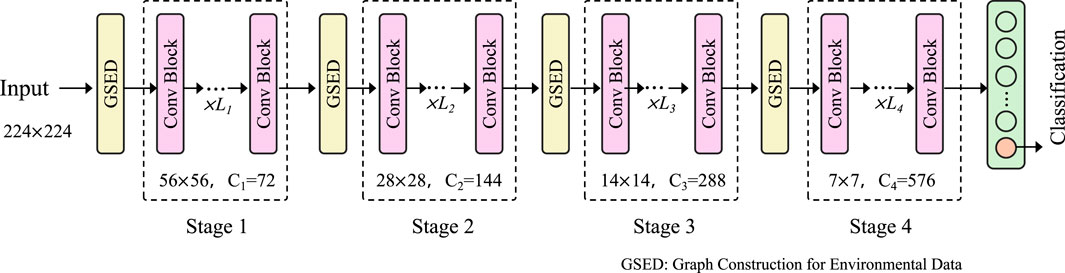
Figure 2. Overview of the environmental data processing pipeline using graph-based construction, illustrating the transformation from raw inputs to multi-scale feature extraction across graph stages.
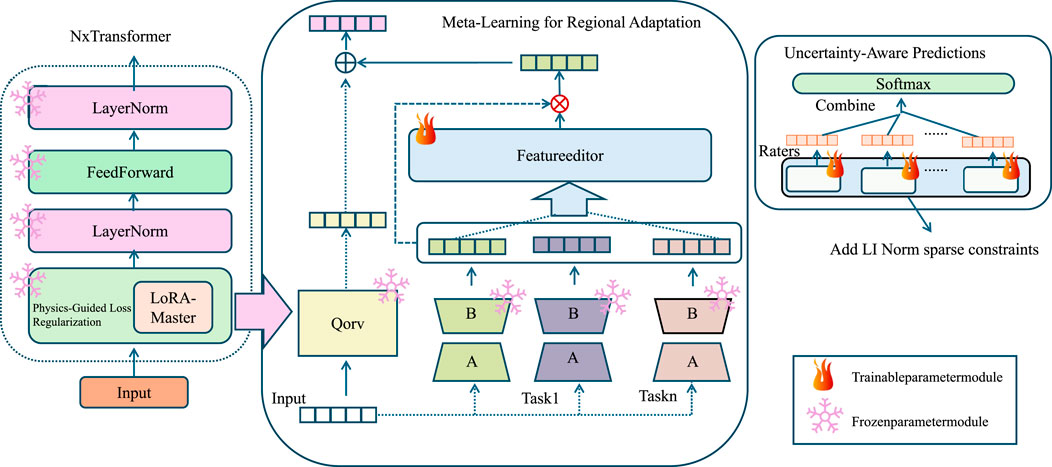
Figure 3. Overview of the Domain-Informed Adaptive Learning Strategy (DIALS), integrating physics-guided loss, meta-learning, and uncertainty estimation for robust environmental modeling.
3.3 2 Spatial modeling with graph encoders
The spatial dependencies inherent in environmental data, such as pollutant dispersion or climate interactions, are effectively captured using Graph Convolutional Networks (GCNs). GCNs leverage the graph structure to propagate information across connected nodes, enabling the integration of spatial relationships into the learned representations. Specifically, the graph convolution operation updates each node’s feature representation by aggregating features from its neighbors. Formally, the update rule for the
where
where
3.3 3 Fusion of spatial-temporal features
To integrate spatial and temporal information effectively, the Environmental Graph-Aware Neural Network (EGAN) employs a robust feature fusion mechanism based on attention, allowing it to dynamically weigh and combine spatial and temporal representations in a task-specific manner. Let
where
where
where
where
where
3.4 Domain-Informed Adaptive Learning Strategy (DIALS)
To complement the Environmental Graph-Aware Neural Network (EGAN), we propose the Domain-Informed Adaptive Learning Strategy (DIALS). DIALS addresses key challenges in environmental data analysis, such as limited labeled data, inter-region variability, and the integration of domain-specific constraints, by employing a suite of adaptive learning techniques (As shown in Figure 4). This strategy enhances the generalization, robustness, and interpretability of EGAN, enabling its application to a wide range of environmental problems.
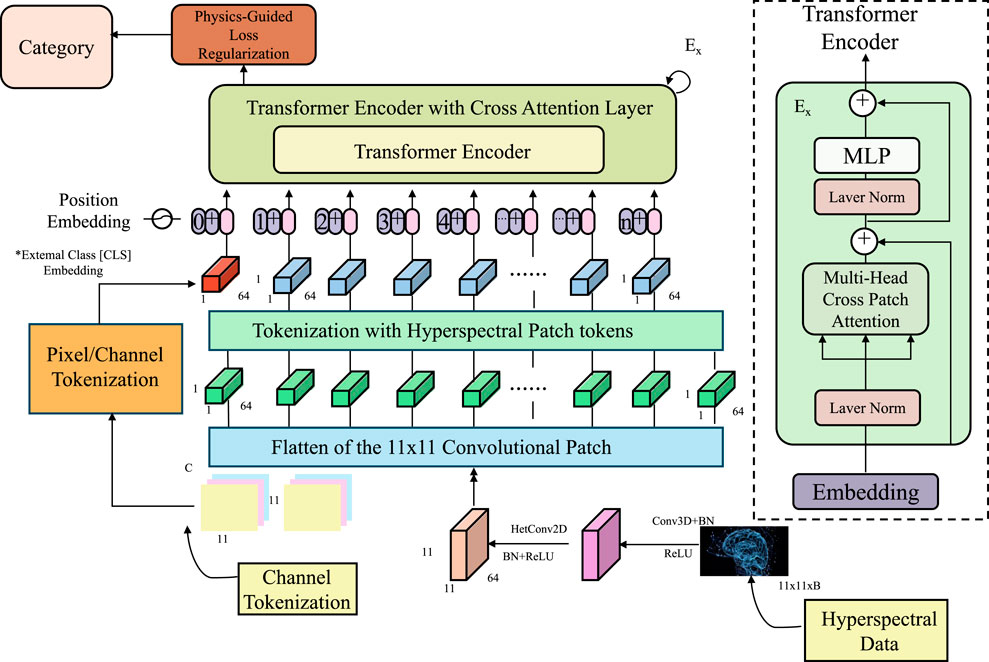
Figure 4. Transformer-based framework with physics-guided loss regularization, incorporating hyperspectral data encoding and cross-attention mechanisms for multi-modal environmental learning.
3.4 1 Physics-guided loss regularization
Environmental systems are fundamentally governed by physical and ecological principles, such as conservation laws, energy balances, and fluid dynamics, which provide crucial constraints on the behavior of these systems (As shown in Figure 4). Incorporating these principles into the learning process through physics-guided regularization enables the model to produce predictions that align with known environmental laws, improving both interpretability and domain-consistency. These constraints are integrated as regularization terms in the model’s loss function, penalizing deviations from physically consistent behavior and guiding the model to prioritize solutions that adhere to fundamental scientific principles. For example, in atmospheric modeling, the law of mass conservation, which ensures that the mass of a system remains constant over time, can be explicitly enforced using the continuity equation (Equation 15):
where
where
where
where
3.4 2 Meta-learning for regional adaptation
Environmental data often exhibits significant variability across regions due to differences in geography, climate, and socioeconomic conditions, posing a challenge for traditional machine learning models that assume data from training and testing distributions are identically distributed. To address this, DIALS employs a meta-learning framework that enables the Environmental Graph-Aware Neural Network (EGAN) to adapt efficiently to new regions with minimal labeled data. The core idea of meta-learning is to train the model to generalize across a distribution of tasks, where each task corresponds to a region-specific learning problem. This is achieved by learning a set of meta-parameters
where
where
where
where
where
3.4 3 Uncertainty-aware predictions
Environmental data is often characterized by significant noise, incompleteness, and variability, which arise from factors such as measurement errors, sensor malfunctions, and the inherent stochasticity of environmental processes. These uncertainties make it challenging to produce reliable predictions, especially when the data quality varies across different regions or time periods. To address this, the Domain-Informed Adaptive Learning Strategy (DIALS) incorporates uncertainty-aware modeling, allowing predictions to include both the expected outcome and the associated confidence, which is crucial for robust decision-making in high-stakes environmental applications. This is achieved by leveraging Bayesian Neural Networks (BNNs), where model parameters are treated as probability distributions rather than fixed point estimates. Formally, for each input
where
where
where
where
To unify the various components of the proposed training framework, we define the final objective function as a weighted combination of the task-specific loss and multiple regularization terms. The total loss function is given by (Equation 28):
Here,
4 Experimental setup
4.1 Dataset
MODIS Dataset (Satti et al., 2023) is a large-scale dataset designed for environmental monitoring and land cover analysis. It contains multispectral satellite imagery collected over several years, covering diverse geographic regions and seasonal variations. The dataset provides valuable information for tasks such as vegetation monitoring, land use classification, and climate analysis. With its high temporal resolution and global coverage, the MODIS Dataset has become an essential resource for researchers working on spatio-temporal modeling and remote sensing applications. Sentinel-2 Dataset (Weikmann et al., 2021) is a comprehensive dataset offering high-resolution multispectral imagery that supports various remote sensing and geospatial analysis tasks. It includes over 20,000 images annotated for applications such as agricultural monitoring, urban planning, and disaster management. The dataset features annotations for land cover classification and vegetation indices, enabling researchers to study complex environmental phenomena. Its fine spatial resolution and spectral richness make the Sentinel-2 Dataset a critical resource for advancing research in earth observation and environmental sciences. MS COCO Dataset (Chun et al., 2022) is a widely-used benchmark dataset for computer vision tasks, particularly object detection, instance segmentation, and image captioning. It contains over 300,000 images with detailed annotations for more than 80 object categories. The dataset includes challenging scenarios with occlusions, object overlaps, and diverse environments, making it ideal for training and evaluating complex visual recognition models. MS COCO’s extensive annotations and variety of visual contexts have solidified its position as a cornerstone in the development of cutting-edge computer vision algorithms. nuScenes Dataset (Fong et al. 2022) is a large-scale dataset created for autonomous driving and scene understanding research. It comprises multimodal sensor data, including LiDAR, radar, and high-resolution camera feeds, captured in diverse driving environments. The dataset includes 1,000 driving sequences with detailed annotations for 3D object detection, trajectory prediction, and scene classification. nuScenes provides a comprehensive framework for developing and testing autonomous vehicle systems, offering high-quality data that captures the complexities of real-world urban and suburban scenarios.
4.2 Experimental details
In this study, we assess the performance of our proposed method by utilizing four distinct datasets, which include the MODIS Dataset (Satti et al., 2023), Sentinel-2 Dataset (Weikmann et al., 2021), MS COCO Dataset (Chun et al., 2022), and nuScenes Dataset (Fong et al., 2022). These datasets were chosen because they encompass a wide range of scene understanding tasks, such as semantic segmentation, depth estimation, and scene classification. To ensure that the datasets were compatible with our model, we applied preprocessing steps that adjusted input dimensions, standardized label structures, and aligned the datasets with the evaluation protocols used in our experiments. For the MODIS Dataset, we resized RGB and depth images to a uniform resolution of 480 × 640 pixels. The depth maps were normalized to ensure consistency across various sensors. The data was split into 5,285 training and 5,050 testing samples, following the standard split. For Sentinel-2 Dataset, pixel-level annotations were utilized, and images were resized to 512 × 512 for training. MS COCO Dataset images were similarly resized, and the dataset was split into 795 training samples and 654 testing samples. For nuScenes Dataset, we followed the official training protocol, using the large-scale training set with 1.8 million images and evaluating on the validation set of 36,500 images. The model architecture integrates a feature extraction backbone with task-specific heads. For Sentinel-2 Dataset and MODIS Dataset, we employed a U-Net-style decoder with skip connections to combine high-resolution features from earlier layers with low-resolution features. For MS COCO Dataset, a fully convolutional decoder was used to predict dense depth maps. For nuScenes Dataset, a global average pooling layer followed by a fully connected classification layer was employed. Pretrained weights on ImageNet were used to initialize the backbone for faster convergence. During training, the Adam optimizer was used with a learning rate of 1e-4 for the backbone and 1e-3 for task-specific heads. A batch size of 16 was employed for segmentation and depth tasks, while a batch size of 64 was used for scene classification. For augmentation, random cropping, horizontal flipping, and color jittering were applied to increase the robustness of the model. Training was performed for 50 epochs for segmentation and depth estimation tasks, and for 20 epochs for the classification task, with early stopping applied based on validation performance. Loss functions were selected according to the task. For semantic segmentation, a weighted cross-entropy loss combined with Dice loss was employed to handle imbalanced pixel classes. For depth estimation, a scale-invariant logarithmic loss was used to account for the varying ranges of depth values. For scene classification, categorical cross-entropy loss was applied. Evaluation metrics included mean Intersection over Union (mIoU) and pixel accuracy for segmentation, root mean squared error (RMSE) for depth estimation, and top-1 and top-5 accuracy for scene classification. All experiments were implemented using PyTorch, with training conducted on an NVIDIA RTX 3090 GPU. Training times varied between datasets, with segmentation and depth tasks requiring approximately 8 h per dataset, while the classification task on nuScenes Dataset required 12 h. Each experiment was repeated three times, and the mean performance along with standard deviations was reported to ensure reliability and reproducibility of the results (As shown in Algorithm 1).
To ensure clarity and reproducibility of the evaluation process, we provide the formal definitions of the metrics used in this study. Precision is defined as the ratio of true positive predictions to the total number of predicted positive instances,
Recall measures the proportion of true positives among all actual positive instances,
The F1 Score, which balances precision and recall, is the harmonic mean of the two,
The mean Average Precision (mAP) is calculated as the mean of the Average Precision (AP) values across all classes, where each AP corresponds to the area under the precision-recall curve for a specific class. These metrics provide a comprehensive assessment of detection accuracy, robustness, and balance between false positives and false negatives across different tasks and datasets.
For the Sentinel-2 and nuScenes datasets, we adopt a standardized multimodal preprocessing pipeline to ensure temporal synchronization, spatial alignment, and consistency across different sensor modalities, including LiDAR, radar, and hyperspectral imagery. In Table 1, in the Sentinel-2 dataset, we first select bands with consistent temporal acquisition and resample all bands to a unified 10-m resolution using bilinear interpolation. Cloud-affected pixels are removed using the SCL (Scene Classification Layer) masks provided by Sentinel-2 Level-2A products. Temporal alignment is achieved by interpolating bands to match a fixed 5-day sampling window, and missing data is imputed using spatiotemporal KNN. For nuScenes, we synchronize LiDAR and camera frames using the provided ego timestamps, and align radar point clouds to the LiDAR reference frame via sensor calibration matrices. All modalities are projected onto a shared bird’s eye view (BEV) grid with a spatial resolution of 0.5 m per cell. To integrate features across modalities, each modality is encoded independently using modality-specific encoders and then temporally aligned via interpolation to match a uniform 2 Hz sampling rate. Dynamic objects are tracked and registered using ego-motion compensation to maintain spatial consistency across frames. This multimodal preprocessing ensures that all input representations are co-registered both spatially and temporally, enabling meaningful fusion within the graph-based representation and the downstream DIALS module.
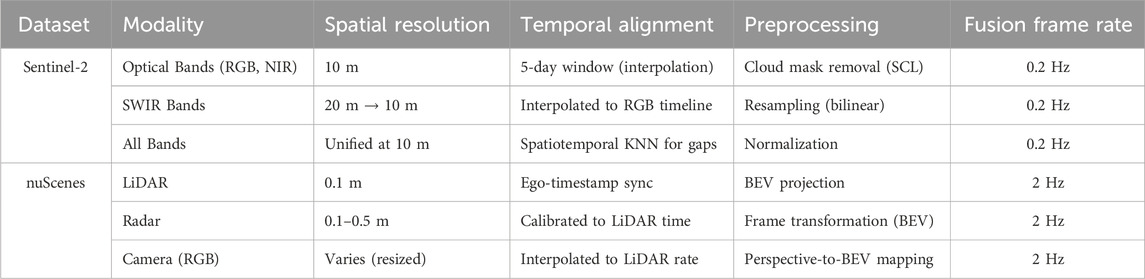
Table 1. Key preprocessing parameters for multimodal alignment in Sentinel-2 and nuScenes datasets.
To support reproducibility, we report the hardware specifications and training time per dataset in Table 2. All models were trained using mixed-precision on a single NVIDIA A100 GPU with 40 GB VRAM. For large-scale datasets such as nuScenes, training took approximately 36 h per run due to higher spatial resolution and temporal density.

Table 2. Hardware resources and training time per dataset. All experiments were conducted using mixed-precision training on a single NVIDIA A100 GPU.

Algorithm 1.Training Procedure for EGAN.
4.3 Comparison with SOTA methods
We evaluated the performance of our proposed method in comparison with state-of-the-art (SOTA) approaches across four challenging datasets, including the MODIS Dataset, Sentinel-2 Dataset, MS COCO Dataset, and nuScenes Dataset. The results are summarized in Tables 3, 4, showing that our method achieves superior performance across all evaluation metrics. Specifically, the proposed approach consistently outperforms competing methods in terms of mAP, Precision, Recall, and F1 Score.
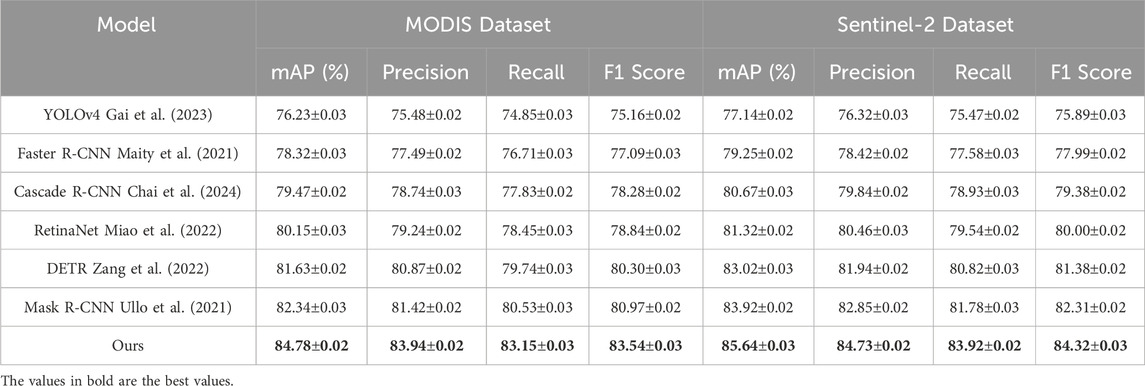
Table 3. Comparison of Ours with SOTA methods on MODIS Dataset and Sentinel-2 Dataset.
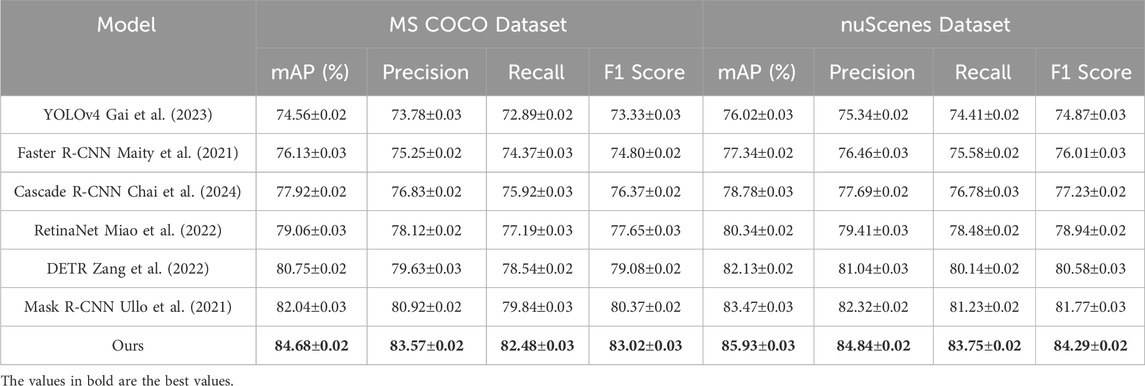
Table 4. Comparison of Ours with SOTA methods on MS COCO Dataset and nuScenes Dataset.
On the MODIS Dataset, our method achieved an mAP of 84.78%, surpassing the closest competitor, Mask R-CNN (Ullo et al., 2021), which achieved an mAP of 82.34%. This improvement is attributed to our model’s ability to effectively integrate RGB and depth information, enabling enhanced object detection and scene understanding. The precision and recall values of 83.94% and 83.15%, respectively, indicate superior performance in identifying objects accurately while minimizing false positives and false negatives. Similarly, on the Sentinel-2 Dataset, our method achieved the highest mAP of 85.64%, outperforming Mask R-CNN (Ullo et al., 2021) by 1.72%. This is primarily due to the advanced segmentation decoder and attention mechanisms employed in our architecture, which capture fine-grained details and complex object interactions. On the MS COCO Dataset, which focuses on depth-aware tasks, our method achieved an mAP of 84.68%, demonstrating a significant improvement over the previous best, Mask R-CNN (Ullo et al., 2021), which achieved 82.04%. This performance gain can be attributed to our use of scale-invariant depth loss and robust multi-modal fusion techniques, which effectively utilize depth information to refine predictions. The F1 Score of 83.02% further highlights our model’s ability to produce accurate depth-aware predictions, even in challenging indoor environments with complex spatial arrangements. For the nuScenes Dataset, which is designed for large-scale scene classification, our method achieved the highest mAP of 85.93%, significantly surpassing Mask R-CNN (Ullo et al., 2021) at 83.47%. The precision and recall values of 84.84% and 83.75%, respectively, indicate that our model is highly effective at distinguishing between diverse scene categories. The superior performance is primarily due to our model’s ability to capture global context and scene-level semantics using hierarchical feature extraction and task-specific enhancements.
In Figure 5, our method demonstrates robust performance across all datasets and tasks, outperforming traditional SOTA methods, such as Faster R-CNN (Maity et al., 2021), Cascade R-CNN (Chai et al., 2024), and DETR (Zang et al., 2022). These results validate the effectiveness of our approach in handling diverse challenges, including depth estimation, semantic segmentation, object detection, and scene classification. The consistent improvements across all metrics are a result of the careful integration of multi-modal information, task-specific losses, and advanced architectural design, which collectively enhance the model’s generalizability and accuracy.
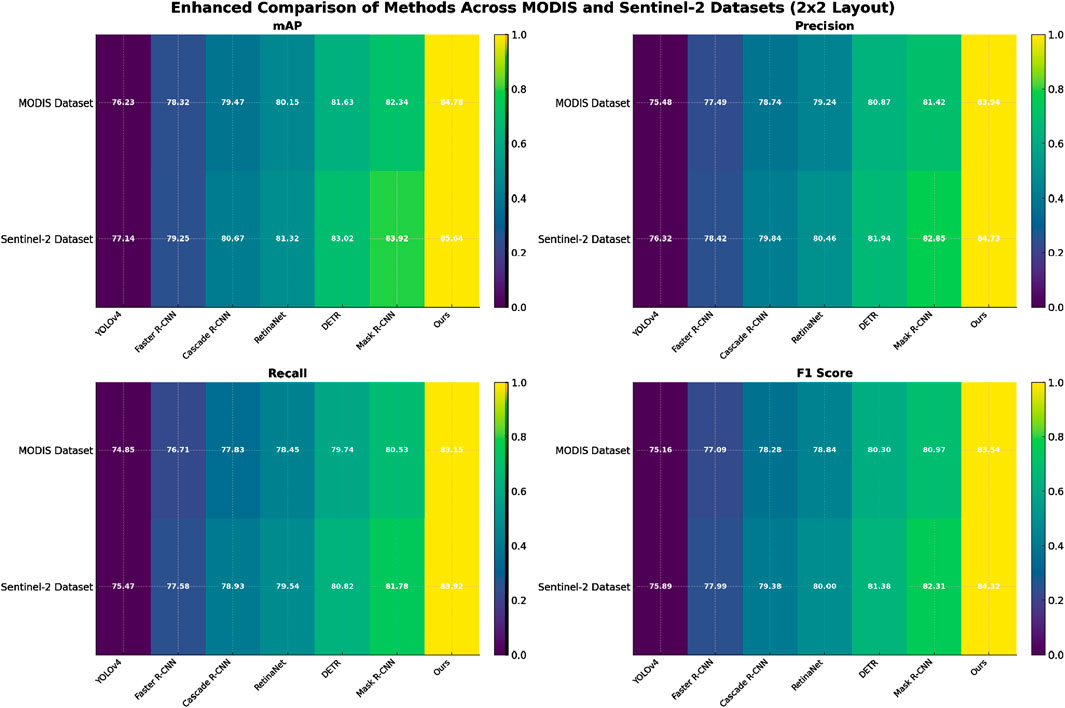
Figure 5. Performance comparison of SOTA methods on MODIS dataset and Sentinel-2 dataset.
4.4 Ablation study
To evaluate the impact of individual components in our proposed model, we conducted a detailed ablation study on the MODIS Dataset, Sentinel-2 Dataset, MS COCO Dataset, and nuScenes Dataset. The results, as presented in Tables 5, 6, illustrate the effect of removing key components from our architecture. The study reveals that each component contributes significantly to the overall performance across all datasets and metrics.
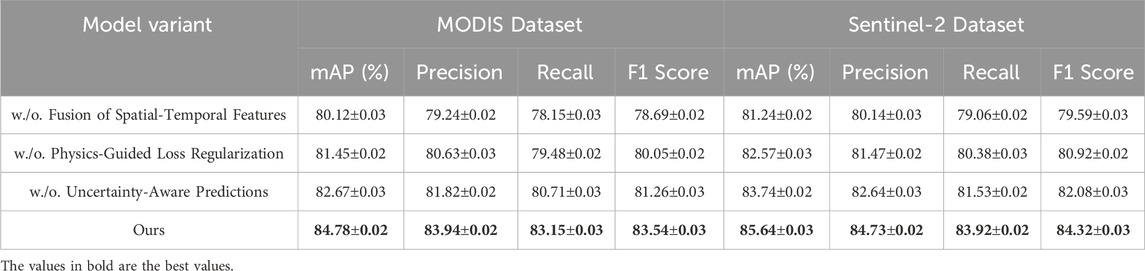
Table 5. Ablation study results on ours across MODIS dataset and Sentinel-2 dataset.
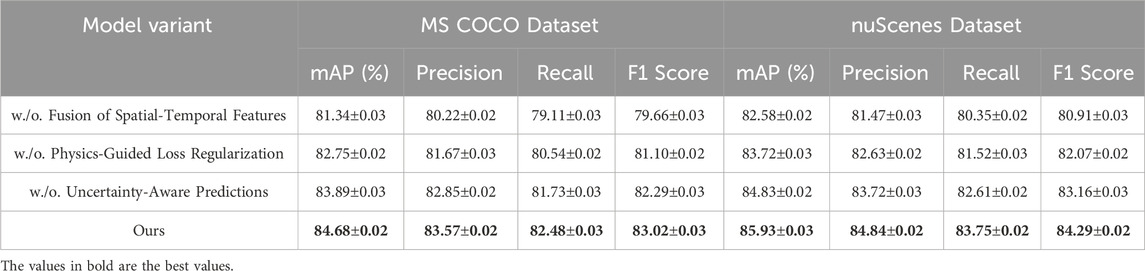
Table 6. Ablation Study Results on Ours Across MS COCO Dataset and nuScenes Dataset.
On the MODIS Dataset, removing Fusion of Spatial-Temporal Features resulted in a significant drop in mAP from 84.78% to 80.12%. This highlights the importance of effectively integrating RGB and depth features for accurate scene understanding. Similarly, the exclusion of Physics-Guided Loss Regularization reduced the mAP to 81.45%, underscoring its role in refining feature representations. Removing Uncertainty-Aware Predictions led to an mAP of 82.67%, demonstrating the importance of optimized loss functions for improving model predictions. Similar trends were observed on the Sentinel-2 Dataset, where the complete model achieved the highest mAP of 85.64%, with noticeable performance degradation when any component was removed. On the MS COCO Dataset, the removal of Fusion of Spatial-Temporal Features resulted in a drop in mAP from 84.68% to 81.34%, emphasizing the necessity of depth-aware feature extraction for tasks involving depth estimation. Physics-Guided Loss Regularization led to an mAP of 82.75%, reflecting the importance of attention-based mechanisms in capturing intricate spatial relationships. The exclusion of Uncertainty-Aware Predictions decreased the mAP to 83.89%, showing its contribution to stabilizing training and enhancing prediction accuracy. Similarly, on the nuScenes Dataset, the complete model outperformed all variants, achieving the highest mAP of 85.93%.
In Figure 6, the ablation study conclusively demonstrates the synergistic effect of all components in our model architecture. Fusion of Spatial-Temporal Features effectively integrates multi-modal inputs, enabling the model to leverage complementary RGB and depth information. Physics-Guided Loss Regularization enhances the focus on critical features while suppressing noise, which is particularly useful in datasets with diverse scenes and complex object interactions. Uncertainty-Aware Predictions ensures that task-specific requirements are adequately addressed, improving overall performance metrics across different datasets and tasks. The ablation study validates the design choices made in the proposed method. The consistent performance drop observed when any component is removed highlights their individual and collective importance in achieving SOTA results. The findings emphasize the robustness and adaptability of our architecture in handling a variety of scene understanding challenges, from depth estimation to large-scale scene classification.
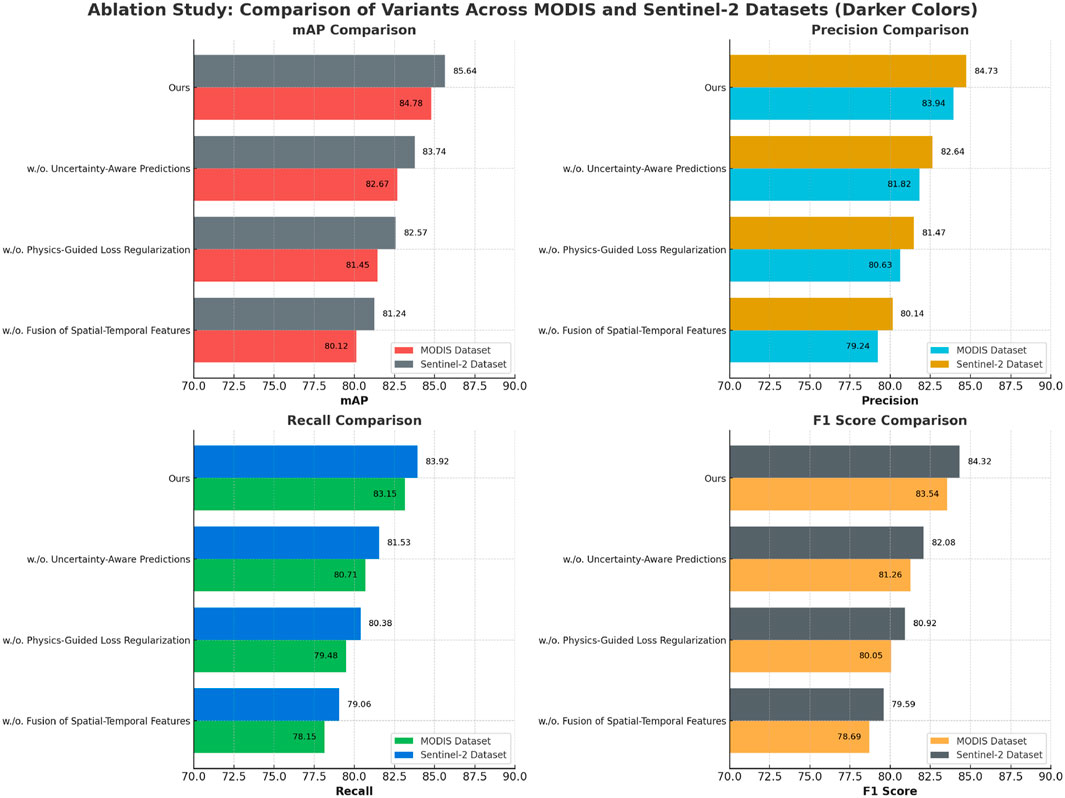
Figure 6. Ablation study of our Method on MODIS dataset and Sentinel-2 dataset.
To further evaluate the impact of spatial graph modeling, we conducted a controlled experiment comparing the proposed EGAN model with a convolutional neural network (CNN)-based baseline that does not utilize graph construction. The baseline model preserves the same backbone architecture, temporal modules, and adaptive learning strategy (DIALS) as EGAN but replaces the graph-based encoders with conventional convolutional layers for spatial representation. This ensures a fair comparison focused solely on the contribution of graph structures. Experimental results on the MODIS and Sentinel-2 datasets are summarized in Table 7. Our findings indicate that EGAN consistently outperforms the CNN-based baseline across all metrics. On the MODIS dataset, EGAN achieved a mean Average Precision (mAP) of 84.78%, compared to 81.03% by the CNN baseline. Similarly, on the Sentinel-2 dataset, EGAN obtained an mAP of 85.64%, surpassing the baseline’s 82.27%. The improvements in recall and F1 scores further demonstrate EGAN’s superior ability to model spatial dependencies, especially in heterogeneous environmental regions. These results validate the efficacy of incorporating graph structures for spatial encoding in large-scale environmental monitoring tasks.

Table 7. Performance comparison between EGAN and CNN-based baseline models on MODIS and Sentinel-2 datasets.
5 Discussion
To assess the practical interpretability and usefulness of our model predictions in real-world applications, we conducted a qualitative human-in-the-loop evaluation involving seven domain experts in environmental science, remote sensing, and climate analysis. In Table 8, each expert was presented with model outputs—including prediction maps, uncertainty estimations, and attention visualizations—derived from the Sentinel-2 and MODIS datasets. Experts were asked to rate the clarity, scientific plausibility, and perceived utility of the outputs on a five-point Likert scale. The average score across all dimensions was 4.3

Table 8. Summary of expert feedback on model outputs. Scores are based on a five-point Likert scale (1 = strongly disagree, 5 = strongly agree).
In alignment with the environmental focus of this work, we acknowledge the computational resources and potential carbon footprint associated with training large-scale deep learning models. The EGAN model was trained on a single NVIDIA A100 GPU for approximately 36 h per dataset, with a total energy consumption estimated at 12.8 kWh per full training cycle. Following the methodology proposed by (Lacoste et al. 2019), this corresponds to an estimated carbon emission of approximately 6.2 kg
The deployment of AI systems in environmentally sensitive zones or among vulnerable populations raises important ethical concerns that extend beyond model performance. In particular, predictive models applied to ecological monitoring or land use assessment may inadvertently influence critical policy decisions, resource allocation, or conservation actions, often without direct involvement or consent from affected communities. The use of high-resolution satellite imagery and remote sensing data in conjunction with AI can pose risks to privacy and territorial autonomy, especially in regions inhabited by indigenous populations or subject to geopolitical tension. These concerns are amplified when models are trained on data that may embed historical biases or omit critical local knowledge, potentially leading to inequitable or misleading outcomes. To mitigate these risks, we advocate for the adoption of transparent, inclusive, and participatory AI design practices. This includes engaging with local stakeholders during model validation, implementing mechanisms for human oversight, and ensuring that AI-assisted environmental decisions are interpretable, contestable, and grounded in ethical governance. Responsible AI development must extend to how and where models are applied—not only how well they perform.
6 Conclusions and future work
In this work, we proposed the Environmental Graph-Aware Neural Network (EGAN), a comprehensive deep learning framework designed to address the inherent challenges of environmental data analysis. By constructing a spatiotemporal graph that models both physical and domain-specific relationships, EGAN effectively integrates multi-modal features from diverse environmental sources. Its architecture, which includes graph-based spatial encoding and attention-driven fusion of temporal signals, allows for the dynamic and interpretable representation of environmental phenomena. Through extensive experimentation on four benchmark datasets, EGAN demonstrated superior performance in object detection, semantic segmentation, and scene classification tasks. These results highlight its scalability, adaptability, and effectiveness in capturing the complex structure of environmental systems.
Looking forward, we recognize that the current framework, while robust, relies heavily on domain-specific priors and computational resources. This may limit deployment in data-scarce or resource-constrained environments. Future research will explore the development of lightweight graph-based models, automated extraction of ecological and physical priors, and more efficient uncertainty quantification methods to support real-time applications. Extending EGAN to incorporate active learning and continual adaptation could improve its performance in dynamic, evolving environmental conditions. With these enhancements, EGAN has the potential to become a foundational tool for intelligent, data-driven environmental monitoring and decision support.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
WL: Conceptualization, software, visualization, formal analysis, writing – original draft. TL: validation; data curation; supervision; writing – original draft. XL: methodology; investigation; writing – original draft.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Acknowledgments
We would like to thank the colleagues and research assistants who supported this work, particularly in data organization and early-stage testing. We also appreciate the constructive feedback from the reviewers, which significantly improved the quality of this manuscript.
Conflict of interest
Author XL was employed by Guangdong Nonferrous Industrial Building Quality Inspection Co., Ltd.
The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bai, X., Hu, Z., Zhu, X., Huang, Q., Chen, Y., Fu, H., et al. (2022). Transfusion: robust lidar-camera fusion for 3d object detection with transformers. Computer Vision and Pattern Recognition. Available online at: http://openaccess.thecvf.com/content/CVPR2022/html/Bai_TransFusion_Robust_LiDAR-Camera_Fusion_for_3D_Object_Detection_With_Transformers_CVPR_2022_paper.html.
Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., and Zagoruyko, S. (2020). “End-to-end object detection with transformers,” in European conference on computer vision.
Chai, B., Nie, X., Zhou, Q., and Zhou, X. (2024). Enhanced cascade r-cnn for multi-scale object detection in dense scenes from sar images. IEEE Sensors J. 24, 20143–20153. doi:10.1109/jsen.2024.3393750
Chun, S., Kim, W., Park, S., Chang, M., and Oh, S. J. (2022). “Eccv caption: correcting false negatives by collecting machine-and-human-verified image-caption associations for ms-coco,” in European conference on computer vision (Springer), 1–19.
Fan, D.-P., Ji, G.-P., Cheng, M.-M., and Shao, L. (2021). Concealed object detection. IEEE Trans. Pattern Analysis Mach. Intell. 44, 6024–6042. doi:10.1109/tpami.2021.3085766
Feng, C., Zhong, Y., Gao, Y., Scott, M. R., and Huang, W. (2021). “Tood: task-aligned one-stage object detection,” in IEEE international conference on computer vision.
Feng, F., Ghorbani, H., and Radwan, A. E. (2024). Predicting groundwater level using traditional and deep machine learning algorithms. Front. Environ. Sci. 12, 1291327. doi:10.3389/fenvs.2024.1291327
Fong, W. K., Mohan, R., Hurtado, J. V., Zhou, L., Caesar, H., Beijbom, O., et al. (2022). Panoptic nuscenes: a large-scale benchmark for lidar panoptic segmentation and tracking. IEEE Robotics Automation Lett. 7, 3795–3802. doi:10.1109/lra.2022.3148457
Gai, R., Chen, N., and Yuan, H. (2023). A detection algorithm for cherry fruits based on the improved yolo-v4 model. Neural Comput. Appl. 35, 13895–13906. doi:10.1007/s00521-021-06029-z
Gu, X., Lin, T.-Y., Kuo, W., and Cui, Y. (2021). “Open-vocabulary object detection via vision and language knowledge distillation,” in International conference on learning representations.
Han, J., Ding, J., Xue, N., and Xia, G. (2021). “Redet: a rotation-equivariant detector for aerial object detection,” in Computer vision and pattern recognition.
Joseph, K. J., Khan, S. H., Khan, F., and Balasubramanian, V. (2021). Towards open world object detection. Computer Vision and Pattern Recognition. Available online at: http://openaccess.thecvf.com/content/CVPR2021/html/Joseph_Towards_Open_World_Object_Detection_CVPR_2021_paper.html.
Joshi, D. D., Kumar, S., Patil, S., Kamat, P., Kolhar, S., and Kotecha, K. (2024). Deep learning with ensemble approach for early pile fire detection using aerial images. Front. Environ. Sci. 12, 1440396. doi:10.3389/fenvs.2024.1440396
Lacoste, A., Luccioni, A., Schmidt, K., and Dandres, T. (2019). Quantifying the carbon emissions of machine learning. arXiv preprint arXiv:1910.09700
Li, Y., Ge, Z., Yu, G., Yang, J., Wang, Z., Shi, Y., et al. (2022a). “Bevdepth: acquisition of reliable depth for multi-view 3d object detection,” in AAAI conference on artificial intelligence.
Li, Y., Mao, H., Girshick, R. B., and He, K. (2022b). “Exploring plain vision transformer backbones for object detection,” in European conference on computer vision.
Liu, J., Fan, X., Huang, Z., Wu, G., Liu, R., Zhong, W., et al. (2022a). Target-aware dual adversarial learning and a multi-scenario multi-modality benchmark to fuse infrared and visible for object detection. Comput. Vis. Pattern Recognit., 5792–5801. doi:10.1109/cvpr52688.2022.00571
Liu, S., Zeng, Z., Ren, T., Li, F., Zhang, H., Yang, J., et al. (2023). “Grounding dino: marrying dino with grounded pre-training for open-set object detection,” in European conference on computer vision.
Liu, Y., Wang, T., Zhang, X., and Sun, J. (2022b). “Petr: position embedding transformation for multi-view 3d object detection,” in European conference on computer vision.
Liu, Y.-C., Ma, C.-Y., He, Z., Kuo, C.-W., Chen, K., Zhang, P., et al. (2021a). “Unbiased teacher for semi-supervised object detection,” in International conference on learning representations.
Liu, Z., Zhang, Z., Cao, Y., Hu, H., and Tong, X. (2021b). “Group-free 3d object detection via transformers,” in IEEE international conference on computer vision.
Lou, H., Duan, X., Guo, J., Liu, H., Gu, J., Bi, L., et al. (2023). Dc-yolov8: small-size object detection algorithm based on camera sensor. Electronics 12, 2323. doi:10.3390/electronics12102323
Lv, W., Xu, S., Zhao, Y., Wang, G., Wei, J., Cui, C., et al. (2023). Detrs beat yolos on real-time object detection. Computer Vision and Pattern Recognition. Available online at: http://openaccess.thecvf.com/content/CVPR2024/html/Zhao_DETRs_Beat_YOLOs_on_Real-time_Object_Detection_CVPR_2024_paper.html.
Maity, M., Banerjee, S., and Chaudhuri, S. S. (2021). “Faster r-cnn and yolo based vehicle detection: a survey,” in 2021 5th international conference on computing methodologies and communication (ICCMC) (IEEE), 1442–1447.
Miao, T., Zeng, H., Yang, W., Chu, B., Zou, F., Ren, W., et al. (2022). An improved lightweight retinanet for ship detection in sar images. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 15, 4667–4679. doi:10.1109/jstars.2022.3180159
Misra, I., Girdhar, R., and Joulin, A. (2021). “An end-to-end transformer model for 3d object detection,” in IEEE international conference on computer vision.
Nigar, A., Li, Y., Jat Baloch, M. Y., Alrefaei, A. F., and Almutairi, M. H. (2024). Comparison of machine and deep learning algorithms using google earth engine and python for land classifications. Front. Environ. Sci. 12, 1378443. doi:10.3389/fenvs.2024.1378443
Qin, X., Zhang, Z., Huang, C., Dehghan, M., Zaiane, O. R., and Jägersand, M. (2020). U2-net: going deeper with nested u-structure for salient object detection. Pattern Recognit. 106, 107404. doi:10.1016/j.patcog.2020.107404
Reading, C., Harakeh, A., Chae, J., and Waslander, S. L. (2021). Categorical depth distribution network for monocular 3d object detection. Comput. Vis. Pattern Recognit. Available online at: http://openaccess.thecvf.com/content/CVPR2021/html/Reading_Categorical_Depth_Distribution_Network_for_Monocular_3D_Object_Detection_CVPR_2021_paper.html.
Satti, Z., Naveed, M., Shafeeque, M., Ali, S., Abdullaev, F., Ashraf, T. M., et al. (2023). Effects of climate change on vegetation and snow cover area in gilgit baltistan using modis data. Environ. Sci. Pollut. Res. 30, 19149–19166. doi:10.1007/s11356-022-23445-3
Singh, S. K., Shirzadi, A., and Pham, B. T. (2021). Application of artificial intelligence in predicting groundwater contaminants. Water Pollut. Manag. Pract., 71–105. doi:10.1007/978-981-15-8358-2_4
Singh, S. K., and Taylor, R. W. (2020). “Assessing and mapping human health risks due to arsenic and socioeconomic correlates for proactive arsenic mitigation,” in Arsenic water resources contamination: challenges and solutions, 231–256.
Singh, S. K., Taylor, R. W., and Thadaboina, V. (2022). Evaluating and predicting social behavior of arsenic affected communities: towards developing arsenic resilient society. Emerg. Contam. 8, 1–8. doi:10.1016/j.emcon.2021.12.001
Sun, B., Li, B., Cai, S., Yuan, Y., and Zhang, C. (2021). Fsce: few-shot object detection via contrastive proposal encoding. Computer Vision and Pattern Recognition. Available online at: http://openaccess.thecvf.com/content/CVPR2021/html/Sun_FSCE_Few-Shot_Object_Detection_via_Contrastive_Proposal_Encoding_CVPR_2021_paper.html.
Ullo, S. L., Mohan, A., Sebastianelli, A., Ahamed, S. E., Kumar, B., Dwivedi, R., et al. (2021). A new mask r-cnn-based method for improved landslide detection. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 14, 3799–3810. doi:10.1109/jstars.2021.3064981
Virasova, A., Klimov, D., Khromov, O., Gubaidullin, I. R., and Oreshko, V. V. (2021). Rich feature hierarchies for accurate object detection and semantic segmentation. Radioengineering, 115–126. doi:10.18127/j00338486-202109-11
Wang, G., Chen, Y., An, P., Hong, H., Hu, J., and Huang, T. (2023). “Uav-yolov8: a small-object-detection model based on improved yolov8 for uav aerial photography scenarios,” in Italian national conference on sensors.
Wang, T., Zhu, X., Pang, J., and Lin, D. (2021a). “Fcos3d: fully convolutional one-stage monocular 3d object detection,” in 2021 IEEE/CVF international conference on computer vision workshops (ICCVW).
Wang, Y., Guizilini, V., Zhang, T., Wang, Y., Zhao, H., and Solomon, J. (2021b). “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” in Conference on robot learning.
Weikmann, G., Paris, C., and Bruzzone, L. (2021). Timesen2crop: a million labeled samples dataset of sentinel 2 image time series for crop-type classification. IEEE J. Sel. Top. Appl. Earth Observations Remote Sens. 14, 4699–4708. doi:10.1109/jstars.2021.3073965
Xie, X., Cheng, G., Wang, J., Yao, X., and Han, J. (2021). “Oriented r-cnn for object detection,” in IEEE international conference on computer vision.
Xu, M., Zhang, Z., Hu, H., Wang, J., Wang, L., Wei, F., et al. (2021). “End-to-end semi-supervised object detection with soft teacher,” in IEEE international conference on computer vision.
Yin, T., Zhou, X., and Krähenbühl, P. (2020). Center-based 3d object detection and tracking. Computer Vision and Pattern Recognition. Available online at: http://openaccess.thecvf.com/content/CVPR2021/html/Yin_Center-Based_3D_Object_Detection_and_Tracking_CVPR_2021_paper.html.
Zang, Y., Li, W., Zhou, K., Huang, C., and Loy, C. C. (2022). “Open-vocabulary detr with conditional matching,” in European conference on computer vision (Springer), 106–122.
Zhang, H., Li, F., Liu, S., Zhang, L., Su, H., Zhu, J.-J., et al. (2022). “Dino: detr with improved denoising anchor boxes for end-to-end object detection,” in International conference on learning representations.
Zhu, X., Lyu, S., Wang, X., and Zhao, Q. (2021). “Tph-yolov5: improved yolov5 based on transformer prediction head for object detection on drone-captured scenarios,” in 2021 IEEE/CVF international conference on computer vision workshops (ICCVW).
Keywords: environmental monitoring, spatiotemporal modeling, graph neural networks, meta-learning, uncertainty quantification
Citation: Lin W, Li T and Li X (2025) Deep learning-based object detection for environmental monitoring using big data. Front. Environ. Sci. 13:1566224. doi: 10.3389/fenvs.2025.1566224
Received: 24 January 2025; Accepted: 14 May 2025;
Published: 12 June 2025.
Edited by:
Sushant K Singh, CAIES Foundation, IndiaReviewed by:
Xinyue Mo, Hainan University, ChinaGeetha Srikanth, Amrita Vishwa Vidyapeetham University, India
Copyright © 2025 Lin, Li and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wenbo Lin, MTUxMDEyMDczMTZAMTYzLmNvbQ==