 JianHua Jiang1*
JianHua Jiang1* Zhengshui Wang2
Zhengshui Wang2- 1School of Electronics and Information Engineering, Nanchang Normal College of Applied Technology, Nanchang, China
- 2School of Mathematics and Information Sciences, Nanchang Hangkong University, Nanchang, China
Composite structure is widely used in various technological fields because of its superior material properties. Composite structure detection technology has been exploring efficient and fast damage detection technology. In this paper, image-based NDT technology is proposed to detect composite damage using deep learning. A data set was established through literature, which contained images of damaged and non-damaged composite material structures. Then, five convolutional neural network models Alexnet, VGG16, ResNet-34, ResNet-50, and GoogleNet were used to automatically classify the damage. Finally, the performance of five pre-trained network architectures is evaluated, and the results show that RESNET-50 technology can successfully detect damage in a reasonable computation time with the highest accuracy and low complexity using relatively small image datasets.
1 Introduction
Composite materials are new materials with excellent properties that are composed of at least two different materials combined, which are harder, more wear resistant, and lighter than the original materials of composition. Therefore, composites have become the materials of choice in the aerospace, aviation, navy, and automotive industries. Despite these excellent advantages, composite structures are prone to various kinds of damage during manufacturing and use, which significantly changes their structural behavior and ultimately leads to structural failure or reduced service life [1]. Most polymer composites are brittle and laminated, and the lack of material reinforcement in the normal direction makes the normal direction more vulnerable to damage. Different damage mechanisms may occur in composite structures, which can be roughly divided into matrix crack, fiber fracture and delamination damage [2].
In order to ensure the structural safety of composite structures, it is very important to know the details of the damage as soon as possible when the structure is damaged. However, the anisotropic properties of composite materials make it difficult to evaluate the damage by common detection methods. At present, there are many nondestructive testing techniques (NDT) that can be used to detect defects inside composite structures, such as infrared thermal imaging testing [3, 4], ultrasonic testing [5], acoustic emission testing [6], optical testing [7], etc. Although these NDT technologies are well established today, most of them do not perform NDT directly with the testing equipment as originally envisioned. They require a skilled operator and a specific testing environment in addition to the relevant equipment. If you want to achieve the goal of nondestructive testing of composite materials, the process is very complicated, which needs a lot of time and money. For example, acoustic emission detection technology needs to detect the elastic wave emitted from the damaged position of the composite structure through sensors installed on the surface of the structure or embedded sensors in the structure. Embedded sensors are more sensitive to acoustic emission monitoring than sensors installed on the surface, but integrated sensors loaded in the structure may shorten the life of the main structure [8]. Therefore, it is necessary to provide a feasible detection solution, which is both cost-effective and reliable to ensure the safety, reliability and longer service life of the composite structure.
Visual inspection is often used for the damage of structural surface [9]. Not only that, visual inspection is the most basic type of NDT used in many instances. Because it can save the time and money needed for testing by reducing other kinds of testing measures, or reduce the need for other kinds of testing at the same time in some special cases, the main advantages of visual inspection are its fast speed and high relative endurance [10]. Nondestructive testing of composite material structure, for example, when performing visual inspection, first send skilled inspectors to detect the scene, and then observe whether there is a crack or dent on the surface of composite structure, if it is found that the composite material structure exists serious damage, the inspector may request relevant departments use other NDT technology for nondestructive testing of structures, Such as infrared thermal imaging to further assess the extent of damage to the internal structure, and ultimately determine whether the tested components need to be repaired or replaced. However, this method also has its inherent disadvantages, because the popular visual inspection is carried out by skilled inspectors, so the accuracy of the test also depends on the judgment of the inspector. Lighting, inspection time, inspector’s fatigue and experience, environmental conditions and other factors will affect the judgment of inspectors, further affect the reliability of visual inspection and the probability of successful detection, and then bring about health and safety risks and other problems [11].
In recent years, due to the rapid development of computer network technology, people have made great progress in automation, data analysis, image acquisition technology, artificial intelligence technology, etc., which makes the computing capacity of low-cost hardware meet the computing needs of software, which also makes it possible to build a practical automatic visual inspection system [12]. Artificial neural network belongs to a semi-supervised machine learning field. In order to improve the performance of machine learning, genetic algorithms can be used to select the optimal kernel function [13, 14]. The neural network algorithm for image classification and detection tasks gains the actual target through the use of advanced equipment of high quality image data set to train the neural network structure. Network has the capability of classification or detecting the target. Choosing the appropriate neural network can even reach and exceed human right recognition accuracy. Among all kinds of artificial neural networks, convolutional neural networks (CNNs) have been highly concerned by researchers in the effective processing of image-based data due to their excellent ability to extract deep patterns. In the field of deep learning, deep convolutional neural networks (DCNNs) are important branches. DCNNs use multiple hidden layers for multilevel feature extraction, and then the hierarchical features of the input image can be obtained for further interpretation. And DCNNs adopt the method of “weight sharing,” which greatly improves the efficiency of target recognition. With the advent of data set enhancement and transfer learning techniques, models trained on limited data are more accurate and faster. At present, many CNN architectures have been successfully used for image classification, such as AlexNet [15], VGG [16], GoogleNet [17] and ResNet [18].
Min Ma et al. [19] used one-dimensional multi-scale residual convolutional neural network (1D-MSK-ResNet) to detect the damage of carbon fiber reinforced polymers (CFRPs), and obtained the damage images of CFRPs based on simulation software and experiments. Training validation and test data sets are constructed to train the algorithm and the training results of the test data sets are used to verify and evaluate the algorithm. The determination coefficient R^2 of this method is as high as 0.885, which is the highest network structure in this group, indicating that the fitting effect of the model is the best. Hidir Selcuk Nogay et al. [20] designed a deep learning model based on acoustic noise data and transfer learning technology to detect cracks in ceramic plates. They applied the same amplitude of shock to the ceramic experimental plate by impact pendulum, and the noise curve generated formed the training dataset. Then, the pre-trained deep learning model AlexNet is trained and tested for crack detection of ceramic plates. Hyun-tae Bang et al. [21] proposed a framework to identify defects in composite materials by combining thermal imaging testing and deep learning techniques. The network was trained using a dataset of thermal imaging images of composites collected from the literature, and the trained network model was then tested using lab-made composite samples. The results show that the technique is widely used. The performance of the system was evaluated by evaluating the ability of the system to identify defects from artificially defective samples. The overall average accuracy of the system reached 75.05%. Bubryur Kim et al. [22] proposed a surface concrete crack detection structure based on shallow convolutional neural network (CNN). They used the Middle East University of Science and Technology (METU) dataset for training, then achieved higher accuracy by fine-tuning the architecture of the LENet-5 model and optimizing some hyperparameters, and finally compared the performance with the other three pre-trained models, VGG16, Inception, and ResNet. The evaluation results show that the proposed model does not rely on high-quality images and high-end computing equipment to build a real-time crack detection model, and can achieve real-time crack detection with the minimum amount of computation. In order to improve detection accuracy, genetic algorithms are often chosen to optimize the structure and initialization weights of convolutional neural networks [23, 24].
In the past proposed applications of CNN on image-based data, the acquired images were obtained by NDT techniques, such as thermal imaging and X-ray, which required professional equipment and experienced operators to acquire. The professionalism and difficulty of these studies are not conducive to the understanding of scholars from other disciplines. In order to solve this problem, this paper proposes a nondestructive testing technique based on deep learning for quantitative assessment of service damage in composite laminates. To address the scarcity of composite datasets, a comprehensive dataset of images of common service injury mechanisms was collected from the literature. This dataset was used to train CNN to evaluate its accuracy and robustness in identifying damaged conditions in composite laminates. In this paper, five methods for detecting composite laminates are proposed. A large number of damaged and undamaged images of composite laminates are collected from the literature. After data enhancement and preprocessing of the obtained images, a dataset is formed for network training. The damage detection process of composite laminate is shown in Figure 1.
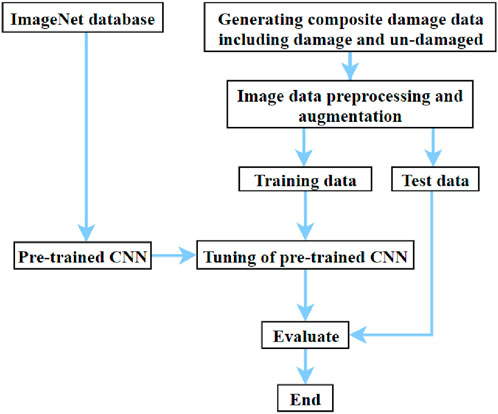
Figure 1. General block diagram.
This paper studies the application of deep learning to the field of composite material damage detection, but due to the fact that there are fewer composite material datasets that can be used for model training, and the research content in this area is relatively sparse. The author of the reference 34 applies deep learning to the field of damage detection, and successfully trains a neural network model through several improved measures. This paper improves on the reference 34 and uses several classical network models to verify the feasibility of deep learning in the field of composite material damage detection.The structure of this paper is as follows. In the section “Dataset,” the method of obtaining training data and the data enhancement method used are introduced. In the “Deep Learning” section, the basic concepts of Deep learning and the components of CNN are introduced. Then, in the section of “Deep Learning Model,” the five network models used in this paper and the corresponding network architecture are introduced in detail. Then the “RESULTS AND DISCUSSIONS” section compares the results of the five experiments and discussions based on the results. At last, in the section of “CONCLUSIONS AND FUTURE WORK,” it expounded the key conclusions and the outlook for the future research.
2 Dataset
2.1 Dataset acquisition
Part of the image data collected in this study are shown in Figure 2, including un-damaged and damaged images. Most of the damaged images are caused by impact dam-age because they are easy to distinguish. A comprehensive set of images has been collect-ed from the literature on laminated composites of different thicknesses, materials, laminations, textures, etc. It is visually obvious to classify each image as damaged or undamaged. 177 images related to damage were collected from literature [25–32], and 63 images of composite laminate with intact surface were collected from literature [33–38].

Figure 2. Some composite laminate images. (A) Damage pictures, (B) Undamaged pictures.
2.2 Data augmentation
The excellent generalization ability of convolutional neural networks (CNNs) de-pends on a large amount of training data, which is difficult to obtain in industrial practice. Data augmentation is usually considered as an effective strategy to solve this problem. Data enhancement can generate more data based on the limited number of data, not only increase the number and diversity of training samples, but also improve the robustness of the model. By randomly changing the training samples, the dependence of the model on some attributes can be reduced and the generalization ability of the model can be im-proved.
The popular enhancement strategies are divided into geometric transformation and pixel transformation. Geometric transformations include flipping, rotation, cropping, scaling, and translation. Pixel transformation methods include adding salt and pepper noise, Gaussian noise, Gaussian blur, adjusting brightness and saturation, etc. The method described next will be used in the experiment. The first is the rotation method, which rotates the image at an Angle of 90 and 180. The second is Gaussian noise, which is added to the image with probability density function following Gaussian distribution. The third is salt and pepper noise, which refers to the random addition of a white dot (255) or a black dot (0), similar to sprinkling salt and pepper on an image.
Using the data enhancement method to obtain more learning data, a total of five images were produced for each original image. Since the aspect ratio of the collected images is inconsistent, each image is enhanced in different forms according to its own conditions [39]. The results of four enhanced images are shown in Figure 3. In this paper, two enhancement methods are prepared to be used, including rotation of 90° and 180° (Figures 3B, C) and addition of Gaussian noise and salt and pepper noise (Figures 3D, E). In this paper, 1,081 and 119 images out of 1,200 image data including data enhancement results are used for training and validation, respectively.

Figure 3. The result of the image augmentation from (A) original image using (B) 90° Rotation, (C) 180° Rotation, (D) Gaussian noise,and (E) salt noise generation.
3 Deep learning
Deep learning is a subset of machine learning that mimics how the human brain processes data by learning tasks directly from sounds, text, and images. In recent years, with the continuous development of automatic tools and advanced Graphical Processing Units (GPUs) hardware, deep learning has become a powerful method that involves a wide range of problems. It can identify targets by automatically learning feature representations from given data. The purpose of deep learning is to determine whether the recognized object exists in a predefined category, and if so, the neural network will return the location of the object and the confidence of the predicted category.
CNN is an important branch of deep learning, which is used to automatically and adaptively process structured data array, and has achieved a lot in image processing. By means of local connection, weight sharing and pooling, CNN can reduce the number of parameters of the model and reduce the difficulty of training the network model, so as to achieve the purpose of optimizing the network structure. The main layers of CNN include convolutional layer, activation layer, pooling layer, fully connected layer and output layer, as shown in Figure 4. The convolutional layer is a basic building block of the CNN model, which uses kernels and filters to help reduce the input original image size. When the image size is reduced, all important features of the image can still be kept unchanged. Reducing the size of the image through the convolutional layer and then identifying the image can reduce a lot of data processing and reduce the overall processing time.
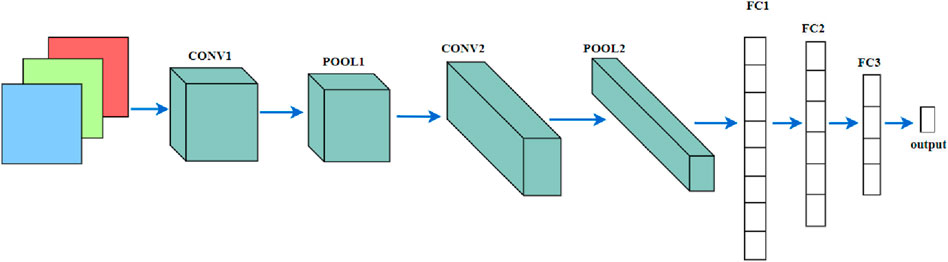
Figure 4. An example of CNN.
The convolution method is used for automatic feature extraction, which is defined as Formula 1.
where M represents the input image matrix,
The convolutional layer consists of a set of filters with learnable weights, and the input data is convolved with each filter by considering fill, stride length, and filter size. Figure 5 is an example of a convolution operation using a 3 × 3 filter with a step size of 2 and a fill size of 1.
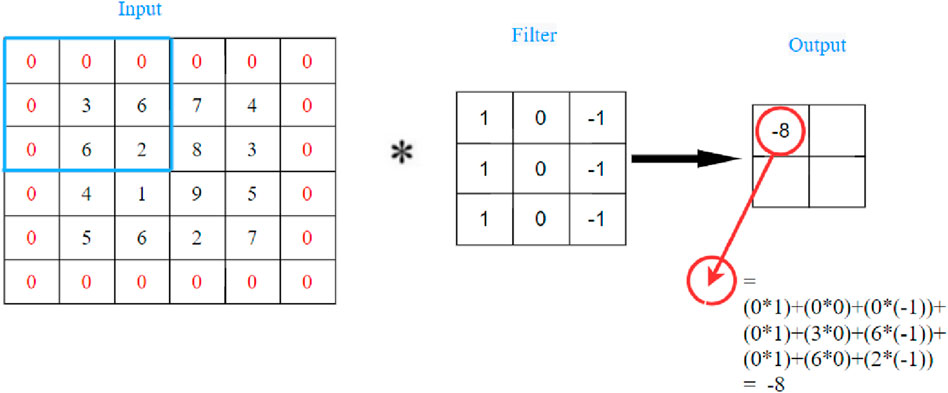
Figure 5. An example of convolution and padding operations with a 3 × 3 filter, stride size of two and padding size of one.
As shown in Figure 5, the convolution operation convolves the input layer by sliding the filter horizontally and vertically, computing the dot product of the weight and the input, and then adding a bias term. The step length of filter movement is determined by the stride size. When you do convolution sometimes you do a fill operation depending on the experimental requirements. The fill operation adds a specified number of layers to the image boundary. The newly added elements within the layer are all 0 elements. Because image edge pixels are only covered once in the process of convolution operation, and the output image size will keep getting smaller, it is easy to ignore the image boundary information. In order to avoid this problem, filling operation can effectively prevent data shrinkage and image boundary information loss, which makes image analysis more accurate.
The pooling layer is usually placed behind the convolution layer, and the pooling mechanism is used to further reduce the size of the convolution image. As the size of the image decreases, the pooling layer helps to minimize the computational power needed to process the data. It downsamples the feature (activation) map output from the convolution step. This step is to slide a filter over the feature map and output representative values such as maximum, mean, or l2 norm values from the subregions. In the average pooling method, the average of the images covered by the filter kernel is returned. Although the information will be lost, the main features can still be extracted and the quality of the image will not be lost. Finally, the number of iterations and weights are reduced, and the computation cost is reduced. Figure 6 is an example of a pooling operation with a 2 × 2 filter and a 2 step.
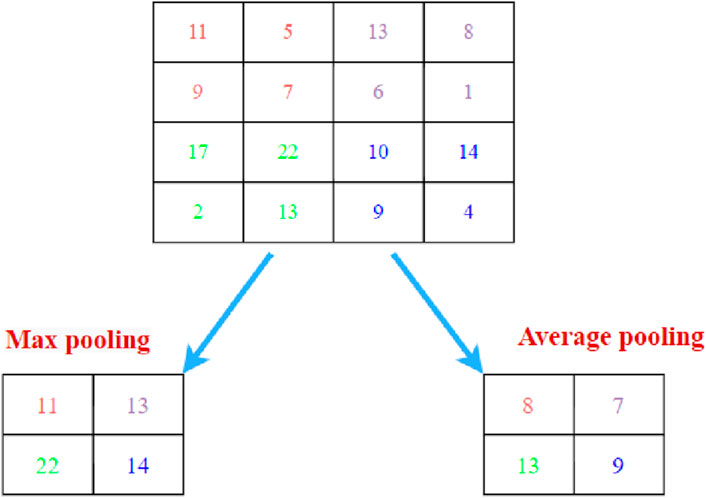
Figure 6. An example of pooling operation with a 2 × 2 filter and stride size of two.
In the process of the convolution image input to the pooling layer, it will first enter the activation layer. Active layer is composed of the activation function, its main function is to add a line to image nonlinear is added to the whole network nonlinear, because most of the operation of the neural network is linear, the actual basic are complex nonlinear problems, so in order to make the network output results more realistic logic, adding the activation layer is very necessary. There are many kinds of activation functions known for neural networks, including sigmoid, tanh, Rectified Linear Activation function (ReLU), etc. All models in this paper use ReLU activation function. In the rectifying linear unit (ReLU) activation function, a threshold operation is used for each element, in which any input value smaller than zero is set to zero, while the rest values remain unchanged [40]. The ReLU activation function can overcome the gradient disappearance problem and its definition is shown in Equation 2.
where x represents the input of the function.
The fully connected layer is located at the tail of the network, which is helpful to classify images into a specific class. The output high-level feature maps of the convolution layer and pooling layer will finally be input into the fully connected layer for further processing. The final output layer uses either the SoftMax function or the sigmoid function depending on the classification task. If the number of pre-categories is more than 3, SoftMax function is often selected, and sigmoid function is generally used for binary classification tasks. Either of these can be used in the final output layer. In this paper, all five models use the SoftMax function in the output layer to set the number of classification categories to 2. The SoftMax activation function is given in Equation 3, and SoftMax activates neurons by limiting the output to (0,1).
where
From previous CNN application results, it can be found that if the dataset is large, then the classification result is good, and vice versa. Therefore, labeled datasets with a large amount of training data are the prerequisite for high precision image classification. However, the data images of some specific detection tasks are difficult to obtain, and the cost of constructing a large dataset is very expensive. In this case, the application of transfer learning technology is very necessary for the purpose of effective classification. Deep models need to be trained from scratch in image recognition tasks, but if the training dataset is too small, the expected training effect cannot be achieved. Transfer learning is a new machine learning method to effectively solve this problem. It places the pre-trained model into a new classification task for image recognition, and the model can recognize the learned features again. Pre-trained model refers to a model that trains parameters on a large training set of a domain, which is usually independent of the classification task. The most commonly used training set for image classification is ImageNet. This pre-trained model can be applied to other classification problems by applying transfer learning. The workflow of transfer learning is to first build the network model to be used, then load the pre-trained weights during model training, freeze the base layer of the model, then fine-tune the model for the new data set, adjust the parameters according to the requirements, and finally train on the new data set. Therefore, transfer learning only needs to use a small amount of data to provide reliable results in the shortest time.
4 Deep learning model
In order to perform automatic damage detection, it is necessary to select an appropriate network model. In this paper, five different deep learning models are considered for classification, each with different constraints, features, architecture, and different trainable variables. The first step is to create a dataset based on damaged and non-damaged images of composite laminates by literature review and online collection. Then the model is trained and validated using these image data. Finally, according to the training and verification accuracy of different network models, the most appropriate model architecture is selected as the neural network for composite laminate damage detection.
4.1 AlexNet model
AlexNet network, one of the most commonly used CNN architectures, has successfully trained more than 1 million images, is the most influential CNN widely used in image classification, and won first place in ImageNet LSVRC-2012 competition with a small error rate of 15.3% [41]. The significance of the model lies in the ability to extract the actual information about the image and understand the features added in each layer. When using ImageNet to train AlexNet, 1,000 categories of input images are classified. Since damage detection only contains 2 categories (damage and undamage), this paper modifies the output vector to only 2 classes. The network architecture of AlexNet is shown in Figure 7. AlexNet architecture is composed of a total of 8 learning layers, among which 5 layers are the combination of convolution layer and maximum pooling layer, and the remaining three layers are fully connected layer.
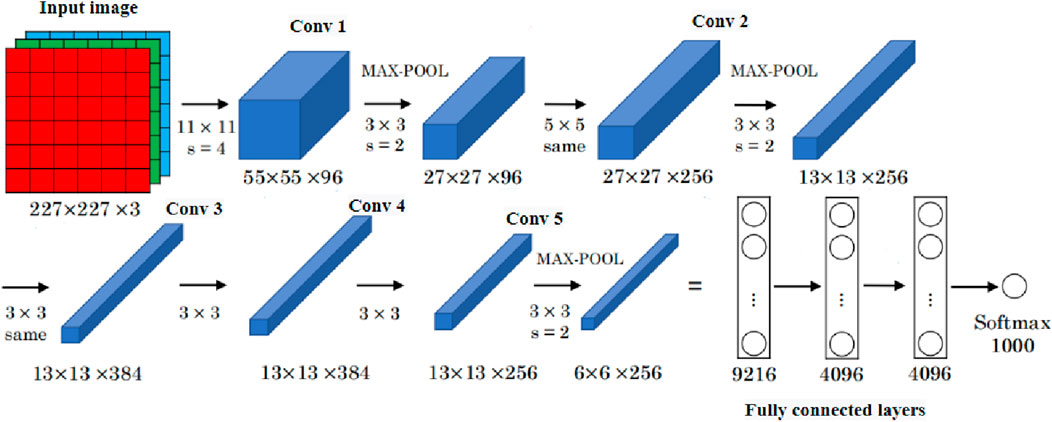
Figure 7. Architecture of AlexNet network.
4.2 VGG16 model
VGG network was first proposed by the Visual Geometry Group (by Oxford University), and the network is also named after the Group. This model achieves a top-5 test accuracy of 92.7% in ImageNet [42]. The standard VGG16 model is shown in Figure 8. VGG network mainly studies the relationship between the depth and the performance of convolutional neural network, which is characterized by its concise structure. This model enhances AlexNet by replacing larger size convolution kernels with many 3
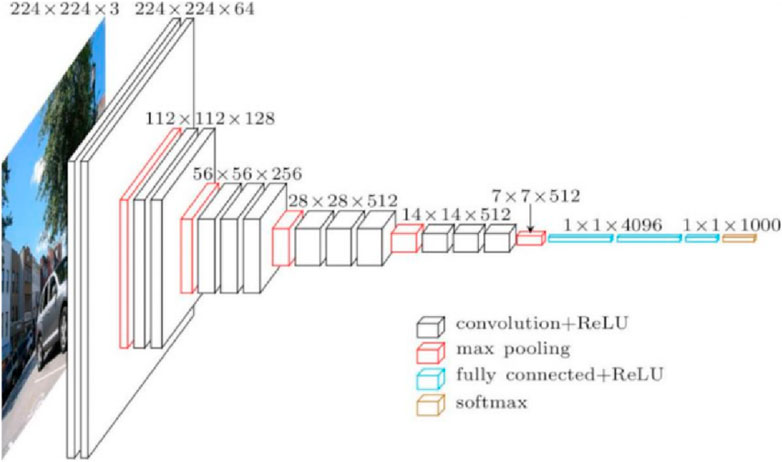
Figure 8. VGG16 model.
4.3 ResNet-34 model
The residual network is a convolutional neural network proposed by He Kaiming and others from former Microsoft Research Institute. It won the title of image classification and object recognition in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) in 2015 [43]. Since VGG was proposed, researchers have begun to believe that the prediction accuracy can be directly and simply increased by improving the network depth. However, the actual experiment results are different. The deeper the convolutional neural network is, the exponential growth of its model parameters will occur, leading to difficulties in network optimization and gradient disappearance. The design concept of ResNet changes the development direction of deep learning. The residual blocks in the network solve the problem of gradient disappearance caused by adding depth in the deep neural network by using jump connection, which makes the parameters easy to optimize and finally improves the performance of the network. Figure 9 is the residual block, where x represents the input, and the output of the residual block is F(x)+G(x) instead of F(x) in the traditional network layer. When the dimensions of the input and output are the same, the value of G(x) is x itself. In this case, the jump connection is called the identity map. Learning the identity map by eliminating the weight of the middle layer makes the network training easier. If the input and output dimensions are not equal, select the replacement of the Identity Connection with the Projection Connection for the residual. The function G(x) changes the dimension of the input x to equal the dimension of the output F(x).
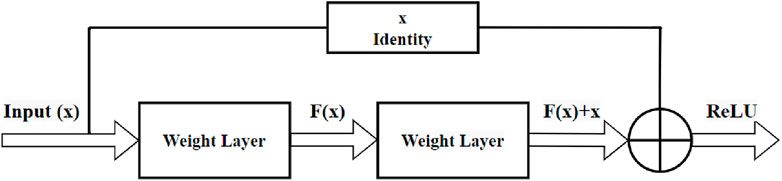
Figure 9. Residual block image.
There are already many versions of the ResNetXX architecture, where “XX” denotes the number of layers. In ResNet-34 [44], the number of network layers is 34. The network structure of ResNet-34 is shown in Table 1, from which you can see the fill, stride, input layer, and output layer. By default, the classification output of the pre-trained model is 1,000 as shown in the table, but the number of experimental classifications performed in this paper is 2, so the first two network models are processed in the same way, and the final SoftMax classification layer is changed to 2.
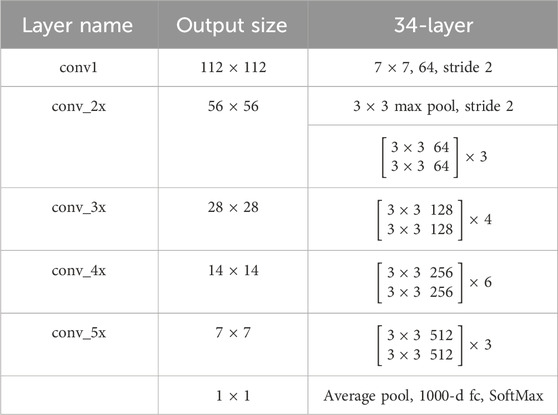
Table 1. ResNet-34 model architecture.
4.4 ResNet-50 model
ResNet-50, the Residual Network-50 model [45], is composed of five stages and one output module. The second stage to the fourth stage are all composed of a CONVBLOCK and IDBLOCK. The network accepts images with the size of 224 × 224 as input images. It can be seen from Figure 10 that the network is stacked by multiple residual blocks. CONVBLOCK and IDBLOCK have three convolutional layers. CONVBLOCK is mainly used to change the dimension of the network. The dimension of the input data in the residual block is different from that of the output, while IDBLOCK is used to deepen the network in series. In the name ResNet-50, the number 50 represents the number of layers. There are many variants, and the principle is similar, but each variant network has different layers. And ResNet-50 is used to describe variants that can work with 50 neural network layers. Just like ResNet-34, the final SoftMax output classification layer is changed to 2 when ResNet-50 network is used to train the collected dataset in this experiment.

Figure 10. ResNet-50 architecture.
4.5 GoogleNet model
GoogleNet was proposed by Google team in 2014 and won the first prize of Classification Task in ImageNet competition of that year [46]. The original convolutional neural networks, such as AlexNet and VGG-Net, are composed of sequential connections of some convolutional layers and pooling layers. As long as the width and depth of the network are increased, the accuracy of such series networks can be improved. However, it will also bring some problems, such as the need for too many parameters and the network is easy to cause the problem of overfitting. Therefore, to solve these problems, researchers proposed the Inception module. Rather than connecting convolution layers and pooling layers sequentially like traditional series networks, the Inception module combines layers with different filter sizes whose outputs are connected into a single output vector, as shown in Figure 11. In this way, it can extract different feature maps in the same layer and achieve the same performance with a greatly reduced number of parameters. According to the data, the VGG-NET model contains a total of 138,357,544 parameters, and the number of parameters of the GoogleNet network model is about 6,994,392, which is one twentieth of the VGG-NET. GoogleNet mainly includes nine modular structures, Inception, which are deeply connected in series. The network structure is shown in Figure 12.
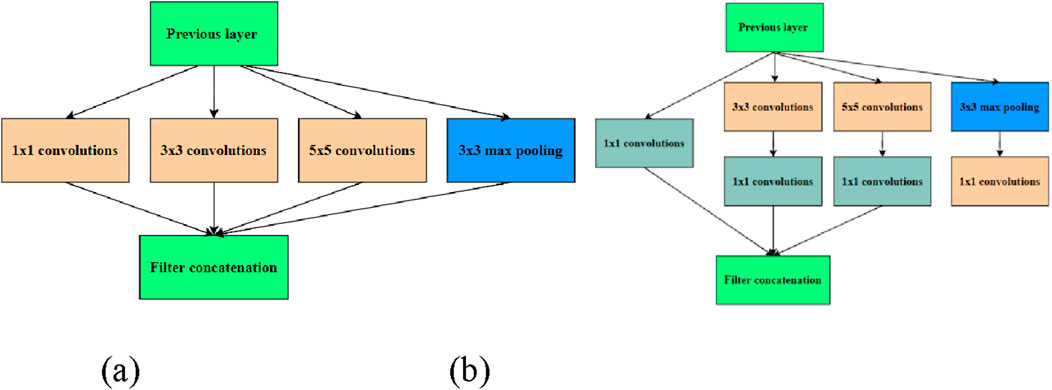
Figure 11. Inception modules in GoogleNet: (A) initial version (B) dimension reduction version.

Figure 12. GoogleNet architecture.
5 Results and discussion
This section describes the experimental setup and parameters for the dataset of five different models used for composite laminate damage classification. The initial dataset is divided into two parts: the training dataset and the validation dataset. 1,200 images (including damaged and undamaged) were randomly divided into 1,081 images for training and 119 images for verification. All models were trained on a device with Intel I7-7700HQ (2.80 GHz) CPU, 8 GB RAM, NVIDIA GeForce GTX1050 Ti, based on PyTorch to build the model framework.
The AlexNet network structure requires the size of the input image to be 227
where
The validation and test results of the network are compared to obtain good results for a given dataset. In order to improve the accuracy, it is necessary to evaluate whether the network has been correctly verified, and the network verification accuracy is defined as:
where TP, FP, FN and TN represent true positive, false positive, false negative and true negative respectively.
According to Equation 5, the accuracy of the model can be calculated. Accuracy refers to the number of correctly classified images among all images. The experimental results of the five models are shown in Table 2. As can be seen from the figure, the verification accuracy of the five network models is very high, basically above 99%. Among them, the verification accuracy of AlexNet and VGG16 networks, which were proposed earlier, both reached 99.16%. The validation accuracy of the later more advanced network models RESNET-34, RESNET-50 and GoogleNet all reached 100%, which also shows that the technology of neural network is more and more advanced, and the classification performance of the model is also getting better and better.
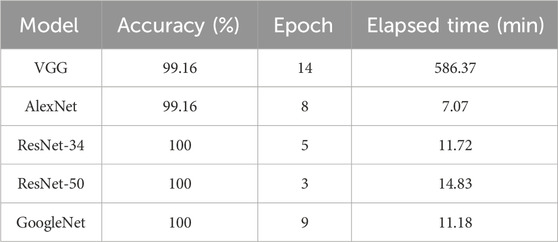
Table 2. Comparison of the models.
The specific training process and results of the five models are shown in Figures 13–17.
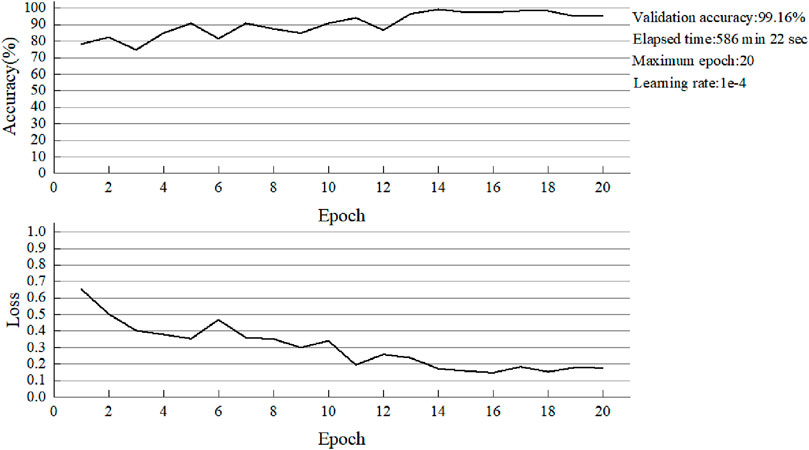
Figure 13. The accuracy of VGG in the classification of validation images.
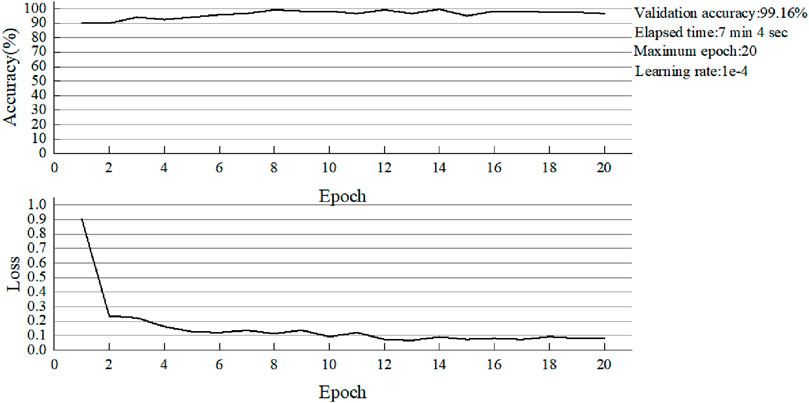
Figure 14. The accuracy of AlexNet in the classification of validation images.
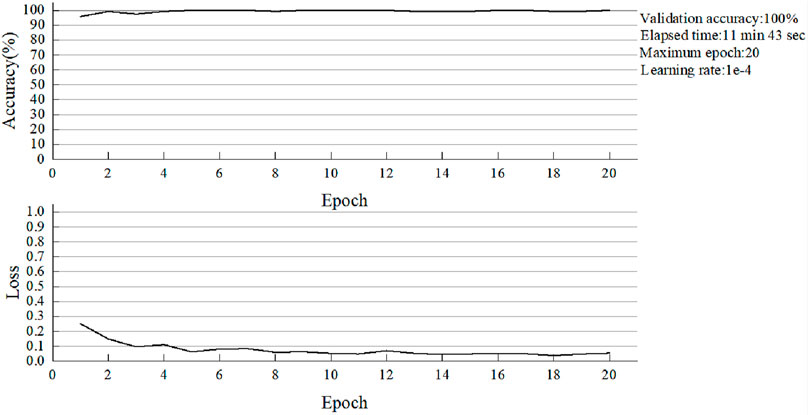
Figure 15. The accuracy of ResNet-34 in the classification of validation images.
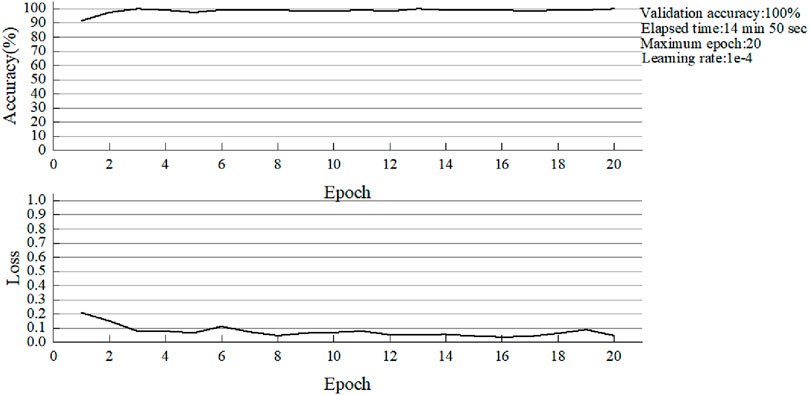
Figure 16. The accuracy of ResNet-50 in the classification of validation images.
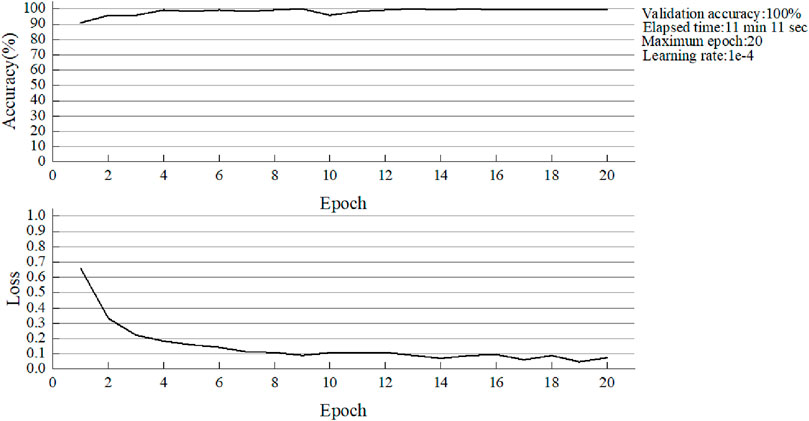
Figure 17. The accuracy of GoogleNet in the classification of validation images.
No single learning model consistently performs best across all domains. Therefore, a most appropriate model needs to be explored. From the above five images, it can be found that when the number of training epochs is 20 and the learning rate is consistent to 0.0001, the batch size of VGG16 is 4. The whole training process takes 586 min and 22 s, nearly 10 h, and reaches the highest accuracy of 99.16% at the 14th epoch. The minimum training loss was 0.148. When the batch size of AlexNet is 32, the highest accuracy is as high as 99.16% of the VGG16 network, but the time consumed is greatly reduced. The optimal accuracy is achieved in the 12th epoch training, and the total training time is only 7 min and 4 s, which is about one of the 84 times of the former. The speed is greatly increased. There are two main reasons for this phenomenon. First, due to the memory limitation of the device, the batch size of VGG16 can only be set to 4. In this way, the network can use fewer images for training in each batch, and the number of training times in each epoch will be more. The second reason is that VGG is a deep neural network, and the number of weight parameters that need to be updated is more, so the time for each training will be more. Then, compared with ResNet-34 and ResNet-50 networks, the highest accuracy of the two networks is 100%, indicating that the performance of the models is very excellent. However, due to the different layers of the network models, there are still differences in the training results. The total training time of ResNet-34 was 11 min and 43 s with a minimum loss of 0.037. The Resnet-50 has a training time of 14 min and 50 s with a minimum loss of 0.038. In terms of overall training time, the former was 3 min and 7 s faster than the latter. However, ResNet-34 achieved a maximum accuracy of 100% at epoch 5, while ResNet-50 achieved the same maximum accuracy at epoch 3. Therefore, although the training time of RESNET-50 is a little longer under the same epoch conditions, the training speed of this model is faster and the optimal accuracy can be achieved in a short time. Finally, for GoogleNet, the highest accuracy is 100%, the minimum loss is 0.048, and the optimal accuracy is achieved at the 9th epoch. As a result, GoogleNet performs worse than ResNet on the basis of the above data comparison.
In conclusion, the most suitable model for automatic damage detection of composite laminates is the ResNet-50 model. Because this model takes very little time compared to other models, the minimum number of epochs also helps to reduce the computational time of the model. In addition, more epochs may cause the model to overfit. The results obtained in this paper are consistent with the claims made by Khan et al. [47]. In that article, it points out that the ResNet model has 20 and 8 times deeper model layers than the AlexNet and VGG models. Because of the presence of jump connections, the computational complexity of the proposed network is also lower compared to Alexnet and VGG models.
6 Conclusion and future work
6.1 Conclusion
Deep learning technology was used to detect the damage of composite laminates. This paper compares the performance of five different models, AlexNet, VGG16Net, ResNet-34, ResNet-50 and GoogleNet, in terms of validation and accuracy, as well as the time to train the model. All models were trained with Adam optimizer for 20 epochs with a learning rate of 0.0001.
The Alexnet model has the lowest validation accuracy of 99.16% in the second phase, but it performs faster (about 7 min) compared to the VGG16 model. ResNet-50 had the highest validation accuracy of 100% compared to all other models, reaching this accuracy at epoch 3. In addition, its training sample took very little time (only 14 min and 50 s).
Deep learning solves complex problems by deeply understanding the complex relationships between a large number of interdependent variables. It can be concluded from the analysis that ResNet-50 is suitable for the classification of composite laminate images because it takes less time and has the highest accuracy compared to other models. In this paper, the model is trained and validated using composite material images collected from literature and the Internet.
6.2 Future work
This paper describes the potential of deep learning technology in automatic damage detection of composite structures. However, many factors need to be considered when applying this technology to the actual scene. Because the computing power of the equipment in this study is limited, it may not achieve the ideal effect. In the future, equipment with stronger computing power can be considered to achieve the highest detection accuracy in a shorter time. In addition this paper only by training network to detect whether composite structure damage, and no classifying damage types, the future can collect more different kinds of composite structure damage (such as shock, erosion, etc.), the image data to carry out further experiments and modeling research, to develop a number of large, high quality and category of the whole data set, Based on this dataset, deep learn-based autonomous inspection can be performed reliably, and even neural networks can measure the surface damage size of composite materials and predict the remaining life of composite structures containing damage.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
JJ: Conceptualization, Data curation, Funding acquisition, Methodology, Project administration, Software, Validation, Visualization, Writing–original draft. ZW: Formal Analysis, Investigation, Methodology, Resources, Software, Supervision, Writing–review and editing.
Funding
The author(s) declare that financial support was received for the research, authorship, and/or publication of this article. This research was funded by the Technology Research Project of Jiangxi Provincial Department of Education, grant number GJJ2203210.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Khan A, Ko DK, Lim SC, Kim SC. Structural vibration-based classification and prediction of delamination in smart composite laminates using deep learning neural network. Compos B-eng (2019) 161:586–94. doi:10.1016/j.compositesb.2018.12.118
2. Fan W, Wang C. Classified segmentation method of carbon fiber composites based on electrical impedance tomography. 2019 Photonics and Electromagnetics Research Symposium - Fall (PIERS - Fall) (2019):3311–7. doi:10.1109/PIERS-Fall48861.2019.9021814
3. Fernandes H, Zhang H, Quirin S, Hu J, Schwarz M, Jost H, et al. Infrared thermographic inspection of 3D hybrid aluminium-CFRP composite using different spectral bands and new unsupervised probabilistic low-rank component factorization model. NDT E Int (2022) 125:102561. doi:10.1016/j.ndteint.2021.102561
4. Su Z, Zhou C, Hong M, Cheng L, Wang Q, Qing X. Acousto-ultrasonics-based fatigue damage characterization: linear versus nonlinear signal features. Mech Syst Signal Process (2014) 45:225–39. doi:10.1016/j.ymssp.2013.10.017
5. Katunin A, Dragan K, Dziendzikowski M. Damage identification in aircraft composite structures: a case study using various non-destructive testing techniques. Compos Struct (2015) 117:1–9. doi:10.1016/j.compstruct.2015.02.080
6. Fotouhi M, Ahmadi NM. Investigation of the mixed-mode delamination in polymer-matrix composites using acoustic emission technique. J Reinf Plast Comp (2014) 33:1767–82. doi:10.1177/0731684414544391
7. Bonello DK, Iano Y, Neto UB, Gomes de Oliveira G, Vaz GC. A study about automated optical inspection: inspection algorithms applied inFlexible manufacturing printed circuit board cells using the mahalanobis distance method 1. In: Proceedings of the 7th Brazilian Technology Symposium (BTSym’21). Campinas, Brazil: Springer, Cham (2021).
8. Senthilkumar M, Sreekanth TG, Manikanta Reddy S. Nondestructive health monitoring techniques for composite materials: a review. Polym Polym Compos (2021) 29:528–40. doi:10.1177/0967391120921701
9. Agdas D, Rice JA, Martinez JR, Lasa IR. Comparison of visual inspection and structural-health monitoring as bridge condition assessment methods. J Perform Constr Fac (2016) 30(30):1–10. doi:10.1061/(ASCE)CF.1943-5509.0000802
10. Gholizadeh S. A review of non-destructive testing methods of composite materials. Proced Struct Integrity (2016) 1:50–7. doi:10.1016/j.prostr.2016.02.008
11. Campbell LE, Connor RJ, Whitehead JM, Washer G. Human factors affecting visual inspection of fatigue cracking in steel bridges. Struct Infrastruct E (2021) 17:1447–58. doi:10.1080/15732479.2020.1813783
12. Jenssen R, Roverso D. Automatic autonomous vision-based power line inspection: a review of current status and the potential role of deep learning. Int J Elec Power (2018) 99:107–20. doi:10.1016/j.ijepes.2017.12.016
13. Abo-Hammour Z, Abu Arqub O, Momani S, Shawagfeh N. Optimization solution of Troesch’s and Bratu’s problems of ordinary type using novel continuous genetic algorithm. Discrete Dyn Nat Soc (2014) 401696:1–15. doi:10.1155/2014/401696
14. Abu AO, Abo-Hammour Z. Numerical solution of systems of second-order boundary value problems using continuous genetic algorithm. Inform Sci (2014) 279:396–415. doi:10.1016/j.ins.2014.03.128
15. Zhu L, Li Z, Li C, Jing W, Yue J. High performance vegetable classification from images based on alexnet deep learning model. Int J Agric Biol Eng (2018) 11:190–6. doi:10.25165/j.ijabe.20181104.2690
16. Kaur T, Gandhi TK. Automated brain image classification based on VGG-16 and transfer learning. In: 18th International Conference on Information Technology (ICIT). India: Bhubaneswar (2019).
17. Sharma N, Jain V, Mishra A. An analysis of convolutional neural networks for image classification. Proced Comput. Sci (2018) 132:377–84. doi:10.1016/j.procs.2018.05.198
18. Mahajan A, Chaudhary S. Categorical image classification based on representational deep network. In: 2019 3rd International conference on Electronics, Communication and Aerospace Technology (ICECA); 12–14 June 2019; Coimbatore, India. IEEE (2019).
19. Ma M, Yu J, Fan W, Cao Z. Damage detection of carbon fiber reinforced polymer composite materials based on one-dimensional multi-scale residual convolution neural network. Rev Sci Instrum (2022) 93:034701. doi:10.1063/5.0076826
20. Nogay HS, Akinci TC, Yilmaz M. Detection of invisible cracks in ceramic materials using by pre-trained deep convolutional neural network. Neural Comput Appl (2022) 34:1423–32. doi:10.1007/s00521-021-06652-w
21. Bang HT, Park S, Jeon H. Defect identification in composite materials via thermography and deep learning techniques. Compos Struct (2022) 246:112405. doi:10.1016/j.compstruct.2020.112405
22. Kim B, Yuvaraj N, Sri Preethaa KR, Arun Pandian R. Surface crack detection using deep learning with shallow CNN architecture for enhanced computation. Neural Comput Appl (2021) 33:9289–305. doi:10.1007/s00521-021-05690-8
23. Abu AO, Singh J, Maayah B, Alhodaly M. Reproducing kernel approach for numerical solutions of fuzzy fractional initial value problems under the Mittag–Leffler kernel differential operator. Math Methods Appl Sci (2023) 46:7965–86. doi:10.1002/mma.7305
24. Abu AO, Singh J, Alhodaly M. Adaptation of kernel functions-based approach with Atangana–Baleanu–Caputo distributed order derivative for solutions of fuzzy fractional Volterra and Fredholm integrodifferential equations. Math Methods Appl Sci (2023) 46:7807–34. doi:10.1002/mma.7228
25. Ravandi M, Teo WS, Tran LQN, Yang MS, Tay TE. Low velocity impact performance of stitched flax/epoxy composite laminates. Compos B-eng (2017) 117:89–100. doi:10.1016/j.compositesb.2017.02.003
26. Sarasini F, Tirillò J, Ferrante L, Sergi C, Russo P, Simeoli G, et al. Quasi-static and low-velocity impact behavior of intraply hybrid flax/basalt composites. Fibers (2019) 7:26–41. doi:10.3390/fib7030026
27. Fu H, Feng X, Liu J, Yang Z, He C, Li S. An investigation on anti-impact and penetration performance of basalt fiber composites with different weave and lay-up modes. Def Technol (2020) 16:787–801. doi:10.1016/j.dt.2019.09.005
28. Selver E. Impact and damage tolerance of shear thickening fluids-impregnated carbon and glass fabric composites. J Reinf Plast Comp (2019) 38:669–88. doi:10.1177/0731684419842648
29. Shohag MAS, Hammel EC, Olawale DO, Okoli OI. Damage mitigation techniques in wind turbine blades: a review. Wind Eng (2017) 41:185–210. doi:10.1177/0309524X17706862
30. Sevkat E, Liaw B, Raju RR. Drop-weight impact of plain-woven hybrid glass–graphite/toughened epoxy composites. Compos A-appl S (2009) 40:1090–110. doi:10.1016/j.compositesa.2009.04.028
31. Go SH, Lee MS, Hong CG, Kim HG. Correlation between drop impact energy and residual compressive strength according to the lamination of CFRP with EVA sheets. Polymers (2020) 12:224. doi:10.3390/polym12010224
32. Subadra SP, Griskevicius P, Yousef S. Low velocity impact and pseudo-ductile behaviour of carbon/glass/epoxy and carbon/glass/PMMA hybrid composite laminates for aircraft application at service temperature. Polym Test (2020) 89:106711. doi:10.1016/j.polymertesting.2020.106711
33. Andrew JJ, Srinivasan SM, Arockiarajan A, Dhakal HN. Parameters influencing the impact response of fiber-reinforced polymer matrix composite materials: a critical review. Compos Struct (2019) 224:111007. doi:10.1016/j.compstruct.2019.111007
34. Fotouhi S, Pashmforoush F, Bodaghi M, Fotouhi M. Autonomous damage recognition in visual inspection of laminated composite structures using deep learning. Compos Struct (2021) 268:113960. doi:10.1016/j.compstruct.2021.113960
35. Chen D, Luo Q, Meng M, Li Q, Sun G. Low velocity impact behavior of interlayer hybrid composite laminates with carbon/glass/basalt fibres. Compos Part B-eng (2019) 176:107191. doi:10.1016/j.compositesb.2019.107191
36. Tang E, Wang J, Han Y, Chen C. Microscopic damage modes and physical mechanisms of CFRP laminates impacted by ice projectile at high velocity. J Mater Res Technol (2019) 8:5671–86. doi:10.1016/j.jmrt.2019.09.035
37. Condruz M, Paraschiv A, Vintila IS, Sima M, Andreea Deutschlander Dumitru F. Evaluation of low velocity impact response of carbon fiber reinforced composites. Key Eng Mater (2018) 779:3–10. doi:10.4028/www.scientific.net/KEM.779.3
38. Li Y, Tian G, Yang Z, Luo W, Zhang W, Ming A, et al. The use of vibrothermography for detecting and sizing low energy impact damage of cfrp laminate. Adv Compo Lett (2017) 26:096369351702600–167. doi:10.1177/096369351702600504
39. Wang Z, Yang J, Jiang H, Fan X. CNN training with twenty samples for crack detection via data augmentation. Sensors (2020) 20:4849. doi:10.3390/s20174849
40. Nair V, Hinton GE. Rectified linear units improve restricted Boltzmann machines. Proc 27th Int Conf machine Learn (Icml-10) (2010) 27:807–14.
41. Krizhevsky A, Sutskever I, Hinton G. ImageNet classification with deep convolutional neural networks. Adv Neural Inf Process Syst (2012) 25:84–90. doi:10.1145/3065386
42. Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition. Computer Sci (2014). doi:10.48550/arXiv.1409.1556
43. He K, Zhang X, Ren S, Sun J. Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 27–30 June, 2016; Las Vegas, NV, USA. IEEE (2016).
44. Gao M, Qi D, Mu H, Chen J. A transfer residual neural network based on ResNet-34 for detection of wood knot defects. Forests (2021) 12:212. doi:10.3390/f12020212
45. Akiba T, Shuji S, Keisuke F. Extremely large minibatch sgd: training resnet-50 on imagenet in 15 minutes. arxiv preprint (2017) 1711:04325. doi:10.48550/arXiv.1711.04325
46. Szegedy C, Liu W, Jia Y, Sermanet P, Reed S, Anguelov D, et al. Going deeper with convolutions. In: 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR); 07–12 June, 2015; Boston, MA, USA. IEEE (2015).
Keywords: composite materials, damage detection, deep learning, neural network, visual inspection
Citation: Jiang J and Wang Z (2024) Damage detection of composite laminates based on deep learnings. Front. Phys. 12:1456236. doi: 10.3389/fphy.2024.1456236
Received: 28 June 2024; Accepted: 09 September 2024;
Published: 20 September 2024.
Edited by:
Lucia Valentina Gambuzza, University of Catania, ItalyCopyright © 2024 Jiang and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: JianHua Jiang, ampfbGxpdXVAMTYzLmNvbQ==