 Yinchong Wang
Yinchong Wang Wenlian Lu
Wenlian Lu- 1School of Mathematics, Fudan University, Shanghai, China
- 2Center for Applied Mathematics, Fudan University, Shanghai, China
Network-based contagion models are widely used to describe the spread of epidemics, computer viruses and opinions, yet estimating their states, parameters and hyperparameters remains challenging, especially when only macro-level data are available. We therefore aimed to develop a data-assimilation framework capable of performing this estimation without requiring node-level observations. An ensemble Kalman filter-based approach was designed to assimilate macroscopic data into network-based Susceptible–Infected–Recovered models with heterogeneous parameters. The method was evaluated under three scenarios: (i) homogeneous parameters with known network topology; (ii) heterogeneous parameters with known topology; and (iii) homogeneous parameters with unknown topology. Across all tested scenarios, the proposed algorithms accurately estimated both the system states and the underlying parameter/hyperparameter when the network size are sufficiently large, demonstrating scalability and robustness even when only aggregate statistics were available. The results indicate that the proposed assimilation framework can reliably estimate network-based contagion dynamics from macro-level observations, obviating the need for costly node-level monitoring and offering a practical tool for real-time epidemic analysis and forecasting.
1 Introduction
In contagion dynamics [4], nodes on a network are in one of several states at any given moment, and the transition of a node’s state depends on its own state or the states of its neighboring nodes. The spread of epidemics, computer viruses, and public opinion over networks can all be characterized and studied using the principles of contagion dynamics. This has led to the emergence of fields such as epidemic dynamics [14], cybersecurity dynamics [20], and opinion dynamics [18]. Owing to the similarities in the underlying mechanisms of these fields, models from one domain are often used to study others and can be enhanced in the process. A prime example is the “compartmental models” in epidemic dynamics, such as the susceptible–infected–susceptible (SIS) and susceptible–infected–recovered (SIR) models [3], which have been adapted to study cybersecurity dynamics with the incorporation of considerations for network topology [22, 25].
Although a variety of models and corresponding theories, such as the epidemic threshold theory associated with the SIS model [1], have been proposed, contagion dynamics and its derived fields still face many pressing issues. The most important of these is the uncertainty of model parameters, a problem that has been raised in both epidemic dynamics [14] and cybersecurity dynamics [21]. Nearly all studies are based on the core assumption that model parameters, such as infection rates of viruses, recovery rates of disease, and the intensity of cyber-attacks and network structures, are known. For example, the epidemic threshold is entirely determined by model parameters [1], and the dynamical evolution of some models is also completely determined by these parameters [22, 25]. Without knowing the model parameters, all these works will remain at the theoretical level and cannot be verified for correctness or used to solve practical problems, contradicting the original intention of establishing these fields.
However, the reality is that these parameters are difficult to obtain. For example, the infection and recovery rates of viruses and computer viruses cannot be directly measured, and network structures often contain substantial erroneous information [12]. Therefore, how to extract model parameters from available data has become an emerging direction [14, 21].
Current work on parameter estimation in contagion dynamics is largely based on traditional contagion models, which assume that (i) connections between nodes are well mixed, and thus, the models do not account for the effects of network topology; and (ii) parameters between nodes are homogeneous [17, 23]. However, Newman pointed out that these two assumptions are not realistic: the number of people each node can come into contact with varies greatly, and the ability of different infectors to infect others is also different [11]. Therefore, it is necessary to incorporate network topology into consideration. In the current work on parameter estimation in network-based contagion dynamics, the data are at the node level—that is, the information of each node over time is required [15]. However, such data are often difficult to obtain in reality. To the best of our knowledge, there are currently no works on estimating parameters of network-based contagion dynamics models with heterogeneous parameters from macroscopic data like the average infection rate.
Data assimilation (DA) is a technique that integrates observational data with numerical models to optimize the state and parameters of the model, thereby bringing it closer to the behavior of the real system. In practical applications, data assimilation methods are used not only to improve the initial state of the model but also to estimate key parameters within the model. For example, in meteorology, by assimilating observational data from ground stations and satellites, parameters such as temperature, humidity, and wind fields in atmospheric models can be estimated, thereby enhancing the accuracy of weather forecasts [8]. By dynamically adjusting model parameters to fit observational data, data assimilation significantly enhances the predictive capabilities of models and the understanding of complex systems.
To address the problem of extracting parameters from available data for contagion dynamics models, we propose a method based on the integration of contagion dynamics models and data assimilation. This method not only estimates model parameters but also aids in predicting the state of dynamics. Our contributions are highlighted as follows:
• We proposed a new algorithm that can assimilate macro-data and estimate the parameters of the underlying network-based dynamical model with heterogeneous parameters, which not only fills the gap in the literature but also strengthens the connection between contagion dynamics theoretical models and practical applications.
• In the absence of real-world data, we validated the effectiveness of the proposed algorithm using toy models and investigated its performance under node-heterogeneous parameters and unknown network topology; these results suggest that even when the information on the network topology is uncertain, relatively accurate parameter estimation is still achievable if certain statistical properties of the network are known.
The remainder of this article is organized as follows: Section 2 lists the related work. Section 3 interprets the models and our method. Section 4 conducts the numerical analysis. Finally, Section 5 concludes the paper. There are many abbreviations of proper nouns in the text. For the reader’s convenience, the abbreviations and their corresponding full names are listed in Table 1.
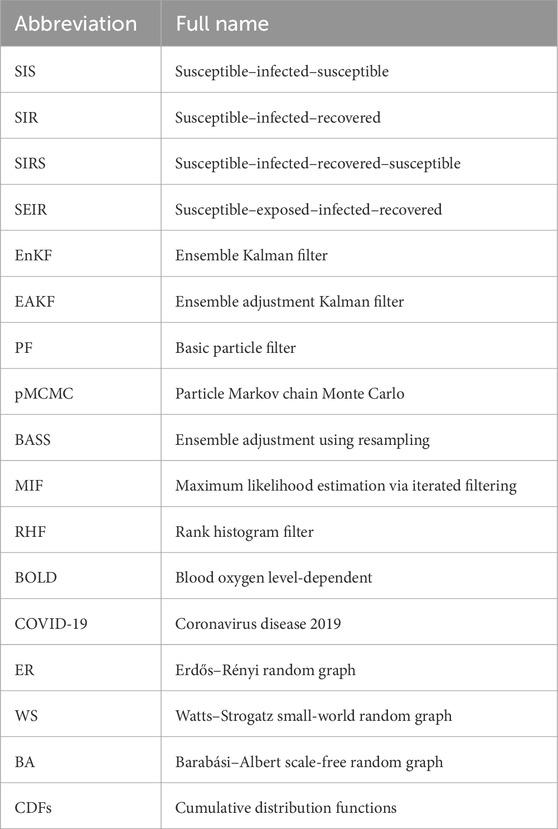
Table 1. Abbreviations and their full names.
2 Related works
There are some studies that utilize data assimilation algorithms to predict the model’s states and estimate parameters.
[17] proposed a framework based on the ensemble adjustment Kalman filter (EAKF) and the susceptible–infected–recovered–susceptible (SIRS) model for real-time prediction of seasonal influenza outbreaks. The study leveraged real-time estimates of influenza infection rates provided by Google Flu Trends, assimilating these data into the SIRS model via the EAKF to optimize the model’s state variables and parameter estimates. The technical strength of the EAKF lies in its ability to dynamically adjust model parameters and state variables, aligning them with actual observational data and enabling the estimation of key epidemiological parameters, such as the average infectious period (D) and the basic reproductive number
[23] compared the performances of six advanced filtering methods in influenza epidemic modeling and forecasting. The six filtering methods include three types of particle filters, namely, basic particle filter (PF), maximum likelihood estimation via iterated filtering (MIF), and particle Markov chain Monte Carlo (pMCMC), and three types of ensemble filters, namely, ensemble Kalman filter (EnKF), EAKF, and rank histogram filter (RHF). The study used a humidity-driven SIRS model and utilized influenza incidence data from 115 U.S. cities for simulation and retrospective forecasting. The results indicate that the basic particle filter and EnKF methods perform better in fitting historical influenza data and estimating parameters.
[9] proposed an improved state filter algorithm for SIR epidemic forecasting, known as ensemble adjustment using resampling (BASS), which aims to enhance the performance of epidemic predictions based on the SIR model by integrating the linear correction of the EnKF with the resampling technique of the PF. BASS corrects the state variables using maximum likelihood estimation and updates the ensemble by sampling from the best-performing particles, thereby optimizing the state variables and parameter estimates of the model. Empirical results demonstrate that BASS achieves the lowest root-mean-square error and the highest correlation coefficient in 11 of 14 real-world scenarios.
[5] presented an extended susceptible–exposed–infected–recovered (SEIR) model with a vaccination compartment to simulate and forecast the COVID-19 pandemic in Saudi Arabia. The model included seven stages of infection: susceptible, exposed, infectious, quarantined, recovered, dead, and vaccinated. To address uncertainties in the model and improve forecasting skills, the authors used a data assimilation method using the ensemble Kalman filter to estimate model states and parameters by assimilating daily COVID-19 data.
[24] proposed a method based on the hierarchical data assimilation framework to estimate the hyperparameters of spiking neuronal network models for simulating and predicting brain activity. The study considered the role of network topology in the model while also allowing the model’s parameters to be heterogeneous across nodes. It combined hierarchical Bayesian estimation with data assimilation techniques to estimate the distribution of parameters in the mesoscopic neuronal network model using macroscopic blood oxygen level-dependent (BOLD) signal data, rather than directly estimating the exact values of each parameter. Through simulation experiments, the hierarchical data assimilation framework demonstrated high efficiency and accuracy in estimating hyperparameters and simulating BOLD signals while avoiding overfitting.
The aforementioned studies can be summarized as follows: in the field of classical epidemic dynamics, most studies that utilize data assimilation techniques to predict state estimation parameters use models based on the assumptions of homogeneous mixing and homogeneous nodes, without considering the impact of network topology and node heterogeneity on the model. In the field of neuroscience, Zhang et al. challenged these two assumptions and proposed a framework, hierarchical data assimilation, for estimating distribution hyperparameters. However, in their estimation process, the network structure is assumed to be known.
Table 2 presents comparisons between previous studies and our work. In the “Network topology” column, “Fully mixed” indicates that the model does not account for network topology; this will be elaborated upon in the model selection section.
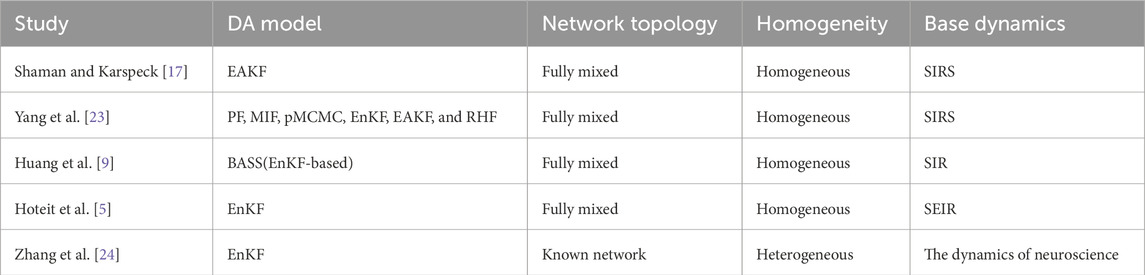
Table 2. Comparison of data assimilation models, network structure assumptions, and node homogeneity assumptions across different studies.
3 Models and methods
3.1 Contagion dynamics
Some classical contagion dynamics models are repeatedly used and investigated across various fields, such as SIS and SEIR [7]. Because the SIR model is the most renowned and extensively studied model in classical epidemiology and is highly representative—with other models such as SIRS and SEIR, mentioned in the Related work section, being its variants [10]—we choose a network security dynamics model based on the SIR model as our model. It is noteworthy that our algorithm can be adapted to other models. Section 4.7 presents a case where we use our algorithm in the SIS model.
Assume that there are
- susceptible (S): nodes that are not yet infected but can contract the virus;
- infected (I): nodes that are currently infected and can transmit the virus to others; or
- recovered (R): nodes that have recovered from the attack of the virus and are now immune.
The network topology can be represented using a directed graph
As emphasized earlier, the original SIR model does not account for network topology and assumes homogeneous parameters across all nodes [9]. We assume that the rate of an infected node successfully infecting a susceptible node is
As mentioned in the Related work section, the original model is far from realistic; therefore, we take the network topology into account and assume that the nodes’ parameters are different.
Let
3.2 Algorithm for estimating the parameters of contagion dynamics based on EnKF
The main objective of our algorithm is to assimilate macroscopic observational states and estimate the parameters of the underlying dynamical model, with adjustments made according to different scenarios.
3.2.1 Selection of the data assimilation method
From the Related work section [23], two types of data assimilation algorithms are often used in the inference and forecasting of infectious disease models: PF and ensemble filters (including the EnKF and its derivations).
PF and EnKF are both advanced methods for state estimation in nonlinear dynamic systems. The particle filter is a non-parametric filtering technique based on Monte Carlo methods, which approximates the posterior probability distribution of the system using a set of weighted particles. In contrast, the ensemble Kalman filter is a linear filtering method based on ensemble members to estimate the error covariance, making it suitable for efficient state estimation in high-dimensional systems.
Both of these filtering methods can be applied to our approach, and the procedures are similar. Compared to the PF, the EnKF avoids the issue of particle depletion caused by resampling and offers more flexible computation, making it suitable for data assimilation tasks in epidemic models. We compare the performances of the two filtering methods in Section 4.4.3. We adopt the ensemble Kalman filter as our basic method.
3.2.2 Three application scenarios
Below are three scenarios that need to be considered:
1) Scenario 1: The network
2) Scenario 2: The network
3) Scenario 3: The network
Scenario 1 is the most basic scenario, which takes into account the network topology but still assumes that the parameters are homogeneous. Scenario 2 considers heterogeneous parameters and demonstrates that when there are a sufficient number of nodes in the network, it is the distribution of these parameters—not the individual node values—that influences the contagion dynamics [11]. Scenario 3 takes into account the possibility that the network information in reality may be erroneous or incomplete [13], and it shows that if one grasps the statistical patterns of the network, it is possible to estimate the parameters without strictly knowing the specific structure of the network topology.
The detailed procedure of the algorithm is introduced in the following section.
3.2.3 Evolution system and state vector
Data assimilation methods require an evolution equation, which is corrected at each time step by observations to bring the variables and parameters of the equation closer to the true situation. The set of variables and parameters that need to be updated is referred to as the state vector of the evolution equation. Assume that the state vector is
where
We define the system state at time
It is worth noting that the evolution system does not directly act on the state variable
where
In system
In Scenario 2, we use the method of “Sampling parameters from the hyperparameter” [24] to update each node’s infection rate and recovery rate. Suppose that
where
The states and parameters we aim to assimilate are those of the System defined in Equation 2. However, the variables of the System in Equation 2 are the probabilities of each node being in one of the three states, which are the continuous values. Moreover,
3.2.4 Instantiation of the evolution system
3.2.4.1 Discrete simulation
First, the System (Equation 2) can be discretized, and then the infection process within each time interval can be simulated. Under this condition,
Specifically, in the simulation, we select a random number
Similarly, if
Moreover, the Evolve System (Equation 3) represents the process of continuing the above simulation until the time reaches
3.2.4.2 Gillespie-based simulation
Second, without considering discretization, the System (Equation 2) can be simulated using the Gillespie algorithm [6, 16]. The Evolve System (Equation 3) for simulating the System (Equation 2) using the Gillespie algorithm over the time interval from

Algorithm 1. Gillespie algorithm for network-based SIR model.
3.2.4.3 Random sampling-based simulation
Third, the Evolve System (Equation 3) can directly evolve the System (Equation 2) and subsequently sample
Then, all the triplets
It should be pointed out that our algorithm is independent of the choice of the System (Equation 3), as long as Equation 3 is a mapping that reflects the discrete-state-to-discrete-state transition of the System (Equation 2). Therefore, our algorithm is applicable to both discrete-time and continuous-time dynamics.
3.2.5 Algorithmic procedure
3.2.5.1 Observation and its generation
The observations are the obtained macroscopic time-series data: assume that during the time interval
where
Due to the lack of real data, we use the Evolve System described in Section 3.2.3 to generate observation data at given time points
3.2.5.2 Initialization
We generate
At the initial time
To distinguish from the components of
3.2.5.3 Forecast process
For the
and
Then,
3.2.5.4 Update process
We recall that
where
The Kalman gain
where
To update the information of
If at time
•
•
•
•
Let the ceiling function be denoted as

Algorithm 2. Modify
Let the result of
The result of a single step in the System (Equation 2) has significant randomness. Here, we introduce a new parameter: the window length
The entire process of our algorithm is presented in Algorithm 3.

Algorithm 3. Estimate parameters in network-based contagion dynamics model with the EnKF.
3.2.5.5 Estimated result
We use the average of the states of the ensemble members as the estimation result of the algorithm:
4 Numerical simulation
4.1 Experiment setting
The proposed algorithm has been implemented using the Python programming language with the NDLib library for simulating the toy model. We conducted experiments on a machine equipped with an Intel(R) Core(TM) i7-10750H CPU running at 2.60 GHz, 32.0 GB of RAM, and a 1 TB SSD.
4.2 Experiment dataset
In scenarios 1 and 2, we use real network data to validate our algorithm. Specifically, we utilize the Internet Gnutella05 peer-to-peer network dataset, which contains 8,846 nodes and 31,839 arcs. The average node in- and out-degree is 3.5993, with a maximal node in-degree of 79 and a maximal node out-degree of 65. This dataset can be accessed from the following link: https://snap.stanford.edu/data/p2p-Gnutella05.html.
In Scenario 3, network
• Erdős–Rényi random graph (ER): The graph
• Watts–Strogatz small-world random graph (WS): The graph
• Barabási–Albert scale-free random graph (BA): The graph
In Scenario 2, where each node has different parameters, we use the exponential distribution to sample
4.3 Evaluation metrics
We define
(i) Measurement of the assimilation effect of observations:
(ii) Measurement of the parameter estimation performance:
or in Scenario 2,
4.4 Homogeneous model and known network
In this subsection, the network topology is explicitly known, and the model parameters are homogeneous across nodes, i.e.,
4.4.1 Performance of the algorithm in continuous-time dynamics
As shown in Section 3.2.3, the algorithm can be applied on the two continuous-time evolution simulation methods. We take
Figures 1, 2, respectively, demonstrate the effectiveness of our algorithm based on the two continuous-time simulation methods mentioned above (Gillespie-based and random-sampling-based). For the Gillespie-based simulation in Figure
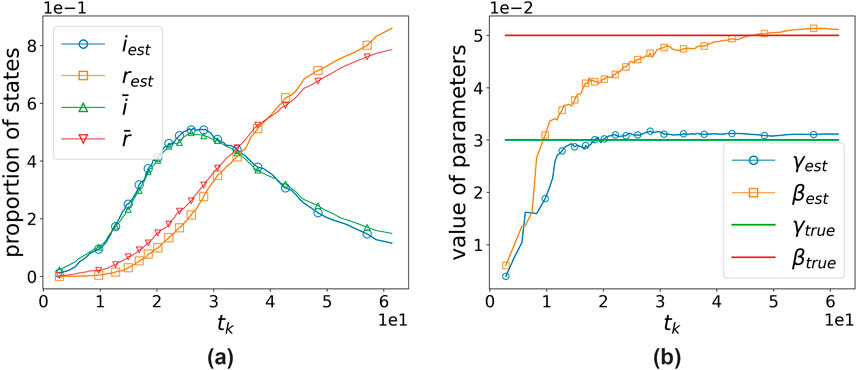
Figure 1. Performance of the algorithm when using the Gillespie-based simulation method.
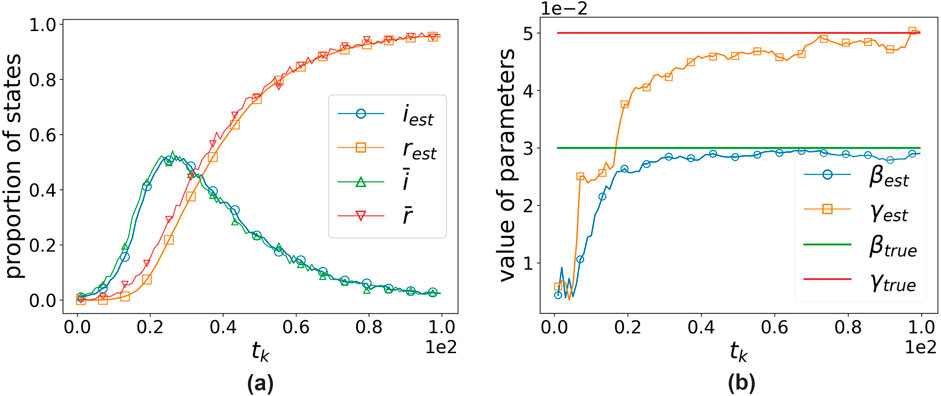
Figure 2. Performance of the algorithm when using the random-sampling-based simulation method.
It can be observed that our algorithm’s estimates are close to the true values using both simulation methods. The assimilation effect using the Gillespie-based simulation method is slightly worse, which may be because the time intervals generated using the Gillespie-based method are not uniform, and thus, the magnitude of each correction cannot be controlled. The average of the results from 10 experiments shows that, for the Gillespie-based simulation,
We compare the differences among the three simulation methods in the following paragraph. Figure 3 illustrates the performance of the three different simulation methods described in Section 3.2.3 when
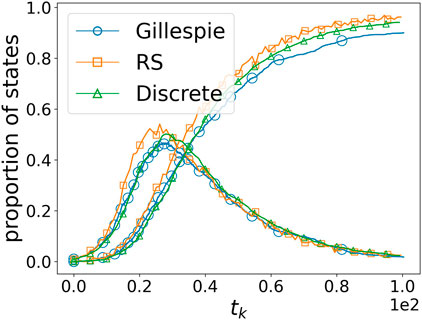
Figure 3. Comparison of the three simulation methods. “Gillespie,” “RS,” and “Discrete” refer to the Gillespie-based simulation, random-sampling-based simulation, and discrete simulation, respectively.
However, there is a significant difference in the running time. The Gillespie-based simulation method generates nearly 2,000 time points each time, with an average running time of 675.2 s for the entire simulation process; the random-sampling-based simulation method, when the number of nodes is very large, consumes a considerable amount of time on each sampling, with an average running time of 136.7 s; the discrete simulation method is the fastest, with an average running time of 10.3 s.
Given that the simulation results are quite similar and that continuous-time dynamics can also be simulated using the discrete simulation method by adjusting the time intervals during discretization (since computations are always discrete in practice), for the sake of efficiency, the discrete simulation method is consistently used in the subsequent experiments.
4.4.2 Necessity of incorporating network topology
When network topology is incorporated, the model’s complexity increases compared to the baseline. Nevertheless, if the standard SIR model remains capable of producing accurate parameter estimates even when observational dynamics encompass network effects, the enhanced model would prove redundant and entail unnecessary computational overhead.
In this subsection, we generate observational data using the dynamics (Equation 2) that incorporate network effects and then estimate parameters through the standard SIR model coupled with the EnKF, replicating the methodology in [9]. With
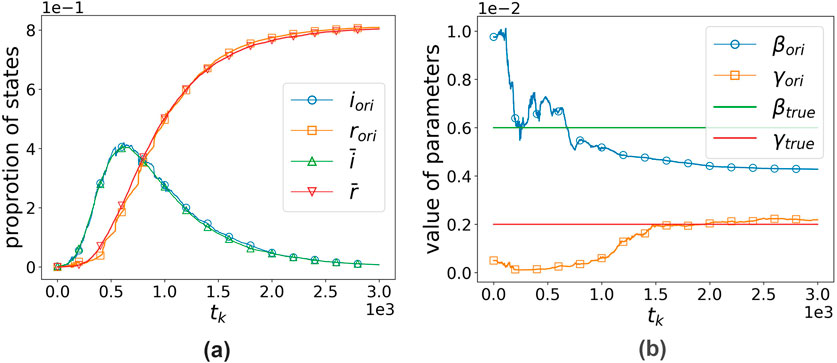
Figure 4. Original SIR model’s performance when
The algorithm exhibits clear convergence. For each parameter set, we conducted 10 independent trials, with the final 50 time-step averages serving as steady-state estimates. Figure 5 displays the experimental outcomes, where the x-axis denotes the six
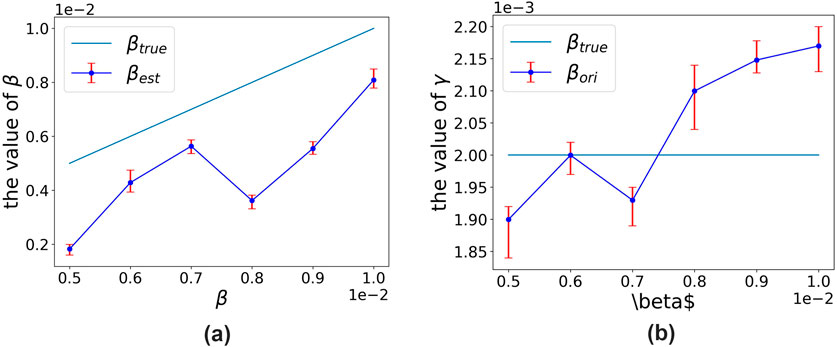
Figure 5. Comparison of true parameters and estimated parameters under the original SIR model. (a) True
It can be clearly observed that the original SIR model systematically underestimates the transmission rate
4.4.3 Comparison with algorithms based on particle filter
Our algorithm can also be deployed on particle filtering. We compared the performance between the EnKF- and the PF-based algorithms, with the same number of particles, for ensemble sizes of 50 and 100. The observational data are derived from the following parameters:
Table 3 shows the performance of the two algorithms. Figures 6, 7 visualize the assimilation effects of the two algorithms when the ensemble sizes are 50 and 100, respectively.
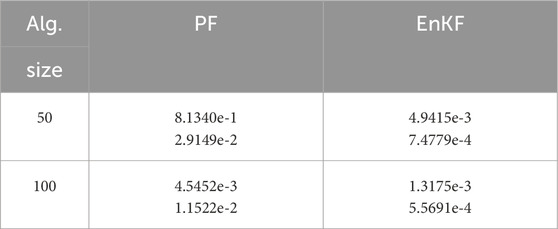
Table 3. Algorithm performance under different filters with sizes of 50 and 100. In each cell, the upper part shows
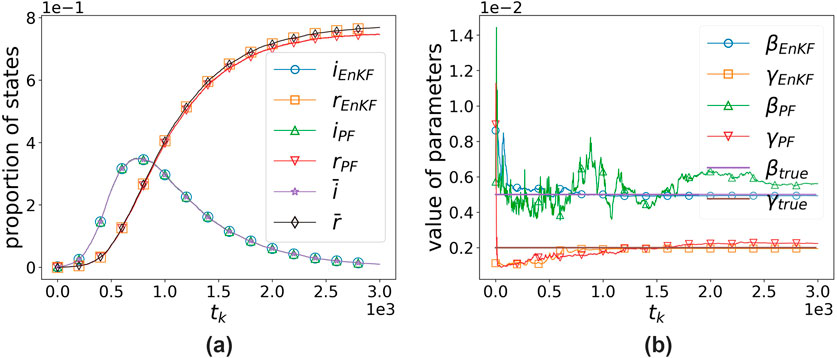
Figure 6. Comparison of algorithms based on the EnKF and PF with size 50. (a) States’ proportion vs. time. (b) Parameters’ value vs. time.
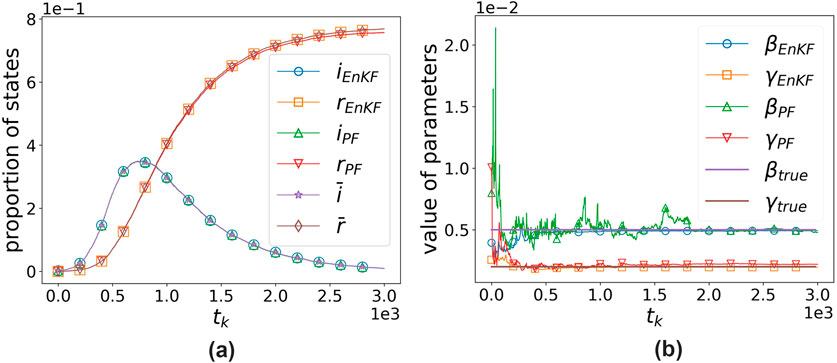
Figure 7. Comparison of algorithms based on the EnKF and PF with size 100. (a) States’ proportion vs. time. (b) Parameters’ value vs. time.
It can be observed that both algorithms perform well in assimilating observational data, with the EnKF-based algorithm showing a slight advantage. However, in terms of parameter estimation, EnKF significantly outperforms PF, with results differing by two orders of magnitude. The EnKF also converges faster and exhibits greater stability, yielding satisfactory results even with an ensemble size of 50. In contrast, PF only shows slightly better performance when the number of particles reaches 100, and its efficiency is far lower than that of the EnKF.
4.4.4 Optimal parameters for this algorithm
We then explore the impact of different hyperparameters: the number of ensemble members
We set the observation’s parameters as
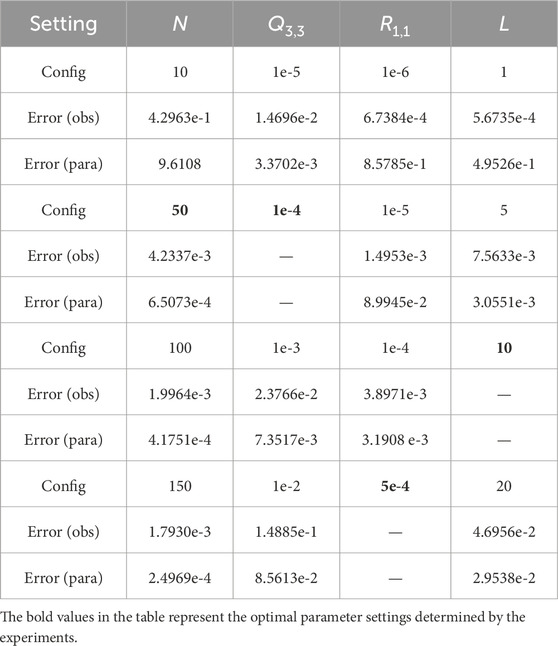
Table 4. Algorithm performance under different parameter settings. Each cell has only one value that differs from the optimal parameters.
Figure 8 illustrates the algorithm’s fitting of observations and estimation of parameters under the optimal parameters. It can be observed that the algorithm exhibits excellent fitting performance for the observations, and the estimated parameters converge to the actual values, which validates our algorithm. For easy comparison, in the example shown in the figure,
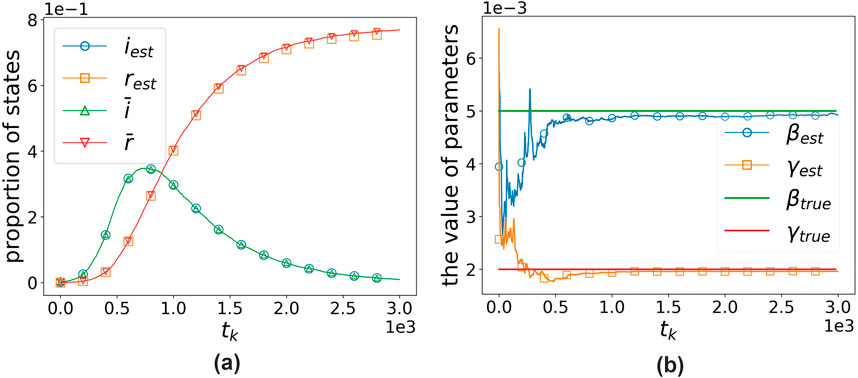
Figure 8. Algorithm’s fitting effect and the estimation effect on parameters under the optimal parameters when
As shown in Table 4, the larger the ensemble size
Therefore, we set the ensemble size to 50 as its performance is not significantly different from that of ensemble sizes of 100 or 150. When the observational covariance
4.5 Heterogeneous model and known network
We assume that the node parameters are different but sampled from the same exponential distribution: the cumulative distribution functions of
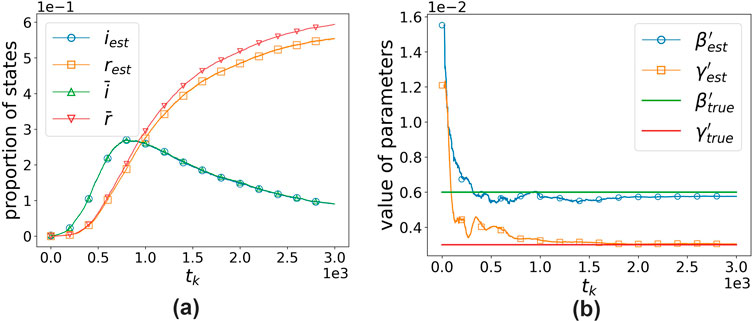
Figure 9. Algorithm’s fitting effect and the estimation effect on hyperparameters.
We then investigated the impact of different parameters on the accuracy. Table 5 lists the accuracy of the algorithm when
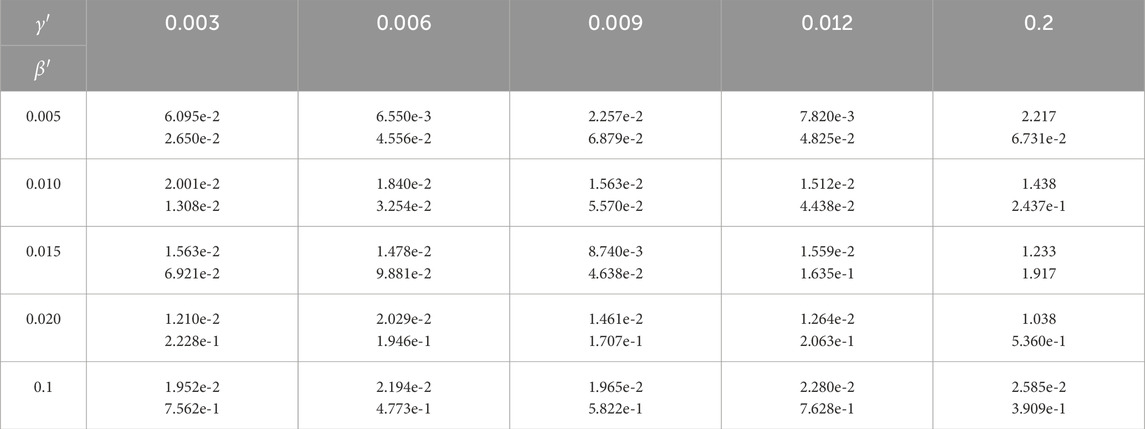
Table 5. Algorithm’s performance under different
Moreover, the success of our algorithm suggests that when there are sufficient nodes in the network, the infection situation of computer viruses may not be related to the specific defense capabilities of the nodes or the infection capabilities of the viruses but rather to the probability distribution of defense and infection capabilities. This is consistent with the ideas of some studies that used statistical physics to study contagion dynamics [11].
4.6 Different networks
In this subsection, we assume that the model is homogeneous and that the network is unknown, but we know that it has a specific structure, and the structural parameters are known. We used this hyperparameter to generate new random graphs for each ensemble member to estimate the model.
We consider three types of synthetic random networks: Erdős–Rényi graph
Figure 10 illustrates the algorithm’s performance in separate experiments conducted on three distinct networks with 5,000 nodes, an average degree of 10, and parameters
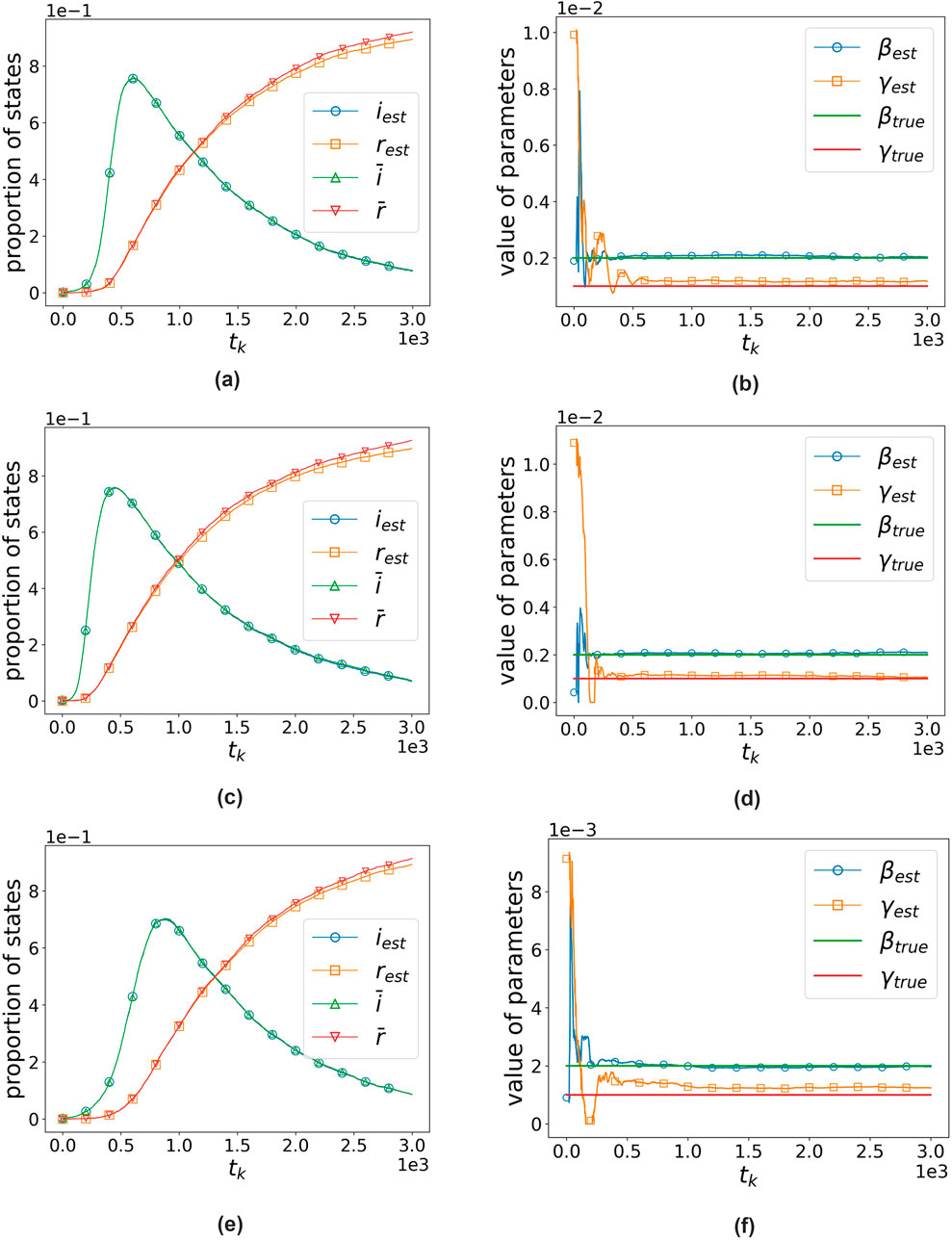
Figure 10. Algorithm’s performance on three random graphs with 5,000 nodes and an average degree of 10 when
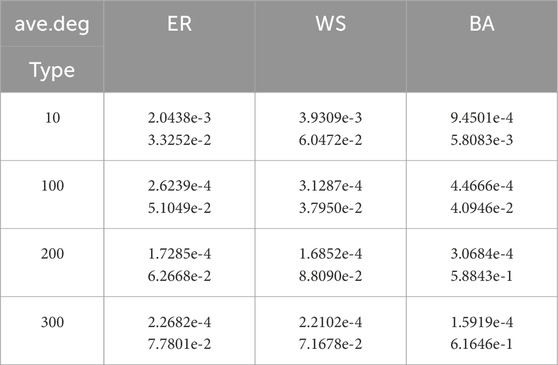
Table 6. Performance of the algorithm when
It can be observed that even without knowing the specific network structure, our algorithm performs well across all three types of networks, demonstrating its robustness. Meanwhile, as shown in the table, when the average degree increases (e.g., to 200 and 300), the performance of our algorithm in estimating parameters on BA networks decreases significantly. We speculate that this is because BA networks are heterogeneous, with highly uneven degree distributions and a significant number of nodes with very high degrees. These high-degree nodes have a substantial impact on the spread of the virus. As the average degree increases, the heterogeneity of the network also increases, rendering the method of averaging less suitable for estimating network parameters. This, in turn, leads to a decrease in the performance of our algorithm.
4.7 SIS model
In the previous section, we focused on the SIR model; however, it should be noted that our algorithm is not only applicable to the SIR model but can also be used for other classic epidemic models. In this subsection, we use our algorithm to estimate a network-based SIS model [19]. We assume that any node
where
In the estimation experiment, we used a 5,000-node ER network, with an average degree of 10. The average infection rate
The two subfigures in Figure 11, respectively, show the algorithm’s data assimilation of observational states and its parameter estimation effectiveness.
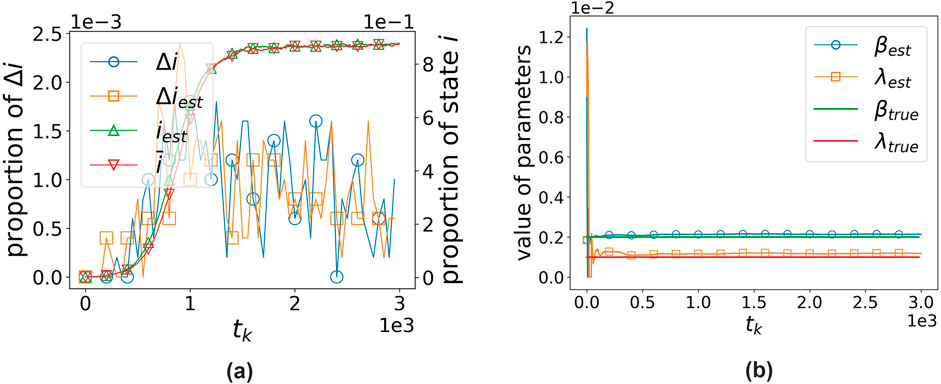
Figure 11. Algorithm performance on the network-based SIS model. (a) States’ proportion vs. time. (b) Parameters’ value vs. time.
5 Conclusion and discussion
This study proposes a data assimilation algorithm to estimate network-based contagion dynamical models, including the states, parameters, and hyperparameters. We validate the performance of the algorithm in three scenarios, demonstrating its powerful capabilities and suggesting that when the network size is sufficiently large, the dynamical behavior may be independent of the specific network and parameters, instead depending on their distributions.
Although our algorithm performed well in experiments, it still has obvious limitations when applied in practice.
(1) Due to the lack of relevant real-world data, we cannot validate the effectiveness of our algorithm on public datasets as other algorithm papers do. Experiments can only be conducted using synthetic data, suggesting that we are not certain about how our algorithm will perform in practical applications.
(2) The method of data assimilation is highly dependent on the choice of the model. For existing data, we must precisely know the underlying model to make accurate predictions and estimates. However, due to the lack of real-world data, we are unable to determine how the algorithm performs on real data. The algorithm also requires information about the specific network structure. In the three scenarios, we know either the exact network structure or that the network structure comes from a specific distribution, which is relatively difficult in reality.
(3) When the underlying dynamics converge too rapidly, our algorithm does not have sufficient time to update the states and acquire information, thus resulting in mediocre performance. We need to understand at what convergence rate of the dynamics our algorithm can ensure accuracy.
(4) There is a lack of theoretical guarantees regarding the reliability of the algorithm and the choice of hyperparameters, and there is also a general lack of publicly available and reliable network-topology-based time series datasets in the field of contagion dynamics. This makes it difficult to validate our algorithm, along with other theoretical results, on public datasets. Ensuring the theoretical reliability of our algorithm and developing methods for collecting data to construct useful datasets will both be important directions for our future research.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material; further inquiries can be directed to the corresponding author.
Author contributions
YW: Data curation, Formal Analysis, Investigation, Software, Validation, Visualization, Writing – original draft, and Writing – review and editing. WL: Conceptualization, Formal Analysis, Funding acquisition, Investigation, Methodology, Resources, Supervision, and Writing – original draft.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work is supported by the Science and Technology Commission of Shanghai Municipality (No. 23JC1400800).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that Generative AI was used in the creation of this manuscript. The author(s) verify and take full responsibility for the use of generative AI in the preparation of this manuscript. Generative AI was used Kimi.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Chakrabarti D, Wang Y, Wang C, Leskovec J, Faloutsos C. Epidemic thresholds in real networks. ACM Trans Inf Syst Security (Tissec) (2008) 10(4):1–26. doi:10.1145/1284680.1284681
2. Javier Cocucci T, Pulido M, Aparicio JP, Ruíz J, Simoy MI, Rosa S. Inference in epidemiological agent-based models using ensemble-based data assimilation. PloS one (2022) 17(3):e0264892. doi:10.1371/journal.pone.0264892
3. Cohen JE. Infectious diseases of humans: dynamics and control. JAMA The J Am Med Assoc (1992) 268(23):3381. doi:10.1001/jama.1992.03490230111047
4. Epstein JM, Parker J, Cummings D, Hammond RA. Coupled contagion dynamics of fear and disease: mathematical and computational explorations. PloS one (2008) 3(12):e3955. doi:10.1371/journal.pone.0003955
5. Ghostine R, Gharamti M, Hassrouny S, Hoteit I. An extended seir model with vaccination for forecasting the covid-19 pandemic in Saudi Arabia using an ensemble kalman filter. Mathematics (2021) 9(6):636. doi:10.3390/math9060636
6. Daniel TG. A general method for numerically simulating the stochastic time evolution of coupled chemical reactions. J Comput Phys (1976) 22(4):403–34. doi:10.1016/0021-9991(76)90041-3
7. Herbert W. The mathematics of infectious diseases. SIAM Rev (2000) 42:599–653. doi:10.1137/s0036144500371907
8. Hoteit I, Pham D-T, Triantafyllou G, Korres G. A new approximate solution of the optimal nonlinear filter for data assimilation in meteorology and oceanography. Monthly Weather Rev (2008) 136(1):317–34. doi:10.1175/2007mwr1927.1
9. Huáng W, Provan GM. An improved state filter algorithm for sir epidemic forecasting. In: European conference on artificial intelligence (2016). doi:10.3233/978-1-61499-672-9-524
10. Matt J, Eames KT. Networks and epidemic models. J R Soc Interf (2005) 2(4):295–307. doi:10.1098/rsif.2005.0051
11. Newman MEJ, Newman MEJ. Spread of epidemic disease on networks. Phys Rev E, Stat nonlinear, soft matter Phys (2002) 66(1 Pt 2):016128. doi:10.1103/PhysRevE.66.016128
12. Mark EJN. Estimating network structure from unreliable measurements. Phys Rev E (2018) 98(6):062321. doi:10.1103/physreve.98.062321
13. Newman MEJ. Network structure from rich but noisy data. Nat Phys (2018) 14(6):542–5. doi:10.1038/s41567-018-0076-1
14. Nowzari C, Preciado VM, Pappas GJ. Analysis and control of epidemics: a survey of spreading processes on complex networks. IEEE Control Syst Mag (2016) 36(1):26–46. doi:10.1109/MCS.2015.2495000
15. Paré PE, Vrabac D, Sandberg H, Johansson KH. Analysis, online estimation, and validation of a competing virus model. In: 2020 American control conference (ACC) (2020). p. 2556–61. doi:10.23919/ACC45564.2020.9147568
16. Ran Y, Deng X, Wang X, Jia T. A generalized linear threshold model for an improved description of the spreading dynamics. Chaos: An Interdiscip J Nonlinear Sci (2020) 30(8):083127. doi:10.1063/5.0011658
17. Shaman J, Karspeck A. Forecasting seasonal outbreaks of influenza. Proc Natl Acad Sci (2012) 109(50):20425–30. doi:10.1073/pnas.1208772109
18. Travieso G, Costa Lda F. Spread of opinions and proportional voting. Phys Rev E—Statistical, Nonlinear, Soft Matter Phys (2006) 74(3):036112. doi:10.1103/PhysRevE.74.036112
19. Xu M, Da G, Xu S. Cyber epidemic models with dependences. Internet Mathematics (2015) 11(1):62–92. doi:10.1080/15427951.2014.902407
20. Xu S. Cybersecurity dynamics. In: Proceedings of the 2014 symposium and bootcamp on the science of security, HotSoS ’14. New York, NY, USA: Association for Computing Machinery (2014). doi:10.1145/2600176.2600190
21. Xu S. Cybersecurity dynamics: a foundation for the science of cybersecurity. Proactive dynamic Netw defense (2019) 1–31. doi:10.1007/978-3-030-10597-6_1
22. Xu S, Lu W, Xu L. Push-and pull-based epidemic spreading in networks: thresholds and deeper insights. ACM Trans Autonomous Adaptive Syst (Taas) (2012) 7(3):1–26. doi:10.1145/2348832.2348835
23. Yang W, Karspeck AR, Shaman JL. Comparison of filtering methods for the modeling and retrospective forecasting of influenza epidemics. PLoS Comput Biol (2014) 10:e1003583. doi:10.1371/journal.pcbi.1003583
24. Zhang W, Chen B, Feng J, Lu W. On a framework of data assimilation for hyperparameter estimation of spiking neuronal networks. Neural Networks (2024) 171:293–307. doi:10.1016/j.neunet.2023.11.016
Keywords: contagion dynamics, ensemble Kalman filter, complex network, data assimilation, parameter estimation
Citation: Wang Y and Lu W (2025) Estimating contagion dynamics models on networks via data assimilation. Front. Phys. 13:1529376. doi: 10.3389/fphy.2025.1529376
Received: 16 November 2024; Accepted: 26 June 2025;
Published: 15 August 2025.
Edited by:
Ayub Khan, Jamia Millia Islamia, IndiaCopyright © 2025 Wang and Lu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Wenlian Lu, d2VubGlhbkBmdWRhbi5lZHUuY24=