 Xubin Wang
Xubin Wang Pei Ma1
Pei Ma1 Jing Lian
Jing Lian- 1School of Information Science and Engineering, Lanzhou University, Lanzhou, Gansu, China
- 2School of Electronics and Information Engineering, Lanzhou Jiaotong University, Lanzhou, Gansu, China
Introduction: The prediction of chaotic time series is a persistent problem in various scientific domains due to system characteristics such as sensitivity to initial conditions and nonlinear dynamics. Deep learning models, while effective, are associated with high computational costs and large data requirements. As an alternative, Echo State Networks (ESNs) are more computationally efficient, but their predictive accuracy can be constrained by the use of simplistic neuron models and a dependency on hyperparameter tuning.
Methods: This paper proposes a framework, the Echo State Network based on an Enhanced Intersecting Cortical Model (ESN-EICM). The model incorporates a neuron model with internal dynamics, including adaptive thresholds and inter-neuron feedback, into the reservoir structure. A Bayesian Optimization algorithm was employed for the selection of hyperparameters. The performance of the ESN-EICM was compared to that of a standard ESN and a Long Short-Term Memory (LSTM) network. The evaluation used data from three discrete chaotic systems (Logistic, Sine, and Ricker) for both one-step and multi-step prediction tasks.
Results: The experimental results indicate that the ESN-EICM produced lower error metrics (MSE, RMSE, MAE) compared to the standard ESN and LSTM models across the tested systems, with the performance difference being more pronounced in multi-step forecasting scenarios. Qualitative analyses, including trajectory plots and phase-space reconstructions, further support these quantitative findings, showing that the ESN-EICM's predictions closely tracked the true system dynamics. In terms of computational cost, the training phase of the ESN-EICM was faster than that of the LSTM. For multi-step predictions, the total experiment time, which includes the hyperparameter optimization phase, was also observed to be lower for the ESN-EICM compared to the standard ESN. This efficiency gain during optimization is attributed to the model's intrinsic stability, which reduces the number of divergent trials encountered by the search algorithm.
Discussion: The results indicate that the ESN-EICM framework is a viable method for the prediction of the tested chaotic time series. The study shows that enhancing the internal dynamics of individual reservoir neurons can be an effective strategy for improving prediction accuracy. This approach of modifying neuron-level complexity, rather than network-level architecture, presents a potential direction for the design of future reservoir computing models for complex systems.
1 Introduction
Time series prediction is a critical task across diverse scientific and engineering domains, including economics, meteorology, and industrial process control [1]. Among various types of time series, chaotic systems pose a unique and formidable challenge due to their deterministic yet highly unpredictable nature, extreme sensitivity to initial conditions (the butterfly effect), and complex, aperiodic dynamics [2]. Accurately modeling and predicting such systems is crucial for understanding their underlying mechanisms and for making informed decisions in applications.
In recent years, deep learning (DL) methodologies have played a important role in time series prediction. Recurrent Neural Networks (RNNs) and their variants, such as Long Short-Term Memory (LSTM) [2] and Gated Recurrent Units (GRU) [3], are designed to capture temporal dependencies. More recently, Transformer-based architectures [4] have demonstrated success in sequence modeling tasks. While these DL models can learn complex nonlinear relationships from data, they often entail significant drawbacks. These include high computational expense for training, the need for large datasets to avoid overfitting, and a “black-box” nature that hinders interpretability and deployment in critical domains requiring decision transparency [5]. Specialized architectures like WaveNet [6] and DeepAR [5] also face challenges such as resource consumption or limitations with sparse data.
Reservoir Computing (RC) has emerged as an alternative paradigm that offers a compelling balance between performance and computational efficiency [7]. Echo State Networks (ESNs), a principal RC model, utilize a fixed, randomly generated recurrent neural network (the “reservoir”) to project input signals into a high-dimensional state space, with only a linear output layer being trained. This drastically reduces training complexity compared to DL models. However, standard ESNs are not without limitations. Their performance is highly sensitive to the initialization of reservoir hyperparameters, which typically requires extensive manual tuning or grid search [7]. Moreover, traditional ESNs often employ simplistic neuron activation functions, which may not adequately capture the rich dynamics inherent in complex chaotic systems. While advancements like Leaky ESNs, Deep Reservoir Computing [8], and multi-reservoir ESNs have been proposed, they can introduce further complexities or still rely on fundamentally simple neuronal dynamics.
The limitations of existing DL and RC approaches motivate the development of novel prediction models that can combine the training efficiency of RC with more sophisticated, adaptive internal dynamics and a systematic approach to hyperparameter optimization. Indeed, current research trends emphasize that network models with internal complexity can bridge artificial intelligence and neuroscience, offering pathways to more robust and capable systems [9]. Drawing inspiration from neuroscience, the Intersecting Cortical Model (ICM) [10] simulates neuronal behaviors like adaptive thresholds and feedback, but its original formulation is primarily suited for image processing and has limitations for continuous time series tasks.
This work proposes a novel framework, the Echo State Network Based on Enhanced Intersecting Cortical Model (ESN-EICM), for discrete chaotic time series prediction, the overall structure of which is illustrated in Figure 1. The ESN-EICM integrates a modified EICM neuron model into the ESN reservoir. The main contributions of this study are as follows:
1. The neural network model EICM can exhibit complex dynamic characteristics, is incorporated into reservoir computing. This novel neuron model is tailored for time series by incorporating features such as continuous sigmoid activation, global mean-driven adaptive thresholds, and introduces mechanisms for inter-neuron coupling and dynamic threshold regulation within each neuron, thereby enhancing the nonlinear representation capability of reservoir computing and forming a reservoir computing model based on biological neurons. The design leverages principles of how biological neural systems integrate information and utilize internal neuronal dynamics for complex computations, such as feature binding through dendritic networks [11] or learning multi-timescale dynamics [12]. While traditional RC research often focuses on optimizing reservoir topology or simplifying dynamics, our work explores a complementary direction: enhancing the computational power of individual neurons within the reservoir. We hypothesize that by equipping neurons with more sophisticated, adaptive dynamics inspired by the cortex, the reservoir can more effectively capture the intricate, non-linear patterns of chaotic systems without requiring complex topological design.
2. The application of a Bayesian Optimization strategy for the automated and efficient tuning of ESN-EICM hyperparameters, mitigating the traditional RC challenge of manual parameter selection.
3. A comprehensive empirical evaluation on three discrete chaotic systems (Logistic, Sine, and Ricker), demonstrating the ESN-EICM’s superior predictive accuracy and stability in both one-step and multi-step prediction scenarios compared to standard ESN and LSTM models.
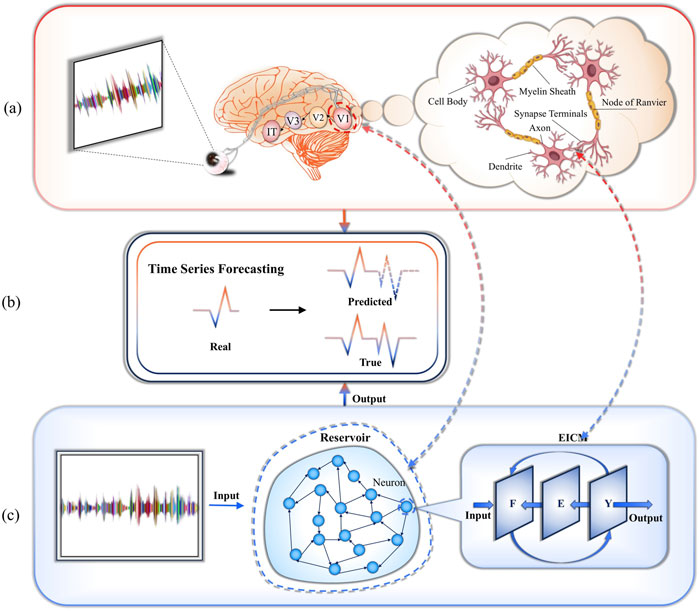
Figure 1. Proposed framework is based on the EICM neuron model of the mammalian visual cortex and uses it to construct a reservoir for performing time-series prediction tasks in chaotic systems.The EICM neuron model used in this framework is inspired by the dynamic characteristics of neurons in the mammalian primary visual cortex. Its core mechanism aims to more accurately simulate the real behavior of these biological neurons. By integrating the EICM neuron model (inspired by the V1 area of the primary visual cortex) into the reservoir, the constituent neurons are randomly interconnected via the weight matrix. (a)Visual pathway of the brain: Visual information from the retina is relayed via the lateral geniculate nucleus to the primary visual cortex (V1) and then processed in V2, V3, and V4, ultimately yielding patterns in the inferior temporal cortex. (b)Real vs. predicted time series. (c)ESN-EICM framework incorporates a V1 neuron model into reservoir computing to effectively forecast complex time-series sequences.
The remainder of this paper is organized as follows. Section 2 reviews related work in deep learning and reservoir computing for time series prediction. Section 3 details the proposed ESN-EICM model, including the EICM neuron design and the Bayesian optimization strategy. Section 4 describes the experimental setup and presents a thorough analysis of the results, covering prediction performance, hyperparameter sensitivity, and training time comparisons. Section 5 then discusses the broader implications of our findings, including the model’s design philosophy and its robustness against chaotic dynamics. Subsequently, Section 6 outlines the limitations of the current study and potential avenues for future research. Finally, Section 7 concludes the paper, summarizing the main contributions.
2 Related works
2.1 Deep learning-based time series prediction methods
With the continuous advancement of deep learning techniques, time series prediction has increasingly shifted toward neural network-based modeling strategies. The Recurrent Neural Network (RNN), proposed by Rumelhart et al. in 1986 [1], models sequential data through recurrent connections, effectively encoding historical information into hidden states. However, RNNs face challenges such as gradient vanishing and exploding gradients when handling long sequences, limiting their ability to capture long-term dependencies [2].
To address these limitations, Hochreiter and Schmidhuber introduced the Long Short-Term Memory (LSTM) network in 1997 [2]. LSTMs are specifically designed to retain long-range temporal information via sophisticated gating mechanisms (input, forget, and output gates), which control the flow of information through the cell. This architecture significantly improved the modeling of nonlinear data and has seen widespread application in diverse fields such as financial market prediction and climate modeling. Owing to their capacity to learn complex temporal dependencies and approximate highly nonlinear functions, LSTMs have also become a prominent benchmark for prediction chaotic time series, where accurately capturing long-range, intricate patterns is essential [13]. Indeed, studies have demonstrated LSTMs’ potential in predicting various chaotic systems, leveraging their ability to learn from historical data without explicit knowledge of the system’s underlying equations [14]. Nevertheless, despite their utility as a powerful baseline, the application of LSTMs, particularly to sensitive chaotic dynamics, is not without its difficulties. LSTM training demands substantial computational resources and a considerable amount of data to prevent overfitting, which can be a significant constraint in scenarios where data is scarce or computationally expensive to generate. They also exhibit high overall computational complexity [3], and their performance can be sensitive to hyperparameter choices, often requiring extensive tuning.
In contrast, the Gated Recurrent Unit (GRU) [3] simplifies the LSTM’s gating mechanism (employing update and reset gates) to reduce model complexity and the number of parameters. GRUs often demonstrate comparable or, in some cases, superior performance to LSTMs, especially in scenarios with limited data volume. However, they may still exhibit higher prediction errors when processing large-scale, highly complex datasets compared to more specialized architectures [4].
More recently, the Transformer architecture [4], originally developed for natural language processing, has transcended traditional recurrent networks through its self-attention mechanism. This allows for powerful parallel computation and has led to outstanding performance in large-scale sequence modeling tasks. However, the standard Transformer’s quadratic complexity with respect to sequence length and its potential sensitivity to noise in high-frequency or irregular time series can compromise its effectiveness for certain types of chaotic data without specific adaptations [15].
Despite ongoing methodological developments, deep learning models exhibit inherent limitations that are particularly pertinent to chaotic time series prediction: 1) Complex architectures generally lead to increased computational costs for training and inference. 2) Their “black-box” nature often weakens interpretability, hindering their deployment in domains requiring decision transparency or a deeper understanding of the model’s predictive reasoning (e.g., finance, healthcare, scientific discovery) [5]. For instance, while WaveNet [6] can model long sequences through dilated convolutions, it consumes excessive resources and is not easily parallelized. DeepAR [5], a probabilistic prediction model, may struggle with very sparse data scenarios sometimes encountered in chaotic systems. Furthermore, hybrid models like LSTM-FCN (LSTM Fully Convolutional Network) [16], while effective for classification, can face efficiency bottlenecks in feature fusion for regression tasks. Additionally, modifications aimed at reducing complexity in Transformers, such as the ProbSparse attention mechanism in the Informer model [15], can often discard critical subtle temporal patterns vital for chaotic systems, potentially degrading prediction stability. Beyond these established deep learning architectures, Spiking Neural Networks (SNNs), which more closely mimic biological neuronal dynamics through event-driven spike-based communication, are also being actively investigated for their potential in efficient temporal processing and learning, with research exploring aspects such as advanced training methodologies like adaptive smoothing gradient learning [17], effective parameter initialization techniques [18], and the role of noise [19]. SNNs are also finding applications in complex learning paradigms like brain-inspired reinforcement learning [20], and are also being developed for energy-efficient applications such as speech enhancement [21].
2.2 Reservoir computing for time series prediction
Diverging from deep learning approaches, Reservoir Computing (RC) offers novel insights through nonlinear dynamical systems. Echo State Networks (ESNs), introduced by Lukoševičius and Jaeger [7], map inputs into high-dimensional dynamic spaces via randomly connected reservoirs. Their efficiency stems from training only the output layer, yet performance critically depends on reservoir initialization and hyperparameter selection [7]. To overcome these limitations, researchers proposed innovations: Leaky ESN balances short-term dynamics and long-term memory through leakage parameters; Adaptive Elastic ESN optimizes reservoir weights using sparse Bayesian learning, dynamically adjusting sparsity to enhance multi-scale feature adaptation, though suffering from high training complexity and hyperparameter sensitivity [22]. Multi-reservoir ESN improves complex dynamic capture by parallelizing multiple reservoirs processing distinct frequency bands, but increases training complexity without unified state-fusion protocols. Deep Reservoir Computing [8] extracts hierarchical features via cascaded reservoirs, achieving excellence in long-period modeling while risking state inflation and overfitting. Recently, the SEP framework advanced lossless byte-stream prediction through semantic-enhanced compression [23], opening new directions for complex temporal modeling.
Current RC methods predominantly rely on simplistic neuron models, failing to simulate mammalian brain structures. This restricts generalization capabilities and robustness–simple reservoirs perform poorly on complex systems, while intricate designs induce overfitting and instability. Furthermore, although RC reduces RNN training costs, its fixed critical parameters necessitate manual tuning, lacking dynamic adaptability [7]. These constraints motivate the integration of biologically inspired neuron models (e.g., ICM) with reservoir computing, aiming to enhance chaos sequence prediction robustness through dynamic weight initialization strategies. The broader field of neuromorphic computing also explores various mechanisms for temporal processing in SNNs, including specialized modules designed to capture temporal shifts [24], build sequential memory [25], or adapt temporal characteristics [26].
3 Methods
3.1 Problem statement and challenges
The existing methods face the following challenges:
(1) The performance of reservoir computing models highly depends on critical hyperparameters such as reservoir size, spectral radius, and input scaling. These parameters not only influence dynamic characteristics (e.g., memory capacity and nonlinear mapping ability) but also directly determine prediction accuracy. In practical applications, extensive experiments and manual tuning are required to identify optimal parameter combinations, leading to significant time costs. Prediction errors vary widely under different configurations, particularly for high-dimensional and long-term sequences, where parameter sensitivity becomes more pronounced. Some parameter combinations even cause training divergence [27], [28].
(2) Most reservoir models rely on basic neuron designs that fail to simulate the complex connectivity and information-processing mechanisms of mammalian cortical neurons. While this simplification reduces implementation complexity, it limits expressive power for tasks involving long-term dependencies or abrupt feature detection. Traditional ESN models maintain reasonable accuracy in short-term predictions [29] but suffer rapid performance degradation with increasing sequence length and dynamic complexity. Model states decay over time, and sensitivity to abrupt changes diminishes [22].
(3) Although expanding reservoir size or introducing multi-layer structures can enhance model expressiveness and achieve low training errors, these modifications introduce new challenges. Increased complexity improves training fit but severely harms generalization on unseen data. Prediction errors fluctuate significantly during testing, indicating overfitting and poor robustness under noise or input distribution shifts. This highlights that boosting model complexity alone cannot resolve generalization issues in time series prediction [8].
3.2 Echo state network based on enhanced intersecting cortical model framework
3.2.1 Input layer
The input layer transforms raw time series data into feature representations suitable for subsequent processing. Given a time series input
where
This approach ensures preliminary nonlinear mapping of input data while introducing an adjustable scaling factor
3.2.2 Reservoir layer
The reservoir layer, the core component of ESN-EICM, comprises neurons governed by the Enhanced Intersecting Cortical Model (EICM). This design simulates biological feedback mechanisms and adaptive responses observed in mammalian cortical neurons.
The internal reservoir connectivity matrix
• Elements of
•Sparsity is applied: a binary mask is generated where each element has a probability
•The elements of the resulting sparse matrix are then clipped to the range [-1,1].
•Finally, the spectral radius of this processed matrix is normalized to the target
The EICM neurons maintain internal states:
Each neuron updates its state using the EICM dynamics, which are detailed in Section 3.3.
•The feeding input
•The neuron’s output
•The dynamic threshold
For numerical stability, the primary state variables
The EICM neuron model introduces critical modifications to the original ICM framework [10]. Feeding input
3.2.3 Output layer
The output layer trains weights via regularized linear regression to produce predictions. Its equation is given by Equation 3:
where
where the regularization coefficient
During inference, future states are recursively generated using historical inputs and reservoir states (Equation 5):
3.2.4 Bayesian optimization strategy
To address the time-consuming manual hyperparameter tuning and susceptibility to local optima in traditional reservoir computing models, we introduce Bayesian Optimization (BO) within the ESN-EICM framework. BO constructs a surrogate function (e.g., Gaussian Process) and an acquisition function to efficiently balance exploration (sampling unexplored regions of the hyperparameter space) and exploitation (focusing on promising regions identified by prior evaluations). This approach rapidly converges to globally optimal configurations by leveraging information from prior experiments [30], a significant advancement over simpler strategies like grid or random search [31]. In our experiments, we employ the gp_minimize function (based on Gaussian Process Regression) for iterative parameter search. The optimization objective is defined as minimizing the mean squared error (MSE) on the validation set. To guide the optimization, the training data (the first 16,000 steps) was further partitioned: the first 14,000 steps were used to train the ESN-EICM’s output weights for a given hyperparameter set, and the subsequent 2,000 steps served as the validation set for calculating the MSE. The final reported test performance is evaluated on the held-out test set, which was never seen during training or optimization. Specify ranges and types (continuous/integers) for all parameters. Generate candidate hyperparameter combinations at each iteration and evaluate their MSE performance. Terminate the search process when the optimization objective (minimizing MSE) shows no significant improvement over consecutive iterations. Apply the optimal hyperparameter combination to train and test the final model. This strategy significantly reduces manual tuning costs while enhancing generalization capabilities for chaotic system prediction. The optimization space for ESN-EICM parameters is detailed in Table 1.
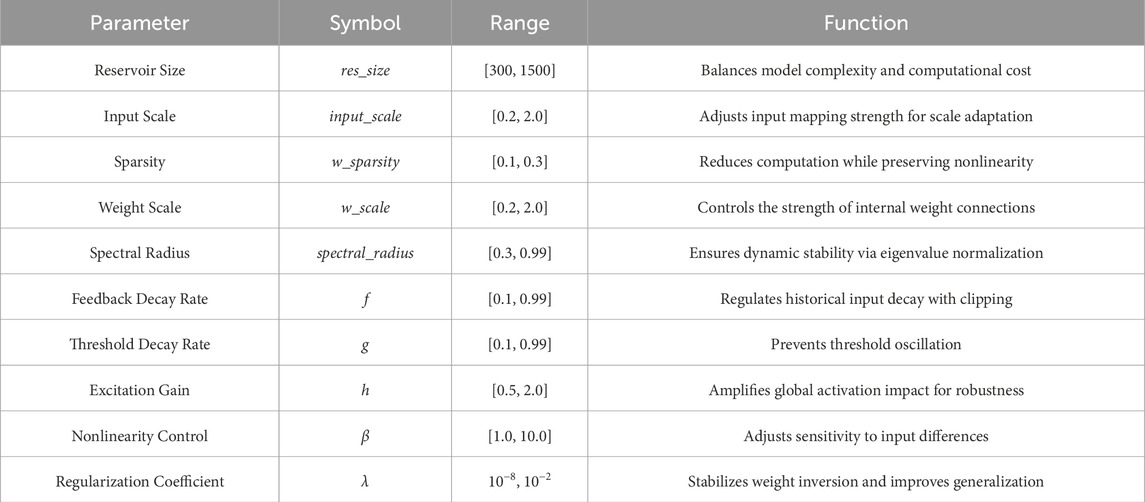
Table 1. ESN-EICM parameters optimization space.
3.3 Enhanced intersecting cortical model
The Enhanced Intersecting Cortical Model (EICM) neuron model (Figure 2 proposed in this work is built upon the original Intersecting Cortical Model (ICM) framework. The ICM was first introduced by Ekblad et al. [10], and was originally designed for image processing tasks—particularly for extracting features with indistinct boundaries. It simulates the behavioral characteristics of neurons in the mammalian primary visual cortex, including feedback mechanisms and adaptive threshold regulation.
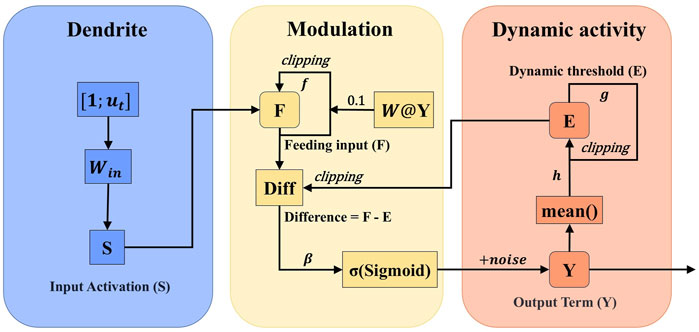
Figure 2. Enhanced Intersecting cortical model.
The original ICM neuron model consists of three key state variables: Feeding input
Its update equations are defined as follows (Equation 6):
where feedback decay rate
This model has demonstrated strong edge detection and noise resistance capabilities in image segmentation applications. However, its binary output mechanism limits its expressiveness in time series modeling. Despite the biologically inspired structure and nonlinear mapping advantages of ICM, several critical limitations arise when applying it to time series prediction tasks such as chaotic system prediction:
(1) The model exhibits a lack of neuron-to-neuron coupling. The feeding input solely takes into account individual history and external input, without incorporating interactions across the reservoir.
(2) The local adaptation mechanism is limited as the dynamic threshold updates based merely on the current output of neuron, failing to reflect global network activity. The static parameter settings without range constraints also pose an issue, causing hyperparameters to remain fixed or loosely defined, which in turn leads to instability during training.
(3) The binary output limitation of the original ICM restricts its applicability to continuous-value regression tasks, as it only employs a binary pulse output of 0 or 1.
These issues significantly impair the ability of ICM to capture long-term dependencies and abrupt changes in complex nonlinear systems, resulting in suboptimal performance in chaotic time series modeling.
To enhance the modeling capability of the original ICM for time series prediction, we propose the EICM neuron design. The key improvements are outlined as follows:
(1) Improved sensitivity to long-range dependencies and abrupt changes. The original ICM model struggles with capturing long-term dependencies and detecting sudden signal transitions due to its local update mechanism. In EICM, we introduce global coupling through reservoir connectivity
(2) Enhanced Expressiveness for Continuous-Value Prediction. Unlike the binary pulse output in standard ICM, output term
(3) Integration of data-driven adaptation mechanisms. We redesign the dynamic threshold
(4) During the implementation, we imposed numerical range constraints on the parameters to enhance training stability, performed numerical clipping on
These enhancements address the limitations of ICM in temporal modeling while preserving its biologically inspired structure. The EICM neuron model operates on three key state variables: the feeding input F, the dynamic threshold E, and the output term Y. To ensure a consistent starting point, these states are initialized at t = 0 as follows:
These coupled dynamics allow the EICM neuron to maintain and process historical information over varying time scales, which is crucial for predicting chaotic systems. Effectively modeling such temporal dependencies is a key challenge in neural computation, with various architectures exploring mechanisms like dedicated delay units or gates to manage temporal information flow [34]. The core parameters intuitively govern the neuron’s behavior:
The enhanced performance of the ESN-EICM stems from the synergistic interaction between its two primary modifications: the global coupling feedback
3.3.1 Feeding input
In the design of the feeding input
where
This enhancement significantly improves the suitability of the model for time series modeling by increasing inter-neuron information flow and cross-neuron coordination, thereby enhancing its nonlinear mapping capability compared to the original ICM framework.
3.3.2 Output term
To improve the expressiveness and robustness of the model, we replace the binary output mechanism in the original ICM with a multi-step process yielding a continuous output. First, the input to the sigmoid,
where
This improvement allows the model to more accurately capture subtle changes in input dynamics. The addition of small-scale noise injection further enhances exploration during training and improves generalization performance, particularly under noisy or uncertain conditions.
3.3.3 Dynamic threshold
For the threshold update mechanism, we modify the original ICM approach which updates based on individual neuron output to a global mean-driven adaptation strategy. The updated equation is defined as (Equation 10):
where
This global adaptive thresholding strategy enables each neuron to adjust its response threshold according to the overall network activity, preventing certain neurons from being overly activated or suppressed. As a result, the model achieves greater stability and consistency across the reservoir.
4 Experiment
4.1 Dataset generation
To evaluate the predictive capabilities of the proposed ESN-EICM, ESN, and LSTM models, we generate three representative discrete chaotic system: Logistic system, Sine system, and Ricker system. These datasets are chosen for their distinct dynamic characteristics:
• Logistic System: A discrete-time chaotic system with strong nonlinearity.
•Sine System: A smooth periodic system with limited chaotic behavior.
•Ricker System: A biological population model exhibiting complex oscillatory patterns.
4.1.1 Data generation Process
Each dataset is generated using the following equations (Equations 11–13):
The initial value
•Logistic System:
•Sine System:
•Ricker System:
4.1.2 Data preprocessing
All datasets undergo the following preprocessing pipeline:
(1) Standardization: Data is standardized using Scikit-learn’s StandardScaler (Equation 14):
where
(2) Input-Target alignment: The input-output relationship is defined as (Equation 15):
This ensures the model predicts
(3) Train/Test Split: All systems use the same split (Equation 16):
The dataset was split chronologically to ensure strict temporal ordering and prevent information leakage from the test set into the training set. The first 16,000 steps were used for training and hyperparameter optimization, while the subsequent 2,000 steps were reserved exclusively for final testing. This partitioning is consistent across all systems to avoid introducing bias.
4.1.3 Dataset properties
A summary of the dataset configurations and properties is provided in Table 2.
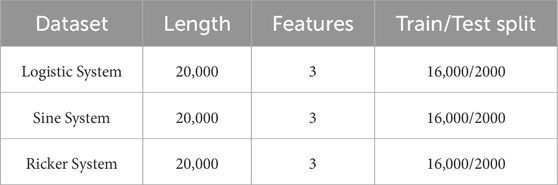
Table 2. Dataset configurations and properties.
4.2 Evaluation metrics
In our experiments, we compute the following evaluation metrics to quantify prediction performance. Let
4.2.1 Mean squared error (MSE)
The Mean Squared Error (MSE) measures the average squared difference between predicted and actual values. It’s a common metric for regression problems, penalizing larger errors more heavily. The equation is as follows (Equation 17):
4.2.2 Root mean squared error (RMSE)
The Root Mean Squared Error (RMSE) is simply the square root of the MSE. It reflects the standard deviation of prediction errors and is in the same units as the target variable, making it more interpretable than MSE. The equation is as follows (Equation 18):
4.2.3 Mean absolute error (MAE)
The Mean Absolute Error (MAE) measures the average absolute difference between predicted and actual values. Unlike MSE, MAE gives equal weight to all errors, making it more robust to outliers. The equation is as follows (Equation 19):
4.2.4 Coefficient of determination
The Coefficient of Determination
4.2.5 Explained variance score (EVS)
The Explained Variance Score (EVS) evaluates how well the model captures the variance in the target variable. It’s similar to
4.2.6 Max error (ME)
The Max Error (ME) reports the maximum residual error between any predicted and actual value. This metric highlights the worst-case prediction scenario. The equation is as follows (Equation 22):
4.3 Model configuration
This section details the configuration of the models employed in our comparative study: the proposed ESN-EICM, the baseline ESN, and the LSTM network. For the ESN-EICM and ESN models, hyperparameters were primarily determined through Bayesian Optimization, aiming to minimize Mean Squared Error on a validation set. For the LSTM model, key architectural and training hyperparameters were also optimized using Bayesian Optimization, while others were set based on common practices in time series forecasting. The specific search ranges and fixed values for each model are presented in the subsequent subsections. All models were trained and evaluated on the datasets described in Section 2 to ensure fair comparison.
4.3.1 ESN-EICM model configuration
Table 3 presents the key configuration parameters for the ESN-EICM model determined through Bayesian optimization in our experiments. A washout period initLen of 1000 steps was used for all experiments. This length was determined through preliminary observations to be sufficiently long to allow the reservoir’s internal state to become independent of its initial zero state and synchronize with the dynamics of the input signal across the range of tested hyperparameters.
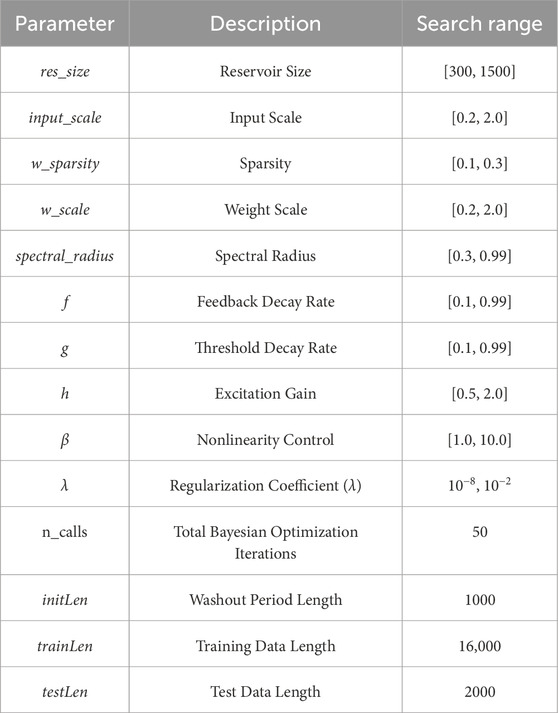
Table 3. ESN-EICM model Configuration parameters.
4.3.2 ESN model configuration
Table 4 presents the key configuration parameters for the Echo State Network (ESN) model determined through Bayesian optimization in our experiments.
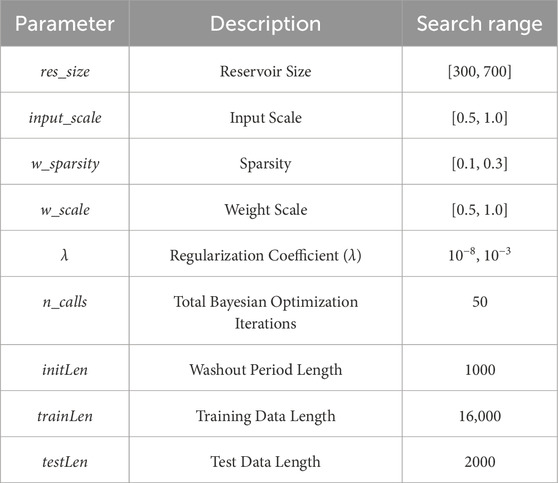
Table 4. ESN model Configuration parameters.
4.3.3 LSTM model configuration
Table 5 outlines the key configuration parameters for the Long Short-Term Memory (LSTM) network model. The hyperparameters were optimized using Bayesian optimization, while other parameters were set based on common practices.
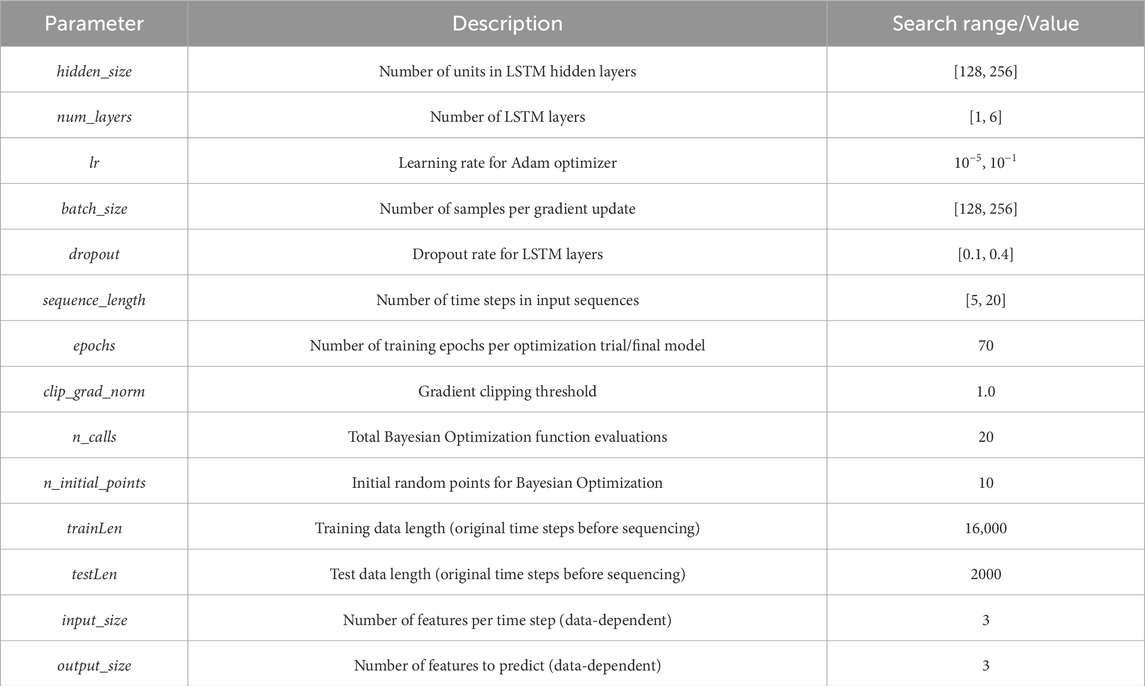
Table 5. LSTM model Configuration parameters.
4.4 Hyperparameter optimization results
To ensure optimal performance, critical hyperparameters for both the ESN-EICM and the baseline ESN models were determined using Bayesian Optimization. This process, guided by minimizing Mean Squared Error on a validation set as described in Section 3, yielded task-specific parameter configurations. The best-found parameters for each model across the different chaotic systems and prediction horizons are presented below.
4.4.1 ESN-EICM best parameters
The optimal hyperparameters identified for the proposed ESN-EICM model through Bayesian Optimization are summarized in Table 6. These parameters cover aspects of reservoir architecture, input processing, EICM neuron dynamics, and output regularization.
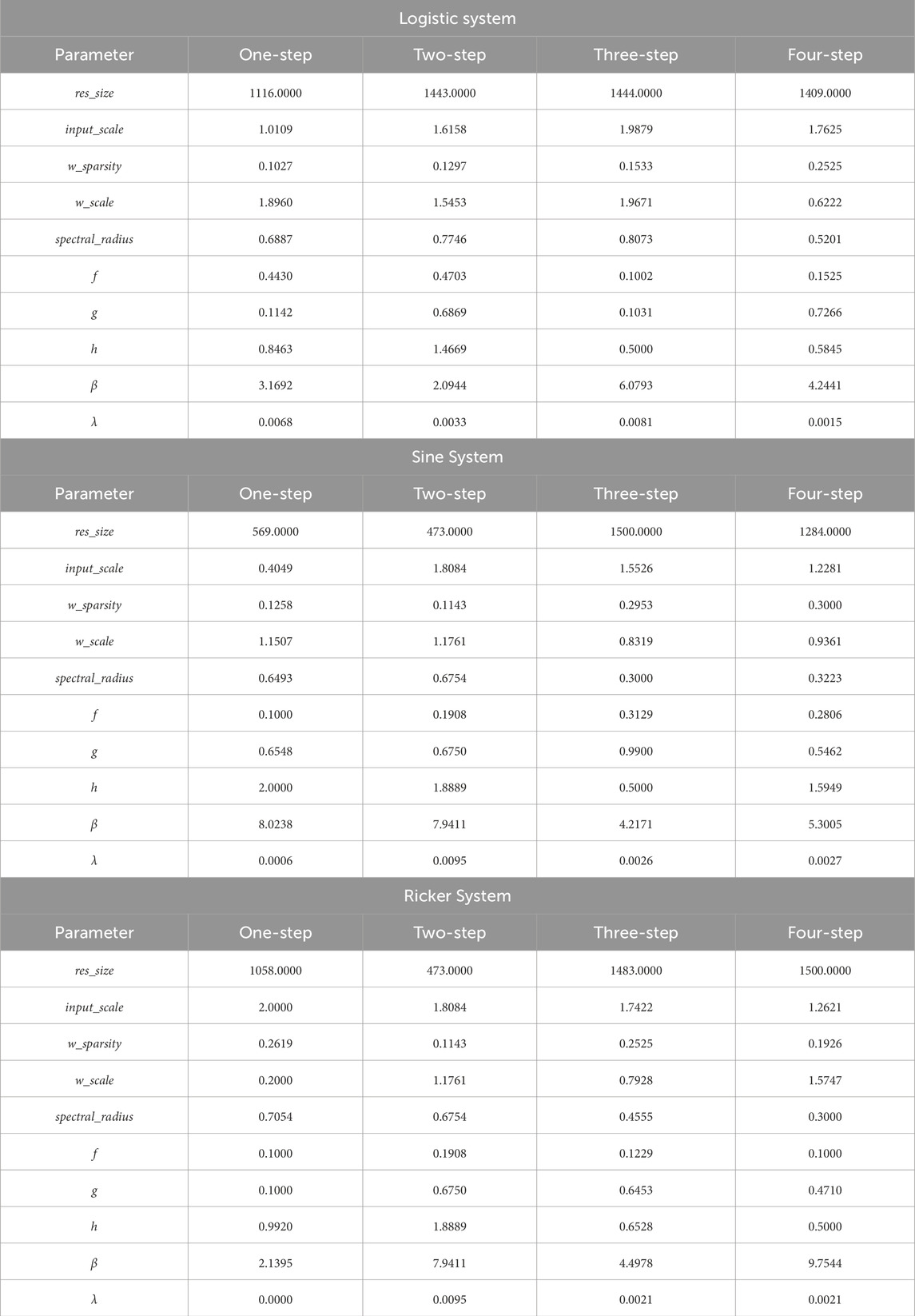
Table 6. Best ESN-EICM parameters for different chaotic systems and prediction steps.
4.4.2 ESN best parameters
For the baseline ESN model, the key hyperparameters tuned via Bayesian Optimization are detailed in Table 7. This allows for a direct comparison with the ESN-EICM model under similarly optimized conditions.
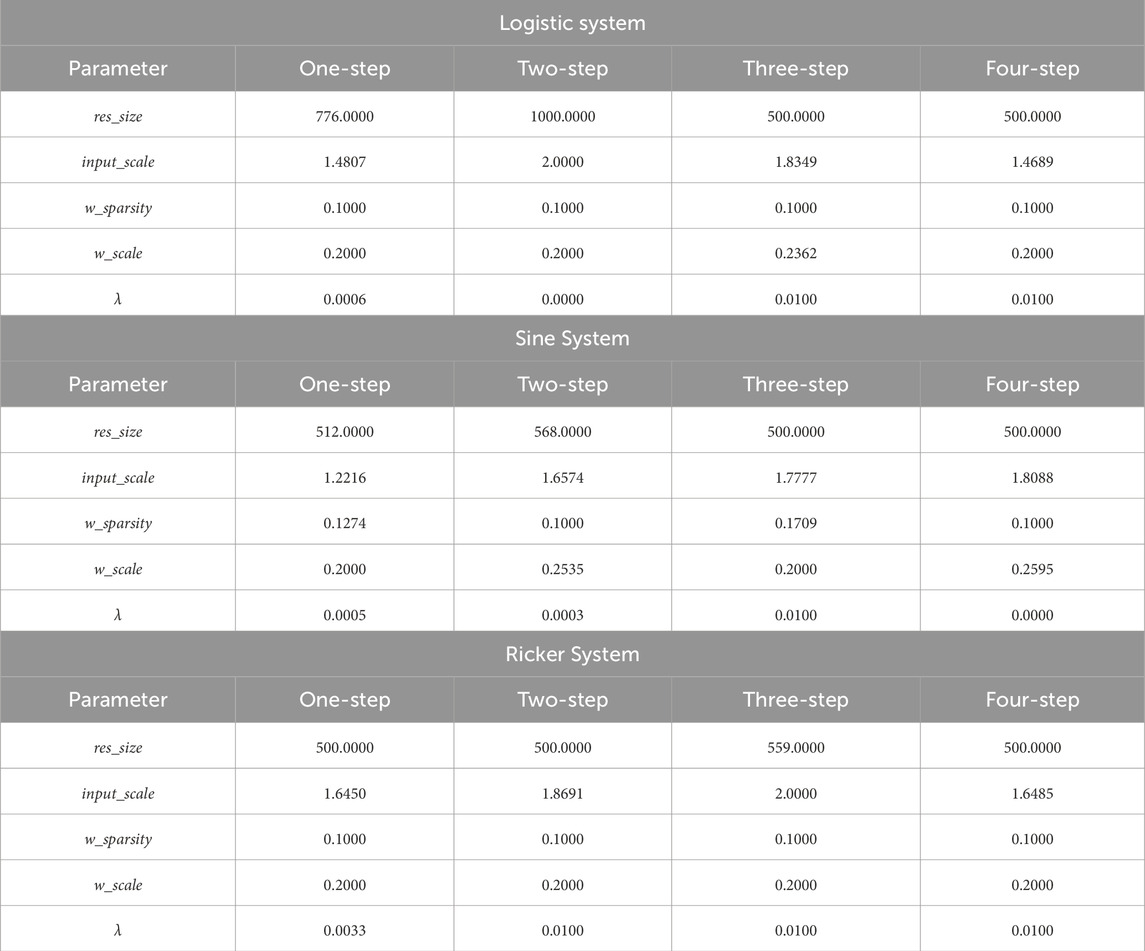
Table 7. Best ESN parameters for different chaotic systems and prediction steps.
4.4.3 LSTM best parameters
The Long Short-Term Memory (LSTM) network, serving as another important baseline, also underwent hyperparameter optimization using Bayesian Optimization. Key architectural and training parameters were tuned to achieve its best performance on each specific task. The optimized values for parameters such as hidden size, number of layers, learning rate, batch size, dropout rate, and input sequence length are presented in Table 8. These results reflect the optimal configurations found for the LSTM model across the different chaotic systems and prediction steps.
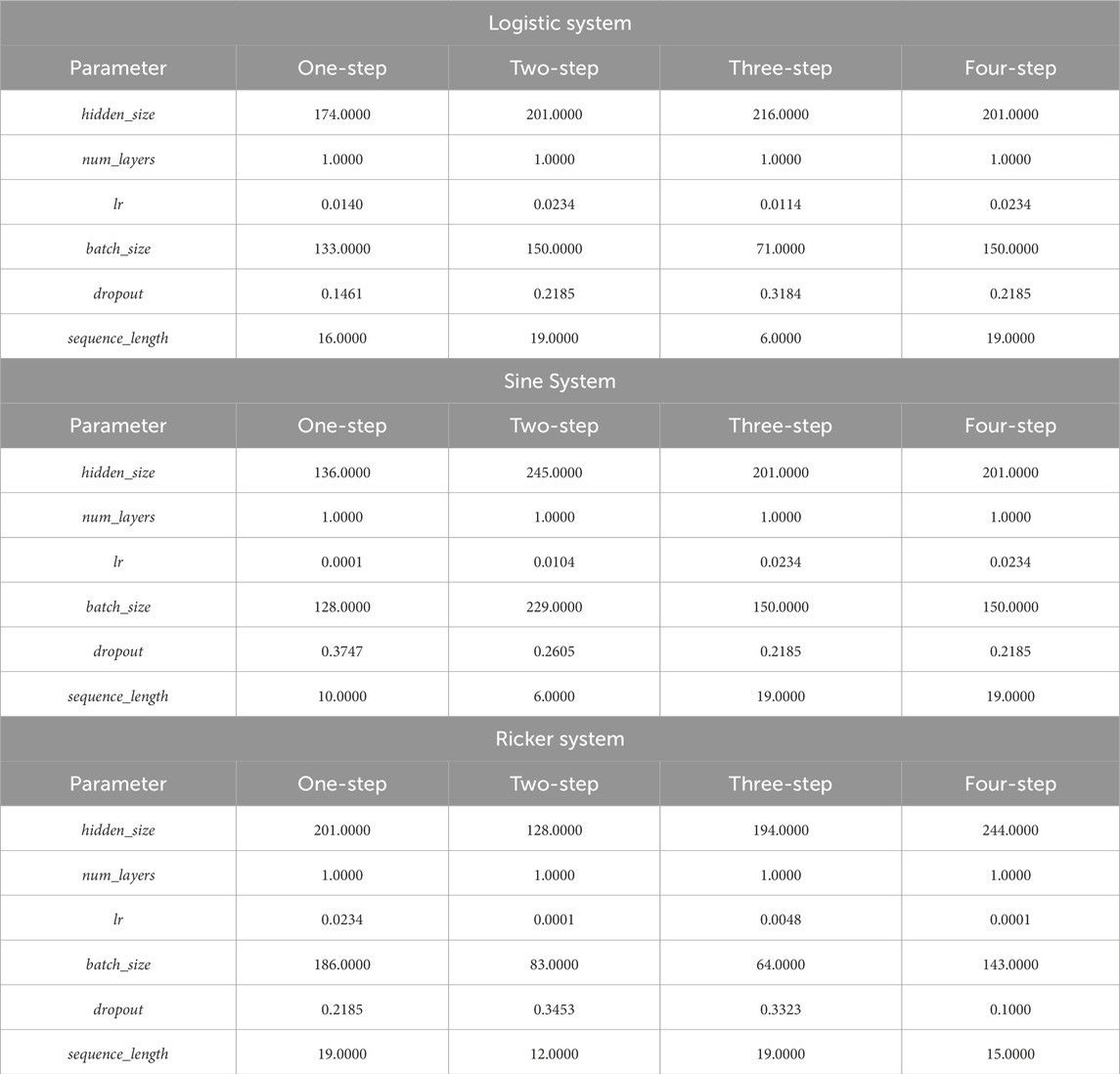
Table 8. Best LSTM parameters for different chaotic systems and prediction steps.
4.5 Hyperparameter sensitivity analysis
AS shown in Figure 3 (Logistic System), Figure 4 (Sine System), and Figure 5 (Ricker System), this section presents the hyperparameter sensitivity analysis for the ESN-EICM model. The analysis investigates the Mean Squared Error (MSE) response to variations in individual hyperparameters, while other parameters are held at their globally optimized values (from Table 6, for one-step prediction). This provides insights into each parameter’s influence on model performance and highlights the complexity of the hyperparameter landscape. The vertical dashed line in each plot marks the globally optimal value found by Bayesian Optimization.
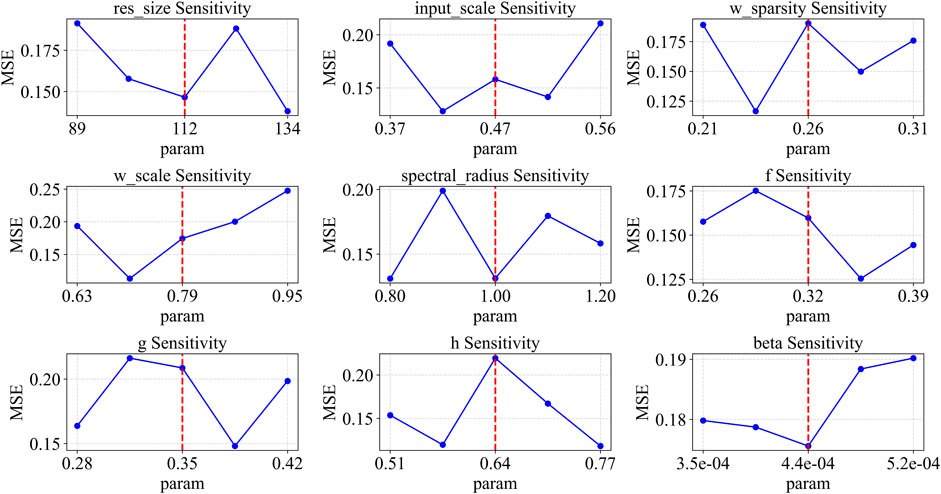
Figure 3. Parameter sensitivity analysis of ESN-EICM in logistic system.
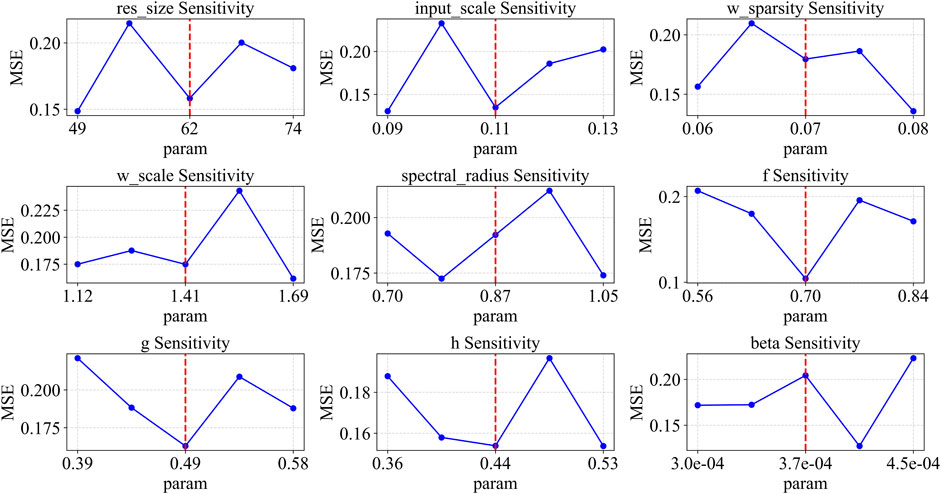
Figure 4. Parameter sensitivity analysis of ESN-EICM in sine system.
For the Logistic system, several parameters show high sensitivity. The res_size has a local minimum around the globally optimized value of 1116. Both input_scale and w_sparsity display V-shaped curves, with their local minima being slightly lower than their respective globally optimized values (marked at 1.01 and 0.10). The spectral_radius is critical, with its lowest MSE point aligning perfectly with the global optimum of 0.69. The EICM neuron parameters also show distinct patterns: f has a local minimum near 0.35, while its global optimum is 0.44. Both g and h exhibit U-shaped curves. Notably, beta is extremely sensitive, with its MSE sharply decreasing to a minimum that coincides with its global optimum of 3.17.
In the Sine system, the parameter sensitivities differ. res_size shows that larger reservoirs in the tested range yield better performance, with the global optimum at 569. For w_scale, a clear trend of decreasing MSE with smaller values is observed. Both spectral_radius and the neuron parameter f are highly sensitive, with sharp V-shaped curves where the local minima are very close to their global optima (0.65 and 0.10, respectively). The parameters g and h have broader optimal regions. For beta, the MSE is lowest at the higher end of the tested range, aligning with the global optimum of 8.02.
The Ricker system presents another unique sensitivity profile. Here, res_size has a relatively flat response curve, suggesting less sensitivity within this range compared to other systems. w_scale is highly critical, with a sharp V-shaped minimum. The spectral_radius plot shows that the global optimum of 0.71 is located on the slope of a broader minimum. For the EICM neuron parameters, f shows a preference for smaller values. The parameter h is highly sensitive, with a distinct local minimum. Finally, beta again demonstrates high sensitivity, with its local minimum near the globally optimized value of 2.14.
Across all three systems, parameters defining the EICM neuron’s core dynamics, such as f and beta, along with reservoir properties like spectral_radius and w_scale, consistently emerge as highly influential. Small deviations from their optimal values can lead to a significant increase in MSE, indicating that precise tuning of these parameters is crucial. In contrast, other parameters like res_size can exhibit broader optimal regions or system-dependent behaviors.
The analysis also reveals that the optimal hyperparameter configurations are distinct for each chaotic system, underscoring the necessity of system-specific optimization. While general trends can be observed, the precise values that minimize MSE vary considerably, highlighting the unique dynamic complexity of each system. This systematic analysis is fundamental for understanding the ESN-EICM’s behavior and validating the configurations found by our optimization strategy.
It is noteworthy that the optimal parameter values marked by the vertical dashed lines (representing the global optimum found by Bayesian Optimization) do not always coincide with the minimum MSE in each one-dimensional sensitivity plot. This is an expected and insightful result. Bayesian Optimization finds the best set of hyperparameters in a high-dimensional space where all parameters interact. In contrast, our sensitivity analysis examines one-dimensional slices of this space by varying a single parameter while keeping others fixed at their global optimal values. The discrepancy between the global optimum and the local minima in these plots highlights the strong coupling and interdependencies among the hyperparameters. It demonstrates that the ideal value for one parameter is contingent on the values of others, reinforcing the necessity of using a multi-dimensional optimization strategy like Bayesian Optimization rather than relying on one-at-a-time parameter tuning.
4.6 Prediction performance evaluation
4.6.1 One-step prediction performance
The efficacy of the ESN-EICM model for one-step prediction was rigorously evaluated on three canonical chaotic systems: the Logistic system, the Sine system, and the Ricker system. Its performance was benchmarked against both traditional ESN and LSTM architectures. The comprehensive results, encompassing both quantitative metrics and qualitative visualizations, consistently underscore the superior predictive accuracy and robustness of the proposed ESN-EICM.
Quantitative analysis, detailed in Table 9, reveals that ESN-EICM generally achieves lower error metrics compared to ESN and LSTM. For instance, in predicting the Logistic system, ESN-EICM recorded a MSE of
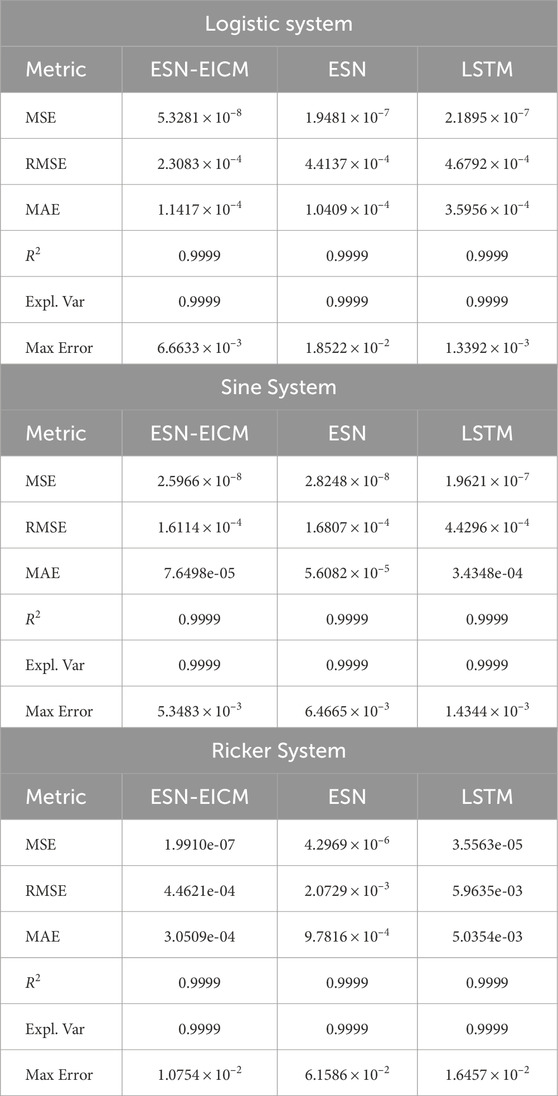
Table 9. One-step prediction performance by different chaotic system.
The qualitative visualizations further reinforce these quantitative findings. The one-step prediction trajectories, illustrated in Figure 6 (assuming this figure shows predicted vs. true time series plots), demonstrate the ESN-EICM’s capability to closely track the actual system dynamics for the Logistic system (a), Sine map (b), and Ricker model (c), even through complex behavioral regimes. The temporal evolution of absolute prediction error, as depicted in Figure 7, confirms the stability of ESN-EICM’s predictions, with errors remaining at consistently low levels (typically on the order of
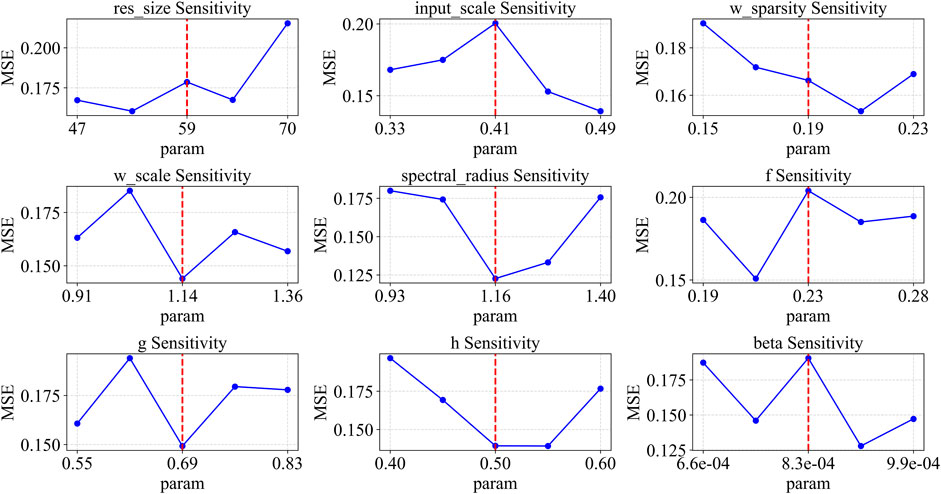
Figure 5. Parameter sensitivity analysis of ESN-EICM in ricker system.
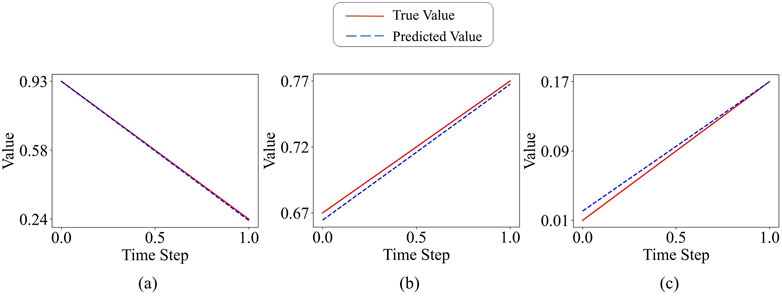
Figure 6. ESN-EICM One-step Prediction in Different Chaotic Systems: (a) the Logistic system, (b) the Sine system, and (c) the Ricker system.
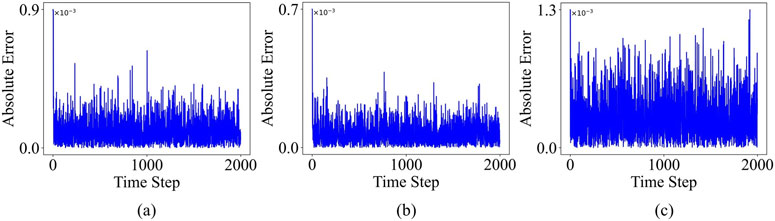
Figure 7. ESN-EICM One-step Prediction Absolute Error Over Time in Different Chaotic Systems: (a) the Logistic system, (b) the Sine system, and (c) the Ricker system.
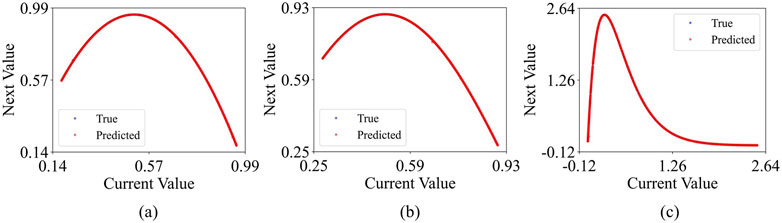
Figure 8. ESN-EICM One-step Prediction Phase Space Reconstruction in Different Chaotic Systems: (a) the Logistic system, (b) the Sine system, and (c) the Ricker system.
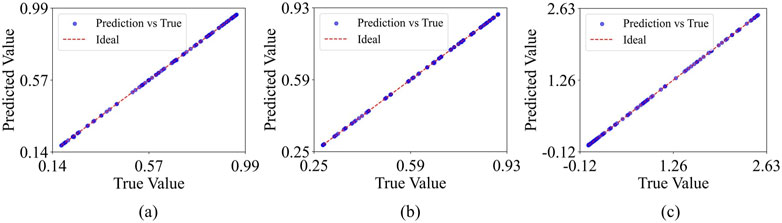
Figure 9. ESN-EICM One-step Prediction Accuracy: Predicted vs. True Values in Different Chaotic Systems: (a) the Logistic system, (b) the Sine system, and (c) the Ricker system.
In conclusion, the combined evidence from quantitative metrics and qualitative visualizations strongly supports the enhanced performance of the ESN-EICM model in one-step prediction tasks for chaotic time series. It consistently outperforms or matches established models like ESN and LSTM in accuracy and robustness, while also demonstrating a strong capability to learn and replicate the intricate dynamics inherent in these complex systems. These results firmly establish ESN-EICM as a promising and effective tool for nonlinear time series prediction.
4.6.2 Multi-step prediction performance
To further assess the predictive capabilities of the proposed ESN-EICM model, comprehensive multi-step prediction experiments were conducted for two-step, three-step, and four-step ahead forecasts. These predictions were performed on the Logistic, Sine, and Ricker chaotic systems, and the performance of ESN-EICM was benchmarked against standard ESN and LSTM models. The quantitative results for these multi-step predictions are detailed in Table 10 (two-step), Table 11 (three-step), and Table 12 (four-step). Visualizations of the ESN-EICM’s multi-step prediction trajectories, corresponding absolute errors, phase space reconstructions, and scatter plots of predicted versus true values are presented in Figures 10–13, respectively.
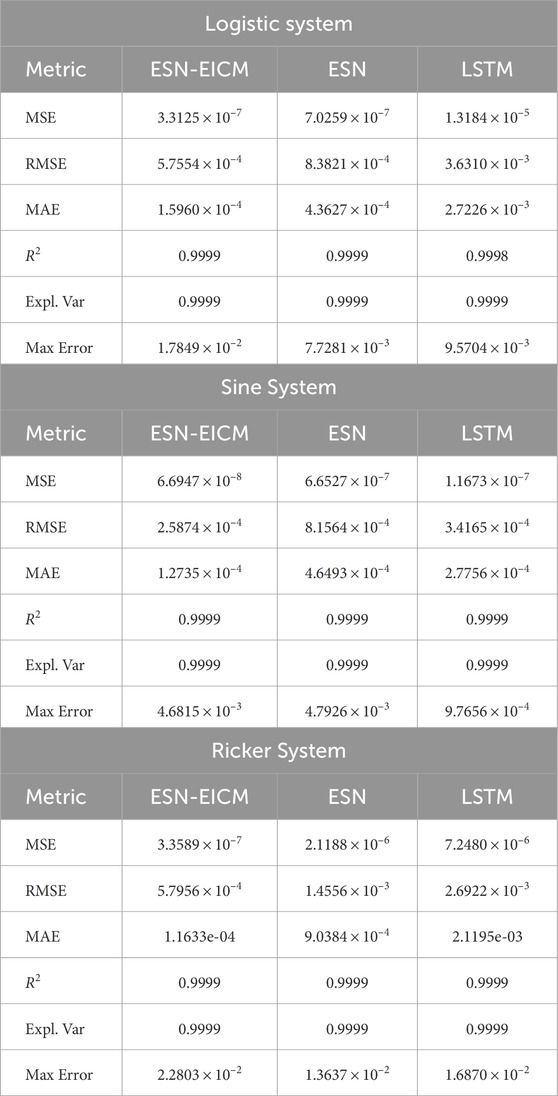
Table 10. Two-step prediction performance metrics by different chaotic systems.
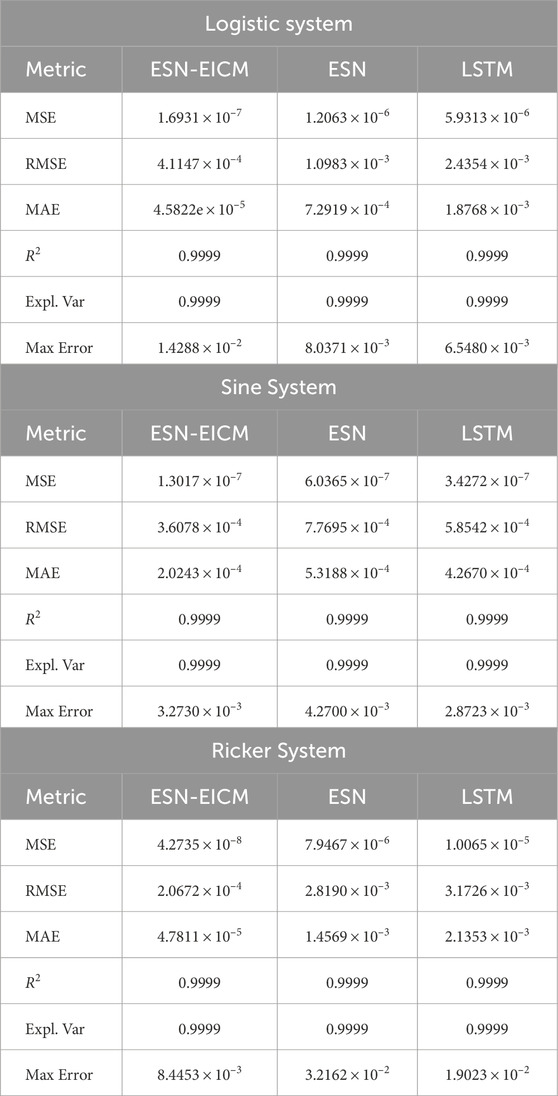
Table 11. Three-step prediction performance metrics by different chaotic systems.
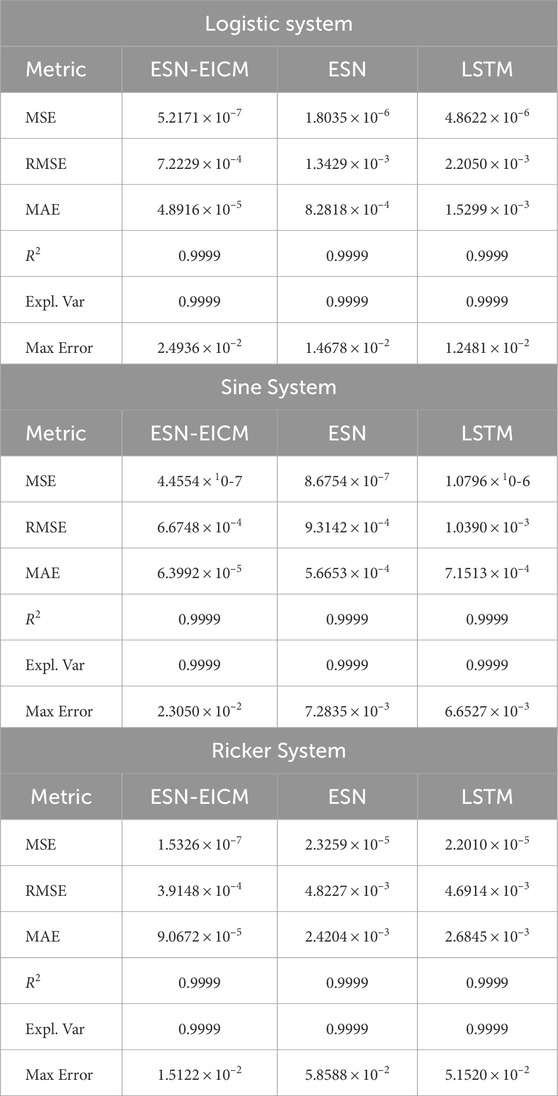
Table 12. Four-step prediction performance metrics by different chaotic systems.
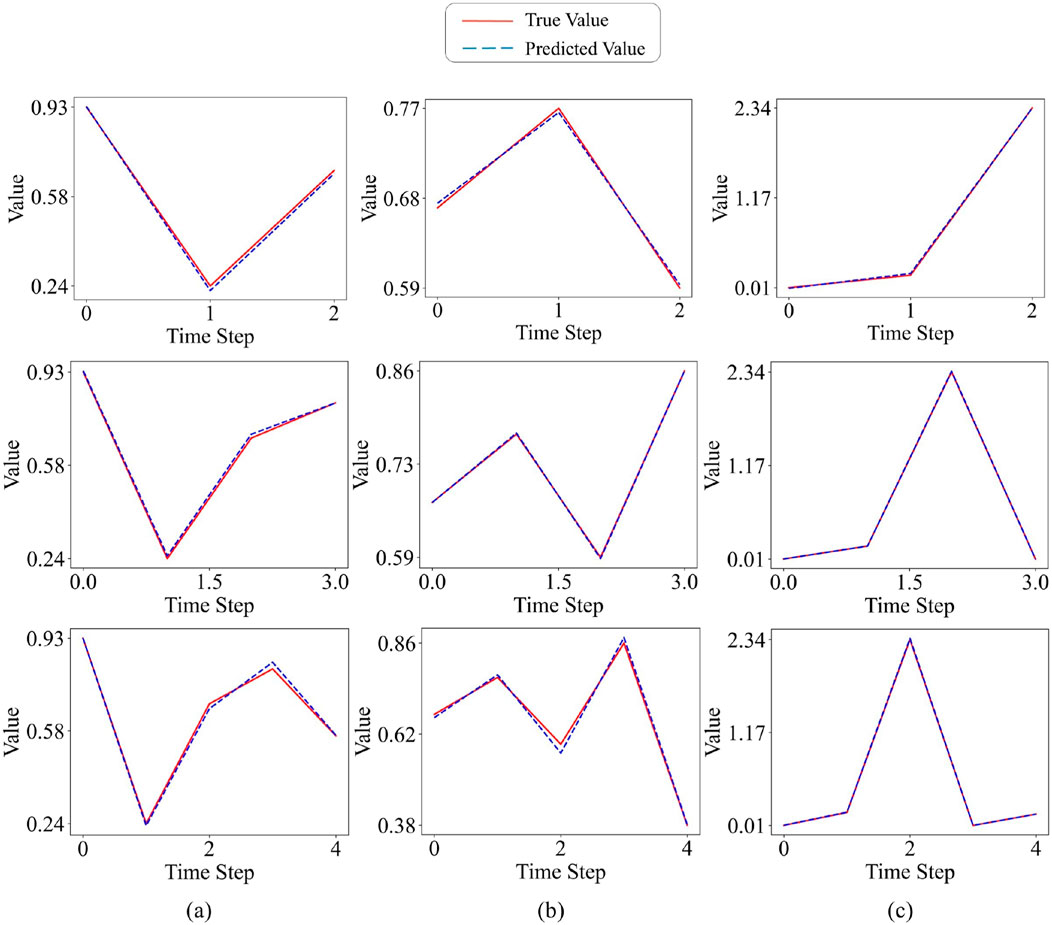
Figure 10. ESN-EICM multi-step Prediction in Different Chaotic Systems: (a) the Logistic system, (b) the Sine system, and (c) the Ricker system.
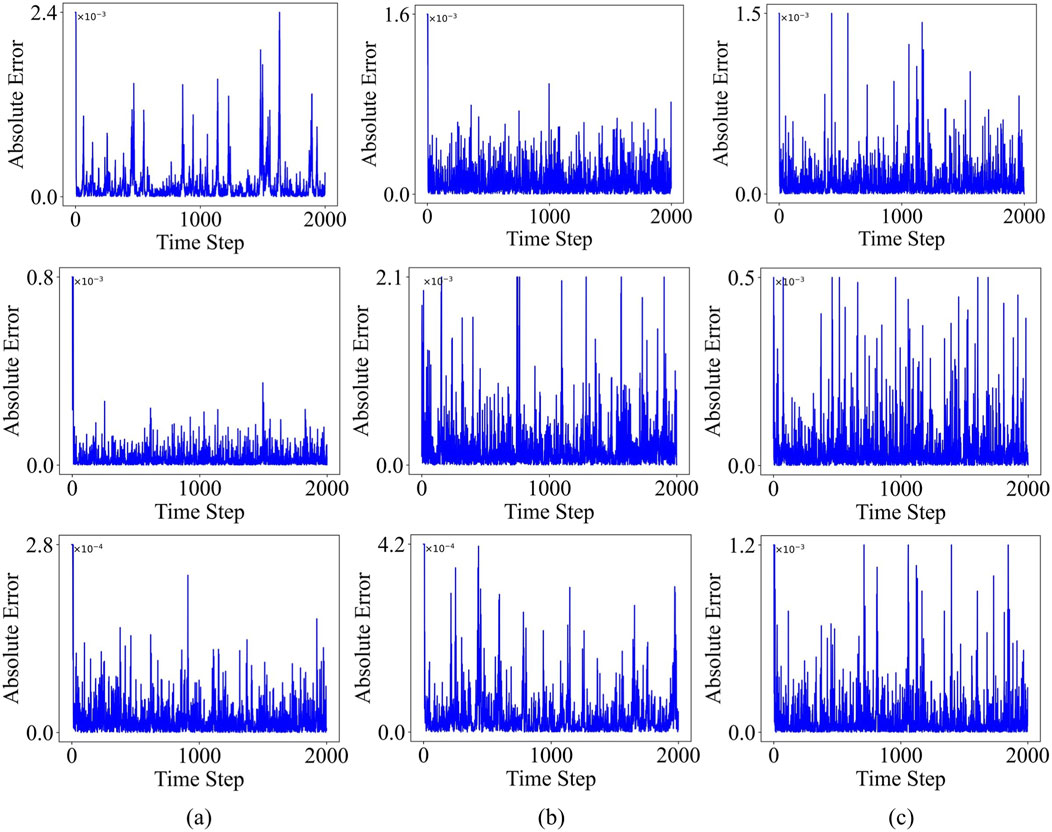
Figure 11. ESN-EICM multi-step Prediction Absolute Error Over Time in Different Chaotic Systems: (a) the Logistic system, (b) the Sine system, and (c) the Ricker system.
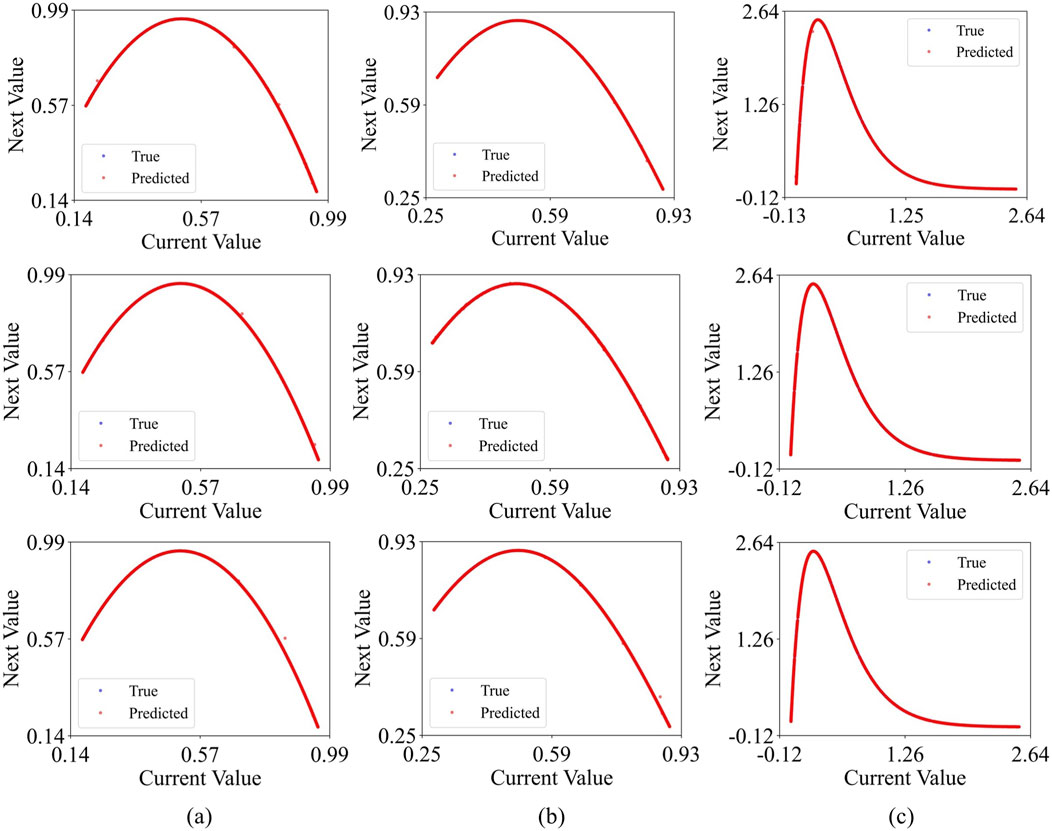
Figure 12. ESN-EICM multi-step Prediction Phase Space Reconstruction in Different Chaotic Systems: (a) the Logistic system, (b) the Sine system, and (c) the Ricker system.
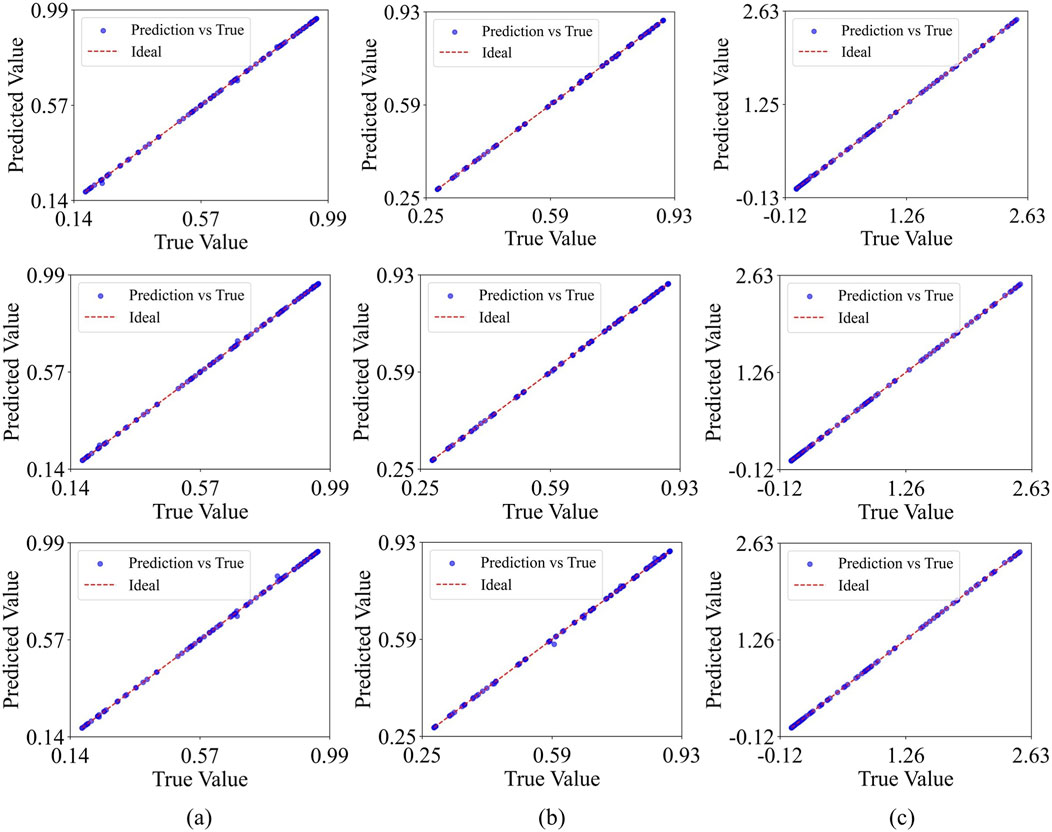
Figure 13. ESN-EICM multi-step Prediction Accuracy: Predicted vs. True Values in Different Chaotic Systems: (a) the Logistic system, (b) the Sine system, and (c) the Ricker system.
Visually, Figures 10–13 collectively demonstrate the robust performance of the ESN-EICM model in multi-step prediction. Figure 10 shows that the predicted trajectories for all three chaotic systems ((a) Logistic, (b) Sine, (c) Ricker) closely follow the true system dynamics even over extended horizons. The absolute errors, as depicted in Figure 11, remain consistently low and bounded over the 2000 time steps, indicating the stability and accuracy of the ESN-EICM. The fidelity of the model in capturing the underlying dynamics of these chaotic systems is further highlighted by the phase space reconstructions in Figure 12, where the predicted attractors exhibit excellent agreement with the true attractors. Moreover, the scatter plots in Figure 13 show data points tightly clustered around the ideal diagonal line (Predicted Value = True Value), underscoring the high point-wise accuracy of the ESN-EICM in multi-step prediction scenarios.
Quantitatively, the ESN-EICM model consistently outperforms both ESN and LSTM across nearly all metrics and prediction horizons for the three chaotic systems.
For the Logistic system, in 2-step predictions (Table 10), ESN-EICM achieved an MSE of
In the case of the Sine system, ESN-EICM also demonstrated consistently lower MSE, RMSE, and MAE. For 2-step predictions (Table 10), ESN-EICM’s MSE
The Ricker system results particularly highlight the strength of the ESN-EICM. For 2-step predictions (Table 10), ESN-EICM’s MSE
Across all tested scenarios, R2 and Explained Variance values were consistently close to 0.9999 for all models, indicating a good general fit. However, the significant differences in MSE, RMSE, and MAE clearly underscore the enhanced precision and robustness of the ESN-EICM model for multi-step chaotic time series prediction. The sustained low error levels, even as the prediction horizon extends, suggest that ESN-EICM effectively captures the complex underlying dynamics and is less prone to error accumulation compared to standard ESN and LSTM approaches in these multi-step prediction tasks.
4.7 Training time comparison
In this section, we describe the measurement of the execution times of the three models for the same prediction task. The computer configuration is as follows:
• RAM: 32.0 GB (31.2 GB available)
•Processor: AMD Ryzen 9 7945HX with Radeon Graphics, 2.50 GHz
•System: 64-bit operating system, x64-based processor
•Operating System: Windows 11 Pro, version 24H2
•Graphics Card: NVIDIA GeForce RTX 4060 Laptop GPU, 8 GB GPU VRAM, NVIDIA
•Python: 3.12.0
•NumPy version: 1.26.4
•SciPy version: 1.14.1
•scikit-learn version: 1.5.2
•Matplotlib version: 3.9.2
•scikit-optimize version: 0.10.2
•tqdm version: 4.66.5
•torch version: 2.7.0
•Pandas version: 2.2.3
The computational efficiency of the proposed ESN-EICM model was evaluated against traditional ESN and LSTM architectures, with total experiment times recorded in Table 13. A key advantage of reservoir computing models, including ESN and our ESN-EICM, lies in their training efficiency compared to deep learning models like LSTM. This is primarily because the reservoir’s internal weights are fixed after initialization, and only the output weights are trained, typically through a computationally inexpensive linear regression. In contrast, LSTMs require iterative backpropagation through time and gradient descent over many epochs (70 epochs in our setup, as per 4.3.3), leading to significantly longer training durations. This fundamental difference is evident across all prediction steps and chaotic systems, where both ESN-EICM and ESN consistently outperform LSTM in terms of speed, often by an order of magnitude. For instance, in one-step prediction for the Logistic system, ESN-EICM took 424.3 s, ESN took 398.8 s, while LSTM required 1649.0 s. This pattern persists and often magnifies in multi-step scenarios; for example, in four-step prediction for the Ricker system, ESN-EICM completed in 570.5 s, ESN in 4006.0 s, and LSTM in 2092.1 s.
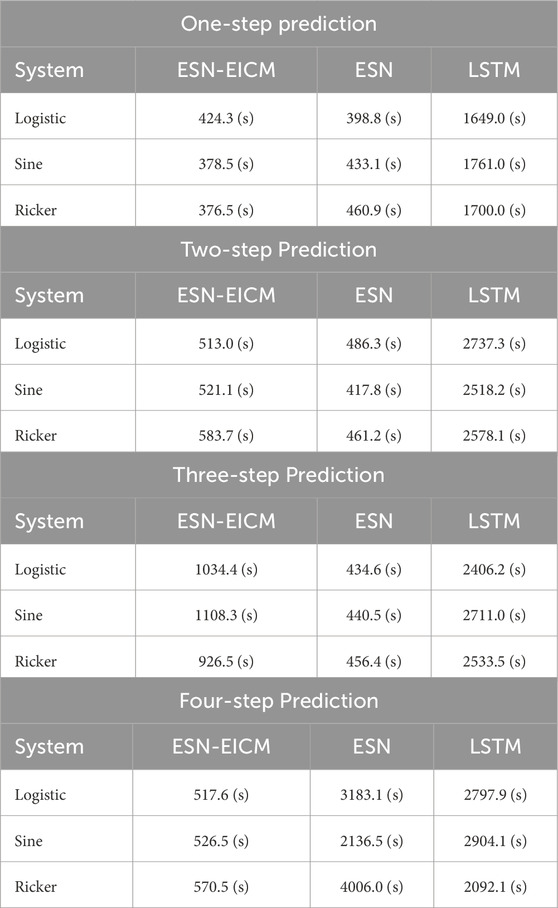
Table 13. Total experiment time for different prediction steps, chaotic systems, and models.
When comparing ESN-EICM specifically with the standard ESN, the time performance presents a nuanced but ultimately favorable picture for ESN-EICM, particularly as prediction horizons extend. In one-step and two-step predictions, the ESN-EICM’s runtime is generally comparable to that of the standard ESN, occasionally slightly higher. This marginal increase can be attributed to the more complex neuron dynamics within the ESN-EICM reservoir (as described in Section 3), which involve updates for feeding input
However, a significant advantage for ESN-EICM emerges in longer multi-step predictions, particularly at the four-step horizon. Here, ESN-EICM demonstrates substantially better time efficiency than the standard ESN. For example, in four-step prediction for the Logistic system, ESN-EICM took only 517.6 s, whereas ESN’s time escalated to 3183.1 s. Similar substantial speed-ups for ESN-EICM over ESN were observed for the Sine (526.5 s vs. 2136.5 s) and Ricker (570.5 s vs. 4006.0 s) systems at four steps. This pronounced improvement in efficiency for ESN-EICM in more challenging, longer-term prediction tasks can be directly attributed to how its enhanced stability impacts the Bayesian Optimization process. The inherent stability of the EICM neurons—stemming from features like adaptive thresholds and bounded activations—creates a “smoother” hyperparameter landscape for the optimizer to explore. This means that fewer parameter combinations lead to divergent or numerically unstable models, which would otherwise result in extremely high error values (penalties) and waste optimization calls. For the standard ESN, finding a stable parameter set for long-term iterative prediction can be more difficult, leading the optimizer to spend more time evaluating poorly performing or unstable regions. In contrast, the ESN-EICM’s robustness means that a larger proportion of the hyperparameter space yields valid, stable models, allowing the Bayesian optimizer to more quickly identify near-optimal configurations in fewer iterations. Therefore, the “faster convergence” mentioned in the abstract is not about the speed of a single training run, but the efficiency of the entire hyperparameter search process, which is significantly accelerated by the model’s intrinsic stability.
5 Discussion
5.1 On model complexity and the design philosophy
A central tenet of traditional ESNs is the use of a simple, fixed reservoir to reduce training complexity. Our ESN-EICM model, by incorporating a more complex neuron, appears to diverge from this principle. This is a deliberate design choice motivated by the specific challenge of chaotic system prediction. Instead of seeking complexity through architectural modifications like deep or multi-reservoir structures, we pursue “internal complexification” at the neuronal level. The rationale is that the rich, adaptive dynamics of the EICM neuron—with its coupled feedback and adaptive thresholds—can generate a more expressive variety of temporal patterns. This allows a reservoir of a given size to map the input into a higher-quality, more dynamically rich state space. The performance gains observed, particularly in multi-step prediction, suggest that for highly complex and sensitive systems like the ones studied, the benefits of enhanced neuronal dynamics outweigh the modest increase in per-neuron computational cost. This approach offers a valuable alternative to topological optimization, focusing instead on the intrinsic computational capabilities of the reservoir’s constituent elements.
5.2 Robustness against sensitivity in chaotic systems
The introduction mentions the “butterfly effect,” the extreme sensitivity of chaotic systems to initial conditions. The ESN-EICM’s strong performance in multi-step prediction suggests an inherent robustness against this sensitivity. This can be attributed to several design features. The adaptive threshold mechanism
6 Limitations and future work
While the proposed ESN-EICM model has demonstrated significant advantages in prediction chaotic time series, certain limitations and avenues for future research warrant discussion.
6.1 Limitations
1. Although Bayesian Optimization (BO) is more efficient than grid search or random search, optimizing a relatively large number of hyperparameters (10 in this study for ESN-EICM, as shown in Table 1) can still be computationally intensive, especially if each evaluation (training and validating the model) is time-consuming due to large reservoir sizes or long time series. The 50 calls to BO used in this study represent a trade-off between search thoroughness and computational budget.
2. The computational complexity of standard ESN training involves matrix operations that scale with reservoir size
3. The ESN-EICM was evaluated on three discrete chaotic systems, which are well-defined and exhibit specific types of chaos. Real-world time series often contain multiple sources of noise, non-stationarities, and varying types of underlying dynamics that were not explicitly addressed or modeled in this study beyond the inherent learning capacity of the reservoir. The model’s performance on such diverse and potentially more complex real-world datasets remains to be extensively validated.
4. While the EICM neuron model is biologically inspired and its mechanisms (adaptive threshold, feedback) are more transparent than the internal workings of an LSTM cell, the collective dynamics of a large reservoir of interconnected EICM neurons can still be complex to analyze and interpret fully. Understanding precisely how the EICM parameters
5. The EICM neuron parameters
6. While the overall training is efficient, the EICM neuron itself is computationally more demanding than a standard tanh or sigmoid neuron due to the multiple state updates (F, E, Y) required at each time step. This introduces a constant factor overhead in the reservoir state generation phase, which could become noticeable for very large reservoirs or extremely long time series.
6.2 Future work
Based on the promising results and current limitations, several directions for future research can be pursued:
1. Exploring more sophisticated or parallelized Bayesian optimization techniques, or meta-learning approaches to warm-start BO, could further reduce the hyperparameter tuning cost. Investigating gradient-based optimization for certain EICM parameters, if feasible, might also be an avenue.
2. Developing mechanisms for online adaptation of key EICM parameters
3. Combining ESN-EICM with other machine learning techniques could yield synergistic benefits. For example, using attention mechanisms in the output layer or employing ESN-EICM as a feature extractor for a subsequent shallow neural network could be explored.
4. A more in-depth theoretical analysis of the ESN-EICM, focusing on its memory capacity, echo state property conditions with EICM neurons, and stability criteria, would provide a stronger foundational understanding.
5. Extending the application of ESN-EICM to a wider range of challenging real-world chaotic and complex time series from domains such as finance (stock market prediction), climate science (weather prediction), engineering (system identification), and neuroscience (EEG signal analysis) would be crucial for demonstrating its practical utility.
6. Investigating the integration of other sophisticated, biologically plausible neuron models (e.g., Izhikevich neurons, adaptive exponential integrate-and-fire models) within the RC framework could lead to further advancements in time series prediction.Further exploration into neuromorphic hardware implementations could also be beneficial, drawing insights from ongoing research into memristive systems and their complex dynamics for specialized tasks [35]. Similarly, advancements in cellular neural networks coupled with novel devices like memristors also contribute to the broader landscape of hardware-oriented neural computation [36]. Exploring efficient hardware avenues, such as FPGA implementations for complex and novel neural architectures, remains an important direction [37].
7. Beyond hyperparameter optimization, exploring techniques for optimizing the reservoir’s topology (e.g., using pruning or growing methods guided by EICM neuron activity) could lead to more efficient and specialized reservoir structures.
Addressing these limitations and exploring these future research directions will contribute to advancing the field of reservoir computing and its application to complex time series analysis.
7 Conclusion
In this work, we introduced the Echo State Network Based on Enhanced Intersecting Cortical Model (ESN-EICM), a novel reservoir computing framework designed for accurate and efficient prediction of dicrete chaotic systems. Recognizing the limitations of traditional deep learning models in terms of computational cost and interpretability, and the constraints of standard ESNs concerning simplistic neuron dynamics and hyperparameter sensitivity, the ESN-EICM offers a compelling alternative. The core innovation lies in the integration of biologically inspired EICM neurons into the reservoir, characterized by continuous sigmoid activation, global mean-driven adaptive thresholds, and explicit inter-neuron feedback. This design endows the reservoir with richer internal dynamics, better suited for capturing the complex patterns inherent in chaotic systems. Furthermore, the adoption of a Bayesian Optimization strategy systematically addresses the challenge of hyperparameter tuning, leading to robust and near-optimal model configurations.
Our comprehensive experimental evaluation on the Logistic, Sine, and Ricker chaotic systems unequivocally demonstrated the ESN-EICM’s superiority. In both one-step and challenging multi-step prediction tasks (up to four steps ahead), the ESN-EICM consistently outperformed both standard ESN and LSTM models, as evidenced by significantly lower Mean Squared Error, Root Mean Squared Error, and Mean Absolute Error. Qualitative analyses, including prediction trajectory plots, error distributions, phase space reconstructions, and scatter plots, further visually corroborated the enhanced accuracy and stability of the ESN-EICM. Notably, while maintaining the characteristic training efficiency of RC models over LSTMs, the ESN-EICM often exhibited comparable or even superior total experiment times (including optimization) compared to standard ESNs in multi-step scenarios, attributed to the increased stability and expressiveness of the EICM neurons facilitating a more efficient hyperparameter search.
The successful application of EICM neurons within an ESN framework, coupled with automated hyperparameter optimization, highlights the potential of integrating more sophisticated, biologically plausible mechanisms into reservoir computing. The ESN-EICM stands as a robust, accurate, and computationally viable tool for modeling and predicting chaotic time series, paving the way for further research into neuro-inspired computing paradigms for complex dynamical systems. Future work will focus on extending its application to diverse real-world problems, exploring dynamic adaptation of neuron parameters, and conducting further theoretical analysis of its properties.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
XW: Conceptualization, Writing – review and editing, Writing – original draft, Visualization, Project administration, Data curation, Methodology. PM: Resources, Conceptualization, Funding acquisition, Writing – review and editing, Writing – original draft, Validation, Software. JnL: Resources, Investigation, Writing – original draft, Funding acquisition, Writing – review and editing, Data curation, Project administration, Supervision. JzL: Project administration, Funding acquisition, Supervision, Writing – review and editing, Writing – original draft, Data curation, Resources, Validation. YM: Resources, Funding acquisition, Formal Analysis, Writing – review and editing, Project administration, Supervision, Conceptualization, Writing – original draft, Data curation.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. Some experiments are supported by the Supercomputing Center of Lanzhou University. Additionasupport was provided in part by the Gansu Computing Center.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1. Rumelhart DE, Hinton GE, Williams RJ. Learning representations by back-propagating errors. nature (1986) 323:533–6. doi:10.1038/323533a0
2. Hochreiter S, Schmidhuber J. Long short-term memory. Neural Comput (1997) 9:1735–80. doi:10.1162/neco.1997.9.8.1735
3. Chung J, Gulcehre C, Cho K, Bengio Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv preprint arXiv:1412.3555 (2014). doi:10.48550/arXiv.1412.3555
4. Vaswani A, Shazeer N, Parmar N, Uszkoreit J, Jones L, Gomez AN, et al. Attention is all you need. Adv Neural Inf Process Syst (2017) 30. doi:10.48550/arXiv.1706.03762
5. Salinas D, Flunkert V, Gasthaus J, Januschowski T. Deepar: probabilistic forecasting with autoregressive recurrent networks. Int J Forecast (2020) 36:1181–91. doi:10.1016/j.ijforecast.2019.07.001
6. Van Den Oord A, Dieleman S, Zen H, Simonyan K, Vinyals O, Graves A, et al. Wavenet: a generative model for raw audio. arXiv preprint arXiv:1609.03499 12 (2016). doi:10.48550/arXiv.1609.03499
7. Lukoševičius M, Jaeger H. Reservoir computing approaches to recurrent neural network training. Computer Sci Rev (2009) 3:127–49. doi:10.1016/j.cosrev.2009.03.005
8. Gallicchio C, Micheli A, Pedrelli L. Deep reservoir computing: a critical experimental analysis. Neurocomputing (2017) 268:87–99. doi:10.1016/j.neucom.2016.12.089
9. He L, Xu Y, He W, Lin Y, Tian Y, Wu Y, et al. Network model with internal complexity bridges artificial intelligence and neuroscience. Nat Comput Sci (2024) 4:584–99. doi:10.1038/s43588-024-00674-9
10. Ekblad U, Kinser JM, Atmer J, Zetterlund N. The intersecting cortical model in image processing. Nucl Instr Methods Phys Res Section A: Acc Spectrometers, Detectors Associated Equipment (2004) 525:392–6. doi:10.1016/j.nima.2004.03.102
11. Tang Y, Jia S, Huang T, Yu Z, Liu JK. Implementing feature binding through dendritic networks of a single neuron. Neural Networks (2025) 189:107555. doi:10.1016/j.neunet.2025.107555
12. Zheng H, Zheng Z, Hu R, Xiao B, Wu Y, Yu F, et al. Temporal dendritic heterogeneity incorporated with spiking neural networks for learning multi-timescale dynamics. Nat Commun (2024) 15:277. doi:10.1038/s41467-023-44614-z
13. Shi X, Chen Z, Wang H, Yeung D-Y, Wong W-K, Woo W-C., et al. Convolutional lstm network: a machine learning approach for precipitation nowcasting. Adv Neural Inf Process Syst (2015) 28. doi:10.48550/arXiv.1506.04214
14. Awad M. Forecasting of chaotic time series using rbf neural networks optimized by genetic algorithms. Int Arab J Inf Technology (Iajit) (2017) 14.
15. Zhou H, Zhang S, Peng J, Zhang S, Li J, Xiong H, et al. Informer: beyond efficient transformer for long sequence time-series forecasting. Proc AAAI Conf Artif intelligence (2021) 35:11106–15. doi:10.1609/aaai.v35i12.17325
16. Karim F, Majumdar S, Darabi H, Chen S. Lstm fully convolutional networks for time series classification. IEEE access (2017) 6:1662–9. doi:10.1109/access.2017.2779939
17. Wang Z, Jiang R, Lian S, Yan R, Tang H. Adaptive smoothing gradient learning for spiking neural networks. In: International conference on machine learning. New York, NY, USA: Proceedings of Machine Learning Research (2023). p. 35798–816.
18. Ding J, Zhang J, Huang T, Liu JK, Yu Z. Assisting training of deep spiking neural networks with parameter initialization. IEEE Trans Neural Networks Learn Syst (2025) 1–14. doi:10.1109/tnnls.2025.3547774
19. Ma G, Yan R, Tang H. Exploiting noise as a resource for computation and learning in spiking neural networks. Patterns (2023) 4:100831. doi:10.1016/j.patter.2023.100831
20. Yang Z, Guo S, Fang Y, Yu Z, Liu JK. Spiking variational policy gradient for brain inspired reinforcement learning. IEEE Trans Pattern Anal Machine Intelligence (2024) 47:1975–90. doi:10.1109/tpami.2024.3511936
21. Hao X, Ma C, Yang Q, Wu J, Tan KC. Toward ultralow-power neuromorphic speech enhancement with spiking-fullsubnet. IEEE Trans Neural Networks Learn Syst (2025) 1–15. doi:10.1109/tnnls.2025.3566021
22. Xu M, Han M. Adaptive elastic echo state network for multivariate time series prediction. IEEE Trans cybernetics (2016) 46:2173–83. doi:10.1109/tcyb.2015.2467167
23. Qin Z, Tao X, Lu J, Tong W, Li GY. Semantic communications: principles and challenges. arXiv preprint arXiv:2201.01389 (2021). doi:10.48550/arXiv.2201.01389
24. Yu K, Zhang T, Xu Q, Pan G, Wang H. Ts-snn: temporal shift module for spiking neural networks. arXiv preprint arXiv:2505.04165 (2025).
25. Zhang M, Luo X, Wu J, Belatreche A, Cai S, Yang Y, et al. Toward building human-like sequential memory using brain-inspired spiking neural models. IEEE Trans Neural Networks Learn Syst (2025) 36:10143–55. doi:10.1109/tnnls.2025.3543673
26. Zhang J, Zhang M, Wang Y, Liu Q, Yin B, Li H, et al. Spiking neural networks with adaptive membrane time constant for event-based tracking. IEEE Trans Image Process (2025) 34:1009–21. doi:10.1109/tip.2025.3533213
27. Lian J, Yang Z, Liu J, Sun W, Zheng L, Du X, et al. An overview of image segmentation based on pulse-coupled neural network. Arch Comput Methods Eng (2021) 28:387–403. doi:10.1007/s11831-019-09381-5
28. Lukoševičius M. A practical guide to applying echo state networks. In: Neural networks: tricks of the trade. 2nd ed. Springer (2012). p. 659–86.
29. Jaeger H, Haas H. Harnessing nonlinearity: predicting chaotic systems and saving energy in wireless communication. science (2004) 304:78–80. doi:10.1126/science.1091277
30. Snoek J, Larochelle H, Adams RP. Practical bayesian optimization of machine learning algorithms. Adv Neural Inf Process Syst (2012) 25. doi:10.48550/arXiv.1206.2944
31. Bergstra J, Bengio Y. Random search for hyper-parameter optimization. J machine Learn Res (2012) 13:281–305.
32. Carandini M, Heeger DJ. Normalization as a canonical neural computation. Nat Rev Neurosci (2012) 13:51–62. doi:10.1038/nrn3136
33. Shen J, Ni W, Xu Q, Pan G, Tang H. Context gating in spiking neural networks: achieving lifelong learning through integration of local and global plasticity. Knowledge-Based Syst (2025) 311:112999. doi:10.1016/j.knosys.2025.112999
34. Sun P, Wu J, Zhang M, Devos P, Botteldooren D. Delayed memory unit: modeling temporal dependency through delay gate. IEEE Trans Neural Networks Learn Syst (2024) 36:10808–18. doi:10.1109/tnnls.2024.3490833
35. Yu F, He S, Yao W, Cai S, Xu Q. Quantitative characterization system for macroecosystem attributes and states. IEEE Trans Computer-Aided Des Integrated Circuits Syst (2025) 36:1–12. doi:10.13287/j.1001-9332.202501.031
36. Yu F, Su D, He S, Wu Y, Zhang S, Yin H. Resonant tunneling diode cellular neural network with memristor coupling and its application in police forensic digital image protection. Chin Phys B (2025) 34:050502. doi:10.1088/1674-1056/adb8bb
Keywords: ESN-EICM, time-series prediction, reservoir computing, complex system, brain-inspired computing
Citation: Wang X, Ma P, Lian J, Liu J and Ma Y (2025) An echo state network based on enhanced intersecting cortical model for discrete chaotic system prediction. Front. Phys. 13:1636357. doi: 10.3389/fphy.2025.1636357
Received: 27 May 2025; Accepted: 17 June 2025;
Published: 21 July 2025.
Edited by:
Fei Yu, Changsha University of Science and Technology, ChinaReviewed by:
Liu Jie, Northwestern Polytechnical University, ChinaTianxiu Lu, Sichuan University of Science and Engineering, China
Copyright © 2025 Wang, Ma, Lian, Liu and Ma. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yide Ma, eWRtYUBsenUuZWR1LmNu