 Fu Chen
Fu Chen Yanlou Liu
Yanlou Liu Tao Xin
Tao Xin Ying Cui
Ying Cui- 1Faculty of Psychology, Beijing Normal University, Beijing, China
- 2China Academy of Big Data for Education, Qufu Normal University, Shandong, China
- 3Collaborative Innovation Center of Assessment toward Basic Education Quality, Beijing Normal University, Beijing, China
- 4Department of Educational Psychology, University of Alberta, Edmonton, AB, Canada
The performance of the limited-information statistic M2 for diagnostic classification models (DCMs) is under-investigated in the current literature. Specifically, the investigations of M2 for specific DCMs rather than general modeling frameworks are needed. This article aims to demonstrate the usefulness of M2 in hierarchical diagnostic classification models (HDCMs). The performance of M2 in evaluating the fit of HDCMs was investigated in the presence of four types of attribute hierarchies. Two simulation studies were conducted to examine Type I error rates and statistical power of M2 under different simulation conditions, respectively. The findings suggest acceptable Type I error rates control of M2 as well as high statistical power under the conditions of a Q-matrix misspecification and the DINA model misspecification. The data of Examination for the Certificate of Proficiency in English (ECPE) were used to empirically illustrate the suitability of M2 in practice.
Introduction
Diagnostic classification models (DCMs) (Rupp et al., 2010) have demonstrated great potential for evaluating respondents with fine-grained information to support targeted interventions. Previous studies have applied DCMs to address some practical issues in education (e.g., Jang, 2009) and psychology (e.g., Templin and Henson, 2006). However, the area of research in DCMs is still relatively new. More research on model data fit statistics are needed for evaluating DCMs. Although relative fit statistics (e.g., de la Torre and Douglas, 2008) are available for determining the most suitable of several alternative models, they cannot be used for evaluating test- or item-level goodness-of-fit. As such, some authors have proposed and developed methods to evaluate the absolute fit of DCMs (e.g., Jurich, 2014; Wang et al., 2015). Specifically, the limited-information test statistics, e.g., the M2 statistic, was recommended by researchers (e.g., Liu et al., 2016) because of its ability to address sparseness in the contingency table. In the study by Liu et al. (2016), the performance of M2 was evaluated under the log-linear cognitive diagnosis model (LCDM; Henson et al., 2009). They found that M2 has reasonable Type I error rates control when models were correctly specified and good statistical power when models or Q-matrix were misspecified, under the conditions of different sample sizes, test lengths, and attribute correlations. More importantly, their study has identified the cutoff values of the root mean square error of approximation (RMSEA) fit index for M2 (RMSEA2). Similarly, the study by Henson et al. (2009) validated the usefulness of M2 in DCMs by a series simulation studies. Specifically, their study showed that M2 is of good performance across different diagnostic model structures and is sensitive to the model misspecifications, the Q-matrix misspecifications, the misspecifications in the distribution of higher-order latent dimensions, and violations of local item independence. Generally, their findings were based on the general frameworks (e.g., LCDM) or the most common DCMs (e.g., DINA; de la Torre, 2009), which assume extremely complicated relationships among items but simple relationships among attributes. However, the more specific models are more suitable for practical use (Rojas et al., 2012; Ma et al., 2016), the results will be more convincing if M2 can be applied in more specific and practical conditions.
In education, students are often required to master certain requisite skills before they move on to learn new knowledge and skills. This indicates that hierarchical relationships often exist among the cognitive skills. To address the presence of hierarchical relationship among attributes, Templin and Bradshaw (2014) developed the hierarchical diagnostic classification models (HDCMs) to model the attribute hierarchies. Hence, applying M2 to evaluate the fit of the DCMs in the presence of attribute hierarchies can help further testify to the utility of limited-information tests for DCMs. In this study, we use M2 and examine its Type I error rates and its power to evaluate the overall fit of HDCMs under different simulation conditions. Specifically, five types of DCMs are considered in our research: LCDM and HDCMs with linear, convergent, divergent and unstructured attribute hierarchies. In addition, the performance of M2 is examined with real data.
Hierarchical Diagnostic Classification Models
Over the past several decades, numerous DCMs have been developed and presented in the psychometric literature. Some of these models are general modeling frameworks, under which other specific DCMs can be subsumed through statistical constraints on model parameters. Hence, the general DCMs can flexibly model the probabilities of examinee's differently structured responses at the sacrifice of model simplicity. In this study, we use as the fitting model the HDCM, which is developed based upon the LCDM framework (Henson et al., 2009). The LCDM defines the probability of a correct response of the ith examinee for item j as
where represents the attribute mastery pattern of examinee i, λj, 0 represents the intercept parameter for item j, and represents the main and the interaction effect parameters for item j. is the Q-matrix entries for the item j, where qjk denotes whether attribute k is required by item j. h is a mapping function and is used to indicate the linear combination of αi and qj:
In the above equation, for item j, all main and interaction effects are included. Specifically, λj,1, (k) refers to the main effect of attribute k for item j, and refers to the two-way interaction effect of attributes k and k′ for item j. Hence, the subscript following the first comma in λj, 1, (k) or indicates the effect level, and the subscript(s) in parentheses refers to the involved attribute(s) for the effect. For example, if and , namely the second and third attributes, are required by item j and the examinee has mastered the first two attributes, then . For , namely the examinee has mastered all attributes required by item j, then , indicating that two main effects and one two-way interaction effect of attributes 2 and 3 are included in item j. Further, a statistical constraint is defined to ensure the monotonicity of the LCDM (see Henson et al., 2009).
Attribute hierarchies representing student knowledge structures often exist in education. However, how to model the attribute hierarchies had not been resolved until the HDCMs were developed by Templin and Bradshaw (2014). As previously mentioned, the LCDM is a general modeling framework under which other specific models can be obtained through statistical constraints. The parameterization of the HDCM, which is based on the LCDM, is no exception. Moreover, because the different types of attribute hierarches correspond to different parameterizations, the linear hierarchies are used for illustration.
With respect to the LCDM, K attributes correspond to 2K attribute mastery patterns. However, for a linear hierarchy with K attributes, the number of attribute mastery patterns is sharply reduced from 2K toK + 1. This change is reflected by , which refers to the possible attribute mastery patterns under the constraints of the linear hierarchy. Allowing to denote the attributes required by item j, the linear hierarchy defines attribute a to be the most fundamental attribute such that any other one attribute is nested within its former attribute. Thus, the matrix product in Equation (2) is modified to :
As such, if item j measures attributes 1 and 2 and attribute 2 is nested within attribute 1, the HDCM defines the probability of a correct response of the ith examinee for item j as
Under the HDCM, the item parameters include only one intercept, one main effect for attribute 1 and one interaction effect for attribute 2 nested within attribute 1. Obviously, regardless of the number of attributes, there will be only one main effect in the item response function owing to the constraints of the linear hierarchies; accordingly, the number of item parameters for items measuring several attributes is also greatly reduced.
In this study, four fundamental hierarchical structures (see Figure 1) by Leighton et al. (2004) were modeled by HDCMs. All attribute hierarchies involve five attributes. Specifically, linear hierarchy defines linear relationships between attributes: the mastery of an attribute is dependent on the mastery of its former attribute. As such, attribute 1 is the most fundamental attribute given that it is required for the mastery of any other attributes in the hierarchical structure. In other words, for example, it is unlikely that an examinee have mastery of attributes 3 and 4 without the mastery of attributes 1 and 2. The linear hierarchy would largely reduce the item parameters of LCDM. As an example, assume item j measures attributes 1, 2, and 4, the linear HDCM defines the matrix product of item j as
It can be found that only the main effect of attribute 1, the two-way interaction effect of attributes 1 and 2, and the three-way interaction effect of attributes 1, 2, and 4 are modeled in HDCM under the constraints of the linear hierarchy. In the convergent hierarchy, the mastery of attributes 3 or 4 are dependent on the mastery of attributes 1 and 2, and both attributes 3 and 4 are prerequisite attributes of attribute 5. As such, the same item measuring attributes 1, 2, and 4 is modeled by the same way as equation (5) under the convergent HDCM. In the divergent hierarchy, attribute 1 is the prerequisite attribute of both attributes 2 and 4, which in turn are the prerequisite attributes of attributes 3 and 5 respectively. Under the divergent HDCM, the same item would be modeled as
In the unstructured hierarchy, attribute 1 is the prerequisite attribute of all other attributes, which are independent from each other. Under the unstructured HDCM, the same item would be modeled by the same way of divergent HDCM. It should be noted that for items measuring four or five attributes, different attribute hierarchies would model the same item in more distinct ways, since more attributes lead to more main and interaction effects.
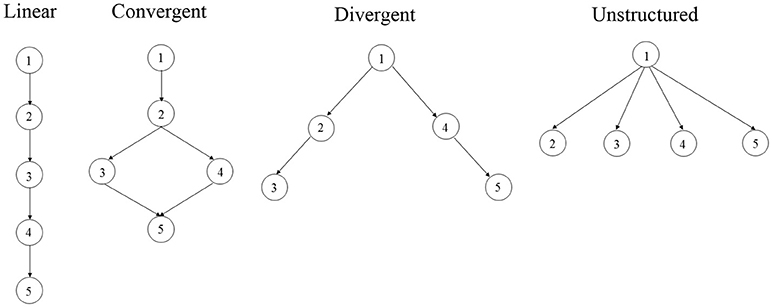
Figure 1. Four hierarchical structures using five attributes.
The M2 Test Statistic
Regarding the issue of fit tests for DCMs, several recent studies have focused on item-level fit statistics for DCMs (e.g., Kunina-Habenicht et al., 2012; Wang et al., 2015). Despite the feasibility of the proposed item-level fit statistics, a way to assess the absolute model-data fit in the test level remains undeveloped because the traditional full-information statistics, such as χ2 and G2, cannot be practically feasible in DCMs. Specifically, the computations of χ2 and G2 should be based on all possible response patterns, namely, the full contingency table. However, it is required that the expected frequency in each cell should be large, i.e., usually exceeding 5, for χ2 and G2 to be effective. This indicates that only a few items and a large number of examinees are required for a test using DCMs because even a small number of items can contribute to a large number of response patterns, a situation that easily leads to the sparseness of the contingency table. As such, some approaches have been proposed to address the issue of sparseness. For instance, although the Monte Carlo resampling technique can be used to produce empirical p-values (Tollenaar and Mooijaart, 2003), it is too time-consuming in practice. Another approach, the posterior predictive model checking method (Sinharay and Almond, 2007), is conservative and requires intensive computations due to the Markov chain Monte Carlo (MCMC) algorithm.
The limited-information tests are promising for model-data fit testing in DCMs. Unlike the full-information statistics, such as χ2 and G2, which use the entire contingency table, limited-information statistics use only some subset of lower-order marginal tables. M2 is a commonly used limited-information statistic that demonstrates good performance for model-data fit tests (Maydeu-Olivares and Joe, 2005; Cai et al., 2006). Specifically, because M2 uses only the univariate and bivariate marginal information, it can be better calibrated for the sparseness in the contingency table (Maydeu-Olivares and Joe, 2006). The performance of M2 has been sufficiently investigated under the structural equation model (SEM) and item response theory (IRT) framework in previous studies (e.g., Maydeu-Olivares and Joe, 2005; Maydeu-Olivares et al., 2011). However, the application of M2 in DCMs has emerged only in recent years (e.g., Jurich, 2014; Hansen et al., 2016; Liu et al., 2016), through which the usefulness of M2 in DCMs has been validated.
M2 is the most popular statistic of one family of limited-information test statistics, Mr, where r denotes the marginal order (Maydeu-Olivares and Joe, 2006). Even though M2 uses only the univariate and bivariate marginal information, it is adequately powerful and can be computed efficiently (Maydeu-Olivares and Joe, 2005). Similar to traditional full-information statistics, the limited-information statistics are constructed using the residuals between observed and expected marginal probabilities. Hence, the residuals of the univariate and bivariate marginal probabilities should calculate first prior to the computation of M2. Let denotes the first-order marginal probabilities, specifically, the marginal probabilities of correctly responding to each single test item, where denotes the marginal probability of correctly responding to the jth item. Accordingly, denotes the second-order marginal probabilities of correctly responding to each item pair. Then, let denote the up-to-order 2 joint marginal probabilities and π denote the true response pattern probabilities, which is a 2J × 1 vector. Thus, the univariate and bivariate marginal probabilities can be calculated as follows: π2 = L2 × π where L2 is a d × 2J operator matrix of 1 and 0 s. The row-dimension, d = J + J(J − 1)/2, is the number of first- and second-order residuals. Using a test of 3 items as an example, the up-to-order 2 marginal probabilities should be
where π (#, #, #) refers to the probability of the corresponding item response pattern.
Then, let p2 = L2 × p and indicate the observed and model-predicted marginal probabilities, respectively, where p refers to the observed response pattern probabilities and refers to the model-predicted response pattern probabilities evaluated using the maximum likelihood estimate . Thus, the univariate and bivariate residuals are computed as . Thereafter, the M2 statistic is derived using r2 and a weight matrix, W2, as follows:
where . The vector of the first- and second-order residuals r2 is asymptotically normally distributed with means of zero and a covariance matrix (Reiser, 1996; Maydeu-Olivares and Joe, 2005):
where and . Another component in W2, Δ2, is the first-order partial derivative of the expected marginal probabilities with respect to the maximum likelihood estimate of item parameters:
The statistic is asymptotically distributed chi-squared with d−k degrees of freedom (Maydeu-Olivares and Joe, 2005), where k refers to the number of free parameters in the model. For a more elaborate description of M2, please refer to Hansen et al. (2016).
Similar to the traditional fit test statistics, the RMSEA2 can be calculated for M2 (Maydeu-Olivares and Joe, 2014). RMSEA2 is recommended to assess the approximate goodness-of-fit when M2 indicates the model does not fit exactly in the population. RMSEA2 can be obtained based on the observed and the df :
In this study, the information matrix, I, is the expected (Fisher) information matrix, which is described in a recent study in detail (Liu et al., 2018).
Simulation Study 1: the Type I Error Rates of M2
Simulation 1 was conducted to examine the empirical Type I error rates of M2 when models were correctly specified under the condition of different attribute hierarchies and sample sizes. For each simulation, three sample sizes, N = 1,000, N = 2,000 and N = 4,000, and a fixed test length, J = 20, were considered with 500 replications. All simulations were performed by R and Mplus.
In this simulation, data were generated from five models: linear, divergent, convergent and unstructured HDCMs, and LCDM (no attribute hierarchy). The Q-matrix (see Table 1) used in this study involved 5 attributes and 20 items with each item measuring one, two or three attributes. In the Q-matrix, the number of corresponding items for each attribute was specified to be equal. In addition, the attributes were specified to follow a multidimensional normal distribution, with the mean vectors randomly selected from the uniform distributionμ(−.5,.5). We used 0 as the critical value to dichotomize the attribute vectors. With respect to the attribute correlations, as suggested by Kunina-Habenicht et al. (2012), 0.5 and 0.8 are typical low and high attribute correlation coefficients, respectively; therefore, the correlation coefficients between the attributes were randomly selected from μ(.5,.8)for each replication. To avoid the effects of the magnitudes of item parameters on the simulation results, the values of all main effects for each item were fixed at a value of 2, the values of all interaction effects were fixed at a value of 1, and the intercepts were fixed at a value of −0.5 times the sum of all main and interaction effects for each item (Templin and Bradshaw, 2014).
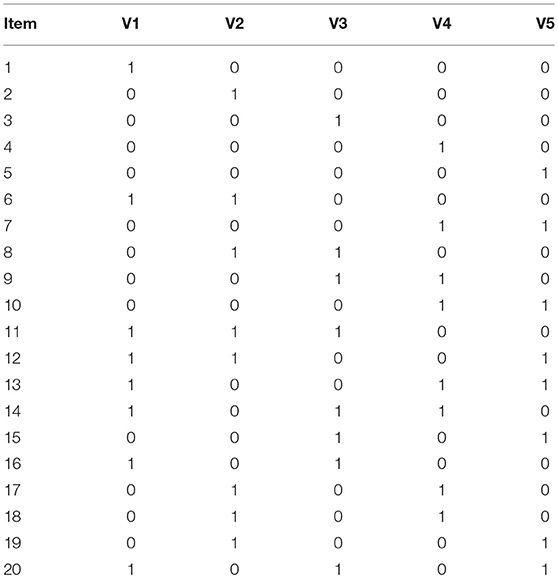
Table 1. Q-matrix with 5 attributes and 20 items.
Table 2 presents the results of the Type I error rates of M2 under the conditions of different attribute hierarchy types at five significance levels. The Type I error rates of M2 matched their expected rates well under different combinations of simulation conditions. Specifically, there was no substantial discrepancy in the performance of the Type I error rate control of M2 for the five different attribute hierarchy types. The average values of the empirical Type I error rates at the five significance levels were 0.014, 0.057, 0.111, 0.220, and 0.271, respectively. Hence, it is evident that the M2 statistic exhibited good Type I error rate control for different attribute hierarchy types. However, further examination of the empirical Type I error rates found that M2 under the LCDM, which indicates the independent relationships for attributes, had slightly better Type I error rate control compared to HDCMs.
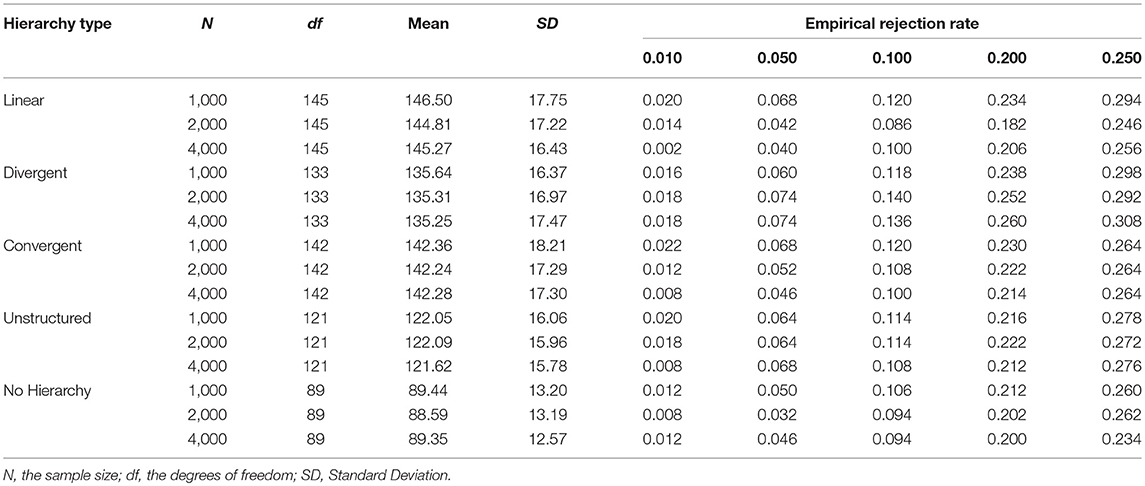
Table 2. Type I error rates for HDCMs with five different hierarchical structures.
Simulation Study 2: the Statistical Power of M2
Simulation 2 was conducted to examine the power of M2 under the conditions of model and Q-matrix misspecifications. The model and Q-matrix misspecifications were regarded as the sources of model–data misfit for DCMs in previous studies (e.g., Kunina-Habenicht et al., 2012; de la Torre and Lee, 2013). Especially, the Q-matrix misspecification can be a very influential source of model-data misfit (Kunina-Habenicht et al., 2012).
The generating models and the Q-matrix in this simulation were identical to those in Simulation 1 except that the LCDM was no longer considered. Identical to Simulation 1, three sample sizes, N = 1,000, N = 2,000, and N = 4,000, and a fixed test length, J = 20, were considered, and each simulation was performed with 500 replications. In addition, according to previous findings (e.g., Kunina-Habenicht et al., 2012; Liu et al., 2016), attribute correlations may affect the power of model-data fit statistics in DCMs, we therefore considered three attribute correlation levels, 0.3, 0.5, and 0.8, to examine the effects of different attribute correlations on the power of M2.
Regarding the model misspecification, we used the DINA model as the misspecified fitting model. The DINA model classifies the examinees into two groups: the examinees who have mastered all measured attributes and those who have not mastered at least one of the measured attributes. With respect to the Q-matrix misspecification, we used the random balance design (Chen et al., 2013) to misspecify 20% of the Q-matrix elements. This means that some attributes that were originally measured by the items are no longer required in the misspecified Q-matrix, and vice versa (see Table 3). The other technical settings are presented in the previous simulation study.

Table 3. Random balance design of Q-matrix misspecification.
Table 4 presents the results of the empirical rejection rates of M2 when the DINA model is used as the misspecified model. According to the table, for each attribute hierarchy, the statistical power increased with the increase of the sample size. This trend existed across different attribute correlations and significance levels. Specifically, when the sample size was 4,000, M2 had good performance in detecting the misspecified model. However, when the sample sizes were 2,000 and 1,000, the statistical power of M2 was unsatisfactory. In addition, the statistical power of M2 for the unstructured HDCM was rather poor in this simulation. Table 5 presents the results under the Q-matrix misspecification. According to Table 5, it is noted that the statistical power of M2 was extremely high for each type of attribute hierarchy. Specifically, the power for the divergent and unstructured HDCMs reached 100%, and the power for the linear and convergent HDCMs was slightly < 100% only when the sample size was 1,000. Generally, the attribute correlations had no effects on the statistical power of M2 for each type of misfit.
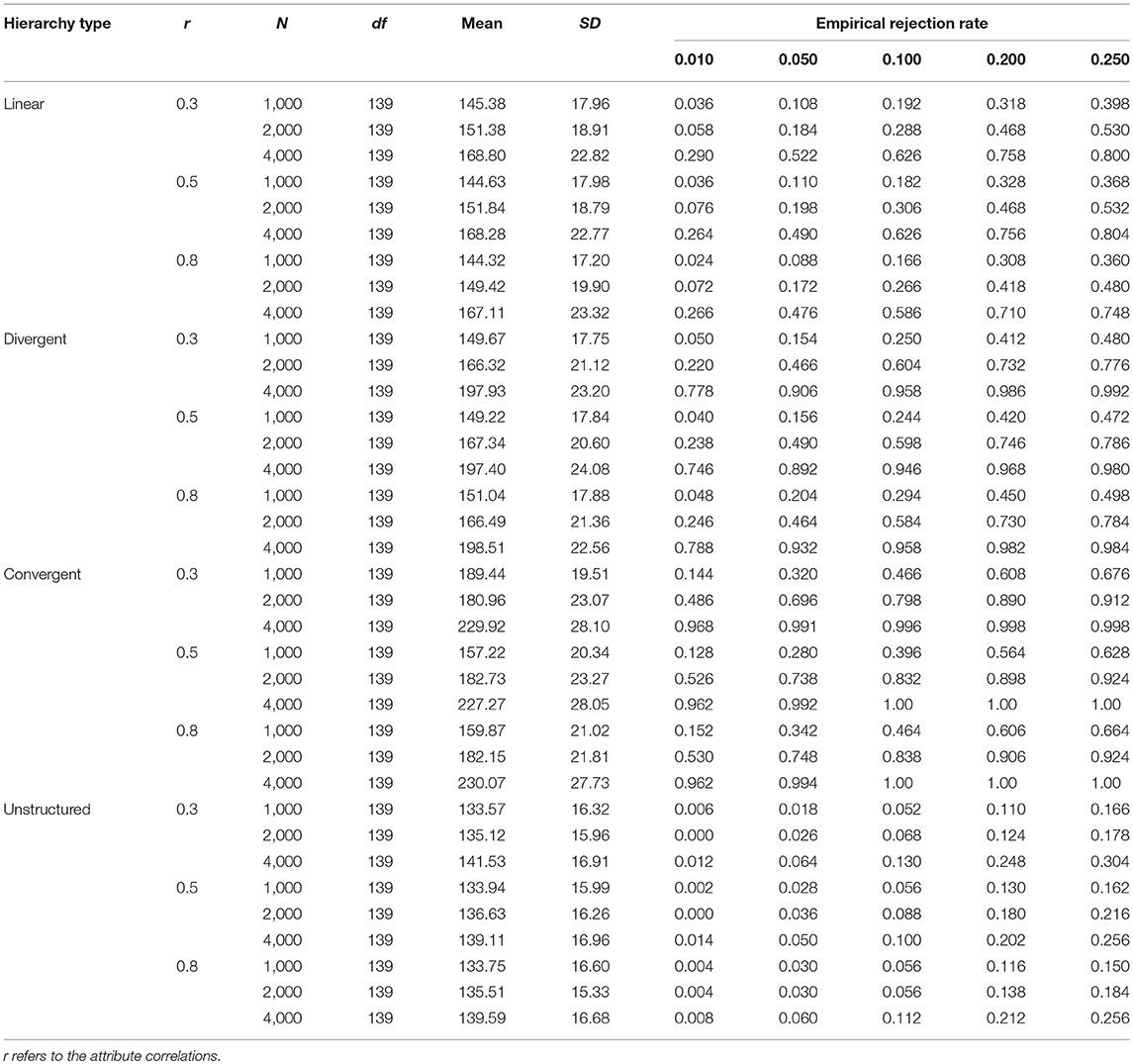
Table 4. The empirical rejection rates of M2 when DINA as the misspecified model.
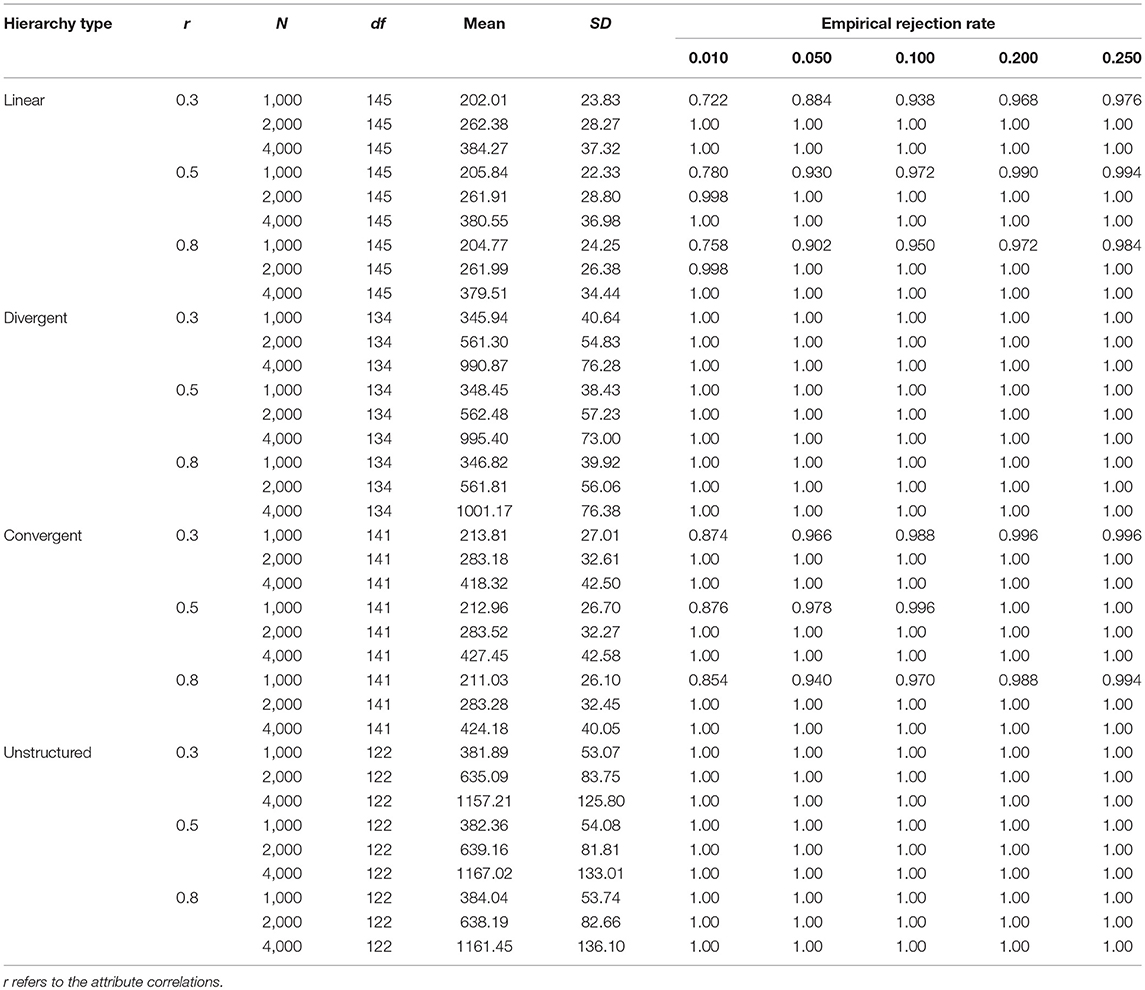
Table 5. The empirical rejection rates of M2 for the Q-matrix misspecification.
Empirical Illustration
We used the Examination for the Certificate of Proficiency in English (ECPE) data (Templin and Bradshaw, 2014) to investigate the usefulness of M2 in real settings. The ECPE data is publicly available in the CDM package in R (Robitzsch et al., 2014). The ECPE data embrace three attributes (knowledge of morphosyntactic rules, cohesive rules and lexical rules), 28 multiple-choice items and 2,922 examinees (Buck and Tatsuoka, 1998). The Q-matrix of the ECPE data is presented in Table 6. There exists a linear hierarchy underlying the three attributes: “lexical rules” is the prerequisite attribute of “cohesive rules,” which in turn is the prerequisite attribute of “morphosyntactic rules.” For illustration purposes, we used the linear HDCM, LCDM, DINA, and C-RUM to fit the data and applied M2 and RMSEA2 to evaluate the test-level model-data fit. As mentioned previously, The LCDM is the saturated model which involves the largest number of item parameters. The DINA model is a parsimonious model which includes two parameters for each item (the guessing and slip parameters). The C-RUM (Hartz, 2002) can be obtained from LCDM by retaining all main effects and removing all interaction effects of attributes. Modeling of LCDM, DINA, and C-RUM can be fulfilled by the gdina function in the CDM package in R. For the linear HDCM, because there is no available function in the CDM package, Mplus was used for the modeling according to the work by Templin and Hoffman (2013). We provided an abbreviated Mplus Syntax for the estimation of ECPE data and the R function for calculating M2 in the online Supplementary Material. The full Mplus Syntax can be accessed at the personal website of the developer of HDCM (https://jonathantemplin.com/hierarchical-attribute-structures/).
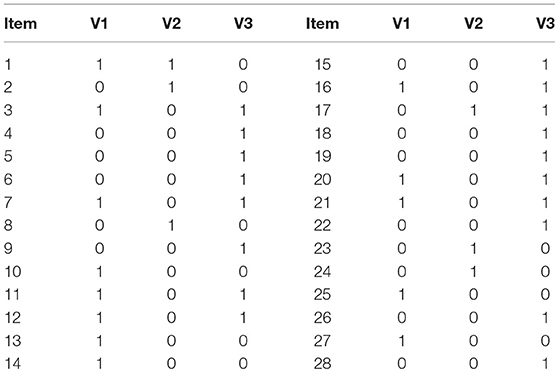
Table 6. Q-matrix of the ECPE data.
Table 7 presents the item parameter estimates of the ECPE data using the LCDM, DINA, and C-RUM models. In this study, we used the same estimation procedure programmed with Mplus as Templin and Bradshaw (2014) for the HDCM estimation. Thus, the item parameter estimates of the HDCM are available in Templin and Bradshaw (2014). The values of M2 and RMSEA2 for these models are presented in Table 8. Unfortunately, the M2 statistic rejected all models for the ECPE data. However, the values of RMSEA2 were small. In addition, the relative model-data fit statistics, AIC and BIC, showed that HDCM was the best fitting model for the ECPE data.
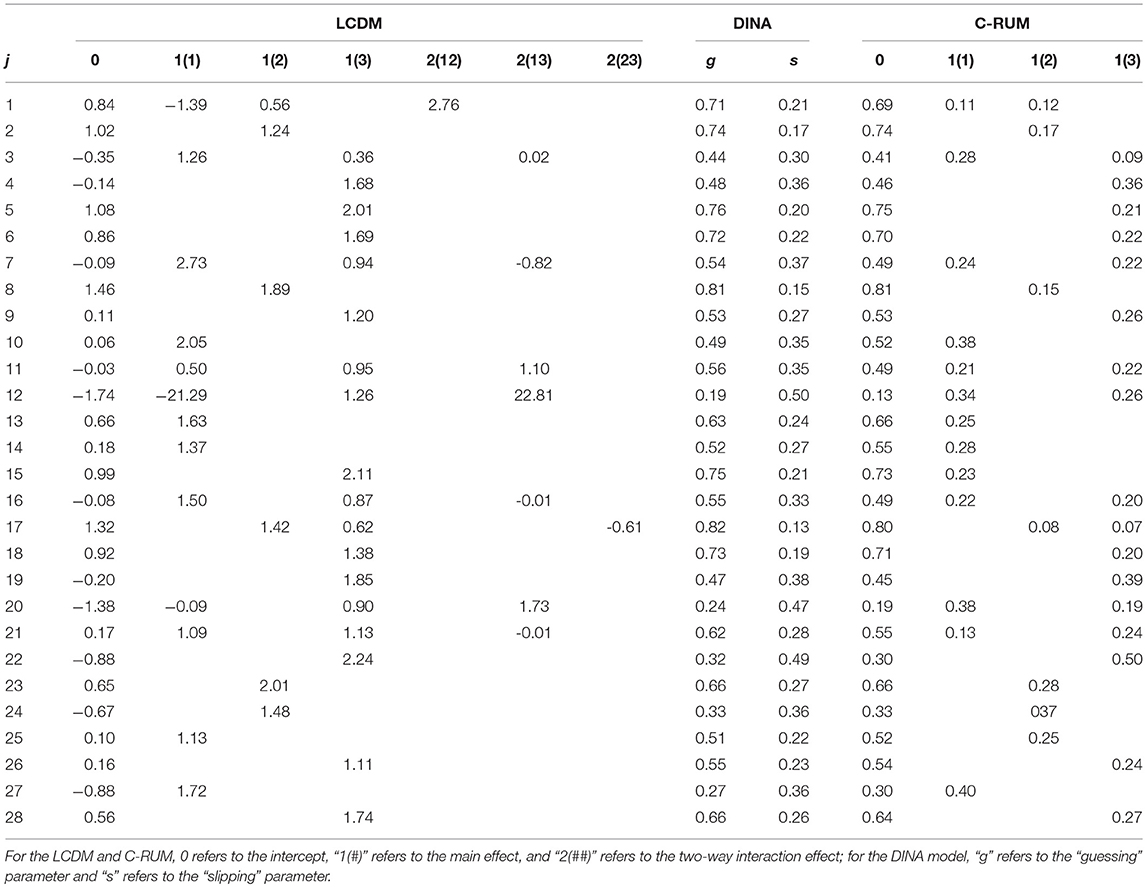
Table 7. Item parameters of the ECPE data by LCDM, DINA and C-RUM.

Table 8. M2 and RMSEA2 statistics for the ECPE data.
Discussion
This article aims to investigate the performance of a widely used limited-information fit test statistic, M2, in the hierarchical DCMs. We used the HDCMs to model the four fundamental attribute hierarchies and conducted two simulation studies and one empirical study to testify to the usefulness of M2.
According to Simulation 1, the observed Type I error rates of M2 are reasonably close to the nominal levels for each attribute hierarchy. This indicates that the M2 statistic can be safely used for different types of attribute hierarchies in DCMs. The attribute hierarchies are of great importance for practitioners using DCMs because hierarchical structures often exist among different knowledge, skills and psychological concepts. However, researchers and practitioners often improperly assume that the attributes involved in the cognitive diagnostic tests are independent. Hence, by examining four fundamental types of attribute hierarchies, in an initial step, we demonstrated the usefulness of M2 for addressing the complex attribute relationships in DCMs. Our findings echo previous findings on Type I error rates of M2 in DCMs (e.g., Hansen et al., 2016; Liu et al., 2016). In the study by Hansen et al. (2016), the Type I error rates of M2 for higher-order DINA, DINA and their variations were close to what would be expected. It should be noted that the Type I error rates of M2 were examined for a fixed test length, 20 items, which is close to that of the study by Hansen et al. (2016), 24 items. The test length was decided to cause the sparseness of the contingency table, based on which the limited-information statistics can be used. However, readers who are interested in how test length affects the Type I error rates of M2 in DCMs, should refer to the study by Liu et al. (2016). In their study, given both non-sparse (J = 6) and sparse contingency tables (J = 30/50), M2 demonstrated good control of Type I error rates.
Thereafter, we further examined the sensitivity of M2 to the specification of an incorrect DINA model and the misspecification of the Q-matrix. According to Simulation 2, the M2 statistic is extremely sensitive to the misspecification of the Q-matrix regardless of sample size and attribute correlation. This finding is consistent with previous studies (Hansen et al., 2016; Liu et al., 2016) that emphasize the importance of the correct specification of the Q-matrix in cognitive diagnostic tests. It should be noted that our study adopted the same approach for the Q-matrix misspecification generation as used by previous studies (e.g., Chen et al., 2013; Liu et al., 2016). The percentage of misspecified Q-matrix elements were set to be 20% considering that the true Q-matrix may not be easily identified by domain experts in reality. Thus 20% of misspecified Q-matrix elements was designed to reflect a substantial Q-matrix misspecification. In addition, due to the fact that the parameter estimation of a single HDCM by Mplus is extremely time-consuming (20–60 min), we did not examine the power of M2 for other levels of misspecified Q-matrix elements considering the infeasible simulation time. However, the study by Hansen et al. (2016) provided the evidence that when only two elements of Q-matrix were misspecified, the empirical rejection rates of M2 reached 100% in most simulation conditions, whereas omitting an existing attribute or adding an extraneous attribute would lead to lower sensitivity of M2 to Q-matrix specification. This finding implies that M2 may be largely sensitive to the Q-matrix misspecification given any percentage of misspecified Q-matrix elements. Future studies are encouraged to investigate how different types and different levels of Q-matrix misspecification affect the statistical power of M2 in DCMs.
With respect to model misspecification, when the DINA model was used as the fitting model, M2 was sensitive to the misspecification for large sample sizes. This expected finding can be explained by different assumptions regarding the relationships between the items and attributes underlying the DINA and HDCMs. Specifically, the DINA model is a non-compensatory model, which indicates that an examinee must possess mastery of all required attributes to correctly respond to some items and that the lack of any one of the required attributes will contribute to an incorrect answer. In contrast, the relationships between items and attributes of the HDCMs are compensatory, indicating that examinees have a higher probability of correctly responding to an item when they have mastered any one of the additional required attributes of the item. Accordingly, M2 was generally sensitive to the specification of the incorrect DINA model due to the huge discrepancy regarding the natures of the DINA and HDCMs. In addition, it is evident that larger sample sizes generally lead to higher statistical power, a finding that is consistent with previous studies (Kunina-Habenicht et al., 2012; Liu et al., 2016). Furthermore, we found that the attribute correlations have no noticeable influence on the sensitivity of M2 to the model and Q-matrix misspecifications. It is possible that the attribute hierarchies already assume strong relationships among the attributes and therefore the specified attribute correlation levels do not affect the performance of M2. This finding echoes previous findings that attribute correlations would not significantly influence the classification accuracy of DCMs (Kunina-Habenicht et al., 2012) and the statistical power of M2 in DCMs (Liu et al., 2016). It should be noted that in the study by Liu et al. (2016), when the sample size was small, a lower attribute correlation would lead to slightly higher power of M2. However, the opposite result was observed for a small sample size in our study. This is possibly due to that small sample sizes would lead to unstable parameter estimation which in in turn affected the classification accuracy and the performance of M2.
Regarding the empirical illustration, the M2 statistic rejected all models. It was expected that M2 would reject models except HDCM because the ECPE data involves hierarchical attribute relationships. One possible explanation is that M2 is, in practice, a strongly sensitive fit test statistic. Undoubtedly, the true generating Q-matrix for the ECPE data cannot be known. Hence, it is unavoidable that there exist some mistakes in the Q-matrix, which is specified by the domain and measurement experts. Moreover, the simulation study shows that M2 is extremely sensitive to the Q-matrix misspecification. So it is not surprising that M2 rejected all models for the ECPE data. The evidence of this finding is also supported by the empirical illustrations of numerous studies (e.g., Cai et al., 2006; Maydeu-Olivares et al., 2011; Jurich, 2014). Considering the sensitivity of M2, which provides only information about whether the models fit the data, many researchers recommended the use of RMSEA2 to assess the goodness of approximation of DCMs and to characterize the degree of model error (e.g., Maydeu-Olivares and Joe, 2014). The RMSEA2 is an effect-size-like index that can be used for the direct comparisons among the different models. According to Liu et al. (2016)'s criteria, the values of .030 and .045 are the thresholds for excellence and good fit, respectively. The values of RMSEA2 for the ECPE data in this study are significantly < 0.030, indicating good model-data fit for all models. However, it was expected that values of RMSEA2 would vary across the four models because they assume different relationships between attributes and items. For example, LCDM is the general modeling framework whereas DINA is one of the most parsimonious models which defines only two item parameters. Despite the fact that RMSEA penalizes the model complexity and measures the degree of model-data misfit, it was found to be influenced by sample sizes and the degree of freedom (df) in other modeling frameworks (e.g., structural equation modeling). For small sample sizes and small df, the RMSEA is often positively biased (Kenny et al., 2015). However, it was also evident that compared with small sample sizes and small df, the model rejection rates of RMSEA were much lower for large sample sizes and large df given the same cutoff value (Chen et al., 2008). Therefore, in our study, it is possible that the large sample size and the large df s led to indistinguishable values and CIs of RMSEA2. More empirical investigations are needed for revealing the performance of RMSEA2 in examining the model-data fit for DCMs.
For the real-life application of DCMs, practitioners should carefully examine the relationships between attributes at the test design stage or the initial stage of data analysis. HDCMs are recommended as the modeling framework if attribute hierarchies are identified. However, the model selection decision should be based on both substantive considerations and technical solutions. Despite the fact that the model-data fit tests in DCMs are under-developed, according to our findings, the M2 statistic is of great value for examining the absolute model-data fit of HDCMs. However, given the strong sensitivity of M2 to model or Q-matrix errors, RMSEA2 is recommended to evaluate the model-data misfit.
Some limitations exist in the present study. First, we used a fixed test length of 20 items, which, in reality, is considered as a reasonable test length. However, future studies are encouraged to investigate the effects of test length on the performance of M2 in DCMs. Second, we considered only the dichotomous data in this study. Future studies regarding the application of M2 should include polytomous models. Finally, although four fundamental afttribute hierarchies were considered in our research, it is recommended that the performances of M2 and RMSEA2 be examined in DCMs with more complicated attribute relationships.
Author Contributions
FC and TX contributed to the conceptualization and design of the work. FC and YL contributed to the analysis and interpretation of data. FC, YL, YC, and TX were involved in drafting and revising the manuscript. All authors approved the final manuscript submitted.
Funding
This work was supported by the National Natural Science Foundation of China (Grant No. 31371047) and the Key Projects of Philosophy and Social Sciences Research, Ministry of Education, China (Grant No. 12JZD040).
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpsyg.2018.01875/full#supplementary-material
References
Buck, G., and Tatsuoka, K. K. (1998). Application of the rule-space procedure to language testing: examining attributes of a free response listening test. Lang. Test. 15, 119–157. doi: 10.1177/026553229801500201
Cai, L., Maydeu-Olivares, A., Coffman, D. L., and Thissen, D. (2006). Limited-information goodness-of-fit testing of item response theory models for sparse 2P tables. Br. J. Math. Stat. Psychol. 59, 173–194. doi: 10.1348/000711005X66419
Chen, F., Curran, P. J., Bollen, K. A., Kirby, J., and Paxton, P. (2008). An empirical evaluation of the use of fixed cutoff points in RMSEA test statistic in structural equation models. Sociol. Methods Res. 36, 462–494. doi: 10.1177/0049124108314720
Chen, J., de la Torre, J., and Zhang, Z. (2013). Relative and absolute fit evaluation in cognitive diagnosis modeling. J. Educ. Meas. 50, 123–140. doi: 10.1111/j.1745-3984.2012.00185.x
de la Torre, J. (2009). DINA model and parameter estimation: a didactic. J. Educ. Behav. Stat. 34, 115–130. doi: 10.3102/1076998607309474
de la Torre, J., and Douglas, J. A. (2008). Model evaluation and multiple strategies in cognitive diagnosis: an analysis of fraction subtraction data. Psychometrika 73, 595–624. doi: 10.1007/s11336-008-9063-2
de la Torre, J., and Lee, Y.-S. (2013). Evaluating the wald test for item-level comparison of saturated and reduced models in cognitive diagnosis. J. Educ. Meas. 50, 355–373. doi: 10.1111/jedm.12022
Hansen, M., Cai, L., Monroe, S., and Li, Z. (2016). Limited-information goodness-of-fit testing of diagnostic classification item response models. Br. J. Mathe. Stat. Psychol. 69, 225–252. doi: 10.1111/bmsp.12074
Hartz, S. (2002). A Bayesian Framework for the Unified Model for Assessing Cognitive Abilities: Blending Theory with Practicality. Unpublished doctoral dissertation, University of Illinois at Urbana-Champaign.
Henson, R. A., Templin, J. L., and Willse, J. T. (2009). Defining a family of cognitive diagnosis models using log-linear models with latent variables. Psychometrika 74, 191–210. doi: 10.1007/s11336-008-9089-5
Jang, E. E. (2009). Cognitive diagnostic assessment of L2 reading comprehension ability: validity arguments for fusion model application to languedge assessment. Lang. Test. 26, 31–73. doi: 10.1177/0265532208097336
Jurich, D. P. (2014). Assessing Model Fit of Multidimensional Item Response Theory and Diagnostic Classification Models using Limited-Information Statistics. Unpublished doctoral dissertation, Department of Graduate Psychology, James Madison University.
Kenny, D. A., Kaniskan, B., and McCoach, D. B. (2015). The performance of RMSEA in models with small degrees of freedom. Sociol. Methods Res. 44, 486–507. doi: 10.1177/0049124114543236
Kunina-Habenicht, O., Rupp, A. A., and Wilhelm, O. (2012). The impact of model misspecification on parameter estimation and item-fit assessment in log-linear diagnostic classification models. J. Educ. Meas. 49, 59–81. doi: 10.1111/j.1745-3984.2011.00160.x
Leighton, J. P., Gierl, M. J., and Hunka, S. M. (2004). The attribute hierarchy method for cognitive assessment: a variation on Tatsuoka's rule-space approach. J. Educ. Meas. 41, 205–237. doi: 10.1111/j.1745-3984.2004.tb01163.x
Liu, Y., Tian, W., and Xin, T. (2016). An application of M2 statistic to evaluate the fit of cognitive diagnostic models. J. Educ. Behav. Stat. 41, 3–26. doi: 10.3102/1076998615621293
Liu, Y., Xin, T., Andersson, B., and Tian, W. (2018). Information matrix estimation procedures for cognitive diagnostic models. Br. J. Mathe. Stat. Psychol. doi: 10.1111/bmsp.12134. [Epub ahead of print].
Ma, W., Iaconangelo, C., and de la Torre, J. (2016). Model similarity, model selection, and attribute classification. Appl. Psychol. Meas. 40, 200–217. doi: 10.1177/0146621615621717
Maydeu-Olivares, A., Cai, L., and Hernández, A. (2011). Comparing the fit of item response theory and factor analysis models. Struct. Equation Model. 18, 333–356. doi: 10.1080/10705511.2011.581993
Maydeu-Olivares, A., and Joe, H. (2005). Limited- and full-information estimation and goodness-of-fit testing in 2n contingency tables: a unified framework. J. Am. Stat. Assoc. 100, 1009–1020. doi: 10.1198/016214504000002069
Maydeu-Olivares, A., and Joe, H. (2006). Limited information goodness-of-fit testing in multidimensional contingency tables. Psychometrika 71, 713–732. doi: 10.1007/s11336-005-1295-9
Maydeu-Olivares, A., and Joe, H. (2014). Assessing approximate fit in categorical data analysis. Multivariate Behav. Res. 49, 305–328. doi: 10.1080/00273171.2014.911075
Reiser, M. (1996). Analysis of residuals for the multionmial item response model. Psychometrika 61, 509–528. doi: 10.1007/BF02294552
Robitzsch, A., Kiefer, T., George, A. C., and Uenlue, A. (2014). CDM: Cognitive Diagnostic Modeling. R Package Version 3.4–21. Available online at: http://cran.r-project.org/web/packages/CDM/CDM.pdf.
Rojas, G., de la Torre, J., and Olea, J. (2012). April. “Choosing between general and specific cognitive diagnosis models when the sample size is small,” in Paper Presented at the Meeting of the National Council on Measurement in Education (Vancouver, BC).
Rupp, A. A., Templin, J., and Henson, R. (2010). Diagnostic Measurement: Theory, Methods, and Applications. New York, NY: Guilford Press.
Sinharay, S., and Almond, R. G. (2007). Assessing fit of cognitive diagnostic models: a case study. Educ. Psychol. Meas. 67, 239–257. doi: 10.1177/0013164406292025
Templin, J., and Bradshaw, L. (2014). Hierarchical diagnostic classification models: a family of models for estimating and testing attribute hierarchies. Psychometrika 79, 317–339. doi: 10.1007/s11336-013-9362-0
Templin, J., and Hoffman, L. (2013). Obtaining diagnostic classification model estimates using Mplus. Educ. Meas. Issues Pract. 32, 37–50. doi: 10.1111/emip.12010
Templin, J. L., and Henson, R. A. (2006). Measurement of psychological disorders using cognitive diagnosis models. Psychol. Methods 11, 287–305. doi: 10.1037/1082-989X.11.3.287
Tollenaar, N., and Mooijaart, A. (2003). Type I errors and power of the parametric bootstrap goodness-of-fit test: full and limited information. Br. J. Math. Stat. Psychol. 56, 271–288. doi: 10.1348/000711003770480048
Keywords: diagnostic classification models, attribute hierarchies, absolute fit test, limited-information test statistics, goodness-of-fit
Citation: Chen F, Liu Y, Xin T and Cui Y (2018) Applying the M2 Statistic to Evaluate the Fit of Diagnostic Classification Models in the Presence of Attribute Hierarchies. Front. Psychol. 9:1875. doi: 10.3389/fpsyg.2018.01875
Received: 01 August 2017; Accepted: 13 September 2018;
Published: 09 October 2018.
Edited by:
Holmes Finch, Ball State University, United StatesReviewed by:
Ben Kelcey, University of Cincinnati, United StatesScott Monroe, University of Massachusetts Amherst, United States
Chanjin Zheng, Jiangxi Normal University, China
Copyright © 2018 Chen, Liu, Xin and Cui. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Tao Xin, eGludGFvQGJudS5lZHUuY24=