 Xiaomin Wang
Xiaomin Wang Fei Ma2
Fei Ma2- 1Key Laboratory of High-Confidence Software Technology, Peking University, Beijing, China
- 2School of Electronics Engineering and Computer Science, Peking University, Beijing, China
- 3College of Mathematics and Statistics, Northwest Normal University, Lanzhou, China
Complex networks have become a powerful tool to describe the structure and evolution in a large quantity of real networks in the past few years, such as friendship networks, metabolic networks, protein–protein interaction networks, and software networks. While a variety of complex networks have been published, dense networks sharing remarkable structural properties, such as the scale-free feature, are seldom reported. Here, our goal is to construct a class of dense networks. Then, we discover that our networks follow the mixture degree distribution; that is, there is a critical point above which the cumulative degree distribution has a power-law form and below which the exponential distribution is observed. Next, we also prove the networks proposed to show the small-world property. Finally, we study random walks on our networks with a trap fixed at a vertex with the highest degree and find that the closed form for the mean first-passage time increases logarithmically with the number of vertices of our networks.
1 Introduction
The exploding interest in complex networks during the several decades of the 21st century is rooted in the discovery that despite the diversity of complex networks, the structure and the evolution of each network are driven by a common set of basic laws and principles. Examples include the Internet and the World Wide Web [1], biological networks [2], social networks [3], and communication networks [4, 5], to mention but a few. There are two common considerable properties, the small-world effect and the scale-free feature. The well-known WS-network (Watts and Strogatz, WS) was proposed by Watts and Strogatz in Nature to explain small-world phenomena in diverse networks by two indices, diameter and clustering coefficient [6]. The most pioneering of generally studied networks is the BA-network (Barabási and Albert, BA) built by Barabási and Albert in Science using two rules, namely, growth and preferential attachment [7].
In currently existing studies, the main concentration is to create networks which have scale-free and small-world properties as mentioned above. However, most networks are sparse, which means that the average degree of networks is asymptotically equal to a positive constant under the limitation of a large number of vertices. The principal reason is that numbers of real-world networks have been found to indicate sparsity. On the contrary, a few scholars have discovered the existence of dense networks in [8, 9]. For probing such networks, several available networks have been presented and analytically explored with primary methods, including mean-field theory [10, 11], generate function [12], and rate equation [13, 14]. In particular, the vast majority of these networks are proved to have no scale-free feature. To put this in another way, the degree distribution of these networks does not obey the power-law distribution. Therefore, it is of interest to develop new theoretical frameworks for producing networks with both the density feature and the scale-free feature. Here, we propose a class of networks with the appropriate structural properties mentioned above. Specifically speaking, these networks are precisely proved to be not only scale-free and small-world but also dense. Throughout this article, because graphs are abstract representations of networks, there is no need to distinguish between graph and network, which indicates that these two terms are considered to be the same.
The remainder of this article can be organized into the following sections. In Section 2, our task is to introduce network construction and discuss some extensively reported structural properties, including the average degree, mixture degree distribution, small-world property, and mean first-passage time. Among them, our networks are analytically proved to show both the density and scale-free features since the power-law exponent of cumulative degree distribution is equal to constant 2. Afterward, all the networks have a smaller diameter and a higher clustering coefficient, suggesting that they share the small-world property. Then, we derive an explicit expression of the mean first-passage time on our networks associated with the trapping problem. Finally, we close this article with a Conclusion and Discussions in the last section.
2 Network Construction and Topological Properties
In this section, our intention is to generate a class of networks: let
A Network Construction
Here, we will present our network,
Step 0: We start from a single vertex, we designate it as the active vertex of the network, and the active vertex is placed in the layer zero, denoted by
Step 1: We add a cycle
Step 2: We generate m replicas of
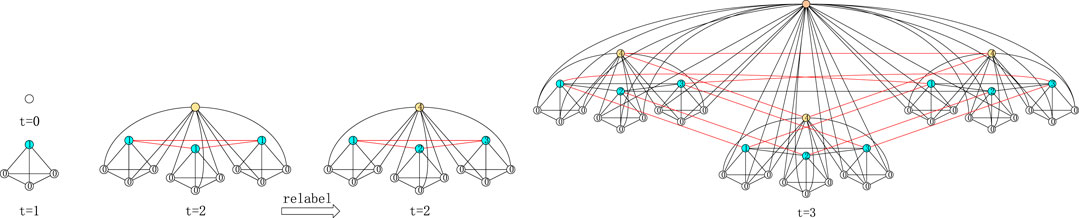
FIGURE 1. Illustration of iterative construction leads to proposed network
Step 3: We add m replicas of
These steps can be easily generalized. In fact, step t will involve the following operation:
Step t: We add m replicas of
Indefinitely repeating the steps of replication and connection, apparently, we obtain a class of networks. As an illustrative example, a network
Now, we compute some related basic parameters of our networks by construction. Let
At step
Until now, we have finished the construction of our networks and computed certain fundamental quantities. It is an extremely evident fact to discover the hierarchy of our network related to the step. It is worth noticing that the involved network construction with hierarchy has been discussed in [1]. In [1], Ravasz et al. constructed a hierarchical network that combines the scale-free property with a high clustering. However, it should be noted that the approach adopted in this article is slightly different from the approach in [1]. While Ravasz etal. applied an iterative process for all vertices, our method is based on an idea that the next network
B Topological Properties
As has been mentioned above, we mainly focus on the investigation of certain topological properties related to the potential structure of the proposed network. In this section, we will calculate several topological properties, including the density feature, mixture degree distribution, small-world property, and mean first-passage time. What we present here will be significant constituents in the coming subsections.
Density feature: A key topological structure of a network is its average degree. Average degree
We give a detailed calculation process of the average degree in the Appendix. From Eq. 3, it goes without saying that the average degree
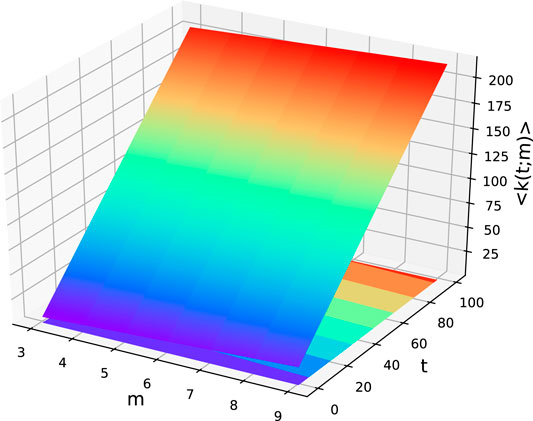
FIGURE 2. Diagram of the average degree
Mixture degree distribution: The concept of degree is the most fundamental character and measure of a vertex in a network. Since in a network every vertex has a degree value, some large and some small, the distribution of vertex in the network is a key topological feature, which may be of great concern in application. The degree distribution is one of the most important topological features of a network. Degree distribution can be applied to determine whether a given network is scalefree or not. Combined with the process of network construction, it is straightforward to find that the degree spectrum of network
where notation
For a network

TABLE 1. Degree spectrum.
On the basis of the aforementioned Table 1 and Eq. 4, the dependence of the cumulative distribution
where power-law exponent
The detailed calculation process of cumulative degree distribution is presented in Appendix. The cumulative degree distribution of our networks is composed of two parts, exponential distribution and power-law distribution. Besides, this result does not match the statement in the previous work. Genio believes that there is no network whose power-law exponent belongs to
Small-world property: Watts and Strogatz proposed the small-world property of complex networks by using two features: a relative smaller diameter and a higher clustering coefficient [6]. The small-world property of our networks is still not well discussed; despite that, they well describe these two important parameters of topological structures. In the coming discussion, we focus on the diameter and clustering coefficient of our networks.
Diameter: The distance between two vertices is the smallest number of edges to get from u to v. The longest shortest path between all pairs of vertices is called the diameter. The diameter is itself a feature of network structure and can be applied to characterize a communication delay over a network. In general, the larger the diameter is, the lower the communication efficiency is. The diameter of our network is denoted as
We give an exhaustive calculation process of diameter in Appendix. The reason comprises two main cases: 1) all vertices of the layer
Clustering coefficient: The clustering coefficient is another vital property of a network, which provides the measure of the local structure within the network. The most immediate measure of clustering is the clustering coefficient
The clustering coefficient of a vertex i in our networks is as follows:
The detailed process of the clustering coefficient will be given in Appendix. The degree of the clustering coefficient of a whole network is captured by the average value of the clustering coefficient,
Taking the limit on the number of vertices, the clustering coefficient
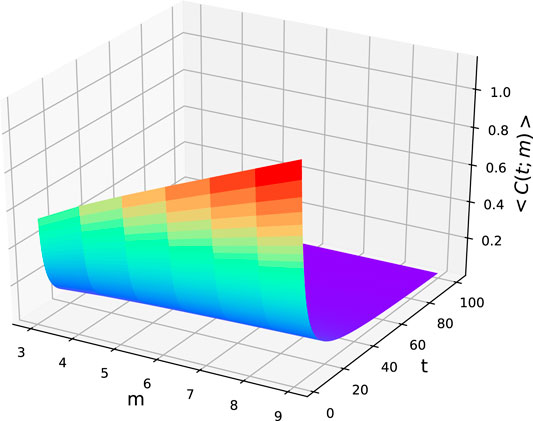
FIGURE 3. Diagram of the clustering coefficient
Consequently, our networks, with a smaller diameter and a higher clustering coefficient, can be considered as small-world networks.
Mean first-passage time: In this subsection, we have an attempt to study the trapping problem on our network
Here we think a walker starts from the vertex v at the initial time. Obviously, we can obtain the fact that the transition probability
where
Armed with the rule mentioned above, we want to discuss the most important quantity for the trapping problem, generally named the first-passage time
The classical method to solve the aforementioned equation is the generating function. Without loss of generality, we can write down the corresponding generating function of
A trial yet helpful fact associated with
Before proceeding further, we first define two notations,
where
Then, together with Eq. 13, the generating function
in which we apply a result
Meanwhile, let
On the basis of Eq. 16, doing the derivative of both sides of Eq. 15 evolves the exact solution of
For each vertex at the layer
Then, the first-passage time
Here, we again apply the hierarchical structure of network
Plugging Eqs 17 and 18 and the value of
Moreover, we think the logarithm of the number of vertices of network
Thus, in the large limit of the number of vertices of network
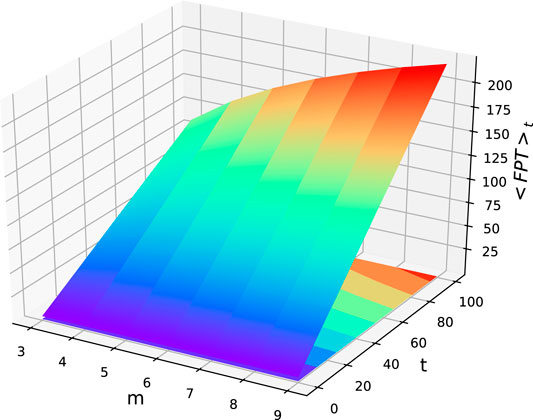
FIGURE 4. Diagram of the mean first-passage time
This is a bit different from some previous results in the existing literature; for instance, for a complete graph with N vertices, the mean first-passage time is exactly equal to
3 Conclusion and Discussion
In our article, we present a class of scale-free networks with the dense feature. On the basis of our analysis, we deduce some striking results.1) The average degree of our networks is not approximately a fixed constant value, and its value diverges with the step t, and then we reveal the fact that our networks are dense. 2) The cumulative degree distribution of our networks
Data Availability Statement
The original contributions presented in the study are included in the article/supplementary Material; further inquiries can be directed to the corresponding author.
Author Contributions
XW provided this topic and wrote the paper. FM discussed and modified it, and BY guided the manuscript. All authors contributed to manuscript and approved the submitted version.
Funding
This research was supported in part by the National Key Research and Development Program of China under Grant No. 2019YFA0706401; in part by the National Natural Science Foundation of China under Grant No. 61632002; in part by the General Program of the National Natural Science Foundation of China under Grant No. 61872399, Grant No. 61872166, and Grant No. 61672264; in part by the Young Scientists Fund of the National Natural Science Foundation of China under Grant No. 61802009, Grant No. 61902005, and Grant No. 62002002; and in part by the National Natural Science Foundation of China under Grant No. 61662066.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
1. Ravasz E, Barabási AL. Hierarchical organization in complex networks. Phys Rev E (2003) 67:026112. doi:10.1103/physreve.67.026112
2. Fornito A, Zalesky A, Breakspear M. The connectomics of brain disorders. Nat Rev Neurosci (2015) 16:159–172. doi:10.1038/nrn3901
3. Iranzo J, Buldú JM, Aguirre J. Competition among networks highlights the power of the weak.Nat Commun (2016) 7:13273. doi:10.1038/ncomms13273
4. Mocanu DC, Exarchakos G, Liotta A. 2004 IEEE international conference on systems, man, and cybernetics; 2004 Oct 10–13; The Hague, Netherlands. (2014). p. 19–24.
5. Albert R, Jeong H, Barabási A-L. Error and attack tolerance of complex networks. Nature (2000) 406:378–382. doi:10.1038/35019019
6. Watts DJ, Strogatz SH. Collective dynamics of “small-world” networks. Nature (1998) 393:440–2. doi:10.1038/30918
7. Barabási A-L, Albert R. Emergence of scaling in random networks. Science (1999) 286:509–12. doi:10.1126/science.286.5439.509
8. Timár G, Dorogovtsev SN, Mendes JFF. Scale-free networks with exponent one. Phys Rev E (2016) 94:022302. doi:10.1103/physreve.94.022302
9. Courtney OT, Bianconi G. Dense power-law networks and simplicial complexes. Phys Rev E (2018) 97:052303. doi:10.1103/physreve.97.052303
10. Barabási A-L, Albert R, Jeong H. Mean-field theory for scale-free random networks. Physica A: Stat Mech its Appl (1999) 272:173–87. doi:10.1016/s0378-4371(99)00291-5
11. Newman MEJ, Moore C, Watts DJ. Mean-field solution of the small-world network model. Phys Rev Lett (2000) 84(14):3201–4. doi:10.1103/physrevlett.84.3201
13. Krapivsky PL, Redner S, Leyvraz F. Connectivity of growing random networks. Phys Rev Lett (2000) 85(21):4629–32. doi:10.1103/physrevlett.85.4629
14. Krapivsky PL, Rodgers GJ, Redner S. Degree distributions of growing networks. Phys Rev Lett (2001) 86(23):5401. doi:10.1103/physrevlett.86.5401
15. Barabási AL. Network science. Cambridge, United Kingdom: Cambridge University Press (2016). p. 10–3.
16. Barabási A-L, Ravasz E, Vicsek T. Deterministic scale-free networks. Physica A: Stat Mech its Appl (2001) 299:559–64. doi:10.1016/s0378-4371(01)00369-7
17. Dorogovtsev SN, Goltsev AV, Mendes JFF. Pseudofractal scale-free web. Phys Rev E (2002) 65:066122. doi:10.1103/physreve.65.066122
18. Del Genio CI, Gross T, Bassler KE. All scale-free networks are sparse. Phys Rev Lett (2011) 107:178701. doi:10.1103/physrevlett.107.178701
19. Ma F, Wang XM, Wang P, Luo XD. Dense networks with scale-free feature. Phys Rev E (2020) 101:052317. doi:10.1103/physreve.101.052317
Keywords: dense feature, scale-free property, small-world property, mean first-passage time, mixture degree distribution
Citation: Wang X, Ma F and Yao B (2021) Dense Networks With Mixture Degree Distribution. Front. Phys. 9:647346. doi: 10.3389/fphy.2021.647346
Received: 29 December 2020; Accepted: 15 February 2021;
Published: 26 April 2021.
Edited by:
Nuno A. M. Araújo, University of Lisbon, PortugalReviewed by:
Haroldo V. Ribeiro, State University of Maringá, BrazilRainer Klages, Queen Mary University of London, United Kingdom
Copyright © 2021 Wang, Ma and Yao. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xiaomin Wang, d214d20wNjE2QDE2My5jb20=