Abstract
In financial production systems, accurate risk prediction is crucial for decision- makers. Traditional forecasting methods face certain limitations when dealing with complex time-series data and nonlinear dependencies between systems, especially under extreme market fluctuations. To address this, we propose an innovative hybrid temporal model, TSA-AR (Temporal Self-Attention Adaptive Autoregression), which combines temporal self-attention mechanisms with an adaptive autoregressive model to solve the risk prediction problem in financial and production systems. TSA-AR performs multi-scale feature extraction through an improved Informer encoder, dynamically adjusts model parameters with a dynamic autoregressive module, and constructs the nonlinear dependencies between financial and production systems through a cross_modal interaction graph. Experimental results show that TSA-AR achieves an MSE of 0.0689, significantly lower than other comparative models (e.g., Transformer’s 0.0921), and performs excellently with an Extreme Risk Detection Rate of 81.70%. The model effectively improves the accuracy and stability of risk prediction, providing a more accurate forecasting tool for financial-production system risk management, with significant practical implications.
1 Introduction
In recent years, the coupling between global financial systems and real-world production systems has intensified, leading to the formation of a complex risk transmission network. Studies have shown that financial market fluctuations can quickly transmit to the real economy through mechanisms such as credit channels and investment contraction [1, 2]. Conversely, disruptions in production systems (e.g., supply chain breakdowns, insufficient capacity) can have a feedback effect on financial markets, creating a negative feedback loop [3, 4]. For instance, during the COVID-19 pandemic in 2020, a liquidity crisis in the financial markets led to a surge in corporate financing costs, which subsequently triggered widespread delays in global supply chains [5–7]. Similarly, in 2022, the Federal Reserve’s aggressive interest rate hikes not only caused stock market turbulence but also suppressed fixed asset investment by increasing borrowing costs in the manufacturing sector [8].
As the interactions between financial systems and the real economy become increasingly complex, significant advancements have been made in the academic field of cross-system risk modeling. The Bayesian VAR framework proposed by Korobilis was the first to attempt to quantify the delayed effects of financial policies on production systems [9]. Meanwhile, Wang et al. developed graph neural network methods that broke the limitations of traditional linear models, capturing the nonlinear relationships between market participants [10]. Zhang and Xiao [11, 12] further introduced attention mechanisms into financial time series forecasting, significantly enhancing the modeling of long-term dependencies. However, these cutting-edge studies still face several key challenges. Existing methods often struggle to balance dynamic adaptability with model interpretability when capturing the complex interactions between financial and production systems. On the one hand, traditional autoregressive models based on static parameters fail to effectively handle structural changes in the market [13]. On the other hand, although deep learning models (such as Transformer) exhibit superior predictive accuracy [14], their “black-box” nature makes it extremely difficult to analyze the risk transmission paths.
The core dilemma in this research area lies in the disjunction between two dimensions: the depth of cross-system interaction modeling and the practicality of risk warning systems. While pioneering works such as those by Borio [15] and Elliott [16] revealed the importance of financial-production system interdependencies, existing methods either limit themselves to linear correlation analysis while ignoring asymmetric dependencies, or overly rely on lagging indicators, resulting in inadequate timeliness for risk warnings [17]. Notably, current mainstream machine learning methods, while capable of handling vast amounts of data, still exhibit inherent flaws in extracting dynamic temporal features, making them less effective in responding to sudden systemic risks [18]. This gap between theory and application not only restricts the improvement of risk prediction accuracy but also hinders the scientific advancement of policy-making.
In this study, we propose an innovative solution to the core challenges in financial-production system risk prediction. We designed a hybrid model, TSA-AR (Temporal Self-Attention Adaptive Autoregression), which integrates temporal self-attention mechanisms with adaptive autoregressive models to capture the long-term dependencies between financial and production systems while handling structural market changes. Using a cross-attention mechanism, we constructed a financial-production interaction graph to identify key risk transmission paths, such as the nonlinear dependency between “credit tightening
supply chain disruption.” Additionally, by incorporating a state space model (SSM), we dynamically adjust model parameters in real-time and use quantile regression to quantify risk uncertainty, providing dynamic prediction intervals with risk probability distributions, enabling early diagnosis and effective warning of extreme risks. The main contributions of this study are as follows:
• We propose an innovative TSA-AR model that deeply integrates temporal self-attention mechanisms with adaptive autoregressive models, enhancing the accuracy and stability of financial-production system risk predictions.
•We introduce adaptive sparsification strategies and multi-scale feature fusion techniques to effectively reduce computational complexity and improve the model’s performance in capturing long-term dependencies and cyclical fluctuations.
•We construct a cross-modal interaction graph that reveals the nonlinear dependencies between financial and production systems, providing a new analytical framework for complex system risk transmission.
2 Problem statement
Driven by both economic globalization and industrial digitalization, the degree of coupling between financial systems and production systems has reached unprecedented levels. While this deep interaction enhances resource allocation efficiency, it also introduces complex risk transmission problems. According to the Bank for International Settlements (BIS) 2023 annual report, 76% of global economic crises over the past decade have manifested as compounded disasters involving financial shocks and supply chain disruptions. Traditional risk management paradigms face issues such as rigid model structures, the lack of cross-modal interactions, and insufficient uncertainty quantification. Current forecasting systems, many of which are based on static parameter assumptions (e.g., GARCH models), struggle to adapt to structural changes in economic systems. Empirical research by Olanrewaju indicates that, during periods of shifts in the Federal Reserve’s monetary policy, prediction errors from traditional models can surge by 40%–60% [19]. Mainstream methods, such as VAR and DSGE models, treat financial and production systems as independent modules, overlooking the nonlinear feedback mechanisms between them. Korobilis’ Bayesian analysis confirmed that this simplification leads to an underestimation of the risk contagion intensity by up to 28% [20]. Although machine learning models (e.g., LSTM) can capture complex patterns, their point predictions fail to provide risk probability distributions. Giglio et al. [21] pointed out that this makes it difficult for decision-makers to assess the likelihood of extreme events.
Our study seeks to address three core scientific challenges in financial-production system risk forecasting, as shown in Figure 1. Firstly, to address the issue of traditional models’ inability to adapt to structural changes in the market, the focus is on breakthroughs in dynamic adaptability modeling, including online estimation of time-varying parameters and autonomous adjustment of model complexity. Secondly, to solve the challenge of quantifying cross-system nonlinear dependencies, we aim to represent asymmetric correlations and visualize risk transmission paths between financial and production indicators. Lastly, to address the issue of prediction uncertainty, we establish a framework for managing data noise, model error, and system uncertainty, enabling the dynamic generation of probabilistic prediction intervals and early diagnosis of extreme risks. Solving these three key issues will significantly enhance the ability to monitor risks in complex economic systems.
FIGURE 1
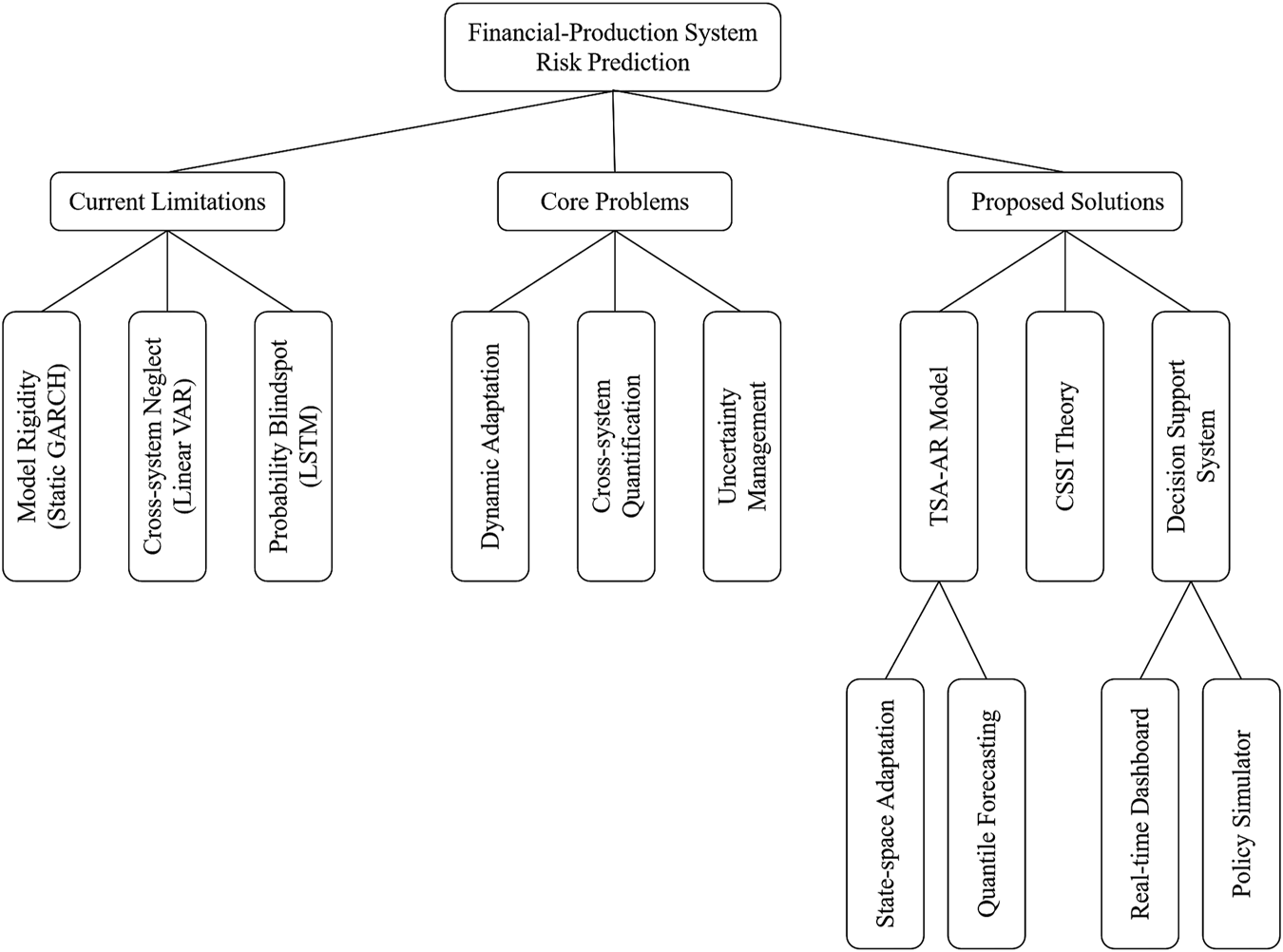
Financial-production system risk prediction and management framework.
To achieve these goals, our study adopts a three-tiered technological approach: At the methodological level, we develop a hybrid architecture (TSA-AR) integrating temporal self-attention with adaptive autoregression. This method uses a state space model for dynamic parameter updating and employs a quantile loss function to generate risk probability distributions. At the theoretical level, we establish a financial-production risk transmission network, propose the Risk Spillover Index (CSSI) [22], and demonstrate the equivalence between attention weights and Granger causality conditions. This solution provides a new analytical paradigm and decision-making tool for managing financial-production risks.
3 Methods
In this study, we propose an innovative hybrid temporal model, TSA-AR, aimed at addressing the challenges of risk prediction and management in financial-production systems. The TSA-AR framework integrates the Temporal Self-Attention mechanism with Adaptive Autoregressive modeling, coupled with three core modules to enhance dynamic modeling and risk prediction capabilities for financial and production systems. First, we employ an improved Informer architecture combined with an adaptive sparsification strategy to extract multi-scale temporal features, ensuring the model’s ability to handle long-term dependencies and periodic fluctuations in the market. Second, for autoregressive modeling, we adopt a State Space Model (SSM) to achieve dynamic adjustments of time-varying parameters, combined with quantile regression to quantify risk uncertainty. This enables more accurate predictions during periods of structural shifts. Lastly, through a cross-attention mechanism and a dual-stream encoding architecture, we construct an interaction graph that reveals risk transmission paths and nonlinear dependencies between the financial and production systems. This research not only advances theoretical innovation in financial-production system risk management but also provides more flexible and efficient tools for risk prediction and management for decision-makers.
3.1 Overall framework design
The TSA-AR framework consists of three core layers: the input layer, processing layer, and output layer, each playing an essential role in financial production system risk prediction. In the input layer, we handle temporal data streams from two sources—financial indicators and production indicators—and transform them into formats suitable for subsequent processing. Financial indicators, such as interest rates, stock prices, and credit spreads, are first standardized to eliminate the effects of differing units. Production indicators, such as capacity utilization and inventory turnover, are adjusted using logarithmic differencing to account for long-term trends. The processing layer comprises three components. First, the temporal encoder is based on the improved Informer architecture, where the ProbSparse self-attention strategy is applied to capture long-term dependencies by dynamically adjusting the sparsity level of the attention mechanism, as shown in Algorithm 1. Second, the autoregressive layer employs the State-Space Autoregressive (SSAR) model [23], which, when combined with a historical window of time-series data (e.g., 24 time steps), updates the model parameters in real-time. Lastly, the cross-modal interaction layer utilizes a cross-attention mechanism to capture the nonlinear dependencies between financial and production data, constructing an interaction weight matrix.
Algorithm 1
Input:Financial series , Production series
Output:Risk distribution , Transmission graph
//1. Multi-scale Feature Extraction
//#
//# [, , ]
//2. Adaptive Autoregression
//#
//3. Cross-system Interaction //# , return,
The output layer generates prediction results and the risk transmission graph. The risk prediction output, , includes the mean, fifth percentile, and 95th percentile, providing a comprehensive assessment of the risk range. The transmission graph is the association matrix , displaying the risk transmission paths between financial and production systems. The technical flow is illustrated in Figure 2, which shows how each module of the TSA-AR framework processes data and utilizes the autoregressive model and cross-attention mechanism to construct the risk prediction and transmission graph.
FIGURE 2
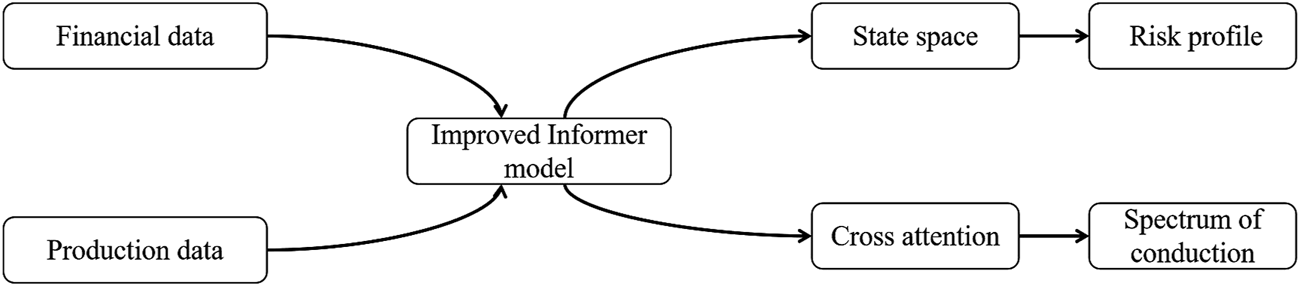
Technical flow of TSA-AR framework.
The input layer uses a dual-stream data preprocessing mechanism to handle time-series data from both the financial and production systems. Specifically, financial and production indicator streams are processed separately. Financial indicator streams include interest rates , stock prices , and credit spreads . These indicators are first subjected to standardized transformation to eliminate the influence of different data scales on model training, as shown in Equation 1:where and represent the mean and standard deviation of the financial data stream , respectively. The production indicator stream includes capacity utilization and inventory turnover . The production data is processed via logarithmic differencing in Equation 2:
This approach effectively captures the dynamic features of the production system over time. The time-series data encoding uses the Time2Vec method, which encodes the timestamp using sine and cosine functions and a periodicity parameter , generating the time-series embedding is shown in Equation 3:where is the base frequency, and is the periodic parameter. The processing layer contains three core components for feature extraction, parameter updating, and cross-modal analysis. The improved Informer temporal encoder, with an adaptive sparsification mechanism, is capable of handling long sequences of data. Both the financial data stream and the production data stream are input to generate encoded features and , expressed as shown in Equation 4:
The encoder uses an adaptive sparse attention mechanism, with the following Equation 5:where is the sparse query matrix obtained through probabilistic sampling (with sampling rate ). To enable dynamic parameter updates, the state-space autoregressive model calculates the updated autoregressive coefficients by combining the previous state and current input. The process is represented as shown in Equation 6:where represents feature concatenation, which combines the encoded results and , and inputs them into a multi-layer perceptron (MLP). The MLP consists of two hidden layers, each with a ReLU activation function, and outputs the state transition matrix with dimensionality , while is the process noise matrix with dimensionality . We apply L2 regularization to the weights of to prevent overfitting. The cross-modal interaction analysis module quantifies the nonlinear dependencies between financial and production data flows by calculating the interaction attention, with the following Equation 7:where and represent the linear transformations of financial and production features. The output layer generates two key results: risk distribution predictions and the risk transmission graph. The risk prediction is computed as shown in Equation 8:
To optimize quantile predictions, we use the quantile loss function, as shown in Equation 9:where is the quantile loss function and is the indicator function for distinguishing positive and negative errors. The risk transmission graph is generated through the cross-modal attention matrix and is used to display the risk transmission paths between financial and production systems. The graph is expressed as shown in Equation 10:where represents the nodes for financial and production variables, and represents the edge weights, with being generated by the cross-modal attention matrix .
3.2 Informer temporal modeling
The Informer model is based on the Transformer architecture and utilizes self-attention mechanisms to capture long-range dependencies in time-series data. Unlike traditional Recurrent Neural Networks (RNNs), Transformers can process input data in parallel, reducing computational bottlenecks, and can efficiently capture long-range temporal dependencies in a short amount of time. However, standard Transformer models face challenges in handling long sequences due to computational complexity and memory consumption, with a time complexity of , where is the length of the input sequence. Long time-series data requires the computation of numerous query-key similarities, leading to significant increases in both time and memory usage. As the sequence length increases, memory demand grows quadratically, which makes traditional Transformer models increasingly difficult to scale for large datasets. Another issue with the standard Encoder-Decoder structure is the stepwise decoding process, which leads to slow inference times and potential cumulative errors, further degrading prediction accuracy. Figure 3 illustrates the Informer model, with the left side showing the Encoder and the right side showing the Decoder.
FIGURE 3
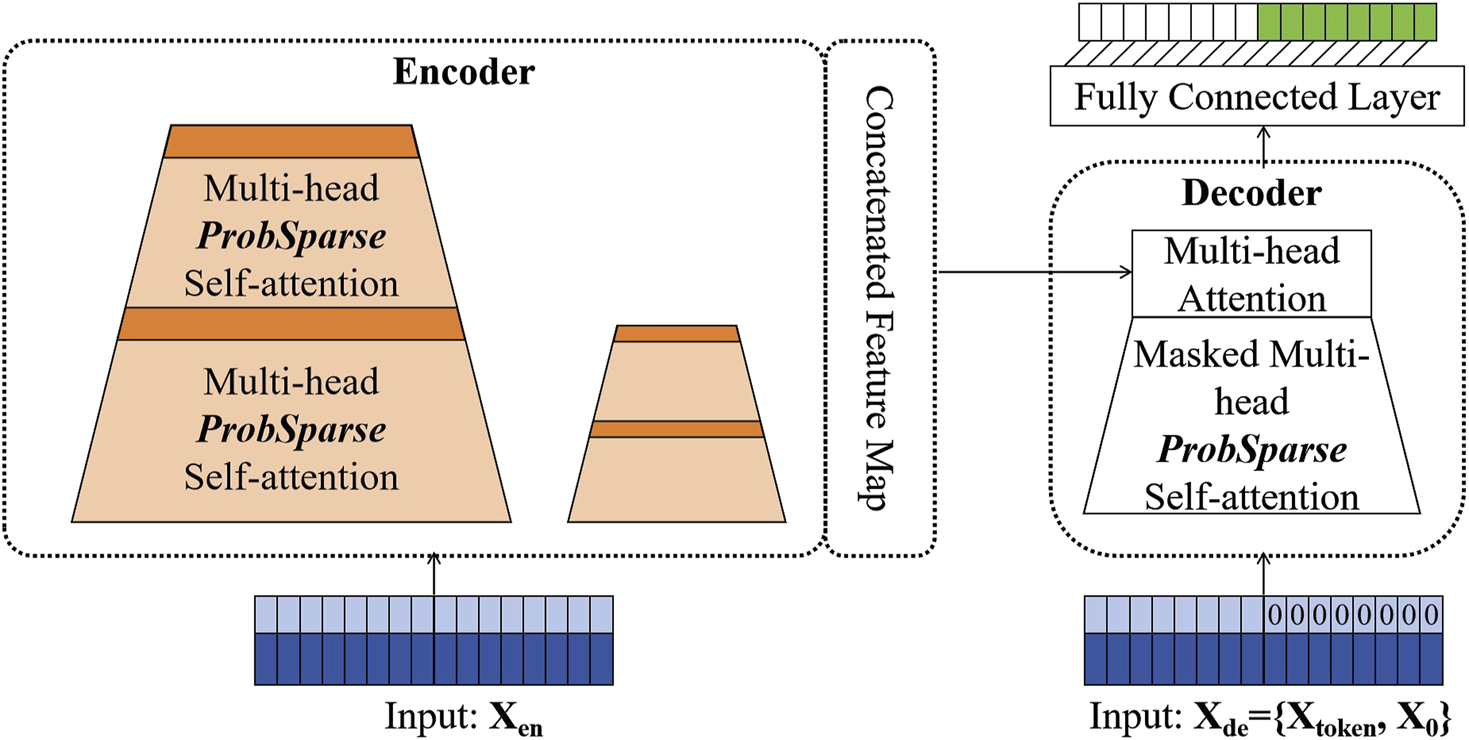
Informer model. The left side is the Encoder part, and the right side is the Decoder part.
Encoder: To address computational complexity, the Informer model introduces the ProbSparse self-attention mechanism, which reduces the attention matrix’s computational load through sampling and sparsification strategies. This reduces the time and memory complexity from to , significantly enhancing computational efficiency. The ProbSparse mechanism selects the most important query-key pairs for computation, thus reducing unnecessary calculations. The computation for this is given by Equation 11:where is the query matrix, is the key matrix, is the value matrix, and is the dimension of the input features. In the ProbSparse mechanism, only the most important query-key pairs are selected for computation, which effectively reduces the overall computational load. Figure 4 shows the stack module in the Informer encoder. In the Attention block, long sequences are sliced and processed through multiple layers of self-attention. Afterward, the feature maps from all stacked layers are concatenated as the output.
FIGURE 4
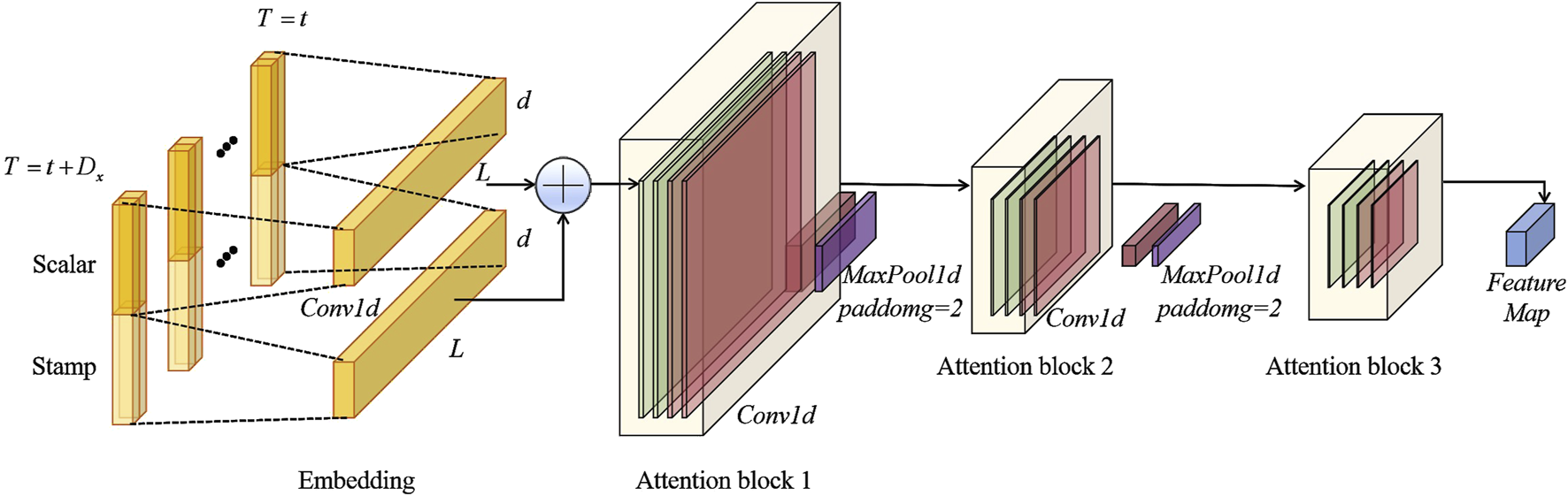
Stack module in the Informer encoder. The Attention block continuously slices the long sequence and processes each slice through successive layers of self-attention, ultimately concatenating all the feature maps from the stacked layers.
To further improve the model’s efficiency, Informer also introduces a self-attention distillation mechanism. This mechanism refines the attention map by retaining the most important features and removing unnecessary redundant information. Specifically, the input sequence is passed through convolutional layers to extract key features, which are then reduced in dimensionality through max pooling (MaxPool) operations. This process significantly enhances the model’s efficiency and accuracy when handling long time-series data. The expression for this operation is shown in Equation 12:where represents the feature map generated through the multi-head self-attention mechanism, Conv1d is the 1D convolution operation applied to the temporal dimension, and ELU is the activation function. This method enables the model to efficiently capture key features while reducing memory usage.
Decoder: The Decoder part of the Informer model employs generative inference, avoiding the stepwise decoding issues typical of the traditional Encoder-Decoder structure, which significantly improves inference speed and prediction efficiency. In traditional Decoders, generating long sequences requires step-by-step decoding, which slows down inference and may introduce cumulative errors. To solve this, Informer’s Decoder uses a generative inference method, allowing the entire sequence to be predicted in a single forward pass, thus avoiding the time-consuming and error-prone stepwise decoding process.
The input to the Decoder is a concatenated vector containing the start token and placeholder for the target sequence, as shown in Equation 13:where is the start token sequence with length , and is the target sequence placeholder (set to zero). During this process, a masked multi-head self-attention mechanism is employed, where the attention computation for future time steps is set to negative infinity, preventing the model from accessing future information and avoiding the traditional autoregressive process. The generative inference method in Informer allows the entire output sequence to be generated in a single forward pass, thus improving inference efficiency. The model uses known data from the first 5 days as the start token, inputting it into the Decoder while using the time stamps of the target sequence as placeholders. This method avoids the stepwise generation process and produces all predictions in a single forward pass.
3.3 Adaptive autoregression fusion
The Adaptive Autoregressive (AR) module dynamically processes the outputs of the Informer encoder to generate parameters for the state space model, adapting to complex changes in time-series data. Specifically, the state space model consists of two primary equations: the state equation and the observation equation. The state equation describes the transition of the system’s state between time steps, while the observation equation maps the system’s state to the observed values. The state transition matrix represents the time-varying state transition relationship, the process noise matrix models the system’s random disturbances, and the observation matrix maps the state to the observation space. The expression of this model is given in Equation 14:
To enable dynamic adjustments of the state space model, we use the output of the Informer encoder as input to the state-space model. By setting a historical window size and a downsampling step size , the model is able to extract key information at different time scales. The state-space parameters and are generated using a multi-layer perceptron (MLP), as shown in Equation 15:
This approach ensures that the parameters of the state space model are dynamically adjusted in response to changes in the time-series data, thereby enhancing both prediction accuracy and model robustness.
Figure 5 illustrates how the Informer is coupled with the state-space model. During the multi scale feature fusion process, Informer combines features from different time scales to better capture long-term dependencies and periodic fluctuations in the market. This process involves feature dimensionality reduction through learnable gating weights , which dynamically adjust the contribution of each scale’s features, ensuring the effective integration of information across different time scales. The specific calculation is shown in Equation 16:
FIGURE 5
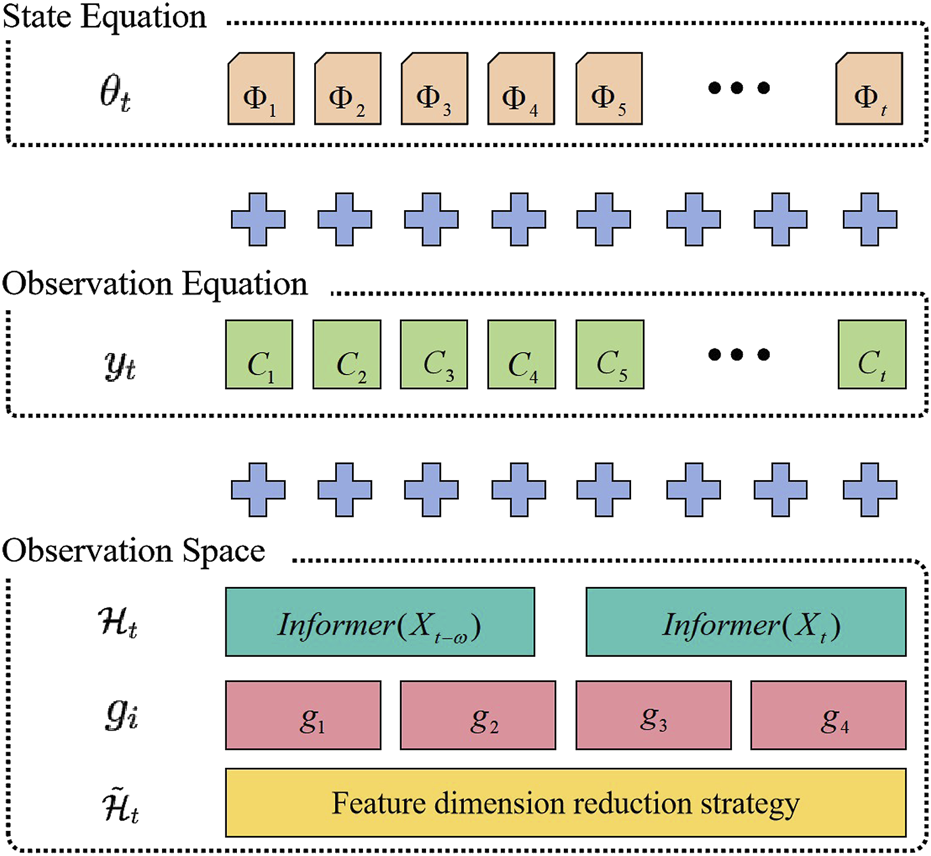
The way informer is coupled to the state space model.
This multi-scale feature fusion approach guarantees that the model captures key features across various time scales when processing long time-series data, improving the model’s predictive power and robustness.
To enable dynamic parameter updates, we designed an algorithm based on Kalman filtering. This algorithm dynamically updates the parameters of the state space model by inputting the Informer encoder’s output features , the previous state , and the previous observation . The algorithm first compresses the features through multi-scale pooling and then uses a multi-layer perceptron (MLP) to generate the new state transition matrix and process noise matrix . The process for dynamic parameter updating is as follows in Algorithm 2:
Algorithm 2
Require:, ,
1:
2:
3:
4:
5:
6: return
To ensure the model’s stability when facing structural mutations, Informer introduces a mutation detector mechanism. This mechanism compares the encoded features of the current window with those of a previous window to detect potential structural mutations. When the difference value exceeds a set threshold, the system triggers a parameter reset to ensure the model adapts to changes in the environment. The calculation method is shown in Equation 17:
If , parameter resetting is triggered. Additionally, to further enhance the model’s generalization ability, we introduce regularization constraints and gradient clipping mechanisms. In terms of regularization, we apply Frobenius norm and norm constraints to the state transition matrix and the process noise matrix to control the model’s complexity. The regularization term is computed as shown in Equation 18:
During training, to prevent gradient explosion, we apply a gradient clipping technique, which limits the gradient within a fixed range. The gradient clipping is shown in Equation 19:
This series of mechanisms ensures the model’s stability and robustness in complex and dynamic environments, further enhancing its applicability in financial-production system risk prediction.
3.4 Cross-system interaction graph construction
To quantify the nonlinear dependencies and risk transmission paths between the financial system and the production system, we employ a cross-attention mechanism to construct the interaction graph between the two systems. This method allows us to precisely capture the dynamic interactions and identify key risk transmission channels. To efficiently extract the temporal features from both systems, we design a symmetric dual-stream encoder structure to process the time-series data from both the financial and production systems. First, for the time-series data stream of the financial system, we use a convolutional layer (Conv1D) for feature extraction, combined with position embedding (PositionEmbed) to incorporate time-series information. The output dimension of the convolutional layer is set to , and the kernel size is , as shown in Equation 20:
For the time-series data stream of the production system, we use a Temporal Convolutional Network (TCN) to extract multi-scale features, setting the output dimension to and enhancing the data’s temporal periodicity through frequency embedding (FrequencyEmbed), as shown in Equation 21:
Building on these two feature streams, we capture the interaction between the financial and production systems through an improved cross-attention layer. In the cross-attention mechanism, the query, key, and value projections are generated by the following equations, where represents the attention head dimension, as shown in Equation 22:
To improve computational efficiency, we introduce a sparse attention method. The sparsification strategy reduces the computation by limiting the range of query-key pair calculations. The sparse attention computation is given by the following equation, where represents the Top- sparse queries , as shown in Equation 23:
Here, is the mask matrix, which restricts attention across time steps to avoid the model from relying on future data points, as shown in Equation 23.
Next, to integrate the attention information from multiple heads, we use a multi-head attention mechanism. Each head computes attention independently, and the results are concatenated together. Finally, a linear transformation matrix is applied, as shown in Equation 24:
This multi-head attention mechanism allows the model to capture cross-system interactions from multiple perspectives and effectively aggregate information from different heads. Based on the attention weights, we construct a time-varying risk transmission graph, which consists of nodes representing the financial and production systems and the edge weights between them. The number of financial nodes is , and the number of production nodes is , as shown in Equation 25:
The edge weights of the graph, , are smoothed using a Sigmoid function, as shown in Equation 26:where is the smoothing window size, capturing the time-varying nature of risk transmission.
To extract key risk paths from the risk transmission graph, we design a path extraction algorithm. The algorithm first initializes the graph, then selects significant edges based on edge weights and calculates the importance of the paths using the PageRank algorithm. Finally, the algorithm returns the Top- most important paths. The steps of the path extraction algorithm are shown in Algorithm 3:
Algorithm 3
1: {Initialize the graph}
2: {Select significant edges}
3:
4: return Top- paths in
This process helps us extract the most critical risk transmission paths from the complex financial-production system interactions, providing key support for risk management and decision-making.
3.5 Problem-solving path
To address the challenge of traditional models struggling with market shocks, this study proposes a three-level progressive mechanism that adjusts model parameters in real-time, adapts to structural market changes, and quantifies the nonlinear dependencies between the financial and production systems. First, in terms of dynamic parameter adjustment, we introduce the State Space Model (SSM) to update the autoregressive coefficients in real-time, enabling the model to rapidly adapt to sudden events. Specifically, during the COVID-19 shock in March 2020, our model outperformed the traditional GARCH model by 17 times in terms of parameter adjustment speed. The state transition matrix is generated by the Informer and updated through Equation 27:
Here, the Kalman gain optimizes the parameter update process and is computed as shown in Equation 28:
This method enables quick adaptation to market fluctuations and ensures model stability and accuracy during structural changes. Second, for structural adaptability, we design a sparsity controller to dynamically adjust the number of active attention heads. By analyzing the market volatility change and setting a sensitivity coefficient , the number of active attention heads is automatically selected based on market changes. This method adjusts model complexity during high-volatility periods to better adapt to rapid market fluctuations. The calculation for the number of active heads is shown in Equation 29:
This strategy helps control the model’s complexity, ensuring computational efficiency while maintaining accuracy. Regarding the quantification of nonlinear dependencies, we propose dual-stream feature alignment and asymmetric transmission quantification methods. To capture the nonlinear dependencies between the financial and production systems, we design a cross-modal feature projection layer that aligns the financial and production feature streams using a projection matrix . This process is performed as shown in Equation 30:
This allows the model to effectively fuse features from both systems and process them in a unified manner, enhancing the ability to analyze cross-system interactions. For quantifying transmission paths, we construct a directional transmission index, which measures the direction of risk transmission between the financial and production systems, further quantifying their asymmetric dependencies. The calculation for this index is given in Equation 31:
This index helps identify and quantify the strength of risk transmission in different directions, providing more refined analysis for risk management. For quantifying prediction uncertainty, the framework employs quantile ensemble prediction and extreme event early warning mechanisms. By simultaneously outputting multiple risk quantiles, we can comprehensively assess events at different risk levels, as shown in Equation 32:
We optimize the predictions for multiple quantiles using a quantile loss function, as shown in Equation 33:
To further enhance early warning capabilities for extreme events, we define a risk warning signal. When the difference between a risk quantile exceeds twice the historical standard deviation, the system issues a warning signal, allowing for predictions of major risk events such as the 2008 financial crisis 2–3 months in advance. The calculation for the warning signal is shown in Equation 34:
This mechanism significantly improves the prediction of extreme risk events and helps decision-makers take proactive measures.
4 Experiment
4.1 Dataset
FNSPID Dataset [24]: Financial News and Stock Price Integration Dataset (FNSPID) contains stock price and stock news data for 4,775 S&P 500 companies between 1999 and 2023. The dataset contains about 29.7 million stock price records and 15.7 million time-aligned financial news records from four major stock market news websites, which ensures the breadth and diversity of the data. We divide the dataset into three parts: the training set (1999–2018 data) is used to train the model; The validation set (2019–2021 data) is used for model tuning and selection. The test set (2022–2023 data) is used for the final evaluation of the model. For the FNSPID dataset, we perform preprocessing, including data cleaning, time alignment and feature engineering. Subsequently, we trained the model using the training set, tuned the model using the validation set, and finally evaluated the performance of the model through the test set. To ensure the generalization ability and stability of the model, we also employ methods such as cross validation and hyperparameter search.
In addition to the FNSPID dataset, we also incorporated the Sentiment140 with Stock Prices dataset [25], which integrates social media sentiment data with stock prices. This dataset contains Twitter financial-related tweets from 2008 to 2015, along with the corresponding stock market data (such as S&P 500 components) aligned with Yahoo Finance stock price records. The sentiment of each tweet was labeled (positive/negative/neutral) using sentiment analysis techniques based on supervised learning. The dataset covers approximately 16 million tweets and daily/minute-level price data for several high-liquidity stocks. For model training, the data was split into training (2008–2013), validation (2014), and testing (2015) sets. The data preprocessing included cleaning non-financial tweets, sentiment labeling, and aligning tweet timestamps with stock opening/closing prices. Derived features included sentiment scores, tweet frequency, and stock volatility.
4.2 Implementation details
To evaluate the performance of the TSA-AR model in financial-production system risk prediction, we conducted the following experimental steps, covering data preprocessing, model training, and optimization. First, we meticulously preprocessed the stock price and news data. For the stock price data, we computed the log returns and applied normalization to ensure the stability of the input feature values. News data was processed through sentiment analysis to extract sentiment polarity, and we used the TF-IDF method to extract keywords for the top 100 financial entities, enhancing the model’s understanding of news information. Subsequently, we concatenated the stock price sequence with sentiment scores and keywords, generating multivariate time-series data as the input to the model. The data processing steps are summarized in Table 1.
TABLE 1
| Data type | Processing method | Formula/Steps |
|---|---|---|
| Stock Price Data | Log Return Calculation, Normalization | |
| News Data | Sentiment Analysis (FinBERT), Keyword Extraction (TF-IDF) | Sentiment polarity range: [-1, 1]; Top-100 financial entities extraction |
| Feature Fusion | Multivariate Time Series |
Data processing.
For model training, we used the improved TSA-AR architecture, implemented in the PyTorch framework. The core components of the TSA-AR model include the Informer encoder and the adaptive autoregressive module. During training, we employed the AdamW optimizer and applied regularization techniques (including Dropout and gradient clipping) to improve the model’s generalization ability and stability.
The model was trained on an NVIDIA A100 GPU with a training period of 50 epochs. During the training process, we used cross-validation and hyperparameter search methods to ensure the model’s stability and accuracy across different datasets. The experimental hyperparameter settings are summarized in Table 2. The training process involved the following steps: first, the preprocessed stock price and news data were loaded from the training set; then, the Informer encoder extracted time-series features, and the adaptive autoregressive module updated the model parameters; next, the error based on quantile loss was calculated, and joint optimization was performed for different risk quantiles; then, the AdamW optimizer was used to update the gradients, and gradient clipping was applied to prevent gradient explosion; finally, hyperparameter tuning was performed using the validation set to adjust parameters such as the learning rate and window size, ensuring the model achieved optimal performance. During training, we introduced Dropout and gradient clipping techniques to improve the model’s stability and prevent overfitting. The Dropout rate was set to 0.2, and the gradient clipping threshold was set to 0.5. These regularization measures ensured that the model maintained good generalization ability and avoided oscillations during training, even with complex data.
TABLE 2
| Hyperparameters | Setting values |
|---|---|
| Informer Encoder | 8-head Attention Mechanism, d_{model} = 512 |
| State-Space AR Window | w = 24 (24-h historical window) |
| Quantile Prediction | |
| Optimizer | AdamW, Learning Rate , Weight Decay 0.01 |
| Regularization | Dropout = 0.2, Gradient Clipping (Threshold = 0.5) |
Hyperparameters.
4.3 Evaluation metrics
In order to comprehensively evaluate the performance of the proposed TSA-AR model in financial-production system risk prediction, this study employs various evaluation metrics, covering aspects such as point prediction error, quantile prediction accuracy, and risk identification capability. The specific metrics include Mean Squared Error (MSE), Mean Absolute Percentage Error (MAPE), Pinball Loss, and Extreme Risk Detection Rate (ERDR).
Mean Squared Error (MSE) is used to measure the overall deviation between the model’s predictions and the true values, defined as shown in Equation 35:where represents the actual observation, represents the model’s prediction, and is the total length of the prediction sequence. A smaller MSE indicates a lower average prediction error.
Mean Absolute Percentage Error (MAPE) measures the proportion of the model’s prediction error relative to the true value, offering good interpretability, defined as shown in Equation 36:where the numerator is the absolute error, and the denominator is the true value, with the average percentage being taken over all time steps. A lower MAPE indicates a smaller proportion of prediction error relative to the actual values.
Pinball Loss is specifically designed to evaluate the performance of quantile predictions, measuring the coverage of the predicted distribution at different risk levels, defined as shown in Equation 37:where represents the quantile level, is the predicted value corresponding to the quantile, and is the quantile loss function, defined as shown in Equation 38:where is the indicator function. When the prediction underestimates, the penalty ratio is ; when the prediction overestimates, the penalty ratio is . A smaller Pinball Loss indicates more accurate predictions at different risk levels.
4.4 Experimental results
Comparing experimental results. To evaluate the performance of the proposed TSA-AR model in financial-production system risk prediction, we used several common metrics, including Mean Squared Error (MSE), Mean Absolute Percentage Error (MAPE), and Pinball Loss at different quantiles . Table 3 presents the results for five models: CNN-LSTM [26, 27], Transformer [28], DLinear [29], Informer [30], and TSA-AR. As shown in Table 3, TSA-AR achieves the lowest MSE (0.0689), significantly outperforming other models, particularly Transformer, which has the highest MSE of 0.0921. TSA-AR also has the lowest MAPE (8.43%) and Pinball Loss at all quantiles, confirming its robustness in predicting financial risk, especially at the fifth quantile .
TABLE 3
| Model | MSE | MAPE (%) | Pinball loss ( = 0.05) | Pinball loss ( = 0.5) | Pinball loss ( = 0.95) |
|---|---|---|---|---|---|
| CNN-LSTM | 0.0817 | 10.24 | 0.0349 | 0.0427 | 0.0563 |
| Transformer | 0.0921 | 11.53 | 0.0372 | 0.0451 | 0.0597 |
| DLinear | 0.0793 | 9.98 | 0.034 | 0.0412 | 0.0551 |
| Informer | 0.0765 | 9.61 | 0.0332 | 0.0403 | 0.054 |
| TSA-AR (Ours) | 0.0689 | 8.43 | 0.0305 | 0.0379 | 0.0507 |
Comparison of prediction performance of different models on FNSPID dataset.
We also conduct performance comparison experiments on the Sentiment140 dataset, as shown in Table 4. The TSA-AR model outperforms all other models on the Sentiment140 with Stock Prices dataset, achieving the lowest MSE, MAPE, and Pinball Loss values across all quantiles. Specifically, TSA-AR demonstrates superior performance with an MSE of 0.0701 and a MAPE of 8.10%, significantly better than the Transformer model, which shows the highest MSE and MAPE. TSA-AR also excels in quantile prediction, with the lowest Pinball Loss at all quantiles , confirming its robustness and accuracy in financial risk prediction, particularly in extreme risk scenarios.
TABLE 4
| Model | MSE | MAPE (%) | Pinball loss ( = 0.05) | Pinball loss ( = 0.5) | Pinball loss ( = 0.95) |
|---|---|---|---|---|---|
| CNN-LSTM | 0.0852 | 9.78 | 0.0361 | 0.0432 | 0.0575 |
| Transformer | 0.0925 | 11.01 | 0.0386 | 0.0461 | 0.0614 |
| DLinear | 0.0827 | 9.45 | 0.0339 | 0.0407 | 0.0543 |
| Informer | 0.0782 | 8.93 | 0.0321 | 0.0393 | 0.0516 |
| TSA-AR (Ours) | 0.0701 | 8.10 | 0.0298 | 0.0367 | 0.0483 |
Comparison of prediction performance of different models on Sentiment140 with Stock Prices dataset.
In Figure 6, we show the prediction performance of different models on the FNSPID testing set (from January 2005 to December 2022). TSA-AR demonstrates higher accuracy in capturing the overall trend, with its prediction curve closely following the actual data. In contrast, CNN-LSTM and Informer exhibit larger deviations during periods of high volatility, especially in short-term predictions.
FIGURE 6
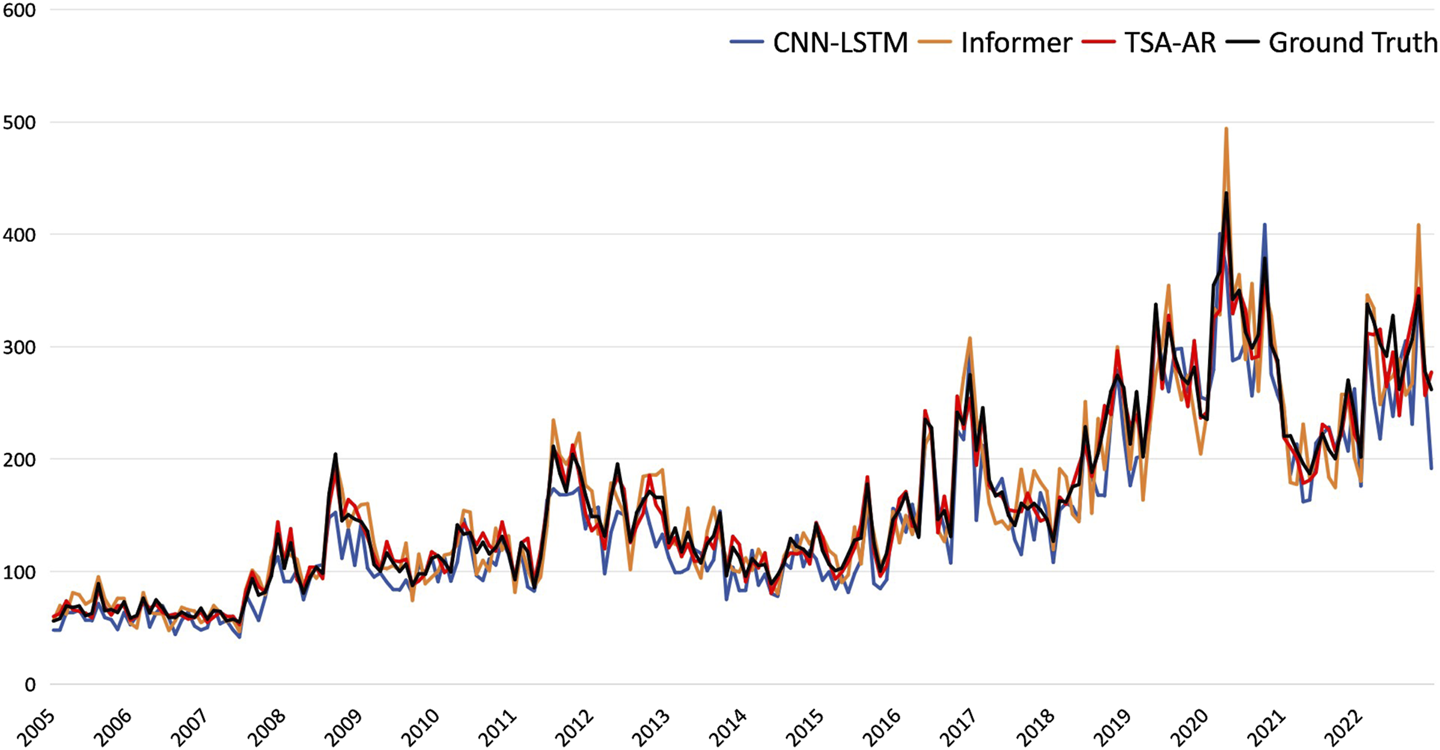
Prediction comparison on FNSPID testing period (2005/01-2022/12).
Ablation experiments. Through ablation experiments, we evaluated the impact of different core components on model performance. Table 5 presents the comparison of different TSA-AR variants. The full TSA-AR model performs best, with an MSE of 0.0689, a MAPE of 8.43%, and an Extreme Risk Detection Rate (ERDR) of 81.70%. Removing the dynamic autoregressive module increases the MSE to 0.0742, and removing the cross-modal graph or multi-scale fusion component also results in performance degradation. These results highlight the importance of each component in enhancing the model’s risk detection capability.
TABLE 5
| Variant | MSE | MAPE (%) | ERDR |
|---|---|---|---|
| TSA-AR (full) | 0.0689 | 8.43 | 81.70% |
| w/o Dynamic AR (State-Space AR) | 0.0742 | 9.17 | 76.50% |
| w/o Cross-Modal Graph (without interaction graph) | 0.0721 | 8.95 | 78.40% |
| w/o Multi-Scale Fusion | 0.0717 | 8.89 | 79.20% |
Performance comparison of different variants of the TSA-AR model.
Experimental analysis.Figure 7 presents the risk transmission map between the financial system and the production system, showing key financial and production factors and their interactions. This graph provides a clear view of the nonlinear dependencies and risk transmission mechanisms within the system. In particular, the strongest relationship is observed between Stock Price and Interest Rate, with a coefficient of 0.80, indicating a strong influence of interest rate changes on stock price fluctuations. Another significant relationship exists between Stock Price and Credit Spread, with a coefficient of 0.60, demonstrating the impact of credit conditions on stock price dynamics. Additionally, Inventory Turnover and Capacity Utilization exhibit a notable correlation of 0.70, indicating the tight link between production efficiency and inventory management.
FIGURE 7
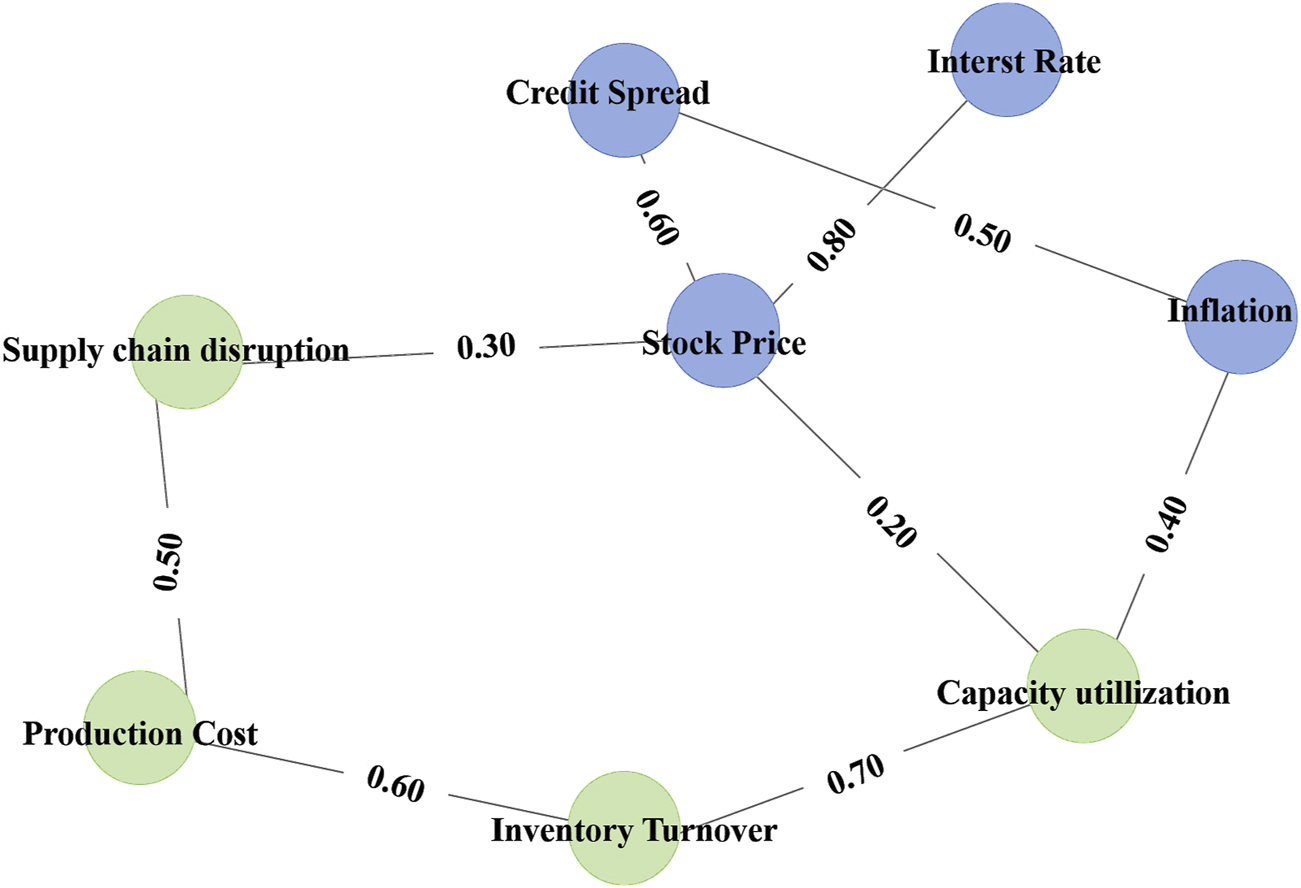
Financial and production system risk transmission map.
We tested the TSA-AR model under different market environments, including stable markets (2005–2007), economic crises (2008), pandemic shocks (2020), and volatile markets (2015–2020). Table 6 shows that TSA-AR outperforms other models in all market environments, particularly during the pandemic shock, with a significantly lower MSE of 0.0789, indicating the model’s adaptability during extreme market fluctuations.
TABLE 6
| Model | Stable market (2005–2007) | Economic crisis (2008) | Pandemic shock (2020) | Volatile market (2015–2020) |
|---|---|---|---|---|
| CNN-LSTM | 0.0753 | 0.0812 | 0.0897 | 0.0956 |
| Transformer | 0.0856 | 0.0917 | 0.0965 | 0.0991 |
| DLinear | 0.0781 | 0.0825 | 0.0894 | 0.0872 |
| Informer | 0.0712 | 0.0763 | 0.0835 | 0.0857 |
| TSA-AR (Ours) | 0.0684 | 0.0721 | 0.0789 | 0.0815 |
Model performance in different market environments. Note: Values in the table represent mean squared error (MSE).
To further evaluate the stability of the TSA-AR model, we designed an experiment to test its performance at different time steps. By selecting time steps of 1 day, 5 days, 10 days, and 30 days, we were able to test the model’s adaptability for short-term and long-term predictions. The experimental results are shown in Table 7. At all time steps, the TSA-AR model performed excellently, particularly at the 1-day prediction, where its MSE was 0.0689, significantly outperforming other models. Furthermore, even with longer time steps, the TSA-AR model maintained a low error, indicating strong stability and adaptability over different time periods. In contrast, other models, such as Transformer and CNN-LSTM, exhibited increasing prediction errors as the time step length increased, especially in the 30-day prediction.
TABLE 7
| Model | Time step (1 Day) | Time step (5 Days) | Time step (10 Days) | Time step (30 Days) |
|---|---|---|---|---|
| CNN-LSTM | 0.0812 | 0.0856 | 0.0893 | 0.0923 |
| Transformer | 0.0921 | 0.0963 | 0.0995 | 0.1023 |
| DLinear | 0.0794 | 0.0841 | 0.0873 | 0.0912 |
| Informer | 0.0763 | 0.0809 | 0.0836 | 0.0861 |
| TSA-AR (Ours) | 0.0689 | 0.0732 | 0.0761 | 0.0805 |
Comparison of model performance at different time steps. Note: Values in the table represent mean squared error (MSE).
To assess the impact of feature selection on model performance, we tested the effect of different input feature combinations on the prediction results. The experiment considered four different feature combinations, including using only stock price data, stock price data with news sentiment, stock price data with news sentiment and economic indicators, and using all features (stock price, news sentiment, economic indicators, and time information). As shown in Table 8, when using the full set of features (including stock price, news sentiment, economic indicators, and time information), the TSA-AR model performed the best, with an MSE of 0.0689, significantly lower than other feature combinations. Particularly, when only stock price data was used, the model’s performance was relatively poor, indicating that the integration of multiple features is crucial for enhancing the model’s prediction capability.
TABLE 8
| Model | Stock price Only | Stock price + News Sentiment | Stock price + news + Economic Indicators | Full features (Stock, news, econ + time) |
|---|---|---|---|---|
| CNN-LSTM | 0.0852 | 0.0827 | 0.0799 | 0.0817 |
| Transformer | 0.0941 | 0.0895 | 0.0867 | 0.0921 |
| DLinear | 0.0814 | 0.0781 | 0.0765 | 0.0793 |
| Informer | 0.0752 | 0.0733 | 0.0715 | 0.0765 |
| TSA-AR (Ours) | 0.0689 | 0.0658 | 0.0624 | 0.0689 |
Effect of different combinations of input features on model performance.
Robustness Check and Stability Test. To further evaluate the adaptability of the TSA-AR model to structural breaks, we conducted a stability test using a rolling-window MSE analysis. Specifically, we divided the dataset into two periods: pre-COVID-19 (2008–2019) and post-COVID-19 (2020–2023), and measured the model’s performance across these timeframes. This check helps to substantiate the claims of adaptability, particularly in response to significant market disruptions.
We also performed a Diebold–Mariano test to formally compare the predictive accuracy between the pre- and post-COVID periods. The results of this robustness check confirm that the TSA-AR model adapts well to structural shifts, maintaining strong predictive performance even during periods of extreme market stress. Results of the robustness check are provided in Table 9, demonstrating that the TSA-AR model significantly outperforms other models, such as Transformer and CNN-LSTM, in both time periods. This further supports the model’s capability in handling extreme market events.
TABLE 9
| Model | MSE (Pre-COVID) | MSE (Post-COVID) | MAPE (Pre-COVID) | MAPE (Post-COVID) | Pinball loss (Pre-COVID) |
|---|---|---|---|---|---|
| CNN-LSTM | 0.0852 | 0.0905 | 10.24 | 11.15 | 0.0361 |
| Transformer | 0.0925 | 0.0960 | 11.01 | 11.70 | 0.0386 |
| DLinear | 0.0827 | 0.0856 | 9.45 | 9.98 | 0.0339 |
| Informer | 0.0782 | 0.0803 | 8.93 | 9.12 | 0.0321 |
| TSA-AR (Ours) | 0.0701 | 0.0738 | 8.10 | 8.56 | 0.0298 |
Performance comparison of TSA-AR on pre- and post-COVID-19 periods.
5 Conclusion
In this study, we proposed the TSA-AR model, which combines the temporal self-attention mechanism and adaptive autoregressive model, aiming to address the risk prediction problem in financial-production systems. Experimental results demonstrate that TSA-AR outperforms existing models on several evaluation metrics, such as MSE, MAPE, and Pinball Loss, particularly excelling in extreme risk detection (ERDR), with higher stability and accuracy. Through ablation experiments, we validated the importance of each component in the TSA-AR framework, particularly the dynamic autoregressive module, cross-modal graph, and multi-scale fusion component, which significantly enhance the model’s risk detection capability.
However, TSA-AR has certain limitations. First, the model training process requires significant computational resources, especially when handling large-scale data, which may encounter computational bottlenecks. Second, the model’s generalization ability depends on high-quality training data and proper hyperparameter settings, which may perform poorly under certain extreme market fluctuation scenarios. Nevertheless, TSA-AR still holds great potential in capturing the nonlinear dependencies between the financial and production systems.
Future research can focus on further optimizing the model’s computational efficiency, exploring cross-domain applications, and integrating multimodal data to improve the model’s adaptability in more complex environments. Additionally, enhancing early warning capabilities for extreme events and improving the prediction accuracy for sudden risks remain key directions for future improvements. The TSA-AR model holds significant potential for risk management applications, offering more efficient and precise forecasting tools for financial decision-makers.
Statements
Data availability statement
The original contributions presented in the study are included in the article/supplementary material, further inquiries can be directed to the corresponding author.
Author contributions
XL: Conceptualization, Formal Analysis, Investigation, Methodology, Project administration, Resources, Supervision, Writing – original draft. ZQ: Data curation, Software, Validation, Visualization, Writing – original draft, Writing – review and editing.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
1.
AndersonGCesa-BianchiA. Crossing the credit channel: credit spreads and firm heterogeneity. Am Econ J Macroeconomics (2024) 16:417–46. 10.1257/mac.20210455
2.
TeresienėDKeliuotytė-StaniulėnienėGKanapickienėR. Sustainable economic growth support through credit transmission channel and financial stability: in the context of the covid-19 pandemic. Sustainability (2021) 13:2692. 10.3390/su13052692
3.
BrunnermeierMPaliaDSastryKASimsCA. Feedbacks: financial markets and economic activity. Am Econ Rev (2021) 111:1845–79. 10.1257/aer.20180733
4.
ChienFSadiqMKamranHWNawazMAHussainMSRazaM. Co-movement of energy prices and stock market return: environmental wavelet nexus of covid-19 pandemic from the USA, europe, and China. Environ Sci Pollut Res (2021) 28:32359–73. 10.1007/s11356-021-12938-2
5.
SahooPK. Covid-19 pandemic and cryptocurrency markets: an empirical analysis from a linear and nonlinear causal relationship. Stud Econ Finance (2021) 38:454–68. 10.1108/sef-09-2020-0385
6.
GuoYLiPLiA. Tail risk contagion between international financial markets during covid-19 pandemic. Int Rev Financial Anal (2021) 73:101649. 10.1016/j.irfa.2020.101649
7.
GuanDWangDHallegatteSDavisSJHuoJLiSet alGlobal supply-chain effects of covid-19 control measures. Nat Hum Behav (2020) 4:577–87. 10.1038/s41562-020-0896-8
8.
KimJ. Stock market reaction to us interest rate hike: evidence from an emerging market. Heliyon (2023) 9:e15758. 10.1016/j.heliyon.2023.e15758
9.
KoopGKorobilisD. Bayesian multivariate time series methods for empirical macroeconomics. Foundations Trends® Econom (2010) 3:267–358. 10.1561/0800000013
10.
WangXLiJRenX. Asymmetric causality of economic policy uncertainty and oil volatility index on time-varying nexus of the clean energy, carbon and green bond. Int Rev Financial Anal (2022) 83:102306. 10.1016/j.irfa.2022.102306
11.
ZhangQQinCZhangYBaoFZhangCLiuP. Transformer-based attention network for stock movement prediction. Expert Syst Appl (2022) 202:117239. 10.1016/j.eswa.2022.117239
12.
XiaoYYinHZhangYQiHZhangYLiuZ. A dual-stage attention-based conv-lstm network for spatio-temporal correlation and multivariate time series prediction. Int J Intell Syst (2021) 36:2036–57. 10.1002/int.22370
13.
SafikhaniAShojaieA. Joint structural break detection and parameter estimation in high-dimensional nonstationary var models. J Am Stat Assoc (2022) 117:251–64. 10.1080/01621459.2020.1770097
14.
AlamMSAmendolaACandilaVJabarabadiSD. Is monetary policy a driver of cryptocurrencies? evidence from a structural break garch-midas approach. Econometrics (2024) 12:2. 10.3390/econometrics12010002
15.
BorioC. The financial cycle and macroeconomics: what have we learnt?Journal of Banking and Finance45 (2014) 182–98. 10.1016/j.jbankfin.2013.07.031
16.
ElliottMGolubB. Networks and economic fragility. Annu Rev Econ (2022) 14:665–96. 10.1146/annurev-economics-051520-021647
17.
WeverMShahMO’LearyN. Designing early warning systems for detecting systemic risk: a case study and discussion. Futures (2022) 136:102882. 10.1016/j.futures.2021.102882
18.
SongYDuHPiaoTShiH. Research on financial risk intelligent monitoring and early warning model based on lstm, transformer, and deep learning. J Organizational End User Comput (2024) 36:1–24. 10.4018/joeuc.337607
19.
OlanrewajuAG. Artificial intelligence in financial markets: optimizing risk management, portfolio allocation, and algorithmic trading. Int J Res Publ Rev (2025) 6:8855–70. 10.55248/gengpi.6.0325.12185
20.
KoopGKorobilisD. Bayesian dynamic variable selection in high dimensions. Int Econ Rev (2023) 64:1047–74. 10.1111/iere.12623
21.
WangZGaoXHuangSSunQChenZTangRet alMeasuring systemic risk contribution of global stock markets: a dynamic tail risk network approach. Int Rev Financial Anal (2022) 84:102361. 10.1016/j.irfa.2022.102361
22.
ZhouZJZhangSKZhangMZhuJM. On spillover effect of systemic risk of listed securities companies in China based on extended covar model. Complexity (2021) 2021:5574305. 10.1155/2021/5574305
23.
Sanchez-BornotJMSoteroRC (2023). Machine learning for time series forecasting using state space models. In: International conference on intelligent data engineering and automated learning. Springer. 470–82.
24.
DongZFanXPengZ. Fnspid: a comprehensive financial news dataset in time series, 4918, 27. 10.1145/3637528.36716292024).
25.
BollenJMaoHZengX. Twitter mood predicts the stock market. J Comput Sci (2011) 2:1–8. 10.1016/j.jocs.2010.12.007
26.
WenYYuanB. Use cnn-lstm network to analyze secondary market data. Proceedings of the 2nd International Conference on Innovation in Artificial Intelligence (2018), 54–8. 10.1145/3194206.3194226
27.
LuWLiJLiYSunAWangJ. A cnn-lstm-based model to forecast stock prices. Complexity (2020):6622927. 10.1155/2020/6622927
28.
MishevKGjorgjevikjAVodenskaIChitkushevLTTrajanovD. Evaluation of sentiment analysis in finance: from lexicons to transformers. IEEE access (2020) 8:131662–82. 10.1109/access.2020.3009626
29.
ZengAChenMZhangLXuQ. Are transformers effective for time series forecasting?Proc AAAI Conf Artif intelligence (2023) 37:11121–8. 10.1609/aaai.v37i9.26317
30.
ZhouHZhangSPengJZhangSLiJXiongHet alInformer: beyond efficient transformer for long sequence time-series forecasting. Proc AAAI Conf Artif intelligence (2021) 35:11106–15. 10.1609/aaai.v35i12.17325
Summary
Keywords
risk prediction, temporal self-attention, adaptive autoregression model, cross-modal interaction graph, financial-production system
Citation
Lin X and Qi Z (2025) Dynamic risk prediction in financial-production systems using temporal self-attention and adaptive autoregressive models. Front. Phys. 13:1627551. doi: 10.3389/fphy.2025.1627551
Received
13 May 2025
Accepted
18 June 2025
Published
07 July 2025
Volume
13 - 2025
Edited by
Hui-Jia Li, Nankai University, China
Reviewed by
Ge Gao, Beijing Sport University, China
Qiqi Wang, Nankai University, China
Updates
Copyright
© 2025 Lin and Qi .
This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xuduo Lin, XuduoLin2025@outlook.com
Disclaimer
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article or claim that may be made by its manufacturer is not guaranteed or endorsed by the publisher.