




- 1 Department of Psychology, Erasmus University Rotterdam, Rotterdam, Netherlands
- 2 Department of Psychology, Leiden University, Leiden, Netherlands
- 3 Department of Psychology, University of California, San Diego, CA, USA
We report an experiment that compared two explanations for the effect of congruency between a word’s on screen spatial position and its meaning. On one account, congruency is explained by the match between position and a mental simulation of meaning. Alternatively, congruency is explained by the polarity alignment principle. To distinguish between these accounts we presented the same object names (e.g., shark, helicopter) in a sky decision task or an ocean decision task, such that response polarity and typical location were disentangled. Sky decision responses were faster to words at the top of the screen compared to words at the bottom of the screen, but the reverse was found for ocean decision responses. These results are problematic for the polarity principle, and support the claim that spatial attention is directed by mental simulation of the task-relevant conceptual dimension.
Introduction
Previous studies found interactions between the meaning of words and the screen location where the words were presented (i.e., spatial position). For instance, people were faster to decide that a stork flies if the word stork was presented at the top of the screen rather than at the bottom of the screen (Šetić and Domijan, 2007). Similar effects were found in a semantic relatedness judgment task (Zwaan and Yaxley, 2003) and also in a letter identification task in which participants identified a single letter (X or O) presented at the top or bottom of the screen immediately following the name of an object with a typical location (e.g., cowboy boot, Estes et al., 2008). Researchers also found interactions between word meaning and spatial position when words refer to more abstract concepts, such as valence or power (Richardson et al., 2003; Meier and Robinson, 2004; Schnall and Clore, 2004; Schubert, 2005; Meier et al., 2007; Zanolie et al., submitted; but see Bergen et al., 2007). Although these abstract concepts have no inherent perceptual spatial positions, they are connected to spatial concepts through metaphorical relations such as good is up and bad is down. These interactions between word meaning and spatial location provide important insight into the underlying mental representations of meaning.
This paper compares two explanations for the interaction between word meaning and spatial position. The first explanation is that readers understand the meaning of a category by mentally simulating associated sensory-motor information (e.g., Barsalou, 1999). Thus, a representation of the meaning of flying animal involves simulating looking up at the sky and seeing the animal fly. Because such simulations occupy sensory-motor systems, they might interfere with other sensory-motor processing. Indeed, interference was found when people simultaneously performed mental visual imagery and a visual perception task (Craver Lemley and Reeves, 1992). Estes et al. (2008) showed a similar interference effect without explicit imagery instructions. In their task, participants viewed word pairs in the center of the screen that referred to objects with typical vertical locations (cowboy hat or cowboy boot). Immediately after presentation of the word pair, a target letter appeared at the top or the bottom of the screen. The participant’s task was to identify the letter as quickly as possible. Estes et al. found that letter identification was slower and less accurate if the letter’s position matched the typical location of the word’s referent than if the position mismatched. They did not report the separate effects for items at the top and bottom positions. Similar results were found by Richardson et al. (2003; see also Bergen et al., 2007). They presented sentences in which a verb had a horizontal (push) or vertical (sink) orientation, followed by a visual target. The target could appear at one of four locations on the computer screen; at the top or bottom (horizontally centered), or on the left or right (vertically centered). They found that the orientation of the verb interfered with the position of the visual target. For example, following the vertical word sink, responses to targets presented on the vertical axis (top or bottom) were slower than to targets presented on the horizontal axis (left or right).
Other studies, using somewhat different designs, found facilitation if word meaning and spatial location were congruent. Bergen et al. (2007) noted that findings of interference or facilitation might be due to differences in timing, but both effects are still explained by the same simulation account. For example, Šetić and Domijan (2007) presented words referring to flying or non-flying animals at the top or bottom of the computer screen. Participants decided whether the word referred to a flying or non-flying animal. Decisions were faster and more accurate for words in a congruent than incongruent position (e.g., performance was better for stork at the top than at the bottom of the screen). This may be due to a congruency between word meaning and position.
Additionally, the task itself – deciding whether or not animals fly – might have directed spatial attention. In order to perform the flying animal task, participants may have systematically directed their mental simulations, and thus their spatial attention, towards the sky. Although Šetić and Domijan (2007) did not find a main effect of position, other studies show such main effects (e.g., Schubert, 2005). On this account, there may be both a general task-related benefit for words presented at the top of the screen (through spatial attention) as well as a word specific benefit for flying animals presented at the top of the screen (because the mental simulation would be easier for a word in this position). Therefore, in the current study, we tested both task congruency (e.g., benefits for all words at the top) as well as word congruency (e.g., additional benefits for flying animals at the top).
A second explanation for these congruency effects lies in the response selection process rather than the representation of meaning. Proctor and Cho (2006; see also Bar-Anan et al., 2007) proposed that in many binary decision tasks, the speed of response selection is affected by polarity correspondence. Stimulus dimensions with binary values are encoded as having a + (plus) polarity or − (minus) polarity. In a similar vein, response alternatives are also encoded as + or −. Response selection is faster when stimulus and response polarities correspond than when they do not correspond. According to Proctor and Cho, the polarity coding of dimensions and responses is not entirely random. Certain dimensions are always coded in the same way. For example, a “yes” response is typically represented as + and a “no” response is represented as −. Up is represented as + and down is represented as −. Right is represented as + and left is represented as −. Accordingly, right key presses are coded as + and left key presses are coded as −.
Related to this idea, Klatzky et al. (1973) argued that many conceptual dimensions (e.g., height, valence) also have polarity. Furthermore, the adjectives representing the opposite ends of these dimensions consist of a default, positive, or unmarked member (e.g., tall, good) that can also be used to name the dimension in its entirety and a negative, or marked member (e.g., short, bad) that is only used to name one end of the dimension. For example, the question How tall is he? is neutral as to actual size, whereas the question How short is he? suggests that the person is unusually short. Such markedness may play a role in binary decision tasks as well. For example, in judgments of power, powerful may be the unmarked (positive) end and powerless may be the marked (negative) end of the power dimension. Alignment of powerful with up therefore leads to faster processing than alignment of powerful with down (Schubert, 2005). Polarity correspondence can also explain similar results that examined spatial congruency with concepts such as valence or number magnitude (Fischer et al., 2003; Meier and Robinson, 2004; Santens and Gevers, 2008; Bae et al., 2009; but see Chiou et al., 2009).
These polarity correspondences might also explain the results of Šetić and Domijan (2007). In their task, the flying animals always required a “yes” response and the non-flying animals always required a “no” response. Therefore, in the congruent condition, the polarities of position and response (up-yes and down-no) were aligned, whereas they were misaligned in the incongruent condition (up-no and down-yes). On this account, the results are due to a lack of counterbalancing between the yes/no answer and spatial position. After all, there was no condition in which the task was reversed, such that non-flying animals required a yes-response (e.g., by asking is this a land animal?).
In sum, stimuli in a task may have polarity values based on markedness, on task-specific judgment (“yes” or “no”), and on spatial position (up or down). In addition, responses also have polarity values, for example based on the spatial position of the manual responses. Thus, rather than supporting a theory of meaning representation through mental simulation, these congruency effects may instead reflect polarity alignment if the role of yes/no response assignment is not counterbalanced or not independently manipulated.
To investigate whether the effects of spatial position of a target stimulus are better explained by polarity alignment or by congruence with mental representations, we used two semantic judgment tasks for which the same stimuli required opposite responses. One task was an ocean judgment (Is it usually found in the ocean?) and the other task was a sky judgment (Is it usually found in the sky?). These tasks were chosen because sky and ocean have clear spatial positions but neither one is a linguistically marked or unmarked end of a dimension. While most people will have more experience with looking at things in the sky than in the ocean, our study was run in San Diego, which is situated on the Pacific coast. Therefore, the participants in our study had above average experience with looking at the ocean. Because perceptual simulation involves activation of previous perceptual experiences we assumed that simulations of seeing things in the sky and ocean would most likely take the perspective of someone standing on land looking straight ahead, with the sky taking up the top half of visual field and the ocean taking up the bottom half of the visual field. The same set of stimuli was used in the two tasks, and consisted of names of things that are typically found in one of the two locations (e.g., whale, submarine, eagle, helicopter). Each word was presented at the top or bottom of the screen. Subjects responded using their two hands, and whether the “yes” response was given by the left or right hand was counterbalanced across participants.
The role of conceptual congruency and polarity alignment can be disentangled by a between task comparison of the interaction between word category and stimulus position. If spatial congruency effects are due to mental simulation, then spatial attention should be directed towards the top of the screen in the sky decision task but towards the bottom of the screen in the ocean decision task. This predicts that in general, reaction times to words at the top of the screen should be faster in the sky task whereas reaction times to words at the bottom of the screen should be faster in the ocean task. Beyond this task congruency effect, the mental simulation account also predicts a word congruency effect. For this effect of congruency between a referent’s typical location and the position of the word, performance should be better for sky words presented at the top of the screen as compared to sky words presented at the bottom of the screen. Similarly, performance should be better for ocean words presented at the bottom of the screen as compared to ocean words presented at the top of the screen. Critically, these effects should occur regardless of the task (i.e., regardless of the yes/no response).
If, on the other hand, congruency effects are due to polarity alignment, performance should be better for “yes” responses to words presented at the top of the screen as compared to “yes” responses to words presented at the bottom of the screen. Furthermore, performance should be better for “no” responses to words presented at the bottom of the screen as compared to “no” responses to words presented at the top of the screen. Critically, these effects should occur regardless of the typical location (ocean or sky) of the word’s referent (i.e., regardless of the word’s meaning). Thus, in the ocean decision task, performance should be better for ocean words at the top and sky words at the bottom than for the opposite positions. Moreover, because the right hand is coded as + polarity and the left hand as − polarity (according to Proctor and Cho, 2006) this effect may be restricted or at least most pronounced when “yes” responses are given with the right hand and “no” responses are given with the left hand.
In summary, the mental simulation account predicts both task congruency effects (task and location) and word congruency effects (word and location), whereas polarity alignment only predicts response congruency effects (response and location).
Materials and Methods
Participants
One hundred and two UCSD students participated for course credit. They were randomly assigned to the ocean decision (n = 52) or sky decision task (n = 50).
Stimuli
A set of 80 words was created. Forty words referred to things usually found in the ocean (e.g., whale, submarine) and 40 referred to things usually found in the sky (e.g., eagle, helicopter). The complete set of stimuli is given in the Appendix. The stimuli were selected from a larger set that had been tested in a pilot study. In this pilot study 50 participants made ocean or sky decisions (25 participants in each task) to a larger set of words presented individually in random order in the center of the computer screen. From this larger set, 80 words were selected for which categorization agreement between participants was greater than 75% (M = 92%). The two sets of words were comparable on word length, log word frequency, and number of items from different types of taxonomic categories (e.g., animals, man-made objects, natural objects, persons).
Procedure
Participants in the ocean decision task were instructed to decide whether an item could be found in the ocean. Participants in the sky decision task were instructed to decide whether an item could be found in the sky. Items were presented individually and in random order on the computer screen following the procedure used by Šetić and Domijan (2007). A trial started with a sequence of three consecutive fixation cues (“+ + +”) presented for 300 ms each, which served to warn participants whether the target word would appear at the top or bottom. The first fixation was presented in the center of the computer screen. In the top condition, the second fixation was presented at 40% from the top of the screen, the third at 30% from the top of the screen, followed by the target word at 20% from the top of the screen. In the bottom condition these positions were at 40%, 30%, and 20% from the bottom of the screen respectively. This sequence of fixations cues did not induce a sense of upwards or downwards motion because the vertical distance between fixations was too great (i.e., there was no apparent motion). The target word was presented immediately after the final fixation cue and remained on the screen until the participant responded or 2,500 ms elapsed. Participants pressed the z or m key of the computer keyboard to indicate a “yes” or “no” response. Feedback was provided for 1,500 ms if the response was incorrect (“INCORRECT”) or slower than 2,500 ms (“TOO SLOW”). The next trial started immediately after the response or, in the case of feedback, after the feedback message. Every target word was tested twice, with the first occurrence during a first block of trials followed by a second occurrence during a second block of trials. Half of the items in a block were assigned to the top position and the other half to the bottom position such that ocean words and sky words were presented equally often at each position. In the second block, the screen position for each word was reversed. Within blocks, the items were presented in random order. The two blocks were presented without interruption. The order of blocks was counterbalanced between participants, as was assignment of the m and z keys to the “yes” and “no” responses.
Results
Correct reaction times were trimmed by removing reaction times that were more than three standard deviations from the participant’s mean for the corresponding response (2.04% of the correct RTs). As block did not interact with any other variable, we collapsed the data across blocks. The mean reaction times are presented in Table 1 and the error rates are presented in Table 2. Figures 1 and 2 show the RT data and error rates collapsed across instruction. Separate ANOVAs (Task × Category × Instruction × Positio) were performed on the RTs and error rates. The results of these analyses are reported in Tables 3 and 4. The factors Task (ocean vs. sky decision) and Instruction (yes-is-right vs. yes-is-left) were between-subject factors, while Category (ocean vs. sky word) and Position (up vs. down) were within-subject factors.
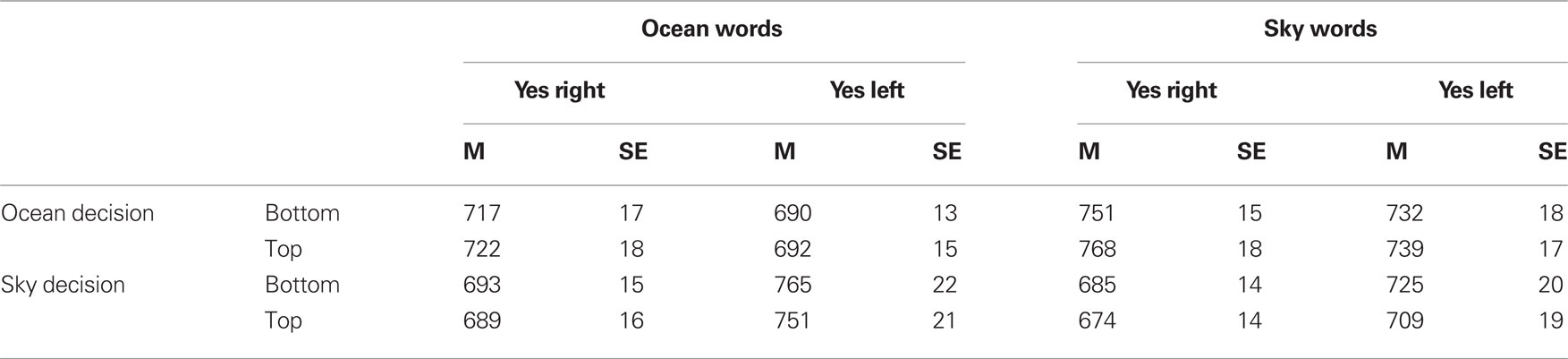
Table 1. Mean reaction times and standard errors in the two semantic decision tasks as a function of word position, word category, and response instruction.
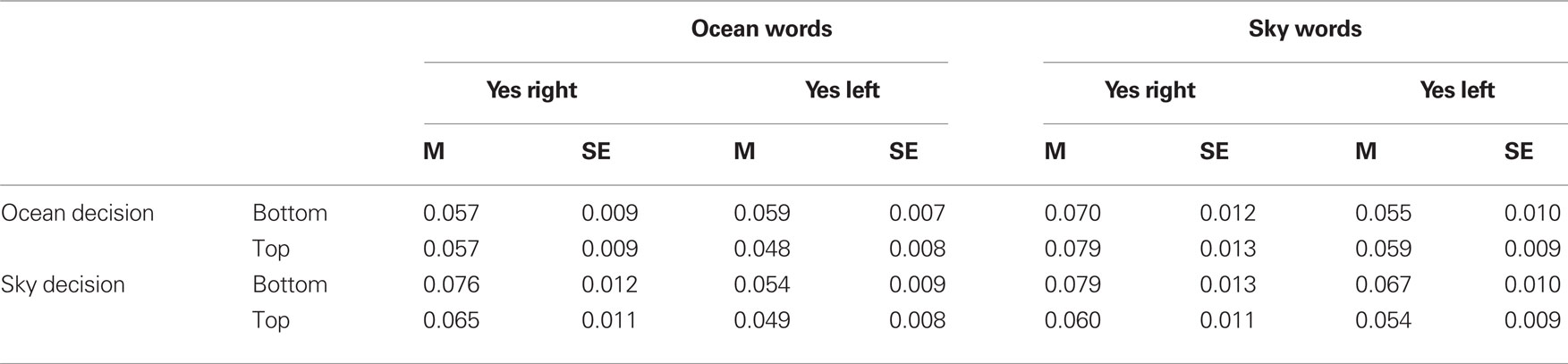
Table 2. Mean error scores and standard errors in the two semantic decision tasks as a function of word position, word category, and response instruction.
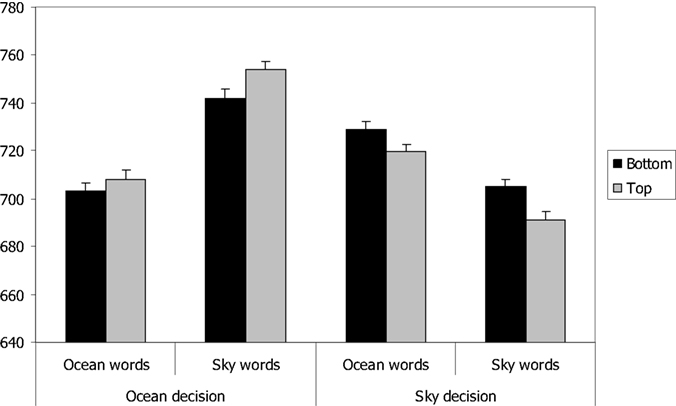
Figure 1. Mean reaction times in the two semantic decision tasks as a function of word category and word position. Error bars represent confidence intervals for the word category × position within-subjects interaction (Loftus and Masson, 1994).
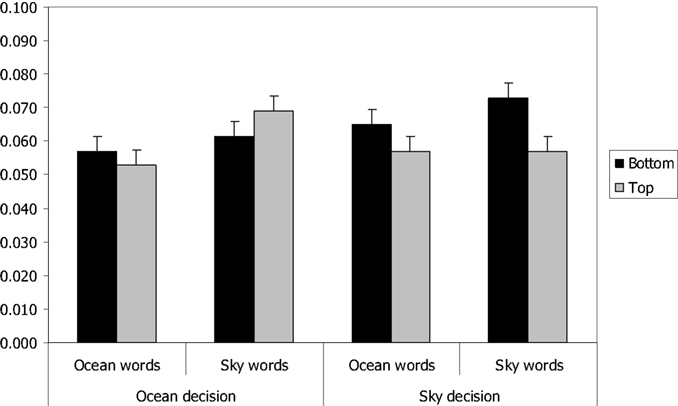
Figure 2. Mean error rates in the two semantic decision tasks as a function of word category and word position. Error bars represent confidence intervals for the word category × position within-subjects interaction (Loftus and Masson, 1994).
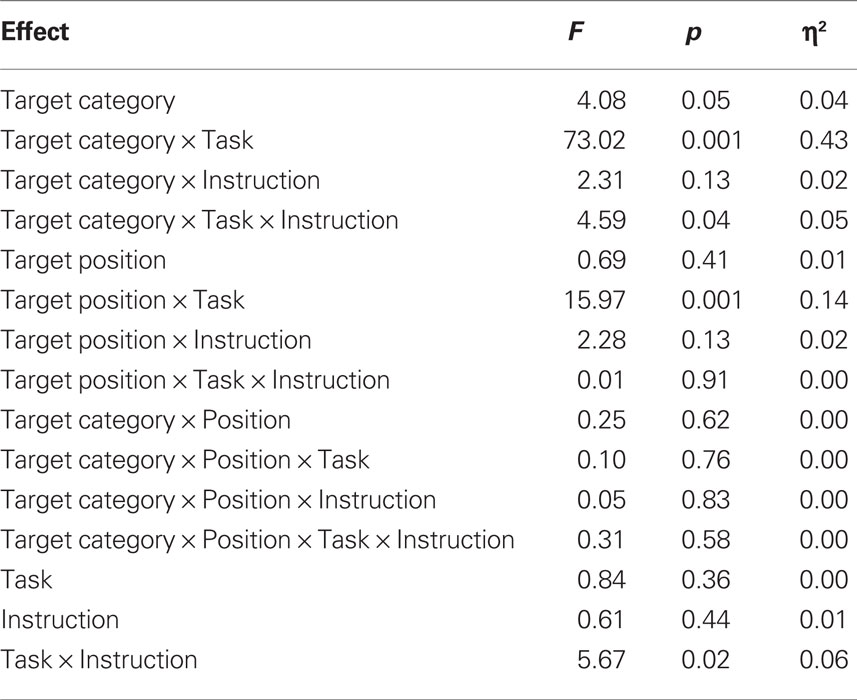
Table 3. Complete ANOVA results for reaction times.
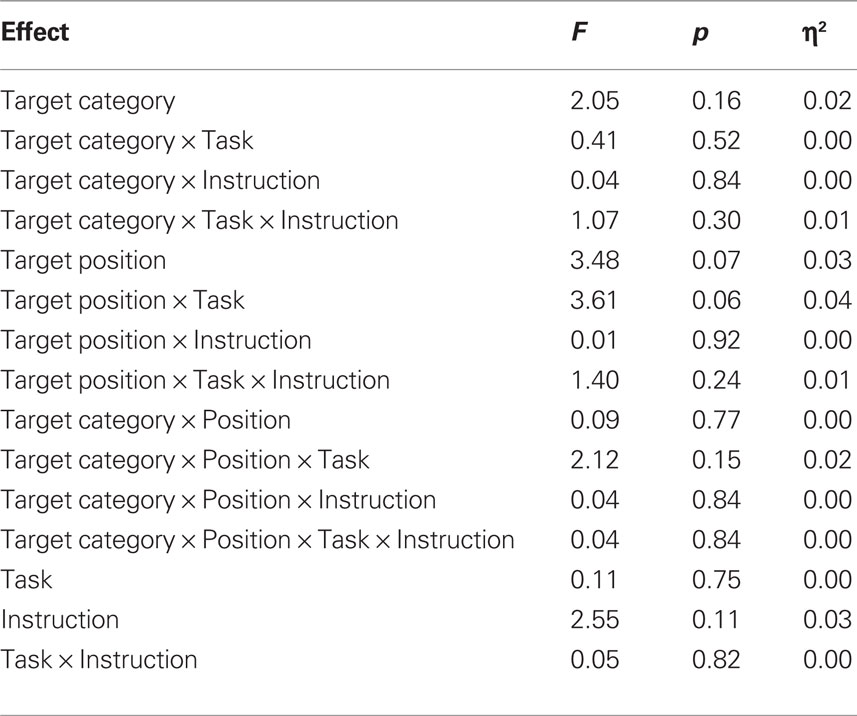
Table 4. Complete ANOVA results for error rate.
Next, we report all significant results of both the RT and error rate ANOVAs. We do so in an intermixed fashion, such that for a given effect, both the RT and error rate results are simultaneously reported (if both were significant). In this manner, it can be ascertained whether speed and accuracy traded off against each other (e.g., RT and error rate changing in opposite directions), or whether there was general performance change (e.g., just an RT effect, just an error rate effect, or situations where RT and accuracy went in the same direction).
The polarity principle predicted an interaction between task, category, and position. This is because the combination of task and category defines whether “yes” or “no” is the correct response to a particular target word. In other words, in the sky task, responses should be easier to sky words at the top of the screen (“yes” responses), whereas in the ocean task, responses should be easier to ocean words at the top of the screen (also “yes” responses). However, there was no three-way interaction between task, category, and position either in terms of RT or error rate, F < 1 for RTs and F(1,98) = 2.12, p = 0.15 for error rate. The polarity principle also predicted that this response and position effect should be more pronounced for right-hand “yes” responses to words at the top position and for left-hand “no” responses to words at the bottom position. This interaction between position, task, category, and instruction was not significant for RTs or error rate, both Fs < 1. Thus, there was no evidence that responses were facilitated when “yes” responses were aligned with the top position.
The only significant interaction that might be attributed to the polarity principle was between instruction, task, and category, F(1,98) = 4.59, p = 0.04, η2 = 0.05 for RTs but F(1,98) = 1.07, p = 0.30 for error rate. Numerically, this interaction showed that in the sky decision task, right-hand responses were faster for sky words (“yes” responses) than for ocean words (“no” responses), whereas left-hand responses were faster for ocean words than sky words. In the ocean decision task, however, right- and left-hand responses were both faster for ocean words than sky words. Collapsing across tasks, participants were faster to give a “no” response with their left than with their right hand, while there was no difference for “yes” responses, but these simple effects were not statistically significant. These effects might be consistent with a polarity account in which “no” and left-hand responses are both coded as – polarity and responses were faster when these polarities were aligned. However, the polarity account also predicts that responses should be faster when “yes” and right-hand responses were aligned (both + polarity), which was not the case. Moreover this effect did not interact with spatial position and thus cannot explain spatial congruency effects.
Conceptual congruency based on mental simulation predicted both a task congruency effect as well as a word congruency effect. In support of this account, there was a significant interaction between task and position, F(1,98) = 15.97, p < 0.001, η2 = 0.14 for RTs and F(1,98) = 3.61, p = 0.06, η2 = 0.04 for error rate. In the ocean decision task, responses were faster to target words at the bottom than at the top, F(1,51) = 5.05, p = 0.03, η2 = 0.09, and in the sky decision task responses were faster and more accurate to target words at the top than at the bottom, F(1,49) = 11.97, p = 0.001, η2 = 0.196 for RTs and F(1,49) = 5.94, p = 0.02, η2 = 0.11 for error rate. Thus, there was a highly reliable task congruency effect, although this effect did not interact significantly with word category, all ps > 0.20. Conceptual congruency also predicted that performance would be better for sky words at the top and ocean words at the bottom in both tasks, because these are typical positions for the entities referred to by these words. However, there was no interaction at all between word category and position, both Fs < 1. Thus, the current experiment failed to replicate the word congruency effect reported by Šetić and Domijan (2007).
In addition to these results, the ANOVA on RTs showed a theoretically uninteresting main effect of category, F(1,98) = 4.08, p = 0.05, η2 = 0.04, and an interaction between category and task, F(1,98) = 73.02, p < 0.001, η2 = 0.43. Overall, responses were faster to ocean than sky words. In the ocean decision task this was also the case, but in the sky decision task responses were faster to sky than to ocean words, indicating that “yes” responses were faster than “no” responses. This effect provides a manipulation check because it shows that the polarity of the items was reversed by the task. No other effects were significant.
Discussion
In two semantic decision tasks (ocean decisions and sky decisions) performance was better for words that were presented at a position that was congruent with the task. Specifically, performance was better for words at the bottom than at the top of the screen in ocean decision and better for words at the top than at the bottom of the screen in sky decision. This finding is not explained by the polarity principle, but it was expected by the perceptual simulation account if the systematic nature of the task (e.g., a long sequence of sky decisions) caused participants to direct their attention to the task appropriate position of the screen, which is something they might do to properly simulate words in the task indicated location (sky or ocean). We will return to this explanation below.
The present results do not support the polarity principle. According to this principle, task performance is facilitated by alignment of polarities between response and stimulus dimensions (Proctor and Cho, 2006). In the present study this principle predicted that the “yes” response, top position of the target word, and the right-hand response would be aligned because they are all coded as + polarity, and the opposites (“no” response, bottom position, left-hand response) would be aligned because they are all coded as − polarity. However, our results showed no advantage when polarity was aligned: there were neither polarity effects when only considering response and screen position nor when considering response, screen position, and response hand.
This failure to find polarity effects is consistent with previous studies finding results in one condition that might be interpreted in terms of polarity alignment, but then failing to find these results in a complementary condition (Meier and Robinson, 2004; Van Dantzig, 2009; Boot and Pecher, 2010). In these studies, effects of congruency between spatial position and concept were observed when considering a sequence of events that went from concept to position (e.g., from power judgment to visual target identification) but not in going from position to concept (e.g., from location decision to power judgment). For example, Van Dantzig found that power judgments of words (e.g., dictator) had an effect on subsequent identification of a letter presented at the top or bottom of the screen. In a separate experiment, identification of letters (e.g., a p at the top of the screen) did not have an effect on subsequent power judgments. Thus, power judgment affected spatial attention, but spatial attention did not affect power judgments. In both experiments, position and power had binary polarities. If polarity alignment was the cause of the congruency effects in the concept followed by position experiment, there should have also been congruency effects for the position followed by concept experiment. Landy et al. (2008) noted that the polarity principle is a general principle that should be observed consistently. Thus, the asymmetry found in these studies is problematic for the polarity principle.
One complication with previous findings is that the stimulus dimensions had polarities that were mostly fixed. For example, in the up–down spatial dimension, up always has + polarity, and in the power dimension, powerful always has + polarity. Therefore, it was impossible to disentangle polarity alignment and meaning congruency. In the present study, we gave the same stimuli + or − polarity by changing the decision task, and we manipulated response side orthogonally. Therefore, the absence of any effect of polarity alignment in the current experiment indicates that, at least for semantic tasks, the polarity principle does not contribute to performance.
The semantic congruency account predicted an interaction between word meaning and spatial position, but we did not find such an interaction. Previous findings (Richardson et al., 2003; Šetić and Domijan, 2007; Estes et al., 2008) were explained by congruency between a perceptual simulation of the word’s meaning and the spatial position or orientation of the target. It should be noted that such congruency effects differ widely. Estes et al. and Richardson et al. found interference when the visual target’s position or orientation was congruent with the meaning of the preceding word. In contrast, Šetić and Domijan (2007) obtained facilitation rather than interference for congruent stimuli. In the current experiment, we found neither interference nor facilitation between word position and word meaning. Rather, we observed a task-wide advantage of the spatial location of the target, regardless of the specific meaning of the target word. Thus, the diversity of these findings indicates that the nature of spatial congruency effects is not fully clear yet. Some researchers (Estes et al., 2008) have postulated two loci for congruency effects. First, concepts that are associated to typical locations direct spatial attention toward their typical location. Second, simulations have perceptual details that are represented by sensory-motor systems. This might interfere with processing when simulation and perception occur simultaneously and differ in perceptual details (e.g., simulation of a cowboy boot and identification of the letter X). In contrast, the simulation may facilitate visual processing when simulation and visual target share perceptual details or when the simulation and visual target are presented sequentially (Bergen et al., 2007). Therefore, whether spatial congruency results in benefits or deficits and whether this effect is found for individual words or task-wide categories may depend on procedural details. These details may include the timing of spatial target presentation compared to the process of mental simulation, whether the simulated concept is concrete (e.g., cowboy boot) or abstract (e.g., power) (see Bergen et al., 2007), and what task is performed on the spatial target. Regardless of these procedural details, our results show that it is unlikely that the polarity principle can explain spatial congruency effects.
An explanation for our results that may also explain other findings is that the task directed spatial attention to the location that was congruent with the decision category. When the task was to decide whether a word referred to an entity typically found in the sky, participants directed their attention to the top of the screen, and when the task was to decide whether a word referred to an entity typically found in the ocean, participants directed their attention to the bottom of the screen. This task-specific spatial attention can be explained by mental simulation of the task-relevant location rather than specific entities. While performing the sky decision task, participants might mentally simulate looking at the sky without filling in perceptual details such as objects with specific shapes and colors. Because such task-induced spatial attention does not involve a simulation with many perceptual details, it will not interfere with perception of the target word. Instead, increased attention at the task-congruent location facilitated processing of the target word, resulting in faster responses.
This attentional explanation is consistent with other findings in which lower level perceptual information facilitated higher level conceptual processing (Van Dantzig et al., 2008). In Van Dantzig et al.’s study, participants verified concept-property pairs (e.g., banana-yellow) presented as words. Responses were faster for pairs that were preceded by a simple perceptual stimulus from the same modality as the property (e.g., a flashing light) than from a different modality (e.g., a burst of white noise). In this study the correspondence between perception and representation was at a more global level, namely the activation of a sensory modality, rather than at the level of specific perceptual details. In other studies investigating the effect of spatial position of words on conceptual processing (Meier and Robinson, 2004; Schubert, 2005; Meier et al., 2007), the task-relevant dimension was always congruent with the top position (e.g., valence, power, divinity), which provides an opportunity to assess whether there may have been an attentional effect similar to the current results. Close inspection of the results shows that, at least numerically, responses were faster to words presented at the top than at the bottom of the screen. Because these studies did not use a second dimension in which the positive exemplars were congruent with the bottom position, it is impossible to say conclusively whether the advantage for stimuli at the top position was due to task-induced spatial attention or a more general advantage for stimuli at the top. However, these previous studies are consistent with the present findings and our explanation.
In conclusion, we did not find evidence for the polarity alignment principle. We also did not find evidence for interaction between word position and word meaning. Our results did show, however, that semantic decision tasks direct spatial attention in a more global way. It may be that people perform a mental simulation of the task-congruent location, which directs spatial attention and facilitates processing of targets in that location.
Conflict of Interest Statement
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Acknowledgments
This research was supported by grants from the Netherlands Organization for Scientific Research (NWO) to Diane Pecher and by National Science Foundation (NSF) grant BCS-0843773. We are grateful to Perrie Chen, Hyun Monica Kim, Kristina Cho, and Aaron Wong for assistance with data collection.
References
Bae, G. Y., Choi, J. M., Cho, Y. S., and Proctor, R. W. (2009). Transfer of magnitude and spatial mappings to the SNARC effect for parity judgments. J. Exp. Psychol. Learn. Mem. Cogn. 35, 1506–1521.
Bar-Anan, Y., Liberman, N., Trope, Y., and Algom, D. (2007). Automatic processing of psychological distance: Evidence from a stroop task. J. Exp. Psychol. Gen. 136, 610–622.
Bergen, B. K., Lindsay, S., Matlock, T., and Narayanan, S. (2007). Spatial and linguistic aspects of visual imagery in sentence comprehension. Cogn. Sci. 31, 733–764.
Boot, I., and Pecher, D. (2010). Similarity is closeness: metaphorical mapping in a perceptual task. Q. J. Exp. Psychol. 63, 942–954.
Chiou, R. Y.-C., Chang, E. C., Tzeng, O. J.-L., and Wu, D. H. (2009). The common magnitude code underlying numerical and size processing for action but not for perception. Exp. Brain Res. 194, 553–562.
Craver Lemley, C., and Reeves, A. (1992). How visual imagery interferes with vision. Psychol. Rev. 99, 633–649.
Estes, Z., Verges, M., and Barsalou, L. W. (2008). Head up, foot down: object words orient attention to the objects’ typical location. Psychol. Sci. 19, 93–97.
Fischer, M. H., Castel, A. D., Dodd, M. D., and Pratt, J. (2003). Perceiving numbers causes spatial shifts of attention. Nat. Neurosci. 6, 555–556.
Klatzky, R. L., Clark, E. V., and Macken, M. (1973). Asymmetries in the acquisition of polar adjectives: linguistic or conceptual? J. Exp. Child Psychol. 16, 32–46.
Landy, D. H., Jones, E. L., and Hummel, J. E. (2008). Why spatial-numeric associations aren’t evidence for a mental number line. Proc. 30th Ann. Conf. Cogn. Sci. Soc. 357–362.
Loftus, G. R., and Masson, M. E. J. (1994). Using confidence intervals in within-subject designs. Psychonomic Bulletin and Review 1, 476–490.
Meier, B. P., Hauser, D. J., Robinson, M. D., Friesen, C. K., and Schjeldahl, K. (2007). What’s “up” with god? vertical space as a representation of the divine. J. Pers. Soc. Psychol. 93, 699–710.
Meier, B. P., and Robinson, M. D. (2004). Why the sunny side is up: Associations between affect and vertical position. Psychol. Sci. 15, 243–247.
Proctor, R. W., and Cho, Y. S. (2006). Polarity correspondence: a general principle for performance of speeded binary classification tasks. Psychol. Bull. 132, 416–442.
Richardson, D. C., Spivey, M. J., Barsalou, L. W., and McRae, K. (2003). Spatial representations activated during real-time comprehension of verbs. Cogn. Sci. 27, 767–780.
Santens, S., and Gevers, W. (2008). The SNARC effect does not imply a mental number line. Cognition 108, 263–270.
Schnall, S., and Clore, G. L. (2004). Emergent meaning in affective space: congruent conceptual relations and spatial relations produce positive evaluations. Proc. 26th Ann. Conf. Cogn. Sci. Soc. 1209–1214.
Schubert, T. W. (2005). Your highness: vertical positions as perceptual symbols of power. J. Pers. Soc. Psychol. 89, 1–21.
Šetić, M., and Domijan, D. (2007). The influence of vertical spatial orientation on property verification. Lang. Cogn. Process. 22, 297–312.
Van Dantzig, S. (2009). Mind the Body: Grounding Conceptual Knowledge in Perception and Action. (Unpublished doctoral dissertation), Erasmus University, Rotterdam, The Netherlands.
Van Dantzig, S., Pecher, D., Zeelenberg, R., and Barsalou, L. W. (2008). Perceptual processing affects conceptual processing. Cogn. Sci. 32, 579–590.
Zwaan, R. A., and Yaxley, R. H. (2003). Spatial iconicity affects semantic relatedness judgments. Psychon. Bull. Rev. 10, 954–958.
Appendix
Ocean words: algae, anchor, anemone, clam, cod, coral, crab, diver, diving mask, dolphin, fishing net, flipper, flounder, herring, jellyfish, kelp, lobster, mermaid, octopus, otter, oyster, plankton, reef, salmon, salt, sand, scallop, seal, shark, shell, ship wreck, shrimp, snorkel, squid, submarine, tsunami, tuna, turtle, wetsuit, whale.
Sky words: angel, astronaut, balloon, bat, bluejay, cardinal, cloud, comet, eagle, fairy, falcon, fireworks, hawk, helicopter, hummingbird, jet, kite, lightning, meteor, missile, moon, owl, parachute, pigeon, pilot, plane, planet, rainbow, raven, robin, rocket, satellite, sparrow, star, starling, sun, Superman, tornado, ufo, vulture.
Keywords: spatial attention, concepts, polarity alignment, grounded cognition
Citation: Pecher D, Van Dantzig S, Boot I, Zanolie K and Huber DE (2010) Congruency between word position and meaning is caused by task-induced spatial attention. Front. Psychology 1:30. doi: 10.3389/fpsyg.2010.00030
Received: 07 April 2010;
Paper pending published: 08 May 2010;
Accepted: 27 June 2010;
Published online: 07 September 2010.
Edited by:
Anna M. Borghi, University of Bologna, ItalyReviewed by:
Patric Bach, University of Plymouth, UKMichael Kaschak, Florida State University, USA
Copyright: © 2010 Pecher, Van Dantzig, Boot, Zanolie and Huber. This is an open-access article subject to an exclusive license agreement between the authors and the Frontiers Research Foundation, which permits unrestricted use, distribution, and reproduction in any medium, provided the original authors and source are credited.
*Correspondence: Diane Pecher, Department of Psychology, T12-33, Erasmus University Rotterdam, Postbus 1738, 3000 DR Rotterdam, Netherlands. e-mail:cGVjaGVyQGZzdy5ldXIubmw=